白:“同桌偷了张三一块橡皮给我。”“张三偷了同桌一块橡皮给我。”
谁是谁同桌?
“同桌偷了张三一块橡皮给李四。”这个能说不?如果能,谁是谁同桌?
“张三逼同桌骂了李四一通”,张三的同桌无疑。“张三逼同桌骂了我一通”,含糊了,我的同桌也是可能的。说话人一直是“在场的(present)”,所以先行的语境里有这么一号角色在。“张三逼李四骂了同桌一通”,似乎又是李四的同桌了。先行与否、就近与否、旁路与否、一直在场与否,都对填这个坑的候选萝卜有影响。刚才列举的选择不同也说明了:兼语式的主支(含兼语动词的那一支)不是旁路,和介词短语不同。
“同桌当着张三的面骂了李四一通。”
好像,既不是张三的同桌,也不是李四的同桌。
李:解析器觉得是李四的同桌,大概是因为张三沉底了:
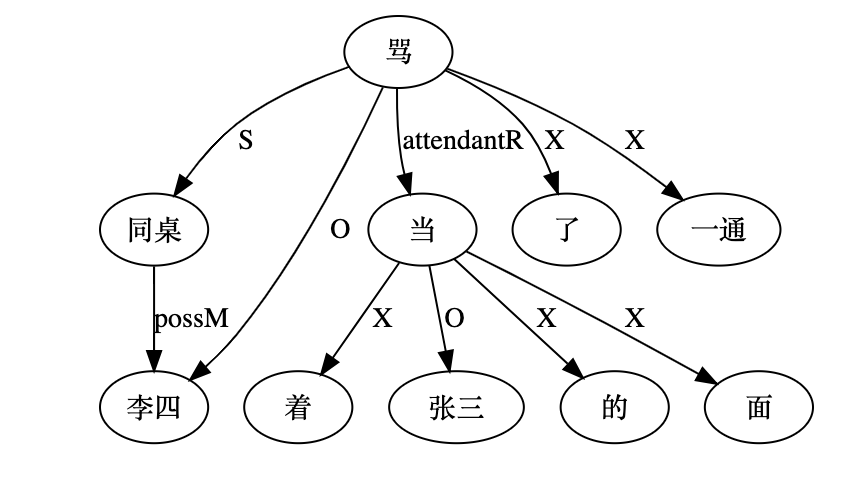
(解析忘了把 hidden link 加上,谁当着张三的面?“当-面”的逻辑主语是“同桌”。这个bug容易fix,结构很清晰。)
所谓伴随情况状语(attendantR),是附带性的谓词,与主句谓语不在一个层次。从句法层次角度,“同桌”更应该是“李四”的,虽然物理距离更远。当然,人的理解机制有点一团浆糊的味道,其实没必要把人的理解神圣化。在诸多因素参与角力的时候,人的认知理解和判断其实不是确定的,因人而异,因背景而已,甚至同一个人也会因时而异。
在物理距离与句法层次的较量中,不同的人有不同关联和解读,是正常的。这个加分减分的较量,即便有一个机制去计算,也没有一个确定性的目标去最终评判。最多是企望有个理解的容忍范围。何况,对于 heterogeneous evidence,整出一个合适的加分减分的算法,一直以来就是挑战。把不同层面的因素,整到(投射到)同一个平面折合成统一的度量,然后根据这些因素之间的冗余性,打合适的折扣,最终能做出一个最优结果,同时又能讲出道理来,听上去就让人头皮发麻。
寄希望于深度神经,哪怕“讲出道理来”这一条暂时达不到也行。
白:“同桌”挖了一个坑,这个坑回指(先行词填坑)时是清晰的,预指(后继词填坑)时是模糊的,一般都是说话人(“我”)填坑。如果硬要别人填坑,除非语境有所交代,否则默认说话人填坑好了。回指的规则就是所谓“最近提及+类型相谐”。
“李四骂了同桌一通”,同桌是李四的同桌。“同桌骂了李四一通”,谁的同桌就不好说了。但说话人的同桌是标配。
李:
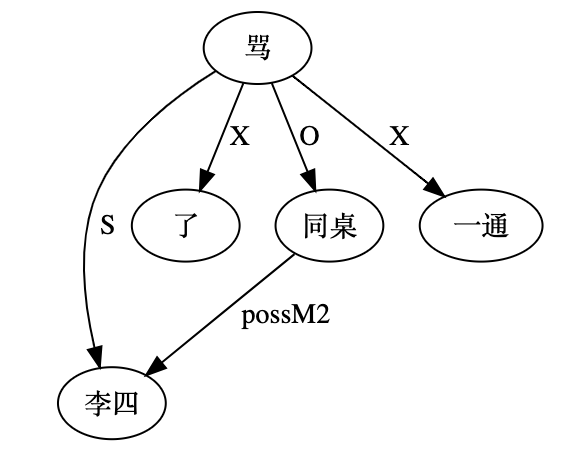
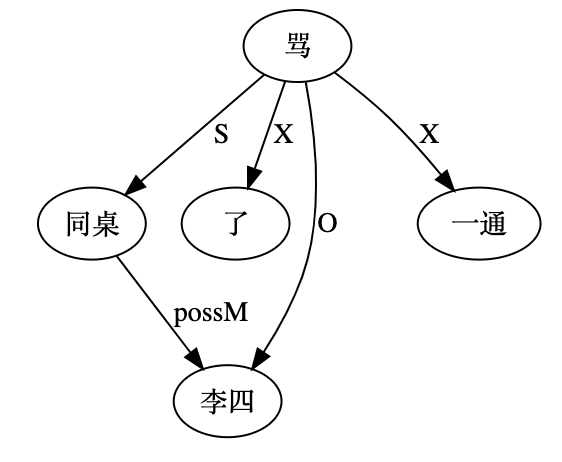
白:旁路上的先行词,待遇差点儿:“张三当着李四的面骂了同桌一通。”好像还是张三的同桌。
李:如果所模拟的人的理解过程就是浆糊,再牛的算法,加上再大的数据,也没辙。也许,有些牛角尖不值得钻。如果是语言理解多项选择问答题,大概是这样:
问:“同桌当着张三的面骂了李四一通”这句中,谁是谁同桌?
答:
- 张三的同桌 (A)
- 李四的同桌 (B)
- 未知人的同桌(不是张三也不是李四的同桌:!A & !B)
- 既是张三的同桌,也是李四的同桌 (A&B)
- 不是张三的同桌,就是李四的同桌 (A XOR B)
- 任何人的同桌 (一团浆糊,语言未指明,A|B|..., 但不care)
【Parsing 标签】
1 词类:V = Verb; N = Noun; A = Adjective; RB = Adverb;
DT = Determiner; UH = Interjection; punc = punctuation;
2 短语:VP = Verb Phrase; AP = Adjective Phrase; NP = Noun Phrase;
VG = Verb Group; NG = Noun Group; NE = Named Entity; DE = Data Entity;
Pred = Predicate; CL = Clause;
3 句法:H = Head; O = Object; S = Subject;M = Modifier; R = Adverbial;
(veryR = Intensifier-adverbial;possM = possessive-modifier);
NX = Next; CN = Conjoin;
sCL = Subject Clause;oCL = Object Clause; mCL = Modifier/Relative Clause;
Z = Functional; X = Optional Function
【相关】