【从IBM沃森平台的云服务谈AI热门中的热门 bots】
屏蔽 |||


我:
哥仨老革命在去 IBM 的 traffic 中 去大名鼎鼎的沃森(Watson)系统探秘

洪:
讲者是这位印度籍女士:http://researcher.watson.ibm.com/researcher/view.php?person=us-vibha.sinha:

郭:
比较有意思的是她后面讲的三点:
1. LSTM based intent recognition and entity extraction
2. "tone" recognition
这里tone指的是从一句话(书面语)反应出的说话人的喜怒哀乐和处事方式等





3. personality recognition
主要基于心理学的分类,用200到2000条tweets训练



她重点强调的是,通过增加tone和personality的识别,人机对话可以有更高的可接受度。
我:
唐老师 诸位 汇报一下昨天的听闻。上面 郭老师也总结了几条,很好。我再说几点。
话说三位老革命慕名而去,这个 meet-up 一共才来了20几位听众吧 大概湾区此类活动甚多 marketing 不够的话 也难。据说北京的 AI 沙龙,弄个花哨一点的题目 往往门庭若市。


1. 没有什么 surprises 但参加沙龙的好处是可以问问题和可以听别人问问题,而主讲人常常在回答的时候给出一些书面没有的数据和细节。否则的话,各种资料都在网上(最后的 slide 给了链接),要写利人似的调研报告,只要不怕苦,有的是资料。

听讲的另一个好处是,主讲人事先已经组织好材料讲解,可以快速了解一个项目的概貌。




2. 特地替唐老师问了他钟情的 Prolog,问你们有用吗,在什么模块用。主讲人说,没有用。我说有报道说有用到。她说,她没听说,至少在她主讲的已经产品化的这个沃森 chatbot 的组建 toolkit 里面没有 Prolog。当然她不排除某个小组或个人 在沃森的某个项目或模块用到。IBM 对 AI 的投入增大,在沃森的名号下的各种研究项目和小组很多。
马:
我问过了IBM中国的,在沃森参加电视节目版本中没有用prolog,但是后续的版本中,确实用到了prolog
陈:
它是很多services构成,用不会奇怪,尤其是某些既有系统
我:


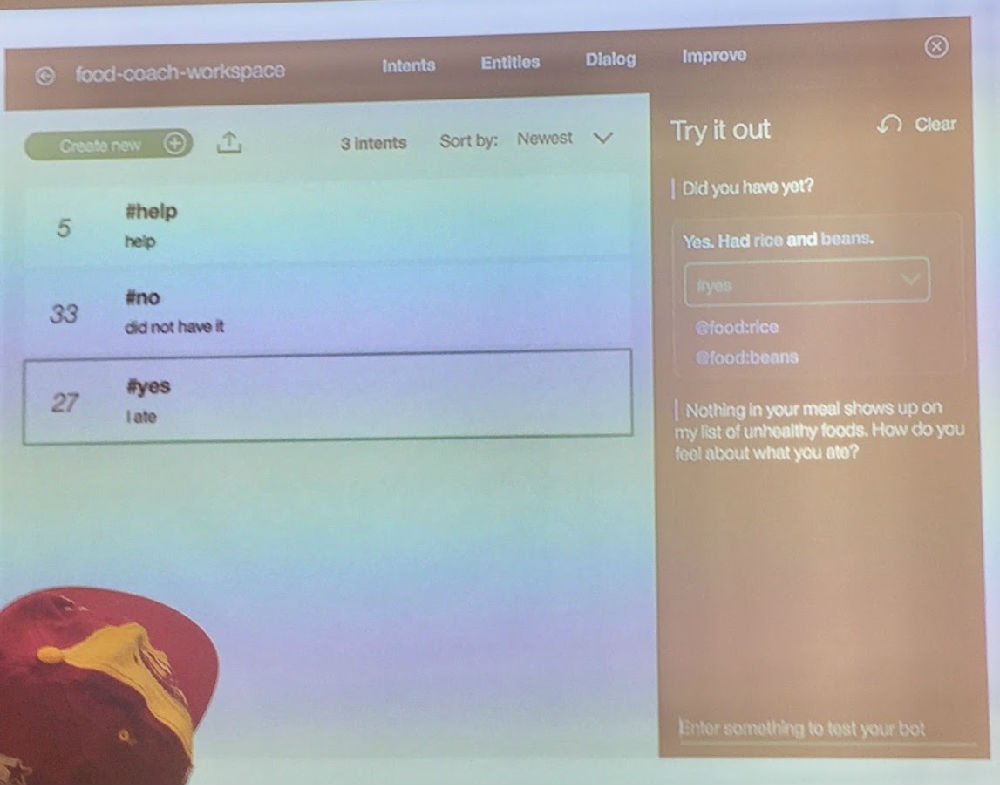

3. 现在不少巨头都在 offer 这样的 toolkit,问微软 offer 的 cortana 的 toolkit 与你们沃森的这套有啥不同。回答是,非常类似,不过她自认为沃森质量更好。亚马逊也有类似的 offer。
所以回来路上,我们就谈到这个 bots 遍地开花的场景。郭老师说,现如今谁要想做一个领域内的 bot,或自己的 app 做一个 bot 接口,根本就不需要编程。只要准备好领域的 experts,把数据准备好,用这些巨头的工具箱就可以构建一个出来。也一样可以 deploy 到 messenger 或嵌入其他场景,这几乎是一条龙的云服务。


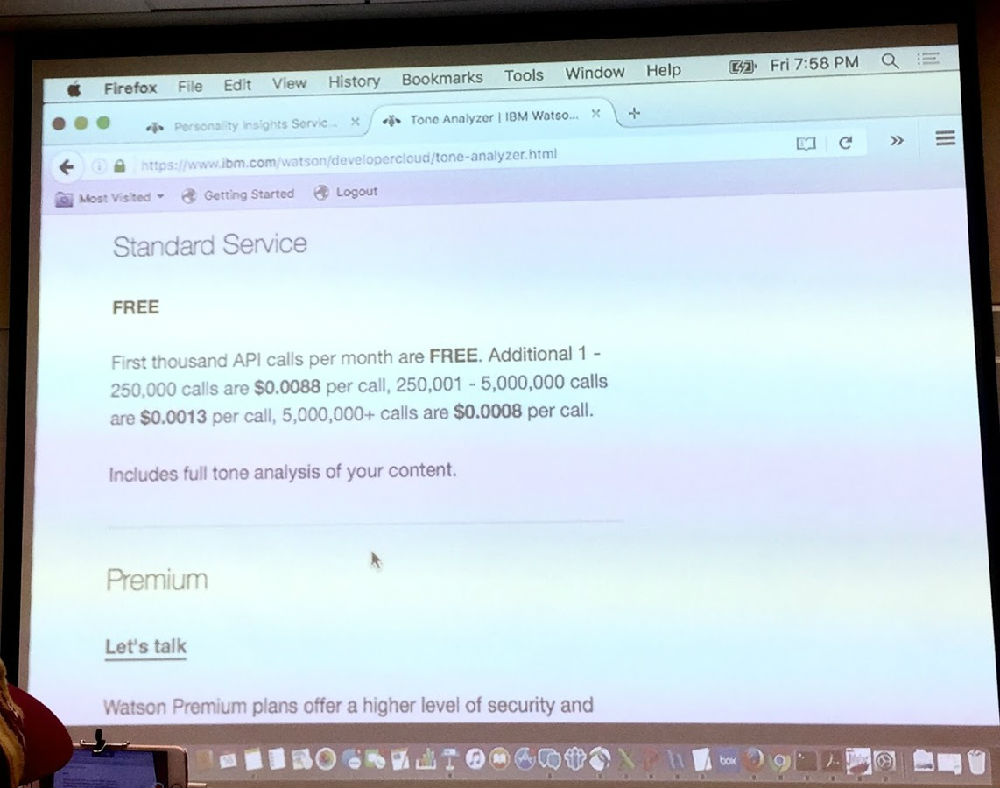
当然 用这些服务是要交钱的,但主讲人说很便宜很便宜的,郭兄说,真用上了,其实也不便宜。便宜与否放一边,至少现如今,bots 的门槛很低,需要的不是软件人才,而是领域数据的人。于是,我看到一种前景,以前毕业即失业的语言学家、图书馆业人士,将来可能成为 AI 的主力,只有对数据和细节敏感的人,最终才是 AI 接口的血肉构筑者,反正架构是现成通用的。这个细想想是有道理的。这是沃森 API calls 的价格。
我:
这就回到我们以前议论过的话题。AI 创业,如果做平台或工具箱,初创公司怎么敌得过巨头呢?我觉得几乎是死路。
大而言之 做平台和工具箱创业的,历史上就没见过什么成功案例(不排除做了被收购那种,那也是“成功”,如果你的技术有幸被巨头看中:其实昨晚介绍的沃森系统的一个重要组件 AlchomyLanguage 就是收购的,洪爷知道收购的来路和细节)。
白:
麦当劳玩法,方便,质量可控,但绝非美食,虽然是“美”食。
我:
不错,这些巨头的 offerring 都是麦当劳式的流程。创业的空间,从工具角度,可以是中华料理的配方辅助工具之类。不过,还是那句话,最好绕过平台本身创业的思维,而是用巨头的工具或者自家建造匕首去做领域的 AI,这样的创业应该具有更大的空间和更多的可能性。
对于 NLP(AI之一种) 我写过 n 篇博文强调,所有的 offshelf 的平台和toolkit(譬如 历史悠久的GATE),甚至一个小插件(譬如 Brill Tagger or some Chinese word segmenter)都不好用。可以 prototyping 但如果稍微有点长期观点 要建一个大规模的NLP的应用,还是一切自家建造为好。当然,自家建造的门槛很高,多数人造不起,也没这个 architect 来指挥。但最终是,自家建造的胜出,从质量上说(质量包括速度、鲁棒性、精度广度、领域的可适应性等关键综合指标)。
巨头的工具箱的产品 offers 一开始也不赚钱,但他们的研发积累已经做了,且还在不断投入,不产品化成工具箱不是傻瓜吗,赚多少算多少。如果真到了AI bots 遍地开花的时候,他们凭借巨大的平台优势,赚钱也是可能的。小公司这条路没门吧。如果你的 offer 的确 unique,譬如是中华料理,譬如是伟哥的 parsing,你可能会吸引一批使用者。但想赚钱必须有规模,而 component tech 或平台工具之类,在小公司的环境中,是成不了规模的。所以不要想赚钱的事儿。
赚钱靠的是产品,而不是工具,这是AI创业铁律。
当然,通过平台或工具打出影响,做 marketing,曲线救国创业,另当别论。
回到 meet-up:
4. bots 构建的核心当然是 conversations 的训练工具。IBM沃森的工具用的是深度神经。
对于 bots,input 是确定的,就是用 bots 的人的输入。自然语言的语音也好 文字也好,语音反正也要转化为文字 所以我们面对的就是人机接口中的“人话”,理论上无止境 千变万化。
bots 的 output 呢?
在目前的框架里,在绝大多数实际场景,这个 output 都是以极为有限的集合
最典型的案例是为 apps(天气、股票、时间之类) 做 bots 作为 apps 的人机接口,
其 output 就是 app 里面的 commands 集合。于是 bot 产品定义为从无限到有限的映射,这是一个典型的分类场景。于是沃森提供这个深度学习为基础的工具帮助你训练你所需要的 classifiers,这是标准做法 无甚新意。
数据越多,分类质量越好。千变万化的死敌是稀疏数据。好在对于 bots,数据的收集会是一个边使用边加强的过程。如果你的 bots 开始有用户,你就形成了正循环,数据源源而来,你不断打磨、训练,这些都是可以 streamline 的流水作业,就越来越好。Siri 如此,Echo 也如此。
白:
分类本身是不带参数的,而bots的应对必须是带参数的,这是硬伤。
拿分类来做对话是看得到天花板的。
我:
I cannot agree more :=)
这里其实是有历史渊源的。IBM 做问答,一直是把问题简化为分类。18 年前我们在第一次 QA 竞赛(TREC-8)中交流 就是如此,这么多年这个核心做法一直不变。当时我们的QA成绩最好,得分66%,沃森的系统印象是40%左右,他们的组长就追在后面问,我们思路差不多呀,都是 question intents(我们叫 asking points,比多数 intents 其实更聚焦),外加 Named Entity 的support。我说我们还用到了语言结构啊。
直到今天他们仍然是没有句法分析,更甭提深度分析。他们当年的 QA 就是基于两点:
1. 问句分类:试图了解 intents;2. NE。有了这两条,通过 keywords 检索作为 context,在大数据中寻找答案,对于 factoid questions 是不难的(见【立委科普:问答系统的前生今世】)。这就是沃森打败人类的基本原理,一点也不奥秘,从来没有根本改变。现在这一套继续体现在其 bots 工具箱 offering 里面。
洪:
昨晚Watson讲座听,
今早广告已跟进。
IBM可真下本,
今天我试Bluemix云。
我:
2. 因此 conversations 训练,其核心就是两条:一个是 intents classification (这个 intents 是根据 output 的需求来定义的),一个 NE,不过 NE 是他们已经训练好的模块(NE有一定的domain独立性),用户只是做一些微调和增强而已。
顺便插一句,这几天一直在想,AI 现在的主打就是深度神经,所有的希望都寄托在神经上。但无论怎么神经,都不改 supervised learning 的本性:所以,我的问题是:你怎么克服缺乏带标大数据的知识瓶颈?
ok 你把机器翻译玩转了。因为 MT 有几乎无限的 “自然” 带标数据(其实也不是自然了,也是人工,幸运的是这些人力是历史的积累,是人类翻译活动的副产品,是不需要开发者花钱的 free ride)。可其他的 ai 和 nlp 应用呢,你还可以像 MT 这样幸运 这样享用免费午餐吗?
现在想,紧接着 MT 的具有大数据的热门应用是什么?非 bots 莫属。
对于 bots,数据已经有一定的积累了,其最大的特点在于,bots 的使用过程,数据就会源源而来。问题是 这些数据是对路的,real life data from the field,但还是不带标啊。所以,bots 的前景就是玩的跟数据打仗:可以雇佣人去没完没了地给数据做标注。这是一个很像卓别林的【摩登时代】的AI工厂的场景,或者是列宁同志攻打冬宫的人海战术。看上去很笨,但可以确定的是,bots 会越来越“智能”,应对的场景也越来越多。应了那句老话,有多少人工,就有多少智能。然而,这不是、也不应该是 唯一的克服知识瓶颈的做法。
毛:
嗯,有多少人工,就有多少智能。这话说得好。
我:
但这个景象成为常规 也不错 至少是帮助解决了一些白领就业。是用高级的专家知识去编写规则来提高系统质量,还是利用普罗标注去提高质量,从帮助就业和维稳角度看,几乎蛮力似的深度神经对于标注大数据的无休止的渴望和胃口,对于社会似乎更为有利。为了社会稳定和世界和平,我们该看好这种蛮力。我们做深度分析和理解的专家,试图尽可能逼真地去模拟人的智能过程,但对蛮力也应该起一份敬意。
将来的AI,什么人都可做:1. 你发现一个领域的 AI 需求; 2. 你雇佣一个对这个需求可以形式化定义的设计家; 3. 你调用巨头的一个通用的 AI 工具箱(譬如 TensorFlow) 或面向专项产品的工具箱(譬如 bot 的沃森工具箱) 4 你雇佣一批失业但受过教育的普罗,像富士康一样训练他们在流水线上去根据设计家的定义去标注数据、测试系统,你于是通过 AI 创造了价值,不排除你的产品会火。因为产品火不火已经不是技术了,而是你满足需求的产品角度。
3. 但是 正如白老师说的 这种用分类来简化问题的 AI 产品化,走不远。它可能满足一些特定领域的特定的需求 但是后劲不足是显然的。其中一个痛点或挑战就是,这种东西走不出三步,三步以上就抓瞎。如果你的应用可以在三步之内就基本满足需求,没问题。
bots 最显然的有利可图的应用场景是客服。一般而言,bots 取代和补充客服是大势所趋,因为客服的知识资源和记忆,根本没法与我们可以灌输给 bots 的知识来相比。利用知识去回答客户疑问,人不如机,是可以想见的。但是 观察一个好的客服与客户的交互 可以发现,三步的交流模型是远远无法满足稍微复杂一点的场景的。三步的说法是一个比喻,总之是目前的工具箱,对于较长时期的对话,还是束手无策。
bots 对用户话语的理解简化为 classification,以此为基础对用户的回答就不是那么简单了。目前提供的做法是:因为 intents 是有限的集合,是 classification 的结果,那么对于每一个 intent 可以预知答案(存在数据库的 hand-crafted text snippet)或回应(譬如展示一个图,譬如天气app的今日天气图表)。 这些预制的答案,听上去非常自然、生动甚至诙谐,它们都是领域专家的作品。且不说这些预制的 snippets,如何根据classification hierarchy 本身需要做不同组装,在存于数据库里面的核心应答的预制以外,还可以加上情感的维度,还可以加上 personalized 的维度,这些都可以使得对话更加人性化、自然化,但每加一个维度就意味着我们开始接近组装式策略的组合爆炸后果。三步、三维以上就无法收拾。





我问主讲人,你的这些预先制定好的应答片段,按照你的工具的组装方式,不就是一个 decision tree 吗?回答是,的确,就是一个 decision tree 的做法。然后她说,有不少研究想突破这种应答模式,但都是在探索,没有到可以产品化工具化的阶段。

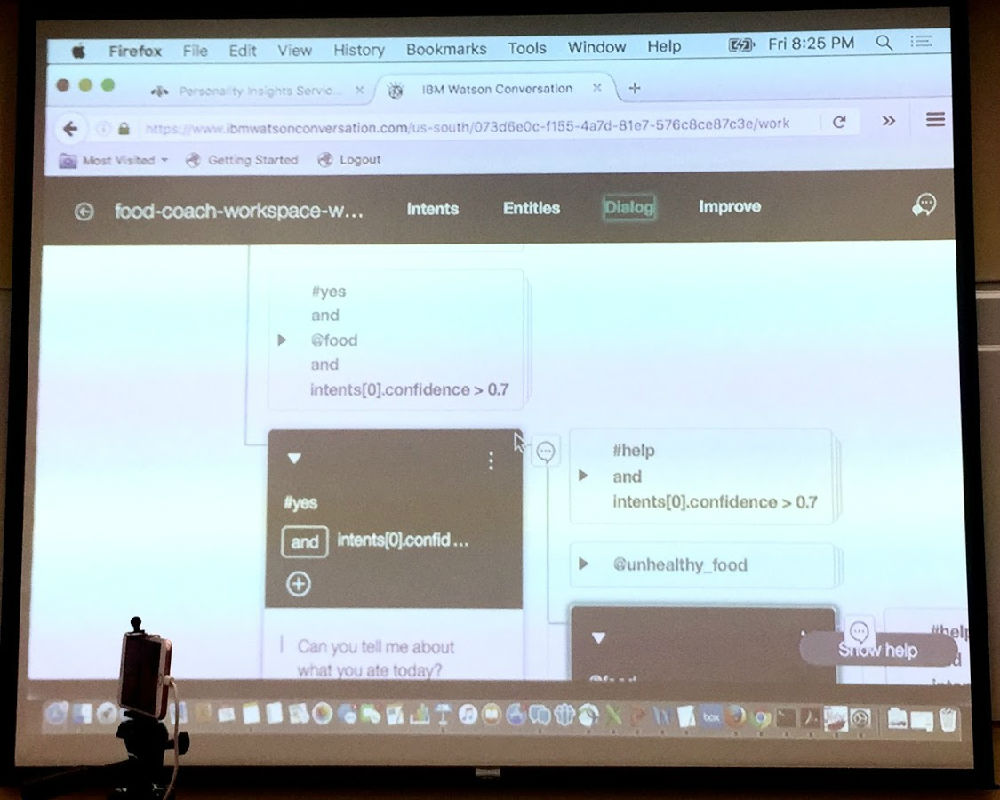
郭老师说,谁要是有本事把人机的 “自然对话”能够延长到 20 分钟,换句话说 就是突破图灵测试,谁就是 AI bots 的真正破局者。如果你证明你能做到,巨头会抢着来高价收购你的。这是所有做 bots 的所面临的共同挑战。
据说小冰最高记录是与单一的人谈了九个小时的心。但那不是真正的突破,那是遇到了一个异常人类。正常的人,我的体会是两分钟定律,你与小冰谈话 超不过两分钟。我试过多次,到了两分钟,它所露出来的破绽就让你无法忍受,除非自己铁心要自我折磨。其实 工业界要求的连续对话,不是小冰这种闲扯。而是针对一个稍微复杂一点的任务场景(譬如订票)如何用自然对话的假象去把相关的信息收集全,来最大限度地满足客户需求。
累了,先笔记和评论如上。其余还有一些有趣的点儿可以讨论,以后再说。这是交给我们唐老师的作业。
郭:
Amazon’s $2.5M ‘Alexa Prize’ seeks chatbot that can converse intelligently for 20 minutes
洪:
亚马逊正设大奖,
chatbot赛悬赏。
对话若超廿分长,
两半米粒到手上。// 2.5M
【相关】
Amazon’s $2.5M ‘Alexa Prize’ seeks chatbot that can converse intelligently for 20 minutes
http://blog.sciencenet.cn/blog-362400-1021860.html
上一篇:【语义计算:从神经机器翻译谈起】
下一篇:【从V个P到抓取邮电地址看 clear patterns 如何抵御 sparse data
1 周健
发表评论评论 (3 个评论)

- 删除 |
 赞[2]张海涛
赞[2]张海涛 - 当年的Watson是建在UIMA(Unstructured Information Management Architecture)的基础上的,确实使用Prolog(The Prolog Interface to the Unstructured Information Management Architecture,https://arxiv.org/ftp/arxiv/papers/0809/0809.0680.pdf)。
- 删除 |赞[1]张海涛
- “IBM沃森的工具用的是深度神经。”
"直到今天他们仍然是没有句法分析,更甭提深度分析。"
当年Watson打败Jeopardy!冠军后,IBM Journal of Research and Development出过专辑,对于Watson的构造的描述好象不是这样的。比如parsing是这样描述的:http://ieeexplore.ieee.org/document/6177729/
“Two deep parsing components, an English Slot Grammar (ESG) parser and a predicate-argument structure (PAS) builder, provide core linguistic analyses of both the questions and the text content used by IBM Watson™ to find and hypothesize answers. Specifically, these components are fundamental in question analysis, candidate generation, and analysis of passage evidence. As part of the Watson project, ESG was enhanced, and its performance on Jeopardy!™ questions and on established reference data was improved. PAS was built on top of ESG to support higher-level analytics. ”现今的Watson的建构和多年完全不一样了吗?