白:
伟哥对主谓vs.述补,️“得”字的作用有何评述?
李:
题目大了点儿
小半部汉语语法了 都。
白:
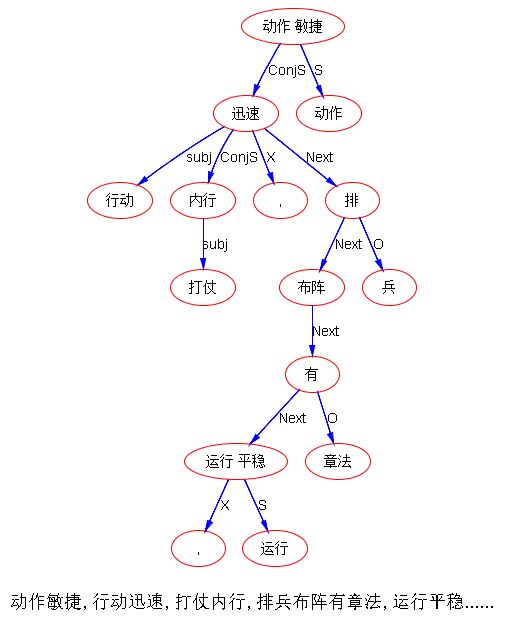
动作敏捷,行动迅速,打仗内行,排兵布阵有章法,运行平稳……
执行命令坚决,干家务不情愿
root感觉上都是在后面,是谓词在填谓词的坑。为什么被填坑的反而成了陪衬,这说不通。第一个“动作”是名词,我拿来跟后面对比的。说大不大,就是上面这些表达,head是谁,谁填谁的坑。如果跟主流是反着的,有什么后果。
李:
拿 practice 说话吧。
他努力工作
他工作努力
一般来说 “工作” 只有一个坑,“努力” 有两个坑: 一个人,一个是人的动作。这就是句法 subcat 与 逻辑 subcat 不尽相同之处。句法上,老子的 subcat 里面有儿子 args 的坑, 没有 mods 的坑。譬如 动词有 主宾等 但没有状语的坑。名词有补足语的坑 但没有修饰语的坑。但是逻辑上不同,逻辑上 任何 mods 定语啊 状语啊 对于与它直接联系的老子,都有一个语义相谐的要求。这种要求可以写进做修饰语的那个词的词典去。但对于语义搭配稍强的情况 也不仿写进做老子的词条去。关系是mutual 的 选择谁去 encode 这种细线条信息 其实没有一定之规。
问白老师一个问题,这样的借助小词接力,一步一步、一对 tokens 一对 tokens 的两两向前推进 parsing,会不会造成过多的假 parses (所谓伪歧义的困扰)?
DG中,语言单位虽然都可以 binary 关系表示,但是 parsing 的时候却不宜两两推进,因为那样的话,条件往往失于过宽。还是我理解有误?
白:
不会啊。(1)小词对距离很敏感,太远了肯定要靠实词自身的互联。(2)小词对结合方向很敏感。实词语序乱了不要紧,坑可以把它们找回来,但是小词语序乱了一定不知所云。什么语法不借助中间件都必然失之于宽。所以,WSD也好,二元关系也好,树也好,最后都要靠中间件摆平。
李:
对着例子谈吧:譬如 是AP的
这个汉语表达 affirmative 的 pattern,就是这么简单的一个 pattern,
用 “是。。。的” 把形成的 AP 包裹一层。因为这种小词没有啥意义,最多不过是给这个谓语加一个 affirmative 的 feature 的信息,其他的关系连接,还是要直接通向 AP:
她是漂亮的 == 她漂亮
白:
AP有两个表达方式,一个是紧靠名词的,一个是松散的(作谓语,作补语,通过“的”作定语)。是……的,是后一种。我们先解决句法成分“一个都不能少”的问题,再解决语义关系的抽取问题。
李:
可是看白老师的图,感觉在小词里面绕。
白:
没有无缘无故的绕。
李:
包裹一层的话,就不需要绕,就当成 AP 的前缀后缀了。说的是 pattern 包裹,结构根本就不用包裹,不过加一点信息而已,甚至丢掉那信息也无大碍。
白:
问题是,不光“是……的”,还有“有……的”还有其他“V……的”。我们可以统一处理。到了语义关系抽取阶段,衣服会脱下来的。二元关系进行到底,应该看不见pattern。pattern体现为判断二元关系成立与否的前后条件。
李:
的字负载结构 统一处理的好处何在?
白:
一视同仁
李:
这个好处貌似不实惠,也不必需。
白:
所有词、所有二元关系一视同仁,用同样的formalism处理,不排除神经。
李:
哦,有无缝挂靠RNN的便利?
一视同仁本身最多是显得 elegant,这种二元推进一视同仁的处理与用长短不同、随机决定的 patterns 处理,除了所用的机制不同,还有什么特别的说法?
白:
没有规则,没有pattern,bug都在词典里,要de,就改词典。语义构造最大限度地平行于句法提供的二元关系。
李:
patterns 甭管怎么写,说到底也是统一的机制,某种有限状态及其延伸罢了。
白:
pattern写了也不矛盾。不改变核心机制,只改变前后条件。
李:
只改词典,不改规则的例子见过,那就是 HPSG,但那是建立在词典结构无限复杂化的基础上。现如今用的是简单得多的词典结构。Categorial grammar 那种吃了吐、吐了吃在 cat 基础上的填坑挖坑,要实现只改词典就能 parsing 的开发,感觉哪里缺了什么。
白:
但是把pattern固化,就会引进来不robust的问题。很多情况下,系统自己找对象比用pattern拉郎配更聪明。
李:
同意,这是一个问题,不好拿捏。但换一个角度,用 patterns 直观易读,与人对语言现象的捕捉非常近似,而且 patterns 其实也还是立足于自己找对象的 subcats 的词典化信息基础。问题不在 patterns 上,而是在 patterns 的条件拿捏上。
白:
对,我就是在扬弃范畴语法复杂结构的方面跨出了一大步,坑和萝卜,都是“单体化”的。直到目前还没有发现什么语法现象必须引入复杂结构的。
都一样,吃了吐的路线,关键也在拿捏。
李:
又要简单统一,又要避免伪歧义,感觉是一个矛盾(当然 结构复杂本身也 adds to 伪歧义 ,那是另一个话题)。
白:
伪歧义在外面,中间件来搞。但是中间件面对二元关系搞非常清晰,中间件面向pattern搞就累了。二元关系是最简单的结构。就是一个词典词一个义项,其pos定义只有一层。只有一个“/”号。
李:
这就是我还没有理解的地方,感觉机制太简陋。机制简单统一,词典信息也简单,pos 只有一层,不过是 encode 了一些坑的信息,用的也是简单的 x/y,规定了输入(挖谁的坑)和输出(填什么坑)。如此简单统一,对付自然语言的窍门在哪里呢?
中间件通过二元关系搞定原则上没有问题。所谓语义中间件,在我这里,不过是把已经成串的珍珠链,经过某个子链,把一些语义相谐的珍珠挑出来,让间接关系变成直接的二元语义关系。假如初始的二元图是: 1--》2 --》3 --》4 --》5,语义中间件可以做到:1 --》3; 2 --》5,揭示诸如此类的hidden的逻辑语义关系。白老师的中间件有所不同,用的也是语义相谐(通过某种无监督训练而来),但目的是确保parsing不受伪歧义的羁绊。
白:
复杂的地方是什么时候有免费额度。
荀:
白老师是把这些简单的范畴放到RNN中,这个Rnn中间件性能决定了分析器性能
白:
句法“是什么”在这种机制下确实不复杂但管用。“怎么达到”是另一个问题。
李:
免费额度怎么讲?
白:
比如定语从句里面的坑,就是不占萝卜名额的。填了里面还可以再填外面。还有“NP1的NP2”,如果NP2有坑且与NP1语义相谐或统计意义上搭配,则NP1填入NP2也不占萝卜指标。比如“张三的弟弟”,“这本书的封面”。
李:
好,作为 syntax 表达,这些都不是问题。说说 ”怎么达到“ 吧。
白:
这一部分是parser最核心的地方了。
荀:
就是白老师的“毛毛”,一种利用大数据无监督的subcat嵌入算法。
李:
不是说只要 debug 词典 就可以达到吗?词典也没太多 debug 的余地,假设挖坑填坑都基本在词一级标注清楚的话。然后就灌输大数据?无监督的大数据在这些词典信息的基础上,学习出来的结果是什么形式呢?应该是词典 subcat 的语义相谐的条件。这些条件一旦学出来,就成为 parsing 的伪歧义的克星。
荀:
借助subcat嵌入的分析器要是突破了,短语和pattern也就嵌入在网中了
李:
换句话说,词典的每个词的粗线条的挖坑填坑先由人工敲定,而这些坑的语义条件 让大数据来填,从而粗线条变成细线条。从而伪歧义急剧减少。我是这么个理解。
白:
WSD和Matcher学出来的东西不一样的。
荀:
原来的做法是借助词的语言模型或词的Rnn消解伪歧义,白老师是把Subcat嵌入了网中。但一直担心前期中间件的可信赖程度,中间件错了,休眠唤醒,那么唤醒时是否用了patten?
李:
利用大数据无监督的subcat嵌入算法,这个方向没有问题,词(直接量)不够,一定要加subcat。唤醒可以看作二阶中间件。唤醒的都是局部的、个别的现象(子图 pattern),至少词驱动这一级唤醒,机制上与中间件利用语义相谐没区别,是靠谱的事儿。唤醒在我的实现中,一定是用 pattern (子树)为基。
WSD和Matcher 各自怎么学?
困了,回头好好学习,明儿天天向上。
荀:
这种唤醒的词典知识,主要是利用词搭配信息
李:
那当然。
荀:
李老师休息吧,明天搬着板凳听你们聊,到了关键地方了
白:
为了保证WSD和Matcher之间在大概率情形下都是串行的,被WSD压抑的候选都休眠。此时流程是线状的。为了对付有迹象可察的小概率情形,休眠的候选可以唤醒。此时流程是闭环。
李:
前半段懂了,后半段,闭环是什么?
白:
唤醒
李:
线状是说的 deterministic 吗?
荀:
如果被唤醒,wsd也会跟着改变
李:
唤醒在我看来就是局部重组。nondeterministic 是从一开始就留多条路径,唤醒是在一开始不留多条的情况下,activate 另一条子路径,摧毁现下的子路径。
荀:
如果是局部的,就是打补丁的机制。白老师的闭环是指唤醒和wsd联动?
李:
唤醒都是打补丁。
既然一开始不留多条路径,那么怎么唤醒另一条路径了?
白:
局部局到什么程度是不以主观意志为转移的,可以理解为一种lazy的、保相谐性的subcat传播。
李:
我这里的诀窍就在,开始不在实现的 parse 中留,但词典里面的潜在路径的种子还留着,因此词驱动可以唤醒它。
白:
唤醒的不是路径,而是词典的pos候选
李:
唤醒了不同的萝卜
荀:
唤醒了另外一个候选,也就是到引导不同的subcat路径,可以这样理解吗?
李:
不就等价于唤醒了不同的路径吗?因为萝卜换了,原来的萝卜所填的路径就废了,新的萝卜要填的坑也变了,新的路径也就唤醒(新生)了。
荀:
填好的萝卜重新拔出来
李:
对呀。
这是摧毁无效路径 为建立更好的路径做准备。
荀:
如果wsd需要频繁被唤醒,唤醒的中间件压力山大。
李:
wsd 常常被夸大 实际中没那么大。太细的也不用做。
白:
所以三省吾身。
@荀 是这样子:休眠唤醒的动态工作空间专属wsd,它的范围是受控的,但之间逻辑较为复杂。中间件依据ontology和大数据统计结果,体现了subcat嵌入,是相对静态的,一组二元关系一个查询,彼此逻辑独立,既为wsd服务也为matcher服务,因此根本不在乎频繁程度。忙了就并发,不会惹到谁。wsd局限到一个句子,最多加上定宽滑动窗口的语境变量,工作负载是可控的。wsd和matcher一切照章行事,没有任何语言知识和常识,只有“过程性的、机械化的”程序。语言知识和常识都在词典和subcat嵌入里。
荀:
明白了,就是根据需要,随时被调用的“语言模型”,这个语言模型嵌入了ontology和subccat信息的RNN网络。
白:
今天说多了,打住。
荀:
开启了一个大话题
白:
过去统计意义上的“语言模型”是一勺烩的,所以难以精准地把有结构潜质的二元关系筛选出来。一旦仅针对这样的二元关系上统计手段,前途就一片光明了。萝卜是第一性的,路径是第二性的。
王:
@白硕 wsd和matcher一切照章行事,没有任何语言知识和常识,只有“过程性的、机械化的”程序。语言知识和常识都在词典和subcat嵌入里。
白:
怎么
王:
白老师,要走”小程序,大词典”路线?
白:
对,小程序、大词典、特大ontology、数据被ontology揉碎消化。前面再加个“零规则”。
王:
不知是否每个词做为Agent?然后多个Agent之间相互自适应?
白:
没那么自主
王:
请教白老师,何为“零规则”?是预留的待扩展的规则?还是压根就不用规则?
白:
是根本不要规则。
我们先解决“谁和谁发生关系”而不必具体明确“是何种关系”,只笼统地分成:“a是b的直接成分”、“a是b的修饰成分”以及“a是b的合并成分”三种情况。
现在还都没说定性,只说定位,谁跟谁有关系。结论是,就这么糙的事儿,也得动用ontology。
李:
句法不必要太细。语义可以细,但那个活儿可以悠着点,做多少算多少。
白:
关系不对,上标签何用。标签可以是句法的,也可以是逻辑语义的
李:
句法的本身就模糊一些。很多语言的主语与谓语是有一致关系的。这就给“主语”这个标签一个独立的句法层面的支持。虽然细究起来,这个所谓的主语,可能是 human agent,也可能是 instrument。
白:
粗粒度不等于错位。位置对上了不知什么标签这叫粗粒度。
位置不对叫啥
李:
位置不对就是父子认错了。这是最大的错,皮之不存,句法或逻辑语义标签也就谈不上。
看看这个: 这些纸我能写很多字
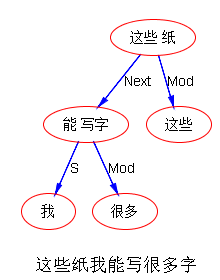
“这些纸”无从着落了。那就用 Topic 或 Next 耍个流氓:它们的句法意义与句首状语(全句状语)差不多,至于是什么状语(时间、地点、让步、工具、结果、原因、。。。),这是逻辑语义的标签。想做的话,让后面的语义模块去做:这些纸 Next 能写字。
其实拿目前的 parser parse 一下大数据,对于 Next 前后的词做一个统计,基本肯定可以挖掘出不少强搭配或弱搭配来。Next 虽然标签模糊,它把有关系的 tokens 的距离拉近了,虽然句法不知道是何种关系。
白:
暂不确定逻辑语义我赞同,但没有坑就不填坑,没有加号就不修饰也是铁律。于是需要一个节点做这个对接。大数据中这个节点有实例支持,引进就更理直气壮而已。
在这个阶段根本没有人去做逻辑语义标记。
李:
逻辑语义是 semantic parsing 的目标;syntactic parsing 可以不管。乔老爷说句法独立于语义肯定是有瑕疵的,但句法确实有相当地独立于语义的部分。这个独立性在形态语言中表现很充分,到了裸奔的汉语表现就差一些。但也不是一点独立性也没有。换句话说,总可以把一部分现象看成是纯粹句法的现象,不牵扯语义,也可以一路走下去。
白:
现在我是在定义syntax,自己定义的东东,自己要认账。
说好了不耍流氓的地方,就是坚决不耍,可以耍的地方也一定当仁不让。
李:
系统内部怎么协调,没法说对错优劣。我是要说,耍流氓也有其耍的道理。不耍,又不想牵扯太多语言外知识,那就只有断链。耍流氓比断链强。
白:
引入虚节点,有大数据背书,挺好。同样达到不断链的效果。
李:
还有一个更重要的特点是:句法模块与语义模块分开,有开发和维护的便利。比一锅炒感觉有优势。
白:
相谐问中间件可以,补虚节点问中间件当然也可以,毕竟大多数情况不需要补。
wsd和matcher现在连一点语言学知识都没有,是最不一锅炒的架构了。
内事不决问词典,外事不决问数据
李:
开发一个模块有两个模式,一个是轻装粗线条,knowledge-poor。另一种是细线条,knowledge intensive,前者的好处不仅在轻装,不仅在覆盖面好,而且在鲁棒性好。后者则是精准度好,而且可以聚焦去做,一步一步 peace-meal 地去做。很多人做了前者,但是带来了一个巨大的伪歧义泛滥的问题。我们做到了前者,而且基本对伪歧义免疫,这算是一个成就。至于后者,那是一张无边无际的网,不急,慢慢做。
白:
大部分不鲁棒都是伪语序造成的。让萝卜和坑自由恋爱,是鲁棒性的最好体现。
李:
白老师主张先不利用语序作为句法的制约,而是立足于词典的对萝卜的预期,以及查与周边 candidates 在中间件表达出来的语义相谐度。这样做自然是增加了鲁棒性(我以前提过,汉语实词之间的语序灵活到了超出想象),但同时也隐隐觉得,不问语序也可能是自废武功的不必要的损失。其实是可以把语序作为一个option加入坑的预期的。
【相关】