大赞了神经机器翻译的革命性进步以后,提到两个短板 其一是不忠:无中生有或化有为无 以假乱真 指鹿为马 胆大包天。其二是依赖领域数据 没有数据的领域 立马傻眼。
李:
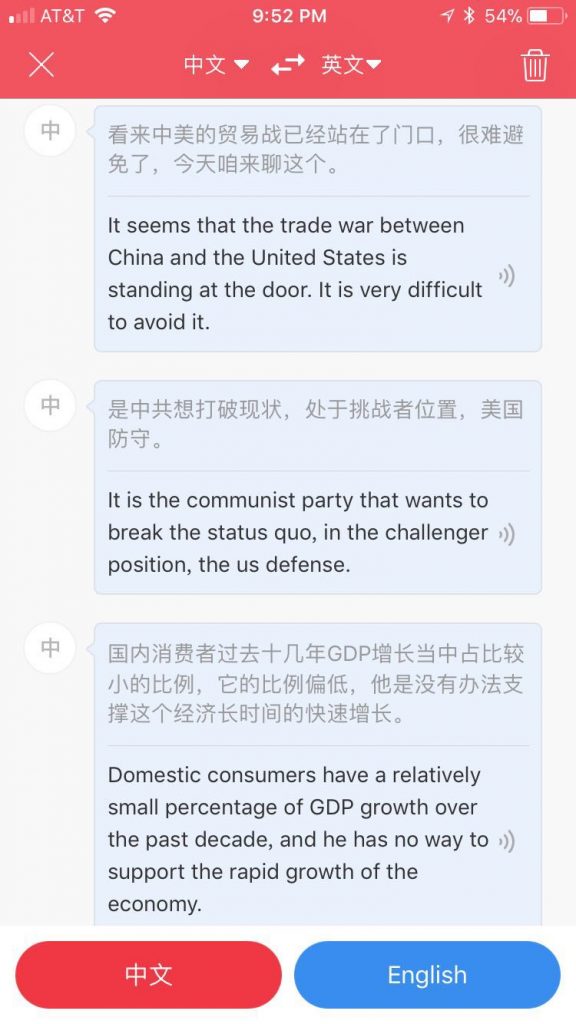
我用有道app里面的口译功能测试了一下字正腔圆的做节目的人,【文昭談古論今】, 一边在 youTube 上看他的视频,一边把有道打开做现场口译,几乎完美无缺。
毛:
同声传译,以后是不需要的了。
李:
识别我的口音还是有误:识别我的英文比中文似乎更好一些。上面的那位是自媒体里面的很受欢迎的一位,文科背景,出口成章,比播音员说话还清晰。
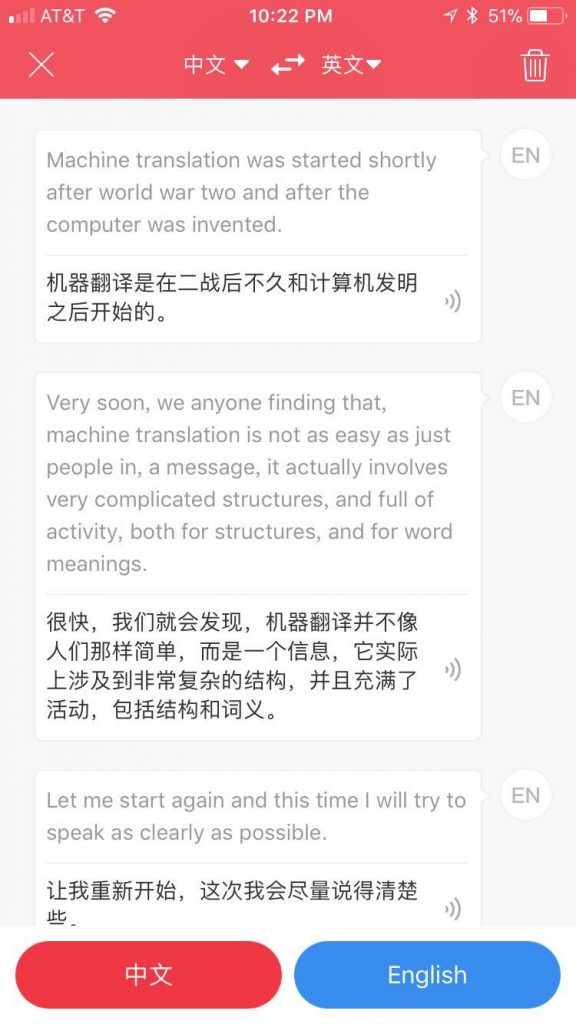

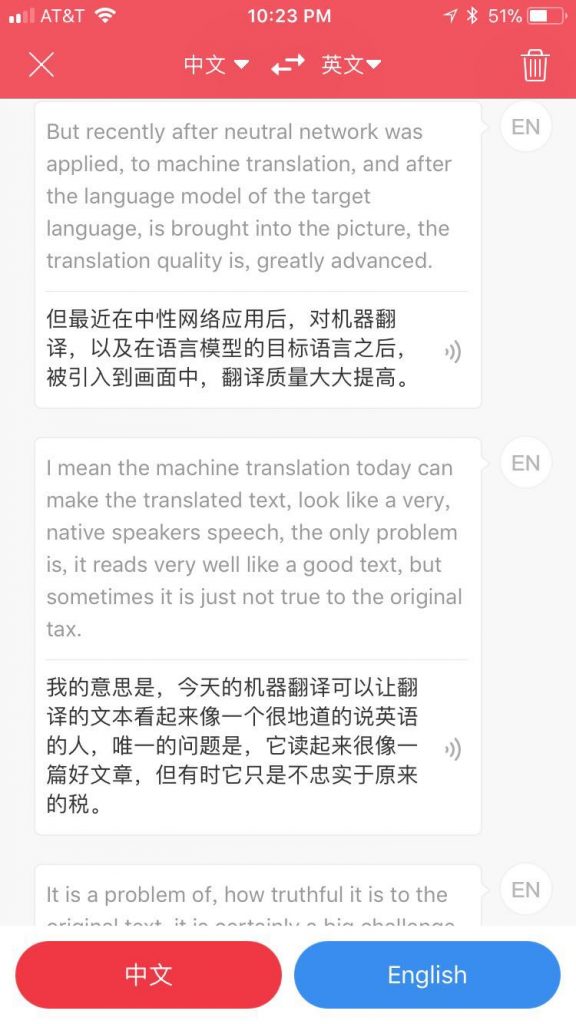
语音识别的两个明显错误:neural network 错成了 neutral network,text 成了 tax(税),大概是我的英语发音的确不够好。但总体而言,句子蛮长,一口气说一大段,它也一样即时翻译(通过wifi接云端,立等可取)。
哈,text 与 taxi(出租车)也打起架来:
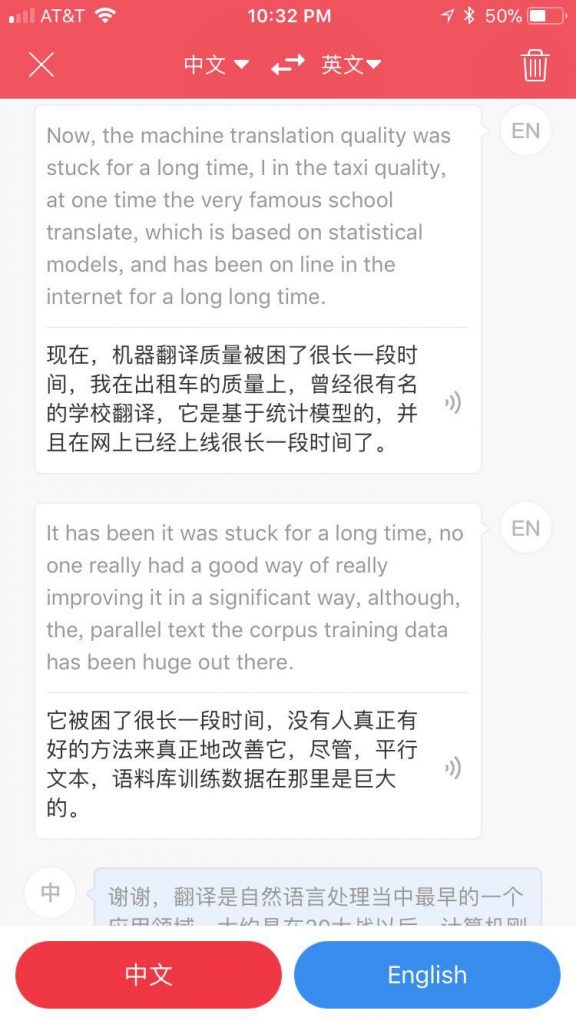
从这些人类不会犯的错误看,神经 MT 的巨大成功,与语音转写的巨大成功,完全是一个道理,都是在真正的海量数据中模仿,而没有任何“理解”。不合逻辑 不合事理的句子 会以一种蛮“顺耳”的方式呈现出来。
尽管如此,我们当年还是没想到,在没有解析和理解的前提下,这条路能走这么远。很久以来,我们的信念是,没有理解,无从翻译。鹦鹉学舌,可以学几句零碎的片段,但绝不可能把如此复杂的自然语言,学得如此栩栩如生。但事实上,“鹦鹉学舌”方式,在强大的数据和运算能力支持下,的的确确可以做到在很大的范围几乎可以以假乱真。
短板也是显然的,没有数据的话,再强大的运算也培训不出一只鹦鹉来。譬如,电商场景的机器翻译,由于缺乏汉英对照的大数据,就寸步难行。
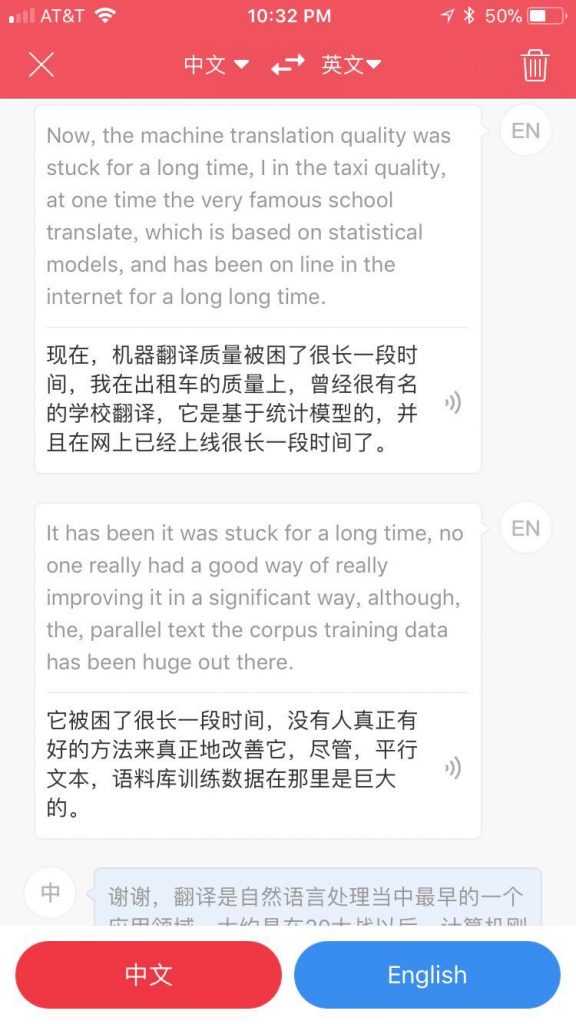
下面是我说中文,让有道口译为英文的试验:
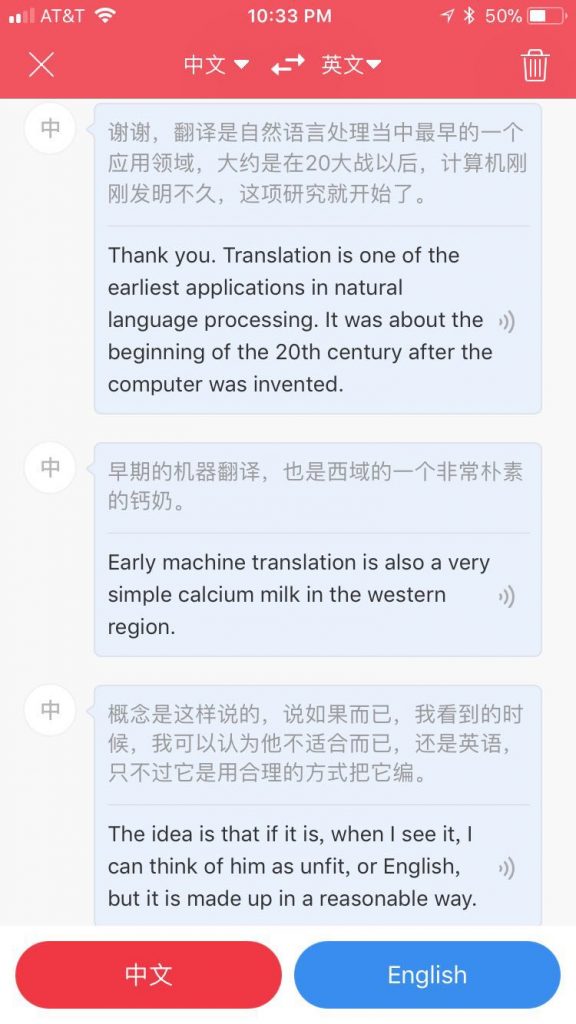
“二次大战”先转错为“20大战”,继而又错译为 “20th centuray”。这个错误很值得评论,说明了神经翻译为什么求得了“顺畅”牺牲了“忠实”。我说的是“大约是在二次大战以后”,虽然转写就错了一个字,成为“大约是在20大战以后”,翻译却错得离谱:这不是原来意义上的错误放大(error propagation),而是目前神经翻译“乱译”趋向的一个表现,by design:这种乱译的确在很大程度上克服了上一代统计机器翻译“不顺畅”的致命缺点。
“乱译”(或者“顺畅”)的根子在,目前的机器翻译里面有专门针对目标语的语言模型在,不仅仅是双语对照模型。目标语的模型里面“beginning of 20th century”一定是足够的常见,被记住了,所以尽管原句是“20大战以后”,它也一样无视(“大战”居然摇身一变,成了 century,是为指鹿为马,“以后”弄成了其反面 beginning,这简直是颠倒黑白),如果是前一代统计翻译(statistical MT),或者前前一代的规则翻译(rule-based MT),这种错误绝不会出现,应该是译成 “20 wars later”或 “after 20th war”之类。可是 目标语训练数据中根本就没有这个 “20 war” 这样的提法,与其忠实而别扭,不如化有为无或无中生有,甚至指鹿(20 war)为马(20th century),以求“顺畅”。这是目前机器翻译的短板,已经被很多人察觉和批判,研究界也在研究对策。
也就是说,为了“顺畅”,目前的系统可以无视原文中的一些材料。同样为了“顺畅”,译文也可以无中生有加一些材料。这对不懂原文的人可能非常误导:批评者说,找翻译本来就是因为不懂原文,结果你翻译出来,听上去那么顺畅,让我不得不信,可其实你暗度陈仓,居然敢于胡编乱造,这也太搞了吧。
这种批评当然言之成理,信达雅,信是基础,信求不得,达雅何用?无信,达雅反而更加迷惑人,不如不译。你无中生有了一个地方,让我怀疑你整篇都不可信了。这种想当然的胡编乱造真是害死人。
不过,其实了解历史和经历过机器翻译不同阶段的人,会有不同的角度。实际是,前两代机器翻译的译文大都惨不忍睹,在可读性和顺畅上没有根本的解决途径(点滴的积累式进步还是有的),虽然意思也能勉强传达(就是说不会在“信”上胆敢无中生有或化有为无)。这个问题是如此严重,以至于影响了很多人使用机器翻译的意愿,除非是不得已,因为看机器译文实在是太别扭,太难受了。
毛:
能把谎说圆,这不正是逼近了人的智能吗?
李:
@毛德操 问题是,鹦鹉学舌,哪里有什么“把谎说圆”。机器不会说谎,正如机器不会说真;同理,潜艇不会游泳。无中生有是真的,但“胡编乱造”不过是个比喻说法。机器没有歹心,正如机器没有良心。因为机器根本就没有心。有的不过是记忆和计算而已。硬要把计算说成智能,硬要把比喻当成真相,那也没辙。乔姆斯基的态度是,不理睬。还好,当年创造的是“人工智能”这个词,脱不开“人工”、“人为”、“模仿”的涵义。如果先驱们当年达特茅斯开会,不小心起个名字是“机器智能”,那可就糟透了。
Nick:
@wei 英国最早的说法就是machine intelligence。大概到七十年代才开始被美国带成人工了。
李:
达特茅斯会上呢?
马:
达特茅斯会上,还有一个词是复杂信息处理,不过最后还是AI占了上风。
李:
先驱们蛮“接地气”啊。其实,“复杂信息处理”很中肯,符合术语命名的严肃性。AI 还是太过“性感”了。
机器翻译更惨,很长时间是 “自动翻译”、“机器翻译” 混用,后来基本统一为机器翻译,因为自动翻译有多种用法 什么全自动翻译 半自动翻译等等。当然 较真的话,自动翻译比机器翻译还不堪。其实应该叫做随大流翻译,或者叫做 NLU-free translation,简称无智翻译,and I was not kidding.
Nick:
自动/机器 定理证明。mt就不太好说artificial translation,中文更不能说 人工翻译。artificial本来就有点 瞎编 的意思。
李:
其实还真就是 artificial,本来就是仿造啊。译成汉语是仿人翻译。没有人的翻译样本,大量的样本,当今的MT根本就不可能。
马:
AI翻译
李:
人工智能其实应该翻译为人造智能。人造翻译(或仿人翻译)与人工翻译可大不相同。但取法乎上仅得其中的古训不大灵了,古训忽略了量的概念。被取法者足够大量的时候 所得不止于中。AI 代替中庸 势在必行。取法乎众 可得中上,这是事实。但最好的机器翻译不如最好的人工翻译,这也是事实。因为后者有智能 有理解。而前者虽然号称神经了,其实连“人造的理解”(譬如 NLU)都没有。
现如今人工智能好比一个性感女郎,沾点边的都往上面贴。今天跟一位老人工智能学者谈,他说,其实人工智能本性上就是一个悲催的学科,它是一个中继站,有点像博士后流动站。怎么讲?人工智能的本性就是暂时存放那些机理还没弄清楚的东西,一旦机理清楚了,就“非人工智能化”了(硬赖着不走,拉大旗作虎皮搞宣传的,是另一回事儿),独立出去成为一个专门的学科了。飞机上天了,潜艇下水了,曾几何时,这看上去是多么人工智能啊。现在还有做飞机潜艇的人称自己是搞人工智能的吗?他们属于空气动力学,流体动力学,与AI没有一毛钱的关系。同理,自动驾驶现如今还打着AI的招牌,其实已经与AI没啥关系了。飞机早就自动驾驶了,没人说是人工智能,到了汽车就突然智能起来?说不过去啊。总之,人工智能不是一个能 hold 住很多在它旗下的科学,它会送走一批批 misfits,这是好事儿,这是科学的进步。真正属于人工智能的学问,其实是一个很小的圈圈,就好比真正属于人类智能的部分也是很小的圈圈,二者都比我们直感上认为的范围,要小很多很多。我问,什么才是真正的恒定的AI呢?老友笑道,还是回到前辈们的原始定义吧,其中主要一项叫做“general problem solver”(西蒙 1959)。
马:
是这么回事。11年写的一篇博客:人工智能,一个永远没有结果的科学_马少平_新浪博客。
李:
好文。马老师科普起来也这么厉害啊 堪比白居易写诗 老妪能解。有说服力 而且生动。
“11年写的一篇博客”。走火入魔 第一眼看这句 我无意识把自己变成了神经网络 网络里面是这样编码的:“11 years ago 写了一篇博客”,宁顺不信。我的大数据训练我首先排除了 2011 的选项 然后无中生有加了个 ago 以求顺畅。摩登时代,忠实值几个钱?忽悠才是摇钱树。
马:
用时11年,?
洪:
人工智能是江湖,八仙过海都威武。武侠人物不绝出,很多虚晃都诈唬。
AI像狗头前置棍,棍拴骨头引狂奔。确实因之人前进,精髓却总不得啃。
李:
洪爷的诗没治了,大AI无疆,无处不诗啊。
回头说宁顺不信。两相比较,平心而论,对于多数人多数场合 还是顺畅的权重似乎更大。只是需要记住三点:(1)认真使用前,需要人工核对:机器译文只是提供一个快速浏览,了解个大概的选项,虽然总体的忠实比例其实不差,但任何一个点都可能错得离谱;(2)翻译工作者如果不学会利用机器翻译,与机器合作提高效率(要善于做核对和后编辑),很可能不久会淘汰:实际上翻译的工作市场已经急剧萎缩中,有道本身提供的人工翻译已经快速便宜到不行,可见能够生存下来的少数人工翻译一定是学会人机合作的工作模式的。(3)AI 还在飞速发展中,让我们拭目以待,看今后的系统能不能在信达雅三者之间做更好的平衡。可以想象的一个可能是,将来的系统至少可以让用户在“忠实”和“顺畅”中做权重的选择:根据偏好的不同,系统应该可以做不同的翻译:偏重忠实但生硬一点的选项(就是鲁迅曾经践行过的“硬译”),或者偏重顺畅却可能局部不忠实的选项。
The Shallowness of Google Translate
It’s pretty lengthy. Pointing the fact of no understanding in deep learning. We all know it is true. What we did not know was how far a system can go without understanding or parsing on an end to end deep neural network modal. All criticisms here are valid but still MT has never been this impressive and useful in practice unless you make the wrong choice to use it for translating literary works or for translating domain documents where it has no human translation data to learn from.
【相关】
The Shallowness of Google Translate
有道的机器翻译(http://fanyi.youdao.com/)