01
开场词
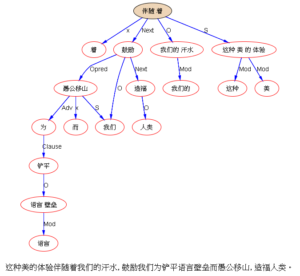
“如果爱因斯坦在时空万物中看到了造物主的美,如果门捷列夫在千姿百态的物质后面看到了元素表的简洁,语言学家则是在千变万化的语言现象中看到了逻辑结构之美。这种美的体验伴随着我们的汗水,鼓励我们为铲平语言壁垒而愚公移山,造福人类。”
02
语言的奥秘:解构
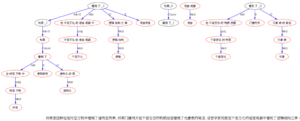
话说这语言学里面有一门学问叫文法,学文法简单来说就是学画树。各种各样形态各异的树,表达了语言的多姿多彩,却万变不离其宗,奇妙啊。当年上帝怕人类同语同心去造通天之塔,乱了天地纲常,遂下旨搅乱了人类语言。印欧汉藏,枝枝蔓蔓,从此语言的奥秘就深藏不露。于是催生了一代一代文法学家,试图见人所不能见,用树形图来解剖语言的内部结构。
本来我们说话写文章都是一个词一个词往外蹦,这样出来的句子数学上叫线性一维。可这线性的东西到了文法家眼里就变了,一维变两维,线性变平面,于是产生了树形结构。
天机不可泄漏,泄漏者非神即仙。历史上有两位功力非凡的文法神仙专门与上帝作对,各自为语言画树,一位是依存文法大师,叫Tesnière(特氏),另一位就是大名鼎鼎的乔姆斯基(乔氏)。本文的结构图表示法(graph representations)取长补短,乃是以特氏依存关系为框架,适当辅以乔氏的短语结构而成。本文所有图示均是我们研发的多语分析器对语句全自动解析而成。

乔神仙(Noam Chomsky)特神仙(Lucien Tesnière)
语言的奥秘在于,语句的呈现是线性的,而语句背后的结构却是二维的。我们之所以能够理解语句的意思,是因为我们的大脑语言处理中枢能够把线性语句解构(decode)成二维的结构:语法学家常常用上下颠倒的树形图来表达解构的结果。树形图分析法(sentence diagramming)也一直是语言教学的一个手段。
计算语言学家的任务就是模拟这个语言解构的过程,创制解析器(parser),使解构自动化。这个任务一直处于自然语言处理(natual language processing, NLP)领域的核心,但长期以来大多是科学家的玩具系统(toy systems),或局限于实验室的原型系统(prototypes),其速度(speed)、精准度(precision)、覆盖面(recall)和鲁棒性(robustness)都不足以在真实语料的大数据场景应用。
而这一切已经不再是梦想,符合处理线速要求的高精准度和高覆盖面的鲁棒parsers已经是现实。这是大数据时代的技术福音。笔者在Netbase时期设计并带领团队研发的多语parsers就已经大规模投入(scale up)社会媒体大数据的应用,帮助自动挖掘针对任何话题或品牌的舆情与客户情报。
03
Deep Parsing 是语言技术的核武器
自然语言理解(natural language understanding,NLU)的关键就是模拟人的理解机制,这套机制的核心是 deep parser,其输入是语句,输出是语法逻辑结构。在结构图的基础上,很多语言应用的奇迹可以出现,如舆情挖掘,情报抽取,自动文摘,智能搜索,智能秘书,聊天机器人,心理疏导机等等。
对于看了树形图觉得眼晕的读者,不必明白细节,只要知道线性转成了平面就可以了,非结构转成结构乃是语言理解应用之根本。以下图为例,我们具体分析一下语言结构分析的结果表达。
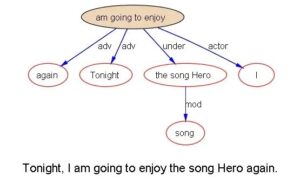
上图叫作依从关系树形图。直观地说,所谓理解了一句话,其实就是明白了两种意义:(1)节点的意义(词汇意义);(2)节点之间的关系意义(逻辑语义)。譬如上面这个例子,在我们的自动语句分析中有大小六个节点:【Tonight】 【I】 【am going to enjoy】 【the 【song】 Hero】 【again】,分解为爷爷到孙儿三个层次,其中的逻辑语义是:有一个将来时态的行为【am going to enjoy】,结构上是老爷爷,他有两个亲生儿子,两个远房侄子。长子是其逻辑主语 S(Actor) 【I】,此子是其逻辑宾语 O(Undergoer)【the song Hero】,父子三人是语句的主干(主谓宾 SVO),构成语句意义的核心。
两个远房侄子,一个是表达时间的状语(adverbial)【Tonight】,另一个表达频次的状语(adverbial)【again】。最后,还有一个孙子辈的节点【song】,他是次子的修饰语(modifier,是同位语修饰语),说明【Hero】的类别。
语言为什么要结构化?盖因语言是无限的,但结构是有限的。本文所示的的全自动解构树形图,用于语言大数据,就为各种数据挖掘(包括舆情挖掘)提供了结构化的情报宝库。对于信息使用者,这就是不尽的宝藏。
对于信息产品,语用语义当然是重要的,但是语义可以临时抱佛脚,结构则不同。用工程的话说就是,语言处理面对的是海量文本大数据,需要做 offline indexing, 不适宜纠缠过细的语义语用,而是应该先结构化了再说,存到数据库去。在应用的层面,通常需要的是领域场景的语用角度的语义(通过领域化信息抽取和文本挖掘)。这时候,做语义的条件已经成熟了。应用层面的语义一般是在一个特定的领域,或者为了一个特定的用场(产品),抽象层的语义纠缠因聚焦而简化,甚至自然化解了。面对大数据,对于难以预测的情报需求,可以直接对大数据所对应的结构图索引做在线即时检索,检索的时候加入适量的语义限制即可。这其实是下一代智能语义搜索引擎的并不遥远的革命性愿景。这样的句法和语义分工,在工程上是合理的。结构化是语言理解应用之本,结构化数据基础是满足语用需求做情报挖掘的质量保证。
04
婀娜多姿,风情万种
上得厅堂,下得厨房
本文所演示的各种树形图就是我们研发出来的文法机器人(parsers)自动生成的,虽然并非完美无缺,倒也风姿绰约。多语结构树没什么奥妙,大家的表达大同小异,都是秉承特神仙或乔神仙的体系。可是怎样达到这个结构,才是硬功夫。
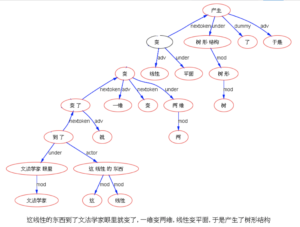
下面以乔姆斯基上世纪五十年代末引发语言学革命的名句 “Colorless green ideas sleep furiously” 为例,请读者与我们一同欣赏多语 parsers是如何透过千差万别的具体语言的词汇词法的排列,解构出类似的句法结构:
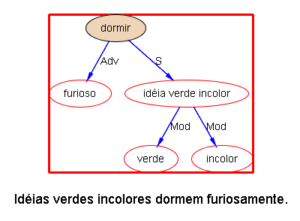
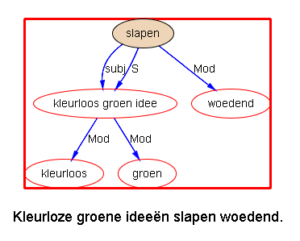
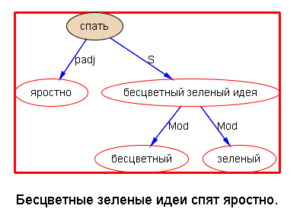
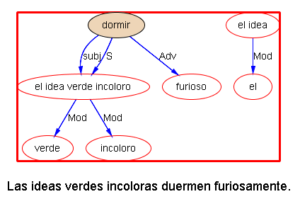
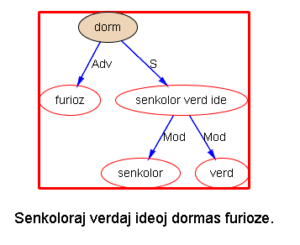
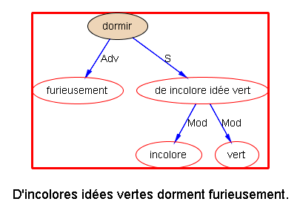
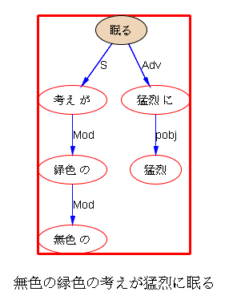
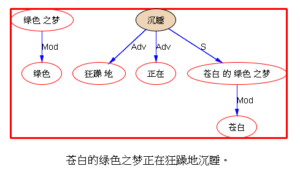
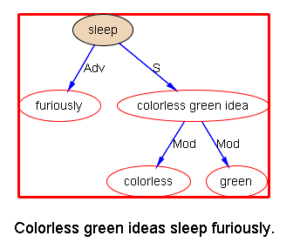
我们每天面对的就是这些树木构成的语言丛林。在我的眼中,它们形态各异,婀娜多姿,变化多端而不离其宗(“语法”)。最关键的是,风情万种的结构丛林,已经不再是象牙塔里供人观赏的艺术模型,她上得厅堂,下得厨房,甚至对于随处可见错别字、不规范用法的社交媒体大数据,也一样适用。这是怎样一个语言奥秘的探测仪,她的作用和巨大潜力才刚刚开始!
NLP自选系列2020专栏连载
