世界语到汉语和英语的自动翻译试验
-- EChA机器翻译系统概述
世界语形态分析
源语文句分析大体可以分形态分析和句法分析两大类. 前者研究的对象小于等于词, 而后者的对象大于等于词(句素). 分析的终极目的就是求解词的正确的CDC成分. 本节先讨论形态分析问题. 我们把构词分析的讨论也放在这一节.
世界语形态分析的主体是消尾算法的建立. 世界语没有形态同形现象, 所以只要削尾正确, 形态分析也就完成. 下面给出EChA的削尾算法. 应该说, 该算法是比较完备和合理的, 完全能够满足世界语自动分析实用系统的要求.
世界语削尾算法
(1) 若该词最末字母为 "-O" 取 "名词 / 普通格 / 单数" 的结论, 该词削尾后查实词词干词典, 转下一步(2), 否则步骤(12).
(2) 若查词典成功, 取词典信息到加工场, 该词加工完毕, 否则下一步(3).
(3) 若该词最末二字母为 "-AD" 取 "AD词" 的结论, 该词削尾后查实词词干词典, 转下一步(4), 否则步骤(5).
(4) 若查词典成功, 取词典信息到加工场, 该词加工完毕, 否则步骤(11).
(5) 若该词最末三字母为 "-ANT" 取 "分词 / 进行式 / 主动式" 的结论, 该词削尾后查实词词干词典, 转步骤(4), 否则下一步(6).
(6) 若该词最末三字母为 "-INT" 取 "分词 / 完成式 / 主动式" 的结论, 该词削尾后查实词词干词典, 转步骤(4), 否则下一步(7).
(7) 若该词最末三字母为 "-ONT" 取 "分词 / 将来式 / 主动式" 的结论, 该词削尾后查实词词干词典, 转步骤(4), 否则下一步(8).
(8) 若该词最末二字母为 "-AT" 取 "分词 / 进行式 / 被动式" 的结论, 该词削尾后查实词词干词典, 转步骤(4), 否则下一步(9).
(9) 若该词最末二字母为 "-IT" 取 "分词 / 完成式 / 被动式" 的结论, 该词削尾后查实词词干词典, 转步骤(4), 否则下一步(10).
(10) 若该词最末二字母为 "-OT" 取 "分词 / 将来式 / 被动式" 的结论, 该词削尾后查实词词干词典, 转步骤(4), 否则下一步(11).
(11) 该词取 "生词" 的结论, 保留削尾结论, 在加工场的目标语语义项里复制该词, 该词加工完毕.
(12) 若该词最末字母为 "-'" 取 "名词 / 普通格 / 单数" 的结论, 该词削尾后查实词词干词典, 转步骤(2), 否则下一步(13).
(13) 若该词最末字母为 "-A" 取 "形容词 / 普通格 / 单数" 的结论, 该词削尾后查实词词干词典, 转步骤(2), 否则下一步(14).
(14) 若该词最末字母为 "-E" 取 "副词 / 普通格" 的结论, 该词削尾后查实词词干词典, 转步骤(2), 否则下一步(15).
(15) 若该词最末字母为 "-J" 取 "普通格 / 复数" 的结论, 该词削尾后转下一步(16), 否则步骤(18).
(16) 若该词最末字母为 "-O" 取 "名词" 的结论, 该词削尾后查实词词干词典, 转步骤(2), 否则下一步(17).
(17) 若该词最末字母为 "-A" 取 "形容词" 的结论, 该词削尾后查实词词干词典, 转步骤(2), 否则步骤(11).
(18) 若该词最末字母为 "-N" 取 "目的格" 的结论, 该词削尾后转下一步(19), 否则步骤(23).
(19) 若该词最末字母为 "-J" 取 "复数" 的结论, 该词削尾后转步骤(16), 否则下一步(20).
(20) 若该词最末字母为 "-O" 取 "名词 / 单数" 的结论, 该词削尾后查实词词干词典, 转步骤(2), 否则下一步(21).
(21) 若该词最末字母为 "-A" 取 "形容词 / 单数" 的结论, 该词削尾后查实词词干词典, 转步骤(2), 否则下一步(22).
(22) 若该词最末字母为 "-E" 取 "副词" 的结论, 该词削尾后查实词词干词典, 转步骤(2), 否则步骤(11).
(23) 若该词最末字母为 "-S" 转下一步(24), 否则转步骤(30).
(24) 若该词最末二字母为 "-AS" 取 "现在时" 的结论, 该词削尾后转步骤(28), 否则下一步(25).
(25) 若该词最末二字母为 "-IS" 取 "过去时" 的结论, 该词削尾后转步骤(28), 否则下一步(26).
(26) 若该词最末二字母为 "-OS" 取 "将来时" 的结论, 该词削尾后转步骤(28), 否则下一步(27).
(27) 若该词最末二字母为 "-US" 取 "虚拟式" 的结论, 该词削尾后转步骤(29), 否则步骤(32).
(28) 取 "陈述式" 的结论, 转下一步(29).
(29) 取 "动词 / 谓语 / 主动语态" 的结论, 查实词词干词典, 转步骤(2).
(30) 若该词最末字母为 "-I" 取 "动词 / 不定式" 的结论, 该词削尾后查实词词干词典, 转步骤(2), 否则下一步(31).
(31) 若该词最末字母为 "-U" 取 "命令式" 的结论, 该词削尾后转步骤(29), 否则下一步(32).
(32) 查虚词词典(因该词无尾可削). 若成功取词典信息到加工场, 该词加工完毕, 否则取 "名词 / 专有名词" 的结论, 返回步骤(11).
[注] 世界语基本法规第16条说: "名词和冠词末尾的元音字母可以省略, 用省略号 ' 来代替". 这种现象多出现在诗歌里, 如 MOND'(103). 我们在步骤(12)对它作了处理(冠词是长度小于 3 的虚词, 直接查虚词词典, 不入削尾一线, 故不予考虑).
我们谈谈构词分析问题, 这包括两个方面: 1. 关于建立削缀算法(派生词处理)的讨论; 2. 关于拆离合成词的讨论. 在现行的EChA系统中, 这两个问题都回避了. 我们建立的词典, 是以词干(包括合成词词干)作存贮单位的, 加工词只要削去语法词尾, 就可以查到. 但是, 应该指出, 这样做, 对于世界语这种构词特别灵活的语言并不合理. 以词干存词, 在做小型实验时还可应付, 如果是实用系统, 就会出现存不胜存的情况. 我们主张实词词典既存词根也存词干, 同时建立一个完全的世界语削缀算法和合成词拆离算法, 以便对付生词. (世界语除国际性的专业词汇外, 基本词根很有限. 所谓生词, 一般都是由基本词根及几十个词缀随机组合的派生词或合成词. 因此, 只要切分正确, 生词便不 "生".)
世界语后缀可以叠加(理论上无限), 但前缀通常只能有一个. 这样词典一线的加工路径应该是:
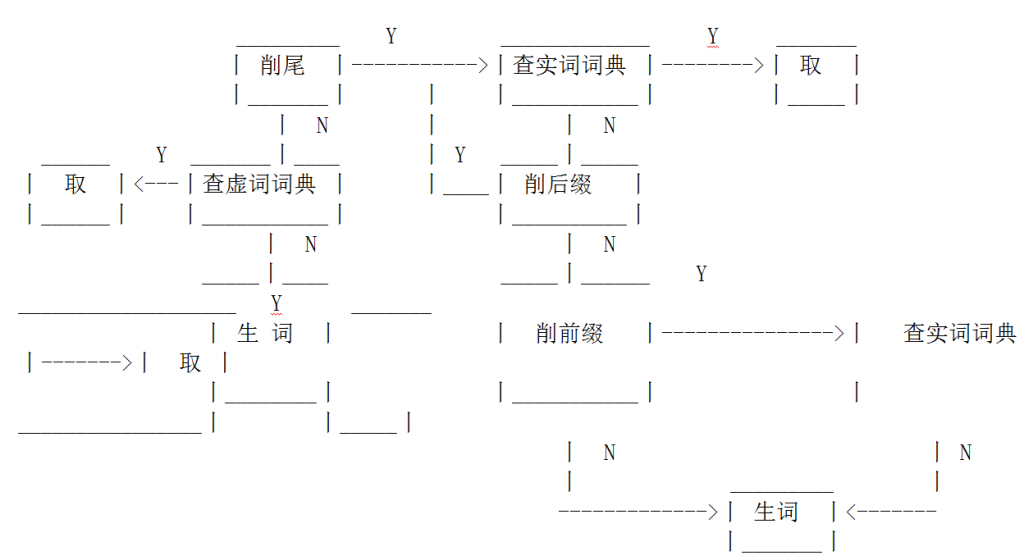
削缀与削尾不同, 并非有缀必削. 对于削尾, 机器是先削后查, 而对于削缀, 则是先查词典, 查不着的生词再去削缀. 这样处理便于我们根据设计要求(实验型还是实用型, 对于翻译速度, 质量, 成本的要求等等)和机器条件(内存容量, 运算速度等)决定实词词典收词干的标准.
现在, 由于计算机技术的发展, 机器功能(存贮, 速度)越来越强, 而成本急遽下降. 因此机器翻译界如今有人提倡存贮单位宜大不宜小(如尽量多收成语的主张[7] ), 以海量存贮和快速查找来减轻分析的负担. 这是很有见地的认识. 单位越大, 确定性就越强, 对分析综合(机器智能)的要求就越低, 研制的难度相对减轻, 而译文的质量会大大提高. 机器翻译是实用性?
很强的学科, 这种主张就显得更有价值. 当然, 单位也不是越大越好, 因为单位每大一级(从词根到词干, 从词干到词, 从词到词组, 从词组到语句), 其组合的可能性呈指数增长.[8] 如果推向极端, 以句子为存贮单位, 则完全不需要分析和综合, 只要对号入座即可输出译文. 这时候, 人工智能的程度等于零, 翻译质量却可以达到最佳(如果以人工水平为最佳). 可惜, 硬件技术无论怎样发达, 其存贮容量和查找速度也总有限, 不可能对付无穷的句子. (但为了某种特殊的需要在有限的范围内, 这种办法是可行的, 如旅游翻译机. 这到底还算不算机器翻译? 应该算的, 只是它不是人工智能意义下的机器翻译.) 机器翻译的另一极是以词素(词根, 词缀, 词尾)为分析单位, 它所需要的词典容量(只存词根)最小, 人工智能的水平最高, 不但有句法分析和综合, 还要有构词分析和综合. 但费了好大劲儿, 质量却最不能保证, 因为一个句子掰得太碎(原文分析), 捏拢来总难免有些难看的痕迹(译文综合). 所以, 现行的机译系统, 一般都是在这两极中根据具体条件和设计者的观点取某个中值. 我们认为, 一个优秀的实用系统应该有两手, 既能分析得很透彻, 又能对常用词组(成语)囫囵儿处理. 该细的地方细得下去, 该粗的地方粗得起来. 一般来说, 对于常用的, 固定的, 个性的可枚举现象粗一点比较有利, 而对于规律性的随机现象, 则适宜较细致的分析. 所以, 对于以世界语为分析对象的实用机译系统, 我们既主张尽可能多收成语和带缀词干, 也充分肯定建立一个完备的削缀算法的必要性.
那么, 世界语实词词典收多少派生词词干比较合理呢? 对于独立型机器翻译:
(1) 如果是小型实验系统, 目的是在有限的材料内试验系统的句法分析和综合能力, 那就词干全收; 否则:
(2) 凡是常用的派生词词干一律收进词典, 而不再入削缀子程序----常用性(出现频率高)是根本标准;
(3) 有助于区别同形多义的派生词词干, 应该收;
(4) 可收可不收的, 主张收;
(5) 在刚开始设计实用系统的机器词典时, 由于世界语词缀的极端灵活性和随机性, 很难一次收入许多带缀的词干, 这样, 削缀算法就显得更重要. 削下缀来, 虽然表义不是很确切, 甚至有时在目标语综合时, 还需要辅以说明性注释(见后面例释), 但总比直接打出生词来(信息量为零)强出百倍. 随着系统的不断扩充和完善, 收的词干自然会越来越多.
如果是具有特定的目标语的相关型机器翻译:
(1) 收多少派生词词干应该考虑目标语的构词特点及词汇状况;
(2) 在目标语中作为一个完整概念, 而不是词根和词缀意义简单相加所能反映的词干, 应该收入词典. 如: DOM-EGO 楼房, 大厦 (而不是一般的 "大-房子" );
(3) 如果以汉语为目标语, 削缀更多一些, 因为世汉构词法很相似, 汉族人的心理本能地习惯于理解词素与词素的组合. (这种民族偏爱心理在引进外来词时表现的很明显, 如 "德律风" 为 "电话" 取代, "莱塞" 为 "激光" 取代等.) 可以举出很多世汉构词神似的例子. 而且也有许多世界语派生词如 DOM-ACHO 虽然整个儿译作 "陋室" 更雅一些, 但也不妨用统一的削缀合成法组成新词 "鬼-房子", 与原义相去也不远. 特别是有些缀与汉字(词素)有很多一致性, 如 VIC-/副-, -IN-/女-, -EBL-/可- 等等, 就更有理由作削缀处理.
世汉构词对比例释(1): 派生词
(1) BO- 姻- : BO-PATRO 姻-父亲 (岳父或公公) , BO-FILO 姻-儿子 (女婿) , BO-FRATO 姻-兄弟 (内弟) ;
(2) GE- (男女)- : GE-AMIKOJ (男女)-朋友们 , GE-KAMARADOJ (男女)-同志们 , GE-AKTOROJ (男女)-演员们 ;
(3) EKS- 前- : EKS-OFICISTO 前-职员 , EKS-MINISTRO 前-部长 , EKS-INSTRUISTO 前-教师 ;
(4) MAL- [反义] : MAL-BONA [反义]好 (坏) , MAL-AMIKO [反义]朋友 (敌人) , MAL-SAGHE [反义]聪明 (愚苯) ;
[说明] MAL-是世界语中用得最广, 随机性最强的前缀之一, 具有极强的造词能力, 可惜, 中文没有对应的词素. 如果系统遇到某个MAL-型生词, 削下前缀后给出[反义]这样的说明性标识, 也还可以使人理解.
(5) VIC- 副- : VIC-PREZIDANTO 副-主席 , VIC-ESTRO 副-队长 , VIC-CHEFMINISTRO 副-总理 ;
(6) FI- 坏- : FI-INSEKTO 坏-虫 , FI-KOMERCISTO 坏-商人 (奸商) , FI-KUTIMO 坏-习惯 (恶习) ;
(7) SEN- 1. 若词根逻辑类为名词则 "无-" : SEN-GUSTA 无-味的 , SEN-SENCA 无-意义的 ;
- 若词根逻辑类为动词则 "不-" : SEN-MORTA 不-死的 (不朽的) , SEN-ATENTA 不-注意的 ;
(8) NE- 若词根逻辑类为名词则 "非-" 否则 "不-" : NE-ESPERANTISTO 非-世界语者 , NE-BONA 不-好的 ;
(9) 介词性前缀: 1. SUR- -上: SUR-TABLE 桌子-上 ; 2. APUD- -旁: APUD-VOJA 路-旁的 ;
- EN- -内: EN-LANDE 国-内 ; 4. LAU- 按-: LAU-VICE 按-次序 ; 5. DE- 从-: DE-NOVE 从-新 ;
(10) -ACH- 鬼- : DOM-ACHO 鬼-房子 (陋室) , KNAB-ACHO 鬼-男孩 (捣蛋鬼) , VETER-ACHO 鬼天气 ;
(11) -AN- -成员 : KLUB-ANO 俱乐部-成员 , KURS-ANO 讲习班-成员 , KOMUNUM-ANO 公社-成员 ;
(12) -UL- -者 : BON-ULO 好-者 , KAR-ULO 亲爱-者 , JUN-ULO 年青-者 , LONG-KRUR-ULO 长/腿-者 ;
(13) -IN- 女- : KAMARAD-INO 女-同志 , INSTRUIST-INO 女-教师 , OFICIST-INO 女-职员 , AKTOR-INO , 女-演员 ;
(14) -EBL- 可- : VID-EBLA 可-见的 , MANGH-EBLA 可-吃的 , UZ-EBLA 可-用的 , NE-ATING-EBLA 不-可-达到的 ;
(15) -EC- -性 : CERT-ECO 确实-性 , NECES-ECO 必要-性 , KLAR-ECO 清楚-性 , LIBER-ECO 自由-性 ;
(16) -EM- 爱- : LABOR-EMA 爱-工作的 (勤劳的) , PAROL-EMA 爱-说话的 , MENSOG-EMA 爱-撒谎的 ;
(17) -IND- 值得- : LERN-INDA 值得-学习的 , LAUD-INDE 值得-称赞 , LEG-INDA 值得-读的 , AM-INDA 值得-爱的 ;
(18) -ON- 1. 若 -ONO 则 "-分之一": DU-ONO 二-分之一 , TRI-ONO 三-分之一 , KVAR-ONO 四-分之一 ;
- 若 X+Y-ONOJ 则 "Y-分之X": TRI DEK-ONOJ 十-分之三 , KVIN OK-ONOJ 八-分之五 .
合成词 ("词根+词根") 也是一样. 比较固定的, 应该整个儿存入词典, 随机组合的, 应该拆开. 但这儿有一个困难, 世界语语法为了方便使用者, 即便对完全随机组合的合成词, 也不作加连字符的规定. 那么怎么拆呢? 词根的数量与词缀不能比, 长度也变化很大, 一个字母一个字母地削查比较, 显然不是办法. 如果坚持不要译前编辑, 还找不到一个合理的解决办法. 目前可以考虑先对中间有连字符的合成词作拆词加工. 我们提倡除比较固定常用的合成词外, 世界语者在运用随机合成词时,为读者的省力和机器的识辨计加上连字符. 鉴于世界语构词法与汉语构词法惊人的一致(组合方式及其高度随机性都很类似), 对于世汉机器翻译这一倡议更加必要.
世汉构词对比例释(2): 合成词
(1) AKVO-FONTO 水/源 ; (2) VARM-ENERGIO 热/能 ; (3) ARBO-BRANCHO 树/枝 ; (4) VAPOR-SHIPO 汽/船 ;
(5) SURD-MUT-ULO 聋/哑-者 ; (6) BLANK-HARA 白/发的 ; (7) NUD-PIEDA 光/脚的 ; (8) FISH-KAPTI 捕/鱼
______________________________________________________________
附注: [7] 参见:
刘涌泉 <<中国的机器翻译>> ( <<情报科学>> 1980, 3 )
王广义 <<机器翻译中的固定词组和固定结构问题>> ( <<语言和计算机>> (1), 1982 )
[8] 参看: 叶蜚声, 徐通锵 <<语言学纲要>> 第二章第二节 " 1. 语言的层级体系", PP.34-36 ( 北京大学出版社, 1981 )
【相关】
硕士论文: 世界语到汉语和英语的自动翻译试验
立委硕士论文:1. EChA概况
立委硕士论文:2. 世界语: 语言学特点及其研究价值
立委硕士论文:3. 层次递归成分体系
立委硕士论文:4. EChA机器词典及词表
立委硕士论文:5. 世界语形态分析
立委硕士论文:6/7 世界语句法分析
立委硕士论文:8. 英语形态生成
立委硕士论文:9. 目标语调序
立委硕士论文:10. EChA 试验结果的分析
立委硕士论文【致谢】【参考书目】
立委硕士论文全文(世界语版)
立委世界语文章 (1987): 《中国报道:通天塔必将建成》
立委世界语论文(1986): 《国际语到汉语和英语的自动翻译》
立委(1988)《世界科技:世界语到汉语和英语的自动翻译试验》