今天微博同仁圈子里盛传下面这个年末搞笑的帖子,标题是 #自然语言理解太难了#,其实一点不难,可见即便是圈子内人,如果没深入做过parsing,有时也被表象迷惑。
#自然语言理解太难了# 转发段子:今年基本已经结束了,我刚在群里问了很多朋友今年挣钱了没?大多朋友都有挣,而且挣得五花八门:有挣个屁的,有挣个锤子的,有挣个毛的,更有甚者挣个妹的,简直奢侈之极!最恐怖的是挣个鬼的!有的还可以,挣个球,下午我碰见一朋友,问今年挣了吗?他望着天空喃喃自语:挣个鸟!
看吧,只要肯努力,什么都能挣到![[坏笑]](https://img.t.sinajs.cn/t4/appstyle/expression/ext/normal/50/pcmoren_huaixiao_org.png "[坏笑]")
liu:
乐呵乐呵,语言理解很不易啊。
白:
真心不难
基本上可穷尽
liu:
“挣”后面的惯常搭配和选择限制反而简单?
我:
早已解决
liu:
但是,“挣一辆车”就是它本身的含义了。
我:
简单确定的pattern 有限的词汇可填充项 这是 pattern 的拿手好戏
liu:
这倒是的,它的“能产性”不高。
我:
如果训练 有可能漏掉低频率填充项 sparse data
但对于确定性的 patterns 规则可以一网打尽。
liu:
蕴含、推理方面的理解反而是重要的?
我:
一辆车 走通则
屁屎鸟、妹妈奶奶等 走特定规则
我们做社会媒体分析的 这类玩意儿早涵盖了
白:
“规则+例外”的总描述长度最短,就踩到点儿上了。高频用变量泛化,低频用实例枚举。
我:
parse results
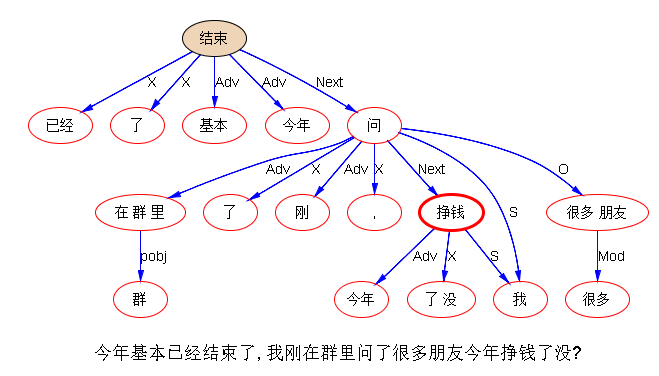
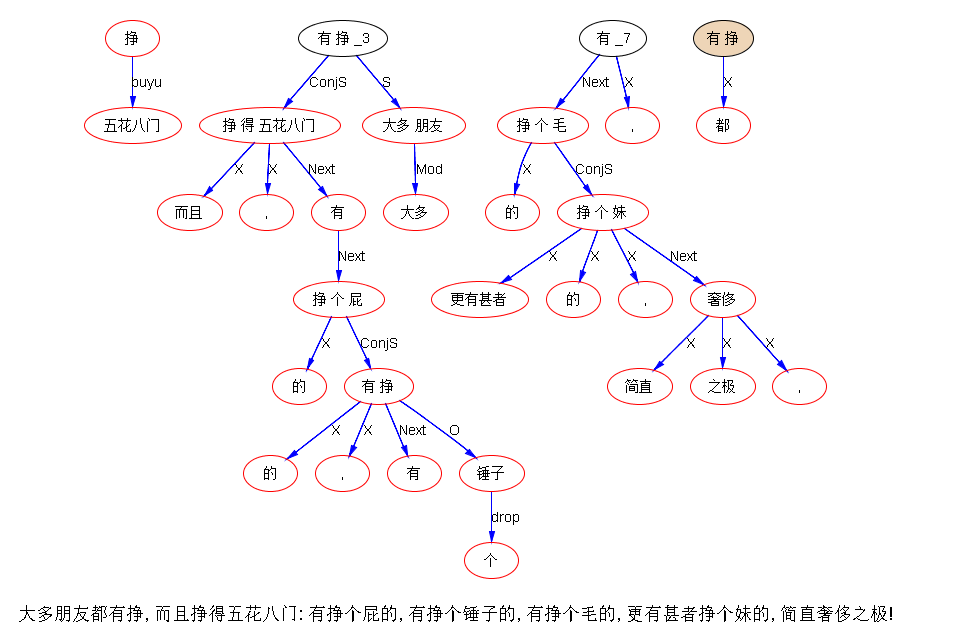
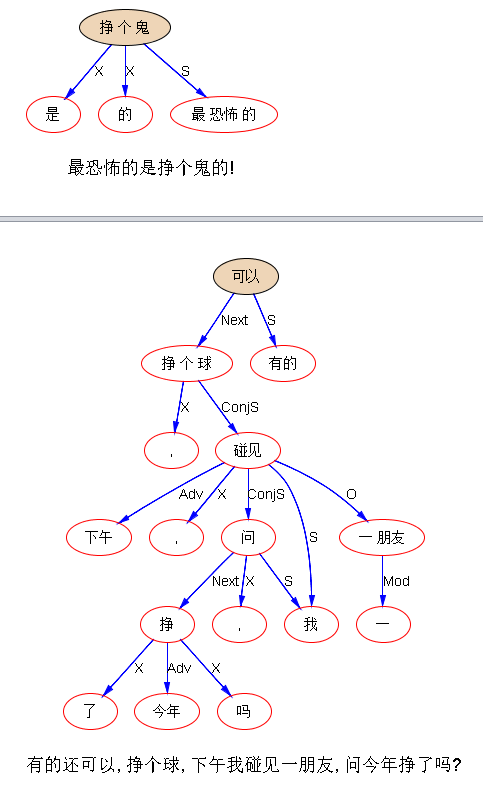
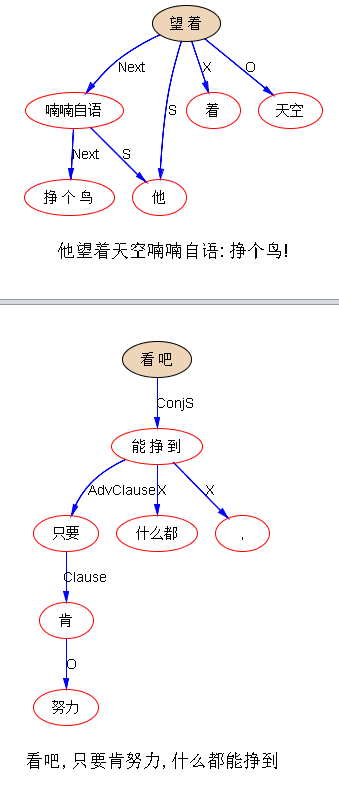
图上只是显示这个结构被抓着了,没有显示系统“理解”这种用法的内部表达:实际上这个 chunk 抓住时,系统也就知道头词是动词“挣”,也知道这是一个口语化的动宾否定式,用了脏字,模式匹配规则“绑架”了这一切。
WD:
放个屁 长个毛 真歧义
白:
不是只针对这些话,是一般性的philosophy
这件事跟“挣”关联弱,跟“个”关联强。
WD:
鬼都挣不着
跟”什么女人“类似,有所谓元语否定用法
就是拒绝前一句话的陈述恰当性 负面评价功能
什么一流大学=什么破大学
甲:挣了不少吧。乙:挣什么屁钱啊,都……
我:
“屁”“鸟”之类 有一个英语 no 的用法,是汉语的np 否定式。一般认为汉语没有 否定限定词 no,其实汉语有 不过汉语的 no 混杂着 负面情绪 用的是脏字。而英语的 no 很单纯。
屁事儿: Nothing
没见屁人。在 “没” 后 脏字成了 any,避免double negative 吧,英语也有:
Ain't see nobody == didn't see anybody
从这个例子说开去:“v个P”,P={P,屁,头,鸟,吊,jiba,妹,鬼,......}
从类似的现象可以看到,小数据为依据的规则系统,有时候比大数据训练的系统,更为有效:更加精准,更加能对抗 sparse data 因此而提高 recall(具有 clear patterns 性质的语言现象,可以一网打尽,完全没有 sparse data 的困扰),模拟语言现象更加直接,因此也更加容易debug和维护。
在 IE 历史上,直到 MUC-7,当时表现最牛的 NE 系统 NetOwl 就是基于 pattern rules 的,几乎所有的统计对手都拿它作为拼杀的对象。NetOwl 从 SRA spinoff 出去想以 NE 为技术基础,进行商业运作,一开始在分类广告业拿下了一些业务,终究不能持续赚钱,后来被 SRA 收回,逐渐销声匿迹了。后来追随潮流,系统里面也混杂了机器学习的模块。https://www.netowl.com/our-story/
从此在学界就再也见不到规则系统了,哪怕是对于规则非常适用的某些 NE 任务:譬如 时间,数量结构,等。可见潮流之厉害。反潮流者不得食,发不了论文,拿不到 grants,带不了学生,自然自生自灭。
但事物的本质和本性并没有改变,尤其是对于自然语言中的具有 clear patterns 的现象,依据小数据,经过人脑的归纳,数据驱动去开发规则系统,仍然是如上述,具有高效高质量。工业界默默实行的这类人、团队和系统并不鲜见,只不过大家心知肚明,只做不说而已。犯不着顶风作案。相对应,发动群众去标注大数据,然后用大数据训练一个系统如何?这是主流的默认 honored 的方法。如果数据足够大,其质量的确可以接近或匹敌规则系统。当数据量不理想的时候,就捉襟见肘了: 或者 underkill (由于 sparse data,漏掉很多统计性稍弱的变体)伤害 recall,或者 overkill (smoothing 过度,把不该抓的现象抓进),影响了precision
什么叫有 clear pattern 的语言现象呢?举个例子,抓取邮政地址,这个工作我自己作为一个 fun 做过。出来的系统请邮局员工测试过,他们啧啧称奇。美国地址大体是 门牌 街道 城市 州 邮政编码 最后是 国名,patterns 相当地 clear ,可你可能无法想象上述 pattern 构件的变体之多,有些变体绝对是 long tails 再大的数据量也不可能涵盖其组合爆炸的本性。如果你收集了一个巨大的美国地址库作为训练集(大数据),你完全可以设计一个学习系统来做这件事儿。而另一边,虽然也是 data driven,但只需要小数据样本,然后经过人的大脑去举一反三进行开发。可以拍胸脯的是,后一种办法做出来的系统绝对是高质量易维护,天生地具有 sparse data 的免疫性。