李:
省略 head 最可恨。从“的字结构”和what-clause始,恨的是 队员都在 头儿却跑了,缺少头就缺少了语义相谐的依据。what I read 的语义是 【book】,可是很难找到这个本体的入口点。语义计算和细线条深度parsing就犯难了。当然,可以转弯抹角通过 “read”的 HowNet 网络里面的 logic subcat 的逻辑宾语的标配,把这个语义节点挖出来,这多费劲啊。
白:
别拿“的”不当头儿
李:
“的” 与 what 一样,可以当头儿,但没有本体的底气。
白:
给它它就有
李:
我尝试过把 V 当头, 也尝试过拿 “的” 当头,都遇到这个本体的滑铁卢。V 麻烦更大一些,V 本身的本体在那儿添乱。理论上可以通过 V 询问 HowNet 去 retrieve 出来逻辑宾语的标配,然后赋值,并替代 V 的本体属性。Word 天,这不是人做的活儿。
我吃的 --》【food】
我看的 --》【ANY】
我修读的 --》【knowledge】
我parse的--》【language】
我干的 --【事业,or 勾当?】
白:
只需要指回来,不需要明确哪个坑。
的当头不是问题,当头的赋予什么subcat才要紧。谓词的坑不饱和不要紧,可以到坑里去挖。谓词的坑饱和了还要“凭空”憋出一个subcat来最麻烦了
李:
出去买外卖,路上冒出个英语打油:
What I read -- is not a book
What I eat -- is not food
What I do -- is not a cause,
What I love, is you.
标配被形式推翻,哈。
白:
not a book, but newspapers; not food, but pills; not a cause, but fun.
看看我自己搞的parser的图:
李:
牛叉!看着就高大上。
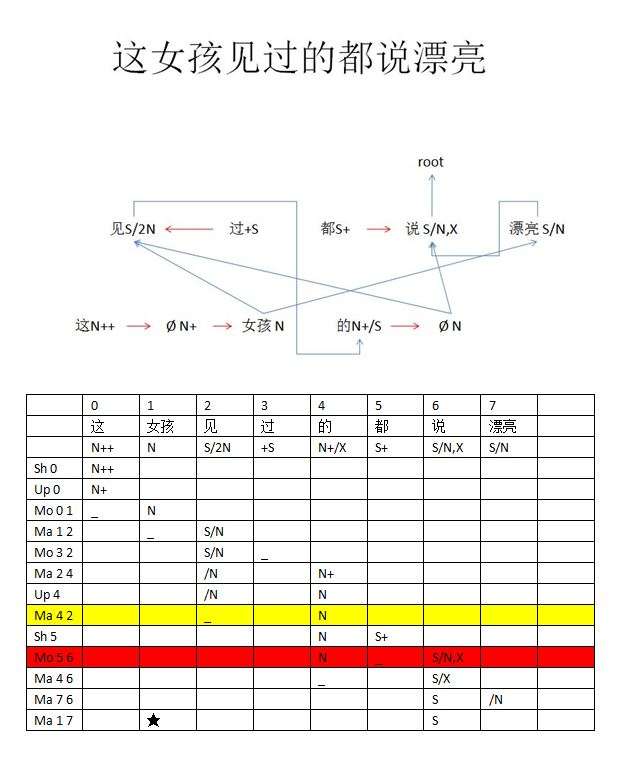
what I love, is the girl:见过的都说漂亮的。
见过的都说漂亮的:有歌为证:“在那遥远的地方,有位好姑娘;人们走过她的帐房,都要回头留恋地张望。” 里面有两个 “的”字结构:
见过的 --》 【human】
都说漂亮的 --》【ANY】
前者是主语,后者是宾语,补全了就是: 见过的【人】都说【她】漂亮的【那个姑娘】
白:
tomita差远了,我这里没有规则只有词典。
sh移进;up升格;ma填坑;mo修饰
比图栈自动机简单,而且跟语义中间件查询一一对应。
李:
就四个操作?跟汇编似的。记得汇编就是两个字母做操作缩写。我自己没整过汇编,我领导当年整天就是汇编。
白:
还有一个me,合并,这个例子木有用到。
match,modify,merge,那么凑巧都是m打头,第二个跟不同的元音。
下划线义为“关闭”。五角星是关闭后又打开复用。
李:
SH 的缩写是?
白:
shift
李:
my bad, I thought it was shit
wondering why this naming
by the way, shit and crap are NOT negative in Oral English when used in NPs
白:
up含元音u,shift含元音i,这aeiou也算集齐了
shift:move to the next token
李:
we call it read head in FSA
白:
pda players like to call it that way.
但实际上我这也不是栈。
李:
能把姑娘那句串出来,真心不易。
我要是硬做也可以做,可是感觉不踏实,不知道哪天又断了。很多事儿是选择不做,因为没有鲁棒的把握,当然也因为不足够常见感觉不值。
match 是填坑,那就是 saturated 了。up 是升格,意思是?
白:
修饰语提升为被自己修饰的pos
坑有指标,填一个少一个
matcher就做这五个动作
李:
为了理解白老师的parsing机制,咱们对照上图来个walk-through吧:
“这” 是 N++,Up 了一下,就成了 N+ ?
白:
对
指示词,数词,都是N++
李:
Up 之前为什么 Shift?
白:
位置一开始-1,进入0就是shift
李:
Mo01 就是被吃掉了,N+ 就是往右边找 N,modifier 找 head,找到了 就自裁了。
白:
对
李:
可是这个 NP 看不出来是一个完整的有 det 的 NP,过了这村,痕迹也没留下的感觉。
白:
弧都在。每条边都是痕迹。
李:
Ma12 那是填坑了,带有 2N 的 “见”,saturate 了一个,成了 S/N,可是怎么知道是主语坑填了 还是宾语坑填了呢?
白:
不知道。也不care。
李:
所以 先吃掉一个再说。也不问问中间件?
白:
目前每步都问
李:
每一步都查相谐?
道理上不需要,只有出现歧义可能才需要查问和比对。
白:
两个如果有一个相谐,就锁定一个,再来只需查另一个。
李:
小词 “过” +S 是向左修饰谓语的,因此 Mo32 就把时态助词吃掉。
so far so good
可这时候没遇到 N,只遇到 “的”。“的” 很特别,谁都要
白:
的,左面吃一坨,吐一个定语N+
李:
X 来了就吃掉。
对 突出了一个 N+
白:
X是wildcard 以前说过的,不管S还是N,来者不拒
李:
嗯
Up 4 晕了
原地踏步就是 Up?
白:
定语升格为NP,实际是创建了一个虚节点,图上有
李:
Up 的原因是因为前后的路都堵死了,等于是默认操作?走不下去了,就 Up 一下。
白:
什么因素驱动什么操作,应该是最核心的东东了。
李:
Ma42 填的啥坑?“见” 还有一个没有填的 arg N。
白:
见,残留的坑。
因为是残留的坑,萝卜不占指标,依然可以它用。
残留的坑就灭了。
李:
哦,那是“的”没找到 head N,自我升格为 N 以后,去填了 “见” 的第二个坑。至此我们其实不知道“姑娘”和“的”各填的什么坑:如果的字结构中被省去的N是【非人】(东西),则“女孩”是主语;否则,“女孩”可能是宾语(也可以是主语),类似于说:
这女孩见过的【东西】
见过这女孩的【人】
其实在本例句“这女孩见过的都说漂亮”中,“女孩”是宾语,而的字结构指的是主语【人】。
不占指标的意思是,这个 V 做了定语从句,所以 V 全部saturated 了
白:
残留是指,head已经填坑去了
我们matcher是没有语言学知识的,只知道填坑去了,定语从句什么的,不知道。
另一面说,如果有其他情形导致残留的,也一样办理。
六亲不认。
李:
Ma42 结果 把 “见” /N 变成了_,关闭了,就是用 “的” 填进去的结果?语言学上对应于 “的”字结构 反填为子句里面的主语。
makes sense
反填不占指标,所以动词saturated,可“的”字还是 N,从这个 N 进一步取下一词 (Sh5) ?
白:
sh是先放着,看下一个
李:
入栈?
白:
不完全是栈,暂且理解为栈也将就
李:
小词 “都” S+ 往右找谓词做修饰(Mo56),于是吃掉了 “都”。
“说”有两个 args?一个是 N 主语,一个是 X 爱咋咋:NP宾语也好,宾语从句也好
这时候 的 N 可以填进去 (Ma46),后面的 A 作为第二个 X 也填进去,大功告成?
白:
要处理残留:谁漂亮
李:
Ma17 于是把“女孩”连上了“漂亮”,填坑。
白:
因为是残留,要在之前已经关闭的N里面找一个做兼职。不占名额。
李:
远距离逻辑关系 不能占句法关系的坑。
白:
_是关闭,五角星是再打开
李:
关闭是入栈,打开是 pop?
白:
好像不是
关闭是了结,打开是废物利用。
李:
这个游戏好玩。
parsing 是走通了,哪里看出怎么给标签?主谓宾等
白:
不给标签,只说谁跟谁有什么关系,留下来的arcs正好构成这么一幅图
李:
“什么”关系不就是标签吗?
MO 是修饰;MA 是填坑,但没说主语关系还是宾语关系
白:
水平的是修饰关系(红色),垂直的是填坑关系(蓝色),跨接是合并关系(橙色)。
李:
没看到跨接
白:
不说没关系的,范围已经框死了
语义层面往下走接得住
李:
主语宾语怎么接得住?
主宾的区分往往是,相谐只是可能,句法才是决定。“老鼠爱大米” 填坑以后 相谐可以决定主宾,“张三爱李四” 呢?
白:
我们汉语可能要反过来,相谐如果搞定,不问语序;相谐搞不定的,再问语序。
语序的原始编号都在。
李:
至少对于此句,不问语序是对的。问了语序的话,“女孩”在主语位置,应该是定语从句的主语了,但其实是宾语。
白:
如果填坑时没有竞争者,也不用查中间件。
大部分情况只用相谐就搞得定。
三省吾身,用得妥妥的。
李:
有意思,太有意思了。
白:
当个玩具吧,希望尽快升格为不再是玩具。
李:
这可不是玩具 玩具哪里能搞定这样的句子。看得出来 小词很关键。实词一边有坑,一边有中间件。
白:
玩小词其乐无穷啊
李:
“的”字的玩法 令人惊诧。
白:
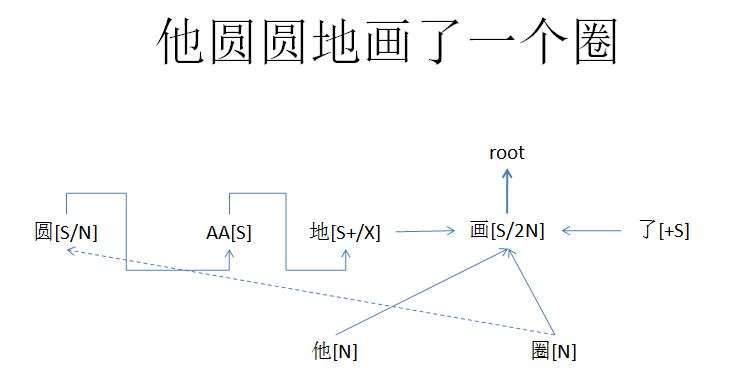
“圆圆地画一个圈”
这里要解决“伪状语”的问题。顺带考查一下小词“地”。
李:
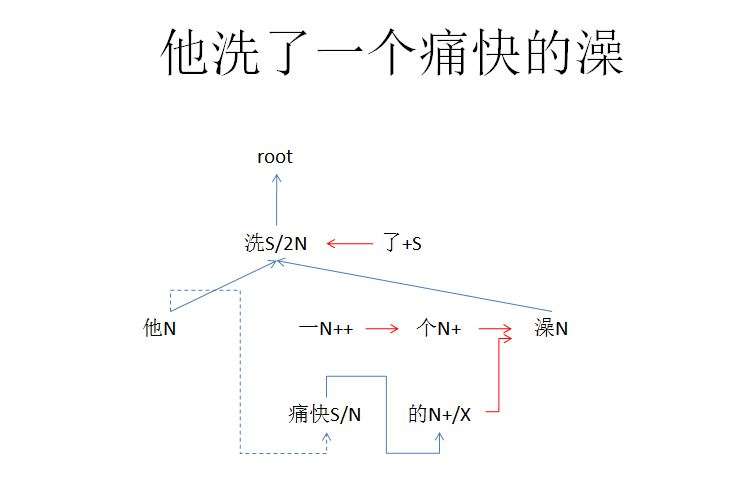
洗一个痛快的澡
是伪定语,同理。
白:
这里,“圆”残留的/N,靠“圈”的废物利用搞定。二者之间的subcat不要太般配哦。
同理,“痛快”残留的/N,找到了subcat相谐的已关闭的“他N”。
李:
这句没看懂。
“圆” 一个坑,后来让 “圈” 填了。类似于 “痛快” 的坑 让 “他” 填。
白:
画的逻辑宾语坑是“图形”,圈的subcat也是图形,这不是般配是什么?
伟哥没看懂的是上海话吧……
不要太 means 太tm
李:
哦。
北方话就是王八绿豆对上眼了。
对上眼的是远距离的 “圆” 与 “圈” 啊,“画” 与 “圈” 哪里需要对上眼,那是句法绑定 父母包办:
v 了 一个 n
白:
父母包办的也送中间件里,无妨
李:
不需要。先婚后恋。不恋也成婚。
白:
圆圈也包办的
不过我还没处理成包办
需要磨
所谓包办,就是word embedding。自由恋爱,就是subcat-embedding。
李:
前者是强搭配?后者是搭配
强搭配在两个直接量之间进行:洗-澡;搭配可以在 subcats 之间
吃 -【food】
or【consume】-【food】
词对词:洗-澡 ==》 词对subcat: 吃-【food】 ==》 subcat 对 subcat:【consume】-【food】
HowNet 基本是后者,因为是概念之间。汉语词典里面有前者,因为有习惯表达法,language-specific。问题是,由于自然语言有多义,词到概念的映射不是一一对应的,除非存在一个完美的 WSD 支持。因此,subcat 对 subcat 的这个宇宙真理,尽管概括性和逻辑性强,但不好实施,容易走偏。除非有大数据做底,指望 WSD 不太现实。
白:
中间件看到的就是实例对实例、标签对实例、标签对标签(含标签它八辈儿祖宗)。
李:
我把 HowNet 的搭配搬过来以后,吃过亏。不过实例对实例,这个不需要大数据,拍脑袋也不会走偏。基本就是词典的记忆,脑袋里都有了,而且因为概括性弱,走偏的可能几乎没有:譬如 洗-澡。实例对标签 处于二者之间。
白:
WSD再怎么不完美也要分开,绝不能搅在一起。宁可分头完善去
李:
我从来不指望 WSD
默认假设是没有 WSD 怎么做 NLU 或落地。WSD 是其他过程的结果或副作用,而不是支持其他模块的前提。
白:
“洗”是万金油,“澡”是单打一。
一个固定搭配入口在哪很要紧,放在万金油那儿就惨了
李:
那是效率的问题。有不同的 indexing 的入口。“澡”作为入口 效率更好而已。
所谓 word driven 其中一个考量就是入口的驱动词的选择。传统的词典编纂也有这个考量。
白:
WSD和matcher工作时都要调用中间件
李:
一时想不出来 parsing 为什么要 WSD,有中间件就可以 parse 了。理论上 parse结果里面,词的节点应该是 WSD 过的概念。
白:
不存在独立于中间件之外的WSD
给Matcher的是单选的pos流,从多选到单选这一步是WSD做。再回到多选,就是休眠唤醒了。就是我说的,“纵向不确定性”WSD负责搞定;“横向不确定性”matcher负责搞定。二者都要借助中间件。
李:
多选到单选不是中间件吗?当然说这里面隐含了WSD也是不错的,因为所谓相谐就是两个节点的某一个 ws 与某一个 ws 对上了。从图上说,node 才有 wsd 的问题,arc 不是。
白:
义项的多选到单选,由WSD借助中间件做。parsing动作的多选到单选,由matcher借助中间件做。
“我想战胜AI的心,仅仅是为了作为棋手的尊严。”
“想战胜AI的心”,遇到“心”属不属于“那个小集合”的问题。可以人为设定“心”的一个属于那个小集合的新义项,(类似“心情、心愿”),在中间件里面靠“想、V、的”等捆绑,希望运行WSD时可以体现出来。目前资源太小,很多时候不顺手。
李:
我来推演一下:
parsing 到某个步骤,需要决定定语从句修饰的N,是不是应该反填子句谓语还未填的坑。如果 N 与坑的arg的要求相谐,则填,否则不填。如果 args 都已经 saturated 也没有填的问题。
“我想战胜AI的心”: “战胜”已经saturated,“心”不填。无需给心做 WSD
“想战胜AI的心”: 这时候,“战胜”还有一个主语的 arg 没有填,“心” 能不能填,决定于大数据中有没有 “心” 做 “战胜” 主语的历史积淀。应该是不相谐,没有积淀,因此不填。即便是那个“小集合”的典型案例,譬如“消息”,也有可能是相谐可填坑的:
他走漏的消息,很关键。
他走失的消息,很关键。
大数据搞定 “走漏-消息” 是肯定的。至于“走失” 与 “消息”,那应该是词典决定的标配,而不是大数据。换句话说,搭配是大数据的统计,不搭配则是默认。
白: 再看:
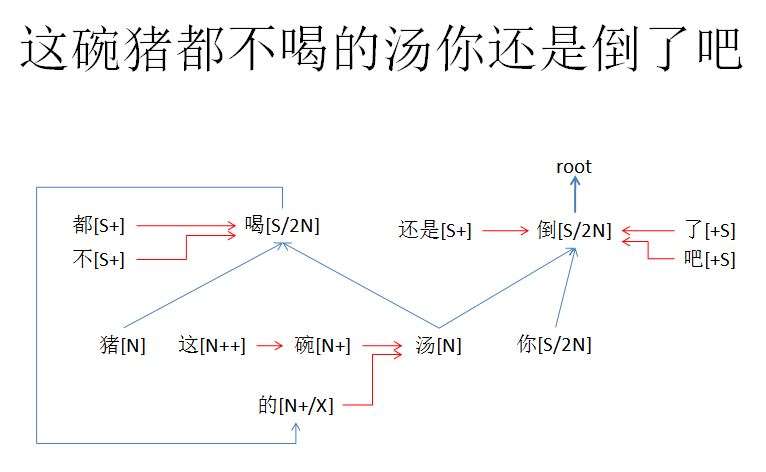
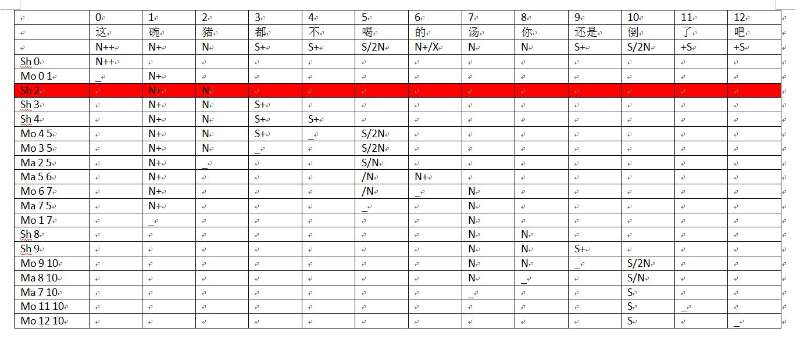
因为“碗”和“猪”不相谐,标红的这一步选择了Sh,而不是Mo
王:
白老师,这个句子最后一步match的是17,可以是47么?
Plus,“这女孩见过的都说漂亮”这个句子似乎有歧义?对比:“老祖宗讲过的都说有理”。
“女孩”在这个带“见”的的字结构里,可以当主语,也可以当宾语。
白:
对。这里只取了一种分析结果
李:
这姑娘见到的都说漂亮。
这小伙儿见到的都说英俊。
这小子见到的都说漂亮(因为他以前根本没遇到过漂亮的)。
这姑娘见到的都说英俊(因为她足不出户,见识太少)。
猪八戒见到的都说漂亮。
这傻瓜见到的都说奇妙。
结论,是 ”姑娘“ 与 ”漂亮“ 的高度相谐性,决定了姑娘与句法标配唱反调,做了 ”见到“的逻辑 宾语。甚至替换成同义词 ”英俊“,这种相谐性有所降低,就很难打败句法标配了。这也说明,语义中间件的相谐性不是好玩的游戏,非高手不能。甚至高手也会失手,过犹不及。
王:
操作有Shift, Modify, Match, Up, 还有这个句子里没用到的Merge,一共五种……
白老师,如何决定每一步用哪种操作呢?是在每一步都把五种操作全部轮一遍,看看哪个能用,然后继续,最后把成功parse全句的依存关系留下,没parse出全句的依存关系丢弃?
另外parsing以前做pos tagging的时候是不是也要把所有可能的pos序列全部给出来?
白:
这里面有大量无效的结合需要排除。算法的核心就体现在这个地方。
目前算法还没有面向所有歧义分析结果,取的是按照系统排序原则首先形成的第一个满足条件的分析结果。
另外不同的pos标记是靠WSD模块来选取的,每个词只有一个pos标记胜出。
如果做不下去了,又发现“里外勾结(甲词的首选pos和乙词的非首选pos类型相配)”,则启动翻盘。
李: 总结一哈。
优选的路径亮相的背后是大量的伪歧义,白老师怎么对付的呢?一个是基于训练出来的语义中间件的WSD,它负责提供每一个词的唯一而合适的pos供给 以 subcats 驱动的 parsing 去匹配。另一个就是 parsing 的算法,想来是糅合了某些语言学原则的,来决定操作的顺序。
这解答了我以前的一个疑问,为什么不可以绕过WSD做深度parsing?
在白老师,是绕不过去的,因为是基础支持。在我这儿,基本上是绕过去了。POS (可以看成是最粗线条的 WSD 的语法表现)我基本是绕过去做parsing的。见:【NLP 迷思之四:词义消歧(WSD)是NLP应用的瓶颈】;【中文处理的迷思之二:词类标注是句法分析的前提】。
能绕不能绕,决定于算法。条条大道通罗马 of course
白老师算法的精炼和操作的简约,是建立在两个基础之上:一个是语言学标注丰富的词典,潜在的路径都藏在里面,就等 matcher去选秀。另一个就是要有一个大数据的语义中间件的有力支持。
我这边也要靠信息丰富的词典,词典的一头是语言学,词典的另一头是HowNet本体,前者是主,后者是辅。
另一个靠山就是规则,根据语言学原则和经验设计出来的支持多层parsing 模块的 hierarchical 的规则集。
多层、细线条规则,为绕过POS和绕过WSD施行对伪歧义免疫的高精度深度分析,提供了条件。parsing 本身的基本机制也很简单,但利用这个机制把语言学揉进去来组织多层,那就是可乐式秘方了。
白:
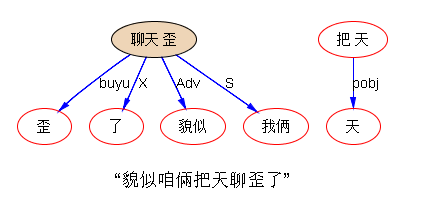
“貌似咱倆把天聊歪了”--隔壁群里的一句话,离合词活用经典。
李: 就此打住吧。
白:
我说,天好好的,没歪。
当规则寓于词典的时候,WSD不是传统含义,POS也不是。某种意义上说,此时选择义项就是在选择规则。也就是说,绕开彼WSD使用的技术,跟此WSD使用的技术是相通的。
李:
WSD 本来是一个独立的与结构分析不必交融的任务,譬如,bank 是选“银行”还是“河岸”的消歧问题。再如,this coach is believed to be tough 这是以前提过的 WSD 经典案例,说的是,利用语义相谐来做 WSD
coach 有n个义项 tough 也有 m 个,二者互谐的只有两个:
coach【human】:教练 ; tough【human feature】:严厉
coach 【vehicle】 :马车; tough 【object feature】:皮实
白:
这不影响结构啊,一个N,一个S/N。pos没有其他选择就不check
李:
这个案例不影响各自的POS,不影响结构,这是 WSD 原本要追求的目标,但不是 parsing 所需要的支持。
然而,如果相谐是需要check的一个条件,出现的情况就是:
1. 由于 sparse data,两个直接量在一起的机会不够,所以系统认为是不相谐: 就是说语义不及格,全靠句法了。如果句法无歧义,没关系。否则影响parsing的质量。
2. 如果数据超大量,不要依赖于 subcat 级别上的相谐,而是利用直接量的 touch 和 coach 就有足够的例证是互谐的,那么语义支持了二者的结合,哪怕这时候究竟是 【human】还是【non-human】仍然无解。
我要说的是,白老师的 WSD 模块不是通常意义的 WSD,而是针对结构歧义(structural disambiguation)而来的相谐的支持,是粗线条的,而且是调用 when needed 的。WSD 的本义不是这个,本义是 lexical disambiguation,是为了确定词义的。本义的 WSD 对 结构 parsing 理论上有帮助,实践中基本不需要。在结构 parsing 的时候,WSD 可以隐含(或成为结果,就是所谓 positive 的副作用),但不必是条件。
即便如此,白老师由于没有显式的多层的 pattern 规则,只有隐含在词典可以被 matcher激发的潜在规则种子,其结果是对所谓 WSD或POS 模块的依赖远远大于多层的规则系统。既然有休眠唤醒,白老师应该也引入了多层。但总体上,白老师的层次是少数的,仍然在传统 parsing 单层搜索空间的延长线上。因此理论上,伪歧义会成为极大的困扰。白老师的创新就在,层次虽然不多,但背靠两座大山。这两座大山,都是传统 parsing 不具备,或者严重不充分的。第一座大山是词典主义标注,这是一个巨大的语言学工作,特别对小词和 top 1000 的用法众多的实词。第二座大山就是大数据的语义相谐的训练。建造这两座山都不是简单的活儿,除了设计家的宏观规划外,牵扯的具体的数据工作和调试测试工作非常庞大。没本事建大山,也就无法克服传统parsing的伪歧义瓶颈。
【相关】
【李白之18:白老师的秘密武器再探】
【李白对话录系列】
中文处理
Parsing
【置顶:立委NLP博文一览】
《朝华午拾》总目录