【立委按】核心成分 args 不过三 句型不过百 是我们语言学家对于世界主要类型的语言观察到的普遍规律 或曰普遍文法。语言的奇妙 莫过于此。可是思维没有这么简单 一个事件可以有很多成分。这个矛盾 语言怎么解决的呢?模型语言的 parser 又有怎样的对策呢?不骗你 做个语言学家真好 可以洞悉很多上帝和人的奥秘。
白:
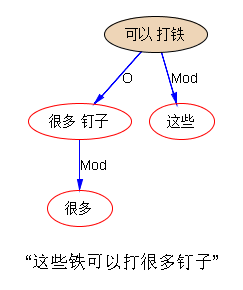
你那个打铁的图,不大对啊
李:
白老师眼毒是出了名的。是的,“打-铁” saturated 在强搭配中了,就不应该再去外挂另一个宾语,这跟娶两个老婆同罪。系统目前没那个严苛,执法不力。但也说明了,后一个老婆也许应该降格,降成姨太太。如果宾语是大房,那么 complement 就是二房,打的是正室的铁(morphology 的 compounding),打的结果就是二房的钉子(syntax)。用逻辑语义的话说,一个是受事宾语,一个是结果补足语:是为打铁成钉。
众所周知,句法的宾语其实可以有很多不同的逻辑语义。默认标配的逻辑语义是受事。但对象、结果等都可以的。“打铁” vs “打钉子”,前者是标配的【受事】,后者是【结果】,但都可以以宾语的身份或分布现身。
白:
如果给盖房子的盖规定只有两个坑的名额:我,房子,木头,怎么填?
“他考清华研究生数学八十五分”
不止四个
李:
这是说的萝卜多,坑不够,是吧?
白:
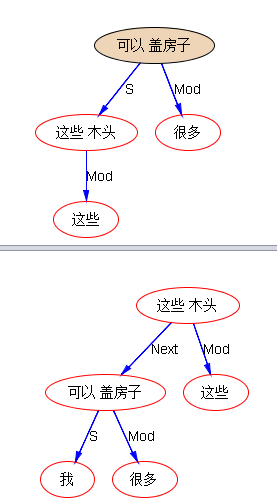
“这些木头可以盖很多房子”
李:
这个不用试我就知道:目前就是主谓宾。将来细磨逻辑语义的话,“木头”是【材料工具】类的逻辑语义坑,房子则是【结果】。
白:
“这些木头我可以盖很多房子”
李:
这个也可以预测到,耍个流氓,不是 Topic 便是 Next,将来细磨 ontology,也可以让流氓从良。
白:
topic是温吞水,上不着天下不着地,既不是标配的成分,又没说填谁的坑
李:
不过一步之遥啊。但是 Topic 或 Next 所直接连接的 token,通常没错。换句话说,坑是填了,不过妾身不明,不知道跳进了啥坑而已。妾身不明是因为 knowledge poor,一旦有了大数据或有了 HowNet 类的本体知识,knowledge rich 了,也就可以验明身份了。
白:
穆斯林比旧中国好。说好了四个就不可以多。再耍流氓也只能在四个范围里耍。
李:
其实不是。这个问题我想过很久:世界上的语言五花八门,主要类型的语言都有一个突出的共性:就是句型非常有限,不过百(主要句型不过二三十个) 。主要原因是,句法上 arg structure 的坑是有严格的数量限制的,不过三。超过的部分肯定属于另类,那就打入另册 mods 。但实际上,语义层面的 args 和 adjuncts 的界限,比句法上的 complements 和 mods 的界限 要模糊得多。这就是为什么 hownet 里面的坑,比 句法词典里面的 subcat 的坑,有时候更多。本来二者是有映射呼应(correspondance)关系的,但从纯粹语义角度考虑,有些 mods 需要被拉进坑来,语义的本体定义才完整。这是我看 HowNet 董老师的处置得出的体会。
考清华那句也是醉了。语义上的 args 包括:
考-清华 【school】
考-研究生 【graduate program】
考-数学【knowledge】
考八十五分【RESULT】
加上主语 ”他“ 就是 5 args,即便把补语“85分” 当成后置 mod(当成谓语亦无不可),也有四个 args,这不符合 arg structure 原则上不过三的普世句法(UG)。我认为,正因为普世句法有这个args不过三的原则,才使得人类的语言的结构变得 tractable,人类语言因而可理解,方便了交流。三个 args 的排列组合可达 6 种,加上其句型变体可控制在百种之内(常用句型也就二三十个),几乎达到了人脑短期记忆的极限,哪怕再加一个,就几乎不可收拾了。人脑很可怜的。不得不佩服自然语言架构的恰到好处:说语言背后没有上帝是很难让人信服的,难怪乔老爷坚持普遍文法是人天生的、普世的。
可是逻辑语义上,同一个谓词可以有很多 args 的,这就造成了思维内容与语言表达的矛盾。自然语言又是怎么解决这个矛盾的呢?思维上的多坑,到了文句的句法不允许有这么多坑,怎么办?
白:
这是理论问题不是技术问题。技术问题是,准备了俩坑,来了三个萝卜,怎么处理?
李:
有了理论,技术还不好办?纲举目张啊。
技术就是:
syntactic parsing: 耍流氓
semantic parsing:根据 HowNet,教育流氓从良。
也就是,没知识就耍流氓,有了知识立地成佛。
白:
技术就是,其中一个萝卜历史上做mod居多,果断降级
李:
历史不历史,那是语言处理的时候,选择谁 out 的一个数据依据。关键是降级:萝卜多了坑不够,不降级还能怎么着?这才叫:英雄所见略同。
你那一路也行,但是还是重负前行。这个从大数据来的历史 不管怎么表示和使用,都是一个很大的 overhead
白:
在中间件里,matcher是极其轻装的。
李:
中间件庞大。call 它一下,等价于一次信息检索??这个也许 overhead 不大,可是怎么对付优选语义呢?不是相谐还是不相谐,而是多大程度相谐?或者比较另一可能,更相谐还是更不相谐?多大程度相谐是个无底洞,不说它。更相谐与否,就是一个是否判断。这时候提交的是两对。两次在线检索 才能在线比较计算大小,是不是?在线是因为无法预知哪两对需要比较,无法预先计算好。
回到白老师上面的问题:盖房子的“盖” 句法上似乎大家都认为就是两个坑:一个主语 一个宾语,who 盖了 what,但是从语义的本体定义和结构看,至少有三个坑: 【who】 盖了 【what】 by【what materials】。我常把这种多出来的语义坑看成是处于 args 与 mods 边缘地带的东西。还有一个典型的例子 translate:绝大多数动词最多有三个 args:主、宾、补足语,但是 translate 四个比较合适:[who] translates [what] [from what source] [into what target]。语言实践中,PP(from)常被当成状语,而不是arg,有人把 PP(into)也当成状语。这就是 args 降格为 mods 的结构处置现象。
面对萝卜多坑不够的语言表达困境,一般而言,主要是两个路子,(1)一个是迫使语言把多个 args 分散到不同的句子去表达,这样一来每个句子的结构还是在限定的坑数之内,subcat upto-3-arg patterns are very tractable;(2)给 args 降格:降格为理论上随机的 mods。由于(1),于是产生了句法的主语、宾语,可以对应10几个不同的逻辑语义的坑。
刚刚 parse 了白老师的句子,看看目前这个根据语言学句法原则制定的parser怎么对付多于3的萝卜, 结果是:
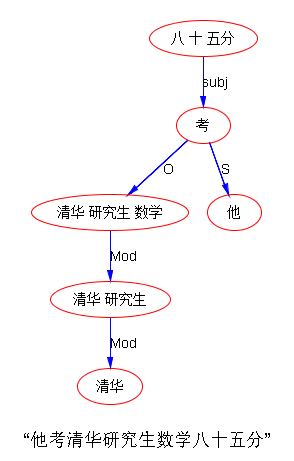
哈,果然。遵循普世文法来模型自然语言的 parser 采用的是降格,策略(2):“清华”的 arg 和 “研究生” 的 arg 都被降格成mods,只剩下 “数学” 作为 head N,堂堂正正填了宾语的坑。作为句法 parsing,这种处理是符合语言架构原则的,非常合理。但是作为深度分析和语言理解,句法被降格的成分,应该重新“升格”到 args 的逻辑语义 slots 去,语言深度解析才比较完美。逻辑升格了,其他句子的 “考清华” 或 “考研究生” 的说法,就会与这一句的说法语义一致,可以 unify。这个升格的任务,也应是语义模块的任务之一。语义模块不仅要填写句法上省略的 hidden args,而且要把部分mods升格为 逻辑的 args。这些 mods 是人类语言表达的时候被 UG 下意识降格的成分。
假如自然语言不是上帝为人类交流而设 假如我们为机器设计语言 我们完全可以扩展坑和句型的数量。Hownet 几个坑, 句型就几个坑 一一对应。不用现在这样,先句法句型入手 然后再 role labeling 填逻辑语义的坑。
白:
其实我并不关心上限是几,只关心超出上限了怎么办。hownet坑的供给比较充分,但是也很难说一定不会超出上限。(董老师可以试试“这场火多亏消防队来得及时”)
【相关】