立委按:谈笑有鸿儒,泥沙龙写照也。毛白立三剑客,隔洋神交,日颠夜倒,天马行空,人生快事也。语言理解,人工智慧,软体硬件,万言不离其宗也。铿锵三人行,行迹可存,笔记于此,以飨同仁也。
白: 转:《夏洛特烦恼》我以为主角叫夏洛特 。原来男一号叫夏洛 ;接下来会不会有《郭敬明天见》《周立波很大》《吴奇隆胸记》《王宝强奸案》《郭富城会玩》《井柏然并卵》《黄秋生无可恋》《贾乃亮了》《奥巴马上来》《周润发财了》《权志龙虾壳》《金正恩仇录》。
李: 边界之争。夏洛特是词典一方 特+烦恼 是句法一方 作为一般原则 句法认输。所有的边界之争 你总可以找到一种语境 来支持任何一方,但是实际系统中 还是按原则办事 除非某特定语境出现频率大 而且可以形式化被捕捉为原则的例外。“郭敬明” 是词典,“明天”或“明天见”也是词典,词典与词典相争。 谁赢呢?要分不同情形。情形对应的是 heuristics。对于此情形,“明天见” 赢。因为有这么一条 heuristic:最少词数胜出。郭敬/明天见, 算两词。郭敬明/天/见 是三词。更深的理由是 音节数量的匀称的 heuristic:3 1 1 不如 2 3 匀称。
白: 无后坐力炮,经常被读成2 3节奏,按构词法,应该是1 3 1。可否不那么早定输赢,都打到上一层。
立:可,keep ambiguity untouched 的办法 也是一招,不过加大了后去 parsing 的搜索空间 也可能不妙。
白: 上层用Ngram也无所谓。看一个滑动窗口激活一个还是两个词袋。
李: 这就是拼积木,难的积木留在最后拼。拼积木ngram比cfg容易,没有爆炸的问题。
白: 正是。
李: 汉语的节奏对称还是很厉害的,举反例总会有,但是实际中发现,音节数的条件,比起其他的条件(词类、子类、语义分类)往往也很好用、可靠。另外一个相关的体会是排比句式,汉语(包括古汉语)排比句式的使用往往可以把本来占有统计劣势的 parse 变得有效起来。不过,至今没想到利用排比句式帮助消歧的好的实现办法。感觉排比的发现和使用是处于另一层,而且排比的 scope 不好事先确定。
毛: 对于汉语NLP, 二位觉得有什么好书可以推荐?不用很深,科普就行。
李: 我很多年不看书了,还是白老师推荐吧。最好的是白老师正在写的,这个无疑问,但你需要等。汉语 NLP 论文献,80% 谈的是切词,全领域走火入魔了,陷入细枝末节和烦琐哲学,很大程度上非常可惜的一种智力浪费。
毛: 等倒没关系,反正暂时也没时间看。其实我不太会有机会用到这方面的知识了,我这是“朝闻道夕死可也”。尼克,Unix的那些Utility,每个都是基于一个while主循环,这就是lambda的语义。Java8让你有一种简洁的方法来表达这种语义,然后它替你生成这样的循环。
白: 自然语言的语义,也有lambda的份儿。
毛: 是,所以我觉得数据流在 NLP 方面可以发挥一些作用。
白: 表函数、表关系、表部件的词(中点、姐夫、抽屉)都是。需要一个带坑的语义结构去定义。坑,就是约束变元。
李: semantic subcat? Syntactic subcat specifies the form of roles in a frame,correspondingly, semantic subcat specifies the preferred semantic classes for the expected roles of a frame. 语义 subcat 都是必填的,虽然句法上还是可省略。
白: 坑有必填的和可选的两种
立:如果加上可选的,那就超出了subcat,而进入 cat 了。因为可选的角色一般针对大类,而必填的才针对子类。
白: 这点商榷一下,时间地点等,往往不是必填的。
李: exactly,时间地点等边缘角色针对的是大类。所有的动作、行为都适用。它们都在时间与空间中存在。而一元谓词,还是二元谓词、三元谓词,甚至零元谓词,这些都是子类的区别。天气动词语义上是零元的,虽然句法上可以加一个:It is raining 、老天下雨了。世界语最接近逻辑,语义的零元,句法也是零元,就不用加这种无意义的主语:Pluvas。
毛: 我觉得最有前景的可能是并行多路的parsing。就如你们刚才说的“无后座力炮”,如果系统能立马分出两个数据流分支,按不同规则加以解析,然后由高一层的规则判断何者为优,那效率就高了。这在NLP方面不是什么新概念,问题在于能否搭出这么灵活而高效的系统。
毛: 但是NLP所处理的原料不太可能是世界语的文本呀。
李: 只是说明语义和句法之间既对应,又不完全对应的情形。比较不同语言,这些不对应的部分反映了不同语言的应对策略,这是很有意思的对比。
白: 标签化的表达比函数式的表达,应对非必选的东东就灵活多了。
李: 英语用 it,谁知道这 it 是什么东西?汉语比较具体,用的是老天。
白: 相反吧,汉语不说。
李: 汉语也可以不说,“下雨了”。如果不说,那就与世界语一样逻辑了,躶体出境。
白: 不说不是省略,是比省略高明的模糊。
李: 这里不是省略,因为逻辑语义上没有这一元的地位。
白: 语义上就有0元谓词,但是句法上没有地位,于是搞了个貌似省略的充数。
立:”老天“ 直译过去就很可笑:The sky is raining, Mother Nature is raining, or, God is raining?
白: 比it还富有想象力.
高: 像黑格尔说的,Was ist Das.
毛: 可以用函数式的方式来处理标签,把二者结合起来。我相信在NLP这一边已经有了许多很好的概念和方法,问题在于怎样搭出好的系统来高效加以实现。所以数据流应该有用武之地。
李: 语言很有意思,可以从三层来看这种“坑”。Filmore 把这个叫做【格语法】,他写过 “Case for case”,许国璋教授翻的,叫《格辩》,得其神韵,很妙。《格辩》是与乔姆斯基唱对台戏,是反乔派中最有分量的历史文献了,高举的是语义大旗。对NLP有深远的影响。所以,“坑”(case)可以分三层来看。第一级是 morphology case,这是“格”的本来用法,主格、宾格、工具格等等的词尾形式所表达的。第二级是 syntactic case,刻画的是 subcat 对语言形式的条件要求,包括具体语言中每个 Role 的词序、介词等的要求。第三级是 semantic case,刻画的是输出框,这是各语言共同的,又叫深层格,是 Filmore 提出的概念,与乔姆斯基的逻辑形式(logical form)对应。要几个元(格)是由谓词的概念子类决定的,它反映的是自然的关系(可以包括常识)。可是每个语言在实现这些深层格的时候,会利用不同的句法或词法的形式,于是穿上了句法或词法的外衣。
毛: 好吧,你们先掐。
白: 毛老,函数式和标签式表达,只有一墙之隔。标签其实就是最高抽象类的里面的“准”全局变量,谁都可以继承来塞点私货。不塞也无妨。
毛: 所以,我认为应该重启五代机的研究。有人说现在神经元网络是六代机了,我认为不对,因为说到底总还是“人工智能机”。
李: AI机只是六代机的一个引擎?
毛: 至少是现在,通过图灵测试是计算机的上限,所以不应该有高于AI机的计算机了。
白: 把RNN、多层FSA、多层词袋这些东东做成硬件就是了。
毛: 神经元系统只是一种计算模型,它也要通过编程在计算机上实现。神经元网络的运转说到底还是程序的执行。
白: FPGA实现就很好,能做成NLP协处理器就更棒了,NPU。
毛: 对是对的,但是如果变化太多,硬件实现就太不经济了。另一方面,如果有很多这样的部件,那么如何灵活高效地加以调度,根据具体情况动态搭出合适的系统,这本身就是个问题,这就又要涉及数据流了。我们平时在碰到困难时说要 “换一个思路”, 实际上就是要换一种数据流。
白: 希望NLP能早日成熟到毛老可以对接上的水平。
毛: 我觉得很可能是反过来的, 搞系统的人何时能搭出适合于NLP的系统,NLP Oriented Systems。 问题是搞系统的人一般都不懂NLP。
白: 是NLP这边说不清楚。回头说格。 “把”在汉语里号称是宾格介词,但是遇到“把我累死了”这种例子,又找不到哪个谓词提供宾格的坑。实际上,“累”是“使累”,是一个使动用法。所以顺序很重要,先使动 ,后宾格,一切OK。先宾格,后使动,北都找不着。
毛: “我累” 怎么解析?
白: 主谓啊。但“我累死你”不是。
毛: 哦。那就是“我使你累死”
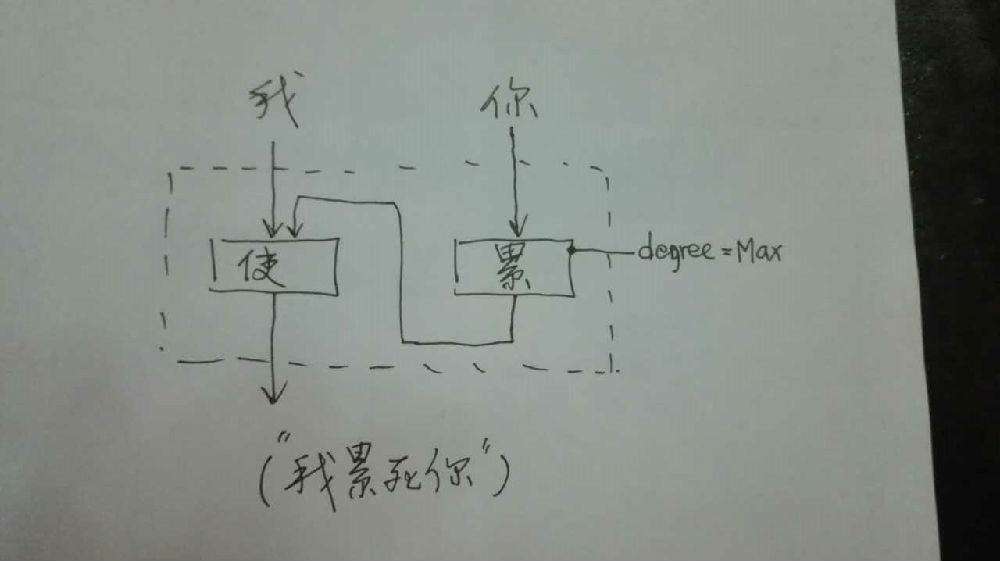
白: 虚线框内形成一个虚拟谓词(复合然后缩合而成),对于这个虚线框,“你”貌似它的宾语,所以也获得了使用“把”表示宾格的能力。在句法层面,“使”不见了,“把”却在横行。
毛: 那么这种“使动”的属性就作为标签加在“累”这个词上?
李: 累和死 先合成,然后针对宾格的坑就出来了。“累死”这样的算是合成词,不过这种合成词是 productive 的。
白: 气糊涂,饿疯, 都一样, "忙晕", "乐坏".
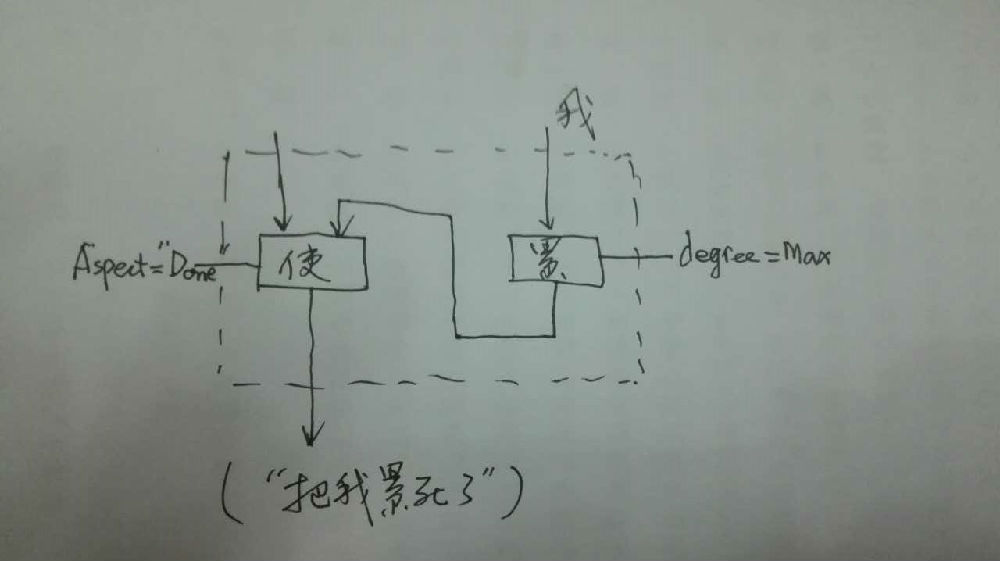
毛: 累死 应该是 累到死 累到要死的程度 的意思,这个死是补语吧?
白: 是补语,语义上对应一个程度标签,非必选的,所以不算框的正式坑。加标签是随手做,填坑是大动静。所以正规军和游击队,待遇就是不一样。
李: 累死我了 --》 把我累死了。符合正常的位移转换(movement/transformation)方式。累(V的某种子类)+死 就是一个造词小规则,是产生式合成词的规则。符合这个规则的合成词就带有如下特征:及物,具体说,是使动的及物,并有表示程度的结果(“死”,不是真死)在内。带“把”提前是及物的共性,不用管。只要这个规则成功的时候,subcat 标签加对了,后去就顺理成章,无需特别操作。
毛: 所以呀,面向NLP的系统应该很方便很灵活地让你动态挖个坑,而且是同时挖上好几个坑,可以并行去试试不同的坑。这样才好。
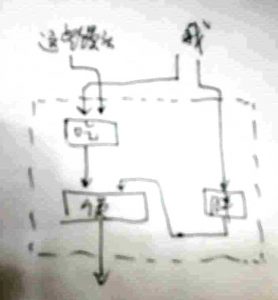
白: “这些馒头把我吃胖了”。这个复杂些,有主有宾,只是虚线框里面拧着,了的时态含义省略了。胖,有一个坑。使和吃,各有两个坑。复合后缩合的虚线框部分,只有两个坑,一主一宾。与“吃”相比,正好颠倒了。所以,这类补语不仅是表程度,而是具体表致使后果的程度。
毛: 期待白老师的科普书早日出来。你的书里会画这些图吗?
白: 会。一个框,本质上就是一个函数定义式,也就是lambda表达式。入矢代表输入(自变量),出矢代表输出(因变量)。复合的时候,正是玩lambda表达式的时候,而且都是带类型的。
毛: 对呀,我在想这些图应该能转化成DAG式的数据流。
白: 每个坑都有类型,譬如,吃,输入类型两个坑分别是有生命、食物,输出类型是事件。
立:对,坑有两个信息:一个是坑本身的类型(what role),一个是坑里面的东西的“格”条件。role 是坑的主人决定的(词典里面的 谓词 subcat 或者规则产出的 谓词 subcat),“格”其实也是 subcat 题中应有之意,规定好的。格是输入匹配条件,roles 是输出事件语义。
毛: 数据流,结合立委的多层 FSA 模型,如果能做成通用的系统,我觉得是个很好的进展。有没有统计过像这样的图大概有多少?(以复盖常用句型为度)
李: 常用句型几十个吧,10-100 的区间。
毛: 哦
李: 看定义的粗细,谓词 subcat 最多只有三元 (所谓 S【V】OC),元里面还可以细分,大体 < 100 可以搞定
毛: 这个就可以用上分层嵌套的方法。
李: 这段对话,毛老、白老师,要我整理出来么?你们定,如果要,我就整理成博文。这次是你们俩主唱,我只是敲边鼓的,纯粹语言学的边鼓。
毛: 那当然好啰,要从尼克提到lambda开始。
白: 没问题啊。
李: 我其实不懂数据流,函数式略懂皮毛。lambda 在学语义学的时候学过一点,但是一直没完全整明白过。
毛: 那是工具性的,NLP本身才是关键。
李: 不过 subcat 在产生式合成词中会有变换,是我在 Morphology 课上学过的,而且学过的案例相当多。复杂案例的变换也不少。白老师的后一个例子是复杂案例之一。语言学家很善于总结这些格框变换的模式。
毛: 尼克最喜欢搞锵锵三人行, 咱就来一下三人行。
李: 总之,昨天我还发懵,搞不清为什么谈多层NLP的时候,毛老非要强调数据流,今天醒过来,原来如此。不过,我个人的感觉是,那种内部数据流的 Cascaded FSTs 后来逐渐淡出视野,一定有它内在的局限或问题。而我走的外部pipeline系统的方法,却得心应手,开花结果了。尽管理论上,数据流的路线应该更容易高效,更容易固化,但是肯定是遇到了什么坎儿过不去。
白:关于数据流,一直感觉NLP涉及的比较细粒度,就算自动机的堆叠或者分层的词袋,仍然粒度过细,一个句子里就可能多次流动,更不要说RNN这种自己转着圈玩的了……把这么细粒度的流动用大数据处理的利器来玩,是不是有点高射炮打蚊子?请毛老指教。
但是,自动机堆叠一个实现上重要的架构就是pipelining。底层边吃进输入,边产生阶段性的输出,又变成上一层的输入。这个pipelining的框架如何在系统层面优化实现,很有油水。
还有,当数千个自动机协同工作时,它们当中一定有共享的数据结构和计算,如何进行优化,乃至硬件层面的优化,这里面大有文章可做。
早年的文献中,最原始最愚蠢的数据结构是 string 进 string 出,然后他们描述怎么在这个一维的string上加各种括号和标签。下一个模块必须在模式匹配的时候要跳过这些人为的括号与标签,才能更新信息,那个愚蠢透顶,不可思议。我还真照文献说的实现过一个prototype,一边做一边骂这帮傻老帽。那个玩意儿根本做不下去,超过两层的处理就焦头烂额了。
后来有人(譬如英国著名的NLP平台 GATE)用 XML 作为模块间连接的标准接口,本质上也还是 string,不过是多了一些现成的工具,可以用来 parsing 这样的数据成内部结构。当然,在不同系统对接的时候,开发者和使用者是不同的组织,XML 作为标准接口往往是最少扯皮的一种方案,因为内部的数据结构不具有这种传递性。然而对于一个系统内部的各模块,用 XML 做数据传输几乎是胡闹。做个 prototype 也许可行,做应用肯定不行。
毛: 立委讲的外部连接和全编译的问题,我理解就是节点间动态局部连接的问题。全编译就是一次性把整个数据流搭好,以后就不变了。所谓外部连接,就是按需要把若干计算节点局部地临时连在一起,灵活可变。当然是后者更好,不过应该是全局框架中的局部变化。我说的要研究怎样根据NLP的特点灵活构筑合适的数据流,就是这个意思。
全局框架的保证就是一个共同的丰富的可扩展的数据结构。只要保证这个数据结构的设计是合理的,一切就好办了。
毛: 昨天群主一声吆喝,立委说话的风格还真的就变了,马雅可夫斯基的调调不见了。
李: 从善如流嘛。
设计一个NLP专项平台,就包括数据结构的设计,NLP语言的设计,该语言的编译和执行,以及数据流流程的配置和优化。这几个环节都是相互联系的,没有丰富的经验根本玩不转。
毛: 在数据流、即函数式程序设计中,不会由多个节点对同一份数据结构进行修改,这就是输入是否immutable和有没有共享变量的问题。不过对于NLP来说这属于实现细节。
李: 为什么不会由多个节点对同一份数据结构进行修改?每个节点都是单向递进的,数据结构因此变得越来越丰富,分析越来越深入,是为 deep parsing。简单的设计允许数据结构信息的增量更新,不允许或者制约了对数据结构的破坏性操作。譬如,推翻一个内部结构,进行重构(因为 patching 的需要)。但是聪明的工程师在实现的时候,不认为破坏一个局部的内部结构有太严重的问题,不过就是实现费劲一点罢了,屁股总是可以擦干净的。所以我说,只有想不到的,没有做不到的,我才不管他内部怎么实现的,只要用起来顺手就好。只有在实现影响了速度的时候,我可以做让步,允许工程师对我的操作做一些限制。
毛: 如果允许,那就有同步等等的问题,不同节点之间就会互相牵制,而且这样的系统是最容易有bug的。而函数式程序设计,其基本的要求就是:每一个计算节点都是数学意义上的函数,都没有副作用,这就要求:1)没有共享变量,2)所有输入都是immutable。把数据流系统设想成一个供水系统,如果水管在一个点上分支,那么在其中的一个分支上投毒,是不会影响另一个分支的。
李: 照这么说,只允许增量式更新是管式系统开发的安全原则?一开始是增量式的,后来是我坚持要多给我一个做 patching 的手段,打破了这个限制。如果不做 patching,我就只剩下一个手段,那就是先扫除例外,后做一般规则。如果允许 patching,我就多了一条路子,先做大路货,然后遇到问题或例外,再做修补。表面上,这两个办法不过就是数据流中个性与共性操作的位置不同而已,但是实践中总是多一条路子,用起来顺手。其实,做破坏性操作,我开始是有担心的,总怕屁股擦不干净。但是,好像还是在可控范围内。
毛: 对,你所说的对工程师们的能力要求,问题就在于那种结构模式本来就是很不可靠的,得要非常高明的人才能对付,所以一般都尽量把同步、互斥这些事情移到操作系统和语言编译器中解决,因为那些都是真正的高手才玩得。但是即使如此,对于复杂的系统,如果不采用函数式即数据流的结构和方法,难度还是很大。
李: 原因可能是,破坏的结构不过是中间的局部结构,还没到要用它的时候,只要最后系统出来的结构是合理的,就似乎没有问题了。
毛: 你挺幸运,手下有几个高明的工程师,要不然恐怕还做不出那么些成果。
李: 因为我是他们的唯一顾客,顾客是上帝。我一直是这么说的。
毛: 端着人的饭碗,就得听人管。
李: 好在我不懂系统,否则可能不敢这么大手大脚。
毛: 但是,这是有限度的,问题再复杂一点,他们可能就会对付不了。这时候就得考虑模式的改变。不走邪路,也不走回头路,咱走正路。
李: 同意这里面有个度。另一方面,系统太漂亮了不顶用。上得厅堂,下得厨房,这个标准对做系统也一样。正路就是厅堂,厨房就是我这样的实用主义,以邓小平思想为指针。
原载 泥沙龙笔记: 铿锵三人行 (2015-10-8 )
【相关】
【相关】