李:
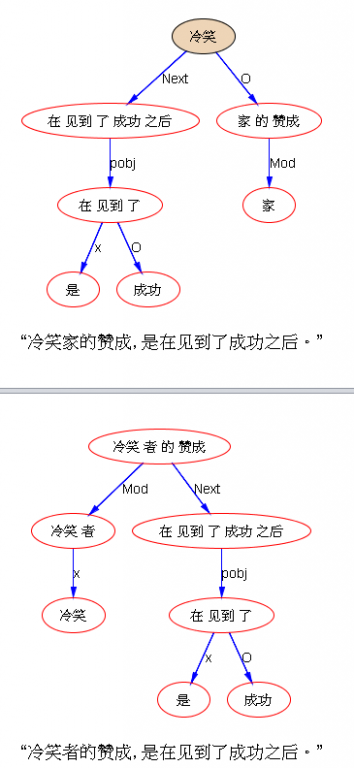
汉语的类后缀(quasi-suffix)有不同的造词程度,“-者” 比 “-家”强。
“者” 是 bound morpheme,“家(home)” 通常是 free morpheme,突然来个“冷笑家”,打了个措手不及 @白老师。
不敢轻易给这种常用的 free morpheme 增加做类后缀的可能性,怕弄巧成拙。即便是人,乍一听这句子中的“冷笑家”也有点怪怪的感觉,怎么这样用词呢?如果硬要去模拟人的造词和理解合成词的功能,倒是有 heuristics,不知道值得不值得 follow:“冷笑”是 human 做 S 的动词,-家 是表示 human 的可能的后缀(“者” 比 “家” 更宽泛一些,可以表示机构或法人),这就为“冷笑家”作为合成词增添了一点语义的搭配证据,但还不足以站住,于是还有另一个 heuristic:“冷笑”的 subcat 的 human 语义坑不仅仅是S,其 O 也是 human: “张三冷笑李四”。而另一条路径(上面输出的 parse)是:"冷笑" 的 O 是"赞成“, 不搭。 这两个 heuristics (一个morphological,一个 syntactic)是如何在人脑里合力促成了正确的理解的,是一个可以想象但并不清晰的下意识过程。机器可以不可以模拟这个过程,利用这种合力做出逼近人类的语言理解呢?道理上当然可以。既然我都可以描述出来,那么硬做也可以做出它来。但是,在遇到这样的语料的时候,说句实话,通常选择不做。原因就是我以前说的:编制一个 NLU 系统,不能太精巧。【科研笔记:系统不能太精巧,正如人不能太聪明】
白: 赞成有俩坑,一个human,一个内容。就算被“的”强制为名词,这俩坑仍旧在。
李:
是,我还没来得及加上 “赞成” 的坑的考量进来,问题的复杂度更增加了。精巧的路线是老 AI 的人和语言学家最容易陷入的泥潭。老 AI 陷入精巧还不当紧,因为 老 AI 做的都是玩具,domain 极为狭窄,精巧不至于造成太大偏向。
白:
“这本书的出版”和“冷笑家的赞成”异曲同工,都是用填坑成分限定有坑的临时名词。所以,两个坑其中一个是human,会给“-家”结构加分。
这是系统性的现象,与精巧无关。
李:
我就怕聪明反被聪明误。在 data driven 的NLU开发过程中,对于偶然出现的“怪怪“ 的语词或句子,我通常是无视它的存在(除非这个现象反复出现)。白老师总说是系统性的现象,但举出的例子常常是 “怪怪”的,是那种介于人话与“超人话”之间的东西,超人指的是,这类话常常是语言学家从头脑里想出来的,或者是高级知识分子抖机灵的作品。白老师宋老师,还有 yours truly 都擅长写出这样句子,可是普罗不这样说话。用白老师自己的话说,就是这类现象处于毛毛虫的的边缘毛糙的地方。虽然是毛毛虫的一个部分,没有它其实无碍。我指的是 “家” 作为类后缀的现象。
白:
对付这种既没有截然的肯定也没有截然的否定,而只是“加分”/“减分”的逻辑,统计比规则更在行。关键是模式长啥样。
梅:
Deep learning 死记硬背,套模式,有了training data,做第四层,第五层,做不出吗?
李:
我对这个统计的能力,好奇多于怀疑。统计或深度神经,真有这么神吗? 连毛毛虫的毛边、灰色地带、长尾,也都恰好能学出来?
梅:
那就需要多run experiments,机器多。一部分靠知识,一部分靠实验。应该能的。
白:
模式过于稀松平常,深度学习或可用上,但效果很差。模式过于稀奇古怪,深度学习可能完全没有用武之地。
李:
“家”作为后缀的产生性不强,基本属于长尾。而“家(home)”作为自由语素则是压倒性的。统计的系统不会看不见这一点。
白:
在找到合适的模式之前,过于乐观或过于悲观都是缺乏凭据的。
梅:
中文的data多啊。再sample一下
白:
都不知道模式长什么样,sample啥呢?我们的关键是看模式长什么样
梅:
做语音识别深度学习的,也是做很多实验,然后发现模式的。
白:
语音的结构是扁平的,拿来套语言,未必灵。假定了扁平再来发现模式,说不定已经误入歧途了。
梅:
不是100%灵,但有analogy
白:
实验不可能对所有模式一视同仁,一定有先验假设的。也许藏在心里没说出来,但是模型会说明这一切的。
李:
【科研笔记:系统不能太精巧,正如人不能太聪明】里面有事不过三的原则。事不过三,无论是中心递归,还是我文中举的否定之否定之否定的叠加。表面上是程序猿的经验之谈,其实属于设计哲学。
梅:
哲学有用的
白:
如果藏在心里的先验假设是错的,多少数据也救不了你
梅:
先验假设 不是不好-立委的知识都可以用到深度学习上
白:
都能用上就好了。问题是他的知识长的样子,深度学习消化得了么?
梅:
那就combine啊
白:
在使用深度学习对付语言结构这件事情上,1、有迷信;2、有办法;3、迷信的人多半不知道办法。combine会引发什么问题,不做不知道
梅: 深度学习一点不迷信,又有定律,又有实践。
李:
哈,曾经遇到一个“超级”猎头,说超级是说的此女士居然对AI和NLU如数家珍的样子,包括人工智能符号逻辑派与统计学习派的两条路线斗争,不像一般的IT猎头简单地认为AI=DL。她的最大的问题就是(大体):你老人家是经验性的,骨灰级的砖家了,你能简单告诉我,你怎样用你的经验为深度学习服务呢?
(哇塞)无语。语塞。
全世界都有一个假定,至少是目前的AI和NLP领域,就是深度神经必然成事。只有在这个假定下,才有这样的问题:你无论多牛,不靠神经的大船,必然没有前途。
白:
深度学习假定的空间是欧氏空间,充其量是欧氏空间的时间序列。万事俱备,只差参数。这个假定要套用到语言结构上,还不失真,谈何容易。其实就是把目标空间的判定问题转化为参数空间的优化问题。
梅:
没说容易啊。现在的深度学习当然有局限性。还要懂data science,the science of data
白:
目标空间错了,参数空间再优化也没有意义。
李:
非常好奇,这么深奥的深度神经是怎样做的 AI marketing 洗脑了全社会,以致无论懂行的、不懂行的、半懂行的都在大谈深度神经之未来世界,把深度神经作为终极真理一样膜拜。
第一,我做工程语法(grammar engineering)的,句法分析和主要的语义落地场景都验证非常有效了,为什么要服务深度神经?本末倒置啊。他本来做得不如我,无论parsing还是抽取,为啥反倒要我服务他成就他呢?不带这样的,当年的希拉里就被奥巴马这么批评过:你不如我,为啥到处谈要选我做你的副总统搭档呢?
第二,深度神经也没要我支持,我自作多情什么,热脸贴冷屁股去?据说,只要有数据,一切就自动学会了,就好比孩子自动学会语言一样。哪里需要语言学家的出场呢?
最奇妙的是把一个软件工程界尽人皆知的毛病当成了奇迹。这个毛病就是,学出来的东西是不可理解的,很难 debug 。假设学出来的是一个完美系统,不容易 debug 当然可以,因为根本就没有 bugs。可是,有没有 bugs 最终还是人说了算,数据说了算,语义落地的应用说了算。如果发现了 bug,在规则系统中,我一般可以找到症结所在的模块,进去 debug,然后做 regressions,最后改进了系统,修理了 bug。可是到了神经系统,看到了 bugs,最多是隔靴搔痒。
张: 感同身受
李: 要指望在下一轮的训练中,通过 features 的调整,数据的增加等等。幸运的话,你的bugs解决了,也可能还是没解决。总之是雾里看花,隔靴搔痒。这么大的一个工程缺陷,这也是谷歌搜索为什么迄今基本是 heuristics 的调控,而不是机器学习的根本理由之一(见 [转载]为什么谷歌搜索并不像广泛相信的那样主要采用机器学习?),现在被吹嘘成是深度学习的优点:你看,机器多牛,人那点脑量无论如何不能参透,学出来是啥就是啥, 你不认也得认。是缺点就是缺点。你已经那么多优点了,连个缺点也不敢承认?牛逼上天了。
梅:
不是这样的。内行的不否认深度学习的长处,但对其局限性都有认识的
李: @梅 这个是针对最近某个封面文章说的,白老师不屑置评的那篇:【泥沙龙笔记:学习乐观主义的极致,奇文共欣赏】
李:赞。
宋:自然语言处理 不同于图像处理和语音处理,相当一部分因素是远距离相关的。词语串的出现频率与其长度成倒指数关系,但语料数据的增加量只能是线性的,这是机器学习的天花板。
李:
宋老师的解释听上去很有调性。
image 不说它了,speech 与 text 还是大可以比较一下的, speech 的结构是扁平的?怎么个扁平法?text 的结构性和层级性,包括 long distance 以及所谓 recursion,这些是容易说清楚的,容易有共识的。
宋: @wei 什么叫“调性”?
李: 这是时髦的夸赞用语。:)
宋: tiao2 or diao4?
李: diao4,就是有腔调。
深度神经没能像在 speech 一样迅速取得期望中的全方位的突破,这是事实,是全领域都感觉困惑的东西。全世界的 DLers 都憋着一股劲,要不负众望,取得突破。终于 SyntaxNet 据说是突破了,但也不过是达到了我用 grammar engineering 四五年前就达到的质量而已,而且远远没有我的领域独立性(我的 deep parser 转移领域质量不会大幅度下滑),距离实用和落地为应用还很遥远。
宋:
在不知道结构的情况下,只能看成线性的。知道有结构,要把结构分析出来,还得先从线性的原始数据出发,除非另有外加的知识可以直接使用。
李:
这个 text 迄今没有大面积突破的困惑,白老师说的是模型长什么样可能没弄清楚,因此再怎么神经,再多的数据,都不可能真正突破。宋老师的解释进一步指出这是结构的瓶颈,特别是long distance 的问题。如果是这样,那就不复杂了。将来先把数据结构化,然后再喂给深度神经做NLP的某个应用。这个接口不难,但是到底能有多奏效?
宋:
SyntaxNet宣称依存树的分析准确率达到94%。也就是说,100个依存弧,平均有6个错的。n个词的句子有n到2n个依存弧。因此,10几个词的句子(不算长),通常至少有一条弧是错的。即使不转移领域,这样的性能对于机器翻译之类的应用还是有很大的问题,因为每个句子都会有翻错的地方。
李:
错了一点弧,只要有backoff,对于多数应用是无关大局的,至少不影响信息抽取,这个最主要最广泛的NLP应用,对于不完美parsing是完全可以对付的,几乎对抽取质量没有啥影响。即便是 MT,也有应对 imperfect parsing 的种种办法。
宋:
这个数据的结构化不仅是clause层面的,而是必须进入clause complex层面。首先需要人搞清楚clause complex中的结构是什么样子的。就好像分析clause内的结构,要让机器分析,先得让人搞清楚clauses内的结构体系是什么,还需要给出生成这种结构的特征和规则,或者直接给出一批样例。
李:
现在的问题是,到底是是不是因为 text 的结构构成了深度神经的NLP应用瓶颈?如果真是,那只要把结构带进去,今后几年的突破还是可以指望的。结构其实也没啥神奇的。不过是 (1) 用 shallow parsing 出来的 XPs 缩短了 tokens 之间的线性距离(部分结构化);(2)用 deep parsing 出来的 SVO 等句法关系(完全结构化),包括 reach 远距离。这些都是清晰可见的,问题是深度神经是不是只要这个支持就可以创造NLP奇迹?
宋:
把结构带进去了再机器学习,当然是可能的。问题就是怎么把结构带进去。什么都不知道的基础上让机器去学习是不可能的。
李:
以前我们就做过初步实验做关系抽取,把结构带进ML去,是有好处,但好处没那么明显。挑战之一就是结构的 features 与 原来的模型的 features 之间的 evidence overlapping 的平衡。
宋:
clause complex的结构与clause的结构不一样。google把关系代词who、what往往翻译成谁、什么,就是没搞清楚层次区别。
首发 【新智元笔记:工程语法与深度神经】
【相关】
[转载]为什么谷歌搜索并不像广泛相信的那样主要采用机器学习?
《新智元笔记:对于 tractable tasks, 机器学习很难胜过专家》
【why hybrid? on machine learning vs. hand-coded rules in NLP】