【立委按】人工智能热潮下,进入自然语言领域的新人也随之增多。新人的好处是喜欢问问题。于是有了答问。
新人:
读过您的parsing方面的系列博文,parsing 及其落地应用的种种,很有意思的领域。把 parsing 这一块做好就非常 exciting 了,能落地就更棒啦
答:
必须落地。否则站不住脚。parsing 做好根本不是问题,已经做了N次了,been there done that(【谷歌SyntaxNet是“世界上最精确的解析器”吗?】)。NLP 是个力气活,但不是看不到头的活儿。达到接近专家的水平是验证过的。落地有所不同,落地需要找到切入点,需要有一套领域化的有效方法。
力气活指的是迭代:就是不断的迭代,每天迭代10次,一年就是3600次。设计思想和框架机制对路了,剩下的就是不断地根据数据制导,去修正系统,保证走在正路上,避免或尽可能减少 regressions,终会达到彼岸。
新人:
力气活是真的,我之前做 NLU badcase 分析,后来能看到准确率确实在上升。我相信迭代的力量。
现在的 parser 已经足够好了吗?您博客中提到的休眠唤醒机制,世界知识的引入,非确定性表达的问题都已经解决得差不多了吗?
答:
还没有,时间和人力的投入不够,一切重起炉灶,系统架构更加合理科学,但血肉不足。没关系,目标导向,急用先做。有些来不及做的,先放在那里。
新人:
想起您博客中各种奇怪的例子
答:
那是刁难系统的,多是语言现象的犄角旮旯,其实不值得太花力气。古怪的句子的好处是测试鲁棒性(robustness)或者测试有没有补救措施(backoff),主要精力还是应该花在统计性强的常用句子身上,不能被长尾牵着鼻子走。
做中文 parsing 特别让人兴奋,比做英语等 要有意思多了,后者太缺乏挑战性了。
新人:
嗯,中文本身很有魅力
答:
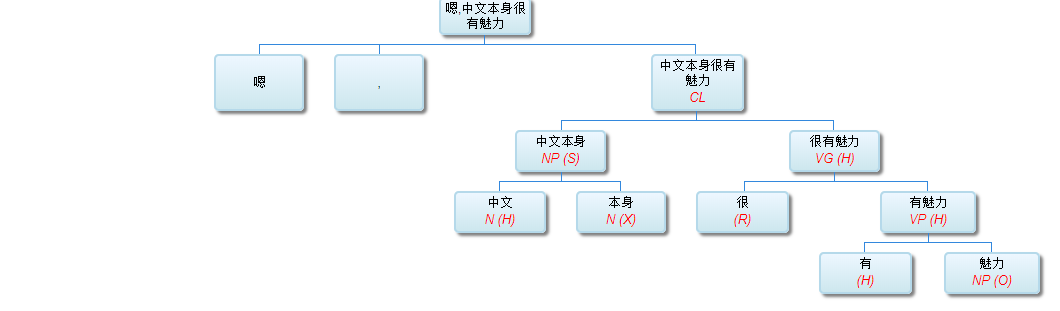
看上去一个字符串 人看着都头晕,如果能自动 parse 出结构来,很让人开心的。
新人:
“看上去一个字符串 人看着都头晕”这句感觉对 parsing 挺难的?
答:
不妨试试:
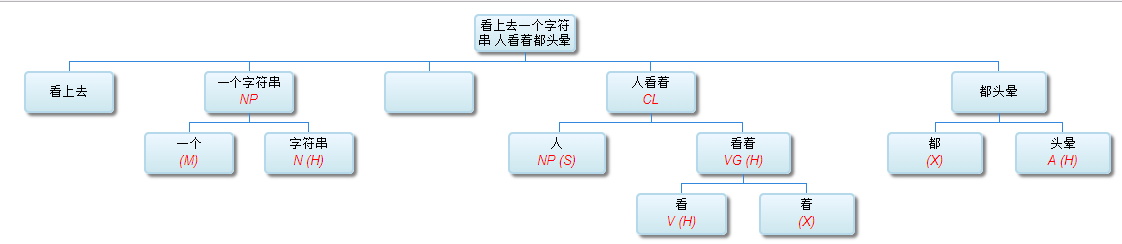
这个当然有问题,但很容易修正。现在的序列是:NP,CL,AP,这个 CL 是一个插入语,最后的结果应该是在NP与AP之间建立主谓关系,把插入语附加上,就完美了。(CL 是 clause,M 是定语,R 是状语。)修改后的结果:
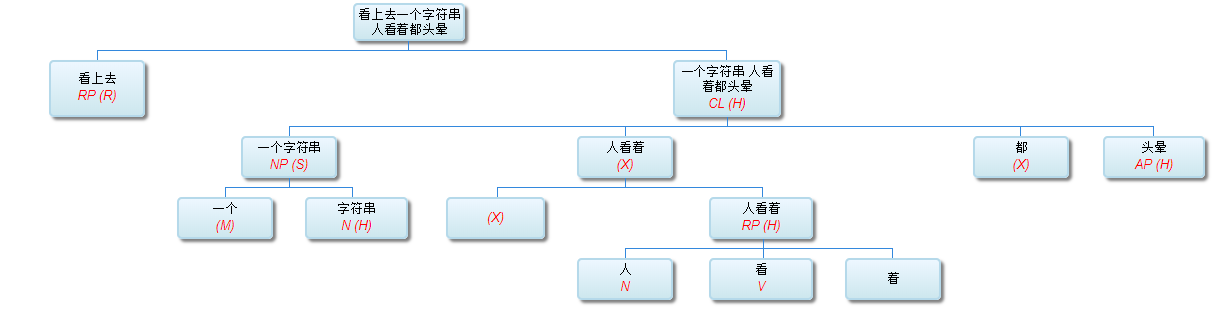
这个结果还合理吧?
新人:
是不是把“看上去”作为RP,就能fix之前的问题了?
答:
主要还是带有插入语性质的 “NP人看着(都)AP",插入语“人看着”是 RP(副词性短语),“看上去”也是RP,但在句首,好办。
新人:
如果去掉“看上去”,整个句子是“一个字符串 人看着都头晕”,改之前的 parser 能解析正确吗?
答:
不能,因为没有处理好这个插入语。与“看上去”无关。插入语在语言中是很有限的表达法,迟早可以穷尽,原则上不是问题。
你以前做过什么parsing有关的工作?遇到过什么挑战?
新人:
之前做parser的离合词这一块。例如“吃了一顿饭”这样的结构,可以从语料中很容易统计到,例如“吃不吃饭”这样的就相对少,只能靠观察。当时是这么做的。首先从研究离合词的论文里找出一个两个字的离合词列表,例如'AB'。然后用'A.*B'在语料中筛选句子,对选出的句子做pos,然后统计'A.*B'中间'.*'的部分的pos组合,但是“吃不吃饭”这样的结构在词性标注的时候就没法搞定了。
答:
这不是简单的离合,而是夹杂重叠。A不AB,是一个相当普遍的现象,对于所有 V+N 离合词都有效的。退一步,V不V 也是一个确定的选择疑问句式。
“对选出的句子做pos,然后统计'A.*B'中间'.*'的部分的pos组合”
做POS 后,你在统计什么?
新人:
当时的需求是,判断"AxxxB"是不是词“AB”的离合现象。因为想提高泛化能力,所以想从语料里产生词性级别的pattern,比如“吃了一顿饭”对应的pattern是“v u mq n”(限定 v 和 n 是单字)。比如“吃不吃饭”词性标注的结果是“吃_v 不_d 吃饭_v”,从词性的层面就不能用“v d v”来匹配了
答:
那两个v是重叠,需要unification机制的,单看POS,根本没戏。如果只是统计 POS-序列,没有什么意义,
新人:
做完了才发现,确实没什么意义。。
答:
是啊,因为就是一个动宾结构,这个 POS 序列,与 NP 中的修饰语序列应该是一致的。
新人:
当时就我一个人在瞎做,都是我拍脑袋想的方法,比较挫
答:
这个不用做统计,就可以想见的。
新人:
能想出来的是有限的呀,肯定有想不到的情况。。
答:
离合词不难处理,它是搭配的一种。搭配现象的本质都是词典的搭配规定与规则的实例化(instantiation)的机制,就是词典与句法需要平台机制上有一个灵活的接口。英语的短语动词 take NP off;put NP on;subcat 句型中对 PP 的 P 的要求(borrow sth from sb),汉语中量词与名词,这些都是搭配现象。
"能想出来的是有限的呀,肯定有想不到的情况。" 但那不是离合词的问题,那是 NP 的问题。NP 当然有很多种组合可能,拍脑袋是想不全的。所以要数据制导,要迭代。类似你上面的语言调查,也是一种。所有的语言现象,不仅仅是NP,都需要数据制导。都有想不到的序列。不过从 POS 序列着手,是远远不够的。POS 太粗,根据 POS 做 NP 或做其他现象,最后都是窟窿。
新人:
是的,最后做了个 字+pos 的规则
答:
字 太细,POS 太粗,加在一起,抓了两头的确会好很多。但是 从字 到 POS 中间还有很多,譬如 【human】以及类似的一整套的本体概念网络(ontology)可以利用(譬如董老师的《知网(HowNet)》)。
新人:
【human】是什么意思?
答:
譬如 “演员”,“总统”,“那家伙”,。。。。就是语义概念标签。【human】是最常用到的标签了,比 N 细线条一些,比 “演员”这些关键词是粗线条了。所以说,一个系统不能光靠最粗的POS分类,也不能光靠最细的关键词,还需要语义概念的 ontology。
新人:
引入语义造成的歧义问题,是用句法来解决吗?比如“演员”是一首歌名
答:
引入并不造成歧义。要是有歧义,那个词不引入也还是歧义的。与引入无关。引入语义只会增加词的信息量,多一些可利用的手段。不是因为引入,所以需要消歧。歧义如果需要解决,也是那个词本身需要这么做。但很多时候,歧义是不需要解决的。
{演员 N},这里有两个信息:(1)演员(2)N。{演员 N 【human】【song】},这里多了两个信息。原来没引入之前,我们根本不知道 “演员” 是什么,不是什么。现在引入语义以后,我们至少知道了 “演员”不是人就是歌。它不可能是其他的1000种可能性,譬如 起码,演员 不是 【furniture】,不是【sentiment】,不是【location】。所以引入新的信息不是增加歧义了,而是大大缩小了歧义的可能性。
新人:
明白了
答:
至于区分歌与人,那个任务叫 WSD,很多应用可以绕过去不做。我写过一篇,说的就是 WSD 很难,但绝大多数应用不需要做(【NLP 迷思之四:词义消歧(WSD)是NLP应用的瓶颈】)。
新人:
说实话我不是对 parsing 感兴趣,是对自然语言理解感兴趣,我想知道通用自然语言理解的道路在哪里,但是也不知道往哪个方向发力。
答:
parsing 与 自然语言理解 有什么不同?为什么对后者有兴趣,对前者无所谓?什么叫理解呢?
新人:
以前我一直觉得 parsing 和分词一样,是一种基础的组件。然后我觉得常识才是自然语言理解的核心。不过看了您讲文法和常识的那篇博客(【立委科普:自然语言理解当然是文法为主,常识为辅】),最近也在重新思考这个问题
答:
parsing 强调的是对语言结构的理解,WSD 强调的是对词的理解。粗略的说,语言理解至少包括这两个大的方面。既要知道这个词对应的是什么概念,也要知道这些概念在句子中表达怎样的关系。其实后者更重要。纲举目张啊。做一条项链光有珍珠不成,更需要的是串子,好把散落的珍珠连起来。
新人:
我说下我对自然语言理解的粗浅的想法啊。比如“我喜欢吃苹果”。从句法上很容易就能解析出来,但是计算机通过什么方式才能理解“我喜欢吃苹果”和“我讨厌吃苹果”的区别?虽然能通过词典知道“喜欢”和“讨厌”是不同的概念,那么要怎么这两个概念有什么方向什么程度的不同?然后要怎么表示这种不同?
答:
然后怎样呢?你前面的话没说完啊
新人:
我也不知道要怎么理解这种不同啊。确实,没有句法是不行的。
答:
1 计算机根本没有什么理解不理解。说计算机理解了人类,那是胡扯。说计算机不理解,也是高抬了机器。人类意义的“理解”根本不适合机器。
2. 所谓自然语言理解,那只是一个比喻的说法,千万不要以为电脑能自主“理解”(或者“不理解”)人类语言了。
3. 所以,自然语言理解的本质就是把语言表达成一个内部的数据结构,根据这个结构,比较容易地落地到应用所需要的方向去。譬如 情感分析的应用 需要区分正面情绪(如 “喜欢”)和反面情绪(譬如 “厌恶”)。
4. 换句话说,所谓理解,不过是人跟人自己在玩,与电脑智能没一毛钱的关系。
5. 既然是人自己跟自己玩,那就要看一个系统的内部表达(所谓理解)的设计能不能用有限的表达和逻辑,去捕捉无限的语言表达方式;能不能根据这个表达和逻辑,达到(或模拟)人在理解了语言之后所产生的那些效应。譬如人看了一句话 可以判断是什么情感,情感的强烈程度,谁对什么产生的情感,等等,因此可以得出舆情分析的结论,计算机可以不可以也达到类似的分析效果?
6 因此 脱离应用(理解以后的效应)谈理解,很难。应该通过应用来验证所谓理解。
7 所谓端到端的系统,就是直接模拟应用:里面的过程是黑箱子,叫不叫理解无所谓。
8 符号逻辑派的先理解后应用,不过是用人可以理解的方式把这个理解到应用的过程,透明化。透明化的好处,比较好 debug,可以针对性解决问题。这是黑箱子系统的短板。如果有海量带标(应用效果的标注)数据,黑箱子的好处是可以很快训练一个看上去很不错的系统。如果没有,标注数据就是一个令人生畏的知识瓶颈。
新人:
我是一直从类似微软小冰那种对话系统来考虑自然语言理解,所以不太能接受seq2seq的对话生成系统…
答:
闲聊系统,因为人的对话无时无刻不在进行,理论上有无穷的带标数据,其实可以训练出很好的以假乱真的闲聊机器人的。一个 MT , 一个 闲聊,这两个应用具有天然的海量数据,是少有的知识瓶颈不严重的应用方向。多数NLU应用没有这么幸运。所以不得不组织成千的标注队伍,还是赶不上应用现场的变化中的需求。
新人:
MT 感觉和闲聊机器人还是不一样?闲聊机器人的系统在单轮的时候可以以假乱真,但是在多轮的时候基本都不能维持对话的连续性。
答:
多轮的挑战可能还是源于稀疏数据,这是因为虽然对话的数据是海量的,但是从 discourse 的角度看一个完整的对话篇章,数据就可能很稀疏了。每个对话都是一个特定的话题,以及围绕这个话题的对谈序列。从话题和对谈序列的角度来看,数据就不再是海量的了。突破口应该在对于不同对话序列从篇章脉络角度做有效的抽象,来克服稀疏数据的短板,学会篇章的应对技巧,easier said than done,这个显然有相当的挑战性。篇章(discourse)向来是计算语言学中最不容易形式化的部分。
新人:
我个人觉得如果是通用/闲聊场景,即使有海量数据,对话的话题和序列还是很可能大部分和可获得的数据集的不一致。
答:
那自然,组合就会爆炸。爆炸了 当然数据就稀疏了。
新人:
很多场景还是有办法细分成小的垂直场景,然后通过在系统设计上做一些功夫来达到一个比较好的效果的吧?
答:
垂直当然有利多了。垂直了,就成了子语言,很多歧义也自动消解了。垂直了,就聚焦了,剩下的歧义也就好办了,词驱动(word-driven)也有了发力的场景。
【相关】