白:
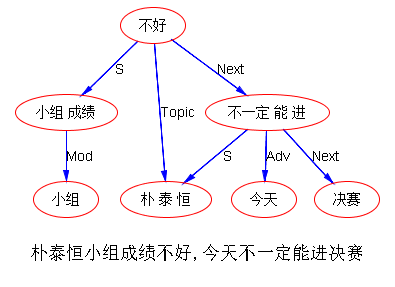
朴泰恒小组成绩不好,今天不一定能进决赛
上面例子,“小组”怎么摆,是个考验。
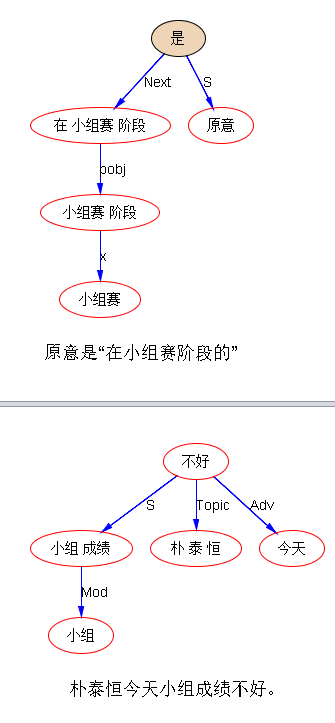
原意是“在小组赛阶段的”
梁:
朴泰恒今天小组成绩不好。
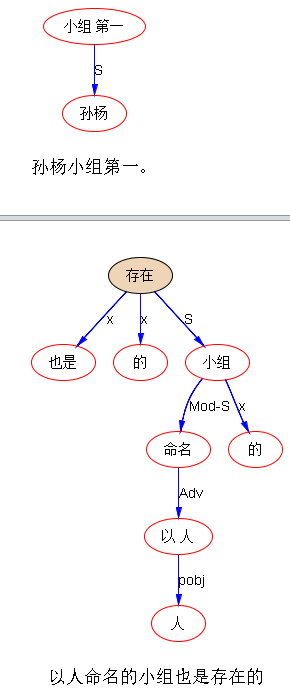
孙杨小组第一。
白:
以人命名的小组也是存在的
梁:
是啊,感觉“小组成绩不好”是谓语。这里小组也不是“朴泰恒的小组“,考验来了。
我:
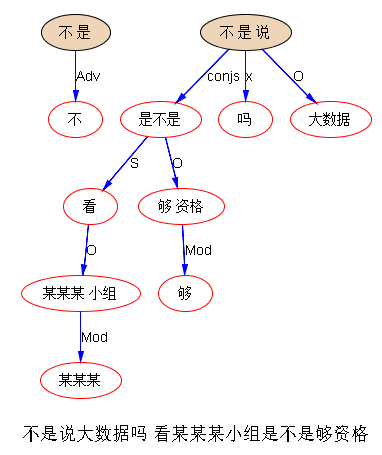
不是说大数据吗 看 某某某小组 是不是够资格

梁:
@wei 很棒! 有个 Topic.
宋:
@wei 确实很好。但是确实能区分两种“小组”,还是只顾一头?
我:
没有大数据,应该是只顾一头吧,可以试试另一头的典型案例
宋:
即使有大数据,还得区分时代、地域、行业等,不好办。
而且,这就成了有监督的学习了,需要做语料标注。
白:
不一定宋老师。可以词典里离线加标签,目标文本在线只需计算标签密度,不涉及监督学习。
宋:
具体解释一下吗?
我:
词典习得本质上是无监督的 ngram 频率做底。假设北京大学不在词典 应该可以学出来,某某某小组 亦然。白老师说的是在线词典化 通过现场计算。
宋:
@wei 就这个例子而言,对比“朴泰恒小组”和“朴泰恒……小组”的频率,是吗?
我:
能不能解决这个问题:北京大学、中学、小学要立刻全部动员起来
xyz 相交切分的通则:xy 强 还是 yz 强,这个道理上可以在线检索计算
“北京大学” 还是 “大学、中学” 强
宋:
如果看作交搭型歧义问题,那么在大数据中,肯定是“小组成绩”频率高过“朴泰恒”的频率,除非朴泰恒这个人太红。因此,以此决定句法结构,似乎理由不足。
我:
人是怎么决策的呢?
这里可能涉及大数据的范围问题。
数据不是越大越好 尤其不能杂 大而杂 就把领域抹平了,而很可能这是领域知识
宋:
对,我糊涂了。
白:
其实,和人名结合是兜底的,要学的只是不和人名结合的高频词串。
向右结合的条件不满足,就默认向左好了。
大数据不是这么用的。
宋:
不过无论如何,一般来说,X小组 比不上 小组成绩。这里是领域知识问题,不大好用词频去处理。
我:
先说一下篇章现象 one sense per discourse.
如果同一篇中 还有 某某某小组 再现。那个原则是过硬的 可以 在篇章内搞定,这时候大数据认输。
宋:
张三小组第一,李四小组第二。
白:
@宋柔 这个是歧义
我:
分为四级
第一级 是词典绑架 北京大学基本如此
第二级 是篇章原则
第三级 是领域数据
第四级 才是大数据 超领域的
涉及到专名 术语的 走不到超领域的大数据,大数据抹平了领域知识 反而不妙
白:
词例级如此,特征级未必
特征级可以把xx小组一起拿上来统计。
我:
明白。不过具体操作起来,还是一笔糊涂账。xxx 小组 与 小组成绩 打架,要赢多少 算赢?在多大的数据里?如果特别悬殊 好说,稍微有些接近 就是烂帐,or 烂仗。
白:
另外,针对篇章可以计算特征密度,如果某种特征密度显著比其他特征高,也可用。比如体育特征显著,“小组”做前缀就优先级较高。
宋:
我在11年人民日报中检索,“小组赛”1013次,“小组成绩”4次,“小组赛成绩”两次,人名+小组3次。对于一个毫无体育比赛知识的人,如果有一般的比赛知识,知道比赛会出成绩,就能推知“小组比赛”是一个短语。首先是从黏着的“赛”黏着到“小组赛”,知道有“小组赛”这个术语,并能理解这是分小组而比赛。由于知道比赛会出成绩,就能推知“小组成绩”是一个短语,指某人在小组赛中的成绩。人名+小组7次,但都与体育无关:赵梦桃小组,郝建秀小组等,都是棉纺厂的。一个人,没有体育比赛知识,但有一般的比赛知识,又有语言知识,就可以有这样的推理
我:
“周恩来思想深刻 谈吐幽默”,vs. “毛泽东思想深刻”
“思想” 与 “小组” 类似
宋:
1940年代以前,汉语中好像没有“人名+思想”作为一个词的。此后,“毛泽东思想”频率越来越高。但其他人名+思想就不能成词。
我:
这个政治有意思:从此 其他 人名+思想 成为禁忌:我花开来百花杀啊。
白:
@宋 “小组循环赛”“小组出线”“小组第一”……等各种组合均以“小组”为前缀,如果只对实例,其实比“朴泰恒小组”好不到哪里去。统计频度多一点少一点都做不得结构优选的依据。但是如果抽象地考察“前缀模式”和“后缀模式”的优先程度受什么影响,必然会追溯到特征以及特征在篇章中的密度分布。如果“体育”或“竞赛”特征及其密度优势显著,“小组”倾向于做前缀,否则倾向于做后缀。如果前缀所带的实例碰巧在大数据里固然好,不在,也可通过特征及特征密度间接获得友军的支持。同样,如果“人名”“任务名”特征或特征密度显著,“小组”倾向于做后缀。
【相关】