李:
发现 “引进” 与 “引入” 可能方向不同 虽然应该是同义词。读【李白之29】(“依存关系图引入短语结构的百利一弊” ),突然觉得不对劲 这不是我的原意。原来想说的是,“依存关系图引进短语结构的百利一弊”,或者,“短语结构引入依存关系图的百利一弊”。a 引进 b,语义主体是 a 而 b 是逻辑修饰成分;b 引入 a,a is semantic head while b is modifying element。不知道这个语感对不对 是不是语言共同体的 还是语言学家的走火入魔?
另 并列排比的力量很大 汉语为最 英语也有:
“One in the morning and one afternoon”
力量大到了可以生生把 one afternoon 拆散,棒打鸳鸯 可 NLP 界对这种现象研究和应对却远远不够。排比句式的自动处理及其与parsing 的无缝连接 可以做一些博士课题 排比是并列的延伸,而并列现象早就公认为是nlp的拦路虎之一。
白:
何以见得?程序员会首先说,编译通不过
李:
万一编译器鲁棒通过了呢。
两个什么?论最近原则 是两个西红柿。但还有一个更大的力量,就是前面说过的排比的力量:一个x ……两个【 】。
白:
通过的那种编译不叫鲁棒叫自作多情。如果论排比,那“一个啥啥”前面也得加“如果啥啥”。
李:
排比的力量真地很大 感觉强过距离 虽然这几句不 make sense.
白:
“孩子”是称呼对方还是指称对方子女,这是个问题:

白:
“拍的一手好照”……第一次见到这个说法。
李:
洗的一把好澡
吃的一桌好饭
拍的一屁股好马
吃的哪门子醋
吃的一坛好醋 双关 嘲讽
白:
你那些统计频率够高,这个不行
李:
露一手
拍一手好照片
踢一脚好球
踢的一脚好球
想一脑门心思?
“脑门” 与 “心思” 搭配,“一手” 却与 “照片” 并不怎么搭,“一手” 与 “拍” 似乎搭。
白:
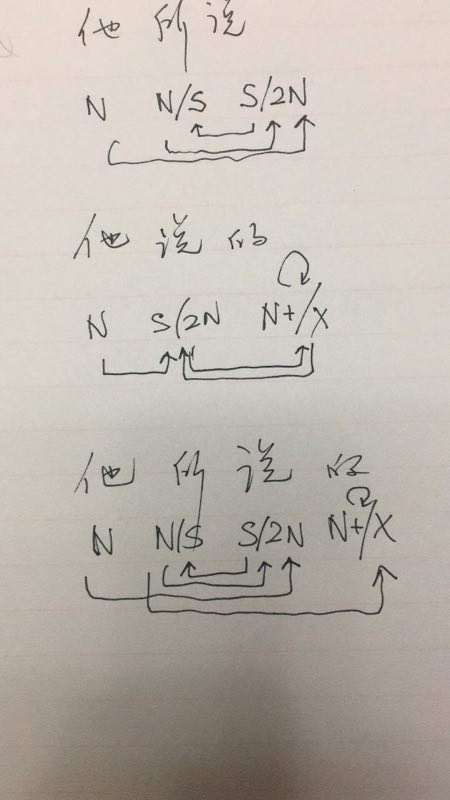
如果“所”负载“他所说”,那么“他所说的”就是“所”填“的”坑。交叉了不说,感觉有点怪。
“所”是个纯粹的逻辑宾语提取算子,“的”则广谱一些,既能提取逻辑宾语,也能提取逻辑主语,而且接名词能构成定语,不接名词自己就升格而名词化。
李:
小词负载结构 也负载语义吗?我想请问的是 白老师系统如何区别 “所” 提取宾语的标配,与 “的” 既可提取宾语 也可以提取主语?这个区别如何在语义上实现?体现
在 pattern rules 里面的话,这个区分很容易实现。
白:
词负载语义结构,使用的是subcat类型演算。也就是说,“所”和“的”的提取对象,在cat层面不做区分,在subcat层面做区分。“的”提取“剩下的那个不饱和坑”所携带的subcat,“所”提取“代表逻辑宾语的那个不饱和坑”所携带的subcat。如果两个以上坑不饱和,如“卖的”,则取两个坑的subcat的最小公共上位(上确界):sup(human,human,object)=object。等待一旦其他成分做出更加specific的限定,比如“买的不如卖的精”或者“卖的都是假货”,再图改变。
李:
那是 unification 的本来意义:unspecified until more specific
两个小词提取(代表)的不同,在 subcat 演算上实现。这个 subcat
是谁的 subcat,又是怎么做 subcat 演算的?对于实词,cat 决定句法(萝卜与坑 以及 mods),subcat 决定语义(semantic lebaling 解析逻辑语义),我们可以想见。
对于小词呢?
白:
小词要具体分析
李:
从哪里看出来 “所” 指的是宾语。
我的所爱在高山。
我所爱的在高山
我所爱在高山
我所爱的人在高山。
我所爱的东西在高山。
我爱的在高山。
爱我的在高山
*所爱我在高山
白:
上面讲的“所”和“的”,我们用的词是“提取”,意思就是说它的subcat是copy来的,在copy之前,它是一个指针变量。说清楚了,谁填你的坑,你提取谁的哪个坑所要求的subcat
李:
“爱我” 只剩下一个萝卜 所以 “爱我的” 就是那个萝卜(代表)。为什么 “所爱我” 不成立?“所我爱” 其实也不成立,只有 “我所爱” 才成立,这个体现在哪里?
白:
我不管什么不成立啊,又不做生成只做理解。做生成也不这么做
李:
哈 这总是少了一个 leverage。赶巧了 词序不对的序列 不会出现 因此把词序 leverage 从 parsing 中扔开 貌似多数时候可行。但总是会遇到某种时候,词序的条件恰好就起到了帮助 parsing 的作用。
白:
subcat完全相同才会考虑次序,这时逻辑宾语右侧填坑优先。但是“所”提取逻辑宾语是硬性的,比只是“优先”来得更加强大。所以有了“所”,就轮不上这些右侧优先了。
李:
这种优先度的调整 听上去是宏观算法的考量,而句型subcat里面所规定的词序(如果词典规定的话)则是微观的。后者比前者更加精准。
白:
前者更加robust。我之所以放弃pattern,就是因为它管了不该管的事儿。
李:
动词句型的subcat,管得恰到好处呀,句型里面说在左边,那就一定在左边。
白:
好好说话是生成该管的事儿。而在各种糟糕语序下尽可能猜测对方意思是分析的事儿。
李:
句型里面的词序规定,与对小词的规定,以及对实词的规定(强搭配规定实词本身,弱搭配规定实词的本体)。所有这些规定都是一以贯之的。不管是分析还是生成,一个句型长什么样子 是植根在句型 subcat 的词典里面的。这是词典内语言知识。至于这个知识用于分析,可以适当放宽而鲁棒,或者用于生成,适当收紧而顺溜,那是知识的实用层面的考量,而不是知识本性发生了变化。
譬如 “邮寄” 带三个坑,其句型就是:
1. [human] 邮寄 [human] [object]
2. [human] 把 [object] 邮寄 (给) [human]
白:
理想的词负载结构,是可以100%把句型语序再现出来的。使用刚性方式(override)还是柔性方式(优先级),只不过是实施当中的工程选择,与理论无关。如果我愿意,也可以都采用刚性方式。但是我不愿意。比如及物动词六种组合语序,双宾动词24种组合语序,其中有多少种是合法的,我不需要关心。也不会用罗列的方式去挑出合法的组合。
李:
不同策略的选择 如果信息无损 当然无所谓。说的就是,在采用优先级柔性方式对付词序的时候,至少在词典化的句型信息方面,条件是受损的,词序这个显性形式没有得到充分利用。弥补它的手段包括中间件的查询。但是中间件的查询,其本性是隐性形式的使用,而词序是显性形式。
白:
没看出来受损。
李:
受损在:本来是由谓词本身来决定萝卜的词序,作为条件之一来填坑,现在却交给了谓词以外的东西。交给了算法中的优先级 and/or 中间件的查询。这个损失蛮显然的,对于所有把谓词本身与其句型的词序规定分开的算法。
白:
搞混了吧,这是谓词自带的,不是交给了算法。
李:
谓词自带词序??
白:
第一个坑、第二个坑谓词自己是有指针的,自带优先序。
李:
NP1 eat NP2:NP1 NP2的词序是词典决定还是......?至少 S/2N 貌似没反映词序。这个2N 里面没看出词序信息。
白:
说的就是第一个坑优先左侧结合,第二个以后的坑优先右侧结合。句法不管而已,subcat管。但是句法和subcat是时时刻刻互通的啊。不相谐时看后续选择。
李:
第一个坑优先左侧结合,这个东西,是对于所有 2-arg 的谓词有效,还是可以对于不同谓词有不同?如果是前者,就不能说是词典信息决定词序。
for another example:
1. translation of NP1 by NP2
2. translation by NP2 of NP1
这类词序原则上都是谓词 translation 在词典就决定好的,到了具体句子坐实其中之一而已。
白:
比如“饭我吃了”,1、吃是S/2N。2、“我”最先从左侧遇到“吃”。3、“我”与其中一个坑相谐。4、锁定human,留下food。
“我饭吃了”:1、同上。2、“饭”最先从左侧遇到“吃”。3、查相谐性,发现是第二个坑subcat相谐。4、锁定food,留下human。
至于查相谐是否必须从左到右遍历,这纯粹是一个算法问题。数据库还允许做索引呢,我为什么一定要遍历?“饭”都有了,跟“吃”的第二个坑匹配为什么必须先查第一个坑。
李:
句型规定词序的做法有下列特点:
1 在词序占压倒优势的句型里面,根本不用查语义和谐。就是词序绑架。
2. 在词序不能决定语义的时候,可以明确提出是哪两对发生冲突:然后让语义在这两对中去比较力量来求解(消歧)。白老师的上述做法貌似在情形1的时候,不必要地查询了中间件,多做了功来锁定。
白:
总而言之,在部分分析树上匹配目标句型,是我N年前使用的方法,现在已经放弃了。放弃的道理是在分析环节追求更好的鲁棒性。在生成环节,有另外的做法。
李:
在情形2的时候,不知道是不是也是查询中间件的力量对比(牵涉两个可能的二元关系),还是只查询一个关系?
白:
没有。一步到位。 说的就是没有使用遍历的方法。只有一个匹配结果就是第二个坑,第一个不用出现都。
李:
遍历也不是“遍”历,n个元素并没有理论上的所有词序排列,而是句型决定了哪些词序排列是可能的,哪些排列根本就不可能。而这些决定都是那个词的知识。
白:
白名单制。
有点对不上频道,我说的遍历是查询时对坑的遍历,不是对可能语序的遍历。我的结论就是,不需要遍历。
李:
这二者在句型实现或坐实中是相交的。譬如两个坑加一个谓词,句型的所有排列是:
1. 谓词【1】【2】
2. 谓词【2】【1】
3. 【1】谓词【2】
4. 【1】【2】谓词
5. 【2】谓词【1】
6. 【2】【1】谓词
当然对于一个特定的谓词,其句型就是这里面的一个子集。
白:
3!
李:
对。如果牵涉小词,上述句型还要扩展。
白:
我现在是一个句型都不写。
李:
然后加上省略,也要扩展:
7. 谓词【1】
8. 谓词【2】
9. 【1】谓词
10. 【2】谓词
白:
嗯,你这充分说明了我不写句型的优越性。
李:
看上去很多,但第一很清晰,第二具体到谓词,只是一个子集,有些排列被句型一开始就抹去,第三,每一个这种句型排列都可以确定性地决定,是歧义还是不歧义,从而决定是不是要求助或留给后面的语义模块。所谓文法,主体也就是这些句型。没了句型,文法也就差不多消失了。
白:
专制的文法消失了,民主的文法还在。中心化的文法消失了,去中心化的文法还在。拉郎配的文法消失了,自由恋爱的文法还在。
李:
很多年前我们的英文文法大体稳定在 600 条规则左右,其中大约有 400 条就是这些句型排列。400 条还在可以掌控的尺度之内。为什么 400 条就可以包揽呢?这是因为上帝造语言有个仁慈的设计:args 不过三。以前说过这个。args要是过了三,排列就至少是5!,必然引起句型爆炸。自然语言的谓词绝大多是是 2 args or 1 arg,只有少量的 3 args or 0 arg。决定了机器人通天塔并非不可能建造。如果当年设计语言的上帝忘了人脑的有限,弄出不少 4-args or 5-args,就傻眼了。一个事件往往关涉很多成分。但人在描述这个事件的时候,总是碎片化描述,每个句子遵循 args不过三去描述,然后利用冗余和合一,最后在篇章中才拼凑出完整的语义图谱出来。这就是自然语言简约有效、与人类脑容量相匹配的奥秘之一。
白:
这就是老话说的,一碗豆腐豆腐一碗,本来不需要区分的,语序一成刚需,得,不区分也得区分了。
一碗豆腐和豆腐一碗,语义上没差别,差别在语用上。数量词后置,是“报账”场景专用,可以让人联想到饭馆里跑堂的。如果将来都用移动终端触摸点菜,“二者的语用差别”就会成为历史。跟自称“奴婢、在下”一样,只能在文艺作品里看到听到了。用于分析的句法,不适合画“毛毛虫”的边界,画出毛毛虫的“包络”就很好了。
【相关】