白:
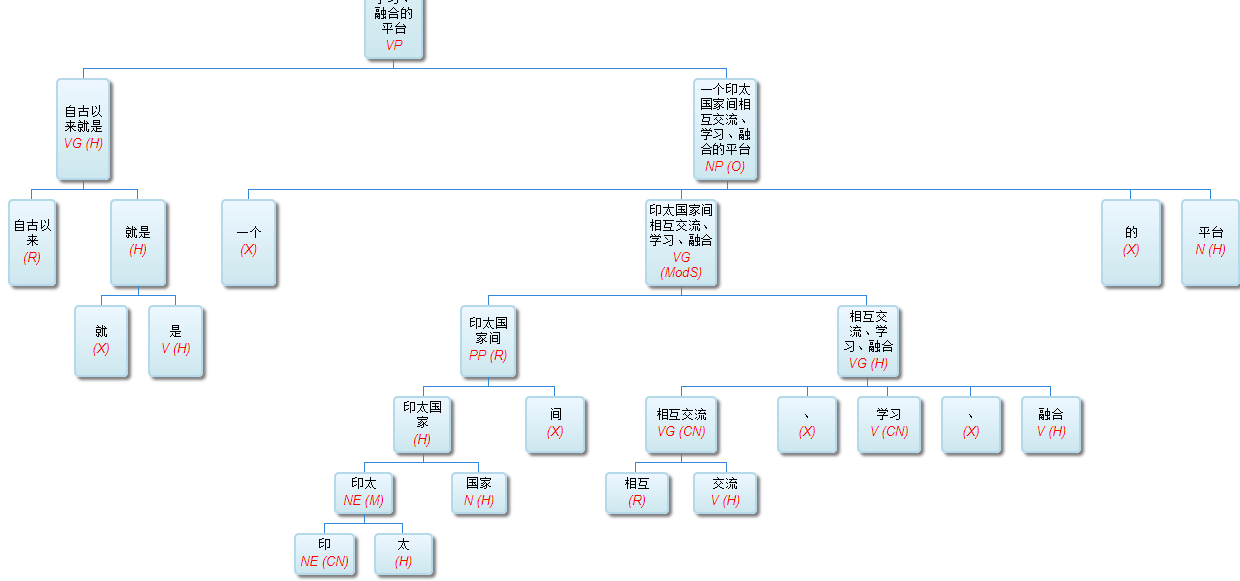
“所谓印太区域自古以来就是一个印太国家间互相交流、学习、融合的平台。”
一个-国家,赋予国家单数特征,与“间”矛盾。一个-间,不搭配。所以只好 一个-平台。这是利用subcat相谐性的传导来排除不合适的量词搭配。
李:
这么做量词搭配 感觉不大合算 实现繁难 还容易错。对于普适性量词如 “个” 和 “种” 最大的heuristic 是最大跨度原则 有更有效的实现办法。
先说老办法容易错。容易错 源于相谐的软性要求 和 排除法 的脆弱性。举个例子:
“我们可以建造100个印太国家间互相交流、学习、融合的平台。”
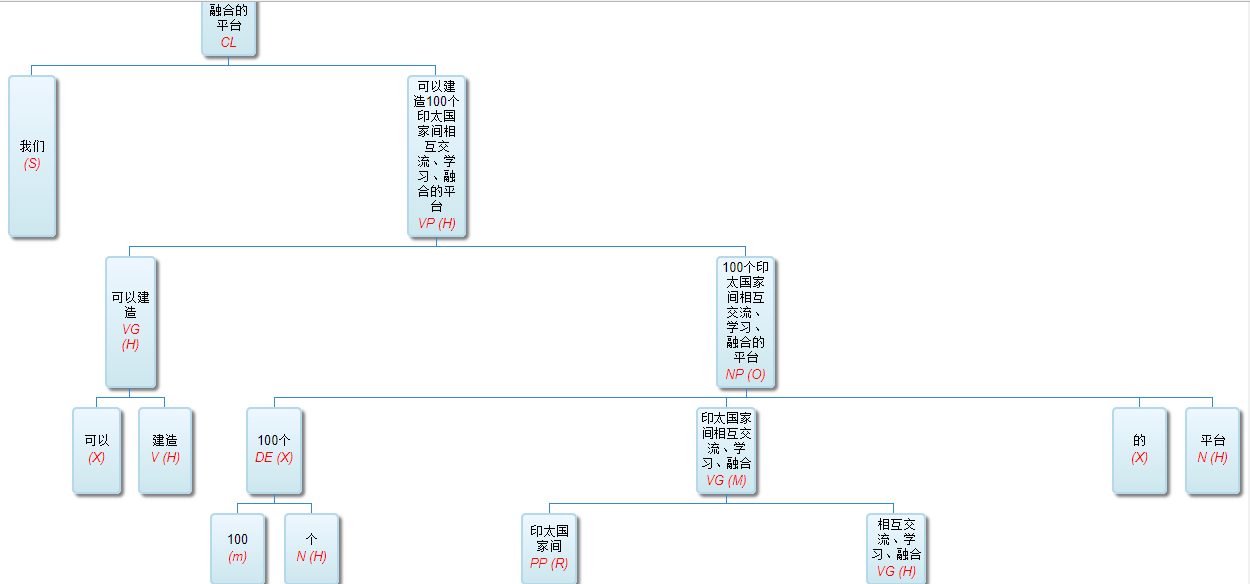
利用 “间” 的相谐 颇不容易。最大跨度原则最简单而且有效的实现就是 见到 “一个” 先挂起来。 然后 该干嘛干嘛 等定语从句 和 其他乱七八糟的前置修饰语都扫荡干净了 一头一尾 拼接一下就完了 无需额外发力。所谓原则 必有漏洞 一定可以找到反例。但比起一个一个的相谐排除法 感觉可靠性更大 更符合国人的表述习惯。国人特别喜欢用这种跨度很大的左右边界搭配的np:
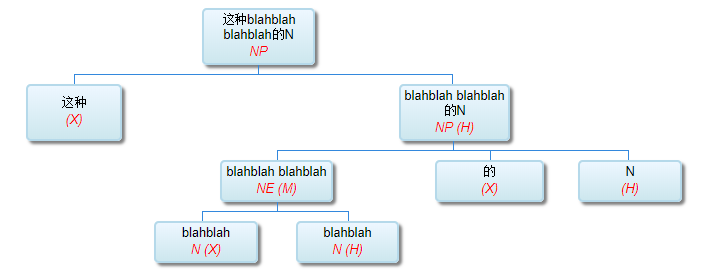
一个 blah blah 又 blah blah 的 N
这种 blah blah blah blah 的 N
写着写着 突然觉得似曾相识 好像就这个量词话题 在某个时间点 说过几乎完全相同的话 相似的论点和论据。 懒得查了 也不好查 这种感觉很真切 说明聚焦一个领域唠嗑 免不了会有车轱辘话 也说明一个人的观点很难轻易改变 尤其是实践中提炼出来的观点。
汉语中框式结构很值得利用。量词结构是一,前置词后置词搭配是另一个常见的框式结构。
白:
不搭配和搭配是不对称的。不搭配一票否决,搭配就近解决,这两个原则一点都不矛盾。
李:
“一个间 还是 两个间?”
一票否决如何鲁棒呢?这里牵涉好几个层面的方法论问题:
第一 我们说的是强搭配还是弱搭配,“个” 与 “种” 通常被认为是弱搭配,基本上是一个名词的标配。
第二 维护搭配词典是一回事,维护不搭配词典 又增加了一个维度和工作。前者是系统标配知识 后者要不要费那费力气 可以讨论。
白:
一个间,有反例吗?可以探讨。遇到一个+NP+间,中间推理过程可以省,记住最终结果(NP+间结合,一个留下不结合)就ok。推理过程离线做,最终结果在线用。
李:
强搭配一票肯定 基本不错。如果要考虑更细致的话 大概是如果有多个强搭配 最大跨度胜出。不过 这已经有点吃力不见得讨好了,因为二分法的强弱搭配 忽视了强弱的连续性。强不搭配 如果维护的话,可以考虑一票否决。弱搭配 或 弱不搭配 还是不如最大跨度。
白:
维护不等于人工维护。
李:
“间” 是方位词 属于后置词。n+间 基本上是 PP,做状语为多,通常还到不了要与量词纠缠的环节。
宋:
@wei 说的框式原则,或者说括号原则,应该是认知层面的规则,应适用于各种语言,确实有用。
白:
间是催化剂,自己不参加有关量词的反应,但偶尔可决定量词搭配的方向。就如“张三与李四的婚姻”当中的“婚姻”,决定了“张三与李四”是序偶(ordered pair)还是列表(list)。后者有分配性,前者没有。“鲁迅的书不是一天能读完的”通过谓语部分的周遍性补语“完”,确定话题主语“鲁迅的书”是“例”还是“类”。都是这个道理。不一定亲自下场子,但对别人的subcat特征取值有决定性影响力。特征不是专门为句法一个任务抽取的(否则确实有是否值得的问题),如果背后有N个任务等着要特征,搂草打兔子,何乐不为。
李:
做量词搭配很多时候是醉翁之意不在酒。怎么讲?我们知道,最常见的量词词组是不定量词组 “一个”、“一种”、“一类”、【一+量词】或有定量词组“这个”、“这种”、“这类”、【这/那+量词】。这些量词组本身语义很虚,除了不定有定的语义(大体上是英文冠词的语义)外,量词本身几乎没有意义(汉语用量词的地方,对应到英语往往是空白),它附着对了或错了,对其头名词的语义解读影响不太大。但是,量词组对于名词短语(NP)起到了左边界的作用,因此量词与右边界头词(head word)的搭配,这种框式结构,对缺乏形态的汉语搞定NP这种最基本最常见句子成分,具有非常重要的形式指征的作用。
从框式搭配结构的角度看量词处理,我们发现,对于比较长的往往内含定语从句的名词短语,人在交流的时候也利用了这个搭配,总是先来一个量词组,等于是跟听众说,注意,我这里给你打左括号了,下面我要说一个具有N多修饰语的实体名词了。换句话说,如果没有量词搭配这种形式标识,为了交流的顺畅和避免歧义,国人不会这么经常地使用长NP。
鉴于此,在短语抱团的浅层解析过程中,善用量词搭配,在最大跨度原则的范围里,容忍某些“出格”或不和谐的修饰语,是解决长NP的非常有效的know-how之一。
【相关】