中文合成词、术语命名可以很长很长,如果顾及内部的修饰关系的边界,是一种典型的结构歧义的组合爆炸。排列组合算一算,N个修饰语有多少种结构歧义?
怎么整?其实,人对于这种超长短语的理解,也基本上是糊里糊涂听,对于里面潜在的歧义无感居多。那机器去做呢,两个办法,一个是凑合大局,不拘小节,出个 deterministic 的结果。另一个办法就是穷举其中的潜在歧义,也不难,问题是穷举了以后如何是好,还是糊涂。
量子区块链AI韭菜盒子店
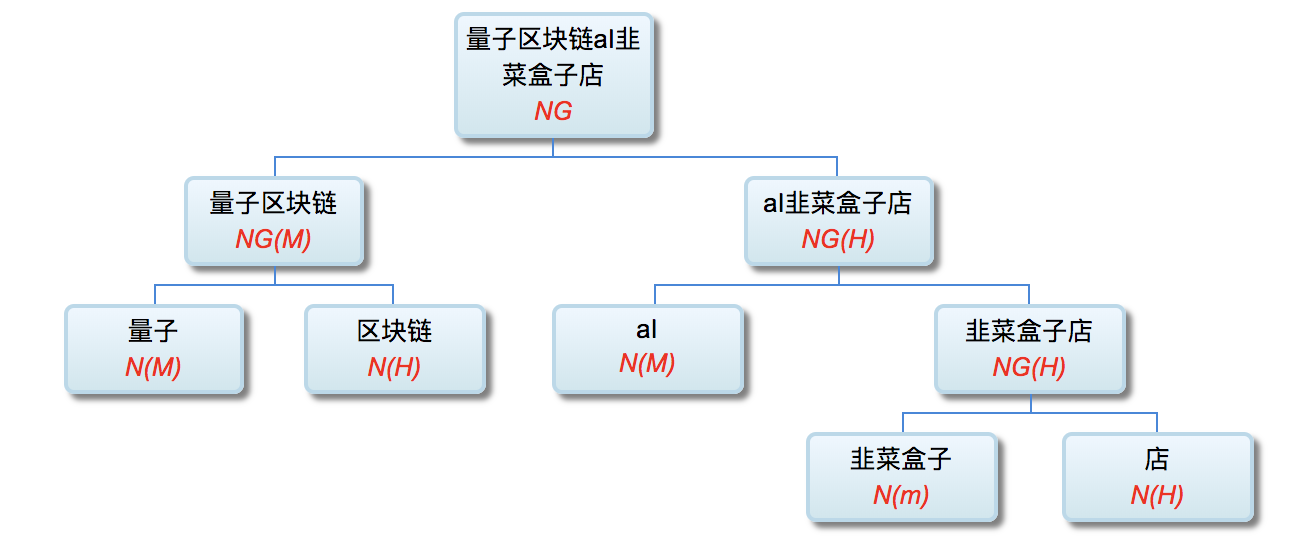
NG=Noun Group; AP = Adjective Phrase; NE = Named Entity;
M/m=Modifier; H = Head; O/o=Object;
N = Noun; A = Adjective; V = Verb;
what is 量子区块链?
马氏体区块链智能韭菜盒子
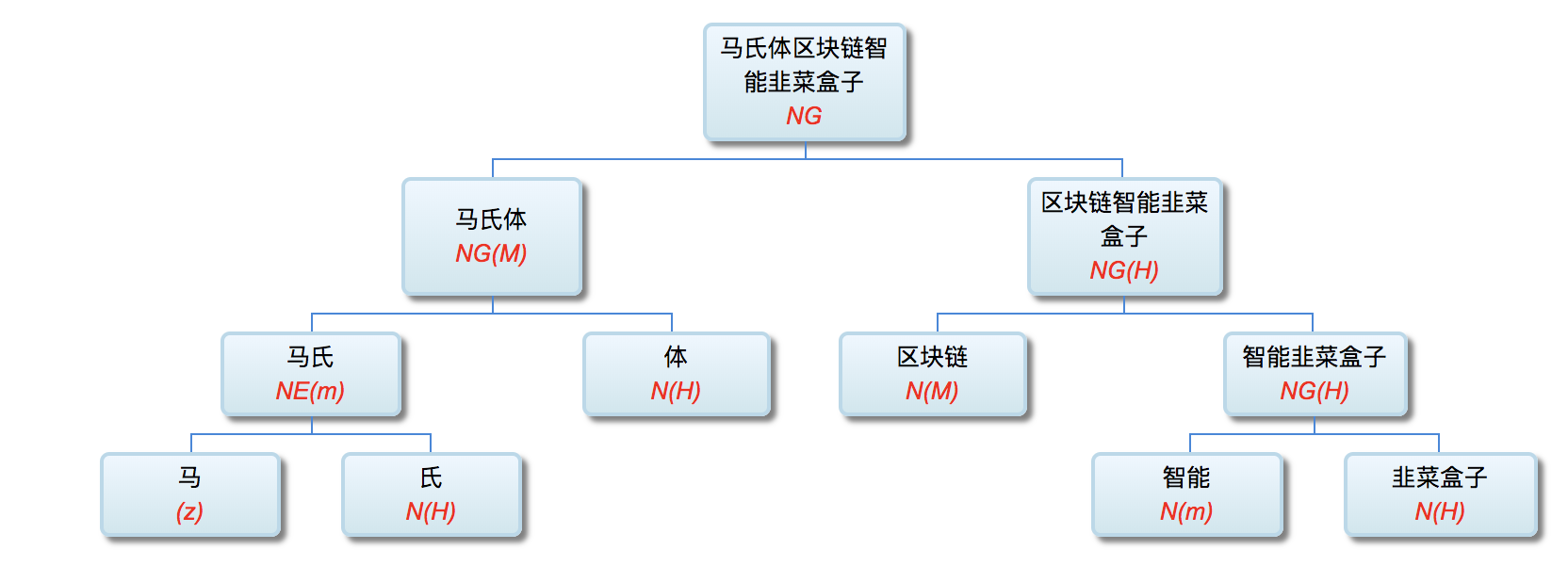
马氏体?or 体区块链?马氏-style?
AI牌马氏体大数据区块链智能云韭菜盒子
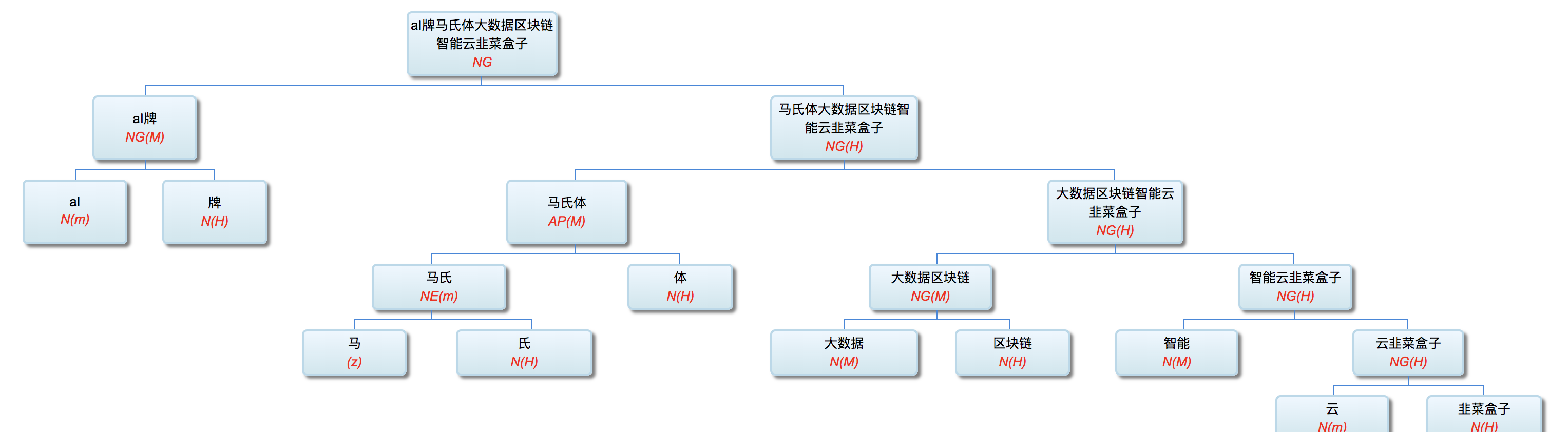
智能云 or 云韭菜盒子?
AI牌马氏体大数据区块链智能云全自动去中心韭菜盒子
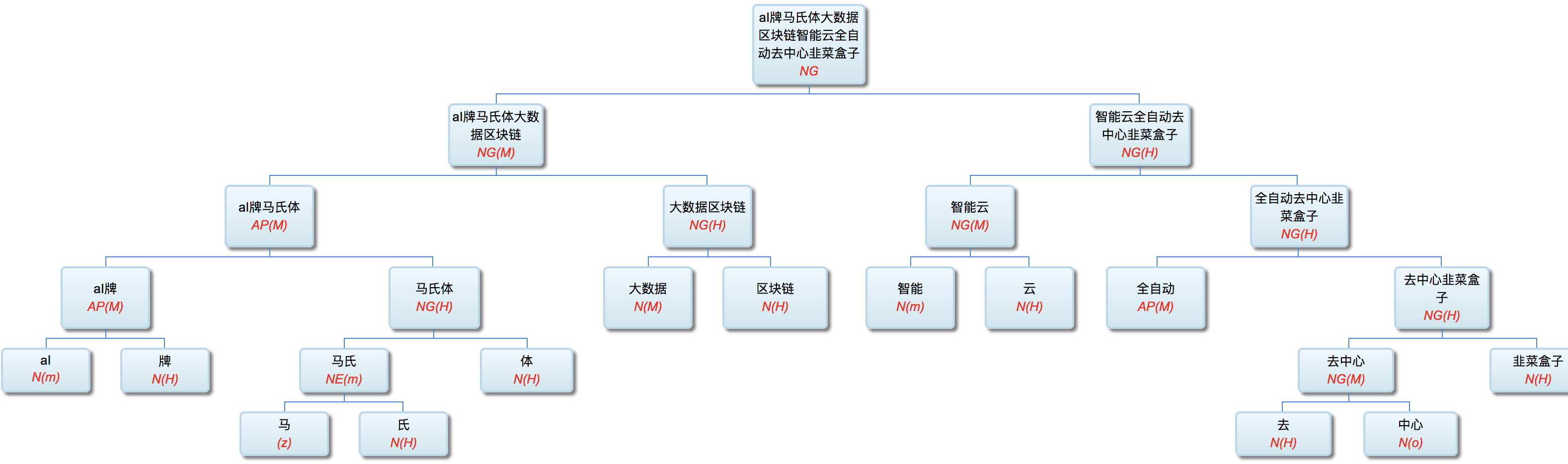
AI牌马氏体大数据区块链智能云全自动去中心韭菜盒子声控密钥无人店
这已经超过10个修饰语了:AI牌 / 马氏体 / 大数据 / 区块链 / 智能云 / 全自动 / 去中心 / 韭菜盒子 / 声控 / 密钥 / 无人店
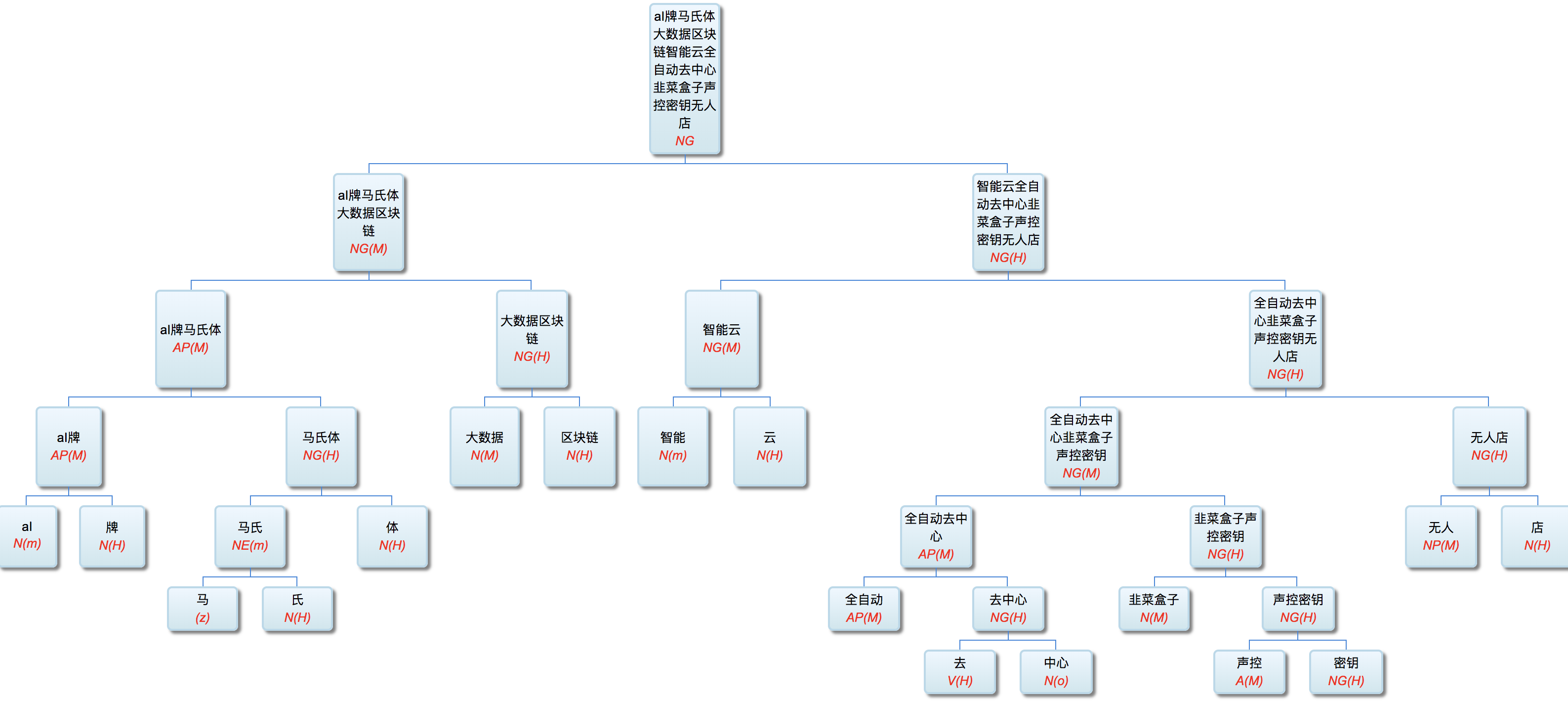
“声控密钥” 感觉是直接修饰 “无人店“ 也许更合理。可现在这种结构也凑合了。好在 XP 内部的纠结,对于句子中 XPs 之间的关系基本没有影响。不过,这种超长NE或NP其实也很少出现在句子里面,通常都是做标题用。
(注:以上例句是尼沙龙人工智能群老友故意拿 buzz words 调侃清华人工智能马教授的一手好菜“生造”出来的。但这些例子反映现代汉语的语言事实,并不离谱。)
O网页链接 【一日一parsing:修饰语的组合爆炸挑战】@马少平THU @立委_米拉 @算文解字 @冯志伟文化博客 @zhazhaba @李利鹏-汇真科技 @永恒的侠少 @白硕SH 就此谈点自己的看法:
1. 正规文档无论标题还是内容,应该不会出现这种过多个不相关的(即便相关)词罗列堆砌在一起的,既不利于传播也不利于理解。当然,有些新闻媒体,或者某些政府公文的题头内容,比文中本身内容都难理解,可能是另有用意,其实并不相信撰稿人就是真水平不及,或许让人产生印象或其他?无论文章或标题,若是总摆着一副“万层茧”的姿态话,我个人意见,人不用去看,机器更犯不着去分析,即便分析那结果也难看的很,无实用价值,就当是那样的是数据传输的一串乱码。要么,文者水平太差,此文不必去读;要么文者就是想着难为人,那我为何还耐着性子去受难呢。
2. 少数几个词组合在一起,在人们容忍范围内的,还是有一定价值的,毕竟不能要求每个人都有通文晓典,行文都能如丝滑般的顺畅。这种平素不相往来的几个词临时组团赴会,初期可以先作为一个团体来看,然后再在随后的文里看看是否离队的分子,若有,再看看是谁谁频繁结伴单游,再回头看看原来这个团的豪华标签,基本上就有所清晰理解。正所谓“不怕你们聚得紧,就看你们分开时”。若通篇没有一处是分开的,而且大块头的合成词语还挺愿意抛头露面的,且不嫌穿那么长衫而行动不便,那这八成就是专有词了,专有词,何去分析拆解它?作为一个词能从文首进,从文尾出就好,也懒得分析了。
3. 至于是凑合大局还是用穷举来罩它,既然早晚都是糊涂,那单独就句分析句就是没太多必要,别累坏俺们的不经世事的幼年机器哈。
1. 正规文档无论标题还是内容,应该不会出现这种过多个不相关的(即便相关)词罗列堆砌在一起的,既不利于传播也不利于理解。当然,有些新闻媒体,或者某些政府公文的题头内容,比文中本身内容都难理解,可能是另有用意,其实并不相信撰稿人就是真水平不及,或许让人产生印象或其他?无论文章或标题,若是总摆着一副“万层茧”的姿态话,我个人意见,人不用去看,机器更犯不着去分析,即便分析那结果也难看的很,无实用价值,就当是那样的是数据传输的一串乱码。要么,文者水平太差,此文不必去读;要么文者就是想着难为人,那我为何还耐着性子去受难呢。
2. 少数几个词组合在一起,在人们容忍范围内的,还是有一定价值的,毕竟不能要求每个人都有通文晓典,行文都能如丝滑般的顺畅。这种平素不相往来的几个词临时组团赴会,初期可以先作为一个团体来看,然后再在随后的文里看看是否离队的分子,若有,再看看是谁谁频繁结伴单游,再回头看看原来这个团的豪华标签,基本上就有所清晰理解。正所谓“不怕你们聚得紧,就看你们分开时”。若通篇没有一处是分开的,而且大块头的合成词语还挺愿意抛头露面的,且不嫌穿那么长衫而行动不便,那这八成就是专有词了,专有词,何去分析拆解它?作为一个词能从文首进,从文尾出就好,也懒得分析了。
3. 至于是凑合大局还是用穷举来罩它,既然早晚都是糊涂,那单独就句分析句就是没太多必要,别累坏俺们的不经世事的幼年机器哈。
from 微博
【相关】