白:
“这瓶酒他只喝了一杯。”
两个量词(瓶、杯)和一个名词(酒)关联。
三个问题:1、“这瓶酒”是什么成分?为什么?2、“一杯”是回指到句中的“酒”还是指到另一个省略了的“酒”?3、如果“喝”的逻辑宾语是杯中酒,那么瓶中酒又是什么逻辑角色?
就是说,如果把逻辑宾语看成“部分”,其相对的“总体”提前为“话题主语”或“大主语”,那么后者到底填了什么坑?目测已经没位置了
詹:
“语文他答对了三道题。”跟白老师例子类似。
他只喝了这瓶酒中一杯的量
这瓶酒他只喝了一口
这瓶酒他只喝了二两
“喝”事件可以设计一个“消耗量”的事件元素
“这瓶酒他喝了一大半”
白:
随意增减动词坑的数目总是不好,量词倒是可负载两种结构:一种是绝对量,一种是相对量。相对量有坑,绝对量没坑。
詹:
动词的坑的数量可以设计(因而可调)。消耗量设计为“喝”的一个坑,可以跟“讨论、谈、喜欢”这样的动词对比。“这瓶酒他们讨论了一杯”不能接受。因为“讨论”类动词没有预留这个坑
“这瓶酒他们讨论了一天。”
请教白老师说的绝对量和相对量具体如何理解?形式区别是什么?
白:
相对量和绝对量都是数量组合。绝对量与中心语结合,相对量中心语省略,但与同形的先行中心语形成远距离照应。
“山东聊城市”
我:
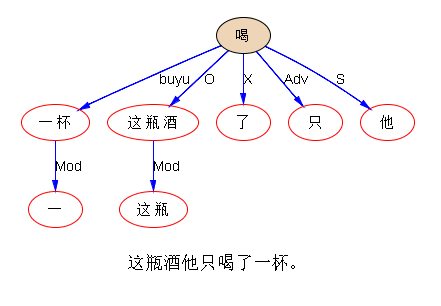
句法是清楚的。
白:
buyu是个大杂烩 装了很多不同的东西,从填坑角度看更是五花八门缺少共性。
我:
那就加个标签【数量补语】,与其他补语对照:【程度补语】【结果补语】或【原因补语】等。如果想进一步区分 “喝了一杯” 与 “喝了一斤”,还可以进一步区分 根据数量结构本身的子类即可。句法到这一步 落地应该水到渠成了。
白:
那倒不必。喝了一口有点麻烦。可是这不是一个好的二元关系。
或者说,buyu才是真正的宾语,O反而只跟buyu发生直接关系,通过buyu才跟动词发生间接关系。O跟buyu的关系是明确的总分关系
我:
喝---酒 应该是直接的关系 否则 语义不搭。
白:
一杯后面有个省略的酒
正常也可以说,走,喝两杯去。省略是肯定的,省略的是酒,则是通过先行词照应出来的。先行词是茶,省略的就是茶。杯和酒,也有强关联,不管语义上还是统计上。
试试:“这瓶酒张三只喝了一杯,李四却喝了三杯。”
要想把“一杯”和“三杯”都分析成buyu,还有点小难度呢。
“一瓶酒四个人喝,张三和李四各喝了一杯,王五和赵六各喝了两杯,瓶里还剩一杯,问这瓶酒共有几杯?”
我:
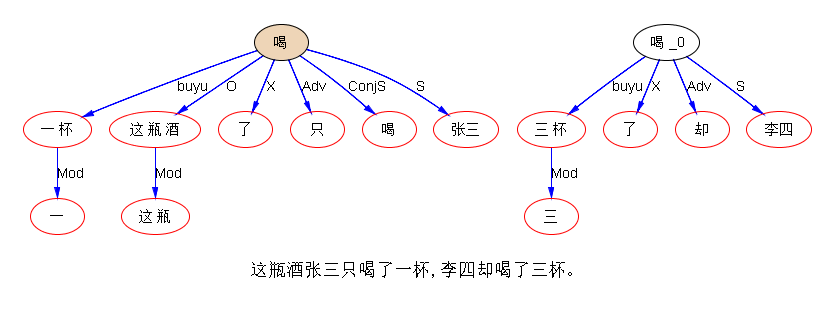
一致不一致 只要后面是有准备的 就可以我们在落地模块里面 其实是有这个心理准备的,
并不指望句法分析出现完全一致的结果。关系标签只是落地的条件之一,不是全部条件,如果 x 和 y 的关系都有可能,对付不一致就是 x|y,一般不影响结果。
白:
“X杯”都分析成buyu吗?
不好的句法不一致多些,好的句法不一致少些
我:
一切都是平衡,某个条件宽了,另外的条件就可以弥补。
白:
遇到不好的句法,不一致不是不能对付,只是一边对付一边喷语言学家而已。
我:
哪里都一样。arsing 做不好 可以喷 POS 模块开发人,OS 做不好 可以怪词典学家没弄好。或者学习模块很操蛋 对付不了 sparse data,但是 说到底 在一个真实开发环境里 还是内部协调为纲。要是踢皮球,做不了好系统
白:
但是句法稍作调整,就可以做得更好。
我:
铁路警察各管一段 是一个非常坏的原则,adaptive dev 才是正道。当然,凡事都一个度。
白:
补语和宾语补足语弄成两个东西,一个指向动词,一个指向名词。已经做了初一,还怕十五么?
我:
一杯和酒 脱离上下文 也有很强的特征上的不同 而且也有ontology或大数据方面的高度相关性。因此 句法把它们连成 x 也好 y 也好 都不是大问题,因为各自的本性的、静态的标签是恒定的、随时可check 的
白:
这话推到极端,就是不要句法也行
可你老人家早就有话等在那里,有现成的梯子,为什么不用?
我现在要说,反正也没到顶,有另一部可以爬得更高的梯子,为什么不用?
与大数据或ontology的关系,自然语言是跑不掉的,波粒二象性摆在那里。
其中可以帮到句法的部分,封装成中间件直接拿来用,早已不是禁忌。
我:
真地没看到显然的必要性,起码对于抽取情报,V 连上了实体 N做 O,连上了数量做 Buyu,想从中抽取啥都可以。要细做,也最多是把 Buyu 和 O 再加一条通道,说 Buyu 是限定 O 的。
白:
看看上面的应用题。要解题,不知道总分关系怎么解?不把句法关系标成一致,怎么获取总分关系?
我:
自然语言理解落地为自动解题,作为复杂问答系统的一个分支,这个倒是确实要求比一般情报抽取要高。那天与胡总聊到高考机器人项目,胡总说,数学应用题道理上应该电脑是大拿吧。可惜,电脑读不懂应用题。自然语言理解是拦路虎。如果读懂了题,转化成了公式,电脑当然当小菜来解题。
白:
NLU做应用题,@约翰 师兄三十几年前就在做了。
我:
做几何题,@严 也兴趣了很久。
白:
用填坑来统领句法关系,就不会那么为难了。把二元关系进行到底,把词例化进行到底。吴文俊团队实际上也做了部分几何题理解的工作。不过数学家们认为这是脏活累活,没有学术价值。所以浅尝则止
wang:
机器做数学应用题,是验证自然语言理解效果的一个非常好的测试。但是没有市场。
本人2000年是在做小学数学应用题求解系统,当时也是为了检验自然语言理解效果的。当时系统,本群的刘群老师,周明老师,詹卫东老师,董强老师都见过,只是这些老师是否想起16年前的事就不得而知了。
当时演示的应用题“一条河里有4条小船,5条大船,河里一共有几条船?”--对于求解有几条小船,几条大船,或者颠倒顺序,都可以演示OK。但是在北大詹卫东老师把“一条河”改成“一个河”,系统就出不来结果,量词啊,量词没细致考虑。
这都是过去多年的事了,只是这个系统没有市场,最后只能搁浅。落不了地就被历史淹没了。记得当时台湾的中研院许文廉老师也做数学应用题求解。对于几何求解系统前几年看过文献,好像已经非常成熟了。可能语义理解的信息不是复杂,还是封闭环境非歧义语义,也许相对容易,这个后期我关注就不是很多了。
白:
应用题这东西,换个内容就是上市公司的报表,谁还敢说分析上司公司的报表没有市场?
wang:
白老师,我那个时候抱着系统广泛寻求市场,却没有市场关爱我。
白:
关键是不要被技术的表现形式所迷惑,要看穿技术的实质,有没有用是由实质决定的,不是由眼下的表现形式决定的。定位问题了。天上不会掉下个产品经理,最初的产品经理就是你自己。这世界上能看穿技术实质的人少之又少,要把技术包装对方向,还要扶上马送一程,理解的人才有可能多那么一点点。现在的教育里用人工智能逐渐多起来,但是系统更像系统而不是老师。要想让系统像老师,必须有NLP。像伟哥这样可以躺在垄断场景上高枕无忧,犯不着关注其他场景的人毕竟也是少数。
wang:
遗憾当初没有遇到白老师啊!以白老师的眼力,就活了。
觉得李老师也是在找更宽的场景。
回到昨天的话题“这瓶酒他只喝了一杯”。我的想法是“这瓶酒”--不是补语
应该是个强调部分。类似英语“It is .... that”
这瓶“酒”和一杯(“酒”),这酒是同质的事物,后者必须省略。不同质的事物,必须交代。
白:
还有不涉及量词的总分关系:“我们班的同学就他混到了正部级”
“我们班的同学”相当于瓶中酒,“他”相当于杯中酒。
总分关系,“总”表现为话题主语,“分”表现为动词的直接成分,主语或宾语。
但是按照移位理论,移出来的话题主语的原位必须是某个论元,所以一定要找到这个坑。
wang:
这种情况可否理解介词短语省略了介词“在...中”,(among)
单独“总”这个论元好像对应不了谓词,比如这里“混”
白:
英语介词短语可以修饰名词 总直接对分,分对谓词
我早上核心观点就是这个
wang:
恩,同意白老师
我:
I drink a cup of tea
cup is O of drink and then tea is linked to cup??
this is not what has been practised for long
tea is O of drink and cup (or a_cup_of) is Mod of tea
these are standard treatments
白:
@wei 这个treatment我太同意了。
英语不能省略tea吧。
即使前面提及了tea
壶里的茶我只喝了一杯,英语怎么说?
我:
NMT: I only drank a cup of tea, how to say English?
壶呢?
原来神经做翻译的时候,怎么常见怎么来,拉下的词没处放,就不放,一笔抹去,眼不见为净。这倒是顺溜了,可不带这么糊弄吧以前的 MT,无论 SMT 还是 RMT,大概
不敢这么玩
白:
有些口译人士倒是真的如此
刘:
SMT也一样的,经常丟词,还有论文专门研究SMT的丟词问题
白:
我在上交所的时候,就领教过知名公司的随团口译。我们提出的尖锐问题,一律抹平了翻,尖锐的词儿影都没有。有时我不得不自己用英语纠正一遍。
我:
那就是 RMT 不敢丢,其实也不是不敢,是丢不掉。除非生成程序有意设计了丢的条件。默认,实词是不能丢的。
“壶里的茶我只喝了一杯” 应该是:
as for the tea in the pot, I only drank one cup of it.
“it" refers to the "tea"
白:
it,相当于移走的tea的trace 在汉语是空范畴 在英语里总要有个真实代词。从伟哥的英译可以看出,他是真心不把“壶里的茶”当主语或宾语的。
我:
顺便一提,我觉得将来机器口译会有更好的用户体验
这是因为人的口译也就那么回事儿,糊弄的时候多,不合格的口译多,合格的在时间紧张的时候也老出乱子。这个观察在前些时候尝试用 NMT 翻译汉语到英语的时候就很清晰了。当时翻译到了英语以后,第一个震惊是,NND,神经真厉害,然后看到谷歌翻译下面有一个 speech 的按钮,就顺手一按,这一听,是第二个震惊,听上去比读居然更顺耳!读起来别扭或不合法的地方,给当今的语音合成一糊弄,居然那么自然,加上人的口译也是错误不断,相比之下,机器读出来里面有几个错就相当可以接受了。于是我用 iPhone 把那一段录音下来,放到了我的博客里面,让世人见识一下,机器口译不是梦。见:
以前一直认为,口语到文字是第一层损耗,文字翻译是信息的第二层损耗,再从目标语文字到语音,是第三层损耗,损耗这样叠加下来,语音机器翻译是一个完全没谱的事儿。但实际上不是这么回事儿。
这第三层损耗,由于有人的陪绑和陪衬,不但不减分,反而加分。第一层的问题也基本解决了。当然前提是语音技术要神(经),语音合成要做得自然巧妙,而这些现在已经不是问题了。前几天讯飞合成一个广告词,居然声情并茂。
赵忠祥当年深陷录音门丑闻,声誉形象大减,那是错了时代。隔现在,赵大叔可以一口咬定那个录音是机器假冒的。
白:
啥时候声乐也能人工合成了,让帕瓦罗蒂唱我写的歌。
我:
白老师等着吧,不远了。