董:
刺死前妻男友男子获刑5年 死者系酒醉持刀上门 -- 百度新闻
Stabbed her boyfriend man jailed for 5 years, the drunken knife door --百度翻译
Stabbed his ex-boyfriend boyfriend was sentenced to death for 5 years the Department of drunken knife door -- 谷歌翻译
不知道这样结果是什么智能? -- 人工?鬼工?骗工?
白:
也是醉了
董:
我主要是要探讨“连动”--酒醉,持刀,上门。这三个动词在知网词典里都是有的。 酒醉 -- {dizzy|昏迷:cause={drink|喝:patient={drinks|饮品:{addict|嗜好:patient={~}}}}}
持刀 -- {hold|拿:aspect={Vgoingon|进展},patient={tool|用具:{cut|切削:instrument={~}},{split|破开:instrument={~}}}}
上门 -- {visit|看望}
酒醉的上位可达:“状态”;持刀的上位可达“行动”,但它与“拿”不同,它是“拿着”,所以定义描述里多了“aspect=Vgoningon”;最后是“上门” 它是“行动”。于是我试下面的规则:
DefineVP1 0712 CN[*pos==`verb`,*def_h=={act|行动},*syl==`2`];L1[*pos==`verb`,*def_h=={act|行动},*def_s==`aspect={Vgoingon|进展}`,*syl==`2`]$L1[*log==`preceding`]@chunk(CN,L1)# // 酒醉持刀上门;
DefineVP1 0722 CN[*pos==`verb`,*def_h=={act|行动},*syl==`2`];L1[*pos==`verb`,*def_h=={state|状态},*syl==`2`]$L1[*log==`preceding`]@chunk(CN,L1)# // 酒醉持刀上门;
心里还是不踏实,因为没有大数据的支持。想听你们的意见。其他例子如:骑车上街买菜遇到一个老同学;
白:
直观感觉,状态的标签不是太好贴。比如,拿着刀子砍人,拿着是状态;抡起斧子砍人,抡起就不是状态?隔着玻璃射击,隔着是状态;打开窗户通风,打开算不算状态 ?
买菜和遇到老同学,谁是前景,谁是背景?谁是主线谁是旁岔,很难说。像伟哥这样一律next最省事。
打开保险射击,打开保险就不是状态
我:
伟哥于是成为懒汉的同义语 。工业界呆久了 想不懒都不成。我曾经多么勤勉地一条道走到黑啊。Next 的好处是拖延决策 或者无需决策。可以拖延到语义中间件,有时也可以一直拖延到语义落地。更多的时候 拖延到不了了之 这就是无需决策的情形。
白:
董老师说的就是语义落地啊。花五毛钱打酱油,花五毛钱打醋。花五毛钱该贴啥标签?
要不是语义落地谁费这事儿。
我:
花 money vp
这个是 subcat 可以预测的模式。凡是subcat可明确预测的句型 通常都不是事儿。给标签于是成为 system internal 的内部协调。
白:
关键是不知道该有多少标签,如何通过粒度筛选、领域筛选、时空背景筛选,快速拿到最有用的标签。
我:
通常的给法是:money 是 o (object),vp 是 c (complement),这是句法。
句法之上这几个节点如何标签逻辑语义 也可以由 subcat 输出端强行给定。譬如 可以给 vp 一个【结果】的标签,vp 是 “花钱” 的结果。
subcat 的实质就是定义输入端的线性模式匹配 并 指明如何 map 到输出端的句法和逻辑语义的结构。这种词典化的subcat驱动简化了分析算法 而且包容了语义甚至常识。
董:
我是因为首先要解决句法关系引起的。例如:欢迎参观;争取投资,就是VO关系,而不是参观游览。也就是说,两个或更多的动词连着时,如何排除歧义?试着只给两个标签:动宾、连动。
我:
一般而言 动宾 是动决定的,连动可以是第一个动决定, 也可以是随机的组合。后者有一个与conjoin区分的问题。
“欢迎” 在词典subcat 中决定了可以带 “参观” 这样的宾语,就事论事 这个“欢迎-参观”的关系几乎是强搭配,与 “洗-澡” 类似。
连动也有词典 subcat 决定的,譬如 “去” vp,“驱车” vp,“出门” vp。
词典决定的东西 没有排除歧义的问题 就是词典绑架 通过 subcat。只有随机组合才有歧义区分的问题。而动宾的本质是不随机,原则上不存在歧义 一律是强盗逻辑 本质就是记忆。可以假设 人的动宾关系是死记在词典预测(expectation)里的,预测实现了 动宾就构建了 这符合 arg structure 的词典主义原则。
董:
负责挖坑,负责浇水,负责填土。。。动宾关系;
我:
负责 vp
为 vp 负责
后者是变式
董:
这么看来,动宾还是连动还是修饰(限定),都由词典解决了。统统做进词典里,就可以了。明白了。
我:
词典主义。随机度太大的组合比较难做进词典。所以一方面尽量做进词典,另一方面 来几条非词典化的规则 兜个底。
随机性而言 似乎 修饰大于连动 连动大于动宾。
白:
如果只有这三个标签,当然做进词典是首选,就怕落地时要的不止这三个。
董:
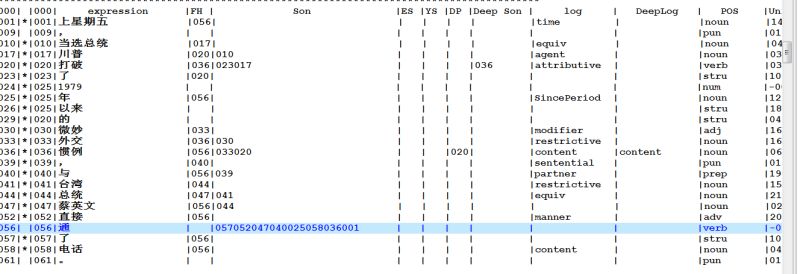
这是我刚才试的一个句子。我们为每个节点预留10个子节点。动词与动词也得包括这些。
我:
进不进词典 主要不是有几个标签 而是这个标签的性质。
语言学的理论比较文科,说的东西有些模糊,但大体还是有影子的。
语言学理论中一个最基本的概念区分就是 complement vs adjunct,这是句法的术语,对应到较深的层面 就是 argument vs modifier。一般而言,arguments or complements 都是词典的主导词可以 subcat 预测的。HowNet 从语义层面对 args 已经做了预测。语言学词典(譬如英语的计算词典,汉语的计算词典等)就是要相应地从具体语言的句法表达方式的角度把 subcat 预测的 complements 定义出来。至于 modifier 和 adjuncts,他们的组合性随机,词典就难以尽收。最典型的就是普世的时间地点状语等。世界上的所有事件都是在时间和地点中进行。
白:
跑步去公园,去公园跑步。前者去公园的路上都在跑步,两个事件在时间上重合;后者只有到了公园才开始跑步,在时间上只是先后衔接。
如果语义落地需要对此作出区分,该有什么标签?怎么词典化?
动词为其他动词挖坑的情况都不难处理,难的是压根儿没有标配的坑。这是从ontology的事件根结点继承下来的。
我:
跑步去公园,去公园跑步。
先说第二句:【去 + NP + VP】 这是可以词典预测的,万一预测不准,可以 fine-tune 条件,譬如:【去 + 地点 + 动作】,总之是词典预测的。既然词典预测了,那么该给什么标签就不是问题了。给什么都可以,要什么给什么。
再看第一句:跑步去公园。
去公园 不是问题 这是一个动宾 VP 是词典预测的:【去 + NP】 或 【去 + 地点】。
问题于是就成为 “跑步” 与 VP(人类动作)之间的关系。 这种关系在哪里处理,词典可以不可以预测?
白:
吃口饭去单位,又是接续关系不是重叠关系了
我:
这个的确有些 tricky 但不是无迹可寻。
白:
跑会儿步去公园,也是接续关系了。
我:
偷懒的办法就是有一条非辞典化的模糊的规则 Next 连接二者。
费劲的办法也有:一个是 “跑步去” 词典化 作为“去”的变体,“跑步”是对“去”的方式限定。
白:
现在的问题是,句法上承认next,语义上细化next
我:
另一个词典化的做法是,在“跑步”词条下,预测 movement 的动词 VP, 【去NP】 、【来NP】 、【到达NP】 等等 都符合条件,可以跟在“跑步”后面。
白:
为啥跑步加了时态,限定就失效?
我:
这个预测的subcat里面的句法规定是:
1. 本词不许有显性时态,不许分离;
2. 后面的 VP 必须是 movement;
3. 输出端:本词作为后一个 VP 的限定方式(句法叫方式状语:adverbial of manner)。
Binggo!
至于为啥?这个问题,系统可以不回答,系统可以是数据驱动的。
系统背后的语言学家可以一直为了 “为啥” 去争论下去,系统不必听见。总之是让 “跑会儿步去公园” 不能在此预测pattern中实现。词典化实现不了,那就只好找兜底的规则了,于是 Next 了。【限定】与【接续】的区别由此实现。前者是词典强盗,后者是句法标配。
白:
在词典之外搞几个标签模版也不难,句法上都对着next,只不过依据前后subcat细化了,这有多困难,而且清爽。
我:
亦无不可。差不多是一回事儿。一碗豆腐,豆腐一碗,就是先扣条件还是后补条件的区别而已。无论前后,总之是要用到词典信息,细线条的词典信息。
白:
看上去不那么流氓
我:
先耍流氓【注1】,还是先门当户对,是两个策略。
很多年前跟刘倬老师做专家词典。他是老一代无产阶级革命家,谆谆教导的是不能耍流氓,要门当户对,理想一致了才能结合成为革命伴侣。后来到了美国闹革命,开始转变策略,总是先耍了流氓再重新做人。其实都是有道理的。
白:
@董 跑步和上班是先后关系,跑步和去是同时关系。
董:
这句分析后,有两个“preceding”,不符合我们理想的结果。我们要的是“跑步”是“去上班”的manner 才好。因为我们要准备用户提出更多的信息要求。例如:系统要告诉用户,我平时是HOW去上班的。
我:
刘老师做系统是在科学院殿堂里面,可以数年磨一剑,we can afford to 不耍流氓。来美国闹革命拿的是风投的钱,恨不能你明天就造出语言理解机器人出来,鞭子在上,不耍流氓出不了活。形势比人强,不养童养媳成不了亲,不抓壮丁打不了仗,于是先霸王,然后有闲再甄别。
董:
是的,我们现在连科学院殿堂都不是,而是家庭作坊,可以慢慢磨。其实已经磨了20多年了。
我:
我还记得当年我们为了一个不足100句的英语sample,翻来覆去磨剑磨了两三年,反复地磨平台、磨算法和磨规则。当时的董老师已经大数据(现在看也不是大数据了)开放集测试“科研一号”【注:中国MT划时代的第一款工业产品“译星”的前身】了。
董:
我们给我们的现在开发的中文分析的目标是:看看能最大限度地挖掘出多少信息。
我:
董老师20年磨出的 HowNet 打下了语言分析的牢固基础。现在是把普世的 HowNet 细化为具体语言的句法规定。路线上是一脉相承的。换个角度看,董老师在 HowNet 中已经把普世的 Subcat 的输出端统一定义了,现在是要反过来再进一步去定义具体语言的句法表达形式,也就是输入端的pattern和条件,然后把二者的映射关系搭上,大功即告成。先深层结构 和 UG,然后回过头来应对每个语言的鸡零狗碎的形式。
董:
这倒是的,我们这个中文系统还没到半年,就有点模样了。词典22万义项,规则近4000条。当然,要真正交给用户,那还有一段磨的。
我:
蛮 impressive。我们开发四年多了,但绝对没有 8x 的规则量。
董:
这回我们不做中英翻译,因为英语生成我们做不起,又没有大数据的。其实做出来也只是给别人添砖加瓦,多一个陪着玩的。这种事情我们不玩的。
我:
对,MT 从大面上就拱手相让吧,数据为王。 符号逻辑和规则路线现在的切入点就是应对数据不足的情境:其实数据不足比人们想象的要严重得多,领域、文体等等,大数据人工标注根本玩不起。不带标的 raw 数据哪里都不缺 但那比垃圾也好不了多少。
宋:
"中国对蒙出口产品开始加征费用"
白:
这个哪里特殊?
宋:
中国对(蒙出口产品)开始加征费用, (中国对蒙)出口产品开始加征费用
白:
进口出口,应该站在自己立场吧
宋:
出口是自己的立场,但也有两种解读:蒙古出口,中国对蒙古出口。我一开始理解为后者,看了内容才知道是前者。
我:
这个 tricky,在争抢同一个介词“对”:对 np 征税;对 n 出口。
远距离赢。
白:
常识是保护自己一方的出口,限制非自己一方的进口
我:
远距离原则有逻辑 scope 的根据。但是具体看 很难说 因为汉语的介词常常省略。scope 的起点用零形式 并不鲜见。
“对阔人征税” 可以减省为 “阔人征税”;“对牛肉征税” 可以简化为 “牛肉征税”。但 “对蒙古出口”,不可简化为 “蒙古出口”。本来也可以简化的,但赶上了 “出口” ,逻辑主语相谐。“牛肉” 与 “征税” 没有这种逻辑主谓的可能,于是“对”可省 而NP的逻辑语义不变。
白:
势均力敌时,常识是关键一票
宋:
这个例子在我所看到的语境下是远距离赢,在别的语境下则不一定。因此,分析器是否应当给出两个结果,然后在进一步的处理中再筛选?
我:
给两个结果 原则上没难度,但后去还是麻烦。
白:
其实关键是什么时候定结果,几个倒在其次
我:
"中国对蒙出口产品开始被加征费用"
加了一个 被 字 哈哈 可能是蒙古对中国的反制。
白:
两个对,有一个和被不兼容
【注1】所谓parsing耍流氓,指的是在邻近的短语之间,虽然他们之间句法语义关系的条件和性质尚不清晰,parser 先行把他们勾搭上,给个 Next 或 Topic 之类的虚标签,类似未婚同居,后去或确认具体关系,明媒正娶,或红杏出墙,另攀高枝,或划清界限,分手拉倒。