白老师在他的NLP语义计算群转了一个让人喷饭的神翻译,如此之神(原文的谐音而不是语义保留下来),可以认定是人工的调侃段子,而不是“神经的翻译(NMT)”:神经再深度,还不可能如此之疯,疯得如此机巧。

马老师说,“端到端的(语音输入)翻译有可能性,不过应该是人翻译的”。但那要把两种语言混杂的情况考虑进去,“you cannot” 的英译汉状态 在遇到不可解片段时(beyond 语言模型的某个 thresholds),动态调整到反向的 mei more tai 的汉译英状态。这一直是MT的一个痛点,在同声传译场景更是如此。我们这些中文中喜欢夹杂英语单词的用户,也常常把MT弄晕,错得离谱。但注意到他们有做这方面的努力,如果汉语夹杂特别常见的英文词,如 ok,yes,等,有些系统已经可以对付。
As usual,“parse parse see see":你将来可能会赚更多的钱,但你没茅台
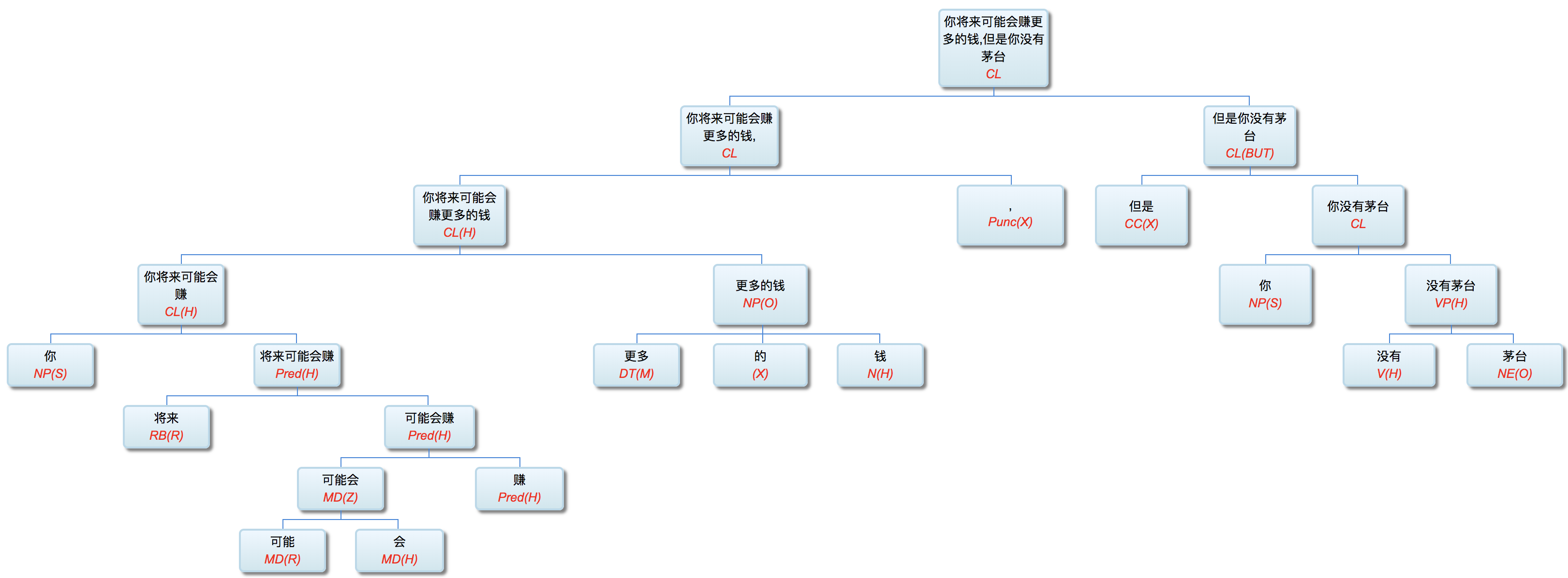
两个分句是转折(BUT: contrast)的关系。显然是提醒家有珍藏的老板们如虎总,要好好珍惜茅台啊:票子会跑风,而茅台越久越值。
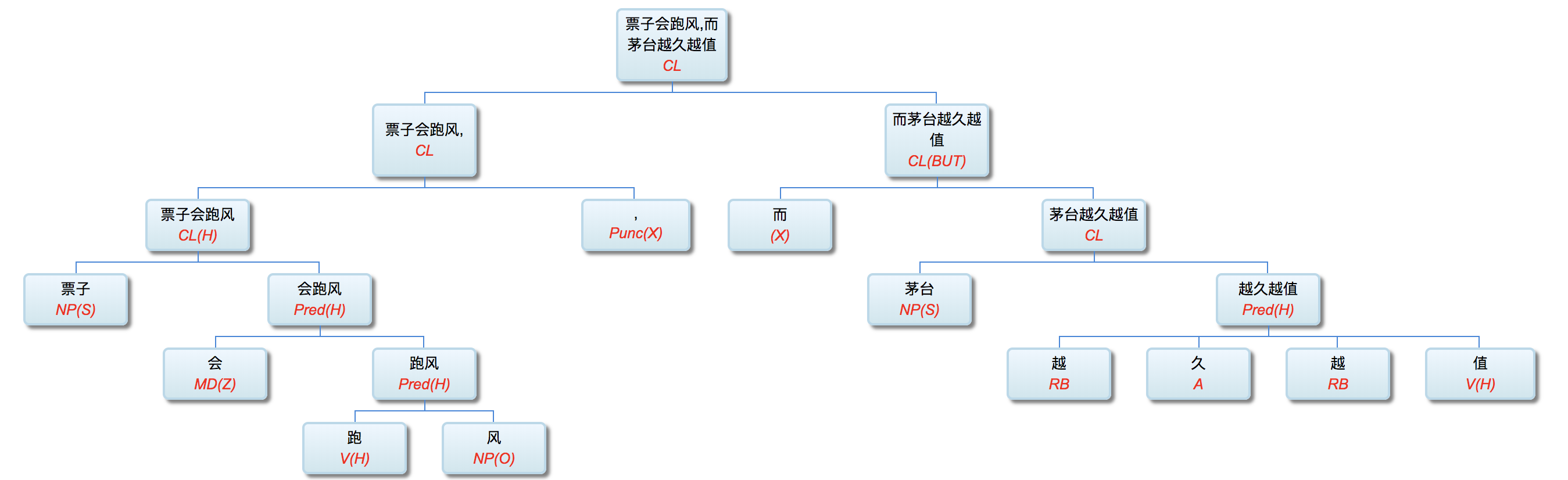
这仍然是一个带转折的复句。其中的看点之一是“越久越值”,就是不久前提到的“成语泛化”(【从博鳌机器同传“一带一路”的翻译笑话说起】):越A1越A2。可见,成语泛化就是在固定语素字符串的成语用法里面有合适的变量来应对成语的活用,因此成语不再是单纯的词典和记忆问题,而是参杂了泛化的成分。以前提过,成语泛化在中文并不鲜见,其典型案例是:“1234应犹在,只是56改”:
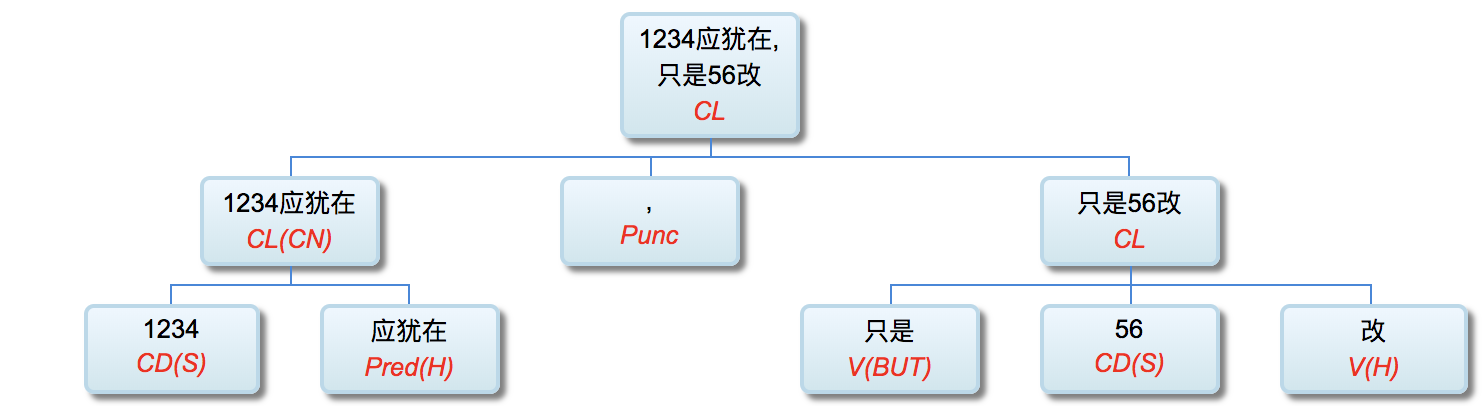
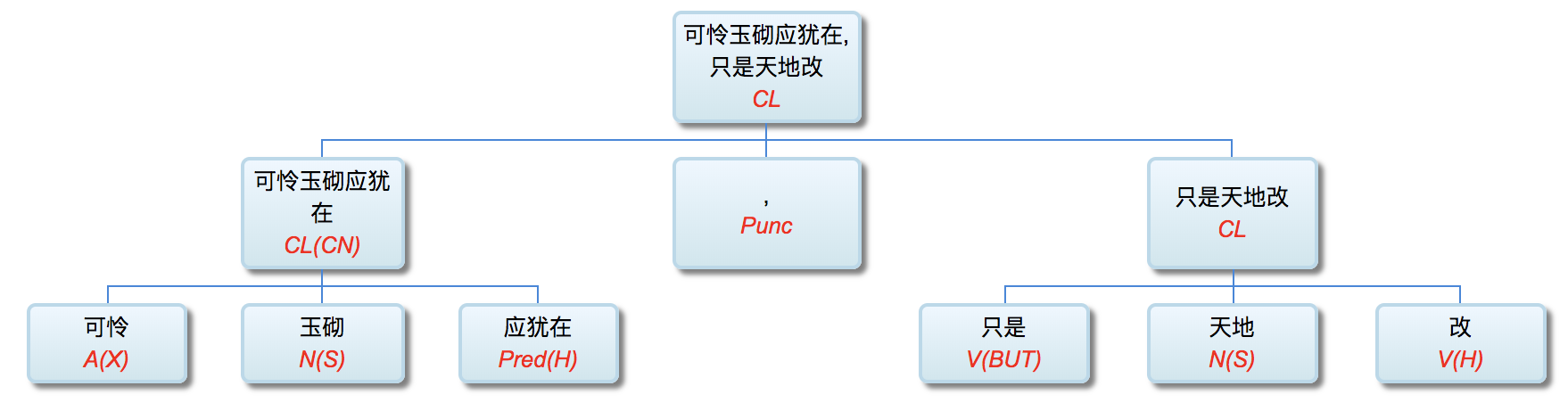
由于汉语的音节特性和汉字语素与音节一一对应的特性,成语泛化的一个根本约束是字数(或音节数),甚过对变量词类或子类的约束,否则读起来就不像个成语。受众如果不能联想到一个特定的成语,说者也就失去了“活用”的妙趣和幽默。下面是 1234(四个音节) 和 56(两个音节) 这两个变量的自然活用案例:
可怜玉砌应犹在,只是天地改
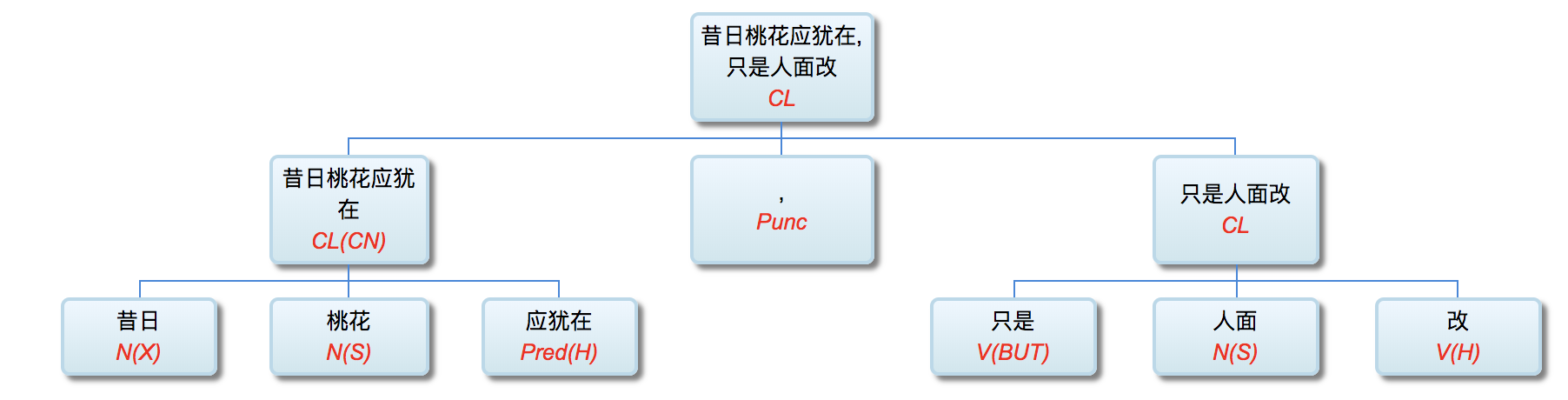
昔日桃花应犹在,只是人面改
再举一些成语活用的解析案例:
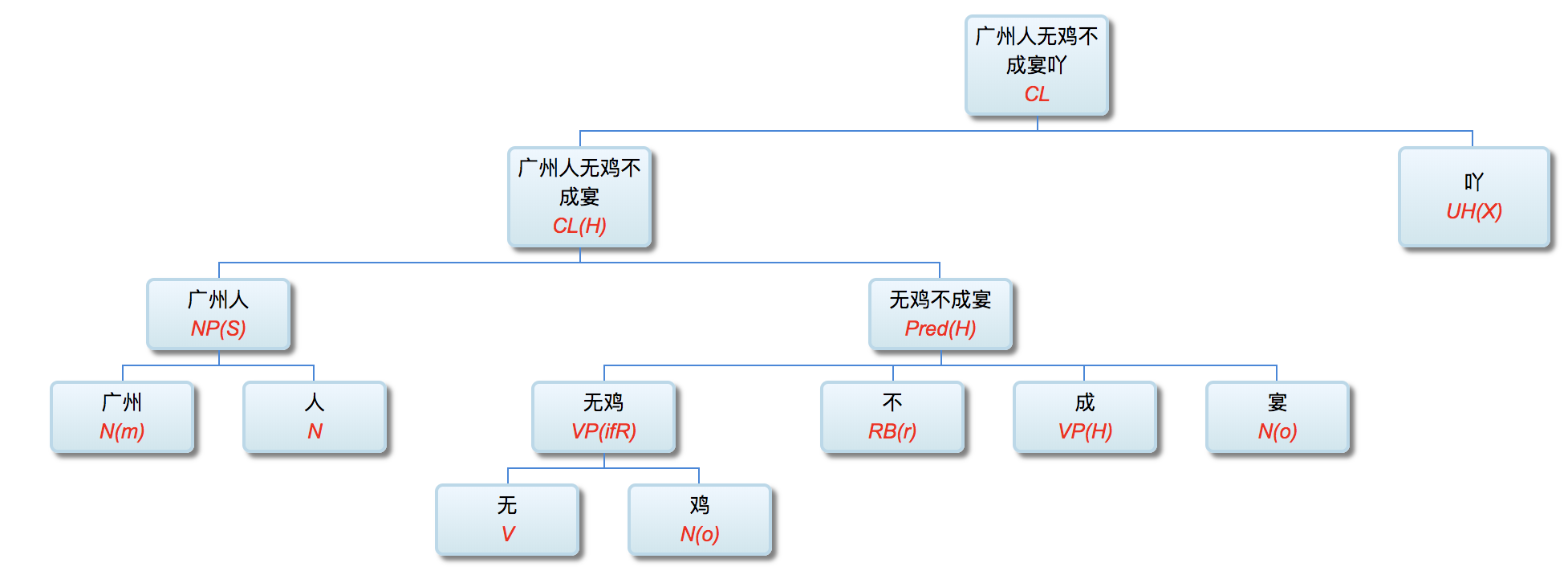
(1) 无巧不成书 --> 无x不成y: 广州人无鸡不成宴吖
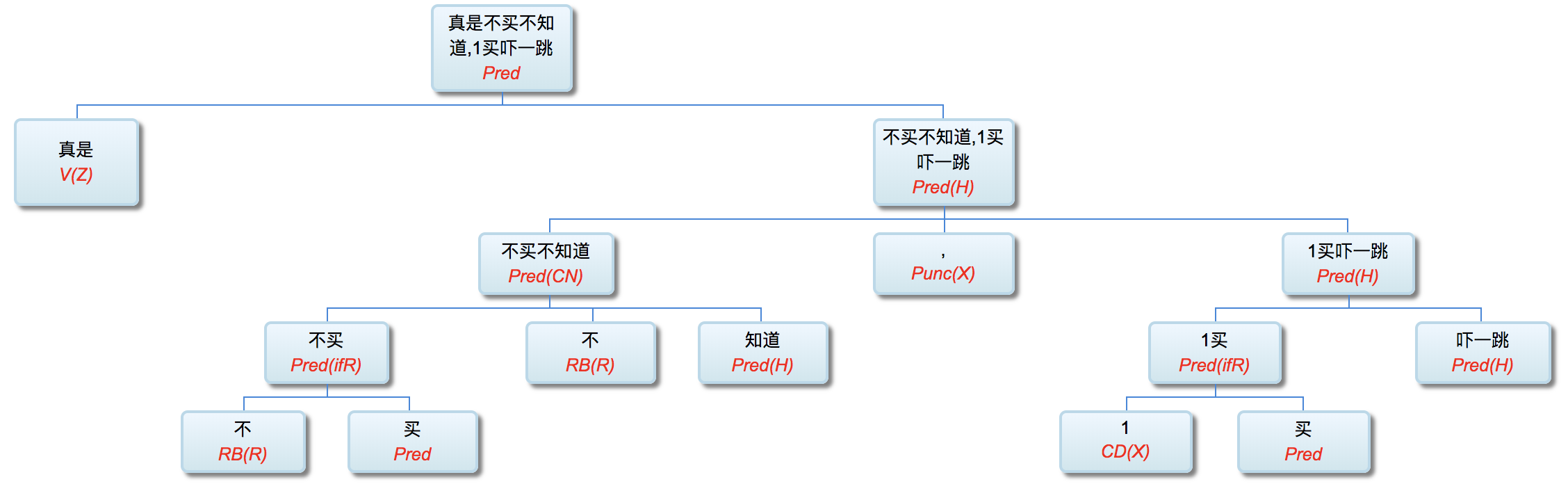
(2) 不V不知道 / 一V吓一跳: 真是不买不知道,1买吓一跳
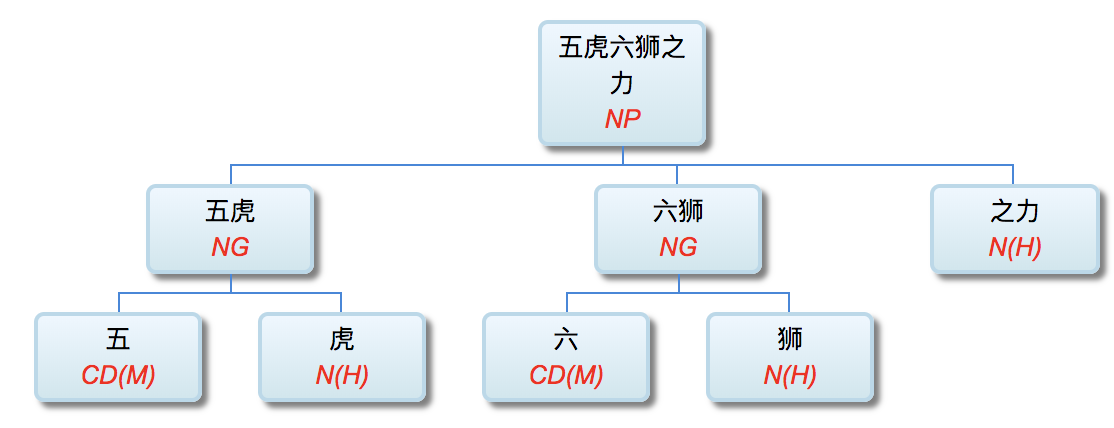
(3) n [animal] m [animal] 之力: 五虎六狮之力
(5) 不费 vn 之力: 不费眨眼之力
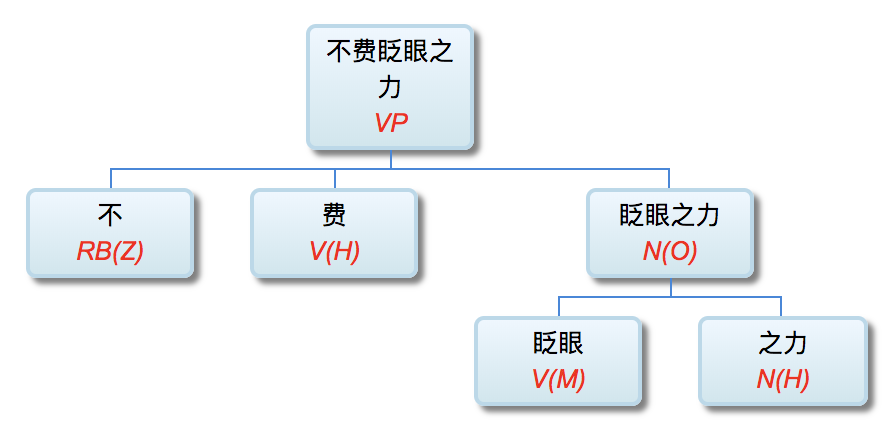
成语泛化,是不为也,非不能也!
【Parsing 标签】
1 词类:名 N; 形 A; 动 V; 副 RB; 介词 P; 冠词 DT; 叹词 UH; 标点 Punc;
2 短语:名词短语 NP; 动词短语 VP; 形容词短语 AP; 介词短语 PP;
名词组 NG; 动词组 VG; 实体专名 NE; 数据实体 DE;
谓语 Pred; 分句 CL;
3 句法:头词 H;主 S; 宾 O; 定 M; 状 R; 补 B;
接续 NX; 并列 CN; 转折 BUT;
主语从句 sCL;宾语从句 oCL; 定语从句 mCL;
条件状语 ifR; 程度状语 veryR;
功能成分 Z; 其他虚词 X
【相关】