【立委按】专业探讨的时候,第一要义是互相搞懂各自的术语。老司机的毛病是经年积淀,自成体系,自创术语,不拘一格。白老师有一套自己的术语,立委也有一套术语。好在过去一年来,在白老师的语义计算群唠嗑唠久了,互相开始明白了各自术语的所指。但对于后学,很可能就麻烦了。为深入虎穴,三探奥秘,我把相关术语编辑在篇末,供各位查阅,不准确处可请白老师指正。
白:
我们先解决“谁和谁发生关系”而不必具体明确“是何种关系”,只笼统地分成:“a是b的直接成分”、“a是b的修饰成分”以及“a是b的合并成分”三种情况。
洪:
@wei 八九十年代 Steven Small 有套Word Expert distribute parsing理论,当时ucsd的Garrison Cottrell和 umass的 wendy lehnert也有类似研究。
白:
word expert理论当年也跟踪过,因为跟汉语实际相差太远,后来不了了之了。
李:
Small 的工作以前常引用,因为我导师刘老师给自己的 MT 机制也取名叫专家词典。术语撞车了,不得不引。句法词典化作为大的方向,在parsing的人以及整个的NLP共同体,长期以来是有相当大共识的,虽然各有做法不同(GPSG以后盛行的词典主义的LFG和HPSG就是这种共识的一个反映)。白老师的分步走,想来是一条结合大数据和词典化的大道。第一步只做 dependency,而且允许以后反悔。只依赖词典,先塔个句法的架子,靠中间件的语义化操作来减除伪歧义的困扰。Parsing 的语义化不外两个层面,一路是 nodes 的语义,即wsd;另一路是 arcs 的语义,就是 matcher 的结构消歧工作,为了求解靠谱的 parses(白老师所谓二元关系)。其后的细线条逻辑语义解析,包括部分二元关系的休眠唤醒以及揭示隐藏的逻辑语义关系,算是深度语义计算。这两路靠的都是大数据与初始结构的“恋爱”结果来克服知识瓶颈,而不是靠带标的treebank。其中最有意思的工作应该是这个无监督大数据与初结构的恋爱学习过程,貌似水性杨花 漫天撒网 愿者上钩,最后根据统计性落实各自秉性与最佳搭配。等着听白老师这个无监督的核爆炸吧,大数据引爆这种针对 deep parsing 的语义知识习得,据说可借力深度学习的 RNN 机制。
白:
不务虚了,讨论点昨天出的具体的例子吧。总会有突如其来的不带介词的NP,让没有坑的VP措手不及。躲得过初一躲不过十五。大数据会告诉我们什么呢?比如,“那堆砖让我垒了鸡窝了”,垒,没有预备坑给“那堆砖”,怎么办?
李:
不务虚 那请教白老师几个问题:第一层词典化二元parsing 是 nondeterministic 吗
还是绝对 deterministic?那么粗糙的 parsing - 如果是后者的话,对后去的学习和反悔 感觉会不够给力。
白:
大数据变了,结果会不同。这算nondeterministic?
李:
不算。那是两套系统,依据的是不同的数据和训练,在不同的时间框架。
不是说不需要大数据吗?连二元关系的性质都模糊,就是先勾搭上而已。
白:
不需要带标大数据。性质可以模糊,但约束必须明确。比如萝卜什么时候占名额什么时候不占名额。Matcher不是语义中间件,他要用到语义中间件。wsd也要用到。一个确定节点标签,一个确定留下的二元关系。
李:
约束不就是词典里面的挖坑,实际中的填坑 ➕ 挖坑么?用的是 cat,因为一个词可以有多个 cats(or subcats),所以调用了 WSD 模块来决定。根据这个决定来填坑构成二元结构。好像就是这么个过程。
白:
“这碗猪”还记得吧。
李:
不搭没关系吧 - 开始的时候。
白:
【碗,猪】这个二元关系有还是没有,问中间件。没有,就不建立arc。虽然cat相配,也不建。
李:
那是大数据训练以后的事儿了,训练之前呢?语义中间件就是一个大数据训练出来的类似 hownet 的资源。在训练之前 大数据怎么结构化的?
白:
训练是独立的,跟matcher无关,跟ontology有关,ontology是结构化的
李:
无监督训练,总要有个啥吧。训练是独立的 offline 进行,利用大数据得出的语义相谐的统计性历史总结,作为 parsing 的资源。Matcher 是 online runner,来对新的 input 做 parsing 的。这跟我们专家去写 patterns 道理一样。训练的结果包含 ontology,
训练的支持难道不是结构化的大数据?这个结构怎么来的?谁给的第一推动?
白:
这是一个冷启动窗口长短的问题。matcher可以只看3个,大数据看13个。大数据的13个中包含被matcher拉近到3个的概率不低。
李:
拉近不是结构化的作为吗?
白:
大数据中非结构化的词串,十三个词里面“碗”和“猪”的共现,以及背后subcat的共现,同“碗”和“汤”的共现相比,这数据有统计意义不?我说的是“包含”。
李:
有意思。非结构化词串就是 ngram,13 词区间大体就是一个子句的长度,再长也没啥统计价值的关联了。
白:
碗,背后的subcat是“容器”“餐具”;汤,背后的subcat是“液体”“食物”。统计subcat共现,可以脱离具体的词例,获得大样本。在大窗口里进行,跑都跑不掉。所以,有无结构的说法是含混的。从parse角度讲,冷启动时无结构;从ontology角度讲,冷启动时结构很丰富。
李:
嗯,为了统计性,脱离具体词,先用 hownet 或 wordnet 支持一下。
白:
冷和热的唯一区别,就是有了冷的基础,热应该更好做。因为大窗口的关联都挖出来了,小窗口更不在话下。
只有一种情况,就是热的情况下,小窗口里面的关联,是把大窗口都覆盖不到的远距离关联拉近了的结果,这种会失手。
李:
好,在 onyology 支持下,在13词窗口内,系统学到了“碗”与“汤”的搭配,so what?
白:
在遇到这碗猪的时候,会选择不match,把“这碗”留着,让“猪”去找自己的坑
李:
这口气得憋多久啊
白:
就是所谓的“过程性因素”,用中间件的查询结果来控制,而不是用手编的语言学知识或规则来控制。
李:
停下的意思类似于入栈。稍有闪失就沉底出不来了。
白:
对啊,RNN+栈。入栈,等着填坑
李:
不知道栈有多深
白:
出不来的情况,参见刚才的例子 “那堆砖让我垒了鸡窝了”。在“垒”只有两个坑的情况,“那堆砖”就是进去了出不来的,如果不想其他办法的话。
荀:
如果这种二元决策是确定性的过程,如果出错,填入的坑的萝卜就得靠唤醒了。
白:
不妨仔细推演下这个例子。
李:
赶巧这个【工具】的坑,处于可有可无的边缘。“垒” 其实也可以带三个坑的。
白:
如果大数据中,存在着大量“砖”带着明确的介词和“垒”共处一个窗口的情况呢?或者投射到subcat上,“建筑材料”带着介词和“建筑行为”共现?
荀:
如何辨认“工具”和“施事”就很重要了
李:
【工具主语】 与 【人主语】 几乎有类似的统计性。
荀:
需要用启发式信息,引导RNN训练,这个引导过程是至关重要的。
白:
这里有“我”,已经明确会填坑。我说的是,没有坑可填不可怕,翻翻大数据,历史上别人用它带什么介词,就把那个介词补上好了。然后就堂而皇之地做状语了。这些东东,有了ontology和大数据的结合,就不要人来操心了。
荀:
把subcat嵌入到RNN中,用启发式信息结合LM训练方式引导RNN编织权重。
李:
如果加上显性形式“用”,工具作为萝卜有很多数据。
白:
我昨天出了那么多例子,伟哥居然没觉出用心良苦:
“这些纸能写很多字”
“这些铁可以打很多钉子”
荀:
[用]这些铁可以打很多钉子
[在]这些纸能写很多字
白:
从形式上,为严谨起见,我们不会去给这个句子凭空添加任何一个莫须有的介词,但总可以用一个不占位置的虚介词吧……
【phi】这些铁可以打很多钉子。
荀:
利用大数据可以做“小词“还原,这对缺少标记的汉语很重要了。
白 :
哈
至少有了这个phi,栈里的不会出不来了。
荀:
借助大数据,RNN做“还原”这类事情很在行。把小词“虚化”,也是一种subcat处理。抓住了小词就抓住了汉语结构命门,白老师在这上花足了心思。对句子做“结构归一化”处理。
白:
推而广之,就是利用大资源+大数据把看起来不那么规范的句子有理有据地整理成更规范的,这样parser负担就轻了,无需独自面对复杂情况。“这场火多亏消防队来得及时”,这里的“这场火”同样面临“没给留坑”的尴尬。但是,把句子中的“火”“消防队”两个实词送入中间件,可以发现与他们共现频次相当高的“救”。有“救”垫底,就可以引入及物的虚动词phi,这样萝卜和坑就相安无事了。
荀:
白老师提到的parser需要确定的三种关系,权重信息编织在网中了,在应用时,词典发出请求,RNN做认定。Parsing就是做<W1,W2,Relation>认定的过程, W1或者W2 可以是小词。 功夫在于Relation定义,在承载结构的小词处理以及<W1,W2,Relation>训练过程,白老师对这些都有一套不同以往的做法。
李:
如果没有坑可跳,就自己挖个坑去跳,这也是 mods 的常规了。在形态语言中,mods 有显性小词或词尾帮助确定该怎么挖坑自裁。在裸奔的汉语,形式没了,只好靠搭配。
白:
救火这个例子,已经不是subcat嵌入了,根本就是词嵌入。
李:
wait:“这场火多亏消防队来得及时”,这里的“这场火”同样面临“没给留坑”的尴尬。
咱们走一走这场火。哪里出来的“救火”,“消防队”本体里面的吗?Hownet 里面肯定有。
常规的做法是,遇到句首 np 没法填坑,就给个 topic 标签。有点像英语的 as for,with regards to,topic 很像pp做的状语。往后找一个谓语挂靠:“这场火” 挂靠到 “来”。
白:
人家只有一个坑,还是给human预留的。
李:
不需要啊。状语是随机的。状语可以看成是不填坑,而是挖坑,挖个坑让谓语填进去
或者让自己跳进去 再去找主儿。
白:
比如“为了”?
李:
想不出来为什么要绕那么大弯,让“救火”出来救驾。Topic 式状语,无需那么清晰的标签,就是把np 降级为 pp。至于什么 p 什么格,另说着。
世界语有个万能介词 je,柴门霍夫这样解说:介词就是格,都是确定性语义的。
几十个介词 就是几十个格。但是如果有一个状语,你不知道哪个介词合适
或者你懒得费劲琢磨什么格合适,你就用 je。与前面提的phi,异曲同工啊。
白:
那样活儿太糙。补介词合适还是补动词合适,大数据说了算。
李:
用了 je 就确定了其地位。不是没有道理。人如果要清晰,他可以有清晰的形式,譬如介词或词尾。如果他不用,那就模糊。虽然模糊,句法地位和关系还是大体确定了。这类模糊要确定语义关系,可以在后面的语义模块(我以前也叫它语义中间件)决定,而不是白老师的中间件在parsing 过程中调用。我选择把二者分开,因为这类情形句法没有到走投无路,就算耍个流氓 亦无不可。先躲过初一,到15再说。其实 15 到了,要求很可能与初一不一样了。人走茶凉不了了之也是有的。
白:
数据支持的话,可以冒进一点。中间件就是在过程中调用啊,否则有啥用。
李:
deep parsing 的过程可以分两个阶段,两个模块:句法和语义。我叫语义中间件是指它在句法模块之后,产品语义落地之前,夹在中间。怎么没用?几乎所有的 hidden 逻辑语义,都可以留到这里做,而不必在句法模块做。
不仅句法模块内部可以多层去做,句法到逻辑语义,也可以分开,成为两个层面的 parsing,Syntactic parsing to semantic parsing。非谓语动词的主宾等都可以后延,
句法只要确定其状语还是定语或补足语身份即可。对于谓语的主宾等,也可以先在句法做一个糙活,到语义中间件再细化或修正。糙活是不到不得已不调用 ontology,如 np 主语,管他 【human】 还是 【instrument】:
张三砍了李四
斧头砍了李四
开始都是同一个parse。
张三吃了大餐
乌云吃了月亮
也是如此。
白:
现在还都没说定性,只说定位,谁跟谁有关系。结论是,就这么糙的事儿,也得动用ontology。
李:
句法不必要太细。语义可以细,但那个活儿可以悠着点,做多少算多少。
回到白老师前面给的句子,试试我目前语义模块还没丰富完善的 parsing:
“那堆砖让我给搭鸡窝了”
“这辆车能坐六个人”
“这个方向不被看好”
“这些铁可以打很多钉子”
“这些纸能写很多字”
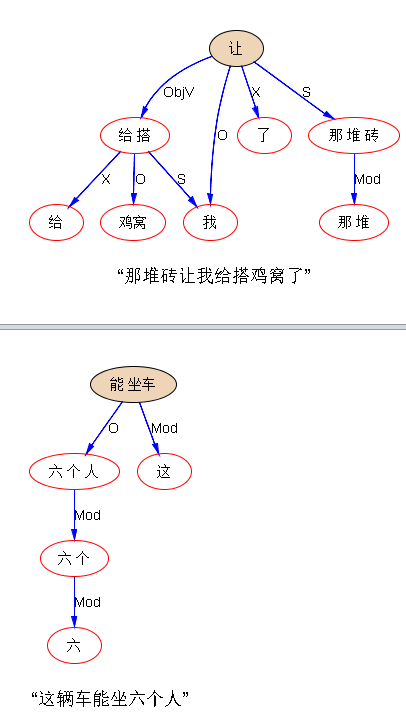
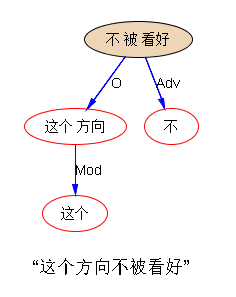
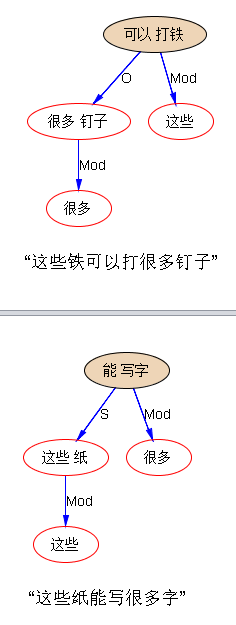
see,句法架子是出来了,但未尽如意的语义还有一步之遥。这一步补不补,不紧急,因为语义落地的时候,如果是 integrated 一体化的直通车,而不是提供给第三方做 offshelf support 的,就可以在落地模块内部协调。譬如,“坐车” 带了“六个人” 为 O,ideally,语义模块应该把 “六个人” 从句法的 O 转为 逻辑语义的 S。但是,如果是内部协调,转不转也无所谓。O 不过是一个符号而已。词驱动落地的时候,“坐车”的 arg 是 O 或 S,完全不必计较。当然,如果要补足这一步,虽然琐细,但真要做也不难。在没弄清楚多少利益之前,懒得做这细活。同理:“那堆砖”最好是加一条线,连上“搭”,标签是 【Instrument】。“这个方向不被看好”已经把表层的小词 “被” 带入考量,直接给了 O,一切到位,没有可做了。“打铁” 和 “钉子”,最好是加上标签【Result】。最后一句,最好给 S 进一步加上逻辑语义标签【Instrument】or 【Material】,但其实落地也未必需要这个,就是加上了显得很酷,很智能,让人看着爽,倒未必是对落地产品真地就有多大利益。
【术语 Index】
Matcher:the syntactic parsing program,有时候我们叫 runner,在白老师的系统里面,就是接受输入文句,对其二元依存关系解析的模块。
WSD:与 community 的依据义项划分的定义有别,白老师的 WSD 模块指的是:在词负载结构的体系里,一个具体的词负载了好几种可能的结构,结合上下文选择其中一种的模块,称之为wsd模块。事实上,这里的WSD 是利用大数据得来的词与词或其上位概念之间的语义相谐,来决定采纳某种区分一个词不同用法的扩展的 POS tags or 白老师所谓 subcats,来帮助结构消歧。粗线条义项的区分成为二元关系结构消歧的副产品。当(细线条)义项区别不影响结构的时候,义项区分就不是这个WSD模块的任务。
二元关系:两个词之间的句法依存关系(bianry dependency)。白老师的系统分为三类:修饰关系(如 定语、状语),算元(args)关系(如主语、宾语)和合并关系。
POS(cat):part-of-speech (or category,相对于 subcat 子类而言)词类,不必是 PennTree 定义的集合。作为模块,指的是根据系统给定的词类标准,自动做词性标注。一个词可能跨类,POS 模块可以根据上下文决定最合适的类别(词性)。在白老师的系统中,是所谓 WSD 模块做这个 POS 的事儿,来供给 Matcher 充当合法填坑的 candidates。在白老师的系统,我们可以把 POS 的词性标注理解为粗线条的 WSD。不影响结构的词义区分不是白老师所说的 WSD 模块的任务,虽然 community 的 WSD 不是这样定义的。
subcat:subcat 的原义指的是谓词的子类,这个子类对应了这个词的特定句型(譬如,双宾句型,宾+宾补句型,等)。白老师说的 subcat 扩展到不一定具有对应句型的子类。譬如,碗,背后的subcat是“容器”“餐具”;汤,背后的subcat是“液体”“食物”。这实际上是本体语义(ontology)的层级结构,如 ISA taxonomy chain:碗 ISA 餐具,餐具 ISA 工具,工具 ISA 商品;商品 ISA 人造物品;人造物品 ISA 物品;物品 ISA 实体(逻辑名词,这是这个 chain 的顶端节点 TOP 了)。
“耍流氓”:指的是对于二元依存关系不能定性,但是可以认定具有某种关系。汉语句法中,句首的名词短语在没有确定其性质是主语、宾语或定语、状语之前,往往先给它一个 Topic 标签,挂靠到后面的谓语身上,白老师认为这就是耍流氓。同理,当两个实词之间的关系基本可以确认,但是不能定性的时候,我们往往根据其出现的先后次序,让 parser 给一个 Next 的标签把二者连上,作为一个增强句法分析器鲁棒性(robustness)和查全率(recall)的打补丁的手段。这也算是先耍一下流氓,因为理论上后去还是需要语义模块去确认是何种关系才算深度分析到位。如果是两个中文动词一先一后系统给了 Next,其默认关系是【接续】,就是汉语文法书上所谓的“连动”结构。
Topic:汉语分析中,句首名词短语如果不直接做主语、宾语等,很多分析就给 一个Topic(主题)的标签。汉语文法的一个突出语言句型现象就是所谓双主语句(常常分析成一个Topic or 大主语,加一个小主语:譬如,他身体特别好。这家公司业绩直线上升。)由于这种关系逻辑语义的性质不明,聊胜于无,所以也称这种二元关系的建立为“耍流氓”。
Next:两个词一先一后,但不能确认他们发生了什么句法语义关系,系统常常给一个特殊的关系标签,叫 Next,其默认关系是【接续】。 这是一个增强句法分析器鲁棒性(robustness)和查全率(recall)的打补丁的手段。由于这种关系逻辑语义的性质不明,聊胜于无,所以也称建立这种二元关系为“耍流氓”。
mod:修饰成分或关系。包括定语、状语、补语。
arg:算元成分或关系。包括主语、宾语、(宾语)补足语或间接宾语。
Hownet:董振东前辈发明的面向MT和NLP服务的跨语言本体知识(ontology)网络《知网》的英文名称。
小词:教科书上叫做功能词。包括介词、连词、代词、副词、感叹词、联系动词等。
伪歧义:也叫伪路径,指的是 parsers 产生出来的貌似成功但没有价值的结构分析路径。伪歧义,是相对于真(结构)歧义而言。真的结构歧义的典型案例是某些 PP-attachment 的现象,同一个 PP 可以理解为两种可能:做宾语的后置定语;或做谓语动词的后置状语,这两个 parses 都是有效的语义解析。但是,很多传统的 parsers,会产生很多貌似成功解析输入文句的分析路径(numerous parses),给人以文句结构歧义严重的假象,但其实这些不同路径大多没有区别意义,是为伪歧义。这是一个困扰了传统 parsing 很多年的难题。白老师和立委的系统都利用不同的策略(包括休眠唤醒机制)很好地解决了这个问题。
中间件:白老师的所谓语义中间件,指的是在 ontology(本体知识库,如 HowNet,WordNet)的支持下,通过大数据训练得出来的语言词汇之间的语义相谐(各种关系之间的语义搭配)的统计知识库。这个中间件被 WSD 和 Matcher 模块调用作为对于输入文句的 parsing 的资源。立委以前的NLP博文种的所谓语义中间件虽然有与白老师的中间件相同的一面,但却是不同的所指。在立委的 deep parsing 的系统种,语义中间件不是一个知识库资源,而是指的句法模块后面的语义模块。这个模块利用句法框架,负责深度分析的逻辑语义细化、隐含的逻辑语义关系的解析、休眠唤醒新的语义结构关系(包括改正此前的错误路径),如果需要的话,也可以在这个模块做一些词义消歧工作(WSD的本义)。总之,这个语义模块是独立于领域,夹在句法分析之前和领域的语义落地之前,为了更好地服务于语义落地。为了不再混淆术语,立委考虑今后不再称此模块为中间件,而是把术语让出,就叫语义模块。
坑:坑是role-provider,萝卜是role-fulfiller。就是依存关系(dependency)的被预期的节点。对于谓词,其坑就是它预期的算元(args)成分,主语、宾语、补足语。对于修饰关系(mods),譬如定语、状语和(汉语)的补语,一般认为是附加的边缘语义,不占坑。也可以看成是修饰语预期了谓词,或看成是谓词不占坑地吃掉了修饰语。在知网里“坑”叫“角色”;“萝卜”叫“典型演员”a) 只从语义考虑,与特定语言无关。
萝卜:指的是那些参与谓词结构(所谓 argument structure)所要求的实体角色的词,譬如充当主语、宾语、补足语的成分。谓词结构通常被认为是一个语句的核心语义。谓词以动词为主(但也有形容词和名词做谓词的),在词典主义(lexicalist)的系统中(白老师和立委的系统均属于词典主义),一个谓词的潜在的结构都标注在这个词的词典信息 subcat 里面。换句话说,谓词的 subcat 规定了它期望什么样的成分(所谓挖坑),需要什么样的词(萝卜)来填。譬如,“走路”挖了一个坑,需要一个优选语义位【human】的名词萝卜来充当其施事主语。再如,“喜欢” 挖了两个坑:谁喜欢什么。充当主语的是【human】名词,充当宾语的是几乎任何词。
填坑:一个词(包括代表短语的头词)根据谓词对坑的句法(甚至语义)要求,充当了其谓词结构的成分,建立了与谓词的二元关系(binary dependency),这个建构过程叫做填坑。谓词结构的成分填满了,核心语义就完整了,这个状态叫 saturated。
萝卜指标:指的就是坑。所谓不占萝卜指标,是说的一个词可以合法填两个坑的情形,其中一个坑不影响其填另一个坑的能力。听上去似乎与坑与填坑的概念出发点相违背,但在依存关系图的构建过程中,是必须考虑一个萝卜填多个坑(一个儿子多个老子)的情形才可以把依存关系进行到底(有些一个萝卜多个坑的情形在短语结构表达中,可以借助非终结节点避免)。
优选语义:最早由著名人工智能和机器翻译前辈 Wilks 提出的概念,指的是在本体网络(ontology)中,概念之间的语义相谐表现在自然语言的表达的时候,呈现的是一个区间,而不是一个固定的语义约束。譬如,【eat】这个概念对于【受事】的优选语义是【food】,但是这只是其优选,并不是一定要是【food】。语言表达的时候,优选语义可以根据句法的约束条件不断放松,以至于达到完全不相谐的程度(nonsense)。乔姆斯基认为,句法可以独立于这些语义相谐的约束,举的就是句法约束决定结构关系,偏离优选语义到极端的例子:Colorless green ideas sleep furiously。对于形态语言,句法独立性的原则有较多的证据。对于汉语,这个原则需要打折扣,合理利用优选语义的约束就成为汉语解析的关键依据。立委 parser 改造使用了 HowNet 来弥补句法形式的不足。白老师的系统是依靠大数据训练出来的中间件来实现优选语义的对 parsing 的约束。
逻辑语义:指的是深层结构关系。最早起源于乔姆斯基的深层结构和费尔默的深层格(关系)。中国NLP和MT的旗手级前辈董振东老师发扬光大,深化了这方面的研究,指出解析逻辑语义是深度自然语言理解的关键:所谓理解一个句子,主要就是理解了这个句子里面概念之间的逻辑语义,谁是施事,谁是受事,时间、地点、条件,等等。在 community,对应于所谓 role labeling 的任务。一般而言,主谓宾定状补之类的句法关系比较粗糙,这些是表层关系,一个语言深度解析器(deep parser)不仅要解析(decode)句法关系,而且要进一步揭示后面的逻辑语义关系,包括细化句法关系(譬如句法主语可以进一步标注为施事、受事、工具等逻辑语义,句法宾语可以标注为受事、对象、结果等逻辑语义,诸如此类),和揭示隐含的逻辑语义关系(所谓 hidden links,就是句法上没有直接联系但逻辑语义上具有直接联系的结构关系,譬如宾语是宾语补足语的隐藏的逻辑主语)。
休眠唤醒:在李白的系列研讨中,这个术语指的是一种把可能性较小的路径暂时搁置的parsing策略,被搁置的路径可以在适当的条件下被唤醒。这种策略据信反映了人的语言解析的过程,可以从段子、相声抖包袱等现象看到这个过程的表现。立委有系列博文专谈这个机制。譬如:【立委科普:结构歧义的休眠唤醒演义】
【相关】