置顶:立委NLP博文一览(定期更新版)】
屏蔽 |||
【立委NLP相关博文汇总一览】
【立委科普:自然语言parsers是揭示语言奥秘的LIGO式探测仪】
《泥沙龙笔记:沾深度神经的光,谈parsing的深度与多层》
【立委科普:语言学算法是 deep NLP 绕不过去的坎儿】
《OVERVIEW OF NATURAL LANGUAGE PROCESSING》
Comparison of Pros and Cons of Two NLP Approaches
【why hybrid? on machine learning vs. hand-coded rules in NLP】
钩沉:Early arguments for a hybrid model for NLP and IE
《泥沙龙笔记:铿锵众人行,parsing 可以颠覆关键词吗?》
【NLP主流的反思:Church – 钟摆摆得太远(1):历史回顾】
Notes on Building and Using Lexical Semantic Knowledge Bases
Domain portability myth in natural language processing (NLP)
《科普随笔:keep ambiguity untouched》
【一日一parsing:NLP应用可以对parsing有所包容】
《语义计算沙龙:基本短语是浅层和深层parsing的重要接口》
泥沙龙笔记:parsing 是引擎的核武器,再论NLP与搜索
泥沙龙笔记:从 sparse data 再论parsing乃是NLP应用的核武器
泥沙龙笔记:再聊乔老爷的递归陷阱
【泥沙龙笔记:人脑就是豆腐,别扯什么递归了】
Parsing nonsense with a sense of humor
Parent-child Principle in Dependency Grammar
《泥沙龙笔记:NLP component technology 的市场问题》
Deep parsing 每日一析:内情曝光 vs 假货曝光
【deep parsing 吃文化:植树为林自成景(60/n)】
【deep parsing (70/n):离合词与定语从句的纠缠】
【deep parsing (90/n):“雨是好雨,但风不正经”】
【deep parsing (100/n):其实 NLP 也没那么容易气死】
3. 关于NLP抽取
泥沙龙笔记: parsing vs. classification and IE
Pre-Knowledge-Graph Profile Extraction Research via SBIR (1)
Pre-Knowledge-Graph Profile Extraction Research via SBIR (2)
Coarse-grained vs. fine-grained sentiment extraction
4.关于NLP大数据挖掘
Automated survey based on social media
【科研笔记:big data NLP, how big is big?】
《扫了 sentiment,NLP 一览众山小:从“良性肿瘤”说起》
5. 关于NLP应用
《新智元笔记:知识图谱和问答系统:how-question QA(2)》
泥沙龙笔记:parsing 是引擎的核武器,再论NLP与搜索
【从新版iPhone发布,看苹果和微软技术转化能力的天壤之别】
【非常折服苹果的技术转化能力,但就自然语言技术本身来说 ...】
【科研笔记:big data NLP, how big is big?】
【与机器人对话】
6. 关于中文NLP
【deep parsing (70/n):离合词与定语从句的纠缠】
【新智元笔记:parsing 汉语涉及重叠的鸡零狗碎及其他】
【deep parsing:“对医闹和对大夫使用暴力者,应该依法严惩" 】
【沙龙笔记:汉语构词和句法都要用到reduplication机制】
钩沉:博士阶段的汉语HPSG研究 2015-11-02
【中文NLP迷思之三:中文处理的长足进步有待于汉语语法的理论突破】
【专业老友痛批立委《迷思》系列搅乱NLP秩序,立委固执己见】
【突然有一种紧迫感:再不上中文NLP,可能就错过时代机遇了】
【大数据挖掘:“苦逼”小崔2013年5-7月为什么跌入谷底?】
继续转基因的大数据挖掘:谁在说话?发自何处?能代表美国人民么
新浪微博下周要大跌?舆情指数不看好,负面评价太多(疑似虚惊)
Chinese First Lady in Social Media
Social media mining on credit industry in China
Sina Weibo IPO and its automatic real time monitoring
Social media mining: Teens and Issues
Social media mining: 2013 vs. 2012
尝试揭秘百度的“哪里有小姐”: 小姐年年讲、月月讲、天天讲?
8. 关于NLP的掌故趣闻
围脖:格语法创始人菲尔墨(Charles J. Fillmore)教授千古!
http://blog.sciencenet.cn/blog-362400-902391.html
上一篇:泥沙龙笔记:再聊乔老爷的递归陷阱
下一篇:人机接口是机器人的面子











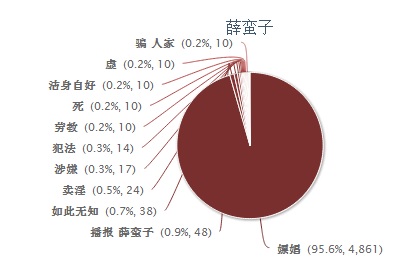
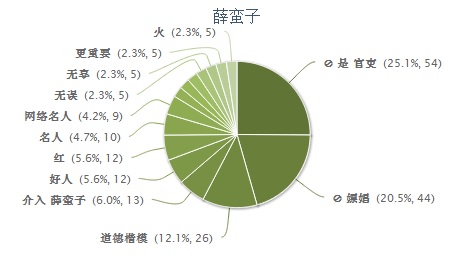
 【科普随笔:NLP主流最大的偏见,规则系统的手工性】
【科普随笔:NLP主流最大的偏见,规则系统的手工性】



 ,也许是我的电脑有问题
,也许是我的电脑有问题













 and the first two. What behind is, I have the assumption (a truth I think) that ALL (well, except for 葡萄, 玻璃 and the like) multi-character 'words' are ambiguous (so-called hidden ambiguity) and hence have to be handled with dictionary at 'application' time (
and the first two. What behind is, I have the assumption (a truth I think) that ALL (well, except for 葡萄, 玻璃 and the like) multi-character 'words' are ambiguous (so-called hidden ambiguity) and hence have to be handled with dictionary at 'application' time (


