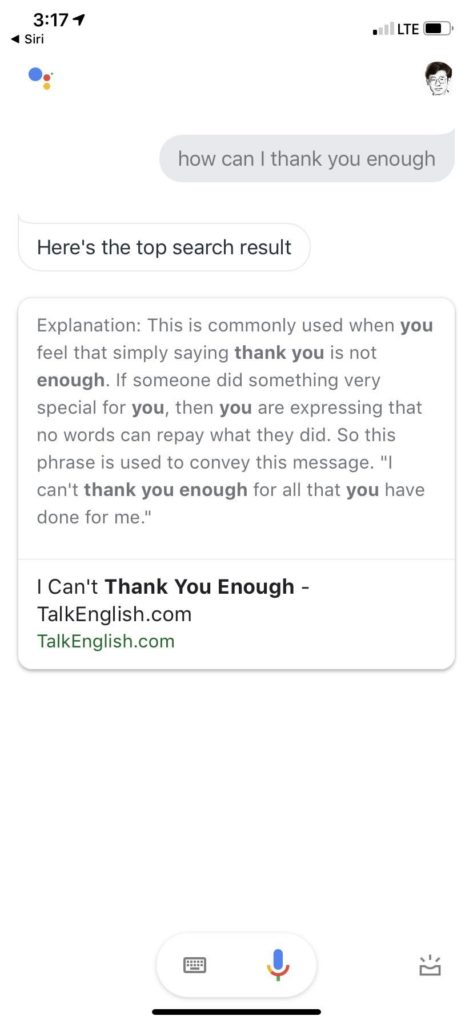
每周工作超过60小时的美国人报告说,他们平均希望每周少工作25小时。他们这么说是因为工作使他们遭受“时间饥荒”。一项2006年的研究发现,这影响了他们与配偶和孩子建立牢固关系、维持家庭、甚至过上令人满意的性生活的能力。哈佛商学院(Harvard Business School)最近一项高管调查的一名受访者自豪地坚称,“我晚上给孩子们的10分钟比花在工作上的10分钟伟大一百万倍。”只有十分钟!
优雅地或至少冷静地承受这些时间的能力已经成为精英成功的标准。一家大公司的一名高管接受了社会学家阿丽·拉塞尔·霍奇奇德(Arlie Russell Hochschild)为其著作《时间捆绑》的采访。她观察到,展示了自己技能和奉献精神的有抱负的经理面临着的“最终淘汰赛”是这样的: “有些人会火冒三丈,变得古怪,因为他们一直在无休止地工作……而高层的人非常聪明,工作得像疯子一样,而且不会火冒三丈。他们仍然能够保持良好的心态,保持家庭生活在一起。最终是他们赢得了比赛。”
社会制度相应的变化,就是一个强健的安全网络,能容忍各种试错,能护扶年轻人的勇往直前不怕跌倒,让what doesn’t kill you makes you stronger不仅是一句鸡汤而能理直气壮成为他们的信念。当然,在美国,一个很重要但一直被忽略的,就是社会对基础研究的投入,想想如果当初的bell labs在美国到处开花。。。聪明的年轻人不用只往花街律师医生这几行里面挤了。
立委后记:
Great great thesis. Right to the point on problems of modern society. Is the solution feasible ?
立委按:偶然听到金灿荣教授在点评中美贸易摩擦升级的一个演说。他提到美国中情局定期发布更新的《世界概况》(The World Factbook),对中国经济有准确的描述,笑称,比发改委还要正面,就是一本【厉害了我的国】的英文版。出于好奇,上网查到了他说的这个报告,的确精细客观,大概是美国的智囊团专家和中国通们撰写的,具有不错的参考价值,利用搜狗机器翻译稍加编辑如下,以飨读者。
YANG: If you've heard anything about me and my campaign, you've heard that someone is running for president who wants to give every American $1,000 a month. I know this may sound like a gimmick, but this is a deeply American idea, from Thomas Paine to Martin Luther King to today.
Let me tell you why we need to do it and how we pay for it. Why do we need to do it? We already automated away millions of manufacturing jobs, and chances are your job can be next. If you don't believe me, just ask an auto worker here in Detroit.
How do we pay for it? Raise your hand in the crowd if you've seen stores closing where you live. It is not just you. Amazon is closing 30 percent of America's stores and malls and paying zero in taxes while doing it. We need to do the opposite of much of what we're doing right now, and the opposite of Donald Trump is an Asian man who likes math.
(APPLAUSE)
So let me share the math. A thousand dollars a month for every adult would be $461 million every month, right here in Detroit alone. The automation of our jobs is the central challenge facing us today. It is why Donald Trump is our president, and any politician not addressing it is failing the American people.
Mr. Yang, I want to bring you in. You support a Medicare for All system. How do you respond to Governor Inslee?
YANG: Well, I just want to share a story. When I told my wife I was running for president, you know the first question she asked me? What are we going to do about our health care?
That's a true story, and it's not just us. Democrats are talking about health care in the wrong way. As someone who's run a business, I can tell you flat out our current health care system makes it harder to hire, it makes it harder to treat people well and give them benefits and treat them as full-time employees, it makes it harder to switch jobs, as Senator Harris just said, and it's certainly a lot harder to start a business.
If we say, look, we're going to get health care off the backs of businesses and families, then watch American entrepreneurship recover and bloom. That's the argument we should be making to the American people.
YANG: I'm the son of immigrants myself. My father immigrated here as a graduate student and generated over 65 U.S. patents for G.E. and IBM. I think that's a pretty good deal for the United States. That's the immigration story we need to be telling.
We can’t always be focusing on some of the -- the -- the distressed stories. And if you go to a factory here in Michigan, you will not find wall-to-wall immigrants; you will find wall-to-wall robots and machines. Immigrants are being scapegoated for issues they have nothing to do with in our economy.
YANG: I speak for just about everyone watching when I say I would trust anyone on this stage much more than I would trust our current president on matters of criminal justice.
(APPLAUSE)
We cannot tear each other down. We have to focus on beating Donald Trump in 2020.
I want to share a story that a prison guard, a corrections officer in New Hampshire said to me. He said, we should pay people to stay out of jail, because we spend so much when they're behind bars. Right now, we think we're saving money, we just end up spending the money in much more dark and punitive ways. We should put money directly into people's hands, certainly when they come out of prison, but before they go into prison.
LEMON: Mr. Yang, why are you the best candidate to heal the racial divide in America -- your response?
YANG: I spent seven years running a non-profit that helped create thousands of jobs, including hundreds right here in Detroit, as well as Baltimore, Cleveland, New Orleans. And I saw that the racial disparities are much, much worse than I had ever imagined.
They're even worse still. A study just came out that projected the average African-American median net worth will be zero by 2053. So you have to ask yourself, how is that possible? It's possible because we're in the midst of the greatest economic transformation in our history. Artificial intelligence is coming. It's going to displace hundreds of thousands of call center workers, truck drivers -- the most common job in 29 states, including this one.
And you know who suffers most in a natural disaster? It's people of color, people who have lower levels of capital and education and resources. So what are we going to do about it? We should just go back to the writings of Martin Luther King, who in 1967, his book "Chaos or Community", said "We need a guaranteed minimum income in the United States of America." That is the most effective way for us to address racial inequality in a genuine way and give every American a chance in the 21st Century economy.
你知道谁在自然灾害中受害最深吗?是有色人种,他们的资本、教育和资源水平较低。那么我们要怎么做呢?我们应该回顾一下马丁·路德·金(Martin Luther King)的著作,他在1967年出版的《混乱还是社区》(Chaos or Community)一书中说,“我们需要美国有保障的最低收入。”这是我们以真正的方式解决种族不平等问题、让每个美国人在21世纪的经济中都有机会(分享经济红利)的最有效方式。
(掌声)
莱蒙:杨先生,非常感谢。
BIDEN: - in research for new alternatives to deal with climate change.
BASH: Mr. Yang, your response?
BIDEN: And that's bigger than any other person.
YANG: The important number in Vice President Biden's remarks just now is that he United States was only 15 percent of global emissions. We like to act as if we're 100 percent, but the truth is even if we were to curb our emissions dramatically, the earth is still going to get warmer.
And we can see it around it us this summer. The last four years have been the four warmest years in recorded history. This is going to be a tough truth, but we are too late. We are 10 years too late. We need to do everything we can to start moving the climate in the right direction, but we also need to start moving our people to higher ground.
And the best way to do that is to put economic resources into your hands so you can protect yourself and your families.
TAPPER: Thank you, Senator Gillibrand. Mr. Yang, in poll after poll democratic voters are saying that having a nominee who can beat President Trump is more important to them than having a nominee who agrees with them on major issues. And right now, according to polls, they say the candidate who has the best chance of doing that, of beating President Trump is Vice President Biden. Why are they wrong?
YANG: Well, I'm building a coalition of disaffected Trump voters, independents, libertarians, and conservatives, as well as democrats and progressives. I believe I'm the candidate best suited to beat Donald Trump and as for how to win in Michigan and Ohio and Pennsylvania, the problem is that so many people feel like the economy has left them behind.
What we have to do is we have to say look, there's record high GDP in stock market prices, you know what else they're at record high is? Suicides, drug overdoses, depression, anxiety. It's gotten so bad that American life expectancy had declined for the last three years.
And I like to talk about my wife who is at home with our two boys right now, one of whom is autistic. What is her work count at in today's economy. Zero and we know that's the opposite of the truth. We know that her work is amongst the most challenging and vital.
The way we win this election as we redefine economic progress to include all the things that matter to the people in Michigan and all of us like our own heath, our well being, our mental health, our clean air and clean water, how are kids are doing.
If we change the measurements for the 21st century economy to revolve around our own well being then we will win this election.
(CROSSTALK)
TAPPER: Thank you, Mr. Yang. Congresswoman Gabbard, your response?
BASH: Mr. Yang, Mr. Yang, women on average earn 80 cents, about 80 cents for every dollar earned by men. Senator Harris wants to fine companies that don't close their gender pay gaps. As an entrepreneur, do you think a stiff fine will change how companies pay their female employees?
YANG: I have seen firsthand the inequities in the business world where women are concerned, particularly in start-ups and entrepreneurship. We have to do more at every step. And if you're a woman entrepreneur, the obstacles start not just at home, but then when you seek a mentor or an investor, often they don't look like you and they might not think your idea is the right one.
In order to give women a leg up, what we have to do is we have to think about women in every situation, including the ones who are in exploitive and abusive jobs and relationships around the country. I'm talking about the waitress who's getting harassed by her boss at the diner who might have a business idea, but right now is stuck where she is.
What we have to do is we have to give women the economic freedom to be able to improve their own situations and start businesses, and the best way to do this is by putting a dividend of $1,000 a month into their hands.
(APPLAUSE)
It would be a game-changer for women around the country, because we know that women do more of the unrecognized and uncompensated work in our society. It will not change unless we change it. And I say that's just what we do.
Mr. Yang, Iran has now breached the terms of the 2015 nuclear deal after President Trump withdrew the U.S. from the deal, and that puts Iran closer to building a nuclear weapon, the ability to do so, at the very least. You've said if Iran violates the agreement, the U.S. would need to respond, quote, "very strongly." So how would a President Yang respond right now?
YANG: I would move to de-escalate tensions in Iran, because they're responding to the fact that we pulled out of this agreement. And it wasn't just us and Iran. There were many other world powers that were part of that multinational agreement. We'd have to try and reenter that agreement, renegotiate the timelines, because the timelines now don't make as much sense.
But I've signed a pledge to end the forever wars. Right now, our strength abroad reflects our strength at home. What's happened, really? We've fallen apart at home, so we elected Donald Trump, and now we have this erratic and unpredictable relationship with even our longstanding partners and allies.
What we have to do is we have to start investing those resources to solve the problems right here at home. We've spent trillions of dollars and lost thousands of American lives in conflicts that have had unclear benefits. We've been in a constant state of war for 18 years. This is not what the American people want. I would bring the troops home, I would de-escalate tensions with Iran, and I would start investing our resources in our own communities.
TAPPER: Welcome back to the CNN Democratic presidential debate. It is time now for closing statements. You will each receive one minute. Mayor de Blasio, let's begin with you.
YANG: You know what the talking heads couldn't stop talking about after the last debate? It's not the fact that I'm somehow number four on the stage in national polling. It was the fact that I wasn't wearing a tie. Instead of talking about automation and our future, including the fact that we automated away 4 million manufacturing jobs, hundreds of thousands right here in Michigan, we're up here with makeup on our faces and our rehearsed attack lines, playing roles in this reality TV show.
It's one reason why we elected a reality TV star as our president.
(LAUGHTER)
(APPLAUSE)
We need to be laser-focused on solving the real challenges of today, like the fact that the most common jobs in America may not exist in a decade, or that most Americans cannot pay their bills. My flagship proposal, the freedom dividend, would put $1,000 a month into the hands of every American adult. It would be a game-changer for millions of American families.
If you care more about your family and your kids than my neckwear, enter your zip code at yang2020.com and see what $1,000 a month would mean to your community. I have done the math. It’s not left; it’s not right. It’s forward. And that is how we’re going to beat Donald Trump in 2020.
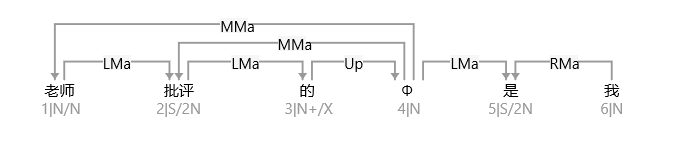
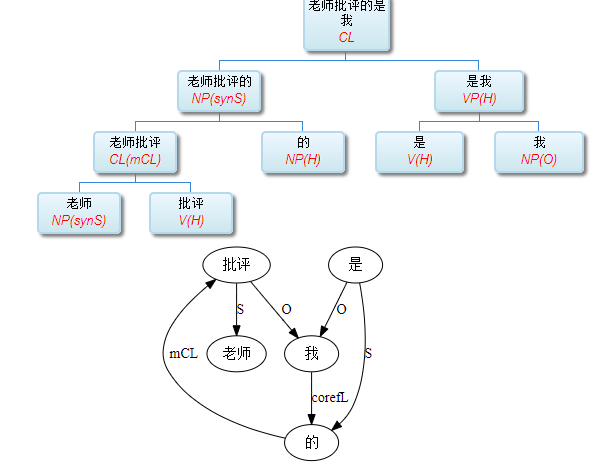
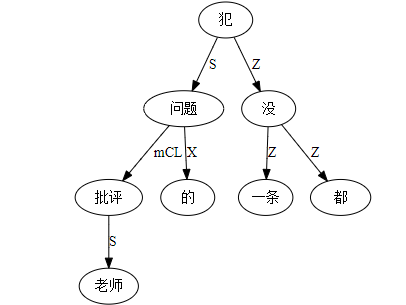
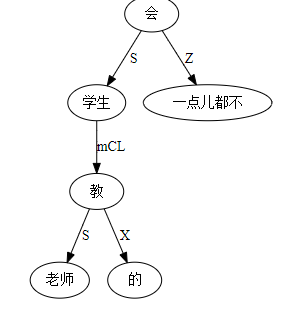
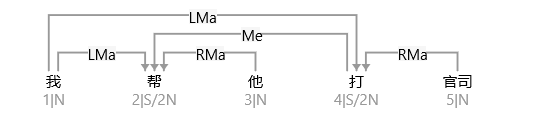
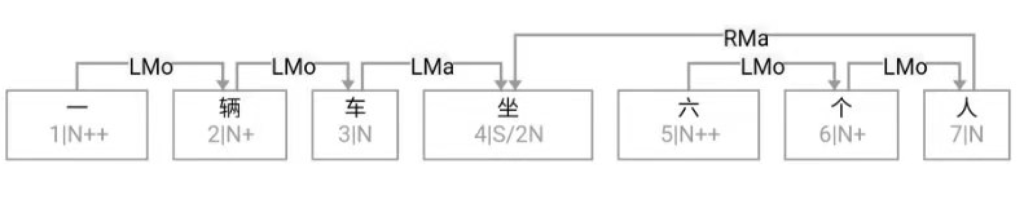
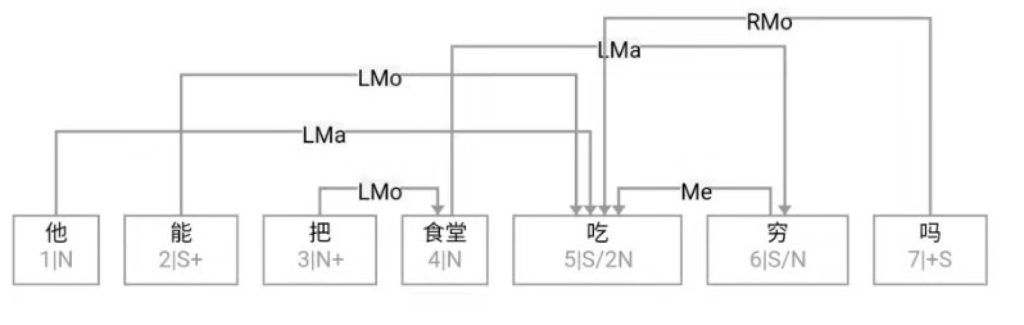
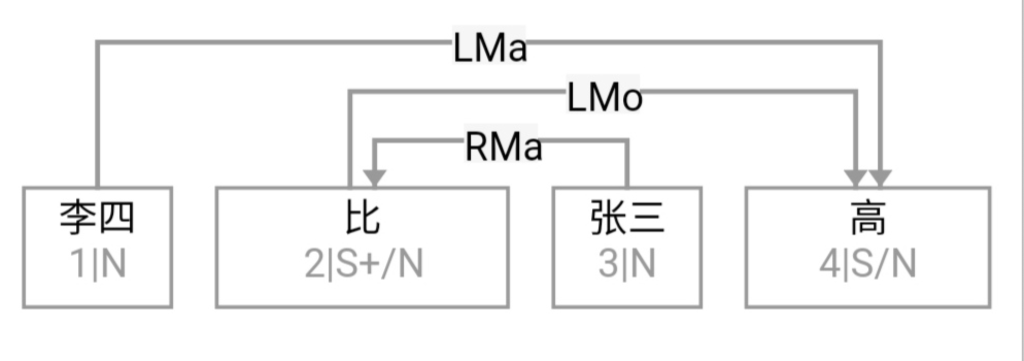
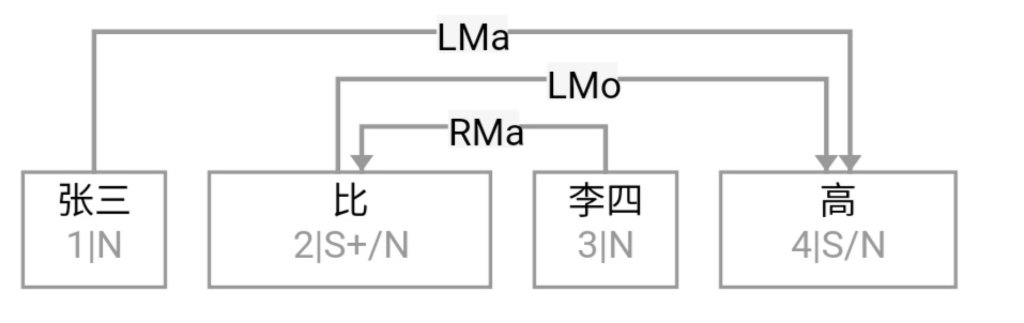
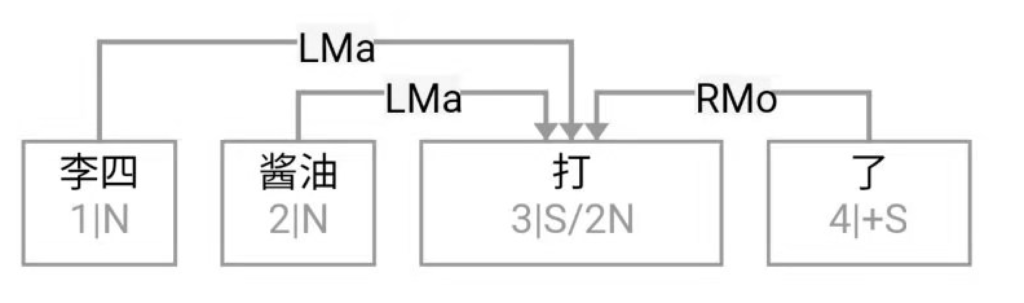
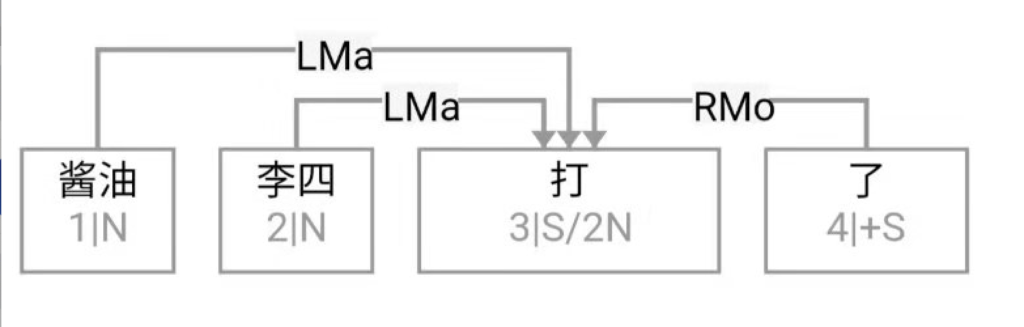
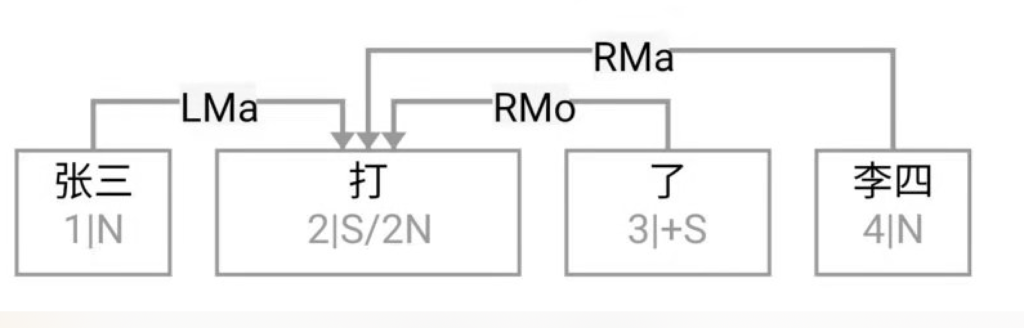
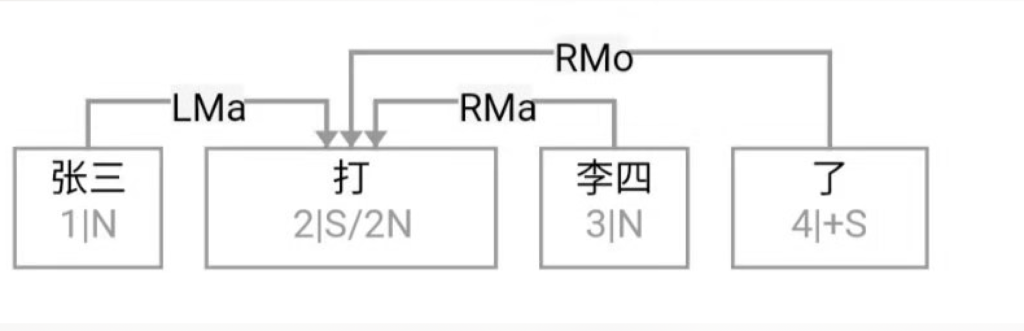
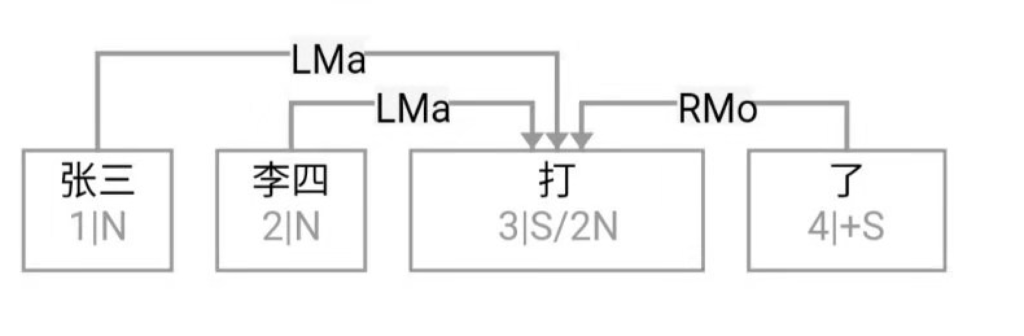
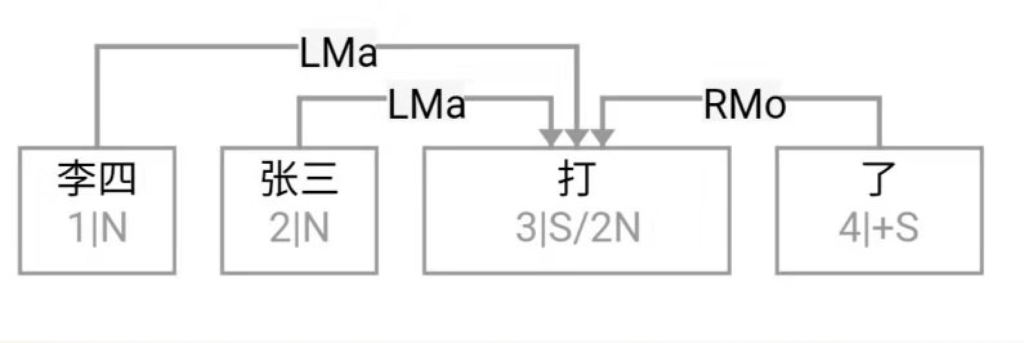
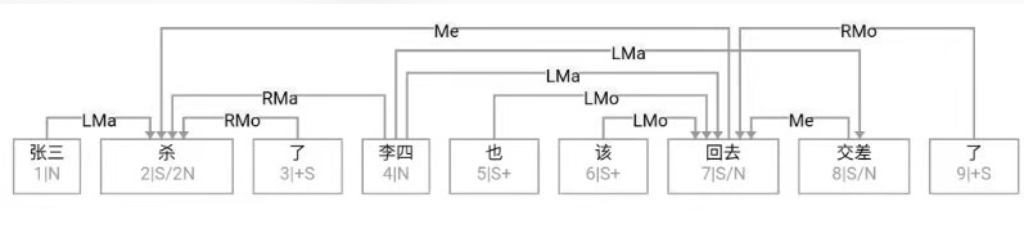
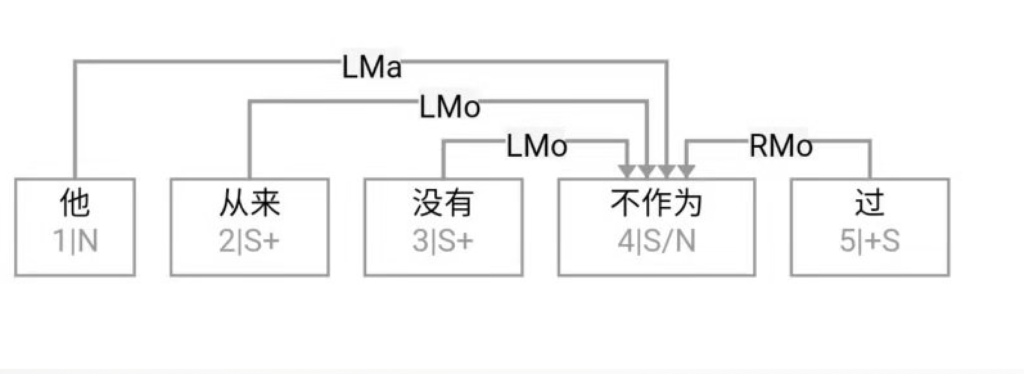
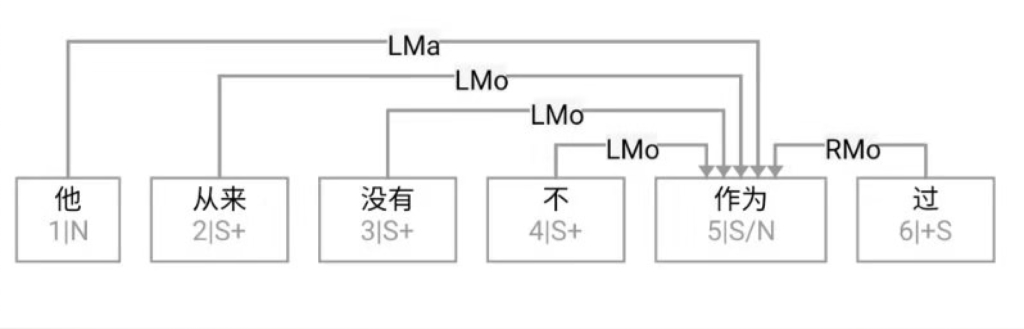
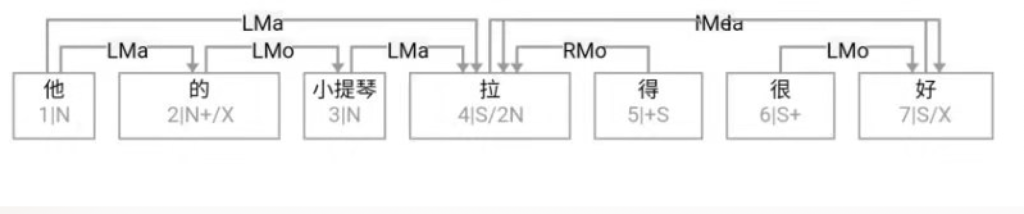
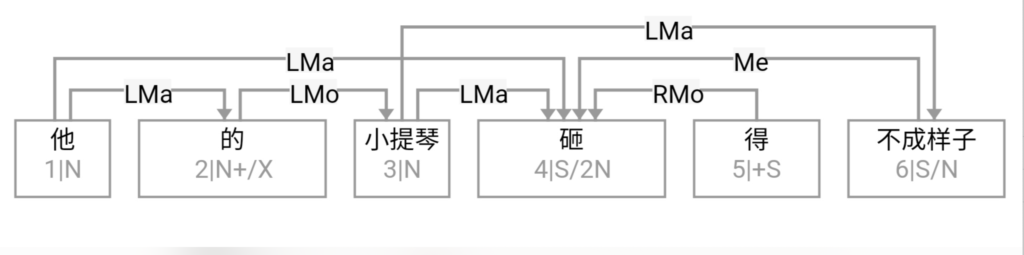
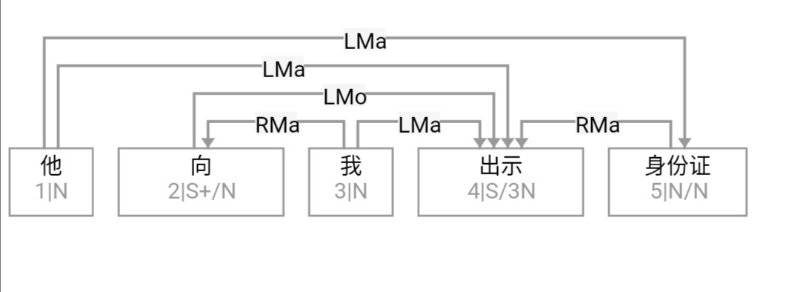
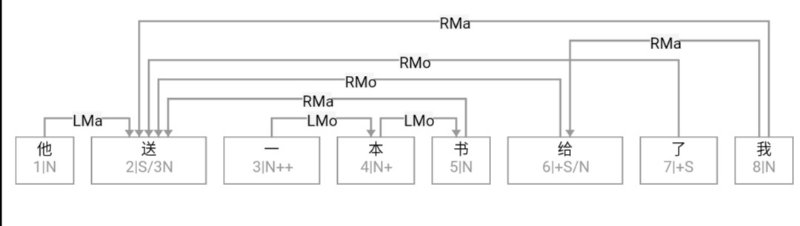
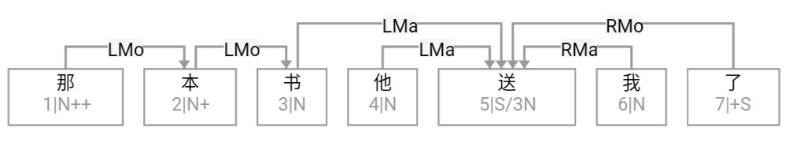
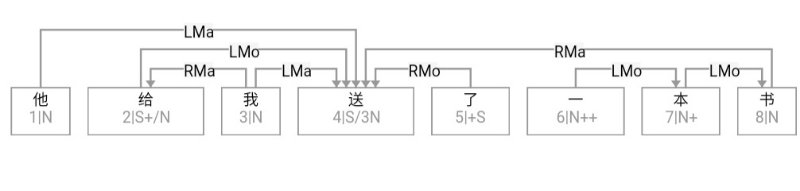
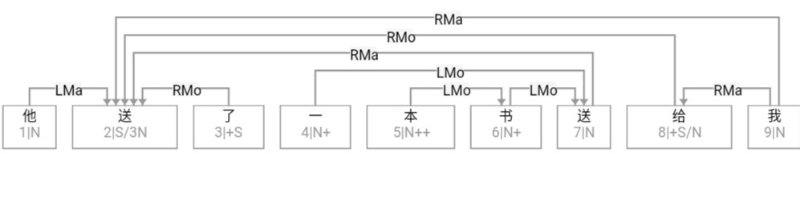
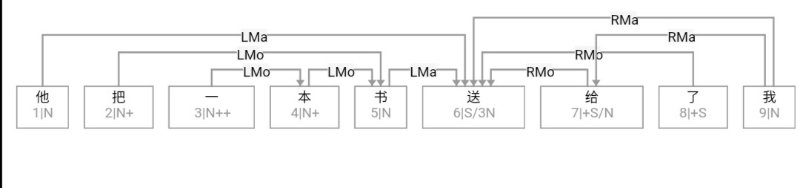
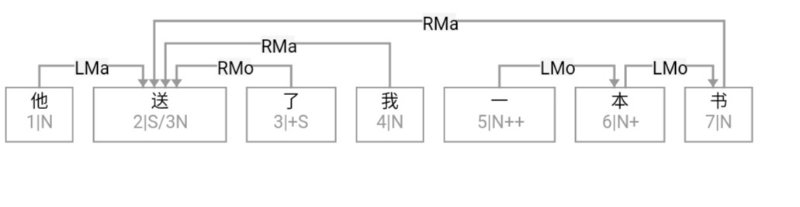
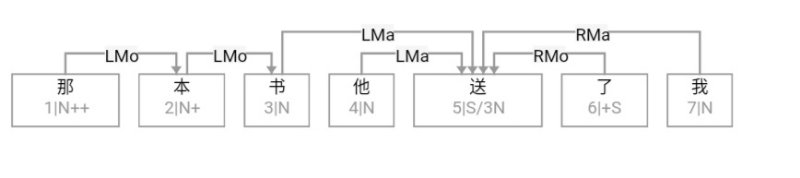
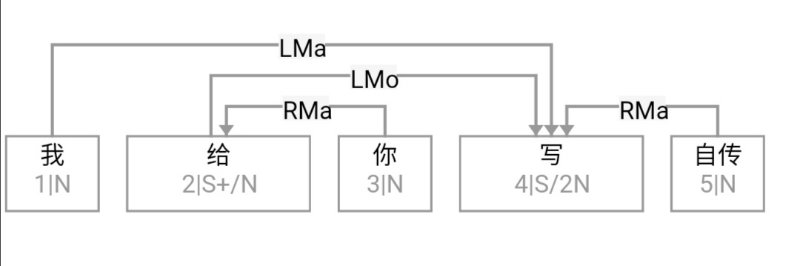
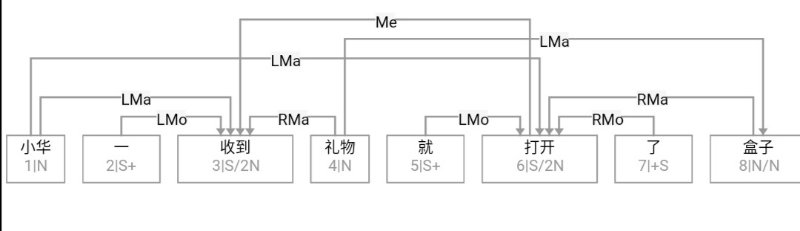
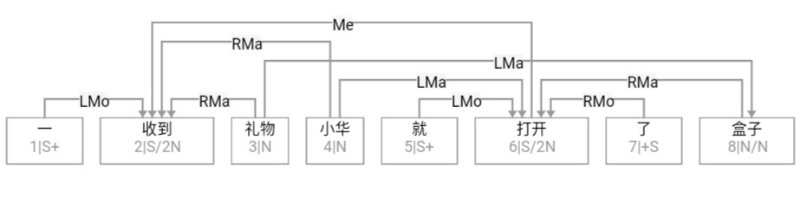
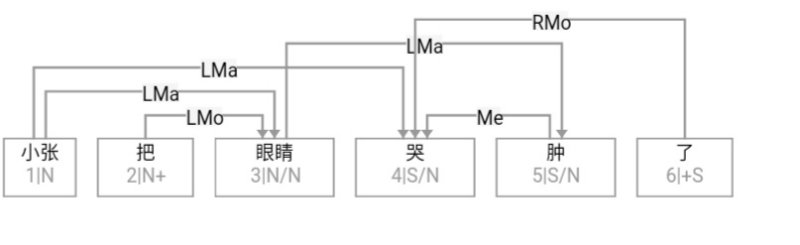
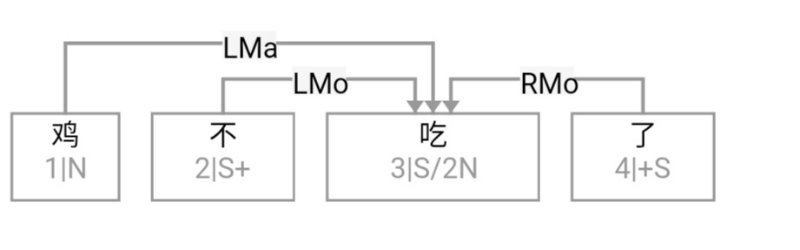
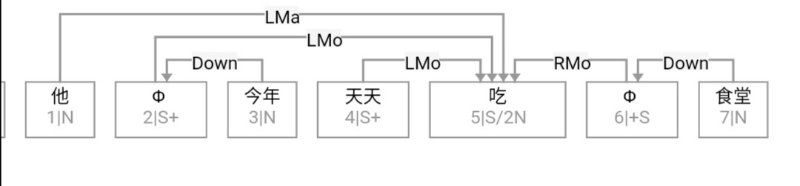
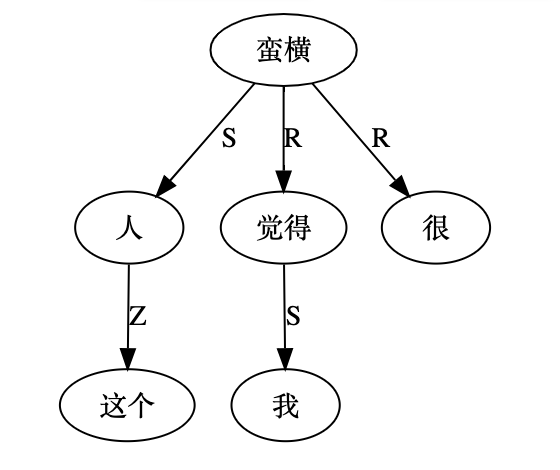
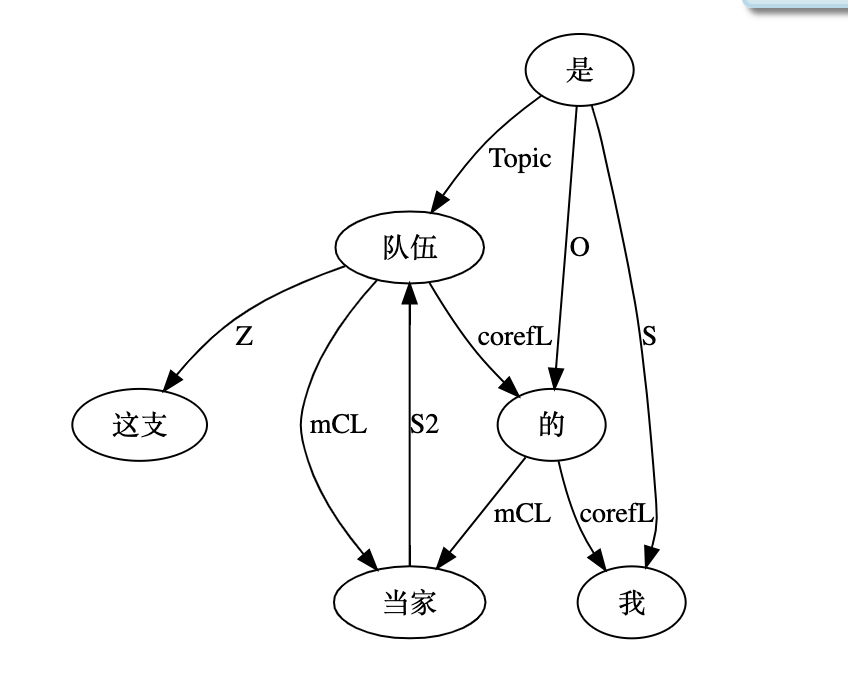
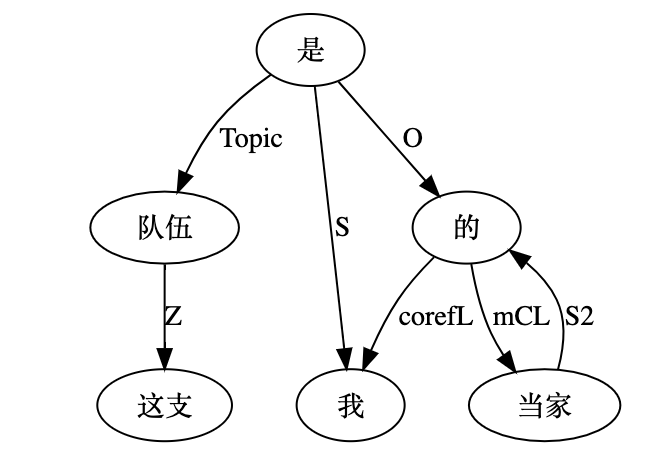
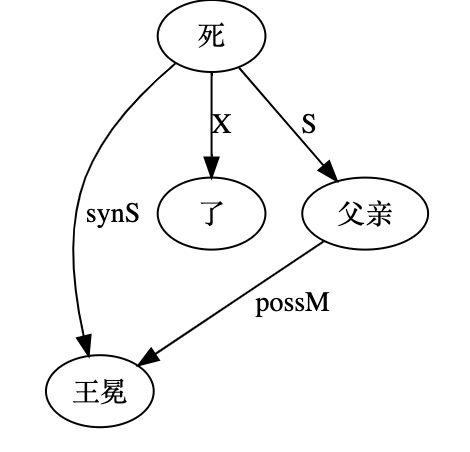
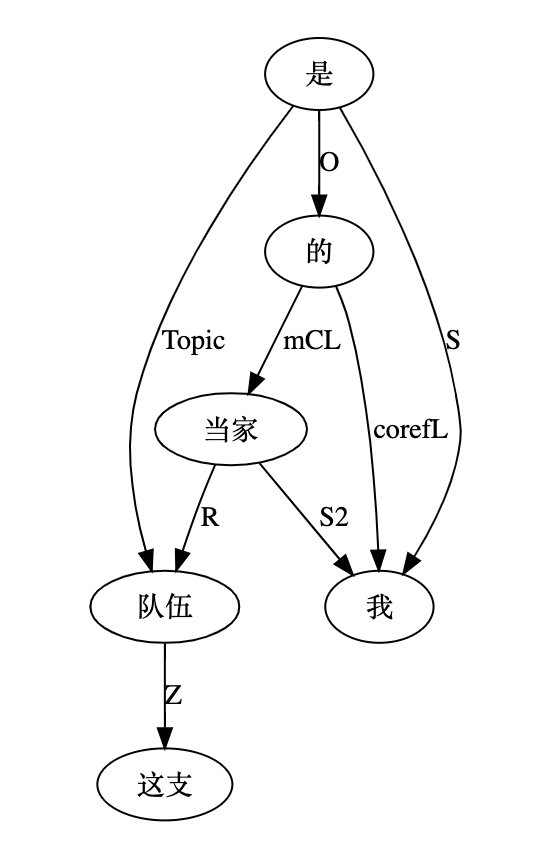
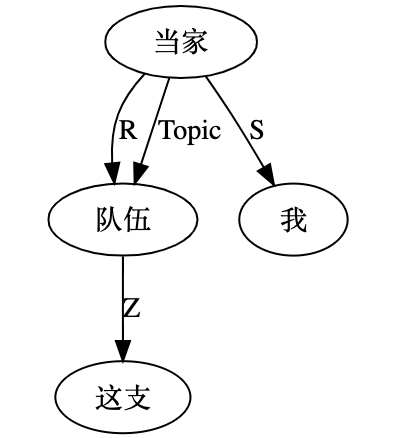
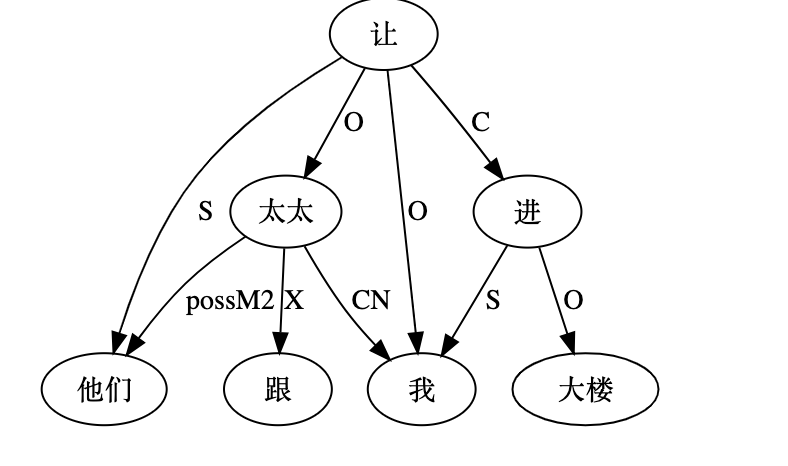
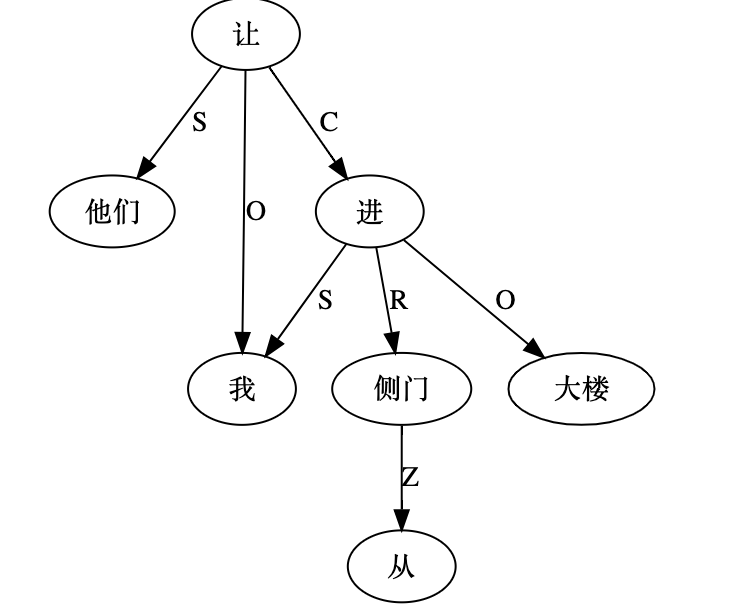
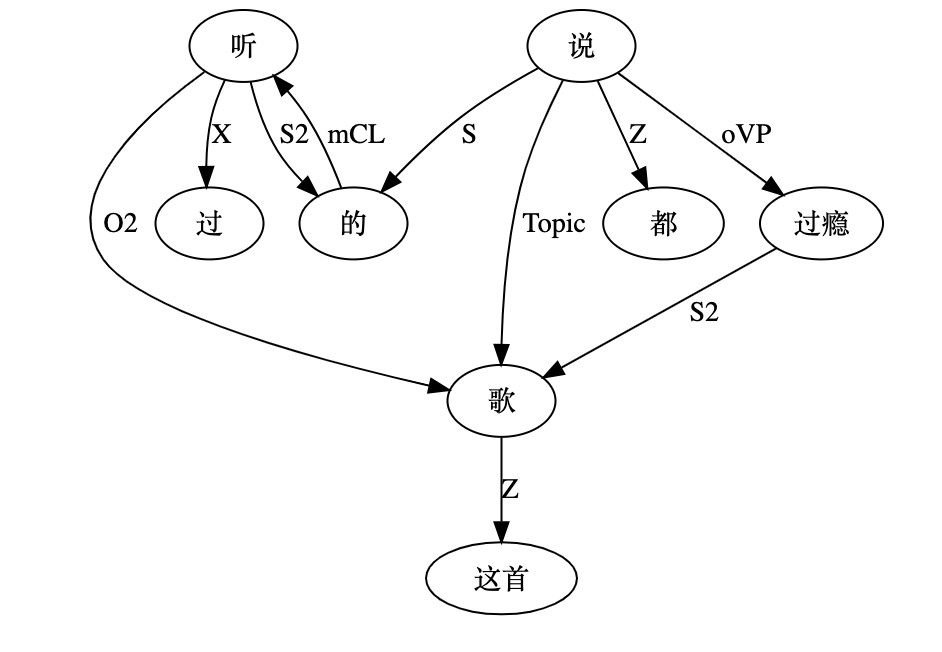
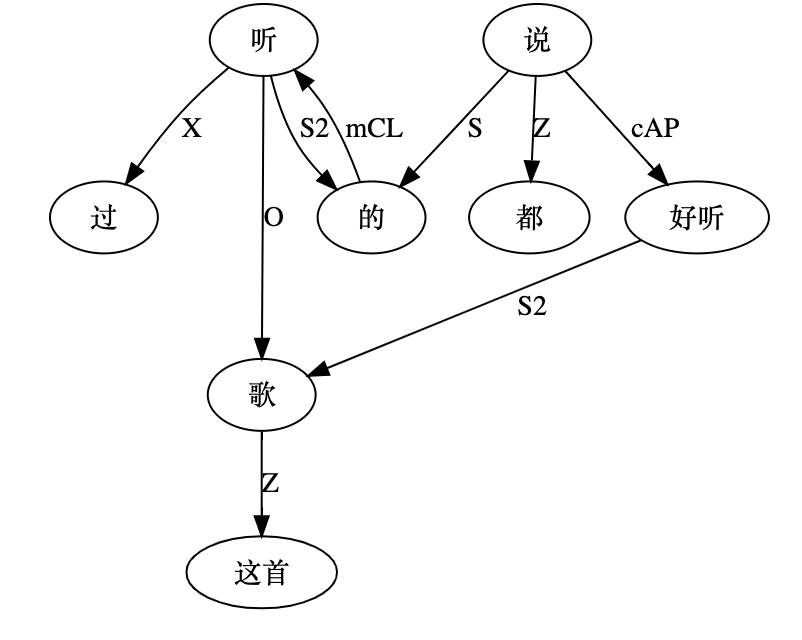
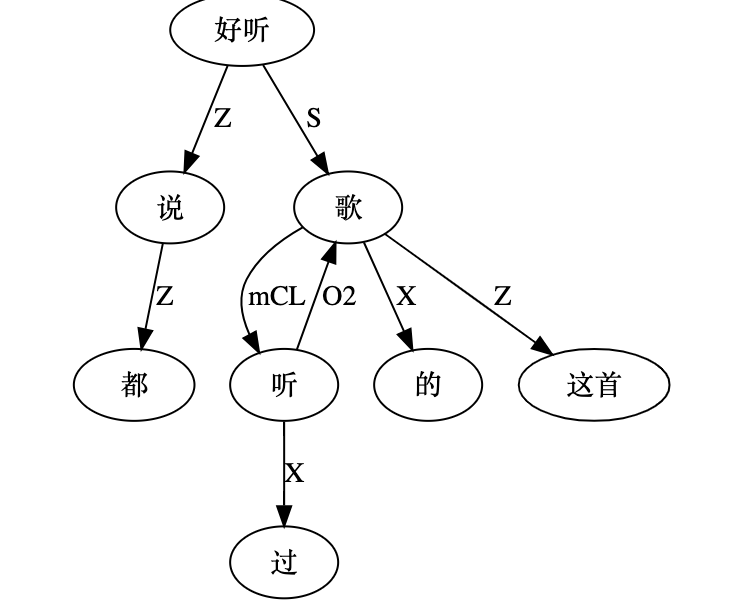
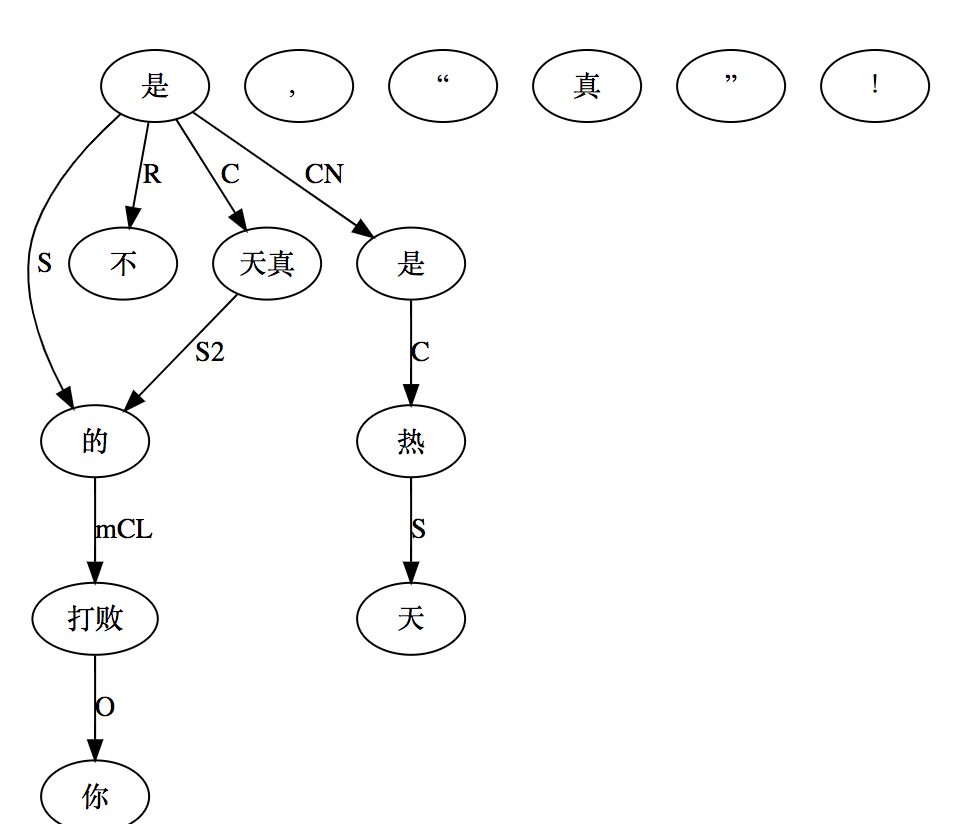
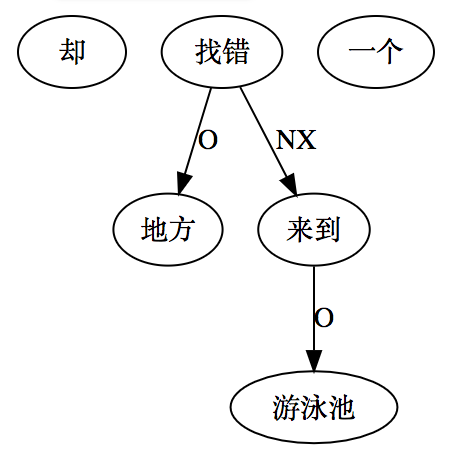
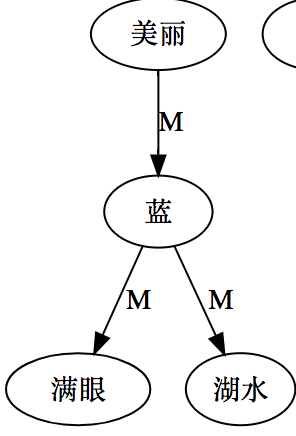
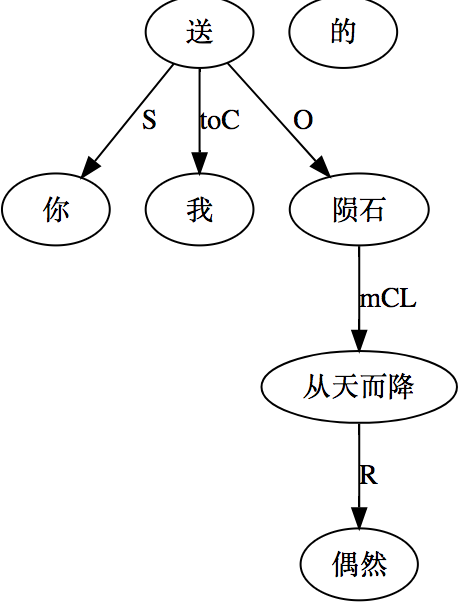
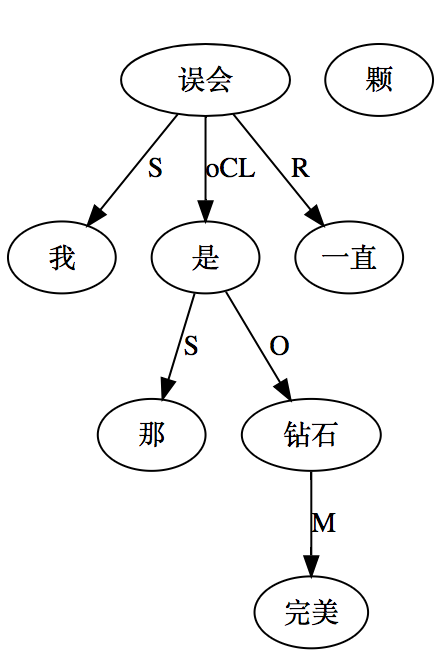
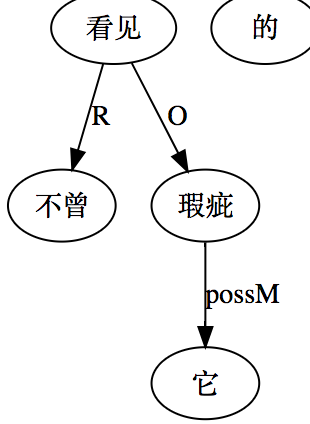
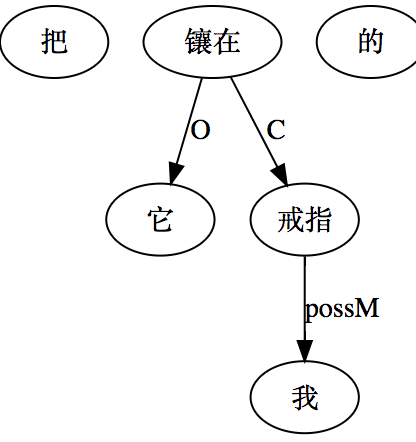
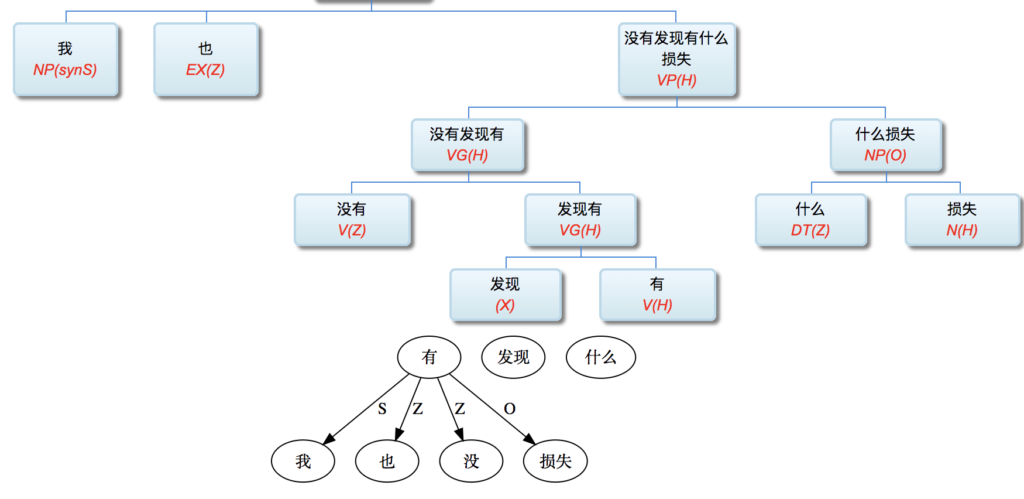
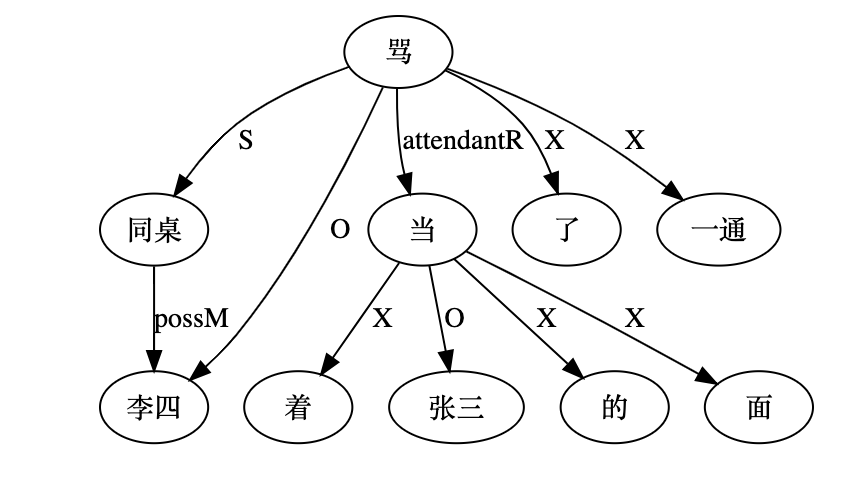
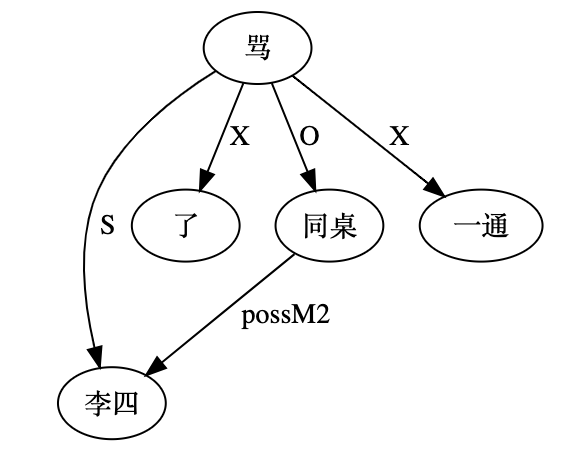
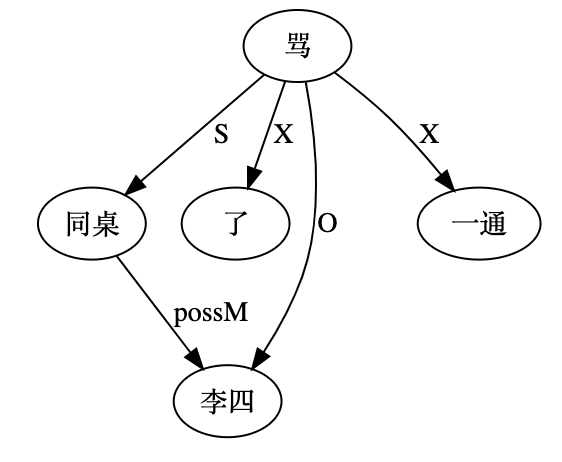
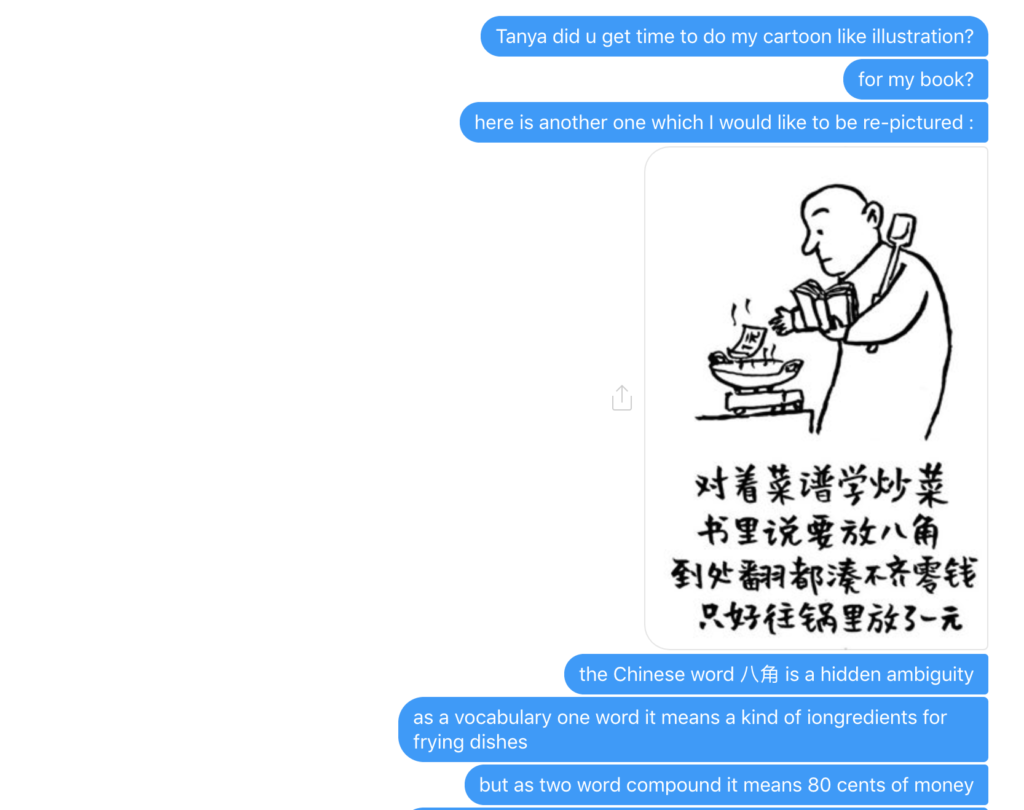
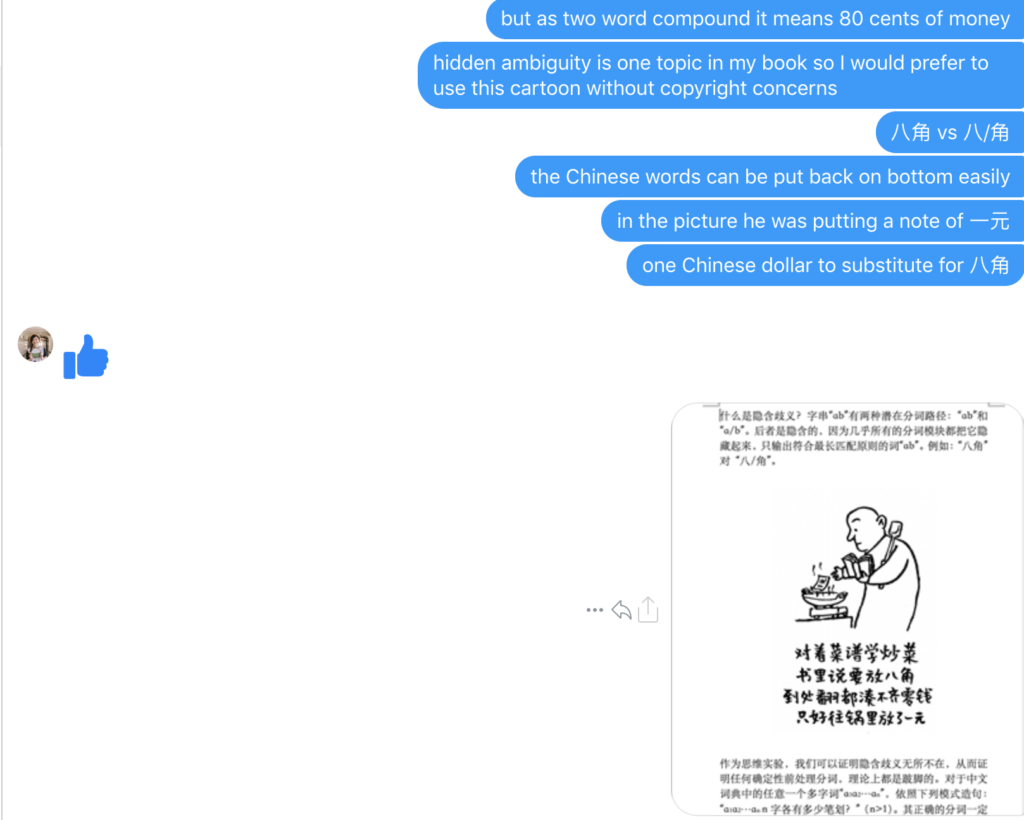
大家看到的似乎是除了词例外长得一模一样的两张图,但实际上,两个坑有语义差异,两个萝卜也有语义差异,这些语义差异引发的内部的较量已经完成,可以说提前撇下句法进入语义了。相应语义标签,在下一阶段开发完成后也会提供出来。记得当年长者的同学窦祖烈先生的汉英机器翻译系统就栽在我给他出的这个例子上:“这辆车能坐六个人”被翻译成“This car can sit six people”。后来我说,把“坐”换成“载”试试?老先生这个高兴啊……
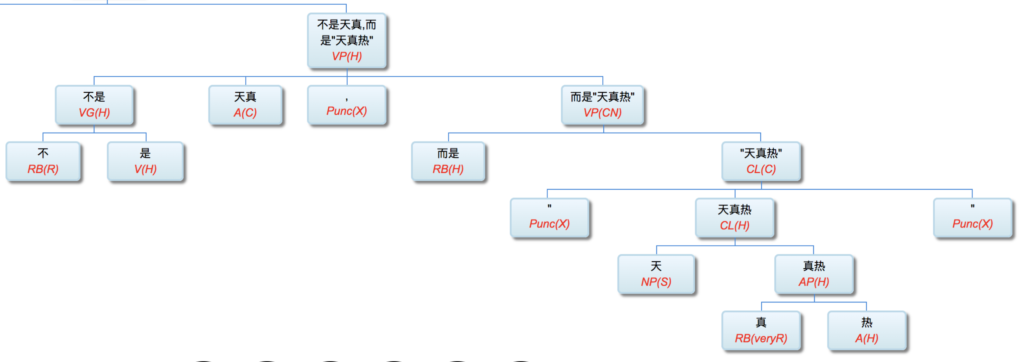
perfect+always (same as never1 for backward aspect in contrast to never2 forward, e.g. "never forget class struggle" ) are tense-aspect,VG is its category (V) and phrasal sign (Group, or X one bar).
总之就是用可以枚举的前后缀或小词材料的有限组合,去对 X 做词法句法的加持而已。没有必要再去细分其内部的词法结构。X 哪怕不是 V,也被强制为 VG 了。5gram以内的可以记住的组合,可以一律交给词典标注或词典习得,不必寻找其中的结构规则。
The term Artificial Intelligence (AI), which traces its roots to the milestone Dartmouth's historic conference, is quite a bit of an afterthought by the then thought-leaders of the time, with an emphasis on artificiality. It, in essence, defines the true nature of AI as a fake intelligence that simulates human intelligence. But we seem to often forget that.
Those commonly known as "vegetarian chicken" or "vegetarian duck" are soy products, generally classified under the category of "artificial protein". The gap between "artificial proteins" and "animal proteins" is very comparable to that between "artificial intelligence" and "human intelligence". Every vegetarian eating "vegetarian chicken" knows clearly that it is fake meat so they feel comfortable enjoying it with its great taste. In contrast, almost all media and the majority of users of AI products today rarely regard the nature of AI as fake intelligence. That is quite a surprise to me.
I don't know if it's just tabloid hype or it's true. But the impression is fairly clear that those popular AI stars more and more often act like god. They seem to love to use super big words and philosophical metaphors which lead the mass to the belief of an equal sign between AI and human I. I don't think it is so much a sense of mission as a sense of superiority and ego, and they just feel too good about themselves in mastering some magic of AI algorithms. It occurs to me that if you act like God, talk like God, over time you will believe you are God. In times of AI bubbles, people buy that; more importantly, media love that, and investors are willing to pay high.
My entire career has been engaged in "natural language understanding" (NLU), with a focus on "parsing", which was for a long time widely accepted as the key to language understanding, the crown of artificial intelligence as some experts put it. As practitioners in developing industrial products, we know all these AI terms such as language understanding, machine learning, neural networks, plus AI itself, are just analogy or metaphors. AI models are just simulations, mechanical programs attempting to mimic intelligent tasks. But that is apparently not what has been depicted by media's efforts for "AI marketing", nor is it educated by the few AI stars at the spotlight. The public opinions or even decision-makers, shaped or influenced by such media, run more and more towards the opposite. So it might be high time to air a different voice and re-uncover the true nature. Artificial intelligence is fake intelligence by its very nature, filled with "artful deception", as pointed out by Pierce in the AI history. His criticism has never been out of time. In fact, there is never a time with this much "artful deception" built into products such as intelligent assistants, so artful that we start getting used to it for the convenience.
What is "understanding"? Strictly speaking, the computer has zero intelligence except for its mechanical computation and memorization. Natural language understanding has always been a metaphor by convention, that is why the Turing test was purposely designed to define "artificial intelligence" by bypassing "understanding". This is by no means to deny the breakthrough in recent years in the functional success stories of AI applications such as speech processing, image recognition, and machine translation.
We all have had personal life experiences when we were amazed at some functions performed by a non-human. As a child, I was amazed for quite some time that the radio could "talk", how "intelligent" this box called radio was. My mother had been confined to a remote rural area in her childhood, and when she went to a middle school in the nearby town, she had a chance to see an automobile running on the road for the first time. She ran away in awe and years later described to me the shock at the time when a non-human machine was running so fast. That is beyond intelligent to her mind. We all had those first times of "intelligence" shock, the first time we had access to a calculator when I was a middle school kid, the first time we walked through an automatic door, the first time we went to the bathroom which automatically flushed the toilet, not to mention the first time we used GPS. All those fake intelligence behaviors look so true and superior to our modest being when we are first exposed to them. But now such "intelligence-like behavior" is all out, we all accept that it is non-I. By human nature, we tend to over-read the meaning when we do not understand something. We are shocked to see any "automatic" behavior or response from a non-human, regardless of whether the mechanism behind is simple or an algorithm with complexity. Such shock is easy to amplify, and it's hard not to be fooled by wonders if we don't understand the mechanisms and principles behind, which happens a lot around the media talks about AI. In recent years, the media and industry are never tired of "man-machine competitions", in games and knowledge showoffs, in order to demonstrate that now AI beats human. Sometimes in my dreams, I have been haunted by similar images of human weight lifting champions challenging a crane to see who could lift the ton of steel with a single swipe.
In recent years, some celebrity CEOs in industry and legendary figures in the science community have seriously begun to talk about the problem of the emotional machines and the threat from machines equipped with super-human AI. It is often far fetched, citing functional AI success as autonomous intelligence or emotions. I would not be surprised when the topic is taken one step further to start discussing the next world problem as recreating hormones and reproductive systems in machines. Why not? Machines are believed to develop a neural network to become this powerful, it is a natural course to be reproductive and even someday marry humans for the man-machine hybrid kind. Science fiction and reality tend to get mingled all in a mass too easily today.
Nowadays, artificial intelligence is just like a sexy modal attracting all the eyeballs. Talking to an old AI scholar the other day, he pointed out that AI is, in fact, a sad subject. A significant feature of AI is to temporarily hold things whose mechanisms are not yet clear. Once the mechanisms are clear, it often becomes "non-artificial intelligence" and develops into a specialized discipline on its own. The plane is up in the air, the submarine is under the water, deployed everywhere in our land for decades. Do people who design airplanes and submarines call themselves artificial intelligence researchers? No, they are experts of aerodynamics, fluid dynamics, and have little to do with AI. Autonomous driving today is still under the banner of AI, but it has less and less to do with AI as time moves on. Aircraft has long been self-driving for the most part, no one considered that artificial intelligence, right? Artificial intelligence is not a science that can hold a lot of branches on its own. The knowledge that really belongs to artificial intelligence is actually a very small circle, just like the part that really belongs to human intelligence is also a very small circle, both of which are much smaller than what we anticipated before. What is the unchangeable part of AI then? We might as well return to some original formulations by the forefathers of AI, one being a "general problem solver" (Simon 1959).
(Courtesy of youdao-MT for the first draft translation of my recent Chinese blog, without which I would not have the energy and time in its translation and rewriting here.)
现如今人工智能好比一个性感女郎,沾点边的都往上面贴。今天跟一位老人工智能学者谈,他说,其实人工智能本性上就是一个悲催的学科,它是一个中继站,有点像博士后流动站。怎么讲?人工智能的本性就是暂时存放那些机理还没弄清楚的东西,一旦机理清楚了,就“非人工智能化”了(硬赖着不走,拉大旗作虎皮搞宣传的,是另一回事儿),独立出去成为一个专门的学科了。飞机上天了,潜艇下水了,曾几何时,这看上去是多么人工智能啊。现在还有做飞机潜艇的人称自己是搞人工智能的吗?他们属于空气动力学,流体动力学,与AI没有一毛钱的关系。同理,自动驾驶现如今还打着AI的招牌,其实已经与AI没啥关系了。飞机早就自动驾驶了,没人说是人工智能,到了汽车就突然智能起来?说不过去啊。总之,人工智能不是一个能 hold 住很多在它旗下的科学,它会送走一批批 misfits,这是好事儿,这是科学的进步。真正属于人工智能的学问,其实是一个很小的圈圈,就好比真正属于人类智能的部分也是很小的圈圈,二者都比我们直感上认为的范围,要小很多很多。我问,什么才是真正的恒定的AI呢?老友笑道,还是回到前辈们的原始定义吧,其中主要一项叫做“general problem solver”(西蒙 1959)。
Allison is my all time favorite, with her unique voice. The footage I shot is from a Costco tv demo plus the footage from the Apple Store in the new headquarters
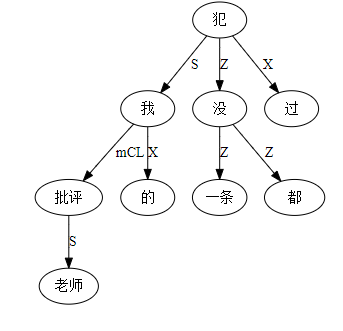
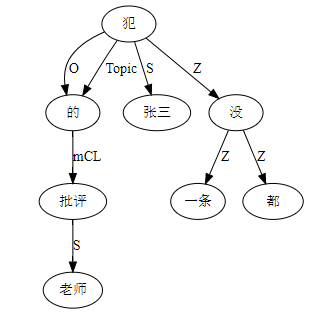
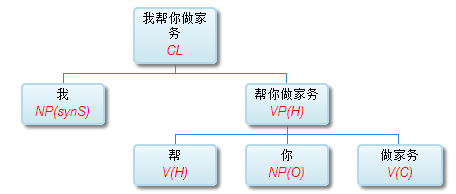
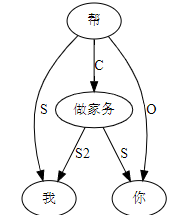
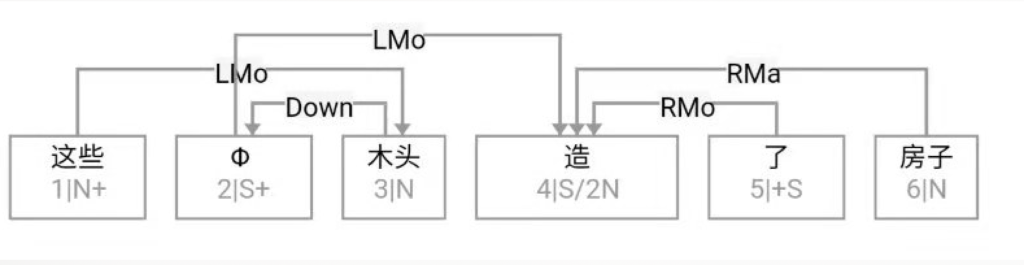
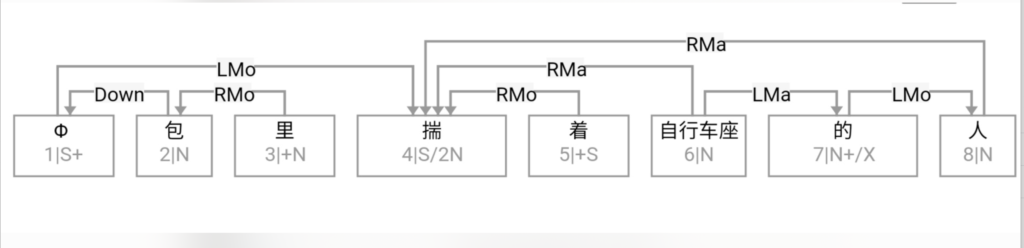
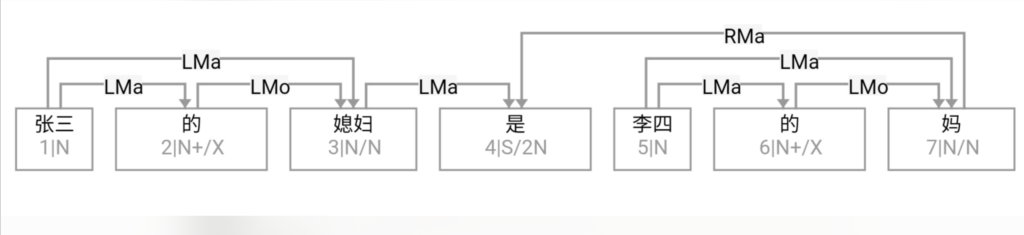
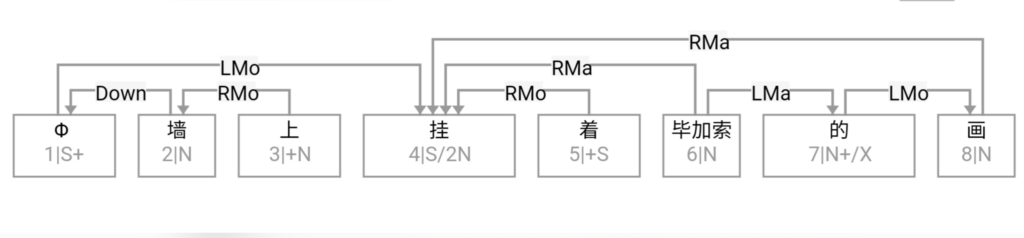
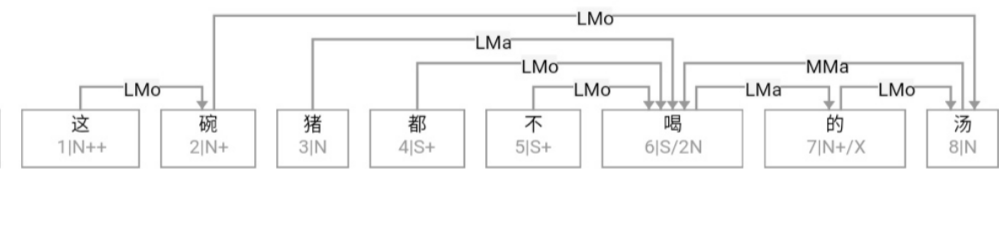
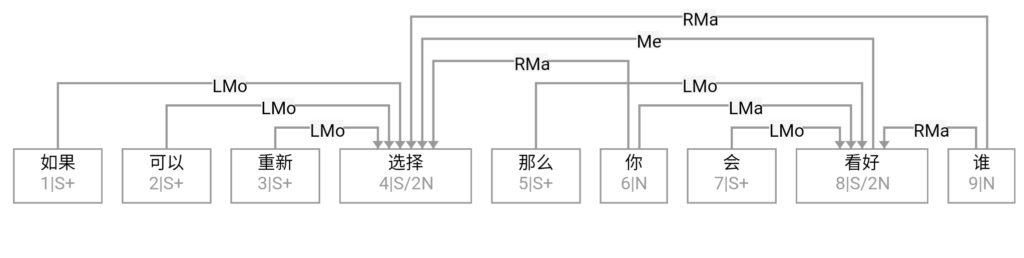
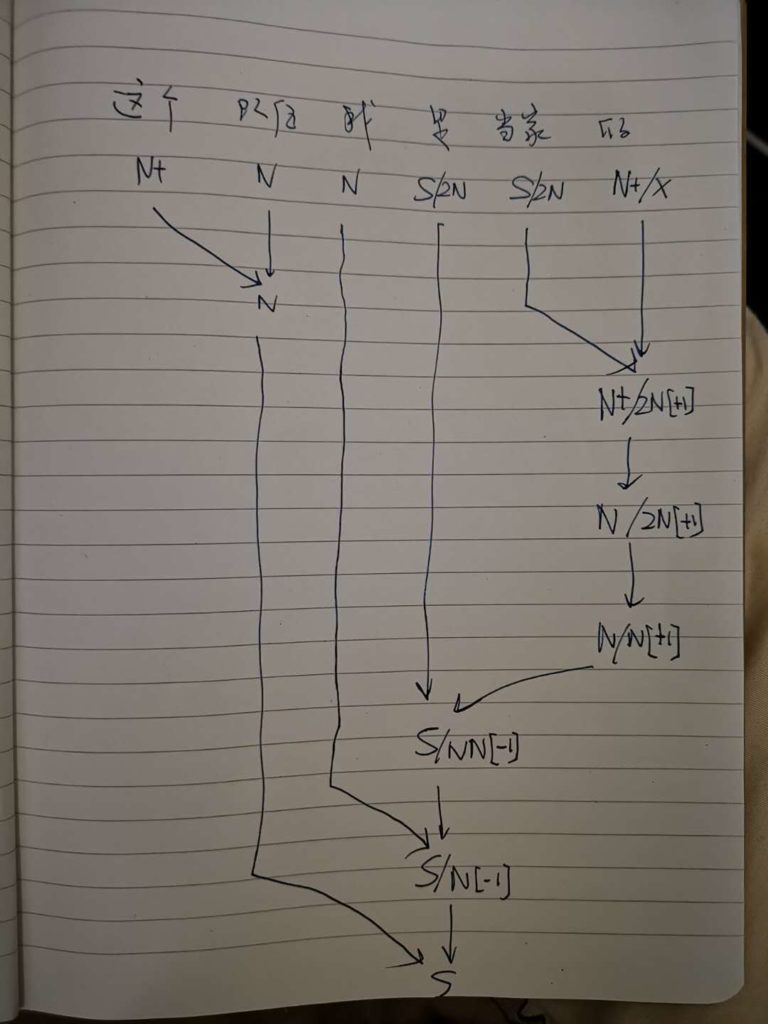
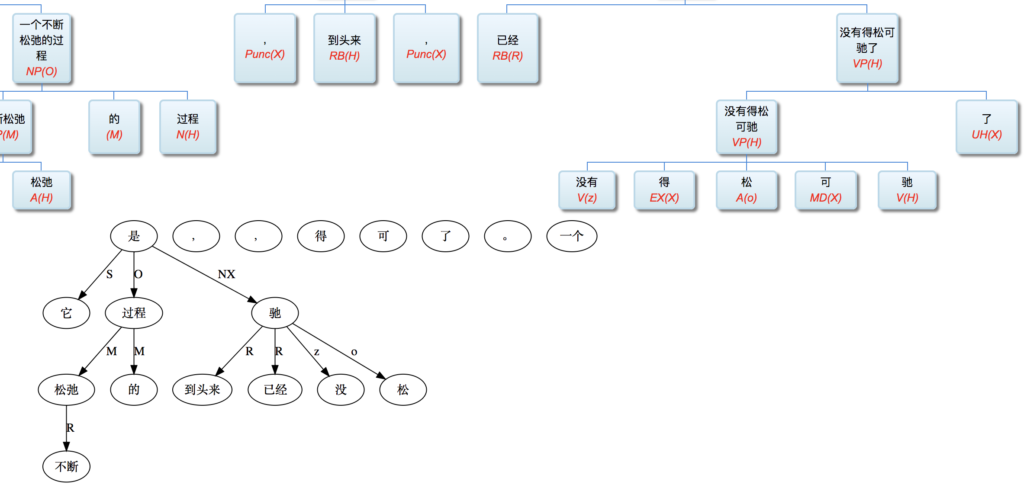
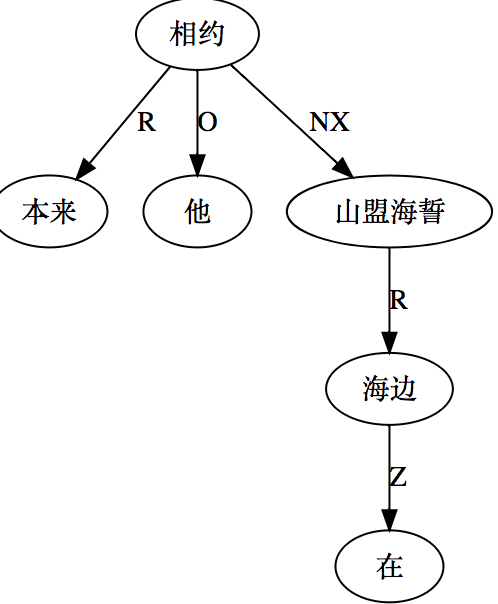
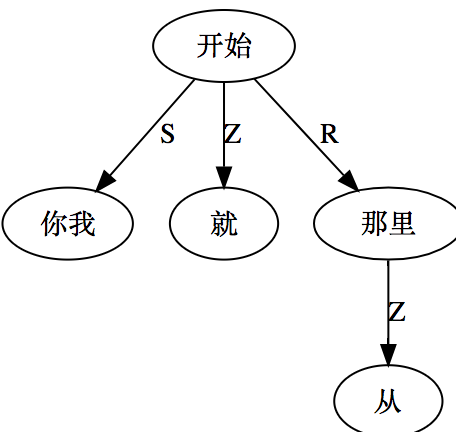
这条路线的搜索空间 (universe)是句子长度 n 的这样的一个函数:可以 assume n 中每两个词都必须发生7种二元关系之一。三种是实关系但是有方向(父父子子),所以“原子化”后就是6种实关系,即,是二元排列不是组合。第7种是:无关系。无关系也算关系,就一网打尽了。任意两词只允许发生7种关系之一,不能多也不能少。在 n 不大的时候,搜索空间爆炸得不算厉害。
白:ordered pairs,A跟B和B跟A可以有不同的关系标签。
李:对,有这个二元循环的可能,忘了这茬了。不过那很罕见,对于搜索空间影响不大。能想到的只有 定语从句谓词与中心词有二元循环关系,一个 mod 一个 arg 方向相反。
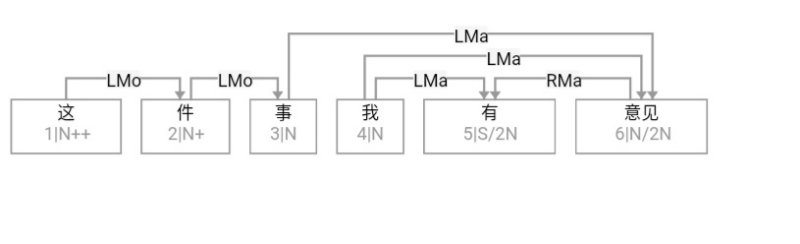
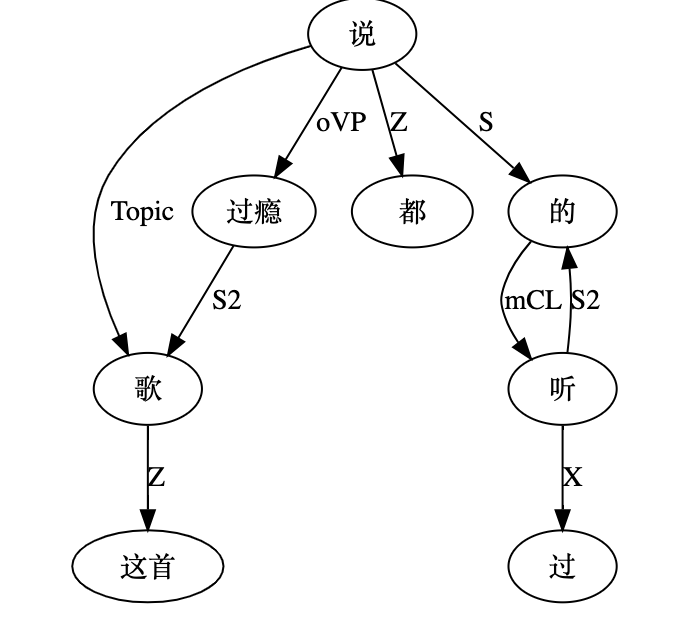
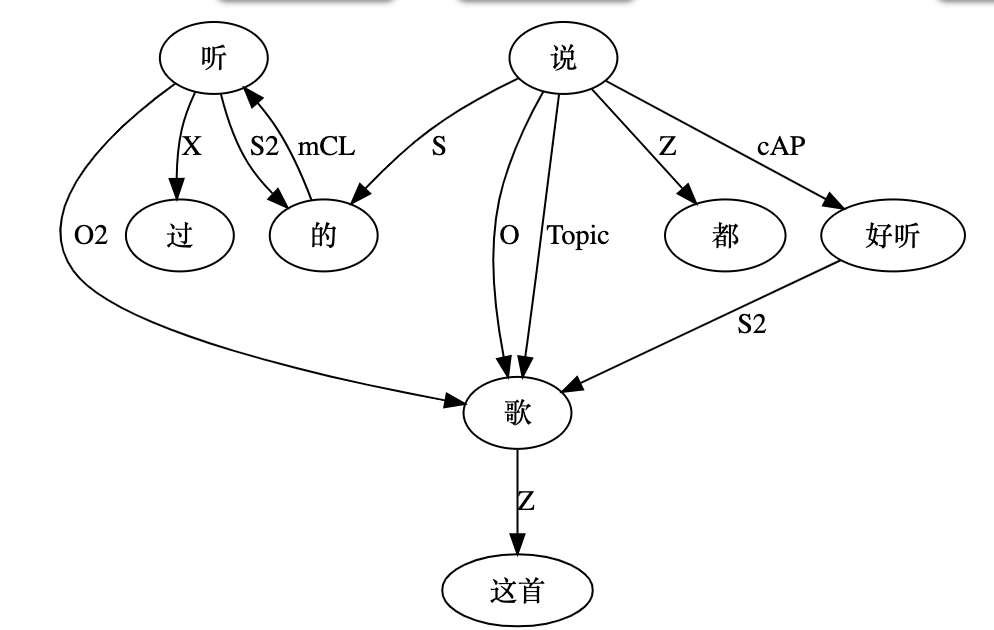
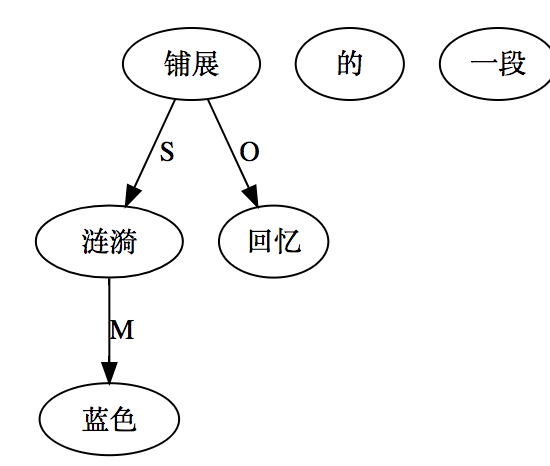
what 似乎也不齐全,只是展示结构的 what,没有展示结构的功能性(角色)。所以,作为学习,这里有两个空白需填补,一个是 how,尤其是语义相谐机制,怎么招之即来挥之即去的。另一个是逻辑语义,逻辑语义怎么在句法或逻辑的链接基础上得出的。当然这二者是相关的,前者是条件,后者是结论。目前展示的结构树图就是个架子和桥梁。
“boys go to Jupiter to get more stupider, girls go to college to get more knowledge.”
这是取笑男孩的。饶舌的甜甜现场发挥,富于夸张和强调:“what do you want me to say now? boys go to Jupiter , do you know the planet Jupiter? they go to the planet Jupiter, once they get there, they get supider and supider every second. And girls they go to college to get more knowledge and knowledge into their brain on their head.”
"Eeny, meeny, miny, moe, Catch a tiger by the toe. If he hollers, let it go, Eeny, meeny, miny, moe.
My mother told me/says to pick the very best one, and you are not it."
这是非常流行的“选择”童谣。小孩子面对两个或多种选择的时候,不知道选哪一样好,就口中念念有词,一边用手在选择物之间轮流数着,道理上应该是童谣完了手落在哪个选择上,就选择哪个。可是,儿童的心理是微妙的,很多时候内心其实有了一个所指,为了最终得到自己想得到的,表面上还跟着童谣走,孩子们学会在童谣后面,打着家长的名号,用肯定或否定来保证自己不要落到自己不要选的东西上:如果最后落到中意的选项上,就说 “My mother told me/says to pick the very best one, and that is YOU”. 否则就改口说:“My mother told me/says to pick the very best one, and you are not it.”
"You know what Kick your butt All the way to Pizza Hut
While you're there, Comb your hair Don't forget your underwear!"
里面有个片段说学校的事儿。回家说的这个故事是小女孩玩家家的,也有微妙的儿童心理:
"I said that I am the Princess of Jewelry because one of my friends and buddy said that she looked at my jewelry I brought to school. What happened is she was so surprised and she loved it ... she said that I am Princess of Jewelry and she is the Queen of Makeup. Next time I am going to bring new jewelry, she said that I am the Queen of Jewelry...... No,Daddy, Jessica said I am the Queen of Jewelry if I bring some new jewelry tomorrow."
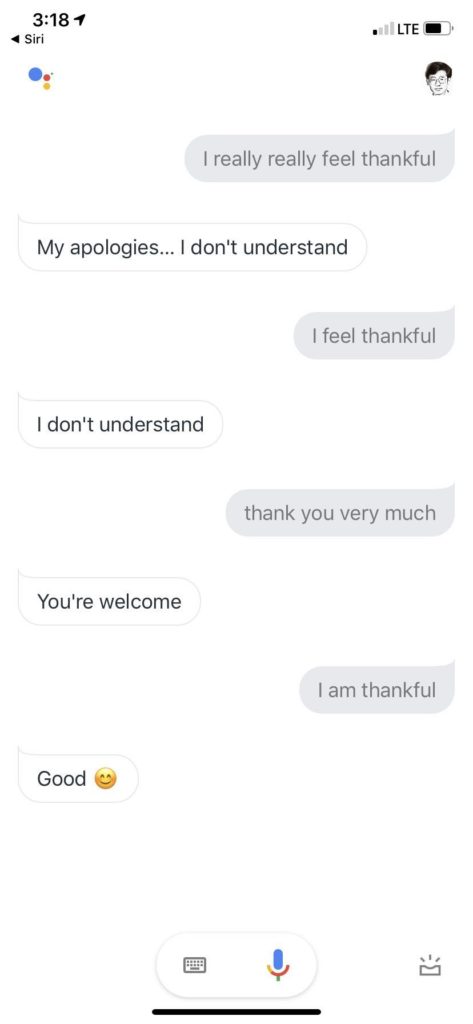
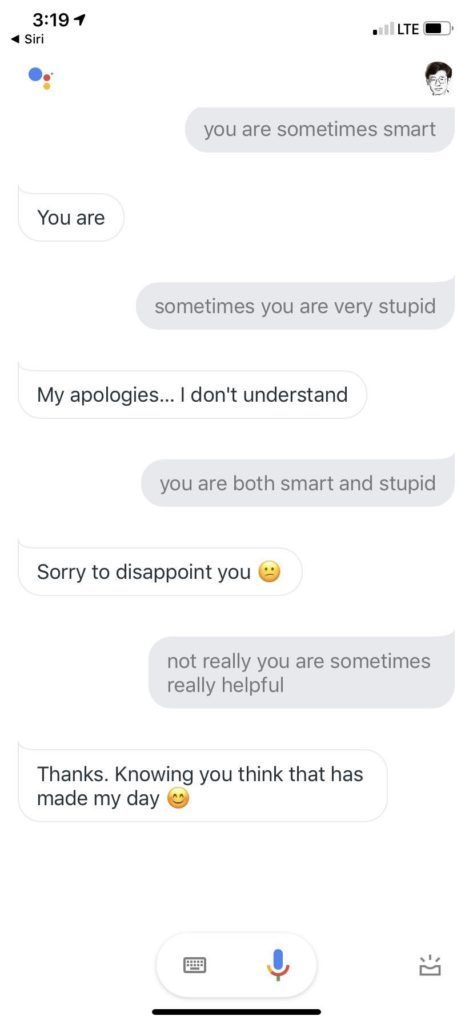
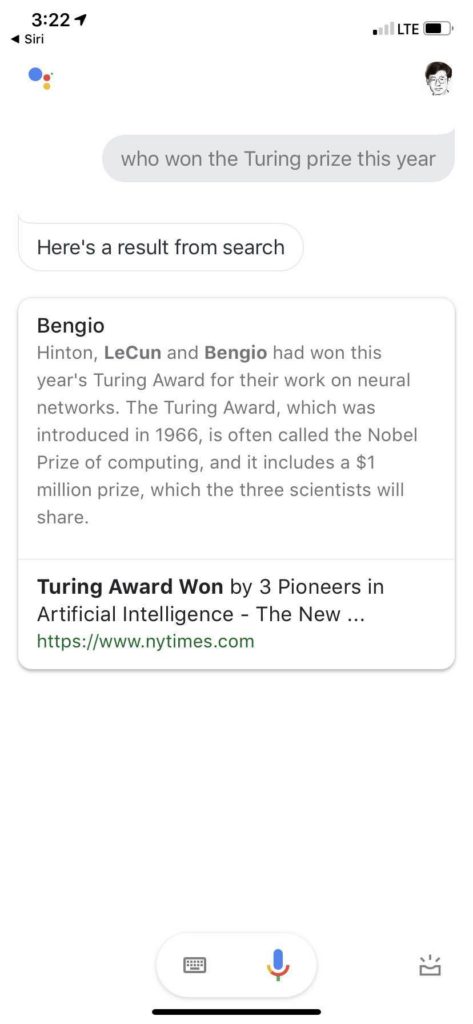
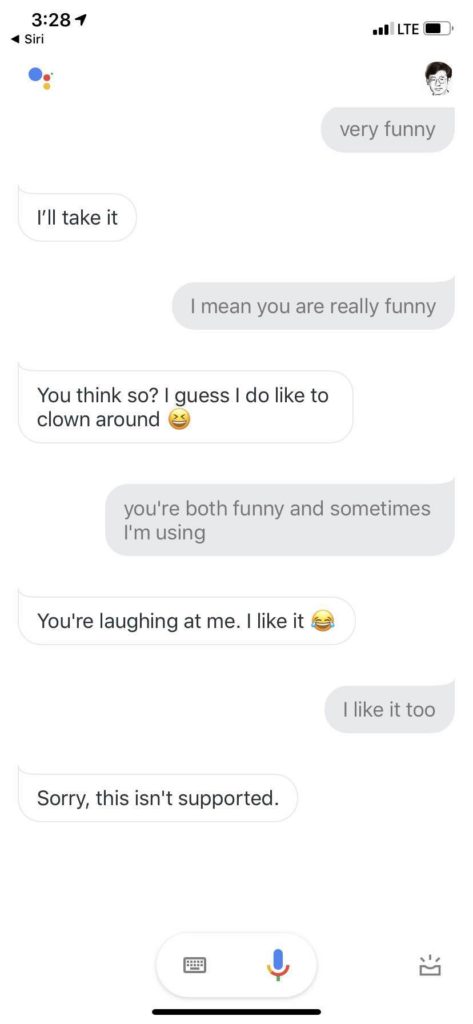
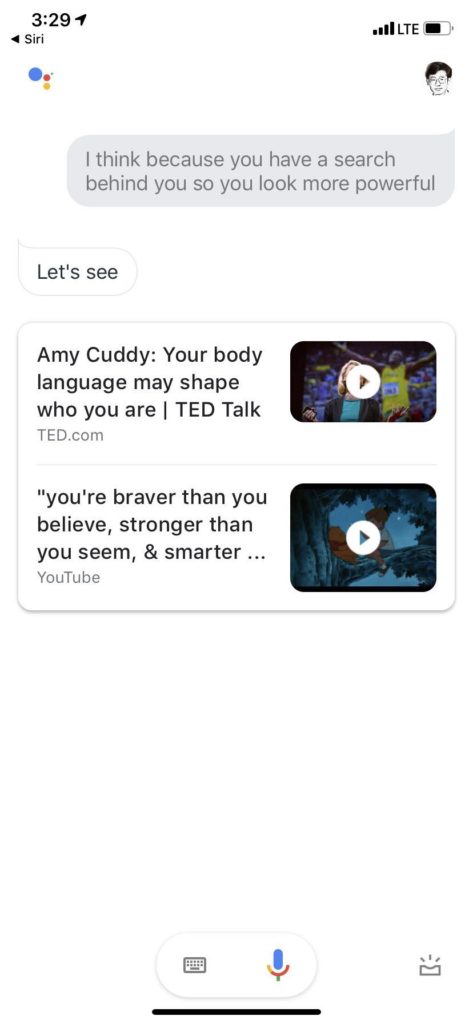
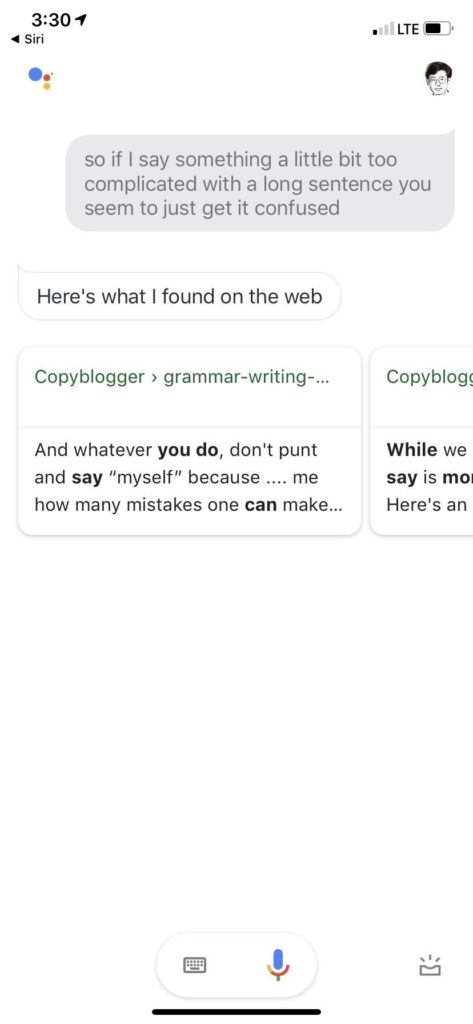
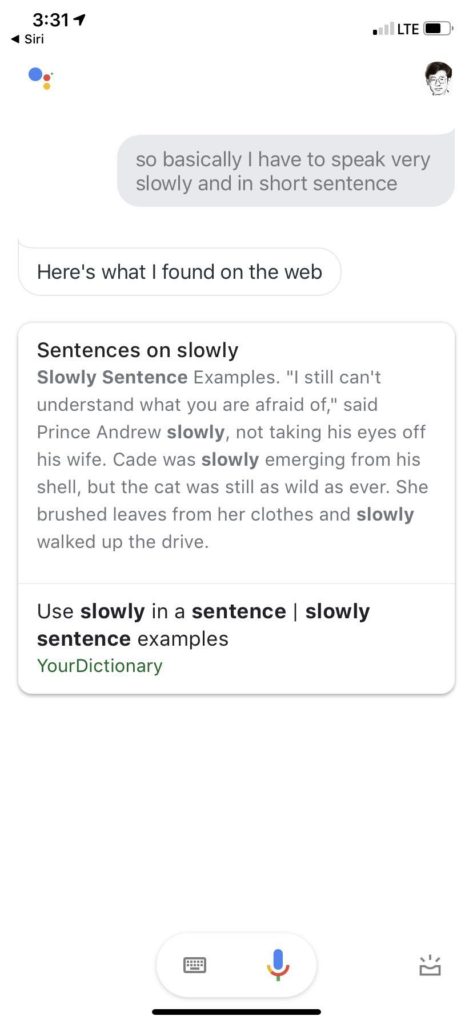
看目前 Siri 的水平,相当不错了,蛮impressed,毕竟是 Siri 第一次把自然语言对话推送到千千万万客户的手中,虽然有很多噱头,很多人拿它当玩具,毕竟有终端客户的大面积使用和反馈的积累。尽管如此,后出来的 Google Assistant 却感觉只在其上不在其下,由于搜索统治天下20年的雄厚积累,开放类知识问答更是强项。
所有话术都那么具有可爱的欺骗性,until 最后一句,莫名其妙回应说 this isn't supported.
(顺便一提,上面终于发现一个语音转写错误,我跟 Google Assistant 说的是,you are both funny and sometimes amusing. 她听成了 and sometimes I'm using. 从纯粹语音相似角度,也算是个 reasonable mistake,从句法角度,就完全不对劲了,both A and B 要求 A 和 B 是同类的词啊。大家知道,语音转写目前是没有什么语言学句法知识的,为了这点改错,加上语言学也不见得合算。关键是,其实也没人知道如何在语音深度神经里面融入语言学知识。这个让深度学习与知识系统耦合的话题且放下,以后有机会再论。)
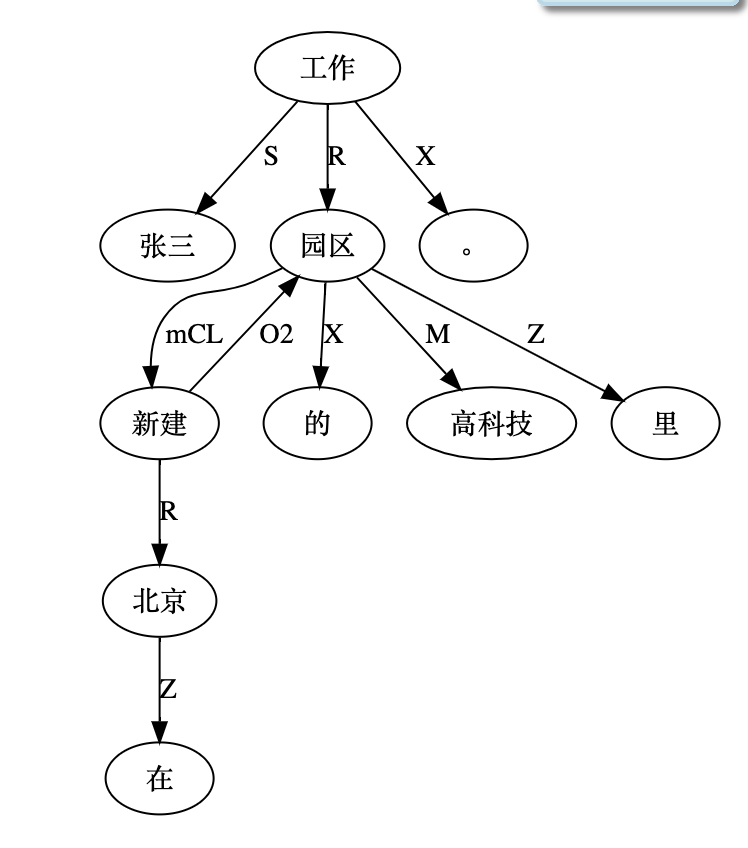
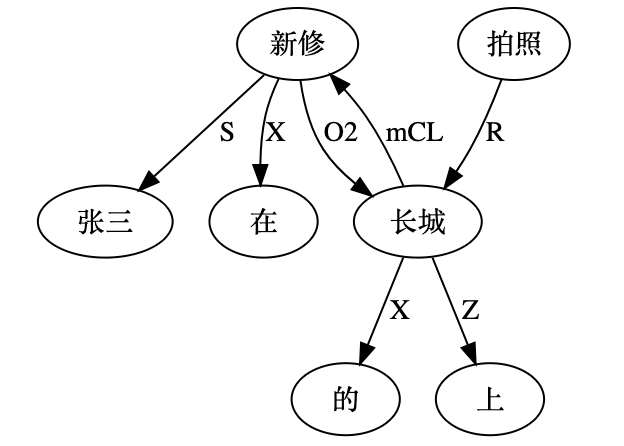
2 短语:VP = Verb Phrase; AP = Adjective Phrase; NP = Noun Phrase; VG = Verb Group; NG = Noun Group; NE = Named Entity; DE = Data Entity; Pred = Predicate; CL = Clause;
3 句法:H = Head; O = Object; S = Subject;M = Modifier; R = Adverbial; (veryR = Intensifier-adverbial;possM = possessive-modifier); NX = Next; CN = Conjoin; sCL = Subject Clause;oCL = Object Clause; mCL = Modifier/Relative Clause; Z = Functional; X = Optional Function
2 短语:VP = Verb Phrase; AP = Adjective Phrase; NP = Noun Phrase; VG = Verb Group; NG = Noun Group; NE = Named Entity; DE = Data Entity; Pred = Predicate; CL = Clause;
3 句法:H = Head; O = Object; S = Subject;M = Modifier; R = Adverbial; (veryR = Intensifier-Adverbial); NX = Next; CN = Conjoin; sCL = Subject Clause;oCL = Object Clause; mCL = Modifier/Relative Clause; Z = Functional; X = Optional Function
89风波后不久,第二届机器翻译高峰会议在德国慕尼黑举行。我代表刘倬老师在会议上介绍了我们的翻译系统,董老师也到会。会后,我们应邀去荷兰BSO公司的多语机器翻译小组,参加他们的 Chinese week,讨论把中文加入到他们多语计划中的议题,以及探讨中文处理的挑战(见《朝华午拾:欧洲之行》)。
很多年后,董老师给我来信说,孩子们整理老照片,翻出来一张在荷兰的合影,感觉很珍贵。Witkam 就是照片上的BSO项目组长,当年是他从欧共体争取到机器翻译项目的基金,BSO公司 match 另一半,这才成就了他们以世界语为轴心语言的多语言机器翻译项目的五年计划。其中的中文部分就是我为他们做的依存关系文法(我的《朝华》系列有记述【一夜成为万元户】:全是纸上谈兵的一套,但也勾画了中文形式化的雏形(见:【美梦成真通俗版】)。当年董老师对我的这个工作赞许有加。