【立委按】“真心说,语言学虽然不是显学,乍看颇落寞穷酸,但的确是最有趣的学问之一,是少有的能与上帝同在和对话的“科学”。要不世界几千年美国几百年不世出的千古学霸乔老爷能以此扬名立万呢。” 当然,乔老爷的天下无敌的引用数与崇高名声,只能说最多一半是语言学的功劳,另一半是他的左派社会主义的独立知识分子情怀及其犀利的现实批判精神。
王:
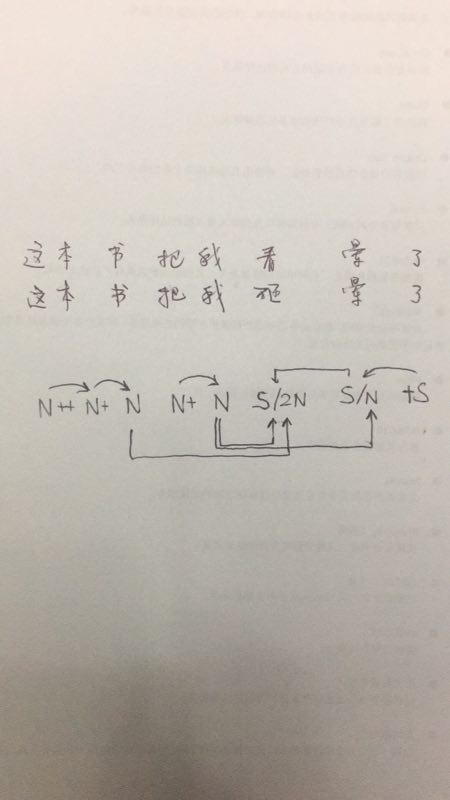
这本书把我看晕了。
这本书把我砸晕了。
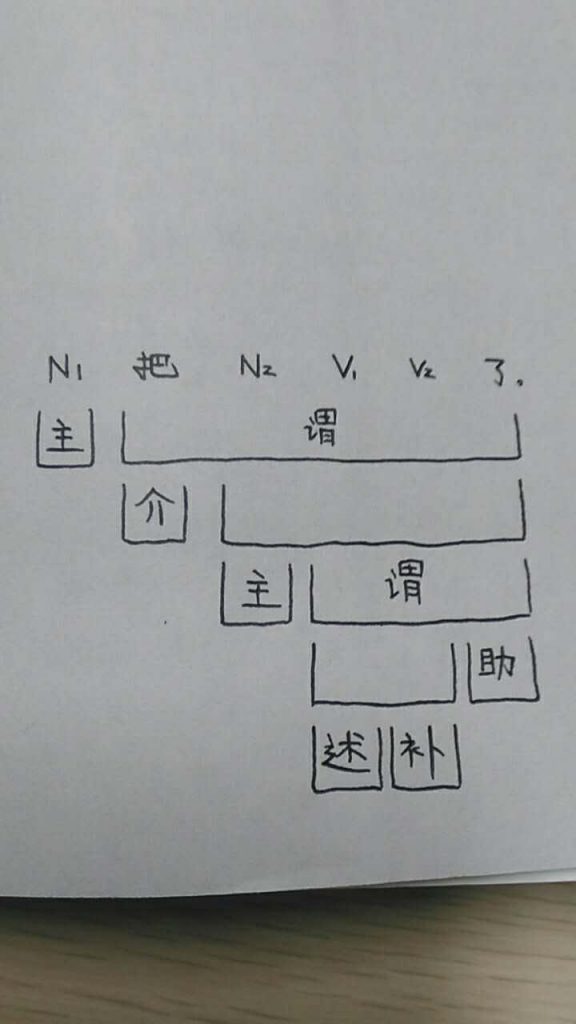
N1 把 N2 V1 V2 了。
V2和哪个N发生语义关系、发生什么样的语义关系好像比较好确定;但是对V1来说,如果不看具体的句子,好像就不能确定,当N1 N2与V1结合后,各自的论元角色是什么。
李:
不确定这个句法树画得对不对……
白:
要用次范畴
但是,如果句法的目的仅仅是确定“谁跟谁有关系”而不在乎“是什么关系”,是主是宾,根本无须过问。“看”和“砸”都有两个坑,“我”填一个,剩下的N填另一个。句法的任务就完成了。所以这两句的分析在我的体系里长得没差别:
王:
谢谢白老师!下一步确定哪个萝卜进哪个坑,是不是就是知识本体的工作了。
就是您说的次范畴设计,是不是就是在词库里设定一些语义相谐的规则,萝卜只能进和它语义相谐的坑。
白老师,您的体系里只有两种pos tag?
白:
利用subcat可以确定“我看书”
但“书砸我”并不典型。
“我砸书”也不是不可以。
N、S、X 三种 X意思是“可N可S”。真正排除“我砸书”需要常识或者统计,subcat并不能做出这样的区分。通常是“硬砸软”而不会“软砸硬”,人体属于“标配软”,书则“标配硬”,也不排除硬的人体(冻僵了那种)和软的书(帛书)。
王:
谢谢白老师指点!
白:
语义相谐不一定要通过规则,也可以通过统计。
subcat只对词条标注,不对短语标注。
注意到我画的图里,“我”一个萝卜填了“看/砸”“晕”两个坑。这是因为补语动词并入谓语动词,相应的坑不占同一个萝卜的额度。
王:
对,李维老师上周推的文章里好像也说了,本体是人编的,知识图谱是统计出来的,都可以用来判断语义相谐。
李:
本体(ontology)也可以从大数据统计学出来 叫习得(acquisition),但跨领域的一般性本体不值得费劲儿去学。一来有现成的高质量的本体在 如董老师的 hownet,语义大师几十年打造的。跨领域跨语言的基本放之四海而皆准,仅次于上帝的工作。二来 学了半天 也难系统化 。但是 本体自动习得还是有一席之地,主要在,习得可以对领域 对数据有自动调适能力。更主要的是 习得可以包含本体常识的相谐的程度和或然性比较,这是人工标注 哪怕是大师的工作 所难以达到的。最终 常常是二者的结合。以专家本体框架为指导 以数据为对象 学出领域本体。
白:
相对标记,并不是每个本体都有的:“你打了他不该打的朋友。” 打,二价,但“朋友”自身仍有坑。
李:
当然 玩本体 这种 元层次语义 需要一些修为 非新手可玩 玩了也不会用 。但是 玩知识图谱这种 倒是相对人人可为 基本就是个力气活,砸的是人力和计算资源,不需要一定有语义全局的高度。
白:
标注种子词条,习得种子关联,推荐更多词条,推荐更多关联。所谓bootstrap。

李:
另外 所谓相谐(semantic coherence, or, attribute-value appropriateness) 是元知识 是本体的属性和功能 与一般的知识图谱无大干系。如果硬要 argue,在碎片化信息抽取整合成知识图谱的过程中,领域概念之间的相谐蕴含在图谱中,也不是没道理。但是关键在,相谐是作为一个软条件帮助语言分析理解,从而帮助抽取挖掘图谱的。图谱是结果,达到结果了 相谐已然过去式了。过河不必拆桥,但桥是为过河而设置,过了河就没桥什么事儿了。
另,“subcat只对词条标注,不对短语标注”,白老师这话不错。不过短语也可以继承词条的 subcat,继承的时候 已经填坑的要“折算”。换句话说 短语的 subcat 坑减少了。减少为0的时候 就功德圆满了 就没有了 subcat,譬如 s,那是最高的短语。
白:
坑的subcat没了,自身作为萝卜的还有
李:
当然 譬如右嵌套:s 可以作为子句 作宾语,是VP的右嵌套。这时候不圆满还不行 不圆满就做不了所要求的宾语子句。语言学理论里面 把这种条件叫做 configurational constraints, 也就是乔老爷的 x bar 的条件。如果这个条件要求的是尚未圆满(not fully saturated, or partially saturated) 的短语,就带着未填满的坑前行,各种好玩的语言逻辑的戏就开场了。
白:
如果词负载结构,这一切都在填坑中自然完成,无需另外的句法来“制导”。
李:
譬如 【书砸我】 还是 【我砸书】 这样的公案就出现了。到了 【书看我】 还是 【我看书】,本体常识或本体统计可以发力,当然 这种强搭配也可以不劳驾本体,而是当成词法或词典与句法的交互和接口,但是不强的搭配太柔软,句法就无计可施了,只能 identify 可能性 不能确认语义的唯一性。本体或反映本体的大数据 不得不上场。如果由于数据稀疏 上场了也不能解决 ,那只能保留歧义 有可能本来的语言表达就是双关。
真心说,语言学虽然不是显学,乍看颇落寞穷酸,但的确是最有趣的学问之一,是少有的能与上帝同在和对话的“科学”。要不世界几千年美国几百年不世出的千古学霸乔老爷能以此扬名立万呢。
【相关】