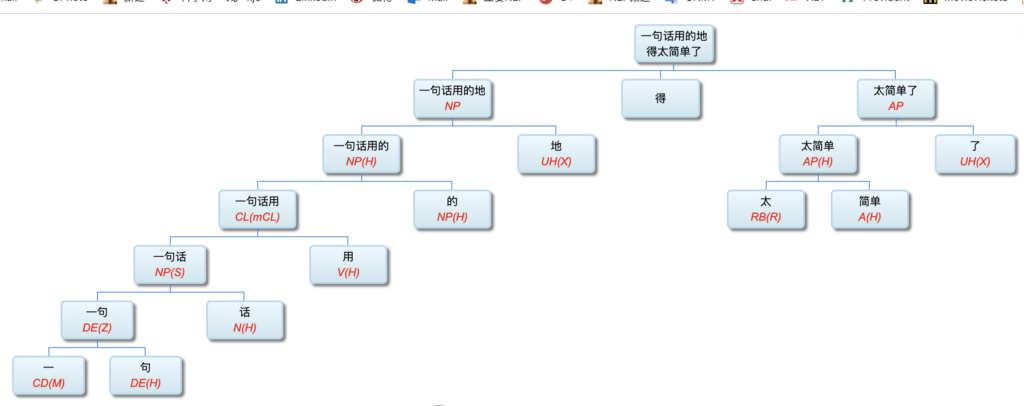
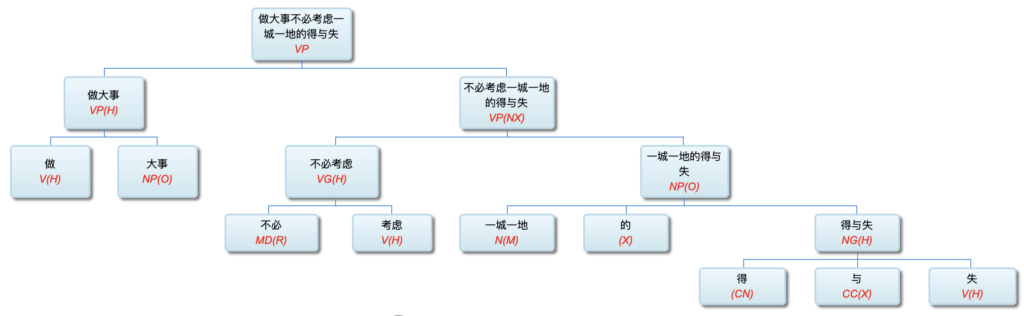
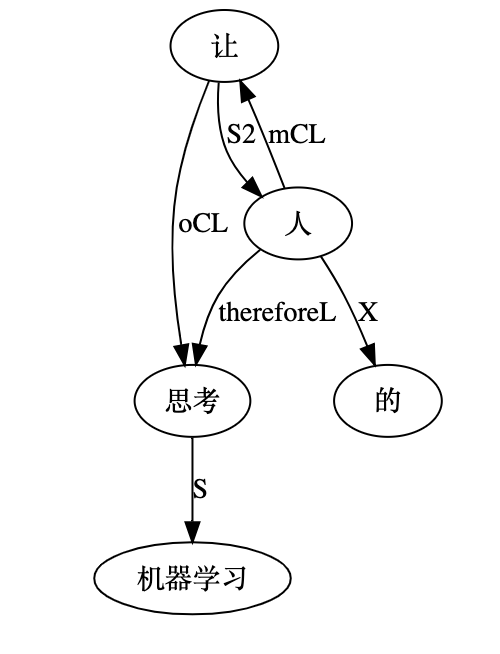
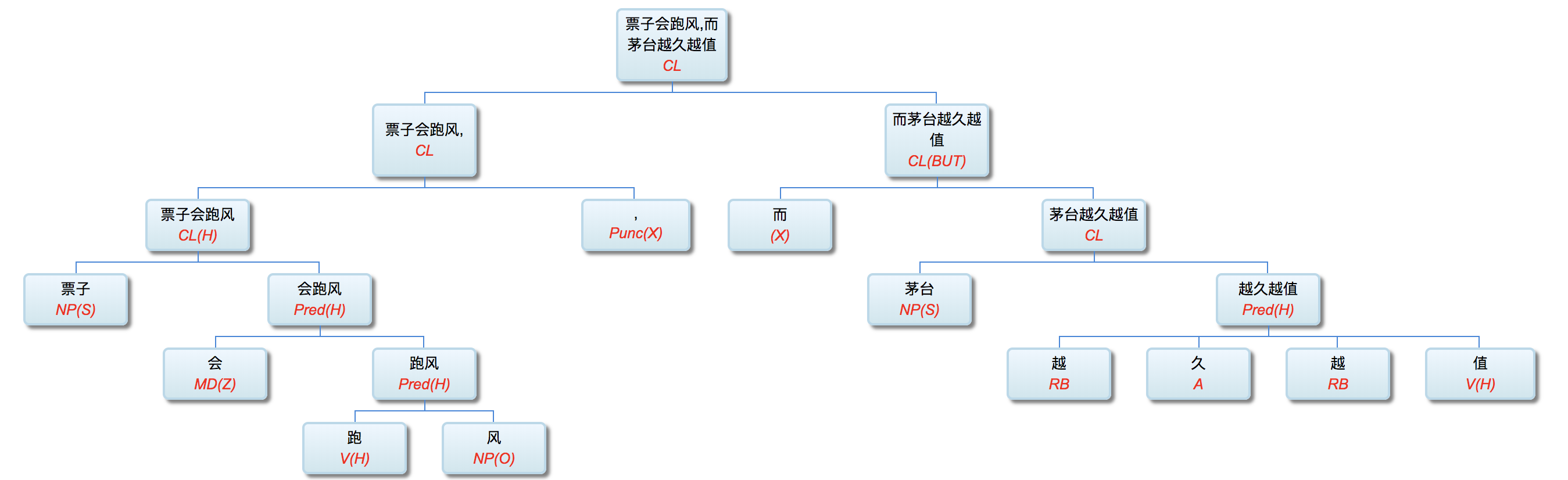
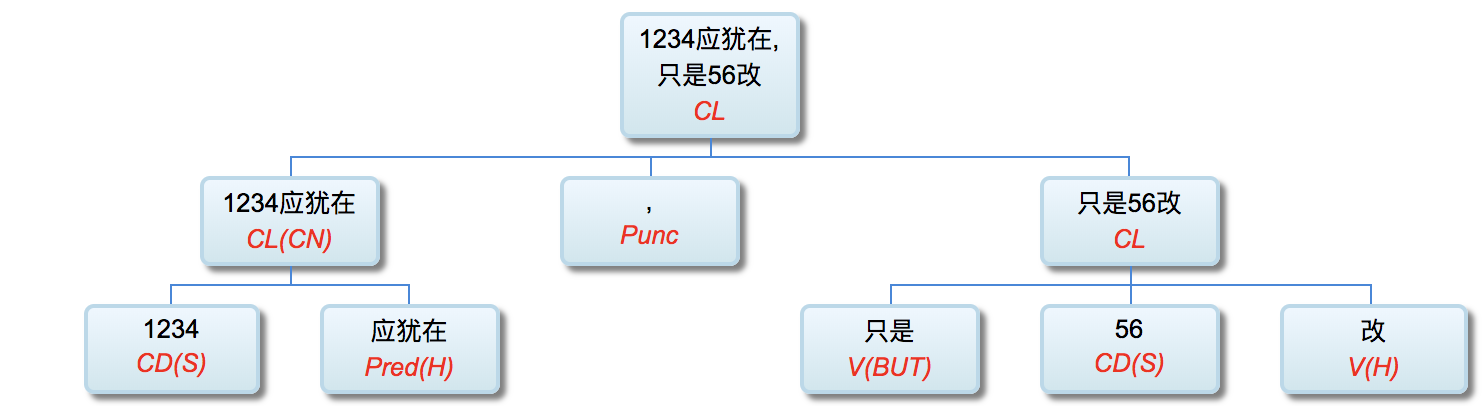
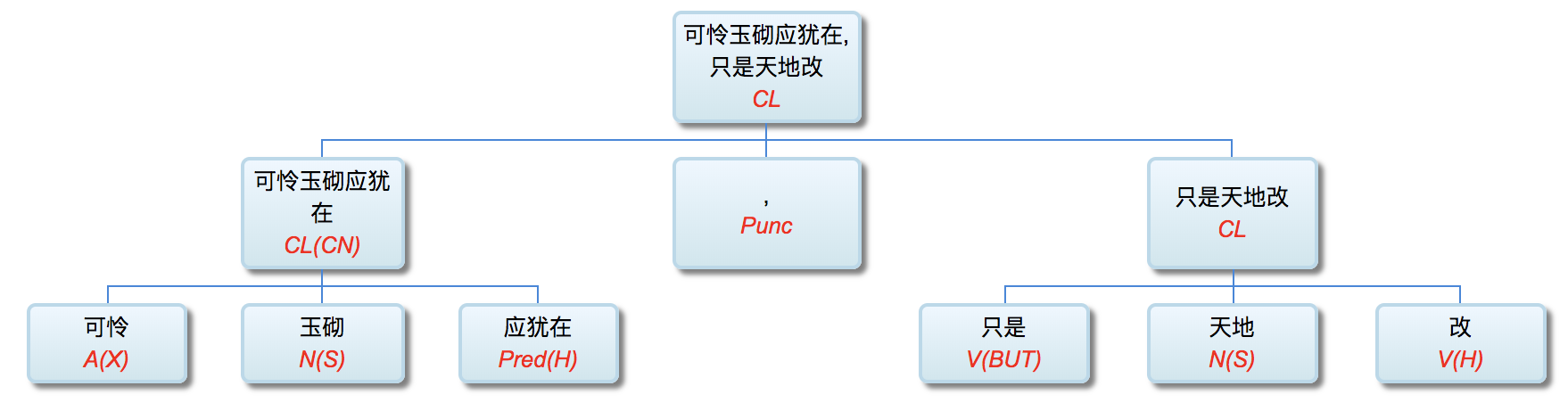
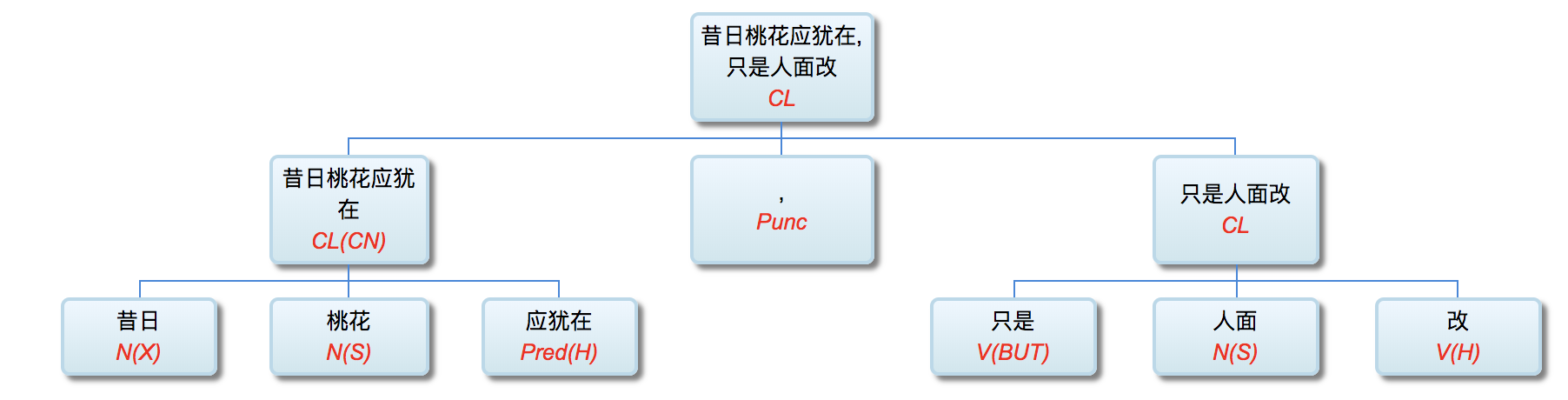
Q: Lao Li, I have been paying close attention to your academic track. I deeply admire you for more than 30 years' in-depth study of symbolic logic in the field of natural language understanding with your unique innovation. On your NLP Channel, I notice that you've been critical of Chomsky. Chomsky is the representative figure of the rationalist school. Like many others, I admire Chomsky. As far as I know, you are also a rationalist. So why do you, as a linguist who practices rationalism, criticize Chomsky?
A: First of all, although I have criticized Chomsky, pointing out his theoretical issues and objective misguidance in the field, these are "criticisms within the school". There is no doubt that Chomsky is the father of computational linguistics and the banner of rationalism in the field of artificial intelligence. His theory of formal language is the cornerstone of computational linguistics. All of us computational grammarians, as practitioners of the symbolic logic of rationalism in language, are his disciples. When we criticize him, we still use his formal mechanism as the frame of reference.
From the perspective of language formalization, Chomsky, who has a deep mathematical background, brings mathematical rigor into the formal study of language. At least in terms of formalism, Chomsky unified human language with computer language to have achieved a highly abstract symbolic system no others could dream of reaching. Without Chomsky's formal language theory, computer science could not develop high-level languages, and all the achievements of the information industry would be unimaginable.
On the other hand, it can be said that Chomsky's negative impact on the field is as big as his revolutionary contribution to linguistics and computer science. His formal language hierarchy is a theory of pure genius, which lays the foundation of language formalization. This formalism has become the theoretical basis of computer high-level languages and their compiling algorithms. It is used at its best to create, parse and compile computer languages as a perfect guide. However, perfection is sometimes only one step from fallacy. Chomsky criticizes the finite state machine as not suitable for modeling natural languages due to a lack of recursion mechanism. Too many people are misguided and fall into the so-called "more powerful" context-free mechanism.
Such an intelligent and powerful figure, if he misleads, can impact an entire generation. The generation that was affected was my direct supervisors and predecessors when I entered this field (in the 1970s and 1980s), their work in natural language understanding was almost exclusively toy system confined to labs, difficult to scale up and demonstrate in practical applications. This directly led to the rebellion of the next generation. This is the piece of history in artificial intelligence, the famous competition between rationalist symbolic school and empirical statistical school, with long struggles between the two paths. The rationalists of the old generation were at a disadvantage in competition and gradually withdrew from the mainstream stage.
All the advance of the statistical school over the last 30 years has been a practical critique of Chomsky because almost all of these models are based on finite state models, which he repeatedly criticized as inappropriate for natural language. The context-free grammar he advocates has achieved limited success in the field of natural language.
Q: Now that everyone is advocating neural networks and machine learning, is there still room for the symbolic rule school? Rationalism has lost its voice and visibility in the natural language community. What do you think of the history and current situation of the two?
A: Well, machine learning has been on the rise in natural language processing since about 30 years ago, with the rapid development of data and computing resources. Especially in recent years, deep neural networks have achieved breakthrough successes in learning. The success of empiricism, in addition to the innovation in neural network algorithms, also benefits from the availability of unimaginably big data and big computing power today. In contrast, the rationalist school of symbolic logic, due to its implacability, gradually withdrew from the mainstream stage of the academia after a brief upsurge of phrase structure grammars with innovation based on unification about 20 years ago. There are several reasons for this situation, including Chomsky's long-term negative influence on computational grammars, which deserves serious reflection.
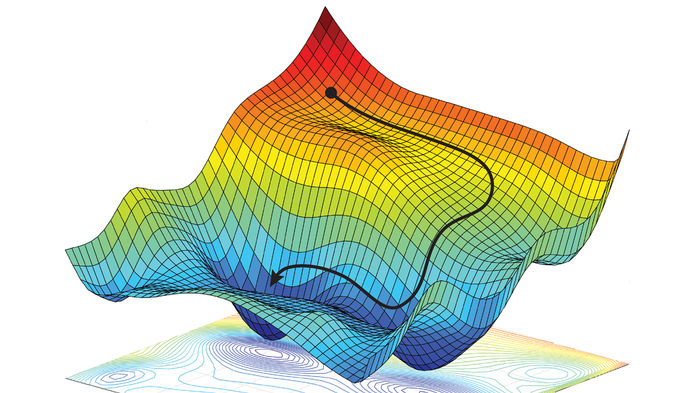
Looking back at the history of artificial intelligence and natural language, the pendulum of empiricism and rationalism has swung back and forward, but the pendulum of empiricism has been on the rise for the last 30 years (see the red dot in figure 1). In his article "Pendulum Swung Too Far", Professor Church predicted and called for the resurgence of rationalism and presented an illustration below:
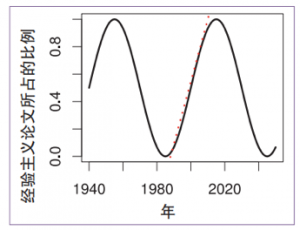
At present, due to the breakthrough of deep learning, empiricism is still in the limelight. Although rationalism has been accumulating efforts by itself for many years, it has not yet reached the tipping point where it can compete, head-on, with empiricism. When one school becomes mainstream, the other naturally fades out of sight.
Q: I have a feeling that there is some confusion in the community and outside the community at large. Deep learning, which is a method of empiricism, now seems to be regarded by many people as equivalent to artificial intelligence and natural language processing. If the revolution in deep learning sweeps through all aspects of artificial intelligence, will it end the pendulum swing of rationalism? As professor Church says, the pendulum of empiricism has swung too far, but it looks far from falling back.
A: My definite answer is no. These are two different philosophical bases and methodologies, each with its own natural advantages and disadvantages. Although there are reasons for the status quo of the existing one-sided empiricism in the current academic world, it is not a healthy state. In fact, both schools are competitive on one hand and also highly complementary on the other hand. Some older generation mainstream pioneers like Church have been warning about the disadvantages of one-sidedness in empiricism, and some new scholars in deep learning have been exploring the integration of the two methodologies to solve the problems of natural language.
Yes, much of the current surge in AI is based on breakthrough performance from deep learning, especially in the areas of image recognition, speech processing as well as machine translation, where AI systems have reached or exceeded human quality. This is an unprecedented amazing achievement indeed. However, the fundamental limitation still exists with deep learning, as well as all the other successful empirical methods at present, that is, the dependence on massive annotated data, what we call the knowledge bottleneck. The reality is that in many fields and application scenarios, such as natural language parsing, machine translation of e-commerce data, data of massive annotation or domain translation do not exist. This knowledge bottleneck severely limits the performance of the empiricist school in natural language understanding and other fine-grained cognitive tasks. There is simply not enough annotated data in many sub-fields, and without, it is almost impossible to make bricks without straw for learning. This is especially true for deep learning, which has a much larger appetite, like insatiable, than traditional machine learning.
Q: So it seems that deep learning is not an all cure. Rationalism has its place. You said the two schools have respective strengths and weaknesses. Can you compare and contrast them? Why are they complementary?
A: Let me summarise the merits and demerits of the two for a serious contrast.
The advantages of empirical statistical models include: (1) good at coarse-grained tasks, typically, document classification, for such tasks, statistical learning is naturally better to draw the overall conclusion; (2) robustness; (3) high recall: due to the lack of structures and understanding, many tasks might face a ceiling for accuracy, but recall-wise, learning usually performs well; (4) development efficiency: it can quickly scale to a real application scenario of big data.
The main limitations of the statistical school are: (1) the dependence on massive annotated data: this is the biggest knowledge bottleneck; (2) it is difficult to make targeted debugging: the statistical system is more like a black box, a big defect for maintenance and iterative incremental enhancement of a software system; (3) lack of interpretability: whether the result is right or wrong, it is difficult to explain, which affects the user experience and confidence. The main reason is the lack of explicit structural representation and symbolic logic in the algorithm that people can follow.
The rationalist approach simulates human cognitive processes without relying on massive labeling data to imitate on the surface strings. Rationalism directly formalizes the experience of domain experts and uses the explicit rule system from symbolic logic to simulate human intelligence tasks. In terms of natural language understanding, the grammar school formalizes the rules summarized by linguists so as to parse natural language in detail at all levels and achieve deep syntactic-semantic analysis. In this respect, rationalism has its natural advantages.
To sum up, the advantages of rationalist rule-based school include: (1) good at tasks of fine-grained tasks: very detailed analysis, such as the deep parsing of syntactic semantics with logical reasoning; (2) accuracy: the rule system written by experts is easy to guarantee high accuracy, but the improvement of recall is usually a long iterative process; (3) debuggable in error correction: the basis of the rule system is symbolic logic, which is easier to trace to the root of the error in debugging; (4) interpretable: this also benefits from the understandable symbolic logic basis.
The main defect of the rule school is the low efficiency of manual coding, and the dependence on expert coding is the knowledge bottleneck of the rule school. Supported by the same platform and mechanism, different levels of expertise determine different levels of quality. The two paths have their own knowledge bottlenecks, so to speak. One is to rely on a large quantity of "low-level" labor, labeling, though very monotonous, is work that can be assigned to ordinary students with a little training. The other is to rely on a few experts of "high-level labor", much like software engineering, for coding and debugging rules, the knowledge engineer training costs are high, making it more difficult to scale up to the real world. Finally, the talent gap can also be regarded as a realistic severe limitation of the rationalist school. 30 years is exactly one generation, during which empiricism has occupied the mainstream stage, and attracted almost all newcomers, causing a generation shortage of talents in the rationalist camp.
As for the recall, it cannot be simply concluded that high precision is bound to have a low recall rate for rule systems. The actual situation is that, on the one hand, it is not at all difficult to achieve a balance between precision and recall, by deliberately relaxing rule conditions and sacrificing accuracy. On the other hand, while high precision can also be maintained, the more rules added to the system, the more phenomena will be captured, hence the recall rate will come up naturally and incrementally in the iterations as time moves on. In other words, recall is a function of time and development resources put in, without having to compromise precision.
Q: Since each has its own strengths, as the rationalist pioneer and father of computational linguistics, why doesn't Chomsky exert its due influence in the field of natural language processing? His impact has been waning, and the newcomers to the field hardly hear of him.
A: Indeed it is. Although I am a rationalist, I also see that there is a considerable historical burden from this school that needs to be seriously reflected on from the perspective of formalism architecture.
Chomsky is the founder of modern rationalism, but the theory and practice he developed also involve some misconceptions. We must recognize these so that we can move forward the linguistic rationalism in symbolic logic steadily and deeply for natural language. In fact, after decades of theoretical exploration and practical experiments, the grammar school has seen fairly clearly its own theoretical limitations. Those who stick to the symbolic rule systems have broken through the path of innovation in the inheritance of rationalism, and have made their own breakthrough in deep parsing, the very core of natural language understanding, and in its scale up to big data for real-life information extraction and text mining applications. That's what we're going to focus on in this series of interviews.
Q: I know you have great faith in rationalist symbolic approaches in general. However, you have also seen a number of misconceptions in Chomsky's theories. which are the most critical?
A: On his formal language theory, there are two fallacies to my mind, one I would name Recursion Fallacy and the other Monolayer Fallacy. On his linguistics theories, one of the very basic propositions in his linguistic revolution is "syntactic autonomy" or "self-contained syntax". It involves serious potential consequences in the analysis of certain languages such as Chinese. His phrase structure grammar tree represenation with his X-bar theory in syntax is also worthy of reflection and criticism, especially when it is put in the comparative study with the alternative dependency grammar and its representations for NLU. Let's look at Recursion Fallacy first.
In my view, Chomsky's greatest mislead was to use the so-called recursion nature of natural language to criticize pattern matching in finite states. His cited English examples of center recursion are far-fetched and rare from real life, making it difficult to argue for its being the nature of natural language. Nevertheless, a generation still chose to believe in his theory, taking it for granted that finite states had to be abandoned in order to be able to parse natural language.
Q: Isn't it generally accepted that natural language is recursive? How to say it is a fallacy?
A: Exactly because it is widely accepted, it is of the more misleading nature and consequences, hence requiring more serious critique.
Recursion in natural languages typically comes in two types: (i) right (branching) recursion and (ii) center recursion. Many people don't consciously make that distinction, but in computational theory, they are two very different things. Right recursion is linear by nature while center recursion is nonlinear, a completely different monster, of much more computational complexity. In natural languages, right recursion is fairly common and can at times be as many as seven or eight levels nested, which still reads natural and easily comprehensible. For example, the VP nesting example:
(to request A (to beg B (to ask C (to do something))))
For right branching recursive structures, we usually do not feel a burden in the communication. The reason is that, although the right recursive left boundary is in an uncertain position, they all end at the same poin for the right boundary, like this: (... (... (... (... (...... ))))). Thus, we do not need a "stack" mechanism in memory to deal with it, it remains finite-state.
Chomsky cannot criticize finite-state devices with right recursion, so he needs to base his argument on center-recursion, a rarity in language. The fact is that natural languages have little manifestation of center recursion. Center recursion is much like matching parentheses. You want the parentheses to match each other so you can express and understand the proper nesting structures, like this: { ... [ ... ( ...... ) ... ]... }. After as many as three levels of center recursion, our brain can no longer cope with the pairing complexity, which is why it's hard to fine such phenomena in real life language data.
Q: I remember some examples of center recursion in English:
The man who the woman who had lost all the keys was calling all day finally came...
A: Is this "human" language? Chomsky repeatedly attempt to teach us that not only this is human speech, but it is the very nature of human language, hardly any hypotheses about language as far-fetched as this to my mind.
Q: Let me try to understand what you mean: center recursion does not exist, or does not exist over three levels, so natural language is finite-state?
A: Well, not that it does not exist, it's so rare and far-fetched, and it's never more than three levels deep unless you're pulling a prank. Therefore, it can by no means be the "nature" of natural language.
The very idea of unbounded center recursion in language, far from the observable facts, in effect violates the limits set by the short-term memory following psychology. Where in the world do people talk like that, like, keep opening the doors without closing them behind, in a maze-like complex castle, with nested sub-structures after substructures? A path of 3 doors opened, an average person will get lost in the maze. Even if you're a super linguist, and you can stand it, your audience will be bound to be trapped. Is natural language not to communicate, but deliberately making difficult for people to follow you? This is not in accordance with the consensus that language is born for communication and serves the ultimate purpose of communication.
Using pranks and verbal games as evidence of linguistic competence and the nature of language is one of the most misleading aspects of Chomsky's recursion theory. This recursion trap leads many people to automatically accept that natural language is recursive and therefore we must discard the idea of finite states. The people who believe in him, on the one hand, are influenced by his authority as the father of modern linguistics; on the other hand, they often mis-regard the more common and deeper right recursion for center recursion as evidence in support of Chomsky's recursion hypothesis. Chomsky himself is intelligent and rigorous as not to use readily available right recursion as evidence, he only uses center recursion as an argument. But he's in effect misleading.
Q: I guess this is a typical behavior of mathematicians and philosophers: they pursue formal perfection. As long as it is theoretically impossible to exclude multi-level center recursion, it is required that the formal mechanism must have a built-in recursion mechanism. But practitioners of natural language understanding do not have to be bound by that theory, do they?
A: after all, the foothold of the theory should be based on the real-life natural language object and data, right?
In fact, in the research of corpus linguistics, some scholars have conducted a very extensive survey and found that the so-called center recursion in natural language never exceeds three levels, and the occurrence of three-level recursion is extremely rare [reference]. The phenomenon of natural center recursion beyond three levels is simply not found in a very large running corpus, not a single case found. So why boil a very limited center loop down to what seems like an infinite level of recursion, and furthermore consider it the essence of natural language, and use it as an argument to determine the choice of the formal model for natural languages? This has had serious consequences for computing and NLU going beyond labs for applications.
In order to deal with theoretically infinite center recursion, the human brain, or computer memory, must have a "stack" device and a "backtracking" algorithm. Without going into the technical definitions of these computer terms, computer science studies have demonstrated that stack-based backtracking is expensive for computation. Using it as a basic device for natural language severely impedes language parsing from leaving the laboratory. Specifically, Chomsky's "context-free grammar" with built-in recursive devices is theoretically bound not to have corresponding linear speed algorithms. The absence of linear algorithms means that the computing time is beyond control, so when entering big data out of the lab, this kind of thing is one limiting factor in practice. This is one of its fundamental flaws in his formal language arguments for natural language.
Q: I agree with you: there are only very limited levels, we don't have to stick to recursive grammars. But I still have a question. Short-term memory is a psychological concept, and most of us in computational linguistics believe that psychology has no place in linguistics. Don't you agree?
A: I don't agree. The limitations of psychology have a direct effect on real linguistic phenomena, that is, psychological effects are reflected in linguistic phenomena. Real language phenomena, not imaginary phenomena, are the goal and final foothold of our natural language study. What we're dealing with is a data set with a psychological constraint, and it's obviously not appropriate for us to adopt a mechanism to deal with it based on a hypothesis that disregards psychological constraint.
Q: But even with the addition of psychological restrictions, don't real corpora still have recursion? If yes, without the formal recursion device, such as the finite state machine, how can it handle the actual existence of the center recursive structure as long as it is not a non-existence?
A: Not a problem at all. As long as the recursive structure is bounded, the finite states have no problem in dealing with it. All we need is just cascade a few more finite state machines. Since you have at most three levels of center recursion, then it is 3 machines with 3x time needed, which is still linear. Even 10-level center recursion is not a thing, just add up 10 finite state automata. In our deep parsing practice, we have once applied up to 100 cascaded finite state machines for very deep parsing, in high efficiency. This kind of finite state pipeline systems, often called cascaded FSAs, is essentially the same concept of the pipeline as used in software engineering.
Q: Chomsky Hierarchy, named after Chomsky, is the most famous discovery in Chomsky's formal language theory, which divides grammars into four types, type 0 to type 3, corresponding to different automata. What do you think of his hierarchy?
A: Chomsky's formal language hierarchy is like a hierarchical castle with four enclosing walls safeguarding inner cities. Each formal device is like an internal forbidden city. Here we particularly recommend and quote an insightful study of Chomsky Hierarchy by Prof. Bai, which I call a "caterpillar" theory of natural language (S. Bai: Natural Language Caterpillar Breaks through Chomsky's Castle):
If we agree that everything in parsing should be based on real-life natural language as the starting point and the ultimate landing point, it should be easy to see that the outward limited breakthrough and the inward massive compression should be the two sides of a coin. We want to strive for a formalism that balances both sides. In other words, our ideal natural language parsing formalism should look like a linguistic "caterpillar" breaking through the Chomsky walls in his castle, illustrated below:
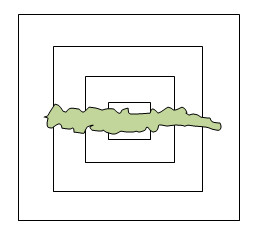
Prof. Bai also clearly sees that Chomsky's recursion theory is too far away from linguistic facts, so he puts special emphasis on "real-life natural language". After all, formal systems serve as formalized models for natural language, that is, they need to provide an appropriate framework for what natural language looks like. The common answer shared by Prof. Bai and me is that a suitable natural language model needs to get through the walls inside the Chomsky Castle. Any single device in Chomsky's existing formalisms, when used to model natural language, is either too small to fit, or too large lacking appropriate restrictions. In both theory and practice, it is necessary to penetrate the walls of Chomsky Castle and form an innovative formal system, so as to lay a good foundation for the revival of grammars in natural language modeling. In the formalization process of penetrating the walls, Mr. Bai has his own innovation, and I have mine. My proposition is to extend and overlay the finite-state mechanism, so as to establish a shallow and deep multi-layer rule system for natural language deep parsing and understanding.
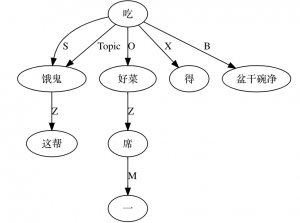
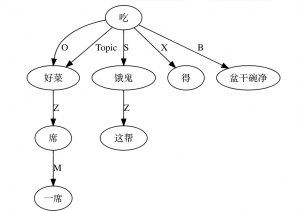
Do not look down upon finite state machines, which seem to be a very simple mechanism for pattern matching. When they are added layer by layer in the architecture of a reasonable pipeline system, they can cope with very complicated structures and phenomena and reach the depth of language parsing that is never before made possible by traditional context-free grammars or other devices. Of course, the mechanism itself can be reinvented and recrafted, such as incorporating the unification operation in handling language reduplications, e.g. in Chinese, "看一看": V 一 V (literally look-one-look: "take a look"). There are also rules for pattern matching that can effectively eliminate ambiguities by adding post-context conditions, similar to the "look ahead" effect in backtracking algorithms, to the pattern matching device.
It is worth emphasizing that maintaining the linear nature is the premise of any formalism innovation. No matter how we extend the mechanism of finite-state devices, this one remains an unchanged goal, that it must retain the essential characteristics of finite state to ensure the "line speed". We use a multilayer cascade to bypass the recursion trap, hence eliminating the biggest hidden trouble that hinders linear speed. Since the linear multiplication remains linear, the cascaded finite state system does not change the linear benefit of the system. Computationally, the processing speed required for three-layer recursion is only 3x, which will not affect the scalability potential of the system. In fact, we have deployed multi-layer systems, usually with more than 50 layers. Our Chinese system sometimes cascades up to 100 layers in the architecture, where capturing recursive structures is just a relatively simple task inside.
Q: That's fascinating. And very imaginative, too. It is apparent that you and Prof. Bai have both accumulated years of practice and deep dive into natural language so you two have such insights as summarised above in breaking through the internal walls of the Chomsky Castle. Ok, so the first issue with Chomsky formal language theory is the recursion fallacy, what's the second fallacy?
A: The second major problem with the Chomsky formal language theory is briefly mentioned above, which I call Single-layer Fallacy.
Turn to the chapter on parsing in the computational linguistics textbook, the typical algorithm for parsing, known as chart-parsing, is often introduced on the formalism of a context-free grammar (CFG). CFG contains recursive calls in its rules for covering recursive structures, a point emphasized by Chomsky as the key feature for natural language. The implementation of this rule system is carried out in the same search space on the same plane, thus the so-called chart-parsing can be illustrated on a flat chart. Successful parsing is represented by one or n search paths that cover the entire sentence.
[consider a chart parsing sample.]
The essence of single-layer parsing is like cooking a hodgepodge. Everything in an input string, from morpheme to word, from word to phrase, from phrase to clause, from clause to a complex sentence, all are carried out in the same space.
Q: So Chomsky wants to solve everything at once. Isn't that good?
A: Problem is, there are three main disadvantages. First, there is no linear algorithm. Many people have tried, but they just can't find a linear algorithm, it's a combinatorial explosion.
The second disadvantage is that it is not suitable for modular development, because the surface or shallow level language phenomena and the deep language structures are all mixed on one plane.
The third disadvantage is the so-called "pseudo-ambiguity" issue. "Pseudo ambiguity" is in contrast to true ambiguity. If there is one true ambiguity in the input sentence, the correct identification is for the parser to produce two parses to express the ambiguity. "Pseudo-ambiguity" means that a sentence is not ambiguous in people's understanding, but the parser still outputs several parses, which are all considered to be grammatical.
The problem of pseudo-ambiguity is a recognized challenge in single-layer parsers. Even for a simple sentence, traditional parsers based on context-free grammars often produce dozens or even hundreds of parses. Most of the time, the differences are so subtle that they don't make difference in communication. The consequence is that very few true ambiguities are hidden among many false ambiguities. In effect, the parser loses the ability to parse ambiguity completely. Of course, such a single-layer grammar approach is difficult to be truly deployed in parsing and semantic decoding of big data.
Q: Lao li, I think I have now started understanding the drawbacks of the single-layer parsers you discussed. Could you elaborate on why it is not a feasible model for real-life applications?
A: Too big a search space, and too many parses. In essence, the system makes explicit all possibilities, low probability events as well as high probability events all in the same search space,. The whole idea is that it makes sense in theory, that any small possibility is a possibility, and then from a perfect theoretical model, you can't block any path in advance. This way, you have to save all the search paths until the global path is complete. And this leads to the fact that the space where the resolution is, in fact, a combinatorial explosion space, so there's no efficient corresponding algorithm.
Q: why isn't a single layer suitable for modularity?
A: there is no modularity at all in a single layer. The approach of a single layer means that the whole resolution is a module, and a single layer means non-modularity. Its theoretical basis also has some truth. It says that language phenomena are interdependent, and a complete language analysis scheme cannot completely separate them. As low as participles and as low as the boundaries of basic phrases, these shallow structures are difficult to determine outside the overall structure of the sentence. This is because a locally sound structure can always be overridden in a larger context.
(for instance)
From this interdependent, locally subordinated global perspective, structural analysis, once cut up, creates a chicken-and-egg problem. To deal with this problem of interdependency, theoretically, a single-layer model makes sense. In a single-layer system, all the interdependent phenomena are explored in the same plane according to the global paths as solutions. That forms, of course, an argument against multiple layers, that language phenomena are interrelated, so we can hardly treat them by first cutting them into multiple layers. Interdependency in a modular pipeline is very susceptible to "premature pruning" of branches. To be honest, if we leave aside the pseudo-ambiguity problem and the non-linear speed from the single-layer system design for a moment, it is quite difficult to refute the above argument against the multi-layer system design. However, single-layer is not very feasible in practice. The consequences of a single layer far outweigh the benefits, and the concern on premature pruning in a multi-layer system actually has its own countermeasures.
Q: Your point of view is not quite the same as my understanding of modularity. In my understanding, a module is actually a concept without hierarchy. Just like with bricks, you can build roads, it's like a complete horizontal jigsaw puzzle of bricks. Of course, you can also build a wall in which case bricks are hierarchical. It goes up one level at a time. So, in my understanding, modularity and hierarchy do not have to be correlated. Does it make sense?
A: Yes, you're right. Modules are bricks. They do not have to have layers. If there are layers, like building a wall, then there has to be a sequence architecture of modules. But it is also possible that there is no sequential dependency between the modules and the layers. The modules are defined from an angle beyond layers, which is like paving a road. Road paving does not have to be serial, which can be parallel. In practice, they may as well still be arranged in a uniform pipeline, combining the style of road paving with the style of wall building.
Modularity itself is a seasoned practice that comes from software engineering. That is, when building a complex system, we always attempt to divide tasks into subtasks and sub-subtasks. Modularity makes the development process more tractable and easier to maintain. Natural language is undoubtedly a fairly complex system. Faced with a complex object like language, a good way is to emulate the approach that has worked in engineering for years. That is to say, the task should be reasonably decomposed and cut into modules as far as possible to implement modular development.
Thanks to http://fanyi.youdao.com/ based on which this translation is revised and polished by the author himself. This is the first chapter of our book on NLU which consists of 10 interviews on key topics of AI symbolic logic as used in natural language parsing. Stay tuned.
[References]
S. Bai: Natural Language Caterpillar Breaks through Chomsky's Castle