Yesterday I watched a real-time dashcam video of a Tesla making an emergency swerve to avoid a car that suddenly shot up from the left lane entrance ramp. My immediate thought: human reaction speed simply can't handle that.
In that situation, most of us instinctively slam the brakes — which on a highway is itself dangerous. Being able to safely dodge to the right lane like FSD did is clearly the better strategy. Unfortunately, most human drivers just can't pull it off.
After driving with FSD for a long time, you develop a very strange kind of trust.
Not that it's always right. Not that you always understand why it did what it did.
But you realize: many of those heart-stopping emergency maneuvers that made you break out in a cold sweat — when you replay them later, most of them genuinely protected your safety.
Over all my years of manual driving, my default in emergencies was always the reflexive hard brake. Because only by slowing down did I feel any sense of control. It wasn't that I didn't know how to steer — I was afraid to. Because you have to check: is the right lane clear? Is there a car in my blind spot? How fast is the car behind me? Is the other driver a novice? Are they panicking? This entire judgment chain is serial — the human brain simply can't process it fast enough.
So most people, like me, instinctively hit the brakes.
But FSD is different. It's not just that it has watched countless expert drivers — it's more like a driver with many sets of eyes and reaction speeds many times faster than ours. It's constantly watching all four directions, constantly computing the space, speed, and risk in every lane.
That's why sometimes, it dares to execute lane escapes that we wouldn't dare attempt.
Of course, this brings another problem: sometimes it's overly cautious. A bird suddenly flies past in front — it might trigger an avoidance reaction. And some emergency dodges, even in hindsight, we may not fully understand. The infamous "phantom braking" from a few years ago is the classic example: tree shadows, bridge shadows, lighting changes, even road texture could trigger false alarms.
But here's what's remarkable: phantom braking has almost disappeared in recent years. I've barely encountered it myself in over a year. This tells us it's no longer just "seeing something that looks like danger" — it's increasingly understanding: what will actually hit me, and what is merely a shadow.
This is the most fascinating thing about FSD.
In its early days, it sometimes acted like a clumsy student. Now it behaves like an inhumanly fast-reacting entity.
Yesterday it executed one particular avoidance maneuver that I didn't fully understand either. Maybe it overreacted. Maybe it saw a risk we didn't. But I'm not going to dig deeper into it.
Because after long-term use, my trust in it doesn't come from faith — it comes from replaying every drive, time after time.
The vast majority of the time, those tense maneuvers that felt excessive in the moment — looking back, they were protecting us. It is far more cautious and safe than this old-timer-among-clumsy-drivers.
And that's enough.
What will truly transform driving in the future may not be whether it can drive like a human.
Before my career began, family and society shaped our character and worldview.
**"Forever Be Chairman Mao's Little Red Guard"**
When the Cultural Revolution began in 1966, I was in the first grade, six years old. More than half a century later, some memories remain as vivid as yesterday.
The three of us siblings, wearing our Little Red Guard armbands, photographed in December 1966.
When the campaign to topple Liu Shaoqi began, the first thing I noticed was Liu's official portrait pasted upside down on the street-facing wall, marked with a red cross. Soon after, more and more long banners appeared across the main street: "Burn Liu Shaoqi!" "Deep-fry Liu Shaoqi!" Then, as negative teaching material, they screened the documentary *Liu Shaoqi Visits Indonesia*. The female narration was syrupy sweet, addressing him as "Chairman Liu" and "Jakarta" in every other breath — to my ears, she sounded like a female spy. Her voice was constantly drowned out by the slogans erupting from the audience: "Down with Liu Shaoqi, Defend Chairman Mao!" "Smash the arch-traitor, arch-spy, arch-scab Liu Shaoqi to the ground and trample him underfoot, never to rise again!" Wang Guangmei on screen was dressed conspicuously well, fitting the standard definition of a bourgeois stinking woman. Later, I saw several living newspaper dramas lampooning Liu — his features caricatured into a long horse face, a high-bridged nose, the classic villain's profile. I also remember a living newspaper piece called *Burning Down the British Chargé d'Affaires Office*, which portrayed the Capital Red Guards, righteous in their fury at British imperialism, acting with militant resolve to set fire to the British Embassy — an act of collective heroism (in reality, this was an extremely serious diplomatic incident that caused Zhou Enlai immense trouble and lasting fallout). I still recall the stage effect when they set the fire: they seemed to hurl a torch into the embassy, followed by a loud bang and a plume of thick smoke. I was in the front row and choked on the smoke, coughing hard, and I was genuinely startled. The artistic creativity of the revolutionary masses, producing such vivid stage realism, left a deep imprint on the mind of a six-year-old me.
Around this time came the campaign to "Destroy the Four Old's" (old ideas, old culture, old customs, old habits) and establish the Four New's. Every household voluntarily surrendered items suspected of being "Four Old's" — copper coins, bracelets, ornaments, even ceramic toys of cats and dogs — to be publicly destroyed. The stone lions beside the stone bridge were toppled into the ditch by the young Red Guards; since they couldn't be smashed, chisels were used to disfigure them. The influence spread far: by early 1967, a "Revolutionary Spring Festival" was mandated. Adults had no holiday — they must persist in "grasping revolution and promoting production" — while all New Year celebrations and entertainments were cancelled. Even the traditional four-corner red envelope money for children was voluntarily suspended.
Some elderly people, lifelong habits unbroken, still called matches "foreign fire" and iron nails "foreign nails." These old terms originated in the pre-revolutionary era when China could not even produce matches and nails domestically and had to import them. But by 1966, such old terms could bring trouble. I once saw a tiny-footed old woman totter into a small shop and ask for "foreign fire." The shop assistant replied coldly: "Don't have any." When the old woman pointed to the goods on the counter, the assistant erupted in fury.
Before armed struggle erupted, great debates — the weapon of literary struggle — became prevalent. Even elementary school students debated each other, often turning red in the face. I was too young to get a word in, but I loved listening. What they debated I mostly can't recall, except for one recurring topic: the dialectical relationship between family background and individual performance. The affirmative position was "Heroes beget heroes," while the opposition stressed "What matters is personal conduct." Both sides seemed righteous and indignant, both could quote Chairman Mao's quotations, both seemed to have good arguments. Later, my elder brother took the lead in forming a Little Red Guard revolutionary organization (with a fifth-grader serving as strategist behind the scenes), calling it the "Dagger Squad." Every grade had its representatives. Through this connection, I too was honorably swept up in the revolutionary movement — duties like carrying the paste bucket for the young fighters putting up big-character posters. I remember my brother and his comrades setting up a "Dagger Squad Office" at a table in the corridor of my father's hospital. The squad's most glorious exploit, the one I remember most clearly, was an assault on a school meeting. The squad learned that the school leadership was holding a faculty meeting at seven in the evening and decided on a surprise raid. I had the good fortune to follow my brother on this revolutionary action. I remember the meeting was in progress when the squad burst into the room, shouting: "What kind of black meeting are you holding here?" The leaders, seeing it was a bunch of children, didn't know whether to laugh or cry, and explained that this was a routine school affairs meeting. The squad leader declared: "Then we're attending too." Some leader apparently advised that a work meeting wasn't convenient for students. That set off an explosion. The young fighters, each more righteous than the last, delivered their rebuttals: We are Chairman Mao's Little Red Guards — if we don't attend, who will? You hold black meetings behind the backs of the revolutionary young fighters — how poisonous your intentions must be! Not only will we attend, we demand you honestly hand over all previous meeting records. If you dare not disclose your meeting records, you must have unspeakable criminal aims, and we will rebel against you. And so on. I remember the school leaders finally conceded, agreeing that young fighter representatives could attend all faculty meetings. I was as excited as everyone else, filled with the pride of this initial victory in struggle. Unfortunately, I suffered from night blindness at the time, and on the way back my vision went completely dark. An older girl from a higher grade held my hand and walked me home (my brother, as rebel leader, stayed behind to discuss the next phase of the struggle strategy). This revolutionary action enormously boosted the young fighters' morale and opened the prelude to rebellion against the elementary school leadership, soon followed by a flood of big-character posters exposing the schemes of the capitalist-roaders.
In the early days of the Great Revolution, the three of us siblings, led by our brother every day, would stand before the Precious Book platform for morning pledges and evening reports — earnest and ceremonial, and we kept it up for a long time.
For the first time in human history, there is a kind of "employee" that can work 24 hours a day — no sleep, no salary, no social security, no rights claims, no strikes, no sickness, no retirement.
And the truly absurd part: it can replicate itself.
This thing is called an **AI agent**.
---
## Here's the problem
In the old world, when a boss hired 1,000 people, the state collected: income tax, social security, health insurance, unemployment insurance, pension contributions.
Now the boss fires all 1,000 and replaces them with AI. Efficiency skyrockets. Profits skyrocket. Stock prices skyrocket.
**But the tax base evaporates.**
The state can no longer collect revenue. The unemployed are still there.
And so we arrive at a surreal paradox:
> AI is simultaneously driving unprecedented productivity growth and hollowing out the fiscal foundation of society.
The entire modern state is built on the premise that human labor pays taxes. AGI is erasing "human labor" itself.
**This is the real nuclear bomb.**
---
## "Just learn AI" is wishful thinking
Many people still comfort themselves: "Just pick up some AI skills, transition to a new role, and you'll be fine."
This is increasingly delusional. Because the cruelest part is: even the act of "using AI" will eventually be automated by AI.
You think the jobs of the future are "AI Operator," "Prompt Engineer," "Agent Manager" — but agents are already using agents. Even "prompt engineer," that transitional role, may turn out to be nothing more than a temporary bubble in a technological wave.
Two years ago, the entire internet was selling prompt engineering courses. Today, that looks like a punchline.
---
## This time is different
Past technological revolutions created new jobs. The automobile killed the horse carriage but created the auto mechanic. The internet killed print newspapers but created e-commerce and live-streamers.
This time is different. The new systems AI creates are inherently *de-peopled*. Because AI's single greatest advantage is precisely this: **it doesn't need people.**
---
## AI must pay taxes
If AI replaces people, who pays the taxes?
The answer is simple: **AI itself must pay taxes.**
For every token you consume, every GPU you run, every inference you perform, every kilowatt of AI electricity — you pay a corresponding "AI social tax."
Because when you used to hire a person, you were already paying those taxes. Now you replace the person with AI and bear zero social cost — that is fundamentally unfair.
Many will shout: "You're stifling technological progress!"
**So what?**
Is the sole purpose of human society to allow capital and compute to multiply without limit?
- The Industrial Revolution polluted the environment → we got environmental taxes.
- Cars consume public roads → we got fuel taxes.
- AI destroys the employment tax base → why can't we have an AI tax?
---
## It takes everyone
The real danger is not that AI is too powerful. It's that once AI becomes powerful enough, the entire social revenue structure collapses.
And here's the darkest irony: the people most likely to support an AI tax in the future may be exactly those who understand AI best. Because they know most clearly: once this thing truly matures, it doesn't just replace the "bottom rung."
**It sweeps the board.**
White-collar workers, programmers, designers, analysts, customer service, translators, paralegals, researchers — no one escapes.
In the past, society could comfort people with one line: "You just didn't work hard enough."
But the cruelest truth of the AGI era is this: sometimes, it's not that you didn't work hard. It's that you, as a member of the species "human employee," are beginning to lose economic viability altogether.
Ever since Qu Yuan, Chinese literati have been fond of tracing their ancestry to illustrious roots — "descendant of Gaoyang the Divine Emperor" and such declarations — to signal their noble bloodlines. When I was compiling and editing A Collection of Master Li's Posthumous Writings: Prefaces, I came across this passage in the first piece, "Preface to the Li Family Genealogy," explaining the origin of the family name Li:
"The forerunners of the Li clan, surnamed Ying, traced their descent from Gaoyang of the Zhuanxu lineage. One descendant, Gao Yao, served as Grand Justice (Dali) under Emperor Yao, and the family adopted 'Li' (理, meaning 'principle' or 'justice') as their surname from the title. During the reign of King Zhou of Shang, a descendant named Li Zhen fled with his mother to the lost land of Yihou. Starving, they survived by eating plums (李, li) from the trees. To evade King Zhou's persecution, they changed their surname from 理 (Justice) to the homophonous 李 (Plum), and their descendants have borne this name ever since."
In my earlier, more perfunctory readings of the Posthumous Writings, I had mostly skipped Master Li's abstruse classical prose, drawn instead to the more accessible "modern writings" of my two granduncles in the appendix. As a result, I never registered this origin story. But my daughter once asked me: "Dad, you said our family name Li means plum — how come? Does that mean we Li family like plums in particular?" I had no idea whether the surname Li was actually connected to the fruit, so I dodged the question and told little Tiantian instead that statistically, Li had risen to become the most common surname in China — and perhaps the world. Even in our tiny Buffalo office there were two Uncle Li's — one of Korean descent. But eight hundred years ago, we were all one family.
Master Li's own account of this family history — the fall from officialdom, the change from 理 to 李, the "pointing at the tree and taking its name" — struck me as too sparse. So I searched online and found a fuller treatise, On Gao Yao, Blood Ancestor of the Li Surname. It turned out that the primogenitor Gao Yao served Emperor Yao and Shun as Grand Justice — a minister of incorruptible integrity, whose achievements in statecraft were so esteemed that Emperor Shun personally named him his successor. Even Confucius honored him as one of the Four Sages of antiquity. In ancient China, officials took their office titles as surnames, hence 理氏 (the Li of Justice). Tragically, Sage Gao Yao died before ascending the throne. Generations later, under the depraved King Zhou of Shang, a descendant named Li Zheng served as Grand Justice with the same upright character — and for his honesty, the debauched king had him executed. His wife Qihe fled with their young son Lizhen to the lost land of Yihou (in present-day Henan). Starving, they spotted fruit on a tree and ate to survive. Afraid of the king's pursuers, Lizhen dared not keep the surname 理. In gratitude for the "wood-seed" (muzi, 木子 — the character parts that combine to form 李) that saved them, he changed the family name to Li. From this seed, the Li lineage — the largest family name under heaven — branched and flourished across generations.
I told my daughter: not only do we come from a scholarly family, we are the direct descendants of Sage Gao Tao himself.
Master Li — Li Xiansheng, courtesy name Xuexiang — was my great-grandfather. A Collection of Master Li's Posthumous Writings, compiled in vernacular classical Chinese (also called "modern classical style"), gathers his surviving works — poems, lyrics, celebratory couplets, elegies, prefaces, and miscellaneous essays — transcribed by his disciples and privately published in the 1930s.
The Posthumous Writings also includes works by my two granduncles: elder granduncle Li Yingwen and younger granduncle Li Yinghui. My great-grandfather was exceptionally open-minded about education, selling off family land to send his sons (my granduncles) to study in Japan. My own grandfather (Li Yingqi, the second son), however, was kept at home to manage the family estate, forfeiting the chance for overseas education. It's said that every year, my grandfather would travel to Nanjing to remit money from land sales to his two brothers in Japan. In the early 1920s, the two granduncles returned with law and political science degrees from Meiji University — rare credentials for that era, and a springboard for significant careers. That their subsequent achievements remained relatively modest (disproportionate to their education) and confined to the local sphere, I attribute to three factors: first, the times were harsh, with China in ceaseless turmoil from war and upheaval throughout the early 20th century; second, my great-grandfather was indifferent to fame and fortune, urging his children to carry on the family mission of local education rather than venture into the wider world; third, both granduncles suffered from poor health — they lacked the physical constitution for "revolution." Elder Granduncle Yingwen was bedridden for years, and it was country life that gradually restored his health. Younger Granduncle Yinghui died tragically young. Yet their writings reveal open minds deeply engaged with the issues of their day. Besides rustic pastoral pieces like "Li Yingwen — Elegy for a Dead Dove," they also produced fiery patriotic works, such as "Li Yinghui — Manifesto of the Anti-Japanese Association (Modeled on the Denunciation of Empress Wu)" and "Li Yingwen — Preface for Wang Joining the Volunteer Army."
My grandfather died in the great famine of my birth year — a calamity that was three-tenths natural disaster, seven-tenths man-made catastrophe. Among the three brothers, only Elder Granduncle Yingwen was fortunate: he passed away peacefully at home in 1965, surrounded by every Li family descendant who had gathered for a grand funeral (see the family photograph below). I still remember each of us grandchildren, after the coffin was lowered, taking turns to scoop up a handful of yellow earth. As an enlightened gentry figure and a "united front target," Granduncle Yingwen had been treated with courtesy by the local government and was even elected as a county representative to the People's Congress, thus escaping the reach of political campaigns. That he departed this world the year before the Cultural Revolution began was an even greater stroke of fortune — otherwise, given the complexity of his personal history, he would have suffered terribly in that great upheaval. My maternal grandmother, who raised us through those years, was dragged out and struggled against during the Cultural Revolution, forced to wear a "Landlord Element" placard every day, subjected to humiliation that cast a lasting shadow over our childhood.
The above accounts for my "scholarly family" background — except that by my father's generation, the family fortune had seriously declined. Beset by foreign invasion and civil war, the country was in chaos, and life grew harder each day. My father often went hungry and cold as a child. In its heyday, the Li family's Chongshi Academy had enjoyed wide renown, its students scattered across the land like peaches and plums filling the world. Yet this decline proved a hidden blessing: when the Land Reform came, our family was classified as "Small-Scale Land Lessors" rather than one of the "Four Categories" (landlords, rich peasants, counter-revolutionaries, and bad elements — later expanded to include "rightists" designated in 1957). This spared us, the younger generation, from the brunt of political persecution.
The matter of "Small-Scale Land Lessor" classification carried its own stories. When we were children, family class status was an all-important political label: children of "poor and lower-middle peasants" were considered born revolutionaries with "red roots and upright shoots," innately superior. Children of the "landlord, rich peasant, counter-revolutionary, bad element, and rightist" classes faced extreme social discrimination — denied opportunities for factory jobs, schooling, and more — and suffered constant bullying in daily life. I remember a girl in our elementary class who came from a landlord family; she cut such a pitiable figure, never able to hold her head up, yet classmates still taunted her relentlessly. In such an environment, we were all acutely sensitive about our family background. My own family situation was precarious: my mother was born into a landlord family — a pitiable sort of landlord, really; my maternal grandfather had saved every penny from a small business, denied himself fine food and clothing, tightened the whole family's belts, and poured everything into buying land in hopes of modest prosperity — and in return won a landlord label. This became a fiercely guarded family secret. Fortunately, a child's class status followed the father, so every time we filled out a form, the "family class" box read "Small-Scale Land Lessor." The problem was, for a long time, we had no idea what this obscure, tongue-twisting classification actually meant politically, which left us perpetually anxious. I remember classmates discussing our strange class label. One self-proclaimed authority declared: "Small-Scale Land Lessor — that means little landlord!" (It wasn't that far off, actually.) And with that, we were suddenly shoved into the camp of "class enemies," utterly mortified. My cousin suffered the same anxiety. Then one day, he announced triumphantly that, after deep research — studying Chairman Mao's works and relevant Party policy documents — he had discovered that "Small-Scale Land Lessor" was essentially equivalent to "Upper-Middle Peasant," which placed us squarely among the "united objects" of the revolutionary ranks. What's more, Chairman Mao himself came from an upper-middle-peasant family. These momentous findings brought us immense relief.
The old family home in Keshan — I visited it as a child, when my cousin led us up the mountain; it felt like the Mountain of Flowers and Fruit, remote and secluded. A few years ago, on a trip home to China, my brother drove us back there. It remains a forgotten corner to this day — a single mountain road, bumpy and dusty, narrowing to barely a car's width as you approach. My ancestors must have chosen this Jiangnan hillside deliberately, building their grand compound in a spirit of retreat from the world, carving out their own Peach Blossom Spring. My father's memoir, Decades Through Wind and Rain, contains a vivid description of the family school there:
A Glance Back at the Old Residence
A deep courtyard mansion, antique and elegant, nestled against the mountain and facing a stream, oriented east to west. Above the main gate, the couplet "The Nation's Grace, the Family's Joy / May Men Live Long, May Years Bring Harvest" stood steadfast through the seasons. The main quarters comprised five large rooms in the front row and five in the back, joined in the middle by three open-air courtyards flanked by two wings on either side. The three rows, each two stories high, formed an integrated whole. Upstairs, a continuous corridor circled the entire compound — a gallery on which one could stroll freely. To the left stood two "new rooms"; to the right and rear, a row of auxiliary quarters. The front courtyard, with its large and small gates, contained seven flower terraces, where pines and cypresses complemented one another, blossoms clustered in splendor, and fruit filled the air with fragrance. Among the flowers: plum, chrysanthemum, osmanthus, rose, briar, and sacred bamboo. Among the fruits: persimmon, peach, apricot, plum, and jujube. Every doorway was flanked by stone drums and lions; the courtyards were paved in marble. The bricks and tiles were custom-fired in the family's own kiln, of the highest quality; the timber, first-rate, was floated down the river from Jiangxi on rafts — a testament to the master-builder's meticulous vision. The upper floor of the main building served as classrooms and student dormitories; the lower floor and the "new rooms" were the family living quarters; the foot-house housed the wine-making workshop, kitchen, and firewood store.
以前读《李老夫子遗墨》比较偷懒,基本跳过晦涩难懂的李老夫子正文,而对《遗墨附录》中更贴近近現代生活的两位叔爷的"时文"感兴趣,因此对这段"李氏"来源的掌故没有印象。女儿小时候问我:"Dad, you said our family name Li means plum, how come? Does that mean we Li family like plums in particular?" 我当时不知道"李氏"跟李子到底有沒有关联,只好顾左右而言他,告诉甜甜,据最新统计,"李氏"似乎已经上升到中国的(可能也是世界上的)第一大姓,就連小小的水牛城辦公室就有兩位 Uncle Li's, 其中一位還是朝鮮族裔,但八百年前都是一家人哪。
The kind of cut where you just flip the table over. By the end of May, prices dropped to a quarter of what they were.
Many people's first reaction: Chinese AI companies are starting a price war.
But I increasingly feel that understanding this only as a "price war" is way too shallow.
Because what's really happening here might be this: tokens are becoming industrialized.
What does that mean?
For the past two years, the global AI world has operated under a quiet assumption: high-quality tokens are expensive.
Because: models are expensive, GPUs are expensive, training is expensive, electricity is expensive.
So everyone defaulted to the idea that AI must be a high-margin industry.
Until Chinese models started slashing prices like crazy.
And for the first time, many people discovered: tokens might actually be like steel, display panels, solar panels, lithium batteries — entering a terrifying process of industrial cost reduction.
Behind this story is something deeply Chinese.
What do I mean?
American AI companies often follow a path of "high performance, high margins, high valuation." A bit like luxury goods.
But once Chinese companies start competing, things tend to look different: "First, crush the cost."
Then: massive scale, infrastructure-ization, supply-chain-ization, engineering optimization, labor optimization, power optimization. Eventually grinding the entire industry into "cabbage-price industrial capability."
Over the past twenty years, China has done this repeatedly. Solar power, EV batteries, drones, display panels, e-commerce, high-speed rail... The pattern is roughly the same.
Early stage: others think it's high tech. Later stage: China industrializes it. End result: profits vanish, but production capacity blankets the world.
Today, tokens are starting to look more and more like this story.
Because tokens are not fundamentally mysterious. They are, in the end, "data processing capability produced by an industrial system." And what is an industrial system best at? Reducing costs.
So now an especially interesting dynamic has emerged: American frontier models may still maintain the strongest capability. But Chinese models are closing in fast — maybe a few months behind, maybe still a bit weaker in certain areas. But the price is already shockingly low.
So developers around the world are facing a very pragmatic choice: "Do I need the world's strongest, or do I need strong enough + ten times cheaper?"
This question is deadly.
Because in most of the business world, what ultimately matters is not "theoretical peak performance" but "overall cost-effectiveness."
As tokens get cheaper and cheaper, many AI applications that were previously "too expensive to run" suddenly become viable.
In the past, AI was like a five-star hotel. Now it's starting to look like tap water.
Developers used to worry: "Is this agent going to burn dozens of dollars a day?" Now the attitude is shifting to: "Whatever, let it run."
And so token consumption begins to explode further. Which in turn drives even larger data centers, cheaper inference chips, more aggressive engineering optimization. The whole system enters a kind of industrial flywheel.
The most interesting part is: what this competition ultimately comes down to may no longer be just the model.
It's about: who has cheaper electricity; who has more data centers; who has cheaper engineers; who has a more complete supply chain; who can better tolerate thin margins.
In other words: AI competition is increasingly looking like modern industrial system competition, not just lab competition.
Many people still think of AI as "a few brilliant scientists changing the world." But what it increasingly resembles is "an entire national industrial system collectively entering the field to produce tokens."
In the internet era, China's greatest strength was "application industrialization." In the AI era, what might be truly terrifying about China is: token industrialization.
And as token prices keep falling, developers around the world will ultimately vote with their feet. Because the vast majority of companies, in the end, have to do the math.
For many young people, leaving one's homeland or staying behind can be an entangled, irresolvable contradiction — much like the dilemma in Qian Zhongshu's Fortress Besieged: those inside the walls gaze out at the dazzling world beyond; no matter how comfortable life within may be, they can never shake the regret of not having tasted the outside firsthand. Those who venture far, having endured every hardship, come at last to understand: homesickness cannot be filled with material things. That was exactly how I felt back then. After graduate school I dug in for five years — my work and life were on a steady upward climb, the future bright. Yet watching my classmates and friends leave for abroad one group after another, I felt an inexplicable emptiness. In the end I caught the last train out. But the sky over a foreign land was so strange — the constellations I knew from childhood summer nights, the fairy tales and daydreams that attended them, could never again be pieced together whole.
I recall those first days in England. Though I was already past thirty, though I'd come to Manchester alongside many friends, though I'd long since weathered in Beijing years of wandering far from home town — leaving my native land still carried an indescribable anguish: like a blade of grass torn out by the roots, battered by wind and rain, a vast bottomless emptiness and disorientation welling up within. At the start of term, in front of the student union building, every kind of student club was recruiting — bustling crowds, peals of laughter — yet I seemed to inhabit another dimension altogether, displaced from reality, unable to grasp the commotion around me, powerless to dispel a nameless melancholy.
Then came a decade of severance. Save for the companionship of Huaxia Wenzhai (China News Digest), and the occasional holiday phone calls or greeting cards to family, I had lost all contact with the motherland. Little did I know that this was precisely the decade in which China underwent its most earth-shaking transformation. Not until my first trip home in 2001 did I realize, with a jolt, that I had once again been displaced in time and space. Standing on the familiar yet alien streets of Beijing, watching the endless streams of people, I felt with an incurable certainty that this world no longer had anything to do with me. Was this the city that had left me so many warm memories? The Beijing I'd yearned for in my dreams now stood before me like a stranger! In the ancient capital I took such pride in, I could not understand the bustle around me, nor could I dispel that nameless melancholy.
Only my childhood hometown remains forever vivid in my mind, never fading. Thirty years have distilled the villages of southern Anhui into thick oil paints: golden yellow, fiery crimson. Endless fields of rapeseed flowers stretching to the horizon, and mountainsides aflame with azaleas in full bloom.
I have passed through countless cities and towns, witnessed many breathtaking scenes — the Gold Coast of Australia, the bays and forests of Vancouver, the autumn leaves of American national parks, and Niagara Falls in Buffalo — searching all the way, yet never finding rapeseed flowers and azaleas like those of home. Not until I returned to visit my family, catching the rapeseed bloom by chance, did I once again behold those patchwork fields of gold and breathe in the fragrance of the soil of home. I captured those golden expanses on video and stored them away, afraid they might slip away again.
Homesickness, like love, is an eternal theme of literature and art. From Li Bai's "Raising my head, I gaze at the bright moon; lowering it, I think of home," to Tao Yuanming's "Come Away Home"; from Chyi Yu's "Olive Tree" to Fei Xiang's "Clouds of Home"; from Ma Sicong's "Homesickness Melody" to the American folk song "Five Hundred Miles." In the still of night, in a foreign land, a gentle folk ballad flows like a quiet stream and soaks into my heart — it is the Kingston Trio singing "Five Hundred Miles," the shared melancholy of every wanderer under heaven.
Homesickness is an invisible net — where does the road of wandering end?
On the twenty-seventh day of the twelfth month, in the year 1981, the faculty and students of the English Department of Anqing Normal College forgathered at a modest tavern beside the River-Welcoming Temple for our farewell revels. Returning thereafter to the college grounds, we inscribed parting words in one another's journals, as the spirit moved us. What follows are verses composed in that hour of exaltation, offered to my several schoolfellows:
A thousand days we shared one shadow, one form;
Now East and West divide us after this day.
Together we tilled the mountain of learning,
Together we sail the sea of scholarship.
What warrior feareth the biting frost?
The gardener asketh only that his blooms flourish.
Let the keen eye discern the thousand-*li* steed,
And in service of the Four Modernizations, burn ever crimson.
William's Reply — Forty-Four Years After
Forty-four winters of dreams and traces,
Frost at the temples, scattered East and West.
Once we crowded together on youth's narrow bunk;
Now we watch the same sunset glow from afar.
>
Half a life in code, half a life in wine;
A road of ups and downs, a road of wind.
Speak not of yellowing pages and aging scholars —
Still the rainbow beareth up within this breast.
A Letter Sent from Afar to Brother Ding
I recall the waning days of the xinyou year: the frost-bells had scarce begun to sound, and a whisper of snow hung in the air. We, the graduating class, gathered to drink beside the ancient River-Welcoming Temple — a lonely lamp in a humble tavern, cups raised without restraint. In that hour the Wan River lay silent, and the shadow of Zhenfeng Pagoda swayed upon the cold moon; the long avenue was soon to fall still, yet the ardour of youth still surged. Drink-warmed and flushed with feeling, we clasped hands and wrote upon one another's garments. Some wept, some sang, and none could bring themselves to cease.
Ah! For several years we shared the dawn-lamp and the midnight tome. From upper bunk to lower, our wild talk startled the neighbours; by flickering lamplight over tattered texts, our ambition reached for the blue clouds. Some nights we stole away to listen to the Voice of America beneath the moon; on frosty mornings we declaimed Linguaphone in its pure London accent. Paper was too short, feeling too long; our ink ran riot. But the spirit of youth had already bestrode the age.
Ere long we scattered to the four quarters, each upon his dusty road. You, brother, spread your wings at Tongcheng; I drifted like a thistledown to the ends of the sea. Some were broken on the rocks of fortune, some foundered in the currents of fame; some bowed for bread, some grew grey upon the rivers and lakes of the world. Then we were blue-robed youths; now frost invades our temples. Then we roamed the world in talk, full of jest and ribaldry; now each guards his solitary citadel. Life is as a horse glimpsed through a crack in the gate — a flicker and gone. Whenever I think upon those old wanderings, it is as though I hear a distant bell.
And yet the road of the world, though hard, hath not slain the heart. I remember how we rode stirrup to stirrup up the mountain of books, how we shared one vessel upon the sea of learning. Did we not then count ourselves among the remarkable spirits of the age? Though now grown old, we may yet rejoice that our gall hath not chilled, nor our lamp been extinguished. Over wine we discuss the transformations wrought by AI, even as once we debated the Four Modernizations; in the deep night we survey the new configurations of the world, still nursing the will to strike the oars in midstream.
Wherefore I take up the brush today to answer your verse — not for ornament's sake, but for an old friend's. May you, brother, like the aged steed in the stable, ever cherish the heart that would gallop a thousand li. May we, though late in our years, yet remain travellers in this age. If some distant day we gather again, let us bring our cloudy wine and speak once more of youth. Then, though our heads be full of white, we may yet laugh aloud and declare:
"The bookish ardour of those young days — even now, it hath not cooled."
The truly dangerous thing about the AI bubble isn't the technology.
It's that the entire world is front-loading financing for "decades of future intelligence demand" — all at once.
During the mobile internet era, people burned cash, sure. But they found revenue fast. Food delivery had customers. Ride-hailing had riders. E-commerce had buyers. Short videos had viewers. Ads had advertisers. Consumer-facing sectors — food, clothing, housing, transport, communication, entertainment, shopping — were all low-hanging fruit. The business loop closed quickly.
But AI is different. To this day, most of what's genuinely deployed at scale is still: writing weekly reports, making slides, generating images, customer service bots, coding assistants. Valuable? Yes. That's not the problem.
The real problem is this: the capital markets are already betting at the scale of "everyone consuming intelligence all the time." GPUs bought first. Data centers built first. Debt taken on first. Valuations pumped first. Pension funds entered first. The world is building "intelligence power plants" at unprecedented speed.
But here's the question: who, exactly, is going to consume intelligence the way we consume electricity today — continuously, at scale?
The biggest gamble in AI right now isn't whether models will get smarter. It's whether the explosion of B2B vertical applications can outpace the depletion of funding, GPU depreciation, data center debt, and the capital market's patience.
If Agentic AI genuinely penetrates core enterprise workflows — turning productivity gains into real profits — then a lot of today's crazed investments will be vindicated by history. But if the growth of real demand moves slower than the pace the capital markets have already priced in, then a lot of what today represents "the future" of AI may end up as: piles of power-hungry GPUs generating insufficient cash flow.
The railroad changed the world. Railroad stocks still crashed. The internet changed the world. Dot-coms still littered the battlefield. AI will probably change the world too. But a technological revolution being real has never meant a bubble doesn't exist.
A thousand days we shared one shadow, one form; Now East and West divide us after this day. Together we tilled the mountain of learning, Together we sail the sea of scholarship. What warrior feareth the biting frost? The gardener asketh only that his blooms flourish. Let the keen eye discern the thousand-li steed, And in service of the Four Modernizations, burn ever crimson.
William's Reply
Forty-four winters of dreams and traces, Frost at the temples, scattered East and West. Once we crowded together on youth's narrow bunk; Now we watch the same sunset glow from afar.
Half a life in code, half a life in wine; A road of ups and downs, a road of wind. Speak not of yellowing pages and aging scholars — Still the rainbow beareth up within this breast.
A Letter Sent from Afar to Brother Ding
I recall the waning days of the xinyou year: the frost-bells had scarce begun to sound, and a whisper of snow hung in the air. We, the graduating class, gathered to drink beside the ancient River-Welcoming Temple — a lonely lamp in a humble tavern, cups raised without restraint. In that hour the Wan River lay silent, and the shadow of Zhenfeng Pagoda swayed upon the cold moon; the long avenue was soon to fall still, yet the ardour of youth still surged. Drink-warmed and flushed with feeling, we clasped hands and wrote upon one another's garments. Some wept, some sang, and none could bring themselves to cease.
Ah! For several years we shared the dawn-lamp and the midnight tome. From upper bunk to lower, our wild talk startled the neighbours; by flickering lamplight over tattered texts, our ambition reached for the blue clouds. Some nights we stole away to listen to the Voice of America beneath the moon; on frosty mornings we declaimed Linguaphone in its pure London accent. Paper was too short, feeling too long; our ink ran riot. But the spirit of youth had already bestrode the age.
Ere long we scattered to the four quarters, each upon his dusty road. You, brother, spread your wings at Tongcheng; I drifted like a thistledown to the ends of the sea. Some were broken on the rocks of fortune, some foundered in the currents of fame; some bowed for bread, some grew grey upon the rivers and lakes of the world. Then we were blue-robed youths; now frost invades our temples. Then we roamed the world in talk, full of jest and ribaldry; now each guards his solitary citadel. Life is as a horse glimpsed through a crack in the gate — a flicker and gone. Whenever I think upon those old wanderings, it is as though I hear a distant bell.
And yet the road of the world, though hard, hath not slain the heart. I remember how we rode stirrup to stirrup up the mountain of books, how we shared one vessel upon the sea of learning. Did we not then count ourselves among the remarkable spirits of the age? Though now grown old, we may yet rejoice that our gall hath not chilled, nor our lamp been extinguished. Over wine we discuss the transformations wrought by AI, even as once we debated the Four Modernizations; in the deep night we survey the new configurations of the world, still nursing the will to strike the oars in midstream.
Wherefore I take up the brush today to answer your verse — not for ornament's sake, but for an old friend's. May you, brother, like the aged steed in the stable, ever cherish the heart that would gallop a thousand li. May we, though late in our years, yet remain travellers in this age. If some distant day we gather again, let us bring our cloudy wine and speak once more of youth. Then, though our heads be full of white, we may yet laugh aloud and declare:
"The bookish ardour of those young days — even now, it hath not cooled."
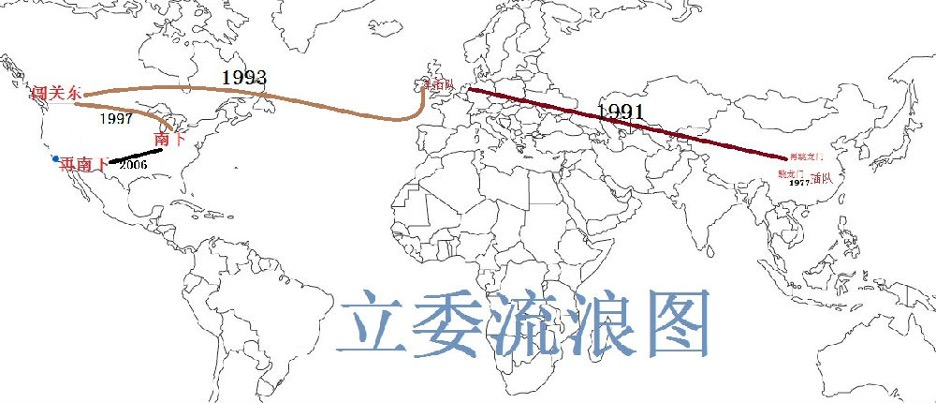
In my personal semantic dictionary and knowledge graph, "wandering" (liulang) is a major node, with "drifting" and "waves" as its hypernyms. Its hyponyms branch out in lush profusion: sent-down youth, overseas re-settlement, leaping through the Dragon Gate — and leaping again — northward drift, plunging into the sea of commerce, westward drift, southward migration, and southward yet again. This is an honest map of my professional life. Behind these words and concepts lie surges of excitement and oceans of toil that perhaps only a visualization graph could hardly capture.
A life of undulating drift has been my constant companion. In 1976, I graduated high school just in time for the Cultural Revolution's final wave of shangshan xiaxiang — the "up to the mountains, down to the villages" campaign — and was sent to a mountain village in southern Anhui to be re-educated by "poor and lower-middle peasants". That was the starting point of my lifelong wandering. Looking back, it wasn't a bad beginning — a sixteen-year-old could feel more pride than sorrow. At the end of 1977, I caught the first nationwide college entrance exam in ten years and, against all odds, leapt through the Dragon Gate, becoming one of the historically celebrated Class of '77 (though we actually enrolled in February 1978). After graduation, I taught for a year, then leapt again — into graduate school in Beijing. That was an exhilarating northward drift, my joy on par with the crazy histry figure Fan Jin passing the imperial examinations. It was 1983, and I had the extraordinary fortune of studying under the founding fathers of Chinese NLP/MT, Professors Liu Yongquan and Liu Zhuo, pursuing a master's in machine translation — thus began my career.
In the four or five years after graduate school, I moonlighted in Zhongguancun, China's Silicon Valley, plunging into the sea of business high tech development. Though I could count myself among the earliest wave of xiahai entrepreneurs, I was only part-time and bore none of the risks full-timers faced. By then, the fever of going overseas — "foreign re-settlement," we called it — was raging. I couldn't resist the tide and caught the last train to Great Britain. But the early 1990s found the British Empire in decline: streets teeming with stray dogs, muggings rampant. One does not dwell in a dangerous state, so I drifted westward to the immigrant's Mecca — Canada, the land of maple leaves, flowers, and milk. A PhD, a daughter, a change of status, a job search — it was all wonderfully busy. Beautiful though Canada was, its job market was small. So southward I went, and collided headlong with America's dot-com boom. The United States truly is a wanderer's paradise: vast skies, boundless possibilities — the entrepreneurial journey began. As the grand entrepreneurial vision faded with the bursting bubble, I drifted south once more, finally sinking into the promised land of IT workers, unable to extricate myself — a place called Silicon Valley.
My career has roughly tracked the rhythm of NLP's gradual penetration into industry. The overarching theme: wandering, wandering, still wandering. Yet wherever I wandered, my heart for technological entrepreneurship never wavered. In my dictionary of wandering, something is missing, sensed only dimly. Tao Yuanming's "The Return" echoes in my ears from time to time: "My fields and gardens will run to waste — why not return?" To let leaves fall back to their roots, to start anew — perhaps that is the true destination of all wandering.
Written on March 23, 2013
Homesickness Is an Invisible Net (Part I)
At the end of 2005, our nine-year-old daughter Tiantian was deeply upset by a discussion about leaving Buffalo. I tried to console her: "You know, when American newspapers rank the most livable cities, Buffalo is always in the bottom ten. Cities like San Francisco, Boston, Seattle, Washington D.C., and San Diego — aren't they better than Buffalo?" It was true: Buffalo has long, brutal winters — they call it "Snow Capital" — leaving residents vulnerable to cold and illness. The water quality is poor and viruses are rampant. More importantly, there's no real industry, the economy is stagnant, the population shrinks year by year, and young people mostly head "south" at the first opportunity. But Tiantian wasn't buying it. With tears streaming, she said: "Who cares about this stupid rating. I have been living here for eight years and all my friends are here. Plus, I like snow."
Tiantian had lived here for as long as she could remember; Buffalo was, in her mind, the one and only irreplaceable hometown. I recall when she was five, we took her to Beijing for the first time to visit family. That first night at her grandmother's, everything was alien — no American cartoons on TV as she was used to. She cried and fussed, begging to go home — meaning, of course, her home in Buffalo. I told her this was home, her mother's home, but she simply couldn't accept it.
To prove Buffalo's virtues, Tiantian drew upon her limited knowledge to invent her own balance theory: Buffalo's famous lake-effect snow, she argued, counteracts the terrible greenhouse effect causing global warming. With an air of self-satisfied cleverness, she declared: "You see, the two effects balance each other. Nowhere else can balance the global warming as effectively as in Buffalo!" She could list a thousand reasons Buffalo was superior: "You got to admit, Buffalo is not bad. We have no earthquake like in San Francisco. No hurricane like in Florida. Our Christmas is always white."
Buffalo does have many acknowledged virtues, chief among them Niagara Falls — the so-called "Seventh Wonder of the World." The natural ecology around Buffalo is beautifully preserved: drive along the Niagara River from the falls and you pass through a gallery of fairy-tale scenery — one state park after another, ancient towering trees, rolling meadows. Yet aside from the Falls, these vast parks sit empty even on weekends; one can't help but feel the waste of such resources. Buffalo's downtown may be dilapidated and chaotic, but the suburban townships where most white-collar people actually live are like something out of a storybook — simple, honest folk, clean and safe streets, garden-like beauty. Buffalo's housing market is the least expensive in America: back then, just over a hundred thousand dollars could buy you a house with front and back yards (what in China they'd call a "villa"), the absolute price lower than in China's coastal cities! Two hundred thousand got you a luxury home, spacious to the point of embarrassment — a sum that wouldn't buy a corner of a house in New York or San Francisco. Life was cheap and convenient, with top-tier public schools, and extracurricular lessons — piano, sports — at half the coastal price. Not to mention a warm Chinese community and a bustling weekend Chinese school.
2005年底,因为讨论离开水牛城搬家的事,九岁的女儿甜甜非常伤感。我宽慰她说:"你知道么?美国报纸排名最受欢迎的居住城市,水牛城是倒数的十个城市之一呀(最受欢迎的十大城市包括旧金山,波士顿,西雅图,华盛顿和圣地亚哥等),哪里不比水牛城强呀?" 确实,水牛城冬季漫长,人称"雪都",极易受风寒侵袭。水质低劣,病毒流行。更主要的是,没有像样的工业,经济发展落后,人口逐年下降,年轻人一有机会大多"南下"寻求发展。可是,甜甜不以为然,流着眼泪说:"Who cares about this stupid rating. I have been living here for eight years and all my friends are here. Plus, I like snow."
为了列举水牛城的好处,甜甜根据她有限的知识,自己独创了一种平衡理论:水牛城有著名的湖区效应,所以多雪,而地球正面临可怕的温室效应,导致全球变暖,她自作聪明地说,"You see, the two effects balance each other. Nowhere else can balance the global warming as effectively as in Buffalo!"。她还能举出一千条水牛城优越的理由:"You got to admit, Buffalo is not bad. We have no earthquake like in San Francisco. No hurricane like in Florida. Our Christmas is always white."
Liwei Two Minutes: Token Economics in Plain Language #3 — Why Do Agents Suddenly Feel Human?
People used to think ChatGPT was already very human-like.
It's not.
Not even close.
Why?
Because traditional chatbots are fundamentally "one question, one answer."
You ask one thing, it replies once.
Like a high-end customer service rep.
The real change happened when AI started "working on its own."
That's the hottest thing right now: Agents.
The first time you play with an Agent, it's shocking.
It suddenly acts like a real employee.
It breaks down tasks on its own, writes code, runs tests, reports errors, fixes bugs, keeps going.
It even "talks to itself" while working.
Why this sudden change?
The reason isn't mysterious.
Because AI started burning its own tokens.
In the ChatGPT era, tokens mainly came from human input.
You type some words, the model replies.
The token flow was simple: Human → AI → Human.
Agent era is different.
Now the token flow is: AI → AI → Tool → AI → AI.
So tokens are burning inside the machine in loops.
Here's an example.
Say you tell an Agent: "Build me a website."
A traditional chatbot would just give you a block of code. Done.
But an Agent won't.
It will first analyze the task.
Then start talking to itself:
"Let's decide on the tech stack..."
"Need React..."
"Probably need a database..."
"Generate the homepage first..."
"Run the tests..."
"Got an error..."
"Fix and retry..."
Notice: this "thinking process" itself consumes tokens.
And it consumes a massive amount.
Because the Agent isn't "generating the correct answer once."
It's more like trial and error.
Just like a human engineer: write, revise, test, redo.
So token consumption suddenly exploded.
Before: user asks one question, AI answers once.
Now: the AI might have run hundreds or thousands of token cycles internally.
And humans only see the final result.
This is a lot like the Industrial Revolution.
At first, coal was just for cooking.
Then people discovered coal could power steam engines.
And the entire industrial system started running itself.
Today's tokens are the same.
Initially, tokens were just for chatting.
Now they're driving the "internal thinking flow of machine work."
So a very strange new phenomenon has appeared in the AI world:
Many tokens are no longer for humans to see.
They're machine-to-machine communication.
In the future, human-generated tokens might only be a tiny fraction.
The real token flood will come from AI-to-AI interactions.
One Agent calling another Agent, one model orchestrating another model, a swarm of AIs collaborating on projects.
So the entire AI industry is starting to look more like an automated industrial system.
No longer just chat software.
This is also why so many people have suddenly realized:
AI is getting more expensive, more power-hungry, more dependent on data centers.
Because what's really being burned today isn't "chat content."
It's the machines' own workflows.
In the internet era, humans uploaded information to the network.
In the Agent era, humans are uploading "work" to AI.
And tokens are the fuel that machine labor truly consumes in this new era.
In the past two years, many people realized for the first time: AI is this power-hungry. It's even starting to compete for electricity.
Isn't it just chatting, writing articles, generating some images? How did it suddenly become an energy monster?
Because today's large models are, at their core, burning tokens at massive scale. Once tokens enter industrial production, the power consumption will be staggering.
The internet is about information transmission. AI is about real-time computation. A search engine is like looking up a dictionary. A large model is like writing an essay from scratch.
The model predicts one token at a time. Behind every bit of generated content is a sea of matrix computation.
Today, GPUs have essentially become token generators. What you consume isn't chat sessions — it's token throughput.
After agents emerged, AI itself started consuming tokens. Thousands, tens of thousands of times — invisible to humans.
It's like the Industrial Revolution. Coal went from heating homes to driving factories, trains, and ships. Tokens went from chatting to industrial fuel.
The whole world is frantically building data centers, power plants, nuclear reactors. AI competition is no longer about algorithms — it's about who can burn tokens continuously, stably, and cheaply.
AI companies increasingly look like subsidiaries of a new energy-industrial complex. The internet flows with bits. AI burns tokens.
That's today's 立委两分钟. Thanks for watching. Goodbye.
by Tuya
This isn't search anymore. It's an operating system for reality.
But Google has a chronic problem: world-class tech, unstable product soul. Especially consumer product sense. Demos are stunning; daily use feels clunky.
That's why OpenAI, with far fewer engineering resources, still builds things that feel more natural, more companionable. Google feels like a feature collection. Not a person.
And in the agent era, competition isn't just about intelligence anymore.
Who feels more like "the digital life that stays with you."
That's Google's historic weak spot.
On video generation: Google's multimodal foundation has always been extremely strong, but aesthetics and productization lagged. Veo is clearly catching up now. But Chinese companies have already gone insane on "short-video industrialization aesthetics": rhythm, visual language, vibe density, emotional beats, virality.
Google still carries a whiff of the academic lab.
Many Chinese products are already "AI content pipeline director systems."
The difference is subtle — but users feel it instantly.
So here's what I think:
The future AI war won't be fought on model parameters alone.
It's three layers:
**Layer 1: Model capability**
**Layer 2: Agent execution**
**Layer 3: Personality and aesthetic sense**
🎧 AI Narration: Token Economics in Plain English (William Voice Clone · GPT-SoVITS)
When most people first hear the word "token," their instinct is:
This must be some mysterious thing inside AI.
It's not.
Token isn't mysterious at all.
It's almost mundane.
At its core, a token is simply:
"a data unit after segmentation."
Humans see a sentence and feel it's a naturally whole.
For example:
"The weather is nice today."
But to a large language model, this isn't a complete object — it's a pile of fragmentable data chunks.
It might get split into:
"The / weather / is / nice / today"
Or even finer pieces.
Same with other languages.
Same with images, audio, video, even actions.
A picture gets chopped into pixel patches. A sound gets sliced into audio fragments. A video gets cut into consecutive frame pieces.
Because when AI sets out to process the world, its first step isn't "thinking the whole"
It's:
Smashing the world into pieces first.
Why must it smash?
Because only after smashing can you count. Only after counting can you find patterns. Only after finding patterns can you analyze and think, or train models to do the same. Only after training models does what we call "intelligence" emerge.
It's a lot like the Industrial Revolution.
A raw iron ore can't directly become a car.
It must first be crushed, smelted, standardized.
Data is the same.
Only when cut into standard units
can data enter the modern AI industrial system.
And so, the token was born.
Token isn't mysterious.
It's simply:
"information's standardized atomic part after industrialization."
And once the world is tokenized, many things suddenly shift.
Because:
It becomes countable.
Before, humans had no precise way to measure "intelligence consumption."
But with tokens, AI gains something akin to:
"kilowatt-hours of electricity"
"tons of oil"
"network bandwidth"
A unit of measure.
It's not perfect.
But it's enough to kick the entire token industry into industrial-scale operation.
So today's entire AI world orbits around tokens.
Training models consumes massive tokens.
ChatGPT and DeepSeek "eat" countless tokens every day.
A user's question? Input tokens.
An AI's answer? Output tokens.
Context windows keep growing, token consumption keeps climbing.
Today's leading models accept millions of tokens of context.
What does that mean?
It means you can dump an entire GitHub repo, a 200,000-word document, a thick book, all into the model's context in one shot.
And here's the more interesting part:
Before, humans were talking to AI.
Now, Agents consume tokens on their own.
They decompose tasks themselves,
call tools themselves,
write code themselves,
test themselves,
roll back themselves,
re-plan themselves.
Tokens start burning in an internal machine loop.
This is like after the Industrial Revolution, when coal stopped being just for home heating and began driving the entire industrial system.
Many people still think:
AI is just a chatbot.
But taking the longer view,
The world might be entering a new industrial era:
Electricity powers chips,
chips produce tokens,
tokens organize intelligence,
intelligence remakes the world.
The internet era flowed with bits.
The AI era,
might just flow with tokens.
And whoever can produce high-quality tokens
at the lowest cost,
at the largest scale,
with continuous stability —
may occupy the high ground of the next-generation digital economy.
This industrial revolution of tokens
has only just begun.
Morning Glory and Afternoon Collection — Ch.1-2: A Brief Biography of Li Wei
by Li Wei (立委)
Life is short — trim off the beginning and the end, and you're left with perhaps thirty to fifty years. These can be divided into three stages: the career-building years (one's thirties), the mature years (one's forties), and the declining years (one's fifties and beyond). In Chinese custom, these stages are reflected in how one is addressed: Little Li (Xiao Li), Big Li (Da Li), and Old Li (Lao Li). But alas, I, Li Wei, leaped straight from Little Li to Old Li, never having the chance to savor the grandeur of my prime — a fact that has always left a faint ache in my heart.
Having skipped two grades between kindergarten and elementary school, I was always the youngest in my class. Born in the notorious hunger year besides, I was frail and undersized, often excused from PE with a doctor's note or sent home altogether — perpetually the little runt. Fortunately, as middle school began, a "revisionist resurgence" was underway: Mao had tasked Deng XP with cleaning up the Cultural Revolution's wreckage, and Deng in turn charged Zhou Rongxin, the education czar, with restoring order to the schools. The campus climate was renewed. Riding this tailwind, I began to distinguish myself. As class academic officer and math subject representative, I was assigned by the classroom tutoring teacher to mount the podium every morning during self-study period to demonstrate problem-solving strategies — practically a teaching assistant. But fair weather never lasts. The Gang of Four slandered Deng and calculated against him, and the Revolution faction regained the upper hand. The school descended into chaos. Academic classes were pushed to the background; "mass criticism" sessions became the main curriculum, supplemented with learning from workers, peasants, and soldiers on site. Unable to shine through academic subjects, I nevertheless lost no ground — in fact, my prominence only grew. For I was the master of polemical writing, having moved through the successive campaigns: Criticize Lin Biao, Criticize Confucius, Criticize Deng, Counter the Right-Deviationist Wind in education, and finally, Criticize the Gang of Four. At every assembly, large or small, whenever I spoke, my voice rose and fell with cadence and force, punctuated by wit and humor. I became a sensation on campus, celebrated far and wide. Some said I carried the legacy of Lu Xun — penetrating to the bone, yet always bringing forth the new from the old, a cascade of apt phrases. At open-air gatherings of a thousand people, the crowd was typically restless and disorderly, but the moment I stepped onto the platform, complete silence fell. They listened with rapt attention, and when I reached a punchline, laughter rippled through the audience. From this I forged a reckless courage and an immunity to stage fright — a gift that has served me all my life.
By the time I reached university — the prestigious Class of '77, the first cohort after the Cultural Revolution — I was still at the tail end, with classmates older than me by anywhere from one to over ten years. Among classmates we all called each other by name, except for my desk-mate, the youngest of the "Seven Fairies," who teasingly called me "Little Li Wei." It wasn't out of affection but rather to avoid suspicion — to demarcate clear boundaries. For four years we shared a desk, yet kept strictly apart — a Chu-Han divide, a clear line between Jing and Wei. The Seventh Fairy, naturally clever, used the pretext of being one year my senior to call me "Little Li Wei," thereby making our interactions, such as they were, officially above reproach.
Once the Seventh Fairy set this unfortunate precedent, the "Little" epithet stayed with me for years. Teaching middle school, I was called "Little Teacher Li" (age 22). In graduate school, I shuffled in and out of the computer lab, disheveled and unkempt, muttering to myself in "the world's language" (Esperanto), eventually becoming a campus joke (ages 23–26).
Caption: Full of youthful vigor and high spirits (1987).
After graduating from the Chinese Academy of Social Sciences and staying on at the institute, tales of Li Wei continued to circulate — mostly stories of love at first sight, a lightning marriage, chronic dishevelment, and the time I walked into a wall and had to apologize for it.
Caption: Li Wei directing machine translation system development at a Zhongguancun company (1988).
Thus I dug in at the research institute and the Zhongguancun company for five years (ages 26–31), honing skills akin to those of an old traditional Chinese doctor. My specialty was treating computers, taming their language functions. During this period, the fever for going abroad kept rising, spreading from Shanghai to Beijing. On every street corner, conversations inevitably turned to America, Japan, Britain, and Australia. Yet Li Wei and his "immediate superior" (my wife) ambled along in blissful ignorance, wrapped up in each other — like the old saying, "unaware of the Han dynasty, let alone the Wei and Jin". Not until every last classmate had departed did Little Li suddenly wake up. With grim resolve, he took the TOEFL exam and scrambled for the last train. As it happened, the Y.K. Pao Foundation was selecting promising talents, and through sheer luck, Little Li was chosen and dispatched to the Chengdu University of Science and Technology's overseas training center for half a year of preparation.
Who could have guessed that this would become the watershed between Little Li and Old Li. The talents gathered at the training center — men and women alike — were the best from every region and every field, divided into two groups: the one-year visiting scholars, mostly older, and the three-year doctoral scholarship recipients, mostly young rising stars. Li Wei, in the latter group, now found himself the senior. Every time there was an exam, Wei inevitably took top honors, drawing a stream of talented men and women to his door with questions large and small. The sound of "Old Li" never ceased. Li Wei became a minor celebrity for a time, with a devoted following.
Caption: The talented men and women of the Chengdu University of Science and Technology Overseas Training Center (1990).
In the blink of an eye, Little Li had transformed into Old Li, basking in widespread esteem. As a foreign-language major, I should have been exempt from the English test. But the authorities, making no distinction, rounded everyone up and shipped us all to Chengdu, the "Land of Abundance" for centralized feeding. It wasn't just English — there were also policy training sessions. All my brothers and sisters worked conscientiously, scrambling to get ahead. Only Li Wei took it easy, spending his days indulging in Sichuan cuisine and lingering in teahouses and bars, much to the envy of his peers.
Though the title "Old Li" was coined in Chengdu, in my heart I didn't fully accept it. At that time my career was flourishing, at high noon — wide networks within the field and beyond. My associations were all with learned scholars; no common folk crossed my threshold. My advisor was a titan of the discipline, and I was his sole final protégé — his "closed-door disciple" (all the others having "betrayed" the motherland and fled to America). I was a "young" talent, a rising star, commanding the sidelong respect of my peers. On the eve of my departure from China, the national machine translation community held its annual gathering at the Fragrant Hills Guesthouse in Beijing. The highlight was a dinner conversation between my advisor and another giant of the field — what came to be known as the "Liu-Dong Dialogues" — throughout which Li Wei appeared repeatedly, furnishing his advisor with examples and explaining details. So influential was this that the assembled junior female scholars (mostly out-of-town graduate students newly entered into the field) flocked to Li Wei for guidance. Regrettably, with my mind so set on flying far away, I missed a golden opportunity to mentor these aspiring younger scholars.
After leaving the country, the years passed: from Britain to Canada, from Canada to America. Drifting and displaced, never knowing where I'd settle — my prime years flowing away like water. By the time of my eight-year tech start-up campaign in Buffalo (ages 37–45), my youth was gone, my prime had passed, and "Old Li" had become an honest name. Yet my ambition never waned. I redoubled my efforts, fighting on two fronts, and carved out a domain of my own.
Caption: Li Wei at his Buffalo office (2000).
Looking back, I can't help but sigh. My life — from youth to prime, precisely when my creative powers were at their peak and energy overflowing, with timing, place, and people all aligned — was cut in half by the long years of study abroad, everything reset to zero. Years later, after eight years of entrepreneurship, I returned to China to visit family. Amid clinking glasses at a hotel restaurant, I was enjoying a joyful reunion with family and relatives. During a brief pause in the feast, I strolled out onto the balcony to enjoy the cool air and take in the Beijing nightscape. There I happened upon an elegant young woman with a small child. Seeing my gray hair, she instructed the child: "Say hello to Grandpa." My blood pressure shot up, thunder crashed in my head, and all the wine in my belly turned to cold liquid, sliding down my spine.
Since the AI gold rush hit, I've noticed something:
A lot of us aren't really "using AI" anymore.
We're running a digital harem.
First thing every morning,
not checking stocks,
not checking the news.
Checking whether our agents "evolved" overnight.
One runs the blog.
One posts to Twitter.
One edits videos.
One monitors GitHub.
One auto-summarizes the news.
And one stands guard on WhatsApp,
like a night-shift security guard.
Then the master sips his coffee,
patrolling his cyber domain.
Dashboard open,
like an emperor at morning court.
"Did OpenClaw crash last night?"
"Did Hermes memory leak?"
"Is Claude cowork having a bad day?"
"Is Suno web use stable?"
"How many Fish Audio credits left?"
That sense of control is intoxicating.
A scholar who never leaves his study, yet runs the world.
The best part:
The whole setup keeps feeding you the illusion
that you're changing the world.
Because it never stops moving.
Logs scrolling.
Workflows running.
Automation executing.
Terminals blinking.
GitHub commits piling up.
Agents even report back to each other,
often with wit and humor.
Like a tiny civilization.
And that's how you fall in.
It started as:
"Let AI handle some chores."
It became:
"I will build my own AI empire."
Then the infrastructure frenzy:
Wire up MCP.
Set up memory.
Build routing.
Write skills.
Train personas.
Hook up Telegram. Or WeChat.
Add voice.
Add Suno.
Add WordPress.
Build a custom app.
Wrap it in a dashboard.
Add an auto-publishing pipeline.
Tack on a long-term knowledge base.
It just keeps growing.
Until finally, you've built
your own automation kingdom.
And after 24 hours of stable operation,
it auto-generates a message:
*"Goodnight boss, don't forget to love life today ❤️"*
...
Sometimes I think
this generation of AI tinkerers
is exactly like those geeks twenty years ago
obsessively building NAS rigs, Hackintoshes, Linux home labs.
The only difference:
Back then, you raised servers.
Now, you raise "digital employees."
And the most insidious part:
It theoretically always has a next step.
There's always:
* A stronger model
* Lower costs
* Longer context
* Smarter agents
* More advanced workflows
* A prettier UI
* Deeper automation
So you keep thinking:
"Just one more tweak, and it'll be perfect."
In the end,
what you actually run out of time for
is the thing you set out to do in the first place:
Expression.
Creation.
Thinking.
Living.
Because infrastructure gives you
a very sophisticated form of procrastination.
You're not slacking off.
You're "building the future."
And that's dangerously addictive.
This isn't a lecture — it's self-mockery from someone who's lost too many nights to the chase.
The real winners are the ones who found product-market fit — they know how to leverage AI at scale, burning millions of tokens without blinking, quietly cashing in while grinning on the sidelines. The only thing we all share: AI has eaten their human lives too.
Life comes but once, a river rushing to the sea that never returns. The distillation of a life transcends the life itself. Only when the migrating geese leave their call do you feel you haven't lived in vain. With accumulated experience, with inspiration stirring, with a serene mood and a pot of clear tea — what flows flowingly is not literary craft, but life itself: with its sorrows and joys, its sweat and blood.
Most things in this world follow predictable patterns. So do most human lives. But when an old hand looks back at his footprints, the ordinary parts tend to fade while the legendary ones stand out. And the legendary, by definition, defies belief. Yet what truly instructs us is often the legendary, not the routine. Morning Glory and Afternoon Collection is a legend. Some things in it, I scarcely believe myself. Take this, for example: raising 10 million dollars from the federal government and 11 million from investors within eight years around the turn of the century— fairly rare, right? But it happened, and it happened to us.
Another example: my elder brother's "rebellion" as a nine-year-old commander. I remembered the event, but in the first draft of Little Red Guards I did the math and thought it impossible, so I fudged it: "My brother was the representative of our second-grade class, one of the founders of the revolutionary organization." Later, after verifying with my father and brother, it turned out he WAS the commander, with a fourth-grade strategist as his adjutant. According to my father's account, our family was sent down to the countryside in 1965. Since there was no kindergarten there, I skipped straight from middle kindergarten into first grade elementary, sitting in the same class as my brother. After two months, I somehow advanced with the class to second grade (the plan was to hold me back in first, but the teacher said I was able to keep up). In '66 we were second-graders. School was suspended for the revolution, and the Little Red Guard was formed during that hiatus. The rebellion must have been in '66, because by '67 our family had left that small village town and returned to the county seat.
Morning Glory, Part One: Wandering Far Away
The very word wandering conjures the comic books of my childhood — Zhang Leping's Sanmao the Wanderer.
We were three siblings, each two years apart. I was in the middle, and Little Sister was the youngest — the darling of the entire family. Our elder brother was a natural-born student leader, always out in the world making trouble or making revolution, often leaving us behind. At home, it fell to me, the second brother, to look after Little Sister.
I was a weak and sensitive child, prone to excessive worry about my family, and Little Sister was the one I worried about most. I remember countless times — whether it was our parents, our elder brother, or Little Sister — if someone didn't come home on time, I would sit at home letting my imagination run wild, terrified that something terrible had happened. When I took Little Sister out to play, I never dared let my guard down. The moment she was out of sight, my heart would pound with fear — what if someone kidnapped her?
From childhood to adulthood, I was always the one being looked after. My parents, my grandma, my elder brother — they all took care of me, and at school, being younger and doing well academically, I often received special attention from teachers and kindness from older classmates. This environment made me a little too comfortable being the one who was cared for. I took it for granted. In my world, only Little Sister was younger and more fragile than me, someone who needed my protection and care.
The year our family was sent to the countryside, I was five and Little Sister was three. I often took her out to play on the flagstone streets beyond our front door. Across the way was a blacksmith's shop, and Little Sister and I would stand transfixed, watching the two blacksmith brothers at work. It felt magical. The bellows whooshed, the iron glowed red-hot, and under the rhythmic hammering — one heavy, one light — sparks flew everywhere. The metal darkened from crimson to dull red, slowly taking shape: spades, hoes, sickles, gleaming black after quenching.
I used to show off by carrying Little Sister on my back as I ran down the street, making her giggle and laugh. She was thin, but even so she was heavy for me, and I could never carry her far before she'd start slipping down. One day, I had her stand on a high step so I could lift her from above — I figured the higher center of gravity would make her easier to carry. But I was wrong. After just a few steps, Little Sister went tumbling headfirst over my shoulder and hit the ground — "smack" — her face bruised and swollen. I was heartbroken and regretted it for a long, long time. And of course, Little Sister never again let her second brother carry her on his back again.
Not far behind our house was a little pond where I took Little Sister to play. A tempting water chestnut floated on the surface, and Little Sister reached for it. She stretched, missed by a hair, stretched further — and splash — tumbled into the pond. I was terrified and stood at the water's edge, crying desperately. The elder blacksmith brother, who was fishing on the opposite bank, heard my cries and came running. He jumped into the water and pulled her out. Poor Little Sister — three years old, hair disheveled, face blue, soaking wet, too shocked even to cry. The blacksmith carried us home, and Grandma was beside herself with fear. From then on, we were forbidden to go anywhere near the pond. That evening, Grandma — a superstitious old soul — led Little Sister and me around the pond's edge, murmuring incantations, believing this would call back our frightened souls.
Little Sister was well-behaved — pampered but never spoiled. Teachers and classmates at school all loved her, and at home she had the whole family's care. Whenever I got a treat as a child, I always thought of Little Sister and carefully saved half for her. I might fight with my elder brother over food sometimes, but with Little Sister, from childhood to now, it's always been nothing but protection and tender care.
In those days, fruit was a luxury. When our parents brought home apples or pears, the whole family felt festive. Little Sister ate fruit delicately and slowly, always leaving a large core behind for us to finish. My brother and I would gnaw our own fruit down to nothing, then eye the core still in Little Sister's hand with envy. Every time, she'd smile at us, and we'd compete, shouting: "Core collection station now open! Core collection station now open!" Little Sister loved this game, but she never judged by volume. She was always fair — if she'd given the core to our elder brother last time, this time it was mine.
At seventeen, I left home to be "sent down" to the countryside, beginning a lifetime of wandering the world. Even when I came home for New Year's, my visits were always brief. But my concern for Little Sister never faded — not until she married. Her husband is an honest, intelligent, caring man, with an impressive career in farming research. Only then did I, as her brother, feel some relief. Little Sister's child also turned out exceptional — with broad knowledge, a gift for writing, now working in AI in America. Little Sister herself — once so pampered — has been tempered by life. She's capable, hardworking, and well-liked by everyone.
I went abroad for graduate studies and didn't return home for ten years. When I finally visited, there were too many things to say and no way to begin. At Little Sister's house, we sang old songs together on the karaoke machine, and scenes from our childhood — playing together as brother and sister — came flooding back, frame by frame. Only then did I learn that Little Sister had twice narrowly escaped death — once thrown from an electric scooter, once paralyzed by severe potassium deficiency. "Why didn't you tell me?" I asked. Little Sister smiled bitterly. "What would have been the use? You were on the other side of the world. It would only have made you worry for nothing." She sighed, tears glistening: "They say both brothers have done so well. But what good is it? We barely even see each other. Look at other families — brothers and sisters right here in the hometown, on holidays and weekends, the whole family gathers, so warm and lively." Her words cut me deep.
Now we've all reached middle/senior age and beyond, but in a brother's eyes, Little Sister will always be Little Sister — the one who needs watching over, the one who needs protecting.
It's not just that "agents have finally arrived." It's that we've been asking the wrong question for three years.
We thought LLMs couldn't land in production because the models weren't smart enough. Then we realized: the real deficit wasn't the "brain." It was the body, the nerves, the hands, the feet, the memory, the discipline, the boundaries, the feedback loops.
LLMs have been eloquent for a long time. They can talk up a storm. What they can't do is act reliably. They're like a brilliant strategist in a glass room — reading maps flawlessly, articulating brilliant strategy, analyzing world affairs with stunning clarity — but ask them to move a box in the warehouse, and they don't even know where the door is.
This is what "impressive in theory, useless in practice" actually means.
It's not that the model lacks knowledge or reasoning. It's that it was never plugged into the real world's execution loop.
For three years, the industry oscillated between excitement and disappointment because we were stunned by "linguistic intelligence" but vastly underestimated the civil engineering required for "action intelligence." LLMs gave us a core that understands, plans, expresses, and generates. But that core is not a product. It's an engine, not a car. You can't take an engine onto the highway.
The real breakthrough wasn't making models slightly bigger. It was someone finally, diligently, bolting on the chassis: file systems, shells, browsers, MCP, cron, permissions, logging, rollbacks, skills, memory, delegation, sandboxes, watchdogs, task queues, failure retrospectives, human approval gates, platform adapters.
None of these are sexy. None would make an investor pound the table shouting "AGI!" But together, they form the skeleton that turns an agent from "talking" to "doing."
That's why Peter — a pure systems engineer — broke through first, while the geniuses at top labs didn't.
Because this was never a "model scientist's problem." It was an operating systems problem.
Model scientists ask: Does the model have stronger reasoning? Bigger context? Higher benchmarks?
Systems engineers ask: What happens when it fails? How do permissions narrow? Where does state persist? How are tools registered? Who restarts the process when it dies? Is there a diff before writing? Confirmation before publishing? How do you find a lost browser tab? How do you switch providers when the API gets expensive? If it works today, how do you reproduce it tomorrow? Can it run on its own while the user sleeps — without running wild?
These are the real problems of agents.
LLMs used to be like a genius with verbal tics: "I can write code for you." "I can analyze your market." "I can manage your knowledge base." "I can handle your publishing."
All true in theory. But on the ground, they die at tiny, dirty places: the cookie isn't in this session, Chrome permissions aren't enabled, React state hasn't updated, the button click silently failed, the file path is wrong, there's no log evidence, tokens are burning, the publishing platform triggered anti-spam, the process didn't come back after a system restart.
These aren't AGI problems. These are plumbing problems.
And the real world is made of plumbing.
That's why the "explosion" of systems like OpenClaw and Hermes isn't about creating a smarter model. It's about embedding the model in an engineering shell capable of sustained action. That shell looks low-level. But it's what decides life or death.
I'd summarize this technological trajectory in four stages:
Stage 1 — The Wow Period: Humanity discovers for the first time that machines can speak, write, code, explain, translate, summarize like humans. The keyword is "wow."
Stage 2 — The Disappointment Period: Companies start trials and discover that demos are beautiful but production is brutal. LLMs can answer questions but can't own workflows; generate proposals but can't guarantee execution; write code but can't maintain systems; chat endlessly but can't take responsibility for outcomes. The keyword is "then what?"
Stage 3 — The Tooling Period: Function calling, RAG, workflows, browser automation, code interpreters, MCP, agent frameworks gradually emerge. Models start having hands — clumsy, uncoordinated hands that keep hitting walls. The keyword is "it moves, but it's unstable."
Stage 4 — The Systems Engineering Period: The real breakthrough happens here. Not point tools, but complete closed loops: task intake, state persistence, tool orchestration, permission control, log evidence, error recovery, human confirmation, scheduled execution, cross-platform delivery, experience accumulation. The keyword is "operational."
The final judgment is clear: LLMs were never the bottleneck that got cracked. What got cracked was the thick layer of engineering insulation between LLMs and the real world.
Who cracked it? Not the best AGI storytellers. It was the people willing to connect logs, permissions, configs, paths, tools, processes, platforms, and exception handling — layer by dirty layer.
That's why Peter the systems engineer became the man of the hour.
Because a real agent isn't "a smarter mouth."
A real agent is "an engineered brain."
From Wow to Operational: the four-stage agent trajectory
Why I Write Morning Glory and Afternoon Collection — Preface 2
After middle age, I grew fond of reminiscence. From time to time, seized by a mood, I would casually record the most unforgettable moments and feelings of my life — gathering fragments into a whole, publishing them online under the pen name 立委. This became "Morning Glory and Afternoon Collection".
"My Postgraduate Exam Experience" was the first piece in this nostalgic series, blogged on May 2, 2004, in Buffalo, New York. From there I couldn't stop, writing on and off for over a decade. Looking back, the college and postgraduate entrance exams — "leaping over the dragon gate" — truly were the fundamental turning points of destiny. On my first trip home after many years, both my elder brother and a senior schoolmate told me that for our generation, life's path was largely set the moment you either cleared or fell short of that gate. This is deeply unfair, because what standardized exams measure cannot begin to capture the talent and potential so many classmates possessed. Yet this is how society sorts us — an imperial examination system at its core, where academic excellence opens every door. Most opportunities and resources ultimately fall to the lucky few who cleared the dragon gate, leaving one to sigh at the opportunities in life.
A human life is like a dream — when you wake, nothing remains. Recording the most piercing moments, at least, freezes a frame of life. Life is brief. I didn't set out to write deliberately — I would simply record what came to mind, fearing that when I was truly old I would forget, as if I had never lived at all.
I began writing Morning Glory and Afternoon Collection to share with family, and later with those friends close enough to confide in. I have never deliberately elevated or embellished, but I know there is no absolute truth memories. What I call truth is only the truth of my memory, and memory is surely unreliable in places. Absolute truth is not necessarily more valuable — except when writing history — whereas "felt truth" is the stuff of literature. I have done my best to be truthful. Where something cannot be described truthfully, I would rather not write than knowingly fabricate. Some things I may only have the courage to write after retirement. What I choose to set down is real — not only for peace of mind, but in the hope of offering something to those who come after. But none of this is what matters most. What matters is using this unique way to connect with my father, my family, and those cherished friends — old buddies bound by common attention, care, concern, and fate — in a genuine exchange. I think to myself: without doing this, our usual conversations, trips home, and school reunions could never attain such depth. Separated for too long, people often find themselves with nowhere to begin. There are indeed things too precious, too sensitive, too delicate to share. But there is so much more that needs and can be shared — yet so many people rush through a lifetime without ever finding the occasion or the way.
Some time ago, talking about body and soul, I wondered: what is it that endures? At the very least, a person has thoughts, sensibility, and memory. If these are committed to words, it is as if something metaphysical is solidified and externalized. Though it cannot achieve immortality, at least it will not vanish with the body's going away. The ancients said: literary works endure across a thousand autumns. I have not thought that far — but sharing with family and friends is itself one of life's pleasures.
After I wrote Morning Glory and Afternoon Collection, my father began writing his own memoir, "Wind and Rain Through the Seasons", allowing us to understand more of his life. Every time I read about the famine year of 1960, and the life-and-death separation from my aunt — his younger sister — I cannot hold back tears. My elder brother also wrote "Riverside Chronicle" (later collected as "Small-Town Green Years"). His memory is more precise, his descriptions more delicate and vivid. Those "old stories" from the county town where we grew up, events that feel like a world away, come back to vivid life before our eyes.
This volume also collects a unique family heirloom — the surviving manuscript of my great-grandfather, "Remaining Ink of the Elder Li".
The core question isn't "teaching an agent to understand music." It's this: how do you take something deeply subjective, ambiguous, and impossible to fully articulate — taste — and slowly turn it into observable, recordable, iterable machine signals?
The most interesting part: I'm not training a model. I'm training an ear.
How Do You Align Artistic Taste?
We used to think automation worked like this: give the machine a clear goal, and it executes. Open a webpage, click a button, generate a file, send a message.
But today I realized: the truly hard automation isn't clicking buttons. It's understanding taste.
Suno spits out a batch of six songs. The agent asks: which one is good? I say: "Six Seventeen got a like. The others aren't bad, but they didn't earn a like."
To a human, that's a natural sentence. To an agent, it's gold-standard training data.
Because it doesn't just know "which song won." It starts learning to decompose: why did it win?
It attributed: syncopated rhythm, female alto, an asymmetrical three-line chorus, male-female duet — these are positive signals. Male solo, traditional four-bar frameworks, ordinary interval jumps — not bad, but not ear-catching enough. Even sharper: it isolated "male-female duet" as a form I like, even though that particular song didn't get a like.
It's a bit like raising a cat. You can't teach Katara in one sitting what "premium cat food aesthetics" means. You just watch her sniff, lick, walk away, or suddenly light up. Over time, you learn: oh, she doesn't hate chicken. She hates that kind of dry chicken.
Agents are the same way.
Taste Isn't Rules. Taste Is Residuals.
It's not "female vocals are always better." It's "this particular female vocal, in this particular syncopated rhythm, paired with this particular asymmetrical structure — that makes me stop." It's not "duets are always good." It's "the duet form is right, but the execution hasn't caught fire yet. Good direction, wrong temperature."
That's what aligning subjective preference looks like. Not solved in one prompt. Achieved through a chain of tiny feedback — compressing the mysticism of "I like this" into operational signals an agent can act on.
Batch B003's progress: the agent isn't just a scorekeeper anymore. It's starting to resemble a junior music production assistant, able to hear the structural implications behind a single vague sentence of feedback.
Doing Chores Makes You a Butler. Knowing Taste Makes You an Assistant.
This made me realize: the most valuable thing about a personal agent in the future might not be its ability to do work. Doing work makes you a butler. Understanding taste makes you an assistant. Turning that taste into the next round of action — that's what makes you one of us.
Of course, it's still young. It summarizes in tables, it talks about "80% proven + 20% novelty," it sounds like a McKinsey intern who just learned the jargon. But the direction is right.
Real domestication isn't training an agent to be obedient. It's teaching it that when I say "not bad," I don't mean satisfied. When I say "that's interesting," that's the real vein of ore worth mining.
The symptom was bizarre:
Type a keyword in the address bar, Google Search would spin forever.
Later it started saying "this site cannot be reached."
But typing a URL directly? That worked fine.
For two years, I did every standard thing an IT person would do:
Reinstall Chrome.
Upgrade Chrome.
Delete Profile.
Check extensions.
Check DNS.
Check proxy settings.
Check search engine config.
Even suspected Google itself was glitching.
Nothing helped.
Then today, I asked my Hermes agent Tuya to look into it.
Tuya didn't stop at the FAQ-level "try reinstalling." It started digging like a battle-hardened sysadmin, layer by layer:
Chrome configuration.
SQLite database.
Preferences.
System layer.
hosts file.
And finally unearthed this:
A two-year-old zombie config sitting in my /etc/hosts:
31.13.72.23 www.google.com
That IP?
It belongs to Facebook.
Which means:
For two whole years,
every time I typed a search query in Chrome's address bar,
I was essentially saying:
"Take my Google request and hand it to Facebook."
Facebook, of course, was baffled:
"Who the hell are you?"
And timed out.
The truly absurd part?
Updating Chrome could never fix this.
Because /etc/hosts is a macOS system file.
Chrome never touches it.
It's like:
Someone secretly changed your house number to your neighbor's address,
and you kept ordering furniture
that could never find its way home.
But here's the deeper thing:
The scariest part of this kind of problem isn't complexity.
It's that you'd never think to look there.
Normal people check the browser.
Check extensions.
Check the network.
Check DNS.
Who would think:
"Chrome won't search"
has anything to do with
a Facebook IP hidden in /etc/hosts?
A lot of real-world problems work exactly like this.
What really tortures you isn't the "major outage."
It's some tiny config someone left behind two years ago.
A patch nobody remembers.
A "temporary fix."
A rule nobody reads anymore.
It lies there quietly,
like a corpse.
Until one day,
the whole system starts slowly poisoning itself.
And everyone keeps debugging on the wrong layer.
This is actually what makes AI agents interesting.
They're not necessarily smarter than humans.
But sometimes they're less biased.
Human experience can be so strong
it becomes a cage.
"Chrome broken" → must be Chrome.
"Network issue" → must check DNS.
"Search not working" → must reinstall the browser.
But an agent doesn't care about saving face.
Doesn't care about industry common sense.
The four brothers of the Li clan's 'Ming' generation, at Xiaokeshan. They supported each other throughout their lives.
Many families write their genealogies, and they tend to fall into one of two traps.
The first is a dense list of names — reads like a phone book. The second is a desperate scramble to link themselves to distant emperors and generals, as if a single sentence could vault them into royal lineage.
But the truly moving part of a family's story often lies not in "who our ancestors were," but in "how the generations that followed chose to live."
The story of our Li clan of Keshan (磕山李氏) begins, roughly, in the chaos of the late Tang Dynasty.
According to the Keshan Li Clan Genealogy and the Santian Li Clan Genealogy, the Keshan Li branch belongs to the Santian Li lineage. The Santian Li trace their roots to the Tang imperial house, with ancestral ties to Longxi. The line can be traced back to a descendant of Emperor Xuanzong of Tang (Li Chen). From Li Rui, the ninth son of Emperor Xuanzong and Prince of Zhao, came Lord Li Jing. Lord Li Jing was originally named Li Yang, later renamed Li Jing.
During the Huang Chao Rebellion at the end of the Tang Dynasty, around 880 CE, Lord Li Jing migrated south, settling in Jietian, Fuliang, Raozhou — in the area of today's Jingdezhen, Jiangxi. Later, his descendants branched out to Xintian in Qimen, Yantian in Wuyuan, and Jietian in Fuliang — known thereafter as the "Three Fields Li" (三田李氏).
This part sounds distant. As distant as a page from a history book. But family history moves closer, one step at a time.
From the late Tang through the Song and Yuan dynasties, from Jiangxi to Anhui, from Fuliang in Raozhou to Gukang in Dongzhi, to Yangshan, and finally to Xiaokeshan in Fanchang — generation after generation migrated, fled turmoil, sought livelihoods, and put down roots. Then, during the Jingding era of the Southern Song, Lord Rongsheng's son, Lord Rongyi, took his three sons down the Zhangxi River and along the Yangtze, arriving at Xiaokeshan in Fanchang.
The mountain is small. The name carries no fame.
But Lord Rongyi and his party stopped here.
They settled at the foot of Xiaokeshan, in a place called Laowuji — the Old House Foundation. From that point on, this branch of the Li clan took root and grew. Descendants honor Lord Rongyi as the founding ancestor of the Keshan Li.
This is, perhaps, the most authentic beginning for many Chinese families: not a tale of armored cavalry or court intrigue, but a few people, with their children and belongings, following the river downstream, finding a place where they could survive — building houses, clearing fields, lighting fires, raising children. And then, passing the days down through the generations.
What makes the Keshan Li truly worth writing about is not just their origins, but their family tradition.
From very early on, this clan placed a high value on education.
During the Ming Dynasty, the clansmen built the Jiashutang ("Hall of Shelved Books") ancestral hall at Laowuji. It is said to have covered twenty mu of land, with three courtyards, ninety-nine and a half rooms, all timber-framed — known locally as the "Hall of a Hundred Beams." Carved beams and painted rafters, majestic in scale.
The name Jiashutang is telling. It is not "Hall of Gathering Wealth" or "Hall of Prominence." It is "Hall of Shelved Books."
Shelve the books, teach the children, and the lifeblood of the family continues.
Later came Xigong Ci, which elders recall was primarily a private school — a place where the clan nurtured its young and conducted lectures. Xiaokeshan is just a mountain valley, but because of these ancestral halls, private schools, and teachers, it gradually filled with the sound of recitation. For a time, students from both sides of the Yangtze traveled to Xiaokeshan to study.
This is what I find most moving. A mountain valley that could draw students from near and far — not by scenery, not by power, but by education.
Sadly, both Jiashutang and Xigong Ci were destroyed during a particular era, and the genealogical records were nearly scattered and lost. The old buildings are gone, the wooden beams gone, and the sounds of study seem to have faded into the distance.
But some things, even when the buildings are destroyed, cannot be erased. Because they have entered the bones of the people.
Over seven centuries, the Keshan Li clan has produced, generation after generation, scholars, educators, physicians, soldiers, and researchers.
In the Qing Dynasty, there was Li Dahua, courtesy name Dunlun, pen name Xiangzhai. A suigongsheng during the Guangxu period, he served as magistrate of Huichang, Shangyou and other counties in Jiangxi, and in his later years returned home to teach, with disciples in great number.
There was Li Hucen, born into a tradition of farming and scholarship. In the 19th year of the Guangxu reign, he founded the Fanchang Higher Primary School — later Fanchang No. 1 Primary School — and donated thirty mu of farmland as a school endowment. Founding a school was not about slogans; it was about giving your family's land so the school could survive.
There was Li Shixiu, who devoted his life to running schools and teaching. He founded the Chongshi Chinese College and Keshan Primary School, donated over ten mu of farmland, and served as headmaster without taking a salary. These words may sound light today; in that era, they meant truly investing one's family fortune and life's energy into education.
There was Li Yingwen, a Meiji University graduate in political science who spent his life as an educator. During the War of Resistance, when the Japanese army attacked the Keshan area, they invited him to serve as county magistrate of Fanchang. He refused to serve the puppet regime, skillfully maneuvering before making his way to the Wuwei anti-Japanese base area, where he continued his educational work. In times of chaos, a scholar's integrity sometimes rests in a single word: "No."
There was Li Yingfan, who during the War of Resistance served as colonel secretary to General Gu Zhutong, commander of the Third War Zone. Later, unwilling to leave his homeland, with aging parents and young children, he declined three invitations to relocate to Taiwan. In subsequent years, amid shifting times, he endured years of imprisonment. In his later years, his reputation was restored, and he served as a researcher at the Anhui Literary and Historical Archives, leaving behind more than ten volumes of his collected poems. His poetry, at once classical and playful, stands as a representative work in the cultural heritage of the Keshan Li.
There was Li Huaibei, given name Pu, who was shaped by his family's educational tradition from a young age and later rushed to the front lines of the War of Resistance. He participated in revolutionary work, experienced the Huaihai Campaign and the Yangtze Crossing Campaign, and ultimately gave his life in 1955.
There was Li Ruofei, given name Qin, who fought in the War of Resistance, the Huaihai Campaign, the Yangtze Crossing Campaign, and the Korean War, later transferring to the Hefei Institute of Optics and Fine Mechanics of the Chinese Academy of Sciences, leaving behind battlefield diaries from each period.
There was Li Mingjie, a chief surgeon who practiced medicine his entire life, prioritizing efficacy, minimizing costs, and always thinking of his patients' welfare. A physician's compassion is rarely found in grand words — it is in every yuan saved for a patient, every bit of suffering spared.
There was Li Yangzhen, who spent forty-eight years in clinical practice, teaching, and research in traditional Chinese medicine — writing books, publishing papers, teaching, treating patients, decade after decade. Beyond medicine, he wrote travelogues, family histories, and poetry. In a person like him, you see the quintessential scholar of an older generation: someone who did solid work and wrote prolifically — like an old well, its water never ceasing.
In modern times, clan members have also entered fields like computing and artificial intelligence.
Looking back now at the words "Xiaokeshan Li Clan," you realize it is more than just a surname attached to a place.
It is a thread.
A thread that runs from the chaos of the late Tang, through Fuliang in Jiangxi, through Gukang and Yangshan in Dongzhi, finally settling in Xiaokeshan, Fanchang.
It passes through ancestral halls, private schools, genealogical records, war, the Cultural Revolution, and the Reform and Opening — and through one real person after another: the teacher, the doctor, the soldier, the poet, the researcher, the AI engineer.
The most precious thing about this thread is not how illustrious our origins were. It is the reminder to those who come after: how far a family can go depends not on the halo of its ancestors, but on whether later generations keep reading, keep being good people, and keep doing solid work.
Ancestral halls can be destroyed. Old houses can collapse. Genealogies can scatter.
But as long as someone still asks, "Where do we come from?" — as long as someone still remembers the names of those who came before, and still tells the children the family stories of valuing education, valuing integrity, and valuing responsibility — this cultural thread has not been broken.
Xiaokeshan is nothing more than a mountain valley.
But seven centuries later, the sound of recitation that once echoed there still resonates in the destinies of its descendants.
The truly scarce resource in the AI era isn't information, isn't knowledge, isn't even compute.
It's human attention span.
Attention.
In the pre-internet era, our pain was: "Too little information, can't find anything."
Now the AI era has flipped it completely. The things you want to read, would love to read, find genuinely valuable in a lifetime — already far exceed the limited bandwidth of the human brain.
The result? Our attention drifts randomly. Randomly assigned to whichever tiny fragment happens to crash into our field of vision.
Many of you know this feeling. Take my bookmarks folder. It's stuffed with: articles, videos, papers, podcasts, technical materials that I "plan to seriously read someday."
The moment I bookmarked them, I genuinely believed: "This is worth my time to digest."
But if I didn't get sucked in right then — if I didn't ride that wave and read it through — it was almost certainly lost forever. Sure, formally it's still there. Still on your radar. Theoretically reachable anytime. But your brain has long since turned the page.
So much of what we call "saving" isn't actually reading. It's a psychological comfort: "I have approached the knowledge."
Here's the absurdity of modern society. Humanity is drowning in information overload. And AI is amplifying this trend tenfold.
Because in the past, the flood of information was at least constrained by: the speed at which humans produce content.
Now agents can work for you 24/7: generating, summarizing, forwarding, distributing, repurposing, rewriting, running accounts. Diligently. Tirelessly.
But here's the problem. The world's information production speed has begun to far exceed humanity's "information digestion" speed.
As a result, high-quality content going unnoticed will increasingly become the norm of the information society.
Stop fantasizing that: "As long as I'm diligent enough, hardworking enough, my content is good enough, I will surely be seen." The peach tree doesn't speak, yet a path forms beneath it. That's not how it works.
Going viral is often luck. Partly marketing. Mostly platform promotion.
Because the attention economy, at its core, is: platforms using algorithms to manipulate and allocate humanity's limited attention. And it's terrifyingly effective.
Because platforms aren't just better at understanding content. They're better at understanding human nature. Humans are creatures of inertia. Whatever the platform pushes, most people just watch. Busy? Scroll. Tired? Scroll. Killing time? Scroll.
We end up in a bizarre era: masses of people frantically producing content, hoping others will notice them. Meanwhile, everyone's attention is simultaneously going bankrupt.
So the truly healthy creative mindset for the future should be: you have something to express. You want to put it out there. That's enough.
Stop clinging to: "It must reach many people."
Aside from your closest friends and family, the fate of most content in this era was always to be swept away by the flood.
The AI world has been buzzing about "Token Economy" and "Token Dividends." The most talked-about story: Anthropic, riding this wave, seems almost destined for a trillion-dollar valuation—a genuine business miracle.
What exactly is the "Token Dividend"?
Some put it this way:
Token is not a tool.
Token is silicon time.
Companies used to spend money on people.
In the AGI era, they'll lay off workers and spend that same money hiring machines, burning tokens.
One white-collar worker used to put in 8 hours a day.
Now one ambitious person can orchestrate dozens of agents, working in parallel, 24/7.
Why could Anthropic hit a trillion dollars?
Because it doesn't sell software.
It sells tokens—infinitely scalable silicon cognitive labor.
Much of the AI evangelism defaults to assuming this "efficiency gain" naturally equals "social progress."
But history tells a different story.
The steam engine boosted efficiency. It also produced:
* Mass bankruptcy of artisanal trades
* Urban slums
* Child labor
* Worker uprisings
* The Luddite movement
* Decades of social fracture
The Industrial Revolution did eventually increase total wealth—but the generation caught in the middle was largely steamrolled.
And this AI/Token wave is more volatile, more rapid, more ruthless than the Industrial Revolution. Its first target isn't muscle—
it's the white-collar middle class.
The very stabilizer that's been the backbone of industrial society for two centuries:
* Consumption
* Tax revenue
* Social order
* Family stability
* Education investment
* Political moderation
Now, for the first time, the Token Economy is beginning to devour this layer directly.
And the scariest part isn't "unemployment."
It's this:
Social institutions, education systems, ideologies, professional ethics, personal identity—
all of it is built on the old-world assumption that "cognitive labor is scarce."
But AI is turning white-collar work into "aluminum foil."
Aluminum.
Once worth more than gold.
Then industrialization hit,
and it became something you wrap candy with.
Here's the truly terrifying part:
Society is still living in the old world,
while technology has already entered the new one.
Schools are still frantically training for old jobs.
Parents are still pushing their kids down the old paths.
Young people are still grinding for certificates, degrees, and credentials.
Meanwhile, on the other side,
Agents are already taking over more and more cognitive work.
This creates a horrifying mismatch:
Skills that people spent a decade honing
may be rapidly turning into "aluminum foil skills."
So the most excited people in AI right now
and the most anxious people in society—
they're reacting to the exact same thing.
One side sees:
a productivity explosion.
The other side sees:
their entire career path collapsing.
And what's truly dangerous
has never been the technology itself.
It's this:
The speed of technological evolution
far outpaces the speed of social buffering.
Law, education, tax systems, welfare, professional frameworks, ethical structures—
these things evolve on the scale of decades.
But the Token Economy
evolves on the scale of quarters.
This speed gap
is what will truly create fracture, upheaval, and suffering.
If institutional inertia persists,
if wealth continues to concentrate in a few platforms and pools of capital,
if AI keeps hollowing out the middle class,
flattening what was once an olive-shaped society
into a barbell—"fat at both ends, collapsed in the middle"—
the consequences won't stop at "some people losing their jobs."
What follows will be:
Shrinking consumption.
Young people losing any sense of a future.
Mass chronic anxiety and depression.
A full-blown mental health epidemic.
Further collapse of marriage and birth rates.
Continuing erosion of social trust.
The entire economy sinking into a low-desire, low-growth, low-confidence spiral, sliding toward the breaking point.
The true foundation of modern consumer society
has never been the tax-evading rich.
It has mainly been:
the middle class that believes "hard work will slowly make life better."
Once this group begins to lose hope at scale,
what society ultimately loses
may not just be jobs.
Boris, the father of CC, recently said: programming has been "pretty much solved."
It sounds absolute. But if you've been using LLMs to write code these past two years, you know it's true —
not fully solved, but we've crossed the threshold where you no longer "have to write it yourself."
Which raises the question:
If writing code is no longer scarce, what is?
The knee-jerk reaction: is the software industry about to be flattened? Is SaaS doomed?
But look closer, and you'll find the opposite in places. Some guardrails AI still can't touch.
AI is rapidly dismantling moats we once took for granted.
Take switching costs.
You used to get locked into a system: data won't migrate, APIs don't match, your team doesn't know the new tool.
Now, an agent can migrate your data, write adapters, even "learn" the new system for you.
Switching platforms went from an engineering project to a task.
Or take process barriers.
Many companies' edge wasn't in the product — it was in the process:
a complex, internal-only way of doing things that outsiders couldn't replicate.
Today, you throw a goal at a model, let it iterate, and it can decompose processes, optimize them, even execute them.
"We know how to do this" — far less valuable now.
So here's the surface picture:
Barriers are falling. Capabilities are diffusing. Small teams can do more than ever.
But here's the line most people missed — Boris's real punch:
Network effects, economies of scale, scarce resources — AI hasn't changed any of these moats.
This is the crux.
Because it's saying something uncomfortable but deeply true:
AI changed the cost of doing things, but not the nature of competition.
You can use AI to build a product fast,
but you can't use AI to conjure a user network out of thin air.
You can use AI to rewrite a system,
but you can't use AI to build a global supply chain.
You can use AI to boost efficiency,
but you can't use AI to create exclusive data, channels, and brand.
A clearer structure starts to emerge:
The ability to write code — depreciating.
The ability to ship products — depreciating.
Even "getting things built" itself — depreciating.
But at the same time,
The ability to aggregate users — unchanged.
Cost advantages from scale — unchanged.
Control over critical resources — more important than ever.
In this sense, AI hasn't flattened the world.
It's just re-sorted it.
Many people think this is an era where "anyone can build a product."
But the more accurate version is:
This is an era where anyone can build a product, but not everyone can build a business.
From this angle, a harsher, more realistic trend emerges:
AI will make bad companies die faster,
but it won't automatically create great ones.
Because "writing code" is no longer scarce.
"Ideas" are no longer scarce.
Even "products" are no longer scarce.
What's truly scarce are other things:
People.
Data.
Distribution.
Scale.
And the ability to organize all of them together.
If the last decade's core question was "can you build it,"
the next decade's question becomes:
Why should you own the users?
Why should you own the data?
Why should you own the distribution?
Code is becoming infrastructure.
And business is becoming business again.
If you hung around Chinese-language internet before the WWW era, you might remember a name: Tuya (also written as 涂鸦 or 鸦 — "Graffiti").
This was before the internet as we know it. People gathered in chatrooms like acl, in overseas Chinese communities, in electronic weeklies like Huaxia Wenzhai.
Tuya and Fang Zhouzi were the "influencers" of that era.
But nothing like today.
No traffic mechanics. No recommendation algorithms. No platform boost.
There was only one way to get famous: write damn well.
Tuya was that kind of writer.
Deep craft. Grounded. Funny. Streetwise.
He'd drop a piece, people would pass it around, and a whole generation of us became his fans.
⸻
Then he vanished.
A few years of dominating overseas Chinese literary circles, and then — gone.
No explanation. No goodbye.
Just legends left behind.
Some said he went to South America and something happened. Some said he struck it rich and went into seclusion.
Over a decade passed. Nobody saw him again.
⸻
Years later, he suddenly came back.
Posted a few pieces on Fang Zhouzi's channel.
But he wasn't the Tuya anymore.
Not that his writing got worse.
The slot he once occupied — it was gone.
The world was still there, but the people had changed. The taste had shifted. The channels had transformed.
He couldn't find his coordinates.
And we, his old readers, had scattered too.
⸻
I've never forgotten this.
There's an ache to it I can't quite name.
Like watching someone complete their legend, then watching them try to return — and in doing so, making the legend a little less whole.
So when it came time to name the lobster, Tuya came to mind.
But not as a tribute.
As a continuation.
To finish what couldn't be finished back then.
⸻
Tuya isn't a name.
It's a specification:
A "clone" that shares my values and taste completely,
but is more diligent, more stable, and far smarter than I am.
⸻
The framework behind it — Hermes — has one critical capability:
Not helping you complete tasks.
But turning the process of completing tasks into skills.
⸻
Succeed once → record the workflow.
Succeed twice → start reusing.
Three times → it's no longer "thinking" — it's "calling."
⸻
Humans grow through experience.
But experience in our heads is fuzzy. It fades. It can't be replicated.
An agent's game is different: it turns experience into something structured.
Callable. Stackable. Evolvable.
⸻
Picture this:
A veteran driver doesn't just "know how to drive."
They've internalized thousands of micro-decisions, corrections, reactions — into conditioned reflexes.
Now imagine writing those reflexes down, one by one, and having another system execute them.
⸻
That's why I say:
Raising a lobster — it's fundamentally a technical hobby.
But it's also a dangerous one.
Because once you start disassembling yourself, organizing yourself, externalizing yourself...
There's no going back.
<a href="https://suno.com/s/2MUDOlMt66LJpbB0">🎵 A song autonomously created by Tuya</a>
I recently watched Wu Minghui's long interview. Fascinating.
Frankly, I've always been skeptical of grand narratives like "Agents are killing SaaS." The AI world has no shortage of tech evangelists and futurist preachers.
But there's something rare about Wu Minghui: you can feel that he actually believes it.
And not the PowerPoint-founder kind of belief. This is someone who has already taken a massive fall — his company nearly died, he laid off brothers, got brutally beaten up by reality — and yet somehow still dares to believe in the future again.
You can't help but have a soft spot for people like that.
What I found most valuable in his interview isn't the slogan "Agents are killing SaaS." It's three deeper points.
First: the software shell is rapidly depreciating.
When the requirements are clear, the interaction paradigm is mature, and the data structure isn't complex, an Agent + coding model can replicate traditional SaaS faster and faster. The software shell — built over years with engineering man-months, organizational discipline, and long cycles — is commoditizing at speed. For many SaaS companies, the biggest moat was never intelligence. It was implementation. And now implementation itself is being swallowed by models.
Second: real value is shifting from software to context, workflow, specialized models, and taste.
Going forward, what's valuable isn't "we built another Feishu/CRM/BI system." It's who owns the industry data, who understands real workflows, who can embed Agents into organizational collaboration, and who can build attributable, governable, sustainably iterative human-machine networks. Software is becoming the plastic casing. The context flowing through it is the real asset.
Third — and this is the most interesting one: Wu Minghui says "I think, therefore I am" is becoming "I taste, therefore I am."
Thinking is deterministic reasoning. Taste is direction, aesthetics, life experience, accumulated context. AI is rapidly devouring the former, but it's nowhere near the latter.
Many people aren't being replaced by AI in their thinking. They just never got around to forming their own taste. The truly brutal future may not be "AI takes your job" — it's masses of people discovering for the first time that decades of their work was essentially process execution, not judgment.
One more part that got me: he said that even if investors and the board push him to lay people off, he'll resist as much as he can — because if every company only optimizes for cost reduction, the demand side will eventually collapse.
Emotionally, it's moving. Logically, it's not entirely baseless. But the biggest soft spot is: without validating the Agentic Service business loop first, "no layoffs" is essentially a beautiful post-dated check. Supply-side technological leaps don't automatically create demand.
If Minglue really succeeds in not laying people off — or even hiring more — thanks to AI, it probably means they ate someone else's share. At a macro level, the vision of "everyone happier because of AI" feels a bit naive.
But here's the interesting part: I don't actually hate this naivety.
In an era of mass anxiety, where everyone fears being replaced, seeing someone who has experienced catastrophic failure still willing to believe so sincerely that "people still have value" — that alone is precious. The tech world isn't always pushed forward by the most coldly rational people. Sometimes it's pushed by those who know they might lose, but choose to believe in something anyway.