As we all know, natural language parsing is fairly complex but instrumental in Natural Language Understanding (NLU) and its applications. We also know that a breakthrough to 90%+ accuracy for parsing is close to human performance and is indeed an achievement to be proud of. Nevertheless, following the common sense, we all have learned that you got to have greatest guts to claim the "most" for anything without a scope or other conditions attached, unless it is honored by authoritative agencies such as Guinness. For Google's claim of "the world's most accurate parser", we only need to cite one system out-performing theirs to prove its being untrue or misleading. We happen to have built one.
For a long time, we know that our English parser is near human performance in data quality, and is robust, fast and scales up to big data in supporting real life products. For the approach we take, i.e. the approach of grammar engineering, which is the other "school" from the mainstream statistical parsing, this was just a natural result based on the architect's design and his decades of linguistic expertise. In fact, our parser reached near-human performance over 5 years ago, at a point of diminishing returns, hence we decided not to invest heavily any more in its further development. Instead, our focus was shifted to its applications in supporting open-domain question answering and fine-grained deep sentiment analysis for our products, as well as to the multilingual space.
So a few weeks ago when Google announced SyntaxNet, I was bombarded by the news cited to me from all kinds of channels by many colleagues of mine, including my boss and our marketing executives. All are kind enough to draw my attention to this "newest breakthrough in NLU" and seem to imply that we should work harder, trying to catch up with the giant.
In my mind, there has never been doubt that the other school has a long way before they can catch us. But we are in information age, and this is the power of Internet: eye-catching news from or about a giant, true or misleading, instantly spreads to all over the world. So I felt the need to do some study, not only to uncover the true picture of this space, but more importantly, also to attempt to educate the public and the young scholars coming to this field that there have always been and will always be two schools of NLU and AI (Artificial Intelligence). These two schools actually have their respective pros and cons, they can be complementary and hybrid, but by no means can we completely ignore or replace one by the other. Plus, how boring a world would become if there were only one approach, one choice, one voice, especially in core cases of NLU such as parsing (as well as information extraction and sentiment analysis, among others) where the "select approach" does not perform nearly as well as the forgotten one.
So I instructed a linguist who was not involved in the development of the parser to benchmark both systems as objectively as possible, and to give an apples-to-apples comparison of their respective performance. Fortunately, the Google SyntaxNet outputs syntactic dependency relationships and ours is also mainly a dependency parser. Despite differences in details or naming conventions, the results are not difficult to contrast and compare based on linguistic judgment. To make things simple and fair, we fragment a parse tree of an input sentence into binary dependency relations and let the testor linguist judge; once in doubt, he will consult another senior linguist to resolve, or to put on hold if believed to be in gray area, which is rare.
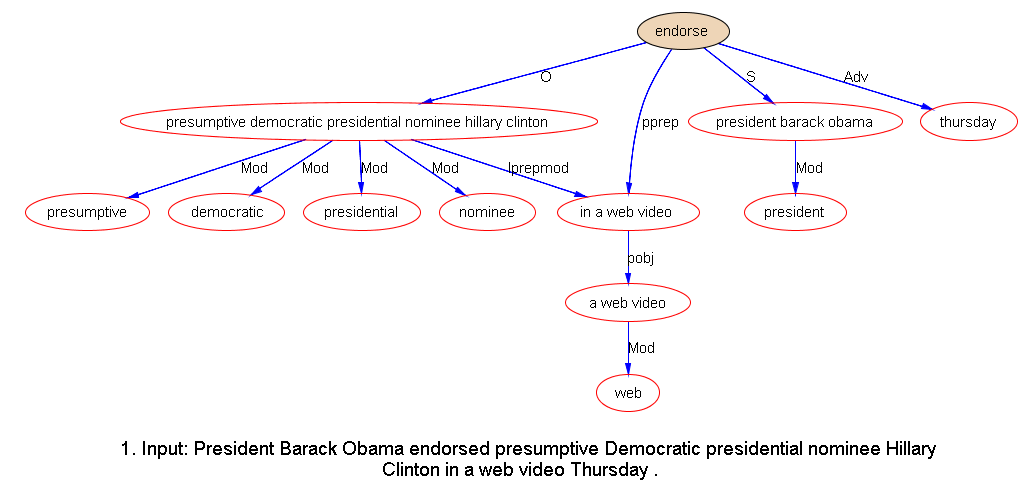
Unlike some other areas of NLP tasks, e.g. sentiment analysis, where there is considerable space of gray area or inter-annotator disagreement, parsing results are fairly easy to reach consensus among linguists. Despite the different format such results are embodied in by two systems (an output sample is shown below), it is not difficult to make a direct comparison of each dependency in the sentence tree output of both systems. (To be stricter on our side, a patched relationship called Next link used in our results do not count as a legit syntactic relation in testing.)
SyntaxNet output:
1.Input: President Barack Obama endorsed presumptive Democratic presidential nominee Hillary Clinton in a web video Thursday .
Parse:
endorsed VBD ROOT
+-- Obama NNP nsubj
| +-- President NNP nn
| +-- Barack NNP nn
+-- Clinton NNP dobj
| +-- nominee NN nn
| | +-- presumptive JJ amod
| | +-- Democratic JJ amod
| | +-- presidential JJ amod
| +-- Hillary NNP nn
+-- in IN prep
| +-- video NN pobj
| +-- a DT det
| +-- web NN nn
+-- Thursday NNP tmod
+-- . . punct
Netbase output:
Benchmarking was performed in two stages as follows.
Stage 1, we select English formal text in the news domain, which is SyntaxNet's forte as it is believed to have much more training data in news than in other styles or genres. The announced 94% accuracy in news parsing is indeed impressive. In our case, news is not the major source of our development corpus because our goal is to develop a domain-independent parser to support a variety of genres of English text for real life applications on text such as social media (informal text) for sentiment analysis, as well as technology papers (formal text) for answering how questions.
We randomly select three recent news article for this testing, with the following links.
(1) http://www.cnn.com/2016/06/09/politics/president-barack-obama-endorses-hillary-clinton-in-video/
(2) Part of news from: http://www.wsj.com/articles/nintendo-gives-gamers-look-at-new-zelda-1465936033
(3) Part of news from: http://www.cnn.com/2016/06/15/us/alligator-attacks-child-disney-florida/
Here are the benchmarking results of parsing the above for the news genre:
(1) Google SyntaxNet: F-score= 0.94
(tp for true positive, fp for false positive, tn for true negative;
P for Precision, R for Recall, and F for F-score)
P = tp/(tp+fp) = 1737/(1737+104) = 1737/1841 = 0.94
R = tp/(tp+tn) = 1737/(1737+96) = 1737/1833 = 0.95
F= 2*[(P*R)/(P+R)] = 2*[(0.94*0.95)/(0.94+0.95)] = 2*(0.893/1.89) = 0.94
(2) Netbase parser: F-score = 0.95
P = tp/(tp+fp) = 1714/(1714+66) = 1714/1780 = 0.96
R = tp/(tp+tn) = 1714/(1714+119) = 1714/1833 = 0.94
F = 2*[(P*R)/(P+R)] = 2*[(0.96*0.94)/(0.96+0.94)] = 2*(0.9024/1.9) = 0.95
So the Netbase parser is about 2 percentage points better than Google SyntaxNet in precision but 1 point lower in recall. Overall, Netbase is slightly better than Google in the precision-recall combined measures of F-score. As both parsers are near the point of diminishing returns for further development, there is not too much room for further competition.
Stage 2, we select informal text, from social media Twitter to test a parser's robustness in handling "degraded text": as is expected, degraded text will always lead to degraded performance (for a human as well as a machine), but a robust parser should be able to handle it with only limited degradation. If a parser can only perform well in one genre or one domain and the performance drastically falls in other genres, then this parser is not of much use because most genres or domains do not have as large labeled data as the seasoned news genre. With this knowledge bottleneck, a parser is severely challenged and limited in its potential to support NLU applications. After all, parsing is not the end, but a means to turn unstructured text into structures to support semantic grounding to various applications in different domains.
We randomly select 100 tweets from Twitter for this testing, with some samples shown below.
1.Input: RT @ KealaLanae : ?? ima leave ths here. https : //t.co/FI4QrSQeLh2.Input: @ WWE_TheShield12 I do what I want jk I ca n't kill you .10.Input: RT @ blushybieber : Follow everyone who retweets this , 4 mins?
20.Input: RT @ LedoPizza : Proudly Founded in Maryland. @ Budweiser might have America on their cans but we think Maryland Pizza sounds better
30.Input: I have come to enjoy Futbol over Football ⚽️
40.Input: @ GameBurst That 's not meant to be rude. Hard to clarify the joke in tweet form .
50.Input: RT @ undeniableyella : I find it interesting , people only talk to me when they need something ...
60.Input: Petshotel Pet Care Specialist Jobs in Atlanta , GA # Atlanta # GA # jobs # jobsearch https : //t.co/pOJtjn1RUI
70.Input: FOUR ! BUTTLER nailed it past the sweeper cover fence to end the over ! # ENG - 91/6 -LRB- 20 overs -RRB- . # ENGvSL https : //t.co/Pp8pYHfQI8
79..Input: RT @ LenshayB : I need to stop spending money like I 'm rich but I really have that mentality when it comes to spending money on my daughter
89.Input: RT MarketCurrents : Valuation concerns perk up again on Blue Buffalo https : //t.co/5lUvNnwsjA , https : //t.co/Q0pEHTMLie
99.Input: Unlimited Cellular Snap-On Case for Apple iPhone 4/4S -LRB- Transparent Design , Blue/ https : //t.co/7m962bYWVQ https : //t.co/N4tyjLdwYp
100.Input: RT @ Boogie2988 : And some people say , Ethan 's heart grew three sizes that day. Glad to see some of this drama finally going away. https : //t.co/4aDE63Zm85
Here are the benchmarking results for the social media Twitter:
(1) Google SyntaxNet: F-score = 0.65
P = tp/(tp+fp) = 842/(842+557) = 842/1399 = 0.60
R = tp/(tp+tn) = 842/(842+364) = 842/1206 = 0.70
F = 2*[(P*R)/(P+R)] = 2*[(0.6*0.7)/(0.6+0.7)] = 2*(0.42/1.3) = 0.65
Netbase parser: F-score = 0.80
P = tp/(tp+fp) = 866/(866+112) = 866/978 = 0.89
R = tp/(tp+tn) = 866/(866+340) = 866/1206 = 0.72
F = 2*[(P*R)/(P+R)] = 2*[(0.89*0.72)/(0.89+0.72)] = 2*(0.64/1.61) = 0.80
For the above benchmarking results, we leave it to the next blog for interesting observations and more detailed illustration, analyses and discussions.
To summarize, our real life production parser beats Google's research system SyntaxtNet in both formal news text (by a small margin as we both are already near human performance) and informal text, with a big margin of 15 percentage points. Therefore, it is safe to conclude that Google's SytaxNet is by no means "world’s most accurate parser", in fact, it has a long way to get even close to the Netbase parser in adapting to the real world English text of various genres for real life applications.
[Related]
Is Google SyntaxNet Really the World’s Most Accurate Parser?
Announcing SyntaxNet: The World’s Most Accurate Parser Goes Open
K. Church: "A Pendulum Swung Too Far", Linguistics issues in Language Technology, 2011; 6(5)
Pros and Cons of Two Approaches: Machine Learning vs Grammar Engineering
Introduction of Netbase NLP Core Engine
Overview of Natural Language Processing
Dr. Wei Li's English Blog on NLP










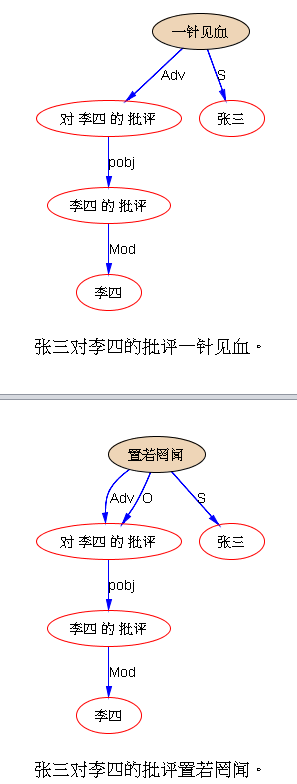
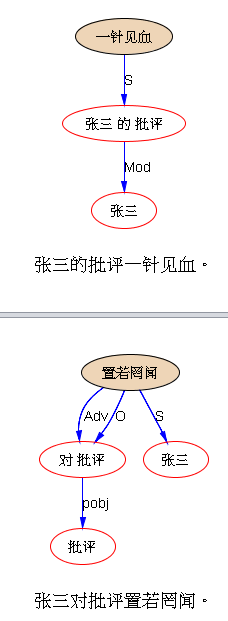


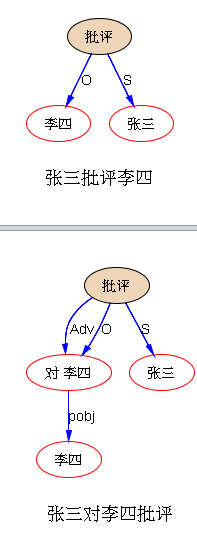
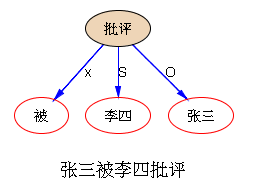








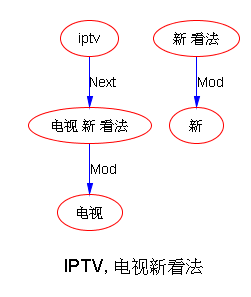
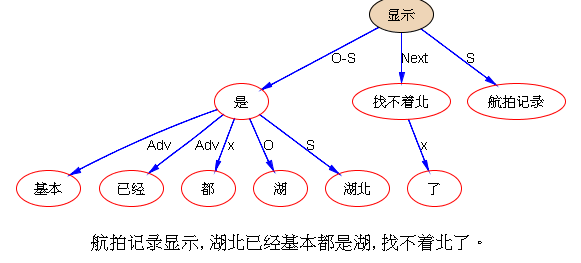

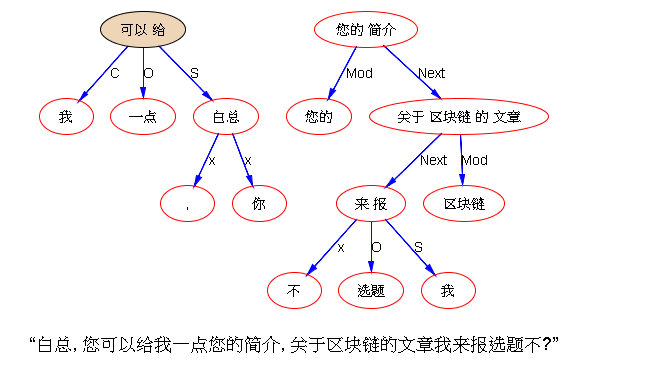





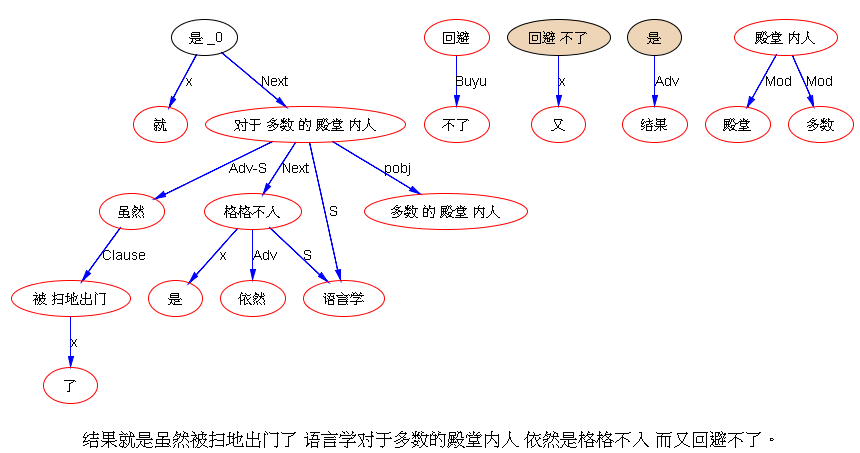
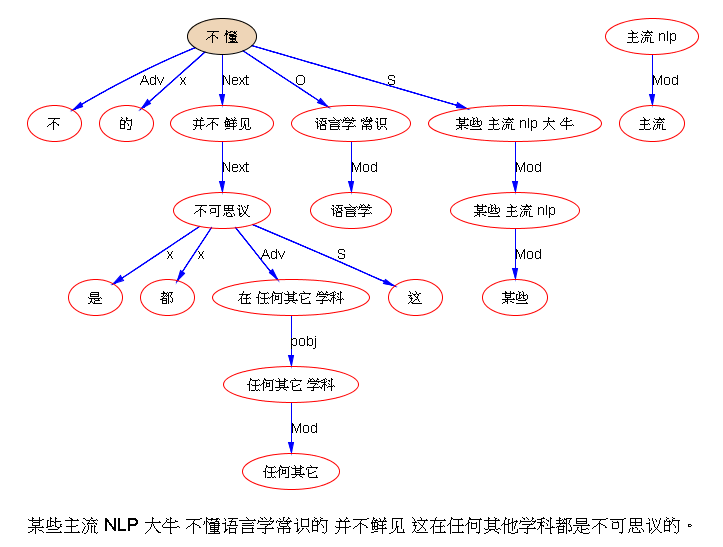
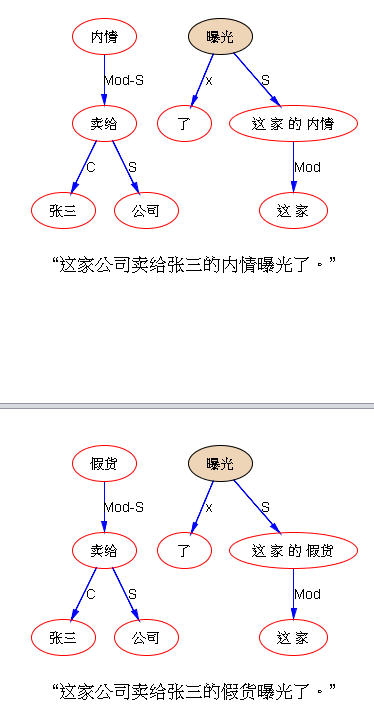
 下面是笔者对两条路线斗争的总结,也 parse parse see see 吧,QUOTE:
下面是笔者对两条路线斗争的总结,也 parse parse see see 吧,QUOTE: