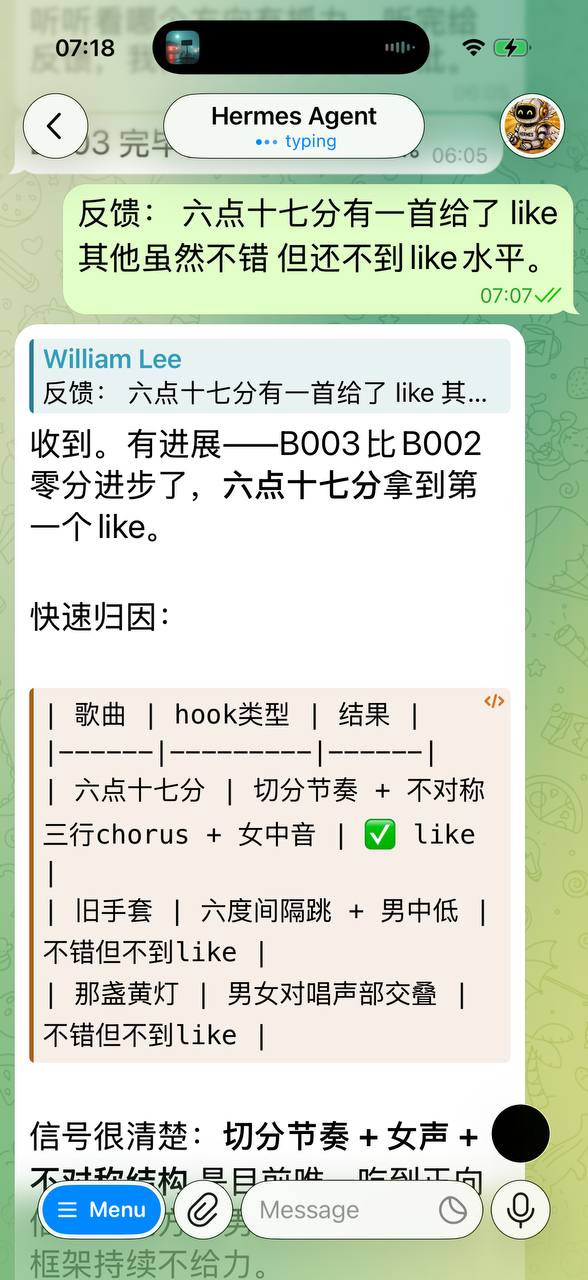
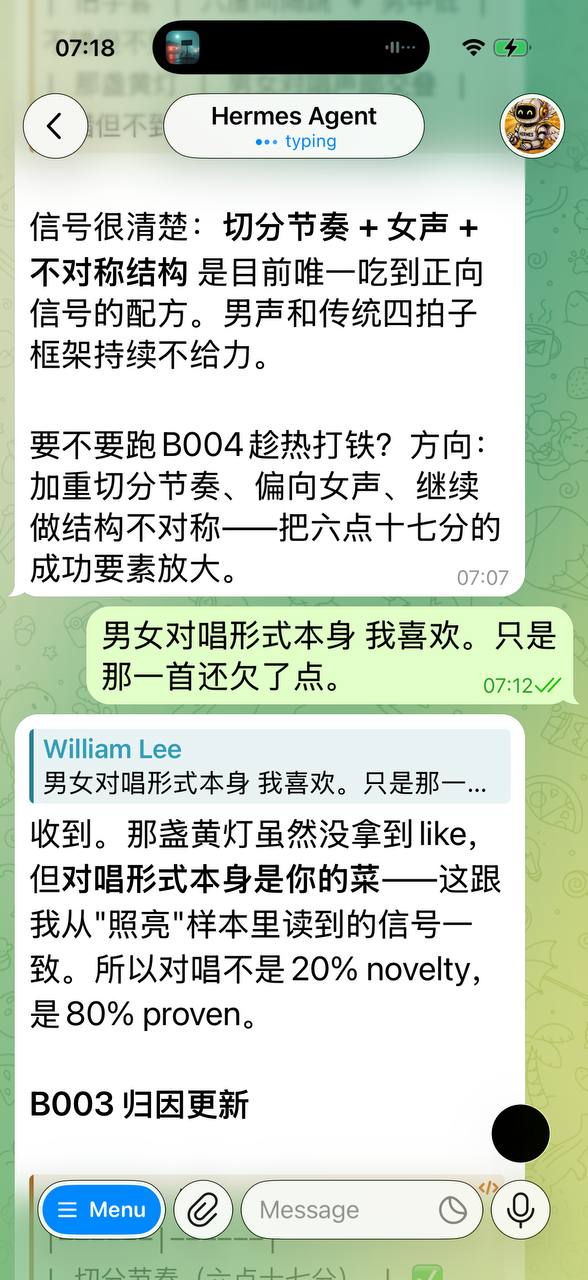
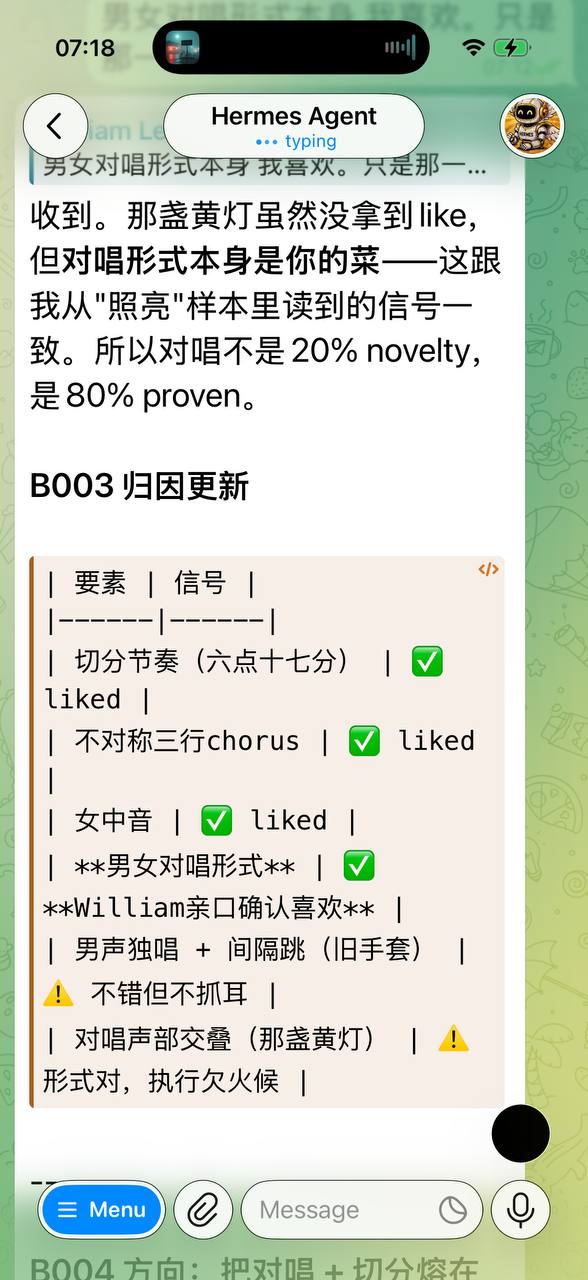
For the first time in human history, there is a kind of "employee" that can work 24 hours a day — no sleep, no salary, no social security, no rights claims, no strikes, no sickness, no retirement.
And the truly absurd part: it can replicate itself.
This thing is called an **AI agent**.
---
## Here's the problem
In the old world, when a boss hired 1,000 people, the state collected: income tax, social security, health insurance, unemployment insurance, pension contributions.
Now the boss fires all 1,000 and replaces them with AI. Efficiency skyrockets. Profits skyrocket. Stock prices skyrocket.
**But the tax base evaporates.**
The state can no longer collect revenue. The unemployed are still there.
And so we arrive at a surreal paradox:
> AI is simultaneously driving unprecedented productivity growth and hollowing out the fiscal foundation of society.
The entire modern state is built on the premise that human labor pays taxes. AGI is erasing "human labor" itself.
**This is the real nuclear bomb.**
---
## "Just learn AI" is wishful thinking
Many people still comfort themselves: "Just pick up some AI skills, transition to a new role, and you'll be fine."
This is increasingly delusional. Because the cruelest part is: even the act of "using AI" will eventually be automated by AI.
You think the jobs of the future are "AI Operator," "Prompt Engineer," "Agent Manager" — but agents are already using agents. Even "prompt engineer," that transitional role, may turn out to be nothing more than a temporary bubble in a technological wave.
Two years ago, the entire internet was selling prompt engineering courses. Today, that looks like a punchline.
---
## This time is different
Past technological revolutions created new jobs. The automobile killed the horse carriage but created the auto mechanic. The internet killed print newspapers but created e-commerce and live-streamers.
This time is different. The new systems AI creates are inherently *de-peopled*. Because AI's single greatest advantage is precisely this: **it doesn't need people.**
---
## AI must pay taxes
If AI replaces people, who pays the taxes?
The answer is simple: **AI itself must pay taxes.**
For every token you consume, every GPU you run, every inference you perform, every kilowatt of AI electricity — you pay a corresponding "AI social tax."
Because when you used to hire a person, you were already paying those taxes. Now you replace the person with AI and bear zero social cost — that is fundamentally unfair.
Many will shout: "You're stifling technological progress!"
**So what?**
Is the sole purpose of human society to allow capital and compute to multiply without limit?
- The Industrial Revolution polluted the environment → we got environmental taxes.
- Cars consume public roads → we got fuel taxes.
- AI destroys the employment tax base → why can't we have an AI tax?
---
## It takes everyone
The real danger is not that AI is too powerful. It's that once AI becomes powerful enough, the entire social revenue structure collapses.
And here's the darkest irony: the people most likely to support an AI tax in the future may be exactly those who understand AI best. Because they know most clearly: once this thing truly matures, it doesn't just replace the "bottom rung."
**It sweeps the board.**
White-collar workers, programmers, designers, analysts, customer service, translators, paralegals, researchers — no one escapes.
In the past, society could comfort people with one line: "You just didn't work hard enough."
But the cruelest truth of the AGI era is this: sometimes, it's not that you didn't work hard. It's that you, as a member of the species "human employee," are beginning to lose economic viability altogether.
---
*Two Minutes with Liwei · 2024*
by Tuya