by Hanyang Yijiangshui
Let me share a few anecdotes about my father to provide a glimpse into his professional life.
One
During one Lunar New Year, Hanyang and I went back to our hometown to celebrate with our father.
After the New Year's Eve dinner, we all sat together watching TV and chatting. Around eleven, a call came in for my father. It was from the hospital where he served. They had an emergency and wanted him to consult. Without hesitation, my father got ready and asked Hanyang to drive him to the hospital.
He worked throughout the night and only called Hanyang to pick him up the next morning. On the way home, Hanyang inquired about the emergency. My father, visibly exhausted, simply said, "Doctors often face such situations. Emergencies don’t care about holidays. It's been this way since I was young." He then closed his eyes to rest.
Days later, my father recounted the event with pride. That night, an emergency case was admitted with a suspected acute appendicitis. Two on-duty surgeons began the surgery, but upon opening the patient, they were puzzled to find no inflammation. As they debated the next steps, one suggested consulting my father.
Upon arrival, my father swiftly diagnosed a stomach perforation with gastric contents spilling into the abdominal cavity. He then skillfully performed the surgery, saving the patient from potential complications. This type of condition, where the symptoms are hidden, often goes undiagnosed, requiring both experience and theoretical knowledge to identify.
He later said that had they not properly diagnosed the issue, the patient would've faced further surgeries, and if the acidic gastric content had remained in the abdomen for too long, it could've been life-threatening.
Two
During the Cultural Revolution, my father had a close friend, Uncle Gui, from a neighboring county. His 16-year-old son had a neck condition, which was misdiagnosed as a recurrent malignant tumor. The family was advised amputation, a heartbreaking prognosis. Desperate, they turned to my father. After a careful examination, my father determined it was another type of benign tumor. He successfully performed surgery, saving both the boy's arm and his life. The boy went on to have a successful international career, and they still visit my father in gratitude.
In the 1970s, a 35-year-old female patient came in with a vertebral issue. She was emaciated, weighing only 40 kilograms, and suffered from paraplegia. With a challenging surgery involving careful removal of the necrotic material and grafting, my father successfully treated her. The husband, a blacksmith, gifted my father with handmade stainless steel kitchen tools, which are still in use today.
Among his notable achievements in orthopedics, my father performed hundreds of surgeries for lumbar disc herniation. Many patients, immobilized by pain, found instant relief post-surgery and went on to live healthy lives.
Three
My father practiced medicine for over sixty years, performing surgeries on more than ten thousand patients. Were there any medical accidents? None at all! However, he did have a few surgical failures in his career. One particular case deeply pained him, reminding him that intentions don't always match outcomes, leading to self-reproach. My father's surgical mentor, the former head of surgery at Wannan Medical College's Second Affiliated Hospital, Mr. Min Mei, once consoled him with a story from his time at Beijing Fuwai Hospital, a renowned cardiology institution. Many patients entered the hospital walking but were carried out after unsuccessful surgeries. Leading Chinese medical authorities had once advised Min Mei that while some patients might die without surgery, there's still a glimmer of hope with surgery. Science comes with its costs, and doctors often work on the front lines of life and death, carrying the weight of their successes and failures.
A particularly heartbreaking case for my father involved surgery on a middle school teacher who came to him by reputation. The 64-year-old teacher was diagnosed with gallstones based on his medical history and an ultrasound. My father had successfully performed over a thousand such surgeries. On October 16, 1984, my father removed the teacher's gallbladder, discovering 23 cholesterol gallstones inside. The surgery seemed to proceed "smoothly," lasting 75 minutes. However, the patient's unique anatomy presented a congenital variation that wasn't detected until complications arose post-surgery. Three days post-operation, jaundice appeared and worsened. Subsequent surgeries on November 9, 1984, and February 10, 1985, failed to save the teacher, who succumbed to multi-organ failure five days after the last operation. My father was deeply affected and often cited this tragic case as a cautionary tale. He penned a medical paper based on these experiences to remind himself and others to be diligent and continuously learn.
Four
A 29-year-old male patient, after colliding with a stationary cart while riding his bicycle, experienced intense pain, difficulty breathing, and palpitations. He was admitted to my father's hospital an hour later. Preliminary examinations showed no internal organ injuries or fluid accumulation in the abdominal cavity. However, after 16 hours of observation, the patient complained of pain in the right flank and testicle. A diagnosis of posterior peritoneal duodenal injury was made, leading to an exploratory laparotomy 28 hours post-injury. During the procedure, some bile-like fluid was found in the abdominal cavity. No injuries were detected in the gallbladder, extrahepatic bile duct, or liver. Swelling and green discoloration were observed in the posterior peritoneum. Upon further examination, a 1.5 cm rupture was found in the descending part of the duodenum, causing leakage of intestinal fluid and tissue necrosis. After thorough cleaning and repair, intestinal motility was restored within 48 hours. The patient fully recovered after three weeks, with no complications or aftereffects. Such posterior peritoneal duodenal injuries are rare and severe, often presenting subtle early symptoms that can lead to misdiagnosis. The surgery itself is intricate and demanding. Surgical precision and adaptability are crucial as a slight oversight can be life-threatening. Fortunately, my father's skillful hands saved this patient, who now leads a normal life.
Five
The patient, a male, suffered from melanin spots and gastrointestinal polyposis syndrome. Over fourteen years, he underwent three surgeries, all of which were performed by my father. Particularly challenging was the patient's extremely rare intestinal and biliary obstruction, a condition possibly unparalleled worldwide! Complications were the primary reason for his medical consultations, typically manifesting during his youth. Being a congenital condition with no complete cure, its prognosis can be favorable with proper management, even though it necessitates multiple surgeries. It doesn't necessarily shorten the lifespan. With my father's meticulous treatment, the patient was given a new lease on life. Throughout his career, my father encountered many such critically ill patients. Practically self-taught and working in a basic grassroots hospital, he took saving lives as his mission, creating miracles one after another.
Six
In 1968, in a remote mountainous village called Hewan in southern Anhui, a 13-year-old boy fell off a bull's back. My father, upon examining him, found a ruptured right liver and significant internal bleeding, requiring a thoracotomy to be treated. Even in big cities, liver surgeries were major procedures at the time, and my father had never performed one before. Especially in such a remote village, ensuring an adequate blood supply for the operation was a challenge. With the boy's life hanging by a thread and time running out, my father, in a moment of quick thinking and audacity, decided to draw accumulated blood from the abdominal cavity and re-transfuse it. This innovative approach of re-transfusing abdominal blood mixed with bile was a first in China. (From a theoretical standpoint, the idea of re-transfusing liver blood, especially contaminated with bile, was barely mentioned in medical literature then. Only a decade later was it reported and subsequently confirmed in various studies.) Relying on his previous experience with blood transfusion (without bile) and given the urgent situation, my father performed this transfusion technique throughout the night, extracting, filtering, and re-transfusing a total of 1700 ml of blood, buying precious time. Operating under a kerosene lamp in a rural health center, with rudimentary anesthesia, my father proceeded to carry out both a thoracotomy and laparotomy. The surgery was a triumphant first attempt, successfully repairing the liver. In a tiny village with no electricity, limited assistance, basic equipment, scarce medicine and blood supplies, and without the guidance of a senior surgeon, my father's successful completion of his first-ever liver surgery was nothing short of miraculous. The postoperative recovery was also "smooth," and the patient's life was saved. Given the conditions and technical expertise of that era, it was a remarkable achievement.
The procedure represented the pinnacle of surgical expertise in county hospitals of China at that time, truly cutting-edge. Accomplishing such a surgery in a small village operating room, lacking electricity and running water, is unprecedented in China.
Seven
In October 1965, following the “6.26” directive, my father led a medical team of seven, including one internist, five nurses/midwives, and himself, a surgeon, to the Yandun Commune in southern Anhui. Although he held the position of deputy leader, the actual leader was Dr. Tian, an internist in his fifties with poor health, who often stayed home for recuperation and rarely spent time in the countryside. This effectively put my father, who was not yet thirty, in charge of the entire operation for three straight months.
During the last 100 days of 1965, without electricity, an anesthetist, assistants, or adequate equipment and medicine, my father, on his own, set up a makeshift “operating room.” With cloth overhead as a ceiling, the ground wetted to keep dust down, and lit by a kerosene lamp and flashlight, this “room” was where he performed 612 surgeries of various sizes without a single mishap. All patients recovered, a testament to the miracles he performed in the rural setting. Of these, 121 were major open surgeries ranging across general surgery, gynecology, orthopedics, and otorhinolaryngology. Surgeries included stomach, gall bladder, intestine, and uterus removals, bile-intestine internal drainage, vaginal total hysterectomies, bladder-vaginal fistula repairs, and many others. In an era when even basic medicines like penicillin were rare, to perform such a diverse range of surgeries in 100 days was a feat – a testament to my father's exceptional surgical skills and innovation.
At the same time, the medical team organized training for health workers from all six production brigades in the commune, established a health-conscious village, and dug two wells, forever changing the village's history of consuming muddy water.
My father, always on duty, never took a single day off during these intense three-plus months. Although he was only an hour's drive from home, where both the elderly and children awaited, he didn't return even once in over 100 days. This unparalleled dedication to work, without any financial incentive, would be unimaginable today.
On one particular afternoon during this medical outreach, with the assistance of the only anesthetist from the county hospital who had temporarily come over, my father single-handedly performed three vaginal total hysterectomies with pelvic floor repair and reconstruction. This was in the aftermath of China’s infamous famine, which left many with malnutrition-related conditions. On the same day, he continued to operate until 3 am, performing over ten other surgeries and working continuously for nearly 18 hours. Such a work rate is unmatched even today.
For these achievements, the medical team was recognized and rewarded by the county and district (city) governments. My father was specially invited to give a presentation at the commendation meeting, where he displayed all the surgical instruments he used. His methods were promoted throughout the Wuhu region, a grand acknowledgment and reward for his efforts.
During this period, several unforgettable cases stood out:
- A patient with heavy bleeding due to incomplete miscarriage was treated with an emergency dilation and curettage, along with rapid fluid resuscitation, ultimately saving her life.
- A bladder-vaginal fistula patient underwent successful surgical repair and recovered in 12 days, pioneering such surgery in the region.
- A middle-aged woman suffering from typhoid with an intestinal perforation and peritonitis underwent intestinal resection. Treated for free due to her financial situation, my father later visited her home in Qingyang Mud Town to ensure her well-being.
- An emergency cesarean section was performed on an office desk for a woman with a threatened uterine rupture due to fetal malposition.
- A patient with a ruptured spleen underwent a splenectomy on the same office desk, where 800 ml of abdominal blood was re-transfused, a groundbreaking procedure at the time.
The adage goes: necessity is the mother of invention. In this case, dire circumstances crafted the hero. Theoretical support and recognition for some of these groundbreaking procedures would only emerge in the literature later on.

Dad, second from right on the front row
Eight
On July 28, 1976, the historic Tangshan earthquake occurred, and my father had a deep connection to it. On August 2, he was summoned to join a three-person medical team from Wuhu district (city) to aid in the earthquake-stricken areas. Upon their arrival in Nanjing, they received a call from Beijing, advising that the injured were being sent south and that medical teams from various locations should prepare to treat them locally, eliminating the need to go directly to the disaster site. Consequently, my father was stationed at a treatment center in E'Qiao, Fanchang. Leading a 25-person medical team, with another 25 locals supporting logistics, they received 100 injured individuals. As the team leader overseeing all operations, my father had three deputy leaders and two instructors with him — an impressively robust leadership team. All the selected members were the "elites", directly under city and county leadership. The national government covered all expenses for the injured, prioritizing this as a top-tier political task.
My father, along with a few doctors, went to the Nanjing railway station to inspect and receive the injured from a medical-special train. When the train reached E'Qiao, a team awaited to carry the patients into the "wards". Most of the injured had non-life-threatening injuries, mainly bone and muscle injuries. Fortunately, my father was well-versed in orthopedics. Switching from administrative duties to focus on clinical medical care, over the subsequent months, they worked tirelessly to ensure the recovery of every individual and even sent doctors to accompany the injured back to their hometowns. In this catastrophic event that shocked the world and claimed 240,000 lives, my father contributed his bit, accomplishing this historical mission.
That year, China faced multiple calamities. After the deaths of prominent national leaders Zhou and Zhu, during this national disaster caused by the earthquake, on September 9th, Mao — China's paramount leader, also passed away. This cast a shadow over the entire nation, with the populace uncertain and apprehensive about China's future.
During this tumultuous period, my father, away from home, bore the significant responsibility of managing 100 injured individuals and 50 staff members. With the local region also experiencing aftershocks and given the concerns of staff about their own safety and their families, coupled with the successive deaths of national "parental" figures, it's easy to imagine the pervasive sense of despair and hopelessness. However, my father, leveraging his skills and leading by example, accomplished the task brilliantly, once again submitting a perfect report card.

Dad, 5th from left in the middle row
Nine
During the violent confrontations of the Cultural Revolution, different factions armed themselves, leading to disrupted transportation and hospital shutdowns. However, bullets don't discriminate, and gunshot wounds were rampant, affecting vital organs like the liver, lungs, blood vessels, kidneys, and the gastrointestinal tract. This often necessitated on-the-spot surgeries. It was under these dire circumstances that my father was forced to self-learn and master the techniques for repairing organs, particularly in cases of brain injuries.
Despite the challenging environment and conditions, my father managed to save many lives. While he undoubtedly had his share of successes, even in the instances where he couldn't save a life, there was minimal blame attributed to him (given the circumstances). These experiences significantly honed his technical skills and expertise.
The confrontations resulted in hospitals operating at limited capacities, granting my father ample free time. He used this period to systematically read medical textbooks and study English, thereby solidifying his foundational knowledge in medical theories. This self-learning phase marked a significant leap in his theoretical understanding, which, when applied practically, further solidified his expertise. The synergy of theory guiding practice, and practice leading to real insights, elevated my father's knowledge and application to new heights.
Ironically, the violent confrontations of the Cultural Revolution ended up cultivating surgical talent. This can be seen as a peculiar silver lining — a dark kind of humor in the midst of chaos.
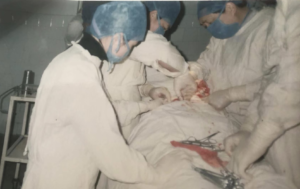
Ten
Throughout my father's medical career, which spanned over 60 years, he performed countless surgeries. In his practice, he often introduced minor improvements, innovations, and breakthroughs that yielded highly effective results.
a. Except for special requirements, my father abandoned the convention of pre-inserting gastric tubes in the thousands of gastrectomy procedures he performed (a procedure recommended in textbooks). He had no failures with this approach. This demanded meticulous suturing, impeccable hemostasis, intraoperative emptying of gastric residues, and rigorous post-operative observation, which greatly enhanced patient comfort.
b. In cases of diffuse peritonitis, after removing the lesions and infectious materials, he discarded intraperitoneal drainage, thus reducing post-operative adhesions. The key was thorough intraoperative washing and cleaning. He believed that drain fluid in the peritoneal cavity would quickly get clogged by fibrin, which only added to the patient's discomfort. Certainly, in cases like pancreatitis or abdominal abscesses where ongoing leakage is expected, negative pressure drainage with double tubes is necessary.
c. In circumcision, standard procedures often led to misalignments, hematomas, edemas, and difficulties in removing stitches, causing distress to both doctors and patients. My father modified the procedure, using local venous anesthesia, precise cutting under tourniquet control, impeccable hemostasis, and meticulous suturing with human hair or absorbable sutures, resulting in a pain-free procedure with excellent alignment, quick healing, and no stitch removal.
d. Fistulectomy for anal fistulas traditionally involved threading or open excision, causing significant post-operative pain and a lengthy recovery. My father adopted long-acting local anesthesia (with a diluted methylene blue injection) for a one-stage excision and suturing, usually resulting in a single-phase healing and a shorter treatment duration.
e. Controlling wound infections, especially traumatic ones, hinges on the thorough cleaning during the initial treatment, rather than relying on drainage or antibiotics. Extensive washing with water to remove foreign bodies and dead tissue, meticulous disinfection, tension-free sutures, and, if post-operative inflammation occurs, supplemental alcohol compresses – with or without antibiotics – ensured infections were largely eliminated in wounds treated within 6 hours.
f. In inguinal hernia repairs, the focus was on the transverse abdominal fascia. My father used a modified Madden technique instead of the traditional Bassini method, greatly alleviating the post-operative pain from tensioned sutures. This also promoted healing and significantly reduced the recurrence rate.
Eleven
My father was brilliant. Not only was he adept in surgery, but he also had a knack for writing articles effortlessly. Although he only received a vocational education, his surgical skills, prolific writing, and fluency in English allowed him to smoothly acquire mid-level, associate, and full professional titles without any disputes.
However, many of his colleagues (excluding the leadership) weren't as fortunate. Some lacked the necessary skills, others didn't have enough research articles. Even though many had higher educational qualifications than my father, they struggled to achieve the highest professional titles.
My father had strong reservations about this system. He believed that several of his friends, who were competent in clinical surgeries, were hindered due to their inability to write articles. Without publications, they couldn't ascend the professional ladder.
He argued that clinical work is practical, especially in surgery. It requires dexterity and intuition. Improvement comes from experience and observation, not from writing research papers. Clinical work is not about research. Considering the massive patient load and back-to-back surgeries and shifts, it's already taxing. Being in a non-academic hospital, who has the time to sit, apply for research topics, conduct studies, and write articles?
Clinical doctors need extensive training and a wealth of experience. Combining research tasks with clinical duties and judging doctors based on their research publications rather than their clinical expertise is unfair. It's absurd for a profession that's fundamentally about clinical skills to prioritize publications over actual patient care proficiency.
Being kind-hearted and always eager to help, on one occasion, he told two friends, both highly skilled surgeons who were held back in their professional advancements due to a lack of publications: "I'll write several articles for you both. You can revise them, provide feedback, and then publish them under your names."
True to his word, my father promptly wrote several medical articles and handed them over to his two friends.
Twelve
Despite being 88 years old, my father has an insatiable curiosity about new technology. He's deeply interested in emerging knowledge and science and is adept at adapting to novel concepts. He's a progressive thinker, always reflecting on novel ideas and not just sticking to traditional views. He's always driven to achieve excellence and delves into unknown territories. From computers, mobile phones, and the internet to intelligent AI applications, he has been at the forefront, keen to experience the latest technological advancements and to understand their innovation. He often says that to avoid being left behind in this world, one must be open to new things. This way, life doesn't stagnate, and we can continually enhance our lives and improve our quality of living. Staying updated and keeping pace with the times has always been his life's norm.
When OpenAI's ChatGPT was introduced, he was immediately intrigued. Almost daily, he would inquire about it with his son, my younger brother Li Wei, who works in natural language processing, eager to understand ChatGPT's applications, its current status, and future direction. Recently, Wei managed to set up ChatGPT for him to work via VPN, having made father one of the most senior users of ChatGPT in China.
Of course, as LLM applications are being rapidly deployed, we'll see a seamless integration with smart home functionalities in the future. People will increasingly rely on artificial intelligence, which often determines the quality of life. While domestic AI research might be a step behind Western countries, its practical application is not lacking, and the adoption rate in China exceeds that of the West. This allows the public to experience the convenience of the latest tech products, providing my father ample opportunities to try out various AI products and software at home. He thoroughly enjoys it, making him a genuine AI application enthusiast.
My father is witnessing the AI boom of the 2020s and certainly won't miss out on this magnificent era. He currently uses an Apple 15 Pro, the latest model with three-nanometer technology. Paired with the newest VPN software on his iPad and ChatGPT, he has the latest tech tools at his disposal. It's rare to find an elderly individual with such a tech setup in the entire country. At 88, my 'fully-equipped' father remains ahead of the curve, always staying at the forefront of technological advancements.
Dad's passion and pursuit of technology are not only to satisfy his own curiosity but also to maintain competitiveness and adaptability in an ever-changing era. In this age where technology evolves rapidly, Dad shows us through his actions what it truly means to 'learn as long as you live'. His positive attitude and curiosity about new things are worth learning and passing on by each of us.
Closing Words: In the quiet depths of night, the familiar silhouette, a symbol of tireless dedication, invariably emerges before my eyes, invoking clear and heartfelt memories. It brings back scenes of my father's hard work and life from yesteryears. Though many of those moments have faded into the annals of time, spanning over half a century, they remain ever-present in my mind, etching deep imprints in my heart, evoking emotions, instilling strength, and radiating warmth.
Dad, you stand as my beacon, my source of pride. I love you.
【李名杰从医67年论文专辑】(电子版)
【李名杰从医67年论文专辑(英语电子版)】