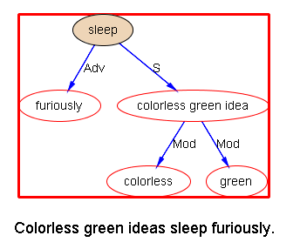
题记:此地有金八百两,隔壁RNN不曾偷。
李:今天我们可以讨论伪句法歧义(pseudo-parses)的问题。我说过,多层 FSA 的 deep parser 不受伪歧义的困扰,虽然这是事实,但也还是需要一个阐释。这个问题是革命的根本问题,虽然文献中很少讲述。
第一章,事实篇。
话说某年某月某日,立委与白老师在微博狭路相逢。其时,立委正海吹深度分析(deep parsing)乃是自然语言之核武器,批评主流只在浅层做文章,摘下的不过是低枝果实(low-hanging fruit)。白老师当时插话说(大意): 你们搞深度分析的不算,你们也有自己的挑战,譬如伪歧义问题。最后留下三个字:你懂的。
各位看官网虫,大凡社会媒体,只要留下这三个字,那就是宣告对手的不上档次,不值得一辩,叫你无还手之力,无掐架之勇,先灭了你的志气。此前,与白老师未有私人交往,更无卡拉ok,江湖上下,白老师乃神人也,天下谁人不知,况青年偶像,粉丝无数。立委见势不妙,战战兢兢,唯唯诺诺:“那自然”。我懂的。心里却颇不以为然:伪歧义其实不是一切深度分析的命门,它只是单层分析的挑战,特别是 CFG (Context-Free Grammar)类 parsers 的困扰。
这是第一章第一节,是锲子。
虽然心里不以为然,但是“我懂的”,却是有丰富的事实依据。骨灰级老革命有一个好处,就是碰壁。无数的碰壁。革命,碰壁,再革命,再碰壁,直至百毒不侵,火眼金睛。老革命可能还有一个好处,就是走运,走狗屎运(譬如赶上上世纪末的网络泡沫,米国的科技大跃进,天上掉馅饼),直至反潮流也没被杀头,硕果仅存。
话说自上世纪80年代社科院出道以来, 就开始做deep parsing, 跟着两位导师,中国NLP的开山前辈,中国MT之父刘先生。他们的几十年的机器翻译积累,在分析这块的传承就是多层模式匹配(multi-level pattern matching)。用 CL术语,就是 multi-level FSA (finate state automata)或 cascaded FSA,有限状态的。我是苦力、主力,新毕业生嘛,为 deep parsing 写了无数个性的词典规则和反复调试精益求精的600条抽象句法规则。埋头拉车,无需抬头看路。从来就没有碰到过什么伪歧义的问题。这是事实一。
事实二发生在我做博士的时候,90年代中期。在风景如画的SFU山头上。当时我的两位导师,电脑系的 Fred 和 语言系的 Paul 合作开了一个自然语言实验室。这两位博导虽也绝顶聪明,但毕竟还年轻。在 NLP 场面上,需要站到一条线上,才好深入。实际上,他们是加拿大 NLP 的代表人物。他们于是选择了当时流行的 unification grammar school (合一文法学派)之一种,就是继 Prolog 以后,开始火起来的合一文法中的后起之秀,名叫 HPSG (Head-driven Phrase Structure Grammar)。这一个小流派,斯坦福是主打,欧洲有一些推崇和践行者,在北美,闹出动静的也包括我的导师的实验室。HPSG 说到底还是 CFG 框架,不过在细节上处处与乔老爷(Chomsky)过不去,但又处处离不开乔老爷。理论上有点像争宠的小妾,生怕得不到主流语言学界乔老爷的正视。
白: 还没进正题
李:白老师嫌拖沓了??现在还在事实篇内。不讲道理。
HPSG 推崇者不少,真懂的怕不多,特别是把 HPSG 用于中文 parsing 方面。看过一些国人不着边际的 HPSG 论,造成了这个印象。这玩意儿得跳进去,才知优劣深浅。当然没跳的也不必跳了,合一(unification)这一路没成气候,现在跳进去也是白跳,浪费时间。HPSG 有一个好处,就是它的词典主义,它实际上就是此前流行的 GPSG 的词典主义版本。NLP 领域各路英豪你争我斗,但有一个很大的共识,就是词典主义,lexicalist approach or lexicalist grammar。这也反映在 HPSG,LFG 等风行一时的文法派中。
我呢,有奶便是娘。本来嘛,导师做什么,学生就要做什么,这才是学位正道。于是,我在HPSG里面爬滚了几年。照猫画虎,写了一个 CPSG,就是 Chinese 版本的 HPSG。用它与实验室的英文 HPSG 对接,来做一个英汉双向机器翻译的实验,当然是玩具系统。这是我博士论文的实验部分。
为什么双向?这正是 Prolog 和所有 unification grammars (又称 constraints based grammars)所骄傲的地方:文法无需改变,文法就是对语言事实的描述,文法没有方向。无论做分析(parsing),还是做生成(generation),原则上,规则都是一样的,不过是执行层面的方向不同而已。理论听上去高大上,看上去也很美,一度让我入迷。我也确实完成了双向的实验,测试了几百个句子的双向翻译,得到了想要的结果。细节就不谈了,只谈相关的一点,就是,伪句法歧义在这些实验中是一个 huge problem。这个 HPSG parsing 中,伪歧义的事实有多严重呢?可以说是严重到令人窒息。当时用PC终端通过电话线连接到实验室的server上做实验,一个简单的句子在里面绕啊绕,可以绕出来上百条 parses。当然,可以设置成只输出一条 parse 来。有时忍不住好奇心,就耐心等待所有的 parses 出来,然后细细察看,究竟哪个 parse 对。
额的神!
乍看全长得差不多,细看也还是差不多。拿着放大镜看,才看出某个 feature value 的赋值不同,导致了 parses 之间的区别。可这种不同基本上没有语义的区别性价值,是为 pseudo parses 之谓也。要都是伪歧义也好,那就随机选一个parse 好了,问题出在,这百来条 parses 里面有时候会混杂一两条真的歧义,即语义上有区别性价值的 parses,这时候,选此废彼就具有了操作层面的价值取向。否则就是以一派压制另一派,反对党永无出头之日。
这个问题困扰了整个 HPSG community(其实是整个 CFG 框架下的 community)。记得在 HPSG 内部邮件组的讨论中,怨声鼎沸,也没人能找出一个理论上和实践上合理的解决途径来。
白: 简单说就是时间复杂性上去了,结果复杂性没下来。折了兵,真假夫人还混在一起不知道赔谁合适。
李:这就是为什么当时您那么肯定地指出我作为深度分析语言工作者所面临的挑战,他是把我归到主流语言学乔老爷 CFG 的框架里说的。
在第一章事实篇结束前,简单说一下实践中的对策。后来我的导师与本省工业界合作,利用 HPSG MT 帮助翻译电视字幕。在真实应用中,他们只好选择了第一条成功的 parse 路径,完全忽略其他的 parses。这也是没有办法的办法。质量自然受损,但因为无区别意义的 pseudo-parses 占压倒多数,随机选第一条,在多数场合也还是可以的。
第一章小结:骨灰级老革命在没有理论探索的情况下,就在 deep parsing 的 field work 中经历了两种事实:一种是不受困扰的多层 parser,一种是深陷其中的单层 parser。因此,当白老师一口咬定深度分析的这个挑战的时候,我觉得一脑门道理,但就是有理说不清。至少一句两句说不清,只好选择逃遁。
对于绝大多数主流NLP-ers,NL的文法只有一派,那就是 CFG,无论多少变种。算法也基本上大同小异,chart-parsing 的某种。这个看法是压倒性的。而多层的有限状态文法做 parsing,虽然已经有半个多世纪的历史,却一直被无视。先是被乔姆斯基主流语言学派忽视,因为有限状态(FSA)的名字就不好听(多层不多层就懒得细究了),太低端小气下位了。由于语言学内部就忽视了它,自然不能指望统计派主流对它有重视,他们甚至对这路parsing没有啥印象(搞个浅层的模式匹配可以,做个 NE tagging 啥的,难以想象其深度parsing的潜力),尽管从有限状态这一点,其实统计派与FSA语言派本是同根生,二者都是乔老爷居高临下批判的对象,理论上似乎无招架还手之力。
白: 概率自动机和马尔可夫过程的关系
李:但是,多层 FSA 的精髓不在有限状态, 而是在多层(就好比 deep learning 的精髓也在多层,突破的是传统神经网络很多年停滞不前的单层)。这就是那天我说,我一手批判统计派,包括所有的统计,单层的多层的,只要他们不利用句法关系,都在横扫之列。因为这一点上还是乔老爷看得准,没有句法就没有理解, ngram 不过是句法的拙劣模仿,你的成功永远是浅层的成功, 你摘下的不过是低枝果实。不过恰好这种果子很多,造成一种虚假繁荣罢了。
另一方面,我又站在统计派一边,批判乔姆斯基的蛮横。实践中不用说了,管用的几乎都是有限状态。乔老爷要打死单层的有限状态,我没有意见。统计派的几乎所有模型(在 deep learning 火起来之前)都是单层,他们在单层里耗太久了不思长进,死不足惜,:)。 蛮横之处在于乔老爷对有限状态和ngam多样性的忽视,一竿子打翻了一船人。
白: RNN可以完美模拟FSA, 但是现在的人都把RNN当做统计派的功劳。
李:但是他老人家忘记了, 我只要叠加 FSA 就可以比他所谓的 more powerful 的 CFG 做得深透,而且合体(特别适合白老师说的自然语言的毛毛虫体型)。他对有限状态的批判是那么的无视事实和缺乏理性。他是高高在上的神,不食人间烟火的,我们各路NLP实践派对他都敬而远之,基本没有人跟他走。在他本应发挥影响的领域,他其实缺乏起码的影响力。倒是语言学内部被他控制了,语言的形式化研究跟着他亦步亦趋走了半个多世纪,离作为其应用场景的 NLP 却渐行渐远。这是一个十分滑稽的领域怪相。
白: RNN加层、计数器、加栈、加长时记忆,本质上都在突破单层FSA的计算能力。
李:好了,咱们接着聊第二章:为什么多层系统,尤其是 多层 FSAs ,不受伪歧义的困扰?
白: 只要证明毛毛虫以外不是人话,就只管放心玩毛毛虫好了。伪歧义跟规则的递归形式无关,跟规则的词例化水平和压制机制有关。但是,要hold住十万百万量级的规则,CFG一开始就必须被排除在外。
李:对。
说到底是规则的个性与共性关系的处理,这是关键。这个不是我的发现,我的导师刘倬先生早年就一再强调这个。刘老师的系统命名为 专家词典(expert lexicon )系统,就是因为我们把个性的词典规则与共性的句法规则分开了,并且在个性与共性之间建立了一种有机的转换机制。
白老师说得对,单层的 CFG 基本是死路。眉毛胡子一把抓,甚至所谓词典主义的 CFG 流派,譬如 HPSG 也不能幸免,不出伪歧义才怪呢。如果规则量小,做一个玩具,问题不严重。如果面对真实自然语言,要应对不同抽象度的种种语言现象,单层的一锅炒的parsing,没有办法避免这种困扰。
白: HPSG 之类可以依托树做语义信息整合,但是在树本身的选择数目都在爆炸时,这种整合是不能指望的。
李:可以说得具体一点来阐释其中道理。分两个小节来谈,第一节谈多层系统中,单层内部的伪歧义问题。第二节谈多层之间的伪歧义问题。
白: 但是仍然困惑的是某种结构化的压制,比如“美国和中国的经济”’。“张三和李四的媳妇”
李:如果这两种伪歧义都有自然的应对方式,那么伪歧义不是困扰就理所当然了。待会儿就讲解白老师的例子。我这人啰嗦,学文科的,生存下来不容易,各位包涵了。
白: 抽象的并列,天然优越于抽象的长短不齐。似乎并不关乎词例,词例化的、次范畴化的规则,都好理解。抽象的结构化压制,处于什么地位呢?
李:但是难得大家围坐在一起,忍不住借题发挥一下,顺带进一步阐释了上次“上海会面”上的论点:我对乔老爷既爱且恨,爱他批判单层统计派的一针见血;恨他一竿子打翻一船人,敌我不分,重理论轻事实。
白: 是因爱成恨好吧
李:我们实际上半条身子在统计派的船上,大家都是有限状态;半条身子在语言派船上,毕竟我们不是单层的有限状态。统计派的有限状态的典型表现 ngram 实际上是 n-word,而我们的有限状态是真正的 ngram,这个“gram” 就是刘老师当年一再强调的 “句素”,是一个动态的句法单位,可以是词、短语或者小句,随 parsing 的阶段而定。这样的 ngram 是统计派难以企及的,因为它反映的是真正的语言学,多数统计学家天然不懂。
白: 世界上只有深层派和浅层派,这是复旦美女教授教导的。我认为只要touch深层,无论什么派都会殊途同归。
李:先说单层内部的伪歧义。这个白老师心里应该没有疑问了,不过为了完整还是先讲它。单层的有限状态说到底就是一个 regex (正则表达式),只不过面对的单位根据语言层次的不同而不同而已。如果是 POS tagging 这种浅层,面对的单位就是 words (or tokens)。如果是句法关系的解析层,面对的单位就是短语(可以看作是头词,它代表了整个短语,“吃掉”了前后修饰语)。
对于单层,有两种结构歧义,一种是伪歧义,占多数;一种是真歧义,占少数,但存在。单层系统里面的每一条规则都是一个 pattern,一个缩小版的局部 parser (mini-parsing),试图模式匹配句子中的一个字符子串(sub-string)。歧义的发生就是 n 个 patterns 对相同的输入文句的字符子串都成功了。这是难免的:因为描述语言现象的规则条件总是依据不同的侧面来描述,每条规则涵盖的集合可能与其他规则涵盖的集合相交。规则越多,相交面越大。每条规则的真正价值在于其与其他规则不相交的那个部分,是那个部分使得 parsing 越来越强大,涵盖的现象越来越多。至于相交的部分,结论一致的规则有可能表现为伪歧义(结论完全一致是异曲同工,没有歧义,但设置一个系统的内部表达,难免涉及细节的不同),这是多数情形。结论不一致的规则如果相交则是真歧义。这时候,需要一种规则的优先机制,让语言学家来定,哪条规则优于其他规则:规则成为一个有不同优先度的层级体系(hierarchy)。
白: 在线?
李:FSA Compiler 事先编译好,是 FSA Runner 在线做选择。
白: 那要隐含规则的优先关系,不能初一十五不一样。
李:个性的现象优先度最高。共性的现象是默认,优先度最低。这个很自然。一般来说,语言学家大多有这个起码的悟性,什么是个性现象,什么是共性。
白: “张三的女儿和李四的儿子的婚事”
李:如果优先语感不够,那么在调试规则过程中,语言数据和bugs会提请语言工作者的注意,使得他们对规则做有意义的优先区分,所谓数据制导 (data-driven) 的开发。
白: specificity决定priotity,这是个铁律。在非单调推理中也是如此。
李:这个优先权机制是所有实用系统的题中应有之意。优先级别太多太繁,人也受不了。实际情形是,根本不用太多的优先级别区分,每一层分析里只要三五个级别、最多八九个优先级别的区分就足够了(因为多层次序本身也是优先,是更蛮横的绝对优先)。
白: 我还是觉得优先级初一十五不一样的时候一定会发生,而且统计会在这里派上用处。
李:一切是数据制导,开发和调试的过程自然做到了这种区分。而更多的是不做优先区分的歧义,恰好就落在了原来的伪歧义的区间里面。这时候,虽然有n条规则都产生了 local parses,他们之间没有优先,那就随机选取好了,因为他们之间其实没有核心 semantic 的区别价值(尽管在表达层面可能有细微区别,hence 伪歧义)。换句话说,真歧义,归优先级别控制,是数据制导的、intuitive 的。关涉伪歧义困扰的,则变成随机选取。这一切是如此自然,以至于用FSA做parsing的从业者根本就没有真正意识到这种事情可能成为困扰。关于初一15的问题,以及白老师的具体实例,等到我们简单阐释第二节多层之间的伪歧义的应对以后,可以演示。
第二章第二节,多层之间可能的真伪歧义之区分应对。
对多层之间的真歧义,不外是围追堵截,这样的应对策略在开发过程中也是自然的、intuitive 的,数据制导,顺风顺水。围追堵截从多层上讲,可以在前,也可以在后。在前的是,先扫掉例外,再用通则。在后的是先做默认,然后再做修补(改正、patching)。道理都是一样的,就是处理好个性和共性的关系。如果系统再考究一点,还可以在个性中调用共性,这个发明曾经是刘老师 Expert Lexicon 设计中最得意的创新之一。个性里面可以包括专业知识,甚至常识(根据应用需要),共性里面就是句法模型之间的变式。
好,理论上的阐释就到此了,接下去可以看实例,接点地气。白老师,你要从哪个实例说起?我要求实例,加问题的解释。
白: “中国和美国的经济”。这就是我说的初一十五不一样。
李:这是真的结构歧义,Conjoin (联合结构)歧义 。在语言外知识没带入前,就好比西方语言中的 PP attachement 歧义。结构歧义是NLP的主要难题之一。Conjoin 歧义是典型的结构歧义,其他的还有 “的”字结构的歧义。这些歧义在句法层无解,纯粹的句法应该是允许二者的共存(输出 non-deterministic parses),理论上如此。句法的目标只是区分出这是(真)歧义(而这一点在不受伪歧义困扰的多层系统中不难),然后由语义模块来消歧。理论上,句法和语义/知识是这么分工的。但是实践中,我们是把零散的语义和知识暗渡陈仓地代入句法,以便在 parsing 中一举消歧。
白: 一个不杀当然省事。但是应该有个缺省优先的。
李:缺省优先由“大数据”定,原则上。统计可以提供启发(heuristics)。
白: 有次范畴就能做出缺省优先。不需要数据。
李:当然。次范畴就是小规则,小规则优先于大规则。语言规则中,大类的规则(POS-based rules)最粗线条,是默认规则,不涉及具体的次范畴(广义的subcat)。subcat based 的其次。sub-subcat 再其次。一路下推,可以到利用直接量(词驱动)的规则,那是最优先最具体的,包括成语和固定搭配。
白: 次范畴对齐的优先于不对齐的,就联合结构而言。但是,about 次范畴,理论上有太多的层。
李:那是,联合结构消歧中的次范畴不是很好用,因为这涉及词的语义类的层级体系。不管是 WordNet 还是董老师的 HowNet,里面的 taxonomy 可以很深,统统用来作为次范畴,不太现实。但理论上是这样使用的。
白: 再一个,“张三的女儿和李四的儿子的婚事”。这个也是真歧义吗?
李:上例的问题和难点,白老师请说明。"的"字结构的 scope歧义加上联合结构的歧义的叠加现象?
白: 上例是处理深度的问题,各自理解即可。歧义叠加,只有更加歧义了。可是实际相反,叠加限制了歧义。
李:在分层处理中,我们是这样做的:
(1)Basic NP, 最基本NP层的结果是:NP【张三】 的 NP【女儿】 和 NP【李四】 的NP【儿子】 的 NP【婚事】
(2)Basic XandY, 最基本的联合结构层:在这个层次,如果条件宽,就可能发生联合错误,错把 【女儿 和 李四】 联合起来。这个条件可以是 HUMAN,二者都符合。而且在 95% 的现象中,这个条件是合适的。如果条件严的话,譬如用 RELATIVES 这个语义次范畴(HUMAN的下位概念),而不是 HUMAN 来限定的话,这个句子在这一层的错误就避免了。
那么具体开发中到底如何掌握呢,这实际上决定于设定的目标,没有一定之规。做细总是可以做到更好质量,大不了多加几层 NP 和 XandY 的模块(FSAs),但还是增加了开发和维护的负担。如果做粗一点,只要所造成的 parsing 质量上的后果能控制在应用可接受的范围,那也未尝不可,因为说到底,世界上没有完美的系统。上帝允许人类的不完美。
白: 把这个换成“AB的中点与AC的中点的连线”?同样的结构。
李:另一个思路,就是多层协调中的修补。对于上述两个例子,修补的办法似乎更好。与其分多层,代入各种繁琐的语义条件来消歧,不如任他出错,然后根据pattern的平行因素加以修正。在多层系统中,这个常常是有效的策略,也符合开发的总体规划。先把系统大体弄得work了,可以对付多数现象,然后有时间和余力了,后面可以 patching。前提是,错误是 consistent 和 predictable 的。对于多层管式系统(pipeline system),错误并不可怕,只要这种错误 consistent 有迹可循,后面总可以把它们修正。
多层管式系统常常被批评存在一个 error propagation(错误放大)的难题。其实,多层系统也可以做到负负得正(矫枉过正是也)。一个好的系统设计,是后者,通过 data-driven,可以做到把错误放大控制到最低限度,并发扬负负得正来得到最终正确的结果。
白: 伟哥的诀窍其实是把握一个适中的词例化-次范畴化水平问题。太粗则伪歧义盛行,太细则边际效益大减。
李:上例中 “中点与AC” 可以联合,不过是一个暂时的内部错误而已,后面可以修正。总之,这些都不是根本的 challenge,想做就可以做,实际操作上,也可以选择不做。问题大了,就做;用户发飙了,就做;否则就无视。很少有歧义是做不出来的,功夫和细节而已。最终决定于值得不值得花这份力气,有没有这样的开发时间和资源。
白: 做与不做,有可能影响架构选择。补丁有好处也有后遗症。
李:NLP 可以做一辈子,在基本机制(优先机制,修正机制,范畴、次范畴机制,专家词典等)由平台实现提供以后,慢慢磨到最后就是 diminishing return,与爬山类似,这决定了我们何时罢手。如果85%的精度作为parsing的目标,那么系统会选择不做一些稀有的现象。有了这个 85%,已经可以满足很多应用的要求了。
有了 85% 做底, 还可以让机器变得智能起来,自动地自我提高,所谓 self-learning,这是研究课题了,但是是可以实现的。实际上在我指导的实习生实验中已经实现,不过就是在线开销太大而已。
白: 再看“馒头吃光了”?
李:这个例子更容易讲清楚。在系统的某一层,可以有个规则 把某种 “V+光" parse 成为动补结构,这个V的限制可以调试出合适的子范畴来。
白: “光”词例化肯定是可以的。
李:好,这就解决了95%以上这类以“光”收尾的现象。如果遇到了反例,譬如,“黑洞吃光了”, 那么或者修正它,或者作为个体知识的规则前置。围追堵截是也。总是可以把零碎的专业知识做成规则,如果需要的话。至于这么做值得不值得,那是应用层面的决定。很多时候是不必要的。错了就错了,不过是显得系统缺乏专家的知识,so what?我们普罗 native speakers 也都不是每一行的专家,也并不是每句话都听懂,不也一样没觉得交流困难。就此例来说,决定于听者的知识面,小学生和文盲一般不能正确 parse 理解 “黑洞吃光” 的动宾语义来。动宾的语义是需要语言外知识在语言内非优先的潜在结构上作用才能得出。而动补结构则不需要,那是语言内的句法知识(最多说是句法子范畴或小规则,但不涉及专业知识),是所有国人的默认理解。
白: 这一点非常重要。一个开放,一个封闭。一个外部,一个内部。外部的事儿,就算没有专业知识,也可以大数据招呼。
李:今天似乎可以结束了,说到底,就是:
一,平台需要提供一些基本机制来处理共性与个性的关系,从而应对歧义,这些在 FSA formalism 的教科书定义中可能不存在,或被忽略,但却是实用系统不可或缺的。
二,NLP 的确是个力气活,有无限的可能深入。当然,我们可以选择不深入,可以选择何时罢手。
至于大数据招呼,那个在前述的自学习上也必须用到。我们教授机器做到 85%,大数据基础的自学习可以让它自行提高到 90%,这个是部分证实了的,可惜还没有发表出来,以前说过,懒得成文。都骨灰级老革命了,谁在乎那个。我说的大数据是指与大语料库对应的 grammar trees 自动形成的 forest,比 PennTree 大好几个量级。
这次神侃算不算基本回答了疑惑,可以得出“伪歧义在多层系统中不是困扰”这个结论?
白: @wei 是,非常感谢。
李:不过,我们一方面实用制导,一方面没有忘记基本面和大局。与纯粹的实用主义,头痛医头,脚痛医脚,还是不同。这种积一辈子挖煤的经验之谈,正式论文中罕见,也算一件功德。难得的是白老师还有雷司令身为主流精英,居然能一开始就高于主流,不排斥异端或少数派。所以上次上海聚会,我就说,火药味的架掐不起来的, 因为相互的理解和欣赏多于分歧。但我知道也有很多统计死硬派,甚至大牛,是不尿这壶的。
白: 只要聚焦于深层,一定会殊途同归。RNN记在统计账上,但已经是深层了。
可以再关心一下NLP的商业模式,怎么能讲一个好故事。我们说fsa也好分层也好,资本都是不感冒的。
李:滑稽的是发现有些死硬派做了n年NLP,却真地不懂语言学,有个别大牛连常识都不懂,让人跌破眼镜。当然这个只能内部说说,不能博客的。所以往往是互相地不尿对方那一壶,与宗教之战类似。
RNN 我不敢发言, 不过从白老师零星的介绍来看, 很可能殊途同归。不过 FSA 这套 deep parsing 是已经稳定成熟的技术。RNN 的工业成熟度如何,我不知道。可能都是核弹, 不过是原子弹氢弹区别而已。
白: Ngram说不定变出个什么花样来,也殊途同归。
李:其实 多层 FSAs 本质上就是 ngram 的花样,不过 gram 不再仅仅是词了,而是等于或大于词的句素。能以动态句素作为 ngram 的对象,是因为多层的原因,跟剥笋子一样,层层扒皮,gram 当然就是动态的了。这一点很关键,是乔姆斯基都没想到的 power。
白: 对,边扫描边归约,边抛出句素。
李:这里面最 tricky 的不是机制而是细节。魔鬼在细节,就是指的这个。FSA 是“古老”简单的机制了,细节就是玩平衡,玩模块之间的协调。玩得好的就好比中餐的大厨,可以做出满汉全席来,玩不好的还不如麦当劳、keywords。到这一步,经验因素开始起作用。没碰过n次壁,甚至几万小时的炼狱,这个火候掌握不好。这类系统很难做得表面上漂亮光洁,总是在混沌中前行,要忍受不完美。这方面的忍受,数学家不如语言学家。数学家天生追求简洁完美,不愿意将就。
白: 句素的个头大,影响范围就大,相当于抛得就远。可以进入远距离的滑动窗口,伟哥说的Ngram的缺点就不存在了。
dirty是必然的。
李:ngram 的缺点是主流的缺点,不是语言多层派的缺点。恰好相反, ngram 多层以后,很容易比任何 CFG 做得细致深入,以至于,想怎么深入就怎么深入, 如果持续开发的话。
CFG 那套单层范式,无论统计模型还是传统文法加以实现,真地深入不下去,是框框决定的。两边都玩过,这种对比太强烈了。我对我的博导说过, HPSG 真地不好用,那边费那么大劲的事儿,在我这儿是小菜。说拿的是牛刀,可对象不是牛,而是鸡。不如我剪刀和匕首好宰鸡。
白: 我一个学生搞蛋白质折叠的分析。蛋白质大分子折叠的点恰好是若干局部的代表(相当于语言的head中心词)之间发生全局相互作用的地方。真是神了。
李:今天到此,特别谢谢白老师的互动和精彩的及时点评。
原载:
科学网—泥沙龙笔记:真伪结构歧义的对策(1/2) ;
骨灰级砖家一席谈,真伪结构歧义的对策(2/2)
【相关】
乔姆斯基批判
【立委科普:管式系统是错误放大还是负负得正?】
【关于NLP方法论以及两条路线之争】
[转载]【白硕 – 穿越乔家大院寻找“毛毛虫”】
【白硕 – 打回原形】
【置顶:立委NLP博文一览】
《朝华午拾》总目录