王:
动词名化确实不好处理的难办事,以前做词性标注,准确辛率不高,就栽在这,n,v,vN上了,还有区别词b。当然现在语法理论,一个小小助词“的“就有管住核心谓词的能力,使之由V变N。
白:
A、“粉红凤凰”,B、“红绿色盲”,C、“真假和尚”。
A、粉修饰红,粉红修饰凤凰。
B、红绿并列,但并不是用本意的叠加修饰“色盲”,而是用不能区分这两种颜色来定义色盲的具体类型。
C、真假并列,通过分配律把共享中心词“和尚”送给二词修饰,表示“真和尚、假和尚”。
修饰成分间的关系很不简单呢。
李:
我对 b 的第一解读是 c 的并列
看了讲解才悟出来 也许还有 nuance
感觉差异已经细微 微妙到很少需要在意区分的程度了
@wei wang 中文中的所谓动词名物化 nominalization
很大程度上是一个伪问题 一个语言学迷思
强加到 POS 模块 作为其难点 更是一个自找的麻烦
工作 学习 睡眠 吃饭 下雨 打雷
这些词 类别很清晰
王:
@wei,对此我也迷惑
李:
(逻辑)动词 万变不离其宗 没有 POS 区分的必要性
Wang:
这点我同意李老师。所以,我说现代语法理论,是否需要调整一下?只是不敢妄论。
如果都能走对,倒无妨,就怕转得有对有不对,就确实是问题了
李:
在 POS 先于句法的通常架构里
把句法的不同用场 强加到 POS 标签去 是真实世界的天下本无事 x人自扰之。
真有好好的路 硬是自己挖个坑 然后就自己跳进去 然后抱怨路不平。
王:
当然,我现在已经跨越POS这个,不使用POS而直接走句法了。不过对别人而言,这词性标注依然存在。即便标注,我也认为动词体征的,就一直动词体征走向去,比较好。
李:
汉语语法学界上世纪50年代的词类大争论,大争论当年没争出结果来,是时代的局限。
王:
我的看法是,也不去争论。
李:
词无定类(“词无定类 入句而后定”)走向一个极端,无法服人,但其思想有闪光之处。
王:
而是拿到系统中去跑,能跑得好的,自然就是好的,至少这正是我们所需要的
白:
结构强制在技术上一点不复杂,问题是算句法还是算词法,但这都不是技术问题,是旗号问题。旗号与我何干?
王:
至于语言学方面,那是另外的一回事
李:
对于具有 consistent ambiguity 的词,
本体上就是无定类,但是一说“词无定类”就扩大化了,以为所有词都是必须要句法,要上下文,这就陷入了鸡和蛋的死循环,当然不能服人。
这个迷思从哲学上不难看穿。可是实践中却坑了人太多 太久 而且还继续在坑人。
王:
@白硕 说的是,确实不是技术问题
李:
如果一个东西 在有些场景下看着是 红色 有的场景下看着是 黑色
自然的结论就是给个 X 的本体标签,让 X 统辖 红 黑 两个标签,至少这个信息的外延是清晰的,是红黑的区域,不是蓝 不是绿 不是紫 等等,这才符合事实 恰如其分。
王:
这是否分两种情况?
1)本来是多义词,兼有多种词性的;2)已经定了就一种(比如纯动词),走着走着,变了,
李:
不说多义词。多义词(细微差别不算)那是两个词,凑巧长得一样了,其归属自然也可能不同。
王:
嗯
李:
只说 2)
2) 没有 POS 半毛钱的关系。
汉语中的 POS 任务中 纠缠了几十年,原来一开始就把任务定义错了。
王:
请问,那么怎么“ X 统辖 红 黑 两个标签”
李:
对于我们讨论的动词名物化,这个 X 就是 V,可以读成逻辑动词。这个 V 是词典给的,没有歧义,何用区分?
王:
嗯
李:
到了结构里面做了主语或者宾语,它没有改变 V 的本性:词义没变,归属自然也没变。所改变的是句法 role。
王:
同意
白:
没有X统辖那么简单。以“出版”为例,被赋予了动词特有的零碎,比如加“不”,仍然可以再通过“的”强制为名词;但是反过来,已经被名词特有的零碎强制过的,不可能再被强制回动词。
本性是动词,强制为名词,然后就凝固了,不接受变回动词的再次强制。
李:
没问题啊。
这些个细节 与标签没大关系,标签还是 X。只要词义不变,标签就没有道理变,这是本体 taxonomy 决定的。词义变了,标签有可能变。在同一个词义下给不同的POS标签,对于汉语这样缺乏形态的语言,是不合理的。
王:
我的看法是,不去改变词性
这本书的出版,----出版依然是动词,---可以看作是一个成句中谓词
这个成句,是一个小句(子句),可以做主语,或宾语,这样,句法上也顺上了,而且,词性也没去改变
李:
换句话说,汉语这样的语言,POS 应该用的是逻辑类
白:
问题是啥叫词义变。“真孙子”里面的“孙子”,我感觉词义变了。
李:
世界上所有的语言的词汇,都有逻辑类。这是语言共性。但是形态语言 在逻辑类之上,经常使用形态变换,把逻辑类穿上不同的衣裳。穿得好的话,可以脱离场景做句法。例如 俄语,morphology 很大,句法就简单了。极端来说,别说 POS 标签,就是本质上是上下文结构决定的 role,也可以脱离上下文 在词上反映:宾格就是宾语 role。
王:
同意@wei 在同一个词义下给不同的POS标签,对于汉语这样缺乏形态的语言,是不合理的。
白:
填坑使用的不应该是逻辑类,应该是角色。比如“这本书的出版怎么没通知我”当中,“这本书的出版”填坑时就是N。“这本书出版怎么没通知我”当中,“这本书出版”填坑时就是S。
王:
这本书的出版----看作一个小句 ,小句也相当于名词作用。出版--作为一个事件出现
事件--->没通知我。
李:
填坑不外两点:
1. 句法上要的是什么形式(包括标签或子类,或直接量),这是输入条件;2. 语义上是什么 role,这是输出角色,是“理解”的形式化。不能混淆输入和输出。输入条件用逻辑类,没有问题。句法的工作,起点就是词典信息。逻辑类是词典信息的重要方面,是词典本体信息体系里面层级最高的那几个标签。
白:
但,“通知”的内容那个坑,就必须是个X,混儿。见人说人话见鬼说鬼话。
李:
“出版”的坑:
(1)第一个坑
输入条件:publication (本体链条属于逻辑名词)
输出角色:【受事】
(2)第二个坑:
输入条件:human_or_organization
输出角色:【施事】
这才是 “出版” 的真实面貌。至于语言应用中,上述类似 HowNet 定义出来的 subcat pattern, 应该如何松绑输入条件 来应对鲁棒与活用,那是另一层面的勾当。
王:
就是说,不能因为一个“的”字,把本来清晰骨架,垫走了样。
李:
“通知”的坑:
(1)
输入条件:thing_or_event
(这就是白老师所谓变色龙,其实本体链条上,不过是在逻辑n与逻辑v上,再抽象一个统辖的 n_or_v,thing 就是逻辑名词的通俗表述,event 就是逻辑动词的通俗表述)
输出角色:【content】
(2)第二个坑是施事【谁】
输入条件:human (具体语言还有格、词序、介词类的条件制约)
输出角色:【施事】
(3)第三个坑是对象【向谁】
输入条件:human (具体语言还有介词、格、词序类的条件制约)
输出角色:【对象】
回来总结一下:坑里面使用逻辑类或者逻辑类下辖的子类 甚至 直接量(等价于具体词义搭配)是天经地义的。至于这些条件的松绑,所谓 preference semantics 那是语言应用中的窍门。为了鲁棒必须松绑,松绑会一步步从具体逻辑子类,向高层的逻辑类去。
王:
同意李老师
李:
HowNet 是独立于语言设计的,它的最上层 top 节点 其实就是逻辑类,event 就是 v
thing 就是 n。其实还应该再往上走一步,thing_or_event,但反正有 OR 算符,所以走不走也无所谓了。
白:
可以看成一个lattice,and就低不就高,or就高不就低。
李:
HowNet 其实是两个东西在里面。第一个是本体,董老师对人类认知和常识体系的总结和设计。第二个是语言落地(汉语,英语,......)。这第二步是通过给汉语词汇标注 HowNet 本体标签的方式实现的。这时候的本体已经落地到具体语言了。
白:
修饰语隐含的被修饰语和真实的被修饰语做or
李:
PennTree 在英语NLP中已经很多缺陷,时代的局限,误导了很多人。
白:
总感觉HowNet不完全满足这个架构
李:
PennTree 的那一套标准用到汉语更是误导,不如直接用 HowNet 来作为标准。
白:
想都不要想,肯定不会用PennTree
李:
至于选取 HowNet 顶层或者中上层的哪些标签作为中文 POS 的任务,可以再议。POS 选得细了,就几乎等价于 WSD 任务了(事实上,白老师很多时候在讨论中就是把二者看成同一回事儿,道理很显然,WSD 说的是词义区分,词义的taxonomy 链条就是逻辑词类)。
王:
现在很多评测都是以宾州树库来做基准的。我也想过,就算那个F值即便很高,那么真实应用就是那么高的吗。
李:
HowNet 在语义领域可以独树一帜,能够站得住,相信也能够经受时间,其中原因之一,是由于董老师是中国人,讲的是“裸奔”的汉语。裸奔的汉语与逻辑最贴近,有自然的亲密关系。这对排除语言的干扰,从逻辑的高度审视语义,有天然的好处。如果要讲中国人对世界文明作出自己的独特贡献,HowNet 可以是一个代表。
王:
李老师对其他语义词典是如何评价?
李:
哪些?
王:
比如wordnet ,同义词词林
李:
早就不用 WordNet 了,麻烦比好处多。擦不完的屁股,以至于用了两年后,不得不全部推翻,宁肯自己零敲碎打,不完备,增量积累做语义标签,也不愿意陷入 WordNet 泥坑。
王:
主要是想说直接是树状,而非网状的这类
白:
标签体系必须是DAG
王:
分类体系做得不好,还是后期建设不好,比如冲突出现?
李:
其实 WordNet 是可以改造得好一点的 好用一点的,但只听说有人说改造,但没见到有人愿意坐冷板凳去真地改造它。
白:
标签体系的数学基础,一是type theory,一是lattice。lattice解决单类型的上下位问题,type解决复合类型的构造问题。
王:
上下位好理解,这复合类型就不好理解了,请白老师讲解
白:
@wei wang 带坑呗
王:
明白了,我还以为复合类型,穿插把不同上下位的分支。又结成了网
白:
上下位是为不带坑的type准备的,带坑的都是复合type。
王:
@白硕 带坑是一个词带n个坑,这几个坑是另外的词
白:
@wei wang 对的
王:
是否有的词,本身就自己萝卜和都带了,这样的词如何分类?比如一些成语
白:
标签也分层。微结构,比如“扫地”,合起来是一个坑,微结构又可析出一个萝卜一个坑。
李:
subcat 既是子类(atomic 的标签),也蕴含了潜在的结构pattern,说 vt 其实是说有这类动词子类 挖了个宾语的坑。
白:
地不扫,何以扫天下
王:
@白硕 那看成一个整体,仍在统一分类体系,
李:
HowNet 开始用的时候也有问题(有些问题与 WordNet 类似,没那么严重),给董老师反映过。问题的根源在 董老师需要一个逻辑完备自足的义元体系,为了这个自足和完备,标注的时候就务求细而全。
HowNet 中的一个个单字的标签特别丰富,特别细,把这个字(词素)各种可能语义都反映了,甚至包括只存在于 idiom或合成词 中的词义。这其实给使用带来很多噪音。我一开始是试图 删减。后来发现对于单字的标签,删不胜删,最后决定索性单字的标签不用。要用的自己临时增量式加入,宁肯 under labeling,不能 over
王:
@wei “后来发现对于单字的标签,删不胜删,最后决定索性单字的标签不用。”
单字,是义原的核心,就是不用单字最基本的,而直接使用信息能独立的,更有代表性?更便于处理?
李:
不好用啊。很多汉字 看上去不过一两个词义,结果里面标了五六个词义,仔细想 确实都存在。但是用起来就是眉毛胡子一把抓了。
王:
嗯,我觉得建造体系可以这样建,想怎么用就是应用来选了
李:
如果这五六个词义的确都是自由语素的词义,虽然统计上出现频率不同,但逻辑上这样标注没有问题。但有些词义从来不作为自由语素的语义出现,只存在于合成词中,那就没有理由标注了。这个问题,董老师后期版本有了 config,可以筛选。做了弥补。这个问题在 WordNet 中更严重。
王:
嗯,谢谢李老师,白老师的解答。时间不早,明天上班,我先拜拜。
李:
晚安 @wei wang
王:
晚安!真的我还没聊够的感觉,特别是,语义分到什么类别,很关键,对系统有很大影响,也深有体会
白:
据我的经验,先别说具体类别,先说长什么样,更容易把握。数学上什么样,计算机里什么样。实体、属性、关系、值,这是一个层面。事件是另一个层面。时间空间因果模态,又是一个层面。知网中很先知先觉地引入了“变关系、变属性、变状态”等事件子范畴,相当高明。真的很赞.
董:
讲一个真实的故事。1988年由日本发起的五国机器翻译项目正在进行。在一次饭桌上,日方的项目负责人内田裕士谈起该项目的语义研究落实问题是说:"这个项目的语义研究,是不是请中方负责,具有中华文化背景的人对于语义有更高的敏感性。"
只是觉得只要由中方来负责,总归是好事情。我就表示同意了。可是对他的那句有关“中华文化背景”的断语,还真没有完全理解,但饭桌上也不适合讨论下去。后来时隔近20年,内田先生来北京,那次我们只是几个人一起吃饭。我问他:“你还记得20多年前,我们在讨论MMT的语义研究时,你说过一句话。你说'具有中华文化背景的人更适合做语义研究吗?我一直想问你你为什么会这么说呢?'”
他说的很简单:"因为是你们有汉字"。那时候我已基本完成了HowNet的研究和开发。HowNet正是以汉字为理念依据的。前两天我跟李维讨论。说到洋人不懂汉语,跟他们讲深了他们不理解。
白:
这些要是落在知识图谱里,不得了。
【相关】
【语义计算:李白对话录系列】
《朝华午拾》总目录
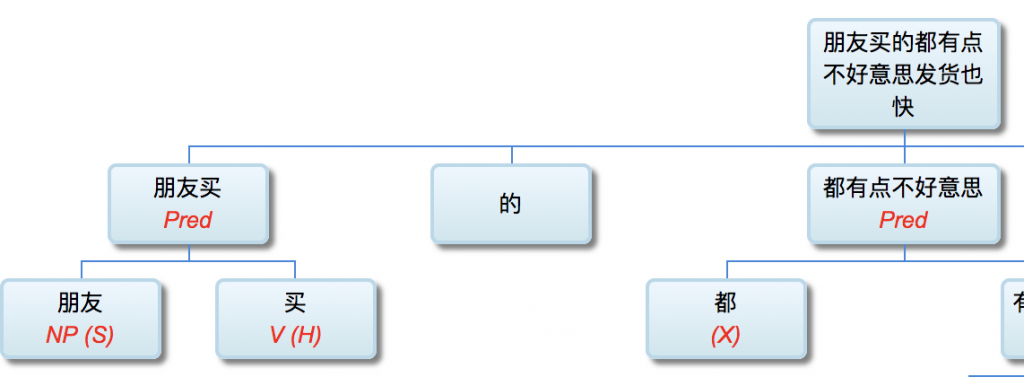
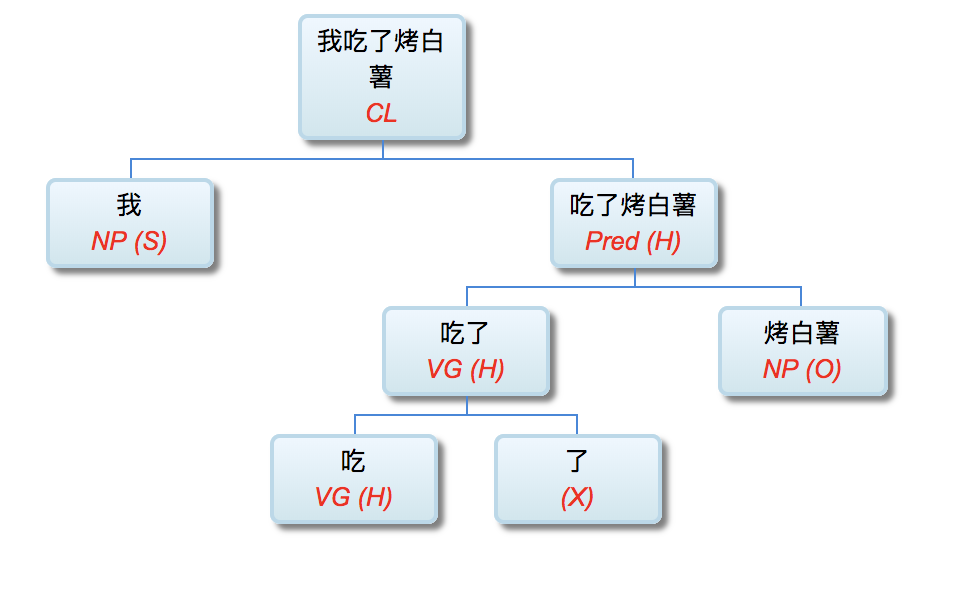
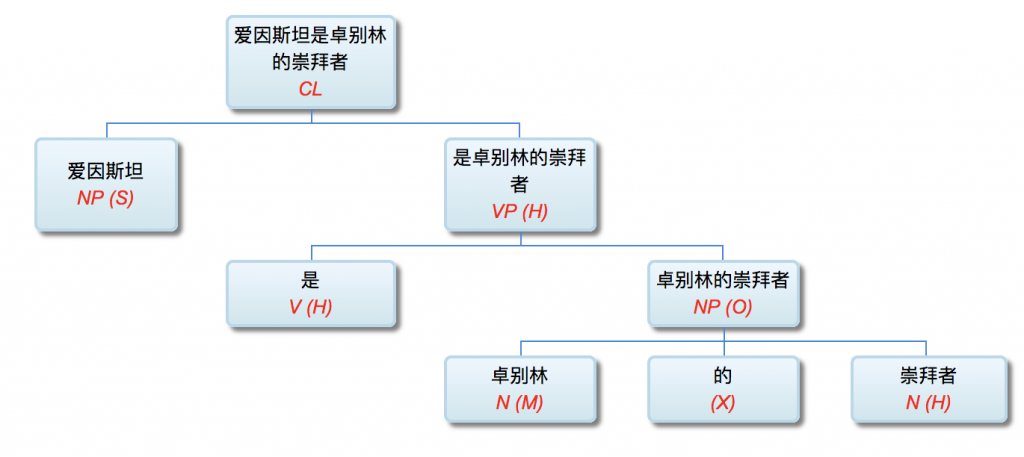
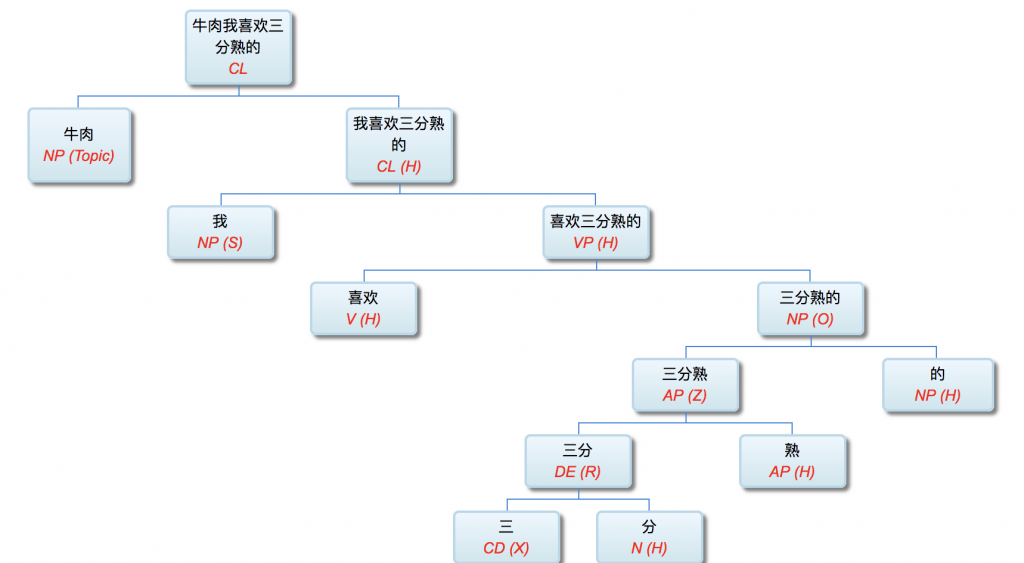
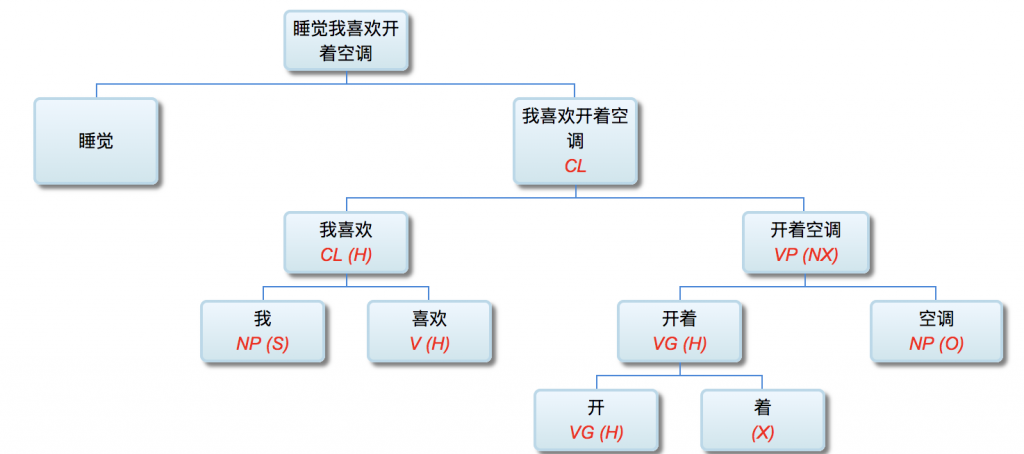


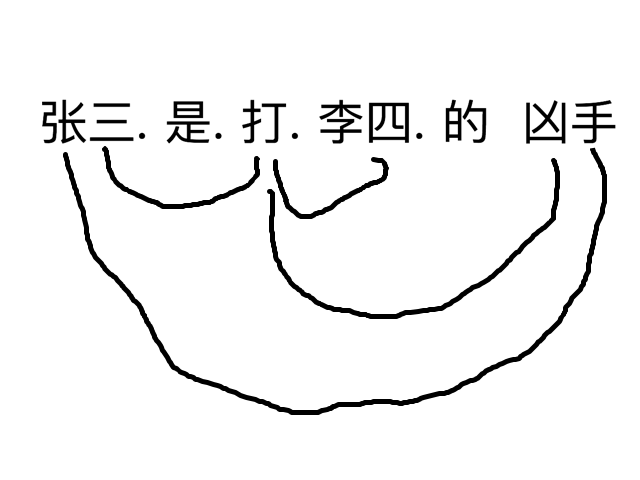 【SV: 张三,打】
【SV: 张三,打】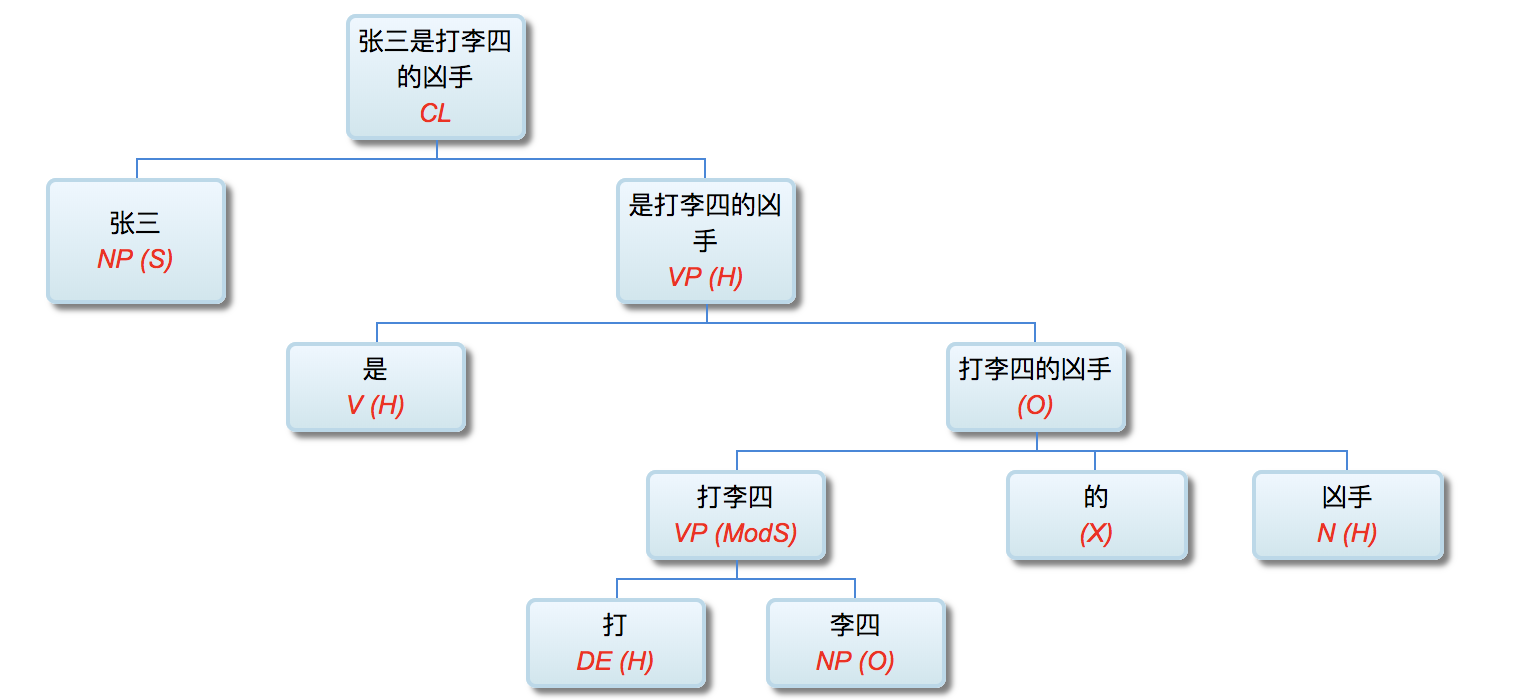
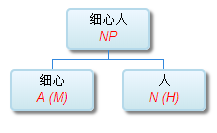
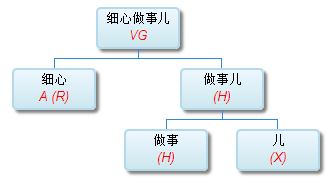
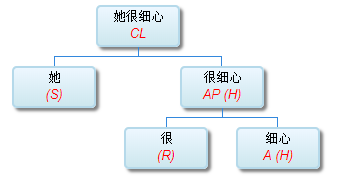
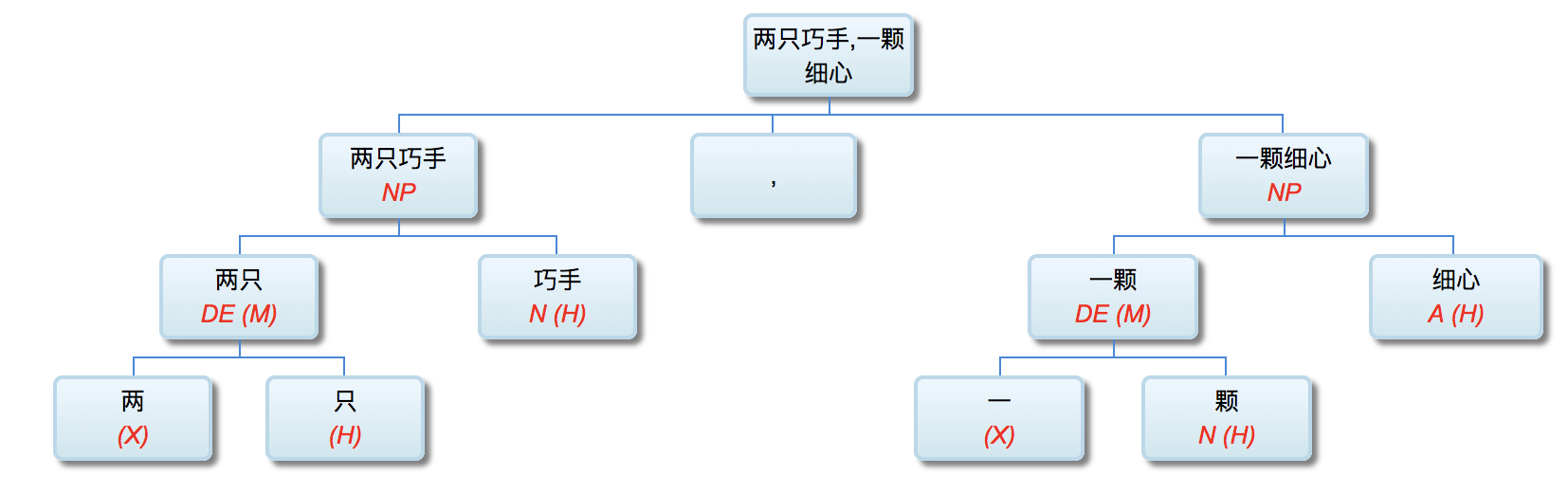
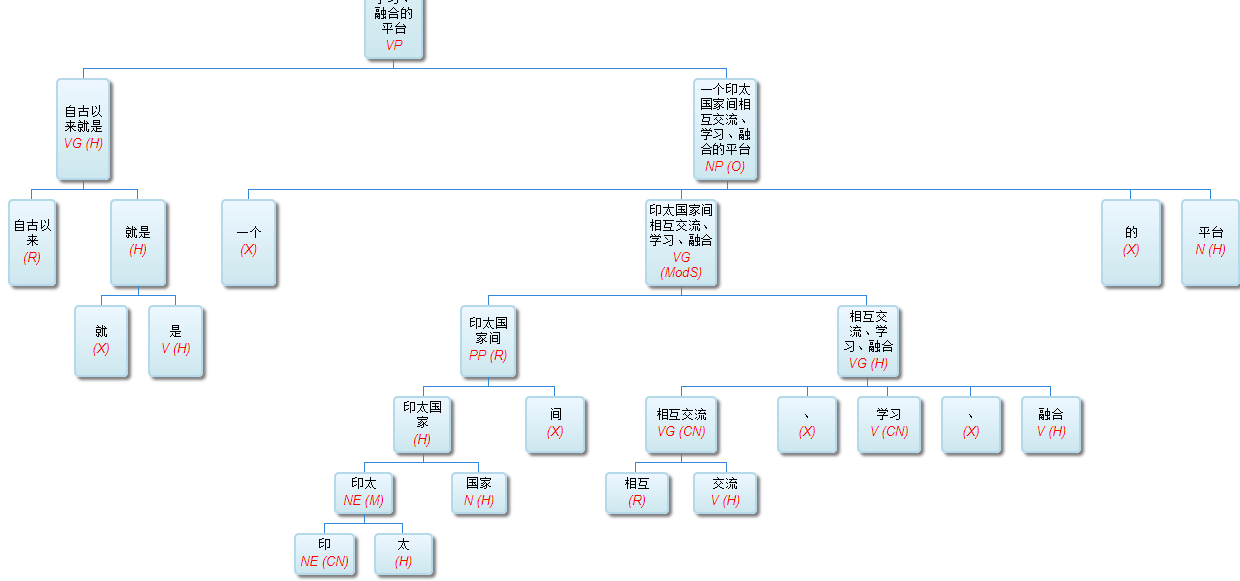
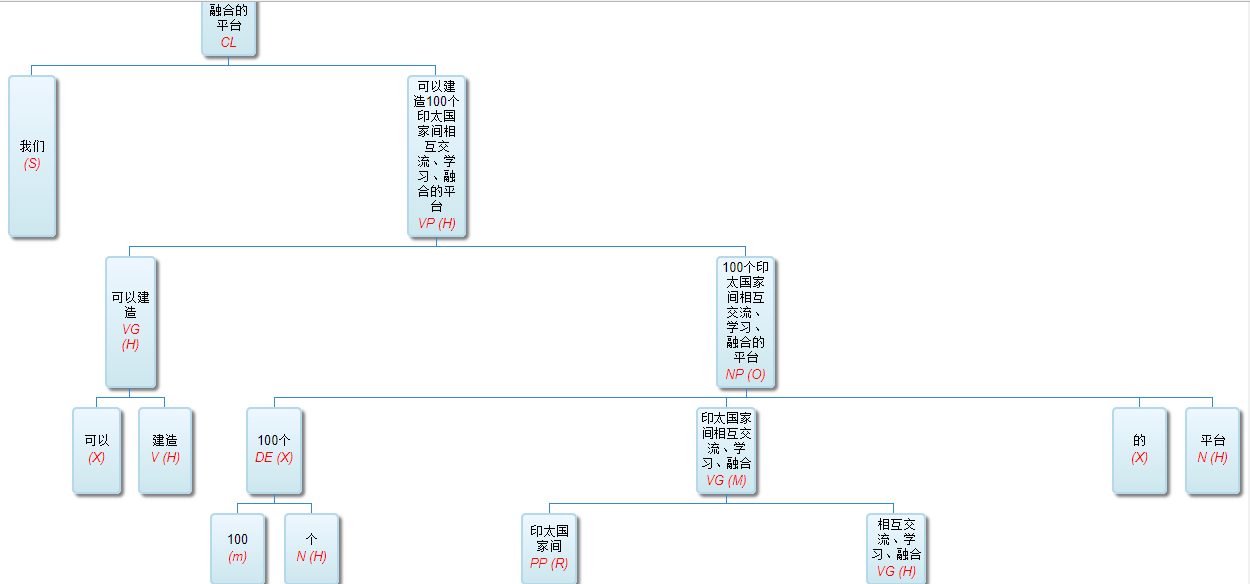
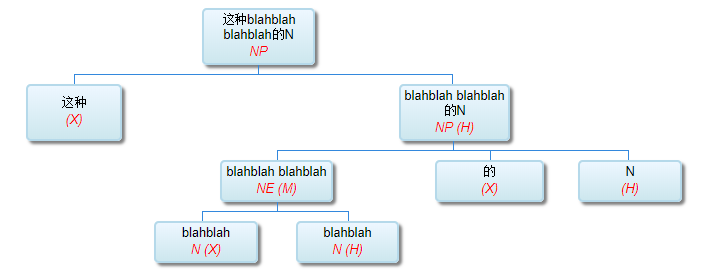






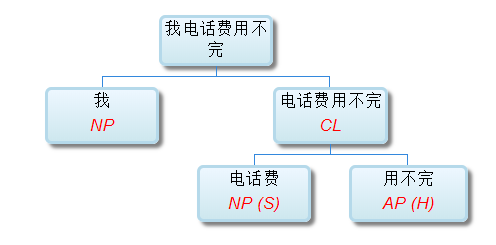
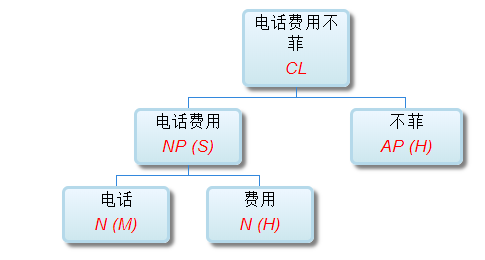
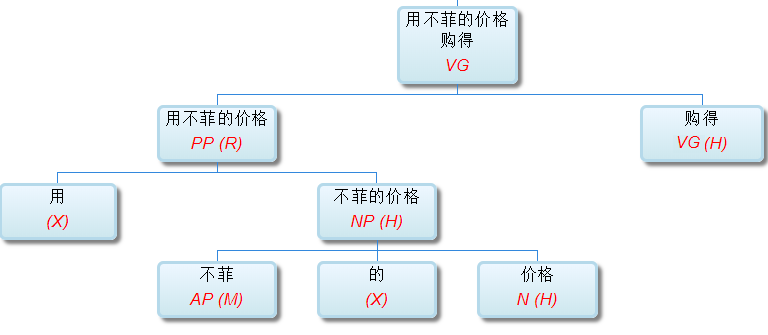
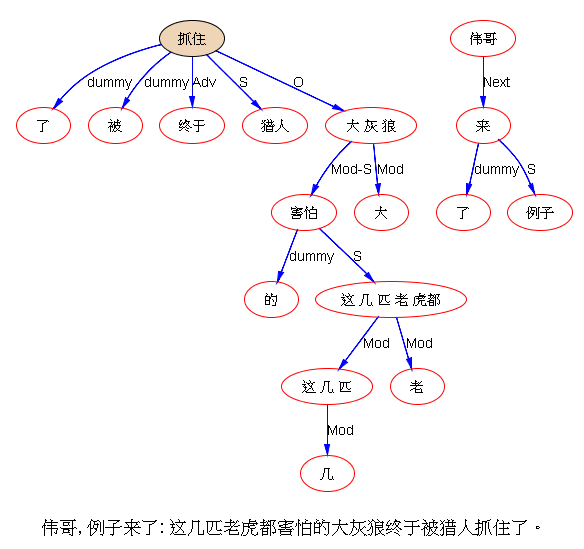
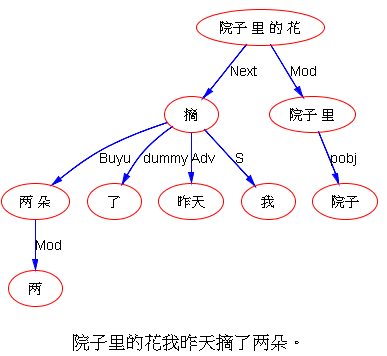
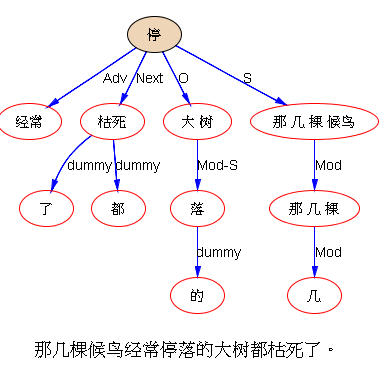
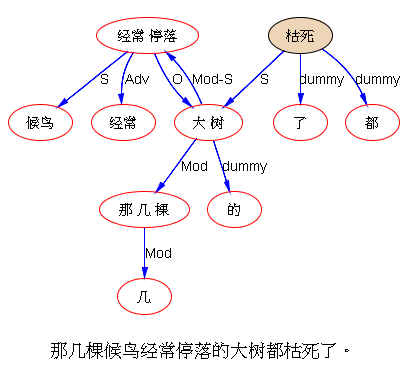
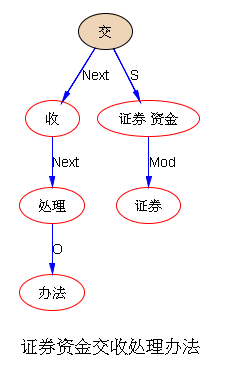
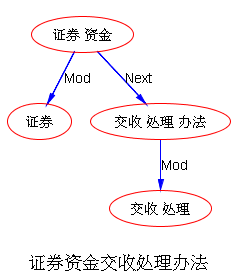

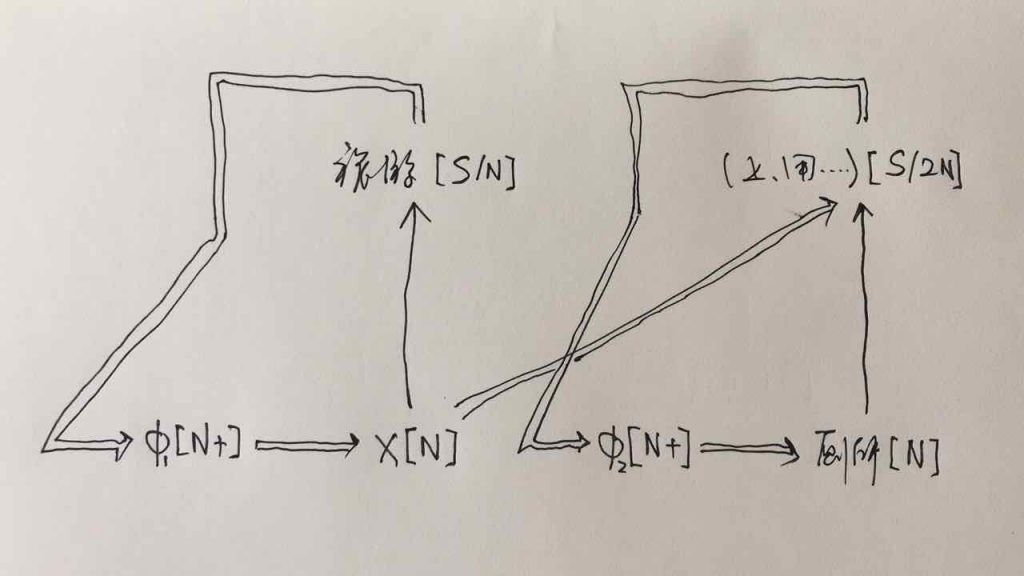
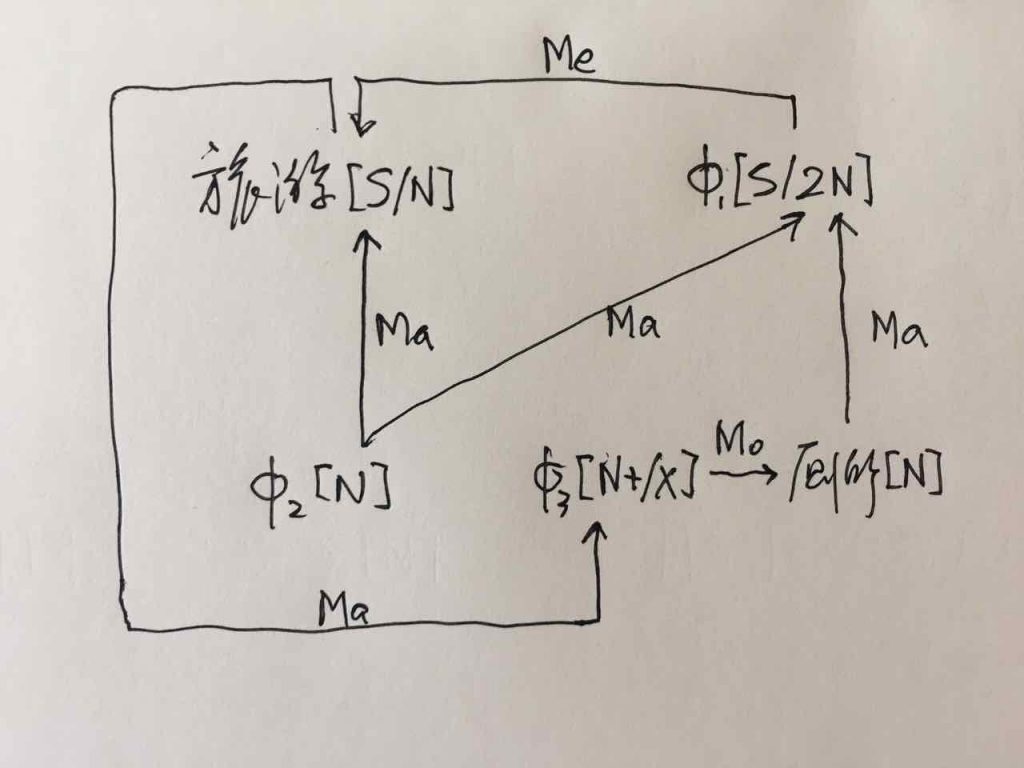
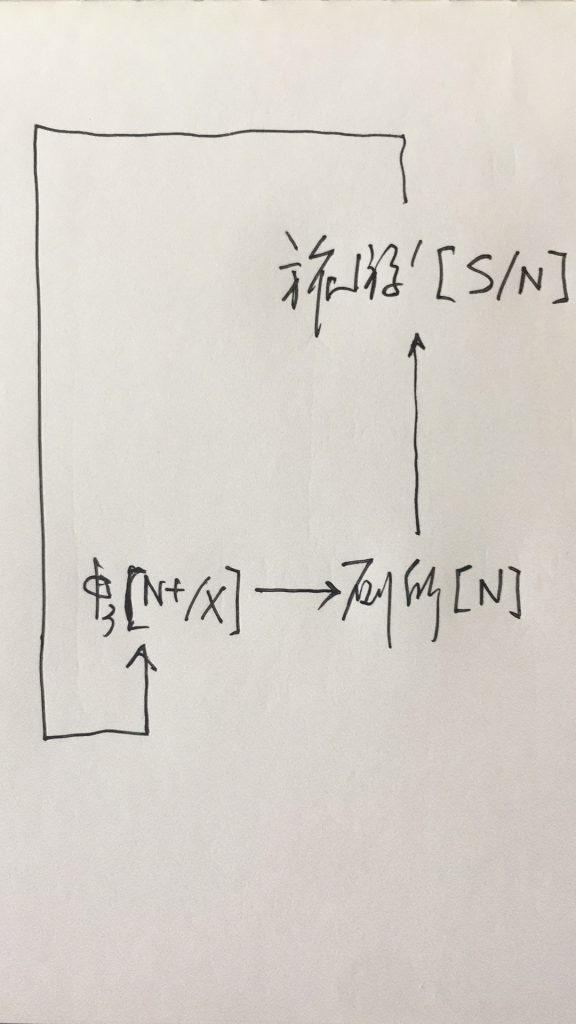
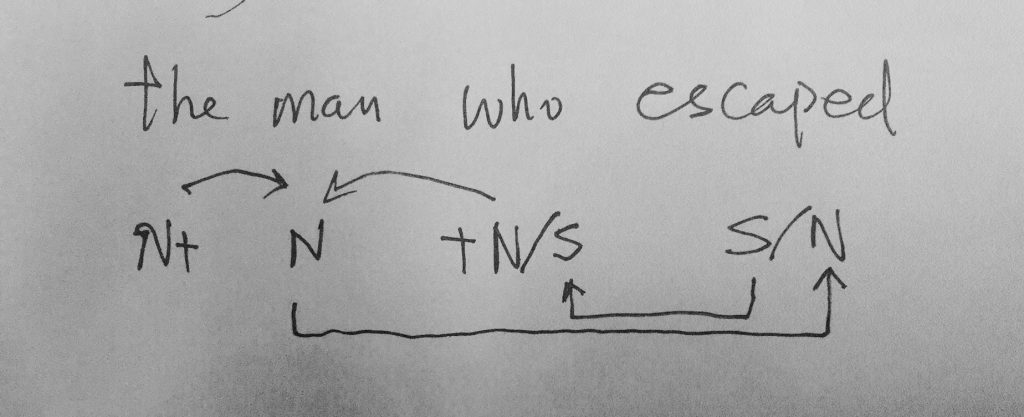
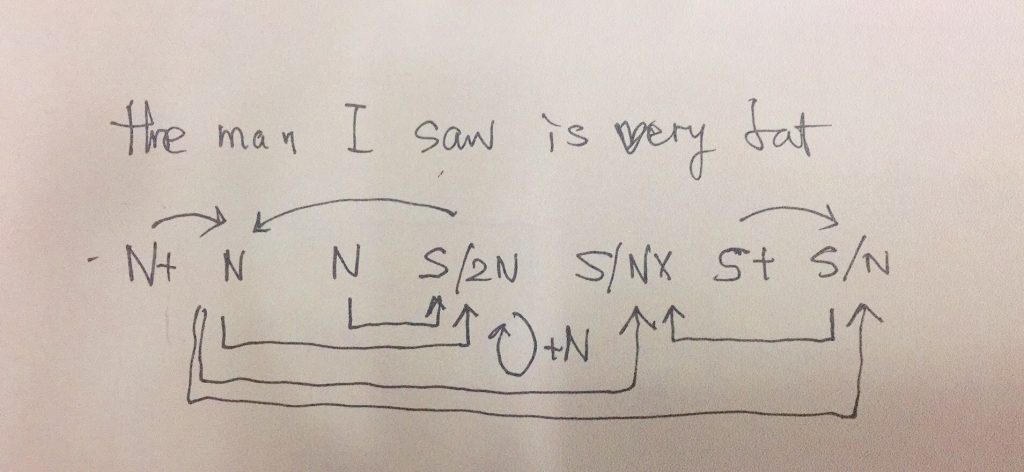

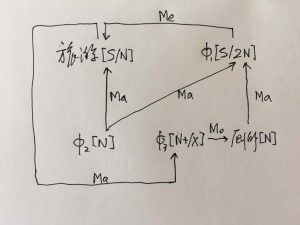

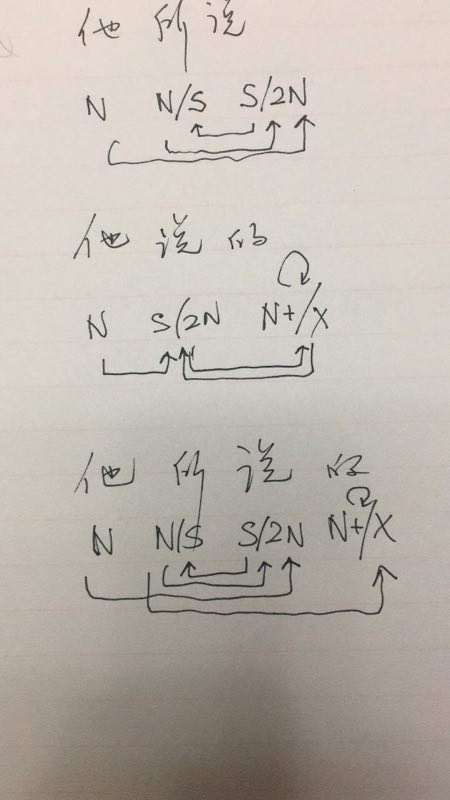



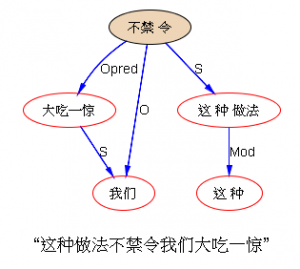
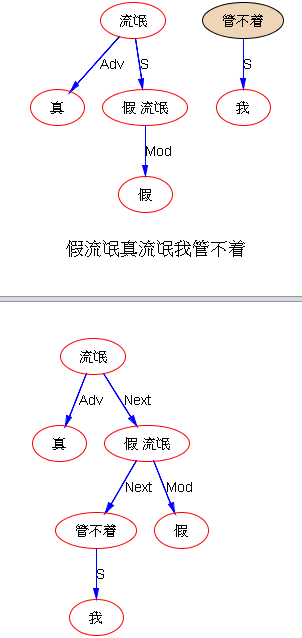
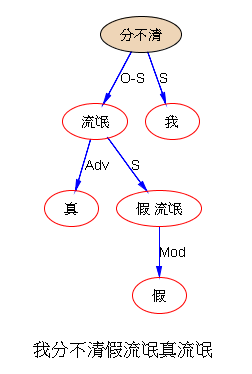
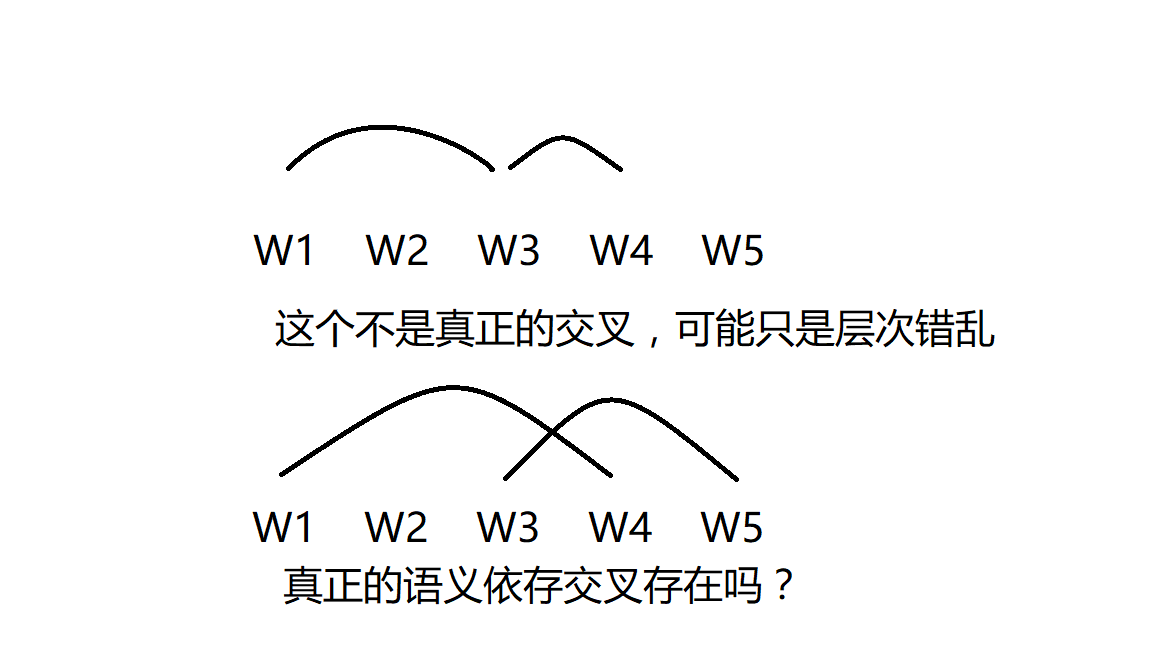
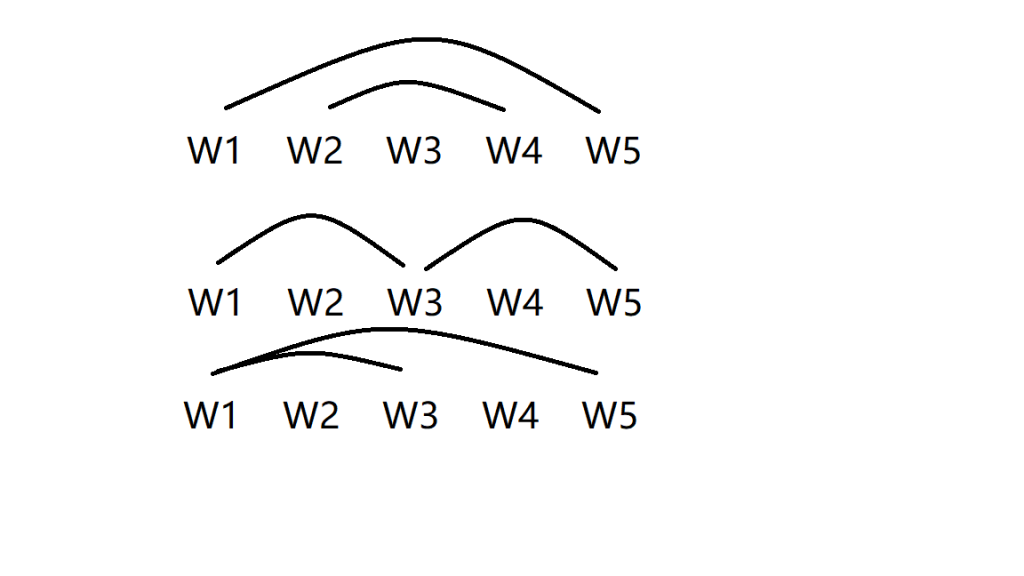
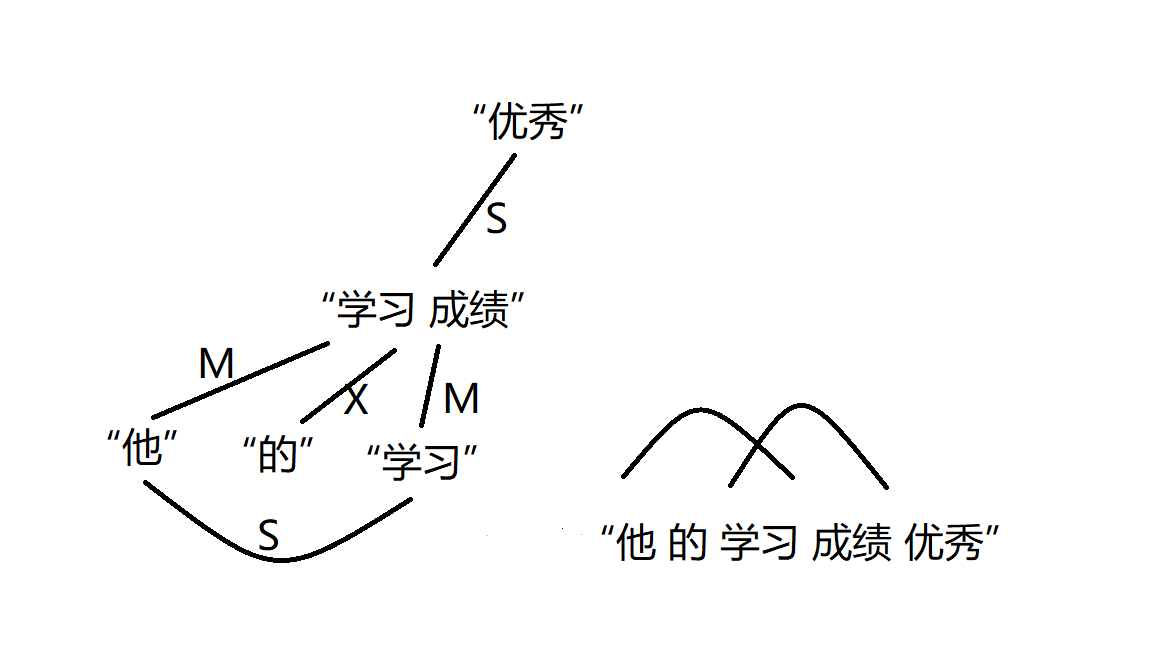 如果DG(Dependency Grammar)揉进了浅层的短语结构及其边界,先做了合成词“学习 成绩”,那么把“他”与合成词内部的“学习”连接成主谓关系,是交叉。但是如果不引入短语结构,一切节点都是终极节点,实行彻底的原汁原味的依存关系(DG)表达,那么“他”作为主语连接给“学习”以及“学习”作为修饰语连接给“成绩”,并没有真正交叉,只是层次(configuration)显得乱了。但是DG的最大特点(或缺点)就是打破层次,只论二元。多年来我们在DG中部分引入 PHG (Phrase Structure Grammar) 短语结构表达,也是为了弥补这个缺陷。
如果DG(Dependency Grammar)揉进了浅层的短语结构及其边界,先做了合成词“学习 成绩”,那么把“他”与合成词内部的“学习”连接成主谓关系,是交叉。但是如果不引入短语结构,一切节点都是终极节点,实行彻底的原汁原味的依存关系(DG)表达,那么“他”作为主语连接给“学习”以及“学习”作为修饰语连接给“成绩”,并没有真正交叉,只是层次(configuration)显得乱了。但是DG的最大特点(或缺点)就是打破层次,只论二元。多年来我们在DG中部分引入 PHG (Phrase Structure Grammar) 短语结构表达,也是为了弥补这个缺陷。