3.0. Introduction
CPSG95 is the grammar designed to formalize the morpho-syntactic analysis presented in this dissertation. This chapter presents the general design of CPSG95 with emphasis on three essential aspects related to the morpho-syntactic interface: (i) the overall mono-stratal design of the sign; (ii) the design of expectation feature structures; (iii) the design of structural feature structures.
The HPSG-style mono-stratal design of the sign in CPSG95 provides a general framework for the information flow between different components of a grammar via unification. Morphology, syntax and semantics are all accommodated in distinct features of a sign. An example will be shown to illustrate the information flow between these components.
Expectation feature structures are designed to accommodate lexical information for the structural combination. Expectation feature structures are vital to a lexicalized grammar like CPSG95. The formal definition for the sort hierarchy [expected] for the expectation features will be given. It will be demonstrated that the defined sort hierarchy provides means for imposing a proper structural hierarchy as defined by the general grammar.
One characteristic of the CPSG95 structural expectation is the unique design of morphological expectation features to incorporate Chinese productive derivation. This design is believed to be a feasible and natural way of modeling Chinese derivation, as shall be presented shortly below and elaborated in section 3.2.1. How this design benefits the interface coordination between derivation and syntax will be further demonstrated in Chapter VI.
The type [expected] for the expectation features is similar to the HPSG definition of [subcat] and [mod]. They both accommodate lexical expectation information to drive the analysis conducted via the general grammar. In order to meet some requirements induced by introducing morphology into the general grammar and by accommodating linguistic characteristics of Chinese, three major modifications from the standard HPSG are proposed in CPSG95. They are: (i) the CPSG95 type [expected] is more generalized as to cover productive derivation in addition to syntactic subcategorization and modification; (ii) unlike HPSG which tries to capture word order phenomena as independent constraints, Chinese word order in CPSG95 is integrated in the definition of the expectation features and the corresponding morphological/syntactic relations; (iii) in terms of handling the syntactic subcategorization, CPSG95 pursues a non-list alternative to the standard practice of HPSG relying on the list design of obliqueness hierarchy. The rationale and arguments for these modifications are presented in the corresponding sections, with a brief summary given below.
The first modification is necessitated by meeting the needs of introducing Chinese productive derivation into the grammar. It is observed that a Chinese affix acts as the head daughter of the derivative in terms of expectation (Dai 1993). The expectation information that drives the analysis of a Chinese productive derivation is found to be capturable lexically by the affix sign; this is very similar to how the information for the head-driven syntactic analysis is captured in HPSG. The expansion of the expectation notion to include productive morphology can account for a wider range of linguistic phenomena. The feasibility of this modification has been verified by the implementation of CPSG95 based on the generalized expectation feature structures.
One outstanding characteristic of all the expectation features designed in CPSG95 is that the word order information is implied in the definition of these features.[1] Word order constraints in CPSG95 are captured by individual PS rules for the structural relationship between the constituents. In other words, Chinese word order constraints are not treated as phenomena which have sufficient generalizations of themselves independent of the individual morphological or syntactic relations. This is very different from the word order treatment in theories like HPSG (Pollard and Sag 1987) and GPSG (Gazdar, Klein, Pullum and Sag 1985). However, a similar treatment can be found in the work from the school of ‘categorial grammar’ (e.g. Dowty 1982).
The word order theory in HPSG and GPSG is based on the assumption that structural relations and syntactic roles can be defined without involving the factor of word order. In other words, it is assumed that the structural nature of a constituent (subject, object, etc.) and its linear position in the related structures can be studied separately. This assumption is found to be inappropriate in capturing Chinese structural relations. So far, no one has been able to propose an operational definition for Chinese structural relations and morphological/syntactic roles without bringing in word order.[2]
As Ding (1953) points out, without the means of inflections and case markers, word order is a primary constraint for defining and distinguishing Chinese structural relations.[3] In terms of expectation, it can always be lexically decided where for the head sign to look for its expected daughter(s). It is thus natural to design the expectation features directly on their expected word order.
The reason for the non-list design in capturing Chinese subcategorization can be summarized as follows: (i) there has been no successful attempt by anyone, including the initial effort involved in the CPSG95 experiment, which demonstrates that the obliqueness design can be applied to Chinese grammar with sufficient linguistic generalizations; (ii) it is found that the atomic approach with separate features for each complement is a feasible and flexible proposal in representing the relevant linguistic phenomena.
Finally, the design of the structural feature [STRUCT] originates from [LEX + | -] in HPSG (Pollard and Sag 1987). Unlike the binary type for [LEX], the type [struct] for [STRUCT] forms an elaborate sort hierarchy. This is designed to meet the configurational requirements of introducing morphology into CPSG95. This feature structure, together with the design of expectation feature structures, will help create a favorable framework for handling Chinese morpho-syntactic interface. The proposed structural feature structure and the expectation feature structures contribute to the formal definition of linguistic units in CPSG95. Such definitions enable proper lexical configurational constraints to be imposed on the expected signs when required.
3.1. Mono-stratal Design of Sign
This section presents the data structure involving the interface between morphology, syntax and semantics in CPSG95. This is done by defining the mono-stratal design of the fundamental notion sign and by illustrating how different components, represented by the distinct features for the sign, interact.
As a dynamic unit of grammatical analysis, a sign can be a morpheme, a word, a phrase or a sentence. It is the most fundamental object of HPSG-style grammars. Formally, a sign is defined in CPSG95 by the type [a_sign], as shown below.[4]
(3-1.) Definition: a_sign
a_sign
HANZI hanzi_list
CONTENT content
CATEGORY category
SUBJ expected
COMP0_LEFT expected
COMP1_RIGHT expected
COMP2_RIGHT expected
MOD_LEFT expected
MOD_RIGHT expected
PREFIXING expected
SUFFIXING expected
STRUCT struct
The type [a_sign] introduces a set of linguistic features for the description of a sign. These are features for orthography, morphology, syntax and semantics, etc.[5] The types, which are eligible to be the values of these features, have their own definitions in the sort hierarchy. An introduction of these features follows.
The orthographic feature [HANZI] contains a list of Chinese characters (hanzi or kanji). The feature [CONTENT] embodies the semantic representation of the sign. [CATEGORY] carries values like [n] for noun, [v] for verb, [a] for adjective, [p] for preposition, etc. The structural feature [STRUCT] contains information on the relation of the structure to its sub-constituents, to be presented in detail in section 3.3.
The features whose appropriate value must be the type [expected] are called expectation features. They are the essential part of a lexicalist grammar as these features contain information about various types of potential structures in both syntax and morphology. They specify various constraints on the expected daughter(s) of a sign for structural analysis. The design of these expectation features and their appropriate type [expected] will be presented shortly in section 3.2.
The definition of [a_sign] illustrates the HPSG philosophy of mono-stratal analysis interleaving different components. As seen, different components of Chinese grammar are contained in different feature structures for the general linguistic unit sign. Their interaction is effected via the unification of relevant feature structures during various stages of analysis. This will unfold as the solutions to the morpho-syntactic interface problems are presented in Chapter V and Chapter VI. For illustration, the prefix 可 ke (-able) is used as an example in the following discussion.
As is known, the prefix ke- (-able) makes an adjective out of a transitive verb: ke- + Vt --> A. This lexicalized rule is contained in the CPSG95 entry for the prefix ke-, shown in (3-2). Following the ALE notation, @ is used for macro, a shorthand mechanism for a pre-defined feature structure.[6]

As seen, the prefix ke- morphologically expects a sign with [CATEGORY vt]. An affix is analyzed as the head of a derivational structure in CPSG95 (see section 6.1 for discussion) and [CATEGORY] is a representative head feature to be percolated up to the mother sign via the corresponding morphological PS rule as formulated in (6-4) of section 6.2, this expectation eventually leads to a derived word with [CATEGORY a]. Like most Chinese adjectives, the derived adjective has an optional expectation for a subject NP to account for sentences like 这本书很可读 zhe (this) ben (CLA) shu (book) hen (very) ke-du (read-able): ‘This book is very readable’. This syntactic optional expectation for the derivative is accommodated in the head feature [SUBJ].
Note that before any structural combination of ke- with other expected signs, ke- is a bound morpheme, a sign which has obligatory morphological expectation in [PREFIXING]. As a head for both the morphological combination ke+Vt and the potential syntactic combination NP+[ke+Vt], the interface between morphology and syntax in this case lies in the hierarchical structures which should be imposed. That is, the morphological structure (derivation) should be established before its syntactic expected structure can be realized. Such a configurational constraint is specified in the corresponding PS rules, i.e. the Subject PS Rule and The Prefix PS Rule. It guarantees that the obligatory morphological expectation of ke- has to be saturated before the sign can be legitimately used in syntactic combination.
The interaction between morphology/syntax and semantics in this case is encoded by the information flow, i.e. structure-sharing indicated by the number index in square brackets, between the corresponding feature structures inside this sign. The semantic compositionality involved in the morphological and syntactic grouping is represented like this. There is a semantic predicate marked as [-able] (for worthiness) in the content feature [RELN]; this predicate has an argument which is co-indexed by [1] with the semantics of the expected Vt. Note that the syntactic subject of the derived adjective, say ke-du (read-able) or ke-chi (eat-able), is the semantic (or logical) object of the stem verb, co-indexed by [2] in the sample entry above. The head feature [CONTENT] which reflects the semantic compositionality will be percolated up to the mother sign when applicable morphological and syntactic PS rules take effect in structure building.
In summary, embodied in CPSG95 is a mono-stratal grammar of morphology and syntax within the same formalism. Both morphology and syntax use same data structure (typed feature structure) and mechanisms (unification, sort hierarchy, PS rules, lexical rules, macros). This design for Chinese grammar is original and is shown to be feasible in the CPSG95 experiments on various Chinese constructions. The advantages of handling morpho-syntactic interface problems under this design will be demonstrated throughout this dissertation.
3.2. Expectation Feature Structures
This section presents the design of the expectation features in CPSG95. In general, the expectation features contain information about various types of potential structures of the sign. In CPSG95, various constraints on the expected daughter(s) of a sign are specified in the lexicon to drive both morphological and syntactic structural analysis. This provides a favorable basis for interleaving Chinese morphology and syntax in analysis.
The expected daughter in CPSG95 is defined as one of the following grammatical constituents: (i) subject in the feature [SUBJ]; (ii) first complement in the feature [COMP0_LEFT] or [COMP1_RIGHT]; (iii) second complement in [COMP2_RIGHT]; (iv) head of a modifier in the feature [MOD_LEFT] or [MOD_RIGHT]; (v) stem of an affix in the feature [PREFIXING] or [SUFFIXING].[7] The first four are syntactic daughters which will be investigated in sections 3.2.2 and 3.2.3. The last one is the morphological daughter for affixation, to be presented in section 3.2.1. All these features are defined on the basis of the relative word order of the constituents in the structure. The hierarchy for the structure at issue resorts to the configurational constraints which will be presented in section 3.2.4.
3.2.1. Morphological Expectation
One key characteristic of the CPSG95 expectation features is the design of morphological expectation features to incorporate Chinese productive derivation.
It is observed that a Chinese affix acts as the head daughter of the derivative in terms of expectation (see section 6.1 for more discussion). An affix can lexically define what stem to expect and can predict the derivation structure to be built. For example, the suffix 性 –xing demands that it combine with a preceding adjective to make an abstract noun, i.e. A+-xing --> N. This type of information can be easily captured by the expectation feature structure in the lexicon, following the practice of the HPSG treatment of the syntactic expectation such as subcategorization and modification.
In the CPSG95 lexicon, each affix entry is encoded to provide the following derivation information: (i) what type of stem it expects; (ii) whether it is a prefix or suffix to decide where to look for the expected stem; (iii) what type of (derived) word it produces. Based on this lexical information, the general grammar only needs to include two PS rules for Chinese derivation: one for prefixation, one for suffixation. These rules will be formulated in Chapter VI (sections 6.2 and 6.3). It will also be demonstrated that this lexicalist design for Chinese derivation works for both typical cases of affixation and for some difficult cases such as ‘quasi-affixation’ and zhe-suffixation.
In summary, the morphological combination for productive derivation in CPSG95 is designed to be handled by only two PS rules in the general grammar, based on the lexical specification in [PREFIXING] and [SUFFIXING]. Essentially, in CPSG95, productive derivation is treated like a ‘mini-syntax’;[8] it becomes an integrated part of Chinese structural analysis.
3.2.2. Syntactic Expectation
This section presents the design of the expectation features to represent Chinese syntactic relations. It will be demonstrated that constraints like word order and function words are crucial to the formalization of syntactic relations. Based on them, four types of syntactic relations can be defined, which are accommodated in six syntactic expectation feature structures for each head word.
There is no general agreement on how to define Chinese syntactic relations. In particular, the distinction between Chinese subject and object has been a long debated topic (e.g. Ding 1953; L. Li 1986, 1990; Zhu 1985; Lü 1989). The major difficulty lies in the fact that Chinese does not have inflection to indicate subject-verb agreement and nominative case or accusative case, etc.
Theory-internally, there have been various proposals that Chinese syntactic relations be defined on the basis of one or more of the following factors: (i) word order (more precisely, constituent order); (ii) the function words associated with the constituents; (iii) the semantic relations or roles. The first two factors are linguistic forms while the third factor belongs to linguistic content.
L. Li (1986, 1990) relies mainly on the third factor to study Chinese verb patterns. The constituents in his proposal are named as NP-agent (ming-shi), NP-patient (ming-shou), etc. This practice amounts to placing an equal sign between the syntactic relation and semantic relation. It implies that the syntactic relation is not an independent feature. This makes syntactic generalization difficult.
Other Chinese grammarians (e.g. Ding 1953; Zhu 1985) emphasize the factor of word order in defining syntactic relations. This school insists that syntactic relations be differentiated from semantic relations. More precisely, semantic relations should be the result of the analysis of syntactic relations. That is also the rationale behind the CPSG95 practice of using word order and other constraints (including function words) in the definition of Chinese relations.
In CPSG95, the expected syntactic daughter in CPSG95 is defined as one of the following grammatical constituents: (i) subject in the feature [SUBJ], typically an NP which is on the leftmost position relative to the head; (ii) complements closer to the head in the feature [COMP0_LEFT] or [COMP1_RIGHT], in the form of an NP or a specific PP; (iii) the second complement in [COMP2_RIGHT]: this complement is defined to be an XP (NP, a specific PP, VP, AP, etc.) farther away from the head than [COMP1_RIGHT] in word order; (iv) head of a modifier in the feature [MOD_LEFT] or [MOD_RIGHT]. In this defined framework of four types of possible syntactic relations, for each head word, the lexicon is expected to specify the specific constraints in its corresponding expectation feature structures and map the syntactic constituents to the corresponding semantic roles in [CONTENT]. This is a secure way of linking syntactic structures and their semantic composition for the following reason. Given a specific head word and a syntactic structure with its various constraints specified in the expectation feature structures, the decoding of semantics is guaranteed.[9]
A Chinese syntactic pattern can usually be defined by constraints from category, word order, and/or function words (W. Li 1996). For example, NP+V, NP+V+NP, NP+PP(x)+NP, NP+V+NP+NP, NP+V+NP+VP, etc. are all such patterns. With the design of the expectation features presented above, these patterns can be easily formulated in the lexicon under the relevant head entry, as demonstrated by the sample formulations given in (3-3) and (3-4).


The structure in (3-3) is a Chinese transitive pattern in its default word order, namely NP1+Vt+NP2. The representation in (3-4) is another transitive pattern NP+PP(x)+Vt. This pattern requires a particular preposition x to introduce its object before the head verb.
The sample entry in (3-5) is an example of how modification is represented in CPSG95. Following the HPSG semantics principle, the semantic content from the modifier will be percolated up to the mother sign from the head-modifier structure via the corresponding PS rule. The added semantic contribution of the adverb chang-chang (often) is its specification of the feature [FREQUENCY] for the event at issue.

3.2.3. Chinese Subcategorization
This section presents the rationale behind the CPSG95 design for subcategorization. Instead of a SUBCAT-list, a keyword approach with separate features for each complement is chosen for representing the subcategorization information, as shown in the corresponding expectation features in section 3.2.2. This design has been found to be a feasible alternative to the standard practice of HPSG relying on the list design of obliqueness hierarchy and SUBCAT Principle when handling subject and complements.
The CPSG95 design for representing subcategorization follows one proposal from Pollard and Sag (1987:121), who point out: “It may be possible to develop a hybrid theory that uses the keyword approach to subjects, objects and other complements, but which uses other means to impose a hierarchical structure on syntactic elements, including optional modifiers not subcategorized for in the same sense.” There are two issues for such a hybrid theory: the keyword approach to representing subject and complements and the means for imposing a hierarchical structure. The former is discussed below while the latter will be addressed in the subsequent section 3.2.4.
The basic reason for abandoning the list design is due to the lack of an operational definition of obliqueness which captures generalizations of Chinese subcategorization. In the English version of HPSG (Pollard and Sag 1987, 1994), the obliqueness ordering is established between the syntactic notions of subject, direct object and second object (or oblique object).[10] But these syntactic relations themselves are by no means universal. In order to apply this concept to the Chinese language, there is a need for an operational definition of obliqueness which can be applied to Chinese syntactic relations. Such a definition has not been available.
In fact, how to define Chinese subject, object and other complements has been one of the central debated topics among Chinese grammarians for decades (Lü 1946, 1989; Ding 1953; L. Li 1986, 1990; Zhu 1985; P. Chen 1994). No general agreement for an operational, cross-theory definition of Chinese subcategorization has been reached. It is often the case that formal or informal definitions of Chinese subcategorization are given within a theory or grammar. But so far no Chinese syntactic relations defined in a theory are found to demonstrate convincing advantages of a possible obliqueness ordering, i.e. capturing the various syntactic generalizations for Chinese.
Technically, however, as long as subject and complements are formally defined in a theory, one can impose an ordering of them in a SUBCAT list. But if such a list does not capture significant generalizations, there is no point in doing so.[11] It has turned out that the keyword approach is a promising alternative once proper means are developed for the required configurational constraint on structure building.
The keyword approach is realized in CPSG95 as follows. Syntactic constituents for subcategorization, namely subject and complements, are directly accommodated in four parallel features [SUBJ], [COMP0_LEFT], [COMP1_RIGHT] and [COMP2_RIGHT].
The feasibility of the keyword approach proposed here has been tested during the implementation of CPSG95 in representing a variety of structures. Particular attention has been given to the constructions or patterns related to Chinese subcategorization. They include various transitive structures, di-transitive structures, pivotal construction (jianyu-shi), ba-construction (ba-zi ju), various passive constructions (bei-dong shi), etc. It is found to be easy to accommodate all these structures in the defined framework consisting of the four features.
We give a couple of typical examples below, in addition to the ones in (3-3) and (3-4) formulated before, to show how various subcategorization phenomena are accommodated in the CPSG95 lexicon within the defined feature structures for subcategorization. The expected structure and example are shown before each sample formulation in (3‑6) through (3-8) (with irrelevant implementation details left out).


Based on such lexical information, the desirable hierarchical structure on the related syntactic elements, e.g. [S [V O]] instead of [[S V] O], can be imposed via the configurational constraint based on the design of the expectation type. This is presented in section 3.2.4 below.
3.2.4. Configurational Constraint
The means for the configurational constraint to impose a desirable hierarchical morpho-syntactic structure defined by a grammar is the key to the success of a keyword approach to structural constituents, including subject and complements from the subcategorization. This section defines the sort hierarchy of the expectation type [expected]. The use of this design for flexible configurational constraint both in the general grammar and in the lexicon will be demonstrated.
As presented before, whether a sign has structural expectation, and what type of expectation a sign has, can be lexically decided: they form the basis for a lexicalized grammar. Four basic cases for expectation are distinguished in the expectation type of CPSG95: (i) obligatory: the expected sign must occur; (ii) optional: the expected sign may occur; (iii) null: no expectation; (iv) satisfied: the expected sign has occurred. Note that case (i), case (ii) and case (iii) are static information while (iv) is dynamic information, updated at the time when the daughters are combined into a mother sign. In other words, case (iv) is only possible when the expected structure has actually been built. In HPSG-style grammars, only the general grammar, i.e. the set of PS rules, has the power of building structures. For each structure being built, the general grammar will set [satisfied] to the corresponding expectation feature of the mother sign.
Out of the four types, case (i) and case (ii) form a natural class, named as [a_expected]; case (iii) and case (iv) are of one class named as [saturated]. The formal definition of the type [expected] is given (3-9].
(3-9.) Definition: sorted hierarchy for [expected]
expected: {a_expected, saturated}
a_expected: {obligatory, optional}
ROLE role
SIGN a_sign
saturated: {null, satisfied}
The type [a_expected] introduces two features: [ROLE] and [SIGN]. [ROLE] specifies the semantic role which the expected sign plays in the structure. [SIGN] houses various types of constraints on the expected sign.
The type [expected] is designed to meet the requirement of the configurational constraint. For example, in order to guarantee that syntactic structures for an expecting sign are built on top of its morphological structures if the sign has obligatory morphological expectation, the following configurational constraint is enforced in the general grammar. (The notation | is used for logical OR.)
(3-10.) configurational constraint in syntactic PS rules
PREFIXING saturated | optional
SUFFIXING saturated | optional
The constraint [saturated] means that syntactic rules are permitted to apply if a sign has no morphological expectation or after the morphological expectation has been satisfied. The reason why the case [optional] does not block the application of syntactic rules is the following. Optional expectation entails that the expected sign may or may not appear. It does not have to be satisfied.
Similarly, within syntax, the constraints can be specified in the Subject PS Rule:
(3-11.) configurational constraint in Subject PS rule
COMP0_LEFT saturated | optional
COMP1_RIGHT saturated | optional
COMP2 saturated | optional
This ensures that complement rules apply before the subject rule does. This way of imposing a hierarchical structure between subcategorized elements corresponds to the use of SUBCAT Principle in HPSG based on the notion of obliqueness.
The configurational constraint is also used in CPSG95 for the formal definition of phrase, as formulated below.
phrase macro
a_sign
PREFIXING saturated | optional
SUFFIXING saturated | optional
COMP1_LEFT saturated | optional
COMP1_RIGHT saturated | optional
COMP2 saturated | optional
Despite the notational difference, this definition follows the spirit reflected in the phrase definition given in Pollard and Sag (1987:69) in terms of the saturation status of the subcategorized complements. In essence, the above definition says that a phrase is a sign whose morphological expectation and syntactic complement expectation (except for subject) are both saturated. The reason to include [optional] in the definition is to cover phrases whose head daughter has optional expectation, for example, a verb phrase consisting of just a verb with its optional object omitted in the text.
Together with the design of the structural feature [STRUCT] (section 3.3), the sort hierarchy of the type [expected] will also enable the formal definition for the representation of the fundamental notion word (see Section 4.3 in Chapter IV). Definitions such as @word and @phrase are the basis for lexical configurational constraints to be imposed on the expected signs when required. For example, -xing (-ness) will expect an adjective stem with the word constraint and -zhe (-er) can impose the phrase constraint on the expected verb sign based on the analysis proposed in section 6.5.
3.3. Structural Feature Structure
The design of the feature [STRUCT] serves important structural purposes in the formalization of the CPSG95 interface between morphology and syntax. It is necessary to present the rationale of this design and the sort hierarchy of the type [struct] used in this feature.
The design of [STRUCT struct] originates from the binary structural feature structure [LEX + | -] in the original HPSG theory (Pollard and Sag 1987). However, in the CPSG95 definition, the type [struct] forms an elaborate sort hierarchy. It is divided into two types at the top level: [syn_dtr] and [no_syn_dtr]. A sub-type of [no_syn_dtr] is [no_dtr]. The CPSG95 lexicon encodes the feature [STRUCT no_dtr] for all single morphemes.[12] Another sub-type of [no_syn_dtr] is [affix] (for units formed via affixation) which is further sub-typed into [prefix] and [suffix], assigned by the Prefix PS rule and Suffix PS Rule. In syntax, [syn_dtr] includes sub-types like [subj], [comp] and [mod]. Despite the hierarchical depth of the type, it is organized to follow the natural classification of the structural relation involved. The formal definition is given below.
(3-12.) Definition: sorted hierarchy for [struct]
struct: {syn_dtr, no_syn_dtr}
syn_dtr: {subj, comp, mod}
comp: {comp0_left, comp1_right, comp2_right}
mod: {mod_left, mod_right}
no_syn_dtr: {no_dtr, affix}
affix: {prefix, suffix}
In CPSG95, [STRUCT] is not a (head) feature which percolates up to the mother sign; its value is solely decided by the structure being built.[13] Each PS rule, whether syntactic or morphological, assigns the value of the [STRUCT] feature for the mother sign, according to the nature of combination. When morpheme daughters are combined into a mother sign word, the value of the feature [STRUCT] for the mother sign remains a sub-type of [no_syn_dtr]. But when some syntactic rules are applied, the rules will assign the value to the mother sign as a sub-type of [syn_dtr] to show that the structure being built is a syntactic construction.
The design of the feature structure [STRUCT struct] is motivated by the new requirement caused by introducing morphology into the general grammar of CPSG95. In HPSG, a simple, binary type for [LEX] is sufficient to distinguish lexical signs, i.e. [LEX +], from signs created via syntactic rules, i.e. [LEX -]. But in CPSG95, as presented in section 3.2.1 before, productive derivation is also accommodated in the general grammar. A simple distinction between a lexical sign and a syntactic sign cannot capture the difference between signs created via morphological rules and signs created via syntactic rules. This difference plays an essential role in formalizing the morpho-syntactic interface, as shown below.
The following examples demonstrate the structural representation through the design of the feature [STRUCT]. In the CPSG95 lexicon, the single Chinese characters like the prefix ke- (-able) and the free morphemes du (read), bao (newspaper) are all coded as [STRUCT no_dtr]. When the Prefix PS Rule combines the prefix ke- and the verb du into an adjective ke-du, the rule assigns [STRUCT prefix] to the newly built derivative. The structure may remain in the domain of morphology as the value [prefix] is a sub-type of [no_syn_dtr]. However, when this structure is further combined with a subject, say, bao (newspaper) by the syntactic Subj PS Rule, the resulting structure [bao [ke-du]] (‘Newspapers are readable’) is syntactic, having [STRUCT subj] assigned by the Subj PS Rule; in fact, this is a simple sentence. Similarly, the syntactic Comp1_right PS Rules can combine the transitive verb du (read) and the object bao (newspaper) and assign for the unit du bao (read newspapers) in the feature [STRUCT comp1_right]. In general, when signs whose [STRUCT] value is a sub-type of [no_syn_dtr] combine into a unit whose [STRUCT] is assigned a sub-type of [syn_dtr], it marks the jump from the domain of morphology to syntax. This is the way the interface of Chinese morphology and syntax is formalized in the present formalism.
The use of this feature structure in the definition of Chinese word will be presented in Chapter IV. Further advantages and flexibility of the design of this structural feature structure and the expectation feature structures will be demonstrated in later chapters in presenting solutions to some long-standing problems at the morpho-syntactic interface.
3.4. Summary
The major design issues for the proposed mono-stratal Chinese grammar CPSG95 are addressed. This provides a framework and means for formalizing the analysis of the linguistic problems at the morpho-syntactic interface. It has been shown that the design of the CPSG95 expectation structures enables configuration constraints to be imposed on the structure hierarchy defined by the grammar. This makes the keyword approach to Chinese subcategorization a feasible alternative to the list design based on the obliqueness hierarchy of subject and complements.
Within this defined framework of CPSG95, the subsequent Chapter IV will be able to formulate the system-internal, but strictly formalized definition of Chinese word. Formal definitions such as @word and @phrase enable proper configurational constraints to be imposed on the expected signs when required. This lays a foundation for implementing the proposed solutions to the morpho-syntactic interface problems to be explored in the remaining chapters.
---------------------------------------------------------------------------------
[1] More precisely, it is not ‘word’ order, it is constituent order, or linear precedence (LP) constraint between constituents.
[2] L. Li (1986, 1990)’s definition on structural constituents does not involve word order. However, his proposed definition is not an operational one from the angle of natural language processing. He relies on the decoding of the semantic roles for the definitions of the proposed constituents like NP-agent (ming-shi), NP-patient (ming-shou), etc. Nevertheless, his proposal has been reported to produce good results in the field of Chinese language teaching. This seems to be understandable because the process of decoding semantic roles is naturally and subconsciously conducted in the mind of the language instructors/learners.
[3] Most linguists agree that Chinese has no inflectional morphology (e.g. Hockett 1958; Li and Thompson 1981; Zwicky 1987; Sun and Cole 1991). The few linguists who believe that Chinese has developed or is developing inflection morphology include Bauer (1988) and Dai (1993). Typical examples cited as Chinese inflection morphemes are aspect markers le, zhe, guo and the plural marker men.
[4] A note for the notation: uppercase is used for feature and lowercase, for type.
[5] Phonology and discourse are not yet included in the definition. The latter is a complicated area which requires further research before it can be properly integrated in the grammar analysis. The former is not necessary because the object for CPSG95 is Written Chinese. In the few cases where phonology affects structural analysis, e.g. some structural expectation needs to check the match of number of syllables, one can place such a constraint indirectly by checking the number of Chinese characters instead (as we know, a syllable roughly corresponds to a Chinese character or hanzi).
[6] The macro constraint @np in (3-2) is defined to be [CATEGORY n] and a call to another macro constraint @phrase to be defined shortly in Section 3.2.4.
[7] These expectation features defined for [a_sign] are a maximum set of possible expected daughters; any specific sign may only activate a subset of them, represented by non-null value.
[8] This is similar to viewing morphology as ‘the syntax of words’ (Selkirk 1982; Lieber 1992; Krieger 1994). It seems that at least affixation shares with syntax similar structural constraints on constituency and linear ordering in Chinese. The same type of mechanisms (PS rules, typed feature structure for expectation, etc) can be used to capture both Chinese affixation and syntax (see Chapter VI).
[9] More precisely, the decoding of possible ways of semantic composition is guaranteed. Syntactically ambiguous structures with the same constraints correspond to multiple ways of semantic compositionality. These are expressed as different entries in the lexicon and the link between these entries is via corresponding lexical rules, following the HPSG practice. (W. Li 1996)
[10] Borsley (1987) has proposed an HPSG framework where subject is posited as a distinct feature than other complements. Pollard and Sag (1994:345) point out that “the overwhelming weight of evidence favors Borsley’s view of this matter”.
[11] The only possible benefit of such arrangement is that one can continue using the SUBCAT Principle for building complement structure via list cancellation.
[12] It also includes idioms whose internal morphological structure is unknown or has no grammatical relevance.
[13] The reader might have noticed that the assigned value is the same as the name of the PS rule which applies. This is because there is correspondence between what type of structure is being built and what PS rule is building it. Thus, the [STRUCT] feature actually records the rule application information. For example, [STRUCT subj] reflects the fact that the Subj PS Rule is the most recently applied rule to the structure in point; a structure built via the Prefix PS Rule has [STRUCT prefix] in place; etc. This practice gives an extra benefit of the functionality of ‘tracing’ which rules have been applied in the process of debugging the grammar. If there has never been a rule applied to a sign, it must be a morpheme carrying [STRUCT no_dtr] from the lexicon.
[Related]
PhD Thesis: Morpho-syntactic Interface in CPSG (cover page)
PhD Thesis: Chapter I Introduction
PhD Thesis: Chapter II Role of Grammar
PhD Thesis: Chapter III Design of CPSG95
PhD Thesis: Chapter IV Defining the Chinese Word
PhD Thesis: Chapter V Chinese Separable Verbs
PhD Thesis: Chapter VI Morpho-syntactic Interface Involving Derivation
PhD Thesis: Chapter VII Concluding Remarks
Overview of Natural Language Processing
Dr. Wei Li’s English Blog on NLP





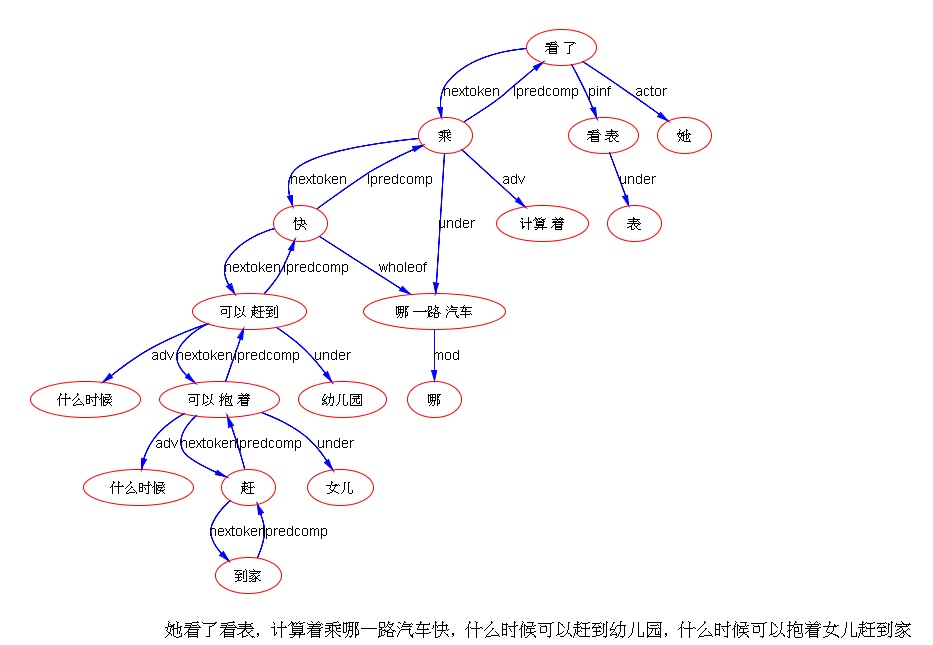

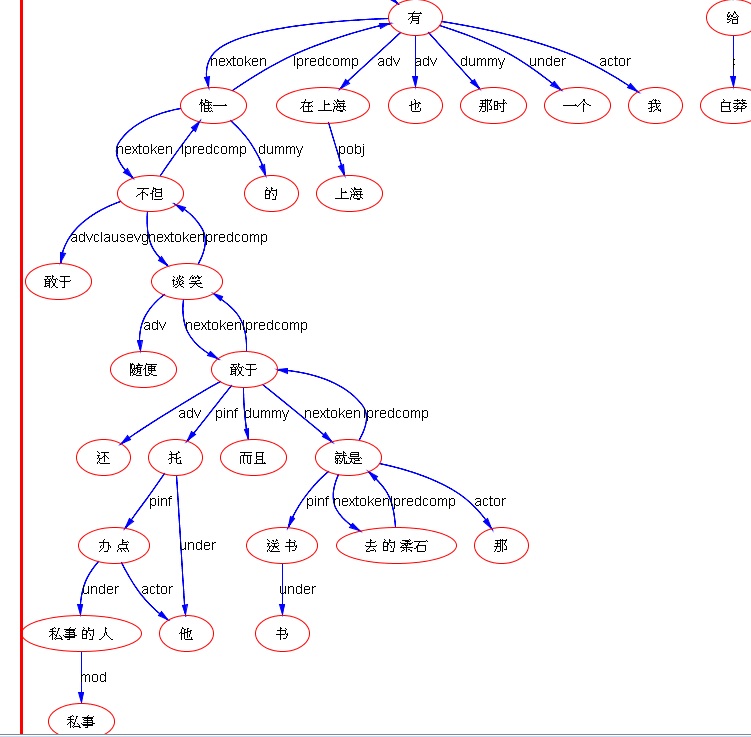
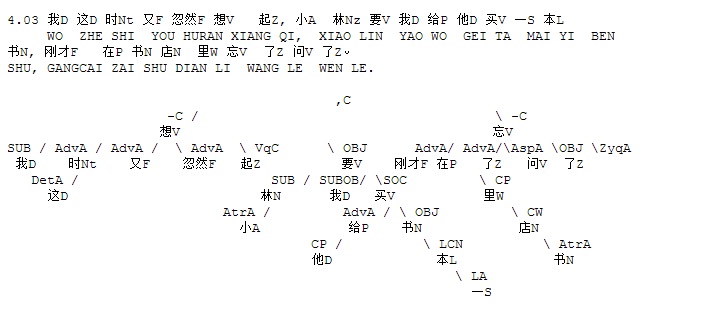
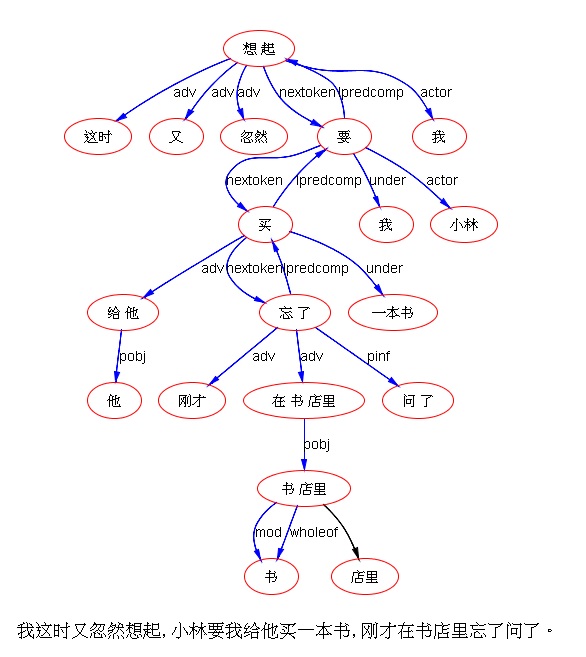




















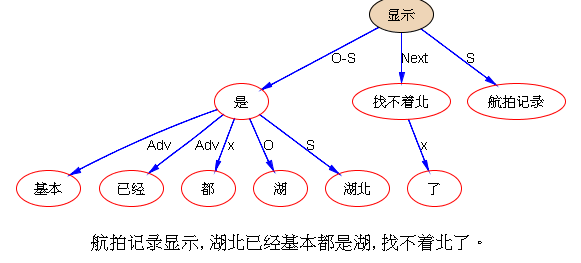

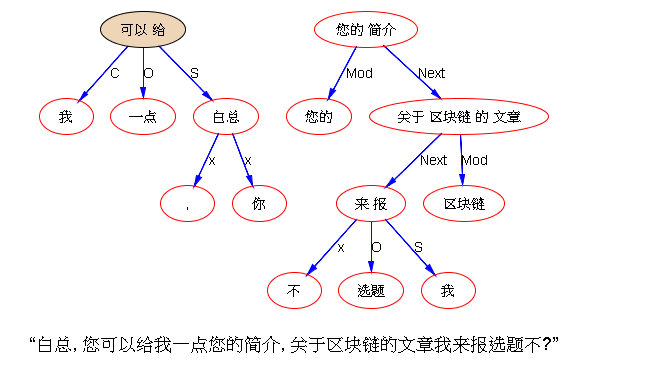

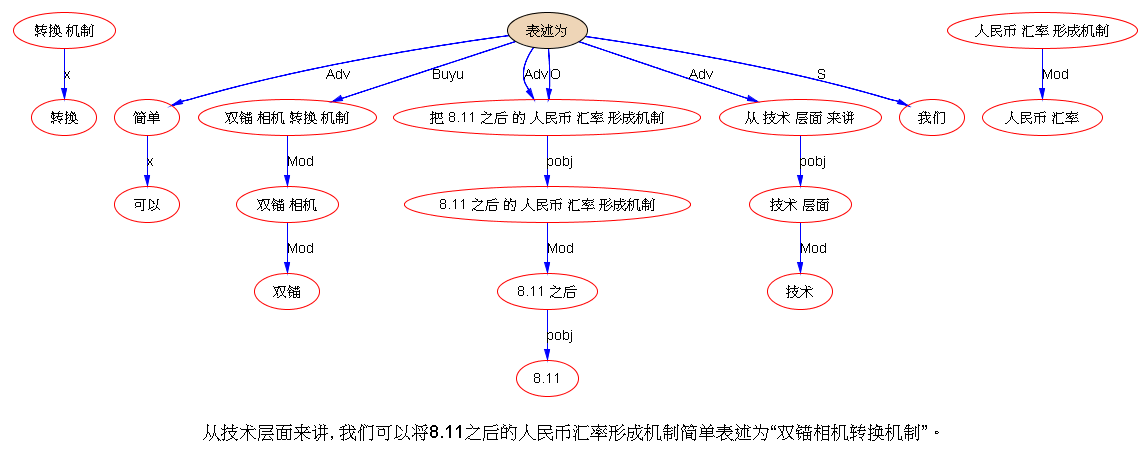




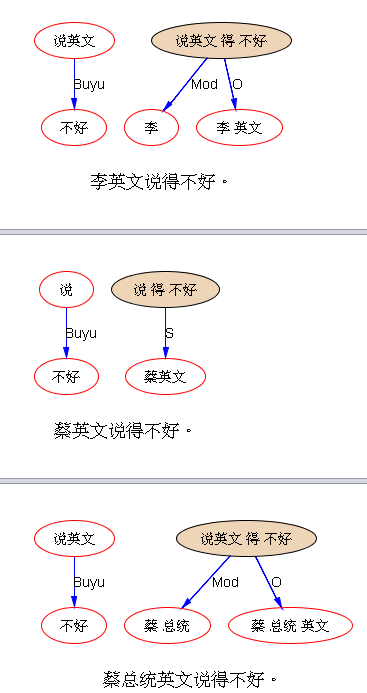

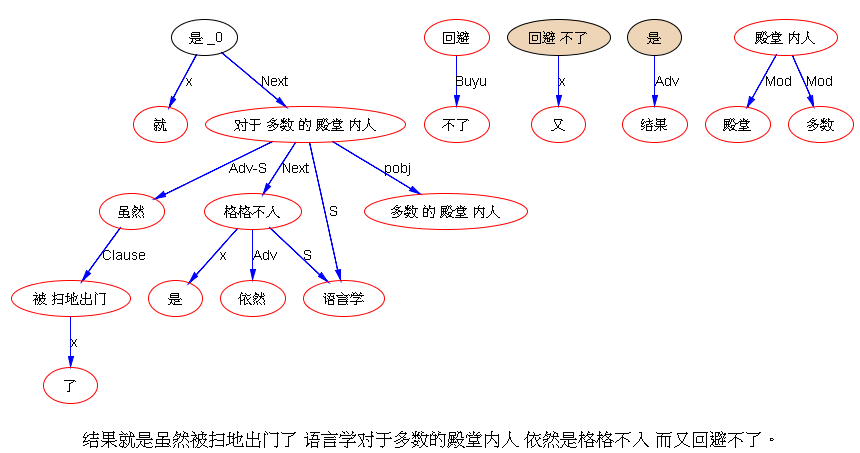
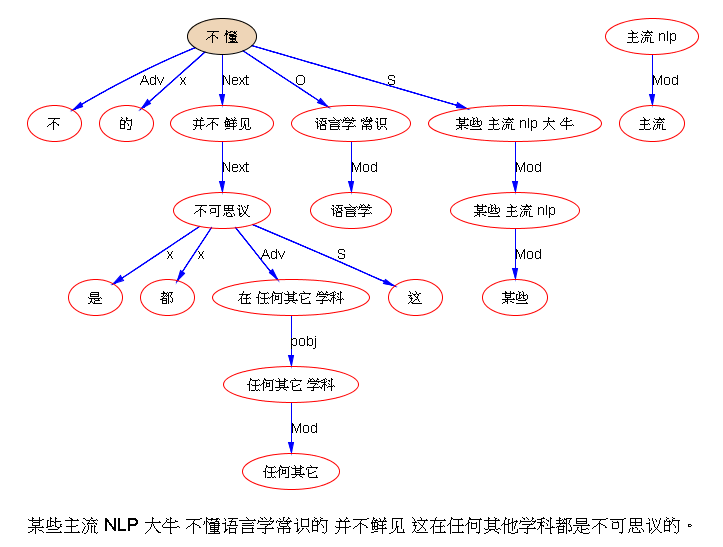
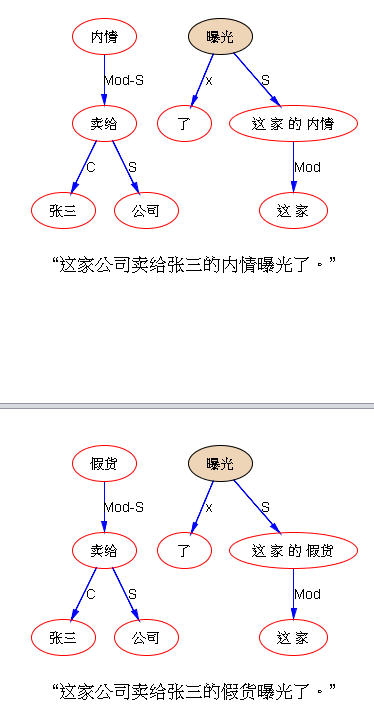
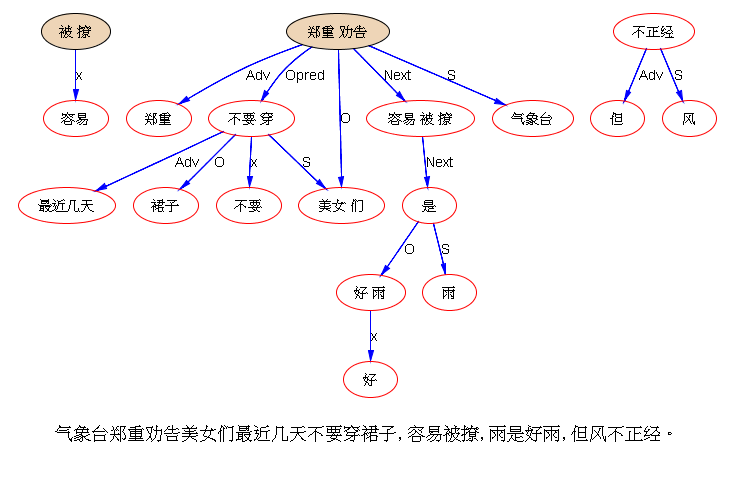 下面是笔者对两条路线斗争的总结,也 parse parse see see 吧,QUOTE:
下面是笔者对两条路线斗争的总结,也 parse parse see see 吧,QUOTE: