立委博士,多模态大模型应用咨询师。出门问问大模型团队前工程副总裁,聚焦大模型及其AIGC应用。Netbase前首席科学家10年,期间指挥研发了18种语言的理解和应用系统,鲁棒、线速,scale up to 社会媒体大数据,语义落地到舆情挖掘产品,成为美国NLP工业落地的领跑者。Cymfony前研发副总八年,曾荣获第一届问答系统第一名(TREC-8 QA Track),并赢得17个小企业创新研究的信息抽取项目(PI for 17 SBIRs)。
屏蔽已有 10652 次阅读2014-5-16 22:40|个人分类:留学资讯|系统分类:海外观察|Berkeley, 伯克利, cal
今年去参加了伯克利每年一度的开放日,叫 Cal Day,人满为患,热闹非凡。伯克利人对UC Berkeley 自称 Cal,源于当年加大球队 California 的缩写,那时候加大别无分店,伯克利就是加大,加大就是伯克利,如今加大已经开了10所分校,成为公立大学的巨无霸,这个简称(比UCB的简称更常见)却沿用至今。
本来想写一篇详细的校园观感,配上图片,但后来在网上发现一位美国教育的业余顶级专家(是一位湾区藤妈,成功把两个女儿送进顶级长春藤名校,对美国高等教育了如指掌,如数家珍,相关博文行文流畅,图文并茂,靠谱得一塌糊涂,叹服),叫白露为霜,她已经写了一篇 Cal Day 观感:伯克利新生录取日:寻找劳伦斯- 白露为霜的日志。想,我怎么写也写不了她那么好,富有知识和历史感,精致、全面而有趣。罢了,就随便写几句,配上照片,意思意思吧,聊胜于无:没有伯克利,我这个《美国校园之旅》系列就太不完整 了。
排名放在一边,必须承认伯克利超强的综合实力。它的科研能力以及教育资源的广度和深度,完全可以媲美全美五强(哈佛、斯坦福、耶鲁、普林斯顿和MIT),是其他小藤无法比拟的。不过,也必须承认超级公校的伯克利对于本科教育和本科生的照顾,比起私校,落差很大。学生的毕业率远不及私校,一度有多达四分之一的学生不得不辍学或转学(伯克利的应对之道是任其自然淘汰,然后再从无数渴望转学来伯克利的社区学院或其他大学的学生中选拔顶尖学生予以补充),这一点影响了伯克利的排名。课业负担沉重,学生心理压力大,有不少学生有畏惧感,怕进来就没有 life 了。网上就有被伯克利和私校南加大(USC,在洛杉矶,排名稍低于伯克利,以前被称为富家子弟的派对学校)同时录取的学生,宁肯放弃伯克利,多缴两倍多的学费去排名低于伯克利的 USC,理由就是 I want to enjoy college life。
劳伦斯当时马上想到是要造更大的加速器。到了1931年的夏天,劳伦斯和他的同事开始建造11英寸的加速器。更大的加速室需要更多的磁铁,更多的电线,更大的地方。他的11英寸的加速器被安装在LeConte Hall的329号房间。这台像冒汽锅炉的加速器被称为第一个真正成功可用的环形加速器,可以把粒子加速到1.2 MeV (million electron volts)。
在以后的8-9年里,劳伦斯在伯克利建造一系列越来越大的加速器,从27寸,37寸,60寸,最后到达184寸。184寸的加速器,磁铁及其附属设备已经大到伯克利的校园都装不下了,劳伦斯的幅射实验室(Radiation Laboratory)最后只好搬到伯克利后面的山上。幅射实验室后来被改名为劳伦斯-伯克利国家实验室(Lawrence Berkeley National Laboratory),是美国能源部主力实验室之一。
有关劳伦斯的故事并没有到此结束。1961年劳伦斯-伯克利国家实验室发现了化学元素103号。它被命名为“铹”(lawrencium),用来纪念他。 1968年,劳伦斯科学馆(Lawrence Hall of Science)成立。用这座俯瞰伯克利的科学馆来向这样一位终生都在积极倡导公众,尤其是小学生,对科学的兴趣的人致敬是非常合适的。科学馆设有劳伦斯一生事迹的永久展览,也是湾区孩子最喜欢的去处之一。
I don't know much about Stanford as I've only visited for brief periods of time. I'm familiar with both MIT (I graduated from MIT) and Tsinghua (many friends from there, and been there many times) and in all honesty I think it's very hard to compare the two schools.
There are many fundamental differences in the school culture, many of which on the Tsinghua side don't stem from the school itself. Many people ask me why there is a lack of startups coming out of Tsinghua and so many from MIT, and of all the reasons, the one biggest reason I can identify is freedom.
In Tsinghua, they turn out the lights in the dorms at night. The network is pretty restricted. There are guards standing at the entrances to every building. In Tsinghua, the overall university culture is to study first. It's evident in Larry Zhang's answer that people in Asia think MIT students are successful because of studying hard. It couldn't be further from the truth.
Well, we do study hard. But that's not where strong computer engineers come from. At MIT, studying isn't why we are here. We're here to hack everything we can lay our eyes upon. In my undergraduate dormitory, we had welding equipment, wood cutting equipment, plenty of EE stations, spare concrete and wood lying around the hallways. We had easy access to supply rooms, machine shops, and all kinds of other facilities for non-academic personal use. We had a mailing list called Reuse where you could race around campus picking up all kinds of wacky stuff labs didn't want, from rack-mount servers to old nitrogen dewars. We have an open network without port restrictions, free static IP addresses, gigabit network drops to dorm rooms with unlimited symmetric bandwidth. And MIT encourages us to use these resources to the fullest extent possible and go build the future. I had 15 computers in my dorm room, until the advent of virtualisation. My neighbor across the hall picked up an industrial laser and built his own laser cutter. Another neighbor was busy with home-made RF electronics analysing security deficiencies of the local subway and the school ID system. Another neighbor built a second floor in his dorm room. Another neighbor managed to launch a camera into space for under $200 in parts just to prove it could be done. Another managed to build a 3D display, another was fooling with virtual reality headsets, another was busy hacking at the Linux kernel for fun.
When was all this stuff done? At the dead of the night. When Tsinghua pulls the power on its dormitories. In fact I'm not sure if I can think of a bigger showstopper to a country's technological future than forcefully pulling power on the brightest students. How are you supposed to build projects? How are you supposed to run your servers in the early stages? Over at MIT, we build companies out of dorm rooms and our bedrooms become datacenters and laboratories.
Did we sacrifice study time to build stuff? Totally. A lot of us weren't at MIT to study anyway, we came here to build, and so build we did.
Did we break any rules? All the time! But fortunately, MIT doesn't watch us. No guards standing everywhere, no cameras, nothing telling us what we can and can't do unless we really do something physically unsafe. And so we hack the hell out of the campus too with high-tech (safe) pranks, not just our dorm rooms, and by doing them I learned about everything from Python to RF circuitry to power electronic design. In Tsinghua, they wouldn't even let me take pictures inside; there was a silly guard at the entrance to every building. Good luck hacking anything there.
Where are these people today? Half of them are CEOs of major computer engineering companies, software companies, or hacking away at the next big innovation from a large Silicon Valley company. Computer engineering skills comes first and foremost from practical experience, not from classes. And that's precisely what we were getting in our dorm rooms at obscene hours of the night.
Don't get me wrong, Tsinghua students are extremely intelligent, bright, smart, and in fact no different from us in the passions they have for inventing the future. I've been there many times. I have tons of friends from Tsinghua. The real problem is not the students, it's the environment of the school, traditional Asian academic value system, and everything else that quickly stops them from putting their dreams and future first rather than studies. That's been my general observation over the years.
Anyway, I was going to check out this new class they're teaching this term, but think I'm just going to screw it and get back to hacking at my app instead ...
市场化是不是能解开这个死结不知道,但是这个制度需要改造是无疑的。而且改造的方向不要向美国学,尽管美国的“德智体美全面考量、黑箱作业”的升学选拔机制听上去确实比东土强。不跟美国学 是因为这边的制度也在检讨,对青少年的四年(高中)摧残几乎不亚于国内的高考。美国有草根运动做调研、拍电影呼吁减轻学生负担,改革升学制度(如草根纪录片《Race to nowhere》)。
老邱并不老, 还不到五十岁。他的中文原名叫邱芳全, 可能没几个人听说过,连我自己也是不久前才知道的。但若提起老邱的英文名字 David Chiu, 那可是江湖上响当当的人物,对于见过点儿世面的玩扑克的人可以说是无人不知无人不晓。梁山一百零八条好汉,真牛的都在三十六天罡数内。在扑克比赛中扬名立万的人物多如牛毛,就我能说出名姓来的也不止一百零八条。我查了一下PokerPages 网站的统计,若按比赛赢的奖金来排,前一百名基本都有三百万以上,老邱以将近六百五十万美元排在第二十四名,绝对是位列天罡的牛人。其实网上的统计不是很准, 比如老邱在1996年拿的 US Open 冠军和1999年TOC 冠军的奖金都给漏掉了。
(一) 技惊四座
我知道有老邱这么个人物,是在十年前。当时老邱刚拿了TOC 冠军,被很多人认为是 Best Limit Holdem player, 也就是最牛的有限豪胆玩家。这个TOC 是 Tournament of Champions ,就是冠军赛的意思, 不是谁都可以报名参赛的,必须是在WSOP 等重要比赛中拿过冠军的人才有资格参赛。1999年是第一届,搞了个入场仪式,三十几个国家的牌手,跟奥运会似的有礼仪小姐打着国旗引领入场。跟随五星红旗入场的选手只有老邱一人。最后咱们的老邱不单拿了第一成为冠军中的冠军,而且展现了令人惊叹的牌技。直到今天还不时有人提起他在 FLOP 前放掉KK的那手牌。TOC比赛前面是Limit Holdem, Omaha Hi-Low, 7 Card Stud 几项混合比赛, 到最后还剩下54个人的时候转为No-Limit Holdem。那把扑史留名的牌的经过是这样的:
盲注为5000/10000, 前面两个人跟进1万,老邱在Button上加注到7万5,小盲全进。大盲和前面跟进的两人都缴枪了。小盲有60多万的筹码,老邱当时有大约85万。老邱冷静地思考了一会儿,淡淡地说道“我放弃”,然后把一对老K面朝上扔到了废牌堆里。网上可以找到一些当时在场者的记述,即便不读这些记述我也可以想象当时在场观战者是怎样的惊诧莫名。KK, 仅次于AA的第二好牌,平均每玩221把才能拿到一次,就这样轻易地给扔了?对手也同样的惊诧,但可能更多的是敬佩老邱非凡的读牌能力,友好礼貌地亮了他的底牌:AA。我们还可以想象观战者是怎样的更加惊愕。虽然佩服,但怎么也不能明白老邱是如何能读出对手底牌的。当时为比赛做解说的迈克-塞克斯顿(Mike Sexton)和费尤-海尔姆斯(Phil Hellmuth)惊叹道“Wow, What a lay down!” (多么了不起的放弃呀). 在FLOP之前能放掉KK,老邱并不是第一个人, 之前Hamid Dastmalchi 也曾在WSOP中干过,但那是经过三次加注之后,而且对手是很紧的牌手。即便这样,也被认为是很了不起的。现在这把牌,对手在老邱加注之后直接全进,实话说,从牌局的进程来看,根本不能断定对手是AA。连大高手泰德-佛瑞斯特(Ted Forest)当时都很不解地说“what the hell is going on(这他妈是怎么一回事)?”是啊,这究竟是怎么一回事呢?直到这次我去拉斯维加斯比赛期间和老邱聊天,他向我道出了其中奥妙,我才恍然大悟,更加佩服老邱的读牌能力,也不由慨叹:大概我永远也做不到了。 老邱少年时游泳耳朵感染,导致部分失聪。这个不足使他在牌桌上格外注意用眼睛观察对手,再加上他在赌场当发牌员的几年,阅尽三教九流牌手,每个牌手的一举一动他都细心观察,养成了他敏锐的观察能力。耳朵失聪正好排除干扰,更专注比赛。长久的磨练,使他即使在WPT和 WSOP的终桌比赛观众呐喊不断,在电视台长枪短炮的摄像镜头下听着现场解说,也能全神贯注比赛而心无杂念。这手牌老邱观察到了以下迹象: 第一,小盲在微微捻开底牌看牌的时候,两张牌分得比他每次分的稍微有点宽, 这是上面那张牌是A的一个迹象,因为只有A要稍微多露一些才能看清楚;第二,看完牌后他小心地放了一个筹码压住底牌;第三,他喊“全进”之前,头向右偏,对他左手边的下家大盲以及跟进的两家连看也不看;是什么牌能够让他有这样的自信?几点综合一起,可以断定他手里一定是AA。
其实,这把牌虽然被人广泛议论称道,但老邱说这并不是他在那次比赛中最得意的一把。他在终桌还有一把惊人的跟进。在桌上全部5张牌都出来之后, 对手下了很大的注。老邱一个对子都没有,手里的大牌是一张K,就是个king high。但他通过观察研究,认定对手就是Q high, 就勇敢地跟了,而对手果然就是Q high!“What a great call!” 天才牌手斯杜-恩戈在和曼苏尔比赛中那J high 惊人的一跟,作为读牌能力和胆略的一个经典范例而载入史册。但白瑞-格林斯坦(Barry Greenstein)曾经说过“大家都谈论斯杜-恩戈的跟进如何天才,但谁见过他什么时候有过了不起的放弃?没有。”伟大的放弃比天才的跟进更难做到。而老邱在同一场比赛中,既展示了一把伟大的放弃,也表演了一把天才的跟进, 能不得意乎?实在是该拿冠军,也拿到了。
跟老邱聊完后我自感也有所悟,在当天的比赛中也有出色表演,上演了一把不算太伟大的放弃(QQ Preflop 放掉,对手亮了KK)和一把不算太天才的跟进(在河牌后A high 跟进Q high 的一个大注),呵呵。所以俺那个比赛进了钱圈也是应该的。但是最后还是没经受住考验,AA在转牌放不掉,输给了对手的同花, 没能拿大钱,教训深刻,也深深体会到理智的放弃比勇敢的跟进更难于做到。还得修炼啊。
扑克有 bad beat, 就是愤输的意思,指的是这样的情形:自己优势很大的情况下把很多筹码推进去了,但运气不佳来了邪门牌让对手赢了。老邱这场牢狱之灾也是愤输,运气不佳的小概率事件发生了,损失惨重。然而,高手毕竟是高手,打牌愤输是常事。愤输以后,低手往往控制不住自己的情绪楞来(术语叫 On Tilt), 通常是损失更加惨重。高手更多的是在乎自己是否做了正确的判断和决策,运气因素不是自己能控制的,愤输也是一把牌,不能把坏情绪带到下一把牌里。老邱是一等一的大行家, 知道怎样控制自己的情绪。出狱之后,很快就赶上第一届TOC 冠军之赛,老邱技惊四座成为冠军中的冠军。当然,那场愤输经历沉淀在老邱的心底,更增加了他对自己的民族和文化的认同感。我觉得,后来老邱在TOC比赛中代表中国出场,以及去年正当奥运火炬传递变成政治风波之后,老邱在世界扑克巡回赛总决赛上赢得冠军后当场身披五星红旗,都折射出这场无妄之灾的沉淀效应。
(五)惊天逆转 (上)
说起扑克比赛来, 最重要的两个赛事是世界扑克系列赛(World Series of Poker, 简称WSOP)和世界扑克巡回赛(World Poker Tour, 简称WPT)。WSOP 有点像奥运会,每年五月底至七月中在拉斯维加斯的 RIO赌场(2004年以前在马蹄赌场)举行,天天有赛事。WPT是2002年才创立的。加盟WPT举办比赛的赌场选择不同时间分别举办比赛,每一站 WPT比赛像个小WSOP,除了主赛(一般为一万元报名费)还有很多报名费比较低的比赛。最后主赛的终桌(Final Table)比赛经过剪辑解说后在电视上播出。每年四月份,在拉斯维加斯的比拉揪(Bellagio)赌场举办的报名费为两万五千美元的比赛,为WPT的冠军赛,获胜者成为年度WPT冠军。由于两万五报名费的门坎儿太高,大部分业余选手因负担不起而被挡在了门外,参赛者基本都是职业选手,因此这个比赛是最难打的比赛之一。因为照顾电视转播时间的原因, WPT比赛的终桌人数限定为6人。
六位牌手中最引人注目的非戈斯-汉森莫属。这不光是因为他的筹码最多,更因为他名头最大。戈斯虽然跟WSOP金手链总是缘悭一面,但在WPT比赛中风头最盛,曾夺得三站比赛的冠军, 并夺得2005年澳大利亚百万冠军赛(Aussie Millions Champinship)冠军,是电视里最脸熟的牌手之一。这位有着威猛面孔的丹麦人曾被时尚杂志评为性感男星。他牌风松猛诡诈,什么牌都玩,别人很难猜出他手上的牌。一旦让他打顺了,收起别人的筹码来就像城管见了街头摆摊儿卖菜的,想怎么来就怎么来,没什么道理好讲。但是,在他貌似胡来的牌风背后,其实是有着十分精明的计算。他所著《Every Hand Revealed》是我读过的扑克书中为数不多的好书之一。
老邱筹码翻身之后有了些回旋余地,但仍然落后。Card Player杂志描述这一段时这么说“He now had some breathing room, and he made good use of it. He stayed out of Hansen’s way, but won the pots he needed to win to keep the momentum shifted his way” 通俗点说,就是老邱充分利用这一喘息机会,避免跟戈斯按他的战法搞阵地战,避开敌人猛烈火力,但是该赢的锅还都赢了,并把战局拉到自己习惯的运动战中来。我听了老邱对这一阶段的自战解说又长学问了。原来老邱翻了个身有了喘气的空间后立即调整战略施缓兵之计。实话说,这么高级战法我此前根本没什么主动意识。一般人也不会跟你讲,书上也不会告诉你。老邱说他非常希望看到有更多华人牌手出人头地,他不在乎用中文讲他的心得。我呢,一时半会好像还出不了头儿,也乐于跟讲中文的朋友吹牛交流,就给抖落出来,相信很多跟我差不多水平的人会从中受益。从整体策略来讲,老邱希望打小锅,慢慢往上追赶,而不是轻易搏命。戈斯气势逼人,抢锅加注比较大,这样进去看FLOP三张牌的成本就很高。而老邱的策略是要打太极,借力打力,希望打小锅,看FLOP之后看再发力。为了把戈斯拉到自己擅长的打法上来,就要缓解他的攻势,让看FLOP的成本降下来。这样,就相当于把盲注变小,自己的筹码相对盲注变多了,生存压力就小了。怎么实施这个战略意图呢? 老邱故布疑兵,几次拿到如AQ这类强牌故意不加注而是平进。在FLOP戈斯放弃之后,老邱又故意亮了几把牌。这样,给戈斯造成老邱在慢打强牌设陷阱的疑虑,戈斯不由的开始防范,不自觉地放慢了攻势,加注变小甚至平进变多起来, 让老邱达到了低成本多看FLOP的战略意图。
这段看似你来我往大体均衡的折冲中,还有一件值得一提的趣事,但我又觉得全写出来可能不一定合适,我就透露一半吧。前边说过,大部分人有tell,连戈斯这样的顶尖高手居然也被老邱读出了破绽!比赛前老邱做了大量的准备,他以前有很多和戈斯同桌竞技的经历,也和其他一些高手讨论过戈斯的打法,也细心研究过电视录像。大家从电视上可以看到,戈斯在打牌时偶尔有转头活动脖子的动作。这么个细微动作被老邱看出了蛛丝马迹。他的头先向哪边歪并不是随机的,呵呵。他向某一侧先歪的时候心态比较消极,看到这个动作后老邱就主动进攻,甚至手里拿着不同花的(2,4)就去 bet in the dark , 就是在发牌员还没开出牌来就提前下注。拿着7 high 什么都没有,在FLOP 上check-call (先过再跟对方的注),然后转牌再主动下注巧取豪夺。老邱曾跟我讲“你们这样看书比较多的,对概率很清楚,这是好的。但是,如果你看到机会不能很好利用,那就是浪费机会”所以呀,要想在大赛中取得好成绩,还得多练习捕捉战机的能力和随机应变的心理素质。
有一次,我说话漏嘴了,女儿大笑,说:“Dad, it does not make sense at all”。我就趁机跟女儿介绍了上述名言,她居然极感兴趣,整整一天都在那里一边唠叨,一边自娱:“haha, this is the most stupid sentence I have ever heard. How can ideas sleep? Ok, even if it can sleep, how can it sleep furiously? Ideas have color? Green? Come on. Ok, if it is green, how can it be colorless.”
就是,在这个短短的句子中,所有发生语法关系的词,在概念上都不具有兼容性,不 make sense. 可是,每一个 native speaker, 都发现这是 perfect grammatical English,否则我们怎么能够理解这个句子的荒谬(how do we make sense of nonsense?)。乔姆斯基的这个俏皮的思维实验是要表明,句法结构是可以独立于语义(和概念)的。语言学家在研究语言的时候,应该排除语义的干扰,才能深入了解语言结构及其转换规律。这个观点实际上是有隐患的(此处不谈),但是把句法(syntax)和语义(semantics)分开,在当时确实极大地推进了语言学的研究深度。
Interpreting “colorless green ideas sleep furiously”
Does it make sense?
In a certain domain, the Chomsky’s famous sentence is well imaginable.
Colorless green ideas sleep furiously.
Imagine the following context:
As we know, Esperantists wear a badge of “a green star”, a symbol for Esperanto
and its ideals. From there, “green ideas” would be easily conprehensible to
their minds.
Suppose now comes an opponent to Esperanto, he may say,
“Your green ideas are really colorless, not only colorless, those ideas are no
longer popular! Colorless green ideas sleep now!”
Well, what is a possible reaction from some Esperantists?
“Yes, our ideas sleep now. But remember,
colorless green ideas sleep furiously! ”
2006年06月18日
———————————————————————–
立委补记:
老乔研究语言学的一个出发点就是:人一辈子在有限的语言exposure的环境里面,input is full of fragments, errors, slips of the tongue, etc. 怎么可能学会语言?他最后归结到人与生俱来的universal grammar机制。外在的imperfect input不过启动了这个机制,对其做微调而已。所以再笨的人母语也还是学会了,有语感。不过学第二语言就不同了,因为universal grammar 的 parameters 一旦置值,就有了固化的顽固。第二外语学得好坏各个不同,看造化了,总体来说,女孩比男孩强,所以立委虽为师兄,也不敢在师妹面前逞强。
我一直不明白的是,在一党专制和民主之间,怎样才能既开放政治(逐渐言论自由,废除党禁等),又不至于引起社会动荡。我不相信当局及御用文人一放就乱的说法,也怀疑和反对民运右派人士激进改革休克疗法不顾人民死活的主张。there must be something in between, but where is it, I know not, either.
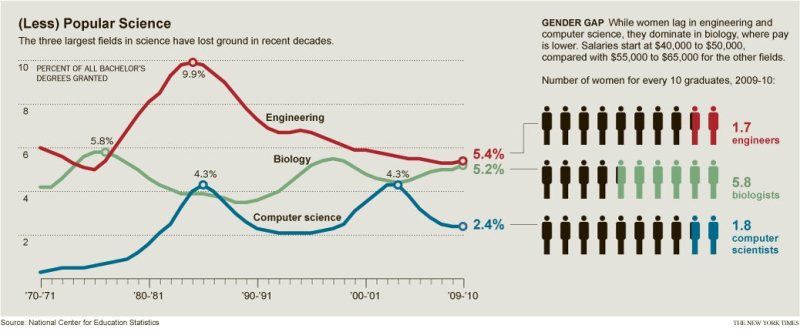
Trends Biochem Sci 34(5):217-23 (2009)
Four stages of a scientific discipline; four types of scientist.
Alexander M Shneider
Cure Lab, 43 Rybury Hillway, Needham, MA 02492, USA.
In this article I propose the classification of the evolutionary stages that a scientific discipline evolves through and the type of scientists that are the most productive at each stage. I believe that each scientific discipline evolves sequentially through four stages. Scientists at stage one introduce new objects and phenomena as subject matter for a new scientific discipline. To do this they have to introduce a new language adequately describing the subject matter. At stage two, scientists develop a toolbox of methods and techniques for the new discipline. Owing to this advancement in methodology, the spectrum of objects and phenomena that fall into the realm of the new science are further understood at this stage. Most of the specific knowledge is generated at the third stage, at which the highest number of original research publications is generated. The majority of third-stage investigation is based on the initial application of new research methods to objects and/or phenomena. The purpose of the fourth stage is to maintain and pass on scientific knowledge generated during the first three stages. Groundbreaking new discoveries are not made at this stage. However, new ways to present scientific information are generated, and crucial revisions are often made of the role of the discipline within the constantly evolving scientific environment. The very nature of each stage determines the optimal psychological type and modus operandi of the scientist operating within it. Thus, it is not only the talent and devotion of scientists that determines whether they are capable of contributing substantially but, rather, whether they have the 'right type' of talent for the chosen scientific discipline at that time. Understanding the four different evolutionary stages of a scientific discipline might be instrumental for many scientists in optimizing their career path, in addition to being useful in assembling scientific teams, precluding conflicts and maximizing productivity. The proposed model of scientific evolution might also be instrumental for society in organizing and managing the scientific process. No public policy aimed at stimulating the scientific process can be equally beneficial for all four stages. Attempts to apply the same criteria to scientists working on scientific disciplines at different stages of their scientific evolution would be stimulating for one and detrimental for another. In addition, researchers operating at a certain stage of scientific evolution might not possess the mindset adequate to evaluate and stimulate a discipline that is at a different evolutionary stage. This could be the reason for suboptimal implementation of otherwise well-conceived scientific policies. DOI: 10.1016/j.tibs.2009.02.002
会散时美教授身边也有一堆人围着问问题,我插到空档,立刻就打了招呼开口自
我介绍,还递上了一篇我所发文章的单行本,美教授一手接过单行本,我立刻把
我的想法说给美教授听,刚说了一句,美教授才刚刚眼睛扫过单行本封面,就眼
也不抬地问我"你用不用韦伯函数?"我一听如雷灌顶,知道对路子了,赶忙说
用,我就是用韦伯函数算的。美教授这才抬头看我一眼,"你似乎正在正确地接
近问题(It seems that you are approching the problem correctly)."。立刻,
别人又插
上来问美教授问题了,我只来得及挤出一句"thank you"。
鬼节的另一好处是促进人们的交往。欧洲和拉美国家有狂欢节,有关狂欢节让人们一时抛弃身份地位的平等作用,在社会学和文学批评中的论述已是汗牛充栋。美国的鬼节虽然没有那么狂,那么欢,那么大面积地“一夜平权”,但在这个理论上没有社会等级,而实事上因经济差异还相当不平等的社会里,鬼节起到了与狂欢节很近似的作用。白天,工作单位里无论是总裁还是职工,大家都换上奇装异服,扮上鬼脸,一反平日正襟危坐的严肃模样,嘻嘻哈哈一天。虽然一年只是这么一天,其效果却令人难以想象。那些平日不待见的人,如果带上了丑陋的面具,你可以痛痛快快地告诉他:“你今天比往常好看多了!”他就是爱生气,也不会生气,俩人在笑声中可能就开始亲近了。如果是老板来了,你不妨直说:“我真希望你老戴着这种面具,比那一本正经的面孔可亲多了。”多数人可能会因此而有所改进。晚上,带着化了装的孩子,拎着小桶,在社区里转悠,只要门口亮灯,就去敲门高叫:“Trick or treat!”无论是深宅大院,还是柴扉小屋,主人都会友善地出来,欣赏你给孩子的装扮,甚至假装吓得半死,再给孩子们一些糖果。在欢笑中,邻里亲近了。即便是平日里“鸡犬之声相闻,老死不相往来”的那种美国人,今晚也会门户大开,以笑脸和糖果相迎,而绝不会像杜甫那样,因为小孩子拿走几根茅草而哭天抹泪地哀怨(真不懂这老夫子怎么还可能大庇天下众寒士)。当然,你自己也应准备好糖果。尤其是没有小孩子的人家,你要是不出门,就等邻居来访,别关着灯,一屋死气沉沉,连鬼都不上门,自绝于这热热闹闹的大千世界。
The one on the left is missing something...K. Welsh, Alamy / R. Cyril, BIOSphoto, Still Pictures
Nature(McLean, C. Y. et al. Nature 471, 216-219 (2011))发表了一篇斯坦福大学科学家们的研究文章,他们要研究人类的某些独特特性到底是如何进化来的。和以前不同的是,他们并没有研究人类在进化过程中如何获得基因或者是旧的基因获得新的功能,而是和人类的近亲黑猩猩的基因组比较,看人类在进化过程中,‘丢失’了哪些DNA。经过比较,他们发现人类的基因组上竟然比黑猩猩少了510段DNA序列,而这些序列基本都属于基因组的非编码区。非编码区或内含子的DNA以前被一些一知半解的科普作者说成是毫无用处的‘垃圾基因’或‘垃圾DNA’,甚至被用来证明人类不是上帝设计的证据
(方舟子:总之,内含子和假基因都是生物在长期的进化过程中堆积下来的垃圾。这类垃圾,是生物进化的最好的证据,也是对于存在智能设计者的观点的最有力的否定。)



































 伯克利日学生载歌载舞
伯克利日学生载歌载舞




















 Trends Biochem Sci 34(5):217-23 (2009)
Trends Biochem Sci 34(5):217-23 (2009)



推荐一个不知道共产主义饿死人的无知老美干嘛?
到立委地面上来踩踩。
在德赛园左派声音太少。以我的经历,在此处发表左派言论,会立即招致怨恨,一些人甚至会堵在门口谩骂。
这应该正是中国读书人争取的“民主”。十方明确,这种“民主”并不是西方意义上的民主,而更接近墨西哥式的“民主”。
按照我对美国的体会,这种情况在美国是不存在的。而且,美国的顶尖大学往往都有左派大本营。象Harvard, MIT,Berkeley.