分类: 杂类
密码保护:神秘花园:我的日本女同窗》
笔细 - 苦夏(三幕话剧) 屏蔽留存
笔细 - 苦夏(三幕话剧)
屏蔽 |||
立委按:笔细兄这出话剧对医疗界的文革场景刻画相当细腻,表现了其荒诞,也反衬了人性的美好的一面。在现在这个快节奏信息爆炸的社会,很少有人有耐心看完这样的历史话剧。文革似乎是个遥远的噩梦,我们已经淡忘。然而,我们怎能忘记!
笔细 - 苦夏(三幕话剧)
苦 夏
卫青 著
人物表
石世文 县医院医生
贾竹君 县医院护士
陈邦孝 派到县医院的军代表
刘芳平 县医院护士
姚素芳 县医院护士长
文美娟 县医院护士
金述兰 县医院护士
齐立人 县医院医生,原医务主任
赵 枫 县医院医生
周克让 县医院医生
老 卢 县总务科科长
于伟英 县医院药房主任
沙树林 县水泥厂厂长
伍家徽 劳改农场干部
李便民 劳改农场干部
王洪兴 劳动教养人员
黑 子 劳动教养人员
霍修文 劳动教养人员
尚天明 劳动教养人员
县医院的医生,护士,和其他工作人员
县水泥厂的工人及其家属
劳动教养人员
第一幕
六十年代
晚上七点多钟
县医院住院部的护士办公室
县医院的主体建筑是一座二层的楼房.住院部在二楼.护士办公室离楼梯不远.有人上下楼梯这儿都听得见.
对着舞台的是一面墙,墙上开有两扇大窗.此时天色还没完全黑下来,但室内的光线已经显得有些暗淡了,所以幕启后不久,贾竹君就嫌光线太暗而把灯开了.随着剧情的进展窗外越来越黑,天上狮子星座清晰可辨.
窗户上方的墙上贴着毛泽东像,像的两旁是两张毛泽东语录:”如果有了正确的理论,只是霸权它空谈一阵,束之高阁,并不实行,那么,这种理论再好也是没有意义的.””我们能够学会我们原来不懂的东西,我们不但善于破坏一个旧世界,我们还将善于建设一个新世界.”
靠窗摆着一张二屉桌.桌上立着一尊白瓷的毛泽东像.桌前有一把椅子,桌的右边则并排放着两把椅子.二屉桌左边有一个存放住院病人病历的鸽笼式分类架.架子上方的墙上是住院病人的姓名牌,可以看到,大部分病床都住上了病人.
台左侧另有一条长桌,上面放着电消毒锅,白色的带盖搪瓷盘,搪瓷缸子等,这是护士们准备注射器等治疗用品的地方.长桌旁边,靠窗户的一侧有一个白色的木制药柜,药柜分两层,每层都有两扇镶玻璃的拉门,都用挂锁锁着.隔着玻璃可以看到里面摆着不多一些磨砂玻璃药瓶,装注射剂的纸盒之类.着是病房里备用的常用药柜,等一会贾竹君就从药柜里取出药品给病人注射或口服.这面墙上还有一副带小红灯的唤人铃,住在哪个病床的病人按铃时,对应该床的电铃就玎玲玲地响,小红灯泡也亮起来.长桌的另一侧,也就是靠舞台前方的一侧,有一个白色的瓷制洗脸池.洗脸池有两个水龙头,但就如国内绝大部分洗脸池一样,其中只有一个水龙头能放出冷水,而另一个热水龙头则是虚设的.
舞台右侧是护士办公室的门,此时门是关着的.门背上钉着衣钩,衣钩上挂着几件白大衣.门边放着一个木制衣架.门打开时衣架会被挡住.此时门正关着,所以能看到衣架上挂着刘芳平和贾竹君的外衣,看得见衣服上都别着毛泽东像章.衣架后方的墙上垂着两条灯绳.
幕启时两位护士--刘芳平和贾竹君坐在二屉桌边.贾竹君在对医嘱,刘芳平在做棉球.
贾竹君 (打哈欠,以手掩口)真困啊,才几点,就觉得发困.怪不得人家说:”春乏秋困夏打盹...”
刘芳平 (接着说)睡不醒的冬三月.
贾竹君 (笑)
刘芳平 我说,你真是一个十足的懒姑娘.老听你说困.
贾竹君 没有不困的时候.(站起来活动活动)
刘芳平 活动一下吧.
贾竹君 要能睡一小会多好.
刘芳平 没你睡觉的地方.有地方,你还会嫌脏不睡呢.
〔铃响
贾竹君 喔唷。铃响了.我看是谁。啊,是三床,可能是那瓶输液完了,我去看看。(下)
〔铃又响
刘芳平 哦.(看红灯亮的床号,下)
〔贾竹君先拿着连着皮管的空盐水瓶回来,拆下皮管,针头,泡在搪瓷盘中;到洗脸池处洗手,接着抄医嘱
〔刘芳平接着也回来
贾竹君 又是哪床叫人?
刘芳平 二十床说胃疼.我给他送一片颠茄.(开药柜,取药下)
〔刘芳平很快回来,洗手,坐到原先的椅子上,继续做棉球
刘芳平 不困了吧?活动一下就精神了.
贾竹君 你说这叫什么事呢?开处方不让用外文.连写ST或SD也不行,非一笔一划写中国字.磺胺噻唑,磺胺嘧啶都要写全,这几个字可都没简化.写ST,SD多简单方便.我数过写”磺胺噻唑”几个字要52笔,写”磺胺嘧啶”要50笔.不让写还能不让说吗?你看有人说”磺胺噻唑”和”磺胺嘧啶”的,谁不是简单明了地说ST,SD呢.连tid,qid也不许写,一定要写成”一天三次”,”一天四次”.这笔画倒还少点.
刘芳平 我还记得在卫校时英语课是齐主任上的.本来学的不多,只会认那些药名.还不让用.再不用还不忘光了。
贾竹君 齐主任够倒霉的。
刘芳平 在我们医院里他技术是最高的,技术高倒成为”反动学术权威”.
贾竹君 好端端挨那么多批斗。
刘芳平 要不说是造反派呢.
贾竹君 都一起工作好几年了...
刘芳平 他们也下得去手。那次批斗会上让他跪在碎石子上,还有好多人打他,把我吓得...今天想起来都害怕.
贾竹君 什么派我都不参加。
刘芳平 赵枫倒想参加.可造反派不要他.他跟石世文一样,出身不好。
贾竹君 我听说,石大夫在政治学习时,老带着他那本英汉对照的<毛主席语录>在那儿看,你也说不清他看的是这一面还是那一面.
刘芳平 这总比聊大天浪费时间好得多.
贾竹君 以后政治学习我就带一本<新华字典>,遇到不认识的字就查字典.这不比秀才认字人半边强?
刘芳平 是啊.
贾竹君 (合上医嘱本)总算抄完了。
刘芳平 抄医嘱也多抄不了几个字.你没听陈代表说下星期要开毛泽东思想讲用会吗,那才叫人发愁呢.没个人都要讲用,都哎哟写讲用稿.写什么呢?
贾竹君 抄报纸啊.
刘芳平 (突然拿腔拿调地)”红旗迎风舞,万里山河笑...”
贾竹君 (掩口而笑)你这是怎么了?做报告啊?
刘芳平 我是学周克让呢.学习会上他一发言,开始一定是这两句.大家听多了忍不住笑,他说讲话写文章总得有个帽儿啊.
〔周克让推门入
〔刘芳平吐了吐舌头
刘芳平 周大夫,收病人了?
周克让 没有,刚才急诊室来了一个手外伤的,我去处理了一下.
刘芳平 不用住院?
周克让 不用.在门诊处理完就走了.
刘芳平 那好.
周克让 病房里没事吧?
刘芳平 太平无事.
周克让 那好.(下)
贾竹君 说曹操曹操就到.
刘芳平 刚才的话也不知他听到没有?
贾竹君 看来他没听到.
刘芳平 那最好.
贾竹君 前两年,大家还是很随便的.现在都互相防起来了。
刘芳平 现在是文化革命.人家是造反派,是军代表支持的左派.
贾竹君 也搞不清到底怎么回事。县政府里几派打成一团,动用起武器来了,闹出人命来了。这倒好,让军队接管了。连学校,医院都派了军代表。
〔从楼梯上传来纷乱的脚步声,嘈杂的说话声,还有人在唱:”大海航行靠舵手,万物生长靠太阳...
刘芳平 我去看看是怎么回事.(下)
〔听到刘芳平与别人的对话:”你们是干什么的?”
”我们来看病人.”
”什么病人.”
’水泥厂的沙厂长.”
”你们知道病人在哪儿?”
”知道,我们来过.”
”你们知道现在几点了?”
”我们真有事要跟厂长说,我们看一下就走.”
”不行,病人该休息了.”
”大姐,我们不高声说话,呆一会就走.”
”就呆十分钟,你们不走我就撵你们.”
”谢谢你,好大姐.”
〔刘芳平上
贾竹君 什么人?
刘芳平 水泥厂的.看他们沙厂长.
贾竹君 是胆囊炎吧?来好几天了.
刘芳平 是啊.已经缓解了.
贾竹君 这水泥厂,还是我们县里最大的企业呢.
刘芳平 可不是.
贾竹君 (看手表)我该去量TPR了.(拿体温计下)
〔刘芳平将做好的棉球收在敷料罐里,将敷料罐放进药柜,坐到桌前方才贾竹君坐过的位置,无聊地翻阅报纸
〔过了一会,贾竹君上,从病历架上取下用铁皮夹子夹着的病历,坐到二屉桌旁的椅子上,将测量结果记到病历首页上
〔楼梯上传来橐橐的脚步声
贾竹君 (倾听)是不是来了?
刘芳平 (没反应过来)谁来了?
〔贾竹君将手中的铅笔夹在耳朵上
〔刘芳平示意贾竹君将铅笔拿下来,
〔贾竹君将铅笔拿下,两人注视着门口
〔门开,石世文上,他没穿白大衣
刘芳平 石大夫。你值班?
石世文 不是。我来看看下午收的那个病人怎么样了。
刘芳平 哦。三床啊?出血止住了。还在输液。烧退下来了,睡着了。
石世文 那就好。病房里没事吗?
刘芳平 没事.
石世文 我想看一下病历(从贾竹君面前的病历中找出一份,阅)
〔铃响,刘芳平看了一下床号,下
石世文 (合上病历夹子,还给贾竹君)谢谢。我想去看看病人。(下)
〔刘芳平上.
刘芳平 石大夫走了?
贾竹君 他去看病人去了.
刘芳平 他哪儿是看什么病人.他分明是看你来的.
〔贾竹君把用完的病历夹子送回架上
刘芳平 只要你值班,他有事没事就往这儿跑.他喜欢你.
贾竹君 芳平!
刘芳平 在咱们医院的年轻大夫里他也属于比较强的。可惜出身不由己.
贾竹君 说他父亲是什么买办.
刘芳平 什么买办.他来医院时跟我聊天说过,他父亲留学美国,回国后在外国公司工作,解放后在中学教英语.
〔陈邦孝上,他穿着军装,领口和风纪扣都没有系上.胸前有一枚硕大的毛泽东像章,直径足有五六厘米.他左耳上夹着一根香烟.看见他近来,贾竹君用手指捏了捏自己的左耳垂
陈邦孝 病房里没什么事吧?
刘芳平 没什么事.陈代表.你没穿工作服?
陈邦孝 下班了嘛,不用穿了。其实我也是挺喜欢穿件白大挂的。(望着门后的衣架)
刘芳平 怎么光站着啊?
陈邦孝 坐一坐.(说着坐到贾竹君旁边的椅子上,贾竹君显得局促不安)那天我穿着白大衣到内科诊室去,医院有些人管我叫陈大夫.他们是什么意思?(愤慨起来)是讽刺我不会看病?其实你们只会治身体的毛病,我会治思想的毛病.
刘芳平 是啊,能治病的当然就是大夫.别管是谁得的病,是哪儿的毛病.农业局门口不是有个农业技术推广站吗?门脸就写着”庄稼大夫”.
贾竹君 (笑)卫生局对过还有家钢笔医院呢.
陈邦孝 政治是统帅,是灵魂.治病也是这样.政治思想带了头,难治的病也好治了。上星期那个胃穿孔的难治不难治,我带领几位政工干部一鼓动,病人怎么样?转危为安了。
刘芳平 早就听说了。可惜我没在场,没能受点教育。不过听手术室小张说,你带领几个孙干事,钱干事,曹干事,站在手术台后,手持<毛主席语录>,高声朗读”下定决心,不怕牺牲,排除万难,去争取胜利”.那场面一定够壮观的.
陈邦孝 (得意)这就是带着问题学,活学活用,学用结合,急用先学,在”用”字上狠下工夫.下星期医院要开一个讲用会,我打算组织人把这生动的例子写成讲用稿,在会上宣讲.掀起一个活学活用毛泽东思想的高潮.
刘芳平 我有一个问题.
陈邦孝 什么问题?
刘芳平 你们戴口罩了没有?
陈邦孝 什么戴口罩?
刘芳平 做手术时大家都得戴口罩.
陈邦孝 当时只考虑抢救阶级兄弟,没考虑戴口罩.
刘芳平 高声朗诵时口腔里的唾沫星子难免喷出,里头会带有病菌,如果污染了伤口,手术就白做了.
陈邦孝 你讲得也对.戴口罩也挡不住毛泽东思想的声音.
贾竹君 (站起来)还有几个q.4h.的药要发.我这就去.(拿着发药盘下)
〔陈邦孝取下耳上的香烟,把手伸到衣袋里掏什么
刘芳平 别掏火柴了.病房里不让抽烟.
陈邦孝 (把香烟放回耳朵上)不抽了,不抽了.
刘芳平 我说整个医院里都不应该抽烟.要抽烟到外头去.
陈邦孝 (随手翻看桌上放的处方笺)我说知识分子成堆的地方崇洋媚外的思想无处不在.以前开处方,尽用外国字.什么意思呢?欺负我们老百姓看不懂吗?文化大革命就是要涤荡这些污泥浊水.凡是反动的东西,你不打,他就不倒.这也和扫地一样,扫帚不到,灰尘照例不会自己跑掉.我以为开处方里的外国字都扫除干净了。还没有。我们中国人有自己的中国字,为什么到处印着曲里拐弯的洋字码?(指着处方笺上的符号 )
刘芳平 (忍住笑)这不是洋字码儿,这是一个符号.是国际通用的处方的符号.
陈邦孝 (察看病人名牌)这是不是外国字?(指着一个名牌下的※号)
刘芳平 这更不是外国字.这也是一个符号,表示”重病”.
陈邦孝 你们这些知识分子就好卖弄点学问,不实际。我们工农兵就讲实际,也解决实际问题。你们动不动拿学历吓唬人。你们都上过什么卫生学校啦,什么大学啦.都是狗屁!还有人问我是什么学校毕业?我是高粱秆大学毕业!医院里有些人瞧不起我们高粱秆大学毕业的呢,架子大得很呢.没有用,高粱秆大学毕业的就是要领导你们.毛主席说过,外行就是要领导内行嘛.
〔刘芳平开始准备大注射盘,不语
陈邦孝 不过知识分子也有好的.也有向工农兵靠拢的.
〔铃响,刘芳平看了看床号,拿着大注射盘和皮肤消毒盘,急下
〔陈邦孝一个人坐着,觉得很没意思,下
〔贾竹君上,放下发药盘
〔刘芳平上
刘芳平 走了?
贾竹君 我刚进来.这儿一个人也没有.
刘芳平 我准备打针去,正好五床按铃,对我是求之不得的机会.我把他一个人留在这儿,他一定呆着没意思,走了。
贾竹君 五床又怎么了?
刘芳平 睡不着,我给送片药去.(开药柜,取药)
贾竹君 针都打完了?
刘芳平 打完了.我送药去.(下)
〔贾竹君洗注射器,刘芳平上
刘芳平 你记得不记得半个月前收的那个休克型肺炎病人?大夫护士抢救了半夜,陈代表来瞎指挥,把回家的人都叫了回来.让大家都上.两个胳膊都吊上瓶了,该用的药都通过大输液用上了.他却指挥周克让切开腿上一条血管.血管切开后才发现根本用不着切开.白白毁一条血管.
贾竹君 出了问题不通知他吧,不行;通知他吧,也不行.真难办.
〔两个人做完手头的工作,坐下来
刘芳平 快九点了.往常这时候文美娟早该来了.
〔门开,文美娟上.这是一个俊美苗条的少妇,她进来以后就脱去外衣
文美娟 今天家里有点事来晚了.
刘芳平 还早呢.
〔文美娟打算把外衣挂到衣架上.衣架靠门一侧的钩上原来挂有一件白大衣,文美娟将它移到另一个钩上,把自己的衣服挂到这个腾空的钩上
文美娟 还有两个钟头.我想睡一会.请不要吵我(下)
刘芳平 文美娟还真是挺漂亮的.
贾竹君 真是.
刘芳平 如果把头发烫了,穿上旗袍,再抹上那么点胭脂,她真是个美人.准能把人迷住.
贾竹君 你被她迷住了?
刘芳平 她迷不住我,可能迷住别人.
〔石世文上
石世文 我想查一下几份病历.你们不用吧?
刘芳平 我们不用.
〔石世文取出几份病历
刘芳平 你天天在办公室看书?
石世文 是,宿舍里很嘈杂,光线又不好,不值班的日子我就在办公室看书.
刘芳平 也不早了.
石世文 我再看一会就走了.(下)
〔陈邦孝上,他耳朵上的香烟已经不见了
陈邦孝 没事吧?(看着衣架)
刘芳平 没事.
陈邦孝 没事就好.
刘芳平 坐坐吧.
陈邦孝 不了.
刘芳平 坐坐吧.给我们讲讲活学活用的经验.
陈邦孝 下次给你们讲.(下)
〔刘芳平和贾竹君做完手头的工作,在桌边坐下来
刘芳平 说点什么吧.
贾竹君 说点什么呢?
刘芳平 说点高兴的.
〔床外传来院子里有人唱歌的声音:”万岁毛主席,万岁毛主席,万岁万岁万岁万万岁,万岁万岁毛主席.”
(幕落)
第二幕
县医院的门诊部。
晚上。
当舞台上的人物静下来的时候可以听到阵阵蛙鸣,这暗示着时令已是初夏。
县医院的主体建筑是一所两层楼的楼房,门诊部设在一楼,二楼就是病房。舞台上看到的就是门诊部走廊一侧的房间。舞台的最左侧有一道楼梯,通往二楼的病房。楼梯又分两段,在两段之间有一个平台。平台处的墙上写着一个很大的静字。楼梯下面就是门诊部的走廊。几个房间开向走廊,第一间是急诊室,第二间是治疗室,第三间是化验室,门的上方都有标示牌。这几个房间都亮着灯,门也开着。看得到屋内人影闪动,这表明有人在里面工作。各个房门之间靠墙摆放着几条带背的长椅。看得出墙面本来是刷的白灰,现在却涂上红漆,用黄色的颜料写上了毛泽东语录:”革命不是请客吃饭,不是做文章,不是绘画绣花,不能那样雅致,那样从容不迫,文质彬彬,那样温良恭俭让。革命是暴动,是一个阶级推翻一个阶级的暴烈的行动。””我们都是来自五湖四海,为了一个共同的革命目标,走到一起来了。”和林彪的指示:”读毛主席的书,听毛主席的话,照毛主席的指示办事,做毛主席的好战士”。这时急诊室与治疗室之间的长椅上躺着一个身穿蓝色工作服的男子,轻声地呻吟着。椅边站着一位穿草绿色军便服的妇女,似乎是病人的家属,此刻正焦急地往急诊室里张望。
过一会,一个身穿蓝色工作服的男子扶着另一个也穿蓝色工作服的男子从急诊室出来,从躺着病人的长椅前经过,走进治疗室。穿军便服的妇女站开一点给他们让路,然后扶起躺着的男子,搀着他走向急诊室。这时正好一位穿白大衣的医生来到门口招呼他们。
一会儿刚才那位搀扶病人进治疗室的男子独自从治疗室出来,手里拿着一张处方,从舞台右侧下去。随后拿着一瓶大输液,一个装注射剂的纸盒和一个纸袋上,回到治疗室。
在本幕以后的时间里有许多穿工作服或不穿工作服的病人上上下下,其中以男性居多;他们中绝大部分是县水泥厂的工人,以下统以”工人”称之。大多数病人由不同性别,不同年龄的人陪同,这些陪同的人不是他们的父母,配偶,子女,就是他们的同事或朋友。为了方便以下一律以”家属”称之。多数家属也穿着蓝色的工作服或便服,因此舞台上,特别是大批病人来到医院那个时刻,是一片蓝色。如果不是有几件白大衣点缀其中,人们会感到色彩非常单调。当舞台上满是来来去去的,站着的,坐着的,或是躺着的蓝色时,这情景会让人想起蚁巢中忙碌的蚂蚁,甚至会产生一种压迫感。
工人1 (从舞台右侧上,手抚着腹部,面有痛苦的表情,简直是踉踉跄跄地走到急诊室门口)喔唷!
工人2 (一面系皮带一面从急诊室走出,见工人1)你也来了?你也闹肚子了?
赵 枫 (穿着白大衣,出现在工人2身后)你自己行吗?
工人2 我自己行。(走向化验室)
赵 枫 (对工人1)进来吧。
工人2 (对小窗口里面的人说话)给我一个装大便的小盒。(接过里面递出来的小盒,从左侧下)
〔刚才躺着的病人由家属搀着出急诊室
石世文 (跟他们一起出来,嘱咐家属1)先把病人送到治疗室,让他躺下,你再到药房取药。 (指舞台右侧)
家属1 好的。(搀扶病人1进治疗室)
〔工人2出急诊室,从左侧下
〔赵枫出急诊室,石世文与两个人站在走廊里
赵 枫 这一个多小时真够忙的。
石世文 这些病人都是水泥厂的。病情都一样。我看水泥厂有点问题。
赵 枫 得了解一下。
石世文 说不定一会还会有病人来。我得先去方便一下。(从右侧下)
〔家属1从治疗室出来,从左侧下
〔工人1拿着装药的纸袋从左侧上,从右侧下
家属2 (急急上)大夫,有担架吗?
赵 枫 有。病人在哪儿呢?
家属2 在小车上。我背不动。
赵 枫 病人怎么了?
家属2 又吐又泻。
赵 枫 哦。(进急诊室,取出一副担架)走吧。(家属2接过担架。赵枫与家属2一同从右侧下)
〔家属1拿着药从左侧上,进治疗室
〔赵枫和家属2两人抬着病人上
赵 枫 你们也是水泥厂的?(两人抬病人进急诊室,从开着的门可以看到他和家属2把病人抬上诊断床)
〔从治疗室传出病人的声音:”喔唷!”
〔石世文从左侧上,走到急诊室门口
石世文 啊,一样的病情。。。
〔工人2拿着化验单从左侧上,进急诊室
〔家属3从治疗室出来,匆匆从左侧下。治疗室有呻吟声
家属2 (出急诊室,到治疗室)都满了!(返回急诊室)
〔家属3拿着一个便盆从左侧上,进治疗室
〔工人2手拿处方出急诊室,从左侧下
家属2 (出急诊室,到治疗室门口,皱了皱眉)护士!
金述兰 (出现在治疗室门口)怎么回事?
家属2 (把一张厨房交给金述兰)大夫请你给打一针。
〔金述兰转身进去,马上拿着吸了药液的注射器出来,与家属2一同到急诊室
〔家属2出急诊室,从左侧下
〔石世文,赵枫,金述兰三人走出急诊室
石世文 我看今晚不好过。一个多小时来了十多个病人,都是水泥厂的。症状都一个样。我看是食物中毒。
赵 枫 我看也是。恐怕还会继续出现病例。
〔家属3端着便盆从治疗室出来,从左侧下
金述兰 四张观察床都满了,再来一个都没地方了。
石世文 病情重一点的就收住院。述兰,你上楼去看一看,还有多少空病床。注射室有事,我们看着。
金述兰 好的。(从楼梯上去)
〔家属3两手湿淋淋地从左侧上
石世文 (叫住家属3)请等一下。(家属3站住)你说你们厂今天卖皮皮虾了?
家属3 是,从小西沽拉来的。读多数人都买了。
赵 枫 集体食堂也做了吗?
家属3 也做了。
〔赵枫和石世文交换了眼光
赵 枫 (对家属3)好的,谢谢你。你照顾病人去吧。
〔家属3进治疗室
〔家属2取了药从左侧上。赵枫与他一起把病人从急诊室掺到治疗室
〔病人4搭着家属4的肩头从右侧上
家属4 (见石世文)大夫,病人发烧。
石世文 好,先测一下体温。(与他们一道进急诊室)
〔金述兰从楼梯上下来,石世文闻声出急诊室
石世文 (对金述兰)怎么样?
金述兰 (摇了摇头)只剩两张床了。怎么办?再来一个重的就不好办了。
沼 枫 (出治疗室)述兰,输液我给扎上了。
金述兰 好的。
〔工人2拿着领来的药从左侧上,走到他们跟前时停了一下,看看他们,又从右侧下
石世文 我看可能是一起嗜盐菌食物中毒。既然水泥厂大多数人都买了,吃了皮皮虾,可能继续出现病例。如果吃食堂的单身汉们也发病,那就是一大批。到时候我们招架不了。得想个法子。
〔家属1拿着拖把出治疗室,从左侧下
金述兰 是啊,得想个法子。再来个要输液的就没地方放了。治疗室里又拉又吐的也不成样子了。
赵 枫 得准备接受住院病人。大夫,护士,药房,人手都不够。这个时候,乱糟糟的,谁能把人组织起来?
石世文 有了。把齐大夫请出来。
金述兰 老主任?
〔家属1从左侧上,进治疗室
赵 枫 可他现在什么都不是。早靠边站了。
石世文 他不是主任了,没有职权了。可他有技术,有威信。只有他能把大家组织起来,动员起来。
赵 枫 咦,军代表哪儿去了?
石世文 由他指挥?那不就乱套了?不过这件事也不能不通知他。
〔又有病人上
石世文 要当机立断了。没时间讨论了。述兰,你去把齐大夫请来!
金述兰 (略一犹豫)请齐主任?
石世文 请他!(这时他们已被病人和家属包围,他只好放大喉咙)这样,你上楼请哪位离得开的帮忙,一起分头去把齐大夫和医院的人请来,再去通知陈代表。这儿的事我们来应付。
〔金述兰快步跑上楼梯。石世文和赵枫忙着接待病人。
〔金述兰和另一位护士跑下楼梯,穿过走廊,从右侧下
〔急诊室内的一位家属出来找医生
〔赵枫进急诊室
〔舞台上都是人。病人和家属还继续来到门诊部。因为人多,原先躺在椅子上的人只好坐起来,让出地方给别人挤着坐。
齐立人 (一面穿白大衣一面从右侧上)世文,是怎么回子事?
石世文 你来太好了。事情是这样的。。。我们先看看病人。(两人进急诊室)
〔在候诊的病人和家属望着急诊室,互相交谈着
齐立人 (与石世文,赵枫一同出急诊室)你们判断得对,像嗜盐菌食物中毒。主要的治疗是矫正脱水和电解质紊乱。也许许多病人需要住院治疗,我们来想想办法。(对石世文)我们到后院看看。(两人同从左侧下)
〔陆续来了几位医院的工作人员。他们相互交谈或同病人交谈。舞台上一片嘈杂。
赵 枫 (从急诊室出来,见到一位刚看来的同事)周大夫,你来了?
周克让 听说把齐立人请来了,是这样吗?
赵 枫 是的。
周克让 你说合适吗?
赵 枫 有什么不合适呢,他是老大夫嘛。
〔齐立人和石世文同上
齐立人 (见到医院同人)同志们都来了。这太好了。大家知道,水泥厂发生了一批食物中毒,看来是嗜盐菌食物中毒。估计还会有病人来到医院。几个值班人员对付不了这个局面,光是医生护士也不行,需要大家帮忙,只好把大家请来了。多数病人需要输液,在门诊治疗解决不了问题。楼上没有病床了。那怎么办?后院那排平房,去年闹流感时不是用来当作简易病房的吗?现在还要用它。好象里面堆了杂物。要把它立即腾出来做临时病房。时间紧迫,我就指挥了。总务科老卢在吗?
老 卢 有!
齐立人 好!你领科里同志收拾那排平房。从仓库里把床搬出来。一会就收病人。再有,还要把茶炉烧起来。
老 卢 好嘞。总务科的,跟我来。(带领几个人下)
齐立人 姚护士长来了吗?
姚素芳 来了。
齐立人 你组织一下护士。留两个在这儿照顾。其余的到好院去。临时病房准备铺单,准备好输液。
姚素芳 (对护士们)你们俩留下,其余的都到后院去。(带走一批护士)
〔从右侧传来人的喊声,马蹄声,拖拉机发动机的突突声
〔上来许多能走的病人和送病人的人。见到门诊部内有这么人,不觉一惊,七嘴八舌的说开了:”这么多人!”
”连坐的地方都没有。”
”有担架没有?”
”等一会。”
......
〔一些病人和送病人的人新把医务人员围住询问,人声鼎沸
齐立人 (大声)大批病人来了。我们得快点。药房谁在?
于伟英 我们都在。
齐立人 估计要用大量大输液。维生素,抗生素也要备足。
于伟英 明白。(与几位同事同从左侧下)
金述兰 (从右侧上)找不到陈代表!县委大院里没有,剧团里也没有。
石世文 算了。都安排好了。你看,大批病人真的来了。
老 卢 (满头大汗地从左侧上)病房收拾好了。
齐立人 好极了。谢谢你。(大声)请大家安静。急病人很多,我们要有条不紊地工作,非则就乱套了。我们去看看来了多少病人。该住院的就安排住院。(与一些医务人员同从右侧下)
〔一些医务人员就在走廊里问病史,或给病人作检查。从右侧抬上来两副担架,就放在走廊里。工作在忙而不乱地进行。石世文和赵枫也一直在忙着。
〔齐立人和一位中年人同从右侧上,中年人一脸苦相。看来病人和家属都认识他,纷纷与他打招呼:”沙厂长!你来了!”
”这下病倒那么多人,可怎么好?”
”沙厂长,你脸色也不好,别也病了。”
沙树林 我也拉了好几次了。
齐立人 你也得治。
沙树林 等一会。我不厉害。先把大家安顿好了再说。你说,一共病了多少人?
石世文 到目前连工人带家属已经有四十多个了。
沙树林 这么多?
齐立人 既然建议病房已经收拾好。各位大夫,你们甄别一下。需要住院的病人就到病房去吧。
〔需要住院的病人由家属或医务人员搀扶着,或由担架抬着从左侧下。沙树林也跟着下去。舞台上只剩下齐立人,石世文,赵枫,和金述兰。
赵 枫 总算消停了。
金述兰 奇怪,陈代表哪里去了?医院里闹翻了天了,他却没有露面。往常有屁大一点事他都要来凑个热闹。今天出这么大事,他老人家不知跑哪儿舒坦去了。
石世文 你倒真盼他来啊?
金述兰 我盼他干什么?
赵 枫 还是石大夫考虑得周到,把老主任请出来,事情办得多么利落。
石世文 齐大夫你要不来,不指挥一下,着台戏真不好唱啊!
齐立人 我现在算什么?无职无权,还是反动学术权威。
石世文 没有你的权威,那么多人,怎么指挥得动?
齐立人 (忽然感慨起来)说起来也可笑,我是个什么权威啊?人的一生,也不能不认命。想当年我也是医学院的高才生,也有过一番抱负。谁知阴差阳错,跑这里工作了这么多年,赶上一次又一次运动,白白蹉跎了青春。唉,我当年确确实实雄心勃勃,一心想烟具出点什么来,在学术上有所成就。那时真是做梦也想成为一个权威。可万万想不到,权威还没当成,倒先反动上了。
金述兰 齐主任!
齐立人 你看我,这是怎么了?我干吗说这些话,让你们年轻人听着都要难过?
石世文 齐大夫,你并不老,你完全可以继续干一番事业。
〔一群医务人员,一些家属从左侧上,沙树林也在其中
姚素芳 全安顿好了。留下两位大夫,两位护士在简易病房值班。其他人可以回家了。
齐立人 谢谢同志们!大家辛苦了。(对沙树林)老沙,该给你开点药。
石世文 我给他开吧。请跟我来。
〔他和沙树林进急诊室
〔忽然从楼上传来女子的尖叫声,响亮的关门声,接着是急促的奔跑声,女子的哭声
〔有人跑下楼梯的脚步声
〔沙树林从急诊室出来,拿着处方往左册走去,听到楼上的声响就停住脚步
〔贾竹君从楼上往下跑,跑到楼梯拐弯的平台处看到下面有着么多人,停了下来。她头发凌乱,脚上没有穿鞋。她穿一件白色的短袖上大衣,前襟撕破了,一个纽扣连着长长的线,挂了下来。
〔姚素芳见状连忙走向楼梯
〔石世文从急诊室出来,听见声响也向楼梯走去
〔贾竹君一见姚素芳就大哭起来
贾竹君 (对姚素芳)姚护士长...
姚素芳 (惊讶)你这是怎么了?
贾竹君 (边哭边说)姚护士长。太欺负人了...
姚素芳 谁欺负你了?
贾竹君 今天本来是文美娟上大夜班。可是她今天下午突然病了,发着高烧,让我替她上班,这你知道。我今天上了一天白班,晚饭后觉得有点累,想到休息室睡一会再接班。我睡得迷迷糊糊,觉得有什么人躺在我身边,搂住我,我以为哪位小姐妹跟我开玩笑。也不想理她,又困得很,于是朦朦胧胧睡着了。想不到那只手解开我的衣服扣子,还伸到我怀里乱摸...(泣不成声)
〔在贾竹君哭诉的时候,陈邦孝悄悄地从楼上走下来,走到接近平台处就停住脚步。他没戴军帽,军服显得皱巴巴的,还是不系风纪扣和领扣,胸前被扯开一块,一个硕大的毛泽东像章挂了下来。他的脸上有一道明显的血痕。
姚素芳 不要哭,你慢慢说。
贾竹君 我吓出一身冷汗。刚转过身看个究竟,那只手更不老实了。我这才发现躺在我身边的人(她转过身,指着陈邦孝)就是他!(陈邦孝似乎有些不自然,但很快就镇定下来)我完全醒了,惊叫起来。他反而把脸凑上来,想亲我的嘴。我使劲咬了他一口。他不但不放手,却更放肆地往我衣服里探。还压到我身上来。我害怕极了。拼了命才挣脱出来。我翻身下床,想拉开房门望外跑,他力气大,又把我拉回去,把我往床上拖。我狠命在他脸上抓了一把,他疼得松了手,我才逃了出来。(哭)
陈邦孝 (大声地)同志们,革命的同志们!大家看看这个女人吧!刚才她,刚才她居然想勾引我,她是想把军代表拉下水啊。
贾竹君 姓陈的!你怎么...(气得说不出话来)
陈邦孝 同志们!你们相信她还是相信我?
贾竹君 (气得大哭)姚护士长!你们听,这个人太不要脸。姓陈的,你不要欺人太甚。你一来就想占我们的便宜。这谁不知道?
陈邦孝 (故作镇静,将领扣扣好)我不是自己来这儿的。我可是代表党来的,代表军队来的。
贾竹君 你代表什么党,你代表什么军队?我们医院的护士,哪个你不想欺负,见了哪个你不动手动脚的?
陈邦孝 我怎么你了?你是什么金枝玉叶,碰都碰不得的?像你这样的人,我见得多了。
贾竹君 我不是那种人。我可没那么贱,我应该想得到的,我应该想得到的,是我太大意了....(泣)
陈邦孝 贾竹君,你不要不识抬举。你污蔑我,就是污蔑军队,就是对党的污蔑。
〔石世文忍无可忍,分开人群,走到楼梯口
石世文 姓陈的!今天县里出现严重的食物中毒,全院都在努力抢救病人,你到哪儿去了?躲起来了?还指望你组织抢救呢!你不来参加抢救,还侮辱妇女!
陈邦孝 (恼羞成怒)石世文,你自以为了不起,抢救个病人就了不起了?这个我懂。
抢救病人我抢救得多了。别以为只有你才治得好病。没有你地球一样转,没有你我一天照样吃三顿饭。
〔姚素芳走上楼梯平台
姚素芳 竹君,你回去休息。今天的大夜班我来上。(转身对还站在楼下的刘芳平)芳平,你送竹君回去。
〔刘芳平走上来,陪还在抽噎的贾竹君下了楼,穿过走廊,从右侧下
石世文 (目送贾竹君和刘芳平下,又对陈邦孝)你是一个好色之徒。见了女的你就没了魂,这县里没有人不知道。军队的脸让你丢尽了。
〔陈邦孝似乎庆幸有了转移目标的机会,便不再躲在上一段楼梯的阴暗处,索性走到平台靠下一段楼梯的地方。这儿的光线比较亮,可以看得清他裤子的纽扣没有系上,白色的衬衫前摆都露了出来;他穿着一双皮鞋,鞋带也松开着。人们看到这个情形,不由面面相觑。陈邦孝对自己的这副狼狈相却毫无觉察
陈邦孝 石世文,你的底我都知道。你不是洋奴的孝子贤孙吗?你父亲留洋学,吃饱了洋面包,放足了洋屁;这一套你都要继承啊?
石世文 (被激怒了)陈邦孝,你怎么什么人都咬?
〔姚素芳望了一下人群,又望了一下陈邦孝,上楼去了
〔赵枫在后面拉了拉石世文的衣服
陈邦孝 你经常到到新华书店去,是不是?你去书店干什么去了?你不买毛主席著作,只买医学书,买英文书,是不是?
石世文 (啼笑皆非)你真是又无知又无耻!书店里的毛主席著作哪一种我没有?总不能去一次书店买一套毛选吧?
陈邦孝 呃,为了把毛泽东思想真正学到手,要反复毛主席的许多基本观点,有些警句甚至要背熟,反复学习,反复运用。
〔大家面面相觑,石世文也不知应如何应答
陈邦孝 (显得有点得意)你不要跟我摆什么知识分子的臭架子。你一向不把军代表放在眼里,我心里是非常明白的。只要在走廊里看到我,你就躲开,你不是拐到哪间屋里去,就是从那头出了去。哪有那么巧啊?
石世文 我跟你有什么好眼的呢?
陈邦孝 我刚到这儿来的时候,你确实是主动找我谈过话的。我以为你要跟我汇报思想改造得怎么样,谁知你思想改造一字不提,倒提了这个那个的建议。毛主席教导我们说:”不论是知识分子,还是青年学生,都应该努力学习。不但学习专业,还要在思想上要有所进步,政治上也有所进步。没有正确的政治观点,就等于没有灵魂。”对你来说,最要紧的就是改造。照你这种反动思想,业务再好,也等于为地富反坏右服务。不过不能怪你,你本来就是他们中的一分子嘛。(指着人群中的齐立人)他是谁?他不是反动学术权威吗?谁把他请到这儿开的?
石世文 是我请来的,请来救死扶伤的。
〔从舞台右侧上来一位妇女,她看到这么多人,不觉一楞。随后走到急诊室门口。
妇 女 哪位大夫值班?
金述兰 (就势拉了石世文一把)石大夫,有急诊!
〔石世文离开人群,进急诊室
陈邦孝 (大声地)大家看见没有?反面教员自己跳出来给我们上课了。(发现自己的裤子未系扣,连忙用手把突出的衬衫前摆塞进去,大声地)阶级敌人出来亮相了!阶级斗争就在我们身边!
〔姚素芳穿着白大衣,从楼上走了下来
姚素芳 (声音很低但有力)已经半夜了。病人需要休息,大家也累了半天了。请大家回去吧。有话明天在说。请大家不要喧哗,说话都轻一点。
〔众人纷纷散去,大部分走向右侧,小部分向左侧走去
(幕落)
第三幕
幕启。这是一个劳动教养队的医务室。
一个夏天的下午
对着舞台是两扇颇大的窗,此刻正大开着。从窗口可以望到天空.天空阴沉沉的.蝉声时断时续.随着剧情的进展,每当有风时就听得到树叶的沙沙声,风越大,沙沙声也就越响.不时有人在窗外走过,有时还有人往屋里张望.窗边挂着一个苍蝇拍。
窗上方的墙上贴着一张毛泽东像.毛泽东像的两侧分别贴着两张毛泽东语录:”领导我们事业的核心力量是中国共产党.指导我们思想的理论基础是马克思列宁主义.”,”在阶级社会中,每一个人都在一定的阶级地位中生活,各种思想无不打上阶级的烙印.”
舞台右侧是一道门,通向外方.左方也有一道小门,通往一间小室,这就是石世文住的房间兼药房,这小间在舞台上当然是看不到的;小门左侧,也就是靠舞台的一侧摆着一张长桌,上面有一个电炉,电炉上放着一个铝锅,用来消毒注射器之类.电炉旁边放着一个白色的方形搪瓷盘,上面又放着一个带盖搪瓷盘和一个很大的棕色玻璃瓶,显然原来是装药的,此时瓶里放了一把大镊子.小门的右侧,也就是远离舞台的一侧,靠墙摆着一张诊断床,用一道屏风挡着。墙上也贴]着毛泽东的词<满江红>和”劳动教养人员就诊需知”。窗户右侧也有一张长桌,桌上摆放着一些盛放药水(如红药水、紫药水)的玻璃瓶,小卷的绷带,缠着胶布的小木版,装有镊子的大玻璃瓶等.桌子下还有一个用来支起脚部的木架。桌边是一个白色的污物桶.
舞台的当中是一张桌子,桌上摆放着血压计,听诊器,和许多文具.幕启时石世文穿着白大衣,正坐在桌前撕胶布,他把成大张的胶布撕成窄条,缠到一块长形的木板上。
〔伍家徽从舞台右侧医务室的门上.因为天热他穿着背心短裤,不穿袜子就穿着布鞋.
伍家徽 就你一个人在这儿。
石世文 伍队长!
伍家徽 我还怕你睡了呢.
石世文 天太热,睡不着,干脆起来干点事.
伍家徽 这几天可真热。
石世文 是啊,闷热得很。(擦汗)
伍家徽 今年的夏天也真叫长,往年到这时候早该秋凉了。天气又热得出奇.也不下场雨。气压低,把人闷得喘不过气来。好多天都吃不下饭,睡不着觉的。
石世文 这几天队里病号也比较多。
伍家徽 太阳太毒。天天在地里晒着也是够受的。想气停吧,气象预报总是35℃,36℃的,差一度也不行啊!今天上午还是大太阳呢,不过下午倒是阴上来了。(望窗外)有门儿,也该下一场雨了。
石世文 (转头望望窗外)好象是要下雨.下场雨倒能凉快点.(见伍家徽用手拭汗)你要扇子不要?(递给伍家徽一把蒲扇)
伍家徽 你还穿着白大挂干什么.这儿不比你从前的医院,用不着那么正规.医院里起码有电风扇吧?你是初来乍到,事情还不摸门.医院的好多规矩在这儿用不上.在这儿你只要把事情办妥了就行.什么规矩不规矩的.用不着那些规矩.
石世文 (脱下白大衣,挂在屏风上)脱了它凉快多了.
伍家徽 这件白大挂原先那个胡大夫穿过.你们俩身材倒真差不多.他的医道不错,有他在这儿也很解决问题.可是他到期了,该走了.总不能不让人走吧.他一走,有病人得领到外头去.挺不方便的.可好你又来了.唉,我们这儿什么人才没有!
〔石世文无语,回到桌边坐下.伍家徽也坐下.
伍家徽 你在撕胶布呐。给我一点。
石世文 你要粘哪儿?
伍家徽 我家的蚊帐破了一个口,夜里蚊子往里钻.想用胶布粘上点。
石世文 (拿起剪刀剪胶布)这么大够不够?
伍家徽 够了够了。
〔石世文剪下一块胶布交给伍家徽,伍家徽接过胶布塞进裤袋里.
伍家徽 你这儿有四环素吗?
石世文 你怎么了?
伍家徽 我不怎么了,不是我自己吃,倒是我家的鸡有点怎么了.我们家不养了几只鸡吗。这几天鸡老打蔫,不爱吃食,怕是病了。记得去年也有过这么一次,吃了点四环素就好了。
石世文 四环素是有。(站起来从左边的门下 ,拿了药出来)
石世文 (回到桌前,将包好的药交给伍家徽)我不懂兽医,不知道该给鸡吃多大的剂量。
伍家徽 (接过药) 我有经验。不过你治人的病还是有一手.我们家小三拉稀拉了两个礼拜,到医院看了两三趟,药水药片吃了不少,就是不好.让你开了一次药,没吃完就好了.怪不得我们家就是信服你.
石世文 伍队长.你听过一个吃馅饼的故事吗?
伍家徽 什么吃馅饼的故事?
石世文 有一个人出门办事.肚子饿了,便下小馆子吃饭.他先要了一张馅饼,吃了没饱.再要了一张,还是没饱.于是要了第三张.等他吃完第三张.就觉得饱了.这时他非常后悔,不该要那头两张饼:早知道吃第三张饼就能吃饱,前两张饼就可以省下来了.我给你们孩子的就是第三张饼.
伍家徽 (笑)不管怎么样.你那第三张饼管了事.我用不着再要第四张饼了.
石世文 伍队长,我想要几本医学书可以不可以。我到这儿来的时候不知道还有这么一个医务室,更没料到会到这医务室里来工作.甚么业务书都没带,全凭脑子记忆是不行的。
伍家徽 可以吧,写封信,家里有人来探视时可以让他们带来。
石世文 不会有人来看我的。
伍家徽 怎么会呢?让他们寄来也可以的。
石世文 那好。
伍家徽 (站起来)我得走了。先把药给鸡吃了看它们能不能缓过来,(走到门口又停住脚步)呆会儿你再替我熬点中药.我托人到医院取药去了.脾胃不和,药倒管事,就是熬药麻烦.下午还有个批判会。你不用参加了,把药给我熬了。批判会就在院子里开.(望望大开的窗户)你在这儿都听得见.常书敏这家伙尽给我们找事。
〔伍家徽下,石世文开始做棉球.
〔窗外传来嘈杂的说话声、脚步声.王洪兴从窗口向里望了一下.
王洪兴 (上,他是一个三十多岁的壮汉,光着膀子,肩上搭着一件背心,背心本来是白色的,因为好久没有洗换,已经变成灰色的了)给我点感冒药吧.
石世文 你觉得怎么不好呢?
王洪兴 你说邪性不邪性,大热天还着凉.我这是热伤风.头疼,浑身难受,流鼻涕,还咳嗽.(说着真的咳嗽起来,他往地上啐了一口痰)胃口也不好。
石世文 (望着地下)你往哪儿吐痰?
王洪兴 (用鞋底把吐在地上的痰蹭掉)这行了吧?
石世文 你这病有几天了?
王洪兴 快一个礼拜了.本来想挺挺就过去了.反倒越来越厉害了.
石世文 你还是一个人住在工具房里?
王洪兴 是的.那屋子四面透风,大清早还有点凉.苍蝇蚊子想来就来,我那破帐子也不太管事。
石世文 (耸耸肩)看你吐的痰,你的气管发炎了.我给你开点药吧.(作记录,又起身到左边的小室去)
〔一位皮肤黝黑的年轻人上场,他胸前挂]着一条已变成灰色的围裙。他的右手紧紧地捏着一块肮脏的蓝布,裹住左手的食指,蓝布上湮出鲜红的血液。
王洪兴 (向小门的方向)来买卖了.(向刚上场的年轻人)你怎么了,黑子?切白菜剁手上了?
黑 子 哪能啊!为了给你们弄好吃的付出血的代价!
〔石世文拿了药从左侧的小门出来.
王洪兴 有好吃的你舍得给我们吃?天天给我们吃老三样,熬白菜、辣白菜、炒白菜..想起吃饭就倒胃口.
黑 子 呆会儿有好东西你别吃。
王洪兴 甚么好东西不先填了你们哥儿几个.
黑 子 你亏心不亏心啊?等会儿把肉吃到嘴里可别忘了我剁排骨都挂了彩了。
石世文 先别耍贫嘴了。让我看看伤得怎么样了?(起身为黑子处理伤口)挺热的天怎么动起荤腥来了?
黑 子 外头宰几头猪.我们沾点光.肥肉留给人家.下水,腔骨归我们.大夏天这东西存不住,来了就得马上加工做熟了.
王洪兴 好,今儿晚上改善。我得早点儿去打饭。(看黑子的伤口)口子可不小。也许还能吃到你的血豆腐呢。也该让你们出点血了。平常你们尽吃我们的,喝我们的。
黑 子 我怎么吃你们的,喝你们的了?
王洪兴 你说,你们吃饭有没有定量?
黑 子 我们没法定量.
王洪兴 这不就结了。你们吃得多,喝得多.除了一天三顿想吃就来点。给大伙吃的都分量不足.你们多吃的从哪儿来?还不是从我们嘴里刮了去?
黑 子 哪能!
王洪兴 我怎么不知道,我也在伙房干过。这可是美差使。在伙房里干一阵子哪个不落一副好 下水?
黑 子 后来你怎么又不干了呢?
王洪兴 后来我不愿意干了.
黑 子 得了.哪有美差不愿意干的。你准是手脚不干净,让人家给轰出来了。
王洪兴 你狗嘴长不出象牙来。
石世文 依我说炊事员稍为多吃那么一点,不但没坏处,而且是应该的。他能多吃你多少?炊事员有积极性,是大家的福分.记得我从前单位的领导曾经订过一条规矩,炊事员也按定量吃饭。这样可好,第二天做出来的饭就没法吃。第三天这规矩就取消了。
王洪兴 说真的.你知道谁真吃大伙的,喝大伙的?
石世文 谁?
王洪兴 去年我还在伙房.每次伙房里做点甚么好的,总有那么一两个人来检查工作。那时朱彦贵那小子是伙房组长.干部一来,朱彦贵就拍马屁,挑最好的盛一大碗尝尝,再倒上一碗酒。人家吃饱喝足,抹抹嘴就走.朱彦贵劳教期满释放,在外边又当上火头军.常常拿大水壶装满一壶菜子油往干部家里送.
黑 子 (看看包扎好的手指头)得。谢谢您了.我不能再聊了,我得赶紧回去干活。
王洪兴 我也得走。(拿了一卷绷带塞进裤袋里)
黑 子 你小子恶习不改,又偷点甚么了?
王洪兴 谁偷甚么了?我的蚊帐破了几个大洞,我拿卷绷带补一补。
黑 子 你这是贼不走空。(两人同下)
〔石世文回到桌前,继续做棉签
〔霍修文在窗口探了探头,随即从右边的门上.他戴着眼睛,像个知识分子.可是这时头发很长,胡子也没刮干净,显得很憔悴的样子
霍修文 大夫.
石世文 你怎么了?
霍修文 肚子不好。
石世文 从甚么时候开始的?
霍修文 从今天早起到现在拉十几次了。
石世文 大便是什么样的?
霍修文 完全是稀的,还有点脓血.
石世文 有没有肚子疼想大便又拉不出的感觉?
霍修文 有.
石世文 这几天除了食堂的饭你都吃什么了?
霍修文 我中午才回队里来.我屋子里那帮人还睡得死猪一样.这几天我没在咱食堂吃饭,在汽车修配厂食堂吃饭来着,那食堂的卫生太差劲。我昨天吃午饭时在柿子椒里吃出一条毛毛虫来,还让我咬断了,现在想起来都恶心。
石世文 是够恶心的。
霍修文 还有人幸灾乐祸,说甚么:“我们一个月半斤的肉票交给伙房,可吃不到三两四两的。你倒好,一顿吃一两多肉。”
石世文 听说今晚真有肉吃.
霍修文 我也不想吃,最希望别吃柿子椒.
石世文 看来你是得痢疾了.先拿点药吧.我给你开点呋喃西林.(在登记本上作记录,开处方,取药)
石世文 (把药交给霍修文)你说你去到汽车修配厂了.
霍修文 我到汽车修配厂去干了好几天活。
石世文 是不是总场部那儿的汽车修配厂?
霍修文 是的,几部拖拉机出了问题,修配厂硬是找不出毛病.知道我是技师,就找到这儿,队里派我去干了好几天.
石世文 给他们修好了?
霍修文 难者不会,会者不难嘛.毛病出在变速箱上.这种负载换档变速箱结构复杂,技术要求也高.那厂子里倒是工种齐全:车,钳,铸,焊样样都有,设备也不错.可没有人玩得转这种型号.
石世文 修配厂离这儿有多远?
霍修文 离这儿有十多里地。
石世文 我还没到过那里.
霍修文 你还没去过?
石世文 我来这儿三个月了,连这大院的门也没出去过.
霍修文 农场医院就在那儿. 一天我伤了手,到医院上过药.那儿真有几位好大夫.听说有个右派大夫是医学院的什么教授,我告诉你那儿连国民党的少将军医都有.你知道不知道那儿有个很大的葡萄园,还有一家酿酒厂.酿的葡萄酒是第一流的.晚上跟厂子里的工人聊天,听他们说这个农场里什么人都有,作家,新华社的翻译,唱花旦,唱武生的.这个农场真是藏龙卧虎之地.
石世文 你每天来回跑?
霍世文 哪能啊.那天队里派车送我到修配厂的。以后谁能天天接我送我呢?白天我在车间里干活,晚上他们给我在车间里支起一张铺,就在那里休息。
石世文 他们也不怕你跑了?
霍修文 往哪儿跑?跑回来?
石世文 队里这几天可跑了好几个。
霍修文 都有谁跑了?
石世文 昨天傍晚收工,点名时少了常书敏、展国光、全兴城三个人,他们逃跑不是第一回了.当时动员了几十个人在苇子地里搜到天黑,果真把常书敏抓了回来,展国光、全兴城两个可就就不知去向。这不,一会儿要开批判会批判常书敏。至于那二位......(传来隆隆的火车声)恐怕已经下了火车了.
霍修文 他们行.全兴城跟我躺在一条炕上.晚上尽听他扯淡.他们行.没有钱一样日行千里.他们不用车票就能上火车,没有车票照样出站.上车时两手空空,下车时就有了行李.这种本事用他们的行话叫什么,你知道不?
石世文 不知道.
霍修文 这叫”滚大包”.你知道他们的”工种”叫什么?
石世文 叫什么?
霍修文 叫”钱工”.
石世文 怎么叫钳工?
霍修文 (笑)不是车,钳,铆,焊的”钳”,是金钱的”钱”.是能从你口袋里把钱拿走的”钱工”.
石世文 (笑) 这也是一门学问.
霍修文 这学问你我是学不会的.
石世文 听说你是挺高级的技师.
霍修文 我这张嘴不好.要不是多说了话,也不至于落到这个地步.
石世文 哦...
霍修文 你愿意听吗?
石世文 愿意.
霍修文 是这么回事:我们厂办公条件很差,办公室就挤在那么几间平房里.早就计划要盖办公楼,一盖就盖了几年,好容易才盖得,我们技术科也搬了进去。你知道搬进新房子要办的第一件事是甚么?
石世文 是什么?
霍修文 挂毛主席像啊。办公楼一盖好,总务科当下就买来,不,请来一批主席像,让各个房间派人去领。每层楼有12个房间,却只来了11个人领主席像,一开始书记也搞糊涂了。他怎么也搞不明白着是怎么回事.十二个房间,只来了十一个人.你猜是怎么回子事?
石世文 (略一思索)我明白了...可是我想每层楼应当只有十个人来领.
霍修文 有你的。你猜得差不多。可你只知其一不知起二。我们的办公楼有四层,男厕所只有一楼和三楼有,而女厕所在二楼和四楼。
石世文 后来呢?
霍修文 我提醒他们:一号还没派人来领主席像呢。我本来想开个玩笑,没成想玩笑开得太大.想不到这下把书记给惹火了。他说我是故意侮辱伟大领袖,是反革命行为。以后的事情就可想而知了.
石世文 (轻轻叹一口气)”病从口入,祸从口出”,你都占全了.
霍修文 (露出难看的表情)我肚子又疼起来了.得上厕所,接着就得吃药.(急下)
〔石世文走到窗前,窗外天色更阴沉了.听得到杂沓的脚步声,说话声,吹哨声.有人大声地喊:”集合,各队集合,到院子开会!”
伍家徽 (提着一捆摞成一摞的小纸包上)石世文,这些中药放在你这儿,你替我熬了.我一会儿来取.
石世文 好的.
〔石世文打开一包中药,把它倒入一个熬药的沙锅,加水,把沙锅拿到电炉上,插上插销
〔李便民上.他穿着短袖衬衫,可没把扣子扣上
石世文 李干事.
李便民 真热.(环视四周)
石世文 看这天气也许会下雨,下了雨就凉快了.
李便民 (看见电炉上熬着中药)你这是干什么呢?
石世文 我给伍队长熬中药.
李便民 一会儿在院子里开批判会,批判常书敏.全队都要参加.不过你就别去了,在这儿批判会的发言也能听得见.你熬药吧.当然你也需要改造思想.思想改造不能放松.可是你跟常书敏是两回事.(下)
〔床外传来高音喇叭播放的革命歌曲,如毛泽东语录歌,<大海航行靠舵手>等,有人往话筒吹气,喊”喂,喂...”
〔杂乱的脚步声,说话声
〔李便民的声音:”安静!安静!批判会开始。”会场上的声音时时传进来
〔石世文走窗前
李便民的声音: 大家安静,开会了.今天开批判会.批判什么人呢?批判常书敏.常书敏是怎么回事,大家一定都知道.把常书敏带上来...
〔会场上嗡嗡的语声
〔口号声:”打倒坏分子常书.敏!””常书敏必须低头认罪!””中国共产党万岁!””毛主席万岁!”...
〔从门口进来一个瘦高个子.
尚天明 我来打针.
石世文 来吧.
〔石世文从消毒锅里取出注射器,从一只安瓿里吸出药液,示意尚天明到屏风后去
尚天明 我打了几个星期的针了.还得打多就才好?
石世文 神经炎恢复得很慢.你的症状减轻得算快的.
尚天明 吃药真能引起这病?
石世文 你那阵用呋喃西林的量的确太大,用药的时间也长了点.你的神经炎很可能就与呋喃西林有关系.
〔尚天明打完针,一面系裤腰带一面走到窗前,他们两人站在那里观看院子里的批判会
尚天明 常书敏这回可是栽了.那天他在苇子地被三小队哥儿几个抓到,给了他一顿臭揍.他们在苇子堆里让蚊子咬得好苦,就拿他出气,打得鼻青脸肿的.
石世文 他们这也不对.常书敏有杀头的罪,也不该打他.那天晚上押着他来处理伤口,我看着也挺不好受的.现在天气热,弄不好伤口要感染,
尚天明 常书敏还算造化呢,只受了点皮肉之苦.去年这儿出了一件大事.有一个名叫张大山的顶撞了队长,队长让把他用绳子捆起来.绳子捆得太紧,捆的时间太长,结果把神经捆坏了.我记得那时胡大夫就说过这样不行,可他是教养分子,算老几?谁听他的?最后他右手的手指头不能动了,手也变得爪子一样.末了让张大山保外就医了事.也不知他到底好了没有.
石世文 常书敏跟你是在一个小队吧?
尚天明 原先是在一个小队的.就在上星期小队重新分过了.他划到二小队去了.
石世文 为什么小队的人员要常常改来改去的?
尚天明 原来的小队太团结了.只好拆了重新分队.
石世文 团结还不好么?
尚天明 小队里团结了就互相包庇,没有人靠拢政府,出了事也不汇报.一小队个个冤家对头似的,谁放个屁队长都知道,好管.二队,三队就讲义气,出什么事都瞒着不揭发.这回可要掺沙子了.如果常书敏队里有个冤家,知道他打算逃跑,给捅了上去,今天这批判回也就甭开了.
石世文 如果大家整天互相揭发,生产也搞不好.
尚天明 改造第一,生产第二嘛.
〔批判会上李便民正在发言,他的声音清晰可辨
李便民 常书敏你是几进宫了?在宫里你还要进宫,还要进宫里的宫.你说,禁闭室你进去多少次了?派出所里的小号你也是常客了.(笑声)他还时不时出点新花样.大家记得,去年外边供应站的后墙让人打了个洞,偷去现金和货物.这是谁干的?常书敏.打洞偷东西,在农场的历史上还是头一会.常书敏有本事,破了农场的记录了.
〔大笑声,还听得到几声稀稀拉拉的掌声
〔突然从批判会上传来愤怒的吼声
愤怒的声音1: 常书敏,你还笑,大家笑,是笑你抗拒改造,你笑什么?笑你能耐,打破记录吗?.
愤怒的声音2: 常书敏!你还敢笑,你还配笑.你还笑得出来!你怎么就没皮没脸.这可不是表扬你破记录.不是夸你有本事!这是批判会,批判你的罪行!
愤怒的声音3: 常书敏,你仰着头干什么?把头低下去!
〔口号声:”打倒常书敏!””打倒死不悔改的坏分子常书敏!””常书敏必须低头认罪!””踩上一只脚,叫他永世不得翻身!””中国共产党万岁!””毛主席万岁!”
愤怒的声音4 常书敏,你要老实交代.你们三个人当初是怎样商量的?跑出去以后怎么办?
石世文: 你不去参加批判会了?
尚天明: 我该走了.(下)
(石世文走到把熬好的中药倒到一个搪瓷缸子里)
(窗外起风了,天空一明一暗的,那是在打闪,有隐隐的雷声.批判会还在进行)
愤怒的声音1: 常书敏!你在干什么?
愤怒的声音2: 他的脚在干什么?
愤怒的声音3: 我说.是我把常书敏带上来的.我就一直就站在常书敏的身边.我清清楚楚地听到他在哼小调!
愤怒的声音4: 他的脚在打拍子!
愤怒的声音5 他还有脸哼小调!大家对他的批判他一句没听进去!
〔乱糟糟的说话声,口号声
〔伍家徽上.
伍家徽 我的药熬好了么?哦!已经熬好了.我这就喝了它.(喝药,皱眉)这药可真叫苦!良药苦口嘛.石世文!今天是探视的日子.你家属可真来看你了.
石世文 (感到意外)我家属来探望我?
伍家徽 你不知道她要来?
石世文 我不会有家属来看我...
伍家徽 这还有假的?
石世文 真不知道是谁.
伍家徽 等一会我让看大门的许师傅领她到这儿来,你们在这儿谈吧.不用到接见室去了.(下)
〔石世文呆呆地望着他的背影,一脸大惑不解的样子
〔贾竹君随一位中年汉子上,她跟前两幕时不同,没有穿工作服.上身是白色的短袖衬衫,下身是蓝色的长裤.肩上挎一个黄色的帆布军用挎包,从挎包里突出一把伞.
汉 子 石世文!你家属来看你了.伍队长让我把她领到这儿来.(对贾竹君)你们谈.有什么事再找我.(下)
贾竹君 (轻声地)石大夫!
石世文 (意外)没想到是你?
贾竹君 没想到是我吧?
石世文 真是没想到.他们告诉我有我的家属来探视.我以为他们搞错了.我哪有什么家属会来看我.
贾竹君 我不说是你家属人家是不允许我进来的.我在火车上就遇到好多妇女来这儿探视的.她们告诉我非直系亲属还不让探视.到了这儿我就说是你家属.
石世文 真委屈你了.
贾竹君 你是为我落到这地步的.
石世文 不要那么说.这跟你没有关系.姓陈的在医院里胡作非为,我早就看不惯.不止我看不惯,谁也看不惯.知识敢怒而不敢言.开始,我也是想,惹不起我还躲不起.可是我想了.这个人欺人太甚,你退一步他进十步.躲是躲不过的.冲突是一定要发生的,只是个时间问题而已 那天的事只不过是导火线.
贾竹君 可是你到底还是因为我得罪了姓陈的.我想起来就心里不安.
石世文 不要为这件事不安.姓陈的早晚是要收拾我的.他想欺负你,不料在群众面前丢了面子.借题报复我.老实说,开头我也觉得够委屈的.痛顶思痛.我认识到这是命里注定.没什么可以埋怨的.哦.你请坐吧!
贾竹君 (坐下)你就在这里工作?
石世文 是的,我就住在里面那间小屋子里.倒也挺清净的.
贾竹君 看到这我真放心多了,我真怕你会跟那些人挤在一个大房间里.你怎么能受得了?我想着都受不了.(悲伤)
石世文 真到了那份田地也会受得了的.人的适应能力还是挺强的.我刚来时就挤在大通铺上.
〔窗外又传来口号声
贾竹君 外面在干什么呢?
石世文 批判会.有个劳教分子逃跑被抓回来.今天开他的批判会.
贾竹君 听到这我都要打寒战.
石世文 我们不谈这个.你说说医院里大家都好吗?
贾竹君 大家都还好.刘芳平知道我要来看你,让我向你问好.她让我告诉你,医院里大多数人都说你是好样的,你为大家出了一口恶气.你为大伙受了罪.大家心里明白,你的罪不会白受.她让我对你说:善有善报,恶有恶报,总有那么一天的.
石世文 谢谢她.你到这儿来别人知道吗?
贾竹君 就刘芳平一个人知道.我打听到你的情况,有意攒了几天公休.我说我姨妈病了,要去看她.其实我跑这儿来了.
石世文 姓陈的后来怎么样了?
贾竹君 这个人坏事做绝,在县里呆不住.走了.
石世文 走了?
贾竹君 你知道他没带家眷,县委大院里有他一间房.大院里住的尽是县里的头头脑脑.这些人你也是知道的,大多是造反派,坐火箭的.都是小人得志.他们的素质你可以想象得到.姓陈的邻居就是文化局长,姓邓,原来是县剧团管道具的.
石世文 我知道这个人.
贾竹君 他有一个十五岁的女儿,像个疯丫头似的.
石世文 我见过她.去年还到医院里看过病.
贾竹君 就是她。学校里的玻璃都敲碎了.课桌椅也砸烂了.老师已经七零八落.学生不上课,在社会上混.也不知姓陈的怎么吸引了她,这丫头整天往姓陈的屋里跑.时间长了,姓陈的就动手动脚起来,有人看见他们俩嘻嘻哈哈在床上闹.也搞不清她父母知道不知道.反正没管他们.你离开不久,那姑娘的肚子就一天天大起来了.天气一天天热,衣服一天天单薄,瞒也瞒不住了.邓局长的面子丢光了,他把女儿送回老家乡下,据说把孩子打了.姓陈的在县里呆不下去,灰溜溜地调走了.
石世文 调走就算了?
贾竹君 这事没人追究.可不就算了.
石世文 真便宜他了.
贾竹君 听说在公社当了什么武装部部长.
石世文 他这是犯罪啊!他欠下全县人民一笔帐走了.
贾竹君 姓陈的走时,医院派总务科的小江帮他装车.他来县医院时也是小江帮他卸行李的.小江对他的家底最清楚了.姓陈的到县里来时,只有一个柳条包,一个包袱皮,还有一袋麦子.他离开时,行李可装了一卡车:家具是整套的,包袱皮没有了,换了几个木箱子.还有几袋粮食,几桶食油.带来的那袋麦子又原样带走了,小江说他记得清清楚楚,还是那一袋.小江对这袋麦子可有个评语.
石世文 怎么说?
贾竹君 他说:最不相信共产党的不是别人,正是姓陈的那样的人,他们认为只要共产党领导,不知哪天肯定还会出现60年那样的饥荒,所以总要储备着一些粮食,到饥荒时好吃.
石世文 (笑)太深刻了.
贾竹君 陈邦孝这样的人才应该往这儿送.可反而把你送来了.(又悲从中来)
石世文 这地方可不收容他那样的人.
贾竹君 文美娟打那以后一直不声不响.我有时觉得她也挺可怜的。
石世文 其实她也是受害的。
贾竹君 石大夫.请你原谅我从前对你的态度.我那时的思想太幼稚,我那时对你不了解,没看出来你是医院里最好的人.
石世文 也许你以前真是把我看低了,可现在又看得太高.
贾竹君 不是的.这不是我一个人的看法.自从你离开,大家都觉得我们失去一个多么好的人.如果我当时对你好一点,姓陈的就不敢欺负我,你也不会为我吃苦...
石世文 你千万不要自责.我看不惯他们那些人,那些事.不谴责他们我做不到,他们一直想收拾我,这只是早晚的事.我拖得过初一,也拖不过十五.我还记得上高中时,老师推荐我们读<历代文选>,我至今还记得”林觉民烈士遗书”中的一句话:”吾何不幸而生今日之中国”,这句话的意思,我今天是真懂了.
贾竹君 你一点不怨我?
石世文 我怎么会怨你呢?...我坦率地说吧,不管会不会冒犯你,我那时真是喜欢你的.
贾竹君 ...现在就不喜欢了吗?
石世文 (苦笑)现在不能想了.
贾竹君 我已经想开了.这些日子我想了很多很多.从前我不了解你,把你从身边给丢了.现在我不能再失去你.我等着,等你出去,我们就走.哪怕到天涯海角,我都跟你去.我们凭技术生活,自己养活自己.
石世文 (感动)竹君....
贾竹君 世文...
〔石世文握住贾竹君的手,把她的手贴近自己的脸,贾竹君悲喜交集
〔天色暗下来.看得见天上乌云滚滚
〔天上打着闪,传来隆隆的雷声
〔窗外传来乱杂杂的人声,树叶的沙沙声
〔窗外传来李便民洪亮的嗓音:”散会!散会!”
〔有人高喊”大家回去收衣服去!”
石世文 (转头望着窗外)要下雨了.
贾竹君 好象是要下雨了.
〔传来木头板凳在地上拖动的声音,杂沓的脚步声,呼喊声
声音1 快收被子!
声音2 我还晾着衣服呢!
〔台上光线已经很暗了
贾竹君 (打开她的帆布背包)你看我给你带什么来了?(取出一个纸包,打开)
石世文 <内科诊疗手册>,<常用药物手册>,好极了.我正用得着.你考虑得太周到了.
贾竹君 我决定来看你,心想带点什么来呢.我觉得你最需要的就是这些书了.着是我在新化书店买来的.
石世文 这些书来得很及时.现在我手里什么专业书都没有.刚才我还跟这儿的一位队长说起,希望能得到几本医学书.他还说可以让家属来探视时带来.没想到一会儿你就把书送来了.谢谢你.
贾竹君 只要你用得着我以后还给你送来.
石世文 我需要什么,你能知道...
〔两个人冒冒失失地撞了进来,看见石世文和贾竹君,又互相看了看,吐吐舌头,匆匆退了出去
石世文 这些天这儿热极了.县里怎么样?
贾竹君 也非常的热.干热干热,却不下雨.怕病人热得受不了,我们拉了一些天然冰来,放在病房里.不到半天就化成水了.你还记得去年冬天我们医院支援食品公司冰窖,到湖上拉冰吗?
石世文 记得.去了二十多人呢.
贾竹君 先是用冰钩推着冰快走,后来许多人干脆踩着冰块走.
石世文 我们踩在大冰块上,用冰钩撑着,在湖面上滑着走,那真是很愉快的.
贾竹君 那是好日子啊.
〔一阵大风从窗口刮进来.把桌上的纸张刮到地上
〔雷声大作
石世文 好凉快!
贾竹君 快下大雨了!
〔天完全黑下来.闪电一个接着一个.雷声越来越响.
石世文 暴风雨就要来了.这个夏天把人热死了.这几天整个世界就好象是一个大蒸笼.来一场暴风雨,起码能让人轻松地喘口气.暴风雨,来得更快些吧!
〔霹雳般的雷声.窗外传来噼啪的雨声.
〔窗外有人大声喊:”下雨了!”
〔高音喇叭播放着歌曲:”毛泽东思想是不落的太阳...”
〔两个人并肩站在窗前.台上光线昏暗,在闪电时窗框中勾出两人清晰的轮廓.
(幕落)
1 金小伟
笔细 - 探亲路上 屏蔽留存
笔细 - 探亲路上
屏蔽 ||
探亲路上
我一大早就动身了。先搭上一趟短途列车到海河之滨,再等上两三个小时。这是一个重要的换乘站,往西、往南、往东北方向的列车在这里交汇,候车室里正天是熙熙攘攘的。一般是列车进站前十来分钟,才给我们这些中途上车的旅客检票。我们踏上月台不久,那趟南去的长途列车便靠站了。同样背着、提着沉重行囊的男男女女一个接一个出现在车门口,匆匆踏上站台,又忙不迭地向出站口走去。我没有跟在那些争先恐后地往车门口挤的人后面,却认准了一节车厢,因为一群显然是集体出行的旅客成群结队地从那节车厢下来。等我上去,车厢里已变得空落落的。我从容地在第二个分隔厢一条可坐两个人的座椅上找到一个靠窗的位置。把简单的旅行包放上行李架,从黄色的帆布挎包里取出毛巾袋,拉开拉链,将毛巾抖开,搭在窗子上访的毛巾架上。车厢里,靠窗的位置最受欢迎。如果你坐夜车,到了夜间,可以把头稳稳地靠在椅背与车身交接处形成犄角里安然入睡,如果小桌没被人占用,也可以在小桌上伏着打盹。
严格说,我此行是去休假的。每年,差不多在同样的时间,我都要坐上同一车次的列车,踏上同样的旅途,去度探亲假。说是探亲假,其实更多是理论上的,这倒不是说我无亲可探,我的亲人都还住在原来的地方,每次回去他们也同样欢迎我的归来,母亲也不会忘记买下一些荸荠和茭白,她知道我喜欢吃这些东西,而我的工作地点又见不到,慈母心是三春晖啊。亲情,恐怕任什么政治运动也难以完全割断的。回家以后,大家围坐在一起,免不了交流阔别一年来的遭际。一年三百六十日,所见、所闻、所历,应该是很丰富的,按理应有说不完的话题。但往往第二天以后许多话到了嘴边又咽了下去,冥思苦想,竟找不出多少可以无所顾忌的话头,可以畅所欲言的题材,范围越来越窄,大家谈着谈着,往往觉得语塞,于是陆续找个理由站起来,各自散迄。回想起来,仅仅过了几年,情况居然恍如隔世。就在几年前,人们相聚时话匣子一打开就再也关不上。现如今人们却要小心谨慎,避免一些敏感的问题。口没遮拦,倒不用怕亲人告密,可是许多事,许多人,却不敢提起。母亲的一位总角之交,后来当了小学教师,与我家来往甚密。那年她当小学校长的丈夫被打成右派,夫妻俩长期受人尊敬,忍受不了对他们人格的侮辱,很快就双双投黄浦自尽。我那次暑假回家不知深浅,问了一句阿姨最近来了没有,害得母亲掩面大恸。以后,我一直小心避免涉及这件事。更万万想不到的是,事隔不到半年,我自己也卷入旋涡,从此不得不忍辱偷生。如今年纪轻轻,竟“不如意事常八九,可对人言无二三”,于是,没消息就成了好消息了。
可是,探亲假的机会我总是不愿放过的。每到这个时期我可以不用牵挂工作,清闲上十几天。不管怎样,见到疏阔的亲人总是件愉快的事。事实上,在探亲假期间我很少呆在家里,却喜欢每日价在城里转悠,也总忍不住故地重游,旧日的师友无心去访,往昔的足迹还想去寻。虽然从前那些亲切的面孔不知去了何方,他们是吉是凶也无从打听,我还是在弄堂里、小街上久久蹀躞。我常留连在展览会、博物馆,沉溺在知识的海洋中可以忘忧。还有一件爱做的事是一连多日光顾书场,欣赏终年听不到的评弹。悦耳的吴音让我暂时摆脱了萦绕在心头的烦恼。江滨公园也是我常去的地方,我常浴着和煦的江风,把往事细细回忆,虽然回忆难免使我心紧紧地缩成一团。
在这条线路上来回走了几年,我已经对它十分熟悉了。我不满足于直来直去,常常在中途下车,到故地重游,或到当地的古迹凭吊一番,然后回车站赶下一趟车。有一次甚至故意坐过了站,游览过名胜再返回头。于是,探亲假成了我的“旅游假”。
火车要走上30个小时才到达目的地。按照规定,休探亲假时只能报销硬席座位的费用。我必须在火车上过一夜。好在旅途中只我只消坐上一宿,加之我年轻力壮,丝毫不以为苦。其实我不算最艰苦的,同事中有人回到四川探亲,竟要在火车上度过三天两夜呢。
我旁边的空座位不久都坐满了。在长途旅行时与偶遇的道伴天南地北地闲谈,确是很惬意的事,这样做不但可以排遣旅行中的寂寞,还可以听到许多平时从其他途径难以获得的信息。旅客们本来是萍水相逢,一到目的地就天各一方,虽然分别时习惯地说声“再见”,大家都明白其实是再也见不着的。除了太过敏感的问题外,讲话的顾忌也相对较少,言谈中也比较肆无忌惮。
与什么人为邻,这本是缘分。我曾有幸与各色人等为邻,这包括引车卖浆者流,读书人,坐办公室的,修理工,庄稼汉……。人本来天生平等,纵使被人为地划分成三六九等,本质上亦无高下之分,不同的仅是兴趣的广窄,知识的深浅而已。尤其是有些道伴见过世面,他们的谈吐真能令你大开眼界。
虽说这趟列车是一趟普通快车,但停靠的车站很多,只作短途旅行的的旅客也很不少。也是机缘不巧,今天我的邻座不但更换得频,而且多不善言谈。我只索取出一本书,独自看将起来。当时我带了一本原版的“Immensee”( 茵梦湖)。以前我读过译本,深深沉浸在这凄婉的故事里。一次出差时在旧书店用很便宜的价钱淘换到这本小册子。既然没有合适的道伴,下车前我就能把这本书读完了。
列车靠站,尤其是停靠在小站时,当地的农民便凑上前来,高举起手里的竹篮子,兜售土特产品。即使在一些小站上列车只停一分钟,乘客只消推开纱窗,就可轻轻松松地买东西了。吃剩的果皮、骨头、碎纸也很好处理,往窗外一扔即可。
列车又到站了。同一分隔厢的旅客几乎都下了车。
站台上立着一个昂首挺胸的铁狮子,背上驮着一个莲座。我知道这只是件仿制品,因为没见过原件,对仿制品还是很感兴趣。
铃声响起。列车徐徐开动。
我把目光从铁狮子移回车厢,刚才空出的座位这会儿又坐满了。
我几乎叫出声来,注意到对侧靠窗的座位上新来了一位旅客。身穿浅紫色的短袖上衣。
那不就是她吗?这娟秀的形像几年来多次进入我的梦中,此刻居然活生生地出现在眼前。
那是好多年以前的事了。我到文学院拜访一位中学校友,他生在苏州,后随父母迁居沪渎,转学后与我同校、同届而不同班。中学毕业后我们同时考上这所著名的学府,但他上的是文学院,而我则进入医学院,两个学院隔了半个城的距离。算来他离开姑胥。已有年矣,可至今乡音不改。我们在校园的湖边谈天,操的自然都是吴语。一位凑巧坐在我们旁边的穿一件浅紫色短袖上衣的女生可能为他动听的苏白所吸引,忍不住与我们搭讪了一句。原来她也来自平江,而且与我的校友同系。这搭讪不打紧,从此我成了文学院的常客。先是(也许应该说以此为借口)找老校友,后来干脆直截了当地找她。
那个年代,真是一个意气风发的年代,年轻人都怀着远大的理想,有幸上了大学的无不珍惜这个机会,个个勤学苦读,准备建设祖国。我们的交往丝毫不影响我们的学业,在某种意义上还成了我们苦学的动力。我总希望以一个成功的学生的形象出现在她面前,她的想法与我也别无二致。
真应了元曲《儿女团圆》中那句唱词:“人无千日好,花无百日红”,厄运很快降临到我们的国家、我们的人民头上。
那个夏天,人民的热情被煽得像烈火一样。一时间,各种报刊上整版整版地登载着各界人士对各方面工作的建议和批评。说也惭愧,医学院课程繁重,师生们也向来对政治不关心,不敏感,校园里的大字报寥寥落落的。只听说文学院的师生思想活跃,运动也搞得有声有色。我也曾到文学院去过多次,可心无旁骛,早把老校友冷落在一边,遑论关心运动了。及后风云乍变,全国各地揪出来许多“右派分子”。 我知老校友一向心直口快,忽然为他担心。我决定到文学院去找他。校园里张铺天盖地贴着花花绿绿的大字报,里面好多张赫然写着他的名字。我门两个顾不得喁喁私语,马上一同找到他的宿舍。他却非常泰然,说目前的事态只是一股逆流,形势会向正确的方向发展的。
他想得太天真了,局面越来越严峻。六月飞雪的日子过去之后,似乎风平浪静了一阵,可是第二年,运动又紧锣密鼓地搞将起来。这时得到一个噩耗:老校友在一个批斗会上突然奔到窗口,纵身跳下四楼,当场毕命。我闻讯不由泪如雨下,痛斥那些那些将他逼向绝路的人。不料第二天大字报就贴到我宿舍的门上,我就被补定为右派。几年后,一位知情的同学私下告诉我,本来医学院的“反右”就被批评为搞得不得力,规定的比例都没完成,还发愁怎样完成任务。我胆敢为自绝于人民的右派分子说话,正好自己撞到枪口上,补了这个数。
我一下不知所措,也不敢分辨。我忍气吞声,熬到毕业,得到了一份工作,可是永远失去了两个最亲密的朋友。一个与我们已经幽明永隔,另一个呢,我不愿拖累她,也无心去寻她,从此暌离有年,天各一方,更不知花落谁家。
不想今天我们又得以同路。
我们确曾同路过。那时一到假期我们就结伴还乡。我们是从起点站上的车。在车上靠窗的位置总是留给她的。
到了苏州,我坚持随她下车,并把她送到家。后来,这样的安排成了习惯。我非常喜欢这个城市,喜欢苏州园林,喜欢这里的小桥流水,喜欢苏州糕团,喜欢苏州的一切。
每次,她母亲都热情地接待我。这个充满江南水乡气息的处所,对我,竟成了遥远的梦。
这几年,我也曾悄悄地重访过这地方。潺潺的小河、白墙青瓦的旧宅、悠长的铺着卵石的小巷,还是老样子,但已物是人非。我没有勇气走近去,只是远远地眺望她家的那个院门,站到红日西沉。
紫衣姑娘坐的是一个靠窗的座位,她把一个黑色的手提包挂上了衣帽钩。我偷偷地往那边瞧上一眼。她正与邻座的一个女人交谈,对面的一个汉子好象也加入了聊天。可能是谈到高兴处,她粲然一笑,脸颊上现出两个酒窝。我看得清清楚楚,左侧面颊上的酒窝比右面的稍深一些。当年我早就注意到这个动人的特征了。她的两条辫子依旧又粗又长,辫稍可及腰际。从前,她坐下时辫子就常常垂在凳面以下。我喜欢把她的辫子拿在手里抚弄,她也听之任之,不以为忤。她的辫根扎得高,高于耳朵的水平,这也是与当年一致的。
从前我敢肆无忌惮地盯着她看,欣赏她姣好的面庞。如今,我只能悄悄地眺望一下,察觉到她的目光转向四周时,我便立即把视线移开。
许多年不曾见面,她一儿也没有改变:那身材,那模样,同样颜色的衣服,同样的发辫,脸上同样的笑靥。岁月竟一点痕迹也没有留下。
她怎么会在沧州上车的呢?难道她被分到这里工作?难道她在这里成了家,要不然她有亲戚在这座狮城?她家在哪里有亲戚,原来我是一清二楚,不过流光易逝,过去的信息早成明日黄花。
我多想再听到那悦耳的吴侬软语,但车轮在铁轨上滚过时隆隆作响,加上车厢里人声嘈杂,我的座位又离她太远,我只能看到她嘴唇的翕动,却听不清一个字音。
她的眼光有好几次扫射到我这个方向,随即又移向他处,好像没注意到我的存在,好象看到的是一个陌生人。她视线的移动似乎是无意识的,但不管怎样,她总应能看见我坐在这里吧,可是她却。
我们早已劳燕分飞,我知道这是迫不得已。我不怪她,反而为自己给她带来的麻烦而自责。但即使旧缘已断,如今旅途邂逅,也用不着“觑得人如无物”,见面也不相认。她可不是绝情的人。实在不想见到我了,满可以换个座位,或者干脆起身走到别的车厢去。这个女子的行止,确实不像她的为人。
假如说不是她吧,又何其相似乃尔,容貌、服饰都不爽累黍。
我想找个机会移坐到她那边的座位上去,这样不但可以就近观察她,还可以找机会与她攀谈。遗憾的是她那边的座位一直不曾空出来。我只能从远处悄悄地注视着她。
这到底是不是她呢?我脑子里进行着不断否定之否定的思想活动。如果确实是她,怎么表现得这么冷漠,这与她热情的性格判若云泥。当年分襟,本来出于无奈,如今偶遇,即使难叙旧情,也不必形同陌路;如果说不是她吧,为什么姿容、装扮都与当年一样?
如果真的是她,我要不要陪她回姑苏呢?
我靠在椅背上,不住地胡思乱想。列车车轮在钢轨上滚动,发出轰隆轰隆的声音和有节奏的颠动,如同催眠曲一样,我竟不知不觉地昏昏进入梦乡。
和煦的春风吹拂着岸边的垂柳。我轻轻地把木桨划过水面,一面望着她泛着幸福的脸庞。湖面上飘荡着叶叶小舟。远远一条船上传来悠扬的手风琴的声音,伴着几副年轻嗓子的歌声。他们唱的是《莫斯科郊外的晚上》,那时多少优美的苏联歌曲在青年学生中间传唱……
火车突然一震,原来是靠站了。我惊醒过来,习惯地用惺忪的睡眼望望窗外,看看有什么可买的土特产。站台上,站牌分明写着:“薛城”。这个站不算大,我知道这儿有一条重要的支线,所以上下车的旅客也比较多。我忽然发现往出站口走去的十多个人中有一件浅紫色的衣服。
我往过道那边的座位瞧。她的座位是空的,衣帽钩上也没有她的手提包。我一下子完全清醒过来了。没有时间考虑了。我猛地站起身来,一把从窗口上方的毛巾架上扽下我的毛巾。毛巾还没有干透,我顾不了许多,把它塞进挎包。再从行李架上拉下旅行包。
列车在这个站上只停两分钟,如果我不赶快一些,就下不去了。
我向车门跑去,刚刚踏上月台,就听见开车的铃声响了。站在车门口的列车员招呼还逗留在月台上的旅客立即回到车上。
五六个拎着、扛着大包小包的旅客向出站口走去,紫衣姑娘也在其中。我远远地跟在这个人群后面,一面想,她怎么会在这个地方下车呢?从没听她讲过这里有什么亲戚。她在旅途中只带了一个不大的手提包,从如此简单的行李来判断,她好像只是出趟短门办点事的。她会在这里安了家么?
出了车站就是一条大街。我猜这可能就是县城的主街了。我看看手表,已经五点多钟。一眼望去,街上见不到什么楼房。房舍虽显老旧,倒也整齐。
我在她身后五十多米处尾随着她。生怕她偶然转过身来看见我。在车厢里,她对我视而不见。可在县城里瞥见我在身后,会不会感到奇怪呢?
我不敢离她太近,又害怕把她丢失,只能小心翼翼地前进,尽量将身体隐在行道树后。街边种着的许多柳树、槐树,还夹杂着一些法国梧桐。我原来只知道法国梧桐在江南很多见,不知道这树种还能生长到这个纬度。
当下我躲躲闪闪地走走停停,不时偷眼瞧瞧街道两边的房屋和商铺。这些店铺与其他地方的店铺原也没有多大差别,只是我注意到有几家店铺的柜台上大书:新到花生。还有一家水果店,除了卖西瓜、香瓜,还摆着石榴。
行不到三百米,来到第一个十字路口。拐角处一个院门上方挂着一块大木匾,上面写着遒劲有力的“进士第”三个黑色大字,左侧竖写着“殿试第三等第十六名”,“朝试第三等第二十名”,“赐进士出身”等字样。木匾挂得高,有一些字看不准足。似乎是清道光年间的,这着实是有些年头了。这块匾表面的漆皮已有些剥落,从木门看来这宅第也一样年久失修了。因为怕失去紫衣姑娘的踪迹,我不敢在匾下久留。这时我与她的距离又增加到了十多米。我赶紧拔脚。
她穿过十字路口,再走完一条较短的街道,向右拐入横街。横街上冷清多了,行人稀稀朗朗。我不怕丢失她的踪迹,却更担心被她发现,每走到一棵行道树边都要停留一下。马路对过有两个颇大的院落相并着,院内各有一栋三层的楼房。院外墙上挂着县委和县政府的大牌子。
她没有发现跟踪的人,却与不多的几个行人打过招呼。因为距离较远,我听不到他们讲的话。又走到一个十字路口,穿过一条狭窄的街道。过马路不久,就是一个一个院门,从中走出一位中年妇女,似乎是要上街的样子。她大声与紫衣姑娘打招呼说:“好几天没见你。你出门了吧?”
紫衣姑娘也大声回答:“我舅舅病了,我去沧州看他。“
“你出去好多天了吧?“
“出去一个礼拜了。刚下车。你上街啊?”
我见到她以来,还是第一次听清她说的话。她说的完全是当地的方言,完全没有吴音的味道,她的音色我也完全是陌生的。
“你舅舅病好了?”
“我和我表姐轮流在医院照顾了好几天。现在他好多了,已经出院回家。用不着我了。”“那就好,你够累的了,快回家歇着吧!我上街买点东西。”
姑娘的音色非常好听,可惜我听着没有亲切感。
中年妇女朝商业街的方向走了。紫衣姑娘再向前走,进了第二个大院的门。
看来事情很明显了,紫衣姑娘显然是另一个人。但我既然走到这里,不搞得水落石出也不甘心。
街上一个人也没有。我小心翼翼地走向她进去的院子。
我在院门口朝里张望。院子很大,地面看不到一片落叶和碎屑。一个人也没有,那姑娘想必是进屋去了。院东、西、北三面各有一间平房,都镶着占了半面墙的玻璃窗。屋里的摆设从院子里就一目了然。
院子里靠东屋和西屋的窗前分别长着两株粗可合抱的乔木:一株是枣树,一株是石榴。两株树上都能看到累累的果实。此刻已近傍晚,要是大白天,院子里一定浓荫匝地,在这里歇息,一定是非常惬意的,这从摆在院内的两把椅子就可以推断出来。
我壮着胆子进了院子。没被人发现。我想,如果有人出来询问。我就找个托词说是问路,要找县政府办事的。
我刚进得院来,听见北屋响了一声,拉上了蓝色的窗帘,接着从窗帘遮不到的缝隙里透出柔和的电灯光。透过不厚的窗帘可以看到影影绰绰的人影。紫衣姑娘的剪影清晰可辨。
东、西两屋都空无一人。我站立的位置离东屋最近,便走到窗前朝里张望。对着玻璃窗的墙上挂着一幅张全家福的照片。我凑近窗前细看。长辈坐在前排,站在后排右侧的明明就是那位姑娘,其他人物我一个都没见过。
到了此时此刻,真相已经大白。紫衣姑娘与我心中的人儿毫不相干。
我没有勇气再停留下去,连忙溜出院门。
暮色更浓。街上依然阒无一人。我已无心在这个地方停留,重新走上来时的道路,向车站的方向走去。疏落的灯柱漠漠地站着街边,投下暗淡的光线。街两边的窗户,透出星星点点昏黄的亮光,回头一望,已经是万家灯火了。
我一边走,一边自己暗笑。我居然在一个陌生的市镇,盯梢一个素不相识的姑娘,如果今天这件事被人知道,他们会怎么想呢?会认为我荒唐吗?会怀疑我的居心吗?盯梢的结果,依然是找不回那久已失去的梦。可是我不得不这样做。如果我不随着她下车,如果我不跟着她进了她家的院子,那我就还会认为车上的姑娘的的确确就是我那个朝思暮想的人儿。如果火车停在薛镇时我还在黑甜乡,如果我来不及下车,如果这是个大都市而我竟然在人群中失去她的踪影,那么我整个假期都会过不好的,不,不止如此,火车上的邂逅我今生都会念念不忘,也许一辈子都为此过不好了。
现在也好,既然事情已经分晓,心中的疑团可以解开。细想起来,这姑娘与她,与当年的她,委实太相似了。惟其太过相似,反足以证明这不是她。无论生活条件怎样的好,无论一个人怎么善于保养,岁月也不会不留下一些痕迹,何况这年月谁没经历过雨雪风霜?
真相大白以后作这样的分析是容易的,但没有听到她的声音,没走进这个典型的北方小院,没见到她们的全家福照片以前,这样的结论是得不出的。
大街上的路灯全都开亮了,但因为数量不多,街上仍显得黑黢黢的。不多的几家餐馆也开始上座,只是食客寥寥。一家食品店的玻璃窗上分明写着出售花生、核桃、板栗、红枣、石榴,可是店员已经摆出打烊的样子。又途经进士第的门口,很想再细细欣赏一下那牌匾的书法,可惜光线过于昏暗,我只能匆匆走过。
我得走得再快一些,否则就赶不上今晚最后一趟在这个小车站上停靠的列车。果真那样,我就不得不这小镇上找地方过夜了。
笔细 - 小 窗 情 史 屏蔽留存
笔细 - 小 窗 情 史
屏蔽 ||
那是很久很久以前的事了,回想起来却宛如昨天发生的一样。一个人所学的知识,由于年深日久可能会忘得一干二净,往昔十分熟悉的脸庞也会随着岁月的流逝而变得模糊不清。可对这件事的记忆却注定要伴我终生。
那时我父亲还在人世,他体弱多病,工作地点离家又远,为了照顾他上班方便,我们不得不毅然放弃了居住了十多年的幽静舒适的淮海别墅,迁到平安弄这条陋巷来。这儿环境嘈杂,房屋设备又差,才搬过来的时候,父亲似乎总有一种对不起家人的感觉;不过我当时年轻力壮,又是应届高中毕业生,正忙着准备升学考试,对这儿的生活条件丝毫也不在意。
这是一幢旧式的二层楼石库门房子,楼上楼下住了好几户人家。每日晨昏一片声地喧嚣,小孩哭,大人喊,热闹非凡。公用的水龙头前更是人来人往,川流不息。整天,弄堂里叫卖声不绝于耳,我常常想,如果将这些行商小贩的营销艺术悉数收集起来,对研究民俗和商业会有很大的参考价值。我们一家四口,我姐姐前年到苏州工作,父母膝前只剩下我一个孩子。迁来之后,我父母住在西厢房,我的卧室则在亭子间里。亭子间其名甚雅,但却低矮狭窄,夏热冬凉。我们所住的宅子位于一排房屋的西端,我的亭子间除北墙有窗外还开有一扇西窗,室内光线极为充足。我们搬来时已入夏季,这段时间雨水又少,一到下午,烈日的西晒便透过西窗外的竹帘迳射进来,把这小房间烤得像蒸笼一般。我的书桌就摆在西窗下,下午温课时即使拉上布帘也不免要汗流浃背。床铺紧靠北窗,从北窗向下望去是一条狭窄的支弄,窄得只能容一辆自行车通过;抬头却望不到青天,一堵高墙挡住了视线。高墙上斜对我的窗口,大约高出一二尺的光景,也开有一扇小窗。我来了几日,可从未见那窗前出现过人影,入夜则发现那儿垂着翠绿色的布帘。我读书久了,感到疲倦,便靠在床上小憩,只要一抬眼就能瞥见那幅色调淡雅的窗帘,渐渐地我的还奇心被挑逗了起来。
室中人到底是个什么样儿的人物呢?也许是一个颟顸的老人,举步维艰,连踱到窗前也感费力;作兴是个可怜的病人,虚弱到终日偃卧在床,只好看天花板打发时光;要不然是个孜孜不倦的实干家,从清晨操劳到晚,直到眼皮再抬不起来,才匆匆回家,和衣睡下,连从窗口朝外望望的功夫都没有;再不然......
我每天这样胡思乱想几次,也悟不出个究竟。我大部分的时间和精力都被复习功课这个首要任务占去,仅仅于攻读疲乏,略事休息时,才往往不自觉地挨近北窗,痴痴地望着那神秘的窗口出神。
一天我突然产生一个奇想:要是我站到北窗外的窗台上,对过那房间的内容即可一览无余,那折磨我多时的谜不就马上解开了么?
这种做法也许是太唐突了些,但我每次躺到眠床上,这念头总是顽固地浮现出来,使我不得安宁。最后我终于下定决心,要把它付诸实现。
我觑着弄内无人,便小心翼翼地踏上那狭窄的稍稍向外倾斜的窗台,两手紧紧抓住窗框,探头向对面望去,小室的景物尽收眼底。
窗前也摆着一张小小的书桌,乌油油的桌面摊着几本大大小小的书籍,当窗的一本翻开着,书页上印了两幅插图,细节可看不真灼。书的夹缝里搁了一支红蓝铅笔,两端都削得非常尖细。既然零乱的桌面未加收拾,似乎刚才还有人在这儿读书,主人一会儿就要回来继续钻研。书桌的右前侧立着一面圆形的小镜子,镜子背面镶的是越剧影片《梁山伯与祝英台》中“楼台会”一折的剧照。这段缠绵悱恻的唱词早脍炙人口 ,连走街串巷卖花生糖的小贩在摆地摊时也要唱上几句,以广招徕。镜前一字儿排着高高矮矮几个小瓶:圆柱形的、扁平的、曲线形的,好象是什么化妆品之类。瓶边横着一角木梳,用得油光锃亮。一盏台灯放在书桌的左前侧,灯盏也是淡绿色的,灯座上镶着一个小小的相框,可容一张二寸的像片,想必是小室主人的写真了,可惜背向着我,看不到庐山真面目。桌后一把交椅,椅背上搭着两条浅红色的布带,无疑这是一只帆布书包,被桌面遮盖住了,只露出两条书包带。
一张眠床紧靠着书桌,铺上了红色大方格子的被单;印有荷花图案的枕巾上压着一本精装的小说,从封面上我辨出那是《简.爱》。一张从画报上剪下的图片钉在床边的粉墙上:四位身穿连衣裙的外国姑娘笑容满面,手挽手地向前迈步,这显然是从哪一期《苏联画报》里选出来的。小室也很狭窄,正对窗口的房门上贴着的《天鹅湖》剧照看得清清楚楚,正是乌兰诺娃扮演的奥杰塔。这些日子,影片《俄罗斯芭蕾舞大师》风靡一时。
四下里静悄悄的,弄堂里一个人也没有,我得以从容观察。由室中布置看来,小室的主人恐怕也是一个学生吧。
一个更为荒唐的念头闪电般掠过脑际:我只消纵身一跳,就可以轻而易举地达到那吸引人的场所。
我刚压抑下这疯狂的冲动,对室的门忽然“呀”的一声开开了,它的主人回来了。
进来的是一位穿着短袖白上衣、蓝短裙的女学生,她掩上门,发现我这副模样,圆圆的脸庞上先露出迷惑的神气,随后不禁莞尔一笑。没料到我的偷窥会被主人(而且是个女学生)撞见,我窘迫得无地自容,全身的血一起涌了上来,耳根都热辣辣的。我愣怔了一下,马上本能地退了回去。我迅速从窗台跳下,顺手把窗帘拉上。这一切都是在一两秒钟之内发生的。
我躺在床上,心里怦怦直跳。我竟像小偷一样让人当场作捉住!对适才的举动我后悔莫及。要是我满足了那无聊的好奇心后立即撤回来呢?其实从室中的布置我早该猜得出来,那是个青年女子的闺房......要是房间主人是个青年男子问题不就简单得多了吗?偏偏是个女子,还是个女学生,偏偏她那个时候回来......。怎么办呢?我无可奈何地用双手掩住脸,羞愧的泪珠从指缝间渗出来。
我失魂落魄地去吃晚饭,饭菜到了嘴里就犹如嚼蜡一般。母亲问我怎么了,我用头痛掩饰过去。她说现在离考期还有两三个月,切不可过于用功,搞垮了身体反而把事情弄糟,我只好诺诺连声。她连饭桌也不要我帮着收拾就让我回房休息去了。
一连几天我都没有勇气拉开北窗的窗帘,更没有胆量抬头望那窗户。那女学生会怎么想呢?她一准会认为我是一个不检点的轻狂少年,甚至是穿墙逾穴之徒!她一定要紧紧闭上窗扉,低低垂下布帘,以防我再去窥视。唉!想不到迁来未久便给人带来这么一个坏印象,今后的日子可怎么过呢?所造成的后果又如何挽回呢?
无论是销魂荡魄的狂喜,无论是撕心裂肺的悲伤,人世间任何激越的感情都会随着时光的流逝而变得淡漠。
又过了几天,那种压迫我的不安渐渐地消失得无影无踪,另一种截然不同的心情突然牢牢地控制着我。那剪得齐刷刷的短发,那炯炯有神的大眼睛,那颀长的眼睫毛,她忍俊不住时露出的洁白的牙齿......总是在我眼前转来转去。短短的一瞥竟然留下如此深刻的印象!我渴望再见到她。我要同她攀谈,同她结识。说实在的,站在自家的窗台上又有什么好奇怪的呢?谁家都不免要擦玻璃,要修理损坏了的窗户,也就是说需要爬上自家的窗台......。这纯粹是个人的私事,别人管不着的。我如果为此而不安,岂不是庸人自扰?
我嗖地拉开窗帘,房间里顿时明亮起来。我不住地往北窗外瞟上一眼,等待着,等待着她。她,终于在窗口出现了。我大着胆子直勾勾地看着她,甚至试图向她笑一笑,可是没有成功,也忘了应该说上一句什么话。
我到底找到机会同她说话。一天,我下课后参加团支部会议,回家已是薄暮暮时分。我走近平安弄斜对过的一家杂货铺,正待横穿马路时,那女学生从杂货铺里出来。她左手提着一只网袋,丁丁当当地几个瓶子在里面乱碰;右手拎着一只草篮,里头盛满大大小小的纸包。她刚跨过门坎,草篮一倾斜,一个粽子形的纸包便一骨碌滚落到人行道上。她想去拾,又不愿把手中的东西放在地上。正在为难之时,我连忙趋向前去把它拣起来,拍去浮土,放回草篮子里 。她低下头,又 嫣然一笑,那是感谢的一笑,这使我勇气百倍。
“我替你拿一样吧!”我伸出手去。
她没有拒绝,我便接过草篮。我们一前一后穿过了马路。
我努力寻找话题:“怎么买这么多东西?家里来人客了?”
她没吭声,只从眼角扫了我一眼,含笑点了点头。
她只让我送到她家的大门口,也没道谢便夺过草篮,迳直走进门去。我如释重负地跑了回去,晚饭时多吃了一碗。
后来我成了她小室的常客,当然不是从窗口进去,而是堂而皇之地从大门进去的。这是她的卧室兼书房。台灯座上的小照果然是她的近影,她在照相里穿的正好就是那天的穿白上衣。她笑容可掬,照得十分自然。这充满青春活力的像片,她洗了好多张,准备毕业后送给同学留念的。我向她要了一张,至今带在身边,虽然这像片因年久有些发黄,我还像保护眼睛一样珍藏着。她也多次到我的房间来过,由于慵懒我平日不大整理房间,桌上常常零乱不堪,有时被子也整天不叠,她看不惯,好几次亲自动手帮我把书籍文具码放整齐,打那以后我就养成了良好的卫生习惯。她勤快,又文静,我母亲也非常喜欢她,常常在我面前夸奖她:“你看看人家李慕安,心又细,手又勤,你该多向她学......”
不过这时,我们都无暇闲谈嬉戏。李慕安是申江女中的高三学生,也行将毕业。在这决定一生命运的关键时刻,我们都在准备参加一场紧张的角逐。我们相聚时经常默默无言地并坐在桌前温习,只是在讨论什么难题时才低声地交谈。一次,趁着同在窗前眺望,我悄悄问她对我们独特的初遇有什么感想,她说开始确实有点莫名其妙,过后便把这件事完全忘记了。一句话轻轻拈去我心头的重负。
青春!无限美好的青春!热情洋溢的青春!情窦初开的少男少女哪个没有伟大的理想?哪个不憧憬着幸福的未来?
常常有这样的事情:我独自闷在斗室之中连续伏案几小时,感到疲劳了,站起来舒展一下酸痛的腰肢,瞥见她也倚在窗前稍事休息,我们便相视一笑。一次,我还沉溺在书中的世界里,突然什么东西重重地打在我的后背,接着跌在地上。我抬起头,李慕安在她的窗口对我致以歉意,又忍不住掩口而笑。原来她要给我一只苹果,可我低头苦读,一动不动,她想把苹果扔到我的床上,可是掼偏了。我威胁地用手指点点她,俯身拾起滚到床下的苹果。那苹果红扑扑的,跟她本人一样鲜艳。我仔细地把它擦干净放在案头,可惜最后还是烂掉了。又有一次,她天女散花似的撒过来一把糖块,我舍不得吃,把它们藏在一只小铁盒里,到雨季糖块粘成一团。我把变了形的糖胶舔食,糖纸洗净晾干,小心地夹在书页里压平保存起来。
考试的一天终于到了。我们的考场一个在江湾,一个在南市。考试的那几天天色阴沉,不过倒没有了酷暑的燠热。
考期过后,我们才忐忑不安地“轻松”一下。我大着胆子挽着她的手爬上佘山,肩并肩地俯瞰锦绣般的大地。我们陶醉了。要知道,我们已不是小孩子了,我们是有选举权的大人了。
盼到了发榜的日子。我考上金陵大学文学院,慕安却名落孙山,她考得不错,本来满有信心的,可是志愿报得不得法,她报的专业招生人数本来就少,再好的成绩也白费了。她失望得哭了。我伴她坐到深夜,用想得出来的话语去安慰她。她是个坚强的姑娘,很快就摆脱了沮丧的情绪,表示要再接再厉,吸取经验教训,明年继续报考。
我们充分利用开学前余下的时间,尽量多地在一起厮磨。在送别的那一刻,她用那双深情的眼睛望着我。在这些日子里,我们互相说过多少蠢话啊!想起来脸上都会发烧。话说回来,哪个年轻人不曾有过这种经历呢?
我开始了新的生活方式,紧张,热烈,生动,朝气蓬勃。建立了新的友谊,却没有建立新的爱情。什么都比不上初恋的甜蜜,刚涉足人生的青年那种纯真、无邪的恋情,回味一下都是醉人的。慕安, 慕安,哪一个少女比得上你?哪怕她千娇百媚,哪怕她名门高第,我心中只容得下慕安一个人。
慕安没有完全兑现她的诺言。那时我们的祖国正是蒸蒸日上,各行各业都需要大批有生力量。我到金陵没几个月,一所为海关培养人才的专科学校在社会招生,慕安动了心,考了进去。她在信中告诉我这个信息,并请求我不要责怪她。 她说:“在哪个岗位上都是建设祖国”,又说她永远在等待着我。唉!慕安,你真是太多虑了,不管你从事什么职业,不管你穿上什么制服,你永远是我的心上人。
每隔半个月,她准时给我寄一封信。看得出,她的心情也迅速好起来,对未来的职业也很感兴趣。她喜欢摄影,一连寄来多张照片:在课堂里的、在海关的、便装的、穿制服的,一律楚楚动人。其中一幅她的半身像照得最好£ 她比以前更丰腴,更漂亮,焕发出青春的光芒。我把这像片放大了挂在床头,这样睡前见到的第一个人是她,醒来见到的第一个人也是她。后来虽然不得不把像片包好收藏起来,每到更深人静,总忍不住取出呆呆地看。当年我写下许多首小诗赞美她,纵然有些不免浅薄,但我至今对这些“少作”毫无懊悔之意。
我进校不久便在学生会办的杂志《金陵潮》担任编辑,这对我是一个极好的学习和锻炼机会。这份刊物主要由文学院学生负责,其他学院也有些热心的学生在编辑部工作,比如说副主编就是理学院的三年级学生。《金陵潮》是综合性杂志,刊载的文章多数短小精干,生动活泼,不但深受金陵大学学生的欢迎,外校的学生也很爱看。过了一学期,我就受命担任副刊“时代之光”的责任编辑。
等我放假回家,见过父母,丢下行囊,我的心便马上飞到她的身旁。她一准在大门口迎着我,亮晶晶的大眼睛闪着喜悦的火花。
离家不远有一座小小的公园,就建在江边。公园设计得十分紧凑,十分雅致,它早就成为我们相会的好场所。华灯初上的时分,我们常常在公园的假山下、花径上散步,更爱坐到绿树丛中、芳草地里的长椅上窃窃私语。慕安总爱紧紧地靠在我肩上,不知她用的什么化妆品,沁人心脾的阵阵幽香飘来,我深深地陶醉了,周围的世界对我们好象也不复存在了。我们有时默默无言地坐到夜深才慢慢地往会走,一路上仍不作声,我偷偷瞟她一眼,发现她也在瞧着我,我们于是相视而笑了。我也依然常到她的小室去。也许是受了我的影响,也许是为了让我高兴,她的案头摆了一本又一本的中国古典文学书籍。
我们可没有光沉溺在谈情说爱之中。摆在我们面前的是一条光明大道。我们要肩负重大的历史责任。全国青年建设社会主义积极分子代表大会刚刚开过,大会好象一座炽热的火炉,把全国青年人的血液烤得沸腾起来。青年的命运与祖国的前途是紧紧地联结在一起的。
谁料得到,百花盛开的春天居然会上冻?谁料得到,一平如镜的湖面下居然会藏着暗礁?
我那时太年轻,而且从小学、中学到大学向来一帆风顺,对人生道路的曲折坎坷毫无思想准备。随着经济的发展,我国的民主生活越来越活跃。那年,党号召全国人民帮助整风,我也和大多数青年一样积极投入运动。我一向办事认真,这时为校刊征集和撰写了大批稿件。在编辑部的努力下校刊办得更是有声有色。投稿十分踊跃,刊物上发表了许多针砭时弊,对学校工作提出积极建议的文章和漫画。不必讳言,并非每一件作品都十全十美,有些不免偏激,甚至有失实之处,但其动机,我敢断言,则都是善意的。不料形势急转直下,见所未见,闻所未闻的场景我得以躬逢其盛。有关当局采取了非常卑劣的手段,从未参加过编辑工作、没好好读过校刊的人被组织起来,按事先拟好的调子对完全不认识的人进行“批判”。编辑部被一网打尽,一顶吓人的大帽子如泰山压顶一般压得我们再也透不过气来。突如其来的灾难令我目瞪口呆,不知所措。一开始我曾据理力辨,但马上发现这是徒劳的。不过我还算头脑清楚。批判会后我冷静地分析了形势,我注意到每个班级、每个教研室,党员中、团员中、非党团员中各有多少人划为右派,这是有一定比例的,我正好处于这比例之内,如果不批判我,那就必须抓另一个倒霉鬼顶我的数,所以我是在劫难逃。认识到这严酷的现实,在以后的批判会上我索性一言不发,这给那些无情打击我们的人造成一个“认识错误”的印象,其实他们大错了,我没有错,怎么会认识错误呢?我心中装着对这一切事件,对制造这一切事件的人的憎恨。最后我受到“开除团籍、留校察看”的处分。对这一切,不论是无据的指责,人格上的侮辱,我倒能挺得住,可我父亲得到这个凶信,竟一病不起,很快与世长辞。我未能亲观启足,也不曾回家奔丧。也许本来他的寿数已尽,但他在这当口猝然逝世,叫人不能不把这与政治运动联系起来。对父亲的逝世我总有一种负罪感,而这种内疚的心情将持续一生。母亲悲痛之余,把房门一锁,到苏州投奔我姐姐去了。
任凭鳞稀雁绝,慕安还是很快获悉真情。想象得出她会是怎样的伤心。她真是个坚强的姑娘。她给我寄来一封长信,信中说,她不相信我会做出什么错事,肯定是他们搞错了。她说,她永远站在我这一边,无论发生什么事情她都要等着我,就算漂流到天涯海角也在所不惜。她劝我千万不要气馁,问我为什么不回家看看?来吧, 她说,她将同以往一样欢迎我,和我一起到“我们的角落”去谈心。她要请我到老城隍庙吃我爱吃的南翔馒头。别人爱怎么说就怎么说吧,她不在乎。在“批判会”上,我是够镇定的,面对着攻击、谩骂、诬陷不实之词我都默默地忍受了,读着这封信我竟哭得像小孩子一样。我不得不使劲咬紧嘴唇,拉过被子把头蒙上。这封信我读了又读,能一字不易地背得出来。她火一般的热情温暖着我受伤的心。可是我已暗暗下定决心,在今后的人生道路上踽踽独行,还要出现什么打击和挫折我将自己承受,无需他人来看分担。慕安是个好姑娘,为什么要让她因我受连累?我现在的处境已经让她难过了,我不该影响她的前途,海关工作人员的社会关系是要受审查的。况且,又跟她说什么呢?解释吗?分辨吗?批评那些指责我的人吗?作检讨吗?她接连来过几封信,我狠狠心一概没有作覆,后来就断了音讯。这可算是我平生所犯的最大的错误,为此我付出了沉重的代价,日后思想起来总是悔恨不已。
我咬紧牙关,逆来顺受,苦熬过了最艰难的岁月。我坚信,我做得对,我没有错,而说我有错的人早晚有一天要承认正是他们自己犯了错误。没有这个坚定的信念,我早就了此残生。我从此变得沉默寡言,只潜心于学业,顽强地锻炼着自己的意志和体格。我相信,所学的知识总有一天会发挥它应有的作用。
我终于修完学业,并得到一个卑微的职位。我孜孜不倦地工作着,学习着 ,我的成绩也得到人们的认可,我不满足,我知道其实我可以取得更大的成绩的。我年纪轻轻,已阅尽世态炎凉。我也结交了几个新朋友,他们和我一样命运坎坷,大家见了面总有“同是天涯沦落人,相逢何必曾相识”之感。从他们和其他人的遭际中我学到了、懂得了许多。我也时时感到一种难以摆脱的抑郁,生怕我会就这样走到人生的尽头,生怕历史上这荒唐一幕的真相会从此湮没。我忍不住偷偷拿起笔将所见、所闻、所历的事情记载下来,心想即使今生这些材料再也不能得见天日,我也要将它们藏之名山,传之其人。我常常想,就算我这次蒙混了过去,恐怕我也会这么做的。个人的恩怨算不了什么,问题是一次又 一次残酷的政治运动,伤害的是自己人中的精英,这些人本来可以为祖国建设作出更大的贡献的,可现在他们含冤负屈,备受折磨,有些人甚至因此命丧黄泉。我希望能用自己的作品将真相告诉人们,希望人们认识到不能再让这样的人间悲剧出现。
多少个寂寥的夜晚,旧事执拗地涌上心头,使我久久不能成寐。我在人前从不轻弹珠泪,但在独处时也愿意放松一下自己的紧张的神经,用被子蒙住脸,让泪水痛痛快快地涌出来,这样心情可以暂时平静片刻。我心上有一处严重的创伤,勉强合上口,只需轻轻一戳就会淌出血来。
好几年过去了,受到一种难以抑制的强烈欲望的驱使,我束装踏上归途,回到久别的故乡。母亲几年来一直在阊门居住,从未回去过;姐姐仍像从前一样疼爱我,怜惜我。我却一共没到那儿去过几次,我实在不愿过于打搅他们。至于我生于斯长于斯的江城,许久以来只在梦中魂游过。栉比鳞次的房舍、车水马龙的长街、熙熙攘攘的百货商店、令人目迷神眩的夜景、昔日亲密的侣伴......这一切,这一切我又将重见。但只怕,只怕已经物是人非了。
火车于黎明时分到达。整个城市笼罩在雾霭里,透着一种朦胧的美。人潮将我推出站口。踏上熟悉的街道,重睹无限亲切的景物,热泪不由夺眶而出。我刚用绢头拭去泪水,眼前又马上变得模糊起来。
看来周围的一切还都跟原来一模一样。横竖路不很远,我没有坐车,索性一步一步走回去,两腿却千斤般地沉重。唐人诗云:“近乡情更怯,不敢问来人。”个中意境,我今天才算领悟到了。
又经过东方大楼,经过那座大自鸣钟。我以前上学途中不知望过几千次,如今它还立在这儿,忠实地报告时间。我的心跳得这样厉害,气都快喘不上来。我扶着墙,几乎没勇气往前挪动了。
我鼓起余勇,走进已从睡梦中醒来的弄堂,弄堂里人来人往,尽是些陌生的面孔。我一口气奔上因年久失修而吱吱作响的木制楼梯,哆哆嗦嗦地拧开发涩的门锁,一股霉味从长期遭人弃置的房间里冲了出来。我赶紧推开紧闭的长窗,放进凉爽清新的空气,光线和嘈杂的声音一起涌进来,使这儿也像个有人居住的地方,房门刚打开时那种阴郁的气氛总算一扫而空。
打扫经年的灰尘足足用去我半天的功夫。这就是我动身去读书以前的那个家么?我记忆中的家还从来没这么凄凉冷清过。这就是母亲离开前的样子么?父亲的遗物仍在,我不忍去动它们。我在楼里连一张熟悉的面孔都没遇到,谁也没问我是什么人。我与不相识的邻居拥挤在一排公用的水龙头前接水洗脸时,隐隐约约听见有人在说什么李家的女儿要结婚了。李家,哪个李家?听到这对我十分敏感的词儿我想问又不敢问,也不知怎么问。可等我洗完,水池边只剩下我一个人了。我决定仍住在亭子间里。就着从老虎灶冲来的开水吃了一只面包,我躺在新换上的床单上休息。对过那扇小窗后仍挂着窗帘,只是换成粉红色的了。新住户是什么人呢?慕安,你又在哪里呢?这些疑问在我脑海里翻腾,我躺下又坐起来。我渴望得到答案,又无从打听,也许还是什么也不打听,什么也不知道的好......疑虑使我焦躁不安,精神和体力的紧张使我筋疲力尽,我终于昏昏入睡。
西斜的阳光并未失去灼人的威力,将我从沉眠中晒醒。我略略挪了挪动身体,阳光却又跟了过来。睡意一下子消失得干干净净,对室里传来一阵笑语声。我陡地坐起来,那窗边出现一个不相识的年轻男子,他漫不经心地瞥了我一眼,弹了弹烟灰,转身离开窗户。我正讶于新邻居的出现,对过又出现一个女子的身影,她凭窗向外张望。是她!就是她!尽管她烫了发,尽管她换穿了旗袍,尽管岁月留下了痕迹,她的轮廓却是不会变的。这盼望已久却又意外的相见反使我手足无措,我只顾怔怔地呆视着她。她分明也认出了我,嘴唇微微动了几下,没有出声。等我定过神来,她已经从窗前消失。
事情完全清楚了,事情完全清楚了。世界上的事情是多么奇怪:当你不了解真相的时候,至少你还存在有希望,可你一个劲儿地探究它的底蕴,好让希望像肥皂泡一样破灭......
粉红色的窗帘已经拉上。那里曾有过我的幸福,是我亲手把它埋葬了。夜幕低垂,我辗转反侧久久不能成寐。好容易合上眼,各式各样的恶梦又轮番骚扰我。后半夜感到头痛欲裂,起床找到一片阿斯匹林服了下去,出了一身透汗。
东方透出鱼肚白色,我一早就醒来。一整天在城市里乱转,寻觅着旧日的足迹,把那无忧无虑的年华里的旧梦重温了一下。
我来到江滨公园,在花木蓊郁的小径上徘徊了许久。到处都有她的影子 ,到处都有她的声音,可都虚无飘渺,捉摸不住。我在绿叶掩映中找到那条长椅,我们曾在那上面度过多少个黄昏。它还放在那儿,经过风吹雨打,变得旧了些,破了些,油漆剥落了,板条开裂了,铁架子生锈了。它是我们纯洁爱情的见证人,又曾给多少情侣服务过,人间的悲欢它一定司空见惯。我在长椅上坐下,它低低地呻吟了几声。啊,我又回到老地方,一个人回到老地方。我一生只做错过一件事,其后果是严重的,我必须为此忍受生活的报复和打击。当年的冤屈也无情地打击了我,但冤屈,我相信,有朝一日总会昭雪,而错误抉择的后果无可挽回,我将因此遗恨终身。
我陷入沉思。什么人挨近我身边坐下来。我微微抬起头,是她!我惊喜交集,目不转睛地凝视着她。是的,在这儿, 在“我们的角落”, 我可以肆无忌殚地盯着她看。她,还是那样。虽然生活的磨炼终究刻下一些印痕,她更大方,更稳重,更成熟,眼光也更深沉,脱略了羞涩和稚气。她的脸色显得有些苍白,眼泡也有些浮肿。我们无言地对视了好一会。我忍不住轻轻抓起她的手,这双手还是那么柔软,那么纤细,在这盛暑季节里 ,却是冷冰冰的。
“你太狠心了!”还是她首先打破沉默,眼泪像断线的珍珠一样沿着她的面颊滚落下来。
“你......你怎么知道我会在这儿?” 我问。
“我看你不在房里,我想你一定出门去了,最后你准会到这儿来。我没有猜错。我认识你也不是一天两天了。过去,你一举手,我能知道你想做什么;你一开口,我能猜到你打算说什么。只有一回,我可没有猜对......”
我低下头,躲避她的眼光。
她又问:“你收到我给你的信吗?”
我点点头。
“你收到了信,那你为什么不回信呢?”她的声音颤抖着,“好几年了,你不理我,连家也不回了......”
“我......,我那时不知道该怎么办了,你知道,我那时处境实在太恶劣了。我前途茫茫,我怕给你带来麻烦......”
"你还说是为我好。你这样做可害得我好苦。我一直揪着心,不知道你到底发生了什么事。你父亲故去以后,你母亲又很快离开了。想打听你的消息,连个可问的人也没有,我心里的苦闷,也没有地方可说去。我俩的交情可不是一天半天了,我们之间还有什么不能说的话?我就不相信你会做什么错事,你就这么不相信我?你连我都不理了......你可以想象得到,周围环境对我的压力有多大!这些我都能顶得住,你不理睬我,好象我不存在,好象我是个不相干的陌生人,我受不了,我受不了......你太伤我的心了。你真是无情无义,你呀,你呀,你好狠心......”
她一口气数落我,说着说着再也说不下去了。她泪如泉涌,咬紧银牙,两只捏紧的拳头雨点似地在我身上乱捶。
“是我不好,都是我不好,是我害的你。”我说:“你打我吧,你骂我吧。你痛痛快快出了这口气吧,这样我还能好受些。”
慕安反而平静了下来,她松开拳头,用手背去擦鼻涕。接着她用手抚摸我的肩背,叹了一口气说:“不,不,我打痛了你没有?我知道,你也是不得已,你也很痛苦。可你也该给我一个信儿啊。我等你的消息多少年了,我等啊,等啊,盼啊,盼啊,老对自己说,也许今天就有消息了,也许明天你就回来了,一点事也没有了。可始终一点消息都没有。这些年我是怎么过来的......你想过没想过?”
泪水又涌出她的眼眶。这双眼睛,一向多么明亮,多么精神,现在充盈着泪水,显得暗淡无光。
“这都是我不好,都是我的过错。是我辜负了你,我对不起你。你理解我,同情我,我却伤你的心。我现在后悔都来不及了。我当时心情恶劣极了,我以为自己已经活不下去了,想给你写信又不知道说什么好。这样一拖再拖就更没有勇气拿起笔了。时间越长,越没有勇气。我都以为今生今世是见不到你的了。一想到这点,心里就难过极了。我丢失的是什么呀,是无价之宝呀。我把无价之宝丢了。其实这些年来,我那一天不想念你。我也常常梦见你。你给我的东西,那怕只是一片纸,对我都成了宝物。我失去了你,我现在后悔也来不及了......”
慕安伏在我的肩上泣不成声。从前她受了委屈,无论是受了别人的欺负,还是我得罪了她,她往往就是这样的。要是在从前,我会搂住她的双肩,抚摸她乌黑的秀发,把嘴唇贴近她的耳边安慰她。可现在我不能,我不能......我只能掏出自己的绢头放进她的手中。这方手帕不一会便湿透了。
慕安抽抽噎噎地说:“我不怪你,我不怪你。命运对你太不公平了。打击太大了,太残酷了,你怎么能挺过来的?多少次我想得非常可怕,想到你......我只要一想都害怕得发抖。好几年了,我不知道这几年你是怎么熬过来的,你可知道我是怎么过的?我已经完全绝望了,以为你不会回来了,以为永远见不到你了,我正要......你却回来了,我们又见面了,你叫我怎么办呢?......”
她把阑干满面的泪水都揩在我的衣服上。
“这样不是很好吗?”我努力使自己镇静下来,“这次能见到你,我也了了多年的宿愿。我曾经让你伤过心,现在看到你有一个很好的归宿,我的心也得到一丝慰籍。如果没有这场劫难,兴许我们会像柴米夫妻一样吵吵闹闹地过日子。不会吗?是的,也许不会。不过,还是像好朋友那样对待我吧。让我们像同胞手足一样相亲相爱吧。我在最困难的时刻,只要念及人间有一个女子,她理解我,同情我,我就充满了信心和力量,就有了生活下去的勇气。让我们就这样生活下去吧。”
“你......你还是一个人过吗?”
“是的。”
“你这样过太苦了。”一丝江风吹来,她往我身上靠得更紧了些。
“这些年来,我一直从早忙到晚,连痛苦的时间都没有。你好记得我从前给你讲过的辛词吗?辛弃疾是这么写的:‘要愁哪得功夫’。他说得多好啊。我也没有功夫发愁。我从工作和学习中得到无穷的乐趣。困难没压垮我,也没把我磨得光滑。我没有颓废,我也不死心。我还在盼望着有一天能真正为自己的国家和人民做点事情。”
太阳已落到地平线下。一抹殷红的晚霞映在天边。小树丛后传来沙沙的脚步声。慕安停止了啜泣,仍靠在我的胸前。我想让人看见了不好,于是轻轻地将她扶坐起来。我就势仔细端详着她的脸。这张脸,许多人见了或许会无动于衷,对我却是那么亲切,那么动人,我自己错过了机会,今生已无由亲近。一时间,后悔、羡慕,嫉妒、惭愧、失望种种复杂的心理交织在一起,咬噬着我的心。忽然,我再也控制不住自己的感情了,便用颤巍巍的双手捧起她泛红的脸颊,把我干涩的嘴唇端端正正地贴上他红润的、热辣辣的樱唇。我自己都被这放放肆的举动惊住了。我的心几乎从咽喉里跳出来。我清清楚楚地知道:我吻她,这是平生第一次,也是最后一次了。_
那时我父亲还在人世,他体弱多病,工作地点离家又远,为了照顾他上班方便,我们不得不毅然放弃了居住了十多年的幽静舒适的淮海别墅,迁到平安弄这条陋巷来。这儿环境嘈杂,房屋设备又差,才搬过来的时候,父亲似乎总有一种对不起家人的感觉;不过我当时年轻力壮,又是应届高中毕业生,正忙着准备升学考试,对这儿的生活条件丝毫也不在意。
这是一幢旧式的二层楼石库门房子,楼上楼下住了好几户人家。每日晨昏一片声地喧嚣,小孩哭,大人喊,热闹非凡。公用的水龙头前更是人来人往,川流不息。整天,弄堂里叫卖声不绝于耳,我常常想,如果将这些行商小贩的营销艺术悉数收集起来,对研究民俗和商业会有很大的参考价值。我们一家四口,我姐姐前年到苏州工作,父母膝前只剩下我一个孩子。迁来之后,我父母住在西厢房,我的卧室则在亭子间里。亭子间其名甚雅,但却低矮狭窄,夏热冬凉。我们所住的宅子位于一排房屋的西端,我的亭子间除北墙有窗外还开有一扇西窗,室内光线极为充足。我们搬来时已入夏季,这段时间雨水又少,一到下午,烈日的西晒便透过西窗外的竹帘迳射进来,把这小房间烤得像蒸笼一般。我的书桌就摆在西窗下,下午温课时即使拉上布帘也不免要汗流浃背。床铺紧靠北窗,从北窗向下望去是一条狭窄的支弄,窄得只能容一辆自行车通过;抬头却望不到青天,一堵高墙挡住了视线。高墙上斜对我的窗口,大约高出一二尺的光景,也开有一扇小窗。我来了几日,可从未见那窗前出现过人影,入夜则发现那儿垂着翠绿色的布帘。我读书久了,感到疲倦,便靠在床上小憩,只要一抬眼就能瞥见那幅色调淡雅的窗帘,渐渐地我的还奇心被挑逗了起来。
室中人到底是个什么样儿的人物呢?也许是一个颟顸的老人,举步维艰,连踱到窗前也感费力;作兴是个可怜的病人,虚弱到终日偃卧在床,只好看天花板打发时光;要不然是个孜孜不倦的实干家,从清晨操劳到晚,直到眼皮再抬不起来,才匆匆回家,和衣睡下,连从窗口朝外望望的功夫都没有;再不然......
我每天这样胡思乱想几次,也悟不出个究竟。我大部分的时间和精力都被复习功课这个首要任务占去,仅仅于攻读疲乏,略事休息时,才往往不自觉地挨近北窗,痴痴地望着那神秘的窗口出神。
一天我突然产生一个奇想:要是我站到北窗外的窗台上,对过那房间的内容即可一览无余,那折磨我多时的谜不就马上解开了么?
这种做法也许是太唐突了些,但我每次躺到眠床上,这念头总是顽固地浮现出来,使我不得安宁。最后我终于下定决心,要把它付诸实现。
我觑着弄内无人,便小心翼翼地踏上那狭窄的稍稍向外倾斜的窗台,两手紧紧抓住窗框,探头向对面望去,小室的景物尽收眼底。
窗前也摆着一张小小的书桌,乌油油的桌面摊着几本大大小小的书籍,当窗的一本翻开着,书页上印了两幅插图,细节可看不真灼。书的夹缝里搁了一支红蓝铅笔,两端都削得非常尖细。既然零乱的桌面未加收拾,似乎刚才还有人在这儿读书,主人一会儿就要回来继续钻研。书桌的右前侧立着一面圆形的小镜子,镜子背面镶的是越剧影片《梁山伯与祝英台》中“楼台会”一折的剧照。这段缠绵悱恻的唱词早脍炙人口 ,连走街串巷卖花生糖的小贩在摆地摊时也要唱上几句,以广招徕。镜前一字儿排着高高矮矮几个小瓶:圆柱形的、扁平的、曲线形的,好象是什么化妆品之类。瓶边横着一角木梳,用得油光锃亮。一盏台灯放在书桌的左前侧,灯盏也是淡绿色的,灯座上镶着一个小小的相框,可容一张二寸的像片,想必是小室主人的写真了,可惜背向着我,看不到庐山真面目。桌后一把交椅,椅背上搭着两条浅红色的布带,无疑这是一只帆布书包,被桌面遮盖住了,只露出两条书包带。
一张眠床紧靠着书桌,铺上了红色大方格子的被单;印有荷花图案的枕巾上压着一本精装的小说,从封面上我辨出那是《简.爱》。一张从画报上剪下的图片钉在床边的粉墙上:四位身穿连衣裙的外国姑娘笑容满面,手挽手地向前迈步,这显然是从哪一期《苏联画报》里选出来的。小室也很狭窄,正对窗口的房门上贴着的《天鹅湖》剧照看得清清楚楚,正是乌兰诺娃扮演的奥杰塔。这些日子,影片《俄罗斯芭蕾舞大师》风靡一时。
四下里静悄悄的,弄堂里一个人也没有,我得以从容观察。由室中布置看来,小室的主人恐怕也是一个学生吧。
一个更为荒唐的念头闪电般掠过脑际:我只消纵身一跳,就可以轻而易举地达到那吸引人的场所。
我刚压抑下这疯狂的冲动,对室的门忽然“呀”的一声开开了,它的主人回来了。
进来的是一位穿着短袖白上衣、蓝短裙的女学生,她掩上门,发现我这副模样,圆圆的脸庞上先露出迷惑的神气,随后不禁莞尔一笑。没料到我的偷窥会被主人(而且是个女学生)撞见,我窘迫得无地自容,全身的血一起涌了上来,耳根都热辣辣的。我愣怔了一下,马上本能地退了回去。我迅速从窗台跳下,顺手把窗帘拉上。这一切都是在一两秒钟之内发生的。
我躺在床上,心里怦怦直跳。我竟像小偷一样让人当场作捉住!对适才的举动我后悔莫及。要是我满足了那无聊的好奇心后立即撤回来呢?其实从室中的布置我早该猜得出来,那是个青年女子的闺房......要是房间主人是个青年男子问题不就简单得多了吗?偏偏是个女子,还是个女学生,偏偏她那个时候回来......。怎么办呢?我无可奈何地用双手掩住脸,羞愧的泪珠从指缝间渗出来。
我失魂落魄地去吃晚饭,饭菜到了嘴里就犹如嚼蜡一般。母亲问我怎么了,我用头痛掩饰过去。她说现在离考期还有两三个月,切不可过于用功,搞垮了身体反而把事情弄糟,我只好诺诺连声。她连饭桌也不要我帮着收拾就让我回房休息去了。
一连几天我都没有勇气拉开北窗的窗帘,更没有胆量抬头望那窗户。那女学生会怎么想呢?她一准会认为我是一个不检点的轻狂少年,甚至是穿墙逾穴之徒!她一定要紧紧闭上窗扉,低低垂下布帘,以防我再去窥视。唉!想不到迁来未久便给人带来这么一个坏印象,今后的日子可怎么过呢?所造成的后果又如何挽回呢?
无论是销魂荡魄的狂喜,无论是撕心裂肺的悲伤,人世间任何激越的感情都会随着时光的流逝而变得淡漠。
又过了几天,那种压迫我的不安渐渐地消失得无影无踪,另一种截然不同的心情突然牢牢地控制着我。那剪得齐刷刷的短发,那炯炯有神的大眼睛,那颀长的眼睫毛,她忍俊不住时露出的洁白的牙齿......总是在我眼前转来转去。短短的一瞥竟然留下如此深刻的印象!我渴望再见到她。我要同她攀谈,同她结识。说实在的,站在自家的窗台上又有什么好奇怪的呢?谁家都不免要擦玻璃,要修理损坏了的窗户,也就是说需要爬上自家的窗台......。这纯粹是个人的私事,别人管不着的。我如果为此而不安,岂不是庸人自扰?
我嗖地拉开窗帘,房间里顿时明亮起来。我不住地往北窗外瞟上一眼,等待着,等待着她。她,终于在窗口出现了。我大着胆子直勾勾地看着她,甚至试图向她笑一笑,可是没有成功,也忘了应该说上一句什么话。
我到底找到机会同她说话。一天,我下课后参加团支部会议,回家已是薄暮暮时分。我走近平安弄斜对过的一家杂货铺,正待横穿马路时,那女学生从杂货铺里出来。她左手提着一只网袋,丁丁当当地几个瓶子在里面乱碰;右手拎着一只草篮,里头盛满大大小小的纸包。她刚跨过门坎,草篮一倾斜,一个粽子形的纸包便一骨碌滚落到人行道上。她想去拾,又不愿把手中的东西放在地上。正在为难之时,我连忙趋向前去把它拣起来,拍去浮土,放回草篮子里 。她低下头,又 嫣然一笑,那是感谢的一笑,这使我勇气百倍。
“我替你拿一样吧!”我伸出手去。
她没有拒绝,我便接过草篮。我们一前一后穿过了马路。
我努力寻找话题:“怎么买这么多东西?家里来人客了?”
她没吭声,只从眼角扫了我一眼,含笑点了点头。
她只让我送到她家的大门口,也没道谢便夺过草篮,迳直走进门去。我如释重负地跑了回去,晚饭时多吃了一碗。
后来我成了她小室的常客,当然不是从窗口进去,而是堂而皇之地从大门进去的。这是她的卧室兼书房。台灯座上的小照果然是她的近影,她在照相里穿的正好就是那天的穿白上衣。她笑容可掬,照得十分自然。这充满青春活力的像片,她洗了好多张,准备毕业后送给同学留念的。我向她要了一张,至今带在身边,虽然这像片因年久有些发黄,我还像保护眼睛一样珍藏着。她也多次到我的房间来过,由于慵懒我平日不大整理房间,桌上常常零乱不堪,有时被子也整天不叠,她看不惯,好几次亲自动手帮我把书籍文具码放整齐,打那以后我就养成了良好的卫生习惯。她勤快,又文静,我母亲也非常喜欢她,常常在我面前夸奖她:“你看看人家李慕安,心又细,手又勤,你该多向她学......”
不过这时,我们都无暇闲谈嬉戏。李慕安是申江女中的高三学生,也行将毕业。在这决定一生命运的关键时刻,我们都在准备参加一场紧张的角逐。我们相聚时经常默默无言地并坐在桌前温习,只是在讨论什么难题时才低声地交谈。一次,趁着同在窗前眺望,我悄悄问她对我们独特的初遇有什么感想,她说开始确实有点莫名其妙,过后便把这件事完全忘记了。一句话轻轻拈去我心头的重负。
青春!无限美好的青春!热情洋溢的青春!情窦初开的少男少女哪个没有伟大的理想?哪个不憧憬着幸福的未来?
常常有这样的事情:我独自闷在斗室之中连续伏案几小时,感到疲劳了,站起来舒展一下酸痛的腰肢,瞥见她也倚在窗前稍事休息,我们便相视一笑。一次,我还沉溺在书中的世界里,突然什么东西重重地打在我的后背,接着跌在地上。我抬起头,李慕安在她的窗口对我致以歉意,又忍不住掩口而笑。原来她要给我一只苹果,可我低头苦读,一动不动,她想把苹果扔到我的床上,可是掼偏了。我威胁地用手指点点她,俯身拾起滚到床下的苹果。那苹果红扑扑的,跟她本人一样鲜艳。我仔细地把它擦干净放在案头,可惜最后还是烂掉了。又有一次,她天女散花似的撒过来一把糖块,我舍不得吃,把它们藏在一只小铁盒里,到雨季糖块粘成一团。我把变了形的糖胶舔食,糖纸洗净晾干,小心地夹在书页里压平保存起来。
考试的一天终于到了。我们的考场一个在江湾,一个在南市。考试的那几天天色阴沉,不过倒没有了酷暑的燠热。
考期过后,我们才忐忑不安地“轻松”一下。我大着胆子挽着她的手爬上佘山,肩并肩地俯瞰锦绣般的大地。我们陶醉了。要知道,我们已不是小孩子了,我们是有选举权的大人了。
盼到了发榜的日子。我考上金陵大学文学院,慕安却名落孙山,她考得不错,本来满有信心的,可是志愿报得不得法,她报的专业招生人数本来就少,再好的成绩也白费了。她失望得哭了。我伴她坐到深夜,用想得出来的话语去安慰她。她是个坚强的姑娘,很快就摆脱了沮丧的情绪,表示要再接再厉,吸取经验教训,明年继续报考。
我们充分利用开学前余下的时间,尽量多地在一起厮磨。在送别的那一刻,她用那双深情的眼睛望着我。在这些日子里,我们互相说过多少蠢话啊!想起来脸上都会发烧。话说回来,哪个年轻人不曾有过这种经历呢?
我开始了新的生活方式,紧张,热烈,生动,朝气蓬勃。建立了新的友谊,却没有建立新的爱情。什么都比不上初恋的甜蜜,刚涉足人生的青年那种纯真、无邪的恋情,回味一下都是醉人的。慕安, 慕安,哪一个少女比得上你?哪怕她千娇百媚,哪怕她名门高第,我心中只容得下慕安一个人。
慕安没有完全兑现她的诺言。那时我们的祖国正是蒸蒸日上,各行各业都需要大批有生力量。我到金陵没几个月,一所为海关培养人才的专科学校在社会招生,慕安动了心,考了进去。她在信中告诉我这个信息,并请求我不要责怪她。 她说:“在哪个岗位上都是建设祖国”,又说她永远在等待着我。唉!慕安,你真是太多虑了,不管你从事什么职业,不管你穿上什么制服,你永远是我的心上人。
每隔半个月,她准时给我寄一封信。看得出,她的心情也迅速好起来,对未来的职业也很感兴趣。她喜欢摄影,一连寄来多张照片:在课堂里的、在海关的、便装的、穿制服的,一律楚楚动人。其中一幅她的半身像照得最好£ 她比以前更丰腴,更漂亮,焕发出青春的光芒。我把这像片放大了挂在床头,这样睡前见到的第一个人是她,醒来见到的第一个人也是她。后来虽然不得不把像片包好收藏起来,每到更深人静,总忍不住取出呆呆地看。当年我写下许多首小诗赞美她,纵然有些不免浅薄,但我至今对这些“少作”毫无懊悔之意。
我进校不久便在学生会办的杂志《金陵潮》担任编辑,这对我是一个极好的学习和锻炼机会。这份刊物主要由文学院学生负责,其他学院也有些热心的学生在编辑部工作,比如说副主编就是理学院的三年级学生。《金陵潮》是综合性杂志,刊载的文章多数短小精干,生动活泼,不但深受金陵大学学生的欢迎,外校的学生也很爱看。过了一学期,我就受命担任副刊“时代之光”的责任编辑。
等我放假回家,见过父母,丢下行囊,我的心便马上飞到她的身旁。她一准在大门口迎着我,亮晶晶的大眼睛闪着喜悦的火花。
离家不远有一座小小的公园,就建在江边。公园设计得十分紧凑,十分雅致,它早就成为我们相会的好场所。华灯初上的时分,我们常常在公园的假山下、花径上散步,更爱坐到绿树丛中、芳草地里的长椅上窃窃私语。慕安总爱紧紧地靠在我肩上,不知她用的什么化妆品,沁人心脾的阵阵幽香飘来,我深深地陶醉了,周围的世界对我们好象也不复存在了。我们有时默默无言地坐到夜深才慢慢地往会走,一路上仍不作声,我偷偷瞟她一眼,发现她也在瞧着我,我们于是相视而笑了。我也依然常到她的小室去。也许是受了我的影响,也许是为了让我高兴,她的案头摆了一本又一本的中国古典文学书籍。
我们可没有光沉溺在谈情说爱之中。摆在我们面前的是一条光明大道。我们要肩负重大的历史责任。全国青年建设社会主义积极分子代表大会刚刚开过,大会好象一座炽热的火炉,把全国青年人的血液烤得沸腾起来。青年的命运与祖国的前途是紧紧地联结在一起的。
谁料得到,百花盛开的春天居然会上冻?谁料得到,一平如镜的湖面下居然会藏着暗礁?
我那时太年轻,而且从小学、中学到大学向来一帆风顺,对人生道路的曲折坎坷毫无思想准备。随着经济的发展,我国的民主生活越来越活跃。那年,党号召全国人民帮助整风,我也和大多数青年一样积极投入运动。我一向办事认真,这时为校刊征集和撰写了大批稿件。在编辑部的努力下校刊办得更是有声有色。投稿十分踊跃,刊物上发表了许多针砭时弊,对学校工作提出积极建议的文章和漫画。不必讳言,并非每一件作品都十全十美,有些不免偏激,甚至有失实之处,但其动机,我敢断言,则都是善意的。不料形势急转直下,见所未见,闻所未闻的场景我得以躬逢其盛。有关当局采取了非常卑劣的手段,从未参加过编辑工作、没好好读过校刊的人被组织起来,按事先拟好的调子对完全不认识的人进行“批判”。编辑部被一网打尽,一顶吓人的大帽子如泰山压顶一般压得我们再也透不过气来。突如其来的灾难令我目瞪口呆,不知所措。一开始我曾据理力辨,但马上发现这是徒劳的。不过我还算头脑清楚。批判会后我冷静地分析了形势,我注意到每个班级、每个教研室,党员中、团员中、非党团员中各有多少人划为右派,这是有一定比例的,我正好处于这比例之内,如果不批判我,那就必须抓另一个倒霉鬼顶我的数,所以我是在劫难逃。认识到这严酷的现实,在以后的批判会上我索性一言不发,这给那些无情打击我们的人造成一个“认识错误”的印象,其实他们大错了,我没有错,怎么会认识错误呢?我心中装着对这一切事件,对制造这一切事件的人的憎恨。最后我受到“开除团籍、留校察看”的处分。对这一切,不论是无据的指责,人格上的侮辱,我倒能挺得住,可我父亲得到这个凶信,竟一病不起,很快与世长辞。我未能亲观启足,也不曾回家奔丧。也许本来他的寿数已尽,但他在这当口猝然逝世,叫人不能不把这与政治运动联系起来。对父亲的逝世我总有一种负罪感,而这种内疚的心情将持续一生。母亲悲痛之余,把房门一锁,到苏州投奔我姐姐去了。
任凭鳞稀雁绝,慕安还是很快获悉真情。想象得出她会是怎样的伤心。她真是个坚强的姑娘。她给我寄来一封长信,信中说,她不相信我会做出什么错事,肯定是他们搞错了。她说,她永远站在我这一边,无论发生什么事情她都要等着我,就算漂流到天涯海角也在所不惜。她劝我千万不要气馁,问我为什么不回家看看?来吧, 她说,她将同以往一样欢迎我,和我一起到“我们的角落”去谈心。她要请我到老城隍庙吃我爱吃的南翔馒头。别人爱怎么说就怎么说吧,她不在乎。在“批判会”上,我是够镇定的,面对着攻击、谩骂、诬陷不实之词我都默默地忍受了,读着这封信我竟哭得像小孩子一样。我不得不使劲咬紧嘴唇,拉过被子把头蒙上。这封信我读了又读,能一字不易地背得出来。她火一般的热情温暖着我受伤的心。可是我已暗暗下定决心,在今后的人生道路上踽踽独行,还要出现什么打击和挫折我将自己承受,无需他人来看分担。慕安是个好姑娘,为什么要让她因我受连累?我现在的处境已经让她难过了,我不该影响她的前途,海关工作人员的社会关系是要受审查的。况且,又跟她说什么呢?解释吗?分辨吗?批评那些指责我的人吗?作检讨吗?她接连来过几封信,我狠狠心一概没有作覆,后来就断了音讯。这可算是我平生所犯的最大的错误,为此我付出了沉重的代价,日后思想起来总是悔恨不已。
我咬紧牙关,逆来顺受,苦熬过了最艰难的岁月。我坚信,我做得对,我没有错,而说我有错的人早晚有一天要承认正是他们自己犯了错误。没有这个坚定的信念,我早就了此残生。我从此变得沉默寡言,只潜心于学业,顽强地锻炼着自己的意志和体格。我相信,所学的知识总有一天会发挥它应有的作用。
我终于修完学业,并得到一个卑微的职位。我孜孜不倦地工作着,学习着 ,我的成绩也得到人们的认可,我不满足,我知道其实我可以取得更大的成绩的。我年纪轻轻,已阅尽世态炎凉。我也结交了几个新朋友,他们和我一样命运坎坷,大家见了面总有“同是天涯沦落人,相逢何必曾相识”之感。从他们和其他人的遭际中我学到了、懂得了许多。我也时时感到一种难以摆脱的抑郁,生怕我会就这样走到人生的尽头,生怕历史上这荒唐一幕的真相会从此湮没。我忍不住偷偷拿起笔将所见、所闻、所历的事情记载下来,心想即使今生这些材料再也不能得见天日,我也要将它们藏之名山,传之其人。我常常想,就算我这次蒙混了过去,恐怕我也会这么做的。个人的恩怨算不了什么,问题是一次又 一次残酷的政治运动,伤害的是自己人中的精英,这些人本来可以为祖国建设作出更大的贡献的,可现在他们含冤负屈,备受折磨,有些人甚至因此命丧黄泉。我希望能用自己的作品将真相告诉人们,希望人们认识到不能再让这样的人间悲剧出现。
多少个寂寥的夜晚,旧事执拗地涌上心头,使我久久不能成寐。我在人前从不轻弹珠泪,但在独处时也愿意放松一下自己的紧张的神经,用被子蒙住脸,让泪水痛痛快快地涌出来,这样心情可以暂时平静片刻。我心上有一处严重的创伤,勉强合上口,只需轻轻一戳就会淌出血来。
好几年过去了,受到一种难以抑制的强烈欲望的驱使,我束装踏上归途,回到久别的故乡。母亲几年来一直在阊门居住,从未回去过;姐姐仍像从前一样疼爱我,怜惜我。我却一共没到那儿去过几次,我实在不愿过于打搅他们。至于我生于斯长于斯的江城,许久以来只在梦中魂游过。栉比鳞次的房舍、车水马龙的长街、熙熙攘攘的百货商店、令人目迷神眩的夜景、昔日亲密的侣伴......这一切,这一切我又将重见。但只怕,只怕已经物是人非了。
火车于黎明时分到达。整个城市笼罩在雾霭里,透着一种朦胧的美。人潮将我推出站口。踏上熟悉的街道,重睹无限亲切的景物,热泪不由夺眶而出。我刚用绢头拭去泪水,眼前又马上变得模糊起来。
看来周围的一切还都跟原来一模一样。横竖路不很远,我没有坐车,索性一步一步走回去,两腿却千斤般地沉重。唐人诗云:“近乡情更怯,不敢问来人。”个中意境,我今天才算领悟到了。
又经过东方大楼,经过那座大自鸣钟。我以前上学途中不知望过几千次,如今它还立在这儿,忠实地报告时间。我的心跳得这样厉害,气都快喘不上来。我扶着墙,几乎没勇气往前挪动了。
我鼓起余勇,走进已从睡梦中醒来的弄堂,弄堂里人来人往,尽是些陌生的面孔。我一口气奔上因年久失修而吱吱作响的木制楼梯,哆哆嗦嗦地拧开发涩的门锁,一股霉味从长期遭人弃置的房间里冲了出来。我赶紧推开紧闭的长窗,放进凉爽清新的空气,光线和嘈杂的声音一起涌进来,使这儿也像个有人居住的地方,房门刚打开时那种阴郁的气氛总算一扫而空。
打扫经年的灰尘足足用去我半天的功夫。这就是我动身去读书以前的那个家么?我记忆中的家还从来没这么凄凉冷清过。这就是母亲离开前的样子么?父亲的遗物仍在,我不忍去动它们。我在楼里连一张熟悉的面孔都没遇到,谁也没问我是什么人。我与不相识的邻居拥挤在一排公用的水龙头前接水洗脸时,隐隐约约听见有人在说什么李家的女儿要结婚了。李家,哪个李家?听到这对我十分敏感的词儿我想问又不敢问,也不知怎么问。可等我洗完,水池边只剩下我一个人了。我决定仍住在亭子间里。就着从老虎灶冲来的开水吃了一只面包,我躺在新换上的床单上休息。对过那扇小窗后仍挂着窗帘,只是换成粉红色的了。新住户是什么人呢?慕安,你又在哪里呢?这些疑问在我脑海里翻腾,我躺下又坐起来。我渴望得到答案,又无从打听,也许还是什么也不打听,什么也不知道的好......疑虑使我焦躁不安,精神和体力的紧张使我筋疲力尽,我终于昏昏入睡。
西斜的阳光并未失去灼人的威力,将我从沉眠中晒醒。我略略挪了挪动身体,阳光却又跟了过来。睡意一下子消失得干干净净,对室里传来一阵笑语声。我陡地坐起来,那窗边出现一个不相识的年轻男子,他漫不经心地瞥了我一眼,弹了弹烟灰,转身离开窗户。我正讶于新邻居的出现,对过又出现一个女子的身影,她凭窗向外张望。是她!就是她!尽管她烫了发,尽管她换穿了旗袍,尽管岁月留下了痕迹,她的轮廓却是不会变的。这盼望已久却又意外的相见反使我手足无措,我只顾怔怔地呆视着她。她分明也认出了我,嘴唇微微动了几下,没有出声。等我定过神来,她已经从窗前消失。
事情完全清楚了,事情完全清楚了。世界上的事情是多么奇怪:当你不了解真相的时候,至少你还存在有希望,可你一个劲儿地探究它的底蕴,好让希望像肥皂泡一样破灭......
粉红色的窗帘已经拉上。那里曾有过我的幸福,是我亲手把它埋葬了。夜幕低垂,我辗转反侧久久不能成寐。好容易合上眼,各式各样的恶梦又轮番骚扰我。后半夜感到头痛欲裂,起床找到一片阿斯匹林服了下去,出了一身透汗。
东方透出鱼肚白色,我一早就醒来。一整天在城市里乱转,寻觅着旧日的足迹,把那无忧无虑的年华里的旧梦重温了一下。
我来到江滨公园,在花木蓊郁的小径上徘徊了许久。到处都有她的影子 ,到处都有她的声音,可都虚无飘渺,捉摸不住。我在绿叶掩映中找到那条长椅,我们曾在那上面度过多少个黄昏。它还放在那儿,经过风吹雨打,变得旧了些,破了些,油漆剥落了,板条开裂了,铁架子生锈了。它是我们纯洁爱情的见证人,又曾给多少情侣服务过,人间的悲欢它一定司空见惯。我在长椅上坐下,它低低地呻吟了几声。啊,我又回到老地方,一个人回到老地方。我一生只做错过一件事,其后果是严重的,我必须为此忍受生活的报复和打击。当年的冤屈也无情地打击了我,但冤屈,我相信,有朝一日总会昭雪,而错误抉择的后果无可挽回,我将因此遗恨终身。
我陷入沉思。什么人挨近我身边坐下来。我微微抬起头,是她!我惊喜交集,目不转睛地凝视着她。是的,在这儿, 在“我们的角落”, 我可以肆无忌殚地盯着她看。她,还是那样。虽然生活的磨炼终究刻下一些印痕,她更大方,更稳重,更成熟,眼光也更深沉,脱略了羞涩和稚气。她的脸色显得有些苍白,眼泡也有些浮肿。我们无言地对视了好一会。我忍不住轻轻抓起她的手,这双手还是那么柔软,那么纤细,在这盛暑季节里 ,却是冷冰冰的。
“你太狠心了!”还是她首先打破沉默,眼泪像断线的珍珠一样沿着她的面颊滚落下来。
“你......你怎么知道我会在这儿?” 我问。
“我看你不在房里,我想你一定出门去了,最后你准会到这儿来。我没有猜错。我认识你也不是一天两天了。过去,你一举手,我能知道你想做什么;你一开口,我能猜到你打算说什么。只有一回,我可没有猜对......”
我低下头,躲避她的眼光。
她又问:“你收到我给你的信吗?”
我点点头。
“你收到了信,那你为什么不回信呢?”她的声音颤抖着,“好几年了,你不理我,连家也不回了......”
“我......,我那时不知道该怎么办了,你知道,我那时处境实在太恶劣了。我前途茫茫,我怕给你带来麻烦......”
"你还说是为我好。你这样做可害得我好苦。我一直揪着心,不知道你到底发生了什么事。你父亲故去以后,你母亲又很快离开了。想打听你的消息,连个可问的人也没有,我心里的苦闷,也没有地方可说去。我俩的交情可不是一天半天了,我们之间还有什么不能说的话?我就不相信你会做什么错事,你就这么不相信我?你连我都不理了......你可以想象得到,周围环境对我的压力有多大!这些我都能顶得住,你不理睬我,好象我不存在,好象我是个不相干的陌生人,我受不了,我受不了......你太伤我的心了。你真是无情无义,你呀,你呀,你好狠心......”
她一口气数落我,说着说着再也说不下去了。她泪如泉涌,咬紧银牙,两只捏紧的拳头雨点似地在我身上乱捶。
“是我不好,都是我不好,是我害的你。”我说:“你打我吧,你骂我吧。你痛痛快快出了这口气吧,这样我还能好受些。”
慕安反而平静了下来,她松开拳头,用手背去擦鼻涕。接着她用手抚摸我的肩背,叹了一口气说:“不,不,我打痛了你没有?我知道,你也是不得已,你也很痛苦。可你也该给我一个信儿啊。我等你的消息多少年了,我等啊,等啊,盼啊,盼啊,老对自己说,也许今天就有消息了,也许明天你就回来了,一点事也没有了。可始终一点消息都没有。这些年我是怎么过来的......你想过没想过?”
泪水又涌出她的眼眶。这双眼睛,一向多么明亮,多么精神,现在充盈着泪水,显得暗淡无光。
“这都是我不好,都是我的过错。是我辜负了你,我对不起你。你理解我,同情我,我却伤你的心。我现在后悔都来不及了。我当时心情恶劣极了,我以为自己已经活不下去了,想给你写信又不知道说什么好。这样一拖再拖就更没有勇气拿起笔了。时间越长,越没有勇气。我都以为今生今世是见不到你的了。一想到这点,心里就难过极了。我丢失的是什么呀,是无价之宝呀。我把无价之宝丢了。其实这些年来,我那一天不想念你。我也常常梦见你。你给我的东西,那怕只是一片纸,对我都成了宝物。我失去了你,我现在后悔也来不及了......”
慕安伏在我的肩上泣不成声。从前她受了委屈,无论是受了别人的欺负,还是我得罪了她,她往往就是这样的。要是在从前,我会搂住她的双肩,抚摸她乌黑的秀发,把嘴唇贴近她的耳边安慰她。可现在我不能,我不能......我只能掏出自己的绢头放进她的手中。这方手帕不一会便湿透了。
慕安抽抽噎噎地说:“我不怪你,我不怪你。命运对你太不公平了。打击太大了,太残酷了,你怎么能挺过来的?多少次我想得非常可怕,想到你......我只要一想都害怕得发抖。好几年了,我不知道这几年你是怎么熬过来的,你可知道我是怎么过的?我已经完全绝望了,以为你不会回来了,以为永远见不到你了,我正要......你却回来了,我们又见面了,你叫我怎么办呢?......”
她把阑干满面的泪水都揩在我的衣服上。
“这样不是很好吗?”我努力使自己镇静下来,“这次能见到你,我也了了多年的宿愿。我曾经让你伤过心,现在看到你有一个很好的归宿,我的心也得到一丝慰籍。如果没有这场劫难,兴许我们会像柴米夫妻一样吵吵闹闹地过日子。不会吗?是的,也许不会。不过,还是像好朋友那样对待我吧。让我们像同胞手足一样相亲相爱吧。我在最困难的时刻,只要念及人间有一个女子,她理解我,同情我,我就充满了信心和力量,就有了生活下去的勇气。让我们就这样生活下去吧。”
“你......你还是一个人过吗?”
“是的。”
“你这样过太苦了。”一丝江风吹来,她往我身上靠得更紧了些。
“这些年来,我一直从早忙到晚,连痛苦的时间都没有。你好记得我从前给你讲过的辛词吗?辛弃疾是这么写的:‘要愁哪得功夫’。他说得多好啊。我也没有功夫发愁。我从工作和学习中得到无穷的乐趣。困难没压垮我,也没把我磨得光滑。我没有颓废,我也不死心。我还在盼望着有一天能真正为自己的国家和人民做点事情。”
太阳已落到地平线下。一抹殷红的晚霞映在天边。小树丛后传来沙沙的脚步声。慕安停止了啜泣,仍靠在我的胸前。我想让人看见了不好,于是轻轻地将她扶坐起来。我就势仔细端详着她的脸。这张脸,许多人见了或许会无动于衷,对我却是那么亲切,那么动人,我自己错过了机会,今生已无由亲近。一时间,后悔、羡慕,嫉妒、惭愧、失望种种复杂的心理交织在一起,咬噬着我的心。忽然,我再也控制不住自己的感情了,便用颤巍巍的双手捧起她泛红的脸颊,把我干涩的嘴唇端端正正地贴上他红润的、热辣辣的樱唇。我自己都被这放放肆的举动惊住了。我的心几乎从咽喉里跳出来。我清清楚楚地知道:我吻她,这是平生第一次,也是最后一次了。_
《旧文翻新:澳洲之行散记》 屏蔽留存
《旧文翻新:澳洲之行散记》
屏蔽 |||
《朝华午拾:澳洲之行散记》
Posted by: 立委
Date: February 25, 2007 04:41AM
1995年,我在温哥华攻读博士期间,去澳大利亚开会。大会结束,我跟我同门师妹的父母联系上,她母亲开车接我到她家住了几天。师妹父母是澳洲农民,经营一家农场多年。退休时把农场卖了,到著名的旅游城黄金海岸(Gold Coast)买了一批房产,劳苦一辈子的农民摇身一变成为房东,从此过着地主(landlord)老财不劳而获的剥削阶级生活。两位年过七十的老人朴实爽朗,日子过得有条不紊,屋子也收拾得窗明几净,家里轻轻飘荡着音乐声,环境优雅而闲适。这是我见到的最令人羡慕的退休生活。老人对远道而来的我,非常客气,照顾有加,让我有宾至如归的感觉。他们白天放我出去自己游荡,让我尽兴玩,嘱咐我完累了,随时打电话给他们接回家去。


这是一个天堂一样美丽的城市,让人沉迷。到处是奇花异木,五彩的鹦鹉和各类水禽优哉游哉,如入无人之境。绿树成荫,街道整洁。沿海滩有很多造型别致的饭店,多由日本投资商兴建。据说这个充满了异国情调和金发丽人的澳洲城市,已经继夏威夷之后成为日本人海外度假的首选。



连续两天的下午,我光着膀子在数英里的海滩漫游, 不敢相信大自然能生产这样的美丽。北美的春天是澳洲的秋天,刚刚过了黄金海滩的避暑盛季。少了一份喧闹的海滩,更加别有情调。

有如 Bay Watch,抬眼望去,美不胜收。海滩上三三两两,有健硕的小伙子在冲浪,性感的少女在嬉戏,天真的小孩在堆古堡。


天边慢慢卷来一片乌云,遮住了刺目的阳光,海风呼啸,人渐稀落。有一个小女孩,有如自天而降的仙女,不疾不徐在暗淡下来的滩上溜狗,小狗在卷来的潮水里雀跃。几颗雨点下来,姑娘身影朦胧。阳光重现,欢笑声又起,而仙女与狗,却随风飘去。

雨后晴空,一望无垠的金色沙滩,仙润清新。见一金发女童,坐在色彩鲜艳的救生筏上,眺望海的尽头。


再向前,有一个轻灵活泼的teenager女孩,身着蓝色露脐泳装,身材绝美,在逗引她的两三岁的小弟弟兜着圈玩儿。

晚霞映照下,一对古铜色臂膀的青年男女,沿海滩慢跑。游览黄金海滩,仿佛天堂敞开了一扇窗口,空灵洗净,纤尘不染,祥云笼罩,仙女飘飘,怎不令我流连忘返。
晚上,老太太忙着给我们弄吃的,老头儿把我带到地下室,耐心教我打康乐球。他说,地下室的角落是他的office,摆放着一台电脑,他每月月底工作几天,在电脑上写写算算收租情况,照应一下租户的出出进进。平时的主要活动之一是打高尔夫球,参加一个local的俱乐部,非常投入。老太太主要在家料理家务,平时把自己修饰得极为体面,没周一次去老人院看望她90多岁已经话语不清的老妈。两位老人很愿意跟我唠家常,谈起当年闹兔子荒的故事。这个故事我以前给彭丽媛们讲授《New Concept English》时,在课本里面读过,老人则是亲历。说从欧洲来的早期移民把兔子带到澳洲大陆,没成想这澳洲没有兔子的天敌,而狡兔性欲旺盛,繁育能力特强。刹那间,兔子铺天盖地而来。老人跟我说,那真是恐怖,整个农场到处流窜着兔子,毒药火枪短兵全部用上,就是打不尽,杀不绝。
离开澳洲,从飞机上看新西兰,恰似一只人的耳朵,沿耳廓隐隐约约可以看到海滩、石壁和丛林。此前也已多次乘飞机跨洲旅行,但是每次乘飞机,从万米高空向下俯瞰,都令我诧异。耀眼的太阳,瞬息万变的云彩,玩具一样的房舍,蚂蚁般的车辆。总觉得不可思议。
这次澳洲之行,使我大饱眼福,真正领略到旅游的乐趣。美中不足的是在海滩游览时,皮肤被太阳灼伤。我在国内,向来不怕晒。插队那阵在炎热的暑期,从来都是图省事,只穿条短裤衩,光膀子暴晒,硬是晒脱了几层皮,成了地道的小黑鬼,比村子里多数人都黑。也怪,国内太阳不管怎么晒,没有紫外线灼伤的顾虑。倒是出国以后,习惯性以为太阳不可怕,根本想不起要涂防晒霜,几度灼伤。这次最为严重,晚上睡觉怎么也睡不着,后背火辣辣的,躺在那里,翻身都难,这才领教了太阳的厉害。回温哥华,领导查看,发现背部满是难看的黑点,吓坏了,以为得了皮肤癌,拿了油膏涂了一个多月,才慢慢好起来。
2007年二月二十五
http://blog.sciencenet.cn/blog-362400-887412.html
上一篇:微博:多米音乐,抗堵神器
下一篇:低温冷冻电镜的门道和方法学
1 王善勇
【旧文翻新:立委小传】 屏蔽留存
【旧文翻新:立委小传】
屏蔽 |||
人生苦短,掐首去尾,不过三五十载,可分三段:立业阶段(而立之年),成熟阶段(不惑之年)和下滑阶段(天命之年),反映在称呼上,叫小李、大李和老李。可怜,立委却从小李一跃到老李,没有机会品尝壮年人生的豪情,心尝有戚戚焉。

红小兵立委(1966)
自幼儿园至小学连跳两级,立委在班上始终最幼。更加荒年生人,孱弱矮小,体育课常告病假,或遭遣送回,始终是个小可怜儿。所幸中学伊始,正值“修正主义回潮”,先帝启用邓公收拾文革残局,邓公责成教育总管周荣鑫整顿教育,校风日新。乘此东风,立委崭露头角,以学习委员兼数学科代表之身,受班主任委派,每日早自习登台主讲,演示解题思路,俨然助教。然好景不长,先帝昏庸,文革派重居上风,学校大乱,文化课退居后台,大批判遂成主课,兼以学工学农学军。立委不能以文化课呈威,然风头不减反盛,盖因立委最长批判文字,历经批林、批孔、批邓,反击右倾翻案风,直至批四人帮。大会小会,凡立委发言,必抑扬顿挫,铿锵有力,佐以诙谐幽默,风靡校园,称颂于一时。有言,立委颇具鲁迅遗风,入木三分,且能推陈出新,妙语连珠。露天千人大会,常嘈杂狼藉,然立委登台,全场必静肃,洗耳恭听之,听至妙处,笑声一片。立委由此炼得糊涂胆大,从不怯场,终身受益。
及至大学,文革后首届,立委仍居尾,同学长一到十多岁不等。同学之间皆直呼其名,唯同桌七仙女戏称 “小立委”,不为亲热,却为避嫌,以示划清界限。同桌四载,楚河汉界,泾渭分明。授受不亲,避而远之。然仙女文具笔墨滑落在地,自有立委抢先一步,拾拣归案。类此者三,春风化雨,润物无声。七女天生聪颖,想出一招,以长立委一岁为由,呼 “小立委”,就此来往,当可名正言顺也。
由七仙女开此恶例,随后多年,“小”字即不离身。中学教书,人称小李老师(22岁)。上研究生,小李出入机房,蓬头垢面,且口中念念有词,言“世界之语”(Esperanto),终成笑谈(23-26岁)(见《朝华午拾:我的世界语国》)。

风华正茂,意气风发(1987)
及至毕业留所,立委事迹亦有流传:一见钟情,闪电结婚,不修边幅,撞南墙而道歉云(见

立委在中关村公司指导机器翻译系统的开发(1988)
立委如此这般在研究所及中关村公司一扎五年(26-31岁),练就一身绝技,与老中医相若,专事疗治电脑,驯其语言功能。其间,出国热持续升温,由上海蔓延北京,街头巷尾,言必议美日英澳,以致居委会大妈亦知考托福鸡阿姨乃上进青年之标杆。立委及其贴身领导却浑浑噩噩,卿卿我我,不知有汉,无论魏晋。其间送上门两次良机,留学德美,均因导师明阻暗挡,本人木呐,擦肩而过。直至身边同学悉数走尽,小李幡然醒悟,痛下决心,赶末班车。其时,适逢包玉刚基金会遴选才俊,滥竽充数,小李竟被选中,送至成都科大出国培训中心修行半年。
岂料想,此一去竟成小李老李的分水岭。来培训的诸位才子才女均是全国各地选上来的各行好手,共分两拨:一年的访问学者大多年长,而拿三年博士奖金的多为年轻新秀,立委在后一拨里遂成老大。每有考试,立委必中头彩,引来才子才女,大事小事,纷纷登门请教,“老李”之声不绝于耳。立委名噪一时,响应者众。然从小习惯了倚小卖小,乍一被老,立委不免郁闷。


成都科大出国培训中心的才子才女们(1990)
小李变老李,心里虽别扭,好处却多多。龙头大哥大,备受尊崇。立委外语本科出身,本应免试英语,无奈官家财大气粗,慷人民之慨,不问青红皂白,悉数押解天府之国,集中喂养。不止英文鸟语,更有政策轮训。众兄弟姐妹兢兢业业,争先恐后,唯立委悠哉游哉,终日沉迷天府美食,流连于茶肆酒吧,众兄弟钦羡有加。
成都一站始称老李,立委心内实不以为然也。其时立委事业发达,如日中天,业内行外,交游甚广,出入皆鸿儒,往来无白丁(见《朝华午拾:“数小鸡”的日子》)。导师为本行泰斗,立委乃导师仅有的关门弟子(其他弟子皆叛国投美去也),“青年”才俊,明日之星,业内同侪为之侧目。去国前夕,全国电脑翻译界在香山招待所年度聚会,点睛之笔为导师与本行另一大牛的席间对谈,人称“刘董对话录”,其间立委频频亮相,为导师提供实例,讲解细节。影响所及,与会众学妹(多为刚入门的外地在读研究生)纷纷上门请教立委,无奈立委远走高飞心切,痛失辅导上进学妹之良机。

立委在加拿大(1995)
去国经年,由英而加,由加转美。颠沛流离,不知所止,壮年人生,如水流逝。及至水牛城八年抗战(37-45岁),立委青春不再,壮年已过,“老李”名至实归。然立委壮心不已,励精图治,双线出击,称雄一方(见《朝华午拾:创业之路》,《朝华午拾:在美国写基金申请的酸甜苦辣》)。

立委在水牛城办公室(2000)
回首往事,不胜唏嘘。立委一生,由青年而壮年,正值创造力最盛,精力充沛流溢之时,天时地利人和,飞黄腾达有望,却为漫长的留学生涯拦腰截断。大而言之,立委固赶上出国之末班车,却误了千年不遇的中国经济起飞之航。拣了芝麻,丢了西瓜,此之谓也!
去岁归国省亲,杯觥交錯,在某宾馆餐厅与亲友相聚甚欢。席间小憩,踱步凉台,享清凉之气,赏京华夜色。偶遇一妙龄少妇,携一幼童,见立委两鬓染霜,嘱曰:“叫爷爷”。立委血压骤升,如雷轰顶,满腹酒意,化为凉液,由脊背滑落。
立委老矣,尚能饭否?
记于2006年11月5日

立委老矣
【作者简介】立委先生,IT业技术研发首席兼架构师,自然语言处理资深专家。曾任红小兵,插队修地球,文革后第一届77级大学生,后进社科院修读硕士,主攻机器翻译。1991年去国离乡,漂流海外。由英而加,获计算语言学博士。1997年由加转美,为创业公司研发副总及项目负责人(Principal Investigator), 先后赢得美国政府17个研究创新项目近千万美元资助,同时忽悠华尔街千万风投作商业开发。对于信息抽取有全方位研究,研究成果对美国政府科研立项有直接影响。业余爱好:音乐、科普、微信、博客,舞文弄墨。坐而论道,辟有专栏《立委科普》,著有回忆录《朝华午拾》。
【相关】
原博客在:【朝华午拾 - 立委小传】
5 陈儒军 徐令予 武夷山 韩玉芬 wangqinling
【旧文翻新 - 立委外传】 屏蔽留存
【旧文翻新 - 立委外传】
屏蔽 ||
人生苦短,掐首去尾,不过三五十年。大体分为三段:创业阶段(而立之年),成熟阶段(不惑之年)和下滑阶段(天命之年),反映在称呼上,叫小李、大李和老李。可怜,立委却从小李一跃到老李,没有机会品尝壮年人生的豪情,心尝有戚戚焉。
红小兵立委(1966) (《朝华午拾:永做毛主席的红小兵》)
自幼儿园到小学连跳两级,立委在班上始终最幼。更加荒年生人,孱弱矮小,体育课常告病假,或遭遣送回家,始终是个小可怜儿。所幸中学伊始,正值“修正主义回潮”,先帝启用邓公收拾文革残局,邓公责成教育总管周荣鑫整顿学校,校风日新。乘此东风,立委崭露头角,以学习委员兼数学科代表之身,受班主任委托,每日早自习登台主讲,演示解题思路,俨然助教。但好景不长,先帝昏庸,文革派重居上风,学校大乱,文化课退居后台,大批判遂成主课,兼以学工学农学军。立委不能以文化课呈威,然风头不减反盛,盖因立委最长批判文字,历经批林批孔,批邓反击右倾翻案风,直至批四人帮。大会小会,凡立委发言,必抑扬顿挫,铿锵有力,佐以诙谐幽默,风靡校园,称颂于一时。有传言,立委颇具鲁迅遗风,入木三分,且能推陈出新,妙语连珠。露天千人大会,常嘈杂狼藉,然立委登台,全场必静肃,洗耳恭听之,听至妙处,笑声一片。立委由此炼得糊涂胆大,从不怯场,终身受益。
及至大学,文革后首届,立委仍居尾,同学长一到十多岁不等(《朝华午拾:我的考研经历》)。同学之间皆直呼其名,唯同桌七仙女戏称 “小立委”,不为亲热,却为避嫌,以示划清界限。同桌四载,楚河汉界,泾渭分明。授受不亲,避而远之。然仙女文具笔墨滑落在地,自有立委抢先一步,拾拣归案。类此者三,春风化雨,润物无声。七女天生聪颖,想出一招,以长立委一岁为由,呼 “小立委”,就此来往,当可名正言顺也。
由七仙女开此恶例,随后多年,“小”字即不离身。中学教书,人称小李老师(22岁)。上研究生,小李出入机房,蓬头垢面,且口中念念有词,言“世界之语”(Esperanto),终成笑谈(23-26岁)(见 《朝华午拾:我的世界语国》)。
风华正茂,意气风发(1987)
及至毕业留所,立委事迹亦有流传,多为一见钟情,闪电结婚,不修边幅,撞南墙而道歉之类小李“景润”之逸事(见《朝华午拾:shijie-师弟轶事》;《朝华午拾:shijie-师弟轶事(3)——疯狂世界语 》)。
立委在中关村公司指导机器翻译系统的开发(1988)
立委如此这般在研究所及中关村公司一扎五年(26-31岁),练就一身绝技,与老中医相若,专事疗治电脑,驯其语言功能。其间,出国热持续升温,由上海蔓延北京,街头巷尾,言必议美、日、大英,澳大利亚,以致居委会大妈亦知考托福鸡阿姨乃上进青年之标杆。立委及其贴身领导却浑浑噩噩,卿卿我我,不知有汉,无论魏晋。其间送上门两次机会,留学德美,均因导师明阻暗挡,本人木呐,擦肩而过。直至身边同学悉数走尽,小李才幡然醒悟,痛下决心,赶末班车。其时,适逢包玉刚基金会来各单位选拔年轻业务骨干,滥竽充数,小李竟被选中,送至成都科大出国培训中心修行半年。
岂料想,此一去竟成小李老李的分水岭。来培训的诸位才子才女均是全国各地选上来的各行好手,共分两拨:一年的访问学者大都比较年长,而拿三年博士奖金的大多年轻,立委在后一拨里面理所当然,成了老大。每有考试,立委必中头彩,引来才子才女,纷纷登门请教,“老李”之声不绝于耳。立委名噪一时,响应者众。
成都科大出国培训中心的才子才女们(1990)
从小习惯了以小卖小,乍一变老,立委难免诧异。然小李变老李,备受尊崇。立委外语本科出身,本应免试英语,无奈官家财大气粗,不问青红皂白,全数押解天府之国,集中喂养。不止英文鸟语,更有政策轮训。众兄弟姐妹兢兢业业,争先恐后,唯立委悠哉游哉,终日沉迷天府美食,流连于茶肆酒吧,众兄弟钦羡有加。
成都一站始称老李,立委心内实不以为然也。其时立委事业发达,如日中天,行内行外,交游甚广,出入皆鸿儒,往来无白丁(见 《朝华午拾:“数小鸡”的日子》;《朝华午拾:一夜成为万元户》)。导师为本行泰斗,立委乃导师仅有的关门弟子(其他弟子皆叛国投美去也),“青年”才俊,明日之星,业内同侪为之侧目。去国前夕,全国电脑翻译界在香山招待所年度聚会,点睛之笔为导师与本行另一大牛的座谈,人称“刘董对话录”,其间立委频频亮相,为导师提供实例,讲解细节。影响所及,与会众学妹(多为刚入门的外地在读研究生)纷纷上门请教立委,无奈立委远走高飞心切,痛失辅导上进女青年之良机。
立委在加拿大(1995)
去国经年,由英而加,由加转美(《朝华午拾:哦,加拿大!》;《朝华午拾:温哥华,我的梦之乡》)。颠沛流离,不知所止,壮年人生,如水流逝。及至水牛城八年抗战(37-45岁),立委青春不再,壮年已过,“老李”名至实归。然立委壮心不已,励精图治,双线出击,称雄一方(见 《朝华午拾:创业之路》, 《朝华午拾:在美国写基金申请的酸甜苦辣》,《朝华午拾 - 水牛风云》)。
立委在水牛城办公室(2000)
回首往事,不胜唏嘘。立委一生,由青年而壮年,正值创造力最盛,精力充沛流溢之时,天时地利人和,飞黄腾达有望,却为漫长的留学生涯拦腰截断。大而言之,立委固赶上出国之末班车,却误了千年不遇的中国经济起飞之航。拣了芝麻,丢了西瓜,此之谓也! (《朝华午拾:乡愁是一张无形的网》)
去岁归国省亲,杯觥交錯,在某宾馆餐厅与亲友相聚甚欢。席间小憩,踱步凉台,享清凉之气,赏京华夜色。偶遇一妙龄女士,携一幼童,见立委两鬓染霜,嘱曰:“叫爷爷”。立委血压骤升,如雷轰顶,满腹酒意,化为凉液,由脊背滑落。
立委老矣,尚能饭否?
记于2006年11月5日
立委老矣
【作者简介】立委先生,IT业技术研发经理兼架构师,自然语言处理资深专业人士。曾任红小兵,插队修地球,文革后第一届大学生,后跳龙门进社科院读硕士,攻机器翻译。1991年去国离乡,漂流海外。由英而加,获计算语言学博士。由加转美,作为创业公司研发副总及项目负责人(Principal Investigator), 先后赢得美国政府17个研究创新项目近千万美元资助,同时从资本家腰包亦忽悠千万风险投资作商业开发。对于自然语言信息抽取 (Information Extraction) 有全面的研究,研究成果对美国政府有关科研项目的确立有直接影响。业余爱好:音乐、博客、舞文弄墨。著有回忆录《朝华午拾》。
原载【朝华午拾 - 立委小传】 2010-1-9
【相关】
http://blog.sciencenet.cn/blog-362400-974854.html
上一篇:有那么老吗?
下一篇:【新智元笔记:中文自动分析杂谈】

[转载]《旧文翻新:三伯父跨世纪的生死之恋》 屏蔽
[转载]《旧文翻新:三伯父跨世纪的生死之恋》
屏蔽 ||| |
【立委按】这是一则感人至深的真实爱情故事,由张诗群以报告文学手法撰写,发表在《芜湖日报:真情版》(2009年八月18日)。张诗群文笔细腻流畅,值得欣赏。故事的主人翁是立委的三伯父及其初恋爱人。那是上个世纪40年代抗战之际,出身书香之家的三伯李敏生正值弱冠之年,英俊倜傥,才气过人。虽然那时李大家族日渐衰落,敏生的书生意气不减,是胸怀理想的热血青年。敏生由父母包办,与当地的名门望族谢家订了一门亲,未婚妻谢邦宁知书达理惠中秀外。自古以来,包办婚姻的当事人往往没有机会品尝爱情的甜蜜,更少有轰轰烈烈的爱情故事。可李敏生与谢邦宁的爱情则是异数。这对恋人情投意合,诗文唱和,生死两茫,爱情不朽,演绎了一场跨世纪的生死之恋,阅之令人动容。
共同的理想是他们爱情的基石。国难当头,李敏生决定加入了新四军抗日。谢邦宁对心上人的果敢行为又是自豪又是担忧,写道:“独自倚闺楼,怵欢心内揪。喜将雪国恨,痛定报民仇。勇猛为夫性,安全是妾忧。盼来年获胜,抵去夜常愁。” 三伯回信说:“儿女缠绵须要缓,江山美丽不能丢。他年高唱凯歌返,永抵春闺独怵愁。”
在信息爆炸快餐文化盛行的今天,这样的篇幅较长的真情文字很容易淹没在互联网大海里。因特别转载于此,与更多的朋友分享。希望将来某一天,有导演慧眼识珠,把这样凄美动人的爱情故事搬上银幕。
~~~~~~~~~~~
魂牵一世生死情
张诗群/文
2009年清明节是个阴雨天,繁昌县繁阳镇范冲村西边的一片山岗地浸润在连绵的细雨中。此时,一位高大儒雅的老人在一座新修不久的墓前久久站立,墓碑上方镶嵌着一张精致的烤瓷遗照,年仅17岁便已病逝的谢邦宁在相片上绽开美丽淡然的微笑。老人用感伤的眼神一遍一遍缓缓打量自己为她拟定的碑文:故妻李谢邦宁之墓。然而陪伴他的当地亲友们都知道,相片上的秀丽女子并非他真正意义上的妻子,老人却深情怀念了一辈子……


== 1、不曾见面的订婚 ==
1927年秋,李敏生出生于繁昌县旧县镇(今新港镇)小磕山一户书香门第,其父李应文曾留学日本明治大学,毕业归国后因时局动乱回乡办学,培养了一批知识青年,在当地是名噪一时的教育楷模和爱国名士。在严谨的家风和得天独厚学习环境的熏陶下,李敏生渐渐成长为聪慧灵敏又充满正义感的俊逸少年,李应文对他疼爱有加,期待李敏生早日成家立业,光耀门庭。
抗日战争爆发后,小磕山沦为敌占区,日军得悉李应文在当地的影响便对他进行抓捕,逼迫他出任繁昌县长,以配合日军对繁的统治。一天深夜,李应文乘机逃脱,连夜携家带口迁往他乡,继续在无为黑沙洲、横山等地设馆办学,这期间,李敏生跟随父亲一起过着动乱不宁的生活。
李敏生的姐夫佘之涛是父亲的得意门生,此时在范冲给一个姓谢的大户人家当私塾先生。谢家是繁昌有名的开明地主家庭,抗战初期为新四军供应过粮食和日用品,三支队副司令员谭震林和妻子葛慧敏当年曾在谢家的小洋楼里结婚居住。谢家的学生中,老二谢葆初家的长女谢邦宁最为优秀,不仅容貌出众,知书达理,而且多才多艺,思想进步。姐夫佘之涛特别喜欢这位活泼可爱的女学生,回家与岳父李应文商量,眼下战乱不停,祸福难测,不如给李敏生订门亲也算是早日了却一桩心事,如果谢家答应联姻,对两家来说都是锦上添花的事情。李应文对谢家的开明威望早有耳闻,加上佘之涛对谢邦宁的百般赞赏,自然十分高兴,催促佘之涛出面说合。
1940年春节,在姐夫和父亲的张罗下,双方家长互换了谢邦宁和李敏生的庚贴,按照当时的礼仪,给一对不曾见面的小儿女订下了终生。此时,李敏生刚刚14岁,谢邦宁也只有13岁,两人都懵懂年少,情窦未开,对订婚这件事并没有太多感受。

(年轻时的李敏生)

(李敏生与父亲女儿合影)
== 2、初相见,情意难舍 ==
1942年,谢邦宁以优异成绩考进了设在泾县的皖南名校安徽省第十二临时中学。因一直跟随父亲四处奔波而几次中断学业,1943年春,李敏生在姐夫佘之涛的建议下,被父亲送到繁昌县原马仁乡中心小学读五年级,这时,李敏生和谢邦宁带着几分神秘与好奇,开始了书信往来。两人虽然年幼,却都聪明伶俐,又受过很好的教育,书信格式都是诗词短章,文辞华美,情真意切。他们在信中互致问候,相互了解和鼓励,谈论理想和人生,很快,两颗年轻的心充满了对彼此的好感和对未来生活的美好向往,情感的幼芽开始萌动。
1943年,为抵制日伪办学,谢家与当时繁昌县的另两户名门望族共同出资,在中分村创办繁昌县初级中学,李敏生以名列前矛的成绩连跳两级,考入繁昌中学直接上初二。李敏生把这个好消息在信中告诉了谢邦宁,谢邦宁也非常激动,两人约定,利用暑假期间谢邦宁回家时在中分村见面。
这次相会是李谢二人一生中仅有的会面,它的美好和珍贵谱成了一曲凄美的绝唱,让李敏生一生都难以忘怀,一生为之心心念念。任凭时间消逝得多么久远,这份情感也从未在李敏生心中褪色消减。
7月的中分村绿野平畴,清风拂面,夏日山林的宁静柔美让两个青春无限的年轻人沉浸在纯真浪漫的情怀中。这是李谢二人的初次见面,此时的李敏生已长成一个挺拔英俊的小伙,谢邦宁也已出落成温婉美丽的女孩,乍一相见彼此都被对方的谈吐气质深深吸引。此刻他们才感觉到他们之间的婚约是多么幸福而美好的一件事,带着深深的喜欢和爱意,他们穿过中分村的山林田野,沐浴着阳光清风,聆听蝉噪鸟语,他们谈学习谈友情谈抱负,一切都如梦境般美好,一切都像天地未开般纯粹,眼中一切都是彼此的影子,两颗青藤一样年轻的心,盛满了幸福和爱情。
一连四天,从太阳还未露脸开始,谢邦宁就悄悄从家里出门,步行五里山路赶到中分村与李敏生相见,直到太阳落山一天星光,两人才依依不舍作别。四天中,在树下,在林荫道旁,爱情的甜美盈满了相会的分分秒秒。有一天,他们觉得言语再也无法表达彼此的情意,于是一路跑到县城,找到一家照相馆,肩并肩靠在一起照了一张合影作为爱情的见证(后来,这张合影也在行军途中遗失)。他们商定,等到抗日战争结束和大学毕业,他们将用婚礼来庆祝胜利,然后,要永远生活在一起。
分别时刻,两人都情不自禁泪流满面。1943年8月29日,李敏生在繁昌中学写下了离别时的情景:“伸手互拂泪不净,无言只有咽噎音。唯期早日清秋去,但愿及时腊月临。”他希望秋天早早过去,寒假快快来临。
但是,这一分别,竟是永别。后来李敏生才知道,这次相见也许只是老天爷的怜悯:在这个曾是自己未婚妻的女孩离开人世前,老天爷准许他见她一面,与她相识。他和她的缘分,只有四天。

(李敏生近照)
== 3、把她的牌位娶回家 ==
战争局势越来越严峻,学校已无法正常开课。日军的侵略激起了繁昌人的愤恨,1944年1月,在取得谢邦宁的同意后,李敏生加入了新四军皖南支队繁昌大队。谢邦宁在给李敏生的信中说:“独自倚闺楼,怵欢心内揪。喜将雪国恨,痛定报民仇。勇猛为夫性,安全是妾忧。盼来年获胜,抵去夜常愁。”李敏生深感谢邦宁喜忧参半的复杂心情,回信说:“儿女缠绵须要缓,江山美丽不能丢。他年高唱凯歌返,永抵春闺独怵愁。”充满了革命的理想主义和高昂的激情。
1944年4月,国民党川军144师投降日寇,繁昌成了敌占区。这年秋季开学,谢邦宁带着弟妹们去泾县第十二临时中学报名,但此时十二临中已满员,为了和弟妹们在一起,谢邦宁又带着弟妹去了附近的黄田培风中学就读。1944年12月,谢邦宁突患伤寒,同学将她辗转运送回家后,因为当时繁昌沦陷无法延医,经乡村郎中治疗无效后于发病的第二天去世。这一年,她刚刚17岁,正是花朵初开的年纪。一个对爱情充满遐想和憧憬的女孩,未及盛放便已凋零。
噩耗传来,仿佛惊雷击顶,李敏生彻底呆了。他不敢相信,也不愿相信,那么美丽那么纯洁那么让他深爱的谢邦宁居然已经永离了人世!他写道:“遥知卿病逝,山岳似崩倾。吾笨竟后殁,汝聪何早行?顿脚如锣响,捶胸若鼓鸣。断肠观遗照,洒泪忆昔卿。”声声血泪字字悲情,刚刚品尝到爱情甘醇的李敏生瞬间跌进了苦痛的深渊。
父亲李应文与李敏生商量,既然已经订婚,那么谢邦宁就是谢家的人,生不能作李家的儿媳,死也要进李家的祠堂。李敏生对父亲的仁厚充满了感激,他含泪采纳了父亲的建议。1944年底,李家的花轿吹吹打打地抬到了谢家,李敏生将谢邦宁的牌位虔诚地放置在花轿中,像迎娶新娘一样,将谢邦宁的牌位接回家,安放在李家的祠堂。面对着她的牌位,李敏生心潮翻滚,他深深地鞠躬,在心底一遍一遍诉说着他的思念和哀伤。仿佛,他所有的青春梦想都随着谢邦宁的离去而消逝了。

(永远青春的谢邦宁)
== 4、思念陪伴他转战南北 ==
谢邦宁去世后,李敏生一度异常消沉,为了离开这片伤心地,1945年,在父亲的建议下,他改名李若非,先后进入狮子山第二联立中学和无为县中国人民抗日军政大学第十分校学习,抗大毕业后,他被分到新四军七师政治部,之后,李敏生跟随部队戎马倥偬,转战南北。日本投降后,解放战争期间,李敏生一直在部队从事训练改造国民党被俘军官工作。军中征战艰苦卓绝,他先后经历过鲁南战役、莱芜战役、孟良崮战役、淮海战役、京沪杭战役等许多生死攸关的大战役。
战争的紧张激烈是可以让人忘却缠绵的回忆的,但是每当夜深人静,谢邦宁的身影就会在李敏生的眼前浮现,四天的相会场景无数次在他心头回放,他生命中最美丽的四天已成为李敏生一生永久的怀念,他写诗词纪念她,他一次次在梦里和她对话,醒来却是泪洒枕畔,惆怅满怀。1949年5月上海解放的第二天,李敏生站在原国民党上海港口司令部的大楼窗口,他看着马路上正在游行庆祝解放的大学生,不禁热泪盈眶。他想,如果谢邦宁还活着,以她的成绩一定考进了大学,她应该也会在他们的行列中,穿着学生裙,梳着齐耳发,挥舞着拳头高喊着口号,也许,她会回头向他展开甜蜜的微笑。想到此,李敏生悲伤得无法自持。
1950年6月,朝鲜战争爆发,11月,他随部跨过鸭绿江进入朝鲜,参加抗美援朝战争,27日,他和战友们在补给不畅、粮弹不足的情况下,冒着零下三四十度的严寒血战长津湖,以伤亡一万多人的代价歼敌近一万四千人,扭转了朝鲜战局。
1952年底,李敏生从朝鲜轮换回国,1953年2月,奉命与经亲友介绍并订婚的戈国秀完婚。戈国秀是李敏生的同乡,家境富裕,曾和李敏生一起在父亲的学馆里读过书,容貌俊美,温良贤淑,当时在县委组织部工作。戈国秀早就知道李敏生和谢邦宁的婚约,她十分同情两人的遭遇,也非常理解李敏生时常表露的忧伤心情。
婚后,李敏生和戈国秀育有三女一子,虽然长期两地分居,但彼此相敬如宾,产生了深厚的感情。1956年,戈国秀调到杭州市轻工业局任职,结束了夫妻两地分居的生活。1957年次女出生前,夫妻俩商定孩子出生后取名为“宁”,以纪念已经离逝13年之久的谢邦宁,后来,因李家亲属中有人同名,戈国秀对李敏生说:“敏”这个字是你与邦宁订婚和上学交往时用的名字,女儿就叫“敏”吧,对邦宁也是一种纪念。李敏生非常感动,妻子知道谢邦宁一直是他心中的隐痛,这么多年来,谢邦宁活在丈夫心中,也在她心中播下了种子。
1965年冬,李敏生转至合肥,在国防光学研究院从事激光反导弹工程的大气传输研究工作,从办公室副主任职务升至研究室主任、书记,直到1987年离休。
离休后,南征北战漂泊了半辈子的李敏生终于清闲了下来,他开始愈发思念起家乡。戈国秀提醒他说,打听一下邦宁的墓还在不在,回家后也好去看看。
掐指算来,离谢邦宁去世已近半个世纪。中间经历过文化大革命等许多波折,当年地主小姐的墓有没有遭毁,能不能找到,对此,李敏生已不抱太大希望。但是,几年后,反馈来的消息让李敏生激动难眠,谢邦宁的墓,居然还在。

(李敏生与妻子戈国秀及女儿合影)
== 5、她是他永远的妻 ==
2001年8月,戈国秀突发脑溢血去世,享年74岁。李敏生怀着沉痛的心情在繁昌老家为老伴选址安葬。而隔山相望的范冲村西,则安眠着自己的另一个亲人谢邦宁。生死两茫茫啊,回首这一生的际遇,想到爱人们此时长眠青山泉下,与他阴阳两隔,李敏生悲从中来。
祭拜完老伴,他又来到谢邦宁的墓前,看着那荒芜的坟茔,墓碑上是一串谢家侄儿的姓名,李敏生内心酸楚,想想自己儿孙满堂,谢邦宁却是玉殒香消,孤寒凄冷地长眠地下。几十年前那四天的场景又不断地浮现眼前,他仿佛又看见她清秀的面容,又听到她清脆的笑声。李敏生五味杂陈:她曾是他的未婚妻啊!他必须要为她做点什么,就算自己大限来临,也不会再有遗憾。
回家后,他找出他一直珍存的谢邦宁唯一的一张照片,拜访了合肥所有能做烤瓷照片的地方,但大多数都是与公墓捆绑订做,最后终于有一家馆所愿意单独给他做。不久,一张放大的烤瓷相片被镌刻在墓碑上方,墓碑正中是一行干净有力的行楷:故妻李谢邦宁之墓,落款是李敏生携子孙的名字。李敏生想,哪怕只是美好的愿望,他也要给她一个归宿。
2005年清明节,李敏生来到他给谢邦宁新修的墓前,他打开随身携带的一个包裹,在众人不解的目光中,取出一堆烤瓷碎片,他说那是之前烤瓷相馆给做坏了的毛坯,这都是邦宁的东西,我带来要一起埋在这里。他又取出一个小包,那是他自己的一缕白发,他说身体发肤受之父母,既然生不能陪伴她,那就剪下自己的头发寄托心意吧。
李敏生又来到当年和谢邦宁约会的地方,回首往事,往事如烟。中分村,北山岗,六十多年前,一个是青葱年少的英俊少年,一个是情窦初开的如花美眷,那四天的美丽,让李敏生用尽了一生的怀念去交换……
【采访手记】
从合肥采访归来,细读李老赠阅的诗词,不觉得竟落下泪来。李老与谢邦宁的故事,我恨自己没有能力写得更加贴近我的感动。一位半生征战跑马沙场的老军人,他本身的故事就是一部传奇,他的人生,甚至他的爱情,都与中国大半个世纪以来宏大的背景有关,所以,他的故事是凝重的。
走进李老的家刚说明来意,老人便说,我和她,只有四天。采访结束后我在想,四天和一生,这是多么奇异的一组时间概念。那四天,该有怎样刻骨铭心的心灵体验,该有怎样美好得无法忘怀的记忆?是的,现今的人们似乎越来越浮躁而功利,但是,看过李老的故事后请你相信,真情,其实一直在人间。
转载自《张诗群新浪博客》:[blog.sina.com.cn]
 |
| From sanbai |
《旧文翻新:拿美国总统寻开心的华裔笑星黄西》 屏蔽留存
《旧文翻新:拿美国总统寻开心的华裔笑星黄西》
屏蔽 |||

这位长相有些滑稽的人叫黄西(Joe Wong),在美国娱乐圈走红,他一上场,随便一句话,一个表情,甚至一个停顿,也会引起阵阵掌声笑声。他算是进入美国喜剧界的主流了,甚至被请到白宫去讲笑话。另一位北京侃爷出身的北美崔哥(Brother Sway)虽然也用英文讲过喜剧小品,譬如去咖啡馆讲中国功夫或者星巴克的笑话。但是崔哥比起黄西来,显得边缘化多了,主要还是在华人社区有些名气。黄西的演出有过非常宏大的场面,现场几千上万人,也曾出现在美国亿万观众的当红电视节目里,听众总是被逗得前仰后合。

黄西显然潜心研究过西方喜剧的路子,他的一鸣惊人是个异数。黄西的英语不纯正,但他深谙西方文化的幽默要素和喜好。除了东方面孔给人以新鲜感外,他非常懂得怎样向主流靠拢,譬如,美国人热衷谈性,有点类似于中国的成人笑话。黄西第一次上全美电视夜间节目 Letterman Show 的一开始就讲了个带色的笑话迎合他们的趣味,说他读到一个研究报告表明,性成熟的巅峰是18岁。他说,可我到了25岁才得知这一点(他是24岁从中国来美的)。他故意顿了一下,一脸茫然的样子,说,在我蜜桃最成熟多汁的时候,怎么就无缘被人咬一口呢?
"I read a report saying that a man reached their sexual peak at the age of 18, but I did not know this until I was 25. So the world would never know what a stud I was. Nobody took a bite out of this peach when I was ripe."
这个笑话暗喻东方的保守文化使得很多人生理成熟以后很久还不懂“人事”,比较西方的性早熟性开放,对比很强烈。引得老外笑到捧腹。
他接着以移民生活为题材讲笑话,说是为了公民入籍考试,他必须学习美国历史,其中一个问题是:谁是本杰明-富兰克林?
"Who's Benjamin Franklin?"
I was like; ahh... The reason our convenience stores get robbed?
And the second one was:
"What's the 2nd Amendment?"
I was like; ahh... The reason our convenience stores get robbed?
因为美钞百元大票上印有富兰克林的头像,他于是调侃说:富兰克林不就是我们商店被抢的诱因么?第二个问题:什么是宪法第二修正案?第二修正案保障的是公民持枪自卫的权利。他接着用完全一样的答案和语气调侃第二修正案,暗讽该案具有很强的副作用,使得美国枪支管制松散,暴力案件加剧。这类笑话没有深厚的文化背景是讲不出来的,很多涉及敏感话题。虽然美国是言论自由的大国,面对亿万观众,尤其是面对上层社会比如白宫的时候,其中的分寸拿捏也很重要。黄西做得非常好。当然名气到了他这个层次,后面的高参估计也少不了。
这是黄西在白宫的经典段子,值得反复咀嚼品味
黄西最出色的段子,我以为就是上面这则在白宫讲美国政治的段子。为此他精心准备了很久,非常经典,相信会作为保留节目流传下去。美国副总统拜登笑得很开心,奥巴马因故没有出席,也被黄西调侃了一番,暗示奥巴马因为害怕被他开涮吓得不敢来了。精彩之处比比皆是,比如下面几段就让人拍案叫绝,这是怎样的天才!
他先是当面拿副总统拜登开涮。他说,我来前就看过了副总的自传,现在当面见到了他本人。他看了一眼拜登,然后转向观众说,我不得不说,书上的拜登比他本人好太多了。这是讽刺他写自传过分美化和宣传自己。这种无伤大雅的玩笑,贵为美国第二号人物,也只能报以掌声。
话题也说到移民后代为什么要学双语。其实第一代移民由于深厚的祖国情结,尽管自己生活在两种文化的夹缝中难以进入西方文化的主流,却也不愿意看到自己的孩子完全“香蕉”化,于是特别强调对中国语言的学习(也因此全美各地的周末中文学校越办越红火),怕孩子失去中华文化的根儿在西方社会迷失自己。黄西却故意把双语学习的原因指向另一面,调侃美国。当儿子不喜欢学习繁琐的中文,问父亲为什么要他学中文?黄西的回答是:孩子,将来你如果做美国总统,你当然需要用英文来签署法令,可你也要用中文与你最大的债主中国谈判不是?
奥巴马不在场,黄西也不放过,一样开涮这位美国新总统。拿总统开玩笑是谐星到白宫表演的一个传统了。总统与演艺界明星一样,都是供大众娱乐的。黄西的诺贝尔和平奖的玩笑我开始觉得有些过分,但似乎并没越线,满场的政客名流一样欢声笑语。他说大家都批评奥巴马太过软弱,但是奥巴马还在同时指挥着两场战争啊,他们居然还授予他诺贝尔“和平”奖!没有比这个更操蛋的事了吧。他停顿片刻,说,唯一可以想到的比这个更操蛋的事就是,如果你拿了诺贝尔和平奖,你却转赠给军方(满堂大笑)。
后来他又开总统和副总统的玩笑,讽刺他们人浮于事,没有效率。他说,如果我当总统,我要用降低生产率的方式彻底解决失业问题,这样,一个人的活就让两个人来做,这就好比我们现在总统和副总统两人做同一份工作一样。他接着说在奥巴马当选总统前,他一直是个悲观主义者,感觉自己如此渺小,对社会毫无影响(does not make a difference,雁过不能留声的痛苦)。对他来说,人生就好象在黑暗冬夜的雪上撒了一泡尿,也许是有点儿影响,可是很难说有什么影响( I felt that life is kind of like, pee into the snow in a dark winter night, you probably make a difference, but it's really hard to tell. (laughter))。黑白混血背景的奥巴马的成功给了他这个新移民以希望。既然半白半黑 (half black half white) 都可以登上权力颠峰,自己是半不白半不黑(half not black half not white)的少数族裔新移民,也应该一样可以竞选总统。
最后黄西开始 mock 自己的总统竞选纲领,讲的都是政治热门话题,一样嬉笑拉扯皆成幽默。首先讽刺竞选口号往往都是华而不实的空架子,他说自己的竞选口号是 Who cares (爱咋咋,谁管你?其双关在他此前交代过自己的昵称就是 Hu,Hu cares, 就是对选民保证他急大家所急)。请看这个段子的上下文:
You may be saying "Hey, what would be your campaign slogan?" You see, I spent ten years in the past decade (laughter) [20] oh you too? okay. (laughter) So I understand that American people are suffering, so my campaign slogan would be "Who Cares". (laughter)
他先说的是同义重复的废话 I spent ten years in the past decade,然后故意面对观众的反应说,哦,原来你跟我一样啊,一个 decade 中花费了十年,来观察美国的社会问题,因而深知美国人民饱受经济不景气的煎熬。然后转到这个 Who/Hu cares 的双关语口号来:表面上是我才不在乎美国人民死活呢,实际是突出自己救民于水火的的亲民形象。
几乎所有竞选中的热门话题都成为他的笑料。他说,为了争取先锋派年轻人的选票,他保证当选以后,不仅要使同性恋合法化,而且成为合法婚姻的必需形式(即,要让异性婚姻非法化)。他讽刺美国高达50%的离婚率,也故意反着说:我现在是结婚了,可婚前我犹豫了很久,我想,哇,多么可怕,有50%的婚姻会一直持续到老,挣脱不了。他说他有解决地球暖化的方案,就是把华氏改成摄氏,原来100度高温,眨眼间就降到了40度了。
黄西在表演过程中,非常注意细节。比如,他说成为公民以后,他立马把选票投给了奥巴马和拜登。然后转身看拜登,没等拜登反应,他抢先说了声不用谢(you are welcome)。这是给拜登一个措手不及,凸显拜登反应迟缓。因为西方的习惯是无论何时你受惠于人,你都要表达谢意。黄西说投票选了拜登,理所当然要领受拜登的谢意,所以他故作脱口而出,说了一声不用谢。可是拜登还愣在那里呢。我们的副总统大人显得多么迟钝啊。
黄西讲喜剧小品,不徐不疾,张弛有度。他对西方观众心理的把握很到位。他自我设计的形象是不露锋芒,故作木纳,甚至有点机器人似的一脸茫然,其幽默机智隐含其中。他的风格受到西方传统的影响,远胜于中国的相声和小品。他的笑话在国人中据说不很讨好。他自己在访谈中也说,他初出道在同胞人圈子里讲过,虽然精心准备了,会心而笑的却不多,这使得他开始很丧气,甚至怀疑自己是否是喜剧演员的材料。后来慧眼识才的还是老外。
他在美国成为华裔谐星而广为人知以后,他对记者说自己还不能算完全成功,一个成功的喜剧艺人不能仅仅局限于到俱乐部甚至电视上,表演几个零星的段子,至少要演几部电视情景喜剧(Sit-com)。他正在朝这个方向努力,最大的难关当然还是情景剧的剧本的创作。
黄西是一个从我们这代留学生新移民中成长出来的值得关注和期待的喜剧艺术家。他的出现有助于改善我们东方人过于拘谨,被主流社会和文化边缘化的形象。
===================
为帮助读者/听众了解这几个段子,我在网络上搜到了热心粉丝的两个帖子,转载如下:
【附1】 Letterman Show transcript:
Hi everybody. So... I'm Irish. I read a report recently that a man reaches his sexual peak at age 18 but I didn't know this... until I was twenty five. So the world will never know what a stud I was. No one took a bite out of this peach when it was ripe.
I'm not good at sports, but I love parallel parking... because unlike sports, when you are parallel parking, the worse you are, the more people that are rooting for you.
I'm an immigrant and I used to drive an old car with a lot of bumper stickers that are impossible to peel off. And one of them said, "if you don't speak English, go home!" I didn't notice it for two years.
I worked really hard to become a U.S. citizen and I have to take these American History lessons where they asked us questions like:
"Who's Benjamin Franklin?"
I was like; ahh... The reason our convenience stores get robbed?
And the second one was:
"What's the 2nd Amendment?"
I was like; ahh... The reason our convenience stores get robbed?
"What is Roe vs. Wade?"
I was like ahh... Two ways of coming to the United States?
I have a family now, but I used to be scared of marriage. I was like wow... 50 percent of all marriages end up lasting on forever!
I just had my first child last year. I was really amazed at it. I was in the delivery room, holding up my son, thinking to myself, "Wow... He was just born... And he's already a U.S citizen."
So I said to him, "DO you even know who is Benjamin Franklin?"
Now I have a sign in my car that says ”Baby On board.”
This sign is basically a threat. It just says that I have a screaming baby and a nagging wife and that I am not afraid of dying anymore.
Thank you very much!
==========================
Implicit explanations to audience with culture difference:
1. Ben Franklin's picture is on the US $100 bill.
2. Second Amendment refers to the US Constitution for the right to keep and bear arms.
"Roe vs. Wade" is a famous court case that you'll learn about in history class that deals with abortion.
Joe Wong used this case in a form of a question: What is Roe vs. Wade? To which he cleverly delivered the punchline "Two ways of coming to the United States".
Roe is used as a play on words to describe "row", as in using a boat to "row" to the US.
The denotation of wade was used, the definition meaning "to walk in water".
from:http://www.chenwangdesign.com/blog/2009/05/joe-wongs-letterman-show-script.html
【附2】
.

某网友:
这几天我很迷黄西/Joe Wong 3月17号在RTCA Dinner (The Radio and Television Correspondents Association Dinner,全美电台电视记者协会年会晚宴)上的表演。这个晚餐会是当天在C-SPAN 和C-SPAN2 频道上现场直播的,但我直到几天后才在youtube上看到的。实在太迷了,而且网上好像也没见他的表演全文,我就决定把它的全文听写下来并集中注释一下。听写中有个别词不确定用"(??)" 标出来了。注释(理解他的包袱是什么意思)是靠的众多的youtube、mitbbs上的留言,以及自己查字典和google。
--------------------------------------------------------
Transcript for Joe Wong at RTCA Dinner, aired on C-SPAN 3/17/2010
Transcribed by PB
-----------
Good evening, everyone. My name is Joe Wong, but to most people, I'm known as "who?!" (laughter) which is actually my mother's maiden name, (laughter) and the answer to my credit card security question. (laughter) [1]
But joking aside, I just want to reassure everybody that I am invited here tonight. (laughter) [2]
I grew up in China, who didn't? (laughter) [3] And my childhood memories are totally ruined by my childhood. (laughter) When I was in elementary school, as part of the curriculum, I had to work at a rice paddy right next to a xxxxx quarry where they use explosives to break rocks, and that is where I learned that light travels faster than sound. (laughter) which is almost as slow as a flying rock. (laughter) [4]
My dad was a grumpy guy, but occasionally he would try to cheer me up with jokes, but he doesn't do it right. When I was seven, one day he said to me, "hey son, why is tofu better than centralized socialist economy?" (laughter) so five minutes later I said "why?" (laughter) He said "because I said so!" (laughter) [5]
I came to the United States when I was 24, to study at Rice University in Texas. (some applaud cheers and some laughter) that wasn't a joke (laughter) until now. (laughter) And I was driving this used car with a lot of bumper stickers that's impossible to peel off. And one of them said "If you don't speak English, go home". And I didn't notice it for two years. (laughter)
Like many other immigrants, we want our son to become the president of this country and we try to make him bilingual, you know, Chinese at home and English in public, which is really tough to do, because many times I have to say to him in public "Hey listen, if you don't speak English, go home" (laughter) And he would say to me, "Hey dad, why do I have to learn two languages?" I said "son, once you become the president of the United States, you are going to have sign legislative bills in English, and talk to debt collectors in Chinese" (laughter) [6]
When I graduated from Rice, I decided to stay in the United States, because in China, I can't do the thing I do best here, being ethnic. (laughter) And in order for me to become a U.S. citizen, I have to take this American history lessons, where they ask us questions like "Who is Benjamin Franklin?", where I was like "ah, the reason our convenience store gets robbed?" (laughter) [7] "What's the Second Amendament?", where I was like "ah, the reason our convenience store gets robbed?" (laughter) [8] "What is roe vs. wade?", where I was like "ah, two ways of coming to the United States?" (laughter) [9]
Later on I read so much about the American history that I started to harbor white guilt. (laughter) [10] In the America they say that all men are created equal, but after birth, it kind of depends on the parents' income, or early education and health care. (laughter) I read in the Max House Men's Health Magazine that President Obama every week has two cardio days and four weight lifting days. You see, I don't have to exercise, because I have health insurance. (laughter) I live in Massachusetts now, where we have universal health care; then we elected Scott Brown (laughter) - talk about mixed messages. (laughter) [11] I think there was a movie about him - it's called "Kill Bill" (laughter) [12]
I'm honored to meet vice president Joe Biden here tonight, (Joe turned to face Biden) I actually read your autobiography, and today I see you. (Joe turned back to face audience) I think the book is much better. (laughter) They should've get guest cast Brad Pitt, or even Angelina Jolie. (laughter)
So to be honest, I was really honored to be here tonight, and I prepared for months for tonight's show, and I showed the white house my jokes about President Obama, and that is when he decided not to come. (laughter)[13] And he started to talk about immigration reforms, (laughter) Take that, Stephen Colbert (laughter) [14] And president Obama has always been accused of being too soft, but he was conducting two wars. and they still gave him the Nobel Peace Prize, and he accepted it. (laughter) You can't be more bad ass than that. (laughter) where actually, I'm thinking the only way you can be more bad ass than that is if you take the Nobel Prize money and give it to the military. (laughter)
We have many distinguished journalists here tonight, whom I consider as my peers. (laughter) because I used to write for campus newspaper. (laughter) I think journalism is the last refugee for puns. [15] Only on the newspaper can you say things like "I was born in the year of horse and that is why I'm a naysayer" (laughter) [16] my point exactly.
And tonight is my first time on C-SPAN, which is a channel I obviously always watch, when I couldn't stand the sensationalism and demagoguery of PBS? and QVC. (laughter) If I still couldn't fall asleep after watching C-SPAN, there's C-SPAN2 and C-SPAN3. (laughter) [17] Thank you very much. (laughter)
So I became a U.S. citizen in 2008, which I'm really happy about. (applause) thank you very much. American is number one, (laughter) that's true, 'cause we won the world series every year. (laughter) [18]
After becoming the U.S. citizen, I immediately registered to vote for Obama and Biden. (Joe turned to face Biden) you're welcome. (laughter) You handed me a had me at "Yes We Can" (laughter) (Joe turned back to audience) that was the their slogan. (laughter)
So after getting Obama and Biden elected, I felt this power trip. (laughter) And I start to think maybe I should run for president myself. Where, I have to take a step back and explain a little bit, you know, because I have always been a morose and pessimist guy. I felt that life is kind of like, pee into the snow in a dark winter night, you probably make a difference, but it's really hard to tell. (laughter) [19] But now, we have a president who's half black half white, it just gives me a lot of hope, because I'm half not black half not white. (laughter) Two negatives make a positive. (laughter)
You may be saying "Hey, what would be your campaign slogan?" You see, I spent ten years in the past decade (laughter) [20] oh you too? okay. (laughter) So I understand that American people are suffering, so my campaign slogan would be "Who Cares". (laughter) [21]
If elected, I would make same-sex marriage not only legal but required, (laughter) that will get me the youth vote.(laughter) You see I'm married now, but I used to be really scared about marriage, I was like "wow, 50% of all marriages end up lasting forever" (laughter)
And I will eliminate unemployment in this country, by reducing the productivity of the American workforce. (laughter) so two people will have to do the work of one, just like the President and the Vice President,(laughter) or the Olsen twins. (laughter) [22]
And despite heart disease and cancer, most Americans die of natural causes. So if elected, I will find a cure for natural causes. (laughter) You seem to like that one. (laughter) but you won't be covered by health insurance though, (laughter) because of pre-existing conditions. (laughter)
And I have a quick solution for global warming. I will switch from Fahrenheit to Celsius, (laughter) It was 100 degrees, now it's 40. (laughter) You're very welcome. (laughter)
And I'm great with foreign policy. Because I am from China, and I can see Russia from my backyard. (laughter) I believe that Unilateralism is too expensive, and open dialog is too slow. So if elected, I will go with text messaging. (laughter) I will text our allies just to say hi, (laughter) and text our enemies when they are driving. (laughter) "OMG you're building a nuclear weapon?" (laughter), "but you're doing it wrong LOL" (laughter)
I just want to thank Video TV correspondence xx xx for having me here tonight. This is the first time I wish my son knew what I was doing. Thank you so much and have a very good night. Thank you Linda Scott.
-------
注解: based on comments from youtube and mitbbs, dictionary look-up, and google
-------
[1] 他妈妈姓“Hu”,刚好跟"Who"同音。 maiden name :大部分老美婚后改跟丈夫姓(所以夫妻俩同姓);女性结婚前的姓就叫maiden name
[2] 黄西这儿强调说“我是被邀请的”,mitbbs上有人指出这是指去年年底两次白宫安全问题--11月份、12月份各有一对夫妇没有邀请函但通过了层层安检进到了白宫宴会并到奥巴马身边。
[3] youtube留言:he said he grew up in china... it's a joke about the over population of china and how? many people there are there。
还是youtube留言,但解释不同:If you related to "I grew? up in US, who wasn't?" You got to be smart to understand him。(Mitbbs上有人同意这一个,说这是讽刺美国redneck动不动就说I grew up in US。 )
[4] 黄西说他小学时(劳动课)在水稻田(rice paddy)干活,旁边就有一个采石场,用炸药炸石头。因为经常看到爆炸光亮听到爆炸声(还可能有碎石飞过来),后面黄西接着说“我学到了光传播的速度比声音快,而声音传播的速度大概跟飞溅的石头差不多”。
[5] youtube留言:tofu and centralize economic joke: you got? understand that China is a Communist country, there is only one party in power, everything is like his dad said "because I said so"
还是youtube留言,稍微有点不同:it's sort of non-sense talk said by his dad, then his dad went 'because I? said so'.... his farther == the centralized social system. the nonsense == whatever enforced by the centralized social system.
[6] youtube留言:it is "debt collector"..Because of the huge current account deficit? US owes to China.
还是youtube留言,稍微有点不同:China is the country that holds the most US treasure bonds now.
[7] youtube留言:Benjamin Franklin - 100 dollar bills. Convenience stores have 100 dollars bills. (100美元币上是美国总统本杰明-弗兰克林的头像;便利店/社区小超市当然有100刀币;所以被抢劫了)
[8] youtube留言:Second Amendment: is the freedom to carry gun. - It gives the robbers guns to rob convenience stores.? (因为民众能自由持枪,所以小店被抢劫了)
黄西这个笑话之前在别的地方也讲过。我google的一个中文网站的解释:什么是美国宪法第二修正案(允许公民拥有枪支)?黄西接着说:这是不是我们杂货店被抢的原因?
[9] youtube留言:Roe vs Wade, famous? court case on abortion. Joe thought two ways of coming to US, on boat or swim
我找的别的地方的:In 1973, the US Supreme Court had prohibited states from making laws that interfered with a woman's right to an abortion during the early months of pregnancy. Joe 把 roe vs. wade 转换成 row (rowing the boat) & wade (swimming ) to USA. (划船和游泳偷渡到美国)
[10] youtube留言:He studies America history. It talks a lot of white Americans kill Indians, slavery, kills, etc. Basically, white American were guilty of many things, i.e. white guilt. He starts to harbor (to feel inside)? white guilt (as if he were white).
[11] youtube留言:Obama does exercise, but Joe himself doesn't need to because he has health insurance. MA has universal health care which is viewed as the result of Democratic dominance in MA. But they recently voted a Republic senator Scott Brown, mixed message. (MA就是Massachusetts,常说的麻省)
[12] youtube留言:Scott Brown is a? Republican and their motto on health care reform seemed to be "Kill (the health care reform) Bill"
[13] 新浪北美网上报道说,这个年会历来是“上至总统下到各大媒体负责人都会出席”。本来奥巴马已应邀出席,但因为health insurance reform bill最后投票是3月21日,他“亲自四处催票拉票,频上媒体呼吁支持。临时排定当晚6点上保守倾向的Fox电视台的访谈,所以无法出席”;白宫于是请副总统Biden代为出席。“黄西说,当然有点失望,不过没问题,听说‘副总统人也挺幽默的’ ”。(我想这样他一定临时修改了讲稿,而他开的副总统的那个玩笑效果很好,考虑到他有限的修改时间,可见他的功底!)
[14] 黄西说“Stephen Colbert,把这个表演出来”。Stephen Colbert 是一个美国喜剧演员,因他的讽刺和扑克脸式的喜剧表演风格在美国广为人知。2006年4月29日,科拜尔受邀在白宫新闻记者协会晚餐会上进行表演。科拜尔用他一贯的风格当面挖苦了当时的美国总统小布什。(“历史”的相似性)
[15] pun: a humorous use of a word or phrase which has several meanings or which sounds like another word (以转意或谐音的方法达到诙谐的效果)
[16] youtube留言:"Nay-SAYER". Horses go “Nay" . It was a joke on a bad pun.
neigh: a long, loud, high call that is produced by a horse when it is excited or frightened. (马嘶叫声)
neigh: a long, loud, high call that is produced by a horse when it is excited or frightened. (马嘶叫声)
[17] C-SPAN, C-SPAN2, C-SPAN3 是美国的有线电视频道(一家三个)新闻频道,创办于1979年,节目内容主要探讨政府及公共事务议题,也有转播国情咨文、共和党全民大会、民主党全民大会。所以黄西说用它来催眠。
[18] youtube留言:Because the World? Series is not for the world...only 2 countries play in the World Series. America and Canada. (World Series 指棒球比赛,说是国际/World,其实就美国和加拿大两国的球队。大部分时候都是美国赢)
[19] youtube留言:actually it means pee in snow will melt it, as pee is warmer. but since? it is a dark winter night, so it is hard to tell
[20] "I spent ten years in the past decade" -- ten years 是十年,decade也表示十年。
[21]我的理解 “Who cares” 有两层意思:1。"Who"指黄西自己(表演开始的时候黄西说大部分老美不知道他,指代他为"Who"),这个竞选口号是“我关心你们”;2。“Who cares”直接的意思是“谁在乎呢?!” 因这双重意思而逗笑。
[22] “Olsen twins” 好莱坞最红双胞胎姐妹花奥尔森姐妹。看你认不认得出这张她们小时候的图片及她们演的那部电视剧(我很喜欢那部电视剧)
【相关信息:美国深夜节目收视率冠军的「大卫赖特曼秀」,上月(Apr. 2009)17日晚上破天荒邀请中国口音极重的黄西(Joe Wong)亮相,以英语讲美式笑话,近六分钟的演出,观众反应热烈。...
--------------
from http://hi.baidu.com/%B3%C9%B2%C5%B0%FC/blog/item/dbded0f59724d429bd3109bb.html
【相关】
1 秦承志
《旧文翻新: 王一千起死回生记》 屏蔽留存
《旧文翻新: 王一千起死回生记》
屏蔽 |||
中国绝无仅有的一次手术

1968年,在皖南深山乡镇何湾,一个13岁男孩从牛背上摔下。老爸出诊,发现该小孩右肝破裂,腹内大出血,要开胸、开腹才能完成手术。需要大量血液,当时无法在本地获得。
病人不宜搬动,时间又不容耽误;一要麻醉机,二要血源。时间就是生命。开车回县城,拉麻醉机和输血员。这简陋山路70多里,是时正值山区大雾,一来一去要四到六个小时。如何度过这漫长时间?是一道难解的课题。
不得已,老爸急中生智,大胆决定,从腹腔抽取积血回输,首创混有胆汁的腹血回输。
临床上自血回输,有脾血、肝血、血管破裂积血及宫外孕积血等。老爸有脾血及宫外孕积血回输经验。宫外孕混有羊水和肝破裂混有胆汁,与积血所占比例甚微,少至人体可以耐受。而肝血回输,当时医学上尚极少论及,因有胆汁污染。10年后,文献才有报道:混有胆汁的血亦能安全回输,并在后来的文献上陆续得到肯定。
那一夜,老爸立在病人身旁,“车水战术”,从腹内把积血抽出来,过滤后再静脉输入,共回输1700毫升,赢得了时间,维持血液动力学运转,终于等来了输血员和麻醉机。
接着就在汽油灯下,老爸在山村卫生院,就地全麻开胸、开腹。初战告捷,顺利完成肝修补手术。在一个小山村,没有电,缺乏助手,在设备简陋、药品奇缺、无血源的情况下,老爸成功完成他外科生涯中第一例肝脏手术,这应算是一个奇迹。术后恢复倒也算“顺利”,但术后9天,本拟翌日出院,可是肝内胆道大出血并发症来了。很典型,一阵胆绞痛,血压下来,面色苍白、贫血、休克,反复发作。经一天观察,保守治疗无效。
让其转来县医院,老爸再进腹,作肝固有动脉结扎加胆总管外引流,手术成功。这手术很经典,术中扪得肝动脉震颤,显示在出血,扎后震颤立马消失,胆总管出血表现延缓、停止。终于救回患者一命。在那个时代,那样条件,这技术,是个了不起的成绩。这是当时中国的县级医院外科水平的高峰。
而在山村小镇完成的手术,在中国乃至世界也是绝无仅有的。
这位病人前后两次手术,医药费一千多元,坊间戏称他叫“王一千”。当时老爸月薪才不到50元,是老爸工资二十倍。农家哪能付得起这天文数目。好在那个时代,病人出身贫下中农,又是当时当地最大手术,老爸出面为其申请,政府以民政救济,把费用一笔勾销。这在社会上传为美谈,是毛时代的一曲社会主义赞歌。
(根据老爸《我的外科生涯》节选改编)
http://blog.sciencenet.cn/blog-362400-811160.html
上一篇:没有语言学的 CL 走不远
下一篇:《旧文翻新: 骨科三奇例》
《旧文翻新:曾祖父李老夫子傳》 屏蔽留存
《旧文翻新:曾祖父李老夫子傳》
屏蔽 |||
【立委按】《夫子遺墨》專欄源自我的曾祖父的作品《李老夫子遺墨》,民國二十五年(一九三六年)八月編印,內部發行。家傳孤本掃描上網。歡迎轉載,請註明出處。
==============
任圖南 - 李先生傳
李先生(諱)咸昇,號學香,清歲貢生香齋翁之長子也。世居本邑北鄉之永保圩,旋以地勢低窪,頻遭水患,獻計於香齋翁。擇仁於小磕山大衝口而處焉,置田產,營住宅,皆先生贊助之力也。香齋翁品性端方,學問淵博,遠近之負笈請益者,皆以獲坐春風為幸。凡列門墻者,莫不因熏陶而為成德達材之彥。學香受過庭之訓,讀等身之書,鑽仰高深,獲卓爾之效。群疑其有異聞焉。先生兄弟三人,仲季均早世,香齋翁鐘特甚,先生亦能仰體先志,愈加奮勉,朝夕披吟,於書無所不讀。是以早歲即游泮宮,繼遂食於廩祿。年三十三以明經而蒙國恩,爰貢於鄉焉。先生晚年酷好昌黎文集,揣摩諷誦,終日把玩,未嘗釋手,故下筆即有古大家風範。遠近之人,得先生之片紙只字,均珍如拱璧。即偶有吟哦,朝脫稿而夕傳抄矣。所惜底稿不存,後人不獲梓其專集,以為後進之楷模。香齋翁作古後,陶太孺人效敬姜之無逸,親紡績之劬勞。先生乘歡色喜,甘旨罔缺。
及陶太孺人病卧床褥,先生親嘗湯藥,朝夕侍奉,未嘗廢離。迨至疾革,先生則擗踴號泣,哀毀骨立。其篤於孝養有如是也。先生性情渾樸,淡於名利。國體變更後,遂無意進取。惟以裁成狂簡,傳道來世為務。辦理族學,誘掖家族之俊義。督促諸子留學東洋,使之吸收新鮮文化。及諸子學成回國後,促之於家中辦理崇實學校,以啓迪後進。邑令操震聞其善而降臨之,大加奬勵。先生之勤於勸學有如是也。先生宅傍均系高壠,不宜稼禾,多半荒棄。先生乃審視而竊嘆曰,此大利所在,何久使貨之棄於地也。乃價買而墾藝之,樹以李桃果實之屬。每值春晚,群芳競秀,幾疑董奉之杏林,潘岳之花縣也。夏晚果熟,販夫麇集,獲利頗豐。鄰近居民羡而效之,於是荒山瘠土,悉化為沃壤矣。民國二十年,巨浸為虐,餓殍盈途。此鄉獨免飢寒之慘者,皆食先生樹藝之報也。先生舉子三。長曰應文,畢業於日本明治大學,得法學士歸國後,服務於省立第八師範,繼復應安徽公立法政專門學校之聘。次曰應期,高小畢業後,遂經理家務。三曰應會,畢業於日本明治大學,得政學士位後,與長兄應文於皖城創辦成城中學。繼遵父命回裡與乃兄辦理崇實小學。孫五人,幼即聰穎可愛,可謂後起之秀也。先生享年六十有四而終。贊曰,鯉艇受業,鳳毛濟美,文章壽世,化雨被裡,盈砌芝蘭,滿門桃李。興學校而作育英材,課樹藝而利洽桑梓。倘死者猶可作,實吾黨所矜式。
民國二十五年歲次丙子仲秋月上浣世愚弟任圖南拜撰。
==============
姚學銘 - 序一
余自弱冠時,始識李翁香齋先生,以前輩禮見之。睹其面溫恭儉讓,洵洵如也。先生觀余文藝亦欣賞之。其子學香長余一歲,嘗同考試,嘖嘖有聲,遂與為友。自後心心相契,文字交深。因以長女士偉配學兄季子應會而聯姻焉。學兄亦弱冠游庠,旋食餼,家居教授,以先翁之學紹後生。其為文宏深而淵博,其為詩幽遠而清逸。邑之北區凡有名於學者,皆先翁與學兄父子之徒也。是以鄉之人每敬稱之。余嘗想儒者讀書,本以窮經致用,取科名,策清時,以顯揚於國家,蔚為事功,名彪史冊。至不得志以經生終,雖文如韓愈,詩如杜老,亦幸中之不幸也。以學兄之學,行學兄之志,夫豈不足以展市,胡竟以教授老其身耶。惜哉夫子,今者學兄休矣,享年六四,以壽考終,殆所謂耳順而欲不從心歟。學兄之友門,示不忘先生,爰集學兄之詩文遺稿而付梓,問序於余。余應之曰,人生有三不朽,其亦可矣。因綴數語而弁之。
民國二十五年歲次丙子仲秋月上浣姻愚弟姚學銘拜識
==============
編者: 序二
清恩貢生候補江蘇直隸州州判,李公學香夫子,即清歲貢生太老夫子香齋公之長子也。太老夫子為清末經師,門下由科名發達者遍鄰邑。儒林山鬥,望重一時。夫子承鯉庭之訓,得衣鉢之傳。幼有文名,弱冠入泮,旋食餼。每逢歲科兩試,幾有譽滿江南,群空驥北之慨。無如萼薦屢邀,一售難獲,以恩貢終,非其志也。改革後,無心名利,提倡實業,興辦學校,每欲佑啓後人。暇時則對於古書常加溫習,嘗謂文為載道之器。孔孟而後,惟韓愈其庶幾乎。以故益粹。每有所作,氣盛言宜,置之昌黎集中,幾無以辦。晚年來,淡泊自甘。蒔花種竹,課子課孫。道愈高,文愈精。問字之車,門無虛日。夫子偶一吟哦,執筆立就。諷誦之間,他人不能移易一字。此非僅天分之高,抑亦學力之充有以致之耳。小子等先後受業有年,欲效步趨,望塵莫及。惜乎夫子休矣,天喪斯文,不獲憗遺一老,享年六旬有四。小子等傷音容之莫睹,幸手澤之猶存,爰集其平生所作若干篇,付之梓人,以餉後學雲。夫子之子三,孫五,皆卓卓有聲,聰穎可愛。次子應期世兄由高等學校畢業,經理家務,問事公益,頗得地方信仰。而長子應文三子應會二世兄,留學日本得學士位歸國,辦黨興學,多歷年所。應會雖早世,而文字亦有父風。因各採若干篇,附之冊末,以見師門多賢,經學相傳,歷數代而未有替也。
民國二十五年歲次丙子仲秋月上浣 編者謹識
==============
《李老夫子遗墨》影印件及编者名录






中华民国二十五年八月印
非卖品
编者后学:
高德芬 王继铠
余明 牧邦盛
何秀柏 孙嗣续
方銮 陈瑶琨
胡义生 尚显义
原载 《夫子遺墨:李先生傳》
http://blog.sciencenet.cn/blog-362400-799909.html
上一篇:【旧文翻新:我的世界语国(2)】
下一篇:【旧文翻新:《李老夫子遗墨》简介】
1 徐晓
《旧文翻新:我的世界语国(5)》 屏蔽留存
《旧文翻新:我的世界语国(5)》
屏蔽 |||
1989年夏天,我和导师去德国慕尼黑应参加第二次国际机器翻译最高级会议。此前,我跟荷兰BSO(Buro voor Systeemontwikkeling BV)公司的机器翻译研究组一直有联络,应约为他们的以世界语作为媒介语的多语机器翻译系统 DLT,编写了一部现代汉语依从关系的形式句法。他们听说我们要来欧洲,就邀请我和我的导师,还有中国机器翻译界知名人物董老师,会后顺道访问他们的实验室一周,做学术交流,共同讨论汉语句法里的一些疑难问题。这次活动,他们称作 Chinese Week.
我们是应慕尼黑机器翻译峰会的召集人,西门子公司的S先生特邀,提交论文,介绍我们的JFY英汉系统。这是我第一次出国,一切陌生而新鲜。大会在大酒店的拱圆形讲演大厅举行,气派豪华。我的导师是俄语出身,所以派我上台宣讲论文。初生牛犊不怯场,我报告完后,回答了两个问题下场,正赶上中场休息时间。大概东方面孔的报告人很少,慕尼黑电台的记者现场采访了我,询问我的观感,还好没有涉及64的问题(当时64刚过,风声很紧,我们办到一半的出国手续,又重新审查一遍,险些泡汤)。
大会以后,我们乘火车沿莱茵河往阿姆斯特丹,一路风景如画,赏心悦目。河岸高地上屹立着一座座中世纪古城堡,引人遐想。我们在大学城 Karlsruhe 停留两天,访问两个刚认识的电脑专业的留学生。德国小城的整洁优美、绿地成片和德国人的彬彬有礼给我留下很好的印象。当时感到不解的是,为什么这样一个小城也有一条红灯街,而且就在大学生宿舍楼门前。后来到了号称世界“性都”的阿姆斯特丹才明白,这是小巫见大巫了。当时,本室同事傅大姐正在阿姆斯特丹进修,她请了一位留学生带领我们参观举世闻名的红灯区。这是来阿姆斯特丹的人必游项目之一,对荷兰旅游业很重要(几个月前,报载争议已久的阿姆斯特丹红灯区终于关门大吉)。
运河边的红灯区好像台北的夜市和北京的庙会,熙熙攘攘,热闹非凡。见到有导游打着小旗,带领一队队游客。不时有骑着摩托的警察穿过。红灯区占据了运河边纵横七八条大街,沿街的房子,有一串串布置得很讲究的橱窗,每个橱窗里面有身着三点式的小姐坐台亮相。妓女有各种肤色和体态,有的小巧,有的肥硕,大部分都不好看,甚至倒胃口,但一律打扮得光鲜妖艳。第一次来参观的游客,不大敢正眼看妓女,因为她们总盯着游客频抛媚眼。我们的导游同学显然是老油条了,一路跟这些妓女打招呼,送飞吻,你来我往,但并不进门。看到一位日本人好像在门口讨价还价,等再回头时,这位买春客已经登堂入室,橱窗的帘子也拉上了,表示正在营业。不过,多数橱窗是没有业务的,毕竟众目睽睽之下招徕买春客似乎不是好的商业模式。我怀疑她们也许有政府旅游局的补贴,否则怎么可能经营下去。红灯区还有很多性商店和录象馆。走进一家商店,满目都是各式各色的硕大的性器官模型,吓得我赶紧逃离。


游览阿姆斯特丹后,我们按计划去Utrecht的BSO公司访问一周。DLT 项目研究组十几个人,一半是语言学家,一半是工程师,看得出来,这是个气氛融洽的团队。德国世界语者 Klaus Schubert 博士是系统枢纽“依存关系句法”(dependency grammar)的设计人,在项目第二阶段继 Witkam 成为项目组长。71届大会后招进来的美国世界语者 Dan Maxwell 博士,负责东方语言的句法项目的承包、质询和验收,是我的直接领导(十年河东,十年河西,后来我成为他的 boss,这是后话,见《朝华午拾 - 水牛风云》)。Dan一看就是老实人,照顾我们客人殷勤有加。我看到他早上骑自行车来上班,笑着跟他说:“我在北京上班跟你一样”。
研究组的骨干还有国际世界语协会的财务总监,知名英国籍世界语者 Victor Sadler 博士,我在71届国际世界语大会上跟他认识。作为高级研究员,他刚刚完成一项研究,利用 parsed (自动语法分析)过的双语对照的语料库 (BKB, or Bilingual Knowledge Base) 的统计信息,匹配大小各异的翻译单位(translation unit)进行自动翻译,这一项原创性研究比后来流行的同类研究早了5-10年。显然,大家都看好这一新的进展,作为重点向我们推介。整个访问的中心主题,仍然是解答他们关于汉语句法方面一些疑难问题。他们当时正在接洽欧洲和日本的可能的投资人,预备下一步大规模的商业开发,汉语作为不同语系的重要语言,其可行性研究对于寻找投资意义重大。
期间,Victor以世界语朋友身份,请我到他家吃晚饭。他住在离公司不远的一栋公寓里,太太来开门,先跟丈夫轻吻,然后招呼我进来。太太也是世界语者,忘了哪国人了,总之是个典型的世界语之家,家庭用语是世界语。Victor告诉我,太太实际上会一些英语,但是用英语对她不公平啊。太太很和善,跟我说,他们俩非常平等,她做饭,Victor洗碗。我说,这跟我家的分工一样,我最爱洗碗这种简单劳动。她笑着说,“Victor, vi havas helpanton hodiau (你今天有帮手了)”。饭后Victor洗碗,并没有让我插手,我站在旁边陪他聊天,一边看他倒进大把的洗涤液,满是泡沫把餐具拿出来,用干布擦干。我告诉他们,这跟我的做法不同,我们总是怀疑化学制品有毒或副作用,最后必须用清水涮净才好。太太不解地问:“洗涤液如果有毒,厂家怎么能生产呢?” 这倒把我问住了。Victor夫妇和蔼可亲,我感觉在老朋友家一样,饭后一边吃甜点和水果,一边闲聊,尽兴而归。
记于2006年6月21日
立委《我的世界语国》系列入《世运人物志》
原载 《朝华午拾:欧洲之行》
http://blog.sciencenet.cn/blog-362400-799006.html
上一篇:【旧文翻新:我的世界语国(4)】
下一篇:《旧文翻新:一小时学会世界语语法》
《旧文翻新:叔祖父遗作选-游戲類(四則)》 屏蔽留存
《旧文翻新:叔祖父遗作选-游戲類(四則)》
屏蔽 |||
【立委按】叔祖父李應會思想开明,关注时事。名曰游戏文字,抗日保国之心可鉴,汪洋恣肆,情系笔端。 天妒其才,不幸早逝,呜呼。

應會世兄 (立委叔祖父)
附載應會世兄遺著-游戲類
附載應會世兄遺著-游戲類(150-156);
抗日會宣言(仿討武曌檄)(150);
戲擬討日軍檄(仿北山移文)(152);
戲擬某軍長報孫傳芳書(仿楊惲報孫會宗書)(154);
================
抗日會宣言(仿討武曌檄)
為強暴日本者,地非廣大,人亦不多,昔為蓬萊荒野,曾以維新統治,洎乎晚近,跋扈東鄰,潛隱帝國之私,陰圖侵略之計,處心好利,絲毫不肯讓人,積慮嗜貪,涓滴都是為己。並朝鮮為內廄,吞台灣為外府。加以虺蜴為心,豺狼成性,勾通姦賊,蹂躪中華,殺人掠地,奪利侵權,人類之所同嫉,國際之所不容。猶復妄逞奢欲,窺竊中土,清之遜帝,挾之以重來,我之命官,驅之而遠去。嗚呼,熱河區之已失,喜峰口之又亡。直搗天津,痛華北之全喪,長驅關內,懼華中之頻危。本會抗日先鋒,人民領導,奉良心之使命,受海內之推崇。蔡公時之割鼻,良有道也。張作霖之炸腦,豈無故哉。是用疾首痛心,出生入死,因國聯之失望,順輿論之推心,爰樹漢旗,以驅倭寇。化除私見,摒棄黨爭。眾志成城,同心御侮。九萬方裡,大漢之土地無窮,四兆黎民,黃帝之苗裔靡盡。馬聲嘶而北風起,民氣奮而南鬥平。圍攻則受睏垓心,散擊則竄回海外。以次御侮,何侮能來,以次清妖,何妖不去。同胞或居內地,或寄外邦,或親橫行於目見,或聆殘暴於耳聞。既同一本,豈可貳心。三省之土未回,方寸之地難服,倘能撥亂誅暴,逐寇安民,共立恢復之功,毋負本會之望。凡我華胄,莫不歡迎,若其居家偷生,臨陣怕死,構成滅亡之兆,必遭殺戮之誅。請看今日之滿洲,竟是誰家之領土。
================
戲擬討日軍檄(仿北山移文)
大漢之英,黃帝之靈,馳文郵路,宣言漢人,夫以禮讓為國之標,和平待人之想,以刑威為非是,以德柔為崇尚,吾方知之矣。若其巍巍世錶,昂昂海外,救災厄而不吝,恤睏窮而不迫,聞虎踞西半球,見龍盤北寒帶,固亦有焉。豈期倭小猖狂,心志毒酷,淚人類之悲,慟國際之哭。常行險以僥幸,亦兵窮而武黷,何其謬哉!嗚呼,軒轅不存,總理既往,山河破碎,文物誰賞。世有日本,負隅自恃,既陰既狠,亦蛇亦豕。然而,學彼英暴,習夫德虐,竊壞盟條,濫毀公約,侵我權利,填彼欲壑。雖假口於護僑,乃專心於大陸。其始至也,竟而割台灣,占琉球,屬朝鮮,蹂福州,貪情張日,殺氣橫秋。似干畦之蚯蚓,似涸澗之泥鰍,如汪汪之瞎狗,若蠢蠢之蠻牛。沐猴適可比,小丑真堪儔。及其既望入蜀,故先赴隴。炮轟彈炸,機飛艦動,而乃占據東省,侵掠滬上,蔡廷楷禦敵有方,張學良守土無狀。海上凄其帶憤,華北咽而下愴。痛遼吉之已失,哀人民而如喪。至其陷熱河,下冷口,奪長城之雄,搗北平之首。擊秦皇之島嶼,攻天津之左右。公道長擯,公理久埋,蜂蠆有毒真堪慮,國聯無用弗可懷。滿洲已失,清帝又續,謀寸節之進攻,托傀儡而侮辱,殺越人而於貨,淫婦女以肆欲。希吞三江水,圖並九州域,使猶悠忽無憂,衰頹不舉,印度之伴,朝鮮之侶。國亡家破無所歸,自由幸福徒空佇。至於同舟共濟,眾志成城,奮神武兮我膽壯,殺妖魔兮寇心驚。曾聞投筆以入伍,未見有路不請纓。於是辭別家園,荷負槍炮,鼓我智勇,用我玄妙,聽中國之獅吼,聆漢族之虎嘯。使其狡窮詐盡,聲嘶力竭,還我失土,歸彼本國。處東海以朝貢,來中原稱臣妾。今正水深火熱,一發千鈞,縱國亡之不顧,矧家破而不驚。豈可使黃帝無顏,總理蒙恥,受宰割辱,遭奴隸鄙,睹瘡痍於滿目,聽呼號於充耳,宜塞口岸,堵隘關,輕財命,毋吝慳,截劣貨於海口,抗倭軍於郊端。於是人人瞋膽,個個怒魄,或械鬥以靳元,乍肉搏而滅跡,請回扶桑去,免我寶刀割。
矧 拼音:shěn, 况且。亦。much more, still more; the gums:http://www.zdic.net/zd/zi/ZdicE7Zdic9FZdicA7.htm
================
戲擬某軍長報孫傳芳書(仿楊惲報孫會宗書)
某才疏學淺,軍政無所能,幸賴老友拔擢,得長皖省,適逢時變,以獲司令,終非其任,卒與黨會,鈞座非其行,蒙賜書指責以所背負,言詞深刻,然竊恨鈞座不深維其時勢,而猥偏見之責備也,言鄙陋之苦衷,似巧言而脫罪,默而息乎,恐遭道遠傳言失實之冤,固敢詳陳其情,惟鈞座察焉。某家當貧賤時,游江湖者數年,身為皂隸,職備小兵,侍奉主人,以給衣食,曾不能於早年有所做作,以獲爵位,又不能效同伴相機乘時,籠絡當局之顯宦,已受奚落輕視之氣久矣。懷祿慕勢,不忍終屈,遂值革命,獲取軍官,身頗顯貴,妻子麗都,回思昔日,自分老死不可以得志,豈意獲得富貴,而榮先人之丘墓乎。深維人生有命,不可輕量,君子安分,不事強求,小人得意,定要再往。竊自思念官未高也,祿未厚也,冀享榮華以歿世也。是故身率妻子戮力拍馬,脋肩諂笑,以要鈞座,不意竟爾用以為司令也。夫時勢所不可為者,忠死無益,故鈞座於清室,官其官也,有時而背,某之境遇,亦猶是也。黨軍北伐,大兵偪近,攻城奪地,烈焰莫嚮,官此皖也,能不皖衛,職司令也,理應死戰,而士卒歌者數千人,飯後臂袒,仰天鼓腹而呼嗚呼,其歌曰,上打鼕鼕鼓,下打鼓鼕鼕,兩頭一齊打,當中翦芙蓉。軍心已變矣,思輓救不能。是日也,賚印而出。膝行匍匐,頓首百拜。誠卑污無狀,不知其不可也,某幸有官運,方卸甲投降,除軍長之任,此二品之官,簡任之職,某獲得之,同流之人,眾慕所歸,咸欲效法,而雅知某者,獨昧時而貴,究何損譽之有。俗語不雲乎,明明求貞節,尚恐不能報主者,忠臣之志也。明明順實務,常恐不識者,俊傑之意也。故道不同,不相為謀。今鈞座安得以忠臣之志而責僕哉。夫蔣公黨魁,中山之徒,有李宗仁唐生智之健將,凜然皆有本領。知攻守之機,頃者鈞座離皖垣。臨金陵,金陵岩險之區,逸仙舊壞,民黨羅列,豈保守之天塹哉。而今乃圖子之時也,方當軍務之急,願勉旃,毋多談。
賚 拼音:lài,同“賚”。賜予,給予:~賞。~賜。give, present, confer; surname:http://www.zdic.net/zd/zi/ZdicE8ZdicB3Zdic9A.htm
《夫子遗墨:附载应会世兄遗著-游戏类》影印件:




http://blog.sciencenet.cn/blog-362400-799410.html
上一篇:【旧文翻新:我的世界语国(2)】
下一篇:【旧文翻新:《李老夫子遗墨》简介】
【社煤挖掘:大数据告诉我们,希拉里选情告急】 屏蔽留存
【社煤挖掘:大数据告诉我们,希拉里选情告急】
屏蔽 |||
这是最近最近一周的对比图:
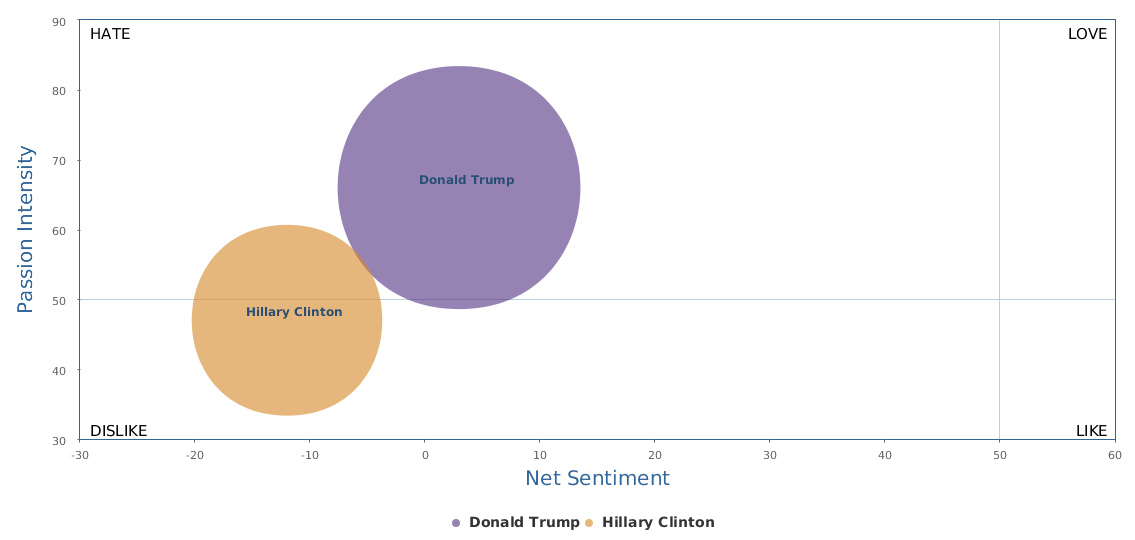
的确显得不妙,川大叔领先了。是不是因为FBI重启调查造成的结果?
这是过去24小时的图:
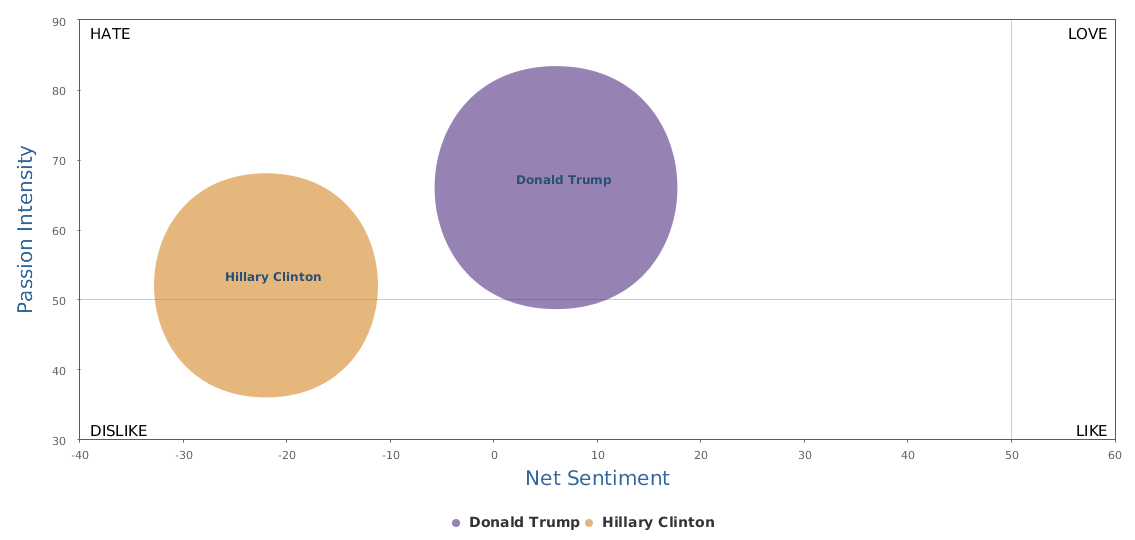
这是一个月的涨跌对比:
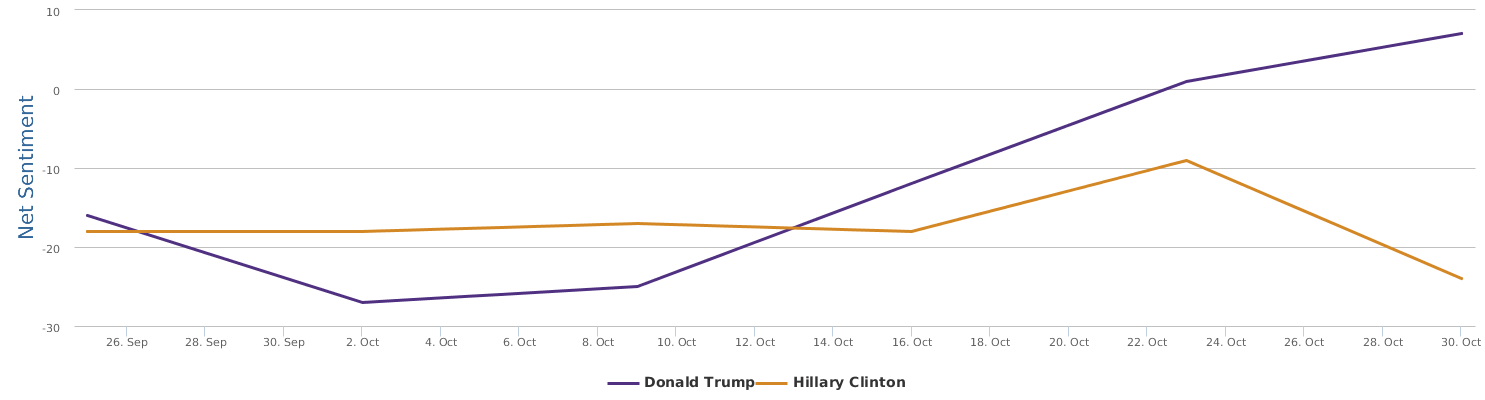
至此局势基本清晰了:希拉里的确选情告急。MD 这大选真是瞬息万变啊,不久前还是喜妈领先或胶着,如今川大叔居然翻身了,选情的变化无常真是让人惊心动魄。
这是last week:
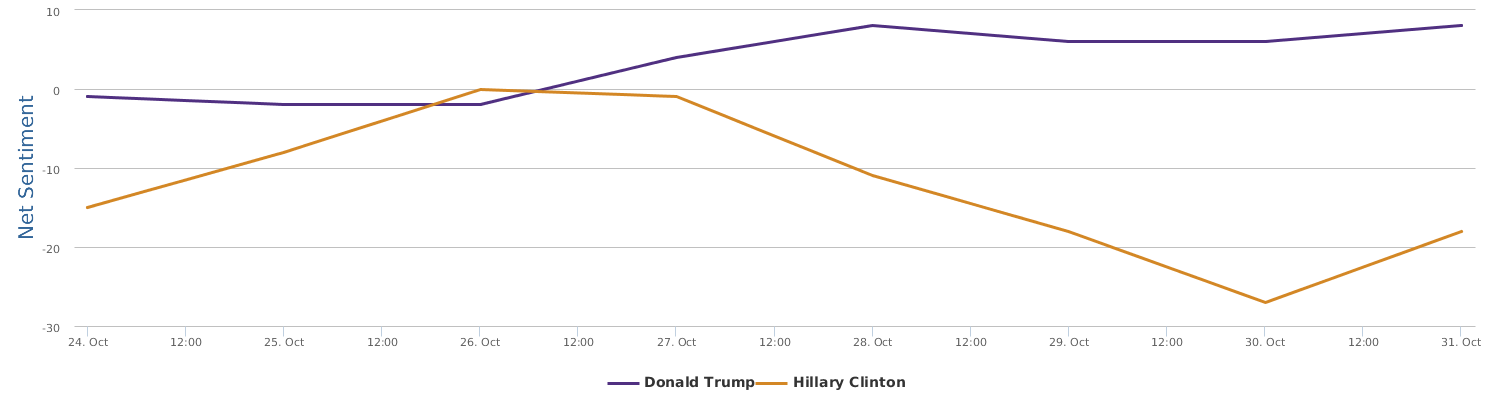
这一周喜婆,很被动很不利。过去24小时 一直在零下20上下,而老川在零上10左右,有30点(note:不是传统的 percentage points)的差距 NND:
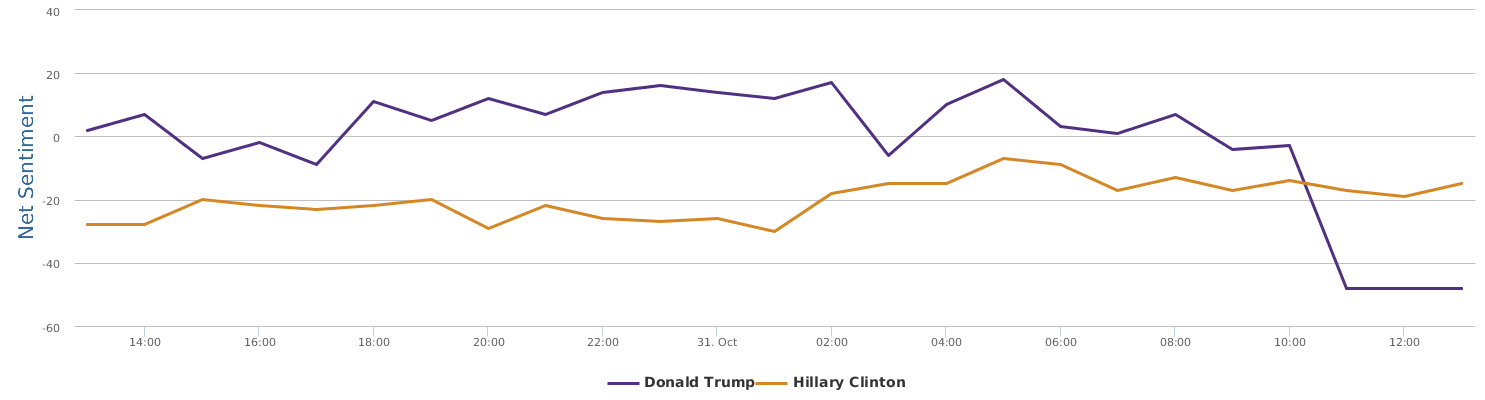
看看更大的背景,过去三个月的选情对比:
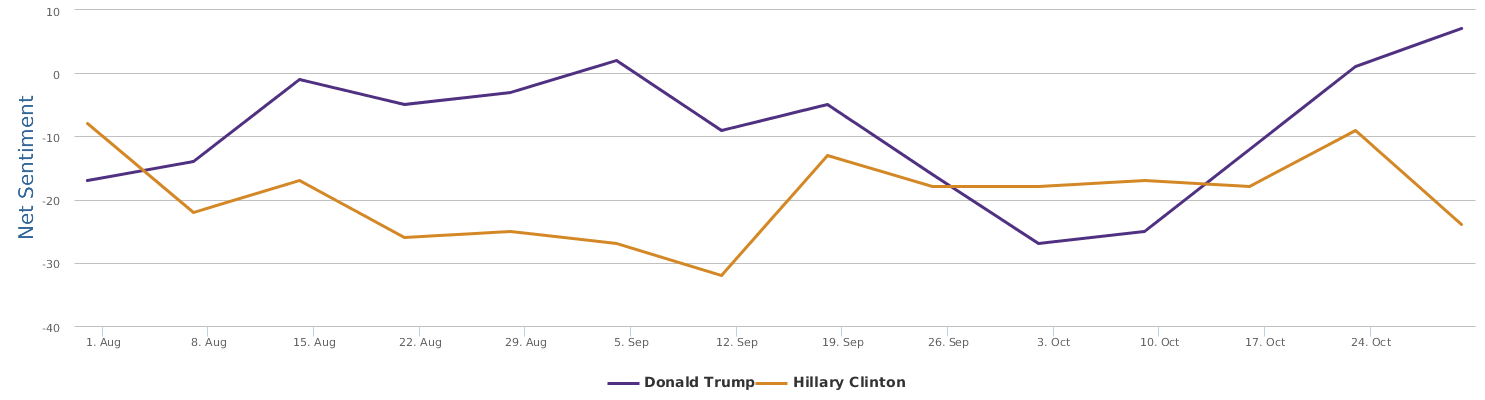
原来是, 喜大妈好容易领先了,此前一直落后,直到九月底。九月底到十月中是喜妈的极盛期,是川普的麻烦期。
至于热议度,从来都没有变过,总是川普压倒:
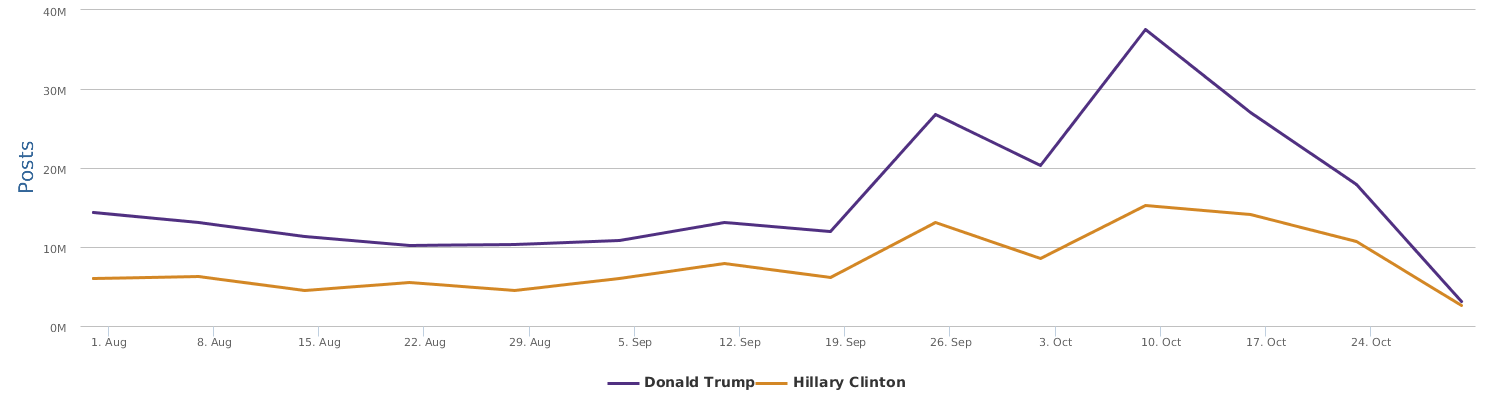
眼球数也是一样:
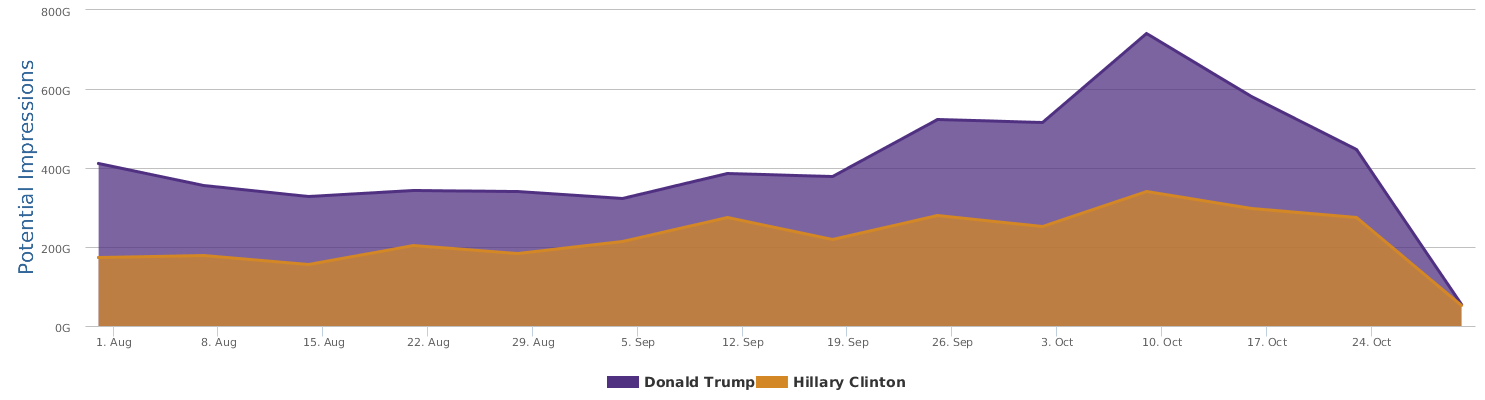
一年来的狂热度(passion intensity)基本上也是川普领先,但喜婆也有不有不少强烈粉她或恨她的,所以曲线有交叉:
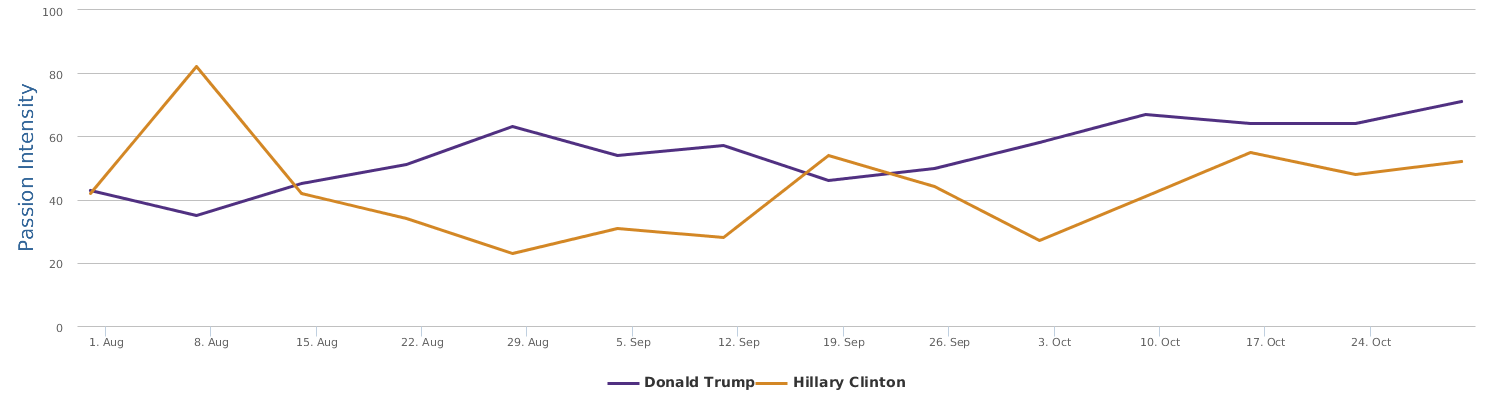
这个 passion intensity 与所谓 engagement 应该有强烈的正相关,因为你痴迷或痛恨一个 candidate 你就愿意尽一切所能去投入、鼓噪、撕逼。
最好是赶快把川大叔的最新丑闻抖出来。这家伙那么多年,难道就留不下比电话录音更猛、更铁的丑闻证据。常识告诉我们肯定有 skeleton in the closet,可是这家伙太狡猾,可能一辈子做商人太过精明,连染有液体的内裤也不曾留下过?是时候从 closet 拿出来了。反正这次大选已经 low 得不能再 low 了,索性 low 到底。不过如果要是有,不会等到今天,大选只剩下一周、先期投票已经开始。
这么看来,作为 data scientist,我不敢不尊重 data 一厢情愿宣传喜妈的赢面大了。赶巧我一周前调查的那个月是克林顿选情的黄金月,结果令人鼓舞。
我们有 27 种 filters,用我们的大数据平台可以把数据任意组合切割,要是在会玩的分析师手中,可以做出很漂亮的各种角度的分析报告和图表出来。地理、时间只是其中两项。
邮电门是摧毁性的。FBI 选在大选前一周重启,这个简直是不可思议。比川普的录音曝光的时间点厉害。那家印度所谓AI公司押宝可能押对了,虽然对于数据的分析能力和角度,远不如我们的平台的丰富灵活。他们基本只有一个 engagement 的度量。无论怎么说,希拉里最近选情告急是显然的。至于这种告急多大程度上影响真正的选票,还需要研究。
朋友提醒所谓社会媒体,其实是 pull 和 push 两种信息的交融,其来源也包含了不少news等,这些自上而下的贴子反映的是两党宣传部门的调子,高音量,影响也大,但并非真正的普罗网虫自下而上的好恶和呼声,最好是尽可能剔除前者才能看清真正的民意。下面的一个月走势对比图,我们只留下 twitter,FB,blog 和 microblog 四种社会媒体,剔除了 news 和其他的社会媒体:
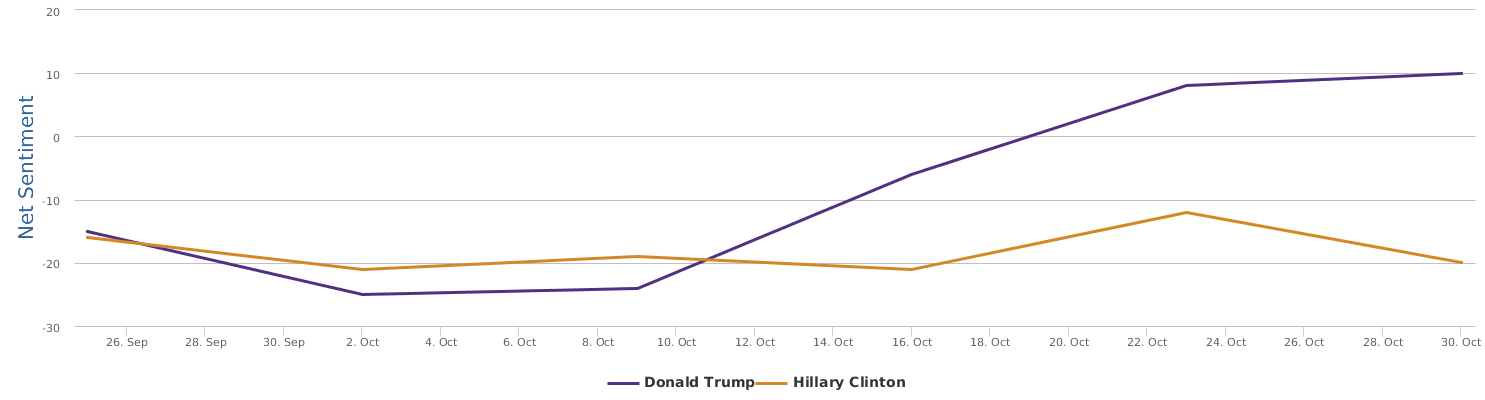
下面是推特 only,大同小异:
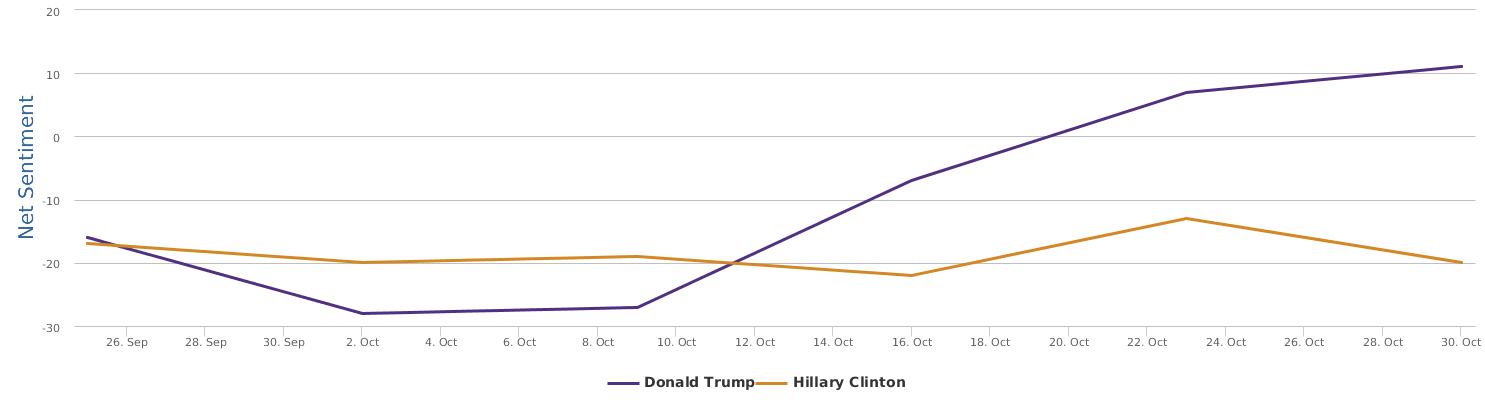
对比一下所有的社会媒体,包括 news 网站,似乎对于这次大选,pull 和 push的确是混杂的,而且并没有大的冲突和鸿沟:
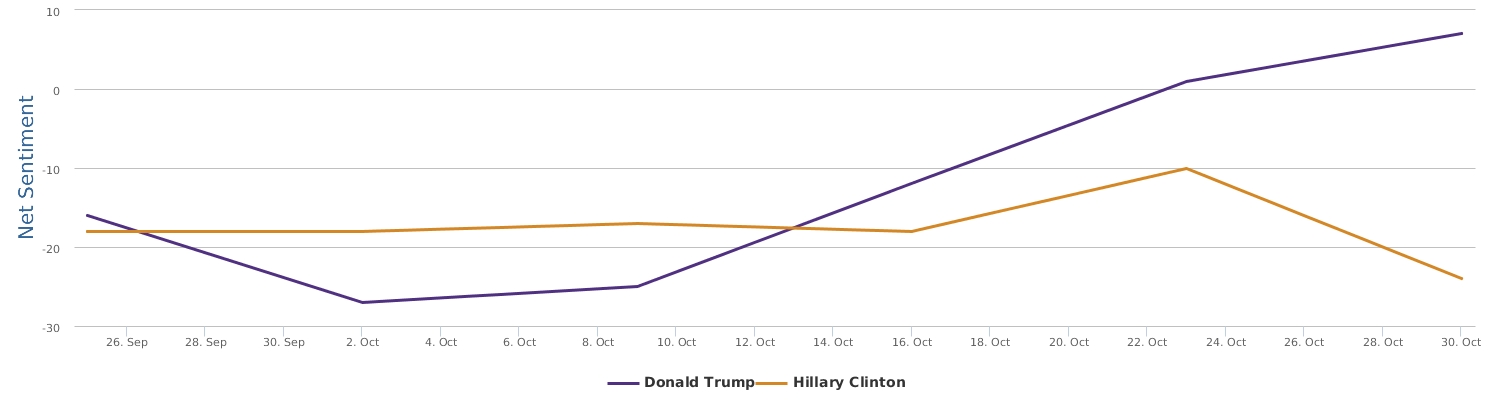
希拉里为什么选情告急?看看近一个月的希拉里云图,开始红多绿少了:


对比一下川普的云图,是红绿相当,趋向是绿有变多的趋势,尤其是第二张情绪(emotion)性云图:


再看看近一周的云图对比, 舆论和选情的确在发生微妙的变化。这是川普最近一周的sentiment 云图:


对比喜婆婆的一周云图:


下面是网民的针对希拉里来的正负行为表述的云图:

not vote 希拉里的呼声与 vote for her 的不相上下。对比一下川普最近一周的呼声:

vote 的呼声超过 not vote for him
这是最近一周关于克林顿流传最广的posts:
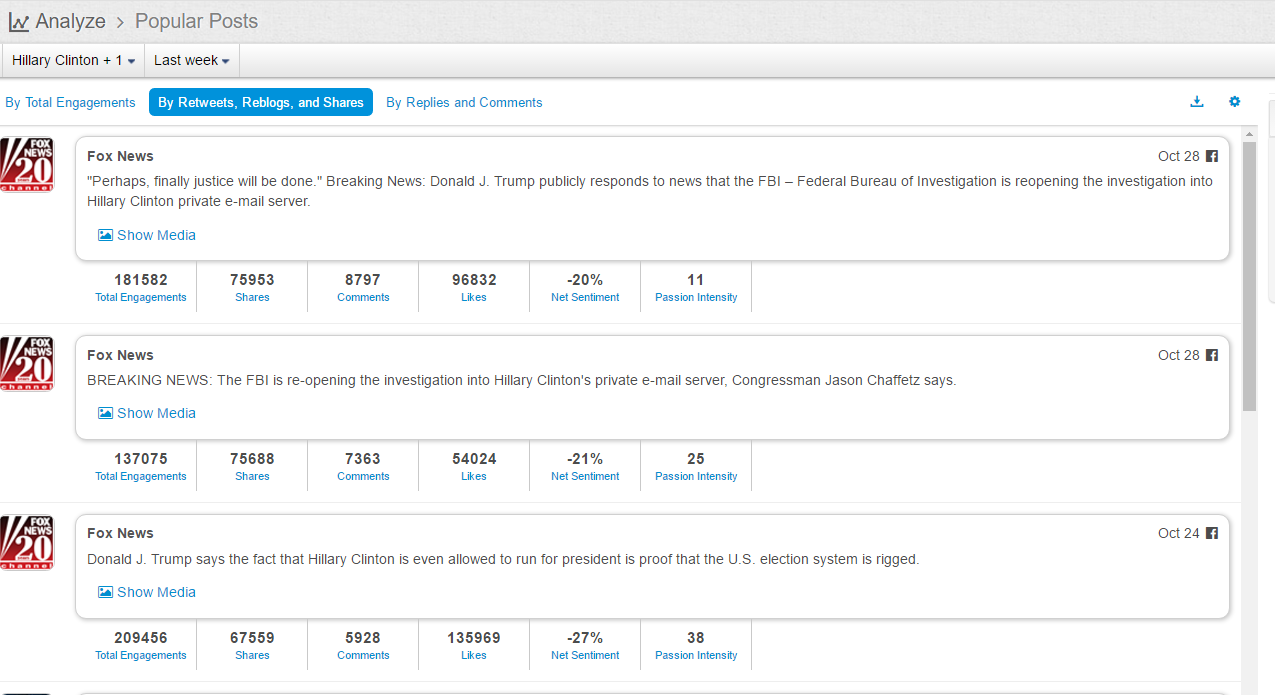
FBI 重启调查显然被川普利用到了极致,影响深远。
Most popular posts last week by engagement:
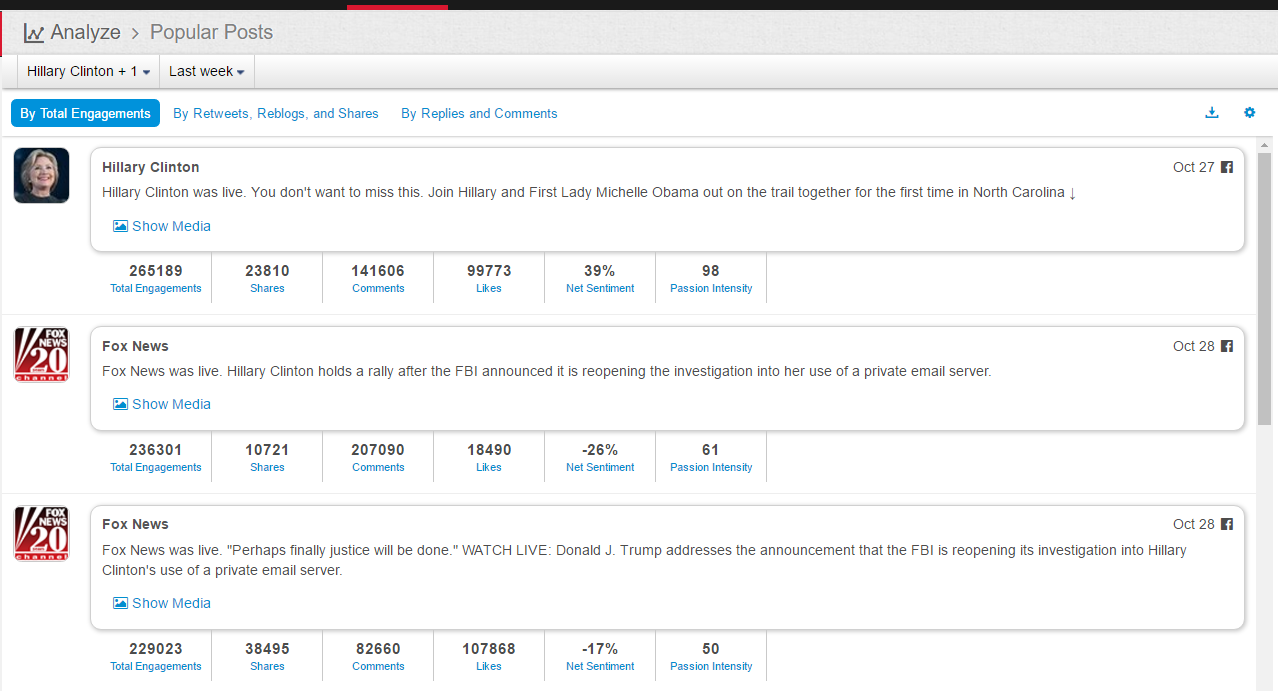
Most popular posts last week on Clinton by replies and comments:
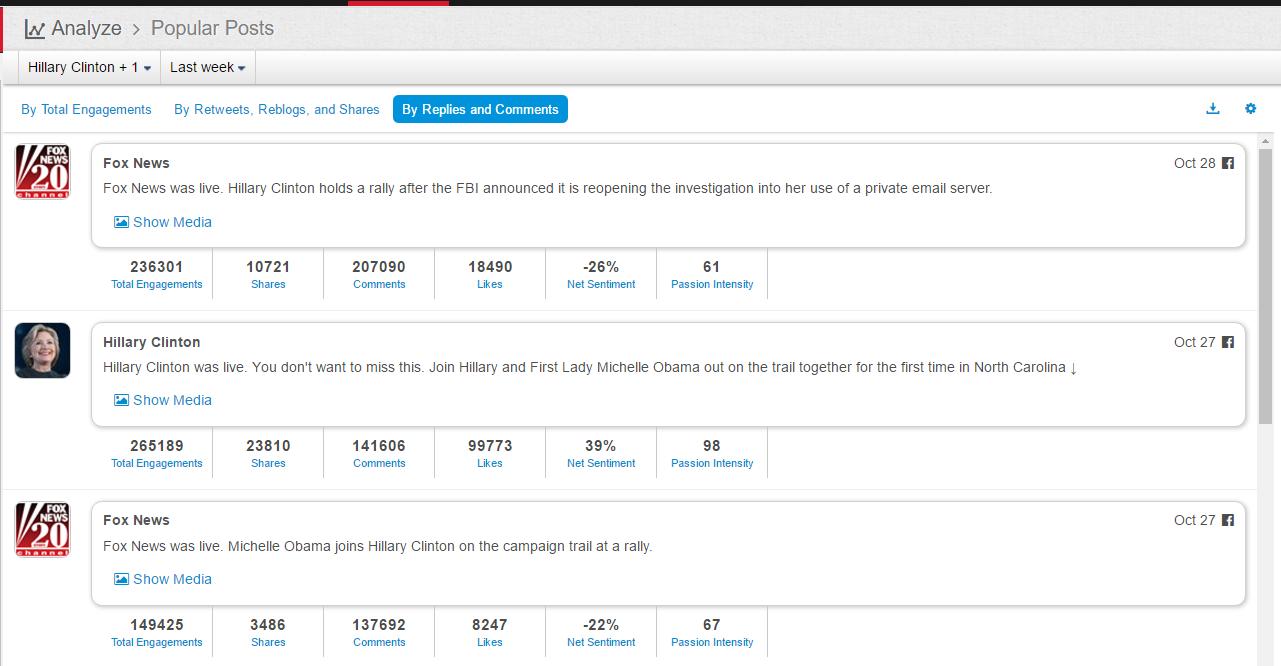
Some random sample posts:

negative comments are rampant on Clinton recently:
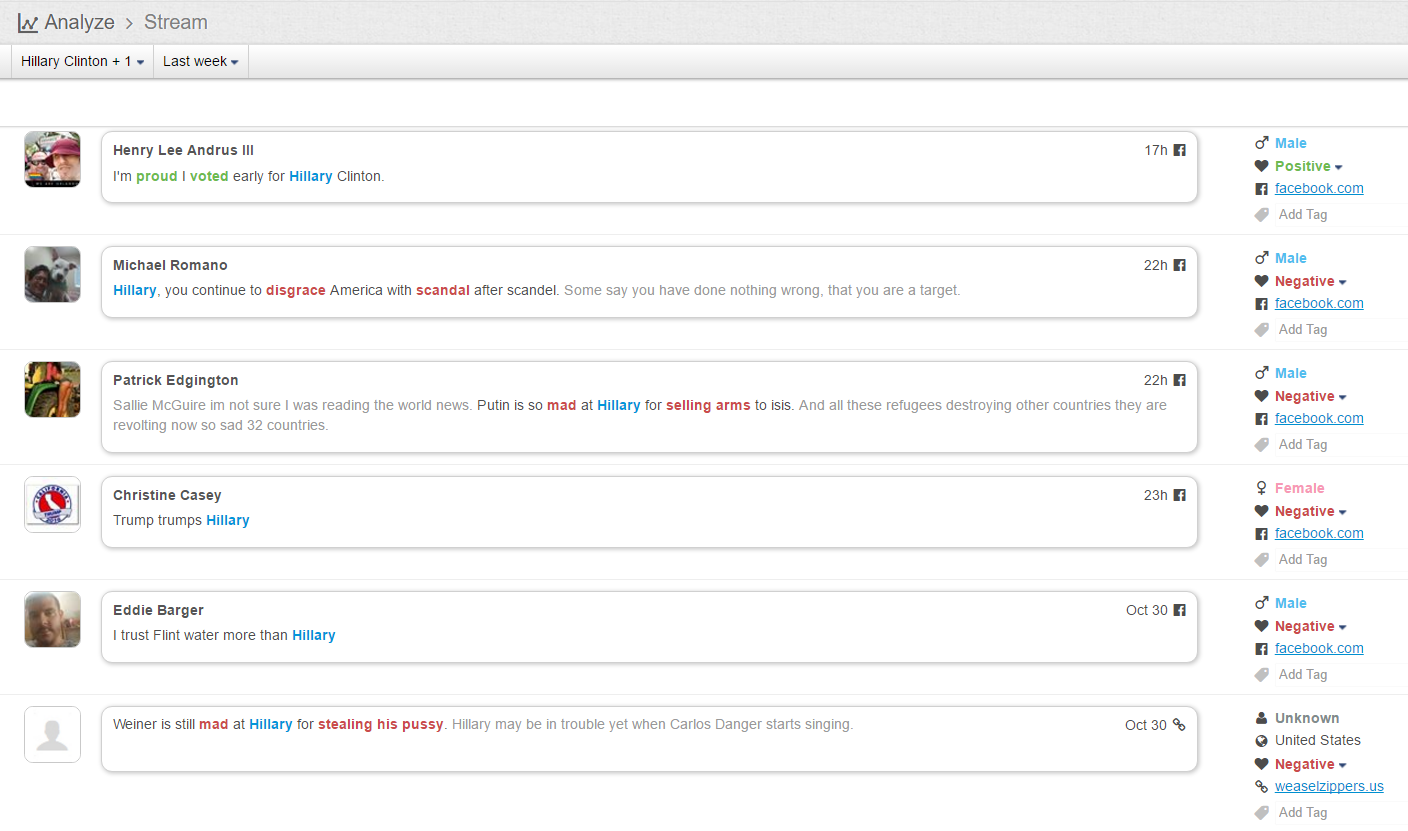
如果这次希拉里输了,the FBI director 居功至伟。因为自从录音丑闻以后,选情对希拉里极为有利,选情的大幅度下滑与FBI重启调查紧密相关。媒体的特点是打摆子,再热的话题随着时间也会冷却,被其他话题代替。这次的问题在,FBI 重启电邮门调查的话题还没等到冷却,大选就结束了,媒体和话题对选民的影响当下为重。而录音丑闻的话题显然已经度过了发酵和热议期,已经冷却,被 FBI 话题代替了。从爆料的角度,录音丑闻略微早了一些,可谁料到在这个节骨眼 FBI 突然来这么一招呢。
看看最近一周的#Hashtags,也可以了解一点社会媒体话题的热度:

与事件有关的有: #fbi #hillarysemails #hillarysemail #podestaemails19 #podestaemails20
Negative ones include: #wikileaks #neverhillary #crookedhillary #votetrump
Look at the buzz around Hillary below: the biggest is "FBI" in the brands cloud mentioned with her in the last week's data:

The overall buzz last week:

这是最近一周有关希拉里话题的emoji图:

虽然说笑比哭还,希拉里及其阵营和粉丝却笑不起来,一周内用到这个话题的emoji总数高达 12,894,243 。这也是社会媒体的特点吧,用图画表达情绪。情绪的主调就是 哭。邮件门终于炸了。
现在的纠结是,【大数据告诉我们,希拉里选情告急】,到底发还是不发?为了党派利益和反川立场,不能发。长老川志气,灭吾党威风。为了 data scientist 的职业精神,应该发。一切从数据和事实出发,是信息时代之基。中和的办法是,先发一篇批驳那篇流传甚广的所谓印度AI公司预测川普要赢,因为那一篇的调查区间与我此前做的调查区间基本相同,那是希拉里选情最好的一个月,他们居然根据 engagement alone 大嘴巴预测川普的胜选,根本就没有深度数据的精神,就是赌一把而已。也许等批完了伪AI,宣扬了真NLU,然后再发这篇 【大数据告诉我们,希拉里选情告急】
FBI director 说这次重启调查,需要很长时间才能厘清。现在只是有了新线索需要重启,不能说明希拉里有罪无罪。没有结论前,先弄得满城风雨,客观上就是给选情带来变数。虽然在 prove 有罪前,都应该假定无罪,但是只要有风声,人就不可能不受影响。所以说这个时间点是最关键的。如果这次重启调查另有黑箱,就更惊心动魄了。如果不是有背后的黑箱和势力,这个时间点的电邮门爆炸纯属与新线索的发现巧合,那就是希拉里的运气不佳,命无天子之福。一辈子强性格,卧薪尝胆,忍辱负重,功亏一篑,无功而返,保不准还有牢狱之灾。可以预测,大选失败就是她急剧衰老的开始。
一周前有个记者interview川普,川普一再说,希拉里这个犯罪的人,根本就不该被允许参加竞选。记者问,哪里犯罪了?川普说电邮门泄密,还有删除邮件隐瞒罪恶。当时这个重启调查还没有。记者问,这个案子不是有结论了吗,难到你不相信FBI的结论?川普说,他们弄错了,把罪犯轻易放了。这是一个腐烂的机构,blah blah。可是,同样这个组织,老川现在是赞誉有加。这就是一个无法无天满嘴跑火车的老狐狸。法律对他是儿戏,顺着他的就对,不顺着他心意的就是 corrupt,rigged,这种人怎么可以放心让他当总统?
中间选民的数量在这种拉锯战中至关重要,据说不少。中间选民如果决定投票,其趋向基本决定于大选前一周的舆论趋向。本来是无所谓是鸡是鸭的,如今满世界说一方不好,合理的推断就是去投另一方了。现在看来,这场竞赛的确是拉锯战,很胶着,不是一方远远超过另一方。一个月前,当录音丑闻爆料的时候,那个时间点,希拉里远远超过川普,毫无悬念。一个月不到,选情大变,就不好说了,迹象是,仍然胶着。
不过,反过来看,川普的 popularity 的确是民意的反映。不管这个人怎么让人厌恶,他所批判的问题的确长久存在。某种意义上,Sanders 这样的极端社会主义者今年能有不俗的表现,成为很多年轻一代的偶像,也是基于类似的对现状不满、对establishment的反叛的民意。而希拉里显然是体系内的老旧派,让人看不到变革的希望。人心思变的时候,一个体系外的怪物也可以被寄托希望。至少他敢于做不同事情,没有瓶瓶罐罐的牵扯。
上台就上台吧,看看他造出一个什么世界。
老闻100年前就说过:
这是一沟绝望的死水,清风吹不起半点漪沦。不如多扔些破铜烂铁,爽性泼你的剩菜残羹。
。。。。。。
这是一沟绝望的死水,这里断不是美的所在,不如让给丑恶来开垦,看它造出个什么世界。
【相关】
Trump sucks in social media big data in Spanish
Did Trump’s Gettysburg speech enable the support rate to soar as claimed?
Big data mining shows clear social rating decline of Trump last month
Clinton, 5 years ago. How time flies …
欧阳峰:论保守派该投票克林顿
http://blog.sciencenet.cn/blog-362400-1012046.html
上一篇:Trump sucks in social media big data in Spanish
下一篇:【大数据跟踪美大选,希拉里成功反击,拉川普下水】

【社煤挖掘:川普的葛底斯堡演讲使支持率飙升了吗?】屏蔽留存
【社煤挖掘:川普的葛底斯堡演讲使支持率飙升了吗?】
屏蔽 |||
反正日夜颠倒了,那就较真一下,看看大数据大知识,对于川普的葛底斯堡演说的所谓舆情飙升到底是怎么回事。先给几个links:
DONALD J. TRUMP DELIVERS GROUNDBREAKING CONTRACT FOR THE AMERICAN VOTER IN GETTYSBURG
报道的是本月22日川大叔的历史性演说,旨在振奋人心,做竞选的最后冲刺,大意:
寡人与美国人民有个约定,看我的,believe me
中文舆论中,这篇似乎流传最广:【川普重磅演讲致支持率飙升 全球股市将暴跌?】。
因为川普演说是22日,为了看舆情的飙升对比,可以以22日为中心取前后几天的社会媒体大数据做分析,看个究竟。至少比传统民调打五百、一千个电话来调查,自动民调的大数据(millions 的数据点)还是靠谱一些吧。
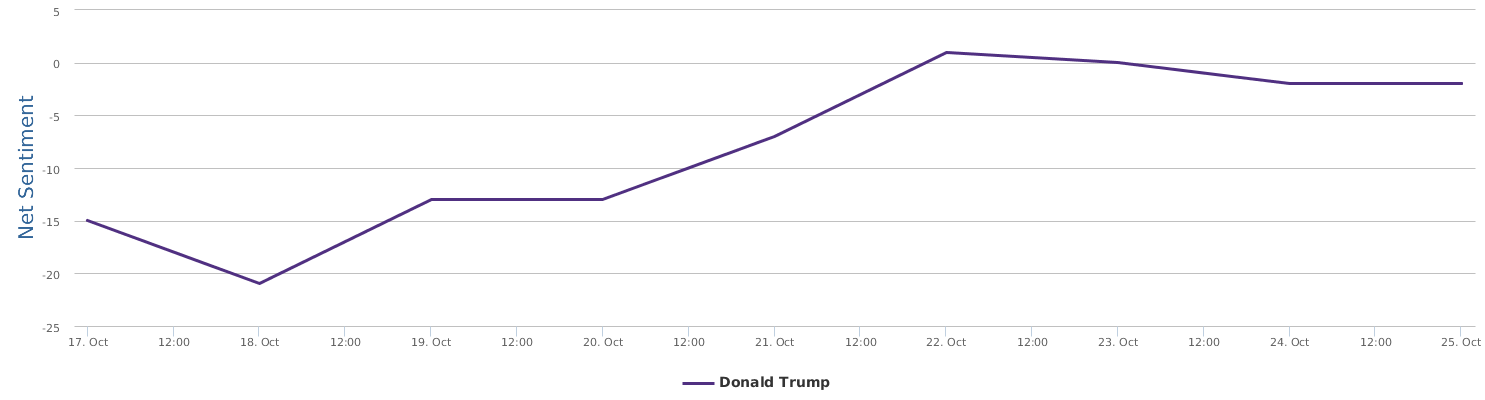
这张趋势图怎么看?
1 川普在这个时间区间总体的确是上升。飙升之说,不完全是无中生有(准确地说,其实是捕风捉影,见下)。
2 但是,仔细看舆情(net sentiment)图可以发现,川普这段时间基本上还是一直没有摆脱负面舆情多于正面舆情的局面,舆情曲线除了22号当天短暂超越冰点,总体一直是零下。
3. 飙升之说经不起推敲,因为凡飙升,必须是事件后比事件前的舆情,有明显的飞跃,其实不然。
4. 事实是,川大叔近期舆情的谷底是本月18号(零下20+),从18号到22号 他 deliver speech 前,他的舆情已经有比较明显的提升(从 -20 到 0),而从 22 号 到 25 号,舆情不升反略降,飙升从何谈起?
5. 虽然没有飙升,但川大叔这次表演还是及格的。至少 speech 后,舆情没有大跌,基本保持了接近零度的基本面。
6 由此可见,媒体造势是多么地捕风捉影。以后各位看到这种明显是宣传(propaganda)的帖子,可以多一个心眼了:通常的宣传造势的帖子都在夸大其词(如果不公然颠倒黑白或歪曲事实的话),从所谓“舆情飙升”到预计“股市暴跌”,都是要显示川普演说的重量级。基本是无稽之言,不能当真的。
下图是这个调查区间的数据小结:
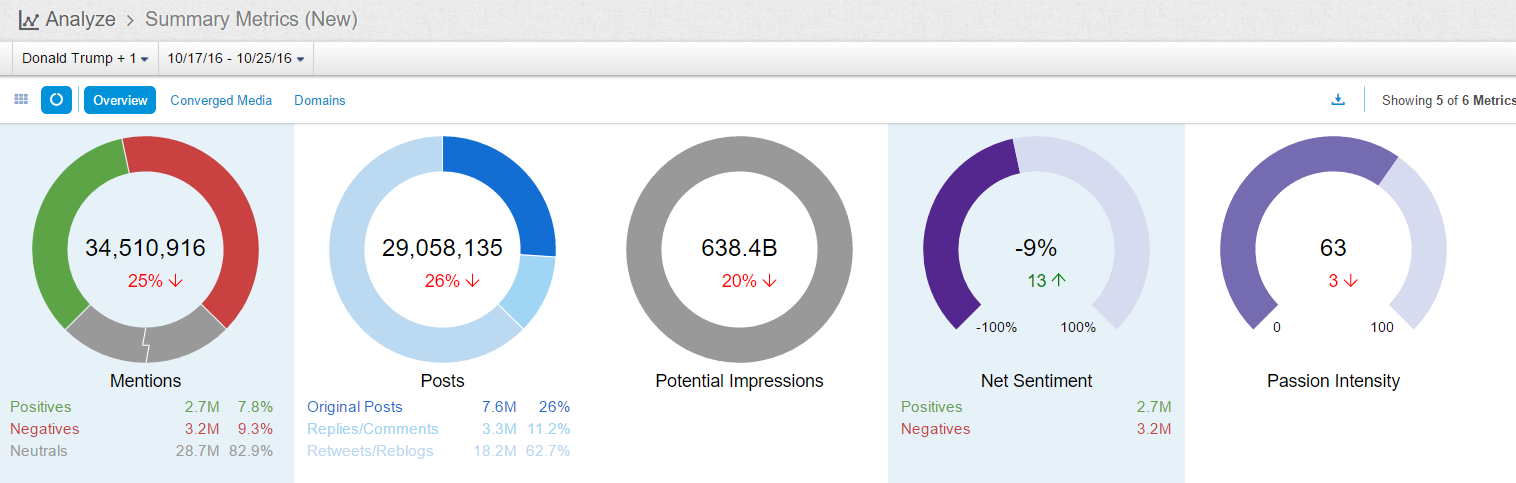
这个区间的平均舆情指数是 -9%,2.7 million 的正面评价,3.2 million 的负面评价。
-9% 是一个什么概念,根据我们以往对政治人物的多次舆情调查来看,这不是一个好的舆情,但也不是特别糟糕,属于平均线下。但是,与川普自己的总体舆情比较,这个区间表现良好,有 13 点的提升,但这个提升并非所谓演说飙升带来的。
这是社煤数据源的统计:
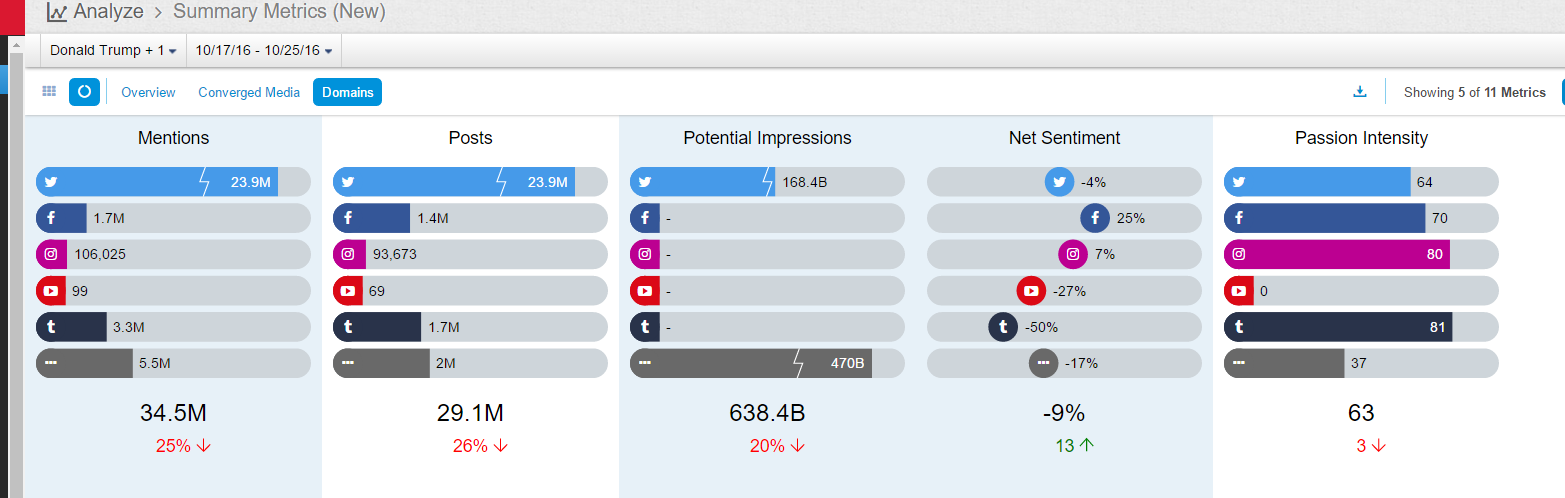
从比例看,推特永远是最 dynamic,量也最大,总热议度 34.5 mentions,推特占了 23.9 million。不少社煤的分析 apps 干脆扔掉其他的数据源,只做推特,作为社会媒体的代表,也基本上可以了。但是,感觉上还是,只做推特,虽然大数据之量可以保证,但可能偏差会大一些,因为喜欢上推特跟踪政治人物和话题,吐槽或粉丝的人,只是社会阶层中的一部分,往往是比较狂热的一批。推特这个公共平台,本来就长于偶像和followers(粉丝或“黑”)互动。其他的社会媒体可能更平实一些,譬如 Facebook 上的发言基本是说给朋友圈的。Facebook 也有 1.7 million 的热议。
好,我们把区间放大,看 last 30 days 的趋势,作为这次演说前后趋势的一个背景。
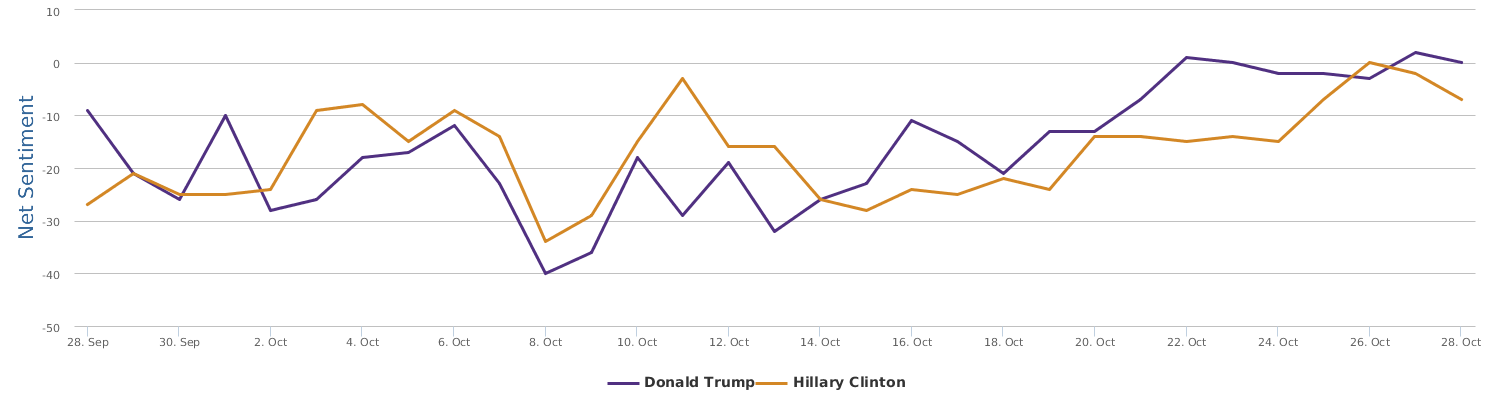
这是 9/28-10/28 的川普与克林顿舆情趋势对比图,by days;仔细解读前,总体印象是够纠缠的。这两位老头老太也真是,剪不断理还乱,不是冤家不碰头,呵呵。两位都那么多丑闻缠身,性格都很tough倔强。看看一个月来 by weeks 的曲线也许更明朗:
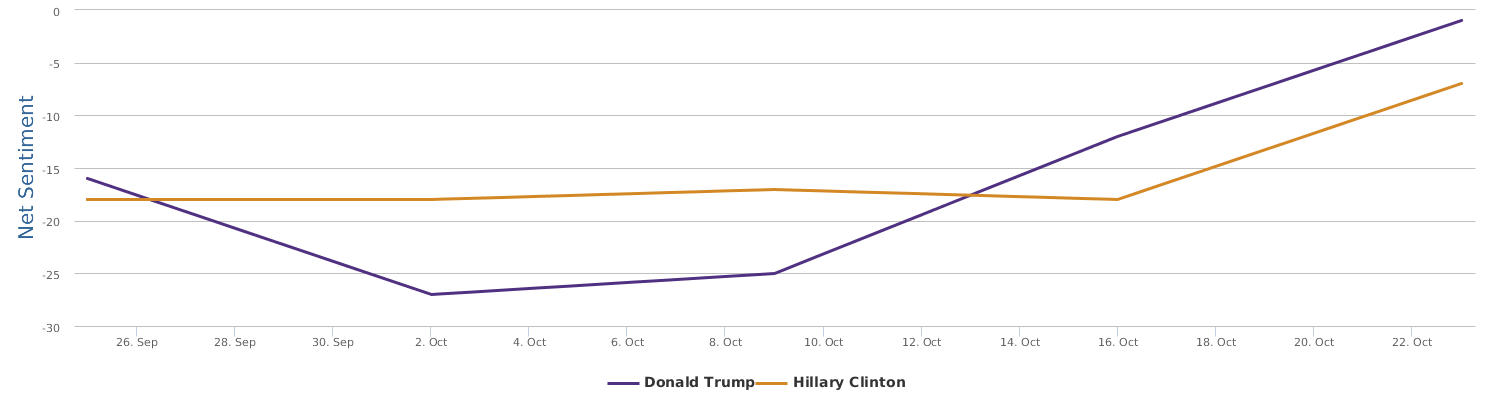
不管我多么厌恶川普,也不管我为了厌恶川普而决定选举并不喜欢的克林顿,作为 data scientist,不得不说,希拉里最近的情势不是很乐观:川普居然开始有点儿领先克林顿的趋势了,NND。
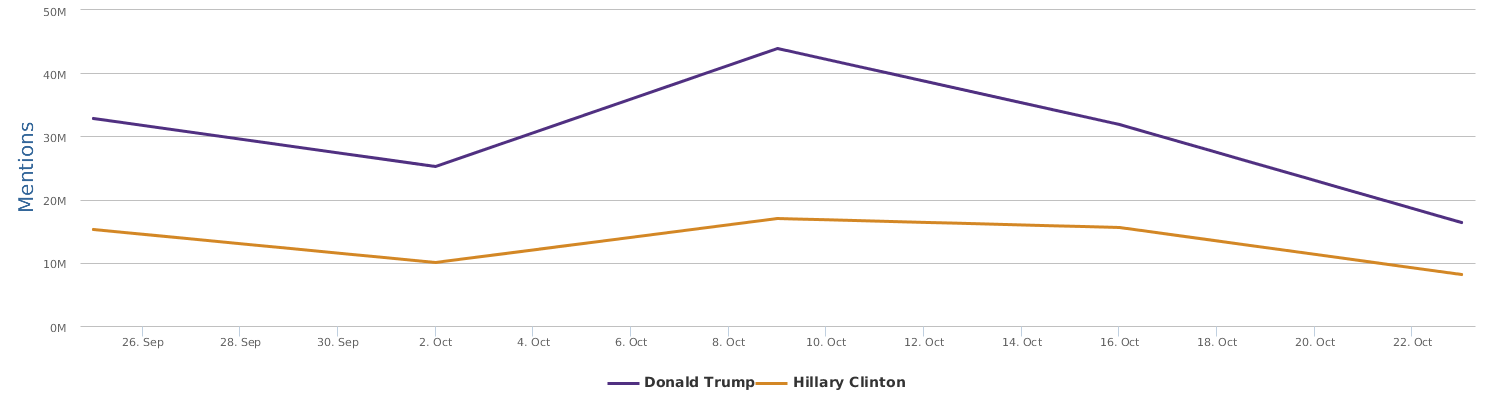
上图是热议度(mentions)的对比。这个没的说,川普天生的话题大王,克林顿无论如何也赶不上。
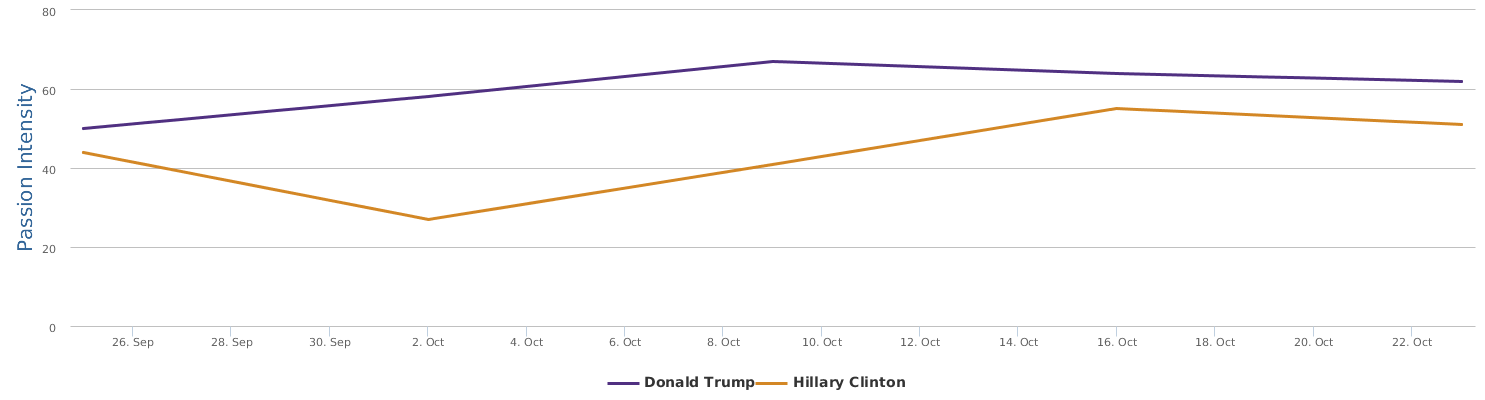
这是舆情烈度的对比:喜欢或厌恶川普的还是更加狂热,虽然印象中希拉里克林顿比起其他政治人物所引起的情绪已经要更趋于激烈了。可是川普是个政治异数,还是更容易引起狂热或争议。
川普在演说中特别强调选举被操纵的危险,他显然在夸大这种危险,为将来的不承认选举结果做铺垫。挺恶心人的。现在的情况是,如果克林顿大幅度领先,川大叔再流氓也没辙。如果是拉锯接近,就麻烦了,老川和川粉几乎肯定要闹事。可现在的选情显得有些胶着拉锯,这也是为什么很多人包括保守派开始有倡议,说为了川普,请投票克林顿。本来我是要投第三党的,或者弃权不投,但是这次选举不同,危险太大,川老是个定时炸弹,而且不可预测。为了防止他撒泼,还是投给克林顿好。至少让他看看,马戏团的表演是上不了台面的,由不得他胡来。沐猴而冠变不成林肯。
对比我 一周前做的自动民调 Big data mining shows clear social rating decline of Trump last month,下面这个品牌对比图似乎更加拉锯,克林顿最近选情不是很佳。
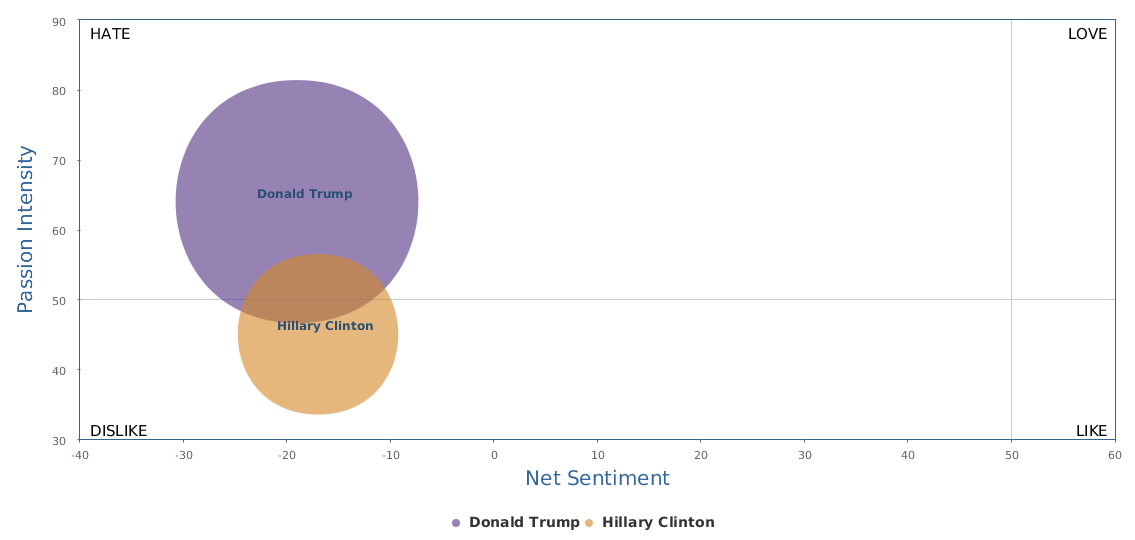
最近30天,克林顿是 -17%,川普是 -19%,略领先于川普。所幸,川普的这次演讲并没有真正扭转两人的差距,从下面这张历史趋势品牌对比看,克林顿从开始的舆情落后,变为领先的趋势还在:
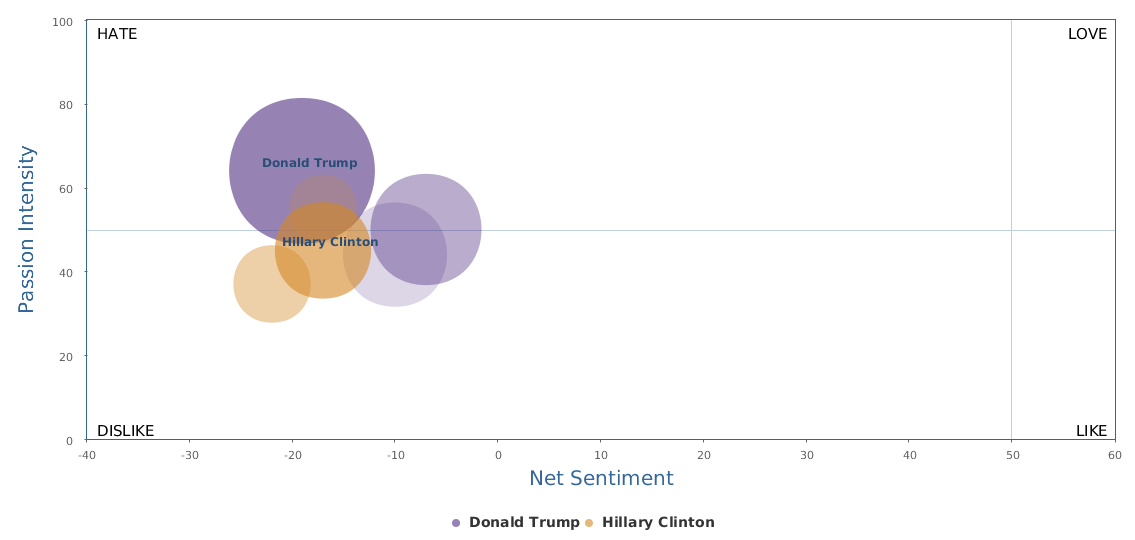
不过最近克林顿的选情是原地踏步,并没有明显进展。比较克林顿的三个圈可知,最淡的圈是过去30天的前10天,明显落后于川普,后两个圈是最近20天,基本原地,只是圈子变大了,说明竞选的投入和力度加大了,但效益并不明显。而从川普方面的三个圈圈看趋势,这老头儿实际的总体趋势是下跌,过去三十天,中间的十天舆情有改观,但最近的十天又倒回去了,虽然热议度有增长。(MD,这个分析没法细做,越做越惊心动魄,很难保持平和的心态,可咱是 data scientist 啊。朋友说,“就是要挖点惊心动魄的”,真心唯恐天下不乱啊。)看看川普的30天社煤的褒贬云图(Word Cloud for pros and cons)和情绪云图(Word Cloud for emotions)吧:
朋友一眼看中了那红红的 fuck 舆情,问:“fuck”的主语和宾语是谁?
主语一般不出现,默认是普罗网虫,fuck 的宾语当然是川普,否则上不来他的负面情绪云图:
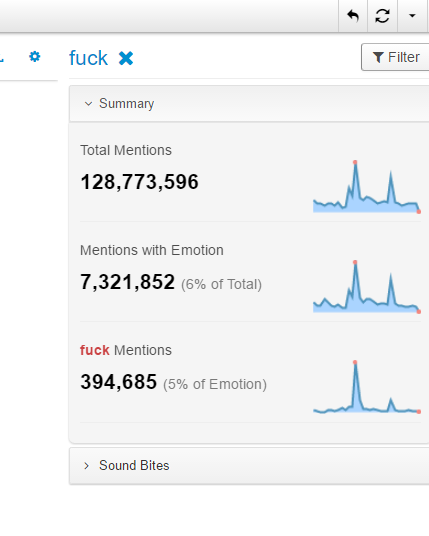
天,fuck mentions 占据了数据的 5%,老川在一个月里被社煤普罗 fuck 了近40万次,可见这家伙如果上台会有多少与他不共戴天的子民。看上面怎么吐槽 fuck 的:
fucking moron
fucking idiot
asshole
shithead
you name it,甚至疑似共和党人也fuck他:
Trump is a fucking idiot. Thank you for ruining the Republican Party you shithead.
看 popular media,貌似流传最广的大多是视频:
Tumblr 超越 Facebook 成为社煤老二?

从来没用过 Tumblr 这名字也拗口 怎么这么 popular?
西方媒体吐槽的,男女比较均衡:male 52% female 48%,对比中文社媒,明显是女人少谈政治的:才占25%。这次调查的种族背景分布:
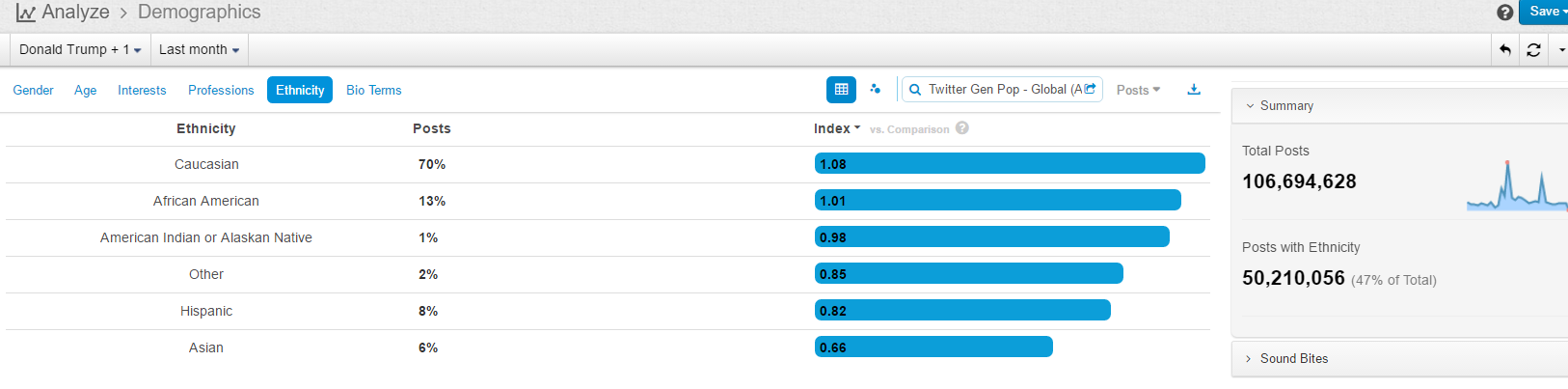
还是白大哥占压倒多数。族裔信息占社煤帖子中的近一半,所以这个社煤族裔分布的情报应该是靠谱的。黑大哥第二,占 13%,亚裔才 6%。墨大哥 8%, 与其人口比例不相称吧(?):由于语言或文化障碍,under-represented here??
这个有点意思,喜欢到社煤吐槽的人,集中在周三和周日的晚上,晚九点达到高峰, 譬如 关于川普话题的社煤,在周日晚上九点高达 1,357,766, 一个小时就有一百三十五万帖啊,够大数据吧。
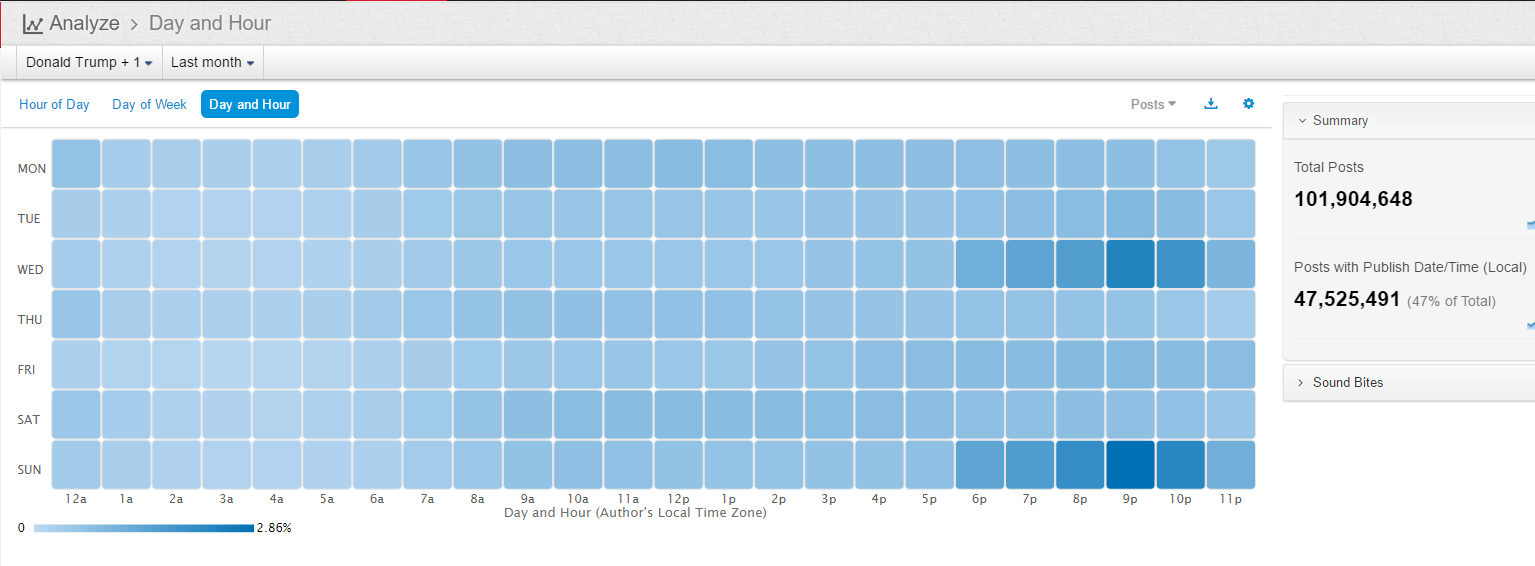
这还才是 sampling 的 data, 推特sampling占总量大约十分之一吧,如果是 data hose (要额外付钱的)一网打尽的话,数据量又要增加一个量级。不过,对于大数据情报挖掘,再增加一个量级已经没有什么意义了,不会实质上改变调查的结果的。说明一下,那个周日的统计量应该是过去一个月的调查中的周日的总和,一个月有四个周日,那个数据应该除以4,然后乘以10,才是川普数据周日九点的那是时间区间的真实量。总之是地地道道的大数据。相比之下,传统民调,不管怎么抽样,感觉都是儿戏,有点胡闹:
500 个电话,说是代表了两亿人的民意舆情,不是儿戏是什么。不过,前大数据时代,那是没办法的办法。自动民调是大势所趋。
下图是影响最大 followers 最多的 authors:
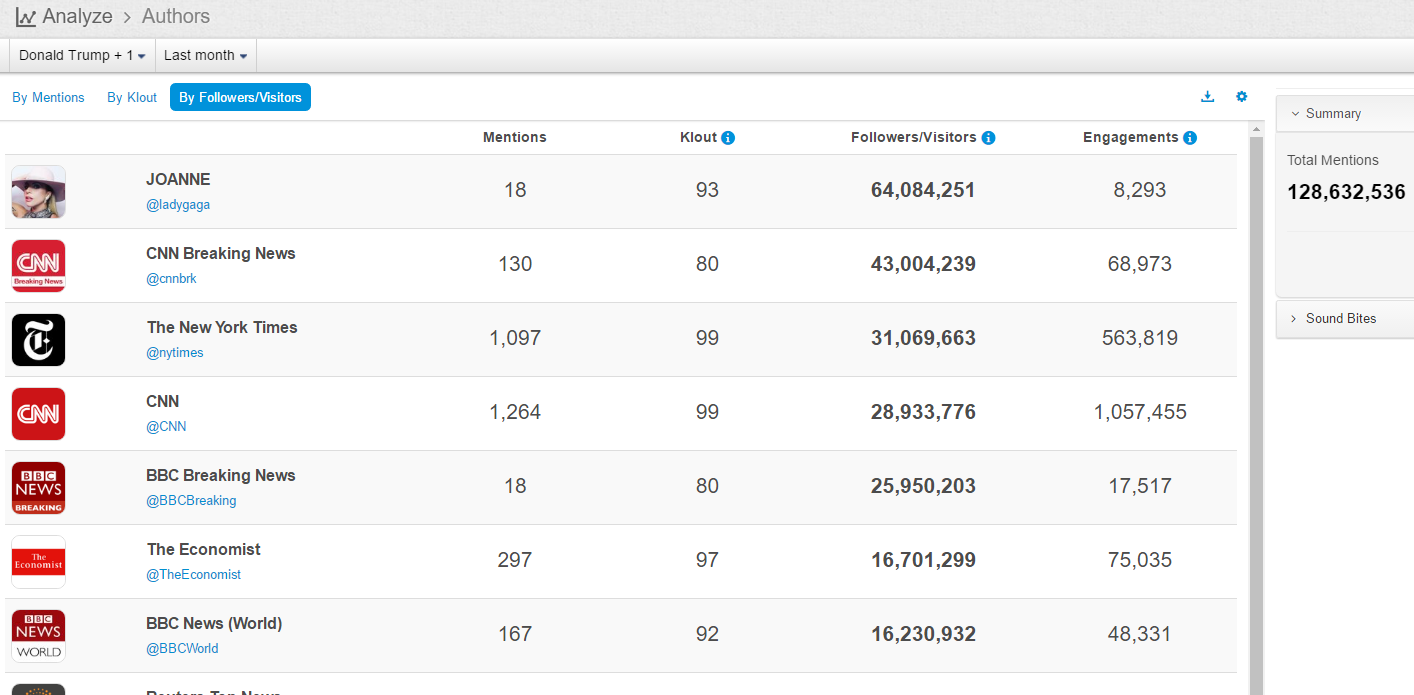
Most mentioned authors below:
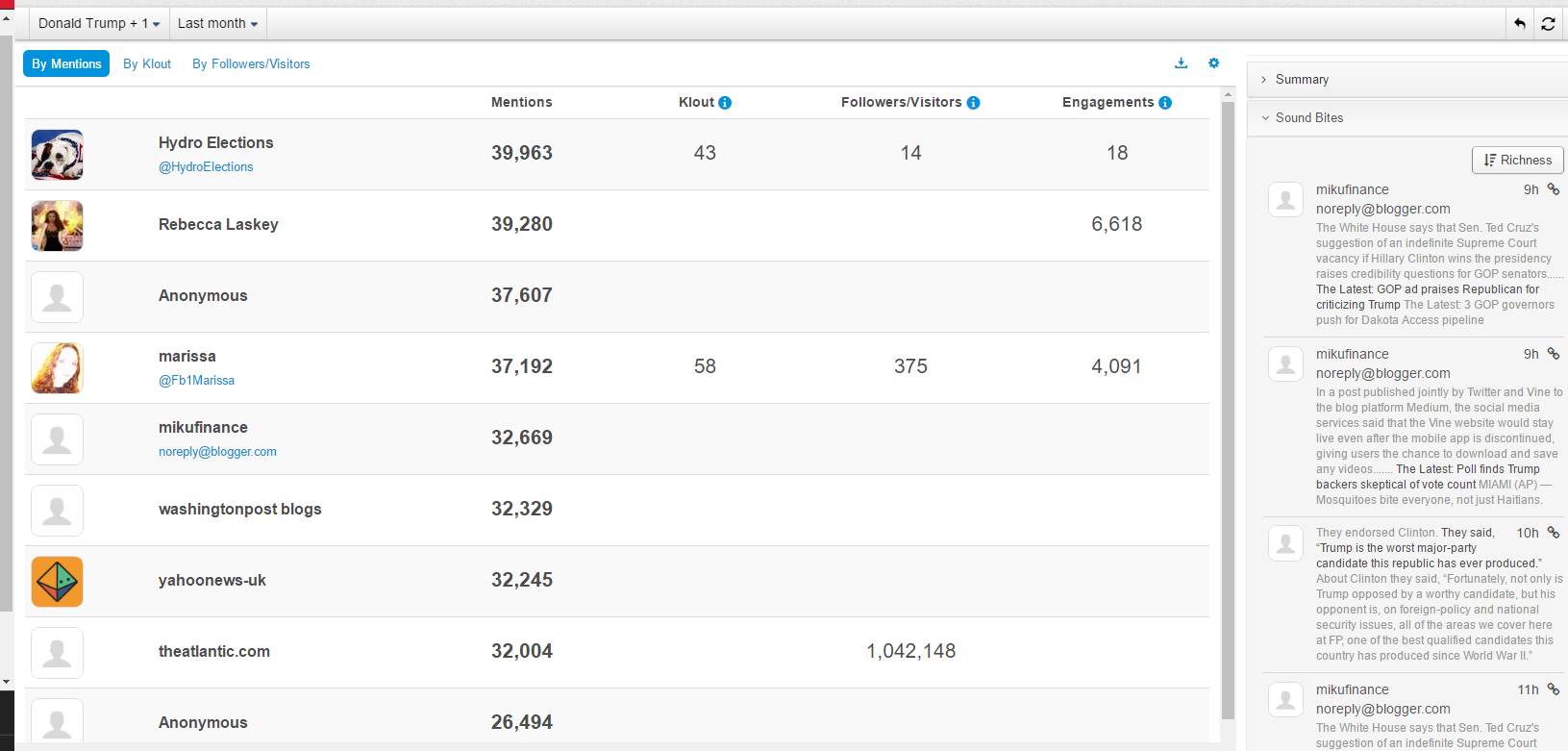
什么时代有过如此丰富的信息与如此强大的数据挖掘能力?
RW:
@wei 你实际上可以好好搞一个大选预测引擎,利用你现在的methodology, finetune 一下,可以吸引很多眼球。效果好,下次就可以收费了。一炮而红,还有什么是更有效的marketing?
我:
我要是有微信数据的话,不打炮也会红。什么都不用变,就是现在的引擎,现在的app,只要有微信,什么情报专家也难比拟。为什么现在发布中文舆情挖掘不如英文挖掘那么有底气?不是我中文不行,而是数据源太 crappy 了。闹来闹去也就是新浪微博、天涯论坛、中文推特或脸书。至少全球华人大陆背景的,这个压倒多数,都在用微信,而数据够不着,得不到反映。
李:
@wei 我公司有团队做着类似的事情
我:
你能染指微信数据?
李:
微信个人数据只有腾讯有。
看看流传最广的社煤帖子都是什么?
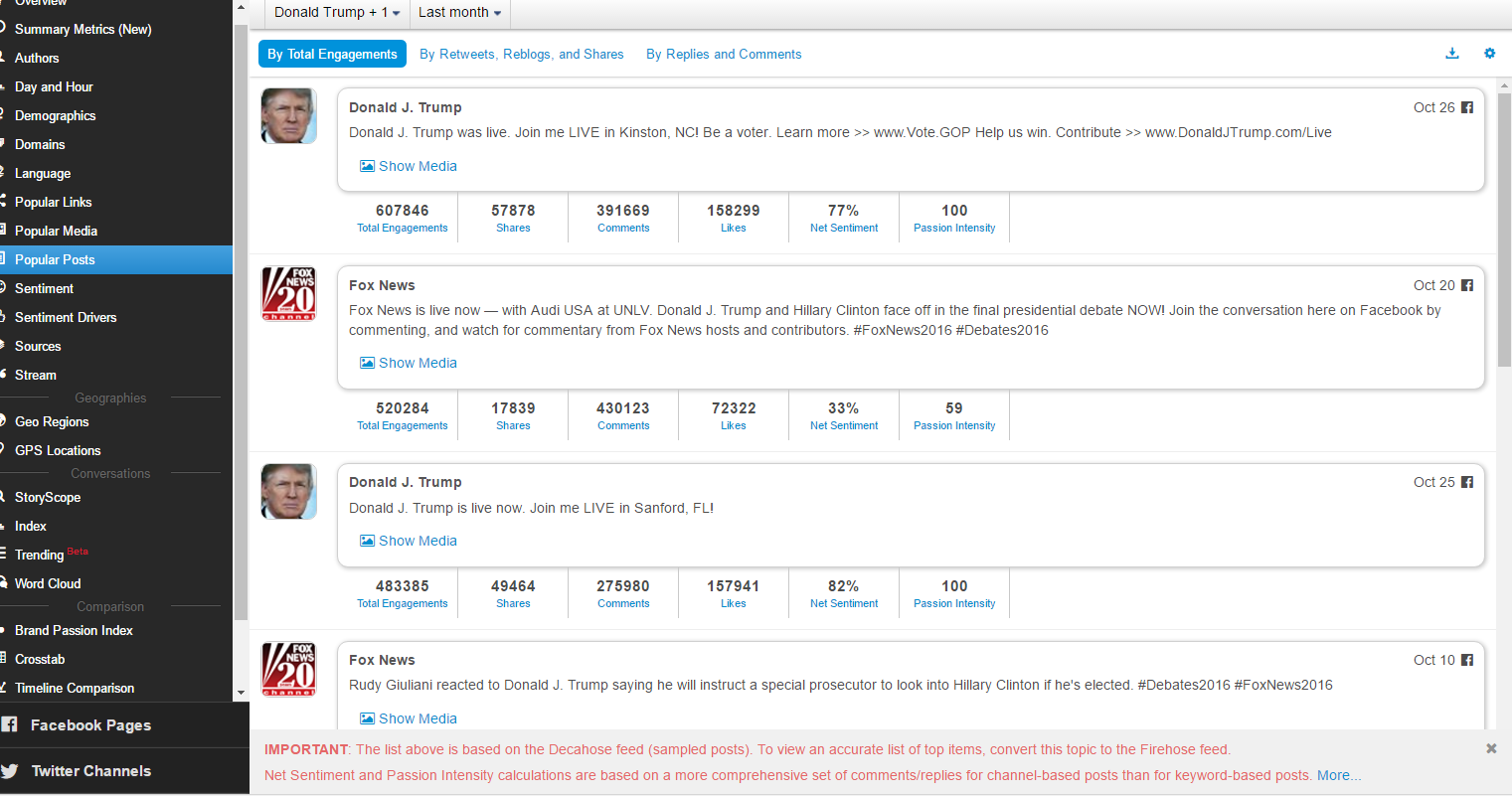
从 total engagement 指标看,无疑是川普自己的推特账号,以及 Fox : 这大概是唯一的主流媒体中仅存的共和党的声音了。也不怪,老川在竞选造势中,不断指着鼻子骂主流媒体,甚至刻薄主持人的偏袒。历史上似乎还没有一个候选人与主流媒体如此对着干,也没有一个人被主流媒体如此地厌恶。
展示到这里,朋友转来一个最新的帖子,说是用人工智能预测美国大选,川普会赢:Trump will win the election and is more popular than Obama in 2008, AI system finds,quote:
"But the entrepreneur admitted that there were limitations to the data in that sentiment around social media posts is difficult for the system to analyze. Just because somebody engages with a Trump tweet, it doesn't mean that they support him. Also there are currently more people on social media than there were in the three previous presidential elections."
haha,同行是冤家,他的AI能比我自然语言deep parsing支持的 I 吗?从文中看,他着重 engagement,这玩意儿的本质就是话题性、热议度吧。早就说了,川普是话题大王,热议度绝对领先。(就跟冰冰一样,话题女王最后在舆情上还是败给了舆情青睐的圆圆,不是?)不是码农相轻,他这个很大程度上是博眼球,大家都说川普要输,我偏说他必赢。两周后即便错了,这个名已经传出去了。川普团队也会不遗余力帮助宣传转发这个。
Xi:
那个印度鬼子也有点瞎扯了。
知道ip地址跟知道ssl加密后的搜索的内容是两码事儿啊!
不知道是记者不懂呢,还是这小子就是在瞎胡弄了。
洪:
印度ai公司预测美国大选,有50%以上测准概率,中国ai公司也别放过这个机会
毛:
伟哥为什么认为川普必赢?不是说希拉莉的赢率是 95% 吗?
南山/邓保军: 不是wei说的
我:
这叫横插一杠子。川普要赢,我去跳河。。。
毛:
哦,伟哥是在转述。
我:
跳河是玩笑了,我移民回加拿大总是可以吧。
李:
韩国这个料就爆得好。希拉里在关键时刻,也有可能爆大料
我:
问题是谁爆谁的料。两人都到了最后的时刻,似乎能找到的爆料也都差不多用了。再不用就不赶趟了。很多地方的提早投票都已经开始了,有杀手锏最多再等两三天是极限了,要给媒体和普罗一个消化和咀嚼的时间。
毛:
@wei 但是老印的那个系统并非专为本届大选而开发,并且说是已经连续报准了三届呀?
我:
我的也不是专为大选开发的呀。而且上次奥巴马决定用我们,你看他就赢了,我们也助了一臂之力呢。
毛:
你们两家的配方不同?
我:
奥巴马团队拥抱新技术,用舆情挖掘帮助监测调整竞选策略,这个比预测牛一点点吧。预测是作为 outsider 来赌概率。我这个是 engage in the process、技术提供助力 呵呵。当时不允许说的。
李:
奥巴马有可能会去硅谷打工唉
毛:
是否在舆情之外还有什么因素?
李:
原来你那个奥巴马照片不是蜡像呀
我:
假做真时真亦假呀。

【相关】
Big data mining shows clear social rating decline of Trump last month
Clinton, 5 years ago. How time flies …
欧阳峰:论保守派该投票克林顿
http://blog.sciencenet.cn/blog-362400-1011526.html
上一篇:为了川普,我选克林顿。
下一篇:Did Trump's Gettysburg speech enable support rate to soar?
3 冯国平 史晓雷 bridgeneer
【社煤挖掘:为什么要选ta而不是ta做总统?】 屏蔽留存
【社煤挖掘:为什么要选ta而不是ta做总统?】
屏蔽 |||
中文社煤挖掘美国大选的华人舆情,接着练。
Why and why not Clinton/Trump?
Why 喜大妈?Why 川大叔?Why not Clinton? Why not Trump?这是大选的首要问题,也是我们舆情挖掘想要探究的重点。Why???
First, why Clinton and why not Clinton? 看看喜大妈在舆情中的优劣对比图(pros and cons)。

why Clinton?剔除竞选表现优秀等等与总统辩论和 campaign 有关的好话(“领先”、“获胜”、“占上风”、“赢得”等)外,主要理由有:
1. 老练 强硬; 2. 乐观; 2. 清楚; 4 换发活力 谈笑风生; 5. 梦想共同市场
拿着放大镜,除了政治套话和谀辞外也没看到什么真正的亮点。舆情领先,只能说对手太差了吧。四年前与奥巴马竞争被甩出一条街去,那是遇到了真正的强手。
OK,why not Clinton?
1. 性侵 性骚扰 威胁(她丈夫做的好事,她来背黑锅,呵呵。照常理她是受害者,可以同情的,不料给同样管不住下半身的川普一抹黑,她倒成了性侵的帮凶,说是威胁被性侵的女性。最滑稽的是,川普自己的丑闻曝光,他却一本正经带了一帮前总统克林顿的绯闻女士开记者会,来抹黑自己的对手克林顿夫人。滑稽逆天了。)
2. 邮件门 曝光 泄密
3 竞选团队的不轨行为 操纵大选 作弊
4. 克林顿基金会的问题
5. 华尔街收费
6 健康问题
7 撒谎、可耻
8. 缺乏判断力
这些都不是新鲜事儿,大选以来已经炒了很久了,但比起她的长处(经验老练等少数几条),喜妈被抓住的辫子还真不少。再看网民的情绪性吐槽, 说好话都是相似的,坏话却各有不同:轻的是,“乏善可陈”、“不喜欢”、“不信任”; 重的是:“妖婆”,“婊子”、“灾难”、“无耻”、“邪恶”。

作为对比,来看川大叔,why or why not Trump?

pros:1. 减税;2. 承诺 崛起 (America great again);3. 真实;4. 擅长 business
cons:
1. 曝光的视频丑闻 性骚扰
2. 偷税漏税
3. 吹嘘
4 咄咄逼人 喜怒无常
5 粗鄙、威胁
6 撒谎
情绪性吐槽,轻的是 “不靠谱”、“出言不逊”,重的是 “恶心”、“愚蠢”、“卑劣”、“众叛亲离”。

上篇中文社煤自动民调博文发了以后有朋友问,为什么不见大名鼎鼎的脸书。(微信不见可以理解,人家数据不对外开放,对隐私性特别敏感,比脸书严多了。不过,地球人都知道,反映我大唐舆情最及时精准的大数据宝库,非微信莫属)。查对了一下,上次做的中文舆情调查,不知何故 Facebook 不在 top 10,只占调查数据的 0.1%:
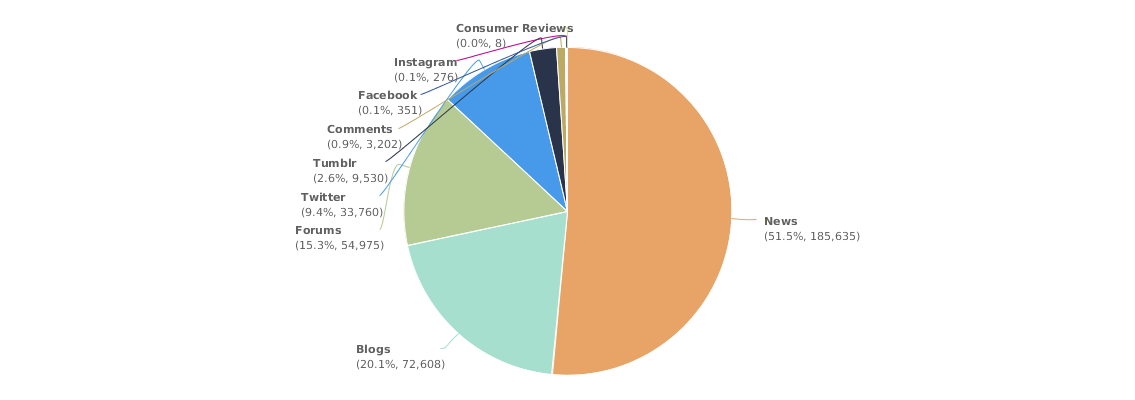
记得以前的英语社煤调查,通常的比例是 70% twitter,20% Facebook, 其他所有论坛和社交媒体只占 10%。最近加了 instagram、Tumblr 等,格局似有变。但是中文在海外,除了推特,Facebook 本来应该有比重的,特别是我台湾同胞,用 Facebook 跟东土用微信一样普遍。
再看看这次调查的网民背景分类。
1. 职业是科技为主(大概不少是咱码农),其次才是新闻界和教育界。这些人喜欢到网上嚷嚷。
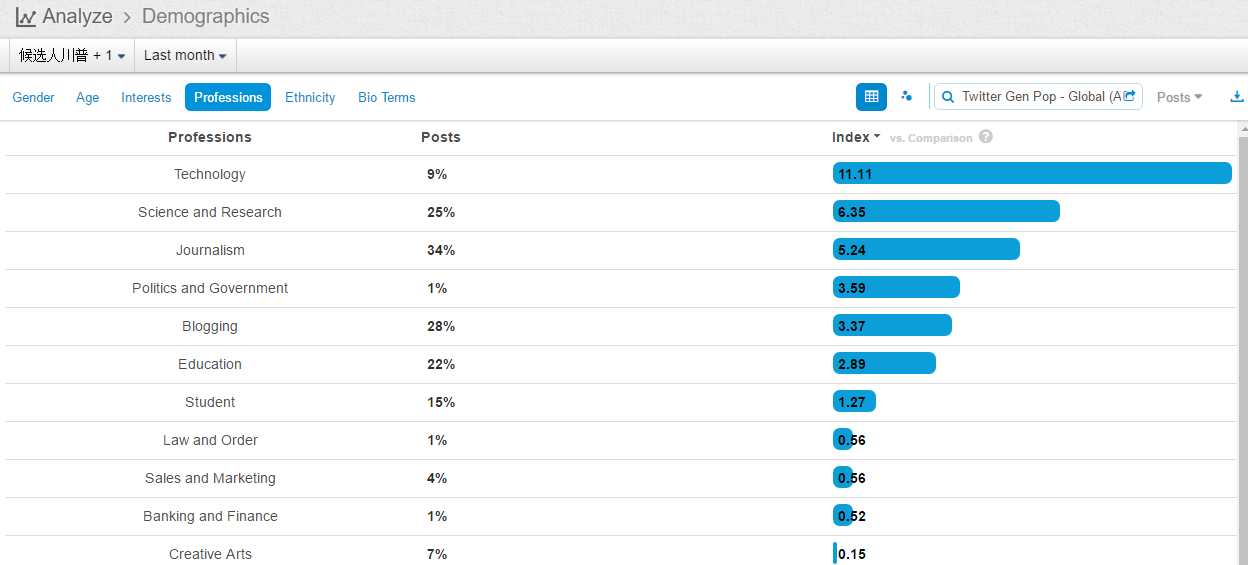
这是他们的兴趣(interests),有意思的关联似乎是,喜欢谈政治的与喜欢谈宗教和美食的有相当大交集。
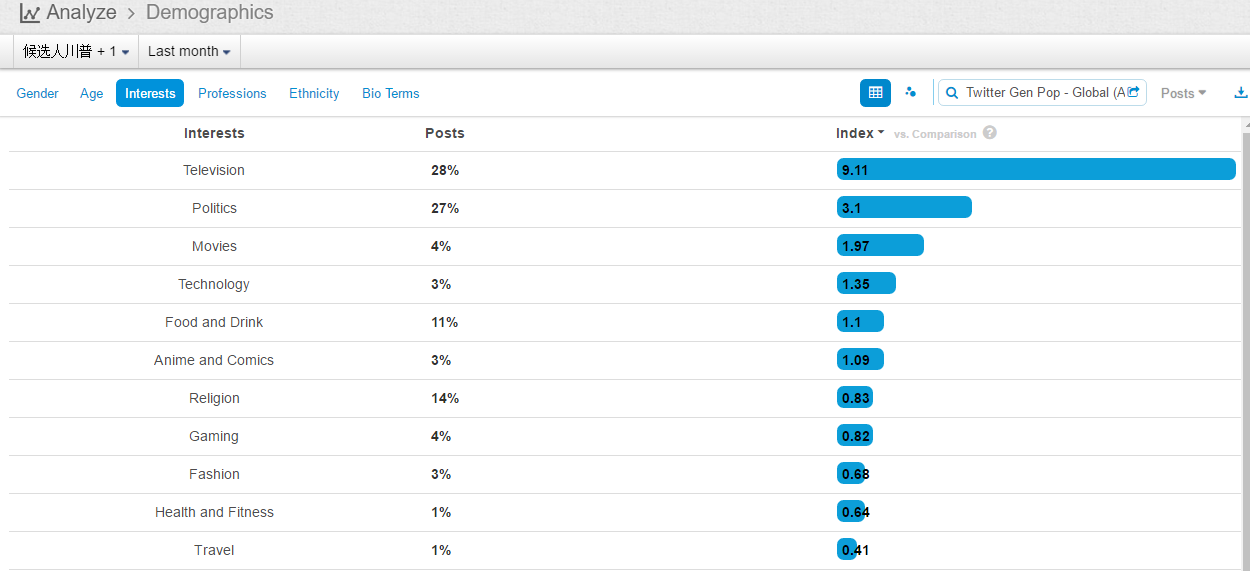
这是年龄分组,分布比较均匀,但还是中青年为主。
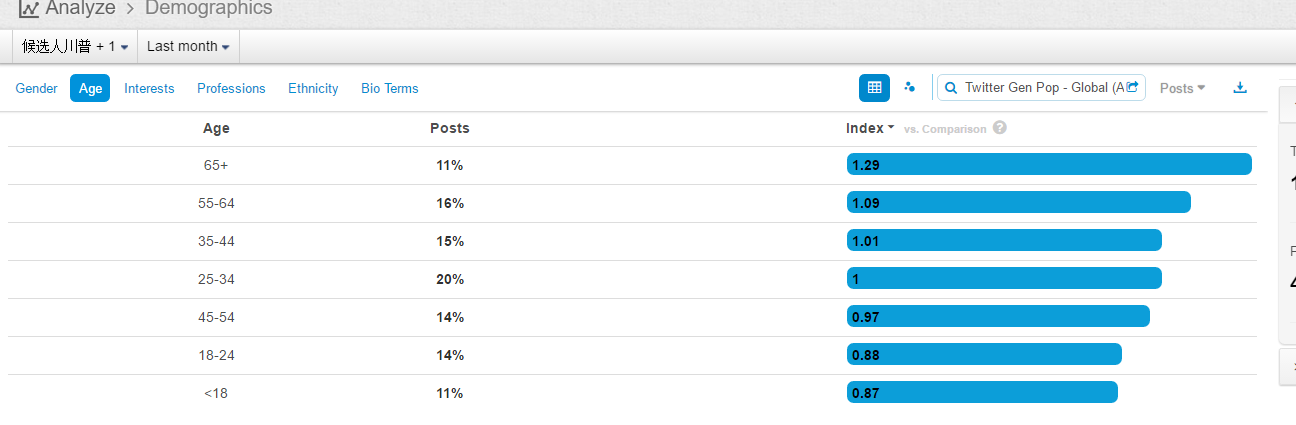
性别不用说,男多女少。男人谈政治与女人谈shopping一样热心。

最后看看地理分布,社煤的地理来源:
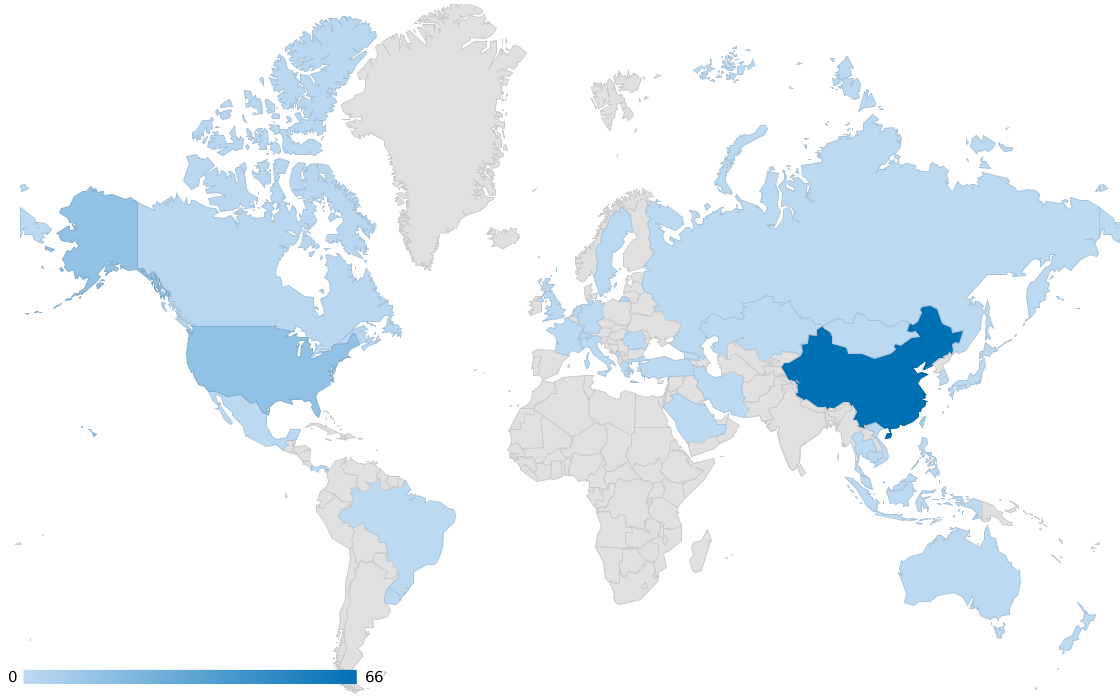
【相关】
Big data mining shows clear social rating decline of Trump last month
http://blog.sciencenet.cn/blog-362400-1011077.html
上一篇:为了川普,我选克林顿。
下一篇:Did Trump's Gettysburg speech enable support rate to soar?
【社媒挖掘:川大叔喜大妈谁长出了总统样?】 屏蔽留存
【社媒挖掘:川大叔喜大妈谁长出了总统样?】
屏蔽 |||
眼看决战时刻快到了,调查一下华人怎么看美国大选,最近一个月的舆情趋势。中文社会媒体对于美国总统候选人的自动调查。

先看喜大妈,是过去三十天的调查(时间区间:9/26-10/25)

mentions 是热议度,net sentiment 是褒贬指数,反映的网民心目中的形象。
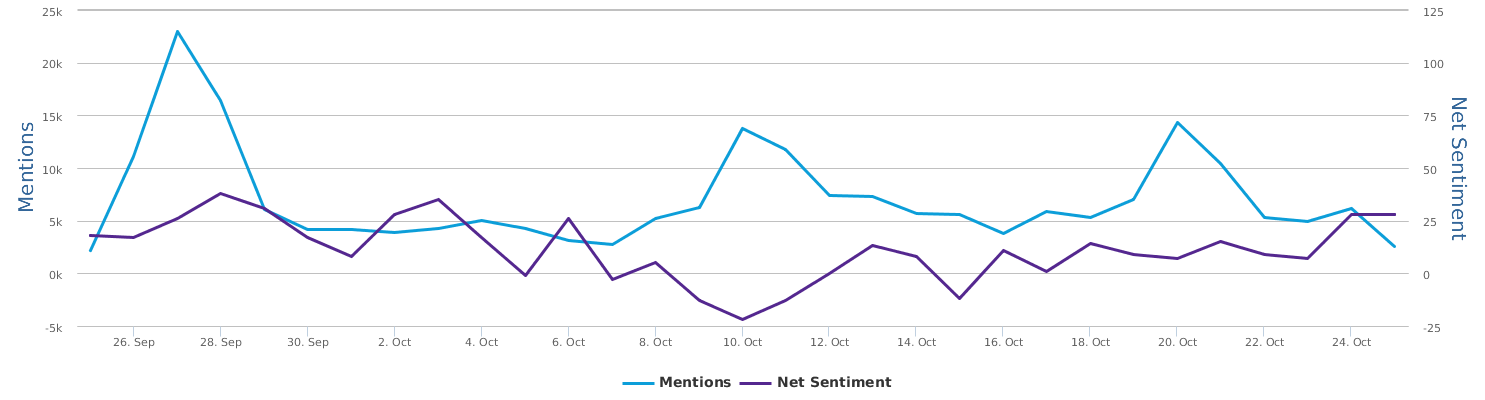
很自然,二者并不总是吻合:譬如,在十月10日到11日的时候,希拉里被热议,而她的褒贬指数则跌入谷底。那天有喜大妈的什么丑闻吗?咱们把时间按周(by weeks)而不是按日来看 trends,粗线条看趋势也许更明显一些:
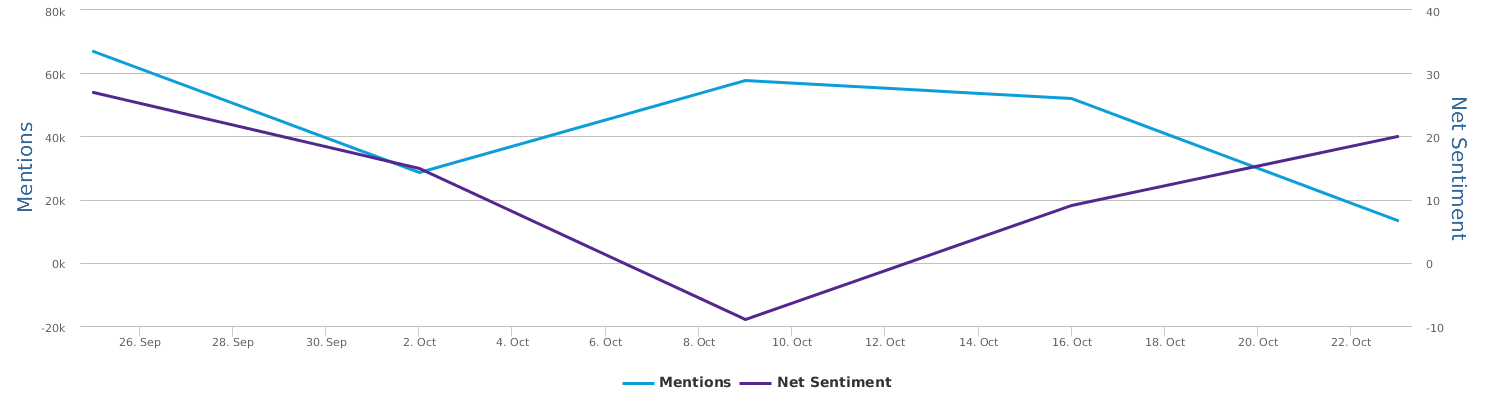
Anyway,过去30天的总社煤形象分(net sentiment)是 11%,比起英语世界的冰点之下(-18%)好太多了,似乎华语世界远不如英语世界对老政客喜大妈的吐槽刻薄。
作为对比,我们看看川普(特朗普)在同一个时期的社会形象的消长趋势:川普过去30天的总社煤形象分(net sentiment)是 -12%,比希拉里的+11%成鲜明对比。
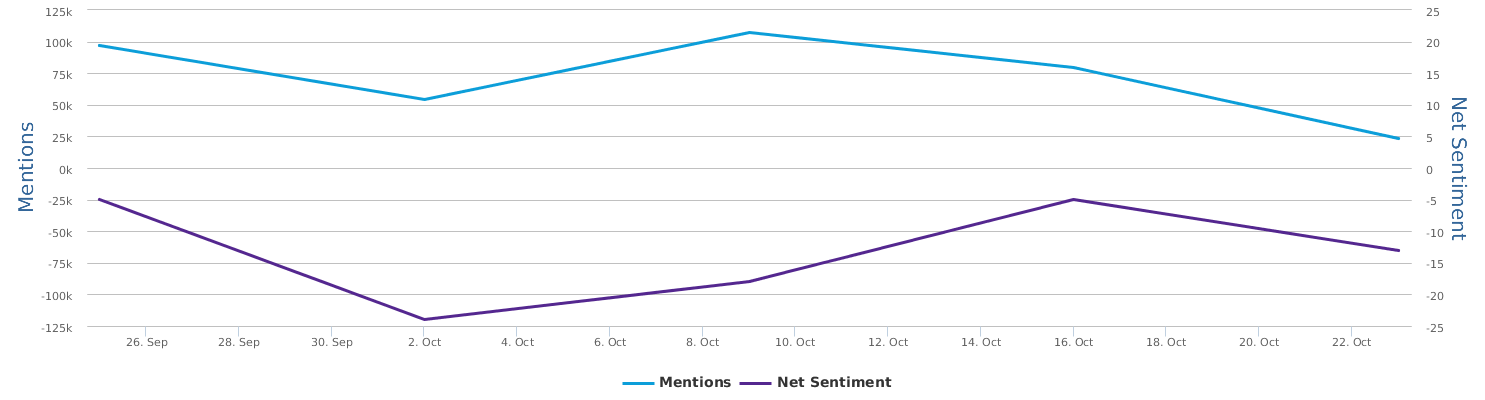
看上面的趋势图(by weeks),川普的热议度一直居高不下,话题之王名副其实,但他的社会评价却一直在冰点之下,十月初更是跌入万丈深渊。同时期的希拉里,热议度与社会评价却时有交叉。趋势 by days:
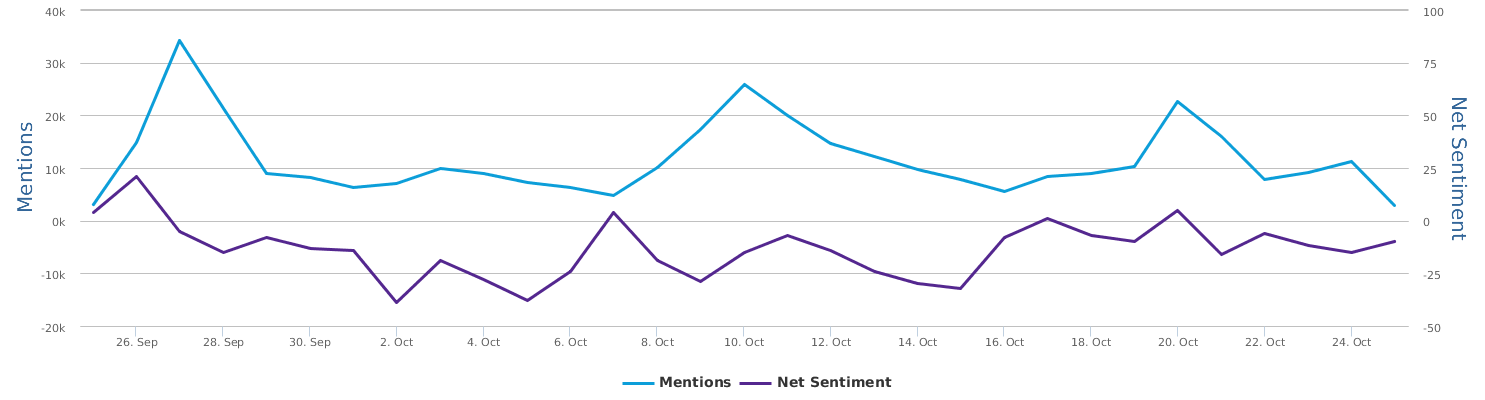
这样看来,虽然有所谓华人挺川的民间鼓噪,总体来看,川大叔在华人的网上口水战中,与喜大妈完全不是一个量级的对手。川普很臭,真地很臭。在英语社煤中,川普也很臭(-20%),但希拉里也不香,民间厌恶她诅咒她的说法随处可见,得分 -18%,略好于川普。譬如电邮门事件,很多老美对此深恶痛绝,不少华人(包括在下)心里难免觉得是小题大作。为什么华人世界对希拉里没有那么反感呢?居然给希拉里 +11% 的高评价。朋友说,希拉里更符合华人主流价值观吧。
这是我们的品牌对比图,三维直观地对比两位候选人在社煤的形象位置:
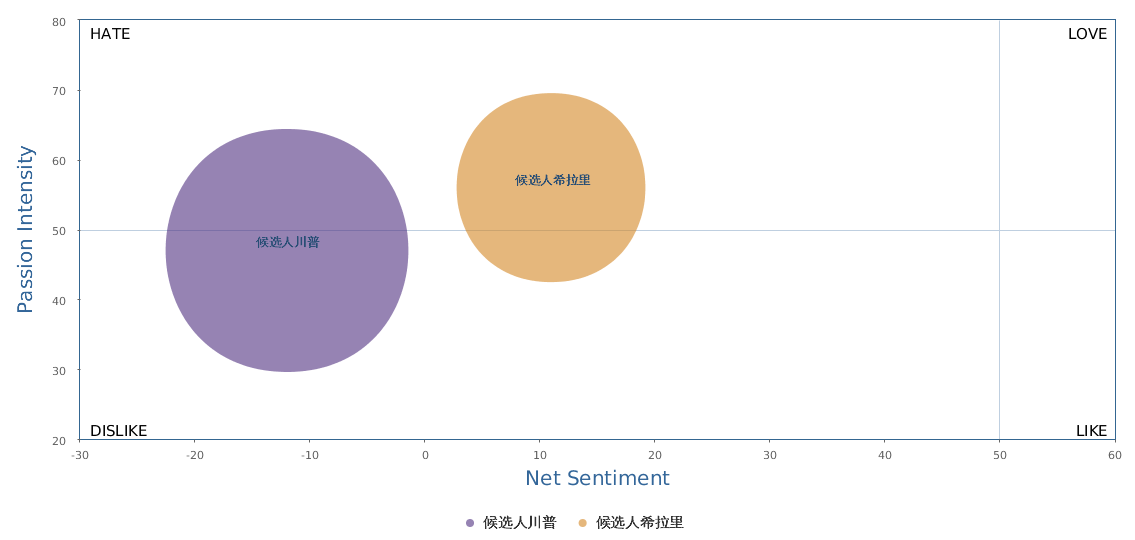
希拉里领先太多,虽然热议度略逊。
总有人质疑社煤挖掘的情报价值,说也许NLU不过关,挖掘有误呢。更多的质疑是,也许某党的人士更愿意搅浑水呢(譬如利用水军或机器人bots)。凡此总总,都给社会媒体舆情挖掘在多大程度上反映民意,提出了疑问和挑战。其实,对于传统的民调,不同的机构有不同的结果,加上手工民调的取样不可能大,error margin 也大。各机构结果也颇不同,所以大家也都是一肚子怀疑。不断有怀疑,还是不断有民调在进行。这是大选年的信息“刚需”吧。
所有的自动的或人工的民调,都可能有偏差,都只能做民意的参考。但是我要强调的是:
1. 现在的深度 NLU 支持的舆情挖掘,已经今非昔比,加上大数据信息冗余度的支撑,精准度在宏观上是可以保障的;
2. 全自动的社煤民调,其大数据的特性,是人工民调无法比的(时效以及costs也无法比,见【立委科普:自动民调】);
3. 虽然社煤上的口水、噪音以及不同党派或群体在其上的反映都可能有很大差异,但是社煤民调的消长趋势的情报以及不同候选人(或品牌)的对比情报,是相对可靠的。怎么讲?因为自动系统具有与生俱来的一视同仁性。
时间维度上的舆情消长,具有相对的比较价值,它基本不受噪音或其他因素的影响。也不大受系统数据质量的影响(当然,太臭的舆情系统也还是糊不上墙,跟抛硬币差不了太多的一袋子词这样的“主流”舆情分类,在短消息压倒多数的社会媒体面前,还是不要提了吧,见一切声称用机器学习做社会媒体舆情挖掘的系统,都值得怀疑)。
我们目前的系统,是 deep parsing 支持,本性是 precision 优于 recall(precision 不降低,recall 也可以慢慢爬上来,譬如我们的英语舆情系统就有相当好的recall,recall在符号逻辑路线里面,本质上就是开发时间的函数)。Given big data 这样的场景,recall 的某种缺失,其实并不影响舆情的相对意义,因为决定 recall 的是规则量,缺少的是一些长尾 pattern rules,而语言学的 rules 不会因为时间或候选人的不同,而有所不同。同理,因为系统的编制是独立于千变万化的候选人、品牌或话题,因此数据质量对于候选人之间的比较,是靠谱的。这样看,舆情趋势和候选人对比的情报挖掘,的确真实地反映了民意的消长和相对评价。下面是这次自动民调的 Top 10 数据来源(可惜没有“她”,我是说 wechat),还是最动态反映舆情的推特中文帖子占多数(其中 66% 简体,30% 繁体,4% 粤语)。
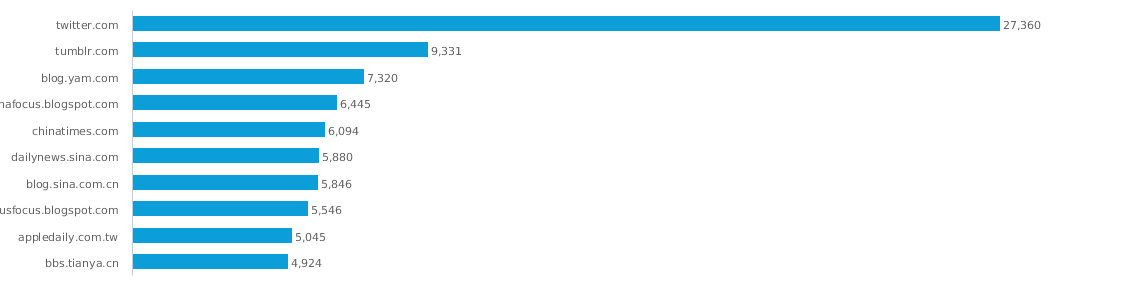
看一下popular的帖子,居然小方的也在其列。倒也不怪,方在中文社煤还是有影响力的。
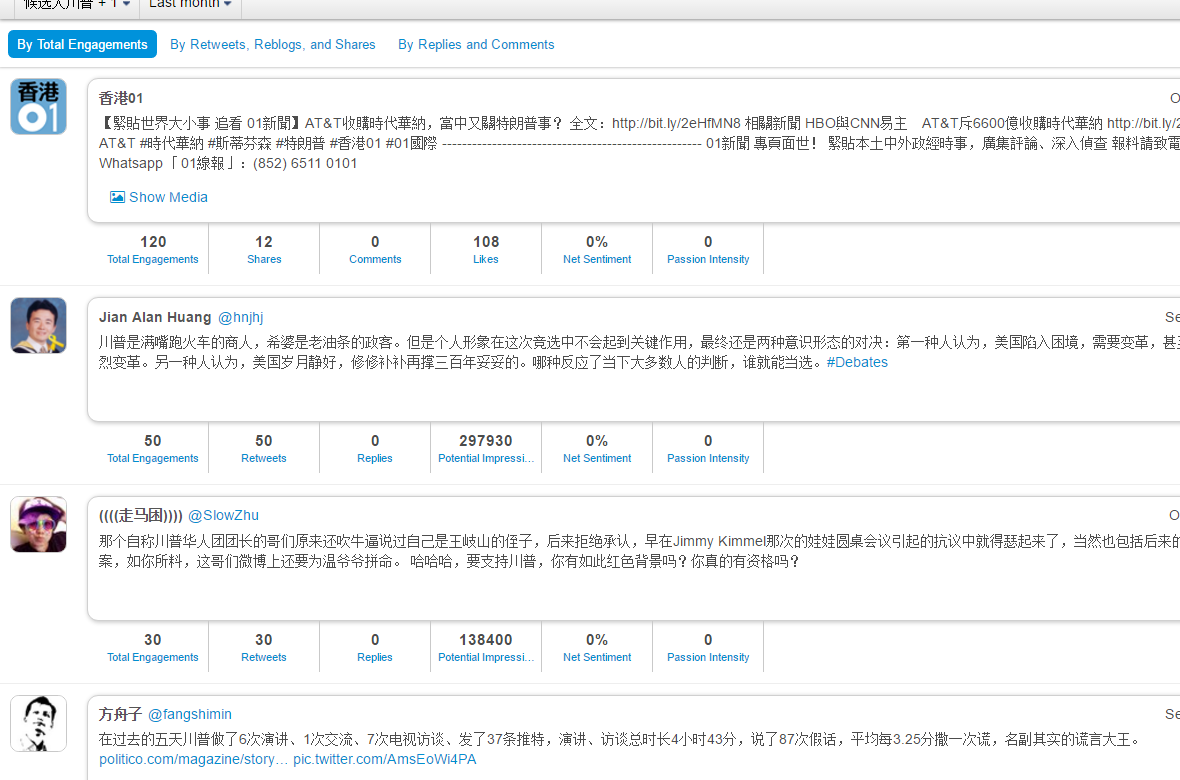
小方总结得不错啊,难得同意他:满嘴跑火车的川大叔是“谎言大王”。其实川普与其说是谎话连篇,不如说是他根本不care 或不屑去核对事实。就跟北京出租司机信口开河成为习惯一样,话说到这里,转一篇我的老友刚写的博文(论保守派该投票克林顿),quote:
川普说话不顾事实是众所周知的。只要他一开口,就忙坏了各种事实核查 fact check ......
更重要的是,川普不仅犯了大大小小众多的事实错误,而且对事实抱着强烈的轻蔑和鄙视。
总结一下这次民调的结果可以说,如果是华人投票,川普不仅是 lose 而是要死得很惨,很难看。(当然,不管华人与否,川普都没有啥胜算。)
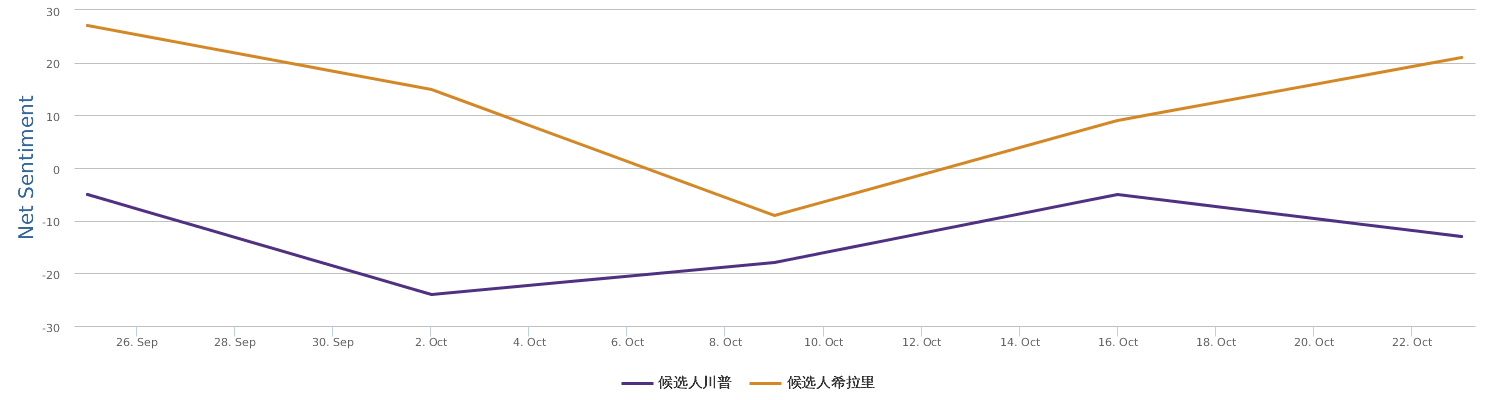
这是 by days 的趋势对比,这种持续的舆情领先在大选前很难改变吧:
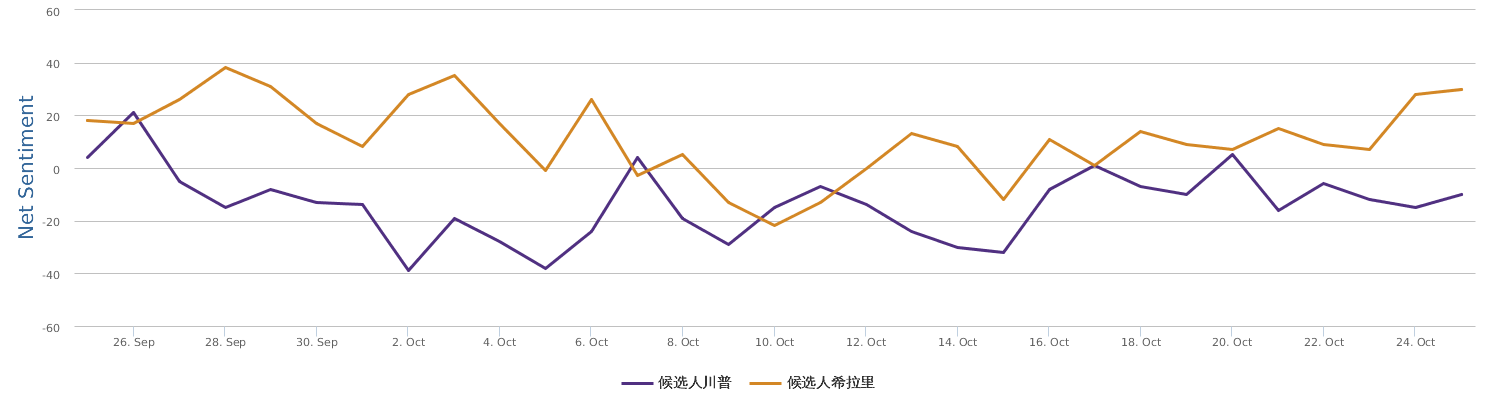
【更多美国大选舆情的自动调查还在进行整理中,stay tuned】
【相关】
Big data mining shows clear social rating decline of Trump last month
http://blog.sciencenet.cn/blog-362400-1010878.html
上一篇:Big data mining shows clear social rating decline of Trump
下一篇:为了川普,我选克林顿。
【关于舆情挖掘】 屏蔽留存
【关于舆情挖掘】
屏蔽 |||
【大数据挖掘:“苦逼”小崔2013年5-7月为什么跌入谷底?】
继续转基因的大数据挖掘:谁在说话?发自何处?能代表美国人民么
新浪微博下周要大跌?舆情指数不看好,负面评价太多(疑似虚惊)
Chinese First Lady in Social Media
Social media mining on credit industry in China
Sina Weibo IPO and its automatic real time monitoring
Social media mining: Teens and Issues
Social media mining: 2013 vs. 2012
尝试揭秘百度的“哪里有小姐”: 小姐年年讲、月月讲、天天讲?
WordClouds: Season's sentiments, pros & cons of Xmas
【社煤挖掘:雷同学之死】 屏蔽留存
【社煤挖掘:雷同学之死】
屏蔽 |||
这是最近的热点新闻,舆情鼎沸,有蔓延之势。值得挖掘和跟踪。



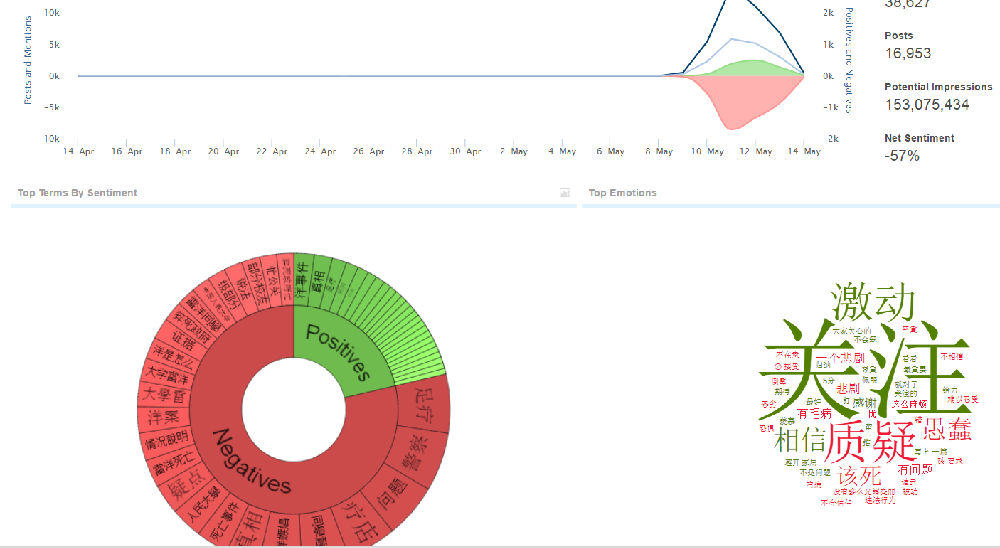
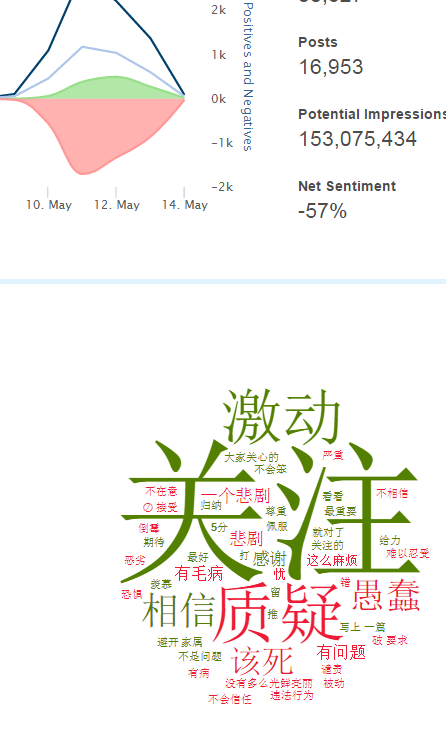
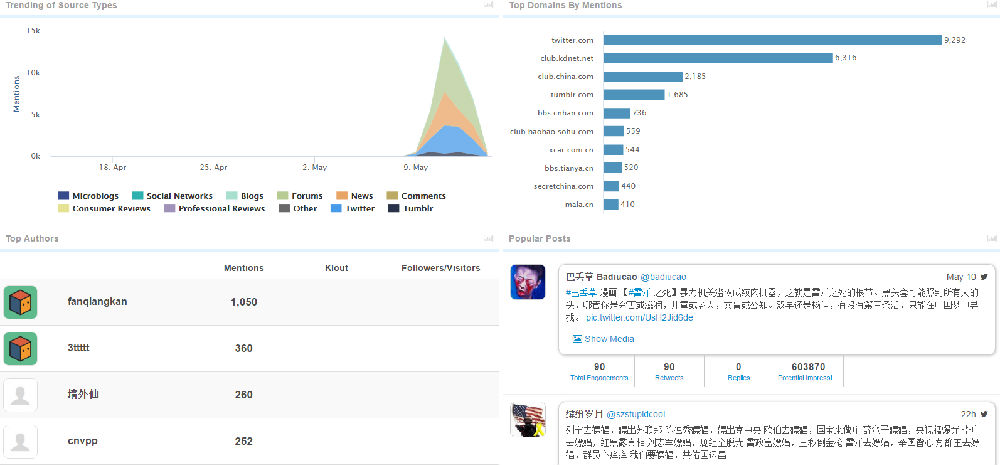
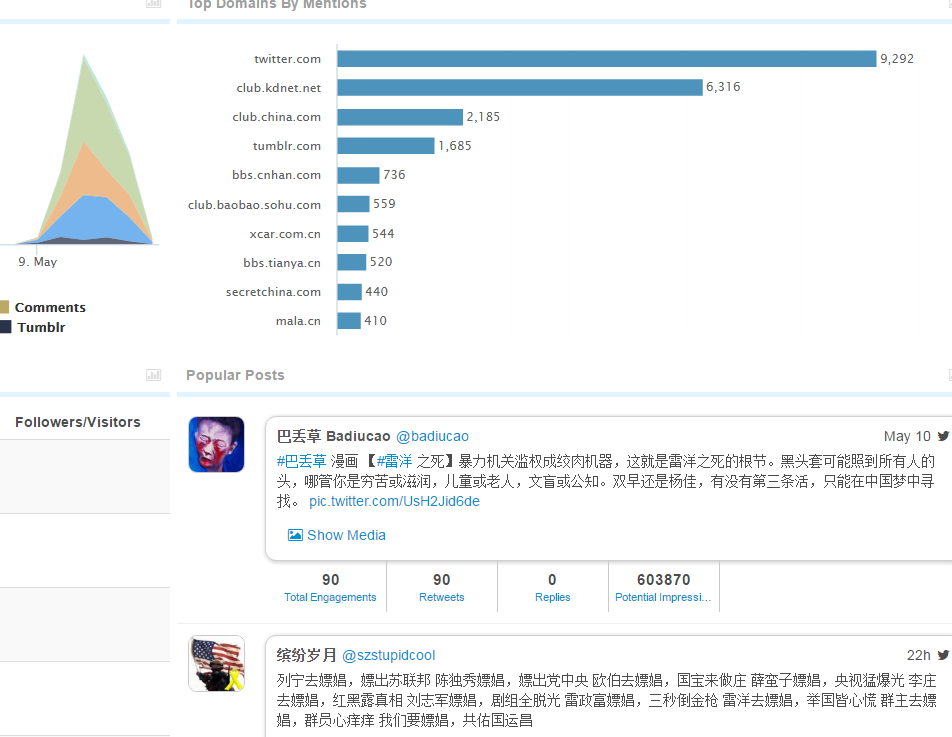
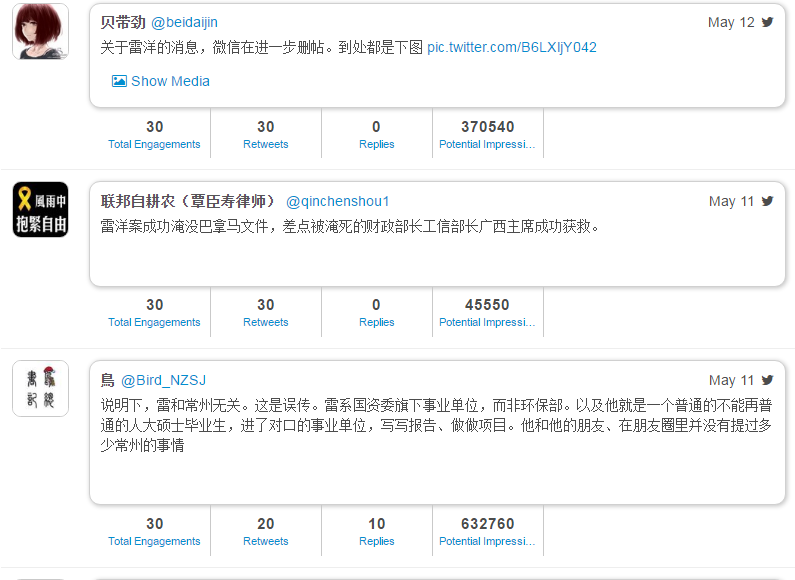
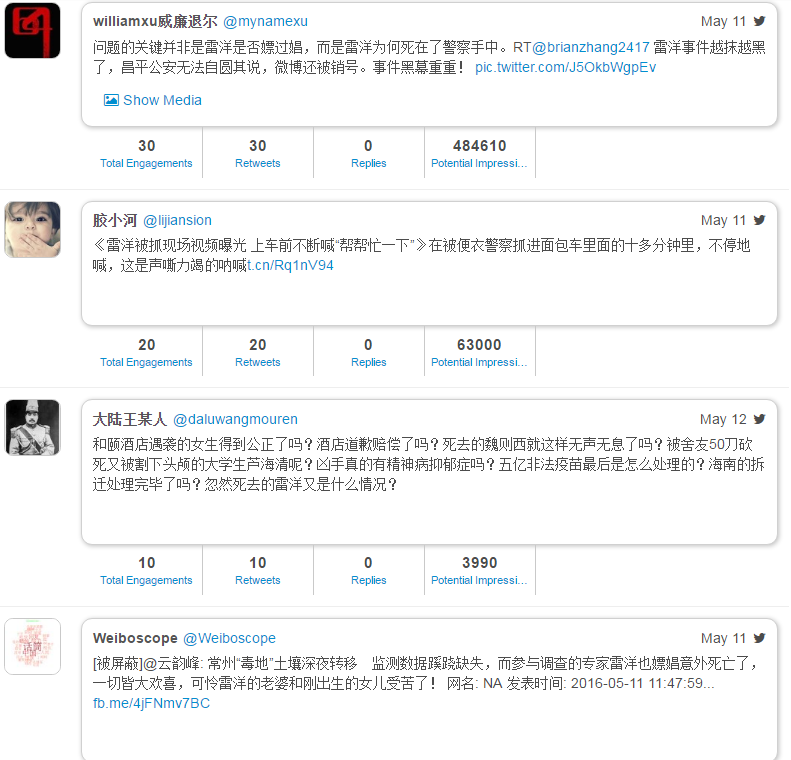



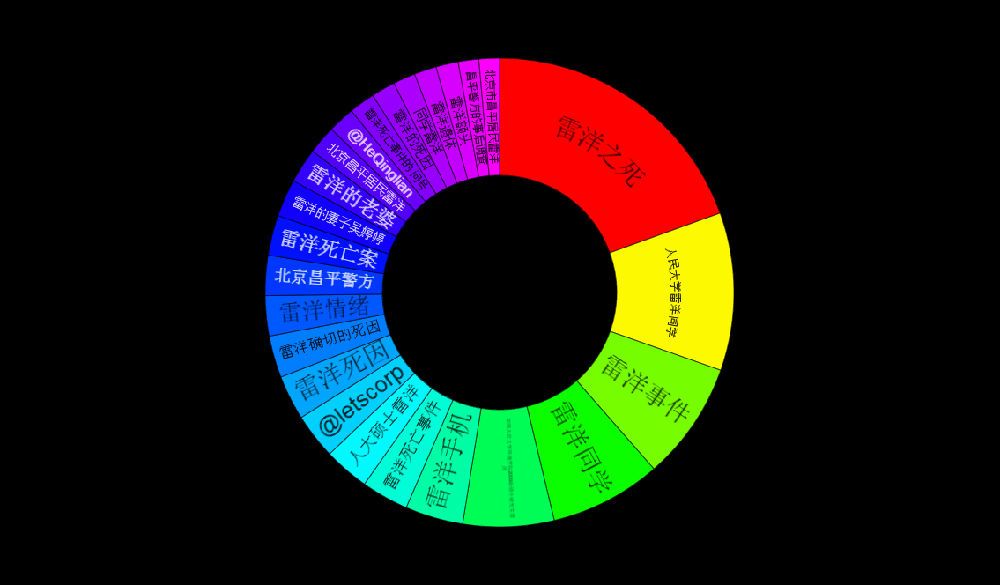
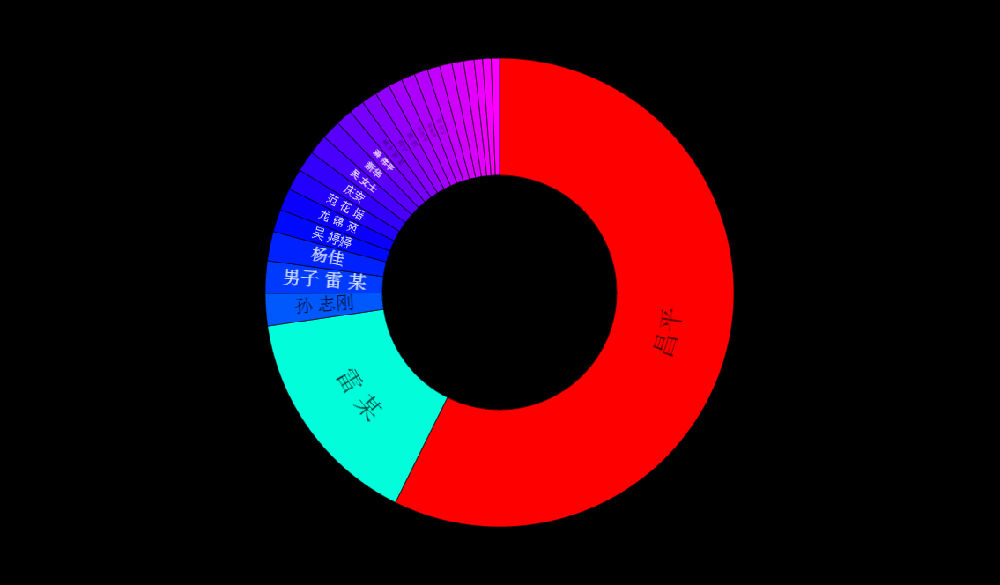
社煤选样:
|
雷洋遗体外伤严重 |
|
质疑雷洋案件十大疑点 |
|
雷洋妻报案:有充分证据警察涉故意伤害致死罪(图) |
|
雷洋事件解决不好,非正常死亡可能成为常态【时局深度】- |
|
蔡慎坤:血与泪的控诉还原雷洋遇害真相 |
|
对比家属报案书和警方通报再看雷洋致死案 |
|
转发雷洋案刑事报案书:描述死亡过程(真相即将到来)-衡阳 |
|
雷洋案件之疑点-第11页- |
|
血与泪的控诉还原雷洋遇害真相- |
|
网传'大学生屁股被警察叔叔打开花',警方:属实!图_中华论坛_中华网社区- |
|
雷洋死亡当晚到底发生了什么?央视专访当事警察 |
|
雷洋家属向北京市检报案要求侦查涉事民警- |
|
'他沒有嫖娼時間' 家屬報案指雷洋被無辜毆死 |
|
吴文萃(雷洋妻子):关于要求北京市检察院立案侦查雷洋被害案的刑事报案书 |
|
血与泪的控诉还原雷洋遇害真相 |
|
雷洋死有余辜! |
|
雷某的家人实在太不要脸了! |
|
“刑事报案书”描述雷洋之死【李鸣生】-常德 |
|
雷洋妻子报案,事件最新爆料!嫖娼是栽赃,雷洋被打死-休闲侃吧- |
|
[原创]雷洋遗孀之报案书等于官媒的死刑判决书 |
|
雷洋父母看完遗体后,为何当场给尸检证人下跪? |
|
雷洋最新情报:“刑事报案书”描述雷洋之死经历 |
|
关于要求北京市检察院立案侦查雷洋被害案的刑事报案书(转载) |
|
我们为什么要关注雷洋之死? |
|
雷洋案刑事报案书,警方涉嫌故意伤害(致人死亡)罪、滥用职权罪、帮助伪造证据罪- |
|
转帖:雷洋妻子向北京市检察院报案:嫖娼是栽赃,雷洋被打死 |
|
1) 雷洋家属告控告警方 2) 雷被殴打致死当日是雷结婚纪念日 3)尸检结果延迟到60天出结果 |
|
一个昌平“嫖娼者”为何引燃了全国公众的怒火?(转) |
|
陈有西律师曝雷洋案发现最新一个重要疑问 |
|
吴文萃(雷洋妻子):关于要求北京市检察院立案侦查雷洋被害案的刑事报案书 |
|
雷洋家属向北京市检报案,要求侦查涉事民警 |
|
【时评】雷洋之死,疑云重重 |
|
人大学生会秘书长郝鹏程说,雷洋嫖娼不是第一次。 |
|
作为正在人大读书的研究僧,分析雷案可能的结果吧- |
|
七律读微信圈雷洋数帖激愤有咏一气呵成重字不改也 |
|
何新:悼雷洋 |
|
哀悼环保烈士雷洋 |
|
血的事实告诉我,雷洋事件很快就平静下来! |
|
警察滥用国家暴力必须予以遏制 |
|
雷洋事件解决不好,非正常死亡可能成为常态【时局深度】- |
|
雷洋之死纯属咎由自取_中华论坛_中华网社区- |
|
人大硕士雷洋真的嫖娼了吗?十三省 |
|
朝吉:足疗送命记 |
|
雷洋之死击碎了中产阶级的优越感! |
|
昌平的一个“嫖娼者”为什么会引发公众的怒火 |
|
雷洋案:尽管真相还在路上,三种共识可以先到 |
|
北京公安回應雷洋案:決不護短 |
|
北京市检察院:已将雷某家属报案材料移送昌平检方 |
|
北京市公安局公开回应雷洋案:高度重视绝不护短 |
|
横河:雷洋案为什么应该怀疑警方 |
|
关于雷阳事件的随想 |
|
警察蜀黍为何喜欢抓嫖?- |
|
“雷洋事件”终于开了个好头 |
|
雷洋用牺牲捍卫一个公务员的尊严 _网上谈兵_中华网社区- |
|
从目击者证言和记者调查的报道看被忽略的雷洋事件关键点 |
|
雷洋被强押致死案,槽点多多,警方说辞漏洞百出 |
|
雷洋事件:中国人民大学88级部分校友向公安部门下战书 |
|
雷洋家属联系第三方鉴定机构将第二次与检方沟通- |
|
雷洋事件,显示了老百姓的焦虑,不安全和无助感_网罗天下_天涯论坛 |
|
雷洋的家属成了大输家!!! |
|
雷洋案真相不难搞清,但很多人打死也不愿相信 |
|
解密雷洋之死的根本原因!-常德 |
|
有见过抓嫖不在店里抓现行而在马路上盘查的吗 |
|
【视点】比雷某嫖娼事件真相更可怕的,是“相信”尽失! |
|
【时评】雷洋事件,送环球时报两字无耻 |
|
中国人民大学88级部分校友就雷洋同学意外身亡的声明 |
|
[原创]雷洋之死:给你真相又何妨? |
|
雷洋遗体外伤严重尸检后家属控告警方涉嫌犯罪 - 中国禁闻网 |
|
呼格案律师谈雷洋之死:涉事警察是嫌犯警方无权再接触证人-常德 |
|
民众为什么关注雷洋的案子? |
|
转载:雷洋妻子正式报案:嫖娼是栽赃,雷洋致命处睾丸异常肿大系被打死 |
|
妻子坚决捍卫老公嫖娼有理正义吗。打飞机不算嫖娼吗_中华论坛_中华网社区- |
|
雷洋之死的九大谜团,谁能告诉我们真相? |
|
雷洋案:守住私德的底线,恢复人性的的良知 |
|
一周新闻聚焦:雷洋之死掀起舆论风暴,各方谴责警方滥权 |
|
雷洋案:守住私德的底线,恢复人性的的良知 |
|
人大学生会秘书长郝鹏程说,雷洋嫖娼不是第一次。 |
|
雷洋案真相不难搞清,可怕的是有人就是打死也不愿相信 |
|
网友热议:雷洋的事,恐怖在哪儿?(图) - 看中国 secretchina.com |
|
雷洋尸检报告未出,但问题已显现:(第3页)_天涯杂谈_天涯论坛 |
|
[原创]嫖娼案拒谈嫖娼,雷洋老婆居心叵测,图谋不轨 |
|
雷洋死亡案铁证如山,雷洋没有白死 |
|
雷洋案新证据浮现:警察有问题 |
|
快讯!雷洋家属正式控告警方涉嫌犯罪 |
|
雷某嫖娼案最终结果的终极预测-第2页- |
|
雷洋怎么死的,我来分析下。 |
|
[原创]雷洋死因的逻辑分析 |
|
[原创]雷洋怎么死的?【猫眼看人】- |
|
雷洋嫖娼,谁又在嫖中国法律_天涯杂谈_天涯论坛 |
|
警方回应雷洋案热点问题昌平检方介入调查 |
|
【转帖】中国人民大学88级部分校友就雷洋同学意外身亡的声明- |
|
橫河:雷洋案為什麼應該懷疑警方 |
|
最新消息:从警方提供及其他方面提供的证据看,雷洋涉嫌“嫖娼”的疑问太多!【铁证】 - 有啥说啥 |
|
我们为什么要关注雷洋之死?(第4页)_关天茶舍_天涯论坛 |
|
雷阳嫖娼就可以打死吗?转_网罗天下_天涯论坛 |
|
我服了雷洋家人了,到底要闹哪样?没见过这么无赖的(第5页)_天涯杂谈_天涯论坛 |
|
[原创]草根今日谈:依法治国请从雷洋事件开始 |
|
人大部分88级校友就同学雷洋身亡声明:对恶我们不会忍太久全文 - 中国禁闻网 |
|
中国人民大学77、78级校友关于雷洋的声明 |
|
大陸雷洋離奇死亡聯合國貼文關注 |
|
雷洋尸检超过12个小时北京昌平警方回避不 |
|
热帖:为什么我们应该感谢雷洋的妻子(图) |
|
雷洋死有余辜! |
|
[原创]由雷洋事件看恶警李乐斌杀人未受惩罚的危害性 |
|
[原创]支持雷洋遗孀依法起诉诬陷其亡夫的媒体 |
|
雷洋之死的真相究竟是什么? |
|
[原创]雷洋,愿你的名字叫做公正与法治【猫眼看人】- |
|
雷洋事件,显示了老百姓的焦虑,不安全和无助感_网罗天下_天涯论坛 |
|
'嫖娼者'雷洋的安全感要不要保护 |
|
亦忱:简评陈有西代理雷洋案的前景 |
|
雷洋案新证据浮现:警察有问题 |
|
雷洋之死的两个最重要真相! - 云中茶社 |
|
[原创]由雷洋事件看恶警李乐斌杀人未受惩罚的危害性 |
|
雷洋家属发表声明:警方的做法是在混淆视听 |
|
昌平警方的行为完全合法! |
|
周小平:酷吏以法杀人,奸生以文灭口-真相为何败给愤怒?-第6页- |
|
雷洋案:守住私德的底线,恢复人性的的良知 |
|
[原创]三点详析雷洋事件严重亏空损耗了XX公信力! |
|
雷洋有没有嫖娼,有一个绝招,立刻就能见分晓! |
|
风云洞评劣等民族情商高?(图) |
|
周小平:酷吏以法杀人,奸生以文灭口-真相为何败给愤怒?-第6页- |
|
周小平:酷吏以法杀人,奸生以文灭口-真相为何败给愤怒?-第6页- |
|
雷洋有没有嫖娼,有一个绝招,立刻就能见分晓! |
|
雷洋案:守住私德的底线,恢复人性的的良知 |
|
涉案警方擅自检验死者DNA是否涉嫌违法犯罪? |
|
贾冀豫__北京出租车司机说雷洋是打死的 |
|
【风青杨专栏】对不起,我并不想知道雷洋如何嫖娼(第8页)_天涯杂谈_天涯论坛 |
|
雷洋之死让普通人感到无比恐惧 |
|
雷洋之死或可推动社会三大进步 |
|
雷洋之死让普通人感到无比恐惧 |
|
这不是两个人死亡的问题_社会热点_中华网社区- |
|
解密雷洋之死的根本原因!-常德 |
|
性价比。。。。_上海汽车论坛_XCAR |
|
有见过抓嫖不在店里抓现行而在马路上盘查的吗 |
|
雷洋嫖娼离奇死亡案。 |
|
重大消息!国资委官员嫖娼被抓猝死(组图) |
|
这不是两个人死亡的问题 |
|
张鸣:雷洋之死 |
|
雷洋案,网友如何“推波助澜”?全民一起破案,真相越来越近了吗?- |
|
人大硕士求救帖,几乎每一段都充斥着谎言! |
|
中国人民大学77、78级校友关于雷洋的声明 |
|
中国人民大学77、78级校友关于雷洋的声明 |
|
2016年05月13日 |
|
人大的校友别再发声了,77,78,84,88级的 |
|
女人天天被杀都激不起水花,雷洋死就激起千层浪! |
|
《雷洋案》引起北京公安局领导高度重视 |
|
雷洋是不是嫖娼不重要?扯淡!笔者用十点给某些人普法 |
|
快讯!雷洋家属正式控告警方涉嫌犯罪 |
|
雷洋案:守住私德的底线,恢复人性的的良知 |
|
雷洋事件也许将有助中国执法部门的公正、警醒? |
|
那些声嘶力竭认为雷洋嫖娼该死的人,他们是些啥人? |
|
雷洋事件也许将有助中国执法部门的公正、警醒? |
|
关注小人物的命运!就是关注自个命运!小人物之死网友理应关注 |
|
雷洋案:守住私德的底线,恢复人性的的良知 |
|
“欺负死人不能说话”乃世间首恶 |
|
“欺负死人不能说话”乃世间首恶 |
|
拿雷洋殒命事件大肆鼓噪的那些人,可把死者一家人害惨了 |
|
“欺负死人不能说话”乃世间首恶 |
|
[原创]“欺负死人不能说话”乃世间首恶 |
|
力瑾:還有多少國人在意雷洋案的真相? |
|
雷阳嫖娼就可以打死吗?转_网罗天下_天涯论坛 |
|
【野渡专栏】草根今日谈:依法治国请从雷洋事件开始_天涯杂谈_天涯论坛 |
|
【野渡专栏】草根今日谈:依法治国请从雷洋事件开始_天涯杂谈_天涯论坛 |
|
雷洋案:守住私德的底线,恢复人性的的良知 |
|
警方续昌平涉嫖男子在查处过程中突发死亡通报有无问题 - 第2页 - 警务探讨 |
|
[原创]草根今日谈:依法治国请从雷洋事件开始 |
|
【野渡专栏】草根今日谈:依法治国请从雷洋事件开始_天涯杂谈_天涯论坛 |
|
雷洋案:为何警方信息发布总显得很被动? |
|
【视点】比雷某嫖娼事件真相更可怕的,是“相信”尽失! |
|
【时评】雷洋事件,送环球时报两字无耻 |
|
中国人民大学88级部分校友就雷洋同学意外身亡的声明 |
|
'嫖娼者'雷洋的安全感要不要保护 |
|
打飞机为何没有改变雷洋案的舆情走向? |
|
一个昌平“嫖娼者”为何引燃了全国公众的怒火?(转) |
|
十族沦为下一个魏则西比雷洋尤恐怖 - 有图有真相 - 中豫爆料 |
|
十日谈;我想说几句了,关于何新的两篇文章_中华论坛_中华网社区- |
|
女人天天被杀都激不起水花,雷洋死就激起千层浪! |
|
女人天天被杀都激不起水花,雷洋死就激起千层浪! |
|
喝我这七星茶听他摆龙门阵再饮三盅 |
|
喝我这七星茶听他摆龙门阵再饮三盅 |
|
喝我这七星茶听他摆龙门阵再饮三盅 |
|
【今言野语】副省长私访被警察殴打的社会问题?_新闻众评_天涯论坛 |
|
[原创]雷洋死亡案铁证如山,雷洋没有白死 |
|
雷洋死亡案铁证如山,雷洋没有白死 |
|
说雷阳打飞机我的看法不成立!_中华论坛_中华网社区- |
|
陈中华;警察威严不容丧尽,法律遵严不容侵犯_中华论坛_中华网社区- |
|
为违法警察洗地,无耻!_中华论坛_中华网社区- |
|
雷洋事件,某些人已经玩过火了! |
|
雷洋父母看完遗体后,为何当场给尸检证人下跪? |
|
雷洋父母看完遗体后,为何当场给尸检证人下跪? |
|
雷洋事件:雷洋律师团调集近20位律师参案 |
|
雷洋事件:雷洋律师团调集近20位律师参案 |
|
雷洋案:守住私德的底线,恢复人性的的良知 |
|
转载:一个昌平“嫖娼者”为何引燃了全国公众的怒火?|洛阳城事 |
|
一周新闻聚焦:雷洋之死掀起舆论风暴,各方谴责警方滥权 |
|
雷洋之死第二季 |
|
规范警务活动:从雷洋案开始 |
|
雷洋之死击碎了中产阶级的优越感! |
|
人大学生会秘书长郝鹏程说,雷洋嫖娼不是第一次。 |
|
人大学生会秘书长郝鹏程说,雷洋嫖娼不是第一次。 |
|
人大学生会秘书长郝鹏程说,雷洋嫖娼不是第一次。 |
|
人大学生会秘书长郝鹏程说,雷洋嫖娼不是第一次。 |
|
人大学生会秘书长郝鹏程说,雷洋嫖娼不是第一次。 |
|
人大学生会秘书长郝鹏程说,雷洋嫖娼不是第一次。 |
|
人大学生会秘书长郝鹏程说,雷洋嫖娼不是第一次。 |
|
人大学生会秘书长郝鹏程说,雷洋嫖娼不是第一次。 |
|
雷洋案:守住私德的底线,恢复人性的的良知 |
|
人大学生会秘书长郝鹏程说,雷洋嫖娼不是第一次。 |
|
人大学生会秘书长郝鹏程说,雷洋嫖娼不是第一次。 |
|
李悔之:比雷洋之死更可怕的是龙兴伟 |
|
从雷洋案看科学研究思维在生活中的应用 |
|
从雷洋案看科学研究思维在生活中的应用 |
|
人大部分88级校友就同学雷洋身亡声明:对恶我们不会忍太久全文 - 中国禁闻网 |
|
民主到底能不能当饭吃? |
|
对警察说两句,你们不感到愧疚吗 |
|
涉嫌嫖娼男突发死亡,你怎么看?- |
|
雷洋事件,让我想起那些年采访过的奇葩嫖娼案_三秦网 |
|
雷洋被嫖被死案,急呼性合法化_京味悠长_天涯论坛 |
|
贪官雷洋嫖娼被抓,畏罪拘捕逃跑未遂身亡 |
|
雷洋父母看完遗体后,为何当场给尸检证人下跪? |
|
[原创]我又不嫖娼,我为什么会成为下一个雷洋 |
|
我们追问雷洋是怎么死的,他们却要证明他是怎么嫖的! |
|
雷洋怎么死的,我来分析下。 |
|
一周新闻聚焦:雷洋之死掀起舆论风暴,各方谴责警方滥权 |
|
雷洋妻儿父母岳父母的今后生活北京警方必须承担- |
|
雷洋案件之疑点-第5页- |
|
投票赢取《狄仁杰之神都龙王》.. |
|
《意外的恋爱时光》都市剩男&.. |
|
为您梦想中的“土豪人生”投票.. |
|
雷洋事件需要真相而非真像 |
|
雷洋案件之疑点-第3页- |
|
有谁认为雷洋不是警察打死的_亚洲论坛_天涯论坛 |
|
拍案尖笑(集锦) |
|
雷阳事件现场群众偷拍视频 |
|
雷洋疑案:史上效率最高最变态最廉价的嫖娼 |
|
雷洋事件解决不好,非正常死亡可能成为常态【时局深度】- |
|
雷洋事件解决不好,非正常死亡可能成为常态 |
|
老徐:雷洋事件需要真相而非真像 |
|
雷洋事件,让我想起那些年采访过的嫖娼案 |
|
雷洋案:守住私德的底线,恢复人性的的良知 |
|
警察能让处女嫖娼,何况男士乎? |
|
雷洋事件解决不好,非正常死亡可能成为常态_中华论坛_中华网社区- |
|
雷洋事件解决不好,非正常死亡可能成为常态_中华论坛_中华网社区- |
|
人大学生会秘书长郝鹏程说,雷洋嫖娼不是第一次。 |
|
雷洋之死击碎了中产阶级的优越感! |
|
雷洋之死击碎了中产阶级的优越感! |
|
贾冀豫__北京出租车司机说雷洋是打死的 |
|
”这份“公平正义”,雷洋听不到了,但我们必须感受到!(第2页)_重庆_天涯论坛 |
|
警察能让处女嫖娼,何况男士乎? |
|
让子弹飞一会:人大硕士涉嫖身亡(集中讨论)(第2页)_国际观察_天涯论坛 |
|
雷阳嫖娼就可以打死吗?转_网罗天下_天涯论坛 |
|
这些事发生在啥国度?! |
|
德媒:雷洋之死公信力缺失之下人人自危(图) |
|
德媒:雷洋之死公信力缺失之下人人自危(图) - 中国禁闻网 |
|
德媒:雷洋之死公信力缺失之下人人自危(图) |
|
女人天天被杀都激不起水花,雷洋死就激起千层浪! |
|
对不起,我并不想知道雷洋如何嫖娼-邵阳 |
|
中国人民大学77、78级校友关于雷洋的声明 |
|
罗竖一:检方应尽快就雷洋一案启动侦查程序 |
|
雷洋死亡案,我持消极看法 |
|
[原创]草根今日谈:依法治国请从雷洋事件开始 |
|
【野渡专栏】草根今日谈:依法治国请从雷洋事件开始_天涯杂谈_天涯论坛 |
|
张鸣:雷洋之死 |
|
说服公众 |
|
【话题】常识变为异端的社会 |
|
下一个“雷洋”不会太远,或是你我,或在身边- |
|
下一个“雷洋”不会太远,或是你我,或在身边- |
|
被雷洋案击中的那根弦 |
|
雷洋案与毒地案有关?网传因特殊身份致死(组图) |
|
警方:已證實雷洋有嫖娼行為 |
|
喝我这七星茶听他摆龙门阵再饮三盅 |
|
喝我这七星茶听他摆龙门阵再饮三盅 |
|
喝我这七星茶听他摆龙门阵再饮三盅 |
|
雷洋嫖娼案的所有证据都是事后补上? |
|
雷洋嫖娼案的所有证据都是事后补上?(图) |
|
雷洋嫖娼案的所有证据都是事后补上?(图) - 中国禁闻网 |
|
重要质疑:就雷洋案请教昌平警方几个问题-常德 |
|
雷洋嫖娼案的所有证据都是事后补上?(图) |
|
关注雷洋,也关注人民警察 |
|
[原创]就雷洋案请教昌平警方几个问题 |
|
没有嫖娼动机的说法很可笑 |
|
[原创]雷洋死亡原因的最简单分析 |
|
雷洋案新证据浮现:警察有问题 |
|
三个字道破宇宙真理,破解《道德经》三千年谜团。 |
|
雷洋家属状告公安局全体民警,称雷洋没嫖娼,一切都是警方伪造,故意杀人后伪造事实 |
|
[原创]凯迪何公然支持传谣?!有关“雷阳视频”的真相 |
|
[原创]十年一觉京华梦赢得娼平嫖客名 |
|
雷洋“嫖资收据”铁证如山_胜利社区_东营论坛_油城茶座 |
|
985各校新闻量排行 |
|
张鸣:雷洋之死.............. |
|
尸检结论获一致认可前雷洋遗体不会被火化 |
|
[原创]洗脚女,昌平警察提供了雷洋没有进入洗脚店的证据 |
|
民主到底能不能当饭吃? |
|
识不足则多虑,不要因个别负面事件过于恐慌 - 我说深圳事 |
|
谁在妖魔化中国人 |
|
中国人开始追求免于恐惧的自由 |
|
有谁认为雷洋不是警察打死的_亚洲论坛_天涯论坛 |
|
致人“屁股开花”的警察有兽性无人性 |
|
有谁认为雷洋不是警察打死的_亚洲论坛_天涯论坛 |
|
雷洋事件,某些人已经玩过火了! |
|
中国人开始追求免于恐惧的自由(转载)_邯郸_天涯论坛 |
|
[原创]雷洋案:“我上车,我必死” |
|
公知们,不要搬起石头砸了自己的脚(转载)_时尚资讯_天涯论坛 |
|
质疑雷洋案件十大疑点 |
|
雷洋父母看完遗体后,为何当场给尸检证人下跪? |
|
雷洋妻报案:有充分证据警察涉故意伤害致死罪(图) |
|
[原创]雷洋案:“我上车,我必死” |
|
欲追究警方刑責雷洋家屬向北京市檢報案 | 暴力執法 | 大紀元 |
|
欲追究警方刑责雷洋家属向北京市检报案 |
|
[原创]雷洋家属及代理律师已提出刑事起诉 |
|
雷洋事件,某些人已经玩过火了! |
|
欲追究警方刑事责任雷洋家属向北京市检报案 - 中国禁闻网 |
|
四川省纪委与厅纪委过去有结论吗?王书记上任后又是什么结论?- |
|
四川省纪委与厅纪委过去有结论吗?王书记上任后又是什么结论?- |
|
有谁认为雷洋不是警察打死的_亚洲论坛_天涯论坛 |
|
每日大盘走势预判和盘中分时高低点的实时分析 |
|
各国《宪法》中几种《权利法案》之比较 |
|
除了移民我们还有什么更好的选蔡慎坤 |
|
家属最大的交代和安慰 |
|
雷某嫖娼案最终结果的终极预测-第2页- |
|
很奇怪,没抓现行,雷洋已死,警方是怎么锁定雷洋所嫖失足女的? |
|
有谁认为雷洋不是警察打死的_亚洲论坛_天涯论坛 |
|
有谁认为雷洋不是警察打死的_亚洲论坛_天涯论坛 |
|
民主到底能不能当饭吃? |
|
[原创]雷洋死亡案,已经形成死结 |
|
喝我这七星茶听他摆龙门阵再饮三盅 |
|
民主到底能不能当饭吃? |
|
雷洋事件引发更深刻的社会问题 |
|
蔡慎坤:雷洋之死真相早己大白于天下 |
|
民主到底能不能当饭吃? |
|
喝我这七星茶听他摆龙门阵再饮三盅 |
|
民主到底能不能当饭吃? |
|
民主到底能不能当饭吃? |
|
蔡慎坤:雷洋之死真相早己大白于天下 |
|
民主到底能不能当饭吃? |
|
民主到底能不能当饭吃? |
|
民主到底能不能当饭吃? |
|
[原创]三点详析雷洋事件严重亏空损耗了XX公信力! |
|
喝我这七星茶听他摆龙门阵再饮三盅 |
|
民主到底能不能当饭吃? |
|
民主到底能不能当饭吃? |
|
民主到底能不能当饭吃? |
|
蔡慎坤:我們為什麼恐懼為什麼憤怒? |
|
童大焕:中国人开始追求免于恐惧的自由|洛阳城事 |
|
蔡慎坤:我们为什么恐惧为什么愤怒? |
|
雷洋是否嫖娼和怎么死亡证据链暴光 |
|
童大煥:中国人开始追求免于恐惧的自由- |
|
喝我这七星茶听他摆龙门阵再饮三盅 |
|
转发:我们追问雷洋是怎么死的,警方却非要证明他是怎么嫖的? |
|
赏析《还原雷洋之死》(续) |
|
一周新闻聚焦:雷洋之死掀起舆论风暴,各方谴责警方滥权 |
|
雷剧大反转之二:让子弹飞一会儿(ZT) |
|
国资委官员嫖娼死的“春秋笔法”- |
|
程序正义高于实质正义的理念,规则重于道德的理念,生命高于一切的理念_胜利社区_东营论坛_油城茶座 |
|
有谁认为雷洋不是警察打死的_亚洲论坛_天涯论坛 |
|
有谁认为雷洋不是警察打死的_亚洲论坛_天涯论坛 |
|
雷洋事件需要真相而非真像 |
|
雷洋之死真相早己大白于天下 |
|
几乎所有关注雷洋之死的舆论和公 |
|
雷洋,你能否为暴力执法敲一个警钟?_新浪杂谈_历史论坛_新浪网 |
|
童大焕:中国人开始追求免于恐惧的自由 |
|
雷洋之死真相早已大白于天下【猫眼看人】- |
|
[原创]雷洋家属有责任立即单方面公布解剖真相 |
|
雷洋案:守住私德的底线,恢复人性的的良知 |
|
转发:我们追问雷洋是怎么死的,警方却非要证明他是怎么嫖的? |
|
童大焕:中国人开始追求免于恐惧的自由 |
|
老徐:雷洋事件需要真相而非真像 |
|
转发:我们追问雷洋是怎么死的,警方却非要证明他是怎么嫖的? |
|
下一个雷洋是谁? |
|
律师从法律角度看雷洋案:警方认定嫖娼的事实不能成立_中华论坛_中华网社区- |
|
转发:我们追问雷洋是怎么死的,警方却非要证明他是怎么嫖的? |
|
力瑾:還有多少國人在意雷洋案的真相? |
|
国资委官员嫖娼死的“春秋笔法”——雷洋事件再反转_中华论坛_中华网社区- |
|
“友邦人士,莫名惊诧,长此以往,国将不国”:是不是鲁讯的文章?!_汽车时代_天涯论坛 |
|
“友邦人士,莫名惊诧,长此以往,国将不国”:是不是鲁讯的文章?! |
|
雷洋“嫖资收据”铁证如山_胜利社区_东营论坛_油城茶座 |
|
让子弹飞一会:人大硕士涉嫖身亡(集中讨论)(第2页)_国际观察_天涯论坛 |
|
雷阳嫖娼就可以打死吗?转_网罗天下_天涯论坛 |
|
人大硕士雷洋真的嫖娼了吗?十三省 |
|
下一个'雷洋'是谁? |
|
雷洋之死击碎了中产阶级的优越感! |
|
雷洋嫖娼,谁嫖了法治? |
|
为北京警方的“嫖资收据管理”叫好 |
|
通过雷洋案,都要洗干净自己的灵魂,多一份正能量,就少一份阴暗 |
|
我服了雷洋家人了,到底要闹哪样?没见过这么无赖的(第5页)_天涯杂谈_天涯论坛 |
|
雷洋之后谁会成为替补 |
|
蔡慎坤:雷洋之死真相早己大白于天下 |
|
【普欣夜话】拿嫖娼说事,最终谁会被嫖娼?(第3页)_天涯杂谈_天涯论坛 |
|
雷洋猝死政府忙公关:雇水军、删贴、掉包视频 |
|
[原创]雷洋嫖娼,谁嫖了法治?【猫眼看人】- |
|
昌平警方说明其实暗示了真相宽带山KDS-宽带山社区-第一城市消费门户 |
|
[原创]雷洋嫖娼,谁嫖了法治?【猫眼看人】- |
|
[原创]草根今日谈:依法治国请从雷洋事件开始 |
|
【野渡专栏】草根今日谈:依法治国请从雷洋事件开始_天涯杂谈_天涯论坛 |
|
端宏斌:国资委官员嫖娼死的“春秋笔法” - 警务探讨 |
|
雷洋案:检方已出手,“涉嫖死”真相,在这 |
|
讨论:雷洋案应抓重点,不然就被人给误导了 |
|
汪剛強:從鄧玉嬌到雷洋 |
|
昌平警方说明其实暗示了真相 |
|
'嫖娼者'雷洋的安全感要不要保护 |
|
成年男子安全路过洗脚屋行动指南 |
|
妻子不关心嫖娼 '雷洋之死'还存疑点真相究竟是什么妻子不关心嫖娼,'雷洋之死'还存疑点。硕士雷洋死亡之夜到底发生了什么?雷洋死了,意外地死在一起嫖娼事件当中,揪住全社会的心。今日,有协调处理此事的警员感叹舆论发酵到这般程度,受到伤害最大的是家人…… |
|
雷洋案中警方存在'钓鱼'抓嫖的可能 |
|
人大硕士雷洋之死 |
|
对“如果雷洋没有死”的一些推论 |
|
端宏斌:国资委官员嫖娼死的“春秋笔法”_上海汽车论坛_XCAR |
|
再次重复:雷洋死后谁是下一个? |
|
中国人民大学77、78级校友关于雷洋的声明 |
|
国资委官员嫖娼死的“春秋笔法”- |
|
雷洋事件引发更深刻的社会问题 |
|
童大煥:中国人开始追求免于恐惧的自由- |
|
中国人开始追求免于恐惧的自由 |
|
女人天天被杀都激不起水花,雷洋死就激起千层浪! |
|
童大焕:中国人开始追求免于恐惧的自由 |
|
新华社连发两篇评论追问 |
|
童大焕:中国人开始追求免于恐惧的自由 |
|
人大学生会秘书长郝鹏程说,雷洋嫖娼不是第一次。 |
|
人大法学院就雷洋案举行研讨会案情惊动联 |
|
昌平警方的行为完全合法! |
|
嫖娼釣魚執法,坐地分贓 |
|
深度剖析雷某嫖娼案… |
|
姜杰律师:雷洋案件管辖权的法律分析 |
|
雷洋案件之疑点-第4页- |
|
雷洋案:守住私德的底线,恢复人性的的良知 |
|
嫖就嫖了,何必美其名——“被嫖娼”?|【新鲜茶馆】 |
|
雷洋案真相不难搞清,但很多人打死也不愿相信 |
|
央视:足疗女帮雷洋打飞机,帮助他射精你怎么看? |
|
看“嫖资收据”雷洋嫖娼铁证!(图) |
|
雷洋之死背后的阴谋论- |
|
雷洋案真相不难搞清,可怕的是有人就是打死也不愿相信 |
|
雷洋之死背后的阴谋论 |
|
人大部分88级校友就同学雷洋身亡声明:对恶我们不会忍太久全文 |
|
不成为下一个雷洋:就要围观不悲观 |
|
蔡慎坤:血与泪的控诉还原雷洋遇害真相 |
|
对比家属报案书和警方通报再看雷洋致死案 |
|
雷洋惊天大推论——喊假警察居然为报信 |
|
觀察:徹查雷洋案誰是獨立方? |
|
对比家属报案书和警方通报再看雷洋致死案 |
|
雷洋妻子正式报案:嫖娼是栽赃,致命处睾丸异常肿大_中华论坛_中华网社区- |
|
转发雷洋案刑事报案书:描述死亡过程(真相即将到来)-衡阳 |
|
血与泪的控诉还原雷洋遇害真相- |
|
雷洋事件:有百姓的信任危机,或许也有被利用!_中华论坛_中华网社区- |
|
雷洋死亡当晚到底发生了什么?央视专访当事警察 |
|
雷洋妻子正式报案:嫖娼是栽赃,致命处睾丸异常肿大 |
|
雷洋家属向北京市检报案要求侦查涉事民警湖南人在北京-常德 |
|
雷洋家属向北京市检报案要求侦查涉事民警- |
|
雷洋案「刑事報案書」細述雷洋之死經歷 | 刑訊逼供 | 暴力執法 | 大紀元 |
|
'他沒有嫖娼時間' 家屬報案指雷洋被無辜毆死 |
|
吴文萃(雷洋妻子):关于要求北京市检察院立案侦查雷洋被害案的刑事报案书 |
|
血与泪的控诉还原雷洋遇害真相 |
|
雷洋事件:有百姓的信任危机,或许也有被利用! |
|
'刑事报案书'细述雷洋之死:外力伤害所致 |
|
雷洋是不是嫖娼不重要?扯淡!笔者用十点给某些人普法 |
|
雷洋死有余辜! |
|
雷某的家人实在太不要脸了! |
|
吴文萃(雷洋妻子):关于要求北京市检察院立案侦查雷洋被害案的刑事报案书 |
|
血与泪的控诉还原雷洋遇害真相 |
|
雷洋妻子报案,事件最新爆料!嫖娼是栽赃,雷洋被打死-休闲侃吧- |
|
质疑雷洋案件十大疑点 |
|
[原创]雷洋遗孀之报案书等于官媒的死刑判决书 |
|
雷洋父母看完遗体后,为何当场给尸检证人下跪? |
|
雷洋最新情报:“刑事报案书”描述雷洋之死经历 |
|
关于要求北京市检察院立案侦查雷洋被害案的刑事报案书(转载) |
|
我们为什么要关注雷洋之死? |
|
雷洋案刑事报案书- |
|
雷洋案刑事报案书,警方涉嫌故意伤害(致人死亡)罪、滥用职权罪、帮助伪造证据罪- |
|
转帖:雷洋妻子向北京市检察院报案:嫖娼是栽赃,雷洋被打死 |
|
雷洋死有余辜! |
|
1) 雷洋家属告控告警方 2) 雷被殴打致死当日是雷结婚纪念日 3)尸检结果延迟到60天出结果 |
|
一个昌平“嫖娼者”为何引燃了全国公众的怒火?(转) |
|
陈有西律师曝雷洋案发现最新一个重要疑问 |
|
吴文萃(雷洋妻子):关于要求北京市检察院立案侦查雷洋被害案的刑事报案书 |
|
别忘了雷洋案中被抓的另五名嫌疑人 |
|
雷洋父母看完遗体向专家证人痛哭下跪 |
|
四川省纪委与厅纪委过去有结论吗?王书记上任后又是什么结论?- |
|
求助帖:别忘了雷洋案中被抓的另五名嫌疑人 - 有啥说啥 |
|
那些声嘶力竭认为雷洋嫖娼该死的人,他们是些啥人? |
|
雷洋事件昌平警方两份通报比较出的问题 |
|
别忘了雷洋案中另五名被抓的嫌疑人 |
|
父母看完遗体向专家证人痛哭下跪-常德 |
|
[原创]雷洋死亡案,已经形成死结 |
|
[原创]警察蜀黍为何喜欢抓嫖? |
|
崔家楠律师认为:确定雷洋死亡的时间,比确定死亡的原因更重要! |
|
歐陽南山:下一個雷洋是誰? |
|
童大煥:中国人开始追求免于恐惧的自由- |
|
[原创]雷洋,愿你的名字叫做公正与法治【猫眼看人】- |
|
我们追问雷洋是怎么死的,他们却要证明他是怎么嫖的! |
|
雷洋没有抗拒执法,铁证如山!证据就在此 |
|
一周新闻聚焦:雷洋之死掀起舆论风暴,各方谴责警方滥权 |
|
哀悼环保烈士雷洋|龙虎文苑 |
|
雷洋案:守住私德的底线,恢复人性的的良知 |
|
雷洋案:守住私德的底线,恢复人性的的良知(第7页)_关天茶舍_天涯论坛 |
|
雷洋案件的焦点应该回归到如何死亡的问题上_文学论坛_中华网社区- |
|
雷洋案件的焦点应该回归到如何死亡的问题上_社会热点_中华网社区- |
|
小区内现蛇窝:5条大蛇吓得消防员直冒汗(图) |
|
程序正义高于实质正义的理念,规则重于道德的理念,生命高于一切的理念_胜利社区_东营论坛_油城茶座 |
|
雷洋的父母下跪为哪般?(原创) |
|
明天就是5.16,大家还是说点什么吧 |
|
[原创]雷阳事件肯定不是跨区执法 |
|
雷洋案中,当事警察说谎了没有? |
|
雷洋案中,当事警察说谎了没有? |
|
天啊——这位律师是在为雷洋鸣不平吗?!_中华论坛_中华网社区- |
|
童大焕:中国人开始追求免于恐惧的自由- |
|
童大焕:中国人开始追求免于恐惧的自由- |
|
童大焕:中国人开始追求免于恐惧的自由- |
|
女人天天被杀都激不起水花,雷洋死就激起千层浪! |
|
女人天天被杀都激不起水花,雷洋死就激起千层浪! |
|
雷洋案件的焦点应该回归到如何死亡的问题上 |
|
雷洋案件的焦点应该回归到如何死亡的问题上 |
|
关注小人物的命运!就是关注自个命运!小人物之死网友理应关注 |
|
童大焕:中国人开始追求免于恐惧的自由 |
|
律师:事后搜集卖淫女的供词根本不能作为证据! |
|
童大焕:中国人开始追求免于恐惧的自由 |
|
天啊——这位律师真是在为雷洋鸣不平吗?! |
|
中国人开始追求免于恐惧的自由 |
|
雷洋案:守住私德的底线,恢复人性的的良知 |
|
我们关注雷某事件的重点:执法人员滥用职权、非法拘禁致人死亡_娱乐八卦_天涯论坛 |
|
律师从法律角度看雷洋案:警方认定嫖娼的事实不能成立-常德 |
|
雷洋案:守住私德的底线,恢复人性的的良知 |
|
雷洋之死击碎了中产阶级的优越感! |
|
力瑾:还有多少国人在意雷洋案的真相? |
|
人大硕士之死果然反转了,这小脸,抽得啪啪的响!(转载)(第35页)_娱乐八卦_天涯论坛 |
|
雷洋之死击碎了中产阶级的优越感! |
|
致人民大学88级部分校友:看了你们的声明我很无语(转载)(第2页)_网罗天下_天涯论坛 |
|
律师从法律角度看雷洋案:警方认定嫖娼的事实不能成立_中华论坛_中华网社区- |
|
雷洋案中案和常州毒地案有關係 ?? |
|
雷洋死于无知 |
|
雷洋嫖娼,谁嫖了法治? |
|
【话题】关于垒洋之死的问答 |
|
通过雷洋案,都要洗干净自己的灵魂,多一份正能量,就少一份阴暗 |
|
如果雷洋案发生在美国 |
|
再次重复:雷洋死后谁是下一个? |
|
人大法学院就雷洋案举行研讨会案情惊动联合国 |
|
狗哥评论雷洋事件!_天涯杂谈_天涯论坛 |
|
中国人民大学77、78级校友关于雷洋的声明 |
|
朋友圈骂交警“擦亮狗眼”被拘2日是执法滥权 |
|
雷洋之死或可推动社会三大进步 |
|
议雷洋之死 |
|
看了这么多人关心雷阳事件,我感觉警察存在钓鱼执法行为。_新闻众评_天涯论坛 |
|
雷洋屍檢釐清死因 校友發聲明轟警違法瀆職 - 東網即時 |
|
再次重复:雷洋死后谁是下一个? |
|
戴套打飞机 |
|
雷洋怎么死的? |
|
女人天天被杀都激不起水花,雷洋死就激起千层浪! |
|
雷洋这事,关键看标题 |
|
雷洋之死牵动人大校友上百人联署声明要真相 |
|
雷洋案中案神秘便衣牵出常州毒地案 |
|
雷洋家属指警方误导公众 |
|
雷洋案新证据浮现:警察有问题 |
|
一周新闻聚焦:雷洋之死掀起舆论风暴,各方谴责警方滥权 |
|
“雷洋嫖娼”案惊动联合国 |
|
立此存照:雷阳的事情经过 |
|
BBC:雷洋之死背后中国人对中国没信心(图) |
|
雷洋死后的人血馒头,不知道网上各位公知吃的好不好? |
|
张鸣:雷洋之死 |
|
观察:雷洋事件舆论风暴眼中的盲点 |
|
朱征夫:卖淫嫖娼收容制度违宪,早该废 |
|
雷洋嫖娼案的所有证据都是事后补上? |
|
为什么雷洋案这么高的社会关注度能持续一周时间? |
|
重要质疑:就雷洋案请教昌平警方几个问题-常德 |
|
雷洋嫖娼案的所有证据都是事后补上?(图) |
|
人大校友声明是粗暴干涉司法的恶劣行为 |
|
关注雷洋,也关注人民警察 |
|
”这份“公平正义”,雷洋听不到了,但我们必须感受到! |
|
[原创]细思极恐,雷洋之死或有更深内幕 |
|
[原创]就雷洋案请教昌平警方几个问题 |
|
对比家属报案书和警方通报再看雷洋致死案 |
|
对雷洋家属说几句话 |
|
橫河:雷洋案為什麼應該懷疑警方 |
|
贪官雷洋嫖娼被抓,畏罪拘捕逃跑未遂身亡 |
|
雷洋死亡案铁证如山,雷洋没有白死 |
|
雷洋父母看完遗体向专家证人痛哭下跪 |
|
雷洋是不是嫖娼不重要?扯淡!笔者用十点给某些人普法_中华论坛_中华网社区- |
|
【江西卫视】北京昌平的警方 |
|
雷洋尸体应严加监控,以防M帝下手 |
|
童大焕:必须全面还原并公开雷洋案执法过程 |
|
对不起,我并不想知道雷洋如何嫖娼-邵阳 |
|
大反转:目击者详述雷洋事发过程:警察没打人!请火速扩散! (转载)_婆媳关系_天涯论坛 |
|
[原创]警方塑造出神一般的雷洋 |
|
雷洋案尸检初步结果出炉:等待病理结果警方回避不在现场 |
|
雷洋之死的看法_北京_天涯论坛 |
|
【调查】探访雷洋案'神秘'专家证人张惠芹 |
|
雷洋用牺牲捍卫一个公务员的尊严!!!!! |
|
雷洋尸检超12小时家属请她全程监督 |
|
“雷洋事件”终于开了个好头 |
|
雷洋之死真相早己大白于天下(转帖)- |
|
雷洋之死击碎了中产阶级的优越感! |
|
滨州刑警支队原副支队长张惠芹,作全程见证雷洋尸 |
|
雷洋案:尽管真相还在路上,三种共识可以先到 |
|
雷洋没有抗拒执法,铁证如山!证据就在此 |
|
雷洋尸检超12小时警方回避家属坚持请她全程监 |
|
雷洋嫖娼案的所有证据都是事后补上?(图) |
|
下一个雷洋是谁? |
|
“雷洋嫖娼”案惊动联合国 |
|
十日谈;我想说几句了,关于何新的两篇文章_中华论坛_中华网社区- |
|
雷洋案蹊跷中国官方的处理手段令人心寒 |
|
郭宝胜呼吁海内外人大校友都来关注雷洋案, 为雷洋讨取公道 |
|
[原创]雷洋没有抗拒执法,特证就在此。 |
|
雷洋是否嫖娼不重要?怎么就不重要了?!很重要好吗!_天涯杂谈_天涯论坛 |
|
中国人民大学77、78级校友关于雷洋的声明 |
|
看“嫖资收据”雷洋嫖娼铁证!(图) |
|
警方续昌平涉嫖男子在查处过程中突发死亡通报有无问题 - 第2页 - 警务探讨 |
|
【麻辣舆情】人大硕士雷洋非正常死亡舆情分析-麻辣棱镜舆情通- |
|
从目击者证言和记者调查的报道看被忽略的雷洋事件关键点 |
|
人大硕士涉嫖身亡死因蹊跷背后真相》给人民一个交代 |
|
应当理直气壮的为“暴力执法”正名! |
|
他嫖不嫖娼关我屁事,我只关心他到底是怎么死的 |
|
雷洋“打飞机”能把自己打死吗? |
|
家属澄清雷洋调查常州毒地等三传言 |
|
雷洋被强押致死案,槽点多多,警方说辞漏洞百出 |
|
时代尖兵:雷洋的官方背景值得关注! |
|
雷洋案的焦点就是有没有受到粗暴对待? |
|
雷洋真嫖娼了吗? - 第2页 |
【相关】

韩春雨事件
http://blog.sciencenet.cn/blog-362400-977111.html
上一篇:【deep parsing:“对医闹和对大夫使用暴力者,应该依法严惩"】
下一篇:【新智元笔记:巨头谷歌昨天称句法分析极难,但他们最强】
12 许培扬 武夷山 蔡小宁 魏焱明 黄永义 汤伯杞 徐晓 苏德辰 张阳阳 侯成亚 gaoshannankai aliala
发表评论评论 (14 个评论)

- 删除 |
 赞[12]liudongshen
赞[12]liudongshen - 警察为什么热衷这项事业?因为这项事业在中国首先具有道德制高点。违法不违法只是技术问题。莫须有的道德污点却在中国更具备杀伤力

- 删除 |赞[11]张阳阳
- 和某个教授一下,是恶法杀人。
这个嫖娼条例,压榨了失足妇女(她们都要直接或变相的缴纳保护费或罚款),恐吓了嫖娼者(如解决生理需求的雷洋同学),肥了某些部分的腰包,增加了社会的不安定因素(如强奸)。这样的恶法,还不能废除,大抵是披着道德的外衣吧。

- 删除 |赞[10]dafwlg
- 围观此事件人群有各种心态:
1、哇!嫖娼!看看有图没?看看真正的嫖娼现场什么样的!满足一下猎奇心理,我还没嫖过呢!
2、哼!硕士也嫖娼吧!学习好怎么了,我当年一直学不好,一直被你们排挤,很自卑!
3、嫖娼被打死也活该!
4、嫖娼也不应该打死啊!

- 删除 |赞[9]gaoshannankai
- 雷洋一案-嫖娼问题是关键问题
http://blog.sciencenet.cn/blog-907017-976650.html
核心是 嫖娼

- 删除 |赞[3]junkscience
- 当最后的结论与大数据不符合时, 就是对大数据最不可靠,最不科学的审判

- 删除 |赞[2]魏焱明
- 我刚刚写了一个呼吁,欢迎好友及时推荐。
《“雷洋事件”是催生文明徭役抵罚和发展慈善机构的大好契机!》http://blog.sciencenet.cn/blog-2339914-977077.html
【社媒挖掘:美国大选候选人大战(1):川普很臭】 屏蔽留存
【社媒挖掘:美国大选候选人大战(1):川普很臭】
屏蔽 |||
这阵子一直忙于调试系统,好久没顾上做热点话题的舆情调查了。老友一直催我用大数据追踪一下美国总统大选。今年的美国大选,情势诡异,尤其是杀出一个不按常理出牌的共和党的川普,不少追随者粉他,恨他的人也很多。
这是几天前(周二前)做的美国大选半年以来的英文社会媒体的大数据调查,直到今天才得空整理上网分享。先给一个一个过去半年的大数据总结图。
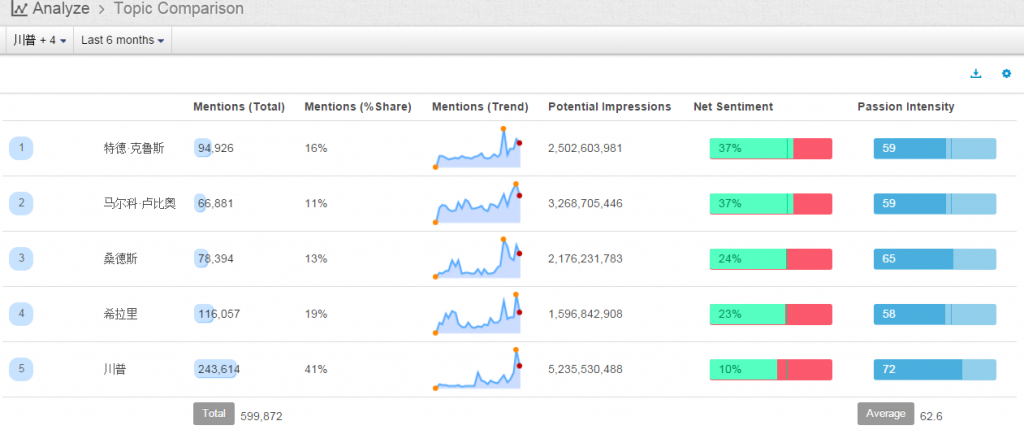
人气评价(Net Sentiment)最高的是民主党的 Bernie,褒贬指数高达正45%,把其他对手远远抛在后面,第二名 Marco 21%,Beinie 的一半还不到,评价最差的是川普 6%.
难怪我女儿是 Beinie 的铁杆粉丝,不断催促我们给 Beinie 投票,不要让希拉里出线。我:
而话题大王,则非川普莫属,一亿五千多万的 mentions,23兆860多亿的眼球数,瑶瑶领先。
第二名的 Ted (眼球数8兆)只有眼球大王川普的三分之一
可见川普这个美国政坛的怪物掀起了怎样的一个风暴
普这个美国政坛的怪物掀起了怎样的一个风暴
http://blog.sciencenet.cn/blog-362400-963290.html
上一篇:【NLP笔记:人工智能神话的背后是汗水】
下一篇:【新智元笔记:强弱人工智能之辩】
《利用大数据高科技,实时监测美国总统大选舆情变化》 屏蔽留存
《利用大数据高科技,实时监测美国总统大选舆情变化》
屏蔽 |||
活生生的大数据,活生生的实时展示。

特别是两党内部总统候选人提名的政策辩论,以及两党候选人的几场总统竞选辩论,来自社会媒体(主要是推特)大数据的舆情实时监测,比传统民调高明许多:反映民情及时、准确、客观,数据点高出传统民调好几个量级。
下面的链接中,点击头像可以立马实时监测舆情的瞬时变化:http://bit.ly/1LiSXrg #NBDebate
This is our live social media monitoring for the debate. We did it before during the last election, and it is ridiculously making sense.
奥巴马赢了昨晚辩论吗?舆情自动检测告诉你:http://blog.sciencenet.cn/blog-362400-623922.html
如今,至少过去一个小时的实时舆情显示,喜大妈远落后于其他两位民主党候选人。点击三位候选人的头像可以立马看到各自的舆情指数 net-sentiment,反映的是他们的 popularity。
http://www.netbase.com//democraticdebates2016/candidates_competitive_view.html
过去一个小时的舆情指数是: 10/13 2015 5pm
喜大妈:-22
http://www.netbase.com//democraticdebates2016/hillaryclinton_livepulse.html
Joe Biden:+39
http://www.netbase.com//democraticdebates2016/joebiden_livepulse.html
Bernie Sanders: +53
http://www.netbase.com//democraticdebates2016/berniesanders_livepulse.html
零下 22 度啊,怎么这么惨呢。我本来还指望她成为历史第一任美国女总,把社会主义的全民健康医保推向深入,并且推进移民改革,让技术移民更容易。
【相关博文】
世人皆错nlp不错,民调错大数据也不会错 2015-10-15
http://blog.sciencenet.cn/blog-362400-927997.html
上一篇:《立委科普:关键词外传》
下一篇:世人皆错nlp不错,民调错大数据也不会错

大数据淹没下的冰美人(之二) 屏蔽留存
大数据淹没下的冰美人(之二)
屏蔽 |||


女神 or 妖精,总之不似人类
好,我们开始范冰冰的社媒深度挖掘,看看网友都怎么说她。
先看网友的赞美(绿字体)和吐槽(红字体)等情绪化评语的词云分布,显然是东风压倒西风:
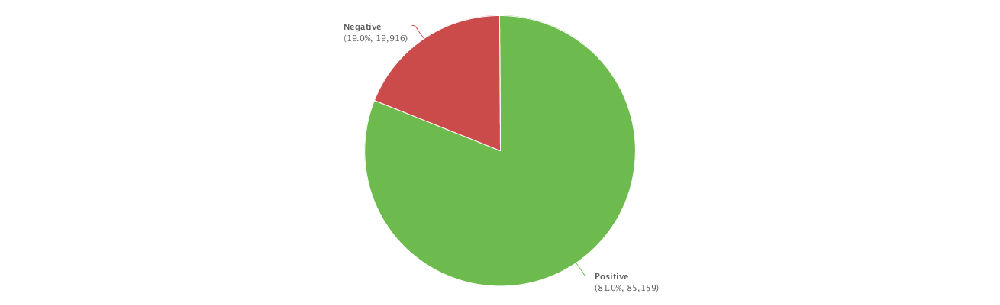

分类总结前五类情绪评语如下。
先看赞誉,毫无悬念,迷恋她、惊艳其美和粉丝的溢美之词占绝大多数,见(1)(2)(3):
(1) 喜欢, 爱,迷恋, 羡慕, 中意, 享受, 怀念, 惊喜,飞吻,?,相中, 看中
(2) QQ, 粉丝,给力,成功,最强,很火,不错,很好,最佳,可爱,受欢迎
(3) 美, 美爆, 绝美, 女神, 传奇, 完美,逆天,耀眼, 精彩, 更胜一筹
(4) 倾国倾城,性感,威武,强大,厉害,独特, 优雅, 经典, 华丽
(5) 支持, 欣赏, 赞, 夸赞, 看好, 期待, 关注
有意思的是(4)中系列形容词所发出的信息:把倾国倾城、性感厉害、优雅华丽与威武强大等集合起来,在当今华裔女星中是不多见的,她反映冰小姐的御姐女皇范儿给观众留下的印象,她是独特的。冰美人绝不是传统的温婉贤淑小家碧玉类的女子。
各花入各眼,萝卜青菜各有所爱,她这一款自然不会人人喜欢。作为娱乐界耀眼的公众人物,在排山倒海的网友和粉丝的赞誉中,自然也不免被吐槽,也分五类如下:
(1) 不喜欢, 吐槽, 讨厌, 抱怨,烦, 骂, 恨, 气,不爱, 不欣赏, 不羡慕,失望, 无语, 受不了,无法忍受,
大跌眼镜,大失所望
(2) 质疑, 怀疑, 鄙视, 讽刺, 嘲讽, 不接受, 批评, 不关注, 抵制, 看不上, 看不惯,不看好,看不起
(3) 不美, 不好, 差, 破, 不怎么样,不完美, 不行, 没多美,没有我美,算不上一流,一无是处, 不给力
(4) 低能儿蠢货, 不要脸,我操,垃圾,变态,傻逼,坑爹,这么狗血,最不要脸, 恶心,鸡肋,操, 吓人,
美个屁,挖鼻屎,白痴,二货
(5) 还不如现在的张馨予,还不如穆婷婷可爱,太胖,臃肿,
第一类表达各种程度的不喜欢不欣赏,第二类是各种鄙视看不惯,第三类酸溜溜的多少带有嫉妒的不屑,这些大多是口味问题,或者源于人皆有之的某种小小的嫉妒之心。第四类竟是破口大骂了,这是社会媒体作为许多匿名网虫无遮挡发泄负面情绪的一个反映,你美了就骂你蠢,你急智就骂你丑,总之是无冤无仇也要骂娘,特别是要骂名人。倒是第五类的负面信息最为具体,说她不如张美人穆美人(张穆都是啥妖精,怎么从来没听说过,演过啥,没有一丝印象),说她太胖臃肿,虽然明显有偏见,却也不是空穴来风。
为了过来看看
@素颜锦诗 350938楼 2014-05-07 19:46:10 萝莉粉真不爱范爷这款长相的, 我觉得也许在萝莉看来, 范爷还不如穆婷婷可爱...
人总是健忘的 RT @zmt0516: 记得当年范冰冰的名声还不如现在的张馨予,现在已经被公关团队刷成女神之神了。。。
#freedom #民主 范冰冰黄裙现身体态臃肿 群众爬墙头睹芳容 组图 http://t.co/xprlcS1RdE
总体来看,情绪化用语无论正面负面,大都当不得真,只是反映了舆情的好恶分布而已。真正有价值的舆情挖掘是情绪背后的理由,为什么喜欢或者不喜欢她?这类细线条的深度舆情挖掘,我们留待下一篇博文给您提供。
【大数据淹没下的冰美人】的系列博文链接:
http://blog.sciencenet.cn/blog-362400-889610.html
上一篇:大数据淹没下的冰美人(之一)
下一篇:吐槽:电话回访
2 刘淼 bridgeneer
Chinese First Lady in Social Media 屏蔽留存
Chinese First Lady in Social Media
屏蔽 |||

 I showed the First Lady's news pictures to my daughter. She was so intrigued, "Dad, Mom told me that you used to teach First Lady many years ago, is that true?" "It is true, but that was only a short time, one or two semesters, and it was not her major course. As a part-time lecturer, I was teaching Advanced English to graduate students in the music conservatory and she happened to be one in my class. She was already famous then as a new star for folk songs." Tanya got excited, "Well, you never know, maybe her English training in graduate school helps her in state visits today. My Dad is cool." She continued, "Dad, Mom also told me that you were interpreter for foreign minister when she dated you, is that true?" "Well, that was largely an accident, only happened once when I substituted some professor to act as interpreter for the former foreign minister and former Chinese congress vice-chairman Mr. Huang Hua. Your Mom agreed to date me partially because of her seeing a picture of me interporeting for the VIP Mr. Huang. So I guess I benefited from that 'accident'." Tanya was amused and felt very proud, "I have the coolest Dad in the world. He was so successful even when he was young, teaching future first lady and interpreting for the then foreign minister. Wow."
I showed the First Lady's news pictures to my daughter. She was so intrigued, "Dad, Mom told me that you used to teach First Lady many years ago, is that true?" "It is true, but that was only a short time, one or two semesters, and it was not her major course. As a part-time lecturer, I was teaching Advanced English to graduate students in the music conservatory and she happened to be one in my class. She was already famous then as a new star for folk songs." Tanya got excited, "Well, you never know, maybe her English training in graduate school helps her in state visits today. My Dad is cool." She continued, "Dad, Mom also told me that you were interpreter for foreign minister when she dated you, is that true?" "Well, that was largely an accident, only happened once when I substituted some professor to act as interpreter for the former foreign minister and former Chinese congress vice-chairman Mr. Huang Hua. Your Mom agreed to date me partially because of her seeing a picture of me interporeting for the VIP Mr. Huang. So I guess I benefited from that 'accident'." Tanya was amused and felt very proud, "I have the coolest Dad in the world. He was so successful even when he was young, teaching future first lady and interpreting for the then foreign minister. Wow."

The personal story aside, Chinese social media are never short of coverage and fans of Chinese First Lady Mrs Peng Liyuan in the last few years. For too long China watched the western media covering first ladies in the US and other countries without being able to brag about its own. Since Mrs. Peng went on the spotlight and accompanied Chinese President Xi Jinping on world trips, the Chinese netters have been overjoyed to follow her all the way with compliments and amazement in her gracefulness. Mrs. Peng has been a star in the Chinese music industry for decades and knows how to present herself in the public. A more recent story came from APEC last year when the Russian president Putin was seen to stand up, gracefully placing a blanket around the shoulders of Chinese First Lady, too gentleman an act that triggered waves of online comments.

Using our own text mining tool, we collected one year Chinese social media data to see what the public image looks like for the First Lady. Overwhelming praises and admiration, on her grace, intelligence and personality, with almost no negative comments. The only eye-catching criticism that was uncovered involves early days of Peng Liyuan "wearing fat army trousers (穿肥大的军裤)", which seems not to be something that agrees with first lady's image in people's mind. (It turned out that this was a story about the First Lady's dating the president long ago when she wanted to test the present if he was only attracted to her appearance by wearing not as nice on purpose.
The story got spread all over the net.) But look at the Photo News today, First Lady is now leading the fashion trend of China.
Related:
社媒挖掘:央视的老毕 屏蔽留存
社媒挖掘:央视的老毕
屏蔽 |||

Chinese TV star Bi Fujian caught on tape privately insulting Mao, which triggered a huge political debate in social media between the leftist and the rightist. China is presently stuck between post-Mao era entering modern society with limited speech freedom (at least on private occastions) and the totalitarian government inheriting Mao's legacy, hence the regulatory pressure to the star himself suspending his job for 4 days. Bi's speech would have made him sentenced to death or life in prison in Mao's time.
这两天微信老有提到他,今晚美国中文电视也报道了,据说社会媒体闹翻天了,于是想到做个舆情自动调查。
本来是私底下对毛时代和毛本人的打趣开涮,没想到闹到了网上,加上这个话题对于左右两派的敏感性,一下成了热点。
下面是针对内容商给我们提供的一周简体中文社会媒体(可惜,不含微信:万能的微信,你什么时候在不侵犯隐私的情况下开放哪怕部分数据,好让民情上达周知?)的自动调查结果,用的是咱独家自然语言挖掘技术。
负面多于正面,老毕形象严重受损:

wow 够上纲上线的,倒退四十年,老毕有十个头也不够杀的:

一周的媒体热议曲线:
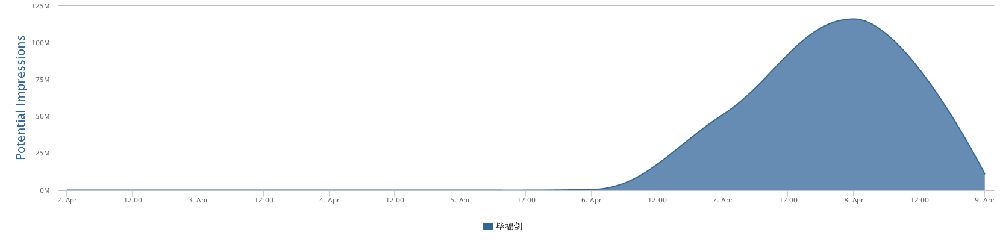
看一周褒贬度的图示如下,毕姥爷的社会媒体形象陡然下跌:
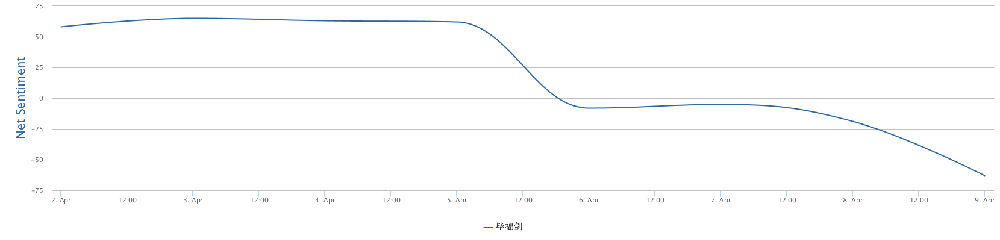
下面是一周的情绪烈度图,可见正反吐槽越演越烈:符合咱老中爱吵架的习惯
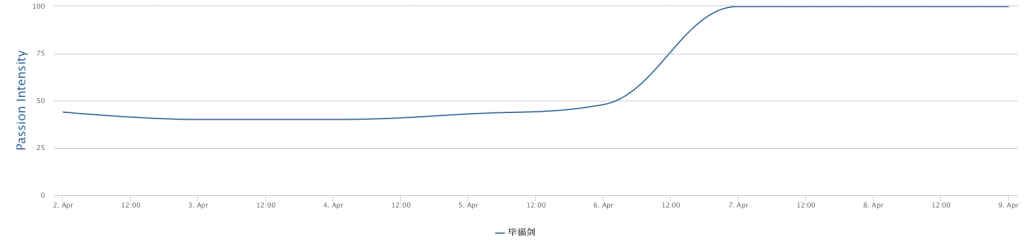
吐槽样本:
|
旗帜鲜明支持毕福剑! |
|
你们可以继续喜欢毕福剑。 |
|
[哈哈] 毕福剑老好人? |
|
旗帜鲜明支持毕福剑! |
|
毕福剑没错 |
|
毕福剑快去死吧! |
|
毕福剑, 骂的客观! |
|
十分认真地支持毕福剑先生 |
|
立场坚定支持毕福剑! |
|
毕福剑无罪 |
|
不喜欢毕福剑, 老流氓架势 |
|
鄙视毕福剑 |
|
毕福剑该死 |
|
毕福剑作死啊 |
|
支持毕福剑 |
|
毕福剑, 变化多端. |
|
毕福剑火了! |
|
毕福剑该出来道歉 |
|
感谢毕福剑敢于捅破了窗户纸 |
|
狗操的毕福剑, 去死吧 |
|
毕姥爷瞎说什么大实话 |
|
毕福剑交友不慎啊。 |
|
毕福剑为什么辱骂毛泽东? |
|
毕姥爷叛国了· |
|
毕福剑明天就死。 |
|
毕姥爷作死啊! |
|
毕姥爷瞎说啥实话 |
|
应该引起重视, 坚决批判毕福剑。 |
|
支持毕福剑! |
|
支持毕姥爷 |
|
央视的毕姥爷这下更火了。 |
|
毕姥爷威武 |
|
特别讨厌毕福剑 |
|
cctv就是仃办也不能再用毕福剑这样的流氓主持。 |
|
毕福剑此事定义准确! |
|
毕福剑是民族英雄, 不畏强暴。 |
|
严惩辱骂毛主席的毕福剑 |
|
难道毕福剑真能一手遮天? |
|
毕姥爷还是很有才的 |
|
毕福剑真的死了吗。 |
|
毕姥爷是在嫖娼吗 |
|
毕姥爷又火了一把 |
|
[哈哈] 毕福剑现象, 中央应该反思! |
|
毕福剑言论不雅视频竟口无遮拦公然骂毛泽东 |
|
网上舆论因此哗然, 纷纷指责毕福剑当面一套, 背后一套。 |
|
毕福剑是真正男子汉, 正直中国人全支持他. |
|
[哈哈] 毕福剑这样的党员在为谁歌唱! |
|
毕福剑诋毁伟人和先烈必须严惩 |
|
[哈哈] 毕福剑的酒桌表演为什么不能容忍? |
|
只怪毕福剑交友不慎, 好事者用心不良。" |
|
这是毕福剑作死的节奏。 |
|
毕姥爷叛国了··· |
|
毕福剑并非第一次"惹事"。 |
|
不作死就不会死毕福剑原形毕露, 就是老兵里的垃圾。 |
|
毕福剑言论不雅视频, 竟口无遮拦公然骂毛泽东。 |
|
狗操的毕福剑, 被车撞死了。 |
|
我喜欢老毕 |
|
东北人支持毕福剑 |
|
开始支持毕福剑了 |
|
强烈要求央视开除侮辱谩骂毛主席的坏蛋毕福剑! |
|
很喜欢毕福剑。 |
|
赞毕姥爷! |
|
毕姥爷威武! |
|
从此鄙视毕福剑...... |
|
从此鄙视毕福剑! |
|
看来毕姥爷央视的饭碗堪忧。 |
|
[哈哈] 有人说毕福剑是酒后吹牛逼不必上纲上线。 |
|
毕福剑骂的太好了, 比我骂的有影响力。 |
|
喜欢这条评论毕福剑诋毁伟人和先烈必须严惩 |
|
话糙理不糙, 支持“毕姥爷”! |
|
我还是觉得毕姥爷厉害来自QQ浏览器快速回帖 |
|
谁敢处分毕福剑必无好下场. |
|
毕福剑的酒桌表演为什么不能容忍? |
|
毕福剑嫖娼的日子不远了。 |
|
毕福剑公开侮辱人不用负责任吗? |
|
面对公众人物毕福剑的信口开河你怎么看 |
|
毕福剑是媒体人的光辉榜样。 |
|
毕福剑侮辱领袖必遭鞭刑。 |
|
毕姥爷的形象瞬间伟岸起来。 |
|
毕福剑无罪, 发视频的应该重判 |
|
毕福剑, 死啦死啦的。 |
|
你毕福剑应该向全国人民谢罪... |
|
毕福剑毕姥爷交友不慎遇人不淑, 被人陷害于不仁不义。 |
|
官媒: 毕福剑侮辱开国领袖应受公众的谴责图 |
|
央视大腕不能人模狗样毕福剑是媒体人的光辉榜样。 |
|
央视对毕福剑处理的越严重, 毕福剑的声誉就会越高; |
|
毕福剑万岁, 万万岁. |
资料来源:

【相关】
社媒挖掘:老毕私下辱毛事件再挖掘 2015-04-12

社媒挖掘:老毕私下辱毛事件再挖掘 屏蔽留存
社媒挖掘:老毕私下辱毛事件再挖掘
屏蔽 |||

毕福剑事件持续发酵,今早起来再做一次中文简体社会媒体的自动民调,发现有些微妙的变化。
我把两天前的调查曲线图(区间是四月二号到四月九号)拷贝在下与现在做的(区间是四月四号到四月11号)做个比较。
(1)热度:
四月二号到四月九号媒体热度曲线图
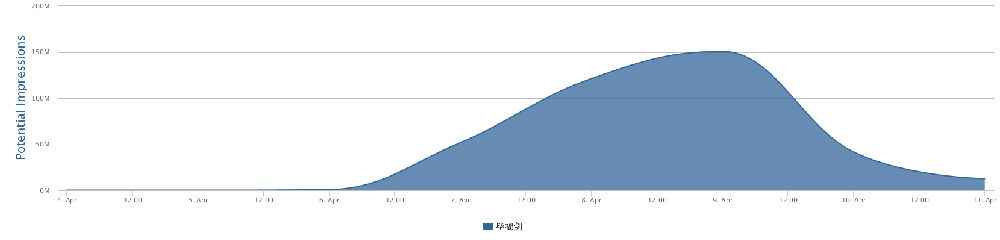
四月四号到四11号媒体热度曲线图
(2) 媒体形象趋向:
褒贬曲线(net sentiment)对比发现毕姥爷形象大损后,四月九号到低谷,这两天又开始显著回升
怎么回事?公关道歉开始收效,还是右派群众(挺毕派)开始有效反击?
四月二号到四月九号媒体褒贬曲线图
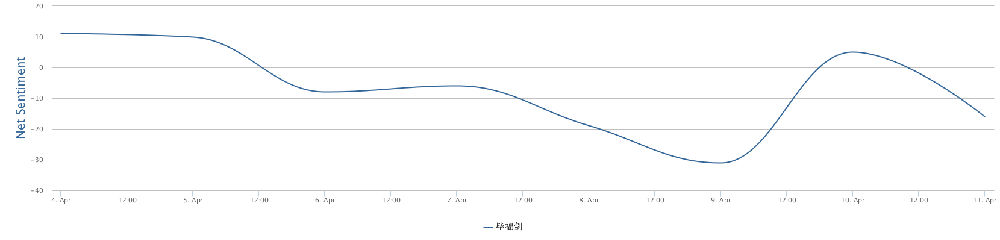
四月四号到四月11号媒体褒贬曲线图
(3)情绪烈度变化图:最奇怪的是吐槽情绪本来越演越烈,两派互骂炽热化,居然从四月九号开始明显收敛,是网众重归理性,还是过激帖子被批量删除?
四月二号到四月九号媒体情绪烈度曲线图
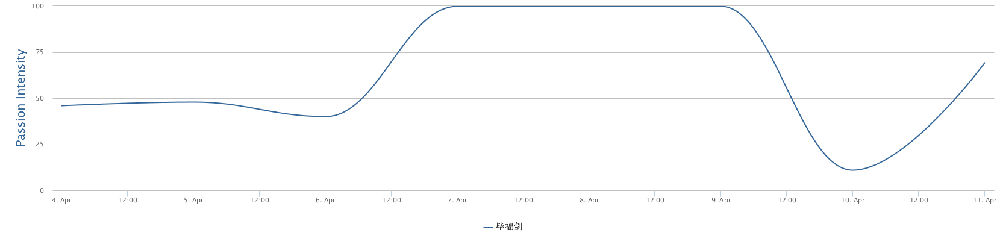
四月四号到四月11号媒体情绪烈度曲线图
相关:
社媒挖掘:央视的老毕 2015-04-09
2 武夷山 bridgeneer
发表评论评论 (7 个评论)

- 删除 |[7]用户名
- 评论已经被科学网删除

- 删除 |赞[6]huangnigang1
- 史上第一个告密者:商纣王时代的崇侯虎
http://news.ifeng.com/history/minjianshuoshi/hemufeng/detail_2009_12/16/320005_0.shtml
- 删除 |[5]用户名
- 评论已经被科学网删除
- 删除 |赞[4]huangnigang1
- 五月,丙寅,禁天下屠杀及捕鱼虾。江淮旱,饥,民不得采鱼虾,饿死者甚众。 右拾遗张德,生男三日,私杀羊会同僚,补阙杜肃怀一啖,上表告之。明日,太后对仗,谓德曰:“闻卿生男,甚喜。”德拜谢。太后曰:“何丛得肉?”德叩头服罪。太后曰:“朕禁屠宰,吉凶不预。然卿自今招客,亦须择人。”出肃表示之。肃大惭,举朝欲唾其面。
译文
五月初一,国家下令禁止天下宰杀牲畜和捕捉鱼虾。江淮地区天旱,粮食不收,人民又不能捕鱼捉虾,饿死人很多。
右拾遗张德,家里生个男孩儿,办喜事,私下宰了只羊请同事,补阙杜肃藏起个肉饼,事后上书告发。第二天,太后在朝堂上跟张德说:“听说你生个男孩儿,挺高兴。”张德跪拜致谢。太后说:“你从哪儿弄来的肉?”张德实说了,叩头服罪。太后说:“我禁止屠宰,而喜事丧事不受干预。不过你以后召请客人,也应该有所选择。”拿出杜肃的奏表让他看。弄得杜肃无地自容,整个朝廷的官员们都要啐他的脸。《资治通鉴》第二百零五卷长寿元年(壬辰,公元六九二年)
- 删除 |赞[3]huangnigang1
- 中国古代帝王中,不少人颇有佛缘,女皇武则天便是其中一位。武则天推崇佛教的目的,是想把佛教当作自己登上权力顶峰的思想武器。她一当上皇帝,便宣布“释教开革命之阶,升于道教之上”。除划拨专款大修寺庙,大造佛像,大量翻译佛经外,还多次用行政手段掀起全民崇佛的热潮。在强制性的全民崇佛运动中,有一道禁杀牲畜、禁捕鱼虾的命令,曾闹出了不少趣闻。
不杀生是佛教五戒之一,是佛门弟子基本的行为准则。但不准普通老百姓吃肉,实施起来无疑有很大难度。为了查验禁屠令的执行效果,武则天特命宰相娄师德下基层巡视。宰相视察工作,基层官吏自然要设宴接待。宴席上,首先送上来的是一盆羊肉。基层官吏解释说:这羊不是我们杀的,是狼咬死的。既然是狼咬死的,吃了当然不算犯禁。接着送上来的是一盘鱼。基层官吏又声明:这鱼也是狼咬死的。娄师德一听喷饭大笑:你咋这么笨呢,应该说这鱼是水獭咬死的才对。欢笑声中,美味佳肴很快成了腹中之物。
由于“上有政策,下有对策”,武则天的禁屠令在基层的执行状况估计不会太理想。事实上,古往今来的任何一项政令,如果不得人心,最终结局必定是草草收场。后来,武则天大约也觉得这个禁令有点过分,因而在处理违禁案例时,对当事人十分宽容。
左拾遗张德的妻子生了一个男孩,便偷偷地杀了一头羊宴请宾客。其中有个叫杜肃的人,饱吃一顿羊肉之后,居然写了一纸状文向皇帝告发张德。
第二天上朝时,武则天对张德说:“你妻子生了一个男孩,可喜可贺啊。”张德向武则天拜谢。武则天又道:“可是羊肉从哪里弄到的呢?”张德赶紧叩头连称死罪。武则天道:“我禁止宰杀牲畜,是吉是凶难以预测。可是你邀请客人,也该有选择地交往。无赖之人,不能一起聚会。”然后拿出杜肃的状文给他看。杜肃卖友求功不成,反遭奚落,吓得直冒冷汗。武则天显然认为杜肃出卖朋友事大,而张德违犯禁屠令事小。由此可见,连武则天自己后来都不把禁屠令当回事了。
还有一桩趣事。一天,洛阳定鼎门外翻了一辆草车,藏在草车上的两只被杀的羊顿时露了馅。这无疑犯了禁屠令。目睹此事的护门人立即将线索报告御史彭先觉。彭先觉可能晚来了一步,没能抓到拉草车的人,便想把责任推到别人身上。他上书给皇帝说:“合宫尉刘缅专门管理屠宰之事,他没有觉察到这件事,应罚他吃一顿棍棒,羊肉则可送给尚书省的官员们吃。”刘缅听说后很是害怕,赶紧做了一条加厚的裤子等着打屁股。没想到,第二天武则天在彭先觉的奏疏上批示:“御史彭先觉奏请杖打刘缅的意见不妥。羊肉应给刘缅吃。”消息传开,满朝官员皆拍手称快,只有彭先觉羞惭不已。
- 删除 |赞[2]huangnigang1
- 武则天有一阵子禁止屠宰牲口。有个叫张德的右拾遗,因为喜得贵子,便违禁宰了头羊,宴请朋友同事。同事中有个叫杜肃的,吃了一顿之后就跑去向武则天告密。第二天朝会,女皇将杜肃的告密信交给张德,然后告诉他:卿今后请客,还是小心一点,那种前头吃了好酒菜一转身就去告密的小人,就不要请了。
自动民调Walmart,挖掘发现跨国公司在中国的日子不好过 屏蔽留存
自动民调Walmart,挖掘发现跨国公司在中国的日子不好过
屏蔽 |||
最近用自家产品做了一次关于沃尔玛的自动调查,总体来看,沃尔玛这个品牌似乎蛮受欢迎的,正面评价为主,褒贬指数达到正48,是相当不错了。指责抱怨也有,主要针对一些负面事件(狐狸肉冒充牛肉、对伪劣产品乱发合格证上架等)。进一步挖掘(drill down)发现了令人惊奇的现象:好话大多是网民自发的评价,而挖掘出来的负面信息几乎一律出自国家新闻机构(CCTV等)的报道。社会媒体挖掘的本意是自动民调,了解客户对于品牌和产品的意见,正式新闻有机构或国家宣传的因素在,是应该加以区分的。可是目前,这种区分还做得不好,很多有影响的传统媒体的新闻被反复在社会媒体中转发传播,与民意混杂在一起。
Some further analysis and findings:
1. The existing data are not very large (400k mentions a year), but the results make sense with decent data quality
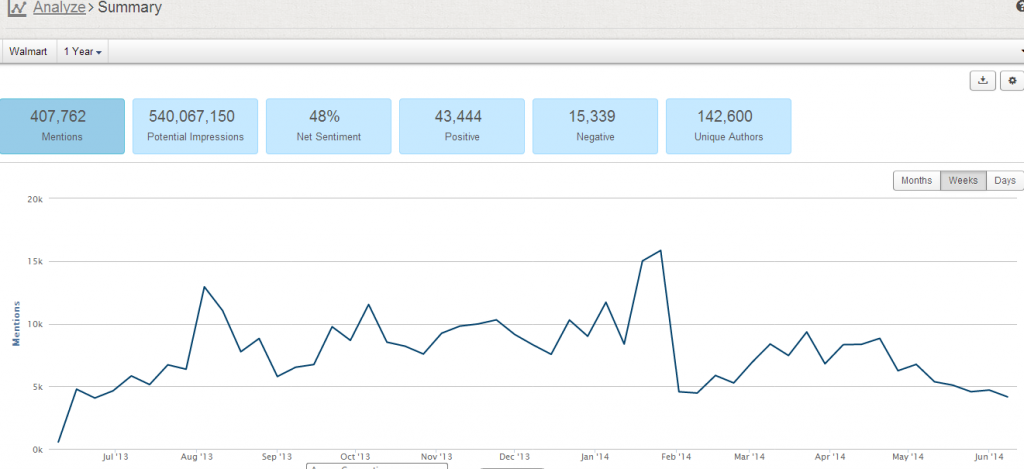
2. From geos stats, we know most data on Walmart come from China (dark color) instead of overseas sources
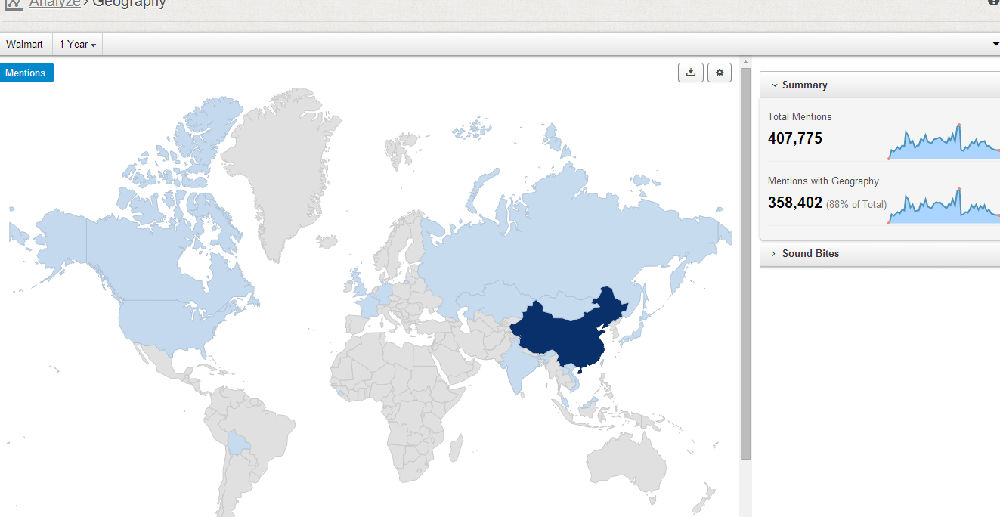
3. From domains stats, the data actually include data from Sina Weibo (weibo.com) and Tencent Weibo (t.qq.com) although the data flow from these two important Microblog sources is not stable at this point. Also the domains stats show that the major domains are all from China. I know that Walmart is a very influential brand in China and has many stores in cities of China.

4. The net sentiment 48% is fairly high, which is reflected in the emotions stats (data quality very good): big green fonts emotional terms include 放心 (piece of mind),喜欢 (like),乐 (happy),支持/推 (support),很好 (very good), 不错(not bad),成功 (success) etc. The negative emotional words (in small red font) are not many, including 差劲 (bad),抱怨 (complain),不喜欢 (dislike),垃圾 (garbage),很一般 (very so-so: meaning not as good as expected).

5. In the proscons word cloud, the likes include money-saving (省钱/便宜)and first-class service(服务一流); more interesting insights come from the dislikes, including (1) fake beef (using fox meat 狐狸肉事件); (2) recall (召回some product?); (3) cheating(欺诈); (4) scandal(丑闻) etc.

6. In order to drill down to see what negative incidents led to the above dislikes, the Walmart_con_sample shows some related sound bites which look like negative news on some incidents: 1st sound bite reports CCTV news on Walmart’s fake alcohol and fake meat (using fox meat) incidents; 2nd sound bite reports using fox meat to fake beef and donkey meat and using chicken to fake beef in the sold burgers at its Sam’s Club; the third sound bite reports three incidents of Walmart at different times and its apologies, including using cheap frozen meat to fake organic green food; using cheap fox meat to fake beef; and its lack of quality control in importing low quality products for sale, having issued 200 permits within 7 years for disqualified products to be on shelf.
7. Note that the above sound bites are selectively collected to show that our system can indeed capture detailed negative incidents of the brand in the media. When I drill down, there are quite some duplicates in our sound bites (one bad news gets re-posted everywhere); another thing is that the negative comments are not mainly from social media users, but from news (state-run news which get posted in social media too).
8. Unlike the overwhelming positive terms in emotions word cloud and the summary, the behavior word cloud shows more or bigger negative behavior terms than the positive terms. This is understandable because of the heavily reported incidents as shown above in the sample sound bites. Eye-catching negative behavior terms include “revealed”(被曝), “take to court”/”being sued”(告上法庭); “closed”(关闭); “have to take off shelf” (下架)etc.

9. From the above negative behavior terms, I drilled down to see more details in the sample sound bites below, which is similar to the sample discussed in 6. These two sound bites both come from negative news of Walmart, which originated from traditional news and got spread all over Internet.
中国新闻媒体对美国的跨国公司的负面报道跟民意没什么关系,倒往往由某种国际关系的大气候所致。当年为了打压谷歌,硬是给谷歌搜索按上了黄色监管不力的莫须有的大帽子,无视国内的搜索、视频和很多其他网站黄色泛滥到令人发指的露骨程度。欲加之罪,何患无辞。
不仅如此,最近还听说,由于中美相互指责对方利用网络偷窃情报,IT 业关系恶化,以至于谷歌和苹果等公司在中国遭到进一步打压,连做学问的信息利器 Google Scholar 都被封杀了。造孽啊,城门失火,殃及池鱼。
10 武夷山 李世春 章成志 孙平 陈筝 周云圣 强涛 高建国 fumingxu bridgeneer
发表评论评论 (13 个评论)

- 删除 |赞[10]davidli91
- 唠叨几句个人意见,仅供参考:
博主回复(2014-6-17 02:07):对付水军和五毛确实是中国社会媒体自动处理的一个关卡。
凡是程序自动做的噪音,技术手段终究可以对付。
......五毛因为只拿五毛,急工出糙活,应该有迹可寻的。反过来看,一个“有实质内容”的帖子,出自五毛的可能性极低。......
......一般而言,认证客户至少要顾及自己的信誉。 ......
=====================
"凡是程序自动做的噪音,技术手段终究可以对付。"---完全同意。
而后两点,有待商榷:
因为简单粗糙的五毛评论(读者还是可以区分一点的)给"雇主"带来的不是"美誉度"而是"毁誉度",故此,做新媒体推广的广告公司中的招商文稿中往往会特别声明是“有实质内容”的,或由“大V”推广!当然,要价也高出了很多很多。
还有就是往往不是一次性集中发多少评论,而是一段时间内发多少篇等等,“定价规则”很灵活。感觉做民调,要特别注意“沉默的大多数”,才不会走偏。
大数据<>高准确性(高可信)!
科学的做法应该是考虑样本群体与对象群体的差异才有意义,特别是在差异巨大时。
就拿大型超市而言,相信绝大多数顾客不会因为买到了一件低价的商品而去某个网络媒体给个好评(潜意识中大型超市应该低价?),只有有了矛盾,才会感到“店大欺客”,想去找个地方“说理”。因此,排除“官方噪声”,差评>>好评似乎应该是正常现象。
再拿所谓的“淘宝信用”来说,用真实的快递单(最有实质内容了)来刷淘宝店信誉已成了公开的“行业秘密”;因此,又有了“天猫”,“1号店”等等的诞生。


- 删除 |赞[7]davidli91
- [6]李世春 2014-6-16 15:36
尖端课题,如何从大数据中剔除五毛的贡献?
=====================
确实不易,再多说一点点:
"单纯好评"的"单价"和"短文好评"的"单价"要差10倍左右。"雇主"也知道要"优质优价"的。


 您知道发一个好评多少钱吗?大公司有公关部的。
您知道发一个好评多少钱吗?大公司有公关部的。 [转载]ZT:牛津大学王宁博士:大数据与有限理性 屏蔽留存
[转载]ZT:牛津大学王宁博士:大数据与有限理性
屏蔽 ||| |
-
大数据似乎在一夜之间迅速走红,它势不可挡地冲击着金融、零售等各个行业。
-
云计算将如何改变计算的世界?未来将有怎样的应用前景?如何解决“信息孤岛”的问题?
-
大数据又将如何提高我们决策的准确性,帮助我们更准确地预测未来?
牛津大学互联网研究院研究员王宁博士分享了《大数据与有限理性》。
大数据与有限理性
要生存还是要毁灭,这是个值得思考的问题,它道出了我们所有人一个共同的难题,就是选择,很多人都惧怕选择,有些人有选择恐惧症,特别是面对一些关于人生、事业、爱情这种重大选择的时候,我们往往看不清楚未来,算不清楚得失,不知道该怎么选,有时候非常纠结。上至一个国家的领导人,大政方针的制定者,再至很多公司的管理层,最后到普通的老百姓,选择可能都是每天需要面对的一个问题。
人类是如何进行选择的呢?早期的经济学家认为人类是理性的,这也就是亚当·斯密在《国富论》中论述的,市场是一只看不见的手,每个人在他个体利益最大化的同时也达到整个群体的利益最大化。然而经济学家可能往往都生活在理性的乌托邦中,当我们的脑科学家在解剖,打开人的大脑后,发现人的大脑是一个异常复杂的系统,是一个复杂性网络,它可能有上亿个节点,可能是迄今为止最复杂的一个系统,正是因为它的复杂性导致了人类很多的行动都是不可知的,也是不可预测的。所以,从另一个方面讲是非理性的。
我们今天讨论的可能是一个有限理性的理论,行为经济学理论,介于理性和非理性之间,人类的理性受制于很多外部条件的限制,最重要的外部条件就是信息,你获取到什么样的信息将直接影响到你所做的选择。
2013年4月23号黑客给Twitter发布了一条虚假信息,白宫有两次爆炸,奥巴马受伤,我们可以看到美国道琼斯指数在相同的时间段应声下跌近140点,这也可能是人类历史上第一次通过社交媒体影响到整个股市行情的崩盘。
信息会影响股市的走向。波士顿大学的一个研究团队分析了从2004年到2011年道琼斯指数走势跟谷歌趋势的相关性,每次股市剧烈的变化伴随而来的都是搜索量急剧的增加。
利用这个策略,他们设计了一个基于谷歌搜索引擎的交易策略,这个策略使用的一个关键词就是“负债”。这个交易策略很简单,当搜索引擎的数据量减少的时候,我们就可以买进下一个星期的道琼斯指数,当搜索量增加的时候,我们卖出下一星期的道琼斯指数。
我们可以很明显地看到蓝色的线是谷歌的交易模型创造的,如果套用这个交易模型,最终它的投资收益率是300%,你投资一块钱,最后能够收回三块钱。红色的线就是你买了这个指数之后一直放在那儿,实际上收益是非常低的。这证明搜索引擎,包括社交媒体的很多东西能够帮助人类做很多决定,也就是今天汤道生先生谈到的怎么利用大数据帮助人类做一些决定。
相同的研究还包括一篇发表在《自然》杂志的文章,关于面向未来的指数,它做的方式是利用搜索量,比如今年的搜索量,明年的搜索量和前年的搜索量。它用明年的搜索量除以前年的搜索量,未来的数据除以过去的数据,这个数据就是基于未来的指数。
通过相关的模型,我们可以发现这个基于未来的指数跟每个国家的GDP有很好的正相关性,从另一个方面讲,当一个国家的国民或者网民更加的偏向于搜索未来的东西,那这个国家的经济情况往往是比较好的。
2012年我跟牛津大学互联网研究院(OII)的一个同事马克一起做了一个基于英国洪水的可视化分析,可以看到在大家左手边的这个是英国官方气象局的一个降雨量的分析,而右边是我们把所有的相关时段内在Twitter里跟洪水相关的信息下载了之后分布到地图上。我们可以看到在一些洪水特别泛滥的地区,我们的图形跟英国的官方的图形有很好的吻合,但是有很多地方也是没有的,可能网上没有这种信息。但是好处是我们数据是实时的,能实时分析出洪水分布的情况,官方的数据可能要等到好几个星期以后。所以,社交媒体的很多数据能帮我们做一些自然灾害预防的决策。
2012年我们做过一个关于美国大选的分析方案,当时美国有两个候选人,罗姆尼跟奥巴马,我们把所有大选之前一个月的跟罗姆尼和奥巴马相关的Twitter上的信息都下载之后,按美国每个区的分布做成了一个可视化图。大家都知道美国的总统选举是选举人制度,就是根据每个州的投票所决定的,我们在美国大选之前已经明显的可以看出网上讨论奥巴马的要远远大于讨论罗姆尼的,基于此我们预言奥巴马的胜算更大一点儿,我们把提到奥巴马的数据和罗姆尼的数据进行对比,52.4%有关于奥巴马,47.6%有关于罗姆尼。下面是大选之后官方的数据,两个数据有很大的相似性。
当时我们这个结果发布出来以后,很多政治评论家都怀疑,说罗姆尼不可能赢得马萨诸塞州的选举。而且奥巴马赢得得克萨斯州的选举也是很多人预测不到的,但是最后结果证明我们的数据对这两个州的分析都是正确的。
Facebook做了一个关于社交网络中人的行为传播的实验,号称是迄今为止最大的一个实验,分析了六千万人的样本,也是美国大选期间,每个人投过票之后可以在Facebook上发布一个消息,Facebook的分析员把人的亲疏关系分成十等,数据越大证明你跟这个人越亲密,10就代表人跟人的关系非常亲密,我们可以通过这个图看到当亲疏关系增加,人跟人的影响力也是在增长的,越亲密它的传播跟影响就会越大。这样我们每个人做的决定,不但影响到你,有可能你这个决定还会影响到别人。比如我更加倾向于投奥巴马,有可能周边的人也更加倾向于投奥巴马。
之前谈了很多大数据的应用,都是很正面的东西,这里我想提两点,大数据研究的风险。
首先,第一个风险是数据的误读,谷歌流感的分析提的很多了,特别是牛津互联网研究院维克多教授《大数据时代》的开篇就以这个案例作为大数据成功应用的典型,但是我们仔细地看这个大数据分析,2012年和2013年之间这一根红色的线就是谷歌流感的数据,绿色的是美国官方疾病控制中心的数据。在2012年至2013年的6、7月份,谷歌流感的数据远远大于疾病控制中心的数据,所以,我们如果基于谷歌的数据做一些预判、风险的预防,有可能导致预判错误,有些网上的数据有可能是夸张地显示出了实际生活的一些情况。
另外一个例子,我们进行大数据研究时,很多学者都忽略了一个最根本的问题就是偏差的问题,这是我们今年发表的一篇文章,我们研究了三个不同的数据库,针对同一种关键词用不同的方法提取,最后我们得到三种不同的数据库。我们把这三个不同的数据进行比较,然后计算各个数据跟各个数据之间的相关性,我们发现这种相关性随着时间的流逝是有变化的,也就是说从另一个方面理解,当三个不同的学者在做一个同样的研究,有可能你用不同的方法,不同的数据采集方式,最后提取的数据不同。你再基于这种数据做出很多的结论,有可能这个结论到最后是有偏差的,而这个偏差是基于数据的,有可能蕴藏于你原始的数据之中。
我们人类在很长一段时间,因为互联网到现在也就几十年的时间,针对人类上千年的历史,人类在很长的时间处于信息稀缺的时代,我们很多决定的时候可能没有信息或者信息不够,就像今天汤道生讲的是一种近似于赌博式的方法,就像中国古代早期很多占卜的方式,没有什么好选择就去占卜、抽签或者利用龟壳的方式。大数据实际上对于人类做决定最重要的影响可能就是改变了这个现状。现在我们不是在一个信息稀缺的时代,而是在一个信息过剩的时代,我们每个人所有的行为模式、方法都会被映射到网上,不但你的,还有你朋友的,社交媒体的行为模式都被映射到网上,这个数据是源源不断的,我们不再担心数据不够,而更需要担心数据过剩的问题。
在传统的人类决策模型中,每个人做一个决定,这个决定转化为信息,它转化的方式更多的通过口传心授,比如你朋友买了一个什么东西,他告诉你,然后你去买,影响到你做决定。或者通过书本的方式,我们通过读书摄取之后转化成自己的知识,通过这个方式做决定,最后形成了一个反馈回路。但是大数据时代这个反馈回路可能要进行扩展。我们有了第二层外环的反馈回路,人类做决定之后,这些所有的决定都会被转化为数据,这就是我们所说的大数据时代,所有人的行为模式,各种各样的东西通过手机、无线互联网都会被转化为数据,这些数据通过大数据分析转化为信息,然后信息给相关的决策者,决策者通过这些信息做判断,这样形成另外一层的反馈回路,通过这种反馈回路的信息数据不停地循环,最后达到一个终极目的:会不会有可能通过机器取代人的位置,人类最大的一个难题可能就解决了,不是人去做,让机器去做很多决定。
谈到机器决定,现在用数据的模式让机器做决定也是非常热的一个话题,我们觉得机器做决定可能有三步走的方式。首先,第一步很明显,人自己做决定。而现在在大数据时代,更多的是人跟机器交互做决定,比如一些常规的决定,一些比较重复性的决定,都是通过机器来做,而人去做一些机器所不能做的决定。最简单的一个例子,你去信用卡公司买东西,你地址换了,信用卡公司会发现有可能是有人盗用你的信用卡,通过数据判断出之后他把这个信息转给一个接线生或者公司员工,这个员工会给你打电话,这就是一个典型的人机交互做决定的模式,人跟你谈完话以后决定到底是不是有人盗用你的信用卡,最后会不会有可能所有的决定都会让机器来做,今天时间有限,我可以在最后再跟大家讨论。
最后我想以一句话结束我今天的演讲,“数据是一种知识源,但是除非数据进行很好的组织加工,并按照正确的方式提供给正确的人进行决策,否则它就是一种负担,不是一种收益”。
==关于我们==
大数据实验室公众平台【ID:bigdata-lab】由资深大数据方向专业人士管理运营,观点聚焦于大数据领域,大数据实验室和顶尖的研究机构和诸多企业建立合作,并 汇聚了学界、商界、业界顶尖的智囊,为开拓者指点迷津。我们将精选大数据行业内最精华的文章或报告,汇聚专业精英,促进学习交流,互相提升思维的深度、广 度和高度。
大数据实验室致力于国内“大数据”领域投资,凡入选的初创企业将获得大数据实验室孵化基金提供的“种子资金”,将会有导师协助完善他们的商业模式,建立一个完整的核心团队,并进行初步的客户反馈和验证。感兴趣的创业团队或初创企业,可以通过以下方式与我们取得**。
感谢关注公众微信:bigdata-lab
也请推荐更多的朋友关注或添加!
**方式:
QQ:361993695
微信:shangjingfu_nus
网址:www.bigdata-lab.com
新浪微博:大数据实验室
也可直接在对话框内给我们留言并留下您的**方式。
来源:http://chuansongme.com/n/588516
http://blog.sciencenet.cn/blog-362400-820065.html
上一篇:是家具?还是家俱?这是个问题
下一篇:到底社媒曲线与股市曲线有没有、有多少相关度?
1 张云
两年来中国红十字会的社会媒体形象调查 屏蔽留存
两年来中国红十字会的社会媒体形象调查
屏蔽 |||
让数据说话,让专家解读。这里提供的是数据的各个侧面,是全自动对社会媒体调查的结果,没有人工参与。
调查的是2012年七月至今两年多(27个月)社会媒体样本对中国红十字会的评价(因为微博数据的 cost 很大,不能选择全样本)。虽然其间出了很多负面新闻,但总体形象分 net-sentiment 41% 显得相当正面,这一方面说明其公关危机处理可能有成效,另一方面很可能是得益于红十字会本身的慈善任务及其天生光环(下面有分析)。
148,889
Mentions
45,866,471
Potential Impressions
41%
Net Sentiment
16,454
Positive
6,831
Negative
47,405
Unique Authors
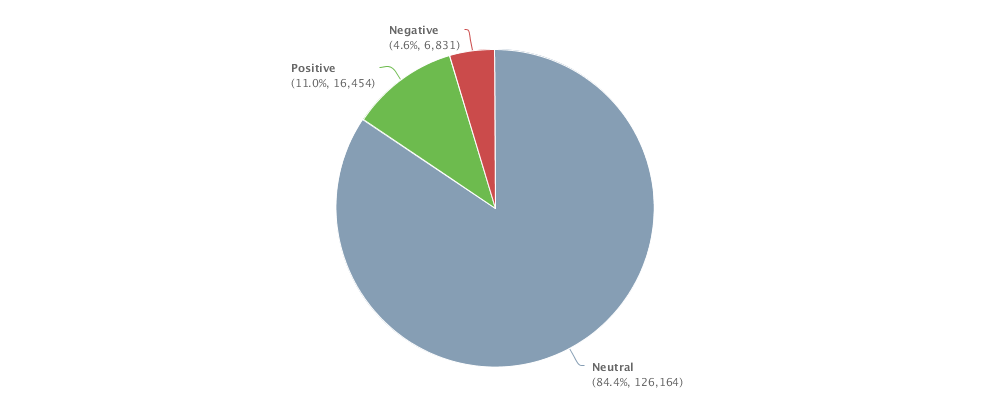
从话题热度看,2013年五月是个大高峰,今年八月是个小高峰。从舆情看,去年七月跌得很惨,九月到谷底,另一个低点是今年七月。
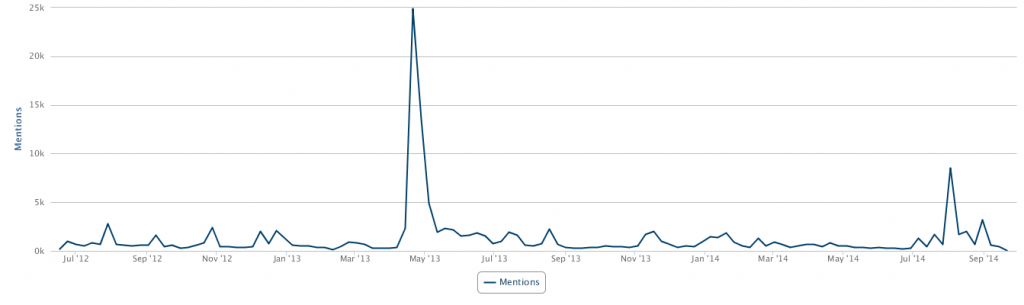
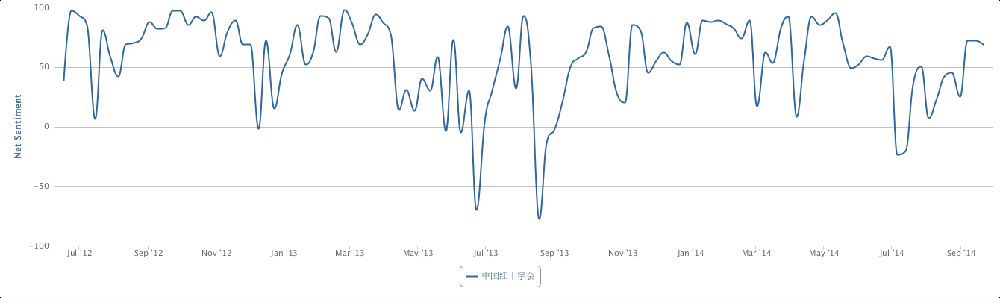
我们先把调查聚焦在前后两个高峰区段,看看前后舆情的变化。
第一个区间选在去年四月到九月。
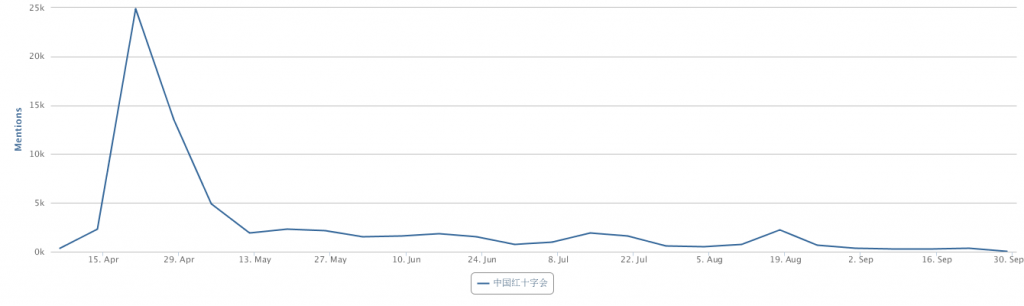
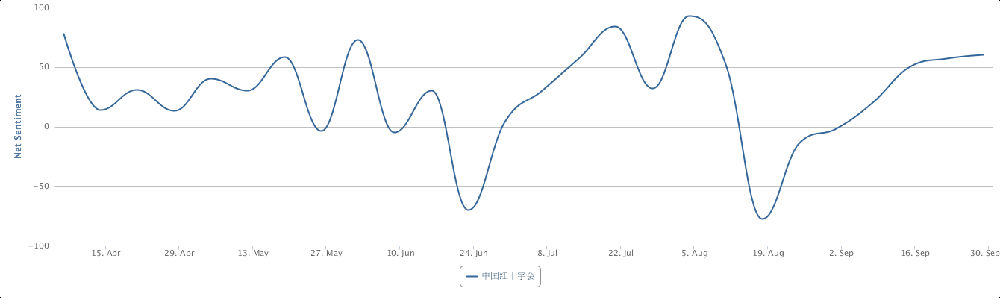



第二个区间是 7/7/2014 - 9/13/2014
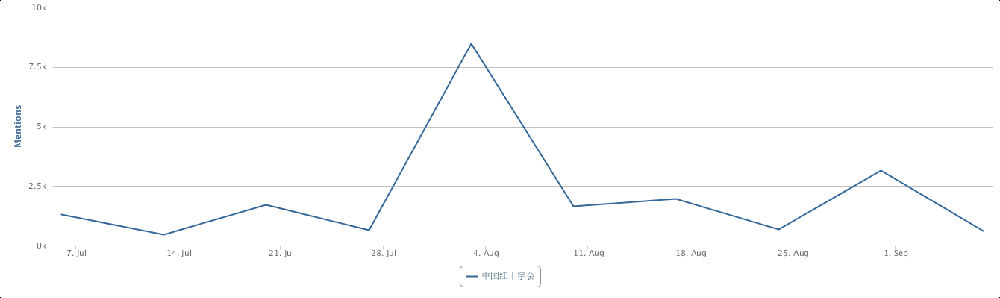
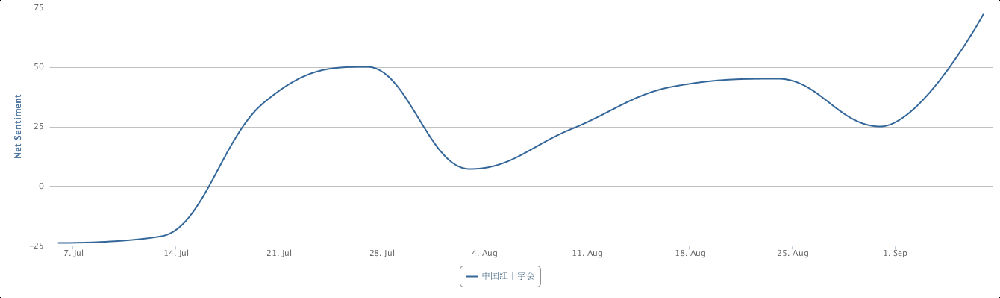



现在我们回到过去27个月的总体调查数据上来,下列的信息挖掘都是过去两年多的数据基础上,有别于上面的两个时间区间。
2 相关关键词和话题:


3 网民情绪
舆情分析的指标之一是网民情绪,从下图看,情绪方面很激愤,中国红十字会受到很多“谴责”和“质疑”,骂他们“狗血”和“太臭”。

4 行为方面的挖掘也很不利,这个组织的慈善体系被郭美美等一干事件“摧毁”了。那个看上去正面的“接受(最大量的捐款)” 行为,drill down 看在语境中也是负面的,讽刺这个慈善组织的老大得钱最多,可做得很差。

行为这项指标也不及格。那么为什么总体评价还是正面多于反面呢?那是因为下面的优劣指标的比例造成的。
5 优劣指标抓取的是喜欢或厌恶的具体理由,这一方面是东风压倒西风,绿多于红:

需要说明的是,红十字会作为慈善组织,从本性和使命上说,它有天生的光环。提到红十字会,最多报道的是他们的“救灾”、“捐赠”等善举。加上一些媒体公关的正面宣传,这就把批评意见压倒了。
仔细看正反优劣的舆情评价,发现表扬的都是它的日常工作和套话,而批评的却辛辣得多,“饱受争议”、“侵吞”、“渎职”、“一落千丈” 等等。这样看来,前面的总体形象指数是偏高了。
6 这次调查的网民地理分布:自然是国内为主,但世界各地的华人都有不同程度的议论参与
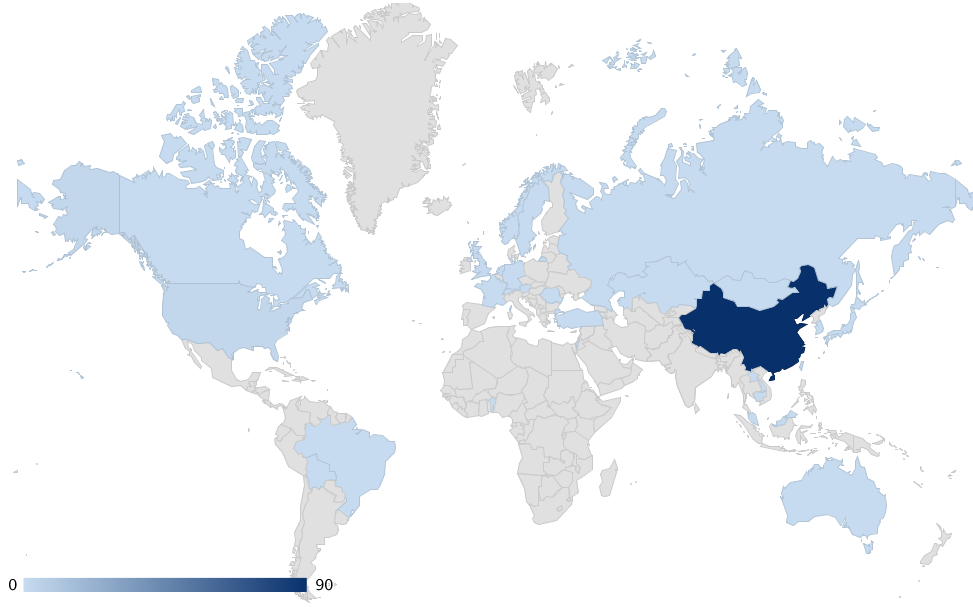
7 此话题网民的男女比例:还是男网友吐槽多得多
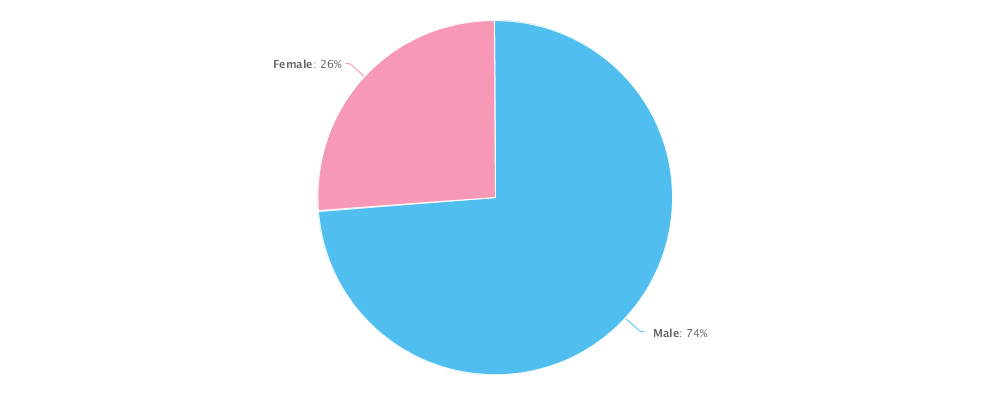
8 关于数据来源和分布:
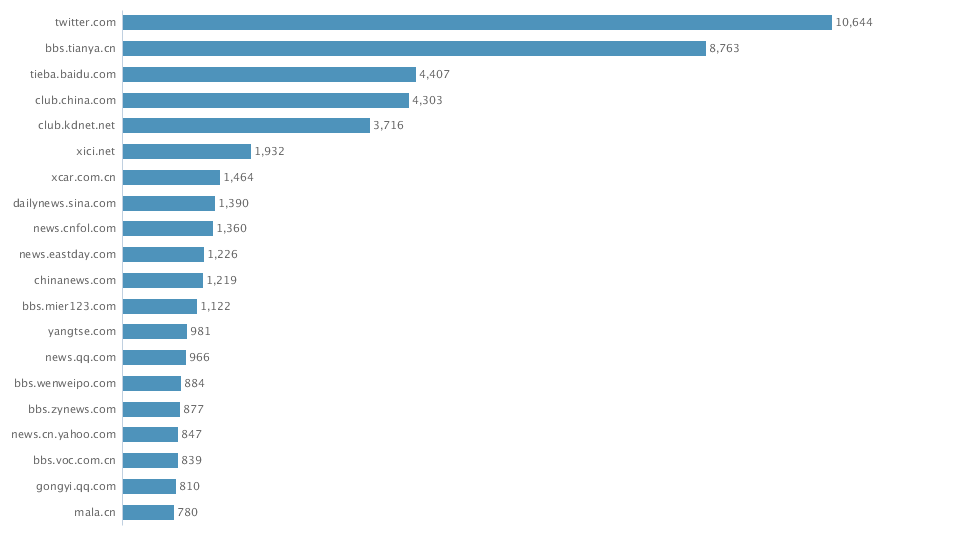
其中主要论坛:
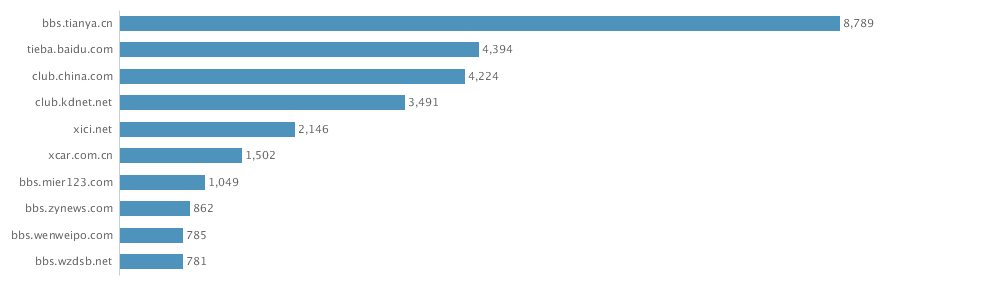
主要的部落格是
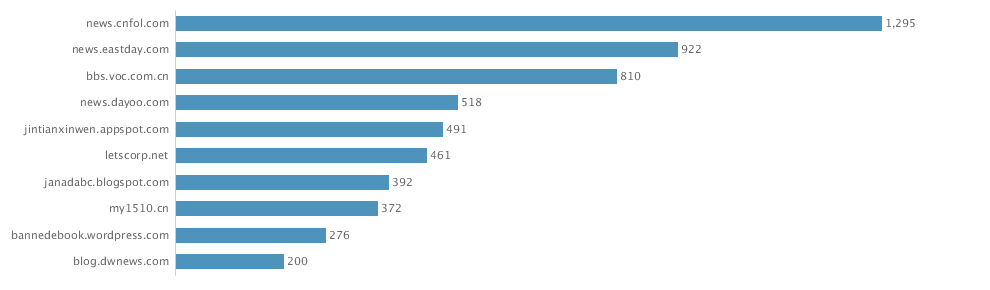
主要的新闻类网站
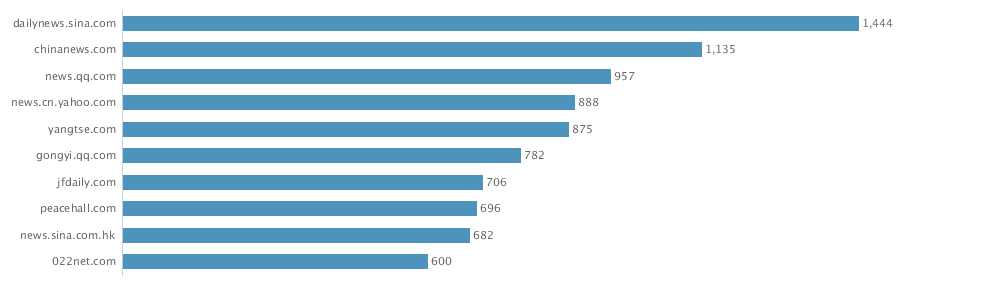
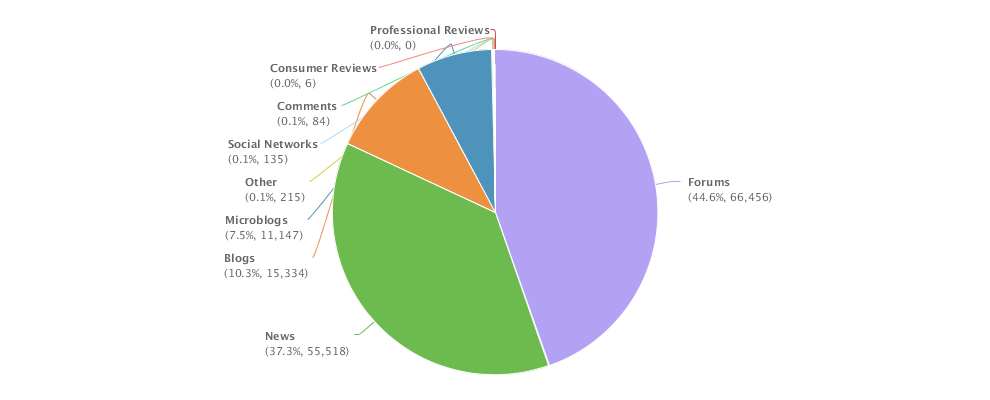
前面说过,最重要的来源微博由于数据代价的问题,无法加入,这是一个相当的遗憾。另外,新闻类比重过大,可能冲淡了来自草根网民的舆情。前者只要有钱就可以弥补,不是系统能力的问题,而是研究项目谁买单的问题。后者在数据量大的时候,可以很容易排除掉,或分别考察对比。其实还有一个地理区分的角度,海外与国内舆情应该分开,这个也容易。业余做这个调查,懒得花更多时间了。
9. 吐槽样本


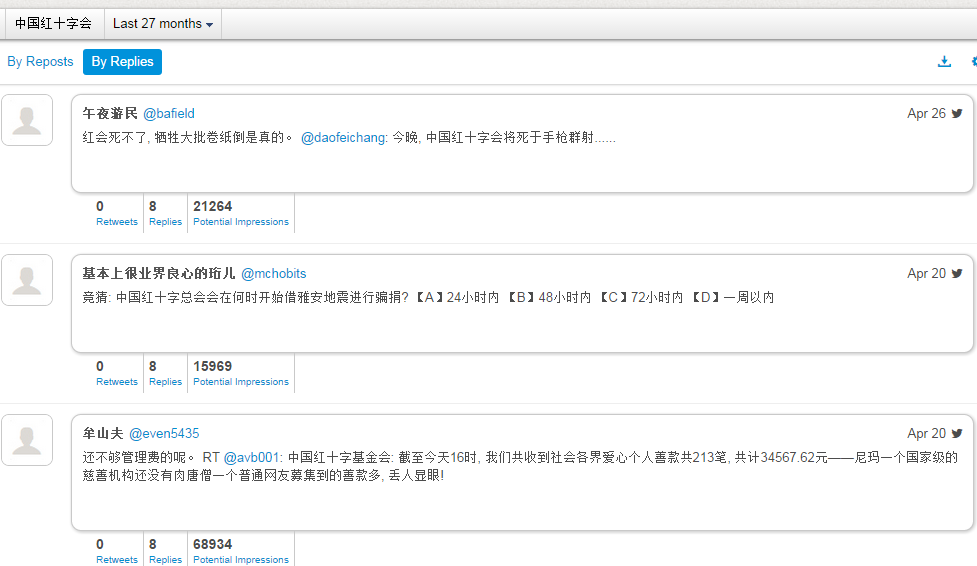
索性再花点时间把郭美美事件及其对红十字会的影响的民意舆情调查一下吧:
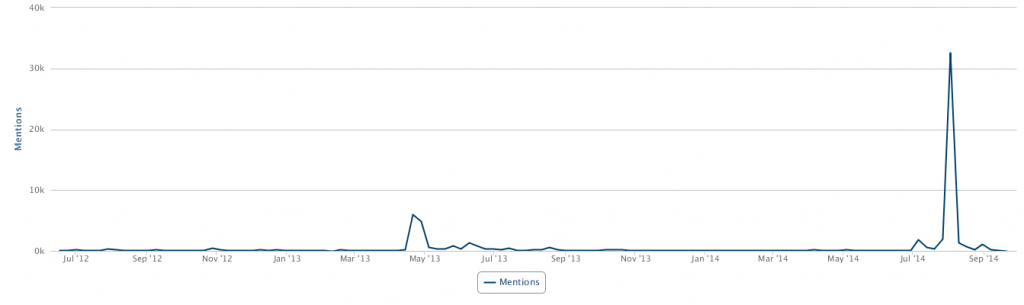
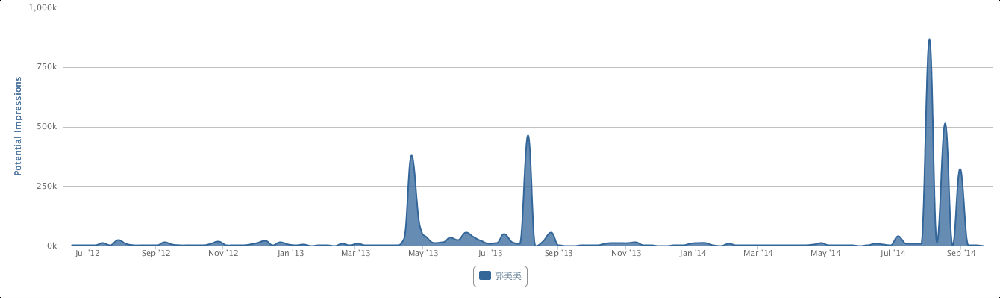
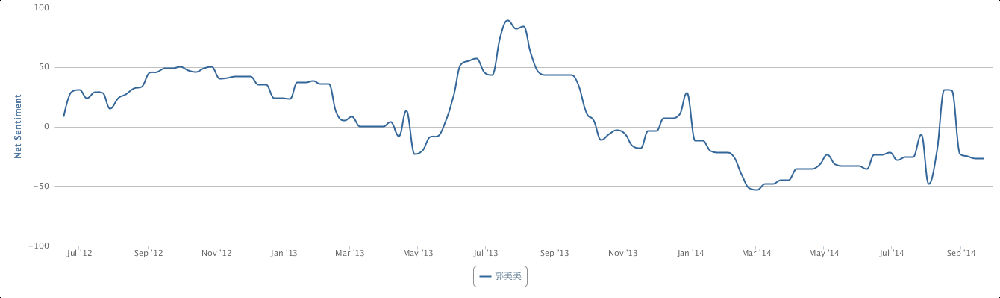

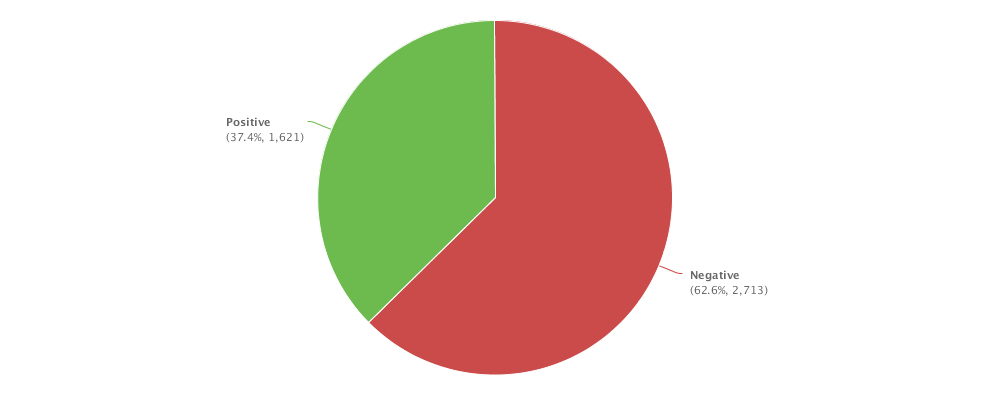


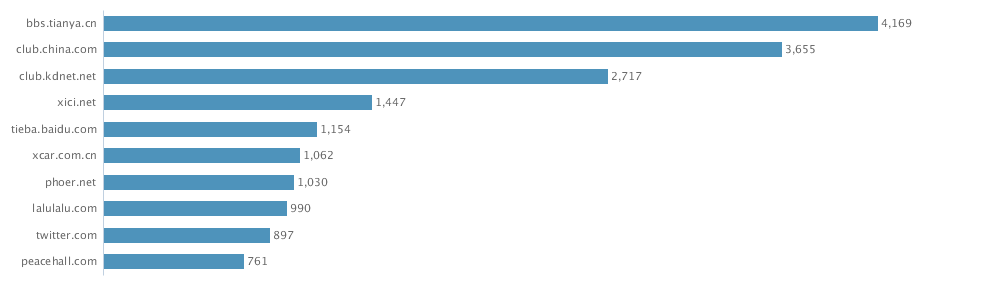

http://blog.sciencenet.cn/blog-362400-829629.html
上一篇:Social media mining on credit industry in China
下一篇:全球社交媒体热议阿里巴巴上市
【大数据解读:方崔大战对转基因形象的影响】 屏蔽留存
【大数据解读:方崔大战对转基因形象的影响】
屏蔽 |||
据说大战是去年九月开始,现在尚未结束。下面的分析是对挖掘结果的一种解读,旨在抛砖引玉。好的解读需要对 domain 熟悉,平时一直在追踪,相信这样的人大有人在,可以做出更合理的解读。
下图反映去年一年对转基因在中文社会媒体大数据的挖掘结果,按照每月的热议和褒贬结果展示其趋势图。热议度(mentions)一年的趋势是在慢慢增长 ,高点在去年十一月。褒贬度(net sentiment)在去年九月前是缓慢上升。随着九月开始的方崔大战,挺转反转打得不可开交,使得过去三四个月,转基因褒贬呈现大起大伏态势。具体说来,九月中挺转呼声达到高峰,但很快从十月到十一月跌下来,11月初跌入谷底。此后挺转再占上风,到十二月中达到第二个高峰。从趋势上看,挺转反转的争辩仍呈胶着状态,难分胜负。

不过全年看下来,转基因的网络形象实际上变得更加正面了因为褒贬指数平均值从全年的4%,上升为半年的8%(近三个月为6%, 最近一个月的指数陡升为 19%)。总的趋势应该是挺转占了上风,东风压倒西风。

半年趋势图:

三个月趋势图:

近三个月(从去年十月五号到今年元月五号)的趋势图是大战最酣的时期,值得仔细研究。从热议度和褒贬度两条曲线的对比看,十月下旬到十一月上旬是热议高峰期,估计也是挺反两派斗争最激烈的阶段,但这个阶段转基因的媒体形象反而略为走低,至 11月18号的谷底(-22%),说明反转呼声占了上风。
但是此后的发展是,热议度基本持平,直到12月底开始有些消停(斗累了?过年了?),但挺转的走势明显上升直到12月16日全年最高点(41%)。但此后又开始下滑。
这些拉锯还在继续,近一个月的跌宕图示是否预示着,这场斗争还远远没有结束?不过最近两周确实有些疲软了。
一个月的趋势图:

一鼓作气,二鼓衰而不竭。挺/反尚未成功,同志仍需努力。
【附:蔡老师精彩点评】
[2]蔡小宁承蒙李老师的热情,我只能做点猜测。上半年支反双方没有特别大的行动,但是下半年就不同了,支转方开展了多次转基因大米品尝科普活动是有效果的,而且五家专业学会等单位联合开办了《基因农业网》,加强了转基因科普的力量,累积至9月中旬达支转方的支持度到高点。也就是9月初,崔永元突然杀出,以其实话实说建立的超高人气,使得支转方遭到重大打击,随后崔永元进一步宣布自费赴美、日调查转基因,使反转方赢得了大量的赞誉,崔永元再次建立起直言不讳的负责任的英雄形象,导致了支转方在10、11月落到低谷。然而,支转方不甘落后,不断组织反击,方舟子多次发文批驳崔永元,由于方舟子的文章往往有理有据,而崔永元没有实质内容、脏话连篇,导致少量崔粉放弃对其的支持,加上农业部发言人出面说话,俄罗斯又批准了转基因作物的种植,支转方逐步收复失地,于是12月中旬达到高点。年终,双方都忙于年终工作总结、过节等,热度都有所下降。博主回复(2014-1-8 03:18):很好的分析,比我盲人说象强太多了。
更多数据在:
【大数据挖掘:转基因一年回顾】 2014-01-06