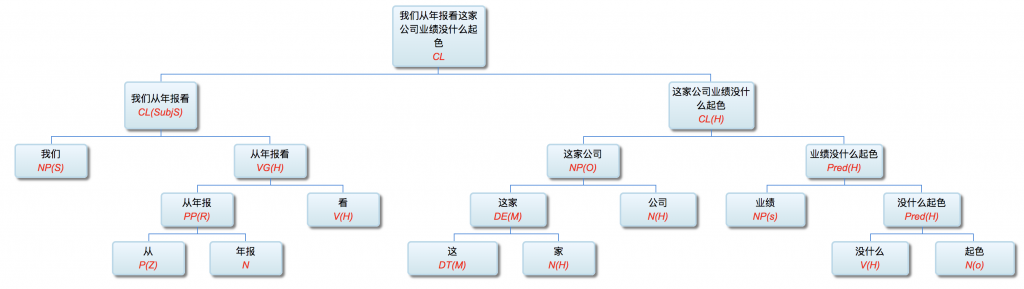
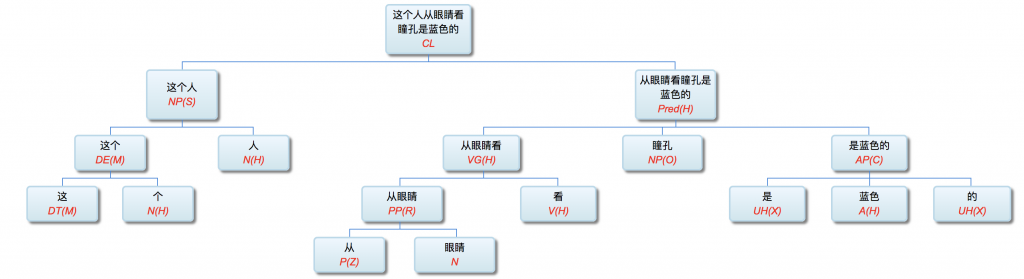
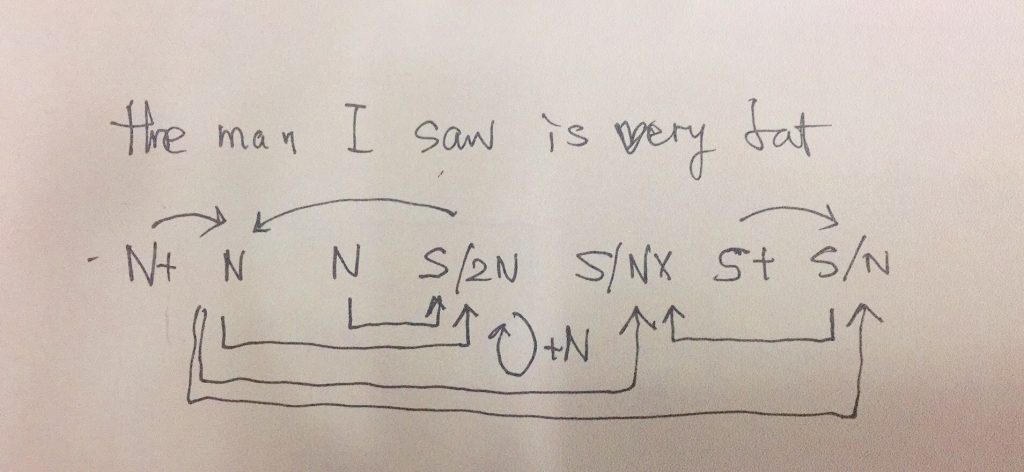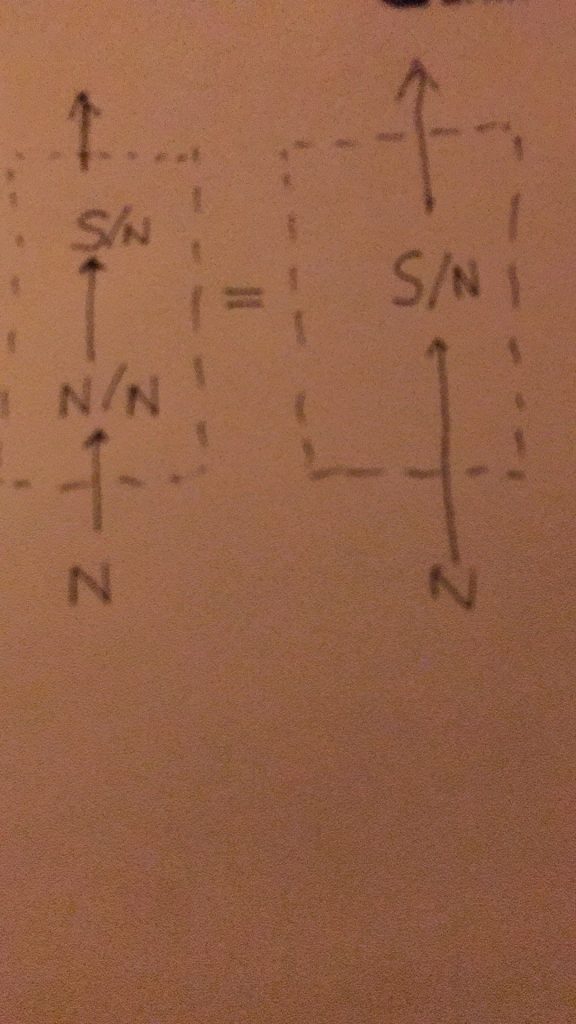有问,这一波热潮会不会是类似2000年的又一个巨大的泡沫?我的观察是,也是,也不是。的确,在大数据的市场还不成熟,发展和盈利模式还很不清晰的时候,大家一窝蜂拥上来创业、投资和冒险,其过热的行为模式确实让人联想到世纪之交的互联网 dot com 的泡沫。然而,这次热潮不是泡沫那么简单,里面蕴含了实实在在的内容和价值潜力,我们下面会具体谈到。当然这些潜在价值与市场的消化能力是否匹配,仍是一个巨大的问题。可以预见三五年之后的情景,涅磐的凤凰和死在沙滩上的前浪共同谱写了大数据交响乐的第一乐章。
所谓大数据,更多的是社会媒体火热以后的专指,是已经与施事背景相关联的数据,而不是搜索引擎从开放互联网搜罗来的混杂集合。没有社会媒体及其用户社会网络作为背景,纯粹从量上看,“大数据”早就存在了,它催生了搜索产业。对于搜索引擎,big data 早已不是新的概念,面对互联网的汪洋大海,搜索巨头利用关键词索引(keyword indexing)为亿万用户提供搜索服务已经很多年了。我们每一个网民都是受益者,很难想象一个没有搜索的互联网世界。但那不是如今的 buzz word,如今的大数据与社会媒体密不可分。当然,数据挖掘领域把用户信息和消费习惯的数据结合起来,已经有很多成果和应用。自然语言的大数据可以看作是那个应用的继续,从术语上说就是,text mining (from social media big data)是 data mining 的自然延伸。对于语言技术,NLP 系统需要对语言做结构分析,理解其语义,这样的智能型工作比给关键词建立索引要复杂千万倍,也因此 big data 一直是自然语言技术的一个瓶颈。
在处理海量数据的问题解决以后,查准率和查全率变得相对不重要了。换句话说,即便不是最优秀的系统,只有平平的查准率(譬如70%,抓100个,只有70个抓对了),平平的查全率(譬如30%,三个只能抓到一个),只要可以用于大数据,一样可以做出优秀的实用系统来。其根本原因在于两个因素:一是大数据时代的信息冗余度;二是人类信息消化的有限度。查全率的不足可以用增加所处理的数据量来弥补,这一点比较好理解。既然有价值的信息,有统计意义的信息,不可能是“孤本”,它一定是被许多人以许多不同的说法重复着,那么查全率不高的系统总会抓住它也就没有疑问了。从信息消费者的角度,一个信息被抓住一千次,与被抓住900次,是没有本质区别的,信息还是那个信息,只要准确就成。疑问在一个查准率不理想的系统怎么可以取信于用户呢?如果是70%的系统,100条抓到的信息就有30条是错的,这岂不是鱼龙混杂,让人无法辨别,这样的系统还有什么价值?沿着这个思路,别说70%,就是高达90%的系统也还是错误随处可见,不堪应用。这样的视点忽略了实际的挖掘系统中的信息筛选(sampling)与整合(fusion)的环节,因此夸大了系统的个案错误对最终结果的负面影响。实际上,典型的情景是,面对海量信息源,信息搜索者的几乎任何请求,都会有数不清的潜在答案。由于信息消费者是人,不是神,即便有一个完美无误的理想系统能够把所有结果,不分巨细都提供给他,他也无福消受(所谓 information overload)。因此,一个实用系统必须要做筛选整合,把统计上最有意义的结果呈现出来。这个筛选整合的过程是挖掘的一部分,可以保证最终结果的质量远远高于系统的个案质量。总之,size matters,多了就不一样了。大数据改变了技术应用的条件和生态,大数据 更能将就不完美的引擎。
3 大数据不是决策的唯一依据,只是依据之一。正确的决策必须综合各种信息来源。大事不提,看看笔者购买洗衣机是怎样使用大数据、朋友口碑、实地考察以及种种其他考量的吧。以为有了大数据,就万事大吉,是不切实际的。值得注意的是,即便被认为是真实反映的同一组数据结果也完全可能有不同的解读(interpretations),人们就是在这种解读的争辩中逼近真相。一个好的大数据系统,必须创造条件,便于用户 drill down 去验证或否定一种解读,便于用户通过不同的条件限制及其比较来探究真相。
分享【3】On Big Data NLP热度 1 李维2013-7-27 20:43Admittedly, it is not easy to develop an NLP ( Natural Language Processing ) system with both high precision and high recall (i.e. high F-score) due to the ambiguity and complexity of natural language phenomena. Social media is even more challenging, full of misspellings, irregularities, and ...个人分类: 立委科普|766 次阅读|2 个评论
【9】【立委科普:所谓大数据(BIG DATA)】热度 3 李维2013-3-21 04:58Big data is not just data that are big. In the sense of data load, big data has been there for quite a while in Internet, on which the entire search industry was based and developed. The current buzz word big data is different, it is innately associated with users' background and social ...个人分类: 立委科普|1175 次阅读|3 个评论
【10】广而告之:科学网“双百”博主立委四月一日在北京演讲大数据挖掘热度 11 李维2013-3-20 19:57UPDATE:立委愚人节北京讲演时间地点已经确认,感谢中文信息学会孙教授的邀请和安排,也感谢董振东前辈教授的建议和推举: The loacation is : Room 334, 3rd floor, building 5 Institute of Software, Chinese Academy of Sciences, No. Zhongguancun South 4th Street 10:00~12:00 It' ...个人分类: 立委科普|1283 次阅读|13 个评论
分享【11】Coarse-grained vs. fine-grained sentiment extraction李维2013-3-12 06:51As for sentiment extraction itself, there are different layers: 1. sentiment classification: thumbs-up and down (or plus neutral) 2. sentiment association: to associate a sentiment with a topic or brand 3. fine-grained sentiment extraction: for example, who made the sentiment comment? about w ...个人分类: 立委科普|671 次阅读|没有评论
Five challenges to keyword-based sentiment classification: (1) domain portability; (2) micro-blogs: sentence/twit classification is a lot tougher than document classification; (3) when big data become small: big data load when sliced and diced based ...个人分类: 立委科普|1372 次阅读|1 个评论
【17】【科研笔记:big data NLP, how big is big?】热度 1 李维2012-10-31 19:03Big data 与 云计算一样,成为当今 IT 的时髦词 (buzzword / fashion word ). 随着社会媒体的深入人心以及移动互联网的普及,人手一机,普罗百姓都在随时随地发送消息,发自民间的信息正在微博、微信和各种论坛上遍地开花,big data 呈爆炸性增长。对于信息受体(人、企业、政府等),信息过载(information overlo ...个人分类: 立委科普|967 次阅读|1 个评论
Automatic survey complements and/or replaces manual survey. That is the increasingly apparent direction and trend as social media are getting more popular everyday. 自动民调(or 机器民调: Automatic Survey / Machine Survey)指的是利用电脑从语言数据中自动抽取挖掘有关特定话题的民间舆论,其技术 ...个人分类: 立委科普|1530 次阅读|3 个评论
分享【23】比起英语,汉语感情更外露还是更炽烈?李维2012-4-28 04:29Chinese is a more sentiment-intensive language than English?? FW: Counts of sentiment words in Chinese and English Interesting finding: that Chinese more than doubles the negative words and more than triples the positive words in comparison with the English vocabulary. This is based on the 5 ...个人分类: 立委科普|1158 次阅读|没有评论
【26】《科普随笔:机器八卦》李维2011-10-14 17:09机器八卦:Text Mining and Intelligence Discovery (13219) Posted by: liwei999 Date: June 10, 2006 10:07PM 犀角提议,干脆用机器挖掘吧。我不想吓唬大家,但是,理论上说,除非你不冒泡,言多必失,机器八卦,比人工挖掘,可能揭示出你的更多特征。好在该技术还不成熟。 Text mining 是我这 ...个人分类: 立委科普|863 次阅读|没有评论
【27】言多必露,文本挖掘可以揭示背景信息热度 1 李维2011-7-11 01:03言多必露,挖掘有商用价值的背景信息 文本挖掘(text mining)中,Demographic Profile Extraction 的任务是要给网虫自动分类,揭示其背景信息(年龄,性别,身份,族裔,人生阶段,家庭背景等)。 一些简单的规则,查准率高(high precision),查全率并不高(moderate recall),譬如: I am X -- X (student, t ...个人分类: 立委科普|939 次阅读
分享【43】只认数据不认人:IRT 的鼓噪左右美国民情了么?热度 3 李维2013-12-30 06:27套用北韩最近流行的歌颂红太阳金正恩的红歌,数据,数据,《除了它我们谁也不认!》 当然,还有上帝: In God We Trust. In everyone else we need data. 大数据时代更是如此,只认数据不认人。道理很简单,在信息爆炸的时代,任何个人的精力、能力和阅历都是有限的,所看到听到的都是冰山一角。小崔如此,其他大V也 ...个人分类: 社媒挖掘|918 次阅读|10 个评论
分享【48】Social media mining: Teens and Issues李维2013-9-9 21:36As is well known, the teenager years are a special and important period of growth for children, or young adults, to be more precise. It is growing pain, mixed with joy. It is often a rebellious phase when both parents and teens find it difficult to communicate with each other. Thi ...个人分类: 社媒挖掘|542 次阅读|没有评论
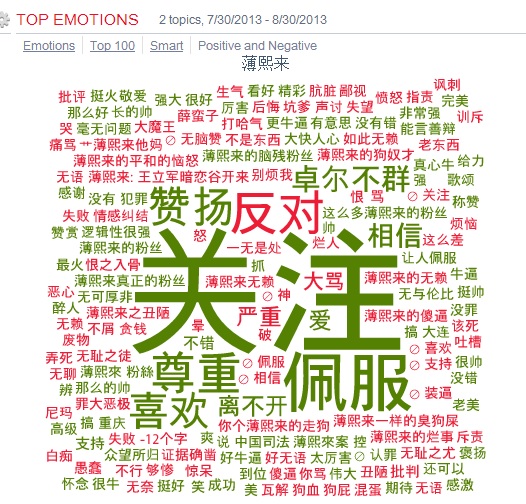
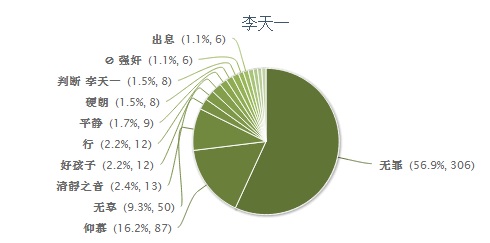
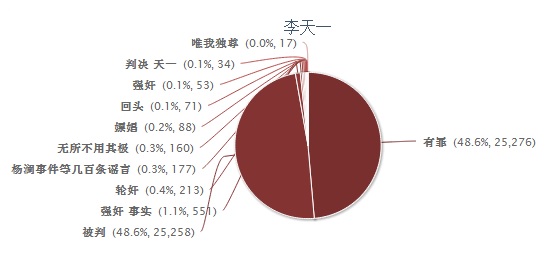
分享【49】【微博自动民调:薄熙来、薛蛮子和李天一】热度 2 李维2013-8-30 09:33Automatic Survey from the last month of Sina Weibo (Chinese twitter, the most influential social media Microblog site) on three major characters: the former Chinese politician Bo Xilai in his on-going trial, the very famous social media figure Charles Xue who is said to have millions of fans and w ...个人分类: 社媒挖掘|898 次阅读|2 个评论
分享【54】【自动民调:美国名牌大学人气排名】热度 1 李维2013-8-12 16:46For the first time, the automatic survey of social media 1-year archive on some US brand name universities shows the rankings as follows, which are quite different from official ranking (Harvard and Caltech accidentally not included): 1. UCSD; 2.Chicago; 3. UPenn; 4. Carnegie Mellon ...个人分类: 社媒挖掘|794 次阅读|1 个评论
分享【57】舆情挖掘用于股市房市预测靠谱么?热度 1 李维2013-4-18 21:24Can social media sentiment mining be used for predicting stock/property market? I tried our Chinese system for that and it proved to be right. Is that pure luck or there is some value in using public opinions and sentiments to assist prediction of markets? 作为技术展示,曾经用中文社交媒体的舆 ...个人分类: 社媒挖掘|605 次阅读|1 个评论
Maytag Maxima 4.3 cu. ft. High-Efficiency Front Load Washer with Steam in Granite, ENERGY STAR Model # MHW7000XG 989.10/EA−EachWAS989.10/EA−EachWAS1,399.0 0 LG Electronics 4.0 cu.ft. High-Efficiency Front Load Washer in Graphite Steel, ENE ...个人分类: 社媒挖掘|943 次阅读|2 个评论
分享【63】《大数据时代的购物策略:洗衣机寻购记(2)》热度 3 李维2013-2-25 22:41洗衣机的选择:top loading 抑或 front loading? 作者: 立委 日期: 02/24/2013 23:35:39 本来我们是要放弃 front loading (镜先生考证,国内叫滚筒式)洗衣机,去选更容易清洁的 top loading (国内称作 波轮式 )的。可是如今大数据了,领导还是要看看二者的优劣,听听用户都怎么选择的。 于是挖掘 ...个人分类: 社媒挖掘|1067 次阅读|4 个评论
分享【64】《大数据时代的购物策略:洗衣机寻购记(1)》热度 8 李维2013-2-25 21:07ABSTRACT Brand Passion Index (BPI) is used to help us make an informed decision in our on-going purchase of a new washer. Using our own product, we generated two BPIs, one to compare the major washer brands in the US market and the other to compare front loading vs. top loading. With ...个人分类: 社媒挖掘|1996 次阅读|10 个评论
【Brand Passion Index 3: international fast food brands in China market face challenges】 Chinese Social Media Mining: Brand Passion Index for international fast food brands McDonald's, Pizza Hut, KFC and Yoshinoya in China. Fairly negative. The golden time when McDonald's ...个人分类: 社媒挖掘|1858 次阅读|9 个评论
Chinese mobile phone market is found to be still in the stage of multiple vendors competing with each other with no single one clearly ahead of others. Even Apple iPhone is on a par, in terms of net sentiments and consumer passion, with HTC, Samsung, Nokia and Chinese brand Xiaomi d ...个人分类: 社媒挖掘|810 次阅读|1 个评论
RE: What do these tell us more than we've known already? very good question: however, if it is known info, it confirms its validity 日期: 01/01/2013 11:11:49 it builds the users' (and developers') confidence in the automatic summerization of the computer processing of t ...个人分类: 社媒挖掘|644 次阅读|没有评论
Let us have a look at the past year 2012, which is more associated with the hardest year in people's mind than a good/best year.个人分类: 社媒挖掘|838 次阅读|没有评论
Most every hot topic coming to my mind these days, I will check our social media system to see how social media reflects it. Word clouds are intriguing vehicles to present the common social image. Most word clouds generated by other systems are based on statistics of keywords mentioned ...个人分类: 社媒挖掘|804 次阅读|1 个评论
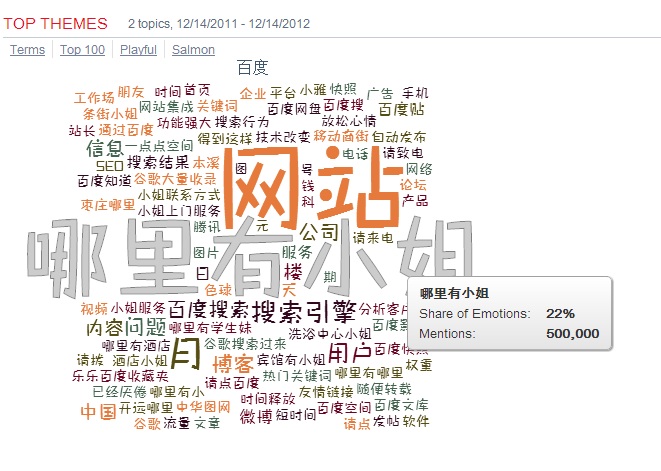
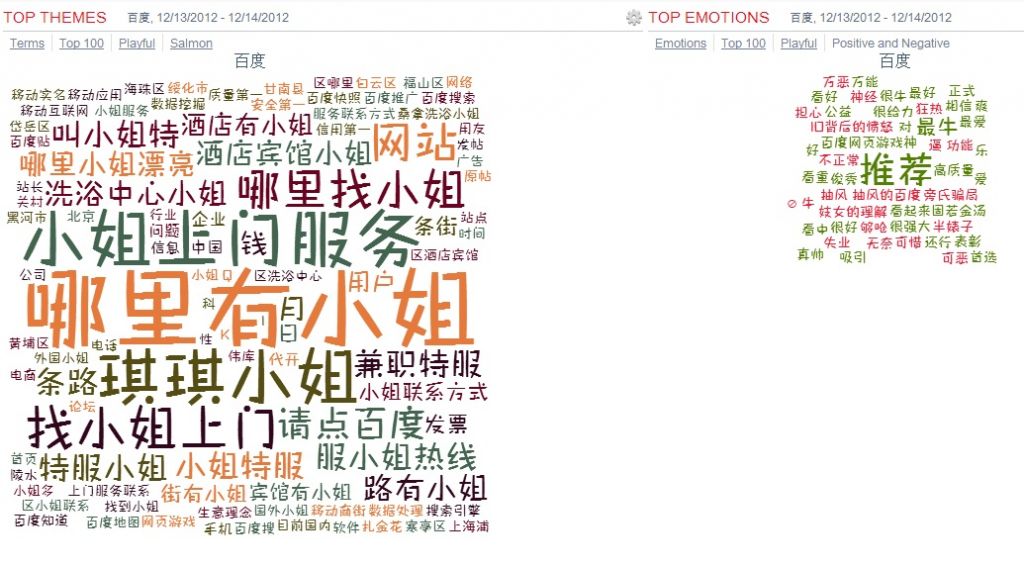
一个偶然的系统测试,暴露出百度与“哪里有小姐”身影相随。这个发现在朋友间立即引起轩然大波,有称妙的(way to go, u r onto sth),有调侃的(曰:百度本来就源自“众里寻她千百度”嘛),有怀疑的( the results are not faked? )。阴谋论者伊妹儿我,指责此云有侮辱百度之嫌。 我跟老友说:我没有结论。有 ...个人分类: 社媒挖掘|1518 次阅读|没有评论
今天测试知名品牌百度的TagCloud,有惊人发现 日期: 12/12/2012 18:51:14 在简体字的world里面,与百度最紧密关联的词语是: 哪里有小姐 在繁体字的 world,最关联的词是 美元 不知怎么就想起了 Google 被赶出中国前对谷歌的指责:说 Google 太黄了。 黄得过百度么? A follow-up post a ...个人分类: 社媒挖掘|888 次阅读|3 个评论
Obama won the debate, see our evidence 民调自动化,技术带领你自动检测舆情: 社会媒体twitter的自动检测表明,奥巴马显然赢了昨晚的第二次辩论。人 气曲线表明他几乎在所有议题上领先罗梅尼。 对奥巴马真正具有挑战性的议题有二:一是他在第一任总统期间的经 济表现(6:55pm);二是批判他对中国不够强硬 ...个人分类: 社媒挖掘|1209 次阅读|1 个评论
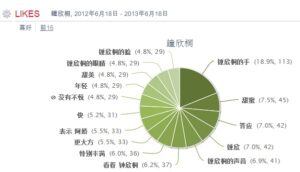
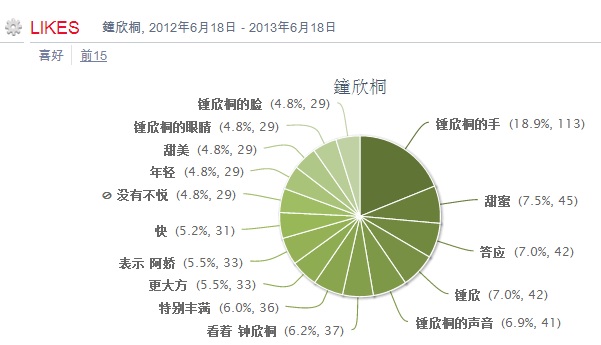
分享【99】社会媒体舆情自动分析:马英九 vs 陈水扁李维2012-9-29 16:51Different social images and social media sentiments for Ma Yingjiu, Taiwan President, and Chen Shuibian, Taiwan former president. 不同的社会媒体评价,截然不同的民间形象,台湾现总统马英九 vs 台湾前总统陈水扁,社会媒体自动分析的初步结果凸显二者的不同形象和风格。 (1) 高频情绪性词的词频分析的对 ...个人分类: 社媒挖掘|830 次阅读|没有评论
分享【101】舆情自动分析表明,谷歌的社会评价度高出百度一倍李维2012-9-8 20:32拖了这么久,中文系统的初步试验终于开始 日期: 09/06/2012 21:04:35 本来核心系统的开发最难,最耗时间 ,结果在真实生活中,工程架构、存贮和搞定content这些纯技术性操作性环节往往也会成为时间瓶颈,怪也不怪。 这次试验只有海外twitter和百度贴吧天涯论坛等来源的半年数据,但做出的分析也蛮有意思。 I did a ...个人分类: 社媒挖掘|987 次阅读|没有评论
国人爱说反话:夸奖的背后藏着冷笑,社会媒体尤其如此 作者: 立委 (*) 日期: 09/07/2012 15:42:32 大陆政客属于敏感词,这里不表。以台湾政客为例, 譬如说陈水扁是“中国最清廉的总统”,就明显是反话。 It is interesting to find that many positive comments about A Bian are sarcastic. In thi ...个人分类: 社媒挖掘|892 次阅读|1 个评论
》》这样的访谈,应该能做到基本不看稿子的。
没有稿子啊,就是一张表格和一张白纸,表格填写了基本信息:题目之类。坏菜的是,我老低头给人一种似乎是在看提纲的样子。其实我根本啥也没看,拿笔和纸做样子而已。纸上就写了两个自我警告的大字:SLOW,CLEAR,但还是没用。说话的时候,啥也看不见,就是在急速找词,赶集似地往外说。因为赶,Broken English 就出来了。还有不少低级文法错误。
博主回复(2013-12-25 07:09):你提到“抓取关键词”,怀疑系统不能处理否定式(“也许是有人说不用 fear 了”),那是你不了解我的背景,虽然我在100多篇科普性博客已经多方面描述过系统的能力。简言之,我们的舆情挖掘不是通常的关键词技术,而是建立在高级得多的深度语法分析(deep parsing)之上的信息抽取和挖掘。不仅可以对付否定式,否定之否定等更复杂的语言现象也能处理。
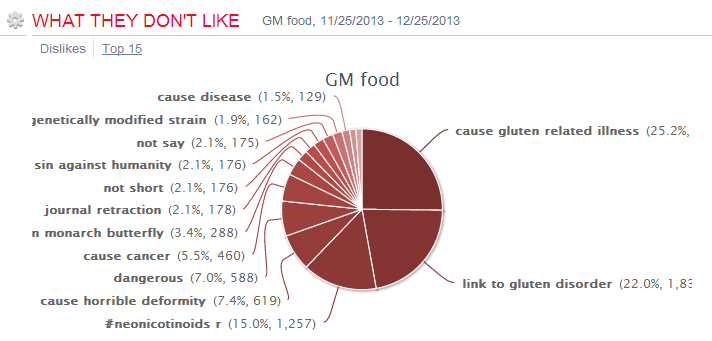
我其实没有什么立场,也没有相关的生物知识背景,转基因从来不是我关注的对象(因为是热点话题才选它当小白鼠做舆情挖掘的试验,而不是对其感兴趣)。通过朋友的争论和综述, 觉得两边的极端派掐架很难看,都有误导和蛊惑。(By the way,我觉得挺转人士当年犯了致命错误,他们不该把 GM 翻译成转基因,要是翻译成生物高科技最新改良食品伍的,就会减少很多阻力和疑虑。名不正则言不顺,言不顺则事不成。现在好多百姓听到转基因就跟听到癌症似的,你说说这个术语翻译是不是害死人。后来金大米起的名字就很好,无奈受转基因的牵累,还是遭到很多人的排斥。)
我本人不介意吃转基因食品,因为从来没有感受到有危险。我去肯德基最喜欢买的就是他们的烤玉米。从来不问出处。但事已至此,转基因就不单是科学的问题了。要上老百姓餐桌的话,老百姓的感受不能不顾及。作为一种过渡,我觉得在中国有必要给转基因食品做标识(或给非转食品做标识,one way or the other),给人民选择的权利。这个不必要循美国不标识的例,原因是国情不同,老百姓为食品安全困扰太久,井绳之忧是自然的反应。转基因的最终胜出,应该靠自己的实力,譬如价格的低廉,日益显示出来的安全性等。标识以后,科学人士和我等无所谓(畏)人士会自然成为其消费者。最后会争取到其他中间用户。至于反转死硬分子,就让他们一辈子多花冤枉钱去消费“纯天然”食品也蛮好的。
【转BT基因的BT蛋白是否引起过敏是FDA/EPA必须检测的项目】就表明了有这个担心。
这里不需要讲什么“转基因的蛋白会引起面筋过敏的实例和原理”,只要相信墨菲的定律(http://zh.wikipedia.org/zh-cn/摩菲定理):“凡是可能出错的事均会出错。”(Anything that can go wrong will go wrong.)。可引申为“若缺陷有很多个可能性,则它必然会朝着最坏、最可怕的方向发展”。
Automatic Survey from the last month of Sina Weibo (Chinese twitter, the most influential social media Microblog site) on three major characters: the former Chinese politician Bo Xilai in his on-going trial, the very famous social media figure Charles Xue who is said to have millions of fans and who was arrested for patronizing prostitutes and Li Tianyi now on trial, who is a spoiled child of Chinese most-known singer. The sentiments for Bo have gone up perhaps due to his outstanding self defence but Charles Xue dropped to the bottom.
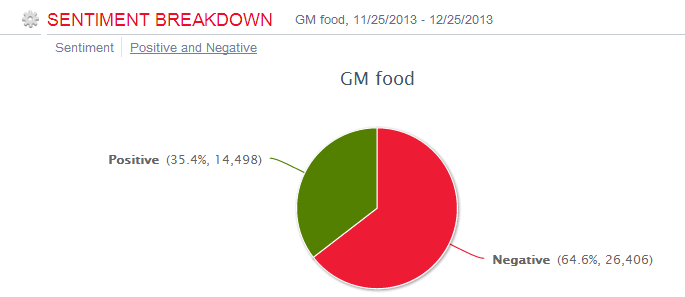
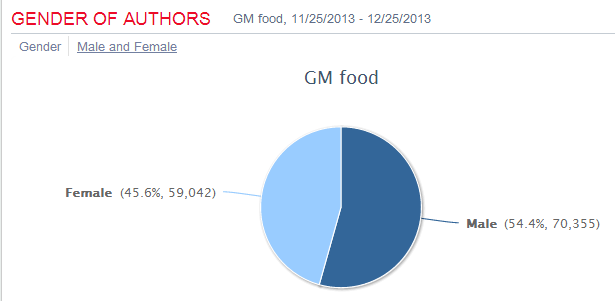
不久后可以深入文体调查一下。从用语看,我怀疑,褒词多来自新闻网站,是公司和科学家的说辞。而贬辞似乎来自民间,对新生事物的自然恐惧。(我们正在研发更好的分类系统,把来自社会媒体中的企业话语与来自社会个体的话语,所谓 push media and pull media 更清晰地分割开来,因为后者才是真正的舆情,无论对错。前者则是宣传和灌输,不可等量齐观。在市场调查和舆情聆听中,这种分类可以屏蔽噪音,更清楚地听到人民的呼声。目前的工具也可以根据domain来源做一些分割,但是不如正在研制的分类器准确、robust和好用)
I showed the First Lady's news pictures to my daughter. Tanya was so intrigued, "Dad, Mom told me that you used to teach First Lady many years ago, is that true?" "It is true, but that was only a short time, one or two semesters, and it was not her major subject. As a part-time lecturer, I was teaching Advanced English to graduate students in the music conservatory and she happened to be one in my class. She was already famous then as a new star for folk songs." Tanya got excited, "Well, you never know, maybe her English training in graduate school helps her in state visits today. My Dad is cool." She continued, "Dad, Mom also told me that you were interpreter for foreign minister when she dated you, is that true?" "Well, that was largely an accident, only happened once when I substituted some professor to act as interpreter for the former foreign minister and former Chinese congresss vice-chairman Mr. Huang Hua. Your Mom agreed to date me partially because of her seeing a picture of me interporeting for Mr. Huang. So I guess I benefited from that 'accident'." Tanya was amused and felt very proud, "I have the coolest Dad in the world. He was so successful even when he was young, teaching future first lady and interpreting for the then foreign minister. Wow"
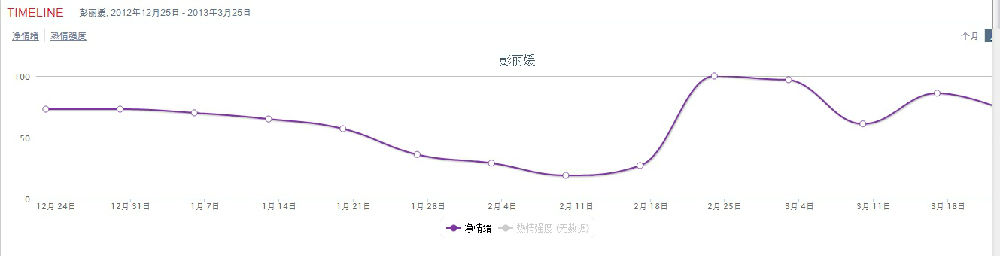
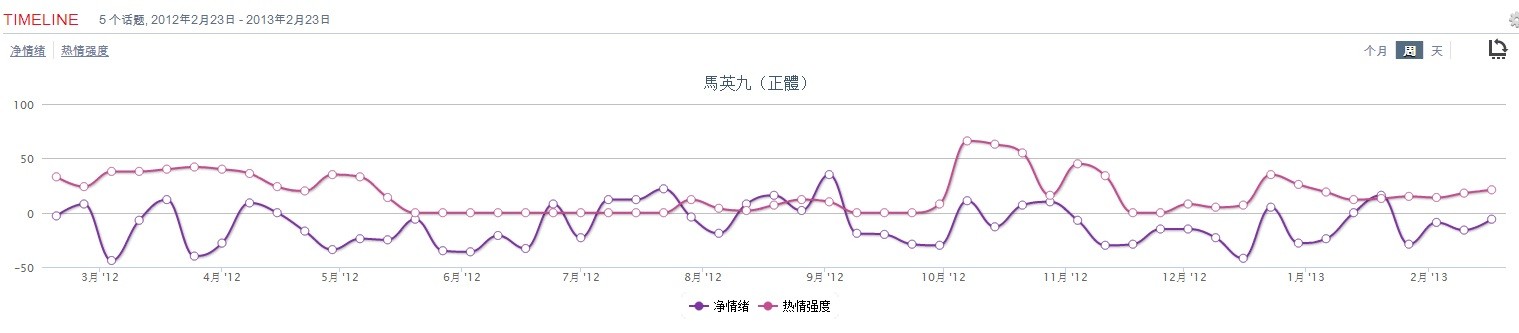
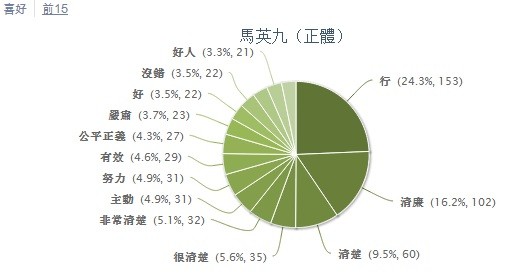
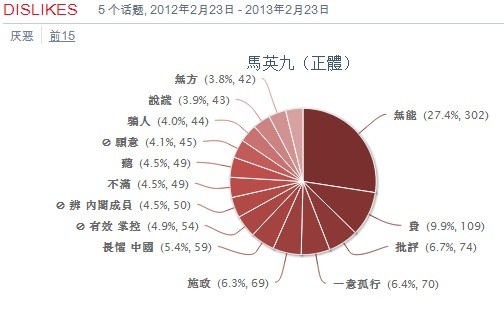
(2)不過一年來也有10多次短暫的亮點,聲望處於零度以上(褒大於貶),雖然都好景不長:從圖上看,去年七月初到九月初之間是正面聲望持續最長的區間(只在八月短暫跌入零度以下),不知道有什麽亮麗的政治表現還是由於團隊公關得力,有興趣的讀者可以查證一下。馬總統宣誓就職的五月中,凈情緒指標尚在零下30度左右徘徊,怎麽到了七月就迅速回暖至零度以上,持續約兩個月,直到九月2日的+35的峰值。我對臺灣政治不熟悉,也沒有精力去探究 data 和證據鏈(盡管我們的工具提供了多項 drill down 的功能),但這個區間似乎確是馬總統二度當選以來得到民眾認可的最佳時期。此後就一蹶不振,只在十月、十一月與今年元月短暫回升。一年來的最低點在三月四日的-44,十二月16日也很慘,一度跌入-42,冰凍刺骨。總而言之,馬英九自從去年初當選以來,不是很順,民眾的失望抱怨情緒彌漫網壇。
一个偶然的系统测试,暴露出百度与“哪里有小姐”身影相随。这个发现在朋友间立即引起轩然大波,有称妙的(way to go, u r onto sth),有调侃的(曰:百度本来就源自“众里寻她千百度”嘛),有怀疑的(the results are not faked?)。阴谋论者伊妹儿我,指责此云有侮辱百度之嫌。
下面说下感受,必须承认之前本人还停留在规则系统教训的层面,另外,就是顾虑要扯入的人工工作量大的问题。若是李老师通过这样的俯瞰语言,化繁为简,调整规则能达到信手拈来,那么在机器学习满天飞的当下,这存量稀少的规则派之花,自有它的春天。如今是个多元的世界,允许各路英雄竞技,只要有独到之处,更何况人工智能皇冠上明珠,尚无人触及,怎下定论都是早。也曾闻工业界很多可靠的规则系统在默默运行,而学术界则只为提高小小百分点而狂堆系统,专挑好的蛋糕数据大把喂上,哪管产业是否能现实中落地。当然对于人工规则系统 VS 机器学习系统,能有怎样的结局,我确实没有定论,要么一方好的东西自然会好的走下去,要么两方都走得不错而难分输赢,或者发现只有结伴相携更能走远,那谁还能拦着么!
可是这个中国的术语到了英语世界,并不是所有受众都记得住准确的说法了。结果,“标准” 的流行译法 “one belt one road”,被有些老外记错了,成了“one road one belt” or "the road and belt" 等。这也是可以理解的,老外没有政治学习时间也不没有时事政治考核,能记得一个大概就不错了。
虽然说法不同了,次序有变,但两个关健词 road 和 belt 都在,这种成语“泛化”对于人译不构成挑战,因为老外的记忆偏差和“泛化”的路数,与译员的心理认知是一致的,所以人工传译遇到这类绝不会有问题。可是,以大数据驱动的机器翻译这次傻了,真地就神经了,这些泛化的变式大多是口语中的稀疏数据,无法回译成汉语的“一带一路”,笑话就出来了。
早期机器翻译广为流传的类似笑话也是拿成语说事(The spirit is willing, but the flesh is weak,心有余而力不足 据传被翻译成了“威士忌没有问题,但肉却腐烂了”),因为一般人认为成语的理解最难,因此也必然是机器的挑战。这是完全外行的思路。成语的本质是记忆,凡记忆电脑是大拿,人脑是豆腐。
真所谓人算不如天算,看潮起潮落。老友谈养生之道,各种禁忌,颇不以为然,老了就老了,要那么长寿干嘛?最近找到一条长寿的理由,就是,可以看看这个世界怎么加速度变化的。今天见到的发生的许多事情,在 30 年前都是不可想象的:NMT,voice, image, parsing,iPhone,GPS, Tesla, you name it.
White House spokesman Sanders said 14th that TV commentator Codro Larry Kudlow will serve as president of the National Economic Council.
Sanders said in a statement that Trump to Codro as president of the economic policy assistant, as well as the President of the National Economic Council, Codro also accepted, the White House will announce later, Codro time.
Cohn, the president of the National Economic Council, resigned on 6th for not agreeing to Trump’s move, announced earlier this month that it would impose tariffs on imported steel and aluminium.
After Cohen resigned, Codro was one of the successors, and in the past year Codro was Trump’s unofficial advisor and advisor to Trump during the 2016 presidential election campaign. Trump 13th to the media that he had a high chance of appointing Codro chief economic advisor Cohen to resign casual vacancies. Trump said, “Codro has been my best friend for a while, and he’s been my first supporter of my early campaign.” He is a very talented person.
” The 70-year-old Codro oversaw the White House administration and Budget Office for 5 years in former President Ronald Reagan. Codro joined the financial media CNBC in 2001 and became a well-known critic and moderator.
Larry Kudlow, a television commentator, will become President of the national economic council, White House spokesman jay sanders said Sunday.
In a statement, Mr. Sanders said he had accepted Mr. Cordelo as an assistant to the President’s economic policy and the President of the national economic council. The White House would then announce that Mr. Cordelo took office.
The chairman of the national economic council, Gary Cohn, said he would resign on June 6 after he announced that he would impose tariffs on imported steel and aluminum.
When cohn resigned, he was one of his successors. Over the past year, he has been an informal adviser to trump and an adviser to trump during the 2016 presidential campaign.
Trump told the media on Wednesday that he had a high chance of appointing the resignation of coderot’s chief economic adviser, korn/ferry. “He was a good friend for a while,” trump said. “he supported me early in my campaign and was one of my first supporters. He is a very talented person.
The 70-year-old has overseen the White House administration and budget office for five years under former President Reagan. Cordelojoined CNBC in 2001 and became a well-known critic and host.
White House spokesman Saunders said on the 14th that television commentator Larry Kudlow will serve as chairman of the National Economic Council.
Saunders pointed out through the statement that Trump had proposed to Cadero as the president’s economic policy assistant and the chairman of the national economic conference. Caldero also accepted it; the White House will later announce the time when Calderon took office.
Trump announced at the beginning of the month that it would impose tariffs on imported steel and aluminum products. Gary Cohn, chairman of the National Economic Council, resigned on the 6th because he did not agree with Trump.
After Keen resigned, Kedlow was one of the candidates for the replacement. In the past year, Kedro was an informal advisor to Trump and a consultant during Trump’s 2016 presidential campaign.
Trump stated to the media on the 13th that he has a high chance of appointing Kodlow to replace his chief economic advisor. Trump said, “Kadelo has been a friend of mine for some time. He supported me early in my campaign and was one of my initial supporters. He is a very talented person.”
Kodlow, 70, oversees the White House’s Office of Management and Budget for 5 years under former President Reagan. He joined the financial media CNBC in 2001 and later became a famous critic and host.
With the development of productive forces, the team of intellectuals has increased faster than the proletariat, the role of the productive forces leaped to the top, and the Marxist proletarian dictatorship theory in the era of electricity will be outdated. Second, the Bolshevik dictatorship of the proletariat will rapidly evolve into a one-party dictatorship, then become a leader dictatorship.
A society based on deception and violence, in itself, contains self-destructive explosives that, once the truth is revealed, Fall apart immediately.
Third, the “cloth” party will encounter four major crises: Famine crisis, ideological crisis, social economic crisis and collapse crisis, the final regime fell apart, this process may last for decades, but this end can notchange. The greatness of the state is not in its territory or even its history, but in its democratic traditions and the living standards of its citizens. As long as citizens are still poor, as long as there is no democracy, the state will not be in turmoil until it collapses.
谷歌:
The words of Plekhanov:
First, with the development of productive forces, the ranks of intellectuals have grown faster than the proletariat, and they have taken the lead in productivity. In the age of electricity, the Marxist theory of the dictatorship of the proletariat will become obsolete.
2. The dictatorship of the proletariat of the Bolsheviks will rapidly evolve into a one-party dictatorship and will become a dictatorship of leaders. The society based on deception and violence itself contains self-destructive explosives. Once the truth is revealed, it will soon fall apart.
Third, the “cloth” party will encounter four major crises in sequence: the famine crisis, the ideological crisis, the socio-economic crisis, and the collapse crisis. The final regime collapsed. This process may last for decades, but no one can change this outcome.
Fourth, the greatness of the country does not lie in its territory or even its history. It is the democratic tradition and the standard of living of its citizens. As long as citizens are still living in poverty, as long as there is no democracy, the country cannot guarantee that there will be no turmoil until collapse.
有道:
His last words:
One, with the development of productive forces, intellectual team increase faster than that of the proletariat, in the role as the first productivity, at the age of electricity of marxism’s theory of the dictatorship of the proletariat will be out of date.
The dictatorship of the proletariat of the bolsheviks will quickly turn into a one-party state and become a leadership dictatorship. Society, based on deception and violence, contains self-destructive explosives, and when the truth comes out, it will fall apart.
Three, “cloth” party will, in turn, have four big crisis: hunger crisis, the collapse of the ideology, social and economic crisis and crisis, the regime collapse, this process may last for decades, but the end no one can change.
The greatness of a nation lies not in its territory or even its history, but in its democratic traditions and the living standards of its citizens. As long as the citizens are still poor, as long as there is no democracy, there will be no unrest until the country collapses.
“Draw a moon for the lonely night sky.
Draw me under the moon and sing.
Draw a large window for the cold house.
Draw another bed.
Draw a girl with me.
Draw another lace bed.
Draw a stove and firewood.
We were born to live together.
Draw a flock of birds around me.
Let me draw green ridge and green slope.
Picture peace and serenity.
The rain fell on the rice fields.
There’s a rainbow you can touch with your hands.
There are stars in the picture that I have decided not to destroy.
There are endless smooth paths.
The end of the family dream has entered.
Picture mother’s peaceful pose.
There’s also an eraser argument.
Paint food that is not sad in four seasons.
A leisurely person never worries.
I didn’t wipe out the quarrel eraser.
There was only one painting of a lonely pen.
The night sky was no longer bright.
Only a sad child was singing.
Draw a moon for the lonely night sky.”
自然有错译的地方(如 there’s also an eraser argument. I didn’t wipe out the quarrel eraser),可是总体而言,专业出身的我也不敢说一定能译得更好,除非有旬月踟蹰。机器翻译超越业余翻译,已经是不争的事实。
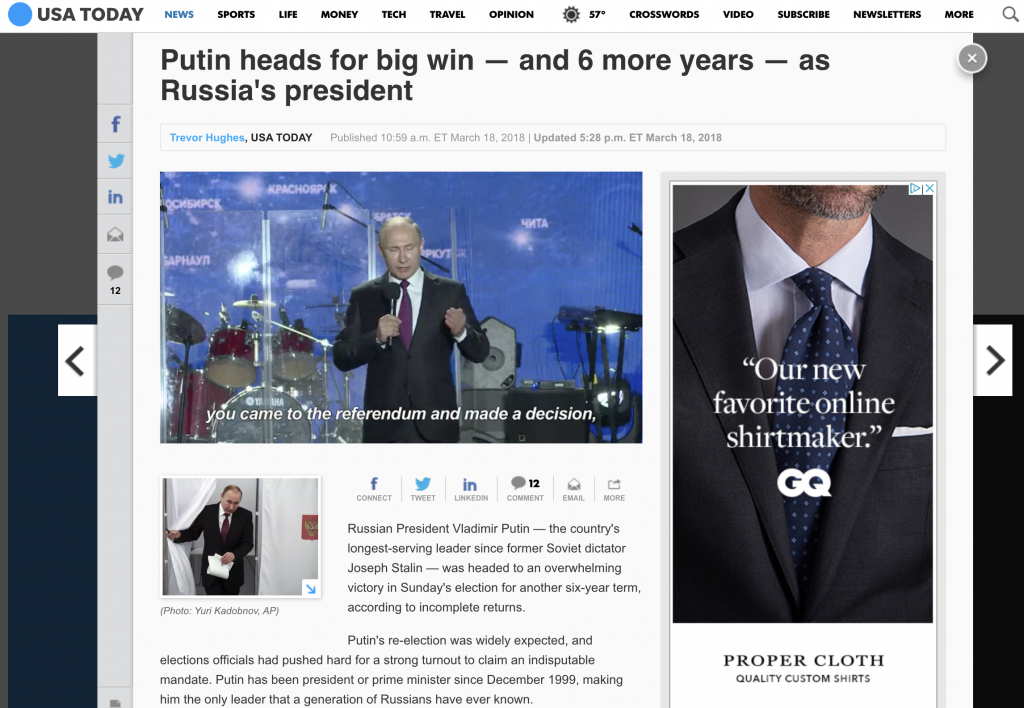
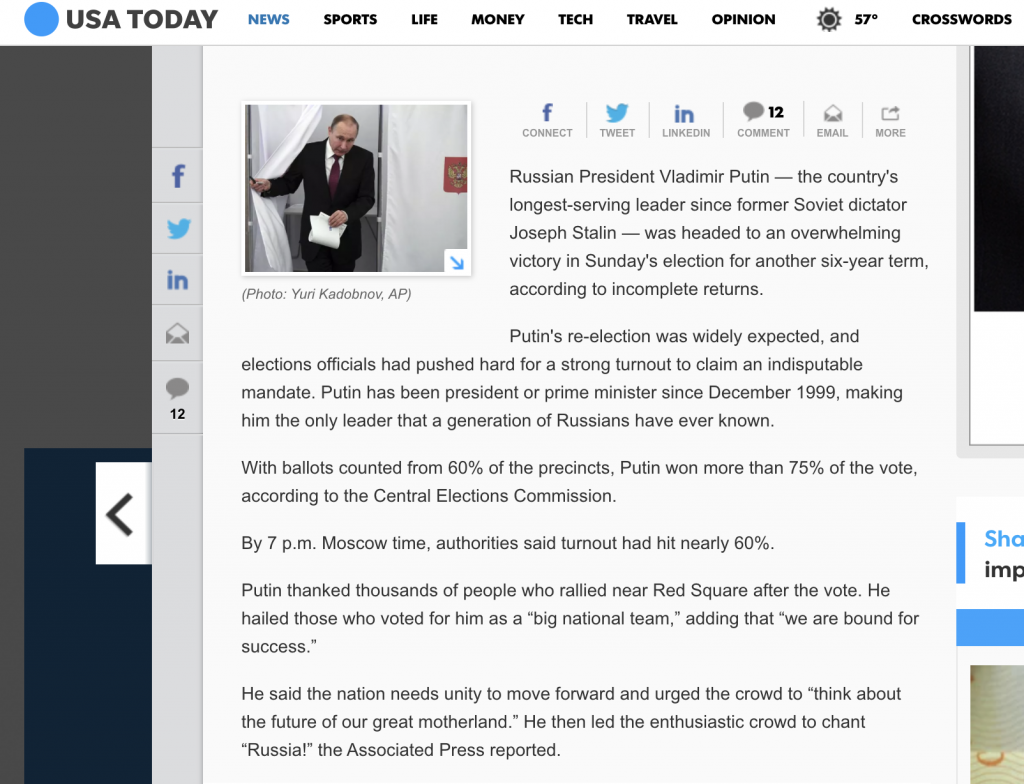
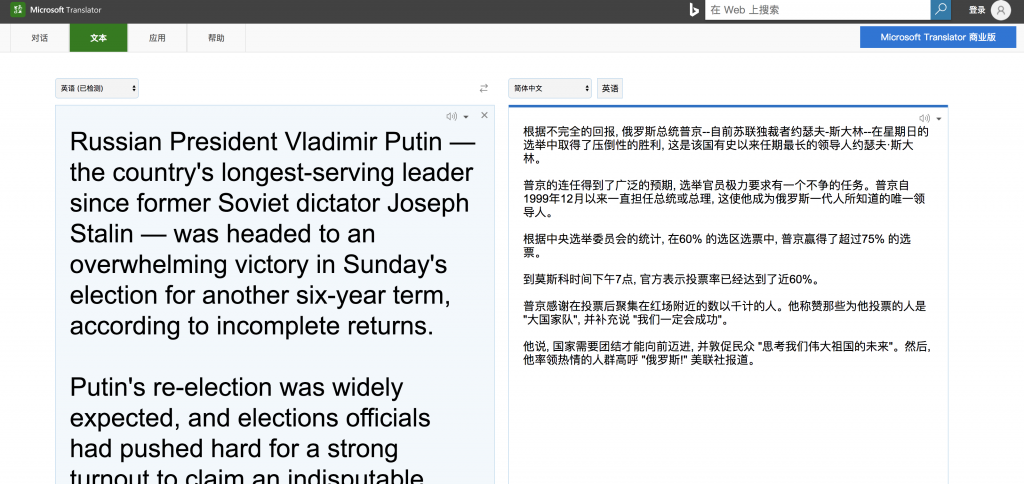
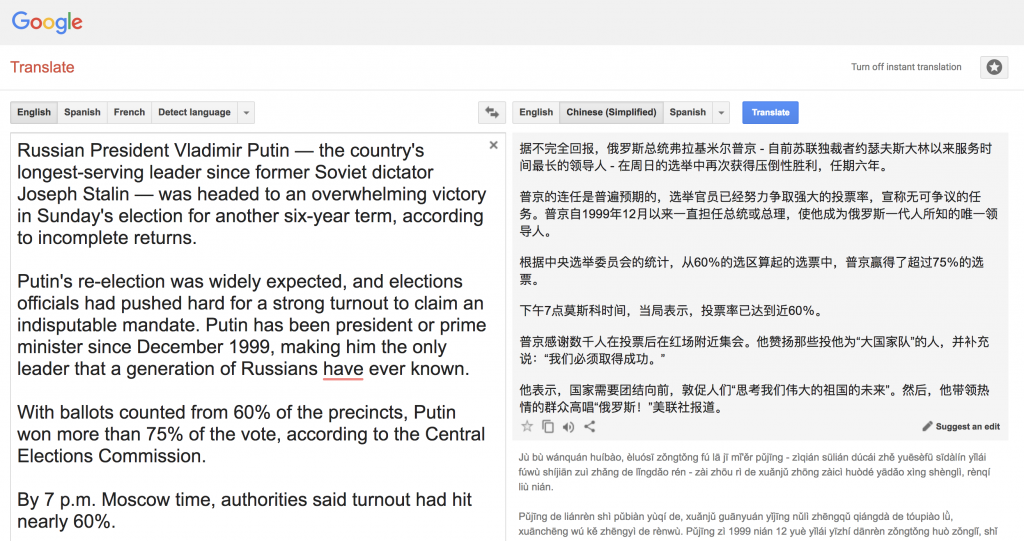
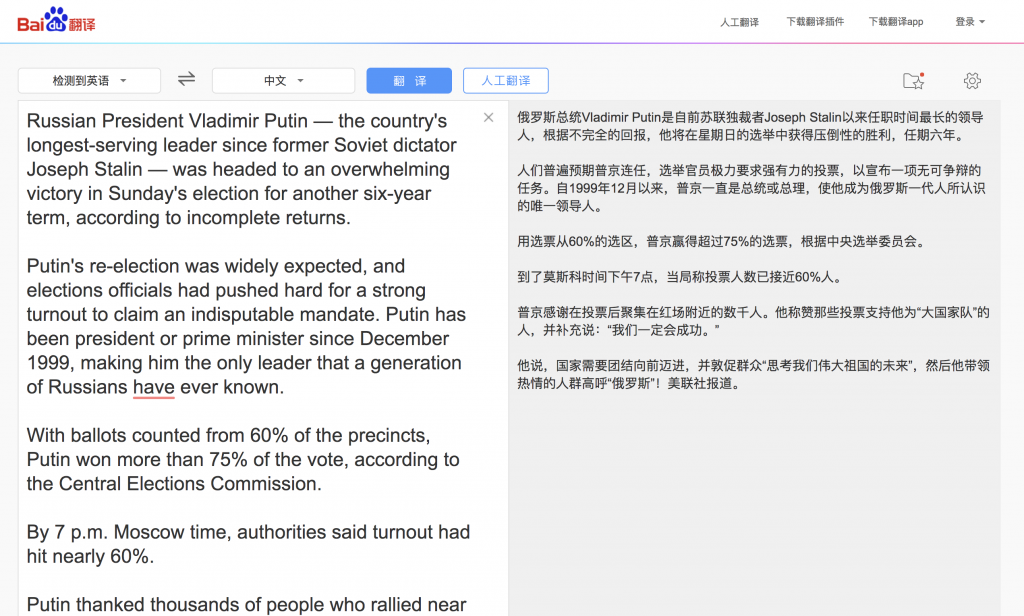
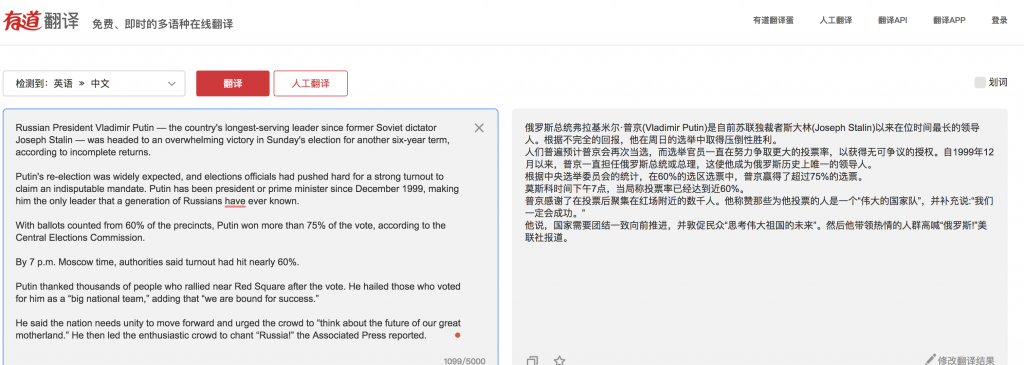
Russian President Vladimir Putin — the country's longest-serving leader since former Soviet dictator Joseph Stalin — was headed to an overwhelming victory in Sunday's election for another six-year term, according to incomplete returns.
Putin's re-election was widely expected, and elections officials had pushed hard for a strong turnout to claim an indisputable mandate. Putin has been president or prime minister since December 1999, making him the only leader that a generation of Russians have ever known.
With ballots counted from 60% of the precincts, Putin won more than 75% of the vote, according to the Central Elections Commission.
By 7 p.m. Moscow time, authorities said turnout had hit nearly 60%.
Putin thanked thousands of people who rallied near Red Square after the vote. He hailed those who voted for him as a “big national team,” adding that “we are bound for success.”
He said the nation needs unity to move forward and urged the crowd to “think about the future of our great motherland.” He then led the enthusiastic crowd to chant “Russia!” the Associated Press reported.
谷歌的问题:
1. 不合适的选词:(不完全)“回报”(returns),(无可争议的)“任务”(mandate),这算小错。
2. as-短语挂错了地方:他赞扬那些投他为“大国家队”的人 (He hailed those who voted for him as a “big national team”,不大不小的错)
3. “we are bound for success.”(“我们一定会成功”)只有谷歌没翻对,它翻成了“我们必须取得成功”。有相当偏差。
百度的问题:
1. 选词不当:(不完全的)“回报”(returns),(无可争辩的)“任务”(mandate),这算小错。
2. 生硬,两个状语的安排不妥:“【用选票从60%的选区】,普京赢得超过75%的选票,【根据中央选举委员会】”。
3. as-短语挂错了地方:他称赞那些投票支持他为“大国家队”的人(He hailed those who voted for him as a “big national team”,不大不小的错)
A couple of months ago one of my old buddies recommended Youdao to me and for some reason, I fell in love with its service and app. So I shifted to Youdao. I downloaded Youdao to my iPhone and use it from time to time for fun, and for real, almost every day. It is very user-friendly and they carefully designed the interface, and most of the time I am very happy with its performance. Despite the name of the app as Youdao Dictionary, we can use the app as an instant speech translator, as if we were accompanied by a personal interpreter all the time. The instant translation is many times just amazing though it makes me laugh from time to time in some crazy translations. From MT as a business perspective, Youdao seems to be gaining momentum. Xunfei is also a big player, especially in speech translation.
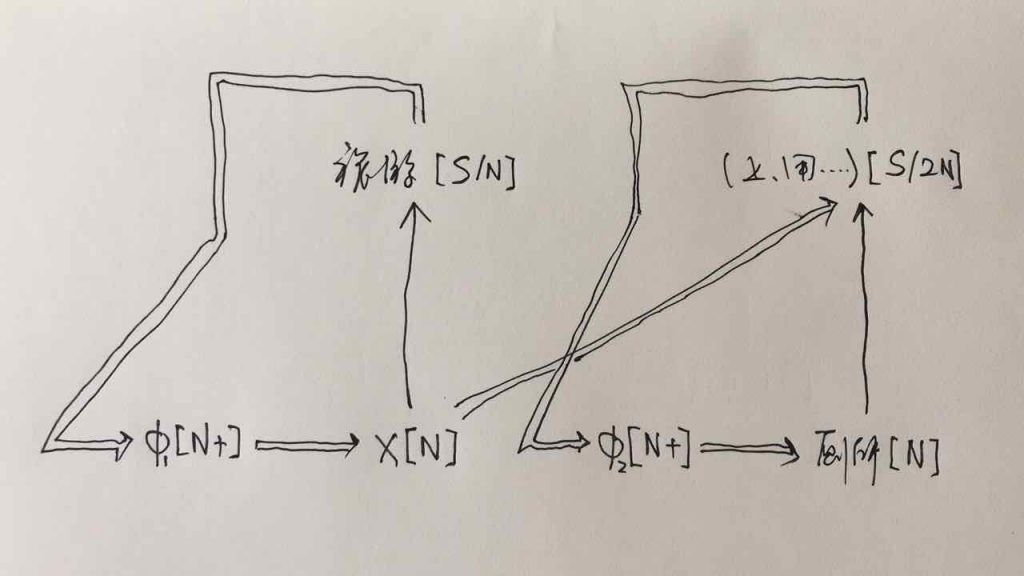
some more examples: 红白喜事,冷热风,高低端,东南向,南北向,软硬件,中青年,中老年,黑白道,大小布什 ......
这些个玩意儿说是一个开放集(合成词)吧,也没有那么地开放;说封闭吧,词典也很难全部枚举。它对切词和parsing都构成一些挑战。这是词素省略构成合成词的汉语语言现象,还原以后是 conjoin 的关系 (Ax conj Bx),至于 ABx --> AxBx 的逻辑语义,还真说不定,因词而异,可以是:(1) and:南北美 --> 南美 and 北美;大小布什 -->大布什 and 小布什;(2)or:冷热风 --> 冷风 or 热风;正负能量 --> 正能量 or 负能量;(3)range:中青年 --> from 中年 to 青年,中老年 --> from 中年 to 老年;(4)and/or: 进出口 --> 进口 and/or 出口;(5)一锅粥(and/or/ranging): 高低端 --> 高端 and/or 低端 or from 高端 to 低端。
白:
小微银行;三五度
李:
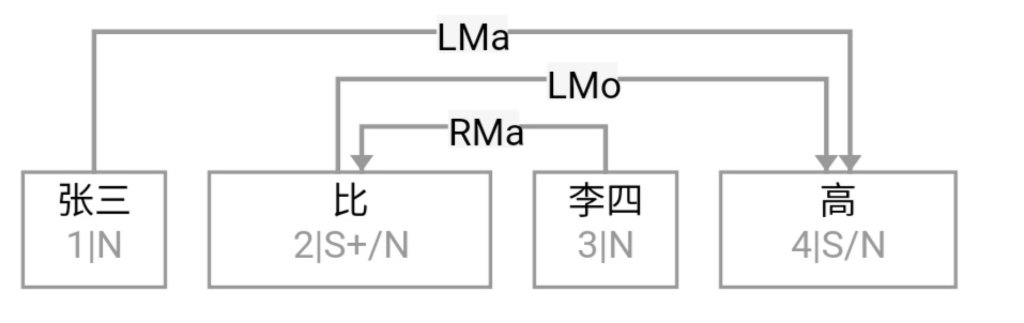
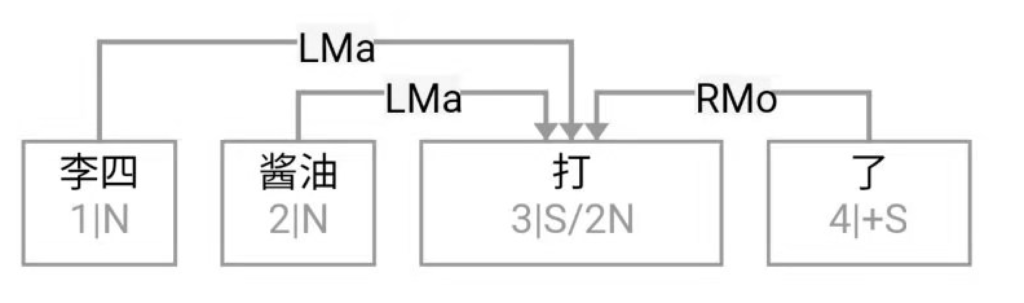
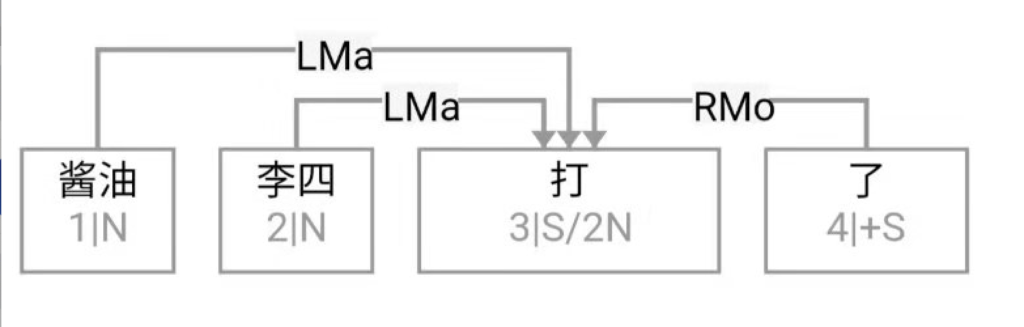
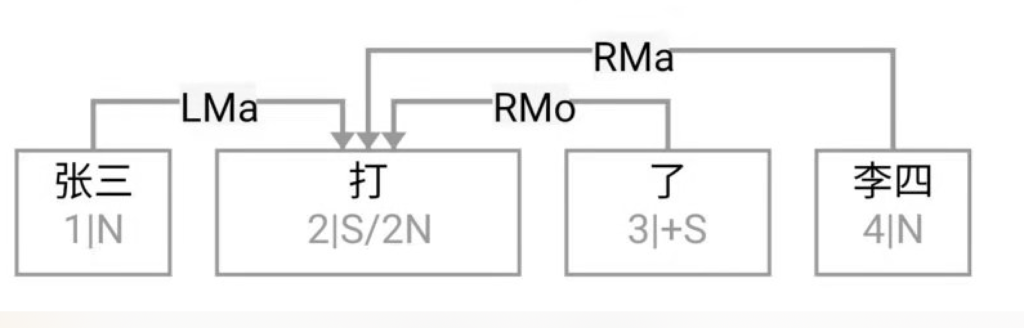
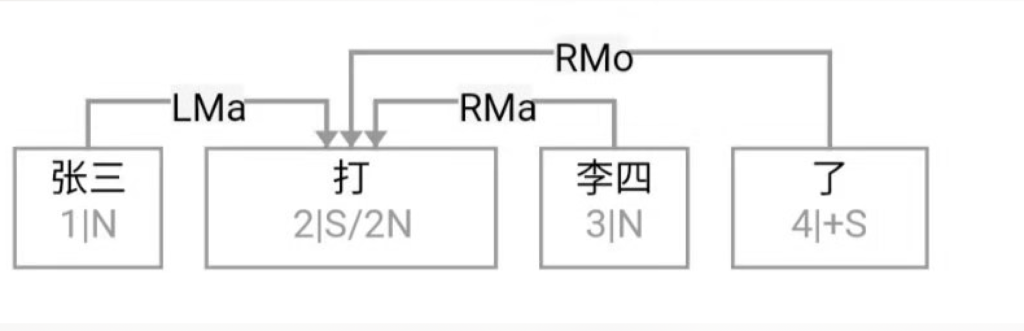
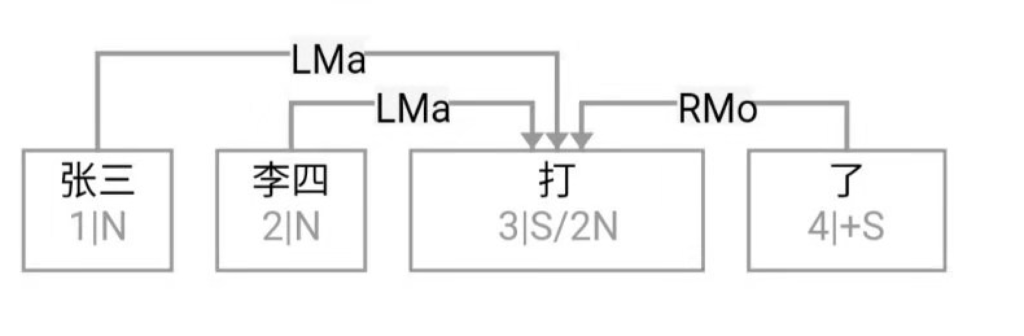
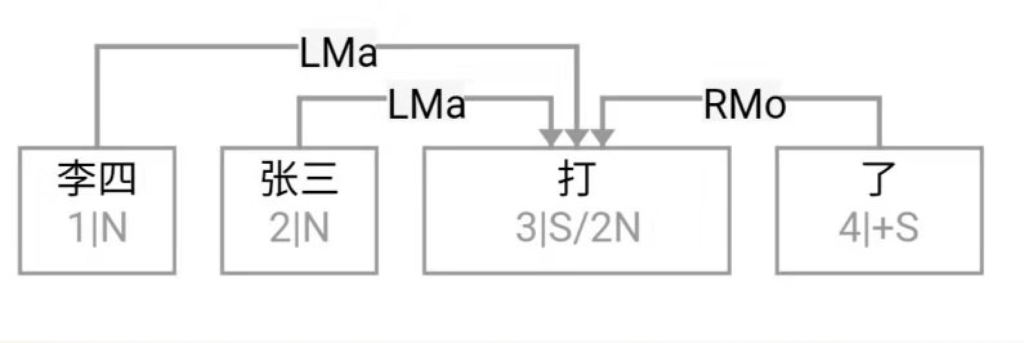
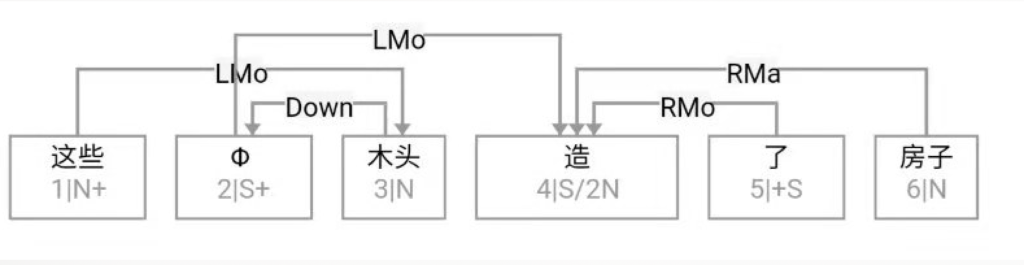
逻辑语义解析先放一边(很可能说话的人自己就一笔糊涂账,不要勉强听话人或机器去解析 and、or 还是 ranging),就说切词和parsing的挑战怎么应对就好。冷热风 在传统切词中是个拉锯战:【冷热】风 vs 冷【热风】;“南北美”:【南北】美 vs 南【北美】。
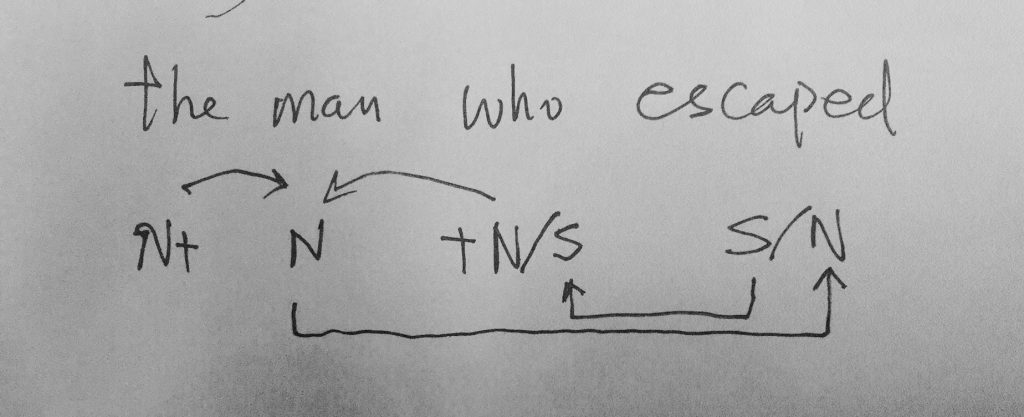
问,难道切词或 parser 还能补语言材料?当然能。不能的话,bank 怎么成的 bank1 (as in bank of a river)和 bank2(as in a com李rcial bank)?举个更明显所谓 coreference 的例子:John Smith gave a talk yesterday. Prof Smith (== John Smith), or John (== John Smith)as most people call him, is an old linguist with new tricks.
白:
高低杠、南北朝、推拉门、父母官……
李:
This last example below demonstrates the need for recovering the missing language material:
A: Recently the interest rate remains low.
B: How low is the rate (== interest rate)? // 不补的话,就不是利率了,而是速率。
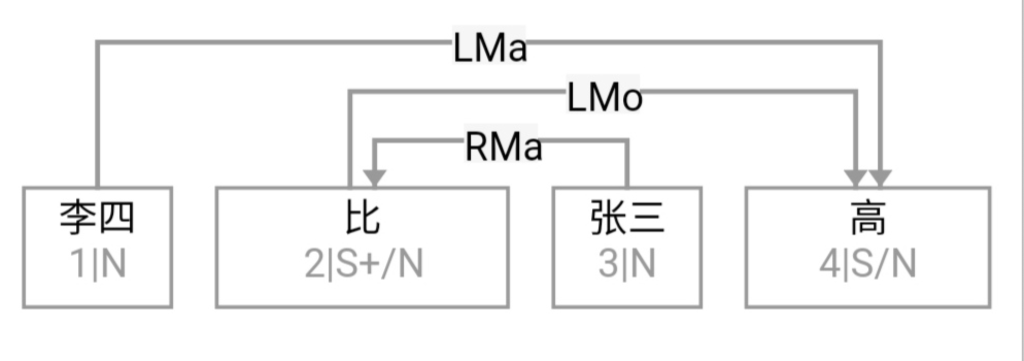
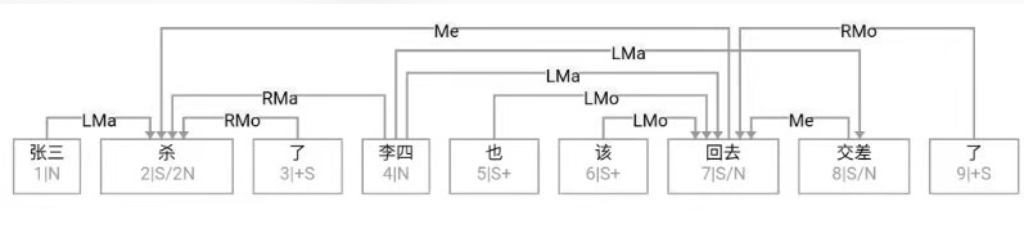
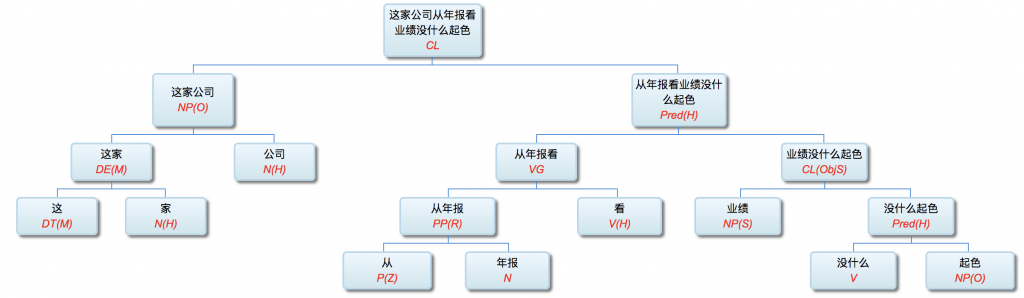
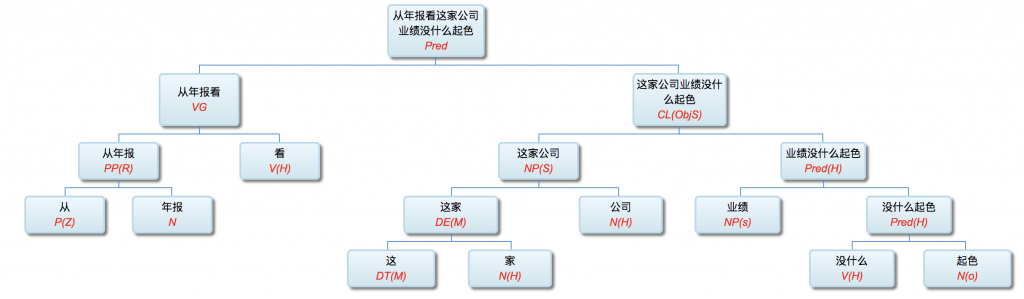
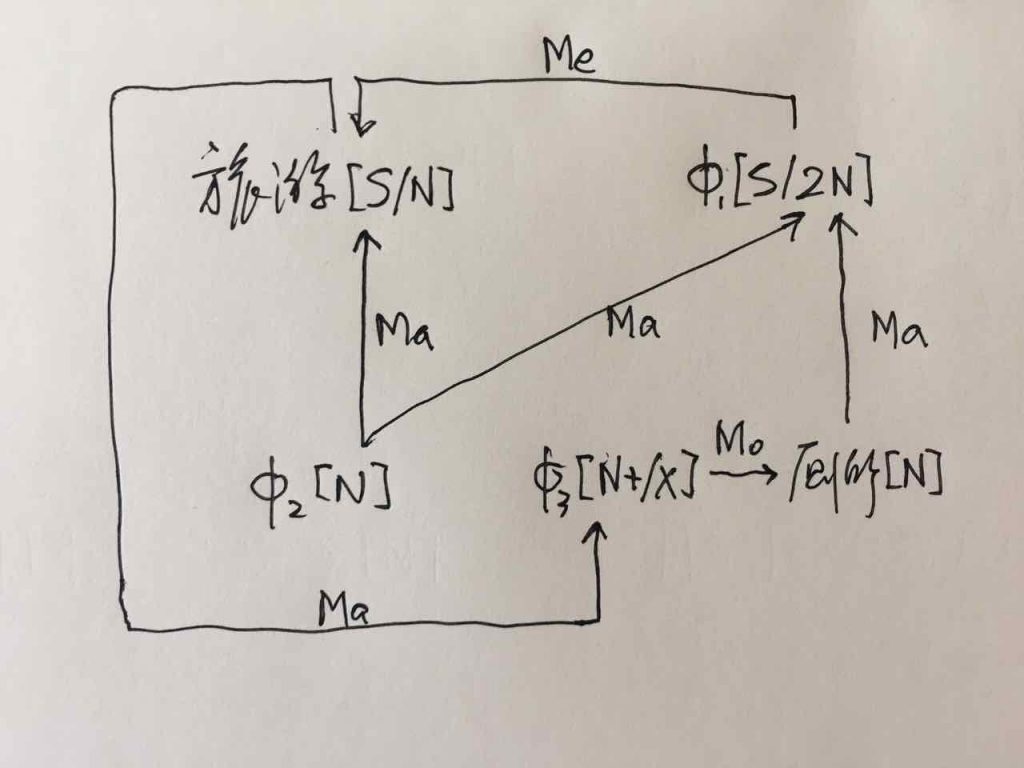
第一章小结:骨灰级老革命在没有理论探索的情况下,就在 deep parsing 的 field work 中经历了两种事实:一种是不受困扰的多层 parser,一种是深陷其中的单层 parser。因此,当白老师一口咬定深度分析的这个挑战的时候,我觉得一脑门道理,但就是有理说不清。至少一句两句说不清,只好选择逃遁。
对于绝大多数主流NLP-ers,NL的文法只有一派,那就是 CFG,无论多少变种。算法也基本上大同小异,chart-parsing 的某种。这个看法是压倒性的。而多层的有限状态文法做 parsing,虽然已经有半个多世纪的历史,却一直被无视。先是被乔姆斯基主流语言学派忽视,因为有限状态(FSA)的名字就不好听(多层不多层就懒得细究了),太低端小气下位了。由于语言学内部就忽视了它,自然不能指望统计派主流对它有重视,他们甚至对这路parsing没有啥印象(搞个浅层的模式匹配可以,做个 NE tagging 啥的,难以想象其深度parsing的潜力),尽管从有限状态这一点,其实统计派与FSA语言派本是同根生,二者都是乔老爷居高临下批判的对象,理论上似乎无招架还手之力。
白: 概率自动机和马尔可夫过程的关系
李:但是,多层 FSA 的精髓不在有限状态, 而是在多层(就好比 deep learning 的精髓也在多层,突破的是传统神经网络很多年停滞不前的单层)。这就是那天我说,我一手批判统计派,包括所有的统计,单层的多层的,只要他们不利用句法关系,都在横扫之列。因为这一点上还是乔老爷看得准,没有句法就没有理解, ngram 不过是句法的拙劣模仿,你的成功永远是浅层的成功, 你摘下的不过是低枝果实。不过恰好这种果子很多,造成一种虚假繁荣罢了。
另一方面,我又站在统计派一边,批判乔姆斯基的蛮横。实践中不用说了,管用的几乎都是有限状态。乔老爷要打死单层的有限状态,我没有意见。统计派的几乎所有模型(在 deep learning 火起来之前)都是单层,他们在单层里耗太久了不思长进,死不足惜,:)。 蛮横之处在于乔老爷对有限状态和ngam多样性的忽视,一竿子打翻了一船人。
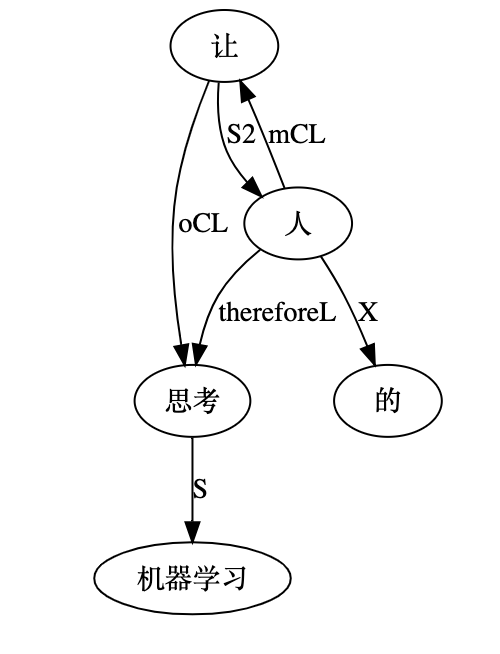
李:当然。次范畴就是小规则,小规则优先于大规则。语言规则中,大类的规则(POS-based rules)最粗线条,是默认规则,不涉及具体的次范畴(广义的subcat)。subcat based 的其次。sub-subcat 再其次。一路下推,可以到利用直接量(词驱动)的规则,那是最优先最具体的,包括成语和固定搭配。
QUOTE: Countless lessons learned over the years in the NLP system development show that a robust real life system should not be too sophisticated just as man should not be too smart. As a rule of thumb, anything involving more than 3 levels of dependency is too delicate. You can "make" it work today, but it will break some day.
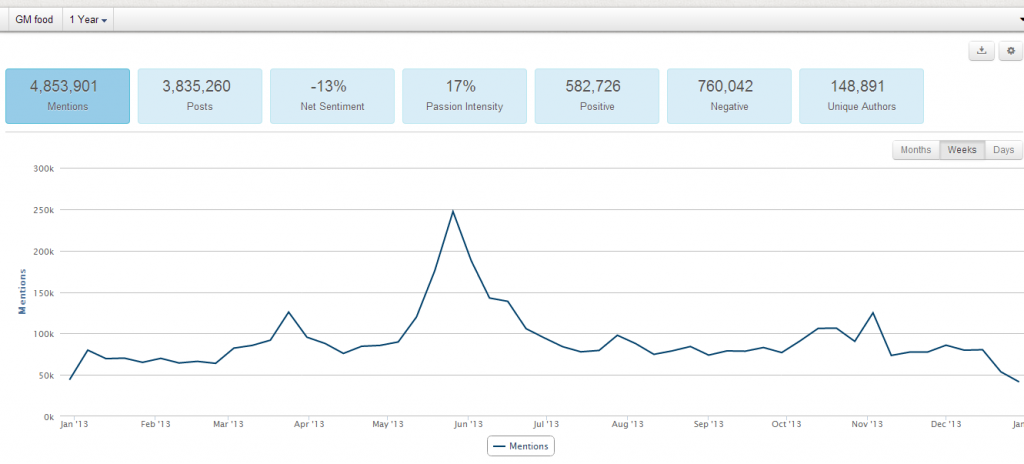
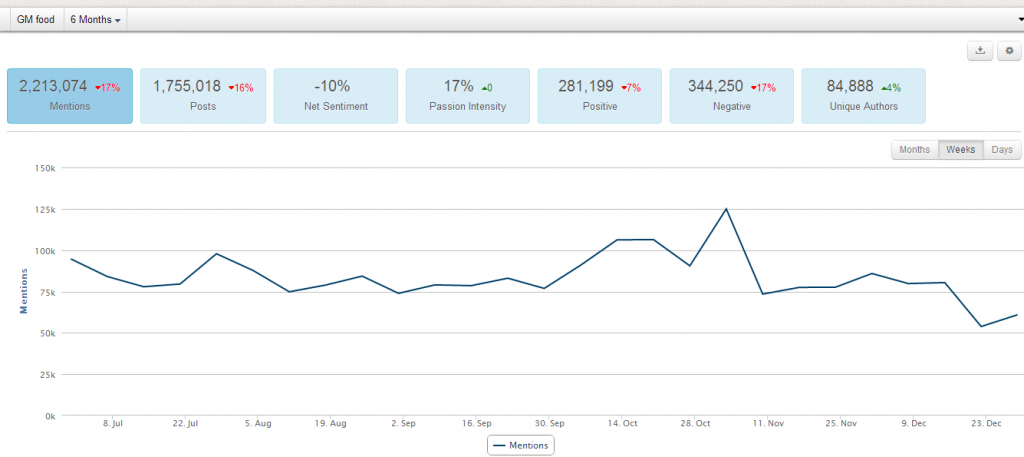
 【大数据挖掘:转基因中文网络的自动民调,东风压倒西风?】 2014-01-03),下面我们进一步做转基因最近一年的网络形象趋势的调查,看看到底转基因在网民中的形象是提升还是损害了?
【大数据挖掘:转基因中文网络的自动民调,东风压倒西风?】 2014-01-03),下面我们进一步做转基因最近一年的网络形象趋势的调查,看看到底转基因在网民中的形象是提升还是损害了?

















 赞[2]蔡小宁
赞[2]蔡小宁 

































 两相对比,立委这个interview让我看到了你坐backoffice的巨大潜力
两相对比,立委这个interview让我看到了你坐backoffice的巨大潜力 - 立委
- 立委  台上一秒钟,台下几年功,一点不错!立委多年的奋斗终于开花结果了!
台上一秒钟,台下几年功,一点不错!立委多年的奋斗终于开花结果了!




















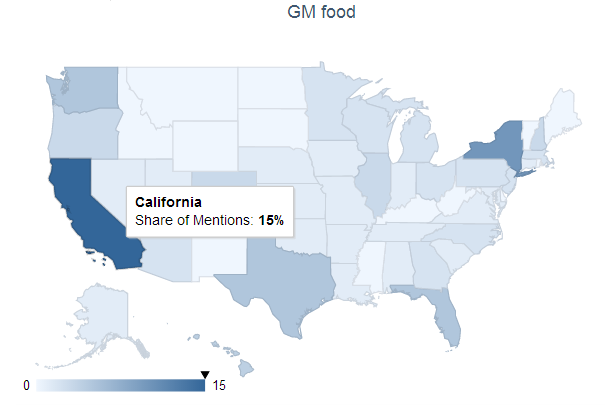












 大数据崇拜要不得
大数据崇拜要不得