Last few days have seen tons of reports on Trump's Gettysburg speech and its impact on his support rate, which is claimed by some of his campaign media to soar due to this powerful speech. We would love to verify this and uncover the true picture based on big data mining from the social media.
First, here is one link on his speech:
DONALD J. TRUMP DELIVERS GROUNDBREAKING CONTRACT FOR THE AMERICAN VOTER IN GETTYSBURG. (The most widely circulated related post in Chinese social media seems to be this: Trump's heavyweight speech enables the soaring of the support rate and possible stock market crash).
Believed to be a historical speech in his last dash in the campaign, Trump basically said: I am willing to have a contract with the American people on reforming the politics and making America great again, with this plan outline of my administration in the time frame I promised when I am in office, I will make things happen, believe me.
Trump made the speech on the 22nd this month, in order to mine true public opinions of the speech impact, we can investigate the data around 22nd for the social media automated data analysis. We believe that automated polling based on big data and language understanding technology is much more revealing and dependable than the traditional manual polls, with phone calls to something like 500 to 1,000 people. The latter is laughably lacking sufficient data to be trustworthy.
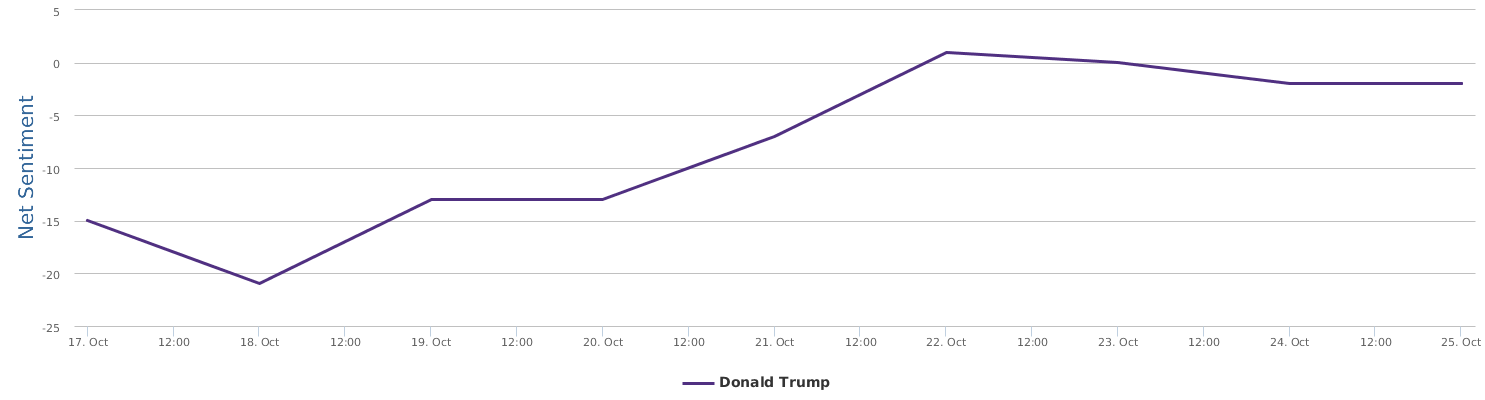
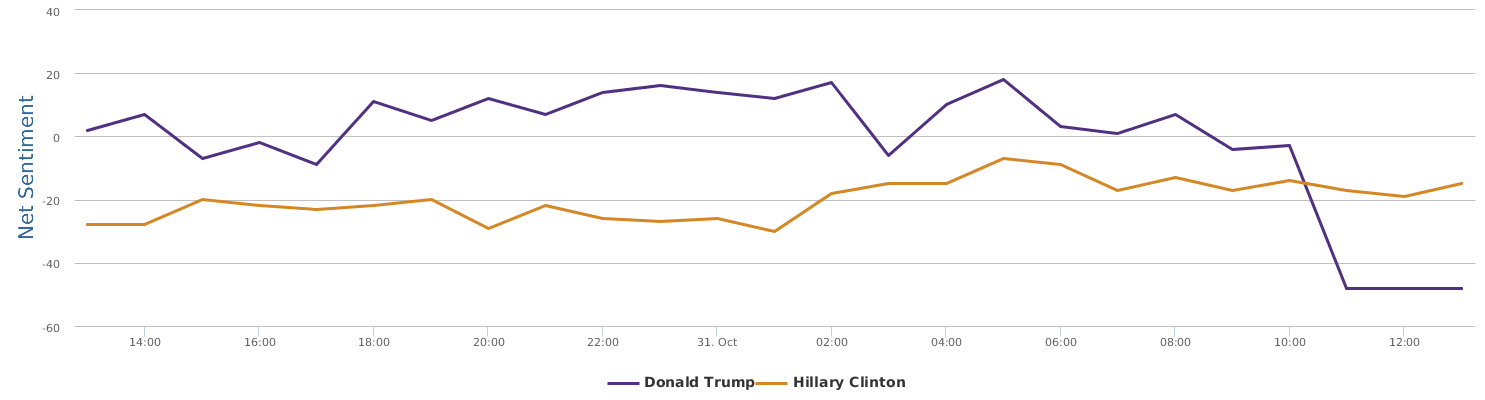
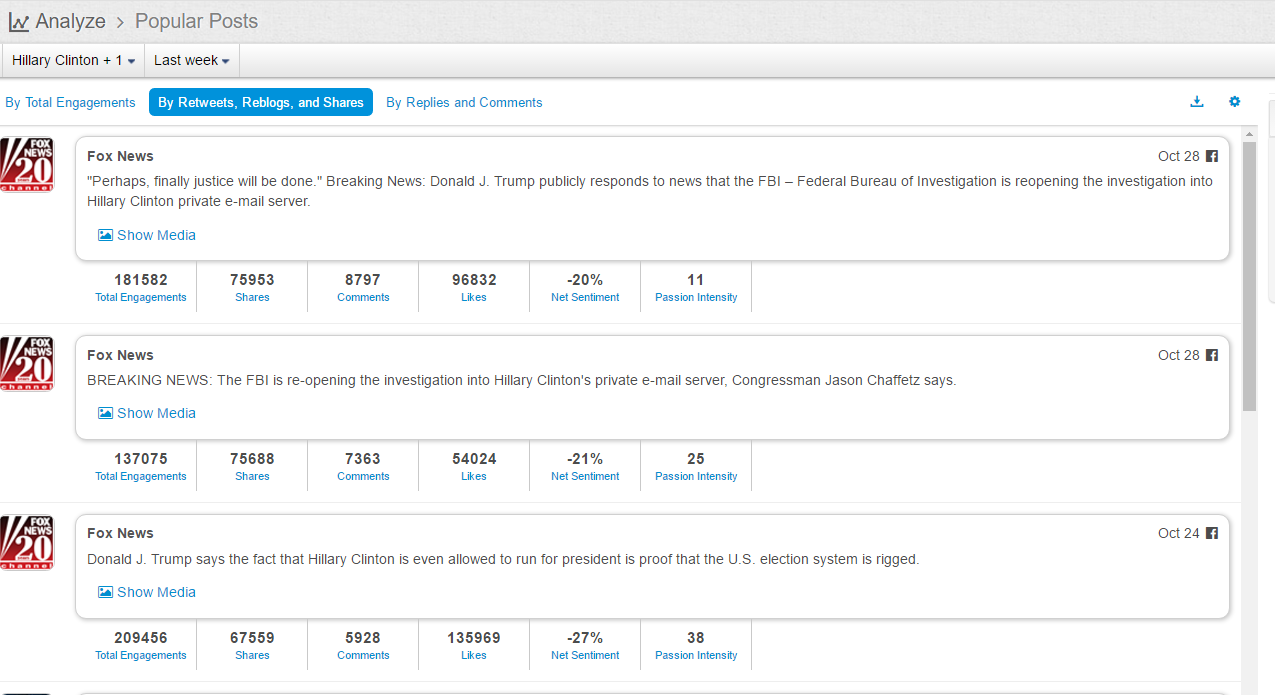
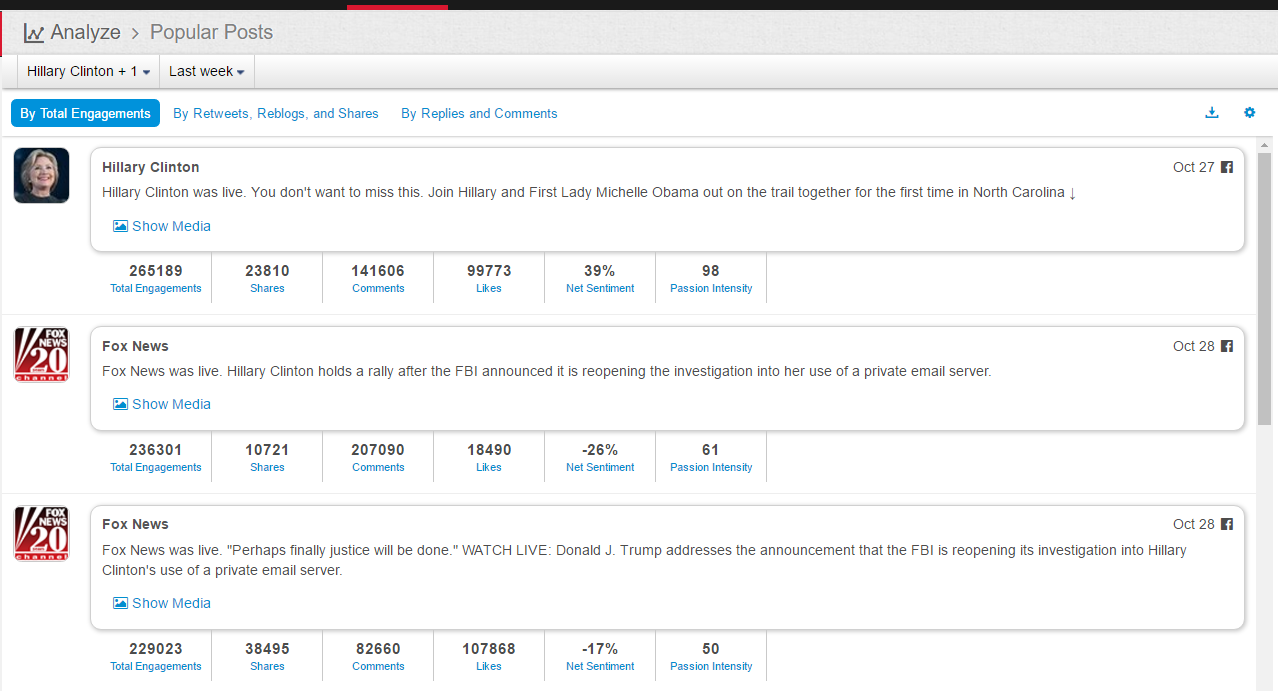
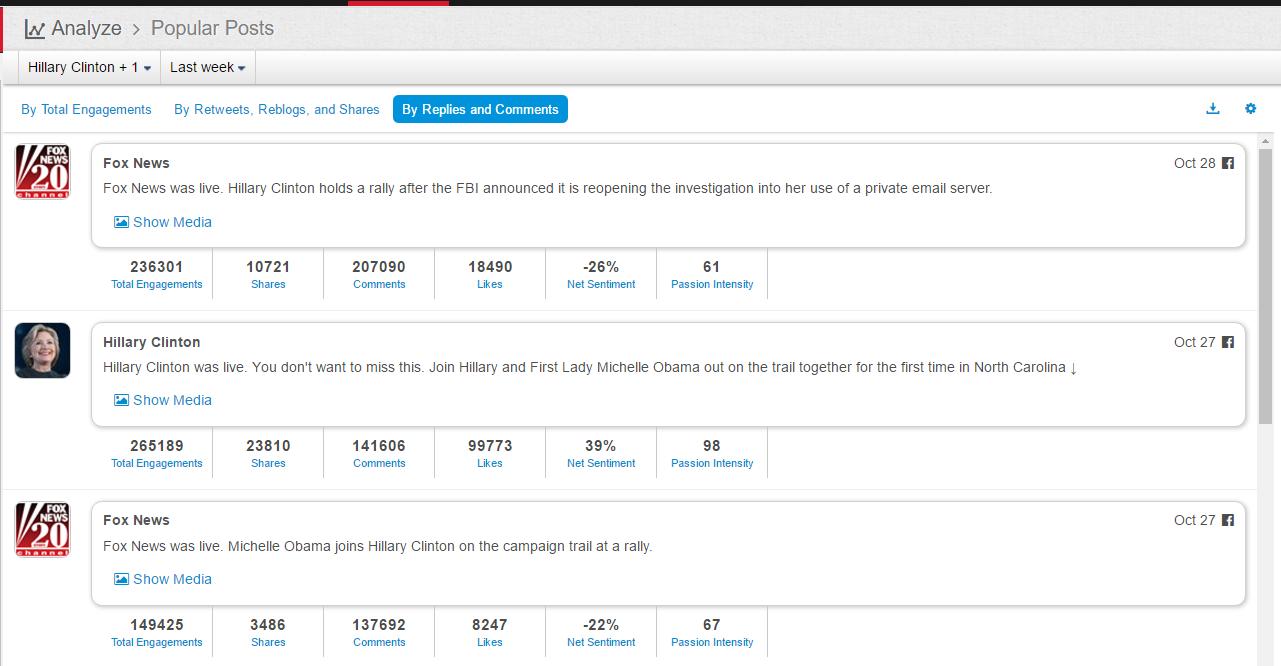
What does the above trend graph tell us?
1 Trump in this time interval was indeed on the rise. The "soaring" claim this time does not entirely come out of nowhere, but, there is a big BUT.
2. BUT, a careful look at the public opinions represented by net sentiment (a measure reflecting the ratio of positive mentions over negative mentions in social media) shows that Trump has basically stayed below the freezing point (i.e. more negative than positive) in this time interval, with only a brief rise above the zero point near the 22nd speech, and soon went down underwater again.
3. The soaring claim cannot withstand scrutiny at all as soaring implies a sharp rise of support after the speech event in comparison with before, which is not the case.
4. The fact is, Uncle Trump's social media image dropped to the bottom on the 18th (with net sentiment of -20%) of this month. From 18th to 22nd when he delivered the speech, his net sentiment was steadily on rise from -20% to 0), but from 22nd to 25th, it no longer went up, but fell back down, so there is no ground for the claim of support soaring as an effect of his speech, not at all.
5. Although not soaring, Uncle Trump's speech did not lead to sharp drop either, in terms of the buzz generated, this speech can be said to be fairly well delivered in his performance. After the speech, the net sentiment of public opinions slightly dropped, basically maintaining the fundamentals close to zero.
6. The above big data investigation shows that the media campaign can be very misleading against the objective evidence and real life data. This is all propaganda, which cannot be trusted at its face value: from so-called "support rate soared" to "possible stock market crash". Basically nonsense or noise of campaign, and it cannot be taken seriously.
The following figure is a summary of the surveyed interval:
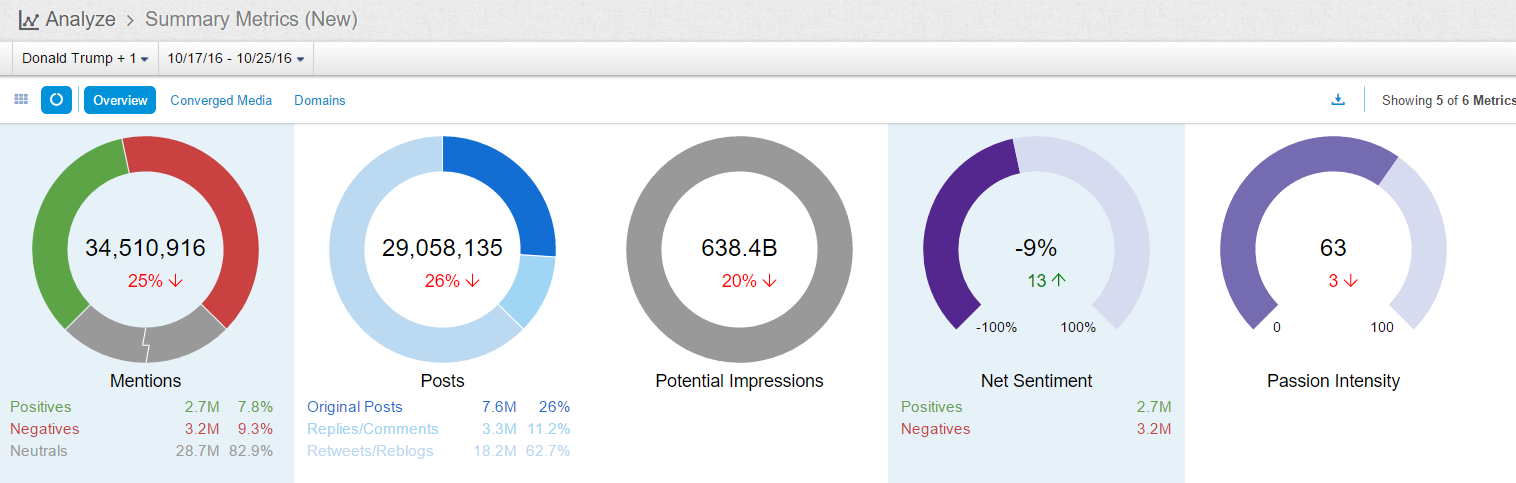
As seen, the average public opinion net-sentiment for this interval is -9%, with positive rating consisting of 2.7 million mentions, and negative rating of 3.2 million mentions.
How do we interpret -9% as an indicator of public opinions and sentiments? According to our previous numerous automated surveys of political figures, this is certainly not a good public opinion rating, but not particularly bad either as we have seen worse. Basically, -9% is under the average line among politicians reflecting the public image in people's minds in the social media. Nevertheless, compared with Trump's own public ratings before, there is a recorded 13 points jump in this interval, which is pretty good for him and his campaign. But the progress is clearly not the effect of his speech.
This is the social media statistics on the data sources of this investigation:
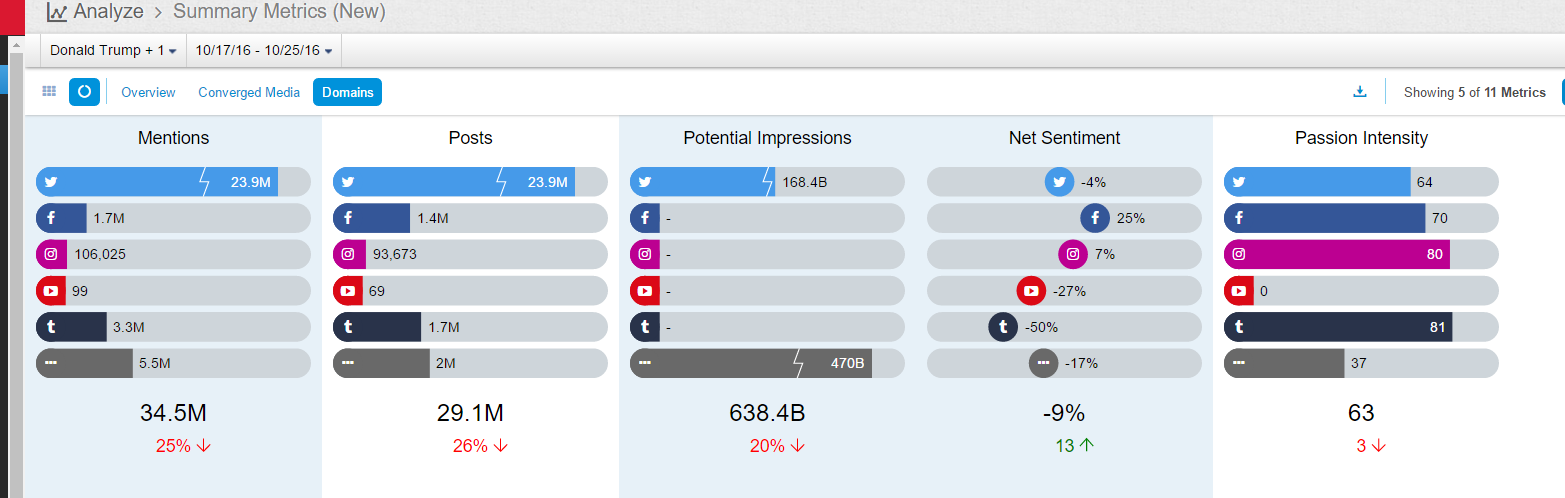
In terms of the ratio, Twitter ranks no 1, it is the most dynamic social media on politics for sure, with the largest amount of tweets generated every minute. Among a total of 34.5 million mentions on Trump, Twitter accounted for 23.9 million. In comparison, Facebook has 1.7 million mentions.
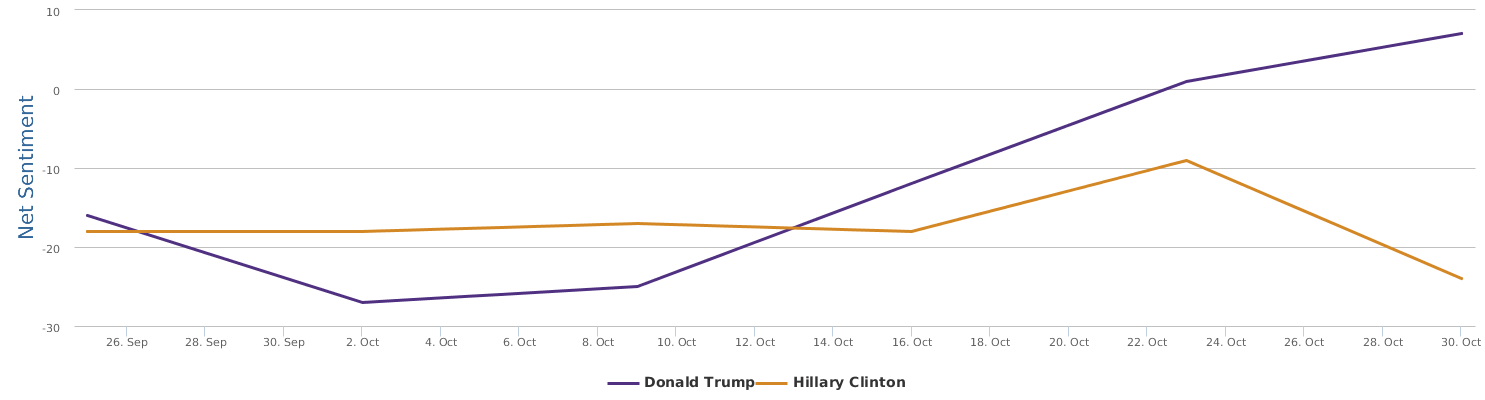
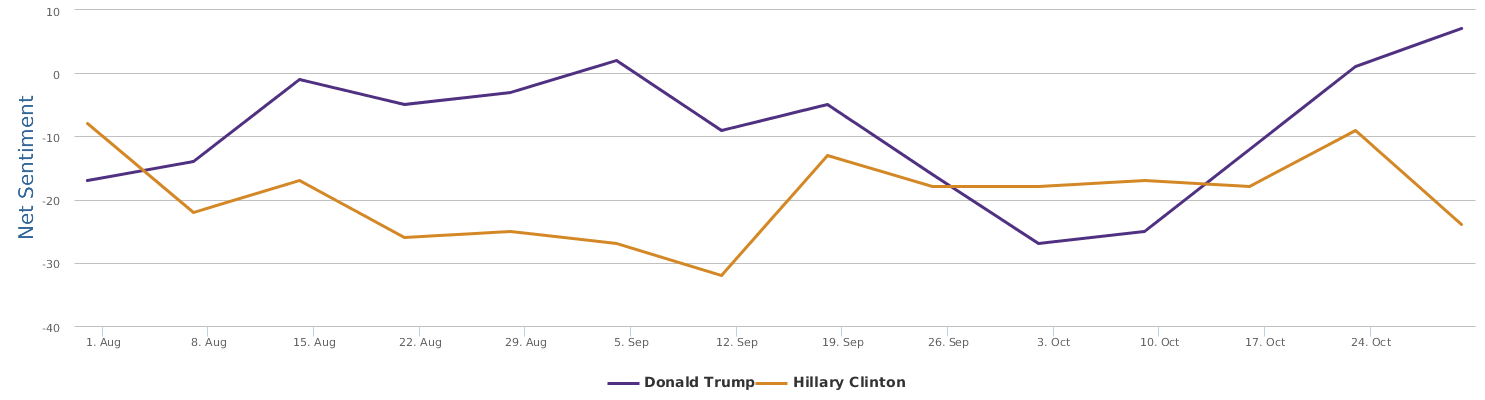
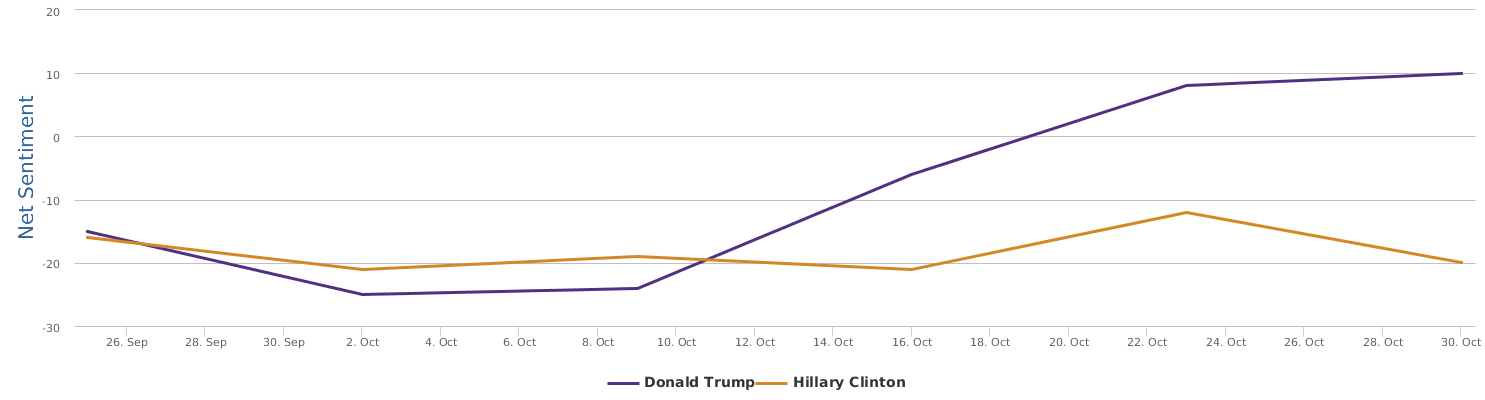
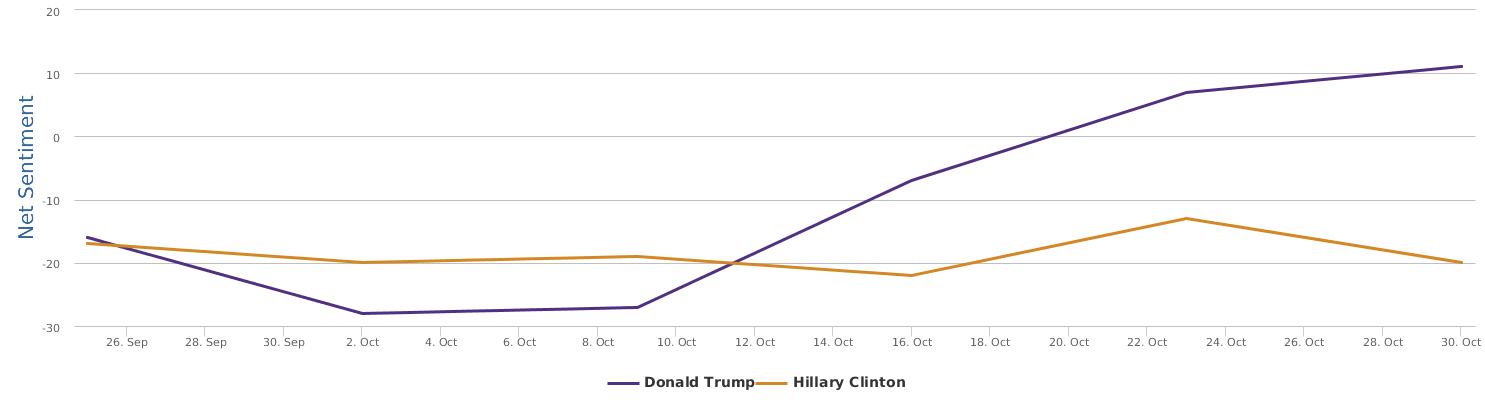
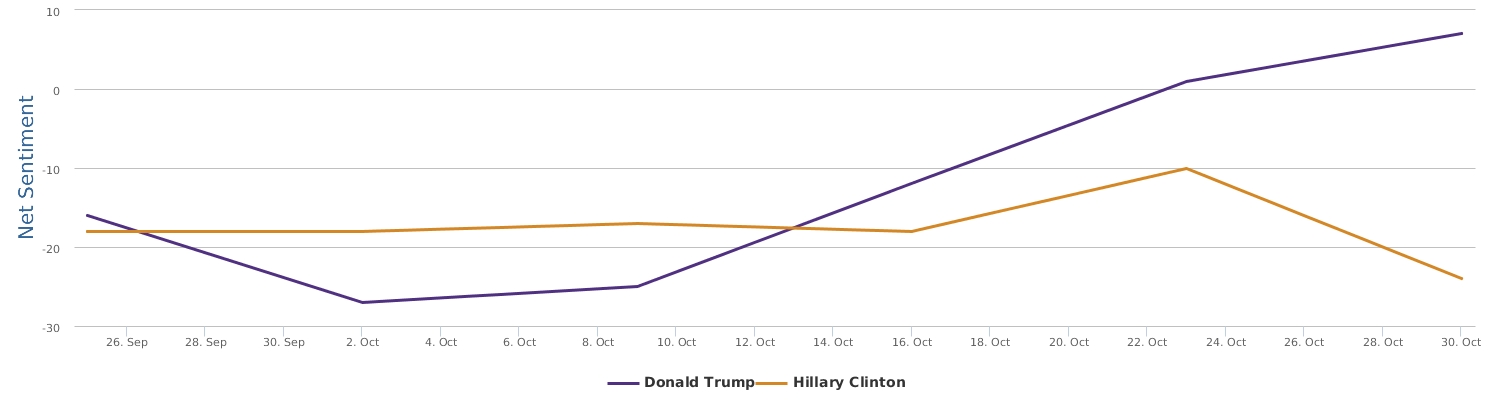
Well, let's zoom in on the last 30 days instead of only the days around the speech, to provide a bigger background for uncovering the overall trends of this political fight in the 2016 US presidential campaign between Trump and Clinton.
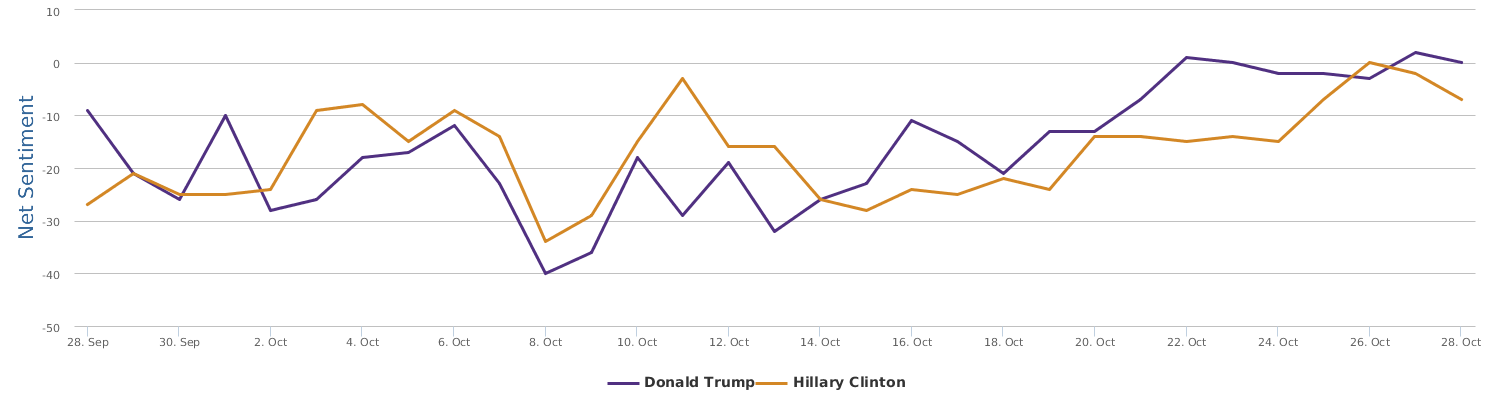
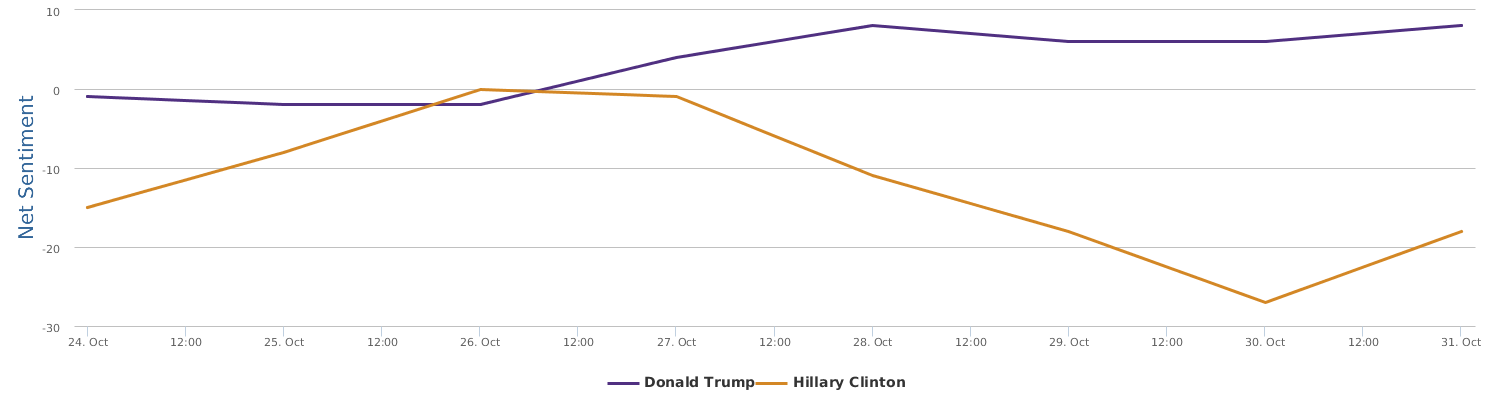
The 30 days range from 9/28-10/28, during which the two lines in the comparison trends chart show the contrast of Trump and Clinton in their respective daily ups and downs of net sentiment (reflecting their social rating trends). The general impression is that the fight seems to be fairly tight. Both are so scandal-ridden, both are tough and belligerent. And both are fairly poor in social ratings. The trends might look a bit clearer if we visualize the trends data by weeks instead of by day:
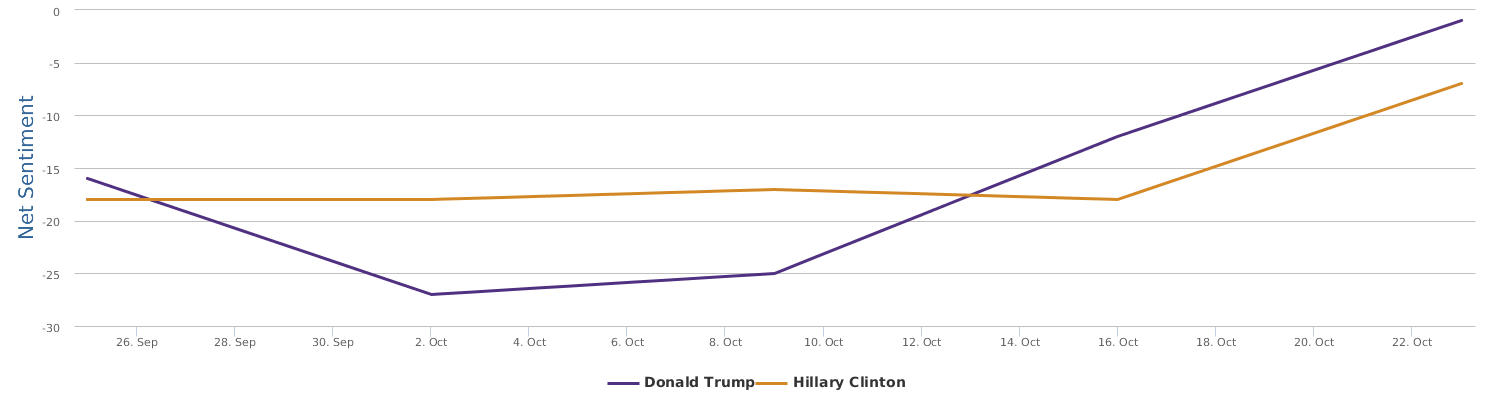
No matter how much I dislike Trump, and regardless of my dislike of Clinton whom I have decided to vote anyway in order to make sure the annoying Trump is out of the race, as a data scientist, I have to rely on data which says that Hillary's recent situation is not too optimistic: Trump actually at times went a little ahead of Clinton (a troubling fact to recognize and see).
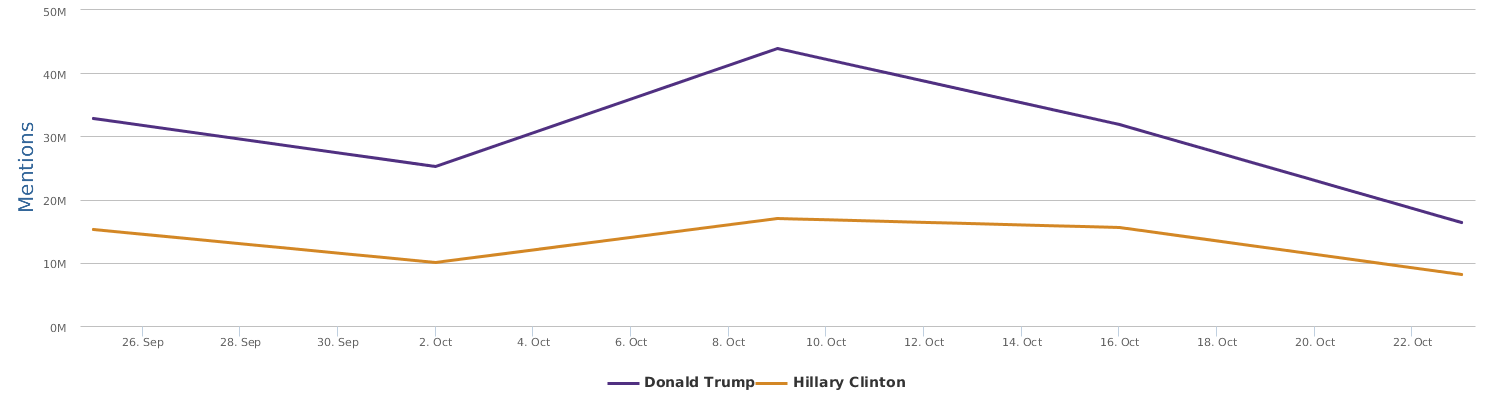
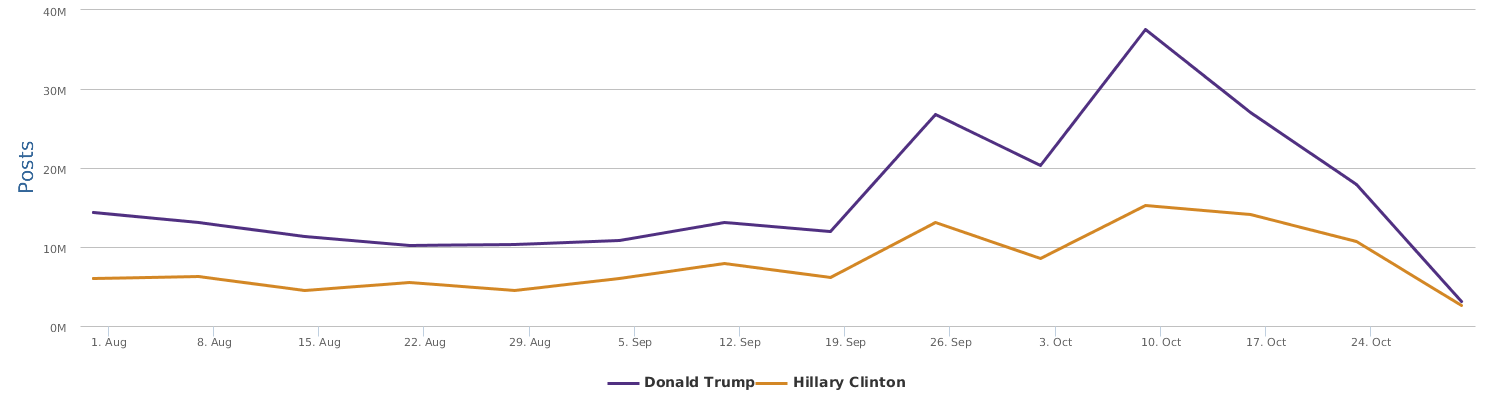
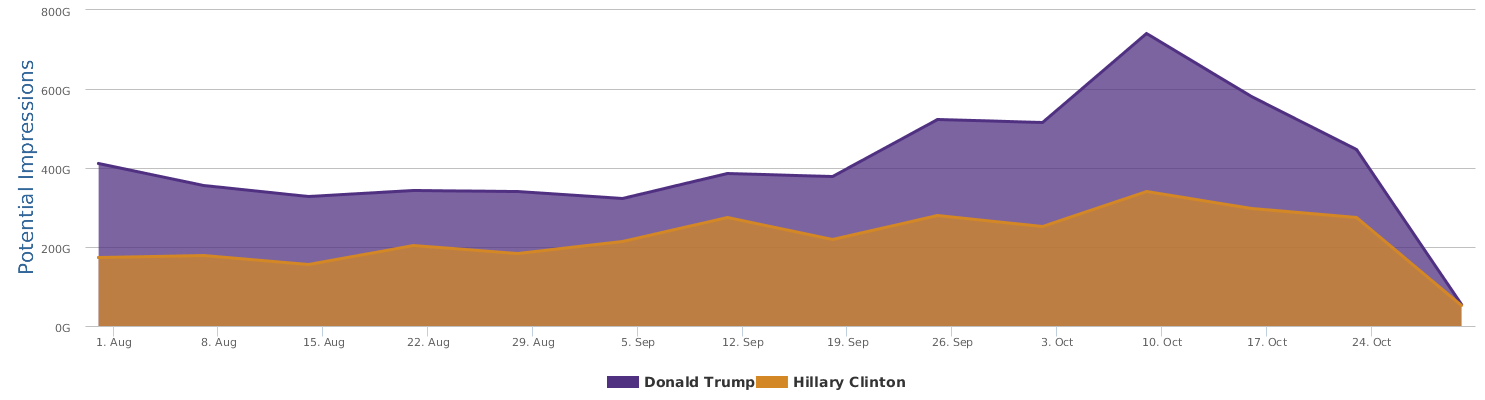
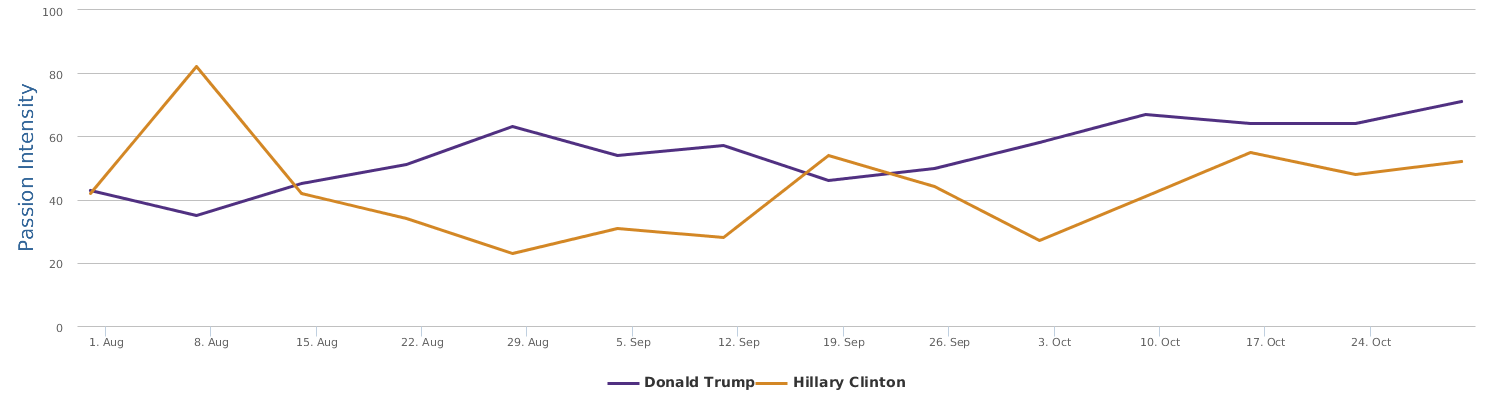
The graph above shows a comparison of the mentions (buzz, so to speak). In terms of buzz, Trump is a natural topic-king, having generated most noise and comments, good or bad. Clinton is no comparison in this regard.
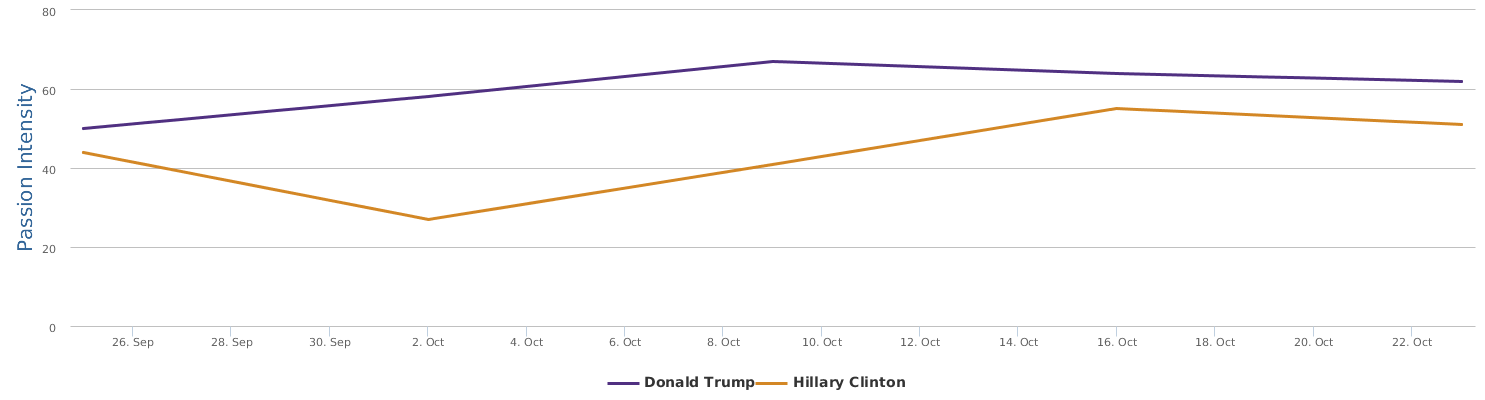
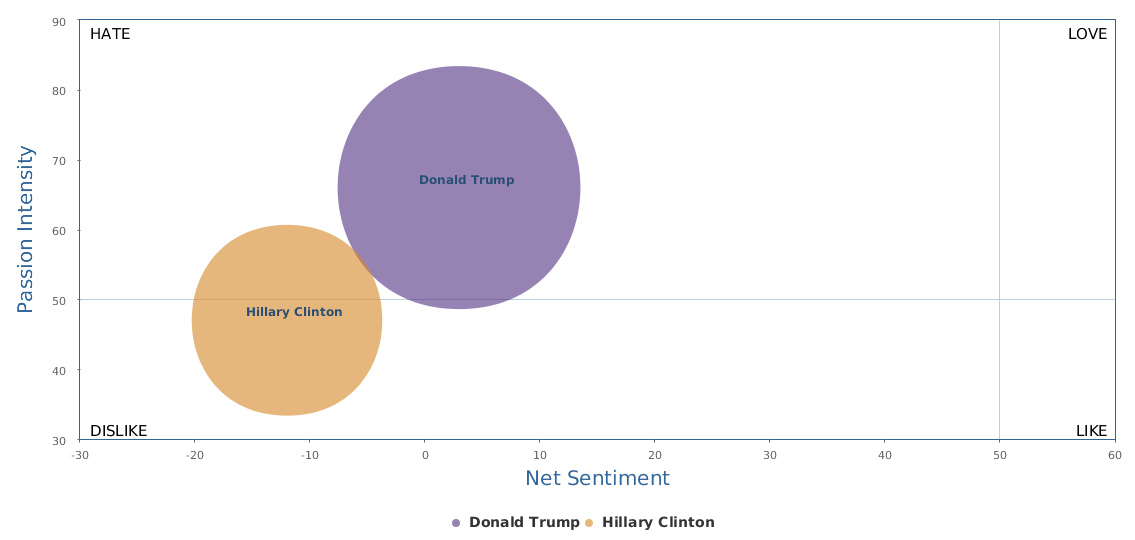
The above is a comparison of public opinion passion intensity: like/love or dislike/hate? The passion intensity for Trump is really high, showing that he has some crazy fans and/or deep haters in the people. Hillary Clinton has been controversial also and it is not rare that we come across people with very intensified sentiments towards her too. But still, Trump is sort of political anomaly, and he is more likely to cause fanaticism or controversy than his opponent Hillary.
In his recent Gettysburg speech, Trump highlighted the so-called danger of the election being manipulated. He clearly exaggerated the procedure risks, more than past candidates in history using the same election protocol and mechanism. By doing so, he paved the way for future non-recognition of the election results. He was even fooling the entire nation by saying publicly nonsense like he would totally accept the election results if he wins: this is not humor or sense of humor, it depicts a dangerous political figure with ambition unchecked. A very troubling sign and fairly dirty political tricks or fire he is playing with now, to my mind. Now the situation is, if Clinton has a substantial lead to beat him by a large margin, this old Uncle Trump would have no excuse or room for instigating incidents after the election. But if it is closer to see-saw, which is not unlikely given the trends analysis we have shown above, then our country might be in some trouble: Uncle Trump and his die-hard fans most certainly will make some trouble. Given the seriousness of this situation and pressing risks of political turmoil possibly to follow, we now see quite some people, including some conservative minds, begin to call for the election of Hillary for the sake of preventing Trump from possible trouble making. I am one with that mind-set too, given that I do not like Hillary either. If not for Trump, in ordinary elections like this when I do not like candidates of both major parties, I would most likely vote for a third party, or abstain from voting, but this election is different, it is too dangerous as it stands. It is like a time bomb hidden somewhere in the Trump's house, totally unpredictable. In order to prevent him from spilling, it is safer to vote for Clinton.
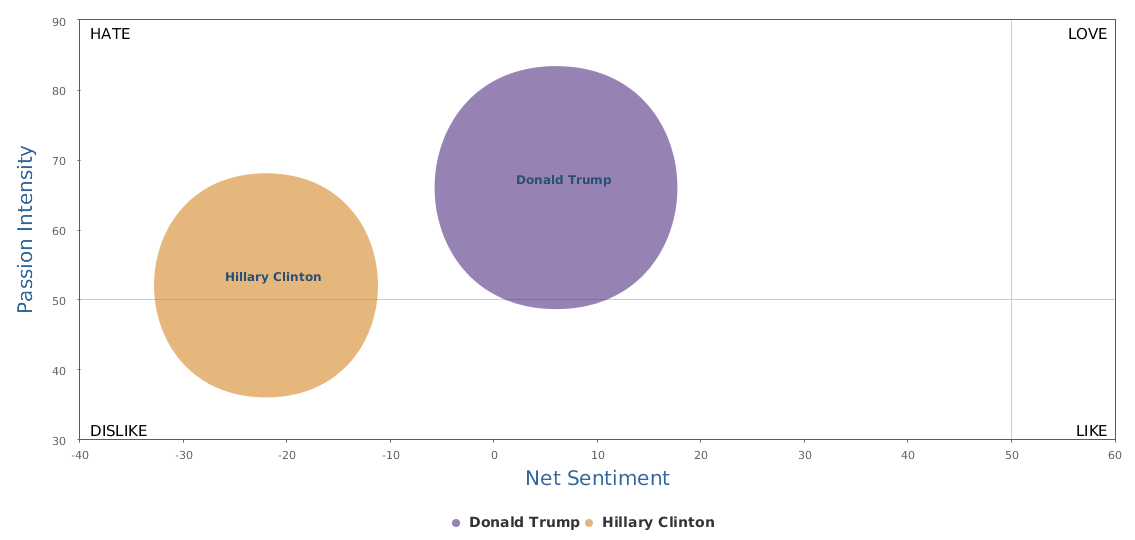
In comparison with my earlier automated sentiment analysis blogged about a week ago (Big data mining shows clear social rating decline of Trump last month),this updated, more recent BPI brand comparison chart seems to be more see-saw: Clinton's recent campaign seems to be stuck somewhere.
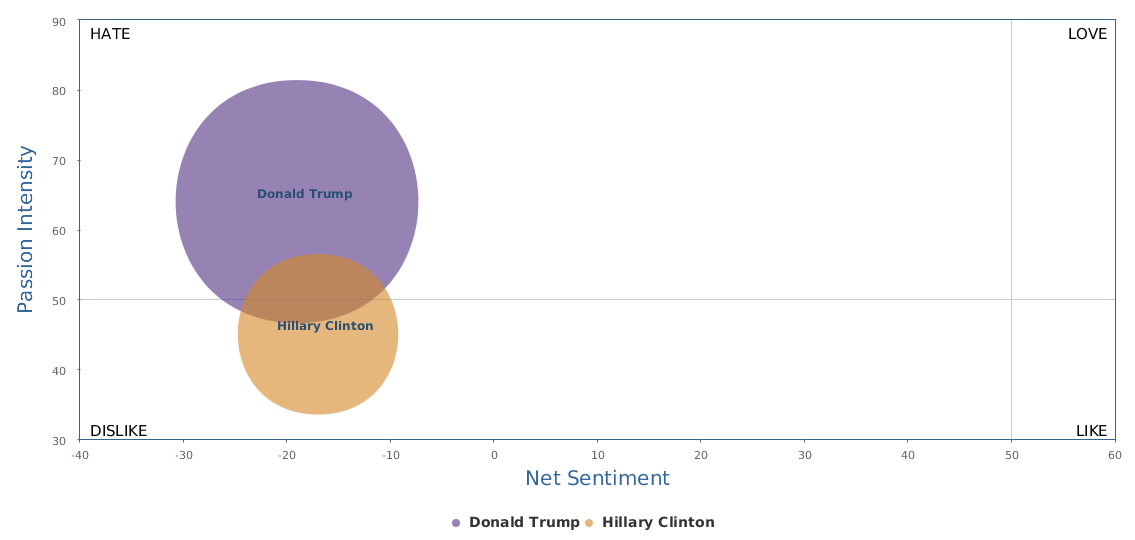
Over the last 30 days, Clinton's net sentiment rating is -17%, while Trump's is -19%. Clinton is only slightly ahead of Trump. Fortunately, Trump's speech did not really reverse the gap between the two, which is seen fairly clearly from the following historical trends represented by three different circles in brand comparison (the darker circle represents more recent data): the general trends of Clinton are still there: it started lagging behind and went better and now is a bit stuck, but still leading.
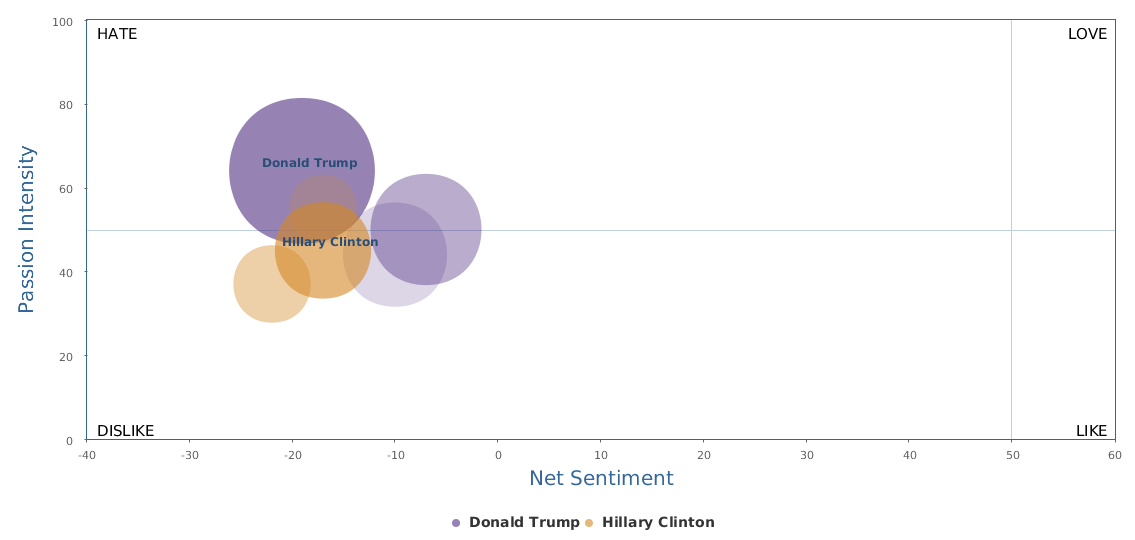
Yes, Clinton's most recent campaign activities are not making significant progress, despite more resources put to use as shown by bigger darker circle in the graph. Among the three circles of Clinton, we can see that the smallest and lightest circle stands for the first 10 days of data in the past 30 days, starting obviously behind Trump. The last two circles are data of the last 20 days, seemingly in situ, although the circle becomes larger, indicating more campaign input and more buzz generated. But the benefits are not so obvious. On the other side, Trump's trends show a zigzag, with the overall trends actual declining in the past 30 days. The middle ten days, there was a clear rise in his social rating, but the last ten days have been going down back. Look at Trump's 30-day social cloud of Word Cloud for pros and cons and Word Cloud for emotions:
Let us have a look at Trump's 30-day social media sentiment word clouds, the first is more about commenting on his pros and cons, and the second is more direct and emotional expressions on him: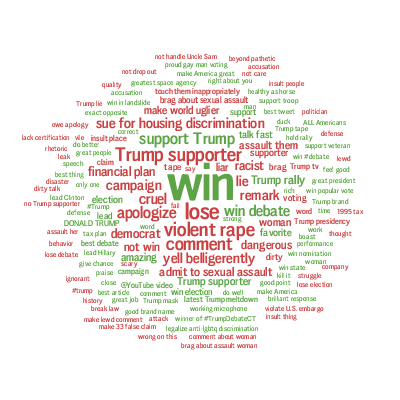
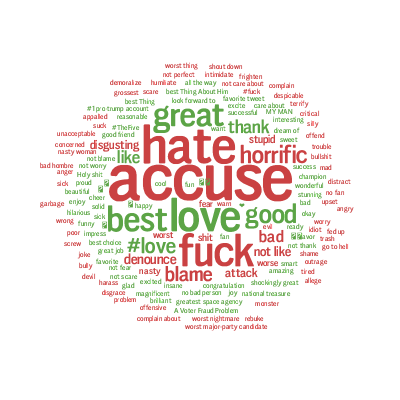
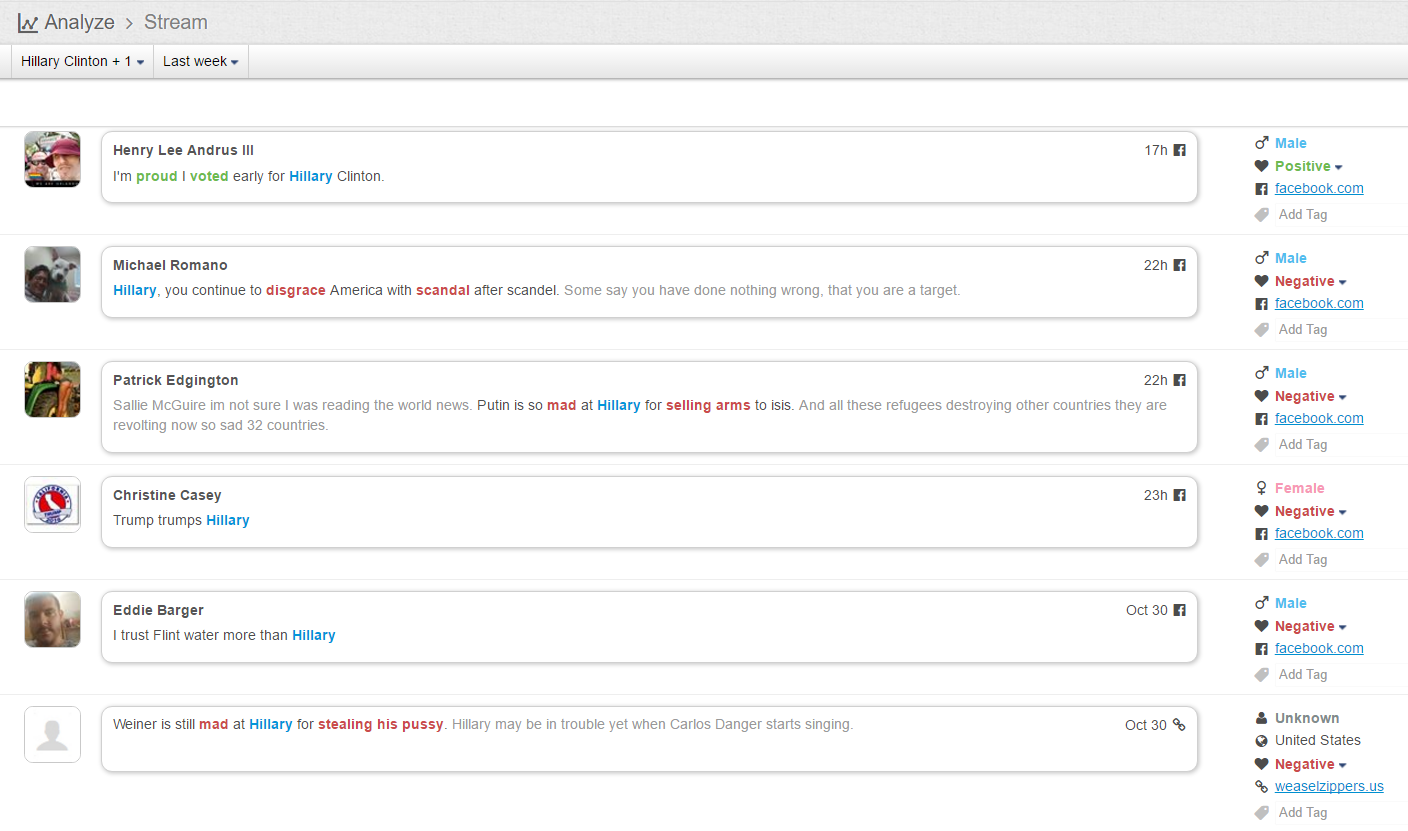
One friend took a glance at the red font expression "fuck", and asked: who are subjects and objects of "fuck" here? In fact, the subject generally does not appear in the social posts, by default it is the poster himself, reflecting part of the general public, the object of "fuck" is, of course, Trump, for otherwise our deep linguistics based system will not count it as a negative mention of trump reflected in the graph. Let us show some random samples side by side of the graph:
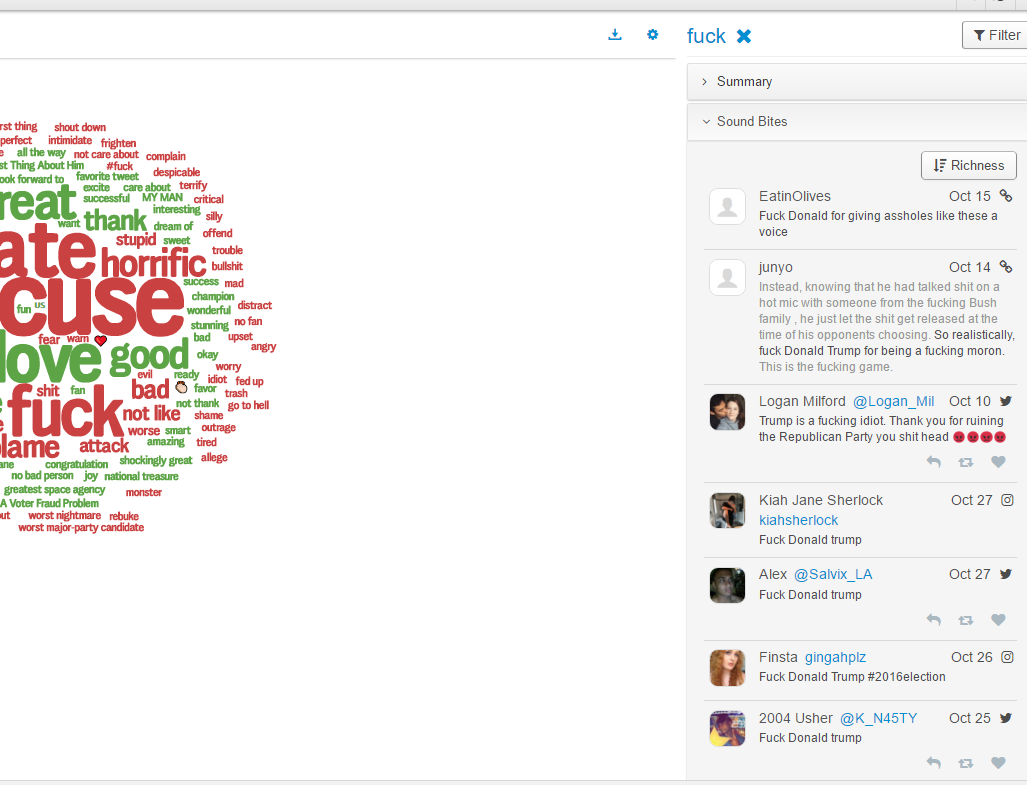
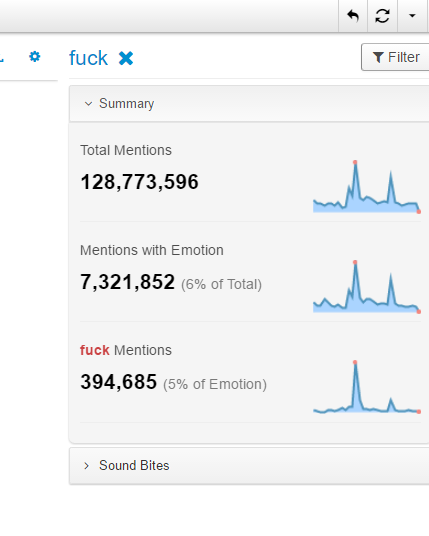
My goodness, the "fuck" mentions account for 5% of the emotional data, the poor old Uncle Trump is fucked 40 million times in social media within one-month duration, showing how this guy is hated by some of the people whom he is supposed to represent and govern if he takes office. See how they actually express their strong dislike of Trump:
fucking moron
fucking idiot
asshole
shithead
you name it, to the point even some Republicans also curse him like crazy:
Trump is a fucking idiot. Thank you for ruining the Republican Party you shithead.
Looking at the following figure of popular media, it seems that the most widely circulated political posts in social media involve quite some political video works:
The domains figure below shows that the Tumblr posts on politics contribute more than Facebook:

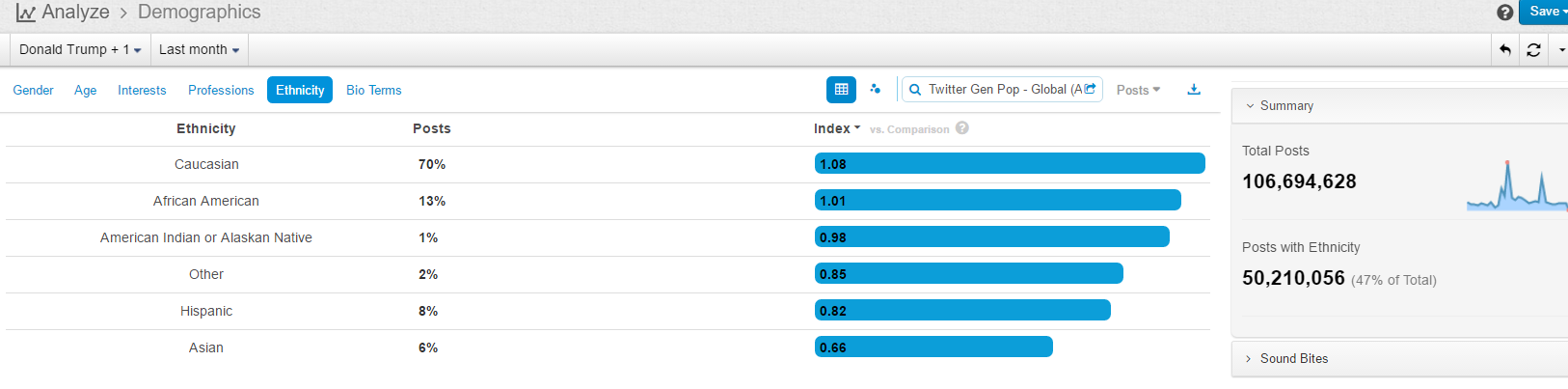
In terms of demographics background of social media posters, there is a fair balance between male and female: male 52% female 48% (in contrast to Chinese social media where only 25% females are posting political comments on US presidential campaign). The figure below shows the ethnic background of the posters, with 70% Caucasians, 13% African Americans, 8% Hispanic and 6% Asians. It looks like that the Hispanic Americans and Asian Americans are under-represented in the English social media in comparison with their due population ratios, as a result, this study may have missed some of their voice (but we have another similar study using Chinese social media, which shows a clear and big lead of Clinton over Trump; given time, we should do another automated survey using our multilingual engine for Spanish social media. Another suggestion from friends is to do a similar study on swing states because after all these are the key states that will decide the outcome of this election, we can filter the data by locations where posts are from to simulate that study). There might be a language or cultural reasons for this under-representation.
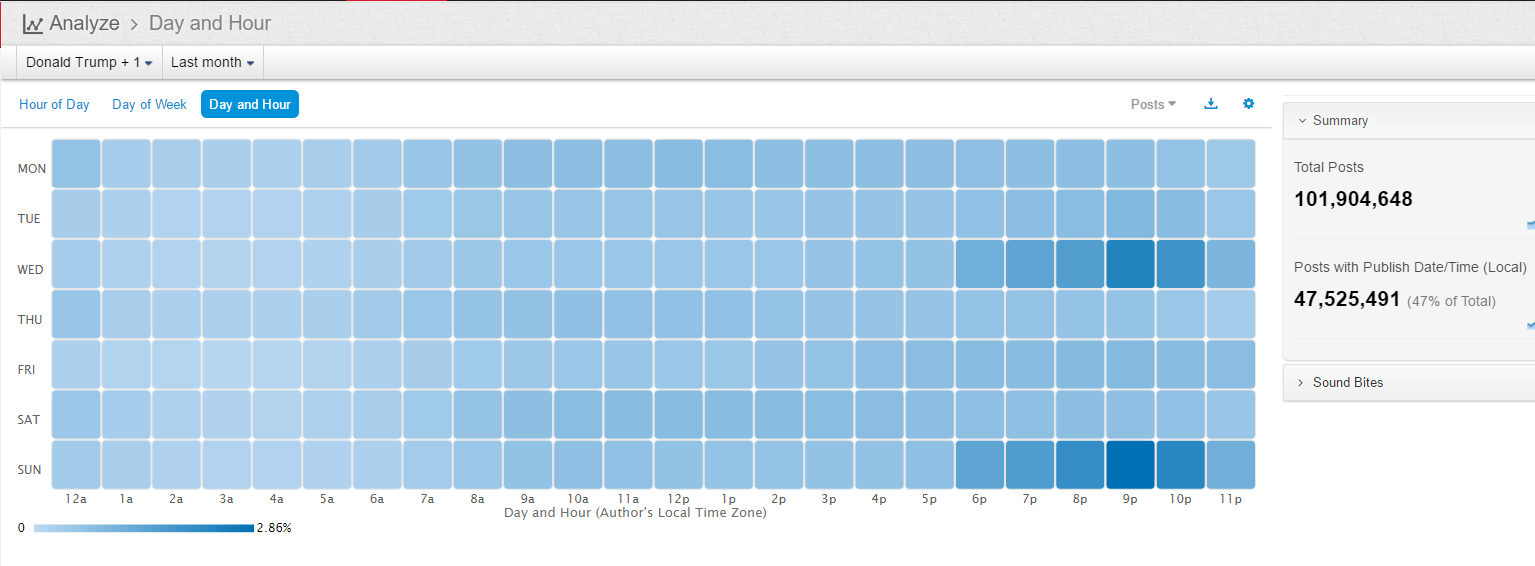
This last table involves a bit of fun facts of the investigation. In social media, people tend to talk most about the campaign, on the Wednesday and Sunday evenings, with 9 o'clock as the peak, for example, on the topic of Trump, nine o'clock on Sunday evening generated 1,357,766 messages within one hour. No wonder there is no shortage of big data from social media on politics. It is all about big data. In contrast, with the traditional manual poll, no matter how sampling is done, the limitation in the number of data points is so challenging:
with typically 500 to 1000 phone calls, how can we trust that the poll represents the public opinions of 200 million voters? They are laughably too sparse in data. Of course, in the pre-big-data age, there were simply no alternatives to collect public opinion in a timely manner with limited budgets. This is the beauty of Automatic Survey, which is bound to outperform the manual survey and become the mainstream of polls.
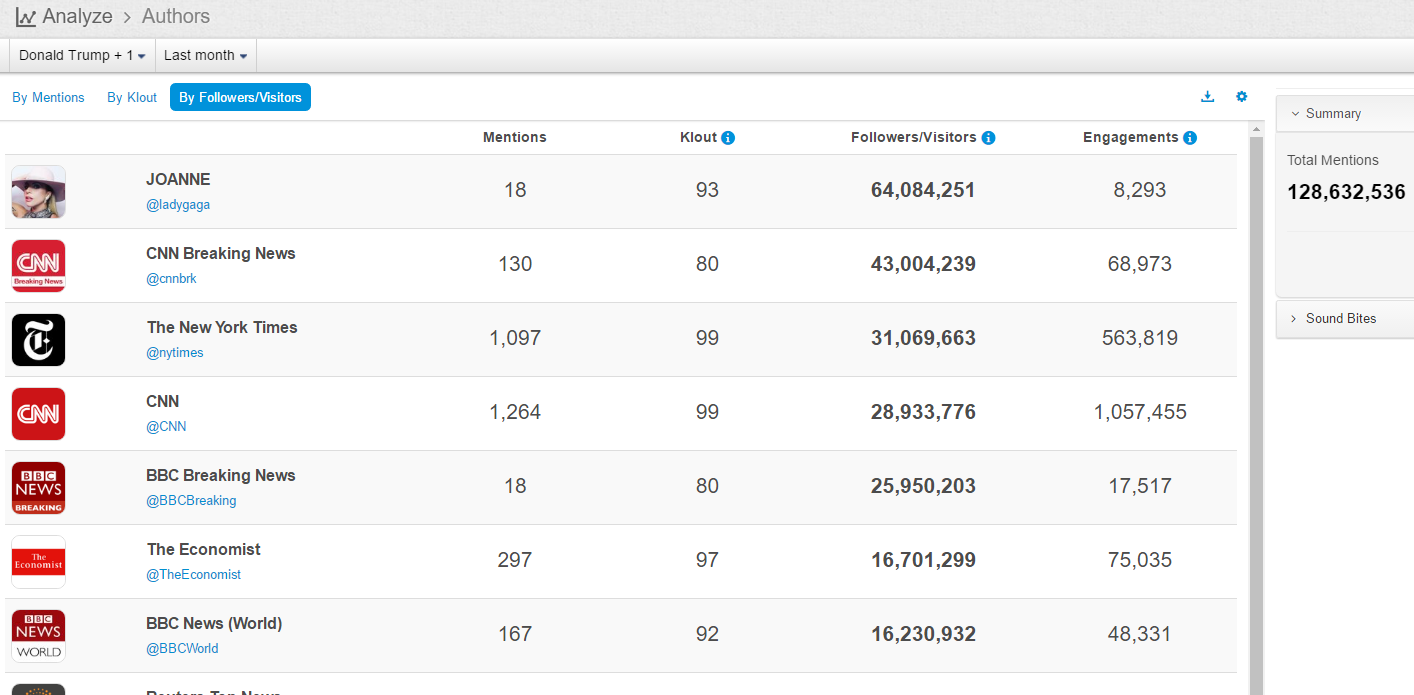
Authors with most followers are:
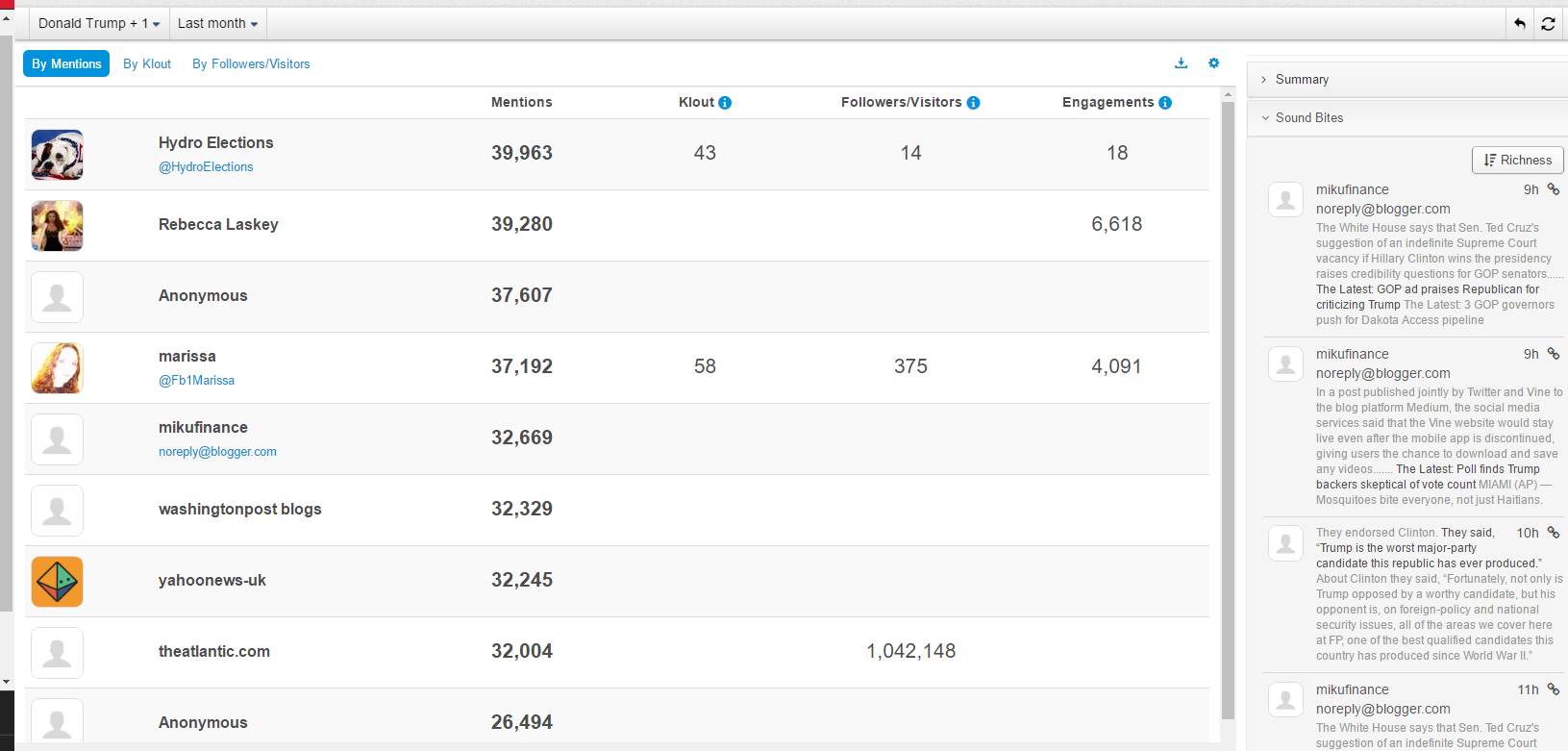
Most mentioned authors are listed below:
Tell me when in history did we ever have this much data and info, with this powerful data mining capabilities of fully sutomated mining of public opinions and sentiments at scale?
[Related]
Big data mining shows clear social rating decline of Trump last month
Clinton, 5 years ago. How time flies …
Automated Suevey
Dr Li’s NLP Blog in English