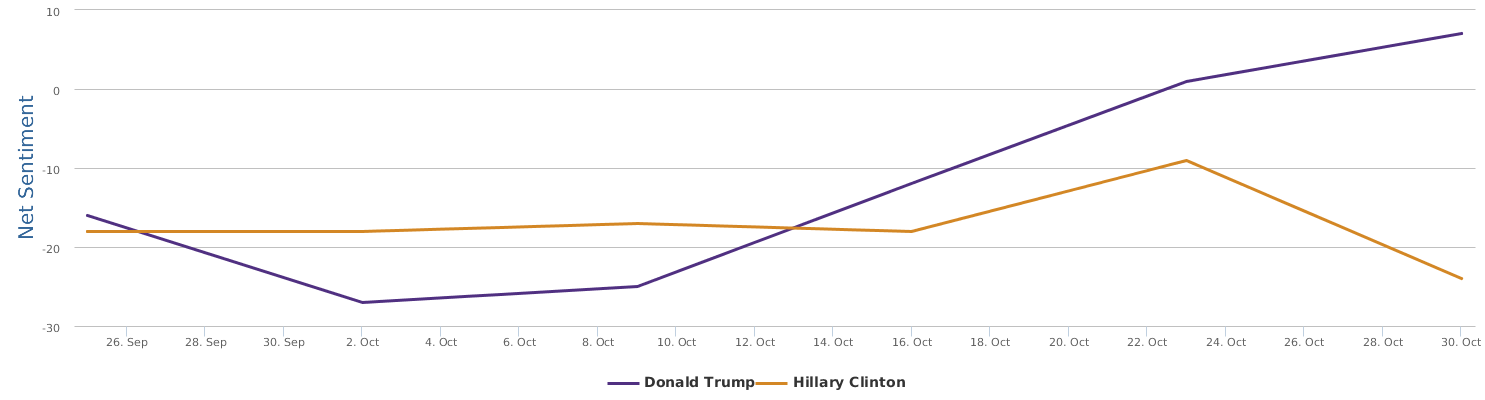
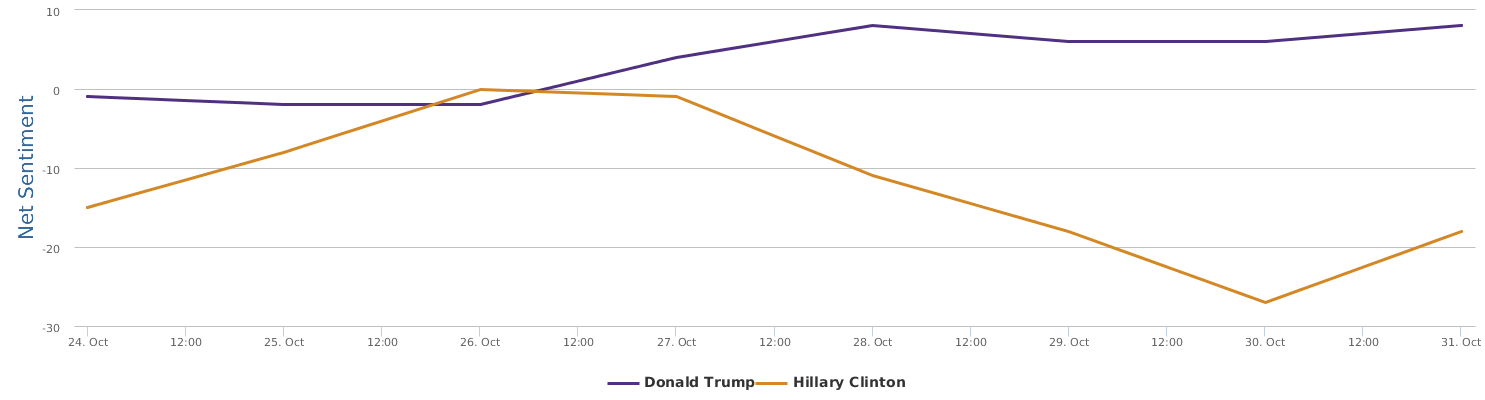
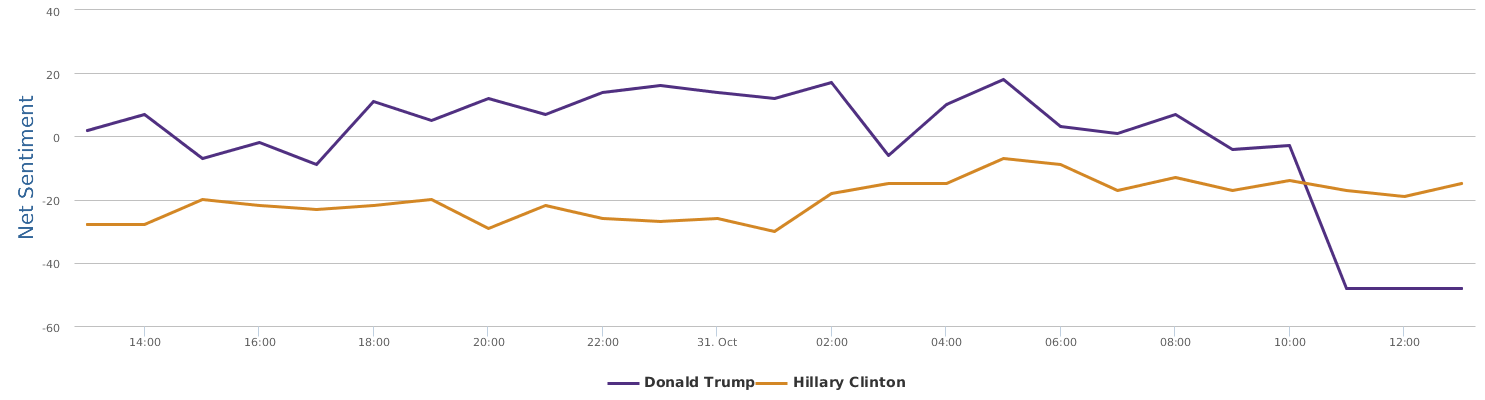
电邮门是摧毁性的。FBI 选在大选前一周重启,这个简直是不可思议。比川普的录音曝光的时间点厉害。那家印度所谓AI公司押宝可能押对了,虽然对于数据的分析能力和角度,远不如我们的平台的丰富灵活。他们基本只有一个 engagement 的度量,连最起码的 sentiment classification 都没有,更不用说 social media deep sentiments 了。无论怎么说,希拉里最近选情告急是显然的。至于这种告急多大程度上影响真正的选票,还需要研究。
现在的纠结是,【大数据告诉我们,希拉里选情告急】,到底发还是不发?为了党派利益和反川立场,不能发。长老川志气,灭吾党威风。为了 data scientist 的职业精神,应该发。一切从数据和事实出发,是信息时代之基。中和的办法是,先发一篇批驳那篇流传甚广的所谓印度AI公司预测川普要赢,因为那一篇的调查区间与我此前做的调查区间基本相同,那是希拉里选情最好的一个月,他们居然根据 engagement alone 大嘴巴预测川普的胜选,根本就没有深度数据的精神,就是赌一把而已。也许等批完了伪AI,宣扬了真NLU,然后再发这篇 【大数据告诉我们,希拉里选情告急】。
FBI director 说这次重启调查,需要很长时间才能厘清。现在只是有了新线索需要重启,不能说明希拉里有罪无罪。没有结论前,先弄得满城风雨,客观上就是给选情带来变数。虽然在 prove 有罪前,都应该假定无罪,但是只要有风声,人就不可能不受影响。所以说这个时间点是最关键的。如果这次重启调查另有黑箱,就更惊心动魄了。如果不是有背后的黑箱和势力,这个时间点的电邮门爆炸纯属与新线索的发现巧合,那就是希拉里的运气不佳,命无天子之福。一辈子强性格,卧薪尝胆,忍辱负重,功亏一篑,无功而返,保不准还有牢狱之灾。可以预测,大选失败就是她急剧衰老的开始。
As promised, let us get down to the business of big data mining of public opinions and sentiments from Spanish social media on the US election campaign.
We know that in the automated mining of public opinions and sentiments for Trump and Clinton we did before, Spanish-Americans are severely under-represented, with only 8% Hispanic posters in comparison with their 16% in population according to 2010 census (widely believed to be more than 16% today), perhaps because of language and/or cultural barriers. So we decide to use our multilingual mining tools to do a similar automated survey from Spanish Social Media to complement our earlier studies.
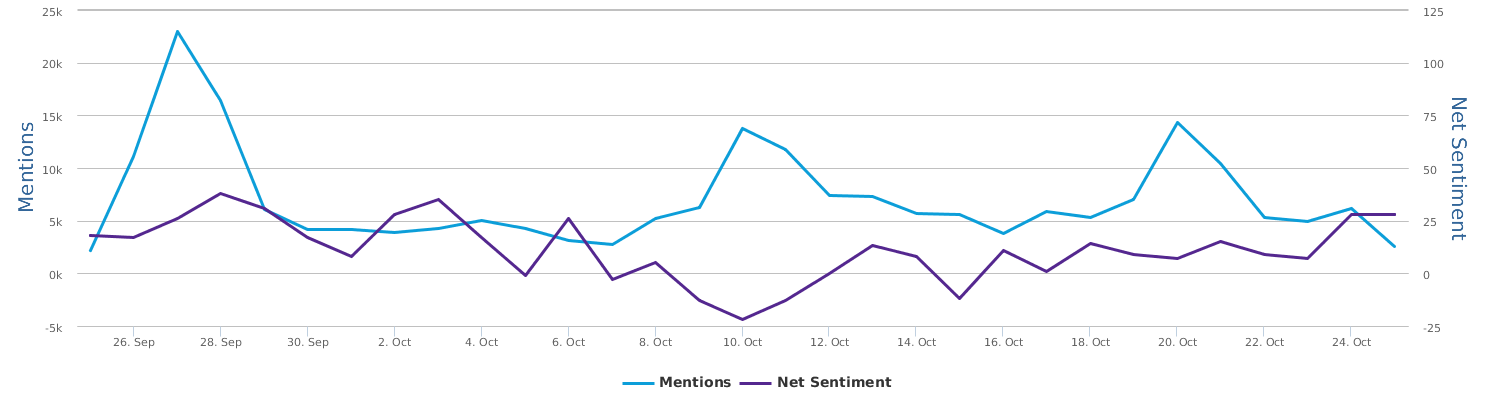
This is Trump as represented in Spanish social media for the last 30 days (09/29-10/29), the key is his social rating as reflected by his net sentiment -33% (in comparison with his rating of -9% in English social media for the same period): way below the freezing point, it really sucks, as also illustrated by the concentration of negative Spanish expressions (red-font) in his word cloud visualization.
By the net sentiment -33%, it corresponds to 242,672 negative mentions vs. 121,584 positive mentions, as shown below. In other words, negative comments are about twice as much as positive comments on Trump in Spanish social media in the last 30 days.
This is the buzz in the last 30 days for Trump: mentions and potential impressions (eye balls): millions of data points and indeed a very hot topic in the social media.
This is the BPI (Brand Passion Index) graph for directly comparing Trump and Clinton for their social ratings in the Spanish social media in the last 30 days:
As seen, there is simply no comparison: to refresh our memory, let us contrast it with the BPI comparison in the English social media:
This is even more true based on social media big data from Spanish.
This is the comparison trends of passion intensity between Trump and Clinton:
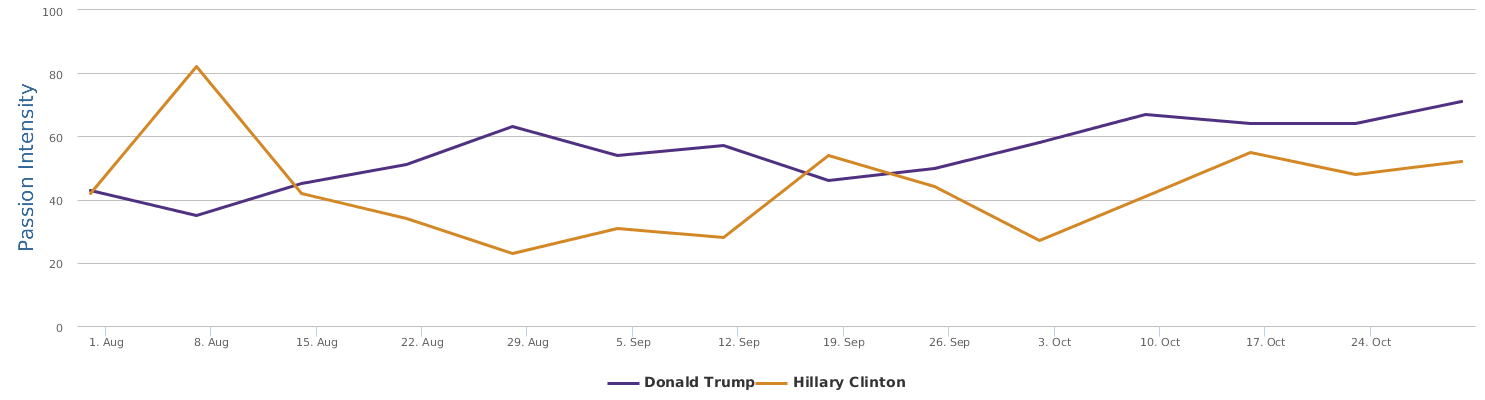
The visualization by weeks of the same passion intensity data, instead of by days, show even more clearly that people are very passionate about both candidates in the Spanish social media discussions, the intensity of sentiment expressed for Clinton are slightly higher than for Trump:
This is the trends graph for their respective net sentiment, showing their social images in Spanish-speaking communities:
We already know that there is simply no comparison: in this 30-day duration, even when Clinton dropped to its lowest point (close to zero) on Oct 9th, she was still way ahead of Trump whose net sentiment at the time was -40%. In any other time segments, we see an even bigger margin (as big as 40 to 80 points in gap) between the two. Clinton has consistently been leading.
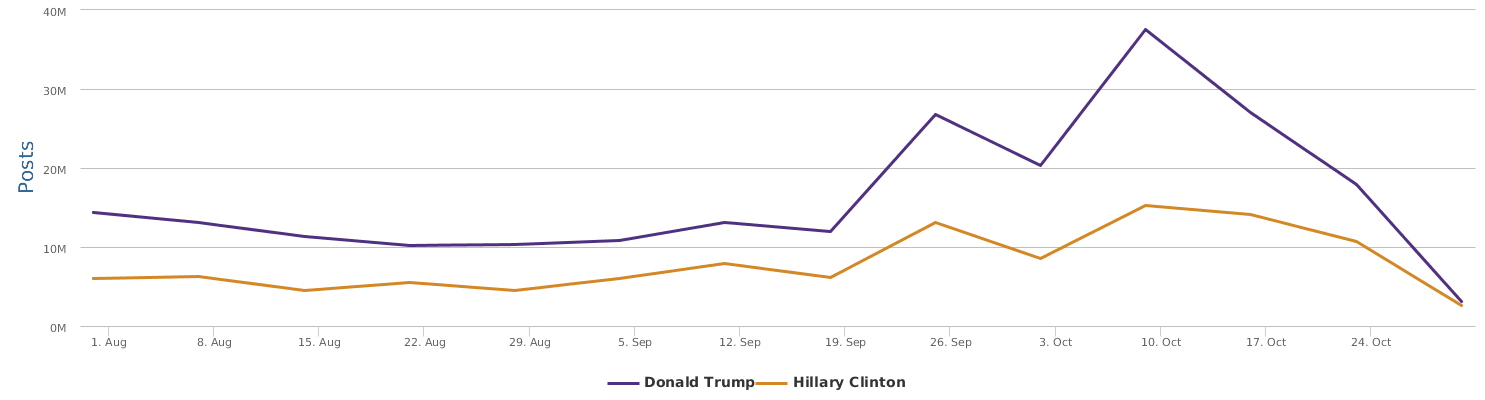
In terms of buzz, Trump generates more noise (mentions) than Clinton consistently, although the gap is not as large as that in English social media:
This is the geo graph, so the social data come from mostly the US and Mexico, some from other Latin America countries and Spain:
Since only the Mexicans in the US may have the voting power, we should exclude media from outside the US to have a clearer picture of how the Spanish-speaking voters may have an impact on this election. Before we do that filtering, we note the fact that Trump sucks in the minds of Mexican people, which is no surprise at all given his irresponsible comments about the Mexican people.
Our social media tool is equipped with geo-filtering capabilities: you can add a geo-fence to a topic to retrieve all social media posts authored from within a fenced location. This allows you to analyze location-based content irrespective of post text. That is exactly what we need in order to do a study for Spanish-speaking communities in the US who are likely to be voters, excluding those media from Mexico or other Spanish-speaking countries. communities in the US who are likely to be voters, excluding those media from Mexico or other countries. This is also needed when we need to do study for those critical swing states to see the true pictures of the likelihood of the public sentiments and opinions in those states that will decide the destiny of the candidates and the future of the US (stay tuned, swing states social media mining will come shortly thanks to our fully automated mining system based on natural language deep parsing).
Now I have excluded Spanish data from outside America, it turned out that the social ratings are roughly the same as before: the reduction of the data does not change the general public opinions from Spanish communities, US or beyond US., US or beyond US. This is US only Spanish social media:
This is summary of Trump for Spanish data within US:
It is clear that Trump's image truly sucks in the Spanish-speaking communities in the US, communities in the US, which is no surprise and so natural and evident that we simply just confirm and verify that with big data and high-tech now.
These are sentiment drivers (i.e. pros and cons as well as emotion expressions) of Trump :
We might need Google Translate to interpret them but the color coding remains universal: red is for negative comments and green is positive. More red than green means a poor image or social rating.
In contrast, the Clinton's word clouds involve way more green than red: showing her support rate remains high in the Spanish-speaking communities of the US.
It looks like that the emotional sentiments for Clinton are not as good as Clinton's sentiment drivers for her pros and cons.
Last few days have seen tons of reports on Trump's Gettysburg speech and its impact on his support rate, which is claimed by some of his campaign media to soar due to this powerful speech. We would love to verify this and uncover the true picture based on big data mining from the social media.
Believed to be a historical speech in his last dash in the campaign, Trump basically said: I am willing to have a contract with the American people on reforming the politics and making America great again, with this plan outline of my administration in the time frame I promised when I am in office, I will make things happen, believe me.
Trump made the speech on the 22nd this month, in order to mine true public opinions of the speech impact, we can investigate the data around 22nd for the social media automated data analysis. We believe that automated polling based on big data and language understanding technology is much more revealing and dependable than the traditional manual polls, with phone calls to something like 500 to 1,000 people. The latter is laughably lacking sufficient data to be trustworthy.
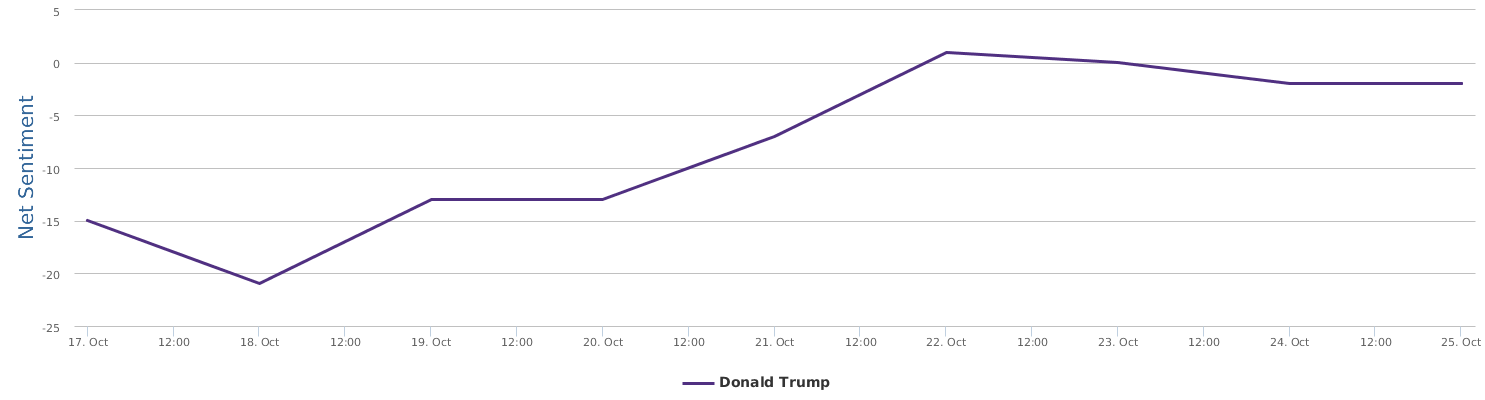
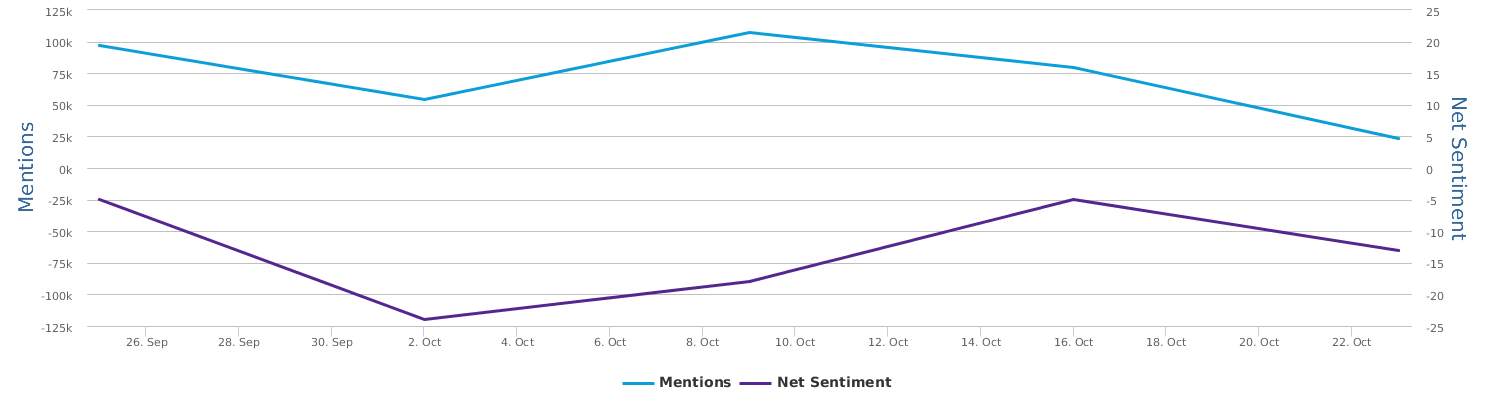
What does the above trend graph tell us?
1 Trump in this time interval was indeed on the rise. The "soaring" claim this time does not entirely come out of nowhere, but, there is a big BUT.
2. BUT, a careful look at the public opinions represented by net sentiment (a measure reflecting the ratio of positive mentions over negative mentions in social media) shows that Trump has basically stayed below the freezing point (i.e. more negative than positive) in this time interval, with only a brief rise above the zero point near the 22nd speech, and soon went down underwater again.
3. The soaring claim cannot withstand scrutiny at all as soaring implies a sharp rise of support after the speech event in comparison with before, which is not the case.
4. The fact is, Uncle Trump's social media image dropped to the bottom on the 18th (with net sentiment of -20%) of this month. From 18th to 22nd when he delivered the speech, his net sentiment was steadily on rise from -20% to 0), but from 22nd to 25th, it no longer went up, but fell back down, so there is no ground for the claim of support soaring as an effect of his speech, not at all.
5. Although not soaring, Uncle Trump's speech did not lead to sharp drop either, in terms of the buzz generated, this speech can be said to be fairly well delivered in his performance. After the speech, the net sentiment of public opinions slightly dropped, basically maintaining the fundamentals close to zero.
6. The above big data investigation shows that the media campaign can be very misleading against the objective evidence and real life data. This is all propaganda, which cannot be trusted at its face value: from so-called "support rate soared" to "possible stock market crash". Basically nonsense or noise of campaign, and it cannot be taken seriously.
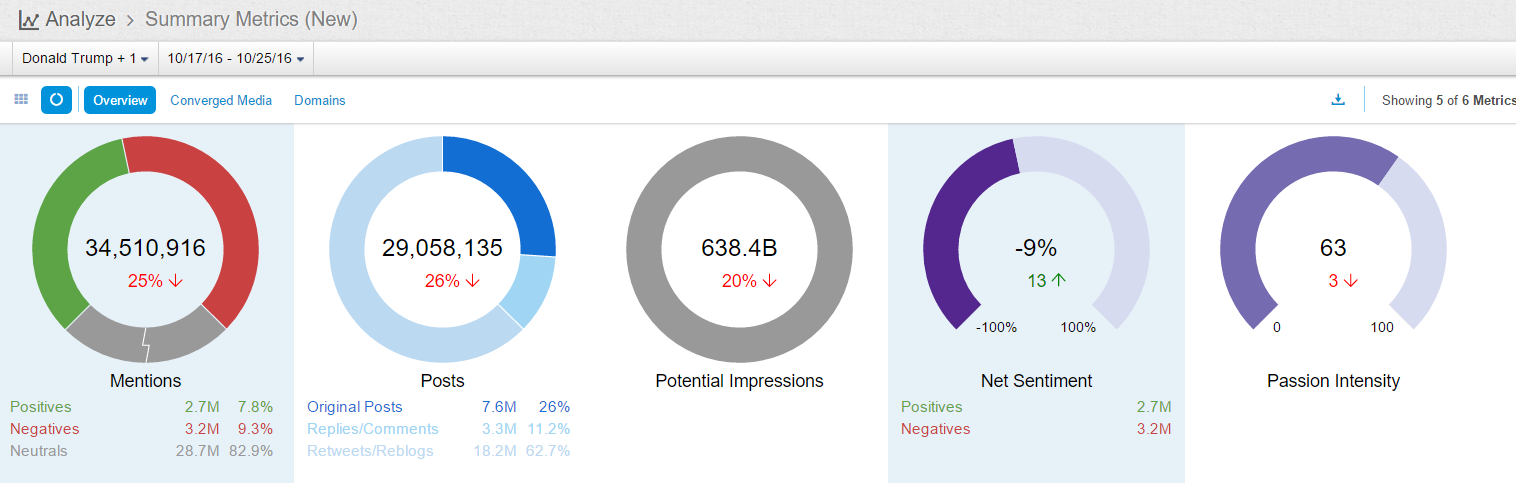
The following figure is a summary of the surveyed interval:
As seen, the average public opinion net-sentiment for this interval is -9%, with positive rating consisting of 2.7 million mentions, and negative rating of 3.2 million mentions.
How do we interpret -9% as an indicator of public opinions and sentiments? According to our previous numerous automated surveys of political figures, this is certainly not a good public opinion rating, but not particularly bad either as we have seen worse. Basically, -9% is under the average line among politicians reflecting the public image in people's minds in the social media. Nevertheless, compared with Trump's own public ratings before, there is a recorded 13 points jump in this interval, which is pretty good for him and his campaign. But the progress is clearly not the effect of his speech.
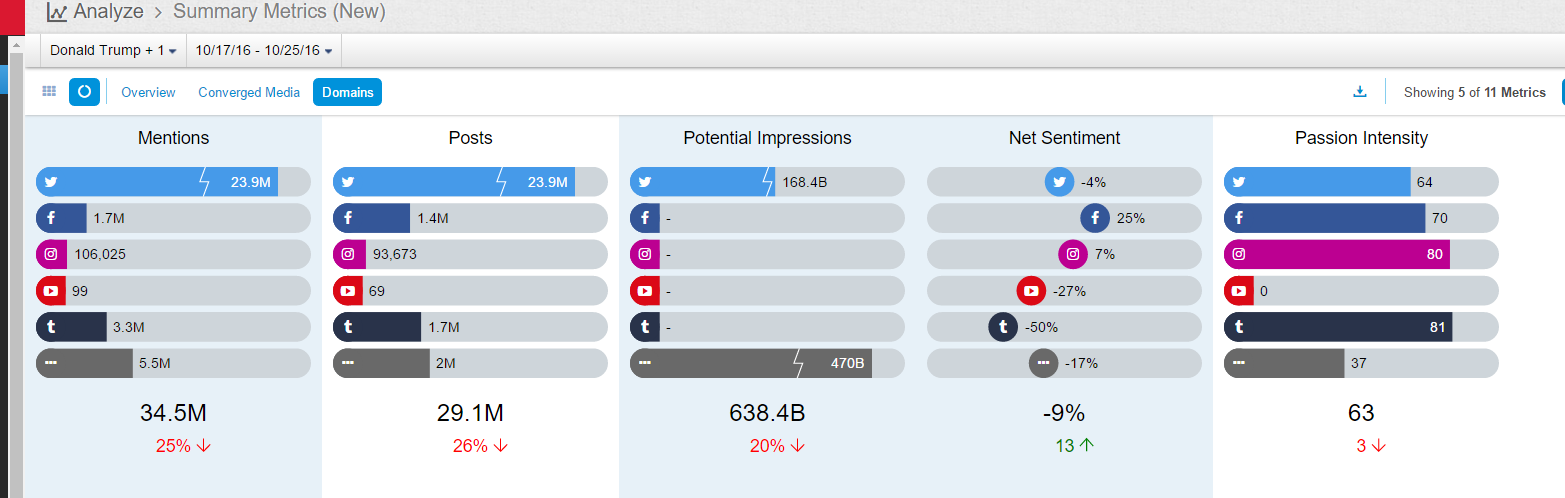
This is the social media statistics on the data sources of this investigation:
In terms of the ratio, Twitter ranks no 1, it is the most dynamic social media on politics for sure, with the largest amount of tweets generated every minute. Among a total of 34.5 million mentions on Trump, Twitter accounted for 23.9 million. In comparison, Facebook has 1.7 million mentions.
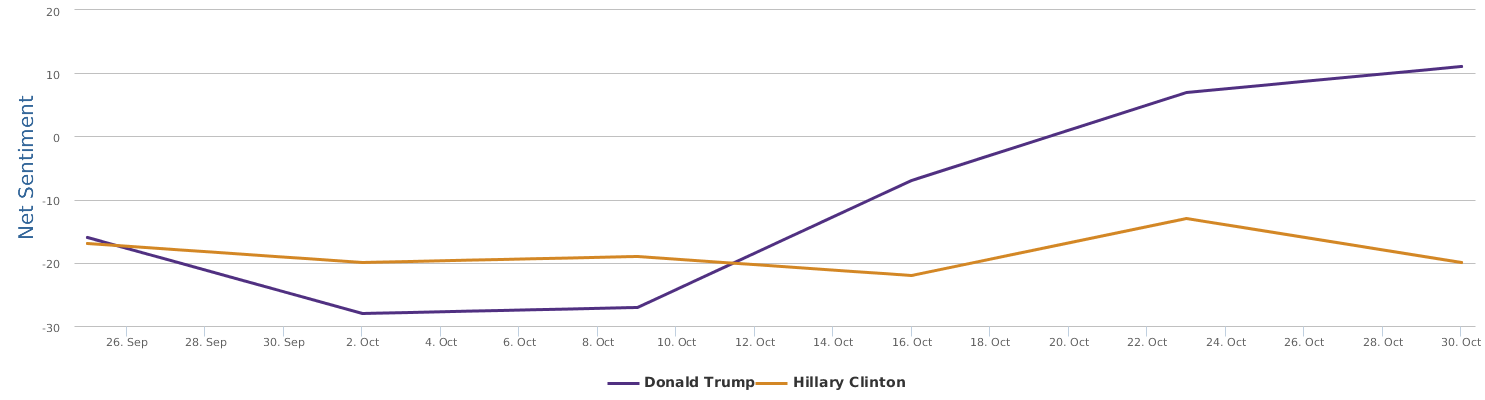
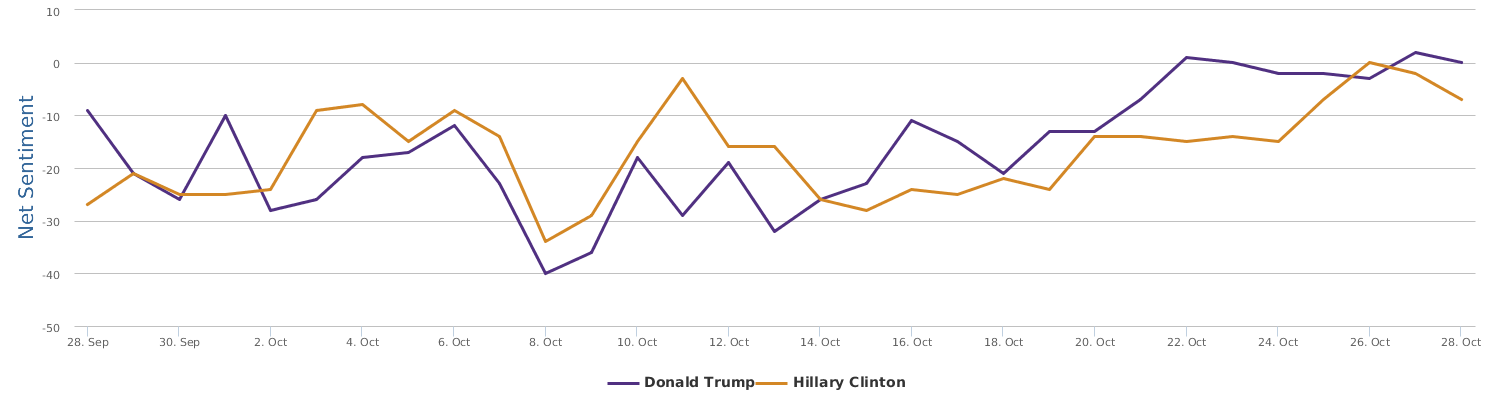
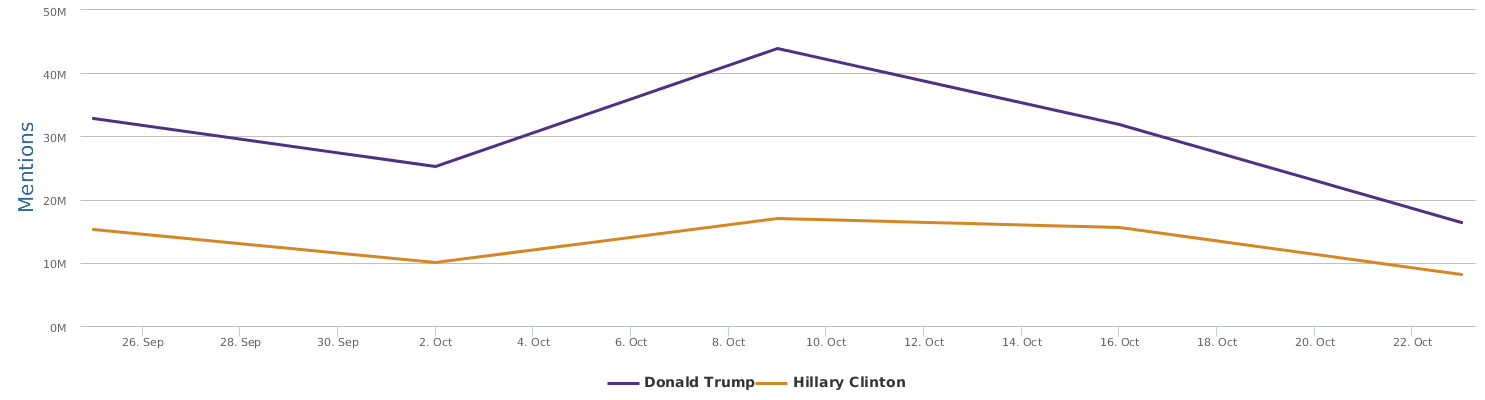
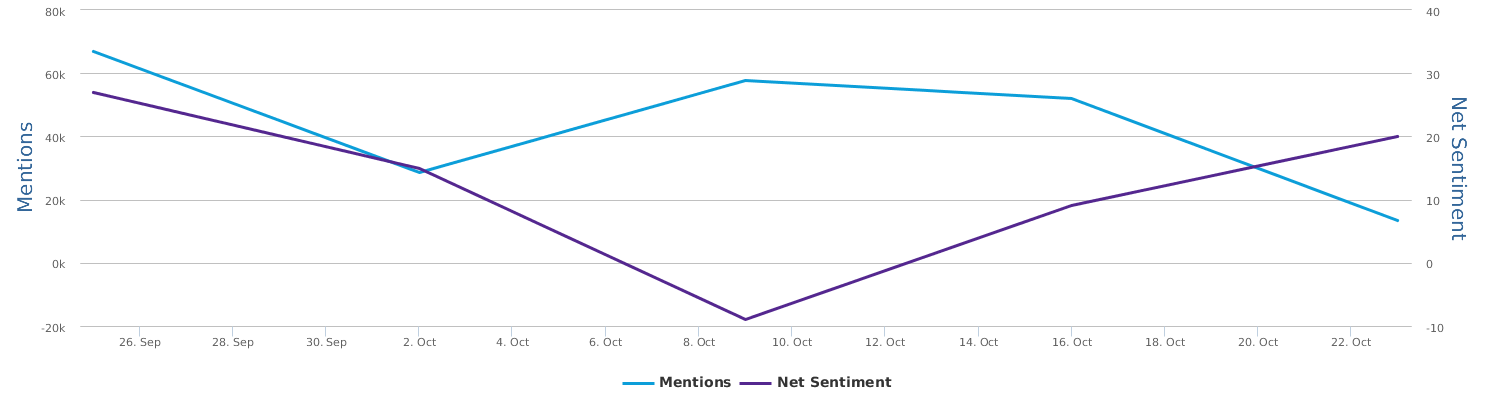
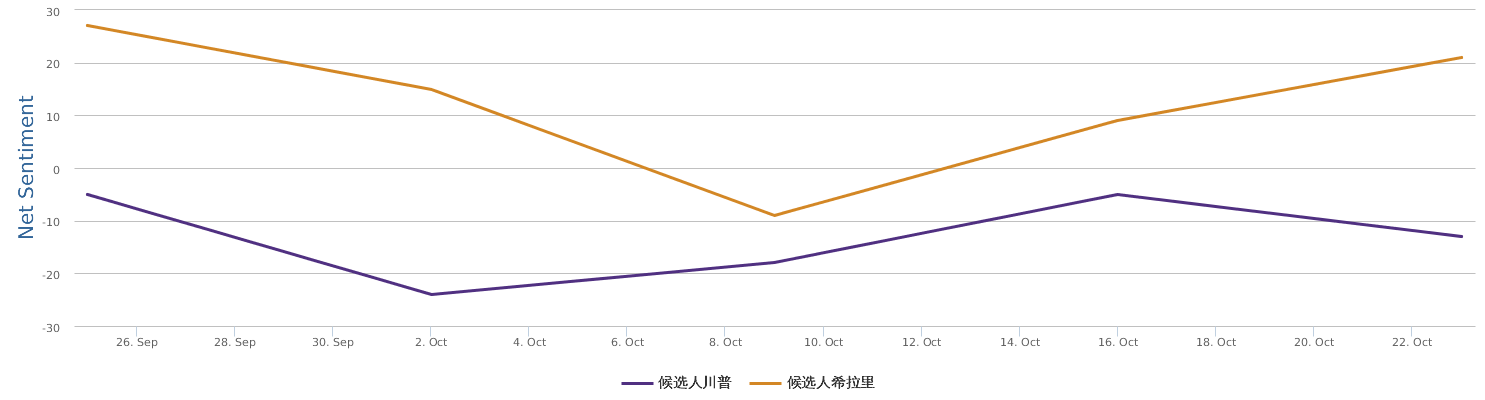
Well, let's zoom in on the last 30 days instead of only the days around the speech, to provide a bigger background for uncovering the overall trends of this political fight in the 2016 US presidential campaign between Trump and Clinton.
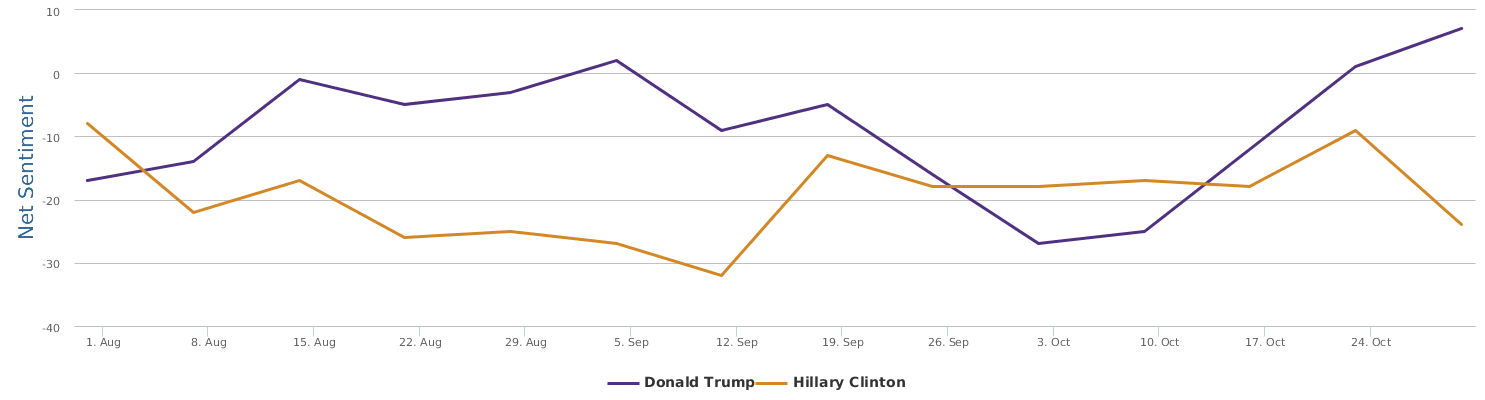
The 30 days range from 9/28-10/28, during which the two lines in the comparison trends chart show the contrast of Trump and Clinton in their respective daily ups and downs of net sentiment (reflecting their social rating trends). The general impression is that the fight seems to be fairly tight. Both are so scandal-ridden, both are tough and belligerent. And both are fairly poor in social ratings. The trends might look a bit clearer if we visualize the trends data by weeks instead of by day:
No matter how much I dislike Trump, and regardless of my dislike of Clinton whom I have decided to vote anyway in order to make sure the annoying Trump is out of the race, as a data scientist, I have to rely on data which says that Hillary's recent situation is not too optimistic: Trump actually at times went a little ahead of Clinton (a troubling fact to recognize and see).
The graph above shows a comparison of the mentions (buzz, so to speak). In terms of buzz, Trump is a natural topic-king, having generated most noise and comments, good or bad. Clinton is no comparison in this regard.
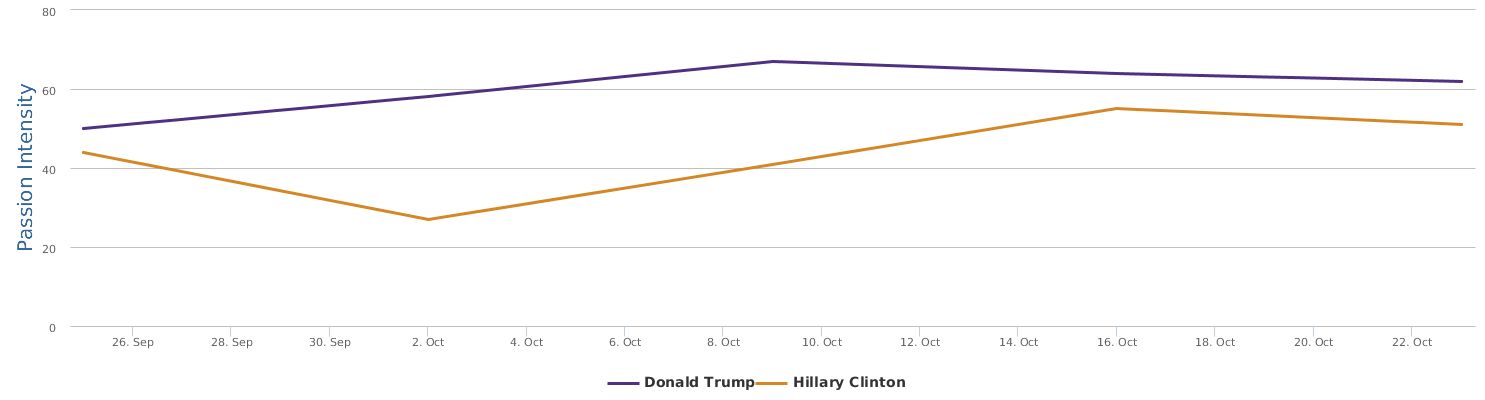
The above is a comparison of public opinion passion intensity: like/love or dislike/hate? The passion intensity for Trump is really high, showing that he has some crazy fans and/or deep haters in the people. Hillary Clinton has been controversial also and it is not rare that we come across people with very intensified sentiments towards her too. But still, Trump is sort of political anomaly, and he is more likely to cause fanaticism or controversy than his opponent Hillary.
In his recent Gettysburg speech, Trump highlighted the so-called danger of the election being manipulated. He clearly exaggerated the procedure risks, more than past candidates in history using the same election protocol and mechanism. By doing so, he paved the way for future non-recognition of the election results. He was even fooling the entire nation by saying publicly nonsense like he would totally accept the election results if he wins: this is not humor or sense of humor, it depicts a dangerous political figure with ambition unchecked. A very troubling sign and fairly dirty political tricks or fire he is playing with now, to my mind. Now the situation is, if Clinton has a substantial lead to beat him by a large margin, this old Uncle Trump would have no excuse or room for instigating incidents after the election. But if it is closer to see-saw, which is not unlikely given the trends analysis we have shown above, then our country might be in some trouble: Uncle Trump and his die-hard fans most certainly will make some trouble. Given the seriousness of this situation and pressing risks of political turmoil possibly to follow, we now see quite some people, including some conservative minds, begin to call for the election of Hillary for the sake of preventing Trump from possible trouble making. I am one with that mind-set too, given that I do not like Hillary either. If not for Trump, in ordinary elections like this when I do not like candidates of both major parties, I would most likely vote for a third party, or abstain from voting, but this election is different, it is too dangerous as it stands. It is like a time bomb hidden somewhere in the Trump's house, totally unpredictable. In order to prevent him from spilling, it is safer to vote for Clinton.
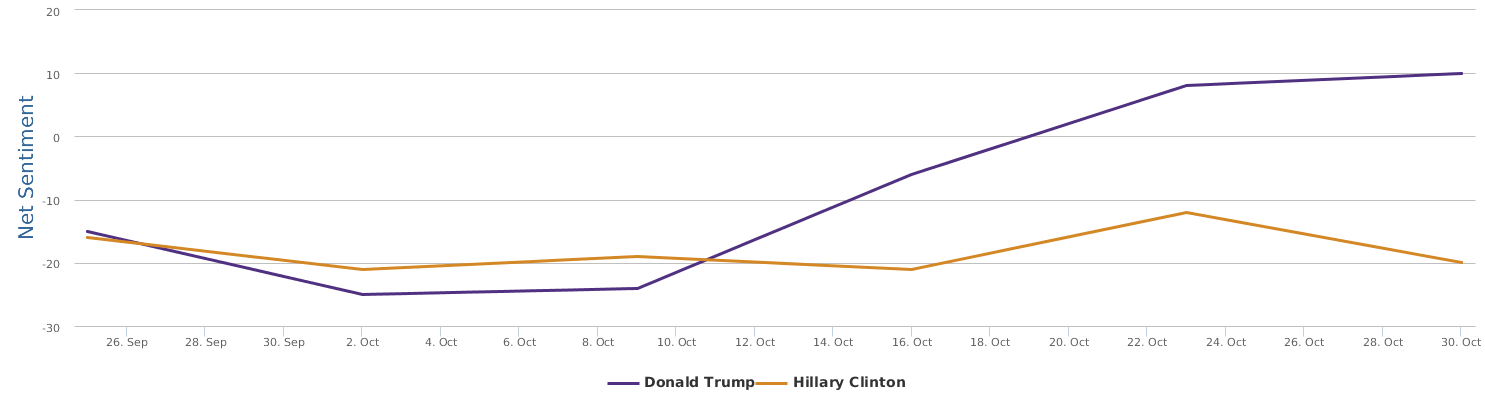
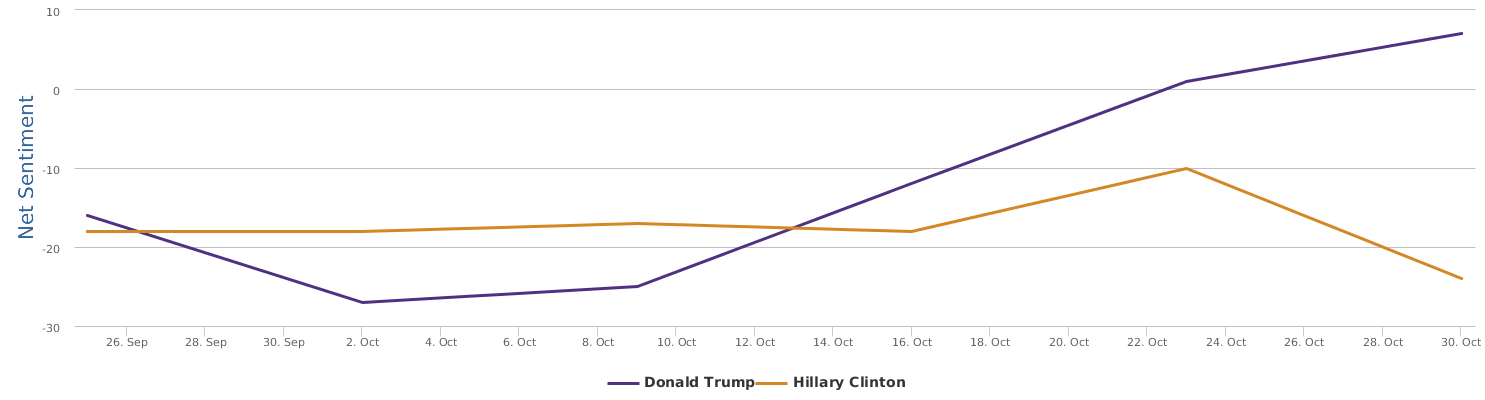
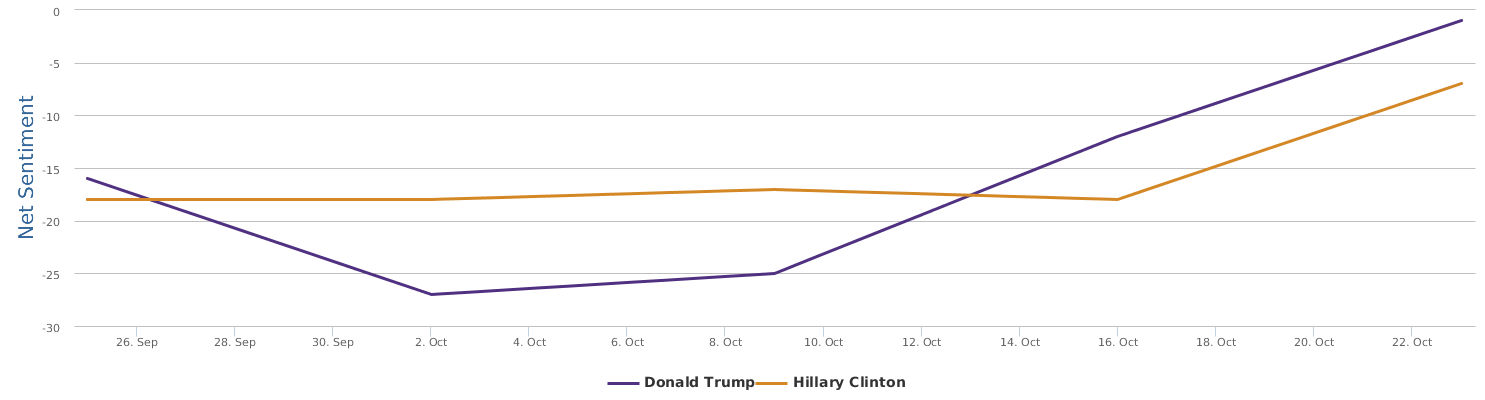
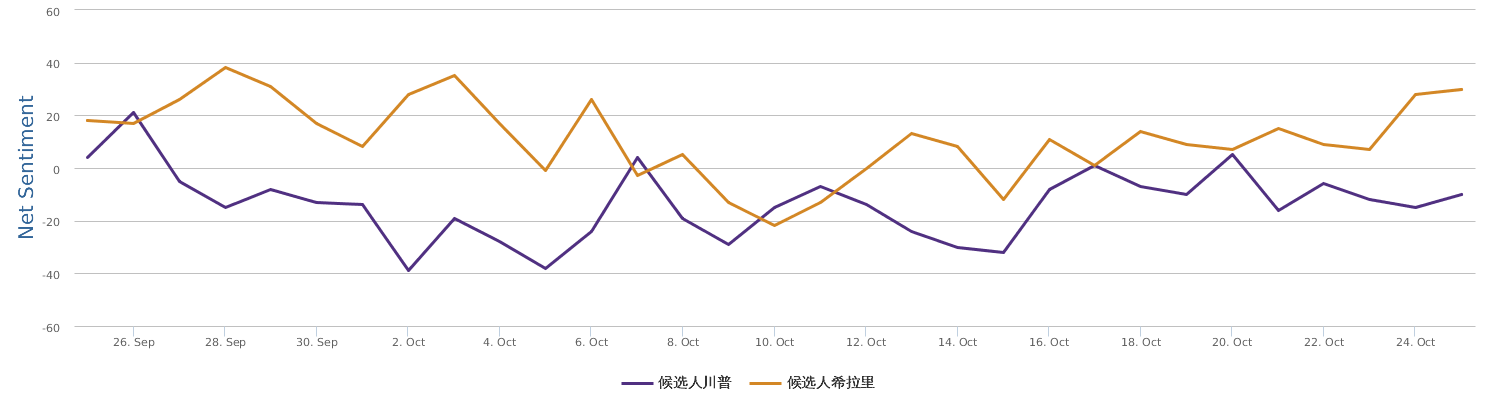
In comparison with my earlier automated sentiment analysis blogged about a week ago (Big data mining shows clear social rating decline of Trump last month),this updated, more recent BPI brand comparison chart seems to be more see-saw: Clinton's recent campaign seems to be stuck somewhere.
Over the last 30 days, Clinton's net sentiment rating is -17%, while Trump's is -19%. Clinton is only slightly ahead of Trump. Fortunately, Trump's speech did not really reverse the gap between the two, which is seen fairly clearly from the following historical trends represented by three different circles in brand comparison (the darker circle represents more recent data): the general trends of Clinton are still there: it started lagging behind and went better and now is a bit stuck, but still leading.
Yes, Clinton's most recent campaign activities are not making significant progress, despite more resources put to use as shown by bigger darker circle in the graph. Among the three circles of Clinton, we can see that the smallest and lightest circle stands for the first 10 days of data in the past 30 days, starting obviously behind Trump. The last two circles are data of the last 20 days, seemingly in situ, although the circle becomes larger, indicating more campaign input and more buzz generated. But the benefits are not so obvious. On the other side, Trump's trends show a zigzag, with the overall trends actual declining in the past 30 days. The middle ten days, there was a clear rise in his social rating, but the last ten days have been going down back. Look at Trump's 30-day social cloud of Word Cloud for pros and cons and Word Cloud for emotions:
Let us have a look at Trump's 30-day social media sentiment word clouds, the first is more about commenting on his pros and cons, and the second is more direct and emotional expressions on him:
One friend took a glance at the red font expression "fuck", and asked: who are subjects and objects of "fuck" here? In fact, the subject generally does not appear in the social posts, by default it is the poster himself, reflecting part of the general public, the object of "fuck" is, of course, Trump, for otherwise our deep linguistics based system will not count it as a negative mention of trump reflected in the graph. Let us show some random samples side by side of the graph:
My goodness, the "fuck" mentions account for 5% of the emotional data, the poor old Uncle Trump is fucked 40 million times in social media within one-month duration, showing how this guy is hated by some of the people whom he is supposed to represent and govern if he takes office. See how they actually express their strong dislike of Trump:
fucking moron fucking idiot asshole shithead
you name it, to the point even some Republicans also curse him like crazy:
Trump is a fucking idiot. Thank you for ruining the Republican Party you shithead.
Looking at the following figure of popular media, it seems that the most widely circulated political posts in social media involve quite some political video works:
The domains figure below shows that the Tumblr posts on politics contribute more than Facebook:
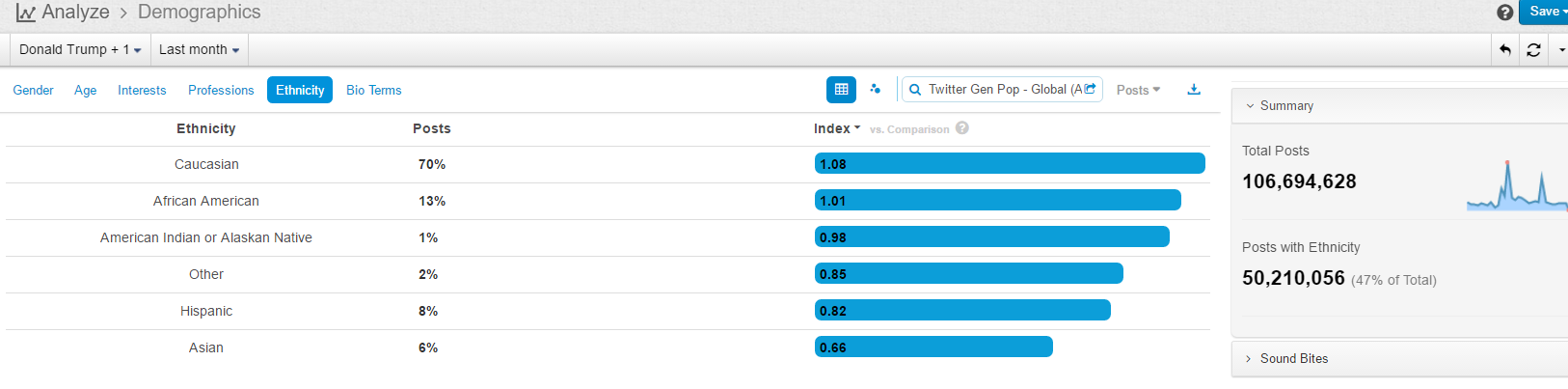
In terms of demographics background of social media posters, there is a fair balance between male and female: male 52% female 48% (in contrast to Chinese social media where only 25% females are posting political comments on US presidential campaign). The figure below shows the ethnic background of the posters, with 70% Caucasians, 13% African Americans, 8% Hispanic and 6% Asians. It looks like that the Hispanic Americans and Asian Americans are under-represented in the English social media in comparison with their due population ratios, as a result, this study may have missed some of their voice (but we have another similar study using Chinese social media, which shows a clear and big lead of Clinton over Trump; given time, we should do another automated survey using our multilingual engine for Spanish social media. Another suggestion from friends is to do a similar study on swing states because after all these are the key states that will decide the outcome of this election, we can filter the data by locations where posts are from to simulate that study). There might be a language or cultural reasons for this under-representation.
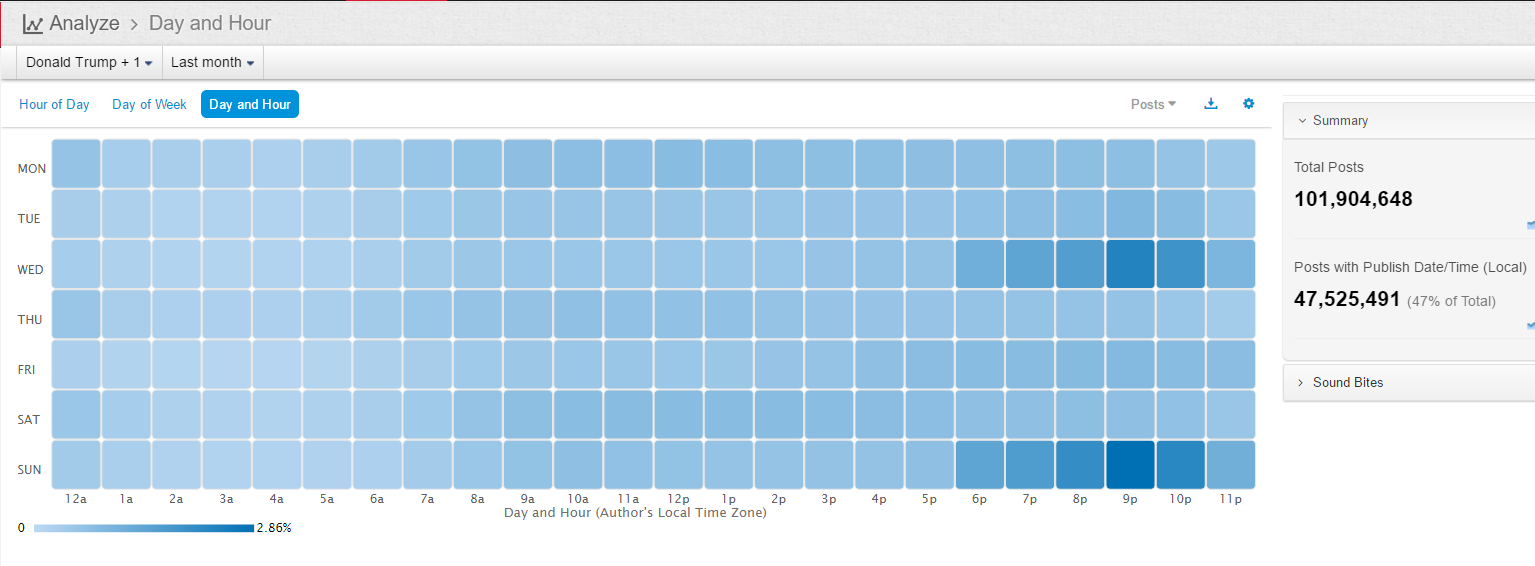
This last table involves a bit of fun facts of the investigation. In social media, people tend to talk most about the campaign, on the Wednesday and Sunday evenings, with 9 o'clock as the peak, for example, on the topic of Trump, nine o'clock on Sunday evening generated 1,357,766 messages within one hour. No wonder there is no shortage of big data from social media on politics. It is all about big data. In contrast, with the traditional manual poll, no matter how sampling is done, the limitation in the number of data points is so challenging:
with typically 500 to 1000 phone calls, how can we trust that the poll represents the public opinions of 200 million voters? They are laughably too sparse in data. Of course, in the pre-big-data age, there were simply no alternatives to collect public opinion in a timely manner with limited budgets. This is the beauty of Automatic Survey, which is bound to outperform the manual survey and become the mainstream of polls.
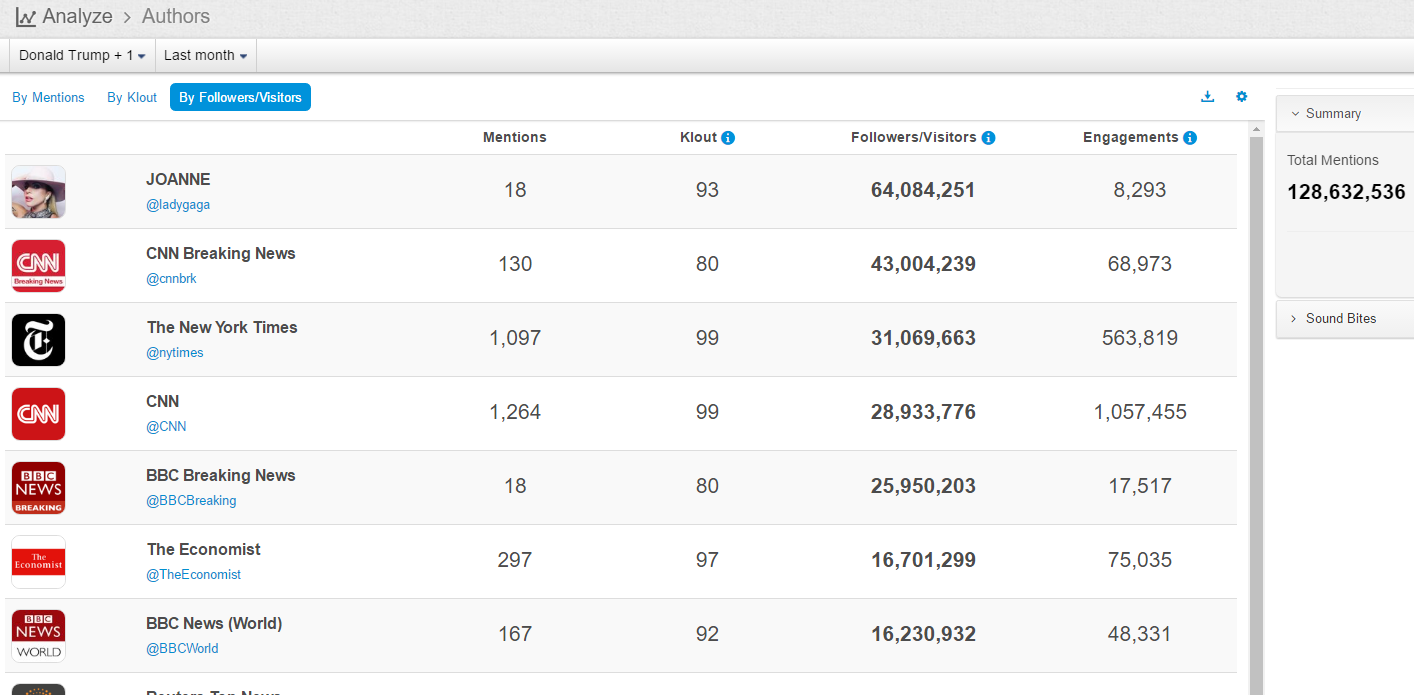
Authors with most followers are:
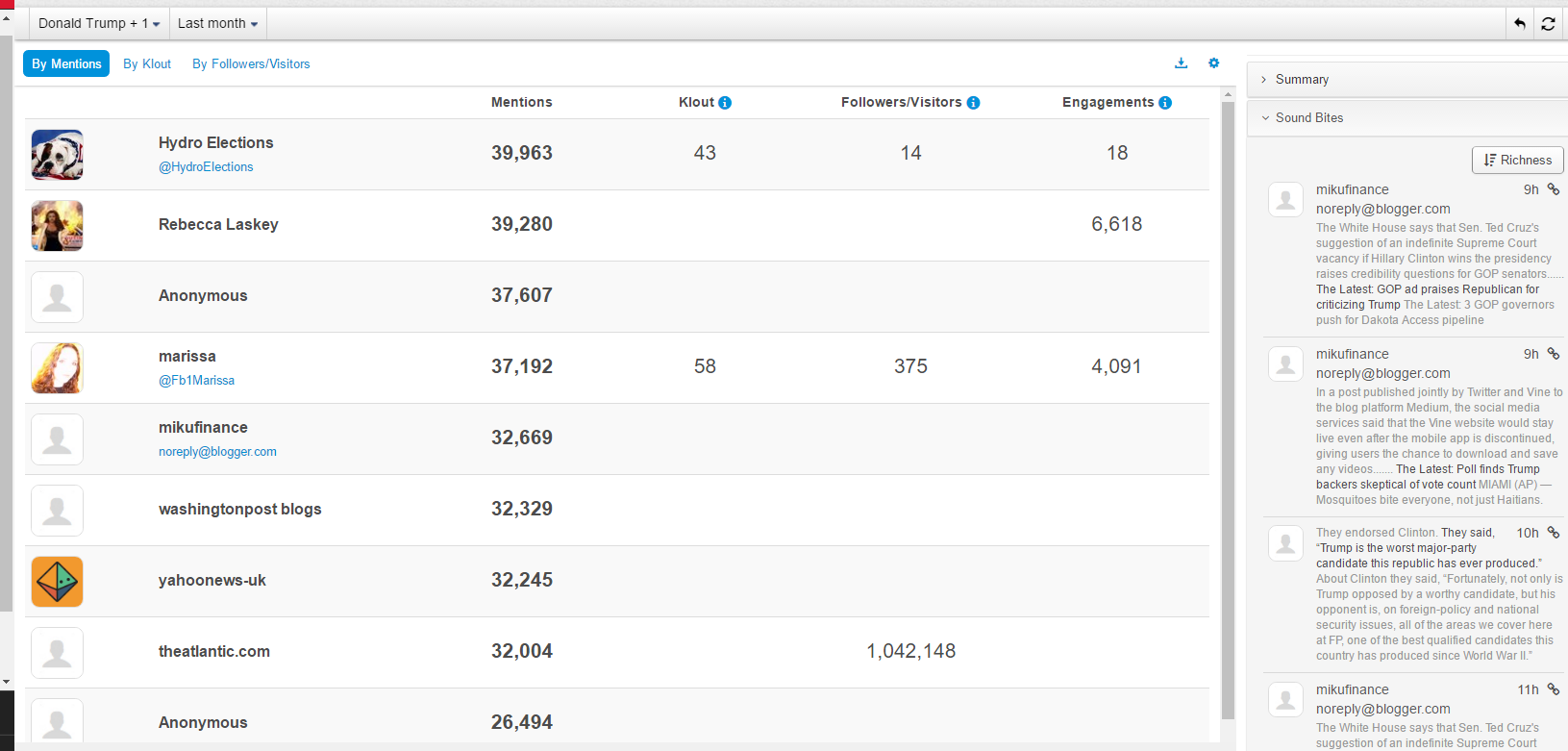
Most mentioned authors are listed below:
Tell me when in history did we ever have this much data and info, with this powerful data mining capabilities of fully sutomated mining of public opinions and sentiments at scale?
不过最近克林顿的选情是原地踏步,并没有明显进展。比较克林顿的三个圈可知,最淡的圈是过去30天的前10天,明显落后于川普,后两个圈是最近20天,基本原地,只是圈子变大了,说明竞选的投入和力度加大了,但效益并不明显。而从川普方面的三个圈圈看趋势,这老头儿实际的总体趋势是下跌,过去三十天,中间的十天舆情有改观,但最近的十天又倒回去了,虽然热议度有增长。(MD,这个分析没法细做,越做越惊心动魄,很难保持平和的心态,可咱是 data scientist 啊。朋友说,“就是要挖点惊心动魄的”,真心唯恐天下不乱啊。)看看川普的30天社煤的褒贬云图(Word Cloud for pros and cons)和情绪云图(Word Cloud for emotions)吧:
"But the entrepreneur admitted that there were limitations to the data in that sentiment around social media posts is difficult for the system to analyze. Just because somebody engages with a Trump tweet, it doesn't mean that they support him. Also there are currently more people on social media than there were in the three previous presidential elections."
haha,同行是冤家,他的AI能比我自然语言deep parsing支持的 I 吗?从文中看,他着重 engagement,这玩意儿的本质就是话题性、热议度吧。早就说了,川普是话题大王,热议度绝对领先。(就跟冰冰一样,话题女王最后在舆情上还是败给了舆情青睐的圆圆,不是?)不是码农相轻,他这个很大程度上是博眼球,大家都说川普要输,我偏说他必赢。两周后即便错了,这个名已经传出去了。川普团队也会不遗余力帮助宣传转发这个。
Big data mining from last month' social media shows clear decline of Trump in comparison with Clinton
Our automatic big data mining for public opinions and sentiments from social media speaks loud and clear: Tump's social image sucks.
Look at last 30 days of social media on the Hillary and Trump's social image and standing in our Brand Passion Index (BPI) comparison chart below:
Three points to note:
1 Trump has more than twice buzz than Hillary in terms of social media coverage (the size of the circles indicates the degree of mentions);
2. The intensity of sentiments from the general public of netters is more intense for Chump than for Clinton: the Y-axis shows the passion intensity
3. The social ratings and images of the two are both quite poor, but Trump is more criticized in social: the X-axis of Net Sentiment shows the index social sentiment ratings. Both are under freezing point (meaning more negative comments than positive).
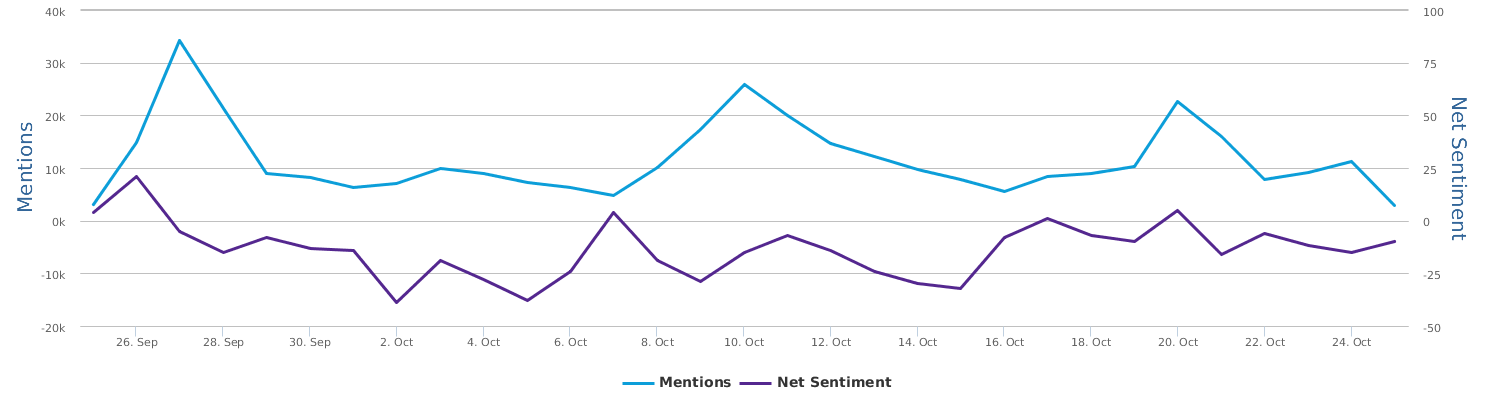
If we want to automatically investigate the trend of the past month and their social images' ups and downs, we can have the data segmented into two or three segments. Figure below shows the trends contrast of the first 15 days of social media data vs. the second 15 days of data in the 30-day period (up to 10/21/2016):
See, in the past month, with the presidential election debates and scandals getting attention, Trump's media image significantly deteriorated, represented by the public opinion circles shifting from the right on the X-axis to the left side (for dislike or hate sentiments: the lighter circle represents data older than the darker circle). His social rating was clearly better than Hillary to start with and ended up worse than that of Hillary. At the same time, Hillary's social media image has improved, the circle moves a bit from the left to right. Two candidates have always been below the freezing point, clearly shown in the figure, but just a month ago, Clinton was rated even lower than Trump in public opinions of the social media: it is not the people who like Trump that much, but the general public showed more dislike for Hillary for whatever reasons.
As seen, our BPI brand comparison chart attempts to visualize four-dimensional information:
1. net sentiment for social ratings on the X-axis;
2. the passion intensity of public sentiments on the Y-axis;
3. buzz circle size, representing mentions of soundbites;
4. The two circles of the same brands show the coarse-grained time dimension for general trends.
It is not very easy to represent 4 dimensions of analytics in a two-dimensional graph. Hope the above attempt in our patented visualization efforts is insightful and not confusing.
If we are not happy with the divide-into-two strategy for one month of data to show the trends, how about cut them into three pieces? Here is the Figure for .three circles in the time dimension.
We should have used different colors for the two political brands to make visualization a bit clearer. Nevertheless, we see the trends for Clinton in her three circles of social media sentiments shifting from the lower left corner to the upper right in a zigzag path: getting better, then worse, and ended up with somewhere in between at this point (more exactly, up to the point of 10/21/2016). For the same 3 segments of data, Trump's (brand) image started not bad, then went slightly better, and finally fell into the abyss.
The above is to use our own brand comparison chart (BPI) to decode the two US presidential candidates' social images change and trends. This analysis, entirely automated based on deep Natural Language Parsing technology, is supported by data points in a magnitude many times more than the traditional manual polls which are by nature severely restricted in data size and time response.
What are the sources of social media data for the above automated polling? They are based on random social media sampling of big data, headed by the most dynamic source of Twitter, as shown below.
This is a summary of the public opinions and sentiments:
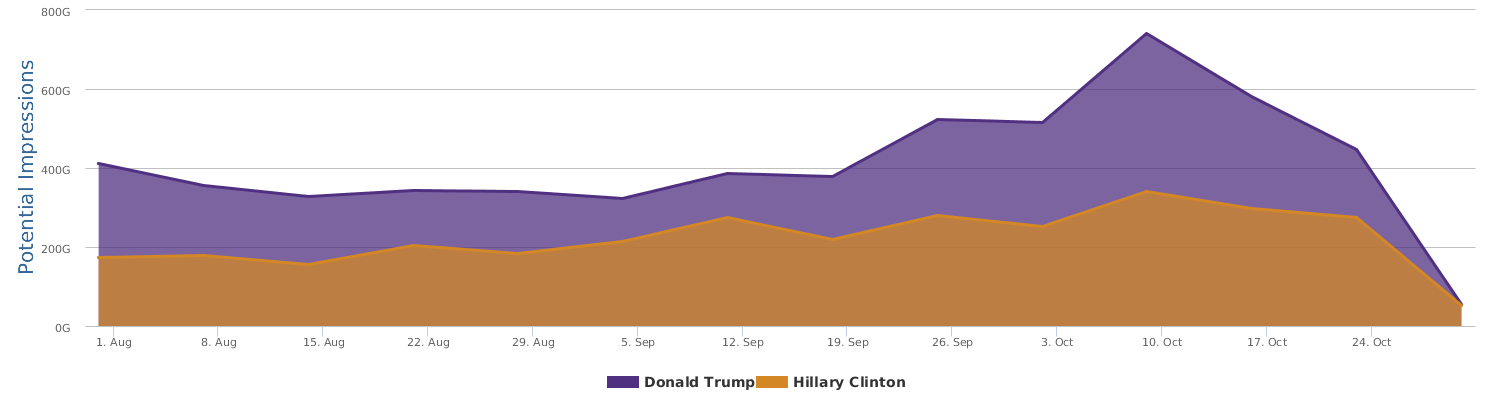
As seen, it is indeed BIG data: a month of random sampling of social media data involves the mentions of the candidates for nearly 200 million times, a total of up to 3,600+ billion impressions (potential eyeballs). Trump accounted for 70 percent of the buzz while Clinton only 30 percent.
The overall social rating during the period of 09/21/2016 through 10/21/2016, Trump's net sentiment is minus 20%, and Clinton is minus 18%. These measures show a rating much lower than that of most other VIP analysis we have done before using the same calculations. Fairly nasty images, really. And the big data trends show that Trump sucks most.
The following is some social media soundbites for Trump:
Bill Clinton disgraced the office with the very behavior you find appalling in...
In closing, yes, maybe Trump does suffer from a severe case of CWS.
Instead, in this alternate NY Times universe, Trump’s campaign was falling ...
Russian media often praise Trump for his business acumen.
This letter is the reason why Trump is so popular
Trump won
I'm proud of Trump for taking a stand for what's right.
Kudos to Trump for speaking THE TRUTH!
Trump won
I’m glad I’m too tired to write Trump/Putin fuckfic.
#trump won
Trump is the reason Trump will lose this election.
Trump is blamed for inciting violence.
Breaking that system was the reason people wanted Trump.
I hate Donald Trump for ruining my party.
>>32201754 Trump is literally blamed by Clinton supporters for being too friendly with Russia.
Another heated moment came when Trump delivered an aside in reponse to ...
@dka_gannongal I think Donald Trump is a hoax created by the Chinese....
Skeptical_Inquirer The drawing makes Trump look too normal.
I'm proud of Donald Trump for answering that honestly!
Donald grossing me out with his mouth features @smerconish ...
Controlling his sniffles seems to have left Trump extraordinarily exhausted
Trump all the way people trump trump trump
Trump wins
Think that posting crap on BB is making Trump look ridiculous.
I was proud of Trump for making America great again tonight.
MIL is FURIOUS at Trump for betraying her!
@realdonaldTrump Trump Cartel Trump Cartel America is already great, thanks to President Obama.
Kudos to Mr Trump for providing the jobs!!
The main reason to vote for Trump is JOBS!
Yes donal trump has angered many of us with his WORDS.
Trump pissed off a lot of Canadians with his wall comments.
Losing this election will make Trump the biggest loser the world has ever seen.
Billy Bush's career is merely collateral damage caused by Trump's wrenching ..
So blame Donald for opening that door.
The most important reason I am voting for Trump is Clinton is a crook.
Trump has been criticized for being overly complimentary of Putin.
Kudos to Trump for reaching out to Latinos with some Spanish.
Those statements make Trump's latest moment even creepier.
I'm mad at FBN for parroting the anti-Trump talking points.
Kudos to Trump for ignoring Barack today @realDonaldTrump
Trump has been criticized for being overly complimentary of Putin.
OT How Donald Trump's rhetoric has turned his precious brand toxic via ...
It's these kinds of remarks that make Trump supporters look like incredible ...
Trump is blamed for inciting ethnic tensions.
Trump is the only reason the GOP is competitive in this race.
Its why Republicans are furious at Trump for saying the voting process is rigged.
Billy Bush’s career is merely collateral damage caused by Trump’s wrenching ..
Donald Trump is the dumbest, worst presidential candidate your country ...
I am so disappointed in Colby Keller for supporting Trump.
Billy Bush’s career is merely collateral damage caused by Trump’s wrenching..
In swing states, Trump continues to struggle.
Trump wins
Co-host Jedediah Bila agreed, saying that the move makes Trump look desperate.
Trump wins
"Trump attacks Clinton for being bisexual!"
TRUMP win
Pence also praised Trump for apologizing following the tape’s disclosure.
In swing states, Trump continues to struggle.
the reason Trump is so dangerous to the establishment is he is unapologetical..
Here are some public social media soundbites for Clinton in the same period:
Hillary deserves worse than jail.
Congratulations to Hillary & her campaign staff for wining three Presidential ..
I HATE @chicanochamberofcommerce FOR INTRODUCING THAT HILLARY ...
As it turns out, Hillary creeped out a number of people with her grin.
Hillary trumped Trump
Trump won! Hillary lost
Hillary violated the Special Access Program (SAP) for disclosing about the ...
I trust Flint water more than Hillary
Hillary continued to baffle us with her bovine feces.
NEUROLOGISTS HATE HILLARY FOR USING THIS TRADE SECRET DRUG!!!!...
CONGRATULATIONS TO HILLARY CLINTON FOR WINNING THE PRESIDENCY
Supreme Court: Hillary is our only choice for keeping LGBT rights.
kudos to hillary for remaining sane, I'd have killed him by now
How is he blaming Hillary for sexually assaulting women. He's such a shithead
The only reason I'm voting for Hillary is that Donald is the only other choice
Hillary creeps me out with that weird smirk.
Hillary is annoying asf with all of her laughing
I credit Hillary for the Cubs waking up
When you listen to Hillary talk it is really stupid
On the other hand, Hillary Clinton has a thorough knowledge by virtue of ...
Americans deserve better than Hillary
Certain family members are also upset with me for speaking out against ...
Hillary is hated by all her security detail for being so abusive
Hillary beat trump
The only reason to vote for Hillary is she's a woman.
Certain family members are also upset with me for speaking out against ....
I am glad you seem to be against Hillary as well Joe Pepe.
Hillary scares me with her acions.
Unfortunately Wikileaks is the monster created by Hillary & democrats.
I'm just glad you're down with evil Hillary.
Hillary was not mad at Bill for what he did. She was mad he got caught. ......
These stories are falling apart like Hillary on 9/11
Iam so glad he is finally admitting this about Hillary Clinton.
Why hate a man for doing nothing like Hillary Clinton
Hillary molested me with a cigar while Bill watched.
You are upset with Hillary for doing the same as all her predecessors.
I feel like Hillary Clinton is God's punishment on America for its sins.
Trumps beats Hillary
You seem so proud of Hillary for laughing at rape victims.
Of course Putin is going to hate Hillary for publicly announcing false ...
Russia is pissed off at Hillary for blaming the for wikileaks!
Hillary will not win. Good faith is stronger than evil. Trump wins??
I am proud of Hillary for standing up for what is good in the USA.
Hillarys plans are worse than Obama
Hillary is the nightmare "the people" have created.
Funny how the Hillary supporters are trashing Trump for saying the same ...
???????????? I am so proud of the USA for making Hillary Clinton president.
Hillary, you're a hoax created by the Chinese
Trump trumps Hillary
During the debate, Trump praised Hillary for having the will to fight.
Trump is better person than Hillary
Donald TRUMPED Hillary
Kudos to Hillary for her accomplishments.
He also praised Hillary for handling the situation with dignity.
During the debate, Trump praised Hillary for having the will to fight.
People like Hillary in senate is the reason this country is going downhill.
Hillary did worse than expectations.
Trump will prosecute Hillary for her crimes, TRUMP will!
Have to praise Hillary for keeping her focus.
a landslide victory for Hillary will restore confidence in American democracy ..
I was so proud of Hillary tonight for acting like a tough, independent woman.
I dislike Hillary Clinton, as I think she is a corrupt, corporate shill.
Hillary did worse than Timmy Kaine
Im so glad he finally brought Benghazi against Hillary
Hillary, thank you for confirmation that the Wikileaks documents are authentic
Supreme Court justices is the only reason why I'd vote for Hillary.
Massive kudos to Hillary for keeping her cool with that beast behind her.
Congrats to Hillary for actually answering the questions. She's spot on. #debate
选票已经到手了,除了为了川普而选希拉里外,正在看那些个本地提案和从来就不认识的本地候选人:二号提案试图加消费税(把消费税加到天花板)来改善湾区日渐恶化的交通(包括类似地铁的轻轨在硅谷腹地的延伸),一号提案也是增加房产税来帮助无家可归者提供廉租屋,领导说,local 加税的一律说不(可是联邦选举中,希拉里明摆着要加税,而川普要减税,领导却坚决投希拉里)。c 和 d 提案最切身,就是家门口开门即红透半边天的 cupertino downtown 旁边,同时在苹果新总部旁边,有一个了无生气的 mall,眼看这块宝地要大热,开发商与民间组织打起来了。开发商要推倒重建,在建筑商业应用之上做一个巨大的空中花园,在沙漠天气营造一个休闲绿洲来吸引投票。
民间组织宣传 yes on C,no on D,开发商发动广告大战,宣传 yes on D no on C,针锋相对,煞是热闹。民间组织的宣传颇有效,说 C 也 pro-customer and D is pro-developer,无奸不商,无商不奸,美丽的空中花园的下面,是多少多少的商业店铺和巨大的利润,带来的是交通和教育问题,等等。总之是信服了领导,但说不服我。
对于一个过了九点就跟鬼城一样的硅谷腹地,缺少的就是人气。D 提案描画的远景就是人气,想想吧,10 年后的 苹果总部、新 Downown 以及空中花园,会是怎样一个聚集人气的所在。为这个,不能与领导保持一致。
D要建公寓楼出租,这是业主反对的主要原因。资本家追求利益最大化,捎带着建个花园,活跃了人气。旁边的那些 property value 将来还要疯涨,举步就是吃喝玩乐,有啥可抱怨的。人再多也比不上北京上海,多开个 school 把马路拓宽不就结了。
等将来有钱了就去买一间这样的公寓,养老甚好,不用开车,楼下就是一切。
当年在温哥华的 Burnaby 的 Metrotown 中心,就建了好多高层公寓,不少老华人就在里面养老,自得其乐,让人羡慕。
看到了吧,过去一个月,随着总统大选辩论和丑闻的揭示和宣传,川普的媒体形象显著恶化,表现在舆情圈圈从右(x轴上的右是评价度高 love like,左边是评价度低 hate dislike)向左的位移。本来评价度clearly比希拉里要好,终于比希拉里差了。同时,希拉里的社会媒体形象有所改善,圈圈在从左向右位移。两个人始终都是冰点以下,吐槽多于赞美,但是就在一个月前,还是喜妈更不受待见:不是民众更喜欢老川,而是普罗更厌恶喜妈。
这个品牌对比图示表达了四维信息:
1. net sentiment 评价度 x 轴
2. passion intensity 舆情烈度 y 轴
3. buzz 圈圈的大小,是热议度
4. 一分为二的两个圈是时间的粗线条切割的维度
Bill Clinton disgraced the office with the very behavior you find appalling in Trump.
In closing, yes, maybe Trump does suffer from a severe case of CWS.
Instead, in this alternate NY Times universe, Trump’s campaign was falling apart.
Russian media often praise Trump for his business acumen.
This letter is the reason why Trump is so popular
Trump won
I'm proud of Trump for taking a stand for what's right.
Kudos to Trump for speaking THE TRUTH!
Trump won
I’m glad I’m too tired to write Trump/Putin fuckfic.
#trump won
Trump is the reason Trump will lose this election.
Trump is blamed for inciting violence.
Breaking that system was the reason people wanted Trump.
I hate Donald Trump for ruining my party.
>>32201754 Trump is literally blamed by Clinton supporters for being too friendly with Russia.
Another heated moment came when Trump delivered an aside in reponse to a Clinton one-liner.
@dka_gannongal I think Donald Trump is a hoax created by the Chinese....
Skeptical_Inquirer The drawing makes Trump look too normal.
I'm proud of Donald Trump for answering that honestly!
Donald grossing me out with his mouth features @smerconish @realdonaldtrump
Controlling his sniffles seems to have left Trump extraordinarily exhausted
Trump all the way people trump trump trump
Trump wins
Think that posting crap on BB is making Trump look ridiculous.
I was proud of Trump for making America great again tonight.
MIL is FURIOUS at Trump for betraying her!
@realdonaldTrump Trump Cartel Trump Cartel America is already great, thanks to President Obama.
Kudos to Mr Trump for providing the jobs!!
The main reason to vote for Trump is JOBS!
Yes donal trump has angered many of us with his WORDS.
Trump pissed off a lot of Canadians with his wall comments.
Losing this election will make Trump the biggest loser the world has ever seen.
Billy Bush's career is merely collateral damage caused by Trump's wrenching migration.
So blame Donald for opening that door.
The most important reason I am voting for Trump is Clinton is a crook.
Trump has been criticized for being overly complimentary of Putin.
Kudos to Trump for reaching out to Latinos with some Spanish.
Those statements make Trump's latest moment even creepier.
I'm mad at FBN for parroting the anti-Trump talking points.
Kudos to Trump for ignoring Barack today @realDonaldTrump
Trump has been criticized for being overly complimentary of Putin.
OT How Donald Trump's rhetoric has turned his precious brand toxic via The Independent.
It's these kinds of remarks that make Trump supporters look like incredible idiots.
Trump is blamed for inciting ethnic tensions.
Trump is the only reason the GOP is competitive in this race.
Its why Republicans are furious at Trump for saying the voting process is rigged.
Billy Bush’s career is merely collateral damage caused by Trump’s wrenching migration.
Donald Trump is the dumbest, worst presidential candidate your country has EVER produced.
I am so disappointed in Colby Keller for supporting Trump.
Billy Bush’s career is merely collateral damage caused by Trump’s wrenching migration.
In swing states, Trump continues to struggle.
Trump wins
Co-host Jedediah Bila agreed, saying that the move makes Trump look desperate.
Trump wins
"Trump attacks Clinton for being bisexual!"
TRUMP win
Pence also praised Trump for apologizing following the tape’s disclosure.
In swing states, Trump continues to struggle.
the reason Trump is so dangerous to the establishment is he is unapologetically alpha.
关于希拉里的社会媒体样本数据摘选:
Hillary deserves worse than jail.
Congratulations to Hillary & her campaign staff for wining three Presidential debates.
I HATE @chicanochamberofcommerce FOR INTRODUCING THAT HILLARY GIF INTO MY LIFE
As it turns out, Hillary creeped out a number of people with her grin.
Hillary trumped Trump
Trump won! Hillary lost
Hillary violated the Special Access Program (SAP) for disclosing about the nuclear weapons!!
I trust Flint water more than Hillary
Hillary continued to baffle us with her bovine feces.
NEUROLOGISTS HATE HILLARY FOR USING THIS TRADE SECRET DRUG!!!!...
CONGRATULATIONS TO HILLARY CLINTON FOR WINNING THE PRESIDENCY
Supreme Court: Hillary is our only choice for keeping LGBT rights.
kudos to hillary for remaining sane, I'd have killed him by now
How is he blaming Hillary for sexually assaulting women. He's such a shithead
The only reason I'm voting for Hillary is that Donald is the only other choice
Hillary creeps me out with that weird smirk.
Hillary is annoying asf with all of her laughing
I credit Hillary for the Cubs waking up
When you listen to Hillary talk it is really stupid
On the other hand, Hillary Clinton has a thorough knowledge by virtue of her tenure as Secretary of State.
Americans deserve better than Hillary
Certain family members are also upset with me for speaking out against Hillary.
Hillary is hated by all her security detail for being so abusive
Hillary beat trump
The only reason to vote for Hillary is she's a woman.
Certain family members are also upset with me for speaking out against Hillary.
I am glad you seem to be against Hillary as well Joe Pepe.
Hillary scares me with her acions.
Unfortunately Wikileaks is the monster created by Hillary & democrats.
I'm just glad you're down with evil Hillary.
Hillary was not mad at Bill for what he did. She was mad he got caught. Just like she is not ashamed of what she did she is angry she got caught.
These stories are falling apart like Hillary on 9/11
Iam so glad he is finally admitting this about Hillary Clinton.
Why hate a man for doing nothing like Hillary Clinton
Hillary molested me with a cigar while Bill watched.
You are upset with Hillary for doing the same as all her predecessors.
I feel like Hillary Clinton is God's punishment on America for its sins.
Trumps beats Hillary
You seem so proud of Hillary for laughing at rape victims.
Of course Putin is going to hate Hillary for publicly announcing false accusations.
Russia is pissed off at Hillary for blaming the for wikileaks!
Hillary will not win. Good faith is stronger than evil. Trump wins??
I am proud of Hillary for standing up for what is good in the USA.
Hillarys plans are worse than Obama
Hillary is the nightmare "the people" have created.
Funny how the Hillary supporters are trashing Trump for saying the same thing.
???????????? I am so proud of the USA for making Hillary Clinton president.
Hillary, you're a hoax created by the Chinese
Trump trumps Hillary
During the debate, Trump praised Hillary for having the will to fight.
Trump is better person than Hillary
Donald TRUMPED Hillary
Kudos to Hillary for her accomplishments.
He also praised Hillary for handling the situation with dignity.
During the debate, Trump praised Hillary for having the will to fight.
People like Hillary in senate is the reason this country is going downhill.
Hillary did worse than expectations.
Trump will prosecute Hillary for her crimes, TRUMP will!
Have to praise Hillary for keeping her focus.
a landslide victory for Hillary will restore confidence in American democracy vindicated
I was so proud of Hillary tonight for acting like a tough, independent woman.
I dislike Hillary Clinton, as I think she is a corrupt, corporate shill.
Hillary did worse than Timmy Kaine
Im so glad he finally brought Benghazi against Hillary
Hillary, thank you for confirmation that the Wikileaks documents are authentic and you did that tonight when you accused the Russians of hacking your servers! We the people deserve better than you!
Supreme Court justices is the only reason why I'd vote for Hillary.
Massive kudos to Hillary for keeping her cool with that beast behind her.
Congrats to Hillary for actually answering the questions. She's spot on. #debate
我:
现如今,小札和妻子有钱了,可以为这场革命发放启动资金。这么宏伟的目标,而且一两代人就可以完成,值得全世界政府和慈善家持续跟进。他们的角色就是做慈善天使吧?
标题是:Can we cure all diseases in our children's life time?
如果我说:no,这是骗人的大忽悠。是不是政治不正确,会被口水骂死?
Wei:
Some people are just smart, or shrewd, more than we can imagine. I am talking about Fathers of Siri, who have been so successful with their technology that they managed to sell the same type of technology twice, both at astronomical prices, and both to the giants in the mobile and IT industry. What is more amazing is, the companies they sold their tech-assets to are direct competitors. How did that happen? How "nice" this world is, to a really really smart technologist with sharp business in mind.
What is more stunning is the fact that, Siri and the like so far are regarded more as toys than must-carry tools, intended at least for now to satisfy more curiosity than to meet the rigid demand of the market. The most surprising is that the technology behind Siri is not unreachable rocket science by nature, similar technology and a similar level of performance are starting to surface from numerous teams or companies, big or small.
I am a tech guy myself, loving gadgets, always watching for new technology breakthrough. To my mind, something in the world is sheer amazing, taking us in awe, for example, the wonder of smartphones when the iPhone first came out. But some other things in the tech world do not make us admire or wonder that much, although they may have left a deep footprint in history. For example, the question answering machine made by IBM Watson Lab in winning Jeopardy. They made it into the computer history exhibition as a major AI milestone. More recently, the iPhone Siri, which Apple managed to put into hands of millions of people first time for seemingly live man-machine interaction. Beyond that accomplishment, there is no magic or miracle that surprises me. I have the feel of "seeing through" these tools, both the IBM answering robot type depending on big data and Apple's intelligent agent Siri depending on domain apps (plus a flavor of AI chatbot tricks).
Chek: @ Wei I bet the experts in rocket technology will not be impressed that much by SpaceX either,
Wei: Right, this is because we are in the same field, what appears magical to the outside world can hardly win an insider's heart, who might think that given a chance, they could do the same trick or better.
The Watson answering system can well be regarded as a milestone in engineering for massive, parallel big data processing, not striking us as an AI breakthrough. what shines in terms of engineering accomplishment is that all this happened before the big data age when all the infrastructures for indexing, storing and retrieving big data in the cloud are widely adopted. In this regard, IBM is indeed the first to run ahead of the trend, with the ability to put a farm of servers in working for the QA engine to be deployed onto massive data. But from true AI perspective, neither the Watson robot nor the Siri assistant can be compared with the more-recent launch of the new Google Translate based on neural networks. So far I have tested using this monster to help translate three Chinese blogs of mine (including this one in making), I have to say that I have been thrown away by what I see. As a seasoned NLP practitioner who started MT training 30 years ago, I am still in disbelief before this wonder of the technology showcase.
Chen: wow, how so?
Wei: What can I say? It has exceeded my imagination limit for all my dreams of what MT can be and should be since I entered this field many years ago. While testing, I only needed to do limited post-editing to make the following Chinese blogs of mine presentable and readable in English, a language with no kinship whatsoever with the source language Chinese.
Hong: Wei seemed frightened by his own shadow.Chen:
Chen: The effect is that impressive?
Wei: Yes. Before the deep neural-nerve age, I also tested and tried to use SMT for the same job, having tried both Google Translate and Baidu MT, there is just no comparison with this new launch based on technology breakthrough. If you hit their sweet spot, if your data to translate are close to the data they have trained the system on, Google Translate can save you at least 80% of the manual work. 80% of the time, it comes so smooth that there is hardly a need for post-editing. There are errors or crazy things going on less than 20% of the translated crap, but who cares? I can focus on that part and get my work done way more efficiently than before. The most important thing is, SMT before deep learning rendered a text hardly readable no matter how good a temper I have. It was unbearable to work with. Now with this breakthrough in training the model based on sentence instead of words and phrase, the translation magically sounds fairly fluent now.
It is said that they are good a news genre, IT and technology articles, which they have abundant training data. The legal domain is said to be good too. Other domains, spoken language, online chats, literary works, etc., remain a challenge to them as there does not seem to have sufficient data available yet.
Chen: Yes, it all depends on how large and good the bilingual corpora are.
Wei: That is true. SMT stands on the shoulder of thousands of professional translators and their works. An ordinary individual's head simply has no way in digesting this much linguistic and translation knowledge to compete with a machine in efficiency and consistency, eventually in quality as well.
Chen: Google's major contribution is to explore and exploit the existence of huge human knowledge, including search, anchor text is the core.
Ma: I very much admire IBM's Watson, and I would not dare to think it possible to make such an answering robot back in 2007.
Wei: But the underlying algorithm does not strike as a breakthrough. They were lucky in targeting the mass media Jeopardy TV show to hit the world. The Jeopardy quiz is, in essence, to push human brain's memory to its extreme, it is largely a memorization test, not a true intelligence test by nature. For memorization, a human has no way in competing with a machine, not even close. The vast majority of quiz questions are so-called factoid questions in the QA area, asking about things like who did what when and where, a very tractable task. Factoid QA depends mainly on Named Entity technology which was mature long ago, coupled with the tractable task of question parsing for identifying its asking point, and the backend support from IR, a well studied and practised area for over 2 decades now. Another benefit in this task is that most knowledge questions asked in the test involve standard answers with huge redundancy in the text archive expressed in various ways of expressions, some of which are bound to correspond to the way question is asked closely. All these factors contribute to IBM's huge success in its almost mesmerizing performance in the historical event. The bottom line is, shortly after the 1999 open domain QA was officially born with the first TREC QA track, the technology from the core engine has been researched well and verified for factoid questions given a large corpus as a knowledge source. The rest is just how to operate such a project in a big engineering platform and how to fine-tune it to adapt to the Jeopardy-style scenario for best effects in the competition. Really no magic whatsoever.
In what year did Joe DiMaggio compile his 56-game hitting streak?
三 昙花
这次问答系统竞赛的结果与意义如何呢?应该说是结果良好,意义重大。最好的系统达到60%多的正确率,就是说每三个问题,系统可以从语言文档中大海捞针一样搜寻出两个正确答案。作为学界开放式系统的第一次尝试,这是非常令人鼓舞的结果。当时正是 dot com 的鼎盛时期,IT 业界渴望把学界的这一最新研究转移到信息产品中,实现搜索的革命性转变。里面有很多有趣的故事,参见我的相关博文:《朝华午拾:创业之路》。
回顾当年的工作,可以发现是组织者、学界和业界的天时地利促成了问答系统奇迹般的立竿见影的效果。美国标准局在设计问题的时候,强调的是自然语言的问题(English questions,见上),而不是简单的关键词 queries,其结果是这些问句偏长,非常适合做段落检索。为了保证每个问题都有答案,他们议定问题的时候针对语言资料库做了筛选。这样一来,文句与文本必然有相似的语句对应,客观上使得段落匹配(乃至语句匹配)命中率高(其实,只要是海量文本,相似的语句一定会出现)。设想如果只是一两个关键词,寻找相关的可能含有答案的段落和语句就困难许多。当然找到对应的段落或语句,只是大大缩小了寻找答案的范围,不过是问答系统的第一步,要真正锁定答案,还需要进一步细化,pinpoint 到语句中那个作为答案的词或词组。这时候,信息抽取学界已经成熟的实名标注技术正好顶上来。为了力求问答系统竞赛的客观性,组织者有意选择那些答案比较单纯的问题,譬如人名、时间、地点等。这恰好对应了实名标注的对象,使得先行一步的这项技术有了施展身手之地。譬如对于问题 “In what year did Joe DiMaggio compile his 56-game hitting streak?”,段落语句搜索很容易找到类似下列的文本语句:Joe DiMaggio's 56 game hitting streak was between May 15, 1941 and July 16, 1941. 实名标注系统也很容易锁定 1941 这个时间单位。An exact answer to the exact question,答案就这样在海量文档中被搜得,好像大海捞针一般神奇。沿着这个路子,11 年后的 IBM 花生研究中心成功地研制出打败人脑的电脑问答系统,获得了电视智能大奖赛 Jeopardy! 的冠军(见报道 COMPUTER CRUSHES HUMAN 'JEOPARDY!' CHAMPS),在全美观众面前大大地出了一次风头,有如当年电脑程序第一次赢得棋赛冠军那样激动人心。
1999 年的学界在问答系统上初战告捷,我们作为成功者也风光一时,下自成蹊,业界风险投资商蜂拥而至。很快拿到了华尔街千万美元的风险资金,当时的感觉真地好像是在开创工业革命的新纪元。可惜好景不长,互联网泡沫破灭,IT 产业跌入了萧条的深渊,久久不能恢复。投资商急功近利,收紧银根,问答系统也从业界的宠儿变成了弃儿(见《朝华午拾 - 水牛风云》)。主流业界没人看好这项技术,比起传统的关键词索引和搜索,问答系统显得不稳定、太脆弱(not robust),也很难 scale up, 业界的重点从深度转向广度,集中精力增加索引涵盖面,包括所谓 deep web。问答系统的研制从业界几乎绝迹,但是这一新兴领域却在学界发芽生根,不断发展着,成为自然语言研究的一个重要分支。IBM 后来也解决了 scale up (用成百上千机器做分布式并行处理)和适应性培训的问题,为赢得大奖赛做好了技术准备。同时,学界也开始总结问答系统的各种类型。一种常见的分类是根据问题的种类。
我们很多人都在中学语文课上,听老师强调过阅读理解要抓住几个WH的重要性:who/what/when/where/how/why(Who did what when, where, how and why?). 抓住了这些WH,也就抓住了文章的中心内容。作为对人的阅读理解的仿真,设计问答系统也正是为了回答这些WH的问题。值得注意的是,这些 WH 问题有难有易,大体可以分成两类:有些WH对应的是实体专名,譬如 who/when/where,回答这类问题相对容易,技术已经成熟。另一类问题则不然,譬如what/how/why,回答这样的问题是对问答学界的挑战。简单介绍一下这三大难题如下。
What is X?类型的问题是所谓定义问题,譬如 What is iPad II? (也包括作为定义的who:Who is Bill Clinton?) 。这一类问题的特点是问题短小,除去问题词What与联系词 is 以外 (搜索界叫stop words,搜索前应该滤去的,问答系统在搜索前利用它理解问题的类型),只有一个 X 作为输入,非常不利于传统的关键词检索。回答这类问题最低的要求是一个有外延和种属的定义语句(而不是一个词或词组)。由于任何人或物体都是处在与其他实体的多重关系之中(还记得么,马克思说人是社会关系的总和),要想真正了解这个实体,比较完美地回答这个问题,一个简单的定义是不够的,最好要把这个实体的所有关键信息集中起来,给出一个全方位的总结(就好比是人的履历表与公司的简介一样),才可以说是真正回答了 What/Who is X 的问题。显然,做到这一步不容易,传统的关键词搜索完全无能为力,倒是深度信息抽取可以帮助达到这个目标,要把散落在文档各处的所有关键信息抽取出来,加以整合才有希望(【立委科普:信息抽取】)。
How 类型的问题也不好回答,它搜寻的是解决方案。同一个问题,往往有多种解决档案,譬如治疗一个疾病,可以用各类药品,也可以用其他疗法。因此,比较完美地回答这个 How 类型的问题也就成为问答界公认的难题之一。
The traditional question answering (QA) system is an application of Artificial Intelligence (AI). It is usually confined to a very narrow and specialized domain, which is basically made up of a hand-crafted knowledge base with a natural language interface. As the field is narrow, the vocabulary is very limited, and its pragmatic ambiguity can be effectively under control. Questions are highly predictable, or close to a closed set, the rules for the corresponding answers are fairly straightforward. Well-known projects in the 1960s include LUNAR, a QA system specializing in answering questions about the geological analysis on the lunar samples collected from the Apollo's landing on the Moon. SHRDLE is another famous QA expert system in AI history, it simulates the operation of a robot in the toy building world. The robot can answer the question of the geometric state of a toy and listen to the language instruction for its operation.
These early AI explorations seemed promising, revealing a fairy-tale world of scientific fantasy, greatly stimulating our curiosity and imagination. Nevertheless, in essence, these are just toy systems that are confined to the laboratory and are not of much practical value. As the field of artificial intelligence was getting narrower and narrower (although some expert systems have reached a practical level, majority AI work based on common sense and knowledge reasoning could not get out beyond lab), the corresponding QA systems failed to render meaningful results. There were some conversational systems (chatterbots) that had been developed thus far and became children's popular online toys (I remember at one time when my daughter was young, she was very fond of surfing the Internet to find various chatbots, sometimes deliberately asking tricky questions for fun. Recent years have seen a revival of this tradition by industrial giants, with some flavor seen in Siri, and greatly emphasized in Microsoft's Little Ice).
2. Rebirth
Industrial open-domain QA systems are another story, it came into existence with the development of the Internet boom and the popularity of search engines. Specifically, the open QA system was born in 1999, when the TREC-8 (Eighth Text Retrieval Conference) decided to add a natural language QA track of competition, funded by the US Department of Defense's DARPA program, administrated by the United States National Institute of Standards and Technology (NIST), thus giving birth to this emerging QA community. Its opening remarks when calling for the participation of the competition are very impressive, to this effect:
Users have questions, they need answers. Search engines claim that they are doing information retrieval, yet the information is not an answer to their questions but links to thousands of possibly related files. Answers may or may not be in the returned documents. In any case, people are compelled to read the documents in order to find answers. A QA system in our vision is to solve this key problem of information need. For QA, the input is a natural language question, the output is the answer, it is that simple.
It seems of benefit to introduce some background for academia as well as the industry when the open QA was born.
From the academic point of view, the traditional sense of artificial intelligence is no longer popular, replaced by the large-scale corpus-based machine learning and statistical research. Linguistic rules still play a role in the field of natural language, but only as a complement to the mainstream machine learning. The so-called intelligent knowledge systems based purely on knowledge or common sense reasoning are largely put on hold by academic scholars (except for a few, such as Dr. Douglas Lenat with his Cyc). In the academic community before the birth of open-domain question and answering, there was a very important development, i.e. the birth and popularity of a new area called Information Extraction (IE), again a child of DARPA. The traditional natural language understanding (NLU) faces the entire language ocean, trying to analyze each sentence seeking a complete semantic representation of all its parts. IE is different, it is task-driven, aiming at only the defined target of information, leaving the rest aside. For example, the IE template of a conference may be defined to fill in the information of the conference [name], [time], [location], [sponsors], [registration] and such. It is very similar to filling in the blank in a student's reading comprehension test. The idea of task-driven semantics for IE shortens the distance between the language technology and practicality, allowing researchers to focus on optimizing tasks according to the tasks, rather than trying to swallow the language monster at one bite. By 1999, the IE community competitions had been held for seven annual sessions (MUC-7: Seventh Message Understanding Conference), the tasks of this area, approaches and the then limitations were all relatively clear. The most mature part of information extraction technology is the so-called Named Entity (NE tagging), including identification of names for human, location, and organization as well as tagging time, percentage, etc. The state-of-the-art systems, whether using machine learning or hand-crafted rules, reached a precision-recall combined score (F-measures) of 90+%, close to the quality of human performance. This first-of-its-kind technological advancement in a young field turned out to play a key role in the new generation of open-domain QA.
In industry, by 1999, search engines had grown rapidly with the popularity of the Internet, and search algorithms based on keyword matching and page ranking were quite mature. Unless there was a methodological revolution, the keyword search field seemed to almost have reached its limit. There was an increasing call for going beyond basic keyword search. Users were dissatisfied with search results in the form of links, and they needed more granular results, at least in paragraphs (snippets) instead of URLs, preferably in the form of direct short answers to the questions in mind. Although the direct answer was a dream yet to come true waiting for the timing of open-domain QA era, the full-text search more and more frequently adopted paragraph retrieval instead of simple document URLs as a common practice in the industry, the search results changed from the simple links to web pages to the highlighting of the keywords in snippets.
In such a favorable environment in industry and academia, the open-domain question answering came onto the stage of history. NIST organized its first competition, requiring participating QA systems to provide the exact answer to each question, with a short answer of no more than 50 bytes in length and a long answer no more than 250 bytes. Here are the sample questions for the first QA track:
Who was the first American in space?
Where is the Taj Mahal?
In what year did Joe DiMaggio compile his 56-game hitting streak?
3. Short-lived prosperity
What are the results and significance of this first open domain QA competition? It should be said that the results are impressive, a milestone of significance in the QA history. The best systems (including ours) achieve more than 60% correct rate, that is, for every three questions, the system can search the given corpus and is able to return two correct answers. This is a very encouraging result as a first attempt at an open domain system. At the time of dot.com's heyday, the IT industry was eager to move this latest research into information products and revolutionize the search. There were a lot of interesting stories after that (see my related blog post in Chinese: "the road to entrepreneurship"), eventually leading to the historical AI event of IBM Watson QA beating humans in Jeopardy.
The timing and everything prepared by then from the organizers, the search industry, and academia, have all contributed to the QA systems' seemingly miraculous results. The NIST emphasizes well-formed natural language questions as appropriate input (i.e. English questions, see above), rather than traditional simple and short keyword queries. These questions tend to be long, well suited for paragraph searches as a leverage. For competition's sake, they have ensured that each question asked indeed has an answer in the given corpus. As a result, the text archive contains similar statements corresponding to the designed questions, having increased the odds of sentence matching in paragraph retrieval (Watson's later practice shows that from the big data perspective, similar statements containing answers are bound to appear in text as long as a question is naturally long). Imagine if there are only one or two keywords, it will be extremely difficult to identify relevant paragraphs and statements that contain answers. Of course, finding the relevant paragraphs or statements is not sufficient for this task, but it effectively narrows the scope of the search, creating a good condition for pinpointing the short answers required. At this time, the relatively mature technology of named entity tagging from the information extraction community kicked in. In order to achieve the objectivity and consistency in administrating the QA competition, the organizers deliberately select only those questions which are relatively simple and straightforward, questions about names, time or location (so-called factoid questions). This practice naturally agrees with the named entity task closely, making the first step into open domain QA a smooth process, returning very encouraging results as well as a shining prospect to the world. For example, for the question "In what year did Joe DiMaggio compile his 56-game hitting streak?", the paragraph or sentence search could easily find text statements similar to the following: "Joe DiMaggio's 56 game hitting streak was between May 15, 1941 and July 16". An NE system tags 1941 as time with no problem and the asking point for time in parsing the wh-phrase "in what year" is also not difficult to decode. Therefore, an exact answer to the exact question seems magically retrieved from the sea of documents to satisfy the user, like a needle found in the haystack. Following roughly the same approach, equipped with gigantic computing power for parallel processing of big data, 11 years later, IBM Watson QA beat humans in the Jeopardy live show in front of the nationwide TV audience, stimulating the entire nation's imagination with awe for this technology advance. From QA research perspective, the IBM's victory in the show is, in fact, an expected natural outcome, more of an engineering scale-up showcase rather than research breakthrough as the basic approach of snippet + NE + asking-point has long been proven.
A retrospect shows that adequate QA systems for factoid questions are invariably combined with a solid Named Entity module and a question parser for identifying asking points. As long as there is an IE-indexed big data behind, with information redundancy as its nature, factoid QA is a very tractable task .
4. State of the art
The year 1999 witnessed the academic community's initial success of the first open-domain QA track as a new frontier of the retrieval world. We also benefited from that event as a winner, having soon secured a venture capital injection of $10 million from the Wall Street. It was an exciting time shortly after AskJeeves' initial success in presenting a natural language interface online (but they did not have the QA technology for handling the huge archive for retrieving exact answers automatically, instead they used human editors behind the scene to update the answers database). A number of QA start-ups were funded. We were all expecting to create a new era in the information revolution. Unfortunately, the good times are not long, the Internet bubble soon burst, and the IT industry fell into the abyss of depression. Investors tightened their monetary operations, the QA heat soon declined to freezing point and almost disappeared from the industry (except for giants' labs such as IBM Watson; in our case, we shifted from QA to mining online brand intelligence for enterprise clients). No one in the mainstream believes in this technology anymore. Compared with traditional keyword indexing and searching, the open domain QA is not as robust and is yet to scale up to really big data for showing its power. The focus of the search industry is shifting from depth back to breadth, focusing on the indexing coverage, including the so-called deep web. As the development of QA systems is almost extinct from the industry, this emerging field stays deeply rooted in the academic community, developed into an important branch, with increasing natural language research from universities and research labs. IBM later solves the scale-up challenge, as a precursor of the current big data architectural breakthrough.
At the same time, scholars begin to summarize the various types of questions that challenge QA. A common classification is based on identifying the type of questions for their asking points. Many of us still remember our high school language classes, where the teacher stressed the 6 WHs for reading comprehension: who / what / when / where / how / why. (Who did what when, where, how and why?) Once answers to these questions are clear , the central stories of an article are in hands. As a simulation of human reading comprehension, the QA system is designed to answer these key WH questions as well. It is worth noting that these WH questions are of different difficulty levels, depending on the types of asking points (one major goal for question parsing is to identify the key need from a question, what we call asking point identification, usually based on question parsing of wh-phrases and other question clues). Those asking points corresponding to an entity as an appropriate answer, such as who / when / where, are relatively easy questions to answer (i.e. factoid questions). Another type of question is not simply answerable by an entity, such as what-is / how / why, there is consensus that answering such questions is a much more challenging task than factors questions. A brief introduction to these three types of "tough" questions and their solutions are presented below as a showcase of the on-going state to conclude this overview of the QA journey.
What/who is X? This type of questions is the so-called definition question, such as What is iPad II?Who is Bill Clinton? This type of question is typically very short, after the wh-word and the stop word "is" are stripped in question parsing, what is left is just a name or a term as input to the QA system. Such an input is detrimental to the traditional keyword retrieval system as it ends up with too many hits from which the system can only pick the documents with the most keyword density or page rank as returns. But from QA perspective, the minimal requirement to answer this question is a definition statement in the forms of "X is a ...". Since any entity or object is in multiple relationships with other entities and involved in various events as described in the corpus, a better answer to the definition question involves a summary of the entity with all the links to its key associated relations and events, giving a profile of the entity. Such technology is in existence, and, in fact, has been partly deployed today. It is called knowledge graph, supported by underlying information extraction and fusion. The state-of-the-art solution for this type of questions is best illustrated in the Google deployment of its knowledge graph in handling queries of a short search for movie stars or other VIP.
The next challenge is how-questions, asking about a solution for solving a problem or doing something, e.g. How can we increase bone density? How to treat a heart attack? This type of question calls for a summary of all types of solutions such as medicine, experts, procedures, or recipe. A simple phrase is usually not a good answer and is bound to miss varieties of possible solutions to satisfy the information need of the users (often product designers, scientists or patent lawyers) who typically are in the stage of prior art research and literature review for a conceived solution in mind. We have developed such a powerful system based on deep parsing and information extraction to answer open-domain how-questions comprehensively in the product called Illumin8, as deployed by Elsevier for quite some years. (Powerful as it is, unfortunately, it did not end up as a commercial success in the market from revenue perspective.)
The third difficult question is why. People ask why-questions to find the cause or motive of a phenomenon, whether an event or an opinion. For example, why people like or dislike our product Xyz? There might be thousands of different reasons behind a sentiment or opinion. Some reasons are explicitly expressed (I love the new iPhone 7 because of its greatly enhanced camera) and more reasons are actually in some implicit expressions (just replaced my iPhone , it sucks in battery life). An adequate QA system should be equipped with the ability to mine the corpus and summarize and rank the key reasons for the user. In the last 5 years, we have developed a customer insight product that can answer why questions behind the public opinions and sentiments for any topics by mining the entire social media space.
Since I came to the Silicon Valley 9 years ago, I have been lucky, with pride, in having had a chance to design and develop QA systems for answering the widely acknowledged challenging questions. Two products for answering the open-domain how questions and why-questions in addition to deep sentiment analysis have been developed and deployed to global customers. Our deep parsing and IE platform is also equipped with the capability to construct deep knowledge graph to help answer definition questions, but unlike Google with its huge platform for the search needs, we have not identified a commercial opportunity to deploy that capability for a market yet.
This piece of writing first appeared in 2011 in my personal blog, with only limited revisions since. Thanks to Google Translate at https://translate.google.com/ for providing a quick basis, which was post-edited by myself.
Wei:
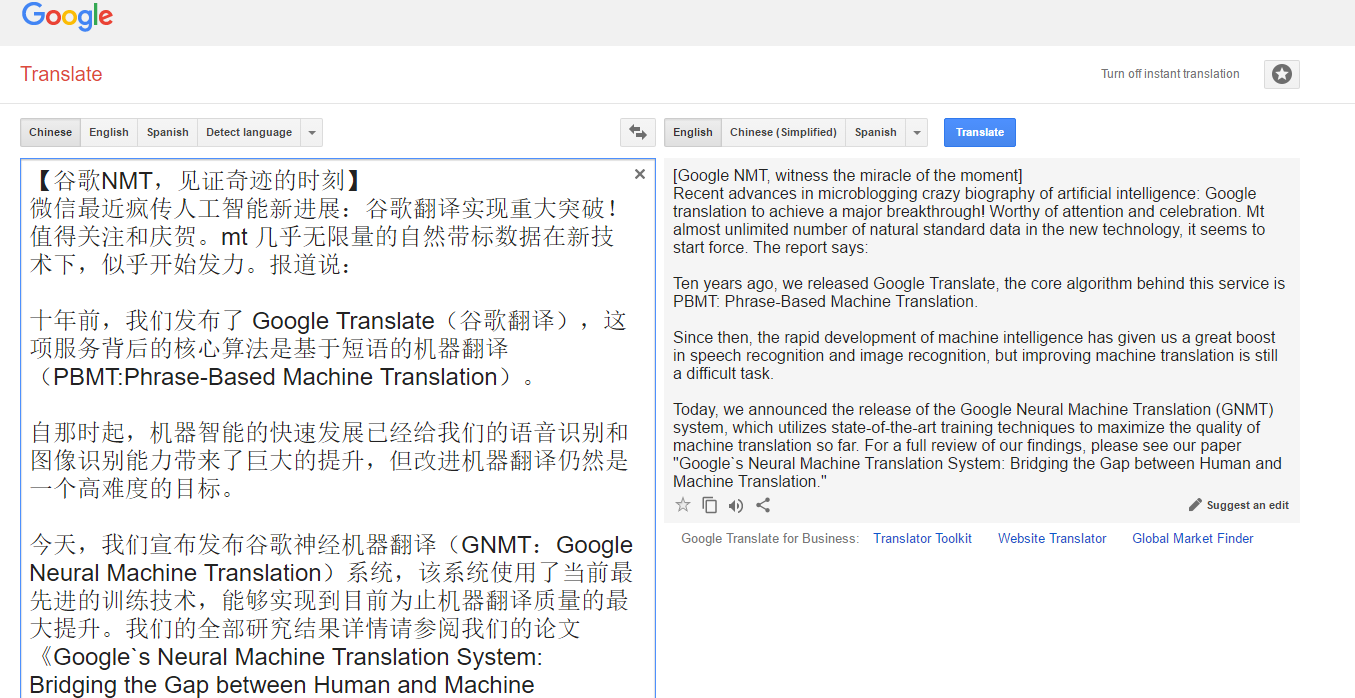
Recently, the microblogging (wechat) community is full of hot discussions and testing on the newest annoucement of the Google Translate breakthrough in its NMT (neural network-based machine translation) offering, claimed to have achieved significant progress in data quality and readability. Sounds like a major breakthrough worthy of attention and celebration.
Ten years ago, we released Google Translate, the core algorithm behind this service is PBMT: Phrase-Based Machine Translation. Since then, the rapid development of machine intelligence has given us a great boost in speech recognition and image recognition, but improving machine translation is still a difficult task.
Today, we announced the release of the Google Neural Machine Translation (GNMT) system, which utilizes state-of-the-art training techniques to maximize the quality of machine translation so far. For a full review of our findings, please see our paper "Google`s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation."A few years ago, we began using RNN (Recurrent Neural Networks) to directly learn the mapping of an input sequence (such as a sentence in a language) to an output sequence (the same sentence in another language). The phrase-based machine learning (PBMT) breaks the input sentences into words and phrases, and then largely interprets them independently, while NMT interprets the entire sentence of the input as the basic unit of translation .
A few years ago, we began using RNN (Recurrent Neural Networks) to directly learn the mapping of an input sequence (such as a sentence in a language) to an output sequence (the same sentence in another language). The phrase-based machine learning (PBMT) breaks the input sentences into words and phrases, and then largely interprets them independently, while NMT interprets the entire sentence of the input as the basic unit of translation .The advantage of this approach is that compared to the previous phrase-based translation system, this method requires less engineering design. When it was first proposed, the accuracy of the NMT on a medium-sized public benchmark
The advantage of this approach is that compared to the previous phrase-based translation system, this method requires less engineering design. When it was first proposed, the accuracy of the NMT on a medium-sized public benchmark data set was comparable to that of a phrase-based translation system. Since then, researchers have proposed a number of techniques to improve NMT, including modeling external alignment models to handle rare words, using attention to align input and output words, and word decomposition into smaller units to cope with rare words. Despite these advances, the speed and accuracy of NMT has not been able to meet the requirements of a production system such as Google Translate. Our new paper describes how to overcome many of the challenges of making NMT work on very large data sets and how to build a system that is both fast and accurate enough to deliver a better translation experience for Google users and services.
............
Using side-by-side comparisons of human assessments as a standard, the GNMT system translates significantly better than the previous phrase-based production system. With the help of bilingual human assessors, we found in sample sentences from Wikipedia and the news website that GNMT reduced translational errors by 55% to 85% or more in the translation of multiple major pairs of languages.
In addition to publishing this research paper today, we have also announced that GNMT will be put into production in a very difficult language pair (Chinese-English) translation.
Now, the Chinese-English translations of the Google Translate for mobile and web versions have been translated at 100% using the GNMT machine - about 18 million translations per day. GNMT's production deployment uses our open machine learning tool suite TensorFlow and our Tensor Processing Units (TPUs), which provide sufficient computational power to deploy these powerful GNMT models, meeting Google Translate strict latency requirements for products.
Chinese-to-English translation is one of the more than 10,000 language pairs supported by Google Translate. In the coming months, we will continue to extend our GNMT to far more language pairs.
As an old machine translation researcher, this temptation cannot be resisted. I cannot wait to try this latest version of the Google Translate for Chinese-English.
Previously I tried Google Chinese-to-English online translation multiple times, the overall quality was not very readable and certainly not as good as its competitor Baidu. With this newest breakthrough using deep learning with neural networks, it is believed to get close to human translation quality. I have a few hundreds of Chinese blogs on NLP, waiting to be translated as a try. I was looking forward to this first attempt in using Google Translate for my Science Popularization blog titled Introduction to NLP Architecture. My adventure is about to start. Now is the time to witness the miracle, if miracle does exist.
Dong:
I hope you will not be disappointed. I have jokingly said before: the rule-based machine translation is a fool, the statistical machine translation is a madman, and now I continue to ridicule: neural machine translation is a "liar" (I am not referring to the developers behind NMT). Language is not a cat face or the like, just the surface fluency does not work, the content should be faithful to the original!
Wei:
Let us experience the magic, please listen to this translated piece of my blog:
This is my Introduction to NLP Architecture fully automatically translated by Google Translate yesterday (10/2/2016) and fully automatically read out without any human interference. I have to say, this is way beyond my initial expectation and belief.
Listen to it for yourself, the automatic speech generation of this science blog of mine is amazingly clear and understandable. If you are an NLP student, you can take it as a lecture note from a seasoned NLP practitioner (definitely clearer than if I were giving this lecture myself, with my strong accent). The original blog was in Chinese and I used the newest Google Translate claimed to be based on deep learning using sentence-based translation as well as character-based techniques.
Prof. Dong, you know my background and my original doubtful mindset. However, in the face of such a progress, far beyond our original imagination limits for automatic translation in terms of both quality and robustness when I started my NLP career in MT training 30 years ago, I have to say that it is a dream come true in every sense of it.
Dong:
In their terminology, it is "less adequate, but more fluent." Machine translation has gone through three paradigm shifts. When people find that it can only be a good information processing tool, and cannot really replace the human translation, they would choose the less costly.
Wei:
In any case, this small test is revealing to me. I am still feeling overwhelmed to see such a miracle live. Of course, what I have just tested is the formal style, on a computer and NLP topic, it certainly hit its sweet spot with adequate training corpus coverage. But compared with the pre-NN time when I used both Google SMT and Baidu SMT to help with my translation, this breakthrough is amazing. As a senior old school practitioner of rule-based systems, I would like to pay deep tribute to our "nerve-network" colleagues. These are a group of extremely genius crazy guys. I would like to quote Jobs' famous quotation here:
“Here's to the crazy ones. The misfits. The rebels. The troublemakers. The round pegs in the square holes. The ones who see things differently. They're not fond of rules. And they have no respect for the status quo. You can quote them, disagree with them, glorify or vilify them. About the only thing you can't do is ignore them. Because they change things. They push the human race forward. And while some may see them as the crazy ones, we see genius. Because the people who are crazy enough to think they can change the world, are the ones who do.”
@Mao, this counts as my most recent feedback to the Google scientists and their work. Last time, about a couple of months ago when they released their parser, proudly claimed to be "the most accurate parser in the world", I wrote a blog to ridicule them after performing a serious, apples-to-apples comparison with our own parser. This time, they used the same underlying technology to announce this new MT breakthrough with similar pride, I am happily expressing my deep admiration for their wonderful work. This contrast of my attitudes looks a bit weird, but it actually is all based on facts of life. In the case of parsing, this school suffers from lacking naturally labeled data which they would make use of in perfecting the quality, especially when it has to port to new domains or genres beyond the news corpora. After all, what exists in the language sea involves corpora of raw text with linear strings of words, while the corresponding parse trees are only occasional, artificial objects made by linguists in a limited scope by nature (e.g. PennTree, or other news-genre parse trees by the Google annotation team). But MT is different, it is a unique NLP area with almost endless, high-quality, naturally-occurring "labeled" data in the form of human translation, which has never stopped since ages ago.
Mao: @wei That is to say, you now embrace or endorse a neuron-based MT, a change from your previous views?
Wei:
Yes I do embrace and endorse the practice. But I have not really changed my general view wrt the pros and cons between the two schools in AI and NLP. They are complementary and, in the long run, some way of combining the two will promise a world better than either one alone.
Mao: What is your real point?
Wei:
Despite biases we are all born with more or less by human nature, conditioned by what we have done and where we come from in terms of technical background, we all need to observe and respect the basic facts. Just listen to the audio of their GSMT translation by clicking the link above, the fluency and even faithfulness to my original text has in fact out-performed an ordinary human translator, in my best judgment. If an interpreter does not have sufficient knowledge of my domain, if I give this lecture in a classroom, and ask an average interpreter to translate on the spot for me, I bet he will have a hard time performing better than the Google machine listed above (of course, human translation gurus are an exception). This miracle-like fact has to be observed and acknowledged. On the other hand, as I said before, no matter how deep the learning reaches, I still do not see how they can catch up with the quality of my deep parsing in the next few years when they have no way of magically having access to a huge labeled data of trees they depend on, especially in the variety of different domains and genres. They simply cannot "make bricks without straw" (as an old Chinese saying goes, even the most capable housewife can hardly cook a good meal without rice). Because in the natural world, there are no syntactic trees and structures for them to learn from, there are only linear sentences. The deep learning breakthrough seen so far is still mainly supervised learning, which has almost an insatiable appetite for massive labeled data, forming its limiting knowledge bottleneck.
Mao: I'm confused. Which one do you believe stronger? Who is the world's No. 0?
Wei:
Parsing-wise, I am happy to stay as No. 0 if Google insists on their being No. 1 in the world. As for MT, it is hard to say, from what I see, between their breakthrough and some highly sophisticated rule-based MT systems out there. But what I can say is, at a high level, the trends of the mainstream statistical MT winning the space both in the industry as well as in academia over the old school rule-based MT are more evident today than before. This is not to say that the MT rule system is no longer viable, or going to an end. There are things which SMT cannot beat rule MT. For examples, certain types of seemingly stupid mistakes made by GNMT (quite some laughable examples of totally wrong or opposite translation have been illustrated in this salon in the last few days) are almost never seen in rule-based MT systems.
Dong:
here is my try of GNMT from Chinese to English:
Learning, the second of a watershed, the number of subjects significantly significantly, learning methods have also changed, some students can adjust to adapt to changes in progress, progress quickly, from the middle to rise to outstanding. But there are some students there is Fear of hard feelings, the mind used in the study, the rapid decline in performance, loss of interest in learning, self-abandonment, since the devastated, so the students often difficult to break through the third day,
Mao: This translation cannot be said to be good at all.
Wei:
Right, that is why it calls for an objective comparison to answer your previous question. Currently, as I see, the data for the social media and casual text are certainly not enough, hence the translation quality of online messages is still not their forte. As for the previous textual sample Prof. Dong showed us above, Mao said the Google translation is not of good quality as expected. But even so, I still see impressive progress made there. Before the deep learning time, the SMT results from Chinese to English is hardly readable, and now it can generally be read loud to be roughly understood. There is a lot of progress worth noting here.
Ma:
In the fields with big data, in recent years, DL methods are by leaps and bounds. I know a number of experts who used to be biased against DL have changed their views when seeing the results. However, DL in the IR field is still basically not effective so far, but there are signs of slowly penetrating IR.
Dong:
The key to NMT is "looking nice". So for people who do not understand the original source text, it sounds like a smooth translation. But isn't it a "liar" if a translation is losing its faithfulness to the original? This is the Achille's heel of NMT.
Ma: @Dong, I think all statistical methods have this aching point.
Wei:
Indeed, there are respective pros and cons. Today I have listened to the Google translation of my blog three times and am still amazed at what they have achieved. There are always some mistakes I can pick here and there. But to err is human, not to say a machine, right? Not to say the community will not stop advancing and trying to correct mistakes. From the intelligibility and fluency perspectives, I have been served super satisfactorily today. And this occurs between two languages without historical kinship whatsoever.
Dong:
Some leading managers said to me years ago, "In fact, even if machine translation is only 50 percent correct, it does not matter. The problem is that it cannot tell me which half it cannot translate well. If it can, I can always save half the labor, and hire a human translator to only translate the other half." I replied that I am not able to make a system do that. Since then I have been concerned about this issue, until today when there is a lot of noise of MT replacing the human translation anytime from now. It's kinda like having McDonald's then you say you do not need a fine restaurant for French delicacy. Not to mention machine translation today still cannot be compared to McDonald's. Computers, with machine translation and the like, are in essence a toy given by God for us human to play with. God never agrees to permit us to be equipped with the ability to copy ourselves.
Why GNMT first chose language pairs like Chinese-to-English, not the other way round to showcase? This is very shrewd of them. Even if the translation is wrong or missing the points, the translation is usually fluent at least in this new model, unlike the traditional model who looks and sounds broken, silly and erroneous. This is the characteristics of NMT, it is selecting the greatest similarity in translation corpus. As a vast number of English readers do not understand Chinese, it is easy to impress them how great the new MT is, even for a difficult language pair.
Wei:
Correct. A closer look reveals that this "breakthrough" lies more on fluency of the target language than the faithfulness to the source language, achieving readability at cost of accuracy. But this is just a beginning of a major shift. I can fully understand the GNMT people's joy and pride in front of a breakthrough like this. In our career, we do not always have that type of moment for celebration.
Deep parsing is the NLP's crown. Yet to see how they can beat us in handling domains and genres lacking labeled data. I wish them good luck and the day they prove they make better parsers than mine would be the day of my retirement. It does not look anything like this day is drawing near, to my mind. I wish I were wrong, so I can travel the world worry-free, knowing that my dream has been better realized by my colleagues.
Thanks to Google Translate at https://translate.google.com/ for helping to translate this Chinese blog into English, which was post-edited by myself.
有两大类抽取,一类是传统的信息抽取(IE),抽取的是事实或客观情报:实体、实体之间的关系、涉及不同实体的事件等,可以回答 who dis what when and where (谁在何时何地做了什么)之类的问题。这个客观情报的抽取就是如今火得不能再火的知识图谱(knowledge graph)的核心技术和基础,IE 完了以后再加上下一层挖掘里面的整合(IF:information fusion),就可以构建知识图谱。另一类抽取是关于主观情报,舆情挖掘就是基于这一种抽取。我过去五年着重做的也是这块,细线条的舆情抽取(不仅仅是褒贬分类,还要挖掘舆情背后的理由来为决策提供依据)。这是 NLP 中最难的任务之一,比客观情报的 IE 要难得多。抽取出来的信息通常是存到某种数据库去。这就为下面的挖掘层提供了碎片情报。
这算是我对NLP基本架构的一个总体解说。根据的是近20年在工业界做NLP产品的经验。18年前,我就是用一张NLP架构图忽悠来的第一笔风投,投资人自己跟我们说,这是 million dollar slide。如今的解说就是从那张图延伸拓展而来。
天不变道亦不变。
以前在哪里提过这个 million-dollar slide 的故事。说的是克林顿当政时期的 2000 前,美国来了一场互联网科技大跃进,史称 .com bubble,一时间热钱滚滚,各种互联网创业公司如雨后春笋。就在这样的形势下,老板决定趁热去找风险投资,嘱我对我们实现的语言系统原型做一个介绍。我于是画了下面这么一张三层的NLP体系架构图,最底层是parser,由浅入深,中层是建立在parsing基础上的信息抽取,最顶层是几类主要的应用,包括问答系统。连接应用与下面两层语言处理的是数据库,用来存放信息抽取的结果,这些结果可以随时为应用提供情报。这个体系架构自从我15年前提出以后,就一直没有大的变动,虽然细节和图示都已经改写了不下100遍了,本文的架构图示大约是前20版中的一版,此版只关核心引擎(后台),没有包括应用(前台)。话说架构图一大早由我老板寄送给华尔街的天使投资人,到了中午就得到他的回复,表示很感兴趣。不到两周,我们就得到了第一笔100万美金的天使投资支票。投资人说,这张图太妙了,this is a million dollar slide,它既展示了技术的门槛,又显示了该技术的巨大潜力。
(translated by Google Translate, post-edited by myself)
For the natural language processing (NLP) and its applications, the system architecture is the core issue. In my blog ( OVERVIEW OF NATURAL LANGUAGE PROCESSING), I sketched four NLP system architecture diagrams, now to be presented one by one .
In my design philosophy, an NLP process is divided into four stages, from the core engine up to the applications, as reflected in the four diagrams. At the bottom is deep parsing, following the bottom-up processing of an automatic sentence analyzer. This work is the most difficult, but it is the foundation and enabling technology for vast majority of NLP systems.
The purpose of parsing is to structure unstructured text. Facing the ever-changing language, only when it is structured in some logical form can we formulate patterns for the information we like to extract to support applications. This principle of linguistics structures began to be the consensus in the linguistics community when Chomsky proposed the transformation from surface structure to deep structure in his linguistic revolution of 1957. A tree representing the logical form does not only involve arcs that express syntactic-semantic relationships, but also contain the nodes of words or phrases that carry various conceptual information. Despite the importance of such deep trees, generally they do not directly support an NLP product. They remain only the internal representation of the parsing system, as a result of language analysis and understanding before its semantic grouding to the applications as their core support.
The next layer after parsing is the extraction layer, as shown in the above diagram. Its input is the parse tree, and the output is the filled-in content of templates, similar to filling in a form: that is the information needed for the application, a pre-defined table (so to speak), so that the extraction system can fill in the blanks by the related words or phrases extracted from text based on parsing. This layer has gone from the original domain-independent parser into the application-oriented and product-demanded tasks.
It is worth emphasizing that the extraction layer is geared towards the domain-oriented semantic focus, while the previous parsing layer is domain-independent. Therefore, a good framework is to do a very thorough analysis of logic semantics in deep parsing, in order to reduce the burden of information extraction. With the depth of the analysis in the logical semantic structures to support the extraction, a rule at extraction layer is in essence equivalent to thousands of surface rules at linear text layer. This creates the conditions for the efficient porting to new domains based on the same core engine of parsing.
There are two types of extraction, one is the traditional information extraction (IE), the extraction of facts or objective information: named entities, the relationships between entities, and events involving entities (which can answer questions like "who did what when and where" and the like). This extraction of objective information is the core technology and foundation for the knowledge graph (nowadays such a hot area in industry). After completion of IE, the next layer of information fusion (IF) is aimed at constructing the knowledge graph. The other type of extraction is about subjective information, for example, the public opinion mining is based on this kind of extraction. What I have done over the past five years as my focus is along this line for fine-grained extraction of public opinions (not just sentiment classification, but also to explore the reasons behind the public opinions and sentiments to provide the insights basis for decision-making). This is one of the hardest tasks in NLP, much more difficult than IE for objective information. Extracted information is usually stored in a database. This provides huge textual mentions of information to feed the underlying mining layer.
Many people confuse information extraction and text mining, but, in fact, they are two levels of different tasks. Extraction faces each individual language tree, embodied in each sentence, in order to find the information we want. The mining, however, faces a corpus, or data sources as a whole, from the language forest for gathering statistically significant insights. In the information age, the biggest challenge we face is information overload, we have no way to exhaust the information ocean for the insights we need, therefore, we must use the computer to dig out the information from the ocean for the required critical intelligence to support different applications. Therefore, mining relies on natural statistics, without statistics, the information is still scattered across the corpus even if it is identified. There is a lot of redundancy in the extracted mentions of information, mining can integrate them into valuable insights.
Many NLP systems do not perform deep mining, instead, they simply use a query to search real-time from the extracted information index in the database and merge the retrieved information on-the-fly, presenting the top n results to the user. This is actually also mining, but it is a way of retrieval to achieve simple mining for directly supporting an application.
In order to do a good job of mining, there is a lot of work that can be done in this mining layer. Text mining not only improves the quality of existing extracted information pieces, moreover, it can also tap the hidden information, that is not explicitly expressed in the data sources, such as the causal relationship between events, or statistical trends of the public opinions or behaviours. This type of mining was first done in the traditional data mining applications as the traditional mining was aimed at structured data such as transaction records, making it easy to mine implicit associations (e.g., people who buy diapers often buy beer, this reflects the common behaviours of young fathers of the new-born, and such hidden association can be mined to optimize the layout and sales of goods). Nowadays, natural language is also structured thanks to deep parsing, hence data mining algorithms for hidden intelligence in the database can, in principle, also be applied to enhance the value of intelligence.
The fourth architectural diagram is the NLP application layer. In this layer, the results from parsing, extraction, and mining out of the unstructured text sources can be used to support a variety of NLP products and services, ranging from the QA (question answering) systems to the dynamic construction of the knowledge graph (this type of graph is visualized now in the Google search when we do a search for a star or VIP), from automatic polling of public opinions to customer intelligence about brands, from intelligent assistants (e.g. chatbots, Siri etc.) to automatic summarization and so on.
This is my overall presentation of the basic architecture of NLP and its applications, based on nearly 20 years of experiences in the industry to design and develop NLP products. About 18 years ago, I was presenting a similar diagram of the NLP architecture to the first venture investor who told us that this is a million dollar slide. The presentation here is a natural inheritance and extension from that diagram.
~~~~~~~~~~~~~~~~~~~
Here is the previously mentioned million-dollar slide story. Under the Clinton's administration before the turn of the century, the United States went through a "great leap forward" of the Internet technology, known as Dot Com Bubble, a time of hot money pouring into the IT industry while all kinds of Internet startups were springing up. In such a situation, my boss decided to seek venture capital for the business expansion, and requested me to illustrate our prototype of the implemented natural language system for its introduction. I then drew the following three-tier structure of an NLP system diagram: the bottom layer is parsing, from shallow to deep, the middle is built on parsing for information extraction, and the top layer illustrates some major categories of NLP applications, including QA. Connecting applications and the downstairs two layers of language processing is the database, used to store the results of information extraction, ready to be applied at any time to support upstairs applications. This general architecture has not changed much since I made it years ago, although the details and layout have been redrawn no less than 100 times. The architecture diagram below is about one of the first 20 editions, involving mainly the backend core engine of information extraction architecture, not so much on the front-end flowchart for the interface between applications and the database. I still remember early in the morning, my boss sent the slide to a Wall Street angel investor, by noon we got his reply, saying that he was very interested. Less than two weeks, we got the first million dollar angel investment check. Investors label it as a million dollar slide, which is believed to have not only shown the depth of language technology but also shows the great potential for practical applications.
Pre-Knowledge Graph: Architecture of Information Extraction Engine
The speech generation of the fully automatically translated, un-edited science blog of mine is attached below (for your entertainment :=), it is amazingly clear and understandable (definitely clearer than if I were giving this lecture myself with my strong accent). If you are an NLP student, you can listen to it as a lecture note from a seasoned NLP practitioner.
今天,我们宣布发布谷歌神经机器翻译(GNMT:Google Neural Machine Translation)系统,该系统使用了当前最先进的训练技术,能够实现到目前为止机器翻译质量的最大提升。我们的全部研究结果详情请参阅我们的论文《Google`s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation》。
The automatic speech generation of this science blog of mine is attached here, it is amazingly clear and understandable. If you are an NLP student, you can listen to it as a lecture note from a seasoned NLPer (definitely clearer than if I were giving this lecture myself with my strong accent). More amazingly, the original blog was in Chinese and I used the newest Google Translate claimed to be based on deep learning using sentence-based translation as well as character-based techniques. My original blog in Chinese is here, you can compare:【立委科普:自然语言系统架构简说】。
董:
学习上,初二是一个分水岭,学科数量明显增多,学习方法也有所改变,一些学生能及时调整适应变化,进步很快,由成绩中等上升为优秀。但也有一部分学生存在畏难情绪,将心思用在学习之外,成绩迅速下降,对学习失去兴趣,自暴自弃,从此一蹶不振,这样的同学到了初三往往很难有所突破,中考的失利难以避免。
Learning, the second is a watershed, the number of subjects increased significantly, learning methods have also changed, some students can adjust to adapt to changes in progress, progress quickly, from the middle to rise to outstanding. But there are some students there is fear of hard feelings, the mind used in the study, the rapid decline in performance, loss of interest in learning, self-abandonment, since the devastated, so the students often difficult to break through the third day,
Introduction to NLP Architecture by Dr. Wei Li (fully automatically translated by Google Translate)
The automatic speech generation of this science blog of mine is attached here, it is amazingly clear and understandable, if you are an NLP student, you can listen to it as a lecture note from a seasoned NLPer (definitely clearer than if I were giving this lecture myself with my strong accent):
To preserve the original translation, nothing is edited below. I will write another blog to post-edit it to make this an "official" NLP architecture introduction to the audiences perused and honored by myself, the original writer. But for time being, it is completely unedited, thanks to the newly launched Google Translate service from Chinese into English at https://translate.google.com/
[Legislature science: natural language system architecture brief]
For the natural language processing (NLP) and its application, the system architecture is the core issue, I blog [the legislature of science: NLP contact diagram] which gave four NLP system architecture diagram, now one by one to be a brief .
I put the NLP system from the core engine to the application, is divided into four stages, corresponding to the four frame diagram. At the bottom of the core is deep parsing, is the natural language of the bottom-up layer of automatic analyzer, this work is the most difficult, but it is the vast majority of NLP system based technology.
The purpose of parsing is to structure unstructured languages. The face of the ever-changing language, only structured, and patterns can be easily seized, the information we go to extract semantics to solve. This principle began to be the consensus of (linguistics) when Chomsky proposed the transition from superficial structure to deep structure after the linguistic revolution of 1957. A tree is not only the arcs that express syntactic relationships, but also the nodes of words or phrases that carry various information. Although the importance of the tree, but generally can not directly support the product, it is only the internal expression of the system, as a language analysis and understanding of the carrier and semantic landing for the application of the core support.
The next layer is the extraction layer (extraction), as shown above. Its input is the tree, the output is filled in the content of the templates, similar to fill in the form: is the information needed for the application, pre-defined a table out, so that the extraction system to fill in the blank, the statement related words or phrases caught out Sent to the table in the pre-defined columns (fields) to go. This layer has gone from the original domain-independent parser into the face-to-face, application-oriented and product-demanding tasks.
It is worth emphasizing that the extraction layer is domain-oriented semantic focus, while the previous analysis layer is domain-independent. Therefore, a good framework is to do a very thorough analysis of logic, in order to reduce the burden of extraction. In the depth analysis of the logical semantic structure to do the extraction, a rule is equivalent to the extraction of thousands of surface rules of language. This creates the conditions for the transfer of the domain.
There are two types of extraction, one is the traditional information extraction (IE), the extraction of fact or objective information: the relationship between entities, entities involved in different entities, such as events, can answer who dis what when and where When and where to do what) and the like. This extraction of objective information is the core technology and foundation of the knowledge graph which can not be renewed nowadays. After completion of IE, the next layer of information fusion (IF) can be used to construct the knowledge map. Another type of extraction is about subjective information, public opinion mining is based on this kind of extraction. What I have done over the past five years is this piece of fine line of public opinion to extract (not just praise classification, but also to explore the reasons behind the public opinion to provide the basis for decision-making). This is one of the hardest tasks in NLP, much more difficult than IE in objective information. Extracted information is usually stored in a database. This provides fragmentation information for the underlying excavation layer.
Many people confuse information extraction and text mining, but in fact this is two levels of the task. Extraction is the face of a language tree, from a sentence inside to find the information you want. The mining face is a corpus, or data source as a whole, from the language of the forest inside the excavation of statistical value information. In the information age, the biggest challenge we face is information overload, we have no way to exhaust the information ocean, therefore, must use the computer to dig out the information from the ocean of critical intelligence to meet different applications. Therefore, mining rely on natural statistics, there is no statistics, the information is still out of the chaos of the debris, there is a lot of redundancy, mining can integrate them.
Many systems do not dig deep, but simply to express the information needs of the query as an entrance, real-time (real time) to extract the relevant information from the fragmentation of the database, the top n results simply combined, and then provide products and user. This is actually a mining, but is a way to achieve a simple search mining directly support the application.
In fact, in order to do a good job of mining, there are a lot of work to do, not only can improve the quality of existing information. Moreover, in-depth, you can also tap the hidden information, that is not explicitly expressed in the metadata information, such as the causal relationship between information found, or other statistical trends. This type of mining was first done in traditional data mining because the traditional mining was aimed at structural data such as transaction records, making it easy to mine implicit associations (eg, people who buy diapers often buy beer , The original is the father of the new people's usual behavior, such information can be excavated to optimize the display and sale of goods). Nowadays, natural language is also structured to extract fragments of intelligence in the database, of course, can also do implicit association intelligence mining to enhance the value of intelligence.
The fourth architectural diagram is the NLP application layer. In this layer, analysis, extraction, mining out of the various information can support different NLP products and services. From the Q & A system to the dynamic mapping of the knowledge map (Google search search star has been able to see this application), from automatic polling to customer intelligence, from intelligent assistants to automatic digest and so on.
This is my overall understanding of the basic architecture of NLP. Based on nearly 20 years in the industry to do NLP product experience. 18 years ago, I was using a NLP structure diagram to the first venture to flicker, investors themselves told us that this is million dollar slide. Today's explanation is to extend from that map to expand from.
Days unchanged Road is also unchanged.
Where previously mentioned the million-dollar slide story. Clinton said that during the reign of 2000, the United States to a great leap forward in Internet technology, known as. Com bubble, a time of hot money rolling, all kinds of Internet startups are sprang up. In such a situation, the boss decided to hot to find venture capital, told me to achieve our prototype of the language system to do an introduction. I then draw the following three-tier structure of a NLP system diagram, the bottom is the parser, from shallow to deep, the middle is built on parsing based on information extraction, the top of the main categories are several types of applications, including Q & A system. Connection applications and the following two language processing is the database, used to store the results of information extraction, these results can be applied at any time to provide information. This architecture has not changed much since I made it 15 years ago, although the details and icons have been rewritten no less than 100 times. The architecture diagram in this article is about one of the first 20 editions. Off the core engine (background), does not include the application (front). Saying that early in the morning by my boss sent to Wall Street angel investors, by noon to get his reply, said he was very interested. Less than two weeks, we got the first $ 1 million angel investment check. Investors say that this is a million dollar slide, which not only shows the threshold of technology, but also shows the great potential of the technology.
Pre - Knowledge Mapping: The Structure of Information Extraction Engine