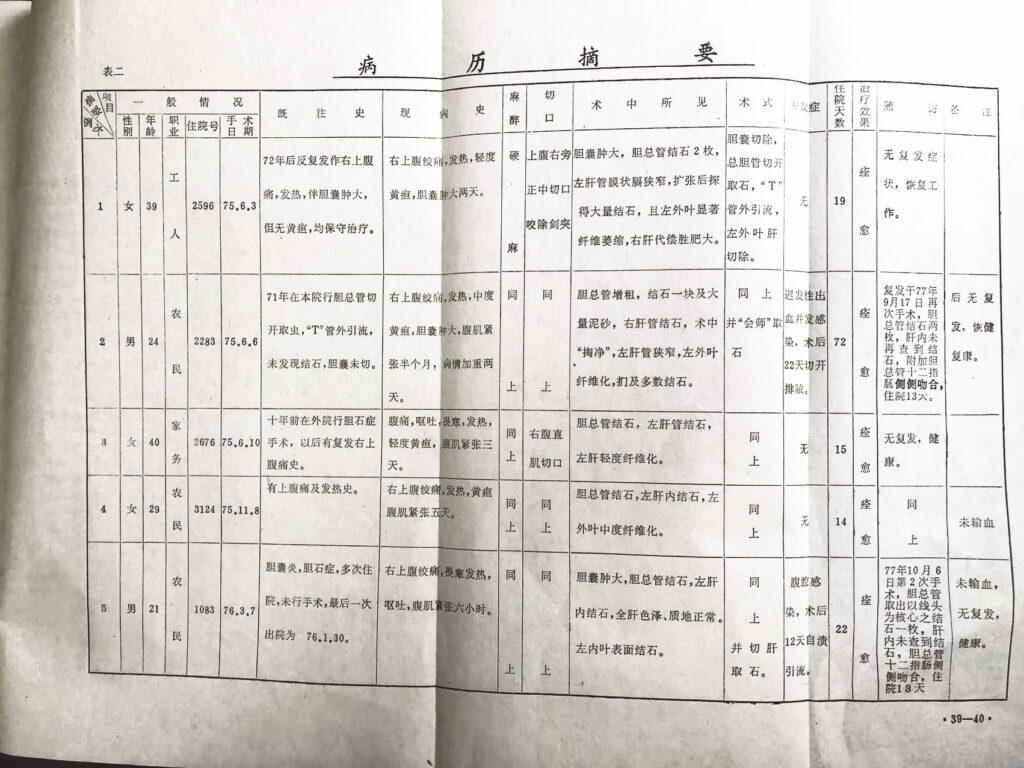
脊椎结核的一次手术治疗
(附三例报告)
南陵县医院骨科 李名杰
脊椎结核占全身骨关节结核的首位,为47.28%(1),临床上常见。保守治疗,虽在抗痨药物问世的今天,亦迁延多年,难以治愈。手术治疗,虽大为改观,但往往需要2-3次的大手术,费时、费钱、增加痛苦; 而一次手术治愈,实为多快好省。兹就我院75、76年间有病历资料的计划一次手术治疗的颈、胸、腰椎结核各一病例报告如下。
例一: 男性,18岁,农民,繁昌县人。病案号: 12179。
颈痛一年。活动受限半年。发烧,颈部肿块,吞咽困难二周。不能进食、进水,不能言语,且有呼吸困难4天。X市医院已穿刺减压为白色稀薄脓汁,并摄片确诊为颈椎3、4结核并巨大咽后脓肿,气管、食道受压。于75年10月26日急诊入我院。检查: 颈部无活动,颌下饱满、膨出、波动。张口呼吸、不语、大汗、脱水,但无紫绀。其他无特殊。快速补液1000cc,入院后两小时局麻下急诊手术,颈左前外侧进路,吸出脓液600cc,刮除脓腔壁,中线切开颈椎骨膜,直视下取出颈椎3下缘脓栓,窥见0.5x0.6cm骨洞,乃咬开外口,小心刮除结核肉芽、干酪样物及砂粒样碎骨,冲洗脓腔,因病椎间隙已消失并自行融合,故未植骨,置入青、链霉素,橡皮片引流,分层缝合,手术顺利。术毕呼吸平稳、正常,并能进食,也能发音说话。术后颈部制动,抗痨,6天拆线,切口愈合,10天出院。注射链霉素60克,服雷米封半年,术后2个月恢复了轻劳动,一年后为整劳力,随访三年半一切正常,颈部活动无碍,79年8月14日摄片复查示3-4颈椎骨性融合,无死骨、脓肿及骨质破坏。(X片号2090)
例二: 男性,23岁,南陵人,农民,病案号: 2875。
因胸椎9、10结核并椎旁脓肿于76年5月31日入院,经术前准备,检查无手术禁忌症,于76年6月19日在气管内乙醚全麻下, 经右胸第9肋骨床进胸, 切开纵膈膜胸进人脓腔达椎体,吸净脓汁,在处理两根肋间动、静脉后,扩大内暴露,直视对侧病灶至肋骨横突头节处,刮除结核肉芽、干酪样物、坏死椎间盘以及死骨并冲洗之。将病椎间上下凿成骨槽,同时植入肋骨片四条,并使其嵌紧,置入抗菌素,严密缝合之。彻底冲洗胸腔,关胸并闭锁引流。术后恢复顺利,26小时拨除胸管,72小时胸透肋膈角已锐。术后第五天体温正常,于76年6月29日出院,住院29天。嘱卧床四个月,抗痨治疗9个月。随访: 术后一个月下地活动,并逐渐恢复轻工作,但出现驼背。一年以后正常劳动。三年后X线摄片复查椎旁无脓肿阴影、无死骨,胸椎9、10已融合,但植骨片被吸收,胸10椎体塌陷,出现驼峰。 (X线片号2104)
例三:男性,50岁,已婚,农民,南陵人。病案号:1462。
腰椎2、3结核并发腰大肌脓肿,已注链霉素20克,于76年8月8日入院。76年8月9日在硬麻下左侧剖腰切口进路,行病灶清除加前路植骨术。切除12肋备用,腹膜外分离,切开腰大肌进入脓腔,继而安全处理椎旁腰横血管2根(2),扩大内暴露并由此途径清理对侧腰大肌脓肿,全面刮除脓腔壁的肉芽,瞬即以大热盐水纱布填塞压迫5分钟以减少大面积渗血,再扩大椎体上骨洞,彻底清除死骨、坏死椎间盘等大量结核组织。清洗后检查认为满意,在病椎间凿成骨槽,嵌入取下之12肋,一次完成清除病灶和前路植骨。术后恢复顺利,切口一期愈合,于78年3月24日出院,住院21天。术后卧床四个月,半年恢复劳动,现在已做9分工,能行50里,无不适,精神和体质均好。术后三年,于79年8月15日检查,两侧腰大肌均未扪及肿块,脊柱无叩痛,活动良好。胸透: 右上肺结核吸收好转期,腰椎X线片示腰椎1-4骨性融合,无死骨、脓肿。(X线片号2101)
讨论:
(1) 脊柱结核的治疗,经历了漫长的演变过程。从长期卧床、全身抗痨到姑息性脓肿切开,脓肿刮除、瘘管缩短术; 根治性的分侧病灶清除加融合术,以至发展到近年来人们寻求一次手术解决问题。但因脊柱的解剖关系复杂,暴露困难,手术风险大,阻碍着“清除彻底”,所以一次手术治愈此类疾病至今尚未普及。通过改进外、内暴露,使清除彻底有了可能,我们经历了上述三例,均在半年内获得痊愈,较其他治疗方案显示了优越性。
(2) 手术治疗脊椎结核,除了清除脓肿和椎体病灶外,也同时打破了“结核屏障”,使抗痨药能够达到病灶部,较之单纯保守治疗大大提高了治愈率 [3]。我院同期另有五例包括其中的二例胸椎结核并发截瘫者,因故只接受了一侧病灶清除或单纯融合术,也都获得了痊愈,不过时间皆在一年左右;而文中病例由于清除较为彻底,所以痊愈时间更为缩短。
(3) 脊柱结核的治疗,既要求病变痊愈,又要求恢复脊柱的支持力和稳定度,故植骨融合术遂成为治疗中重要的一环。后路植骨要承受张力,不利于植骨的生长; 前路植骨却受到压力,有利于植骨的生长,又可在病灶清除的同时施行,以外暴露切下之自体助骨为材料,其方法以支持嵌入较之上盖、充填为好,使之能起到临时支持和融合后的永久支持的双重作用,故较为合理。但必须以病灶清除彻底和没有混合感染为先决条件,否则植骨片易被吸收或坏死 [3]。本文例二、例三均无混合感染,清除亦“满意”,故同时施以前路植骨。
椎体间植骨,受到压力影响,容易移位而被吸收,故必须保证卧床3个月以上。而农村病例常不愿长期住院,在家若擅自过早活动,易使植骨失败。文中例二术后1个月即下床,导致植骨片移位、吸收、椎休塌陷而出现驼背。例三则遵医嘱获得预期效果,实为一经验教训。
(4) 颈椎结核并咽后脓肿形成占位性压迫,致使吞咽、发音甚至呼吸困难,构成急诊。因其进路方便,局麻即可,失血及损伤均少,手术堪称方便。又因脓肿撑开周围组织,病椎前方显露宽敞,只要遵循“中线切开” [1]的原则推开骨模,椎体病灶可在直视下进行彻底清除,加之颈部血运丰富,病灶吸收快,修复能力强,易于获得好的疗效,本文例1术后疗效极为满意。关于植骨、牵引、固定与否要根据病椎的稳定情况来定。但需严防颈髄震损,以避免高位截瘫的严重事故发生。(①不用骨凿,②清除时不越过后纵韧带。)
(5) 胸椎结核,位于3-10者,若条件许可,经胸途径,可一次完成两侧病灶清除及前路植骨(2-7),为病人所欢迎,亦节约床位。虽有开胸之骚扰和感染之虞,在现代麻醉、无菌、抗菌素等条件下,尚称安全。文中例2术后10天出院休养。
(6) 腰椎深在,周围重要组织多,显露困难,手术创伤大,且清除病灶不易彻底,常规需2-3次手术。但在病人体质条件许可下,通过腰血管的特殊处理 [1],遵循骨膜下分离,可以安全而宽敞地显露病椎,便于清除病灶彻底。
关于对侧腰大肌脓肿清除问题: 通过挤压对侧腰部,直视脓液来源,再由扩大的内暴露,用各种弯度之结核刮匙,绕道伸入刮除; 必要时也可在刮匙指引下,于对侧安全处径作切开,“会师”清除。需要说明: 一切重要器官均位于腰大肌之外,故遵循“肌内”脓肿搔刮,尚为安全,但仍应提防血管、神经误伤 [9]。在此基础上同时行前路植骨,也可以预期痊愈,大大缩短了疗程,如例3。
小结:
通过作者三例临床实践,叙述了颈、胸、腰椎结核一次手术治愈的临床经过和3-4年的随访结果。其中例一为急诊,例二、例三均同时前路植骨,指出关键为好的显露和清除彻底,结合复习文献,提出了一些技术措施,并对脊椎结核的治疗作了粗浅的讨论。
参考文献:
①天津病院骨科临床骨科学结核分册P183人民卫生出版社1974
②方先之: 骨关节结核病灶清除疗法 人民卫生出版社 1960
③郭巨灵: 前路植骨在脊柱结核治疗中作用和问题 中华外科杂志11:12: 1963
④刘 忠: 胸椎结核经胸腔病灶清除术 中华外科杂志8:531: 1960
⑤范秉哲: 开胸施行胸椎结核病灶清除术 中华外科杂志7:20: 1959
⑥王志先: 经胸胸施行胸结病灶清除术 中华外科杂志:271: 1959
⑦罗先正: 经胸廓胸膜外脊椎结核病灶清除术的初步报告 中华外科杂志12: 1144: 1964
⑧田成瑞: 病灶清除疗法治疗脊柱结核的几点体会天津医药骨科附刊 2:76:1678
⑨于培礼等: 腰椎结核病灶搔爬术中髂外动脉误伤(临床病例讨论) 中华外科杂志 11:936:1963
原载 安徽省首届骨科学会交流论文 1979