分类: 杂类



李名杰:医学论文集(8):外科论文5-7




李名杰:医学论文集(9):外科论文8




李名杰:医学论文集(10):外科论文9-13





李名杰:医学论文集(11):外科论文14

李名杰:医学论文集(12):外科论文15-16


博文发表新博文 李名杰:医学论文集(13):外科论文17 ”腹部创伤“




李名杰:医学论文集(14):外科论文18-19



李名杰:医学论文集(15):外科论文20-21




博文发表新博文 李名杰:医学论文集(16):骨科论文1



李名杰:医学论文集(17):骨科论文2


李名杰:医学论文集(18):骨科论文3





李名杰:医学论文集(19):骨科论文4-6




李名杰:医学论文集(20):骨科论文7


The Story of My Father (An Epilogue)
by Hanyang Yijiangshui
Let me share a few anecdotes about my father to provide a glimpse into his professional life.
One
During one Lunar New Year, Hanyang and I went back to our hometown to celebrate with our father.
After the New Year's Eve dinner, we all sat together watching TV and chatting. Around eleven, a call came in for my father. It was from the hospital where he served. They had an emergency and wanted him to consult. Without hesitation, my father got ready and asked Hanyang to drive him to the hospital.
He worked throughout the night and only called Hanyang to pick him up the next morning. On the way home, Hanyang inquired about the emergency. My father, visibly exhausted, simply said, "Doctors often face such situations. Emergencies don’t care about holidays. It's been this way since I was young." He then closed his eyes to rest.
Days later, my father recounted the event with pride. That night, an emergency case was admitted with a suspected acute appendicitis. Two on-duty surgeons began the surgery, but upon opening the patient, they were puzzled to find no inflammation. As they debated the next steps, one suggested consulting my father.
Upon arrival, my father swiftly diagnosed a stomach perforation with gastric contents spilling into the abdominal cavity. He then skillfully performed the surgery, saving the patient from potential complications. This type of condition, where the symptoms are hidden, often goes undiagnosed, requiring both experience and theoretical knowledge to identify.
He later said that had they not properly diagnosed the issue, the patient would've faced further surgeries, and if the acidic gastric content had remained in the abdomen for too long, it could've been life-threatening.
Two
During the Cultural Revolution, my father had a close friend, Uncle Gui, from a neighboring county. His 16-year-old son had a neck condition, which was misdiagnosed as a recurrent malignant tumor. The family was advised amputation, a heartbreaking prognosis. Desperate, they turned to my father. After a careful examination, my father determined it was another type of benign tumor. He successfully performed surgery, saving both the boy's arm and his life. The boy went on to have a successful international career, and they still visit my father in gratitude.
In the 1970s, a 35-year-old female patient came in with a vertebral issue. She was emaciated, weighing only 40 kilograms, and suffered from paraplegia. With a challenging surgery involving careful removal of the necrotic material and grafting, my father successfully treated her. The husband, a blacksmith, gifted my father with handmade stainless steel kitchen tools, which are still in use today.
Among his notable achievements in orthopedics, my father performed hundreds of surgeries for lumbar disc herniation. Many patients, immobilized by pain, found instant relief post-surgery and went on to live healthy lives.
Three
My father practiced medicine for over sixty years, performing surgeries on more than ten thousand patients. Were there any medical accidents? None at all! However, he did have a few surgical failures in his career. One particular case deeply pained him, reminding him that intentions don't always match outcomes, leading to self-reproach. My father's surgical mentor, the former head of surgery at Wannan Medical College's Second Affiliated Hospital, Mr. Min Mei, once consoled him with a story from his time at Beijing Fuwai Hospital, a renowned cardiology institution. Many patients entered the hospital walking but were carried out after unsuccessful surgeries. Leading Chinese medical authorities had once advised Min Mei that while some patients might die without surgery, there's still a glimmer of hope with surgery. Science comes with its costs, and doctors often work on the front lines of life and death, carrying the weight of their successes and failures.
A particularly heartbreaking case for my father involved surgery on a middle school teacher who came to him by reputation. The 64-year-old teacher was diagnosed with gallstones based on his medical history and an ultrasound. My father had successfully performed over a thousand such surgeries. On October 16, 1984, my father removed the teacher's gallbladder, discovering 23 cholesterol gallstones inside. The surgery seemed to proceed "smoothly," lasting 75 minutes. However, the patient's unique anatomy presented a congenital variation that wasn't detected until complications arose post-surgery. Three days post-operation, jaundice appeared and worsened. Subsequent surgeries on November 9, 1984, and February 10, 1985, failed to save the teacher, who succumbed to multi-organ failure five days after the last operation. My father was deeply affected and often cited this tragic case as a cautionary tale. He penned a medical paper based on these experiences to remind himself and others to be diligent and continuously learn.
Four
A 29-year-old male patient, after colliding with a stationary cart while riding his bicycle, experienced intense pain, difficulty breathing, and palpitations. He was admitted to my father's hospital an hour later. Preliminary examinations showed no internal organ injuries or fluid accumulation in the abdominal cavity. However, after 16 hours of observation, the patient complained of pain in the right flank and testicle. A diagnosis of posterior peritoneal duodenal injury was made, leading to an exploratory laparotomy 28 hours post-injury. During the procedure, some bile-like fluid was found in the abdominal cavity. No injuries were detected in the gallbladder, extrahepatic bile duct, or liver. Swelling and green discoloration were observed in the posterior peritoneum. Upon further examination, a 1.5 cm rupture was found in the descending part of the duodenum, causing leakage of intestinal fluid and tissue necrosis. After thorough cleaning and repair, intestinal motility was restored within 48 hours. The patient fully recovered after three weeks, with no complications or aftereffects. Such posterior peritoneal duodenal injuries are rare and severe, often presenting subtle early symptoms that can lead to misdiagnosis. The surgery itself is intricate and demanding. Surgical precision and adaptability are crucial as a slight oversight can be life-threatening. Fortunately, my father's skillful hands saved this patient, who now leads a normal life.
Five
The patient, a male, suffered from melanin spots and gastrointestinal polyposis syndrome. Over fourteen years, he underwent three surgeries, all of which were performed by my father. Particularly challenging was the patient's extremely rare intestinal and biliary obstruction, a condition possibly unparalleled worldwide! Complications were the primary reason for his medical consultations, typically manifesting during his youth. Being a congenital condition with no complete cure, its prognosis can be favorable with proper management, even though it necessitates multiple surgeries. It doesn't necessarily shorten the lifespan. With my father's meticulous treatment, the patient was given a new lease on life. Throughout his career, my father encountered many such critically ill patients. Practically self-taught and working in a basic grassroots hospital, he took saving lives as his mission, creating miracles one after another.
Six
In 1968, in a remote mountainous village called Hewan in southern Anhui, a 13-year-old boy fell off a bull's back. My father, upon examining him, found a ruptured right liver and significant internal bleeding, requiring a thoracotomy to be treated. Even in big cities, liver surgeries were major procedures at the time, and my father had never performed one before. Especially in such a remote village, ensuring an adequate blood supply for the operation was a challenge. With the boy's life hanging by a thread and time running out, my father, in a moment of quick thinking and audacity, decided to draw accumulated blood from the abdominal cavity and re-transfuse it. This innovative approach of re-transfusing abdominal blood mixed with bile was a first in China. (From a theoretical standpoint, the idea of re-transfusing liver blood, especially contaminated with bile, was barely mentioned in medical literature then. Only a decade later was it reported and subsequently confirmed in various studies.) Relying on his previous experience with blood transfusion (without bile) and given the urgent situation, my father performed this transfusion technique throughout the night, extracting, filtering, and re-transfusing a total of 1700 ml of blood, buying precious time. Operating under a kerosene lamp in a rural health center, with rudimentary anesthesia, my father proceeded to carry out both a thoracotomy and laparotomy. The surgery was a triumphant first attempt, successfully repairing the liver. In a tiny village with no electricity, limited assistance, basic equipment, scarce medicine and blood supplies, and without the guidance of a senior surgeon, my father's successful completion of his first-ever liver surgery was nothing short of miraculous. The postoperative recovery was also "smooth," and the patient's life was saved. Given the conditions and technical expertise of that era, it was a remarkable achievement.
The procedure represented the pinnacle of surgical expertise in county hospitals of China at that time, truly cutting-edge. Accomplishing such a surgery in a small village operating room, lacking electricity and running water, is unprecedented in China.
Seven
In October 1965, following the “6.26” directive, my father led a medical team of seven, including one internist, five nurses/midwives, and himself, a surgeon, to the Yandun Commune in southern Anhui. Although he held the position of deputy leader, the actual leader was Dr. Tian, an internist in his fifties with poor health, who often stayed home for recuperation and rarely spent time in the countryside. This effectively put my father, who was not yet thirty, in charge of the entire operation for three straight months.
During the last 100 days of 1965, without electricity, an anesthetist, assistants, or adequate equipment and medicine, my father, on his own, set up a makeshift “operating room.” With cloth overhead as a ceiling, the ground wetted to keep dust down, and lit by a kerosene lamp and flashlight, this “room” was where he performed 612 surgeries of various sizes without a single mishap. All patients recovered, a testament to the miracles he performed in the rural setting. Of these, 121 were major open surgeries ranging across general surgery, gynecology, orthopedics, and otorhinolaryngology. Surgeries included stomach, gall bladder, intestine, and uterus removals, bile-intestine internal drainage, vaginal total hysterectomies, bladder-vaginal fistula repairs, and many others. In an era when even basic medicines like penicillin were rare, to perform such a diverse range of surgeries in 100 days was a feat – a testament to my father's exceptional surgical skills and innovation.
At the same time, the medical team organized training for health workers from all six production brigades in the commune, established a health-conscious village, and dug two wells, forever changing the village's history of consuming muddy water.
My father, always on duty, never took a single day off during these intense three-plus months. Although he was only an hour's drive from home, where both the elderly and children awaited, he didn't return even once in over 100 days. This unparalleled dedication to work, without any financial incentive, would be unimaginable today.
On one particular afternoon during this medical outreach, with the assistance of the only anesthetist from the county hospital who had temporarily come over, my father single-handedly performed three vaginal total hysterectomies with pelvic floor repair and reconstruction. This was in the aftermath of China’s infamous famine, which left many with malnutrition-related conditions. On the same day, he continued to operate until 3 am, performing over ten other surgeries and working continuously for nearly 18 hours. Such a work rate is unmatched even today.
For these achievements, the medical team was recognized and rewarded by the county and district (city) governments. My father was specially invited to give a presentation at the commendation meeting, where he displayed all the surgical instruments he used. His methods were promoted throughout the Wuhu region, a grand acknowledgment and reward for his efforts.
During this period, several unforgettable cases stood out:
- A patient with heavy bleeding due to incomplete miscarriage was treated with an emergency dilation and curettage, along with rapid fluid resuscitation, ultimately saving her life.
- A bladder-vaginal fistula patient underwent successful surgical repair and recovered in 12 days, pioneering such surgery in the region.
- A middle-aged woman suffering from typhoid with an intestinal perforation and peritonitis underwent intestinal resection. Treated for free due to her financial situation, my father later visited her home in Qingyang Mud Town to ensure her well-being.
- An emergency cesarean section was performed on an office desk for a woman with a threatened uterine rupture due to fetal malposition.
- A patient with a ruptured spleen underwent a splenectomy on the same office desk, where 800 ml of abdominal blood was re-transfused, a groundbreaking procedure at the time.
The adage goes: necessity is the mother of invention. In this case, dire circumstances crafted the hero. Theoretical support and recognition for some of these groundbreaking procedures would only emerge in the literature later on.

Dad, second from right on the front row
Eight
On July 28, 1976, the historic Tangshan earthquake occurred, and my father had a deep connection to it. On August 2, he was summoned to join a three-person medical team from Wuhu district (city) to aid in the earthquake-stricken areas. Upon their arrival in Nanjing, they received a call from Beijing, advising that the injured were being sent south and that medical teams from various locations should prepare to treat them locally, eliminating the need to go directly to the disaster site. Consequently, my father was stationed at a treatment center in E'Qiao, Fanchang. Leading a 25-person medical team, with another 25 locals supporting logistics, they received 100 injured individuals. As the team leader overseeing all operations, my father had three deputy leaders and two instructors with him — an impressively robust leadership team. All the selected members were the "elites", directly under city and county leadership. The national government covered all expenses for the injured, prioritizing this as a top-tier political task.
My father, along with a few doctors, went to the Nanjing railway station to inspect and receive the injured from a medical-special train. When the train reached E'Qiao, a team awaited to carry the patients into the "wards". Most of the injured had non-life-threatening injuries, mainly bone and muscle injuries. Fortunately, my father was well-versed in orthopedics. Switching from administrative duties to focus on clinical medical care, over the subsequent months, they worked tirelessly to ensure the recovery of every individual and even sent doctors to accompany the injured back to their hometowns. In this catastrophic event that shocked the world and claimed 240,000 lives, my father contributed his bit, accomplishing this historical mission.
That year, China faced multiple calamities. After the deaths of prominent national leaders Zhou and Zhu, during this national disaster caused by the earthquake, on September 9th, Mao — China's paramount leader, also passed away. This cast a shadow over the entire nation, with the populace uncertain and apprehensive about China's future.
During this tumultuous period, my father, away from home, bore the significant responsibility of managing 100 injured individuals and 50 staff members. With the local region also experiencing aftershocks and given the concerns of staff about their own safety and their families, coupled with the successive deaths of national "parental" figures, it's easy to imagine the pervasive sense of despair and hopelessness. However, my father, leveraging his skills and leading by example, accomplished the task brilliantly, once again submitting a perfect report card.

Dad, 5th from left in the middle row
Nine
During the violent confrontations of the Cultural Revolution, different factions armed themselves, leading to disrupted transportation and hospital shutdowns. However, bullets don't discriminate, and gunshot wounds were rampant, affecting vital organs like the liver, lungs, blood vessels, kidneys, and the gastrointestinal tract. This often necessitated on-the-spot surgeries. It was under these dire circumstances that my father was forced to self-learn and master the techniques for repairing organs, particularly in cases of brain injuries.
Despite the challenging environment and conditions, my father managed to save many lives. While he undoubtedly had his share of successes, even in the instances where he couldn't save a life, there was minimal blame attributed to him (given the circumstances). These experiences significantly honed his technical skills and expertise.
The confrontations resulted in hospitals operating at limited capacities, granting my father ample free time. He used this period to systematically read medical textbooks and study English, thereby solidifying his foundational knowledge in medical theories. This self-learning phase marked a significant leap in his theoretical understanding, which, when applied practically, further solidified his expertise. The synergy of theory guiding practice, and practice leading to real insights, elevated my father's knowledge and application to new heights.
Ironically, the violent confrontations of the Cultural Revolution ended up cultivating surgical talent. This can be seen as a peculiar silver lining — a dark kind of humor in the midst of chaos.
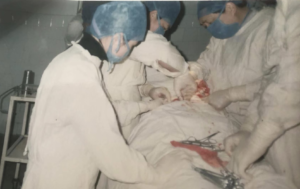
Ten
Throughout my father's medical career, which spanned over 60 years, he performed countless surgeries. In his practice, he often introduced minor improvements, innovations, and breakthroughs that yielded highly effective results.
a. Except for special requirements, my father abandoned the convention of pre-inserting gastric tubes in the thousands of gastrectomy procedures he performed (a procedure recommended in textbooks). He had no failures with this approach. This demanded meticulous suturing, impeccable hemostasis, intraoperative emptying of gastric residues, and rigorous post-operative observation, which greatly enhanced patient comfort.
b. In cases of diffuse peritonitis, after removing the lesions and infectious materials, he discarded intraperitoneal drainage, thus reducing post-operative adhesions. The key was thorough intraoperative washing and cleaning. He believed that drain fluid in the peritoneal cavity would quickly get clogged by fibrin, which only added to the patient's discomfort. Certainly, in cases like pancreatitis or abdominal abscesses where ongoing leakage is expected, negative pressure drainage with double tubes is necessary.
c. In circumcision, standard procedures often led to misalignments, hematomas, edemas, and difficulties in removing stitches, causing distress to both doctors and patients. My father modified the procedure, using local venous anesthesia, precise cutting under tourniquet control, impeccable hemostasis, and meticulous suturing with human hair or absorbable sutures, resulting in a pain-free procedure with excellent alignment, quick healing, and no stitch removal.
d. Fistulectomy for anal fistulas traditionally involved threading or open excision, causing significant post-operative pain and a lengthy recovery. My father adopted long-acting local anesthesia (with a diluted methylene blue injection) for a one-stage excision and suturing, usually resulting in a single-phase healing and a shorter treatment duration.
e. Controlling wound infections, especially traumatic ones, hinges on the thorough cleaning during the initial treatment, rather than relying on drainage or antibiotics. Extensive washing with water to remove foreign bodies and dead tissue, meticulous disinfection, tension-free sutures, and, if post-operative inflammation occurs, supplemental alcohol compresses – with or without antibiotics – ensured infections were largely eliminated in wounds treated within 6 hours.
f. In inguinal hernia repairs, the focus was on the transverse abdominal fascia. My father used a modified Madden technique instead of the traditional Bassini method, greatly alleviating the post-operative pain from tensioned sutures. This also promoted healing and significantly reduced the recurrence rate.
Eleven
My father was brilliant. Not only was he adept in surgery, but he also had a knack for writing articles effortlessly. Although he only received a vocational education, his surgical skills, prolific writing, and fluency in English allowed him to smoothly acquire mid-level, associate, and full professional titles without any disputes.
However, many of his colleagues (excluding the leadership) weren't as fortunate. Some lacked the necessary skills, others didn't have enough research articles. Even though many had higher educational qualifications than my father, they struggled to achieve the highest professional titles.
My father had strong reservations about this system. He believed that several of his friends, who were competent in clinical surgeries, were hindered due to their inability to write articles. Without publications, they couldn't ascend the professional ladder.
He argued that clinical work is practical, especially in surgery. It requires dexterity and intuition. Improvement comes from experience and observation, not from writing research papers. Clinical work is not about research. Considering the massive patient load and back-to-back surgeries and shifts, it's already taxing. Being in a non-academic hospital, who has the time to sit, apply for research topics, conduct studies, and write articles?
Clinical doctors need extensive training and a wealth of experience. Combining research tasks with clinical duties and judging doctors based on their research publications rather than their clinical expertise is unfair. It's absurd for a profession that's fundamentally about clinical skills to prioritize publications over actual patient care proficiency.
Being kind-hearted and always eager to help, on one occasion, he told two friends, both highly skilled surgeons who were held back in their professional advancements due to a lack of publications: "I'll write several articles for you both. You can revise them, provide feedback, and then publish them under your names."
True to his word, my father promptly wrote several medical articles and handed them over to his two friends.
Twelve
Despite being 88 years old, my father has an insatiable curiosity about new technology. He's deeply interested in emerging knowledge and science and is adept at adapting to novel concepts. He's a progressive thinker, always reflecting on novel ideas and not just sticking to traditional views. He's always driven to achieve excellence and delves into unknown territories. From computers, mobile phones, and the internet to intelligent AI applications, he has been at the forefront, keen to experience the latest technological advancements and to understand their innovation. He often says that to avoid being left behind in this world, one must be open to new things. This way, life doesn't stagnate, and we can continually enhance our lives and improve our quality of living. Staying updated and keeping pace with the times has always been his life's norm.
When OpenAI's ChatGPT was introduced, he was immediately intrigued. Almost daily, he would inquire about it with his son, my younger brother Li Wei, who works in natural language processing, eager to understand ChatGPT's applications, its current status, and future direction. Recently, Wei managed to set up ChatGPT for him to work via VPN, having made father one of the most senior users of ChatGPT in China.
Of course, as LLM applications are being rapidly deployed, we'll see a seamless integration with smart home functionalities in the future. People will increasingly rely on artificial intelligence, which often determines the quality of life. While domestic AI research might be a step behind Western countries, its practical application is not lacking, and the adoption rate in China exceeds that of the West. This allows the public to experience the convenience of the latest tech products, providing my father ample opportunities to try out various AI products and software at home. He thoroughly enjoys it, making him a genuine AI application enthusiast.
My father is witnessing the AI boom of the 2020s and certainly won't miss out on this magnificent era. He currently uses an Apple 15 Pro, the latest model with three-nanometer technology. Paired with the newest VPN software on his iPad and ChatGPT, he has the latest tech tools at his disposal. It's rare to find an elderly individual with such a tech setup in the entire country. At 88, my 'fully-equipped' father remains ahead of the curve, always staying at the forefront of technological advancements.
Dad's passion and pursuit of technology are not only to satisfy his own curiosity but also to maintain competitiveness and adaptability in an ever-changing era. In this age where technology evolves rapidly, Dad shows us through his actions what it truly means to 'learn as long as you live'. His positive attitude and curiosity about new things are worth learning and passing on by each of us.
Closing Words: In the quiet depths of night, the familiar silhouette, a symbol of tireless dedication, invariably emerges before my eyes, invoking clear and heartfelt memories. It brings back scenes of my father's hard work and life from yesteryears. Though many of those moments have faded into the annals of time, spanning over half a century, they remain ever-present in my mind, etching deep imprints in my heart, evoking emotions, instilling strength, and radiating warmth.
Dad, you stand as my beacon, my source of pride. I love you.
央视的大美南陵视频
这是我的老家,我长大的地方。山水还是那个山水,但建筑不再是那个建筑。不认识了,但的确很美。城建超出想象。
中国的经济起飞,不仅仅有一线(如上海北京)二线(如南京、武汉)三线(如 芜湖)城市的巨变,四线县城也是换了人间。这个成就还是值得称道的。江南是个好地方,感觉真要生活在三线四线,应该很容易适应。生活的便利、烟火味儿,啥也不缺。并不是只有大城市才宜居。且不说生活成本的差异。
The Tireless Father (Preface)
"Though turtles live long, they meet their end. Though dragons ride the mist, they eventually turn to dust. Aged but still full of fire, ambitious till the very end. The natural order isn't the only clock; contentment brings longevity. How fortunate indeed, to express these sentiments through song." — "Though Turtles Live Long" by Cao Cao of the Eastern Han Dynasty
My father was born on November 3rd, 1936, or September 20th according to the lunar calendar. He's a Rat in the Chinese Zodiac. Following our local tradition, which counts one extra year, he is currently 88 years old.
Father's name is Li, Mingjie, his courtesy name Hao, and his art name is Cuisheng. Born into a struggling intellectual family, his youth was filled with hardship and adversity. Lack of finances kept him from attending university, a lifelong regret.
In March 1956, my dad graduated from the Wuhu Health School and has been involved in medical work for 67 years. After a stint in schistosomiasis prevention and two years in public health administration, he shifted his focus to surgical clinical work in 1961. He has been practicing for over six decades now. He served in Nanling County Hospital for 25 years, Wuhu Changhang Hospital for 22 years, and China Railway Wuhu Hospital for 16 years. Approaching his nineties, he still hasn't fully retired. His vision remains clear, his hearing sharp, and his hands steady. He conducts research, reads literature, remains engrossed in his profession, and stays updated with the latest surgical developments. His thoughts are coherent, and he still performs surgeries. Moreover, as the medical industry transitioned to digital documentation, he adapted seamlessly, never falling behind. His age hasn't dampened his spirit; he continues to contribute to society with undiminished vigor. Truly, he is a tireless father.
My father has dedicated his life to medicine and saving lives. Over the course of more than half a century, he has understood the emotional states of patients, and monitored their health conditions, and with his exceptional intellect, energy, and skilled hands, he has tailored treatments to individual needs. He has brought health to countless patients, saved numerous lives from the brink of death, and restored joy to many families clouded with sorrow.
My father worked diligently at the grassroots level. Despite only having a diploma from a technical health school, he had no formal professor or mentor to guide him. He was self-taught. His medical skills came from personal insights and countless hours spent studying medical books. His natural talent, intelligence, diligence, and unwavering passion paved the way for his medical aspirations. Even in remote and impoverished regions, and in an era when intellectuals were often marginalized, he carved out his own success. As my father often says, 'My surgical career has been one of the longest, with numerous surgeries across a wide spectrum of specialties.' He also notes that many of the surgeries he performed at the grassroots level were highly challenging. Some of these procedures are still considered cutting-edge in the world of surgery. For instance, liver and lung surgeries, removal of cervical spine tuberculosis lesions, and repairs of injuries to the duodenum behind the peritoneum – such surgeries were rarely conducted even in the provincial hospitals during the 1960s. Yet, my father took the initiative to perform these complex operations in a modest county hospital and achieved success. He often proudly asserts: 'In surgery, sometimes, you have to pull a tooth from a tiger's mouth. It's not about blind risk-taking! It's about taking calculated risks, having advanced skills, and providing high-level treatment. Being brave yet cautious, breaking the norm, and always prioritizing scientific and pragmatic approaches are essential.
My father has practiced across a broad spectrum of medical specialties, from abdominal surgery, thoracic surgery, orthopedics, obstetrics and gynecology, neurosurgery, urology, otolaryngology, ophthalmology, radiology to anesthesiology. He has successfully performed many high-difficulty level-4 surgeries in each specialty, which is truly an astounding achievement. These surgeries range from operations for acute pancreatitis in abdominal surgery, carotid artery aneurysm resections in head and neck surgery, spinal tumors in neurosurgery, lung malignancies and esophageal cancer in thoracic surgery, clearing lesions of various osteomyelitis and tuberculosis of the cervical, thoracic, lumbar, and sacral vertebrae, and other fractures in orthopedics. Additionally, he has conducted lymph node stripping in urology, hysterectomy and ovariectomy in gynecology, nasolacrimal duct anastomosis in otolaryngology, cataract surgeries, and artificial pupil operations in ophthalmology. He's also proficient in different forms of anesthesia, including epidural blocks, brachial plexus blocks, spinal anesthesia, intubation general anesthesia, and intravenous composite anesthesia. The breadth of medical categories my father has mastered is unparalleled and unmatched, both domestically and internationally.
The unique circumstances of that era provided my father with a rare opportunity to showcase his talents and capabilities. Facing a continuous influx of impoverished rural patients, the stakes were high. To not treat was to let die. Treating them was always better than leaving them to their fates. He had significant autonomy. With an endless drive to work hard, he performed surgeries almost daily for decades. With exceptional professional skills, noble medical ethics, passion for medicine, dedication to his patients, persistence, diligence, and unwavering perseverance, he emerged as an outstanding major surgery doctor. My father seized fleeting opportunities, often breaking barriers and shining in his field. His achievements made him stand out, eventually reaching the pinnacle of clinical practice in grassroots hospitals.
For decades, when not performing surgeries, he would immerse himself in medical books, often sacrificing sleep and meals. Rarely did we see him rest; he was a true workaholic. We've always felt that my father is the modern-day Hua Tuo, crafted by his era. Considering the breadth of his medical practice, the number of patients he's aided, and the length of his service, he stands almost unparalleled in history—perhaps with the exception of Hua Tuo—and likely unmatched in the future.
Surgical practitioners need intuition. The stability and flexibility of one's fingers and wrists are incredibly crucial. My father seemed to be naturally made for surgery. He had an insatiable thirst for knowledge, a bold yet meticulous approach, an innate intelligence, and an innovative spirit. His expertise in surgery enabled him to comprehend concepts instantly and perform operations with exceptional precision. Especially during his younger years, he honed exceptional skills. Additionally, his team spirit was exemplary. Every subordinate doctor trained under him developed rigor, dedication, and a relentless pursuit of excellence, shaping a generation of medical leaders and experts.
As soon as he stepped onto the operating table, it was as if my father became a different person—calm, confident, and masterfully executing each surgical procedure. His surgical precision and speed earned him accolades from peers, patients, and their families. Over the years, his reputation spread far and wide, attracting a steady stream of patients seeking his expertise. Even the relatives of the chief surgeons from top-tier hospitals would seek my father for surgeries, trusting only in his magic hands. The renowned Director of the Surgery Department from the original Yijishan Hospital, Dr. Chen, entrusted my father with the surgery of his wife, Madam Xie, who was the head of the Nursing Department in Changhang Hospital. Despite her being in her eighties and diagnosed with breast cancer, my father's successful surgery ensured her well-being well into her nineties. She considered my father her lifetime "personal physician". Similarly, Wang Ping, the Head of the ENT department at Nanling County Hospital, trusted my father to operate on his daughter, Dong Wei, who had breast cancer. Years later, the Chief of the Obstetrics and Gynecology Department of the same hospital entrusted the care of her daughter in the same manner to my father.
The director of the surgery department at Changhang Hospital, Mr. Shen, had an elderly father-in-law in Shanghai, a distinguished professor, who was diagnosed with stomach cancer and pyloric obstruction. After being unable to eat or drink for several days and his body deteriorating, his family had almost given up hope. Yet, my father undertook the "risky" direct radical surgery, having saved his life. The patient lived for another five years before succumbing to other illnesses. Conventionally, patients of this age and condition would first undergo a bypass surgery to relieve the obstruction, and only later would they have the surgery to remove the lesion. In reality, few would get the chance for this second operation.
Back in 1970, my elder uncle, Pan Yaoyi, had hepatic and biliary stones along with obstructive jaundice. Refused by a renowned hospital in Hefei, he turned to my father in desperation. At the Nanling County Hospital, my father personally performed the surgery to remove the stones, excise the gallbladder, and establish an internal biliary-duodenal drainage, ensuring his full recovery. In 1986, another uncle of ours, Pan Yaotong, was diagnosed with rectal cancer and similarly turned away by the provincial hospital. Once again, my father stepped in, performing the radical surgery that lasted over seven hours.
Back in the 1980s, numerous patients would report their symptoms over the phone, and my father could make a diagnosis then and there. For instance, his colleague Cheng Daben had a perforated stomach. The young doctors at Yijishan Hospital misdiagnosed it as renal colic and treated it by administering laxatives to clean the intestines. The urinary system imaging examination the next day proved them all wrong! This not only delayed the crucial time for life-saving treatment but also exacerbated the perforation and leakage, pushing the patient into critical condition! The patient, in excruciating abdominal pain, desperately called my father and urged a return to our hospital, where an emergency surgery to cut into the stomach cured him. The husband of the head nurse Gao at the undergraduate department, Tao, experienced a similar ordeal. Nowadays, it's more common for patients to seek medical advice remotely through mobile "WeChat" at any time and place, resolving many medical issues this way. What's particularly remarkable is that all the surgeries for our immediate family members were personally performed by my father. This demanded immense confidence, determination, and mental fortitude.
We once knew a young rural doctor who, feeling constrained in his medical career, chose to pursue an English teaching degree instead. When discussing my father's medical skills, he expressed deep admiration: "Do you know? Your father is one of the most incredible doctors in the world. He can perform complex surgeries that many top-tier hospitals have yet to introduce or popularize." He shared several cases with us, and even though we might not have understood all the medical intricacies, one thing was clear: my father consistently pushed boundaries, always striving for surgical excellence.
Later, when we asked my father about any complicated surgeries he wished to perform but couldn't, he mentioned microsurgery, limb reattachment, and other surgeries requiring advanced equipment that were beyond the reach of the county hospital at the time. He also expressed admiration for the fields of stem cell regenerative medicine, gene-editing techniques, genetic engineering to reverse aging cells, and precision medicine, recognizing them as the frontiers of medical research, while humbly admitting that as a grassroots clinician, he could only admire them from afar.
After the Cultural Revolution, with the resumption of professional promotions, my father climbed the ranks seamlessly, from Medical Practitioner, Physician, Attending Physician, Associate Chief Physician to Chief Physician. His progress was smooth, never missing a step. In all three secondary hospitals, each with over a hundred staff where he served throughout his life, he was the sole Chief Surgeon. In fact, in the entirety of these institutions, there were only one or two with such a distinguished title. Compared to his peers who graduated from technical health schools like him, almost none had the chance to rise to such a senior position. Even graduates from medical colleges in his generation, the majority in secondary hospitals couldn't attain such a high-ranking title. The criteria for grassroots hospitals were even more stringent. One needed to excel in clinical practice, publish academic papers, and be proficient in English. Typically, only one chief position each was reserved for internal medicine and surgery specialties. They preferred having a vacancy rather than compromising on quality. This emphasizes how my father was truly a rare gem among his contemporaries, standing head and shoulders above the rest.
The era shapes individuals. My father never attended elementary school, high school, undergraduate, or postgraduate courses. His formal education consisted of only middle school and a medical diploma from a technical health school. Yet, he relied primarily on countless hours of medical practice, learning through hands-on experiences. With sheer skill and determination, he ascended the ranks to become a Chief Surgeon in general surgery, ultimately earning a reputation as a renowned all-around physician.
While doctors are respected, many lead modest lives. A bit of hardship in life didn't bother my father, but the challenge he faced was how to save up money to buy medical books. Those thick professional volumes like "Surgery" and "Orthopedics" were expensive, yet indispensable for his work. Who could have imagined that many of these medical books were acquired by my father secretly selling his own blood? Each time he would donate 300cc of fresh blood and receive 30 yuan – an amount that would typically take him half a year to save. My father would brush it off, saying: "humans have a hematopoietic system, so losing a little blood doesn't matter. There are often stories of doctors donating their own blood in emergencies to save patients, and I've experienced this myself several times during my medical career". But acquiring professional books by selling one's blood, such instances are probably rare across all of history and around the world and perhaps only characteristic of that particular era in China. Perhaps only in that specific era could a reputed doctor resort to such means to own medical books.
On June 3, 2007, my father faced the greatest ordeal of his life. Suddenly, he began vomiting blood and developed an inexplicable fever reaching 40°C. The once indomitable spirit, who often claimed to be "forever young and vital", was suddenly brought to his knees. He lost over 2000ml of blood, putting him in grave danger. He was rushed to the hospital and was diagnosed with 'low-differentiated gastric adenocarcinoma.' On June 21, he underwent major surgery in Wuhan, having his entire stomach and gallbladder (due to pre-existing gallstones) removed. He narrowly escaped the clutches of death. Having worked tirelessly throughout his life, he always took pride in his robust health and positive attitude. Who would've thought? A man so rarely ill could be brought down so severely. This incident was the most significant challenge he had ever faced and marked a turning point in his health journey.
My father has always been the backbone of our family, typically appearing youthful and vigorous, especially for his age, without a hint of any vices and never having stayed in a hospital before. Despite the hardships, life was always vibrant for him. Thankfully, his sudden illness led to an early diagnosis and timely treatment. Being under the best medical care and surrounded by family during his recovery gave everyone peace of mind. After the surgery, he aged noticeably, and it took him over six months to regain his strength. Now, he speaks with such vigor and frequently performs surgeries, which is a huge relief for our entire family.
Now semi-retired, my father, at the age of 88, is astonishingly spry for his age. Despite his modest living, he keeps an orderly life and continues to be eager to learn new things. Although he no longer drives, his curiosity about the latest tech developments remains. Just this February, he was asking me about the etymology and background of OpenAI and ChatGPT. He's more tech-savvy with smartphones and computers than many youngsters I know, ordering food from Meituan, hailing cars from DiDi, and shopping on Taobao. He also frequently consults English professional materials, absorbing new knowledge, proving the adage true: you're never too old to learn. He even outpaces English-major graduate Wei in English technical vocabulary, truly an exemplary lifelong learner.
Before his major illness, he was a whirlwind of energy, performing surgeries, driving, browsing the internet, writing memoirs, and enjoying chess games. In the decade since his surgery, even with a decline in his physical condition, he hasn't given up his lifelong passion for clinical medicine. He may have set aside other specialties, such as orthopedics, gynecology, and urology, but he remains steadfast in his dedication to general surgery, continuously contributing to the field and aiding patients. Medicine is an eternal bond he could never sever.
Gentle in nature and kind to all, my father has always been upright and warm-hearted. His patience and attentiveness when diagnosing patients, regardless of their socio-economic status, genuinely exemplify the benevolent spirit and humanistic essence of a doctor.
With progressive thoughts and a modern mindset, he always treated his children as equals, never reprimanding them, let alone resorting to physical punishment. He has always gently guided us, both through his words and his actions. Our individual successes are his greatest solace, and the growth and antics of his grandchildren bring him immense joy and satisfaction.
This book is a compilation of some of the medical papers my father published after the Cultural Revolution. Although it's not exhaustive, it preserves many invaluable experiences and theoretical summations from his medical career, standing as an enduring testament to his dedication. These papers encapsulate how a doctor from a grassroots hospital refined himself through challenges, continuously pushing his boundaries. They embody a physician's fundamental principles, conscience, responsibility, commitment, and mission, spotlighting the gallantry of medical professionals in their efforts to save lives and epitomizing the profound essence of "healing the world."
Recently, as we were compiling some of these medical papers, my father reflected on his journey spanning over 60 years, filled with both pride and nostalgia. While his papers primarily encapsulate his clinical experiences and might not be heavily research-oriented, their practical utility is undeniable. They are meticulously crafted, adhering to strict academic standards, and represent the crystallization and theoretical evolution of his medical practice, holding a certain legacy value. The excellence he has demonstrated throughout his life, his unwavering dedication to medicine, his relentless pursuit of knowledge, and his humble, upright, and benevolent character serve as a priceless heritage for our generation.
Given the vast timeline, locating all his papers was challenging, and unfortunately, many have been lost over the years. We've done our best to gather as many of his past medical writings as possible, compiling them into this volume as a birthday gift for our 88-year-old father, who has been practicing medicine for 67 years non-stop. We wish him a happy birthday, good health, and a peaceful twilight year!
候选数字人图库

提示词:a detailed artistic photograph as portrait of a beautiful Chinese young girl next door, beautiful lighting

















图生文
老哥问: 能否用 ChatGTP4 给这几张照片取个名字?汉江边,琴台公园旁






小雅换装
It all starts with this piece of AIGC original about 2 years ago (2021):

Then:

小雅高清 8.3 MB

2.5MB

2 MB

1.9 MB

2.4MB

1.8MB

2.3MB

2MB

1.8MB

1.8MB

309KB

220KB

317 KB

1.8MB

596KB

179KB




285 KB

262 KB

密码保护:东湖改造的一点思路
老爸的故事(代后记)
汉阳一江水

这里讲一讲老爸的几则小故事,就能一窥老爸业务全貌。
一
有一年春节,我回老家陪老爸过年。
大年三十吃完年饭,大家一起看着电视, 聊着家常。大约十一点左右, 老爸电话响了,是老爸服务的医院打来的。说医院有个急诊,希望老爸过来会诊指导一下。老爸二话没说,稍加收拾,叫我开车把他送往医院。
老爸一直工作到第二天,大年初一的早晨,才叫我接他回家。路上我询问老爸,什么急诊,大年三十都过不安稳?老爸很疲劳,眯着眼疲惫地淡淡说:医生吗,常会有这种事,急诊才不管假日不假日。年轻时年年如此,你们小记不得了。说着,就闭眼休息去了。
过了几天,老爸才骄傲地告诉我,那天幸亏他去了。原来大年三十医院来了个急诊病人,初步诊断为急性阑尾炎。两位值班外科医生连夜开刀动手术。打开肚皮后,两位医生懵了,阑尾没有炎症。在手术台上两位医生发生争论,一位提出关腹缝肚,看情况转高一级医院。另一位提出让老爸过来看看,再决定下一步方案。
两位争论一下,最后一致决定请老爸过来一趟。老爸一过来,一边听他们介绍,一边消毒换衣上手术台检查。姜是老的辣,老爸上台一探查,就发现问题。病人是胃穿孔,大量胃中物流出。随后老爸亲自动手,缝合胃孔,清理腹腔,用时二小时,顺利关腹,解决问题。这例胃穿孔,穿孔渗出被包裹,隐匿很深,难以查出,因而易被手术医生漏诊。这需要临床医生先判断,再寻找,没有一定临床经验和理论基础,是很难发现的。
老爸说,如果当时不查明病因就关腹,误诊误治,再次手术是必然的。如果拖久一点,腹部被胃液等物浸蚀,感染扩散,会危及生命。老爸说,这个手术最需要仔细,必须非常细心地清理腹腔残留物,确保术后不被感染,不然,后面麻烦事很多。老爸很兴奋,自己又救人一命。
要知道老爸那时已过八十高龄,虽眼不花手不抖,但五年前他因胃癌做了胃全切手术,因胆结石做了胆全切手术,身体已大不如从前。但老爸一上手术台,就生龙活虎,一站就二小时,也不叫累,下手术台后,也迟迟不回家,继续观察病人病情。
老爸对自己职业,热爱深入骨髓。救人救命,是他一生的追求。直到今天他仍然离不开他的岗位,不是为了收入,而是为了他那份对自己职业的热爱和执着。
二
故事发生在文革期间,老爸有一世交老朋友桂叔,家在邻县,我 们两家当年走动频繁,我们也很熟悉他们一家人。桂叔他有一个16岁 的儿子,患颈椎5结核并寒性脓肿,压迫了食道和气管,不能进食,呼 吸困难,声嘶、脱水、缺氧,生命危急。他们家先去芜湖最大医院弋 矶山医院,骨科陈主任拒收,说,几天前,类似一例,手术,未下得 了台。嘱转合肥省级医院,要备800元。可是,他月工资52元,要养活 一家六口,哪能成行?况且,也不知合肥又如何打发他?火急的他听 说南陵城郊的解放军127医院有位全国骨科权威许竟斌主任(也是老爸 的骨科恩师),怀一线希望,他带着儿子来到127医院。不巧的是,许 军医出差南京,他旗下几位,都不敢接受这例高危病人。无奈,老友 找到老爸,老爸过去一看,发现过去从未接触过此类病人,感觉有些 心有余而力不足,不太敢接受。于是老爸找到127医院的骨科和外科军 医们(老爸与他们都很熟,老爸在127医院许教授门下进修过半年), 做他们工作,与他们一起讨论方案细则,商讨救治方法,希望能在这 所医院救治。但对方院领导仍不愿接受病人,领导建议转合肥或南京 救治,并答应免费派车送行。病情紧迫,病人随时有生命之虞,远水 不救近火,127医院做手术的路堵死了。没办法,老爸毅然决然,决定 自己接手这疑难重症。老爸和老友交底,谈到转院风险和手术风险, 两人决定共担此责,病人送回县医院。老爸临时抱佛脚,复习文献, 重温解剖。半小时后,病人送手术室,局麻下手术。细心解剖,进入 脓腔,放出大量脓汁,解除压迫,患者立即发声,进水,呼吸通畅, 立即脱险。手术继续深入下去,显露颈椎5椎体病灶,祛除死骨,刮除 结核肉芽,冲洗脓腔,置入链霉素、异烟肼,放引流片,缝合,术毕 返回病房。手术顺利、有效,术后3天退烧,病人自己去理发,进食正 常,恢复良好。术后12天出院,医药费仅32元,继续抗痨治疗半年, 病愈。这40多年了,病人一直正常劳动、生活,儿孙满堂。这颈椎结 核病灶清除手术,除了颈前密集血管、神经以及甲状腺、气管、食管 等复杂解剖,更因颈椎脆弱,加之结核破坏,其后的颈髓,稍有闪 失,就会高位截瘫,甚至死亡!是骨科铁4级手术。这类手术就是在北 京、上海大医院做,主任们也都谨小慎微,如履薄冰!难得老爸救人 之心迫切,知道转院那基本上是死路一条。为朋友之子,虽颤颤巍 巍,如临深渊,但靠着自己多年的颈部甲状腺手术经验和熟悉解剖, 又有骨科专科知识的积累,加上深思善谋,胆大心细,勇于实践,终于圆满完成了这基层医院罕见的难题。既治标又治本,病灶根除,终身治愈。
80年代末,芜湖一中初二学生小魏,14岁,曾患右肱骨颈肿瘤。弋矶山医院和上海中山医院两次手术。这次右肩胛骨再发病。市某院骨科主任发话:恶性肿瘤复发、转移,要截肢,难保命!病家投医无门,身处绝境。患者外祖父吴老师是老爸当年初中老师。吴老师知道前述桂老师儿子治颈椎结核病事例,于是,来找老爸商讨。老爸审视前后病历和片子,诊断为另一临界肿瘤,不是原病的复发,也不是转移。在老爸的医院,老爸亲自给他做了右肩胛骨半切除,顺利完事、痊愈。2 0多年过去了,小魏身体健全,一路成了洋博士,游弋于全球,是高端人才。至今,他和他父亲总找机会登门拜望,令人欣慰。
1975年秋,一35岁女性病人,消瘦40公斤,胸椎6、7椎体结核并截瘫入院。全麻下经胸前入路,病灶清除,祛除死骨,坏死椎间盘,椎管内结核肉芽长达8cm压迫胸髓,导致椎管梗阻截瘫。掏刮后,可见此段脊髓恢复搏动,彻底冲洗病灶区,放入抗痨药。以开胸时切下的肋骨,修剪后嵌植于椎间缺损区,完成前路植骨。术后恢复良好,治愈。病家丈夫是一铁匠,他送老爸他亲自打造的不锈钢菜刀和锅铲,至今还在使用,医患之间情深意重。骨科手术中,这也是顶级4级手术。胸椎结核并截瘫,经胸前路一次病灶清除并植骨,在县级医院,当属巅峰。
骨科特例中,值得一提的是腰椎间盘突出症手术,老爸做过几百例,常见奇效。病人大多为中壮年,行动寸步难移,疼痛日夜不宁,抬来医院手术,当日见效,终身恢复!老爸农民表弟骆本炎,老爸同事弟弟开车司机汪锡龙,中壮年均患此症,直视下确保被压神经根及脊膜囊的松解,收到立竿见影的效果,事过二十多年,一直重回健康和劳力!这些病例,在此领域,至今仍居前沿!
三
老爸行医六十多年,手术万例以上,有没有发生过医疗事故呢?
没有,那还真没有!但他一生中也确有几次手术失败的案例,其中一个案例让老爸痛心许久。初衷与效果有时很难一致,为此老爸常常自责。老爸的外科恩师,皖医二附院外科老主任闵梅先老先生就曾开导过老爸,他给老爸讲他当年在北京阜外医院心胸外科进修时故事。在这个中国心胸外科堪称老大的医院里,当年病人不少都是走着进去,然后抬着出来!屡屡手术失败。中国顶尖权威大拿们就曾告诫过老爸恩师,不动手术就是死,动手术还有一线希望。这条血路,我们不走,谁来闯!科学是要付代价的!医生工作,本就在风头浪尖上生活,一医成功有前人的辛酸。
让老爸深刻教训,终身难忘病例是一位老师的手术。老师是慕名来找我老爸医治的。老师64岁,依据病史及B超诊断为胆囊结石,这种病老爸开过千例以上,从未失手。1984年10月16日老爸在本院给老师行胆囊切除手术,术中发现胆囊内胆固醇结石23枚。手术进行很“顺利”,切除胆囊,解剖清楚,历时75分钟,无异常,符合B超报告,术后无渗胆,切口甲级愈合。但病人特别之处在于解剖先天变异,肝肠之间正常通道缺如,代之以胆囊及胆囊管,教科书上及医学文献,亦从未见报,B超也未发现此先天异常,故迟至术中仍全然不知。术后第3天,发现黄疸并进行性加深,1984年11月9日行第二次手术,85年2月10日上级医院作第三次手术,未能挽救。为此老爸十分难受自省,医道充斥甚多未知和意外,遇此任何医生都难以避险。老爸常拿这少数几个痛心案例告诫自己,训诫前后同行,并写成医学论文《胆道手术中几个特殊问题的诊治体会》,用来总结经验、吸取教训,同时鞭策自己今后工作认真,认真,再认真。学习,学习,再学习!化未知为已知。
四
患者,男,2 9岁,骑自行车时,右季肋部撞击于停放的板车手把,当即剧痛、感呼吸困难,心慌,一小时后送入老爸医院。经查,肝脾胰肾均正常,腹腔无积液。胸腹透视无异常。住院观察16小时出现右侧腰背胀痛及睾丸痛,提示为腹膜后十二指肠损伤,于伤后28小时剖腹探查。进腹后见腹腔内有少量胆汁样液、胆囊、肝外胆管及肝脏无损伤,右侧后腹膜广泛水肿、绿染。作Kocher切口游离翻转十二指肠,发现其降部于乳头前上1.5cm处破裂∅1.5cm,肠液外溢,局部 及右肾周围水肿,组织坏死。彻底清除坏死组织、漏出肠液,修补肠 破裂口,毕氏Ⅱ式结肠后胃空肠吻合,48小时肠蠕动恢复,进流汁。 三周后两造瘘管造影正常,先后拔除两管,一期愈合。随访一年,无 并发症及后遗症。这例腹膜后十二指肠损伤是一种严重的、少见的腹 部损伤,早期因症状隐蔽,极易延误诊断。且手术复杂,高大上,考 验医生临床技术。要精准设计,一生难遇二例。手术台上,善思应 变,无规范可循,稍一闪失,危及生命,抢救成功率不高!本例是老 爸亲自手术,现患者还健在,生活正常。
五
患者,男,患黑色素斑点~胃肠道多发性息肉症候群病,十四年三次手术,老爸一人完成的。尤其是患者患极罕见的肠道、胆道双梗阻,十分难治。可能全球独一,世界无双!并发症是使患者就诊的主要原因,往往要到青年时期。因系先天性疾患,又无根治办法,此病的预后,若处理得当,可以长期生存,唯需多次手术。并不妨碍寿命。在老爸细心多次治疗下,病人获得新生。老爸一生中,碰到的这样疑难危重病人很多。在简陋的基层医院里,几乎是自学的他,把挽救患者生命当作使命,创造一个又一个奇迹。
六
1968年,在皖南一个深山小乡镇何湾,一个13岁男孩从牛背上摔 下,老爸出诊,发现该小孩右肝破裂,腹内大出血,要开胸才能完成 手术。肝手术,当年在大城市都是大手术,老爸之前从未做过。何况 在偏僻山村,连手术需要大量血液都无法保障。这时小孩已生命垂 危,时间不等人,救命第一,老爸艺高胆大。一方面老爸急中生智, 当时病人腹内在大出血,老爸大胆决定从腹腔抽取积血回输,首创混 有胆汁的腹血回输。而混有胆汁的腹血安全回输,他创造国内第一 例。(这里也有一个理论问题:肝血回输当时医学上尚极少论及,因 有胆汁污染,10年后,文献才有报道混有胆汁的血能安全回输,并在 后来的文献上陆续得到肯定的。)当时是形势所迫,也是老爸曾有过 一次腹血回输经验,(没有混有胆汁。另外宫外孕破裂的腹腔出血, 虽混有羊水,但也可回输,老爸经历多次。)那一夜,老爸立在病人 身旁,“车水战术”,从腹内把出血抽出来,过滤后再静脉输入,共 回输1 7 0 0毫升,赢得了时间。接着就在汽油灯下,老爸在山村卫生 院,就地全麻开胸开腹。手术,初战告捷,顺利完成肝修补手术。在 一个小山村,没有电、缺乏助手、设备简陋、药品不济、血品又少、 又无指导老师的情况下,老爸胆大心细成功完成他第一例肝脏修补手 术,这应算是一个少见奇迹。术后恢复顺利,终于救回了患者一命。 在那个时代,那样条件,那种技术,是个了不起的成绩。 这是当时中国的县医院,腹部外科水平的最高峰了,绝对前沿! 而在山村小镇简陋无电无自来水的手术室里完成这一手术,在中 国也是绝无仅有的。
七
1965年10月,遵循“6.26”指示,老爸带队带领7(含内科一人, 护士、助产士五人和外科老爸一人)人组成巡回医疗队,去皖南烟墩 公社。虽然老爸是副队长,但队长是位年过半百的内科田医生,他当 年心脏不是太好,多半在家休养,在乡下时间不多,实际是不到三十 的老爸主持全盘,一连干了三个月。 在1965年最后100天里,没有电,没有麻醉师,没有助手,缺器材 少医药。老爸光杆司令一人,带着手术包、手提高压消毒锅,自己搭 建“手术室”。上面蒙块布,就是天花板,下面洒水,?避尘土飞 扬,汽油灯水电筒照明,就是一个“手术室”。以老爸为主角在此做 了大小手术612例次,无一事故,全部痊愈,创造乡村手术的奇迹。其 中开腹手术是121例次,手术遍及普外、妇科、骨科、五官等,手术有 胃、胆、肠、子宫切除,胆肠内引流,阴式全子宫摘除,膀胱阴道瘘 修补 …… 疝、痔、眼球摘除,不全流产急诊清宫等。这在当时医疗卫 生尚处落后,青毒素都奇缺的年代,100天多如此多不同类型手术,是 一项记录,也是老爸外科一次特别展示,创造。
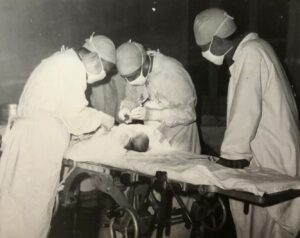
与此同时,医疗队组织全公社6个大队卫生员分批脱产培训一遍,创建卫生村一个,为这个村建了两口水井,改变此地世代饮用“泥水”的历史。
对于老爸,忙,是属当然,三个多月工作,昼夜不分。老爸没离岗一天。虽离家也就几十里地,1个多小时车程,家中有老、有小,百日时间里老爸竟未回家一次。这么卖命工作,其实收入并不增分文,这种对工作投入精神,是现今不可思量的例外。
巡回医疗的某一天下午,在一位临时赶来的县医院唯一麻醉医生的帮忙下,老爸一人连台做了三例阴式全子宫切除术加盆底修补重建术(那是中国著名的大饥荒后,留下营养不良后遗症——三度子宫脱垂(实为盆底疝)的高发病例),也就是这同一天,老爸一直手术到凌晨三点,一人主刀做了十多例其他手术,在临时性“手术室”手术台上连续工作十七、八小时。直到如今,在中国也再不可能再有人单独有如此高的工作效率。
为此,医疗队受到县、地区(市)表彰和奖励,在褒奖会上还专门安排老爸上台作了专题报告, 展览了老爸所用的“ 全部手术器械”,发了专文通告,并在全芜湖地区推广,这是对老爸最大肯定和奖赏。
老爸为前右2
在那段时间里,有很多难以忘怀的病例。
第一例为不全流产大出血,血流如注,分秒面临危局,老爸出诊救急时,与一位助产士在三星大队她农舍家中给紧急清宫并快速补液,回天有术,救回一命。第二例为膀胱阴道瘘,手术修补,12天康复出院,填补空白,开创这一手术本地区的先例。
第三例是一中年妇人,患伤寒病肠穿孔并发腹膜炎(那时此类传染病盛行,近年来罕见),做了肠切除手术。她身无分文,给予免费。出院后老爸骑着自行车,携带由我们医生自掏腰包购得的礼品,再去青阳木镇她农村家中随访和慰问,是体现了“白衣天使”圣洁原味。
第四例是一个剖腹产,横位,子宫先兆破裂,不敢再转运,只得就地行剖宫产,办公桌上当手术台,顶上拉布挡灰,地面洒消毒水,吊上水,局麻下手术,成功救了两条人命。
当年医疗条件特别简陋,遇上急出诊,单枪匹马,就地手术,真是俗话说的好:艺高人胆大。
第五例是一病人脾脏破裂,老爸去出诊,也是在办公桌上为其就地成功作了脾切除手术。称奇的是腹血回输8 0 0毫升,克服无血源难题。这血,无须抗凝亦无法抗凝,是可输入病人的。但这是第一次、国内首创。路是逼出来的,“时势造英雄”,理论支持和认可,是后来才逐渐见诸文献。( 脾出血回输, 过去文献有记载, 但须“ 抗凝”,不“抗凝”是首创。不“抗凝”,是后来才逐渐见诸文献。)
八
76年7月28日那场旷世唐山大地震与老爸也有渊缘。8月2日,老爸被召参加芜湖地区(市)三人医疗队赴震区救援。三人到南京后,接到北京来电:伤员南下,各地准备,就地接纳医治,不用去受灾现场救助。于是,老爸被安在繁昌峨桥治疗点,带25人医疗队,当地再配25人后勤,接收100位伤员。老爸是队长,通管全盘,还有三个副队长和二位指导员(可谓一个强悍的领导班子),人员挑选也都是“精英”,直接受市县领导,一切为伤员的开支由国家包下来,是当时国家的头等政治任务。
老爸带几位医生到南京车站,上卫生专列检查、接收伤员,车至峨桥,大队人马在迎候,担架抬入“病房”,来的大多已无生命危险,主要是骨伤、筋伤,好在老爸还算得上是骨科医生,此时,从行政安排转而重点临床医疗,几个月下来,逐一使之恢复,并派医生全程护送回原籍。这是对这场震惊世界、付出24万人生命、罕见的自然大灾害的做了自己一丁点贡献,老爸完成这一历史性任务。
这一年,中国多灾多难,国家主要领导人,继周、朱作古之后,就在这全国闹地震的国难当口,9月9日,毛——中国一号人物,也溘然去世,给全国人民撒下了阴云,中国前景如何?人们茫然!
老爸当时身在客地,担负这一重任,管理100个伤员和50个工作人员,本地也在闹地震,工作人员自己和家人安危和牵挂,加上国家的“家长”们相继辞世,可以想见,人们心头,抑郁、无望!老爸发挥全身解素,以身作则,出色地完成了任务,又交了一份完满答卷。
老爸为中左五
九
文革武斗期间,各派武装割据,交通中断,医院停诊。但子弹是不长眼的,枪伤是乱来的,穿肝、伤肺、伤血管以及肾、肠胃等,也只得就地手术。肝、肺修补术,尤其是脑外伤,老爸也就是那时被逼上路自学成才实施的。
在各方面环境条件极差状况下,老爸倒也救了不少人的命。好歹有功无过( 真的救不过来, 也少有问责的。当然, 多数还是成功的),这让老爸长技术、练手艺,成就一身本领。
由于武斗,医院半瘫痪,空时多,老爸系统地阅读学习医学专著、英语,并补全了大学医学基础理论,使老爸在医学理论上也有了一次飞跃,理论指导实践,而实践又出真知,老爸无论理论还是实际应用以及经验都达到一个新的高度。
文革武斗造就外科人才,算是一奇迹,这也是另类的黑色幽默。
十
老爸从医六十余年来,手术无数,在实践中他常有些小改进、小
创新、小突破,都取得十分好的效果。
a.除特殊需要外,老爸所做的上千例以上胃切除基本废除预置胃管(书本上要求预置),无失败病例。这就要求精良吻合,完善止血,术中排空胃残物以及术后严密观察,极大地提高了病人治疗的舒适度。
b.泛发性腹膜炎,在除去病灶及感染物之后,废弃腹腔引流,减少术后粘连。关键是术中彻底冲洗拭净。因引流物在腹腔内很快被纤维蛋白粘堵失效,徒增病人痛苦。诚然如胰腺炎、腹腔脓肿等,预计有持续溢漏者,则需双套管负压引流。
c.包皮环切术,常规术式,内外板对合不良,血肿、水肿和拆线困难等,都困扰医患双方。老爸予以改良,局部静脉麻醉,止血带下整齐切割,完善止血,人发或可吸收缝线缜密缝合,可获术中无痛、对合良好、愈合快、免除拆线等优点。
d.肛瘘挂线疗法或切除敞开,均令病人蒙受术后痛苦,且恢复期长。老爸用长效麻醉(局部注入稀释的亚甲蓝),一期切除缝合,大都一期愈合,缩短疗程。
e.控制外伤感染,关键是首诊的彻底清创,而不是依赖引流和抗生素。大量清水冲洗,消除异物及失活组织,认真消毒,无张缝合,若术后炎症反应,局部辅以酒精湿敷,用或不用抗生素,按此,6小时内的外伤,几可消除感染。
f.腹股沟疝修补,重点在腹横筋膜,以改良的Madden术式代替传统的Bassini法,大大减轻病人术后张力缝合的痛苦,也有利于愈合,且复发率大降。
十一
老爸聪慧,不但手术做得好,文章也写得得心应手。
老爸虽是中专生,但因手术高超,论文丰产,英语熟练,虽无官职,但中级职称、副高、正高都评的很顺利,没有疑义。
但不少同事(不包括领导)就没有他那么幸运了,有的水平不行,有的论文不够,虽然大多学历比老爸高,但就是评不上正高。
老爸对此很有异议,他认为有几个朋友,临床手术水平很不错,但不太会写文章,没有论文,就被卡着评不上。
老爸认为临床工作是实践性东西,尤其是外科,需要手巧有悟性,要多做多看,才能提高业务水平。临床不是搞科研,而且病人那么多,那么忙,值班接着值班,手术接着手术,大家都忙得喘不过气来,又不是教学医院,哪有时间坐下来申请课题、搞科研、写文章?
临床医师需要大量病例的训练和临床经验的积累,把科研任务和临床工作混为一谈,让许多临床经验丰富和技术精湛的医生被论文卡住而评不上职称,这是很不公平的。
一个以临床技能为核心的实践性职业,要求论文而不要求临床治病水平,有点荒唐。
老爸是个热心肠,急公好义的人。
有一次他对两位外科水平很高,评职称卡在论文上的朋友说:我替你们写几篇文章,你们拿去修改指正后,再以你们名字去刊物发表吧。老爸说干就干,很快把几篇新写的医学文章给了两位。
果然,经两人修改的文章发表后,很快评上正高,后来他们都成为医院的台柱子,是手术台上一把好手。
这是好多年前的事,老爸每每谈起,没有后悔老爸虽然有违规,但他只是怜惜人才。
助人为乐,成人之美,尽量为他认为值得人才,铺铺路,搭搭桥,这都是他很乐意做的。
他们每一次进步,老爸都要和我唠叨好几天,兴奋之意溢于言表,十分骄傲。
十二
我们曾经的邻居慧姐是这样描述老爸和我们一家:
我是小慧,少儿时曾与汉阳一江水一家是邻居。我父亲是黄埔军校后期学员,五十年代因历史反革命进了大狱并迫害至死,母亲是师范生,但剥夺了做教师的权利。我们是典型的黑五类家属,妈妈不断遭到批斗,子女按规定不能上中学。我算幸运的,因是女生缘故,还能上中学,总算高中毕业。大哥根生是跑到偏僻乡下才勉强读了初中,二哥根宝小学毕业时,政审把他刷下来,连初中也不让上。在那艰辛苦难严酷无助年代里,我的邻居李叔叔一家一直很关爱我们,外婆潘奶奶还认我母亲为干女儿,没有一丝歧视,让我一家倍感温暖。
有病找他们家,没得吃找他们家,有困难找他们家,凡事都找他们家来帮忙。李叔叔串门时经常看我家米罐子有没有米,没有了他就送来了米,有好吃也会给我们送来,需要帮忙时总是尽力帮忙,我们两家小孩也像亲兄妹一样相处,这些我是永远也忘不了。
李叔叔,是我们这个皖南县城医院的一名外科医生。李叔叔五官周正,一表人才,长相清秀,很有古时秀才风韵。他爱读书肯钻研,天赋极强。腹外,胸外,骨科,眼科,五官科都涉略精通,自学成才。那个年代,年纪不大,李叔叔就是当地外科手术一把刀,在那片天下声誉日隆。我现在时常回想过去的岁月,很想念李叔叔他们一家,想到那个年代我们的生活。在李叔叔夫妇身上,真正体现到人类最珍贵的友爱和仁慈,他们就是我妈和我们的精神支柱,是我们全家的大救星,我终身难忘。青少年时期的我,有时真的感到李叔叔就是我的父亲,他对我及我一家关心备至,我从小就看在眼里,喜在心里。遇到李叔叔一家是我妈的福分,更是我一家人的福分,有这样的邻居,我心里充满幸福。感恩上苍派来李叔叔潘阿姨这样的神灵,一直护佑着我们家全体人员。我小时候体弱多病,那是由于营养不良贫困造成的,在缺食少粮,无钱治病的年代,几次大难不死,活到今天,是我的邻居李叔叔和潘阿姨救过来。
有一年,我得了急性肝炎,很重。妈妈带我找李叔叔诊治,李医生通过检查和询问,得出结论,急性甲型肝炎。李叔叔说:保肝治疗,不要吃任何药,因为吃药给肝脏再次伤害。肝脏已经生病不能正常解毒了,再吃药的话会火上浇油的。不要乱花钱,现在猪肝便宜,我给你弄点猪肝吃,增加营养多休息就会好的。我按照医生的嘱咐,没多久甲肝真的好了。这件事,在我少年时代留下了很美好的记忆。
李叔叔妙手回春,手到病除,对症食疗,可敬可佩。几年后我下乡,因为穷,也不太注意卫生,不知道如何保护自己,也不带手套。我们用框子将奇臭无比、经过发酵后的杂草肥料挑到田间,然后用手抓着散开,就这样不干不净的生活。其实当地农村很多人面黄肌瘦,不知道何原因?估计大都可能得了肠虫症,寄生虫虫卵进入寄生于身体,久而久之大量繁殖,总有一天要爆发的,这都是愚昧落后和无知以及生活极度贫困造成的。我也不例外得了肠虫症,期初主要症状肚子隐痛,两条腿上布满红血点,农村医生说是过敏,吃了大量的抗过敏药,一直不好,一拖就是一个月。没多久我极度消瘦又没力气,生命垂危,眼看就要归西天了。妈妈赶过来一看,吓坏了。我肚子上还起包块,人也完全变了形,妈妈很着急了,流着泪立刻找来她的好友和曾经的邻居李叔叔和潘阿姨,两个经验丰富的医生。他们在我肚子上一摸,说是蛔虫,用现代医学名词解释我那个病叫做“蛔虫过敏性紫癜”,上帝又饶了我一次小狗命。我像小猫咪一样有九条命奥!赶快吃了两片驱虫净,第二天我妈倒马桶时惊呆了,里面全是蛔虫夹着血液。第三天我肚子不痛了,身上的血点逐渐消退,立马又是一个活泼可爱的大姑娘了。李叔叔和潘阿姨诊断正确,药到病除。由于他们的高超医学,我的生命得以挽救。李叔叔一家对我家的恩情,我永远无法报答。
祝李叔叔身体健康,永远年轻。

小慧母女与汉阳一家水一家合影
十三
老爸虽然已经8 8岁高龄,但他对新科技的好奇心和兴趣从未减退。他对新知识、新科学有着浓厚的兴趣,接受新事物的能力也非常强。老爸思想开明,勤于思考,不墨守成规,追求卓越,总是喜欢探索未知的领域。从电脑、手机、互联网到智能化应用,老爸总是敢于尝试和应用最新的科技成果。他常说,要想不被这个世界抛弃,就必须具备接受新事物的能力。只有这样,人生才不会停滞不前,才能不断提升自己和提高个人生活质量。紧跟时代步伐,不断更新观念,这是老爸一生的追求。
自从O p e n A I公司的C h a t G P T问世以来,老爸就一直对它充满兴趣。他几乎每天都会向从事自然语言处理的老弟立委询问ChatGPT的使用范围、应用现状和发展方向。为了让老爸能够更深入地了解和使用ChatGPT,不久前立委给他试装了一个。在试装过程中,老爸头脑清晰,能够准确无误地键入各种复杂的口令和操作。与其他同龄人相比,老爸的精神状态和思维能力都非常出色。
随着LLM各家应用落地的加速,未来各种智慧家居功能也将无缝对接,人们的生活将越来越依赖人工智能。很多时候,人工智能甚至能够决定一个人的生活质量和人生高度。虽然国内人工智能在研究领域上落后于欧美国家,但在应用落地方面却一点也不差。而且,国内的人工智能普及率远远高于欧美国家,这让老爸有了更多机会尝试和应用各种最新的科技产品。他在家中试用各种人工智能产品和软件,兴趣盎然,乐在其中。




老爸在使用chatGPT
除了对最新科技的关注和应用,老爸还是一个货真价实的AI应用追随者。他热衷于尝试各种人工智能产品和软件,从中获取便利和乐趣。无论是智能家居、智能助手还是自然语言处理软件,老爸都有浓厚兴辆。他的这种积极态度和学习能力让我们这些下一代人也自愧不如。
老爸赶上了一个科技大爆炸的时代,自然不会错过这个伟大的时代。他现在使用的是苹果15pro手机,这是当代最新的产品之一。他还拥有iPad上的最新翻墙软件以及ChatGPT等最新的科技软硬件。全国也找不到几个这样配置的老人了。“顶配”的老爸,88岁依然不掉队,依然走在最新科技的最前面。
老爸的这种对科技的热爱和追求不仅仅是为了满足自己的好奇心,更是为了在日新月异的时代中保持竞争力和适应力。在这个科技日新月异的时代,老爸用自己的行动向我们展示了什么是真正的活到老学到老。他的这种积极向上的态度和对新事物的好奇心值得我们每个人学习和传承。
结语
每当夜深人静的时候,那伴着我少儿时成长的劳累疲乏背影,总在眼
前呈现,历历在目。这常让我回想起老爸当年工作生活的情景,许多事已
过去半个世纪,却时时萦绕于脑海,烙印在心里,让我感动,赋我力量,
给我温暖。
老爸,您是我的榜样,您是我的骄傲,我爱您!
祝老爸八十八岁生日快乐!

作者与父亲合影

永不知倦的老爸(代序)
汉阳一江水、立委

神龟虽寿,犹有竟时。螣蛇乘雾,终为土灰。老骥伏枥,志在千里。烈士暮年,壮心不已。盈缩之期,不但在天。养怡之福,可得永年。幸甚至哉,歌以咏志。
——东汉曹操的《龟虽寿》
老爸生于一九三六年十一月三日,农历九月二十日,属鼠,按照我们当地习俗“虚”一岁计,今年正是八十八岁。
老爸姓李,名名杰,字豪,号翠生。出身在家道中落的知识分子家庭,从小生活贫困,苦难与艰辛一直伴随他青少年成长过程。因为贫困,没有进入大学学习,成了他的终身遗憾。
一九五六年三月老爸从芜湖卫校医士班毕业,一直从事医务工作达六十七年之久,在经历了三年血吸虫病防治和两年卫生行政工作之后,一九六一年老爸开始从事外科临床工作,至今也已超过一甲子。其中南陵县医院供职25年,芜湖长航医院22年,中铁芜湖医院16年。老爸年近九十,仍退而不休,没有完全放下工作。他眼不花、耳不聋、手不抖,干起专业扎扎实实、做起事来认认真真、走起路来风风火火。查资料,看文献,始终关注外科最新进展。思路清晰,条理分明,至今仍上台手术。并且赶上电子化处理医疗文书时代,他也能游刃有余,毫不落伍。人老不失戎马志,老有所为,尽职尽责,为社会奉献余热,是个永不知倦的老爸。
老爸以行医为生,以救人为本。在半个多世纪救死扶伤的工作中,了解患者心理状态,关注患者病情变化,凭着他过人的才智、精力和手巧,因地制宜,胆大心细,给无数患者带去健康,从死神手中夺回众多生命,让许多笼罩愁云的家庭重拾欢笑。
老爸在基层默默工作,一个中专毕业生,没老师教,没导师带, 自学成才。医技来自个人领悟,“ 老师” 就是医学书籍, 天资、聪颖、勤奋, 一腔热血成就了自己的医学理想。在穷乡僻壤之地, 在知识分子受排斥的年代, 创造了他自己辉煌。诚如老爸所说:
“ 我的外科生命,堪称最长,手术数量亦多,手术科目也广。”老爸还说,当年他在基层做的不少手术,难度很高,这些手术至今还站在外科前沿,很是不易。比如肝、肺手术,比如颈椎结核病灶清除手术,比如腹膜后十二指肠损伤修补手术等,这些手术在上个世纪六十年代,省内都很少有医院开展。而老爸在简陋的基层县医院就独自开展这类手术,并全获成功。老爸常自豪地说:外科,有时,要虎口拔牙,绝非盲目冒险!担风险,高技艺,高配治疗。胆大心细,打破常规,当然科学,求实,是前提。
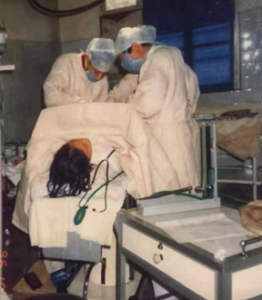
老爸从事过腹外、胸外、骨科、妇产、神外、泌外、五官、眼科、放射和麻醉等各科工作,完成各科不少高难度的四级手术,这是个非常了不起的成绩。腹外的急性胰腺炎等手术,头颈外科的颈内动脉瘤切除吻合等手术,神外的脊髄瘤等手术,胸外的肺部恶性肿瘤、食管癌等手术,骨科的各种骨髓炎的病灶清除,颈、胸、腰、骶椎结核的病灶清除和各类骨折等手术。泌外的肾蒂淋巴结剥脱等手术,妇产的子宫、卵巢切除等手术,五官的鼻泪管吻合等手术,眼科的白内障、人造瞳等手术以及各段硬膜外阻滞麻醉,颈丛、臂丛阻滞麻醉,脊髓麻醉,插管全麻及静脉复合麻醉,老爸都能熟练掌握,游刃有余。老爸所掌握的医学门类之多,是常人难以企及的,在现今国内,乃至国外,也难有其二。
那个特定的时代特定的条件下,给老爸一个难得的施展空间,并提供充分展示他的才能和天赋的机会。面对源源不断,农村各类经济匮乏的农民兄弟患者。不救治就是死,治疗总比自生自灭、听天由命好许多,老爸有充分自主权。有多大精力就有多少工作,几十年来他几乎每天都有几台手术,凭着出众的专业技能和高尚的医德,凭着对医学的热衷和对患者的关爱,凭着毅力恒心、勤奋刻苦、执着坚持,老爸成为出色的大外科医生!老爸把握一瞬即逝的机遇,常常突破禁区,在一亩三分地崭露头角,屡屡取得不凡的成绩,终于登上了基层医院普通临床医生的顶峰。
几十年,除手术外,老爸回家就是一头扎到医书里,废寝忘食,很少见他休息,是个标准的工作狂。我们一直觉得,老爸就是时代造就的现代华佗,就医疗面之广、救助病人之多、服务时间之长,基本是前无古人(maybe 除了华佗),后无来者。
外科医生需要悟性,手指手腕的稳定性和灵活性相当重要,老爸仿佛是天生做外科医生的料。老爸特别好学,胆大心细,慧根极高,勇于创新,有学外科的天赋,一看就懂,一点就通,手术做得赏心悦目。中青年时期尤为特出,练就一身绝技。另外,他的团队精神极佳,他带教的下级医生,无不严谨、敬业、精益求精,培养了一批医疗骨干和专家。

一上了手术台, 老爸似换了一个人,从容不迫,施展自如,飞速下刀、稳准剥离、显露宽敞、术野清晰。老爸手术做得漂亮利索明快,深得同行、病人及家属的好评。多年下来,老爸名震四方,求医者络绎不绝。甚至上一级医院外科主任的亲属需要手术,也来找老爸“这把刀”主刀才觉得放心。外科老辈原弋矶山医院外科陈主任,其夫人,长航医院护理部谢主任,八十高龄,患乳腺癌,经老爸手术根治,现在九十有三,并从此成了他们的终身“保健”医生。南陵县医院五官科主任王平,其大女儿董薇患乳腺癌,这是他家头等大事,心急无耐,托付于老爸,老爸亲自为之手术,终身治愈;几年后,该院妇产科主任席德华女儿,同样如此。长航医院外科主任沈某岳父,上海高龄教授,胃癌并幽门梗阻,多日不进饮食,全身衰竭,家属绝望地准备后事,终于是老爸为之“冒险”直接做了根治手术,五年后终老于其他疾病!然而通常,如此年迈体衰恶性患者,一般均先予短路手术,解除梗阻救命,尔后择期再手术切除病灶。实际,很少能争到“择期手术”机会,衰竭,病灶转移,噩耗,指日可待,后果堪忧!早在一九七零年,我的大舅潘耀毅,肝胆管结石并梗阻性黄疸,合肥安医拒收,无奈之下,从家乡三河寻老爸求医,在南陵县医院,老爸亲自为之手术取石、切除胆囊、再加胆管十二指肠内引流,顺利恢复,两周出院,终身治愈。一九八六年,五舅潘耀童,直肠癌,同样被省医拒收,再來芜湖,老爸在江东船厂医院,手术台上奋战七个多小时,行根治术。早在上世纪八十年代,不少病人电话报告病情,老爸即可确诊,比如同事成大本,胃穿孔,弋矶山医院青年医生误诊肾绞痛处理,给予泻药清洁肠道,次日泌尿系造影检查,全错了!如此,不仅耽误救命的宝贵时间,更加重穿孔外漏,推向病危!患者此时撕心裂肺地腹部绞痛,扒地抓了电话报告老爸,嘱急回本院,急诊手术切胃治愈。本科护士长高某丈夫陶某,也是如此。如今,更多的是手机“微信”远程看病,任何时候任何地点,众多病情,就此解决。尤其称奇的是我们家至亲的所有手术,都是老爸亲自包揽主刀的,这需要很强的自信、果敢和心理素质。立委当年认识一位农村青年医生,由于难能施展,而厌倦行医,转报英文师专,当谈起老爸的医术,却充满钦佩:“你知道么?你爸爸是世界上最了不起的医生。许多省立大医院尚未开展或普及的大手术,你爸爸也能做。”他给立委讲解一些案例,立委也不懂,但是我们心里明白, 老爸一直在超越自己, 向越来越复杂的手术攀登。后来,跟老爸谈话时,我们问他还有哪些疑难手术,想做而做不成。老爸说, 能做的差不多都做了, 但是有些手术,比如显微外科,断肢再植等,对于器械要求太高,当年县医院没有这种条件, 只好遗憾了。另外, 干细胞再生医学,基因编辑技术,基因工程减少或逆转老化细胞,精准医学与个性化医学,这些属于医学研究范畴,我这个基层临床医生只能望洋兴叹。
文革后,职称晋升恢复,老爸从医士、医师、主治医师、副主任医师、主任医师一路走过来,从来都没拉下,总是一路顺风。老爸,在他一生前后任职的三家百人以上的二级医院里,是唯一外科主任医师,就是全院,正高职称,难有一、两位而已!而他的中专同学,几乎没有升正高的机会,即便同时代的医学院本科毕业生,在二级医院绝大多数也无缘斩获正高职称,基层医院,要求更苛刻,论文、临床、英语一样不能少,还有指标限制,一般只有内、外科各一指标,没有过硬的条件,宁缺勿滥!可见,老爸,在同辈人中,凤毛麟角,出类拔萃!”
时代造就人,老爸没上过小学、没上过高中、没上过本科、更没上过研究生,正式教育只有初中和医士中专这两张文凭,主要还是靠无数的医学实践,摸滚爬打拼出来,凭实力顺利晋升普外主任医师,终成一代全科名医。


医生受人尊敬,但却是清贫的。生活苦点,倒也无所谓, 老爸的难题是,到哪里去攒买书的钱呢?那些大厚本的专业书 籍《外科学》、《骨科学》等,定价不菲,却是工作必不可少 的。谁能想到,许多医书是爸爸瞒着家人卖血换来的。一次抽 300cc 鲜血,当时的价格30元,这可是平时半年也难攒下的钱 啊。老爸总是轻松说:人有造血机制,失点血无碍。医生常有 紧急情况下自己输血救病人的例子,我在行医过程中也曾有过 多次。但靠卖血去购专业用书,古今中外应不多见。一个时 代,一种活法,一个享有盛誉、对医术精益求精的医生非卖血 不能拥有医书,这样的事,从古到今,大概也只有那个特定时 代才有。 2007年6月3日,老爸经历一生最大一劫。老爸突然吐血, 那莫名的高烧竟达摄氏40度,自诩“不老不衰”的老爸,一下 被击垮了,出血量2000毫升以上,当即病情十分凶险。急症送 医,诊断为“胃腺癌,低分化”,21日在武汉行大手术,作了 全胃加胆囊切除(原有胆结石),终于闯过这一生死关。他操 劳一辈子,一直退而不休,仗的就是身体好和心态好。没想到 平时不生病,一病吓死人,这次是他一生中遇到的最大挑战, 也是他健康的拐点。 老爸是我们全家的主心骨,平素身体清瘦健康,无不良嗜 好,更没住过一次医院,一直比同龄人显得年轻。很多大风大 浪闯过来,人生很精彩。总算坏事变好事,老爸这次急病倒 下,对病情的早期诊断和及时治疗有利。得以宽心的是,老爸 得到了最好的医疗条件,家人也多在身边照顾。老爸术后恢复 很快,但人比手术前明显苍老,经过大半年休养,才慢慢恢复 底气。现在说话很有力气,精神仍很旺盛,还常常上台做手 术,我们全家人这才终于松了口气。 老爸现在半退休在家, 身体健康, 一点不像8 8 岁的老 人。虽依旧清贫,但生活有条不紊,仍保持对新事物的好学之 心。虽不再开车,但对于科技最新动态好奇心不减,今年二月 还在问立委 open AI 和 chatGPT 的词源和背景。手机电脑玩得 比许 多年轻人还熟,淘宝网购,滴滴叫车,美团订餐。同时 经常查阅英文专业资料,吸收新知识,不断进取。长年的博闻 强识,他的英语专业词汇量比立委这英语“科班”出身高出许 多,普通词汇也有一比,真正是活到老、学到老的楷模。 老爸大病之前,退而未休,青春不减,宝刀不老,手术、 开车、上网、写回忆,还有下棋对弈,乐此不疲。大病开刀后 这十多年来,虽体质下降,老爸终究丢不开他从事一辈子的至 爱——临床医学,他丢不下他的本行,仍然没有最终选择下 课,颐享天年,还是在临床一线工作,发挥余热。 现在老爸基本上放弃普外以外的其他相关专业工作,如骨 科、妇产科、泌尿外科等。老爸坚守这个普外阵地,希望自己 在有生之年,永不落伍,永葆“青春”,而他的多学科的临床 经验,一直能为社会奉献,能为病人解忧。
医学,这是老爸终身无法割舍的情结。
老爸性情温和,与人为善,为人正直,待人热情。问病十分认真,不烦不躁,回答耐心细致,亲切和气。无论病人贫富贵贱,一视同仁,倾尽全力给予医治,真正体现医者仁心和人道主义精神。
老爸思想开明,观念前卫,对子女平等交流,从无训斥,更无打骂,也不给委屈!总是疏而不堵,循循善诱,身教言教并举。子女各自发展,是他最大的安慰,孙儿辈的成长花絮,更给他带来许多欢乐和满足。
本书是老爸文革后公开发表的部分医学论文,虽挂一漏万,还是留下了许多珍贵的从医经验和理论总结,是为不朽的丰碑!老爸这些论文诠释了一位基层医院的医生如何百炼成钢,不断自我超越的过程,表达一位医者的底线、良知、责任、担当和使命,彰显白衣战士救死扶伤的风采和“悬壶济世”的深刻内涵。
最近在整理集结部分医学论文时,老爸回顾60 多年所走过的路程,不胜感慨和自豪。虽然他的论文都是他临床上经验总结,科研成分含量不大,但实用性极强。论文文风严谨,格式规范,是老爸医疗实践的结晶和理论升华,具备一定的传承价值。老爸一生展示出的追求卓越、精诚为医的风范,勤学不辍、孜孜不倦的精神,谦和为人、正直仁善的情怀,更是我们后辈一笔不可多得的宝贵财富。
由于时间跨度太久,论文寻找难度极大,遗失不少,我们尽可能收集老爸过去的医学论文,汇编成册,作为生日礼物,献给八十八岁生日、从医六十七年的老爸。祝老爸生日快乐,身体健康,安享晚年!

老爸与作者汉阳一江水和立委
立委的中文视频
The Tireless Father (Preface)
Hanyang Yijiangshui, Li Wei
"Though turtles live long, they meet their end. Though dragons ride the mist, they eventually turn to dust. Aged but still full of fire, ambitious till the very end. The natural order isn't the only clock; contentment brings longevity. How fortunate indeed, to express these sentiments through song." — "Though Turtles Live Long" by Cao Cao of the Eastern Han Dynasty
My father was born on November 3rd, 1936, or September 20th according to the lunar calendar. He's a Rat in the Chinese Zodiac. Following our local tradition, which counts one extra year, he is currently 88 years old.
Father's name is Li, Mingjie, his courtesy name Hao, and his art name is Cuisheng. Born into a struggling intellectual family, his youth was filled with hardship and adversity. Lack of finances kept him from attending university, a lifelong regret.
In March 1956, my dad graduated from the Wuhu Health School and has been involved in medical work for 67 years. After a stint in schistosomiasis prevention and two years in public health administration, he shifted his focus to surgical clinical work in 1961. He has been practicing for over six decades now. He served in Nanling County Hospital for 25 years, Wuhu Changhang Hospital for 22 years, and China Railway Wuhu Hospital for 16 years. Approaching his nineties, he still hasn't fully retired. His vision remains clear, his hearing sharp, and his hands steady. He conducts research, reads literature, remains engrossed in his profession, and stays updated with the latest surgical developments. His thoughts are coherent, and he still performs surgeries. Moreover, as the medical industry transitioned to digital documentation, he adapted seamlessly, never falling behind. His age hasn't dampened his spirit; he continues to contribute to society with undiminished vigor. Truly, he is a tireless father.
My father has dedicated his life to medicine and saving lives. Over the course of more than half a century, he has understood the emotional states of patients, and monitored their health conditions, and with his exceptional intellect, energy, and skilled hands, he has tailored treatments to individual needs. He has brought health to countless patients, saved numerous lives from the brink of death, and restored joy to many families clouded with sorrow.
My father worked diligently at the grassroots level. Despite only having a diploma from a technical health school, he had no formal professor or mentor to guide him. He was self-taught. His medical skills came from personal insights and countless hours spent studying medical books. His natural talent, intelligence, diligence, and unwavering passion paved the way for his medical aspirations. Even in remote and impoverished regions, and in an era when intellectuals were often marginalized, he carved out his own success. As my father often says, 'My surgical career has been one of the longest, with numerous surgeries across a wide spectrum of specialties.' He also notes that many of the surgeries he performed at the grassroots level were highly challenging. Some of these procedures are still considered cutting-edge in the world of surgery. For instance, liver and lung surgeries, removal of cervical spine tuberculosis lesions, and repairs of injuries to the duodenum behind the peritoneum – such surgeries were rarely conducted even in the provincial hospitals during the 1960s. Yet, my father took the initiative to perform these complex operations in a modest county hospital and achieved success. He often proudly asserts: 'In surgery, sometimes, you have to pull a tooth from a tiger's mouth. It's not about blind risk-taking! It's about taking calculated risks, having advanced skills, and providing high-level treatment. Being brave yet cautious, breaking the norm, and always prioritizing scientific and pragmatic approaches are essential.
My father has practiced across a broad spectrum of medical specialties, from abdominal surgery, thoracic surgery, orthopedics, obstetrics and gynecology, neurosurgery, urology, otolaryngology, ophthalmology, radiology to anesthesiology. He has successfully performed many high-difficulty level-4 surgeries in each specialty, which is truly an astounding achievement. These surgeries range from operations for acute pancreatitis in abdominal surgery, carotid artery aneurysm resections in head and neck surgery, spinal tumors in neurosurgery, lung malignancies and esophageal cancer in thoracic surgery, clearing lesions of various osteomyelitis and tuberculosis of the cervical, thoracic, lumbar, and sacral vertebrae, and other fractures in orthopedics. Additionally, he has conducted lymph node stripping in urology, hysterectomy and ovariectomy in gynecology, nasolacrimal duct anastomosis in otolaryngology, cataract surgeries, and artificial pupil operations in ophthalmology. He's also proficient in different forms of anesthesia, including epidural blocks, brachial plexus blocks, spinal anesthesia, intubation general anesthesia, and intravenous composite anesthesia. The breadth of medical categories my father has mastered is unparalleled and unmatched, both domestically and internationally.
The unique circumstances of that era provided my father with a rare opportunity to showcase his talents and capabilities. Facing a continuous influx of impoverished rural patients, the stakes were high. To not treat was to let die. Treating them was always better than leaving them to their fates. He had significant autonomy. With an endless drive to work hard, he performed surgeries almost daily for decades. With exceptional professional skills, noble medical ethics, passion for medicine, dedication to his patients, persistence, diligence, and unwavering perseverance, he emerged as an outstanding major surgery doctor. My father seized fleeting opportunities, often breaking barriers and shining in his field. His achievements made him stand out, eventually reaching the pinnacle of clinical practice in grassroots hospitals.
For decades, when not performing surgeries, he would immerse himself in medical books, often sacrificing sleep and meals. Rarely did we see him rest; he was a true workaholic. We've always felt that my father is the modern-day Hua Tuo, crafted by his era. Considering the breadth of his medical practice, the number of patients he's aided, and the length of his service, he stands almost unparalleled in history—perhaps with the exception of Hua Tuo—and likely unmatched in the future.
Surgical practitioners need intuition. The stability and flexibility of one's fingers and wrists are incredibly crucial. My father seemed to be naturally made for surgery. He had an insatiable thirst for knowledge, a bold yet meticulous approach, an innate intelligence, and an innovative spirit. His expertise in surgery enabled him to comprehend concepts instantly and perform operations with exceptional precision. Especially during his younger years, he honed exceptional skills. Additionally, his team spirit was exemplary. Every subordinate doctor trained under him developed rigor, dedication, and a relentless pursuit of excellence, shaping a generation of medical leaders and experts.
As soon as he stepped onto the operating table, it was as if my father became a different person—calm, confident, and masterfully executing each surgical procedure. His surgical precision and speed earned him accolades from peers, patients, and their families. Over the years, his reputation spread far and wide, attracting a steady stream of patients seeking his expertise. Even the relatives of the chief surgeons from top-tier hospitals would seek my father for surgeries, trusting only in his magic hands. The renowned Director of the Surgery Department from the original Yijishan Hospital, Dr. Chen, entrusted my father with the surgery of his wife, Madam Xie, who was the head of the Nursing Department in Changhang Hospital. Despite her being in her eighties and diagnosed with breast cancer, my father's successful surgery ensured her well-being well into her nineties. She considered my father her lifetime "personal physician". Similarly, Wang Ping, the Head of the ENT department at Nanling County Hospital, trusted my father to operate on his daughter, Dong Wei, who had breast cancer. Years later, the Chief of the Obstetrics and Gynecology Department of the same hospital entrusted the care of her daughter in the same manner to my father.
The director of the surgery department at Changhang Hospital, Mr. Shen, had an elderly father-in-law in Shanghai, a distinguished professor, who was diagnosed with stomach cancer and pyloric obstruction. After being unable to eat or drink for several days and his body deteriorating, his family had almost given up hope. Yet, my father undertook the "risky" direct radical surgery, having saved his life. The patient lived for another five years before succumbing to other illnesses. Conventionally, patients of this age and condition would first undergo a bypass surgery to relieve the obstruction, and only later would they have the surgery to remove the lesion. In reality, few would get the chance for this second operation.
Back in 1970, my elder uncle, Pan Yaoyi, had hepatic and biliary stones along with obstructive jaundice. Refused by a renowned hospital in Hefei, he turned to my father in desperation. At the Nanling County Hospital, my father personally performed the surgery to remove the stones, excise the gallbladder, and establish an internal biliary-duodenal drainage, ensuring his full recovery. In 1986, another uncle of ours, Pan Yaotong, was diagnosed with rectal cancer and similarly turned away by the provincial hospital. Once again, my father stepped in, performing the radical surgery that lasted over seven hours.
Back in the 1980s, numerous patients would report their symptoms over the phone, and my father could make a diagnosis then and there. For instance, his colleague Cheng Daben had a perforated stomach. The young doctors at Yijishan Hospital misdiagnosed it as renal colic and treated it by administering laxatives to clean the intestines. The urinary system imaging examination the next day proved them all wrong! This not only delayed the crucial time for life-saving treatment but also exacerbated the perforation and leakage, pushing the patient into critical condition! The patient, in excruciating abdominal pain, desperately called my father and urged a return to our hospital, where an emergency surgery to cut into the stomach cured him. The husband of the head nurse Gao at the undergraduate department, Tao, experienced a similar ordeal. Nowadays, it's more common for patients to seek medical advice remotely through mobile "WeChat" at any time and place, resolving many medical issues this way. What's particularly remarkable is that all the surgeries for our immediate family members were personally performed by my father. This demanded immense confidence, determination, and mental fortitude.
We once knew a young rural doctor who, feeling constrained in his medical career, chose to pursue an English teaching degree instead. When discussing my father's medical skills, he expressed deep admiration: "Do you know? Your father is one of the most incredible doctors in the world. He can perform complex surgeries that many top-tier hospitals have yet to introduce or popularize." He shared several cases with us, and even though we might not have understood all the medical intricacies, one thing was clear: my father consistently pushed boundaries, always striving for surgical excellence.
Later, when we asked my father about any complicated surgeries he wished to perform but couldn't, he mentioned microsurgery, limb reattachment, and other surgeries requiring advanced equipment that were beyond the reach of the county hospital at the time. He also expressed admiration for the fields of stem cell regenerative medicine, gene-editing techniques, genetic engineering to reverse aging cells, and precision medicine, recognizing them as the frontiers of medical research, while humbly admitting that as a grassroots clinician, he could only admire them from afar.
After the Cultural Revolution, with the resumption of professional promotions, my father climbed the ranks seamlessly, from Medical Practitioner, Physician, Attending Physician, Associate Chief Physician to Chief Physician. His progress was smooth, never missing a step. In all three secondary hospitals, each with over a hundred staff where he served throughout his life, he was the sole Chief Surgeon. In fact, in the entirety of these institutions, there were only one or two with such a distinguished title. Compared to his peers who graduated from technical health schools like him, almost none had the chance to rise to such a senior position. Even graduates from medical colleges in his generation, the majority in secondary hospitals couldn't attain such a high-ranking title. The criteria for grassroots hospitals were even more stringent. One needed to excel in clinical practice, publish academic papers, and be proficient in English. Typically, only one chief position each was reserved for internal medicine and surgery specialties. They preferred having a vacancy rather than compromising on quality. This emphasizes how my father was truly a rare gem among his contemporaries, standing head and shoulders above the rest.
The era shapes individuals. My father never attended elementary school, high school, undergraduate, or postgraduate courses. His formal education consisted of only middle school and a medical diploma from a technical health school. Yet, he relied primarily on countless hours of medical practice, learning through hands-on experiences. With sheer skill and determination, he ascended the ranks to become a Chief Surgeon in general surgery, ultimately earning a reputation as a renowned all-around physician.
While doctors are respected, many lead modest lives. A bit of hardship in life didn't bother my father, but the challenge he faced was how to save up money to buy medical books. Those thick professional volumes like "Surgery" and "Orthopedics" were expensive, yet indispensable for his work. Who could have imagined that many of these medical books were acquired by my father secretly selling his own blood? Each time he would donate 300cc of fresh blood and receive 30 yuan – an amount that would typically take him half a year to save. My father would brush it off, saying: "humans have a hematopoietic system, so losing a little blood doesn't matter. There are often stories of doctors donating their own blood in emergencies to save patients, and I've experienced this myself several times during my medical career". But acquiring professional books by selling one's blood, such instances are probably rare across all of history and around the world and perhaps only characteristic of that particular era in China. Perhaps only in that specific era could a reputed doctor resort to such means to own medical books.
On June 3, 2007, my father faced the greatest ordeal of his life. Suddenly, he began vomiting blood and developed an inexplicable fever reaching 40°C. The once indomitable spirit, who often claimed to be "forever young and vital", was suddenly brought to his knees. He lost over 2000ml of blood, putting him in grave danger. He was rushed to the hospital and was diagnosed with 'low-differentiated gastric adenocarcinoma.' On June 21, he underwent major surgery in Wuhan, having his entire stomach and gallbladder (due to pre-existing gallstones) removed. He narrowly escaped the clutches of death. Having worked tirelessly throughout his life, he always took pride in his robust health and positive attitude. Who would've thought? A man so rarely ill could be brought down so severely. This incident was the most significant challenge he had ever faced and marked a turning point in his health journey.
My father has always been the backbone of our family, typically appearing youthful and vigorous, especially for his age, without a hint of any vices and never having stayed in a hospital before. Despite the hardships, life was always vibrant for him. Thankfully, his sudden illness led to an early diagnosis and timely treatment. Being under the best medical care and surrounded by family during his recovery gave everyone peace of mind. After the surgery, he aged noticeably, and it took him over six months to regain his strength. Now, he speaks with such vigor and frequently performs surgeries, which is a huge relief for our entire family.
Now semi-retired, my father, at the age of 88, is astonishingly spry for his age. Despite his modest living, he keeps an orderly life and continues to be eager to learn new things. Although he no longer drives, his curiosity about the latest tech developments remains. Just this February, he was asking me about the etymology and background of OpenAI and ChatGPT. He's more tech-savvy with smartphones and computers than many youngsters I know, ordering food from Meituan, hailing cars from DiDi, and shopping on Taobao. He also frequently consults English professional materials, absorbing new knowledge, proving the adage true: you're never too old to learn. He even outpaces English-major graduate Wei in English technical vocabulary, truly an exemplary lifelong learner.
Before his major illness, he was a whirlwind of energy, performing surgeries, driving, browsing the internet, writing memoirs, and enjoying chess games. In the decade since his surgery, even with a decline in his physical condition, he hasn't given up his lifelong passion for clinical medicine. He may have set aside other specialties, such as orthopedics, gynecology, and urology, but he remains steadfast in his dedication to general surgery, continuously contributing to the field and aiding patients. Medicine is an eternal bond he could never sever.
Gentle in nature and kind to all, my father has always been upright and warm-hearted. His patience and attentiveness when diagnosing patients, regardless of their socio-economic status, genuinely exemplify the benevolent spirit and humanistic essence of a doctor.
With progressive thoughts and a modern mindset, he always treated his children as equals, never reprimanding them, let alone resorting to physical punishment. He has always gently guided us, both through his words and his actions. Our individual successes are his greatest solace, and the growth and antics of his grandchildren bring him immense joy and satisfaction.
This book is a compilation of some of the medical papers my father published after the Cultural Revolution. Although it's not exhaustive, it preserves many invaluable experiences and theoretical summations from his medical career, standing as an enduring testament to his dedication. These papers encapsulate how a doctor from a grassroots hospital refined himself through challenges, continuously pushing his boundaries. They embody a physician's fundamental principles, conscience, responsibility, commitment, and mission, spotlighting the gallantry of medical professionals in their efforts to save lives and epitomizing the profound essence of "healing the world."
Recently, as we were compiling some of these medical papers, my father reflected on his journey spanning over 60 years, filled with both pride and nostalgia. While his papers primarily encapsulate his clinical experiences and might not be heavily research-oriented, their practical utility is undeniable. They are meticulously crafted, adhering to strict academic standards, and represent the crystallization and theoretical evolution of his medical practice, holding a certain legacy value. The excellence he has demonstrated throughout his life, his unwavering dedication to medicine, his relentless pursuit of knowledge, and his humble, upright, and benevolent character serve as a priceless heritage for our generation.
Given the vast timeline, locating all his papers was challenging, and unfortunately, many have been lost over the years. We've done our best to gather as many of his past medical writings as possible, compiling them into this volume as a birthday gift for our 88-year-old father, who has been practicing medicine for 67 years non-stop. We wish him a happy birthday, good health, and a peaceful twilight year!
立委的英文视频
李名杰:医学论文集电子版(内部刊印2023)
李名杰:医学论文集英语电子板
咸昇、名杰、汉阳一江水、立委:《李家大院》电子版(内部刊 印 2022)
汉阳一江水:《小城青葱生活》电子版(内部刊印 2022)
汉阳一江水:《江城记事》电子版(内部刊印 2022)
立委:《朝华午拾》电子版(内部刊印 2022)
Clinical observation of a new minimally invasive circumcision (to be reviewed)
Surgical paper XX
Clinical observation of a new minimally invasive circumcision
Introduction
The classical treatment for excessive foreskin has long been surgical circumcision, with little breakthroughs in recent years. From October 2003 to February 2005, our hospital treated 52 cases of excessive foreskin using a minimally invasive surgical technique. Here we present the findings.
Materials and Methods
Clinical Data
The study included 52 patients, with ages ranging from 17 to 56 years and an average age of 38 years. Preoperative measurements of the penis in a flaccid state ranged from 2.5 cm to 10 cm. Of these, 40 were married and 12 were unmarried.
Surgical Technique
- Materials: The procedure utilizes a minimally invasive surgical ring invented by Mr. Shang Jianzhong, a special researcher at the Chinese Academy of Management Sciences (Patent No. 2003.ZL02 237969.X). The surgical ring is made from injection-molded polypropylene engineering plastic and consists of an inner and outer ring. The two rings are secured together using screws. The product comes in various sizes and is for one-time use in sterile packaging.
Attached Figure 1: Inner Ring of the Minimally Invasive Foreskin Cutter, Outer Ring of the Minimally Invasive Foreskin Cutter, Complete Minimally Invasive Foreskin Cutter (See insert for illustration).

Methodology
-
Preparation: Sterilization is performed, and a hole towel is laid out to expose the penis. A rubber band tourniquet is placed around the base of the penis to block venous return. A distended vein is then punctured, stagnant blood is aspirated, and 2ml of 2% lidocaine is injected. After waiting for 5 minutes, anesthesia is found to be highly satisfactory and complete.
-
Ring Placement: An appropriately-sized surgical foreskin ring is chosen. The inner ring is first placed around the penis. The foreskin is then everted over the inner ring. If phimosis is present, a small incision is made on the dorsal side to fully expose the glans. The inner plate is retained up to 0.5 cm beyond the coronal sulcus, and the frenulum is left slightly longer, about 1.0 cm.
-
Outer Ring and Cutting: The outer ring is then placed and screws are tightened. Excess foreskin protruding beyond the compression ring is trimmed. A sterile gauze strip is used to cover the wound, leaving the glans exposed. The tourniquet is then released, completing the surgery.
-
Post-Operative Care: The ring is removed on the sixth day post-operation, and full recovery is generally achieved in approximately 15-20 days.
Attached Figure 2: Post-healing of Minimally Invasive Foreskin Surgery, Completion of Minimally Invasive Foreskin Surgery, Pre Minimally Invasive Foreskin Surgery (See above insert for illustration).
Results
Out of the 52 cases, primary wound healing was achieved in 50 cases post-operatively. In 2 cases, healing was delayed due to infection caused by engaging in sexual activity before the advised period. There were no long-term complications, and the healed wounds left no scars.
Discussion
Excessive foreskin length can lead to phimosis, where the coronal sulcus is not exposed, causing a buildup of secretions that cannot be eliminated, thereby leading to balanoposthitis. Long-term inflammation could even induce penile cancer. Phimosis can also result in poor penile development and impact sexual life. Excessive foreskin is a common issue plaguing male patients.
Minimally invasive foreskin ring resection is suitable for males with excessive foreskin and phimosis. Traditional treatment methods, such as full circumcision, involve cutting, hemostasis, and suturing, and often leave scars after healing; laser surgery also has drawbacks like thermal injury.
This innovative method breaks away from traditional approaches. It eliminates the need for surgical cutting and suturing. After the ring compresses the distal tissues, ischemia leads to tissue necrosis and eventual detachment, thus completing the circumcision. Generally, the ring is removed around the 6th day, and full recovery is achieved in approximately 15-20 days. The healed wounds leave no scars, and the surgery time is only 2-5 minutes. No additional medical equipment is needed, avoiding complicated hemostasis steps. The incidence of infection is low, no estrogen therapy is needed, and patients can move freely post-operatively. Daily life is not impacted; patients can bathe, urination is unaffected, and there are no complications.
Comparison of New Method and Traditional Methods
|
New Method |
Traditional (circumcision,laser) |
|
|
1、surgery |
micro, convenient, no pain, no scars |
invasive and complicated, with pains and scars |
|
2、resources |
one operator only |
at least 2 operators needed |
|
3、materials |
no need for surgery tool |
needs surgery tool in surgery room |
|
4、bleeding |
no bleeding |
bleeding |
|
5、procedure time |
less than 5 min |
more than 30 min |
|
6、cost |
low cost |
more cost |
In the 52 cases treated with this method, some patients experienced varying degrees of penile length and girth increase post-operatively, along with enhanced sexual function, due to the alleviation of the restrictions imposed by the foreskin.
Conclusion
This novel minimally invasive surgical approach is superior to traditional methods, with definite therapeutic effects. It is worthy of broader adoption.



本文原载…….???
Originally published in "???" 90; 4(3):66 by Li Yangzhen, Li Mingjie, Shang Jianzhong, Wang Tong
from 一种全新微创包皮环切术的临床观察
Diagnosis and treatment of close duodenal retroperitoneal injury
Surgical paper X
Diagnosis and treatment of close duodenal retroperitoneal injury
ABSTRACT Closed duodenal injuries represent a unique and severe subtype of intra-abdominal trauma characterized by low incidence but high mortality rates. This study discusses six instances of retroperitoneal duodenal injuries, reporting a successful treatment outcome in four cases and fatalities in the remaining two. Such injuries are particularly elusive to early diagnosis due to their retroperitoneal location, which often results in the absence of overt symptoms and signs associated with hollow organ perforation. Therefore, clinicians must exercise heightened vigilance, carry out meticulous and ongoing dynamic monitoring, and seek robust diagnostic evidence to expedite surgical intervention. Given the specialized anatomical and physiological characteristics of the duodenum, the treatment approaches diverge significantly from those employed for other visceral injuries. This makes surgical choices pivotal to the prognosis. The study finds that comprehensive duodenal decompression and diverticularization techniques are dependable. The Berne procedure is particularly recommended for its efficacy in drainage and infection control, supplemented by requisite supportive care. Keywords: Retroperitoneal Duodenal Injury, Diverticularization, Berne Procedure
The duodenum, located deep within the posterior abdominal wall, is less frequently subjected to injury, making up only 3–5% of closed abdominal injuries and 10% of gastrointestinal injuries [1]. When a rupture occurs within the peritoneal cavity, it typically manifests quickly with signs of peritonitis, much like other hollow organ perforations. This draws immediate clinical attention, leading to timely surgical intervention. However, when the injury is confined to the retroperitoneal region, the leakage of intestinal fluids is concealed within the retroperitoneal space. This presents a diagnostic challenge as it lacks overt symptoms or positive physical signs, leading to delayed diagnosis and treatment. Consequently, the mortality rate for such injuries skyrockets to between 30–60% [2], posing a significant clinical conundrum.
Our hospital has treated 258 cases of closed abdominal injuries over the years, among which 8 involved duodenal injuries. Of these, 6 cases (2.3%) were retroperitoneal injuries. Each presented unique difficulties, resulting in delayed surgical interventions. Here, we dissect the complexities, experiences, and lessons gleaned from these cases.
Clinical Data
All patients in this study were male, ranging in age from 17 to 45 years. Of these, four sustained injuries to the descending part of the duodenum, while the remaining two had injuries in the transverse section. Two patients sought medical attention within four hours post-injury, and the other four within 24 hours. Associated injuries included one case each of liver trauma, inferior vena cava damage, mesenteric vascular injury, and splenic rupture. Additionally, two cases presented with isolated duodenal retroperitoneal injuries. The causes of injuries were varied: two resulted from falls, one from a blunt force injury by a wooden stick, and three from motor vehicle accidents.
As for the timing of surgical intervention, two patients underwent surgery within 24 hours post-injury due to concomitant severe intra-abdominal bleeding. The remaining patients were operated on between 24 and 48 hours post-injury, as positive abdominal signs progressively manifested.
Two patients received a straightforward repair followed by intraperitoneal drainage; however, both cases had unfortunate outcomes. One succumbed to hemorrhagic shock six hours post-surgery, and the other passed away on the 4th and 8th postoperative days due to complications from an intestinal fistula and subsequent infection and electrolyte imbalances, respectively.
The remaining four patients underwent a more complex surgical approach incorporating the Berne-like technique [3]. This involved duodenal and common bile duct fistulization, along with gastric-jejunal anastomosis following gastric antral resection. All four of these patients successfully recovered post-surgery.
Discussion
2.1 Mechanism of Injury
The injury mechanism is often a consequence of blunt trauma or inertial decompression, leading to a sudden shift in intra-abdominal pressure. This forces the duodenum against the spine and induces pyloric spasms, dramatically increasing intestinal pressure. Both internal and external bidirectional shearing forces act upon the frail and fixed duodenal wall, causing it to rupture.
2.2 Pathological Underpinnings of Duodenal Retroperitoneal Injury
In the early stages post-injury, leaked fluids accumulate locally in the ruptured area, manifesting few systemic symptoms and remaining largely undetectable. In our cohort, two cases featured isolated retroperitoneal injuries in the descending duodenum; surprisingly, these patients were ambulatory post-admission, experiencing only lower back discomfort. Symptoms generally worsened after 24 hours. A startling 80% of such cases are not definitively diagnosed preoperatively [4]. The leaking digestive fluids contain a myriad of components like hydrochloric acid, bile salts, cholesterol, and digestive enzymes, among others. These substances cause chemical irritation, autodigestion, and infection, leading to a cascade of complications, including severe inflammation, edema, necrosis, and multiple organ failure.
2.3 Diagnostic Key Points
A hallmark symptom is the dispersion of caustic fluids into the retroperitoneal space, resulting in lower back and right testicular pain. Escaping intestinal gas accumulates in the retroperitoneal space and can be visualized via plain abdominal X-rays; this gas often outlines the right kidney, making it more discernible. Retroperitoneal inflammatory edema may blur the right psoas muscle shadow and abdominal fat lines. A digital rectal examination may reveal presacral crepitus. Elevated levels of pancreatic amylase serve as an additional diagnostic marker. A positive abdominal puncture is favorable for diagnosis, but a negative result does not rule it out. Oral administration of iodine water can confirm and locate the spillage outside the intestine. During laparotomy, methylene blue can be administered via a nasogastric tube to directly visualize the spillage, aiding even in the identification of multiple injuries and avoiding missed diagnoses.
2.4 Surgical Procedure Selection
2.4.1 Minimized Duodenal Injury
For cases with limited duodenal injury and minor local inflammation that undergo early surgical intervention, cautious use of simple repair is possible. However, it's critical to inspect the orifice of the hepatopancreatic ampulla to ensure its patency. In one such case in our cohort, we used a technique akin to ERCP catheter placement and left a side hole for drainage and decompression. No postoperative complications like jaundice or pancreatitis were observed.
2.4.2 Implementing "Three Fistulas"
For effective duodenal decompression and early nutritional perfusion, one approach includes raising the jejunal wall for repair and adding three fistulas: gastrostomy, proximal jejunostomy into the duodenum, and distal nutritional fistulization.
2.4.3 Berne-Like Procedure
Delayed diagnosis often results in late surgical intervention and aggravated local inflammation. We advocate for the Berne-like surgical approach, which comprises multiple elements like intestinal repair, duodenal fistulization, and abdominal drainage. This method has shown to be effective in the complete and permanent diverticularization of the duodenum. This procedure is generally safe and can be completed within three hours.
2.4.4 Pancreatoduodenectomy
This radical surgery is suitable for severe injuries involving the head of the pancreas and the duodenum but should be reserved for extreme cases due to its high mortality rate and the stress it puts on critically ill patients.
2.4.5 Complete Debridement
Intraoperative debridement of the abdominal and retroperitoneal spaces is vital. Removal of necrotic or devitalized tissue, along with extensive irrigation, helps reduce toxin absorption. Effective drainage measures, such as double-tube negative pressure suction, are also crucial and can be used for irrigation and medication postoperatively if necessary.
2.5 Postoperative Management
Maintaining gastrointestinal decompression and ensuring unobstructed suction through the created fistulas are pivotal for sustaining low pressure within the duodenum. Effective abdominal and retroperitoneal drainage systems should be kept in place, and if necessary, they can be removed 5-7 days postoperatively to account for potential intestinal leakage.
Eliminating the stimulating effects of extra-intestinal fluid accumulation at the site of duodenal injury is crucial for successful wound healing. Systemic balance of water and electrolytes, along with nutritional supplementation—particularly albumin and calorie intake—bolsters the body's reparative abilities.
The choice of effective antibiotics, particularly intravenous infusion of anti-anaerobic drugs such as metronidazole, is vital for infection control. Adopting a semi-recumbent position post-surgery helps avoid subdiaphragmatic fluid accumulation and enhances effective drainage, all of which are integral components of a holistic postoperative care strategy.
References
-
Hu Zhenxiong, et al. "Selection of Surgical Procedures for Duodenal Injury," Journal of Practical Surgery, 1989, 9(8): 441.
-
He Liangjia, et al. "Diagnosis and Treatment of Closed Duodenal Injury," Journal of Practical Surgery, 1985, 5(11): 571.
-
Berne CT, et al. "Duodenal Diverticularization for Clodenal and Pancreatic Injury," American Journal of Surgery, 1974, 127: 503.
-
Chen Rufa, et al. "Principles of Surgical Treatment of Duodenal Injury," Journal of Practical Surgery, 1993, 3: 134.
This article was originally published in Proceedings of Wuhu Annual Surgical Conference,1996;28-30 Changhang Hospital, Li Mingjie
from 闭合性十二指肠腹膜后损伤诊治分析
Dad's medical career
Appendix: by Wei li
Dad's medical career
Dad didn't have a chance to enter medical college, instead he went to a junior medical school. However, the achievements he has made in the past 40 years of medical practice are beyond the reach of most of his career peers from college.
The excellence in his amazing career depends on his being bold as well as meticulous, being diligent in practice and studying hard. I remember when we were young, we used to directly go to the operating room to look for our parents when we returned from school. Dad worked very long hours a day, and when he came home, he plunged into medical books preparing for the operations next day. It was rare for him to have time for a full rest. Over the years, Dad built his fame as surgery master. People seeking his medical treatment came in an endless stream. Even when the relatives of the surgical director of the hospital at the next higher level need surgery, he would send them to my father for the peace of mind.
Doctors were well respected, but they had a fixed salary, barely making the ends meet. In Mao's time, wages and prices remained unchanged for decades. My dad’s monthly salary then was 46 yuan, and my mother 43 yuan, so our family income totaled 89 yuan, to maintain a family of six (us 3 children plus my grandmother) for basic food and clothing, it was difficult to have any savings for emergency. Most people lived a poor life in those days, so we never felt we also had a hard time then, although for every meal, the entire family only had one or two small dishes besides rice. Anyway, everyone was struggling, and there were still many people who did not have enough rice to feed the family. Some could only afford porridge or dried sweet potatoes. Dad's problem is, where could he save the money for medical books he badly needed? Those big and thick professional books, such as Surgery and Osteology, are expensive, but they are must-have. Who would have thought that many medical books were actually bought by my father’s selling his blood without telling the family. 300cc at a time, the price then was 30 yuan (to save 30 yuan would otherwise take half a year with strict budget). Once, my mother was very angry when she found out my dad had donated blood for covering the cost of a book. Dad was very thin then, and Mom was worried that his blood donation would harm his health. But my father always argued that people have hematopoietic mechanism, and it's okay to lose some blood. However, is there another way out? No matter how skilled you became, you simply had no way of making extra money. I remember that when the operation lasted long into late night, the subsidy for prolonged night work at that time was only 20 cents, or a bowl of free shredded pork noodles was provided (mom and dad would not consume the delicious noodles by themselves, but would always bring them home to feed us).
It is true that each era has its own way of life. However, it was still hardly imaginable that a medical doctor who enjoys a high reputation and well recognized medical skills could not afford his own medical books unless he exchanged them with his own blood. This kind of thing could only happen perhaps in the Mao’s China. It can't be said that Dad didn't catch up with good times. From the perspective of career pursuit and spiritual satisfaction, the specific conditions of that specific era gave Dad a rare platform for practicing his wisdom and skills to the fullest extent. The grass-root county hospital he served was like a blank sheet of paper for drawing, faced with a steady stream of endless rural patients who had always lacked medical care and facilities. These patients could not afford to be transferred for treatment in primary hospitals, so they had to try the county hospital at best, or quit any treatment leaving themselves to fate. Dad was one of the founding members of the county hospital. He had full autonomy and worked like crazy to cope with the endless incoming cases. For years, there were a series of operations almost non-stop every day. I knew a young doctor who was tired of practicing medicine because he could not see any career future limited in his rural clinic, and changed his career to become an English teacher after reentering a teachers’ college. However, when talking about my father's medical skills, he was full of admiration: "Do you know your father is the greatest doctor in the world. Your father is able to perform major surgeries that are not commonly performed even in larger hospitals." He explained to me some of the highly complex cases my dad has dealt with, which I did not fully understand, but I knew that for decades my father had been continuously challenging himself and mastering more and more complicated procedures. Recently, when I asked my father if there were any surgeries he wanted to perform but had not yet been able to, Dad told me that he had pretty much done everything that could be done in his practice, except for some types of operations that were out of reach, such as microsurgery and replantation of severed limbs, which require expensive equipment and facilities that a county hospital simply could not afford, there were no such conditions for pursuing these.
It is worth noticing that in many cases, even very poor farmers could also enjoy surgery services in grass-roots hospitals like the county hospital my father served. At that time, the fees for minor operations (e.g. appendectomy, etc.) were less than 10 yuan a surgery, those for medium-level operations (e.g. gastrectomy, etc.) cost tens of yuan, while those for major operations (e.g. surgeries involving heart, brain, etc.) were about a hundred yuan. Of course, it's not easy to save enough money for such costs, but most people have come up with a way to manage that as emergency needs. For extremely poor households, there was a way to apply for government subsidies at the Civil Affairs Bureau. This part of the low-cost medical system with socialist subsidy policies in Mao’s time is worthy of praise. The fundamental reason for the low fees is, of course, the very limited basic cost for human resources: doctors and nurses were state employees, getting a modest fixed salary, with few extra expenses.
Speaking of surgery, I myself still have my father's “magic work” on me. It was the time when I was about ten years old. One day, shortly after breakfast, I suddenly had a terrible stomachache. Dad came to check, pressed his hand on my right lower abdomen and asked if it hurt. I said, "It hurts". He suddenly pulled his hand back, and I immediately felt a sharp pain, and could not help with tears out. Dad told me that this is called "rebound pain", which is a typical symptom of acute appendicitis. He told me that I needed an immediate surgery and soon brought me to the operating room before noon. I had been used to seeing operations since I was a small child, knowing that appendectomy is a minor operation, and I should not be afraid of it at all. But when I was really sent to the operating table, I felt I should not be rushed to it. What if it was a mis-diagnosis? In that case , would I undergo an open operation for nothing? I felt just fine in the morning before breakfast. After drinking half a bowl of porridge, I suddenly had a strike of stomachache. I did not even have a blood test or other clinical tests. All diagnosis was based on my father’s checking my lower abdomen with hands, was that sufficient? I simply could not drive my suspicion away and was very reluctant to face the coming surgery. Of course, all these were my over-anxiety. My appendix extracted in the surgery was swollen like a carrot head. Because the operation was timely, it hadn't festered yet. Many surgeons don't operate on their loved ones for fear of being too nervous. But dad would not trust others, so he insisted on doing it himself, with my mother as his assistant. Usually, if conventional spinal anesthesia or epidural anesthesia were used, he could take his time, but dad insisted on using only local anesthesia for the sake of small postoperative response and fast recovery. So I was conscious of every process of the operation clearly. Most similar operations then often left a few inches of incision on the skin, but my father only gave me a small incision of one or two centimeters (only two stitches used after closing my abdomen), barely enough to insert a finger through. Moreover, unlike most incisions, Dad used crosscutting, which makes the operation more difficult to operate. Dad said that cross-cutting conforms to the natural lines of human abdomen, and the scar would not show up after healing (indeed, I have seen the scars of other vertical cutting operations, and they stand out there thick and red, long after healing, which looks really ugly. In contrast, mine was hardly noticeable). Of course, this operation was very successful. I went home the same day, and the next day I was able to get out of bed and slowly walk around. However, there was a real pain during the operation with only local anesthesia, and I cried and shouted, which put a lot of pressure on my father. The pain was most serious when Dad’s finger tried to get to the inflamed appendix, which hurt even if it was not touched, not to say being pressed. Fortunately, it didn't hurt for a long time before my father caught it and quickly made up for some additional anesthetic. My father reflected the procedure later on, and said that despite all his efforts, the place where he cut the knife in was slightly off the target, which unfortunately made me suffer more pains. Local anesthesia should have been fine if the incision were enlarged, an easy way to go, but Dad insisted on making the incision as small as possible, and did not want me to leave a permanent big scar for life. Year later, I told my daughter this story, and she tried to spot my almost invisible surgery scar and exclaimed, "Grandpa did a terrific job! Grandpa's craftsmanship is out of the world! ” From then on, when she had a stomachache, she often shouted, suspecting that she had appendicitis. I felt relieved when I found that there was no "rebound pain". She also said that if she had appendicitis, she would fly back to Grandpa, because the doctors in the United States couldn't be trusted: they had only operated a limited number of cases, and my grandpa had operated tens of thousands of surgeries in his life!
Dad often paid on-call visits to rural clinics and farmers' homes (as director of obstetrics and gynecology, so did my mother). Many cases needed emergency surgeries on the spot, no matter what the conditions were, they had to be carried out to save lives. Many rural areas had no electricity, so flashlights were collected together over the an operating table. In the second year of the Cultural Revolution (1967), the two factions of grass roots organizations were divided into conflicting groups, often with friction, sometimes using fire arms. In the beginning, it was street fighting, using steel knives and the like, and at the later stage, they used real guns. Our county town became a war zone. The county hospital was in a semi-paralyzed state, and it was located in the area controlled by the group named "Sweeping the Black Line" (a more radical mass organization). Mom and Dad were closer to the less extreme group so-called royalists ("royalist" means opposing the struggle against veteran cadres), but they would not participate in their ideological and political activities. The commander-in-chief of this group used to be the uncle next door, tall and robust. In my memory, after serving as the commander, he often wore a wide belt around his waist, carrying a box gun, and staged to be very heroic. One day, he sent someone to our home, quietly inviting our whole family to the base camp of his faction as they urgently needed medical experts to treat the wounded in the warfare. When we were settled down, my father set up a wartime operating table in the camp, just like Bethune's battlefield hospital, which also saved many lives.
In years of peace after that “civil war”, the white ambulance in the county hospital used to carry mom and dad often together with us children for on-call emergency visits, having run around every corner of the county. If the call was from a nearby village, the visit was also on foot or by bike. I still remember when I was six or seven years old, my whole family moved to Hewan, a remote small mountain town, to support a rural hospital for one year. Dad often rode his bike in the night for home visits and sometimes he took me with him on the bike. It was always so dark, often passing one or two cemeteries, with a cold wind blowing overhead. When we entered a village, there were always dogs barking one after another. I hid in my father's arms in the front seat of the bike, too afraid to dare open my eyes. After treatment, under the dim oil lamp, the host often boiled two eggs with brown sugar, and served them steaming hot to entertain us for appreciation. Then, they would use flashlights to send us out of the village, and I was often fast asleep on the way back before we got home.
Dad has always hoped that we children study medicine and follow his footsteps. If nothing else, wouldn't it be a pity that the shelves full of medical books accumulated over the years have no one to carry on? Unfortunately, none of us four children ended up following this path. My elder brother and I were the first college students after the Cultural Revolution (Class 1977). In that year before the entrance exam, following the wishes of our parents, we both placed "Anhui Medical College" as our second choice. As for the first choice, my brother took the initiative to apply for "Nanjing Aviation Institute". At that time, I didn't have my own opinion, so long as I would enter a first-class university to study the then popular physics. So I followed my father's advice, set a popular physics major plasma as top choice for the top school "University of Science and Technology of China”. We were in an age when we were convinced that “good knowledge of maths and physics would carry us all over the world to achieve anything we want". I don't know what plasma was, but I always felt that only such an unfathomable major would be qualified to surpass my father's career of medicine practice. As a result, my brother got his first wish honored and went to pursue his dream of aviation with satisfaction. But all my choices failed to bear fruits, and I was forcibly "assigned" to the English Department of Anqing Normal University. What a disappointment and shock to me! Although I didn't do very well in the college entrance examination, I later learned that my scores had reached the standard set by "Anhui Medical College” and I should be qualified for my second choice. The bad thing is that I "added" foreign language in the test list in the hope for enhancing my college competition. But in the first college entrance examination after the Cultural Revolution, foreign languages were not a compulsory test item, nor were they included in the total score that determined their destiny. The reason was simple: although college had shut down for nearly ten years to have accumulated 10 times of candidates competing for colleges at the same time, many people never learned any foreign languages in school. If colleges insisted on testing foreign language as compulsory, more than half of the candidates would be excluded from the radar. So it was decided to be an elective test item. I myself would not have dared to take the English test if I hadn't followed the English learning programs of Anhui and Jiangsu radio stations for many years. I had hoped that given the same conditions, my additional test on English would help me to be admitted first for my choices. Who would have thought that after the Cultural Revolution, there was a serious shortage of foreign language major candidates in the liberal arts, so some science and engineering students who took additional foreign language tests were simply transferred to the liberal arts pool. That is how foreign language which should simply be a tool for other specialization became my major subject. In those days, the popular mentality favored science majors. After being forced to enter the liberal arts foreign language department, I always felt that I had "strayed into the wrong side door". With that, I decided to insist on further self-study of advanced mathematics and Linear Algebra for another two years after entering college, which unexpectedly laid a foundation for my future interdisciplinary development of arts and sciences in my master’s program computational linguistics. Looking back, I think it was fortunate that I didn't get into medical school as I had hoped, otherwise there would only be one more mediocre doctor trained in the world. I do have some perseverance in studying, but I lack my father's courage, ingenuity and boldness which are required to be an outstanding physician. I would not have been able to be even close to Dad. I have seen many admirable elders and newcomers in my life and career, but I always admire my father the most. He set up an example of excellence way beyond our reach.
Dad is now semi-retired at home, still living a very simple life, in an orderly and healthy way. Unlike most other old men around 70 years old, he still keeps a keen interest in new things, and is more familiar with computers than many young people. He enjoys a solid knowledge of professional English for many years, and his general vocabulary is comparable to that of myself whose major is English. The development of all of us children is his greatest comfort. The little stories of his grandchildren's growth brings him great joy.
The previous work is a debriefing report written by my father ten years ago for applying for the promotion as chief physician. Between the lines of many medical terms and figures, many past events of Dad’s medical practice and life come back to my mind, as if it were yesterday.
【李名杰从医67年论文专辑(英语电子版)】
COLLECTED WORKS IN COMMEMORATION OF MINGJIE LI'S 67 YEARS OF MEDICAL PRACTICE

© Mingjie Li
Dr. Mingjie Li has been practicing medicine for over 60 years. This collection, compiled to commemorate his amazing career, includes three sections: (i) career memoirs, (ii) medicine papers, and (iii) medicine education. The publication of his medicine papers is the culmination of his extensive experience and expertise in the field. His work has been recognized by his peers for its professional value and rigorous style. In addition to surgery, orthopedics, obstetrics, and gynecology, his work at times also incorporates elements of traditional Chinese medicine. The "Operation Records" section in the appendix provides detailed descriptions of operation procedures and emergency measures, making it a valuable reference for professionals in the field. The "Education Section" highlights Dr. Li's practical experiences and medical training materials he compiled, providing valuable insights into a range of clinical topics. Overall, this collection serves as a testament to Dr. Li's impressive career and contributions to the field of medicine."
August 2023, Wuhu, Anhui, China
Table of content
I: Career memoirs
Dad’s medical career (by Wei Li)
II: Medicine papers
Regular resection of left lateral lobe of liver for intrahepatic calculi
Surgical management study of hepatic injury
Surgical treatment of acute gastroduodenal perforation
Diagnosis and treatment of closed retroperitoneal duodenal injury
Surgical treatment of short bowel syndrome
Hepatobiliary basin-type biliary-enteric drainage
Several special problems in diagnosis and treatment of biliary tract surgery
Diagnosis and treatment of close duodenal retroperitoneal injury
Misdiagnosis of subacute perforated peritonitis in gastric malignant lymphoma
Adult retroperitoneal teratoma infection complicated with chronic purulent fistula
Ingested lighter as a foreign body in the stomach
Successful primary repair of congenital omphalocele
Recurrent stones in common bile duct with suture as core
A case of plastic tube foreign body in bladder
Subcutaneous heterotopic pancreas of abdominal wall
Several improvement measures of circumcision
Clinical observation of a new minimally invasive circumcision
A surgical treatment of spinal tuberculosis
Transpedicular tuberculosis complicated with paraplegia
Surgical analysis of surgical paraplegia
Lipoma under soft spinal membrane complicated with high paraplegia
Treatment of femoral neck fracture with closed nailing
Fifth metatarsal fracture caused by varus sprain
Intervertebral disc excision in community health centers
In commemoration of the 50th anniversary of Dr. Xu Jingbin’ s medical career
Intrauterine abortion combined with tubal pregnancy rupture
Rivanol induction of labour by amnion cavity injection
Extraperitoneal cesarean section
Prevention and treatment of trichomonas vaginalis and mold infection
Non-operative treatment of senile cholelithiasis with integrated traditional chinese medicine
Treatment of acute soft tissue injury with moxibustion
Treatment of scapulohumeral periarthritis with acupuncture combined with warm moxibustion
IV: Medicine education
New concept of modern surgical blood transfusion
Surgical treatment of thyroid cancer
Indications of splenectomy and effects on body after splenectomy (DRAFT)
Treatment of carcinoma of pancreas head and carcinoma of ampulla (DRAFT)
Treatment of recurrent ulcer after subtotal gastrectomy
Treatment points of radical resection of colon cancer
The Story of My Father (An Epilogue)
江城记事之代后记
蚁
立委
中午。
蝉唱着歌儿,空气弥漫了睡意。Jonathan Swift的<<Golliver’s Travels>>在手上摇晃,扭曲着身子,化着一个个“8”儿。
哦,我的小“8”儿!
时光在眼前急速倒转,退回到十五年前。
也是中午。
蝉唱着眠歌儿,空气弥满了睡意。父母已呼呼入梦。奶奶仍在门口针线。
我撅着屁股,在太阳底下,悉心观察虫蚂蚁。
不似那黑而大,令人讨厌的山里蚂蚁,这是种极小、棕红、温善而可怜。看上去,恰是幼儿园刚学的标准的小“8”。
“8”儿们在蒙了泥灰的生有斑斑点点苔藓的墙角寻食。寻获物驮在身上,像点了点白痣---那是碎米粒什么的。
而我的丢在稍远处的饭团仍躺在地上,不被发现。我等的不耐了,将小树技挑上一只小“8”儿,但它却顺着枝杆直爬上我手上。我甩手,甩不脱,便用另一手姆指与食指轻轻捉下。可怜的小东西在地上痛的打滚,显然是受了创伤。使我惊异并得以安慰的是,滚了片刻,它便匆匆溜开去,竟无有跛的迹象。
白胖胖的饭团依旧躺着,以其反射的银样的光招来寻食者。
来了一只,围着转了两圈,试着推拽,终于憾不动。又爬上爬下调查了两番,方才回穴搬兵来。
于是,饭团摇摇晃晃预备动了。却没有动,只是摇摇晃晃着。蚁们算来也不少,它们的搬不动,大约可能是没有语言,且又隔着饭山,前后不能联终,相互牵扯罢。正如我们人类,人员多的机关往往办不成事,虽然我们有语言,而且智力商数比渺小的蚁类不知高出几许。
我正替蚁们着急,又一队援军赶来。为首者十分高大,几倍于众蚁,触角长得也令人惊讶,头颅蜻蜓似的大而亮。无疑这是蚁王了。芸芸小生中,突然现出这么一位可怖的强者,我立刻感到一种威严的萧杀和专制的残忍。因为我早已在心内将我同化为小蚁,带着它们的悲和喜,也感受世上不平和倾轧。
好在蚁儿们没有三跪五躬,没有顶礼膜拜。没有早请示晚汇报,没有忠字舞语录歌。蚁王国臣民们显得极端地不恭不敬,圣主的权威一概不见,只余下那威严的外表,引得了我儿时的悚然。
我疑心蚁国可能是地球上最民主的国度,有着最清明的政治和最纯朴的风尚。因为看到它们不论官兵,一概愉快地干活。每一个都在努力单纯地做自己的一份,并无邪心杂念。虽也仍有互相牵扯,抵消能量的时候,那是因为客观条件的限制,主观上却绝不会有丝毫人类所具有的恶意。特别是它们互助、平等、爱劳动的美德,更比人类强许多。
算起来,人类须向蚁类学的,也委实不少啊。
好容易搬过来的食物,却因为蚁穴的洞口不够大,进不去。
蚁们急得团团转。
我也急得不行。焦急中,我突然意识了到什么,于是从“同化”中挣出。其时我刚满五岁,在人类是微不足道的拖着鼻涕的娇弱者,但在蚁们眼中,我一定是个超级巨人了。我也就自以为伟大,挥起小巨手,把大饭团用树技劈为几段,俨然是蚁们的保护神。于是像是听到我的小“8”儿们的欢呼和拥载,我大欣喜,大满足。
太阳依旧大大咧例地照着。奶奶已停下针线,靠着门,打盹儿。
蝉依旧唱着眠歌儿,但声音低下不少,像是也疲倦了,或者是我的耳朵听的疲倦了。
光屁股早已晒得热辣辣的,头也很有些昏的意思,我猛一站起来,眼前一串金花。但儿童的天性与这死气沉沉的混沌环境极不协调。我吸吸鼻涕,揉揉眼睛,重又撅起晒红的屁股来。
蚁们依然忙忙碌碌,似乎永不知慵为何物。
哦,这些我的、辛劳、勤苦、不知疲倦的小英雄们。
将洞口堵起来如何呢?
结果,自然可以预料,几个剩在外面的蚂蚁,找不见家,急的什么似的。我在淘气满足的得意中,颇感到几分过意不去。禁闭在洞里的蚁们岂不更急?这样在洞内,不会闷得慌?我不敢再想了,赶紧打开洞口,却不见半个蚁影。难道全闷死了?等了片刻,忽然我惊喜地发现离墙根二三寸的一块苔藓处串出一溜黑影。好机灵的小鬼!原来专为防我这样的突发灾祸,它们早备有后路,留有二门呢。(我岂不成了我心爱的蚁们的敌人?我不愿。给我糖果也不愿。)此时下面洞口也串出一溜,带上大大小小家什食物,有秩序的撤离。
我明白了,蚁们搬家了,躲避它们永不理解的灾祸。
这灾祸就是我!
我很想将它们什物再搬回洞去,并告诉蚁们:不要紧,再没有别的坏孩子淘气塞蚁穴洞口了。而我也不过是开个玩笑,再也不会。这玩笑对渺小的蚁们是太过分了,它们永不会饶恕我,它们依旧在搬什物。
它们是决计要走了,而这都是为了我!
绝望中,我寻来水,将它们前进的道路封锁,希望它们最后能回心转意,去过自己过去的安宁的生活。然而无效,双方只是僵持着。我不忍再见蚁们焦急模样,撮起土在水上填出一条路。蚁们便急急忙忙地,仍有秩序地拥过桥去,排开了很长很长一条无边有尾的“8”儿组成的线,引向远处。
哦,我的可怜的小“8”儿们!
蝉仍唱上看眠歌儿.空气弥满了睡意.
我揉揉眼,从遐思中回来,想:人类的怜悯心大概是生就有的吧,人之初性本善吗,人与动物的区别也就在这里罢,只是后天造就了野蛮残暴贪婪和罪恶。渺小如蚂蚁者,在凶焊的强者看来,是早就不刻存在这个星球上了。然而却赢得了我儿时最怜爱的同情心,我想这情形与人类也适用。一个人,那怕是小人物,是弱小群体社会底层民众,都应该得到同情和保护。我们号称万物之灵,保护弱小应是我们的良心和天性才对。人生来就应该平等,生命的尊严是不应以贫富强弱而不同。难到欺弱畏强真的是生物界最正当最道德的铁的规律吗?!这些哲学问题我想不深,因而并不了然。了然的只有一点,我也是个弱者,正如蚂蚁。
我了解我自己.我清楚,从社会环境个人经历和家庭背景来看,我无疑是个弱者.一个来自于县城出身于普通知识分子家庭的穷学生,一个没有权势没有背景读死书的青年,我时常感到了冷漠嘲弄和凌辱.但我时终相信这不是人的本性而是人的异化.我沮丧过,但我不绝望,弱者的我会奋斗,不仅能自由地生活下去,而且能生活得好.强弱不会长久,也不会永恒.也许我也会最终成为强者,但一定是一个不欺压弱者乐于帮助弱者的伪强者.
因为我是弱者,我也就更加倍对弱小生活怜爱和关心,我时时在其中看到自己的影子,因而也就更加深了一层苦痛.这凭证便是我熬了多年的仍时时感受到的堵蚁穴口的那个罪孽.因为我可能有意无意成为了残害弱小生命的刽子手,每当想到这点我就心寒.多年来时时在我头脑索回的问题----弱肉强食适者生存,在有智慧的人类还是铁律吗?我思索,一直在想.
蚁们备有二门,难到也备有二穴吗?倘或不然,怎么来得及时建造呢?建那么一个大工程是需要时间的.若临时找不到适合的避难所,它们在那儿过夜呢?就算准备有二穴或新了造新居,或者也不理想,潮湿受淹呢?无论如何是我给它们带来大灾难了.
此后几天,我一直在寻着我的可怜的小“8”儿们,却始终没有再发现,小时俏俏因此而哭过几回,我常常疑惑它们也许确是死了.
我的心也恰似装上了这些蚁们的魂灵,我的心时常难受隐痛.在强者,这大概是很可笑的.我却忘不了,一直到现在,虽然我时时安慰自己说:也许竟活着呢.
蚁们纵然侥幸活下来了,到现在怕也全部成了灰土了罢.或者儿孙还在那儿住呢,(在其间也流传着那场奇怪的空前的灾难的传说和故事.)而这对我,该罪有应得,虽然不并是我的本意,我的心仍然被咬啃着,咬啮着,不见松。
我又常想:那些弱者,在这个世界上也往往为一个强大的弱者,弱者中的强者和巨人,(正如我幼童时一样,是个弱者,对蚁们而言是个巨人)所左右而遭殃。
我们其实都是弱者,用宇宙的眼光看,人和蚂蚁都是弱小生命,一万年和一秒钟也只是一刹那。人真的没必要分成贵贱高低,互相斗争相互欺凌相互残杀。
蝉唱上看眠歌,空气弥满了睡意。我什么也不想了。
“8”儿早已还原为我的abc了,但我丢下了书,我困了。
太阳稍偏了点
1980.8.8

江城记事之十八
那山、那水、那城、那红叶
二十八天加拿大自驾游
一.前言
二.加拿大西部山水游
三.加拿大东部枫叶游
四.多伦多温哥华都市游
五.结语与感触

一.前言
老夫本人没什么爱好,但比较喜欢旅游,尤其喜欢不受约束限制的自驾游。很不喜欢跟旅行团的出游,那太约束,无法自由自在畅快之游,对出国自驾游更是向往。所以我本人在国内大多是以自驾游为主,但对于国外自驾游,苦于自己英语只认识几个单词,无法与人交流,时终不敢贸然跨出那一步。2015年有一个英语不错的人愿与我们一同外出游玩,我顿时气壮,实现了我多年梦想。全程由本人担当司机,自驾在法国意大利希腊三国广袤美丽山水之中,玩了近一个月,虽中途状况连连,但有惊无险,顺利返回。自此,自驾游是我海外观光的不二选择。
2016年9月27日至2016年10月25日,本人和我的夫人一起完成了第二次国外自驾之旅。这次旅游的策划、向导和司机是老夫本人,而领导、摄影和会计自然是我的夫人了。二十八个日夜流淌在地广人稀、景色秀丽、风光旖旎的加拿大。加拿大多姿多彩的高山雪峰,纵横交错的河流冰川与星罗棋布的湖泊岛屿,神奇、独特而别具魅力,一切都让人赞叹、让人惊艳、让人流连忘返。如此色彩斑斓、如此壮丽巍峨,让我们感慨实在不虚此行。在加拿大,那天真他妈的蓝,那水真他妈的绿,那空气真他妈的清洁。用一句话说,那就是:真他妈的太漂亮了!上帝真他妈的是非不分,太眷顾资本主义这块土地了。
对于加拿大,毛泽东的《纪念白求恩》一文,让我从小就对它有所认知。在闭关自守的那个年代,以天朝当年告之我的印象,加拿大是个地大、人少、经济发达的国家,风光秀丽,资源丰富,属于第二世界,是典型资本主义国家,垄断资本家控制国家,劳动人民受尽压迫,贫富差距悬殊,产业工人阶级被工人贵族忽悠,是个正在走向垂死、没落、腐朽的帝国主义深渊。改革开放后,有关加拿大的信息渠道多样化,加拿大给国人印象大为改观,许多人把她美称为不是社会主义制度下的社会主义国家,税收高,福利好,十分关照底层贫困阶层,总之过去我们宣传的社会主义制度的所有优越性,在不少国人心中竟在这个老牌资本主义国家中得到体现。这种认识上的巨大落差使我对这个国家产生了浓厚兴趣,更何况她还有传说已久的绝佳景色和殖民土著文化。去加拿大游玩观光成了我埋藏我心中已久的愿望。
于是我们今年初决定暂不去新西兰而改去加拿大,想去就去,说走就走。于是我立即着手准备资料,开始规划,保证秋天枫叶正红时完成我们这次自驾游。
去加拿大首先就面临签证问题,然后是订计划,购机票和确定住宿。
于是我上网观阅大量加拿大游记,收益不浅。很多行程都参考了他们的攻略,这是网络社会和热心游客带给我们的便利,感谢大家,感谢网络,让我们省了许多时间和精力,让我们加拿大之行更充实更完美。我就是根据自己的时间,参照网上攻略,再对照google地图制定的旅游路线,并排好每天的行程计划表。
有关签证问题,网上有很多详细介绍,很实用,这里不多述说。这次我们不同的是,几乎前后不间断地签了两个国家,先签加拿大后又去签了美国。加拿大是通过中介,美签是自己去办的,都过了。现在签证相对容易,准备的很多材料都没用上,我五年前曾被美国签证处拒签过一次,这次也没多问,都给了十年多次往返的签证。所以大家大可放心,过签率这几年有很大提高。
签完证后就开始做详细行程计划表,在完全自由行的情况,又是要去这么远的一个陌生地方,做行程计划表是件辛苦而又快乐的事。这次我们选择旅行计划概括为“两点两线”,哈哈有点当代天朝八股文模式。所谓两点两线,两点是指多伦多和温哥华都市游,两线是指加拿大西线山水游和东线枫叶游。
去加拿大我选择从上海中转到温哥华,提前两个月浏览机票,在淘宝网订了往返机票,机票订得倒很顺利,结果发现临出发前十五天,机票价格便宜了许多,我们多付了五千多元,心里着实堵得慌。看来早订机票也不一定是最佳选择,尤其是旅游淡季期间。我订了武汉→上海→温哥华→上海→武汉联程往返票,每人 XX元(含税),同时预订了温哥华→多伦多→温哥华联程往返票,每人XX 元(含税)。
住宿是在Booking网上预订,很方便,大多都是可以撤销更改的。我定酒店的原则就是,一,汽车旅馆,二,价格要相对便宜,三,客户评价要好。本来我最想预订B&B家庭旅馆,有厨房,有家庭氛围,当年在欧洲我们就是订的B&B家庭旅馆,感觉非常好。只可惜我英语不好,怕无法与顾主沟通,不敢订B&B家庭旅馆,不得已只好去订汽车旅馆了。
自驾游所用的车辆是通过租车网租的,是Enterprise公司。导航仪是用的佳明2508型,在国内购卖的,中文语音提示。这次自驾游如此顺利它起了很大作用,是功不可没,整个自驾行程全程全靠它,没有它,那真就是寸步难行了。
虽然各住宿地都称有免费WIFI,但是我们还是不放心,在淘宝网上购了5G流量的一个月免费国际长途的北美电话卡,实际证明这个决定十分英明,为我们化解了行途中不少难题。
我们这次外出带了二部尼康单反相机和一部莱卡数码机,同时手机有时也充当照相机的角色,夫人对摄影十分痴迷,有时为取一个镜头,什么危险都不怕,有一种为事业献身的大无畏精神。
这次冲出国内,走出亚洲,飞向世界的自驾游,最辛苦劳累的自然是本人,最操心有功的要归于夫人。我常常因功课做得不好受到夫人严厉批评和耐心指导。虽然我自我感觉,我的功课做得还算周密,但千准备万准备总有遗漏,所以世界上怕就怕认真二字,不认真就会吃苦头。看来我任重道远哟,还得加强学习,为以后的旅游去做更完美的规划,更充分的准备,去当更贴心的导游,更优秀的司机,总之要加强思想改造,让自己充满正能量,为领导分忧,认真落实“二学一做”,学习攻略游记,学习简单会话,做一个合格的业余导游,不辜负我的夫人期望,确保今后旅游安全、顺利和舒适。
二.加拿大西部山水游
我们九月二十七日早晨乘东方航空公司MU2019航班从武汉天河机场飞往上海浦东机场,一早我们就起床,由家人送至机场,打包托运登机,八点四十飞机正点起飞,准时抵达浦东机场。办理出关、安检等手续,一路紧紧张张,跑前跑后,直到踏踏实实坐在登机口的休息室里,方觉得安定下来。在休息大厅里意外碰到在美国工作的侄儿,他也是当天从浦东机场飞回美国。几年都未见过他,小伙子成熟不少,能够在机场相见很出乎我们意外。下午一点半东方航空公司MU581航班在浦东机场缓缓启动,正式开启了加拿大之旅。
飞机往东飞行,十几个小时说慢也慢说快也快,看看录像,间隔睡一会儿觉,不知不觉就过去了。当耳边传来飞机乘务员甜美的声音时,机窗下已是朝霞彩云,绿野悠悠的美景。由于时差原因,飞机于当地时间九月二十七日早晨九点十分抵达温哥华国际机场Vancouver International Airport 。
温哥华机场不算大,但让人很亲切,机场的所有标识都有中英法三文对照,所以即便我这样英文不太好的人,也可以很清楚的找到要去的地方。据说温哥华华人已有一定规模,是一股不可忽视的力量。近年来大陆不少官员子女和富豪子女来此地学习定居,使加拿大不少人认定中国很富裕,中国人很有钱,中国精英子女们大大长了中国人脸,给天朝添了不少光彩,让我等P民在国外也能扬眉吐气。
今天温哥华的天气不错,早上有点寒意,入关时,海关一个白人小伙很亲切,只简单问了我们两个问题,就顺利放行了。

机窗下温哥华
中国有句俗语:在家靠父母,出外靠朋友。为了逐渐适应加拿大自驾游,我们决定加拿大西线游请我交往几十年的朋友Max当临时向导,这个决定后来看来十分英明,为我们后面顺利旅行起了很重要作用。Max是加籍华人,五十岁左右,是个成熟的中年人,我们从八四年开始就来往密切。他开着SUV来机场接我们,未来加拿大六天西部游都将有这位朋友陪同。经我们强烈要求,我们住在朋友在郊区Maple Ridge枫树岭的小别墅里,朋友带我们穿过密集的树丛,走近了一栋似童话世界里才能看到的小别墅,那里很原始,很安静,没有公共的绿地花园,听不到公共汽车声,也见不到什么街角商店,那就是个乡野村房。这是一座有一百多年历史的精致小房,二室二厅一厨一厕,在朋友本人精心打理下,显得温馨平淡安宁舒适,这间小别墅离温哥华城中心不太远,开车四十几分钟就到加拿大广场。朋友在城中心也有一栋二层楼的别墅,但我们更喜欢这乡下的世外桃源般的环境,非常有感觉,非常有特色。

Maple Ridge枫树岭的小别墅
在机场去住处的路上,我们绕道去了温哥华漁人码头Steveston Fisherman’s Wharf,这原本是一座小渔村,八十年代由于渔业的衰落,这里的渔港已经转变成一个市民休闲的旅游景点。其实这里景点真的很一般,就是个海边渔市,不知为什么温哥华人大清早特意跑到这里来买鱼,外国人真是一根筋呀,城里的超市和肉店、水産店都能购买到新鲜的海産,质量也很好。但是仍有不少市民固执地觉得这里的鱼虾与众不同,便宜且质量一流,其实与市内品质相差不大。我们去时,摊贩大都收市了,渔港已没有什么鱼在卖,尤其是非常新鲜三文鱼,这种加拿大最常见最著名的品种,非常遗憾看也没看到。
玩了漁人码头,去了当地一个中歺馆,吃了踏上加拿大国土上的第一顿饭。饭还算合口味,温哥华华人多,所以中歺馆也多,味道相对地道。吃完中歺就去超市购了一些必须品和水果、肉菜,温哥华超市食物很丰富,按当地收入来说那是相当地便宜,即使换算成人民币,也不是很贵,加拿大人民幸福呀。关键是没有食品安全问题,什么地沟油呀,农药菜呀,毒奶粉呀,镉大米呀,苏丹红蛋呀,还有什么神农丹姜,瘦肉精,病死猪肉,假羊肉,速生鸡,毒豆芽,加拿大人民听都没听说过,太孤陋寡闻,缺乏见识了。没有这些东西去磨练,真替加拿大人民身体担心,没有这些穿肠而过,怎么能练成百毒不侵的身体呀。苦难和毒物能使人成长,幸福而清洁的加拿大人民只能是温室里花朵,经不起风浪哟。这样一想,我的自豪感猛生,苦难和毒物万岁。从超市出来就去小别墅休息,晚饭是自己做的,主菜是红烧排骨,十分可口。
经过一夜休息,朋友一早来小别墅接我们,加拿大西部山水游也就是落基山脉游正式开启了。
加拿大西部山水游行程为温哥华Vancouver-亨茨维尔小城Valemount-贾斯柏Jasper-冰原Glacier-班芙Banff-黄金城Golden-温哥华Vancouver。含盖落基山脉风景的精华。我们这次的游程是从温哥华出发,经5号公路进入落基山脉,过贾斯珀、班芙、优鹤三大国家公园,然后从1号公路返回温哥华,整条路线呈一个三角形,不走回头路。
加拿大境内的落基山脉被美国的《国家地理》杂志评为一生最值得去的50个地方之一,是世界遗产。落基山脉不是以奇、峻、险为特色。但落基山有山有水,水有湖有河有瀑布,山有川有雪有峭壁,这里地形复杂多样,瀑布、急流、怪石、温泉,湖水与雪山森林相映,这种刚柔相济、动静交映的山是一幅不可多得、引人入胜的美景。落基山脉还是野生动物的天堂。有珍惜的黑熊、灰狼,也有驼鹿、麋鹿,回游的鲑鱼,旱獭等等。被划分为多个国家公园,其中最为知名的有四个世界级的国家公园,分别是班夫Banff National Park、贾斯珀Jasper National Park、优鹤Yoho National Park和库特奈Kootenay National Park国家公园。还包括三个省立公园,它们是:罗伯森山(MountRobson)、阿悉尼伯因山(MountAssiniboine) 和汉拔 (Hamber)三个省立公园。
闲话少话书归正传,我们先谈谈我们第一个落脚点亨茨维尔小城Valemount (中国有人把它译为山河镇)吧。亨茨维尔小城是个离贾斯柏Jasper国家公园很近的一个小村庄,小庄的目前居住人口不到1000人,这次至所以选择落脚地亨茨维尔小城Valemount而不选稍远的Jasper镇,一是因为怕开太长车过于劳累,二是价格相对便宜。亨茨维尔小城Valemount距Jasper镇130公里,离温哥毕有660公里。小村庄虽小名气可不小,2010年八国集团峰会就在这个小村庄召开的。而且小村庄该有的全都有,商店超市旅店饭馆银行一个都不少。我们预订的是汽车旅馆,名字叫Premier Mountain Lodge and Suites(普雷米尔高山旅舍及套房酒店),旅馆卫生环境位置都不错,不含税的价格为两间667元人民币。向导Max是个有心人,他自带了液化汽炉,怕我们不适应洋鬼子的西歺,可以自己在房间烧点吃的。我们到达亨茨维尔小城比较晚,住下后立即去超市采购水果、肉菜、面包和牛奶,做了一顿较为丰盛的晚歺。这次行程的开始第一段路程距离较远,开车花费时间比较长,中午只吃了个汉堡填肚子,实在有点饿了。
从温哥华到亨茨维尔小城,我们走的是5号公路,虽然也叫高速公路,但并不完全封闭。也无中间隔栏,沿途基本没有固定摄像头和测速仪,很多地方只是双向二股道,弯道也多,有很多非立交岔口可以进车,远不如在中国很多省级非高速公路,加拿大高速公路没有规范的服务休息站,有时候一百公里都看不见一个服务区。我们开车那时段,公路车流量也不少,虽限速90或100,但路上车子大都开在100至120的速度,大货车大客车也如此,而且常常不能不开得90码以上,不然后面车子会堵成一排,二股道的公路吗,超车很不方便。但据说加拿大这种所谓高速公路事故率却很低,这让我很困惑了一番。而我们天朝山区高速,比如湖北恩施段,硬件环境比它不知好多少倍,可却限速80或60,还老出事故,真是让人想不通。当然加拿大本地人虽在高速都超速,但不会超过120码,而其他交通规则他们都严格执行,所以这才保证了行驶的安全,同时又提高了公路的效率,这一点值得我们好好学习。
第二天,也就是九月二十九日一早,我们起床在小村庄周围转了一下。亨茨维尔小城是一个地处偏远山区的村镇,规模不大,就是一个小小的山村,这里只是去往Jasper国家公园的一个中转站。一些旅行团从温哥华到贾斯伯到班芙的线路上,往往把这里作为进山之前的首个宿营地,所以旅馆也不少。亨茨维尔小城还算是个有人气的小镇,旅游旺季时旅馆都是客满。村庄三面靠山,山间烟云缭绕,山谷森林茂盛,是个很美很静很懒散的小村庄,有着美丽的环境和悠然自得的生活!不然八国集团峰会也不会选在这个小村庄召开了,那可是世界最有实力的八个经济发达国家呀,能选中这地方必有独特之处。

亨茨维尔小城Valemount
今天天气十分给力,人品好没办法,在落基山这段时间虽常碰到雨水,但很多时转眼阴转晴,常常给我们一个惊喜,而且多数的时候还是蓝天白云。早上我们吃完早餐即牛奶、水果、面包和香肠后,就立即赶路向贾斯珀Jasper镇进发。在5号公路向北走上几公里,跨过一条河后就转入16号公路东行。亨茨维尔小城到贾斯珀镇有130公里,须开车一个小时多点,突然路前方一个庞大的雪山横在我们的前面,非常雄伟壮观,一查,那就是落基山脉最高峰,也是加拿大的最高峰罗伯逊山Mt. Robson,海拔3954米。我们停下照了几张照片,继续赶路。不久就看到16号公路旁一个美丽的湖泊,名叫moose Lake湖,这是进贾斯珀Jasper国家公园前见到的唯一湖泊,有停车场,我们下车快速欣赏了一下。不久我们就到了Jasper国家公园入口处,所谓入口处也就是在马路中间设一个简陋木板房的收费站,是收落基山四大国家公园的门票的。一个车(含7人)一天费用是20刀(加元),是四大公园的通票,若你打算玩七天以上,买年票就更合算了。

加拿大的最高峰罗伯逊山Mt. Robson
中午时分到达贾斯珀Jasper镇,贾斯珀镇是一个非常漂亮的小镇。贾斯珀镇是加拿大落基山脉北边的门户,小镇的建筑风格多样,色彩艳丽,风景十分优美。小镇位于贾斯珀镇公园的地理中心,这里聚集着公园内最全的服务设施,小镇没有那么多商业气息,保留了几分宁静,在宁静中享受生活之美,很有特色和魅力,它被称为大落基山入口最绝美的小镇,倍受游客们的青睐。古老的火车站、宁静的小教堂和随处可见的驯鹿和山羊(可惜我们在小镇上没见到),让你觉得贾斯珀似乎离喧闹吵杂的现代都市世界很遥远。我们在小镇一家快餐连锁店吃了午餐,吃过午餐后去了火车站斜对面的游客信息中心visitor information center,要了一张贾斯珀国家公园地图,准备游几个湖再出发去冰原大道。由于时间紧张,还要去看哥伦比亚大冰川(ColumbiaIce field)并住在那边,所以决定只去玛琳湖,,因为它被评为世界上最上镜的湖泊之一,不去怕会后悔。然后立即掉头在傍晚落日去观赏著名的冰川景观。
去玛林湖Maligne Lake的路上,要路过玛琳峡谷Maligne Canyon和药湖Medicine lake,玛琳峡谷号称是落基山脉中最长、最深、最奇特的峡谷,我们也看不出什么特别来,且徒步路线过长,只能走一点就返回真奔玛林湖。有人说:“不到玛林湖就等于没有到贾斯珀公园”。所以很期待。在路上,经常会看到大片大片被烧毁的森林,枯黄的牧草。(在住后走,我们看到被山火焚烧的松树林比比皆是。)紧赶慢赶,到了玛林湖,汽车只能到达湖的顶端。玛琳湖是贾斯珀最大的湖泊,是世界第二大的冰河湖,也是贾斯珀国家公园中唯一一个开放游船的湖。我们去时游船已关门了。在贾斯珀镇时天还很蓝,云还很白。可现在天气却不是很好,所以我们看玛林湖真没感到什么特别。属于不来遗憾,来了更遗憾,盛名之下,有所失望。据说想要看到精华,只有乘游船。玛琳湖最美是湖水的颜色和位于湖中的小岛,曾被评为世界上最上镜的湖泊之一。小岛就是所谓精灵岛Spirit Island,大名鼎鼎,是加拿大的一个标志性景点,照片经常会出现在加拿大的旅游宣传册上,但游客是禁止登这个小岛的。回来路上,在药湖停留了一下,虽然水少,但景色还是很美的。药湖是加拿大洛基山中最神秘的湖,每年会消失一次。其水位受地下暗河系统的影响而时高时低,每年不同季节水位不断变化。自春天到夏天冰河水融化,湖水充盈;到了秋天山上的溶雪量减少,水位则开始下降,直至冬季完全干涸见底,整个湖消失。而到了来年春夏湖水又如约而至,如此循环往复。

药湖Medicine lake

途中美景
从贾斯珀国家公园到班夫国家公园,走的是最著名的冰川公路93号公路了,驾车行驶在这条绵延230公里号称世界上最美的公路上,是一场顶级视觉盛宴,美不胜收。车窗前常可看到高大巍峨的冰川雪山、迷人精致的湖泊瀑布、茂密挺拔的冷杉森林,交相辉映,景致多变,美丽如一幅画卷。天继续阴沉,赶到哥伦比亚冰原已近下午四点。哥伦比亚冰原是贾斯珀国家公园最有名的景点,历经万年的巨大冰川,是整个落基山十七个冰原之一,也是太平洋、大西洋、北冰洋的大分水岭,是世界上极少能乘坐车辆直接到达的冰川,是北极圈以外世界上最大的冰原遗迹。据说冰河的冰层密度极高,阳光无法折射,会呈现晶莹剔透的蓝光,在晴空下十分瑰丽,但我们没看到。去晚了,关门了,没有搭乘巨型雪原车SnowCoach,在哥伦比亚冰原上走一趟。只得步行到冰原的边缘。我们与冰原隔着一条小溪与警戒线相对而视,没有那么震撼,靠近我们这边的冰原很脏,人踩的吧,人类战胜了自然,同时也在破坏着大自然。随着全球气候变暖,冰川正在急速后退,每年都在消融一些,也许百年之后,这条冰川将不复存在。越往冰原方向走,天气越是阴沉,一眼望去,灰不溜秋的。领导出来带着大量御寒衣裤和棉胶鞋总算派了点用场,不然从中国背到加拿大,岂不是亏大呢,其实这时到加拿大真不需带那么多衣物。在路上错过了冰川天空步道Glacier Skywalk,但我们在冰原景观酒店平台上蹬守着,希望能云开日出,晚霞印照冰川的景观。功夫不负有心人,有天色渐黑的那一瞬时,西边云稀了,露红了,晚霞照在冰川上方,美极了!在凄凉寒风中的苦等总算有了回报。

哥伦比亚冰原
因为没有订到冰原景观酒店Glacier View Inn,我们在网上预订的住宿地是离冰原景观酒店约几十公里的可若酒店Crossing,位于93号公路与11号公路交汇处,本来我们为没订到冰原景观酒店很是遗憾,很晚赶到可若酒店,第二天一早发现选择可若酒店太正确了。无心插柳柳成行,可若酒店四周太美了。晚上到可若酒店时,我们做了一顿简单晚夕,赶紧睡觉,明早起床去一个神秘地方去照日出。
30日一早,闹铃响了,天刚微亮,蓝天白云,好兆头,我们驱车前去神秘地方照日出。这个神秘地方是朋友Max介绍的,在11号公路旁,离住处约三四十公里。在起伏的山峦中出现一个很大的湖,朋友Max把它叫着泡泡湖,因为湖底有喷泉,到冬天结冰后,冰里全是泡泡,甚是美丽和惊奇。后查地图,这是Cline River河的一段,只不过河面到这段十分宽阔,像湖面一样。在去的路上,我们终于碰到大型野生动物-麋鹿,这是这二十八天行程中唯一的一次撞见大型野生动物,让我们很兴奋一番。泡泡湖景色果然没让我们失望,太美了,是出大片的地方,我们赶紧去找制高点,等待日出,期盼今天有大收获。天有不测风云,山区的天孩子的脸,说变就变,刚刚还透着白光,云彩开始变红,突然间乌云翻滚,下起不大不小的雨来,在车里等了一会儿,不见雨停,只得失望的返回住宿地。快到住宿地时,天空像是补偿我们式的,太阳出来了。可若酒店四周云雾迷蒙 犹如仙境,美得让人不敢相信。刚刚拍完照后,天又阴了,我们在酒店吃了早歺,继续走大气磅礴、令人荡气回肠的冰川公路即93号公路,向最令我们向往的班芙进发。

泡泡湖,这是Cline River河的一段

可若酒店四周

行使在93号公路,隔一断就有一个景点或者观景台。我们首先游览了米斯塔亚峡谷Misaya Canyon峡谷,米斯塔亚峡谷没有玛林峡谷深,也没有它大,但米斯塔亚峡谷比较上镜,急流切割的岩石有漂亮的纹理和奇妙的冰臼,非常美丽壮观。
在93号公路有一个著名湖泊叫贝托湖Peyto Lake,别名叫狐狸湖,贝托湖是镶嵌在群岭之中,很像加拿大国旗上的枫叶,几乎无路可以走近到湖畔,只能从山腰上的观景台向下俯瞰,可以看到湖的全貌。但去观景台须徒步半个小时,据说贝托湖很美,美艳温润宁静,我们怕累没上去。
我们在路边一个不知名的湖泊停留一下,景色也很美,在加拿大落基山脉将近有300座之多得湖泊,其实很多不出名的湖风景也是独有风味,湖光山色, 如在画中。不信?请看我们照片。
93号公路即冰川公路路边可见的最大湖泊是弓湖Bow Lake,弓湖是因沿弓河岸生长着适合制造弓箭的道格拉斯冷杉而得其名。弓湖边有一座酒店,红顶黄墙,为弓湖增添了丰富的色彩。弓湖主要以雪山倒影闻名,弓湖由于矿物质和植被缘故,湖水都呈现出各种蓝绿色,水天一色。如果风平浪静时,湖旁倒影是弓湖特色之一,可惜我们到的时候已经是下午,天气又不好,景致大打折扣。

路边一个不知名的湖泊

弓湖Bow Lake
路易丝湖luise lake被誉为落基山脉最美丽的湖,以维多利亚女王的女儿路易丝公主的名字为其命名。93号公路到路易斯湖附近就转入最著名横贯加拿大东西的1号公路,路易丝湖就在1号公路附近,也是去班芙镇Banff主干道。到路易丝湖时天气不好,又阴沉沉的了,没有出太阳,拍不出她的风姿,更无法拍出落日下的路易丝湖美景,我们决定明早再过来碰碰运气。于是我们去童话城堡一般的露易斯湖费尔蒙城堡酒店Fairmont转了转,露易斯湖城堡酒店历史十分悠久,最早建于公元1886年,它紧临湖畔,气派十分宏伟,从宾馆窗户眺望窗外迷人的露易斯湖,那真是享受。


路易丝湖luise lake
沿1号公路继续往班芙赶,突然发现在1号公路与1A号公路交汇处,风景很是独特,山、水、林、铁路混然一体,特适合摄影,天气已开始下雨,我们下车观察一下,也决定明早一定要来这里,这里太有特色了。
快到班芙,雨忽停忽下,没完没了。突然一处景观让我们眼前一亮,惊呼起来。美,实在是美。这就是朱砂湖Vermilion Lakes。朱砂湖位于班夫镇入口的高速公路旁,这里十月初湖畔风景线真是美的无语。虽然天气不好,仍让我们心旷神怡,十分震撼。我们赶紧下车猛拍了一番,不能辜负此处如朱砂一般色彩斑斓的动人景色。我们不用说,自然明早还会来,祈祷明天天气会好起来。
到班芙镇Banff了,天又下雨了。班芙镇比贾斯帕镇大很多,没有贾斯帕镇淳朴,是加拿大著名旅游城市,被誉为落基山脉的灵魂,加拿大国皇冠上的明珠。班芙镇群山环绕,冬天可以滑雪,夏季可远足。如果登小镇旁硫磺山,可以居高翘望落基山脉磅礴的气势,俯瞰班夫全镇景貌和弓河蜿蜒曲折的美景。硫磺山海拔2285米,有双向缆车到山顶,但因天气与时间原因,我们没有去硫磺山顶,错失俯瞰班夫全景的机会。到班芙镇我们首先到火车站,打听火车时刻表,目的就是希望明天去我们探寻的那个景点时,正好有火车经过,照出一批有特色的照片。天气说好就好,在火车站时天气转晴,太阳出来了,紧赶慢赶照了几张百年老火车站照片,这鬼天气说变就变,不一会又阴转雨了。
我们今晚住处不在班芙镇,而在离班芙20公里外的坎莫尔Canmore小镇的落基山旅馆,我们在这住两晚。这是我们这几天住得最好的旅馆,楼上楼下,日式联排别墅式的,二室二厅二厕一厨,十分干净和方便。
10月1 日国庆节,天仍下着雨,我在班芙镇转了一转,天空雾蒙蒙的,自然去硫磺山顶也无意义了,就再去路易斯湖了。环绕湖畔有许多条健行步道,加拿大国家公园大多建有许多许多步行道,人家对体育与锻炼都很执着。另外湖边还有一条登山路径,可一直到达山顶。在山顶可俯览翡翠般的露易斯湖,由于天气不佳,我们只在湖边走了一下,没有上山去拍路易斯湖全景了。露易斯湖三面环山,层峦叠嶂的露易斯湖,仍然翠绿静谧,在宏伟山峰及壮观的冰川的衬映下还是秀丽迷人。我相信如果不是天气太差,这里一定是现实中的世外桃源,毕竟它久负盛名。下午就回到住处,自己做晚歺去了。傍晚雨仍在下,我们心情自然糟透了,明天就要离开班芙了,没拍几张班芙四周的好照片,该死的天气不给力呀。2日一早,当我起床打开窗户,不由得惊叫:太美呢,太美呢!蓝蓝天空下,白白的雪山,一条云雾缠绕在山间,早霞印照在山顶,多彩多姿,金光闪烁,不似仙境胜似仙境。原来昨晚是山下下雨,山上下雪,清晨突然转晴,就展现出这神奇的景色来。我们呼着极清新的空气,冒着寒凤,拿着相机,在住宿门外不停地拍摄,太让人心动了。

落基山旅馆四周的好照片

班芙镇百年老火车站

班芙镇Banff
随后我们赶紧打包上路,去朱砂湖拍日出下梦幻般的湖景,我们二天前就对那个地方充满期待。果然上天眷顾我们,给我们很多惊喜,枯黄的草,绚丽的霞,碧蓝的水,山顶的雪,多层的云,洁净的天,这些要素全都具备,实在是可遇不可求,这些要素构成了一幅难得的美丽画卷,让人爱不释手。不停的拍,不停的拍,说来你可能不信,当我们拍完照后,天气又大变,一股厚云从西向东飘来,不一会大雨倾盆。虽然我们无法再去我们发现的另一摄像点即1号公路与1A号公路交汇处去取景拍照,但我们心愿已足,便开车直奔优鹤Yoho National Park国家公园。


日出下的朱砂湖
在去优鹤国家公园路上,我们先去离路易斯湖14公里梦莲湖Moraine Lake,这是我们在班夫国家公园看到最后一个湖泊。去梦莲湖须走一段上山的岔路,当时路上不是雨就是大雾,我们对拍美照已不抱希望,到那去纯粹是到此一游了。梦莲湖是一个冰川湖,坐落在著名的十峰谷中,湖泊面积不大,仅仅只有0.5平方公里,它被世界公认为是最有拍照价值的湖泊。因沉积的岩粉矿物质,湖水呈现出美丽的蓝绿色,晶莹剔透,在锯齿状的山谷的拥环下,就像一块宝玉。加拿大老版20元的纸币上就印着这个美丽小湖。到湖边雾小多了,但车多人多,找不到停车位,如果不是突然有一辆车开出,在我们车前让出一个停车位,我们可能就与这美景失之交臂了。虽稍微有一些寒意,天还阴阴的,刚看到时也没特惊喜,第一眼是挺失望的,一是人多,二是没有啥惊艳的感觉。但我们沿着旁边的岩石堆小径Rockpile Trail登顶,整个湖面映入眼帘,完全不一样,湖水的颜色却是神奇地变得比较蓝了。更何况这时太阳突然从厚厚的云层冲出来了,因为湖底有很多含有矿物质的石头,加上阳光的折射,变幻多姿,晶莹剔透,湖面像块晶莹剔透的蓝宝石。十峰环绕的梦莲湖与碧空、白雪形成强烈对比,远山云雾缭绕,神秘梦幻,冰山倒影在一片蔚蓝中,这是一个你不去绝对会后悔的绝美风景。

岩石堆小径Rockpile Trail下梦莲湖Moraine Lake
离开梦莲湖后,我们走1号公路前往优鹤国家公园塔喀可桂Takakkaw瀑布,幽鹤公园的第一个景点不是塔喀可桂Takakkaw瀑布,而是加拿大太平洋铁路,8字型盘山螺旋隧道是加拿大太平洋铁路浩大工程施工中最为险要的路段之一,太平洋铁路观景平台Lower Spiral Tunnel Scenic Viewpoint就在高速公路边上,据说如果有长编组的列车通过,在上下错落的隧道中与腰带般的铁轨上蜿蜒而行,很让人震撼。不过我们没有看到,说实话看不到什么景观,只能看见松林中的隧洞口而已。离开观景台,我们直奔塔喀可桂瀑布,瀑布本身宽幅一般,但是落差很大,位列全加拿大第二,垂真高度达384米,是著名的高山飞瀑景观。到那里去要开很长一段盘山路,狭窄曲折,弯道很多,是我们这次加拿大自驾游所有行程中最险的一段路。据说塔卡可瀑布夏季水量很大,气势磅礴,非常壮观。但我们去时水量一般,虽也有震耳欲聋的轰鸣,但弥漫在山腰间的水雾并不大,美感一般。塔喀卡库瀑布的源头竟然是一条由上个冰川时代遗留下来的冰河,从对面高山上看会有意外惊喜,可惜我们没时间去爬对面山上。
离开瀑布,继续赶路。突然被路边一个美丽小村庄所吸引,这个村庄名叫菲尔德Field,是优鹤国家公园游客服务中心所在地。菲尔德Field景色真的很美,白雪覆盖的山顶,黄叶红叶缠绕的山腰,各色精致的别墅小木屋,晶莹剔透的河水,碧蓝如玉的湖泊和澄净透彻的天空,这就是菲尔德给我的印象和冲击。菲尔德(Field)的居民区与加拿大1号公路隔踢马河相望,中间由一座桥梁连接,村落面积不大,只有2-3条小街,但却十分整洁,真想在这个小村里住在几天,好好享受这人间天堂式的环境。
下一站是翡翠湖(Emerald Lake),又叫绿宝石湖。翡翠湖是约霍国家公园中最大的湖泊,湖底是亿万年来堆积的冰川遗碛,因此湖水在阳光的照耀下会呈现出深浅不同的碧绿色,被誉为“落基山的翡翠”。其实看了好几天的湖,我们对湖泊确实有点审美疲劳了,但走进翡翠湖后,仍感到它非同一般的美。如绿玉般的湖水,宁静隽秀,远远望去就像是镶嵌在落基山脉中的一颗翡翠,太漂亮了。高耸入云的山峰、古老的冰川、未经开采的原始绿色丛林、山谷中的碧绿湖泊,只是因为天气又转差了,找不到好的角度,我们没照出这种超尘脱俗的美。
加拿大幽鹤国家公园的天然桥Natural Bridge位于去翡翠湖的路上,到翡翠湖就必经这个景点。我们是从翡翠湖返回时在那停留观赏的。天然桥就是一块大石头,常年被湍急的水流冲刷腐蚀形成了一个洞口,看上去像个石桥。就景点本身来说,也没什么可特别的。石桥是一座由岩石自然形成的桥,奔腾的水流从上部相连下部已成通道的石头下流过,这是从奥格登雪山上冲下来的千年冰河水--踢马河的水流常年冲刷石灰石的结果,柔弱的水与坚硬的石,千百年的交响曲,碰撞出如此奇景,称得上是大自然的鬼斧神工。石桥很特别,它的瀑布从一个岩洞流向另一个岩洞,像九曲桥似的,在桥洞出口,踢马河河水喷泻而出,气势恢弘,极具动感。而桥上游的水很柔很蓝,翠玉般的流水纯净无比,不信?请看照片!加上远处的雪山、河床和河滩上由于水流冲刷形成的形状各异的岩石、周围葱郁的丛林,这一切共同构成的景色才是天然桥的美之所在。

菲尔德Field村庄

翡翠湖Emerald Lake

天然桥Natural Bridge
玩完天然桥后,我们直奔今天的住宿地黄金镇(Golden音译:戈尔登),到黄金镇我们就算离开落基山脉。虽一路秋色渐浓,但落基山脉地势高,很少看到枫树,可能不适宜枫树的生长,但有很多金黄叶的树。从约霍国家公园过来的山路,一路下坡,颇有几分险意,一路上金黄的色彩也是很迷人的,黄金镇就是被金黄色所笼罩,不愧是“金色”小镇。快到小镇时,在高速公路上就被眼前美景所吸引,也不去住宿地,直接下高速去寻找高处,想好好拍一下这小镇风采。在一铁路旁,我们停下车,爬上附近山坡,可惜树木太多,合适的拍摄点总也找不到,有点小遗憾。
黄金镇我们住在塞尔柯克汽车旅馆Selkirk Inn,整洁、简朴、方便是它的特色,这是我们西部山水游最后一站,明天我们就要回温哥华了,明天路途比较运,我们就没去逛黄金镇,选择休息,养精蓄锐。明天除了看了一些路边的景色和景点外,基本上都用来赶路了。1号公和5号公路在希望镇Hope和甘露市Kamloops(又译坎卢普斯)两处交汇,去时我们从希望镇转5号公路,回时我们不走回头路,过甘露市后仍走1号公路到希望镇直至温哥华。到中午我们路过一个不知名的湖泊,有点特色,就停下吃点简易午歺,观看一下周围景色,也算休整。走这条路最有名的地方叫地狱之门Hell’s Gate!菲沙河流通道里最狭窄的一部分,两岸只有35米宽,涛涌的河流被两边的山壁压迫在一起,产生强大的浪涛,每分钟有2亿加仑的河水冲过。在这里可以听到雷鸣般的河流声和看到脚底下的汹涌水流,感觉像自身在地狱的大门前一般。这里是5个品种的三文鱼的洄游路径,也是看鲑鱼回游的地方。由于地狱之门的河流非常汹涌,所以三文鱼通过的时候需要花费很大的力气和时间,10月正是加拿大有名的鲑鱼回游的季节,据说场景很壮观,是著名的生态景观之一(当然不如最适合看鲑鱼回游Roderick Haig-Brown Provincial Park ,那里地平水静是鲑鱼产卵的地方)。鲑鱼回流的过程非常艰辛,从大海回到河流的距离达数千里。而一当回到淡水里就会停止所有进食,不停的逆流而上,使用身体里剩下的所有力气设法回到记忆中的故乡。为了下一代有一个安全的、适宜生长的环境,它们不仅要漂洋过海,飞瀑越堰,排除千难万险溯河而上,而且还要躲避其它动物如鲨、熊和雕的袭击。但它们仍然锲而不舍,义无反顾,九死而未悔。
历尽千辛万苦到达目的地,完成交配产卵的使命后,鲑鱼已经筋疲力尽,遍体鳞伤。它们在悲壮的洄游中谱就了生命的绝唱。而在它们身旁,随着第二年春天的到来,新的生命即将诞生。小鲑鱼长大后,会顺河流而下,奔向远方,奔向辽阔浩瀚的大海,去体验新的生活。大等到产卵期,再遵循本能的召唤,千里万里洄游回来。如此世世代代,绵延下去;如此循环不已,生生不息。生命,真是一个奇迹。不过很遗憾,我们到地狱之门已近旁晚,大门紧密,每四年才有一次高峰期,今年又是小年,我们没有看到那壮观的场面。
到达温哥华我的朋友Max乡村别墅家里已经很晚了,感谢Max的细致周到安排,让我们加拿大西部山水游充满惊喜,紧凑和舒坦,安全快乐地完成了这趟风光之旅。也使我们对加拿大交通规律,住宿程序,加油习惯和饮食安排都有比较透彻了解,为我们下一步单独的加拿大东部枫叶自驾游打下坚实基础。

回温哥华的路上

路途中休息处景色

黄金镇(Golden音译:戈尔登)
三.加拿大东部枫叶游
在温哥华休整一天后,10月5日我们乘加拿大航空公司AC108航班,早晨七点起飞,从温哥华到多伦多,开始我们计划的第二步,自驾枫叶观赏游。朋友Max一早把我们送到机场,和我们握手告别,希望我们旅途顺利,他在温哥华迎接我们胜利凯旋。
由于时差的原因,我们下午两点四十分才抵达多伦多皮尔森国际机场Toronto Pearson International Airport。我们的朋友Helen来机场迎接我们,并协助我们办理租车手续。幸亏有她帮忙,,租车才比较顺利。Enterprise租车公司就在机场楼下,我们把在国内网上预订的订单递上后,工作人员很热情,忙着办手续,叽哩咕噜说了一大堆话,我一句也没听懂。估计是核对情况和讲解注意事项和保险之事,有Helen帮我们应付。我们预订是丰田rav4车型,不过车库没有该车型了,商家提供两种车型供给我们选择,其中一辆欧洲产的SUV,跑五千公里,还是新车,另一辆日产楼兰跑了三万公里,肯定过了磨合期了,我们在国内就是用的日产车,比较熟悉,就选它了。
拿了车后,大约下午四点我们与朋友告别,对于不懂英语的我们,开始真正独立自驾长途出国之旅了。
先就给我一个下马威,在机场里我们来回绕了两圈都没走出来,这是还不太适应新购的导航仪的结果。经过摸索,我们终于走到400号高速上,今天目的地是阿岗昆Algonquin公园旁的亨茨维尔Huntsville镇,有二百多公里路哟。
一路前行,没什么特别惊人的风景,今年天气一直很热,枫叶最佳观赏期推迟了,平时是十月初,今年阿岗昆现在大约却只红了50%左右,沿途不少大枫树都还没红。路过格雷文赫斯特镇Gravenhurst,白求恩的家乡时,因为时间关系,就没下来而直奔此行的第一站:汽车旅馆6亨茨维尔Motel 6 Huntsville去了。6亨茨维尔这家汽车旅馆,是一家连锁店,整体环境不错,旁边就是麦得龙超市,干净、方便、安静。亨茨维尔小镇是世界闻名的阿冈昆省立公园主要门户,小镇配套设施齐全,规模也不小,是我们此次旅行见到的最大小镇,有近二万居民。小镇虽然没有熙熙攘攘人潮车流,但如诗如画般美丽风景吸引着全世界的游客纷至踏来。在加拿大散落着许多这样的小镇,湖光掠影,宁静雅致。亨茨维尔小镇因传奇的加拿大油画艺术家汤姆汤普森而闻名于世,小镇就是一幅油画,红叶、黄叶,绿叶那五彩斑斓的色彩,山川、河流、村落那动静融洽的景观,真乃是一幅幅醉人的金秋画卷。休整一夜第二天一早,虽然天气阴沉,我们赶往小镇观景点Lion lookout,可气的是我们导航仪搜不出这个地方,幸亏有手机相助,在谷歌地图上找到这个位置。在这里你可以俯瞰整个亨茨维尔镇的美丽景色,小镇没有鳞次栉比摩天大楼,但各自特色的小别墅在晨雾中若隐若现,点缀着浓烈色彩的树叶,好似一幅绝美的素描。看着眼前的美景,呼吸这里极净的空气,世上一切烦恼都会随之云消雾散。因天下不好,远景不好拍摄,我们于是就在这如诗如画小镇穿梭,希望拍到一批构图精美的照片。领导对摄影是非常执著的,对工作也精益求精,有时一个景点可以来来回回几个小时不知疲倦的拍摄。中午在麦当劳吃了汉堡后,回旅馆休息。大约两点多天气又好了起来,在领导的要求下我们又去了观景点Lion lookout,补拍多云天气下的小镇的风光,虽阳光不算柔和,但比早上好多了。

亨茨维尔Huntsville镇
拍完小镇美景后,领导提出想转回到格雷文赫斯特镇(Gravenhurst)看看,毕意这是小时候崇拜的英雄诺尔曼•白求恩家乡,而且她早就听别人说,这个小镇风景优美,尤其秋天更是十分靓丽,所以一直很向住,既然路过当然一定要了结这一心愿。格雷文赫斯特地处安大略省著名的马斯科卡(Muskoka)风景区,马斯科卡湖又称蜜月湖,是加拿大著名的别墅区之一,也是秋季观赏枫叶的绝佳地区。下午四点左右我们到了格雷文赫斯特镇,可惜白求恩故居和纪念馆都关了门,只能在外围瞻仰瞻仰。白求恩故居在一个院子里,是一座淡黄色的维多利亚式建筑,很典雅很有特色,据说国人是这里最常见的客人,毕竟白求恩的光辉形象在中国中老年人群中是无法磨灭的,缅怀这位在世界反法西斯战争中做出贡献的国际主义战士是他们青春记忆的一部分。在故居旁建有一个不大的纪念馆,馆中展示白求恩的一生经历的实物和照片。白求恩家乡这个小镇给人十分宁静、清新、古老的感觉,小镇掩映在枫叶林中,只是枫叶大多未红,不然会更美,这是最大憾事,该死的天气,今年太不给力,该红的时候它却在拖延。我们把车开到小镇一个观景点,从那里可俯瞰马斯科卡湖这个安省最大的湖泊,可以看到湖岸码头上有古色古香的邮船,据说每逢赏枫季节乘船在湖中畅游,是人生一大享受。我们没有时间乘船,只能远远观望无法去享受了。
离开格雷文赫斯特镇我们又返回亨茨维尔小镇,在亨茨维尔小镇四周转转,在往阿岗昆省立公园方向几公里处发现一条小溪有不少老外在照风光照,我们也凑上去拍摄,虽然景色不是特别震撼,但环境那真是十分幽静,生活在这样环境下人的心灵会得到安慰,人的心情会得到放松,人的灵魂会得到洗涤。再往里走我们发现一大片枫叶正红处,漫山遍野的火红枫叶让你真切感受加拿大的秋色,开始感受到加东的色彩之美了。

格雷文赫斯特镇及白求恩故居
在亨茨维尔住了两晚,10月7月我们起个早,今天主题是阿岗昆(阿尔冈金)省立公园Algonquin Provincial Park。阿岗昆省立公园位于加拿大安大略省东南部,建于1893年,是加拿大首个省立公园,是安省重要的野生生态保护区。面积7,653平方公里,比上海城郊加在一起还大。野生动物自然少不了,湖泊溪流自然少不了,划艇垂钓自然少不了,号称是地球上十处人间天堂之一。安大略全省大约有二万五千个湖泊以及全长超过十万公里的河流,是真正水上之省。而阿岗昆(阿尔冈金)省立公园园内就有超过2500个大大小小的湖泊,拥有全长超过1650公里的独木舟航道及大片浓郁幽深的森林,是露营和远足爱好者的天堂,加拿大地大物慱那真不是吹的。尤其值得一提的是,每当秋季来临,这里就成了枫叶的海洋,漫山遍野的各色枫叶让游人感到仿佛置身童话世界一般。只可惜今年最佳赏枫期大大推迟,很多地方枫树刚刚透红,景致大打折扣。我们行驶在60号公路上,该公路横穿公园,只不过是公园东南角,很少的一部分,但却是欣赏枫景最佳走廊,沿途可以发现众多有标牌的自然小径Trail和湖泊Lake。我们从公园西门入,东门出,全长约54公里,据说开车能到的地方景色都一般,反倒是步行深入的景色最为出众。我们在西门购了停车票,说是西门,只是停车场和办公室的小房子,用中国标准来衡量,绝对简陋!每辆车每天$16,游客服务中心有简易地图,说明以英文为主,也有小段的中文、日文和韩文,没有人来找你买票,一切都靠自觉,据说有专职停车管理人员检查非法停车,一旦查到,马上开罚单,但我们在景区开了一天的车,也没见到有专职停车管理人员来查看是否买过票。进入景区后我们曾两次下车,在曲曲弯弯的起伏不平的崎岖小路上步行,公园各条Trail的全程游览时间最快45分钟,最久需要6小时。而我们没看懂英文说明,选择这两条自然小径Trail太长,山路很险阻,翻过这道道陡坡仍看不到居高临下的山崖处,最后我们胆怯了,半途而废没能深入景区瞭望台。这两条小径枫叶大都没红,小径两边都是原汁原味的森林,小径完全是在原始森林里靠人脚踏出来的!完全没有人工刻意修造的痕迹!只有刚开始那一小段被这金色的枫叶围绕着,让我们看到一丝秋色。据说公园清晨湖面上会升腾起白色雾气,与红黄绿三色交织后,仙境一般,只是我们没看到。

阿岗昆(阿尔冈金)省立公园Algonquin Provincial Park
走马观花式游玩了阿岗昆省立公园后,我们立即去渥太华住宿地。这时天开始下起雨来,穿过渥太华市中心到达加蒂诺Gatineau亚当汽车旅馆Motel Adam,去一个中歺馆好好补偿一下,弥补这几天吃汉堡的痛苦。早上起来,一切都还在烟雨中,在住宿地结完账后,我们驾车去渥太华市中心,这时雨越下越大,看来我们只能雨中一睹它的容貌了。渥太华Ottawa是加拿大的首都,但城市并不大,也没有什么繁华热闹的商业街和现代摩登的大厦,只有遍地绿地、宽广街道、众多博物馆,是一座风光优美的花园城市。我们直接去了渥太华标志景点国会山the Parliament Hill的国会大厦Parliament Building,国会大厦是典型的英式宏伟建筑,它建在山顶,风景优美,是渥太华乃至整个加拿大的象征,是加拿大政府及参议院的所在地。国会大厦初期建于1859年,到了1916年,忽然一场大火吞噬了差不多整个建筑。新造的国会大楼尽量保持了原有的风格,广场中心还有为纪念加拿大建国百年而建的长明火台,台之火点燃于1967年的除夕夜,并会长久地燃烧下去。网上说渥太华的国会山在每天上午10点-11点会有士兵换岗表演,但我们在十点前就到国会山也没看到士兵换岗,可能是下雨的缘因吧。去国会山时,我们找停车位花了一点时间,冒雨到国会大厦前,雨时停时落,参观大厦需要凭护照等证件到广场对面领取门票,考虑天气和时间关系,我们没去领这免费的门票,只有国会山四周转了转。国会山四周枫叶只红了不到三分之一,天又那么阴,朦胧中山麓把它的极美遮掩,让人留下期许遗憾。

国会山the Parliament Hill的国会大厦Parliament Building
因为天气下雨,我们决定前往下一个目的地魁北克有名的度假区-蒙特朗布朗国家公园(Mont Tremblant),中国人把它起了个美丽名字叫翠湖山庄,是加拿大度假胜地。蒙特朗布朗离渥太华大约2个半小时车程,他靠近蒙特利尔,约1个多小时车程可去蒙特利尔。从渥太华去蒙特朗布朗沿途虽仍下着雨,但枫叶越走越红,沿途景色十分秀美,这里枫叶到了最佳观赏期。在阴雨中我们不停地下车拍那些无名的湖光山色。这天然无雕饰的自然美,赏心悦目,陶情怡性,我们沉迷大自然独有魅力中,枫林密布,在黄色,绿色树叶的衬托下,漫山遍野的红叶格外显眼,恰是红霞飞舞。这种自然风光让我真正理会什么是返朴归真的意境了。达到我们住处已天黑了,蒙特朗布朗酒店Auberge HI-Mont-Tremblant被网上评价为四星级,我们认为是个汽车旅馆,其实是个青年旅舍,虽然订了个豪华间,但真得不怎么样,没有独立卫生间,是我们这趟旅行中住宿条件最差的一个旅馆,还不如国内私人小旅馆。 给我们惊喜是,到达蒙特朗布朗时,太阳突然从云层中冒出来,看着眼前层层变幻的绚丽,相交相融的色彩,美到震颤的山峰,仿佛置身于画中,我们尽情享受极致的美景,忘记了旅馆给我们带来不快。为了犒劳这次摄影成果,我们准备去本地高档一点西歺厅大吃一番。可一进西歺厅,望着那无法看懂的点菜单,最可恨是没有照片提示,让我们无从小手,只能回旅社吃我们的方便面了。从此我们除了进中歺馆外,西歺只是汉堡这种快歺了,并意外发现A&W连锁店的汉堡最好吃,就只选它。这是后话暂且不表。
第二天一早,天气时晴时阴,不算亏待我们。眼前美景是让我们惊叹,什么叫层林尽染,这次我亲身体会到了。遍地枫叶,紫红、深红、火红、桔黄、明黄、深绿、浅绿各种颜色交织在一起,蔚为壮观,震撼力超强!我们在加东看到的最美的红枫景色就是蒙特朗布朗,绿草如茵的草地,飘渺晨雾的湖面、多彩多姿的红叶、梦幻童话的建筑、湖中游弋的黑鹅,语言无法描述这“湖光山色”的极致。一路上到处都是风景,那隐秘在红黄林间的小木屋,那温馨欢快的小溪湖泊,那造型美观的风情帆船,那浪漫迷人的度假小镇,这是是观赏枫叶的最佳之地,美得无法形容。零污染空气指数,静谧的氛围,恍若隔世般存在于这个世界上,绝对的世外桃源,绝对的伊旬园,绝对的人间仙境。醉了,醉了,太阳醉了,彩云醉了,我的心也醉了!

蒙特朗布朗镇



蒙特朗布朗国家公园(Mont Tremblant)
10月9日下午我们依依不舍地离开醉美的蒙特朗布朗,往蒙特利尔Montreal驶去。途中应该经过赏枫度假地圣索沃尔Saiat-Sauveur,可导航仪就是搜不到它,转来转去,也找不到这么个地方,只好作罢。大约下午三点抵达蒙特利尔马奎斯汽车旅馆Motel Le Marquis,这个紧靠地铁站和超市的旅馆真的很方便,是个物廉价美的旅馆,整洁简朴,是个十分平民化的住宿地,比昨晚住的蒙特朗布朗酒店不知强了多少。下午四点半定居在蒙特利尔的表弟来看我们,并带我们去圣约瑟夫大教堂。圣约瑟夫教堂始建于1904年,历经18年建成,是蒙特利尔的标志性建筑之一,十分雄伟的哥特式教堂。教堂依山而建,正前方是一个广场,教堂的创始人安德鲁教士,是个靠打工谋生的孤儿,从小就立志做一名传教士。安德鲁教士传教、看病40年,其经手的钱不下千百万,却一生都住在简陋的房子里,过着简单的生活,其高尚的人格,倍受信徒们的尊敬。教堂不收门票,我去时,天已近黄昏,在教堂高高的平台上可观赏到蒙特利尔风姿,晚霞印照在圣劳伦斯河 ,蒙特利尔夜景很迷人。晚上在表弟家吃了一顿丰盛的中歺,吃得很饱,吃得解气,汉堡吃多了,馋中歺呀。
第二天我们乘地铁去表弟家,蒙市地铁比较陈旧,但也比较实用,没有检票员,站台也看不到工作人员,更用说中国特有的玻璃隔断。我们由表弟一家人陪同,逛逛著名的蒙特利尔老城。在这座法语城市中,最能体会其欧洲风情特点的便是蒙特利尔老城。漫步在老城,走在石板路上,看着古老欧式建筑,这种怀旧的小资情调与生活是我们曾经向往的。我们先走到位于蒙特利尔圣母街(Rue Notre-Dame E)蒙特利尔市政厅,这是一栋很漂亮的五层楼房,不过当时正在维修。斜对面就是著名的雅克卡迪耶广场,广场上有一批公务员正在示威演讲,真是身在福不知福,不知道稳定是压倒一切的。随后依次去了蒙特利尔老城、诺特丹圣母大教堂、老港口、唐人街。蒙特利尔老城很热闹,到处是川流不息的行人,是蒙城旅游的主要景点。旧城区位于圣劳伦斯河畔,观光马车、石板路、教堂和博物馆,街头巷尾都充满着欧洲情怀。怪不得蒙特利尔这座城市被人们成为“北美小巴黎”,这座讲法语的城市充满浪漫情调,好几百年的历史建筑,闲情逸致的风情和古老的街道都让人感受到法国风味。从雅克卡迪耶广场走到兵器广场,我们来到蒙特利尔老城的心脏,兵器广场正中心矗立着蒙特利尔市的建立者保罗•舒默迪•麦森诺夫的雕像,兵器广场四周的各个时期不同建筑风格的建筑,最有名的圣母大教堂(Notre-Dame Basilica),蒙特利尔银行(Bank of Montreal),纽约人寿保险大厦(New York Insurance Building),和Aldred大厦。其中圣母大教堂是蒙特利尔最著名的旅游景点之一。圣母大教堂据说是参照法国巴黎圣母院的样式建造的,所以人们亲切地称呼它为:“小巴黎圣母院”,但没有巴黎圣母院雄伟奢华,更不如罗马教堂了。教堂须收门票,大堂内流光溢彩,金碧辉煌,散发着艺术的气息,有荡涤人的灵魂的魔力,上帝确实能给人内心安宁,凡是步进圣母院的人都表现出庄重、虔诚、肃静的神情,氛围极其圣洁和伟大,我似乎有点理解宗教这一西方文化和价值最重要载体的重大意义了。游览完圣母院我们就去老港口,老港实际是圣劳伦斯河的一个港口,法裔人来到加拿大时皮毛交易的港口,距今已有350多年的历史,现已繁华不在,近乎废弃。但作为旅游胜地,它有其独特地味道。走了一圈,玩了一圈,累了,倦了,也饿了。我们去附近的唐人街,穿过正在维修的红墙黄瓦的中式牌楼,各种小店铺一家接着一家,都用中外文写就的店招,看的最多是中国人,听到最多是中国话,倍感亲切,还有一个小小的中山公园,有时空交错的感觉,完全没有身在异国的味道。我们选择当地一家名气比较大的广式中歺厅,一方面是为了解决午歺问题,一方面稍微休整一下,歺厅环境和饭菜味道都不错,我们在那坐到快四点才离开。下一站就是大名鼎鼎的皇家山公园Mount Royal Park,皇家山公园辟建于1876年,是蒙特利尔赏枫景点之首选。只可惜,去的时候今年马路两侧茂密枫树的枫叶本该红透却还没有红,让人有点失望。皇家山上的观景台可以俯瞰整座城市,但自然的山水没什么特别的地方,在路上遇到一位骑警和一个小松鼠,给我们带来不少惊奇和乐趣。

皇家山公园Mount Royal Park下的蒙市
10月11日一早我们离开蒙市,走40号公路向下一个目标圣安妮大峡谷Canyon Sainte-Anne进发。途中路过一个城市,看时间还早,就转进去看看,结果大出我们意外,感觉太值得一看了。这就是三河市Trois-Rivieres,一个十三万人口的小城市,因为圣劳伦斯河同圣莫里斯河交汇处形成三个河口而得名。我们去的那日,天瓦蓝瓦蓝的,秋高气爽,小城古色古香,建筑风格独特,枫叶虽未全红,但已五颜六色,把小城装扮的多姿多彩,这种安宁美丽白小城真是百看不厌。

三河市Trois-Rivieres
在小城停留几个小时后,我们驱车赶往距圣安妮大峡谷大约9公里处小村庄Sainte-Anne-de-Beaupré,我们在小村庄著名的圣安妮大教堂旁预订了一个汽车旅馆--海岸公寓汽车旅馆Condo & Motel des Berges,多伦多到魁北克的40号高速路,两侧都是枫树,如果时间合适,枫景会很壮观,可惜我们今年来的不是时候,枫叶推迟盛红期了。到旅馆服务处,其大门紧闭,留下一个条子,让我们自己在门口小盒子里拿钥匙进房。国外旅馆手续简便,走时也不查房,交钥匙就可走人。安顿好住处,我们立即去圣安妮大峡谷,这是一处赏枫名地。圣安妮大峡谷的门票CAD13.50一人,刚进圣安妮大峡谷大门,还有些金色的枫叶,但到峡谷后,只能偶尔见到变黄变红的叶子,看不出是魁北克的“枫”景之最。说什么:山谷红黄的枫叶漫山遍野,峡谷由于在谷底、山腰和山顶枫叶变红时光不一,有丰盛层次感,我完全没感觉到。瀑布很一般,枫景很一般,没有了秋色,峡谷完全无法吸引到我们。该死的气候,今年天气热的太长,延缓了枫叶变色时间,今年我们武汉桂花也延缓15至20天才盛开哟,理解理解。
从峡谷返回我们来到住处,欣赏住处的圣安妮大教堂及四周美景。圣安妮大教堂是一座宏伟的哥特式建筑,矗立在圣劳伦斯河边的这座纯白色教堂,17世纪1658年建立,历史悠久,350多年里,五次扩重建,可惜在20世纪初毁于一场大火,1926年重建这座哥特式教堂。教堂前面的广场上有一个喷水池,青铜铸造的圣安妮怀抱着幼小的圣母玛丽亚安详地站在那里,雕像和喷泉融为一体。大教堂的内部金碧辉煌,气势震撼,我们进去时,主教正在宣教。第二天一早。我们起床想照圣劳伦斯河日出和朝霞,这一天早晨天气十分寒冷,在河边我们穿了冬季衣物,仍感寒气逼人。我们旁边一对老外老夫妇,穿着短裤也在河边拍照,本认为他们从车里出来不会很长时间,没想到他们比我们还久,真佩服他们,老外就是不怕冷,我们惭愧。天气虽冷,也时阴时情,但风景确实不错,我们照得尽兴。

圣安妮四周景观

不惧寒的外国老夫妇
10月12日中午我们来到魁北克市近郊的谢瓦利埃汽车旅馆 Motel Chevalier,稍作休整,便去布蒙特伦西瀑布(又译成脉脉含情瀑布)Montmorency Falls Park景区。蒙特伦西瀑布落差有83米,声势不小,瀑布旁沿着山壁建有阶梯,还有许多近距离的观瀑,水从峭立的悬崖倾泻直落圣罗伦斯河,那是相当的雄伟。这里视野开阔,也是观赏枫叶的绝佳地区,瀑布一侧,一排排枫树红的如血,红的耀眼,当登临悬崖,秋色斑斓壮观,河流泛着金光,雄伟的瀑布、壮观的大桥、蓝蓝的河水、墨绿的松树与红、黄色的枫叶交错后,形成金秋一派美丽的如画如幻的美景!

布蒙特伦西瀑布下美景

布蒙特伦西瀑布公园内枫景
10月13日我们去心仪已久的古城魁北克城,这是加拿大最古老的城市,有400年的历史,是世界文化遗产。这充满浓郁欧陆色彩的古城,历史遗迹处处可见。有北美唯一的古城墙,有雄伟华贵的古堡大酒店,有尖耸造型的老教堂,有蜿蜒斑驳的石板路、干净秀气,优雅古典,充满了浓郁的欧洲小镇气质。在古城找停车位花费我们不少时间。几处著名景点停车场已客满,七找八找,总算在灵气的古城中心处找到一个停车位。漫步在古色古香的旧城街道里,看着载着游客的马车缓缓驶过,穿行在那一座座四五百年的历史的欧式建筑中,让我感受时光倒流,仿佛穿越了时光,不知身在何处。中饭找了几个中歺馆,可他们都要到下午才开门,最后又只得去吃那该死的汉堡了。

费尔蒙芳提纳克城堡饭店Fairmont Le Chateau Frontenca

古城魁北克城
吃完中饭后我们临时决定去河那边的奥尔良岛Île d'Orléans,这个决定太英明了,让我们真正体会到加拿大乡村之美。奥尔良岛通过奥尔良岛桥(Île d'Orléans Bridge)与大陆相连接,在岛上可以远眺魁北克老城,全岛以农业为中心,据说苹果与草莓是岛上特产。岛上土地肥沃,森林茂密,岛上居民生活非常悠闲,非常宁静。一幢幢颜色特别鲜艳漂亮的小洋房和牧草悠闲的田原风光巧妙融洽在大自然里,是绝配,真正的世外桃源。岛上红叶遍布,在红枫中间,点缀着农舍,风景绝美。太阳渐渐落山了,呈现在眼前的是一片灿烂的金黄,在我们过奥尔良岛桥时,晚霞把河面全印红了,景色太震撼,只可惜桥上不能停车,这惊世的景色没有拍摄下来,现在想想都好遗憾。
10月14日,今天路途比较远,一早我们就出发,可没想到不大的魁北克竟也堵车,这是我们这趟行程中唯一碰到这么严重的堵车情况。沿20号公路,500多公里路程,目的地是加纳诺克(又译卡纳诺基) Gananoque小城。我们在网上预订了1000群岛帝国旅馆Imperial Inn 1000 Islands,是个香港人开的,还开了一个中歺馆,总算能吃几顿中歺了。加纳诺克 Gananoque小城坐落在千岛湖伴上,当天我们在小镇转了一转,去了游客信息中心和镇政厅,镇政厅建于1831年,保存完好至今仍在使用。小镇旅游码头是到千岛湖1000 island又称劳伦斯群岛国家公园观光的游客的首选之地,岛湖是世界著名的旅游景点。

奥尔良岛Île d'Orléans

加纳诺克(又译卡纳诺基) Gananoque小城
第二天即15日一早我们就是码头购了三小时游览船票,圣劳伦斯水面宁静而宽阔,一望无际,湖水纯净、水是碧蓝碧蓝的,这里是有名的避暑胜地。整个千岛湖有1865岛屿(其中1个是人工岛),在美国境内的有621个,加拿大境内1244个。岛上郁郁葱葱,坐落着大大小小、豪华精致、古典优雅,风格各异的别墅。湛蓝的湖水中倒映薄雾彩中,树丛中隐约露出红瓦粉墙一角,不是天堂胜似天堂。其中两个岛屿名气最大,一个是心岛Heart Island,心岛是1900年美国纽约白手起家旅馆业大王乔治.博尔特(George Boldt)买下后并投资2500万美元建造了“罗宾兰德古堡”,它被作为献给爱妻露易斯的礼物。 一个是莎维岗岛(Zavicon),一桥跨两国,一头挑着加拿大,另一头挑着美国,桥中心是两国分界线。游船在群岛间狭窄的蔚蓝色水道左穿右插,迂回前进。今天天空晴朗,鸟语花香,清风拂面。感受这没有喧嚣,只有宁静,没有污染,只有纯净自然空气,看红屋顶,白房子时隐时现,岛屿绿树掩映,人仿佛行驶在童话中的仙境中,此乃真正的人间的天堂。

千岛湖1000 island

心岛Heart Island罗宾兰德古堡
中午上岸后,我们自然必须去附近的加拿大曾经的首都金斯顿Kingston,1841年至1857年,它成为加拿大的第一个首都。金斯顿的城市不大,承载并保存了从古至今加拿大历史的变迁,是一座具有悠久历史的魅力城市。整座城市以河滨为中心而建。各种维多利亚风格的红砖头房屋及众多的教堂,沿着河边一字排开,风景如画,美不胜收。金斯顿市政厅(City Hall)、昔日的火车站,游船码头旁边陈列着一个具有悠久历史的蒸汽机火车头“Engine 1095”、 (当时生产“Engine 1095”的加拿大机车有限公司生产就在金斯顿)都汇聚在一起,这是座有历史人文气息的小城,深厚的历史积淀,美丽的自然风景只可惜我们无缘欣赏,逗留的时间太少,只能算是匆匆一瞥。这是因为我们车出事故了,在车开进城不久,我们在停车等红灯时,被左边停车位开出来的碰擦了(待最后一章详谈)。自然原先计划游玩古城和沿最美景观路Thousand Islands Parkway看晚霞和日落算是泡汤了,只得从2号公路返回加纳诺克住处。让我们惊喜的是,刚出城却无意中路过金斯顿重点景观之一亨利堡(Fort Henry),我们在停车场停了车,虽然这座水上要塞的著名建筑群已关门,看不到堡垒内部军事博物馆内容,亨利堡四周美景仍给我们留下了很深的印象。亨利堡位于从圣劳伦斯河突出的一个较高半岛的前端,建在一片山丘之上,位置绝佳。这其中,城堡被石造的坚固城墙和堑壕围住,不仅可以鸟瞰金斯顿全城,四周草地、枫林与晚霞也令人陶醉,宛如仙境。
至此加拿大东部枫叶之旅也就结束了。

金斯顿市政厅
四.多伦多、温哥华都市游
10月15日去多伦多路上,车就开始多了,但我们很顺利到达位于市中心中国城的速8多伦多市区酒店Super 8 Downtown Toronto,酒店前台都是华人,沟通不成障碍了。朋友Helen很快赶来,和我们一起还了租车并预订了17-18日的小型轿车。Helen请我们吃了加拿大的龙虾,不多久我二十多年未见面的两位大学同学赶来,大家自然感叹一番,岁月如梭,虽异国相见十分欢喜,但我们都老了。晚饭又是龙虾,一大桌菜,感谢同学的热情,我们却吃不下了。
绵绵的秋雨、阴沉的天色让我们对多伦多的观感差了不少,街道两侧虽然处处可见现代化楼宇,古老的建筑以及红的枫、黄的树,但总感觉在铅灰色的背景下失色不少。
10月16日一早,领导的中学同学夫妇开车来接我们,吃完早餐准备去海滨转转,结果很多路被临时管制,在路边拍了几张照片,就去传说中的多伦多大学。多伦多大学属于加拿大顶尖名校之一。主校园在市中心,开放式校区,没有校门,没有围墙,校园分布在各地街道上,古朴的教学楼、气派的图书馆,和城市街道混合在一起。绿草如茵,古树参天,清新湿润,整个校园是19世纪英式古典建筑的风格,与城中现代化建筑交相辉映,身处闹市,却又显得那么的从容,在古朴典雅中显示出生机勃勃的现代大学气派。那天天很阴,还有点小毛毛雨,校园十分安静,校园以一片漂亮的草地为中心,是一座远离城市喧嚣的文化公园,整个校园是19世纪英式古典建筑的风格,这是一所快200岁的世界顶尖大学。
接着我们去了伊顿中心,伊顿中心是多伦多市中心最知名的购物中心,最大最现代化百货公司,有着华丽的装修风格,汇集了300多家精品店铺和餐厅,我们走马观花看了一看,中国这类大商场太多,兴趣不大,就去多伦多新老市政厅。走在路上才知道,今天多伦多正在进行马拉松比赛,终点在市政厅,怪不得许多路临时管制了。我们有幸看到比赛,老老小小,各种肤色,大家累并快乐着,有种嘉年华的感觉。我们拍到一位男子推着小孩跑完全程马拉松,后来他被评为此次马拉松最让人感动的运动员。多伦多市新市政厅与旧市政厅挨得很近,新市政厅1965年建成,两幢弧形贝壳式建筑拥抱着中间蘑菇状的议会大厅,现代、简洁。旧市政厅是典型的古罗马式建筑,厚重的墙砖,斑驳的痕迹,这座法定国家古迹透着深厚的人文积淀。而他们四周是最摩登的摩天大楼和古旧的有轨电车,真的很协调,很有风味,不由得不让人赞叹。随后去领导同学家坐了一下,这幢别墅与四周环境都让人感到舒畅。近处绚烂的彩林,远处多彩的山坡,那淡淡的薄雾,那寂寂的马路,各有特色的独栋房屋,无纷无扰无烦无躁的安宁,似烟似雾似纱似线的细雨,太妩媚太妖娆,有一种飘飘欲仙的感觉。怪不得总有人乐不思蜀,在加拿大寻找一席之地呢,理解,这是人的本能。坐了一会儿,他们带我们去卡萨罗马城堡Casa Loma,这是有一百多年历史的城堡建筑,是加拿大历史上最早、也是建造最为辉煌的私人城堡,现在是一处旅游胜地。古堡内有 98 间装饰华丽的房间,但我们去时,已关门不售票了,自然无法欣赏到美轮美奂,极尽奢华、精雕细琢的室内装潢。但仅仅外表,就很震撼,这在山顶上修建的城堡,融罗马式、哥特式、诺曼底式建筑风格为一体,豪华浑厚,有依山而建的花园,在山顶可俯瞰多伦多市区。城堡还有一段关于亨利爵士传奇的一生和他们的爱情故事。百万富翁亨利•柏拉特有感于妻子玛丽出行不便,无法欣赏到欧洲建筑的精髓,便希望请最好的设计师,采用最好的建筑材料,修一栋欧洲古典城堡式样的房子,以此作为送给爱妻的礼物。后来土豪破产了,政府把房子收了,再后来,政府把房子当旅游资源,开始收门票了。身处百余年的豪门巨宅之中,令人有种时光交错的感觉。

多伦多大学

卡萨罗马城堡Casa Loma
10月17日我们去Enterprise租车公司提车,朋友Helen在那等着我们,我们提的小型车车库没有,租车公司同意免费升级七座道奇SUV,两个人开那么大车,是有点浪费,但我们想尽快到尼亚加拉小镇Niagara ,一睹我孩儿时就心仪的最著名的奇景之一,也没多计较纠缠。天气时好时坏,中午时分我们到达最佳西方瀑布景观酒店Best Western Fallsview Hotel。放下行李,吃了汉堡,我们就瀑布方向奔去。还没有见到瀑布时,就会听见如雷贯耳瀑布飞落声,酒店离尼亚加拉大瀑布只有步行20分钟的距离,随着这巨大的声响一直走,就可以看到尼亚加拉瀑布了。尼亚加拉大瀑布与巴西阿根廷交界处伊瓜苏瀑布、赞比亚津巴布韦交界处维多利亚瀑布共称为世界三大瀑布。瀑布位于加拿大安大略省和美国纽约州的交界处,瀑布由三部分组成,包括:马蹄瀑布(Horseshoe Falls)、美利坚瀑布(American Falls)和新娘面纱瀑布(Veil of the Bride Falls)。尼亚加拉河是连接伊利湖和安大略湖的一条水道,河流蜿蜒而曲折,全长仅54公里,海拔却从174米直降至75米,尼亚加拉瀑布平均流量5,720立方米/秒,仅是尼亚加拉河30%的水量,其余70%的水量被用于发电。水势澎湃,声震如雷,十分壮观,太阳的照射下偶尔还能遇见彩虹。我们没有去160m高的观景塔Skylon Tower,它离瀑布较远,反而有一家星级酒店观景塔是能够享受瀑布的美景,可惜闲人免进。我们只得沿河岸观景台来回跑动,观景台是一条长达300米的走廊,连接着马蹄瀑布,看着眼前气势磅礴,景色壮美,无法用词语来形容,心情自然特兴奋,而且这儿水鸟也特懂人性,摆着姿势让我们拍摄,好萌!我们简单吃了点晚歺,期待暮色中的瀑布给我们更大惊喜。今天偶尔有点晚霞,云太厚,不过来对了,瀑布周围的各种巨型聚光灯在夜幕降临之际同时照亮瀑布,五颜六色,多姿多彩,让瀑布七彩缤纷别有一番风姿,实属难得一见,是永生难忘的美好回忆,因此我们很晚才返回住处。
10月18日一早起床,自然是想照日出朝霞下的瀑布,想出大片呀。可惜机位没选好,最美最特色的景观未照出来,看到别人照的瀑布上方一张照片,把我惊呆了。但我们还是有很大收获的,虽然天呢忽阴忽晴,云层很厚漂浮得也很快,不过偶尔太阳也露出来一下,满足我们拍照的基本条件,出不了大片但还是有不少惊奇的。

瀑布下的海鸥

早晨晨光下的尼亚加拉大瀑布
很快厚云又罩住太阳,我们决定去尼亚加拉河上下游转转,沿着Niagara Pkwy公路,向上游走到Kingsbridge Part后,感觉没有太震撼地方,转头沿这条路向下游滨湖尼亚加拉镇Niagara-On-The-Lake方向奔去。沿途的河岸被尼亚加拉河水的冲刷,形成了一条深深的峡谷。尼亚加拉河是美加两国的界河,Niagara Pkwy是沿着尼亚加拉河修建,路的两边非常清秀美丽,或有村庄或有林中别墅出现,很雅致,很清新。途中路过美加两国建造的水电站,在一个九十度转弯处,有一休息观景台,我们刚下来,上天眷顾,太阳又出来了,陡峭笔直的河岸对面色彩艳丽,漫山遍野被火红的枫叶尽染,倒映在清澈的河流中,沿峡谷是一望无际五彩缤纷的枫叶之海,堪称加拿大最美的秋景。我们不停地拍摄,尽情地欣赏这绚烂多姿的枫树,奔腾咆哮的流水和绿草如茵的农庄。我们继续沿着这称为世界最美的乡村大道前行,又路过一处更美的峡谷景色,由于是逆光,我们没停留,准备下午阳光通透时再来补照。建在河岸悬崖边上,坐落在风景优美的尼亚加拉河的路旁,掩隐在绿树花丛中的那些英式乡村风情的特色农舍,还有那随处可见,十分可爱的加拿大鹅canada goose,一切都让人着迷。他们没搞过什么新农村建设,但每个村庄,每户农舍都像公园那样,十分漂亮又十分干净,加拿大乡村秀美的风光是人与自然最和谐的结合。在路上,我们碰到一座小教堂,我们停下在那休息一下,还去旁边小店买了点小礼品。后来才知道那教堂曾出现在中央电视台的知识问答节目中,很有名气,是世界上最小的教堂,里面只能同时容纳三个人。世界各地的人不少都知道这座小教堂,很多人专门来这里举行婚礼,是当地一大景观。到滨湖尼亚加拉镇 Niagara-On-The-Lake已是中午时分,滨湖尼亚加拉镇建于1781年,是尼亚加拉河汇入安大略湖的地方,环境和设施都很好,小镇安静漂亮,是休闲的好去处,是著名旅游区,小镇被丘吉尔称为最适合散步的美丽小镇。安大略湖水很漂亮,蓝绿色的,小镇色彩斑斓的树木,都在红叶的包围之中。我们在妖娆多姿的小镇到处转了转,然后就赶往那处我们认为最美峡谷的地方,想拍大片呀,那地方最有这个机会的。唉,老天太不给面子了,说变就变,刚刚烈日当空,现在乌云翻滚,大片是拍不了呢,只得打道回府。天开始下起雨了,回大瀑布路上居然碰到有一所中式佛教寺庙,只是这时天下起大雨,我们就没进去了。晚上七点左右我们才到多伦多皮尔森国际机场Toronto Pearson International Airport, 在多伦多机场最佳西方酒店Best Western Plus Toronto Airport Hotel 安顿下来。随后我们去还车,在机场不远处一个广场下停车,把钥匙交到墙上一个小箱子里,就算交车子,加拿大确实是信用立国的典范。

尼亚加拉河谷

世界上最小的教堂
10月19日早晨六点乘酒店巴士去机场大厅,但我们走错大厅,问了几个人,说了一通英语,也没听懂,多伦多机场很大,差点误了机,看来不会英语真是会吃大亏的。紧赶慢赶,总算搭上了加拿大航空公司AC105航班,早晨八点准时起飞,当地时间上午十点抵达温哥华。向导Max准时来机场接我们,并告诉我们,自我们离开温哥华后,温哥华就一直不停地下雨,直到今天上午才有点阳光偶尔出现。我听后大笑:我们人好呀,阳光都跟随我们。温哥华现在进入雨季,希望好运常来哟。Max把我们接到他市里家中,这是一栋木制二层楼的别墅,楼上是三室二厅两卫一厨,楼下分别是一室一厅一厨一厕和二室一厅一厨一厕,公共地方还放着一个洗衣机和烘干机,别墅后面有一个可放两辆车的车库,车库与别墅间是花园,进大门处也是个小花园,房子所处的住宿小区没有围墙,让我这天朝来的人感到不可思议。从19日下午开始到24日早晨,我们就在温哥华附近晃荡了,这几天时阴时雨,有时大雨下了整天整夜,下雨就在家窝着,阴天就出门,偶尔出点阳光都让我们惊喜不已。首先我们去了伊丽莎白女皇公园Queen Elizabeth Park,这公园离Max家很近,公园不大,是由一处废置了的采石场兴建而成,下面是个大水池,温哥华备用水源地。这里是温哥华市的最高点,视野开阔,从山顶可以远眺温哥华,北面的群山、温哥华港口以及市中心皆在眼底。据说这里还是温哥华最适合赏樱和郁金香的公园,可惜我们来得不是时候,但参天大树、碧绿草坪、各种虫儿鸟儿和悠闲的人们把闹中取静的公园装扮的分外妖娆。山顶还有一个布罗黛尔温室Bloedel Conservatory,不过这个半球形的植物温室我们没有进去。因为光线不佳,我们只在公园四周走走,拍拍照就回那个乡村农庄去了。20日我们任务很重,要去两所大学英属哥伦比亚大学UBC和西蒙弗雷泽大学SFU还有史坦利公园Stanley Park。UBC大学依托西部海滨,SFU大学占据东方山头,这两所大学一东一西,遥相呼应,据说校园都非常漂亮。我们先到SFU大学,可惜坐落在本那比山的学校完全被云雾罩住,抻手不见五指,转到与SFU大学连成一片的本那比山公园BurnabyMountainPark也是如此,但一下山,能见度就好了许多,我们只得前往下一个目的地史丹利公园Stanley Park。史丹利公园是个典型的城市公园,也是加拿大温哥华最负盛名的公园,在市中心,规模很大,面积有400多公顷,我们是开车进去的,停车要交费,但是自助没人值守。公园内空气清新、有大树,有草地,有海滩,有湖泊,可以看海,可以看雪山,有很多漫步道和自行车道,是温哥华当地人运动、休闲的好去处,也是外来游客不能不到的地方。公园中有一个图腾公园,是印地安人的一种文化表现。由于森林覆盖,三面环海,这里野生动物很多,到处都可以看到可爱的加拿大鹅,还有海狮大型水生类动物。在史丹利公园可全景眺望著名的狮门大桥及大桥四周扬帆出海的渔船,温哥华金融区的高楼大厦,三面环海形成的海湾,北温哥华格罗斯山的彩叶及造型各异色彩鲜艳的豪华别墅,这是一幅多么美丽动人的画面,上帝真是厚待温哥华哟,当然对我们也不薄,虽然没出太阳,但能见度还不错。离开史丹利公园我们立即去UBC大学,UBC大学坐落于加拿大西海岸温哥华市西面的半岛上,依山傍海、绿树成荫、风景秀丽,号称是整个北美最漂亮的校园。我们去时,天又开始下起小雨来,我们在UBC陈氏演艺中心附近停下,这栋建筑是香港鳄鱼恤的陈俊捐赠,故得此名。由于天气雾蒙蒙灰茫茫的,我们无法欣赏到这所有的海岸线、山脉、森林、海洋、沙滩的美丽校园,包括那最撩人的著名的天体海滩“烂船滩”。校园里遍布郁郁葱葱的树林和四季盛开的花卉,盛开樱花的春天看不到,但姹紫嫣红的秋天也都在雨帘中大为失色,基本上也看不到。没办法只好返回Max家去吃晚饭,刚到Max家没多久,雨停了,太阳出来了,时不我待,我们饭也不吃,立马背起相机,直接再去与SFU大学连成一片的本那比山公园照落日晚霞去了。功夫不负有心人,到本那比山公园时机正好,登顶之后,眼前豁然开朗。葱郁的绿里点缀着红黄,极目远望,水光山色尽收眼底。BurnabyMountainPark奇特的雕塑群(日本雕塑Kamui Mintara sculptures,由日本雕塑家 Nuburi Toko 和他的儿子所创作,象征着人类、动物、自然和上帝的和谐统一),秋日叶色微红的树林,和湖、云、山、峡、光融为一体,远处一两汪不知是湖还是海的碧水,让人仿佛置身在童话世界中,这才是美丽的秋景呀,色彩艳丽,如诗如梦。


弗雷泽河旁朦胧美,轻雾如纱

温哥华加拿大广场

与SFU大学连成一片的本那比山公园BurnabyMountainPark
10月20、21、22日天气不好,雨季的温哥华,对它没脾气,我们只得去商场和奥特莱斯转了转,顺道去参观一家湖北籍华人正在建造木结构三层大别墅。10月23日星期六,早晨天气转好,我们准备去惠斯勒(Whistler),没出城前有两处路边景点让我们兴奋不已,都在河边,一处在弗雷泽河旁,是朦胧美,轻雾如纱,烟锁秋波,一层轻纱般薄雾在河面上飘来荡去,河对岸的树林和农舍时隐时现,一切都掩映在宁静、纯净、虚幻的晨雾怀里。那淡淡的地雾,那隐隐的树林,那静静的水面,活灵灵显出一个世外桃源。当车路过皮特河大桥时,我们眼前又一亮,被眼前美丽深深地震撼,赶紧下了主干道,停在河边傍,端起相机不停地拍摄,机会难得。远处山峦披着多层薄雾,河两侧处处可见红的黄的树,湛蓝的河水倒映流光山色,黄草依依在河边随风而笑,宛如仙境。这情让人心灵被净,这景让人飘飘欲仙的感觉。走出温哥华,进入海天高速公路 Sea to Sky Highway (99号高速公路),海天公路蜿蜒于太平洋和群山之间,由海洋、河谷、冰川及高山峻岭所铺陈,道路内侧是山峰林立、悬崖陡峭,另一面则是碧波万顷、海水湛蓝,沿途经过多处海湾、瀑布等风景区,景色如诗如画,还有绿色的小岛、高高的雪山,蜿蜒而上的公路,海天相连的景色尽收眼底,一如其名,完全展现由海至天的丰富样貌。海天公路路过一个非常有特色的高尔夫球场,整个球场顺着山势而建,背山面海,高低错落,真不知老外的灵感怎么如此丰富,设计出如此之美的球场,只是我们找不到俯视这球场的高台,照不出它的神采来。到香农瀑布(Shannon Falls),虽落差335米,但我们看瀑布太多,就没停下来了。后来路过一个不知名的观景台,居高临下拍了一下海湾的大景观。在斯阔米什小镇(Squanmish),我们休整了一下,发现加拿大民众都在为万圣节筹备各色南瓜及物品,看来西方对这个节日挺重视白。村对面的史坦沃斯峰Stawanus Chief很雄奇,很高耸,坐缆车可以登顶,可一览海天高速公路四周美景,可惜我们没上去。中午时分,我们终于到达惠斯勒。惠斯勒是2010年冬奥会场地,世界著名的高山滑雪和山地自行车运动地,闻名遐迩的度假胜地,有“小瑞士”之称。现季节缆车已经停运,让人很是失望。小城很独特,山上滑雪道清晰可见,规划独特的街道,五颜六色的房屋,森林、草地、湖水、雪山,自然宁静的感觉,悠闲自在的情调,构成了一幅美丽的图画。我们在镇上找了一个蒙古歺馆,人气很旺,但总感到是铁板烧的味道,这是我第一次吃蒙古菜,还不错。惠斯勒周边有不少湖泊,我们驱车去了两个湖泊玩玩,只是天又阴沉下来,没什么特别感觉,就打道回府了。在回家路上,沿海天公路又有一观景台,是个峡谷,峡谷下遍布金黄色彩林,美不胜收,如果不是天太阴,这里一定美极,可惜今天出不了大片。到西温哥华,有一观景台,可看温哥华全景,据说很壮观,但我们去时,天已近黄昏,没有晚霞,没有日落,自然也就照不出美景,算是到此一游吧。
10月24日星期天,这是我们到加拿大最后一天,准备在市区转转。首先去了离唐人街不远的煤气镇Gastown,所谓煤气镇就是一条街道,是温哥华最古老的街区,名气很大,不怎么吸引我。蒸汽钟是煤气镇标志性景观,这座世界首个以蒸汽为动力的时钟造型是借鉴1875年的式样,古朴、大方、精准。有不少游客在此合影留念。加拿大广场 Canada Place离煤气镇不远,处于温哥华市中心,加拿大广场建于1986年,是当年万国博览会的加拿大展览馆所在地,建筑外墙为五块白帆,也被称为五帆广场,成为了这个城市的地标之一,广场上的独创的雕塑是2010年冬奥会火炬点起的地方,还有那巨大的蓝色雕塑水滴The Drop。走去加拿大广场旁海边不时有水上飞机起落,远处停泊有许多私家游艇,密密麻麻的桅杆上的五彩旗随风摆动,广场旁是客运码头,我们在时没见到大型游轮。三三两两的人们闲庭信步,一群人在冬奥会火炬照婚礼照,我们自然不会放过,对着他们拍个不停。站在广场上,
看着北岸美轮美奂的山峰远景,看着红透遍野的枫树林一直沿边延伸到斯坦利公园,看着湿润的海风吹拂身后摩天大楼,让人轻松让人宁静,我们陶醉在这难得的悠哉闲适生活中。接着在这里我们观看非常有名的Fly over canada4D电影,FlyOver Canada带大家从加拿大的东岸横跨至西岸,挑战观众的各个感官,最大亮点是用加拿大的自然风光,让观众可以体验到乘坐飞机,还有利用水雾,风和香味让观众们逼真地飞遍加拿大去感受到这个国家的壮美,效果让人叹为观止,非常推荐一看。看完电影后,我们就在广场豪华景观西歺厅里一边沐浴着海风,眺望着雪山,一边喝着咖啡,享受着午歺,过起一把腐朽的资产阶级生活的瘾。天公不作美,刚露点太阳又阴下去,本想去卡普兰奴吊桥公园 Capilano Suspension Bridge,但朋友说林恩峡谷公园Lynn Canyon Park和卡普兰奴吊桥公园类似,只是吊桥小一点,知名度上比卡皮拉诺吊桥的稍微低一些,但公园里面有湍急的溪水和流瀑,有原生态的树木,感觉像走在原始森林之中,喜欢这种纯天然的自然环境,更有野性,关键是还不收门票,节省每人29.9加元门票,一举多得,我们选择是正确的。玩完林恩峡谷公园,我们加拿大行程就圆满结束了,明天我们将离开美丽的加拿大,返回中国。
10月25日早上九点,Max把我们送到温哥华国际机场,托运行李、安检、过关,我们进入候机大厅,我们乘坐的东方航空公司MU582航班从温哥华飞往上海浦东机场,中午一点二十分正点起飞,26日下午四点四十分抵达浦东机场,然后中转乘东方航空公司MU2544航班从浦东机场飞往武汉天河机场,本是晚上九点五分起飞,晚点一个多小时才起飞,天朝与腐败的资本主义国家就是不同,不正点似乎是天朝一大特色,没办法只能听天由命,后半夜才返回武汉家中,完成加拿大的自驾旅游之行。

斯阔米什小镇
五.结语与感想
这次去加拿大自驾游,由西向东行程近一万多公里,耗时一余月,穿过加拿大城镇几十个,说到底还是走马观花,蜻蜓点水,当然不可能准确地、完整地、立体地、全面地了解加拿大民情,而且自己缺乏多层次、辩证法、科学观和历史思维的模式,又受自己接触范围和观察水平所限,所以结语与感想这节所述内容决不可能是放之四海而皆准的绝对真理。我不能保证我的结语与感想是正确的,正能量的和主旋律的,但我能保证我决不会有意弄虚作假刻意伪造,也不会无中生有满口胡言,它是我有限的信息和知识的结累,是我独立判断与分析的结果,属于阶段性的个人认知和结论。我的所有结语都有所依据的,我的所有感想都是发自内心的。
加拿大是个伟大的国家,面积很大,人口不多,经济发达,法制建全。
空气、阳光与水,不得说,一个字:净,是他妈的真净。原生态、无污染、原汁原味,当然也包括食品。
税收高,退休晚,福利好,大家特别遵纪守法,人人都愿做志工社工,社会公德意识强烈,宗教、科学、民主和自由是整个社会共奉的核心价值。全社会尊老爱幼,各种族各宗教相互宽容,整个国家给人一种社会主义的再现,实在想不出这是一个万恶的垄断资本主义国家。
这是结语。
有关感想,大家别急,请我一一道来。
到加拿大首先感觉环境好,没有那该死的P2.5的烦恼,第二天,我在中国常年发病的鼻炎症状消失了,这可是我在武汉大小医院检查诊治多年不见好转的顽疾。医生一会儿说是过敏性鼻炎,一会儿说是慢性鼻炎,药也没少吃,就是不见好。再就是我久治不愈的胃肠道紊乱消失了,大便通畅了,小便不黄了,在中国,我常年大便不正常,经常腹泻,西药中药都吃过,大小便颜色仍不正常。到了加拿大,不用治疗,全好了。这是加拿大这个国家给我赠送的第一个惊奇。
第二个惊奇是,加拿大的居所没有天朝常见的防盗门和铁丝窗,没有小区围墙,每家都靠马路,出入自由,实在不可思议。后来发现,连学校、政府、企业都没有围墙,这说明什么呢?不要小看这个没有围墙的小宅院,说明社会治安好呀,它会给你一份踏实,让你从内心爽快。大家不要认为那一定和中国一样,到处安装监控摄头?不是!是有安装,但真的很少,甚至公路交通监控摄头都安装不多,这让我这个受了几十年正统教育的人惊呆了。贪婪的资本主义制度,腐朽的资产阶级思想,贫困的劳动人民和吸血如鬼的资本家,这样的国度怎么能有比天朝还要好的社会治安呢?没有严酷律令,还能维持社会和谐与稳定,是值得中国学者和当政人物好好思考的。我住在朋友在郊区的小别墅,一个普通木门,一把小锁,朋友一个月不来一次,但从来没有被盗窃过。我们把从中国带来的大包小包放在屋里,然后去东部玩了一圈,也没不放心,更不担心有人入室行窃,这种心态在国内我从来没有过。因为我们居住的小区,有围墙,有保安,有摄像头,但每年都发生盗窃,去年就我所知有五家被盗,有一家损失惨重,百万财产消失了。

中国的防盗窗
第三个惊奇是,没有网络控制,无须翻墙,可随意看阅祖国任一网站。今天社会是网络社会,出国在外人,网络更显重要。我们可以用微信向国内亲友报平安,发照片,也可以上网了解国内外政治经济状况。制度不自信的加拿大,不害怕它的工人阶级通过网络,向往那令人神往的美好制度,造成人才流失?理论不自信的加拿大,不害怕它的人民通过网络,掌握精神原子弹,造成社会动乱?道路不自信的加拿大,不害怕它的公民通过网络,结聚社会正能量,让人民当家作主?文化不自信的加拿大,不害怕它的组织通过网络,被先进文化俘虏,走向社会的异化?不理解!不明白!加拿大这个充满着多元文化色彩的国度,能如此和谐,实属难得。
第四个惊奇是,在加拿大自驾这么久,走过不同道路,各地的公路车水马龙,但井然有序,也没有人横穿马路,没在路上看到一起交通事故。一个月来唯一一起交通事故还是发生在自己身上,这后面再详谈。而我在中国,只要出去游玩,总能碰到交通事故。要知道加拿大很多高速公路硬件条件不如中国,比如横穿落基山脉的东西大通道一号高速,很多地方双向两车道,没有隔离网,但不论大货车,小轿车速度都很快,基本都在110或120公里/小时,山区的路能跑这么快,还看不到交通事故,不能不佩服加拿大的交通制度!加拿大人的交通意识很强,那怕再挤,靠里的两人乘坐的专用道再空,也没有人去转道插队。该停的地方一定停下,唯一普遍违规的就是超速。本来加拿大道路限速起点就高,在中国限速六十至九十的,在加拿大一般限速九十以上,而且道路硬件远不如中国限速六十的道路,但加拿人驾车仍在110至120之间,尤其是大货车,开得挺猛。我问过我朋友,他说加拿大警察默许超速,但过了120后,如果抓到,后果也很严重。加拿大很多地方高速没有限速监控摄像,主要靠巡路警察执法,我们开了一天车去落基山,也没看见一辆巡路警察车,也未看到一起事故,是个奇迹!
第五个惊奇是,加拿大人民真善良,加拿大衙门真亲民。我在加拿大曾经的首都金斯顿Kingston出了一起小事故,在我停车等红灯时,有一车从侧面轻微碰擦了我们车。车主是个年轻妈妈,带着小孩,由于语言不通,沟通十分困难。后来只能求助于多伦多的朋友,作为翻译,双方才明白各自意思。事故发生后,这位女士很友善,不推卸责任,她把车主证,驾驶证和保险凭单让我们拍照,本来这事按当地处理方式就此了结。但这位女士很热心,不放心提出要看看我们租车合同。看后,她告诉我们,合同明确规定在外行驶中,事故不论大小都须报警,並带回当地交警部门责任书,才能理赔。这位白人妇女不顾两个小孩吵闹,立即打了报警电话。警察在电话里说,人手不够,这种小事故不能来现场处理。那位女士马上热心对我们说,她要带我们去警察局报警,并打电话给她丈夫,让他去警察局去接小孩。她拖着两个小孩带我们一起去警察局,真是个活雷锋。到金斯顿警察局,只有一位中年妇女处理交通事故,在等她处理上一起交通事故后,就立马分别给双方车子照相,热情地单独分开询问双方事故发生情况并作笔录。态度极为友善认真,比中国交警处理事故态度要暖心许多,不厌其烦,耐心解释,然后开具责任事故单。唯一缺点是太认真、太热情、太负责、太教条,耗费时间太多。在国外出事故是最麻烦的,我们深有体会,一直到傍晚才了结这个案件。


第六个惊奇是,加拿大把信用看得很重,信用是他们立国之本。宾馆退房不查房,也没压金;大家都会按次序排队,绝没有插队加塞的行为;这里的商场货真价实童叟无欺,你在这里买东西心里觉得踏实,不用担心商品质量和被欺骗;人们都很讲文明,没见过随地吐痰的。记得我们去魁北克市那一家汽车旅馆时,没有一个工作人员,门口有一张留言条,告诉我们房间钥匙在门口小箱子里,可自取自住。第二天退房也没人,只叫把钥匙丢进小箱子里就可走人,这在中国是无法想象的。到各个公园,有部分也需购票,但没人管靠自觉。地铁站只有一位售票员,没见其他工作人员,门也敞开,买票也靠自觉。当然有抽检的,据说查到后信用会受损,但并不频繁抽捡,我一次没碰到过,但也几乎没见到人逃票。
第七个惊奇是,加拿大社会保险体系涵盖广泛,社会福利倾斜贫困者,关心弱势群体成了风尚。服务员、清洁工、木工、水道工、电工,报酬不低,干起来没有低人一等的感觉。我行走加拿大一余月,只在温哥华市加拿大广场碰到一个乞讨者,很是不相信。我朋友告诉我加拿大还是有一些无家可归者,但是政府很关心他们。我这位朋友Max每周都去做义工,照顾无家可归者,对这方面情况相对熟悉。他告诉我们,照顾无家可归者场所实施非常不错,伙食也极好。他每周过去就是给他们做甜点,不少无家可归者以此为家,白天出去,傍晚回来,不受限制,不管来历。费用主要是政府拨款和个人捐助,食品都是十分新鲜卫生也很可口,有时食品剩多了,他们也带点回家,小孩特别喜欢吃。一个代表资产阶级利益,受寡头资本操纵控制的政府对自己压迫的阶级仍能这么细心周到,是某些理论无法自说其圆的。
第八个惊奇是,加拿大农民真幸福。这次自驾游,从西到东,在加拿大广阔田野里奔驰,所见所看,没有发现破旧房屋,最起码从表面看,农民生活很富足。没有地主也没有贫农,大家都是农场主。和中国农民不一样,他们不是农民工,不是弱势群体,更不是收入低,生活苦的代名词。说是农村,给人的感觉真正现代化,他们生活也是高品质的。农村住宅各具特色且体量较大,房前屋后是草坪、鲜花、树林,还有汽车、拖拉机和游艇,不是别墅胜似别墅,内部装饰也干净明亮卫生和舒心,更没有在中国农村常见的鸡鸭、农具、柴草。就居住条件、生活品质而言,在加拿大说不准已没有比农民更好的了。不知道在加拿大农村,还有没有阶级斗争,但贫下中农是绝对绝迹了,这是不争的事实。
第九个惊奇是,加拿大让不少中国人失望,这里没有国内丰富的娱乐活动,在祖国大地遍布的洗脚城、桑拿房、美发室、夜总会,在这里很难寻觅到。更没有我们文学作品中描述的灯红酒绿,歌舞升平的景致。这里一切平淡如水,波澜不惊。有些国内来的人,会非常失望,这里太不热闹,太安静,太讲人权了。加拿大虽是世界上最富有的国家之一,但没有土豪金的嚣张跋扈,暴发户的醉生梦死,不论富人穷人,还是中产阶级,都十分喜爱徒步,划船,滑雪这类活动,人们生活健康,情趣高雅,而且人际关系也简单许多,没有国内那种压力与压抑,恕我眼拙,实在看不出腐朽没落垂死的资本主义即帝国主义的一丝征兆来,对不起胸怀祖国放眼世界解放全人类的中国无产阶级的革命群众,罪过,罪过,实在是罪过,我检讨。
一个月时间十分短暂,看到的也不一定是真实的,但这次旅途给我印象深刻,触动很大,所见所闻再次引起了我的思考,过去给我们的那些教育是否过于偏执?资本主义也在改革,也在自我完善,它们在发展过程中形成了一套良性的运行体系,值得我们好好研究。加拿大的先进经验我们要学习,科技在发展,世界又不大,我们都生活在这个地球村上,有必要为人类共同面对的问题,精诚合作,一起破解。
经过这次短暂而又深刻的游历,我开阔了眼界,增长了见识,看到了差距,收获是大大地,体会是深深地。
我决定:生命不息,探索不止,游历不停。