白:
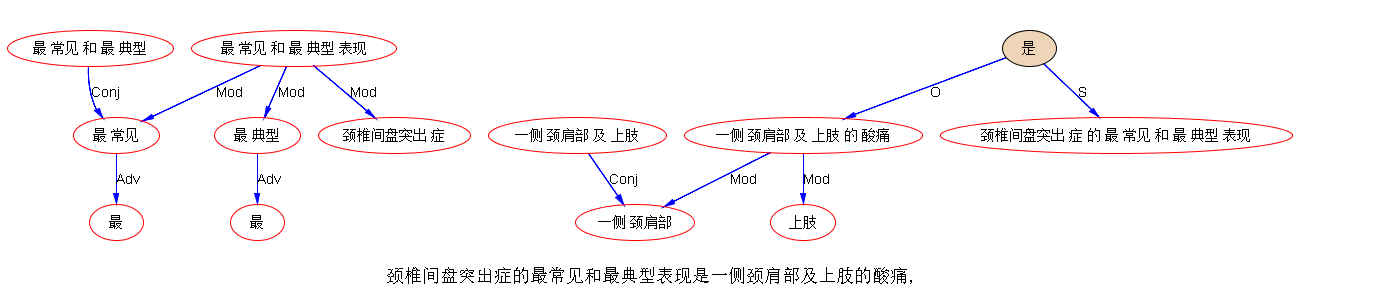
“我讨厌那种窗户不透亮的房间”
“我喜欢家不在本地的女朋友”
“他期盼着进入一个放学不留作业的学校”
@崔佳悦 欢迎
李:


欢迎@崔佳悦 虽然词库目前未登录 好在 ne 还是对了。
1. “秦汉胡同学员作品展” 里切词有错,可是 NP 对了,应该不影响parsing该NP涉及到的句子大局;
2. “蒙太格” 不在词典,更甭提“蒙太格语法”这个术语了,但是 NP 还是没错;
3. “逻辑语义学研究”,初期 parse 成主语 S,到了语义中间件(不是白老师那种中间件,是句法后的语义模块)发现是逻辑宾语 O,但并未删除初始的主语结论(其实是有意为之,因为这个更新不是百分百把握,留下初始结果可以增加语义落地 recall,不过是一个儿子两个老子而已的可以容纳的 non-deterministic 的结果);
4. 从事的主语应该是【human】or 【institution】,现在错了,这个可以在语义模块更正的,如果磨细活的话。
5. 最后的话(怎么听上去像瞿秋白先烈就义前的心灵忏悔?): 所谓鲁棒,就是步步为营,不求完美。有知识就细柔一点,没知识就大老粗。
白:
“我不喜欢穿没有领子的毛衣。”
李:
人在外 领导血拼 估计没问题 等回家测试
人在外 == body 在外
不是领导ing shopping 而是陪领导 shopping
估计what没问题 等回家测试what
这个要问白老师 语义中间件搞不定。
估计【白句的测试结果】没问题 等回家测试【白句】
白句是what 问一问小冰
据说小冰是目前对discourse最能耐的妞儿了。

白:
窗户那个,看不出细节
如果“不透亮”一个坑,而且被“窗户”占了,而“房间”又不属于“那个小集合”,那么“房间”回填“不透亮”应该遭遇阻碍而且不能不了了之。不知道伟哥怎么摆平的。别告诉我就是不了了之了。
李:
做 sentiment 的 这个都摆不平 就完蛋了:窗户不透亮 是 negative 中最具情报价值的信息,我们叫做 actionable insights,比纯粹情绪的宣泄价值大太多
白:
“没有”两个坑,把问题掩盖了。再来:“我最喜欢吃皮儿薄的饺子。”
估计和窗户一样
毛衣、饺子、房间,都是俩爹。
李:

这个、这个 -- 差强人意了点儿。
可毛主席说了,吕端大事不糊涂。大局不错。
白:
领子、窗户、皮儿,都有坑
在图上把俩爹找齐了才漂亮
李:
哪两个爹?
皮尔 是 薄 的 S, 也是 饺子 的 part?
part-of 关系可以作为支持,不必作为 output,因为这个在 ontology 已经预定了
白:
饺子,皮儿一个爹,吃一个爹。
李:
吃是爹,饺子是宾语儿子。
至于饺子与皮的关系,这是一种不易的本体知识,不是动态的语义,有何必要?HowNet 里面就给了这个关系,这是宇宙真理,放之四海而皆准。没有情报价值。
白:
句法层面不需要知道是part-of,只需要知道有坑
“这些饺子皮儿太厚”,饺子的爹是谁?
是“太厚”,不通。是“皮儿太厚”,违反了词负载结构的原则,答案只能是“皮儿”,而且人家俩的关系就摆在那里。
李:

一个大主语,一个小主语而已,层次不同。
做 sentiment 的,对于这样的描述: 皮儿太厚,非常敏感,因为请报价值大。这是一种抱怨,而且抱怨具有 actionable 情报。下次包饺子,就要注意擀皮儿的人了。
白:
我就是不满意这个大小主语的说法
本来可以做得更好,而且是举手之劳
李:
目前这个做法 很合理啊。
你看看 “皮” 虽然也是 S, “这些饺子” 也是 S,但两个 Ss 明显层次不同
白:
“张三不知怎么搞的亲戚那么多。”
亲戚不是part-of,但有坑的特点是一样的
李:
从短语结构即可看出:"皮"几乎就是词法 open morphology 而 "饺子"则是句法。
白:
亲戚也是词法?
sentiment里面所谓的aspect,在句法里都可以显性处理,不用走曲折道路。
一个性质,完全平行的句子,被处理成了不同样子。
李:

这些扩展的主谓结构,处于词法句法边缘地带,是句子一级的句法的一个单元。违反了词负载结构的原则,也没什么。
白:
硬盘也是?
这台机器不知怎么搞的硬盘总坏。
李:

说是 open morphology 也差不多:硬盘总坏;身体好;性格糟糕;屏幕太宽;价钱死贵 。。。。。。
白:
本来可以纯句法处理的,只要更新一下观念
李:
现在的处理办法, 经过太多的测试,一直感觉很顺溜
语义落地,特别是落地到 sentiment,真地是一顺百顺
展示这样的sentiment 的短语结构的结果 也很漂亮。容易理解,情报丰富。
白:
在句法上把坑显性化,只会做得更好
“硬盘总是坏的机器不要买”
“秘书过于漂亮的老板不好当”
李:
这个 这个 这个 。。。。这个 这个。。。

反正这样玩法,白老师铁心要玩残它。不过:
“硬盘总是坏的采购员不要买,好的采购员可以买”
白:
这个例子好。
问题是我有更好的方法
李:
白老师的问题不是我的问题,但白老师的麻烦却是我的问题。(哈,cf:【李白对话录之10:白老师的麻烦不是白老师的】)
白:
有自由度了。中间件该出场了。
如果没有自由度,还轮不到中间件呢
李:
中间件是这样的:没有它 parser 一样行走,而且多数情况下走得还不错。
这就是 parser 第一步要做到的目标。
然后,随着中间件不断丰富,parsing 不断细化、语义逻辑化。这是 parsing 的第二步目标,是 semantic parsing 的终极目标,但不是语义落地的必要条件。
白:
当然。但句法不同,伪歧义表现不同,中间件出场的条件自然也不同。
伪歧义多点少点死不了人,断链子就不同了
李:
无论是 白老师的中间件的 integrated or call-on-the-fly 的做法,还是我的 pipeline 的语义模块的做法,本质是一样的。
白:
我在质疑句法本身,而不是parsing。
李:
现在的情况是,第一步目标几乎达到了,靠谱了。第二步还在断续补足中。
句法的目标只能是方便语义落地。如果较好地支持语义落地,那么就是一个好的句法(representation)。
白:
这里的“方便”往往夹杂着对软件和数据legacy的考量,着眼点不在“地”而在“落“
如果没有legacy,反而更容易着眼于“地”。成功是失败之母。因为任何一种成功都有固化自己的冲动。
李:
评判 syntax 是一个困难的事儿。譬如说吧 虽然我们可以批判 penn tree,抱怨它设计得糟糕透了。但是 换一个人制定标准 估计也好不了太多,我们还会批判它。我可以一口气数落 penn tree 的10大错,而且可以条条是道。所以,在认识到这种评判的困难以后,我们可以退一步说,至少我们评判一个 syntax 的表达,着眼点是多大程度 多么明显地 有助于或妨碍了 语义落地,而不是从一个句法算法的一致性与否的角度。
白:
还是那句话,落地是有潜台词的,站在什么legacy的山上唱什么歌。最后是legacy主导一切,落主导一切,地是啥反而可以不care了。
李:
那是。我是站在 sentiment,或 IE 的legacy 上。
白:
不对,IE/sentiment还是地,不是落。
李:
地 就是 IE (sentiment 也是 IE),落就是 subtree patterns 的 matching白硕:
白:
subtree自身的局限决定了落的局限
我大概4-5年前放弃subtree的。
我当时起名叫 ppt:partial parse tree
李:
结构匹配
聚焦就是这么来的。
叫不叫 tree 无所谓 实际是个 sub-graph,我们以前也叫 svo search or svo retrieval or svo matching,有了这个 老鼠爱大米 就可以挖掘出来了。
白:
“他死去多年的消息终于曝光了”“他死去多年的弟弟终于平反了”
李:

这个是经典 minimal pair 了
同位subcat
白:
“专家对这种方法的意见还是不靠谱。”
“还是”歧义了。
李:

“还是” 还不是问题,“对” 是个隐患。
【对 np 的 n】 ,np or pp?
谁的意见?
专家的。
什么意见?
对这种方法的意见
什么不靠谱?
意见不靠谱。
谈的 topic 是?
专家。
专家作为虚的 topic 和 实的 mod 都 decode 了,parser 也算兢兢业业了吧。
流氓耍到了这个境界,也可以立牌坊了,正所谓:功到雄奇即罪名,流氓耍尽成英雄。
【相关】




































![[坏笑]](https://img.t.sinajs.cn/t4/appstyle/expression/ext/normal/50/pcmoren_huaixiao_org.png "[坏笑]")