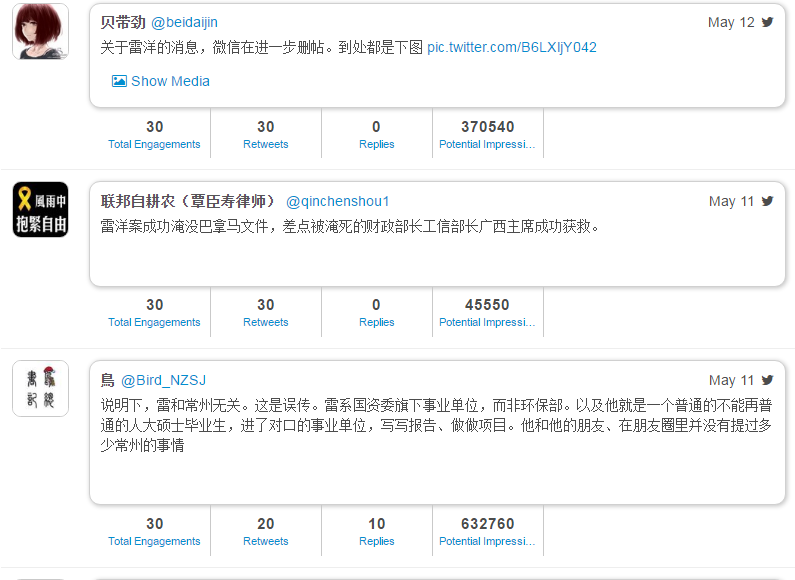
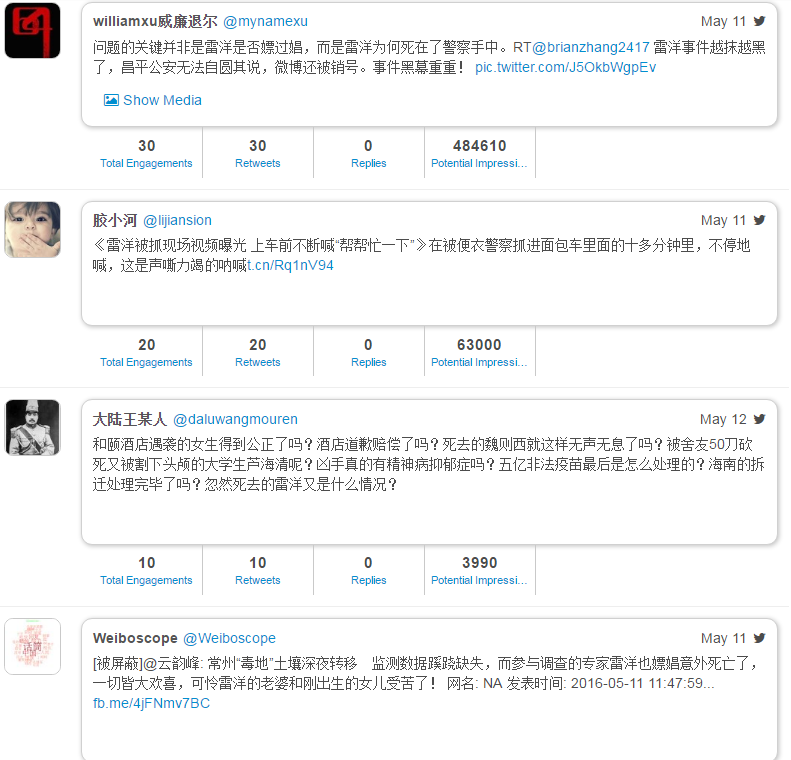
这位长相有些滑稽的人叫黄西(Joe Wong),在美国娱乐圈走红,他一上场,随便一句话,一个表情,甚至一个停顿,也会引起阵阵掌声笑声。他算是进入美国喜剧界的主流了,甚至被请到白宫去讲笑话。另一位北京侃爷出身的北美崔哥(Brother Sway)虽然也用英文讲过喜剧小品,譬如去咖啡馆讲中国功夫或者星巴克的笑话。但是崔哥比起黄西来,显得边缘化多了,主要还是在华人社区有些名气。黄西的演出有过非常宏大的场面,现场几千上万人,也曾出现在美国亿万观众的当红电视节目里,听众总是被逗得前仰后合。
黄西显然潜心研究过西方喜剧的路子,他的一鸣惊人是个异数。黄西的英语不纯正,但他深谙西方文化的幽默要素和喜好。除了东方面孔给人以新鲜感外,他非常懂得怎样向主流靠拢,譬如,美国人热衷谈性,有点类似于中国的成人笑话。黄西第一次上全美电视夜间节目 Letterman Show 的一开始就讲了个带色的笑话迎合他们的趣味,说他读到一个研究报告表明,性成熟的巅峰是18岁。他说,可我到了25岁才得知这一点(他是24岁从中国来美的)。他故意顿了一下,一脸茫然的样子,说,在我蜜桃最成熟多汁的时候,怎么就无缘被人咬一口呢?
"I read a report saying that a man reached their sexual peak at the age of 18, but I did not know this until I was 25. So the world would never know what a stud I was. Nobody took a bite out of this peach when I was ripe."
后来他又开总统和副总统的玩笑,讽刺他们人浮于事,没有效率。他说,如果我当总统,我要用降低生产率的方式彻底解决失业问题,这样,一个人的活就让两个人来做,这就好比我们现在总统和副总统两人做同一份工作一样。他接着说在奥巴马当选总统前,他一直是个悲观主义者,感觉自己如此渺小,对社会毫无影响(does not make a difference,雁过不能留声的痛苦)。对他来说,人生就好象在黑暗冬夜的雪上撒了一泡尿,也许是有点儿影响,可是很难说有什么影响( I felt that life is kind of like, pee into the snow in a dark winter night, you probably make a difference, but it's really hard to tell. (laughter))。黑白混血背景的奥巴马的成功给了他这个新移民以希望。既然半白半黑 (half black half white) 都可以登上权力颠峰,自己是半不白半不黑(half not black half not white)的少数族裔新移民,也应该一样可以竞选总统。
最后黄西开始 mock 自己的总统竞选纲领,讲的都是政治热门话题,一样嬉笑拉扯皆成幽默。首先讽刺竞选口号往往都是华而不实的空架子,他说自己的竞选口号是 Who cares (爱咋咋,谁管你?其双关在他此前交代过自己的昵称就是 Hu,Hu cares, 就是对选民保证他急大家所急)。请看这个段子的上下文:
You may be saying "Hey, what would be your campaign slogan?" You see, I spent ten years in the past decade (laughter) [20] oh you too? okay. (laughter) So I understand that American people are suffering, so my campaign slogan would be "Who Cares". (laughter)
他先说的是同义重复的废话 I spent ten years in the past decade,然后故意面对观众的反应说,哦,原来你跟我一样啊,一个 decade 中花费了十年,来观察美国的社会问题,因而深知美国人民饱受经济不景气的煎熬。然后转到这个 Who/Hu cares 的双关语口号来:表面上是我才不在乎美国人民死活呢,实际是突出自己救民于水火的的亲民形象。
黄西在表演过程中,非常注意细节。比如,他说成为公民以后,他立马把选票投给了奥巴马和拜登。然后转身看拜登,没等拜登反应,他抢先说了声不用谢(you are welcome)。这是给拜登一个措手不及,凸显拜登反应迟缓。因为西方的习惯是无论何时你受惠于人,你都要表达谢意。黄西说投票选了拜登,理所当然要领受拜登的谢意,所以他故作脱口而出,说了一声不用谢。可是拜登还愣在那里呢。我们的副总统大人显得多么迟钝啊。
Hi everybody. So... I'm Irish. I read a report recently that a man reaches his sexual peak at age 18 but I didn't know this... until I was twenty five. So the world will never know what a stud I was. No one took a bite out of this peach when it was ripe.
I'm not good at sports, but I love parallel parking... because unlike sports, when you are parallel parking, the worse you are, the more people that are rooting for you.
I'm an immigrant and I used to drive an old car with a lot of bumper stickers that are impossible to peel off. And one of them said, "if you don't speak English, go home!" I didn't notice it for two years.
I worked really hard to become a U.S. citizen and I have to take these American History lessons where they asked us questions like:
"Who's Benjamin Franklin?"
I was like; ahh... The reason our convenience stores get robbed?
And the second one was:
"What's the 2nd Amendment?"
I was like; ahh... The reason our convenience stores get robbed?
"What is Roe vs. Wade?"
I was like ahh... Two ways of coming to the United States?
I have a family now, but I used to be scared of marriage. I was like wow... 50 percent of all marriages end up lasting on forever!
I just had my first child last year. I was really amazed at it. I was in the delivery room, holding up my son, thinking to myself, "Wow... He was just born... And he's already a U.S citizen."
So I said to him, "DO you even know who is Benjamin Franklin?"
Now I have a sign in my car that says ”Baby On board.”
This sign is basically a threat. It just says that I have a screaming baby and a nagging wife and that I am not afraid of dying anymore.
Thank you very much!
==========================
Implicit explanations to audience with culture difference:
1. Ben Franklin's picture is on the US $100 bill.
2. Second Amendment refers to the US Constitution for the right to keep and bear arms.
"Roe vs. Wade" is a famous court case that you'll learn about in history class that deals with abortion.
Joe Wong used this case in a form of a question: What is Roe vs. Wade? To which he cleverly delivered the punchline "Two ways of coming to the United States".
Roe is used as a play on words to describe "row", as in using a boat to "row" to the US.
The denotation of wade was used, the definition meaning "to walk in water".
这几天我很迷黄西/Joe Wong 3月17号在RTCA Dinner (The Radio and Television Correspondents Association Dinner,全美电台电视记者协会年会晚宴)上的表演。这个晚餐会是当天在C-SPAN 和C-SPAN2 频道上现场直播的,但我直到几天后才在youtube上看到的。实在太迷了,而且网上好像也没见他的表演全文,我就决定把它的全文听写下来并集中注释一下。听写中有个别词不确定用"(??)" 标出来了。注释(理解他的包袱是什么意思)是靠的众多的youtube、mitbbs上的留言,以及自己查字典和google。
Transcript for Joe Wong at RTCA Dinner, aired on C-SPAN 3/17/2010
Transcribed by PB
-----------
Good evening, everyone. My name is Joe Wong, but to most people, I'm known as "who?!" (laughter) which is actually my mother's maiden name, (laughter) and the answer to my credit card security question. (laughter) [1]
But joking aside, I just want to reassure everybody that I am invited here tonight. (laughter) [2]
I grew up in China, who didn't? (laughter) [3] And my childhood memories are totally ruined by my childhood. (laughter) When I was in elementary school, as part of the curriculum, I had to work at a rice paddy right next to a xxxxx quarry where they use explosives to break rocks, and that is where I learned that light travels faster than sound. (laughter) which is almost as slow as a flying rock. (laughter) [4]
My dad was a grumpy guy, but occasionally he would try to cheer me up with jokes, but he doesn't do it right. When I was seven, one day he said to me, "hey son, why is tofu better than centralized socialist economy?" (laughter) so five minutes later I said "why?" (laughter) He said "because I said so!" (laughter) [5]
I came to the United States when I was 24, to study at Rice University in Texas. (some applaud cheers and some laughter) that wasn't a joke (laughter) until now. (laughter) And I was driving this used car with a lot of bumper stickers that's impossible to peel off. And one of them said "If you don't speak English, go home". And I didn't notice it for two years. (laughter)
Like many other immigrants, we want our son to become the president of this country and we try to make him bilingual, you know, Chinese at home and English in public, which is really tough to do, because many times I have to say to him in public "Hey listen, if you don't speak English, go home" (laughter) And he would say to me, "Hey dad, why do I have to learn two languages?" I said "son, once you become the president of the United States, you are going to have sign legislative bills in English, and talk to debt collectors in Chinese" (laughter) [6]
When I graduated from Rice, I decided to stay in the United States, because in China, I can't do the thing I do best here, being ethnic. (laughter) And in order for me to become a U.S. citizen, I have to take this American history lessons, where they ask us questions like "Who is Benjamin Franklin?", where I was like "ah, the reason our convenience store gets robbed?" (laughter) [7] "What's the Second Amendament?", where I was like "ah, the reason our convenience store gets robbed?" (laughter) [8] "What is roe vs. wade?", where I was like "ah, two ways of coming to the United States?" (laughter) [9]
Later on I read so much about the American history that I started to harbor white guilt. (laughter) [10] In the America they say that all men are created equal, but after birth, it kind of depends on the parents' income, or early education and health care. (laughter) I read in the Max House Men's Health Magazine that President Obama every week has two cardio days and four weight lifting days. You see, I don't have to exercise, because I have health insurance. (laughter) I live in Massachusetts now, where we have universal health care; then we elected Scott Brown (laughter) - talk about mixed messages. (laughter) [11] I think there was a movie about him - it's called "Kill Bill" (laughter) [12]
I'm honored to meet vice president Joe Biden here tonight, (Joe turned to face Biden) I actually read your autobiography, and today I see you. (Joe turned back to face audience) I think the book is much better. (laughter) They should've get guest cast Brad Pitt, or even Angelina Jolie. (laughter)
So to be honest, I was really honored to be here tonight, and I prepared for months for tonight's show, and I showed the white house my jokes about President Obama, and that is when he decided not to come. (laughter)[13] And he started to talk about immigration reforms, (laughter) Take that, Stephen Colbert (laughter) [14] And president Obama has always been accused of being too soft, but he was conducting two wars. and they still gave him the Nobel Peace Prize, and he accepted it. (laughter) You can't be more bad ass than that. (laughter) where actually, I'm thinking the only way you can be more bad ass than that is if you take the Nobel Prize money and give it to the military. (laughter)
We have many distinguished journalists here tonight, whom I consider as my peers. (laughter) because I used to write for campus newspaper. (laughter) I think journalism is the last refugee for puns. [15] Only on the newspaper can you say things like "I was born in the year of horse and that is why I'm a naysayer" (laughter) [16] my point exactly.
And tonight is my first time on C-SPAN, which is a channel I obviously always watch, when I couldn't stand the sensationalism and demagoguery of PBS? and QVC. (laughter) If I still couldn't fall asleep after watching C-SPAN, there's C-SPAN2 and C-SPAN3. (laughter) [17] Thank you very much. (laughter)
So I became a U.S. citizen in 2008, which I'm really happy about. (applause) thank you very much. American is number one, (laughter) that's true, 'cause we won the world series every year. (laughter) [18]
After becoming the U.S. citizen, I immediately registered to vote for Obama and Biden. (Joe turned to face Biden) you're welcome. (laughter) You handed me a had me at "Yes We Can" (laughter) (Joe turned back to audience) that was the their slogan. (laughter)
So after getting Obama and Biden elected, I felt this power trip. (laughter) And I start to think maybe I should run for president myself. Where, I have to take a step back and explain a little bit, you know, because I have always been a morose and pessimist guy. I felt that life is kind of like, pee into the snow in a dark winter night, you probably make a difference, but it's really hard to tell. (laughter) [19] But now, we have a president who's half black half white, it just gives me a lot of hope, because I'm half not black half not white. (laughter) Two negatives make a positive. (laughter)
You may be saying "Hey, what would be your campaign slogan?" You see, I spent ten years in the past decade (laughter) [20] oh you too? okay. (laughter) So I understand that American people are suffering, so my campaign slogan would be "Who Cares". (laughter) [21]
If elected, I would make same-sex marriage not only legal but required, (laughter) that will get me the youth vote.(laughter) You see I'm married now, but I used to be really scared about marriage, I was like "wow, 50% of all marriages end up lasting forever" (laughter)
And I will eliminate unemployment in this country, by reducing the productivity of the American workforce. (laughter) so two people will have to do the work of one, just like the President and the Vice President,(laughter) or the Olsen twins. (laughter) [22]
And despite heart disease and cancer, most Americans die of natural causes. So if elected, I will find a cure for natural causes. (laughter) You seem to like that one. (laughter) but you won't be covered by health insurance though, (laughter) because of pre-existing conditions. (laughter)
And I have a quick solution for global warming. I will switch from Fahrenheit to Celsius, (laughter) It was 100 degrees, now it's 40. (laughter) You're very welcome. (laughter)
And I'm great with foreign policy. Because I am from China, and I can see Russia from my backyard. (laughter) I believe that Unilateralism is too expensive, and open dialog is too slow. So if elected, I will go with text messaging. (laughter) I will text our allies just to say hi, (laughter) and text our enemies when they are driving. (laughter) "OMG you're building a nuclear weapon?" (laughter), "but you're doing it wrong LOL" (laughter)
I just want to thank Video TV correspondence xx xx for having me here tonight. This is the first time I wish my son knew what I was doing. Thank you so much and have a very good night. Thank you Linda Scott.
-------
注解: based on comments from youtube and mitbbs, dictionary look-up, and google
-------
[1] 他妈妈姓“Hu”,刚好跟"Who"同音。 maiden name :大部分老美婚后改跟丈夫姓(所以夫妻俩同姓);女性结婚前的姓就叫maiden name
[3] youtube留言:he said he grew up in china... it's a joke about the over population of china and how? many people there are there。
还是youtube留言,但解释不同:If you related to "I grew? up in US, who wasn't?" You got to be smart to understand him。(Mitbbs上有人同意这一个,说这是讽刺美国redneck动不动就说I grew up in US。 )
[5] youtube留言:tofu and centralize economic joke: you got? understand that China is a Communist country, there is only one party in power, everything is like his dad said "because I said so"
还是youtube留言,稍微有点不同:it's sort of non-sense talk said by his dad, then his dad went 'because I? said so'.... his farther == the centralized social system. the nonsense == whatever enforced by the centralized social system.
[6] youtube留言:it is "debt collector"..Because of the huge current account deficit? US owes to China.
还是youtube留言,稍微有点不同:China is the country that holds the most US treasure bonds now.
[7] youtube留言:Benjamin Franklin - 100 dollar bills. Convenience stores have 100 dollars bills. (100美元币上是美国总统本杰明-弗兰克林的头像;便利店/社区小超市当然有100刀币;所以被抢劫了)
[8] youtube留言:Second Amendment: is the freedom to carry gun. - It gives the robbers guns to rob convenience stores.? (因为民众能自由持枪,所以小店被抢劫了)
[9] youtube留言:Roe vs Wade, famous? court case on abortion. Joe thought two ways of coming to US, on boat or swim
我找的别的地方的:In 1973, the US Supreme Court had prohibited states from making laws that interfered with a woman's right to an abortion during the early months of pregnancy. Joe 把 roe vs. wade 转换成 row (rowing the boat) & wade (swimming ) to USA. (划船和游泳偷渡到美国)
[10] youtube留言:He studies America history. It talks a lot of white Americans kill Indians, slavery, kills, etc. Basically, white American were guilty of many things, i.e. white guilt. He starts to harbor (to feel inside)? white guilt (as if he were white).
[11] youtube留言:Obama does exercise, but Joe himself doesn't need to because he has health insurance. MA has universal health care which is viewed as the result of Democratic dominance in MA. But they recently voted a Republic senator Scott Brown, mixed message. (MA就是Massachusetts,常说的麻省)
[12] youtube留言:Scott Brown is a? Republican and their motto on health care reform seemed to be "Kill (the health care reform) Bill"
[15] pun: a humorous use of a word or phrase which has several meanings or which sounds like another word (以转意或谐音的方法达到诙谐的效果)
[16] youtube留言:"Nay-SAYER". Horses go “Nay" . It was a joke on a bad pun.
neigh: a long, loud, high call that is produced by a horse when it is excited or frightened. (马嘶叫声)
[18] youtube留言:Because the World? Series is not for the world...only 2 countries play in the World Series. America and Canada. (World Series 指棒球比赛,说是国际/World,其实就美国和加拿大两国的球队。大部分时候都是美国赢)
[19] youtube留言:actually it means pee in snow will melt it, as pee is warmer. but since? it is a dark winter night, so it is hard to tell
[20] "I spent ten years in the past decade" -- ten years 是十年,decade也表示十年。
1989年夏天,我和导师去德国慕尼黑应参加第二次国际机器翻译最高级会议。此前,我跟荷兰BSO(Buro voor Systeemontwikkeling BV)公司的机器翻译研究组一直有联络,应约为他们的以世界语作为媒介语的多语机器翻译系统 DLT,编写了一部现代汉语依从关系的形式句法。他们听说我们要来欧洲,就邀请我和我的导师,还有中国机器翻译界知名人物董老师,会后顺道访问他们的实验室一周,做学术交流,共同讨论汉语句法里的一些疑难问题。这次活动,他们称作 Chinese Week.
游览阿姆斯特丹后,我们按计划去Utrecht的BSO公司访问一周。DLT 项目研究组十几个人,一半是语言学家,一半是工程师,看得出来,这是个气氛融洽的团队。德国世界语者 Klaus Schubert 博士是系统枢纽“依存关系句法”(dependency grammar)的设计人,在项目第二阶段继 Witkam 成为项目组长。71届大会后招进来的美国世界语者 Dan Maxwell 博士,负责东方语言的句法项目的承包、质询和验收,是我的直接领导(十年河东,十年河西,后来我成为他的 boss,这是后话,见《朝华午拾 - 水牛风云》)。Dan一看就是老实人,照顾我们客人殷勤有加。我看到他早上骑自行车来上班,笑着跟他说:“我在北京上班跟你一样”。
研究组的骨干还有国际世界语协会的财务总监,知名英国籍世界语者 Victor Sadler 博士,我在71届国际世界语大会上跟他认识。作为高级研究员,他刚刚完成一项研究,利用 parsed (自动语法分析)过的双语对照的语料库 (BKB, or Bilingual Knowledge Base) 的统计信息,匹配大小各异的翻译单位(translation unit)进行自动翻译,这一项原创性研究比后来流行的同类研究早了5-10年。显然,大家都看好这一新的进展,作为重点向我们推介。整个访问的中心主题,仍然是解答他们关于汉语句法方面一些疑难问题。他们当时正在接洽欧洲和日本的可能的投资人,预备下一步大规模的商业开发,汉语作为不同语系的重要语言,其可行性研究对于寻找投资意义重大。
期间,Victor以世界语朋友身份,请我到他家吃晚饭。他住在离公司不远的一栋公寓里,太太来开门,先跟丈夫轻吻,然后招呼我进来。太太也是世界语者,忘了哪国人了,总之是个典型的世界语之家,家庭用语是世界语。Victor告诉我,太太实际上会一些英语,但是用英语对她不公平啊。太太很和善,跟我说,他们俩非常平等,她做饭,Victor洗碗。我说,这跟我家的分工一样,我最爱洗碗这种简单劳动。她笑着说,“Victor, vi havas helpanton hodiau (你今天有帮手了)”。饭后Victor洗碗,并没有让我插手,我站在旁边陪他聊天,一边看他倒进大把的洗涤液,满是泡沫把餐具拿出来,用干布擦干。我告诉他们,这跟我的做法不同,我们总是怀疑化学制品有毒或副作用,最后必须用清水涮净才好。太太不解地问:“洗涤液如果有毒,厂家怎么能生产呢?” 这倒把我问住了。Victor夫妇和蔼可亲,我感觉在老朋友家一样,饭后一边吃甜点和水果,一边闲聊,尽兴而归。
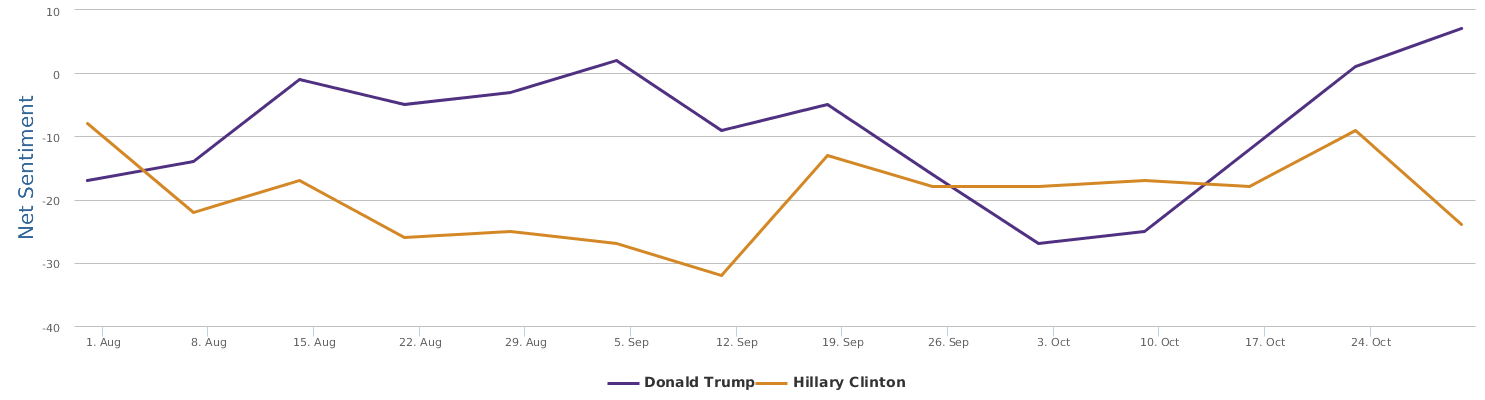
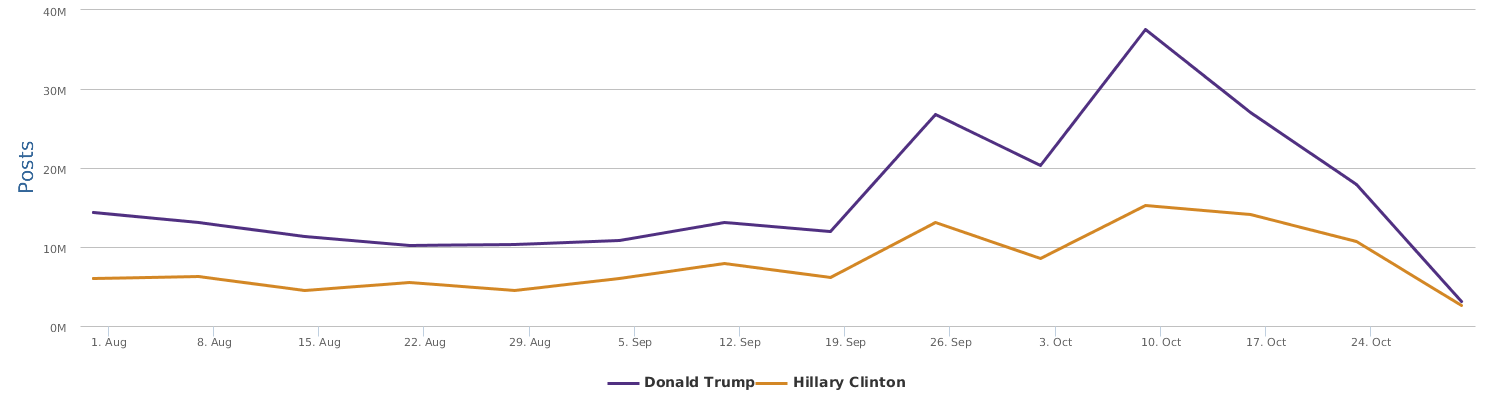
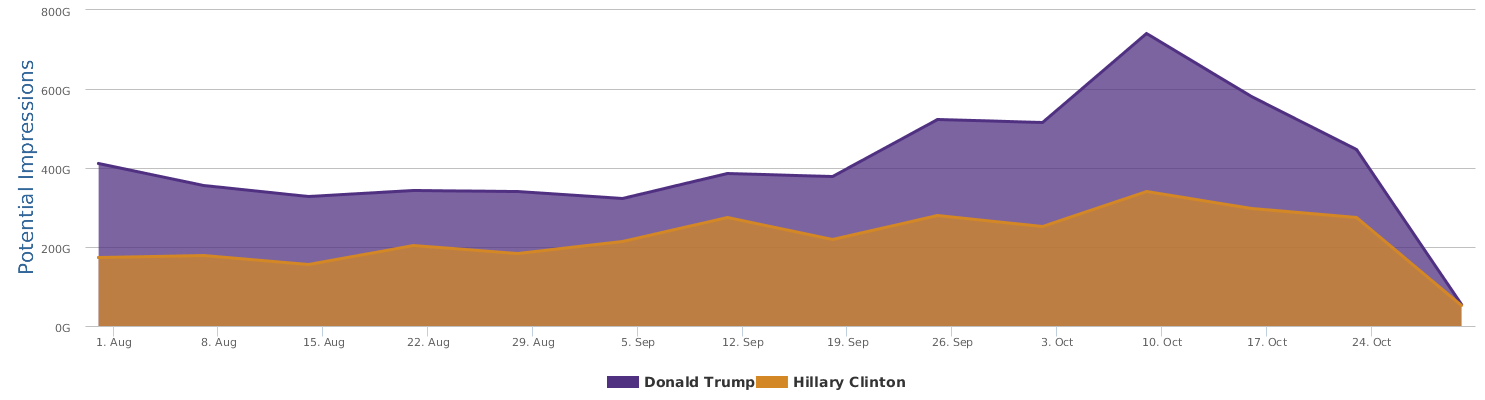
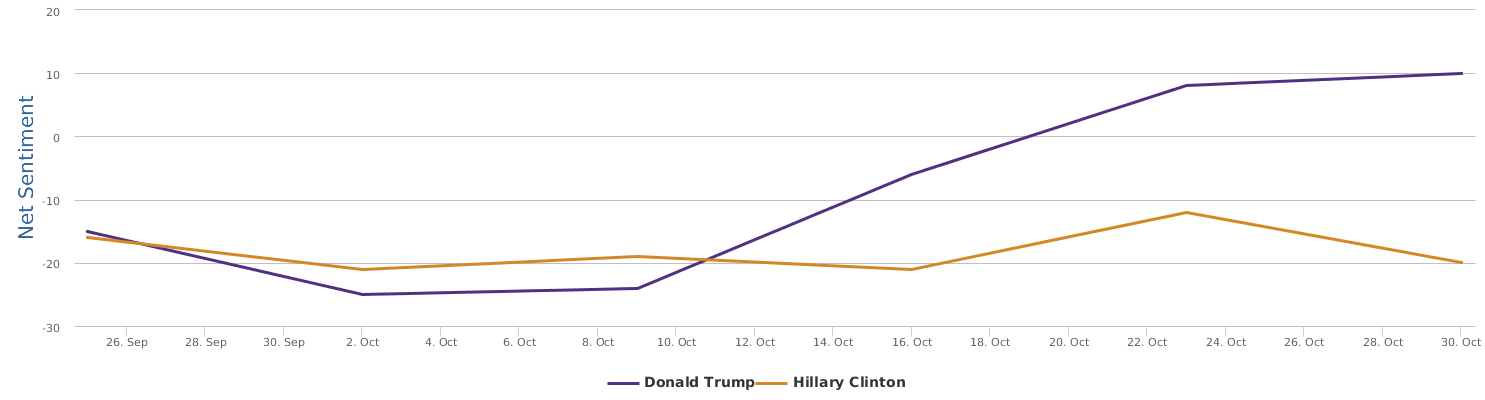
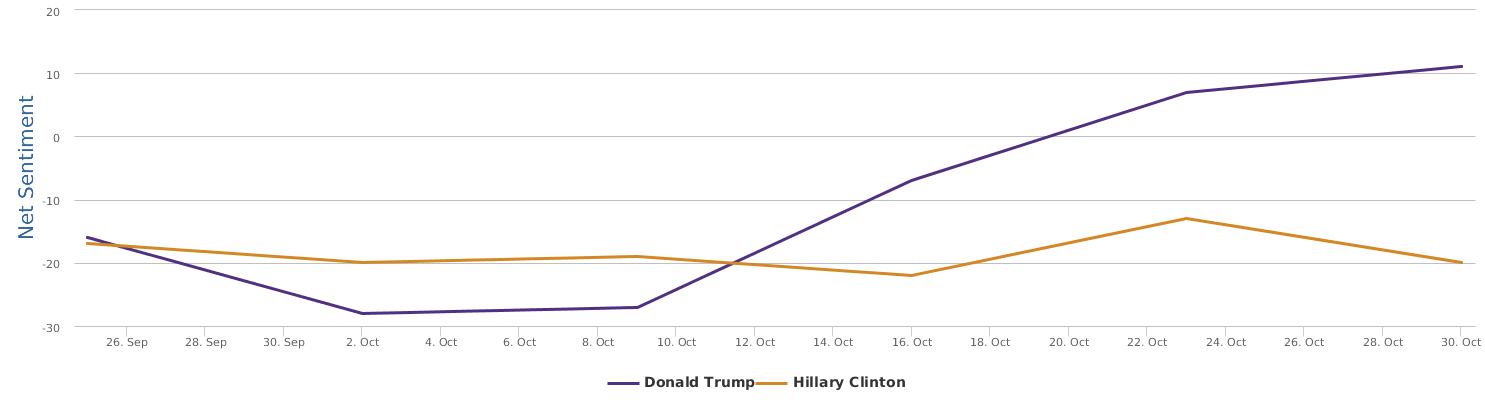
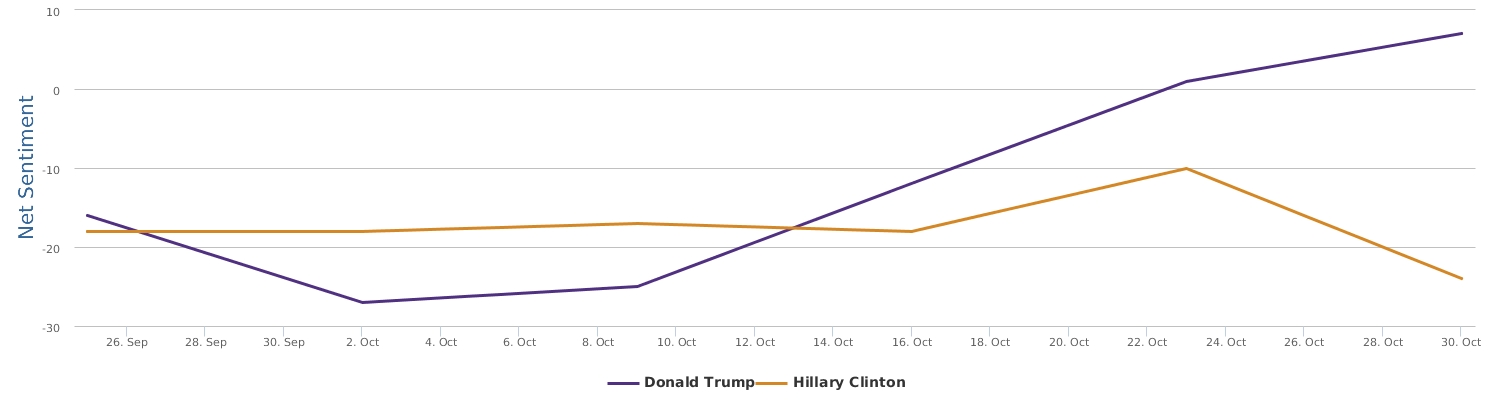
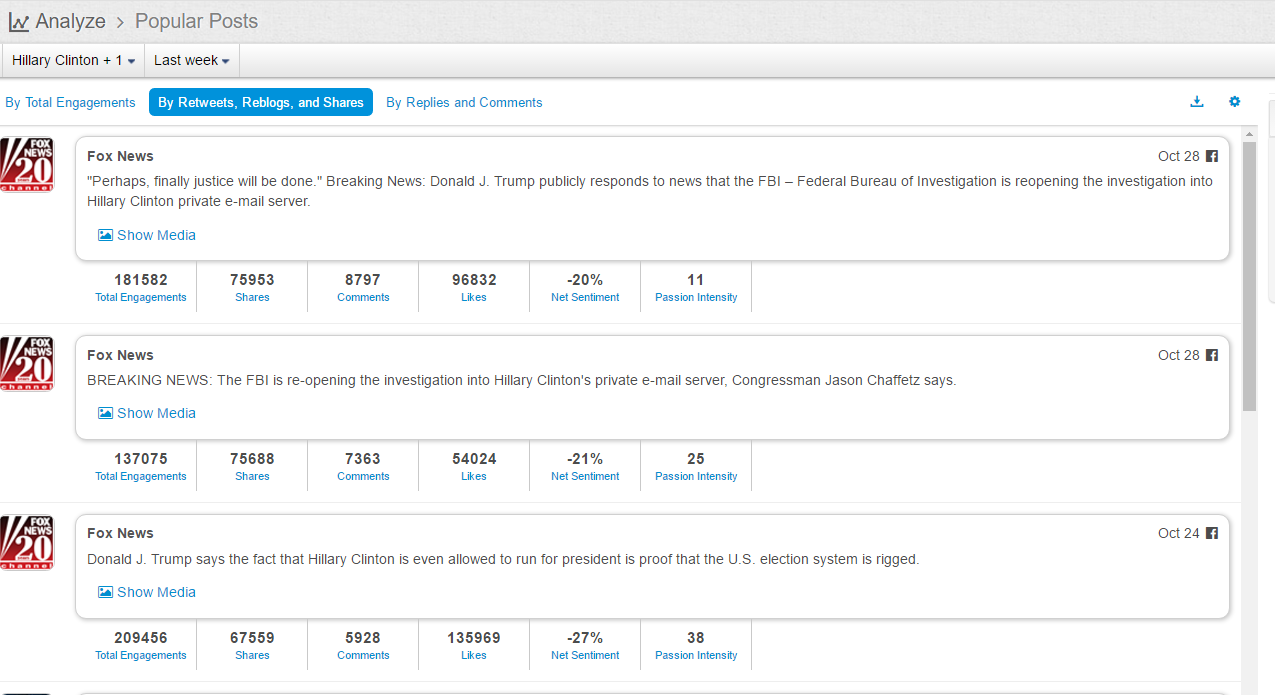
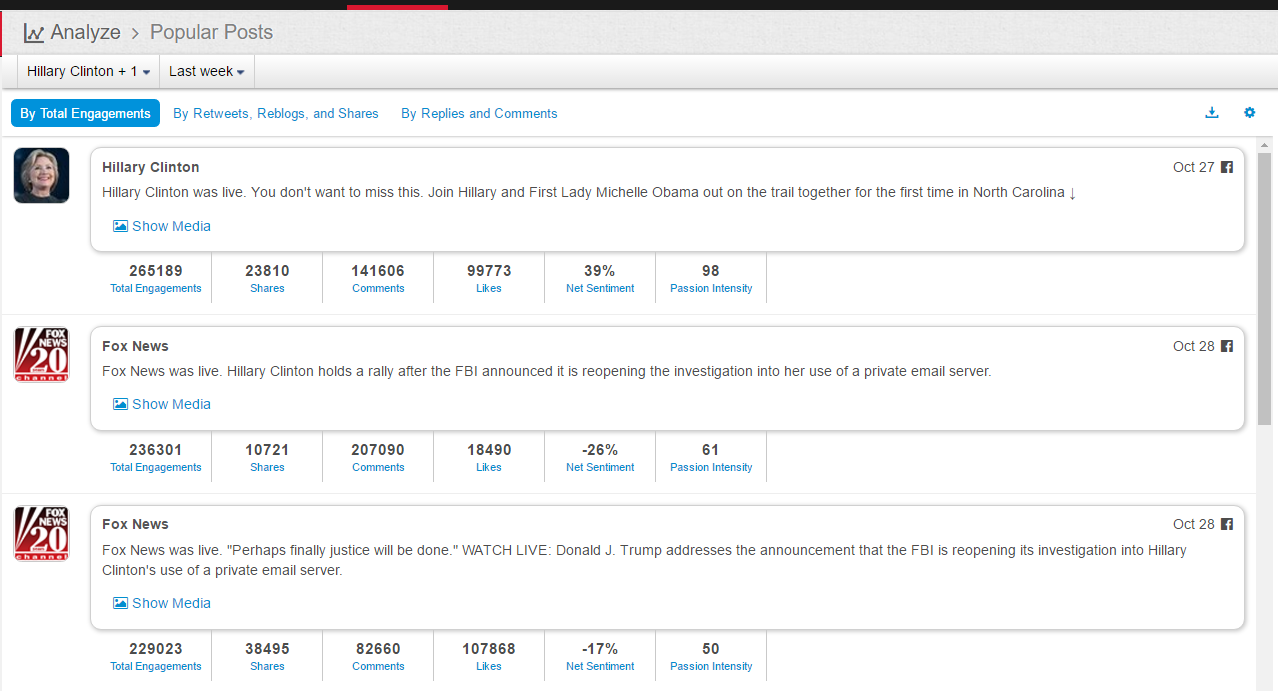
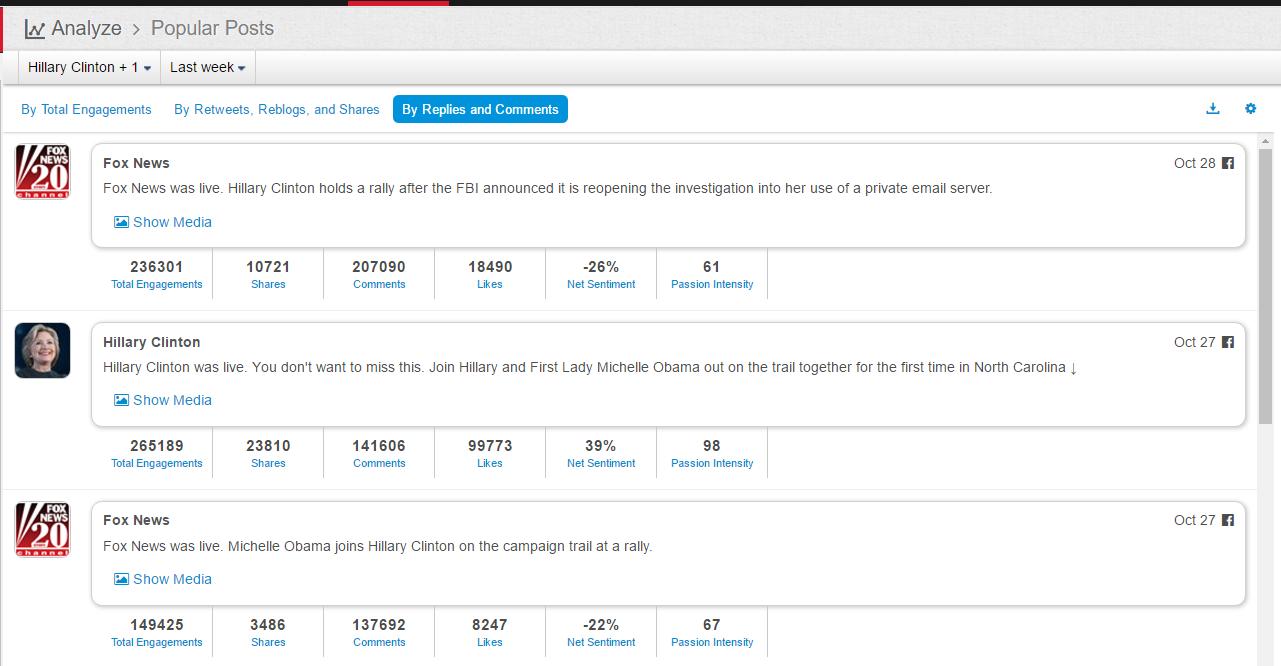
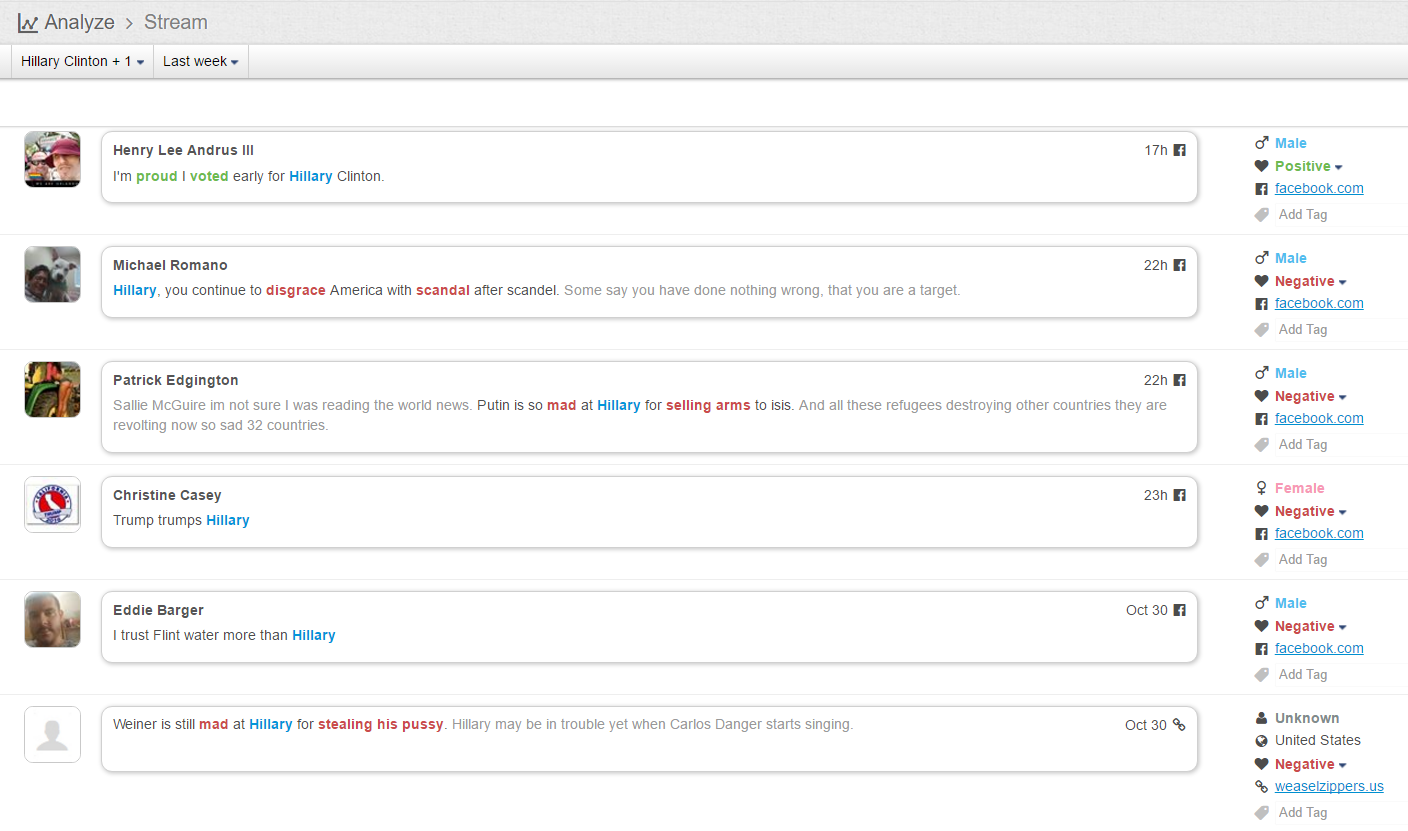
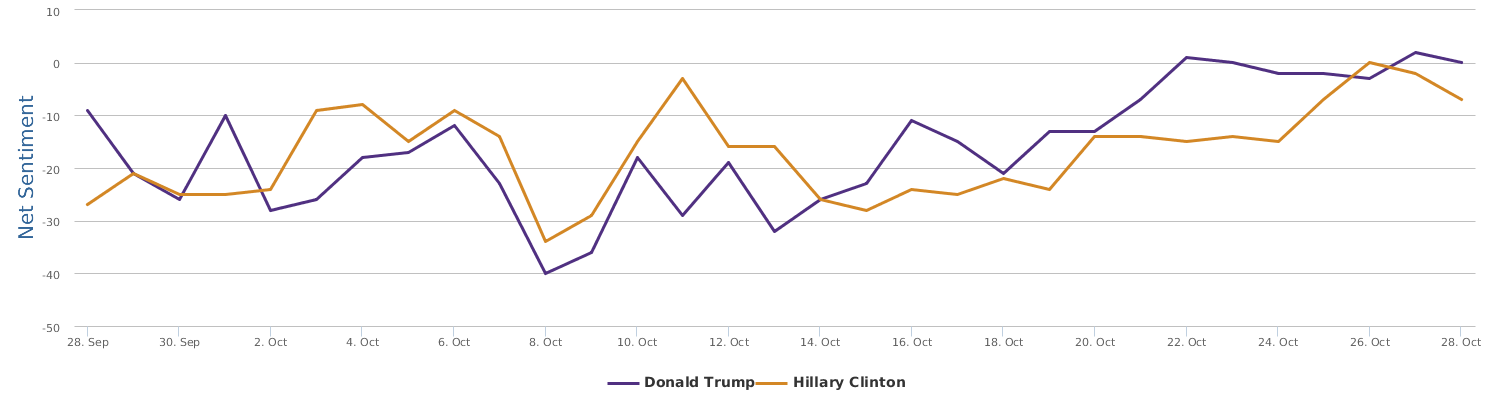
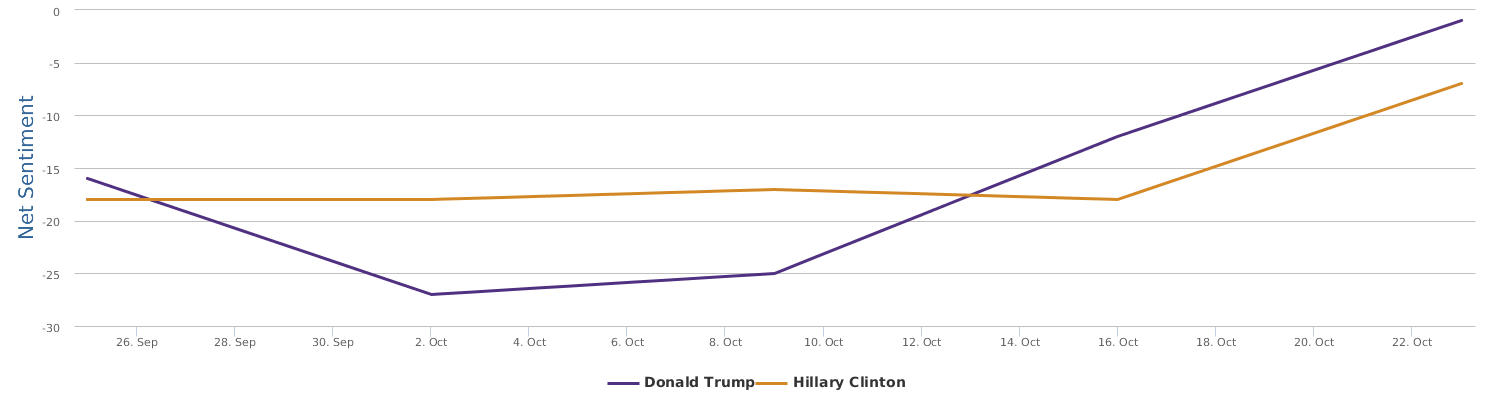
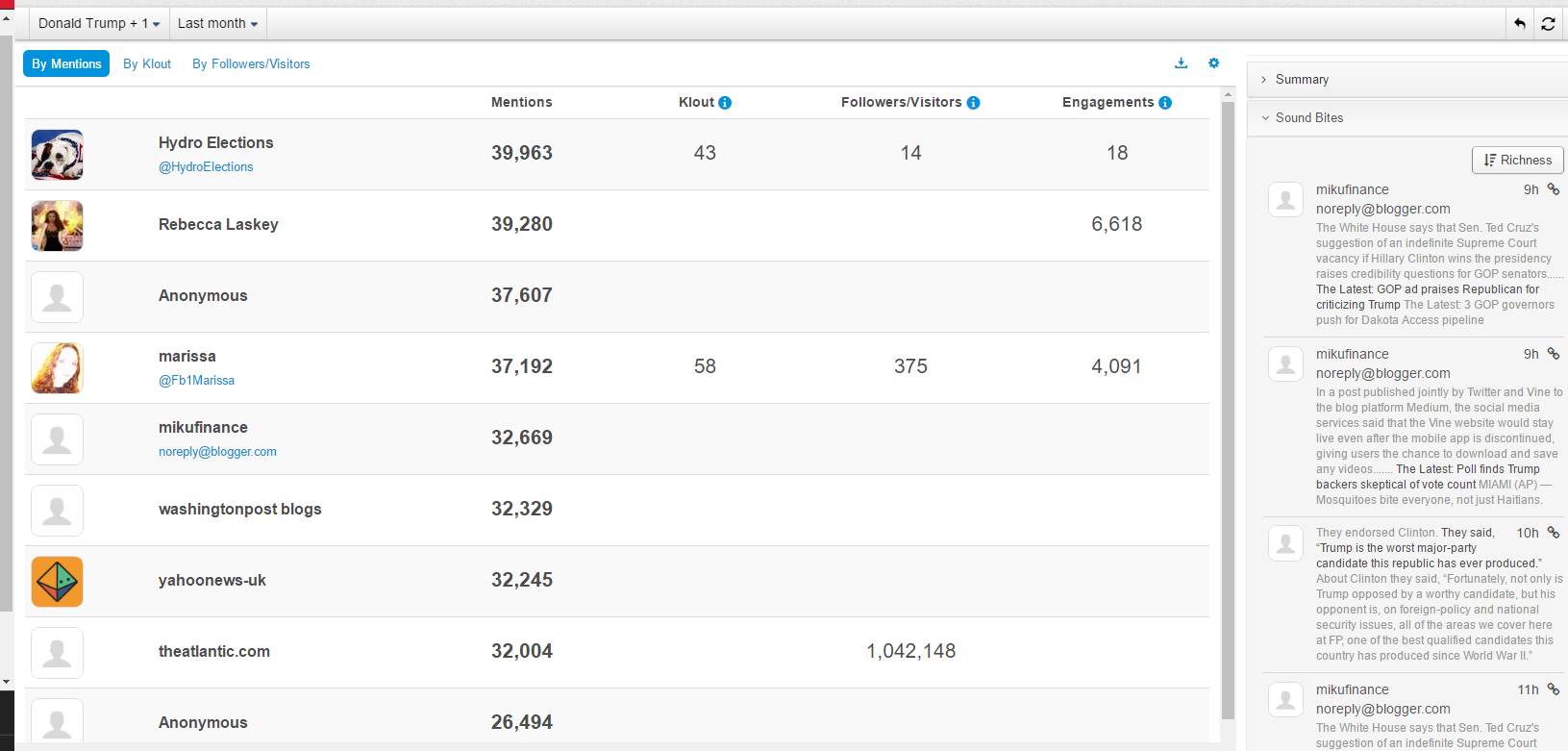
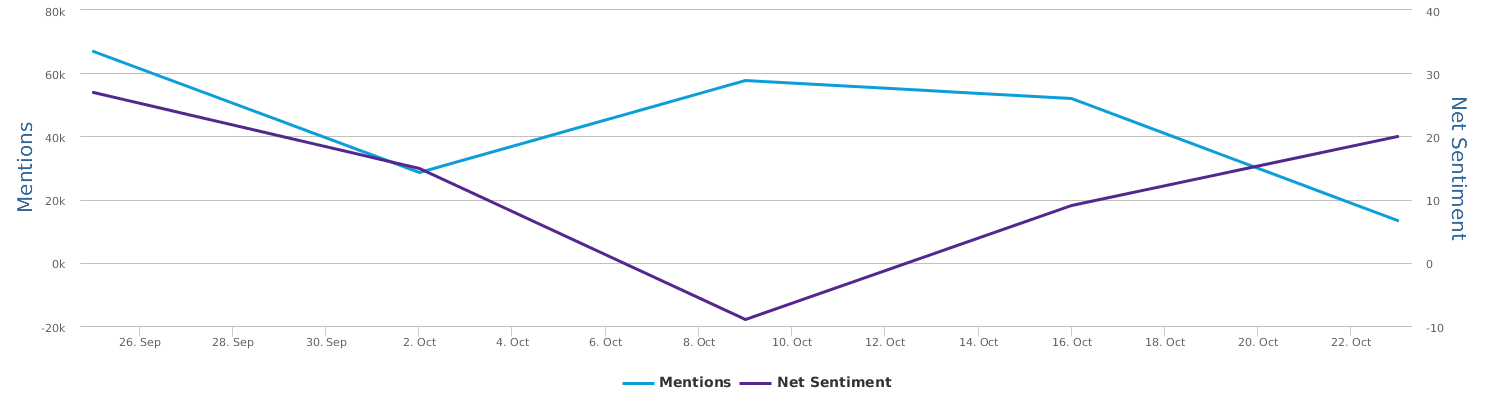
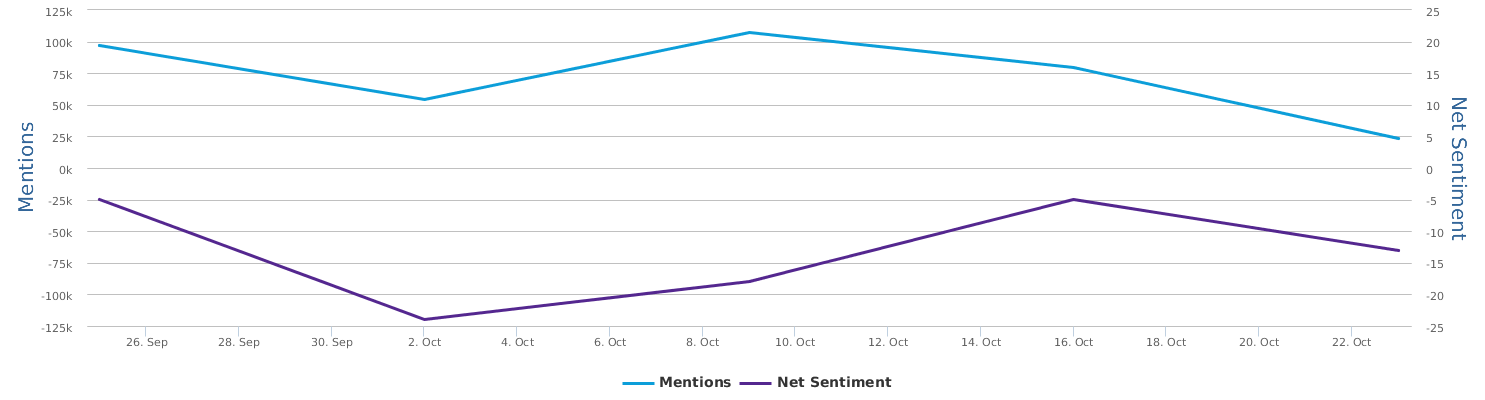
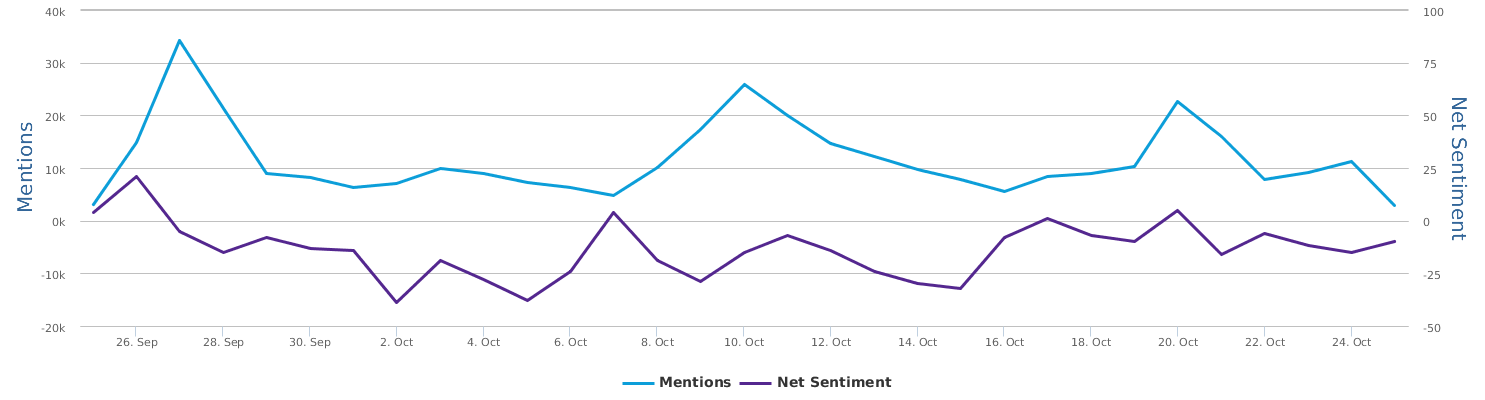
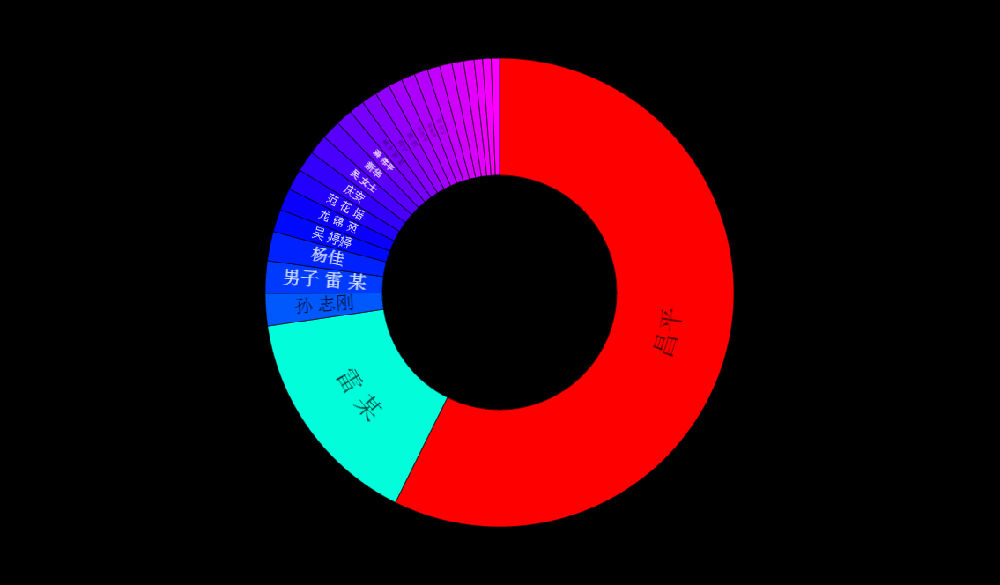
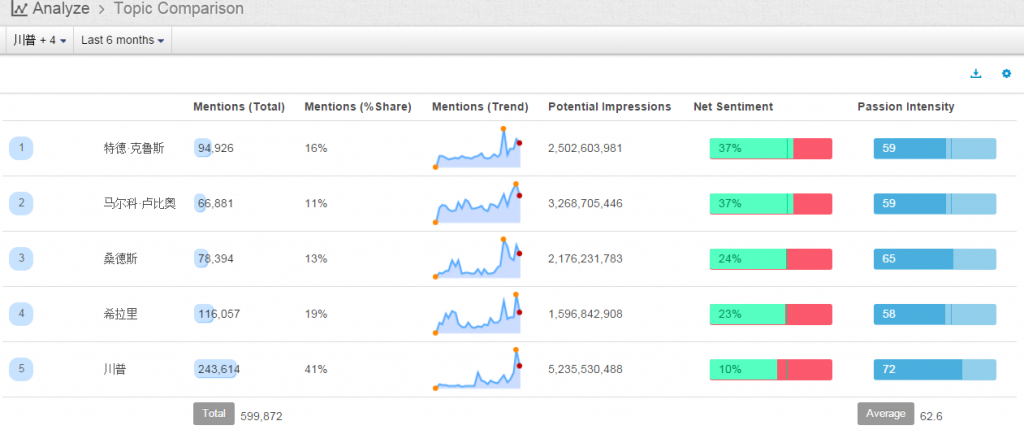
现在的纠结是,【大数据告诉我们,希拉里选情告急】,到底发还是不发?为了党派利益和反川立场,不能发。长老川志气,灭吾党威风。为了 data scientist 的职业精神,应该发。一切从数据和事实出发,是信息时代之基。中和的办法是,先发一篇批驳那篇流传甚广的所谓印度AI公司预测川普要赢,因为那一篇的调查区间与我此前做的调查区间基本相同,那是希拉里选情最好的一个月,他们居然根据 engagement alone 大嘴巴预测川普的胜选,根本就没有深度数据的精神,就是赌一把而已。也许等批完了伪AI,宣扬了真NLU,然后再发这篇 【大数据告诉我们,希拉里选情告急】
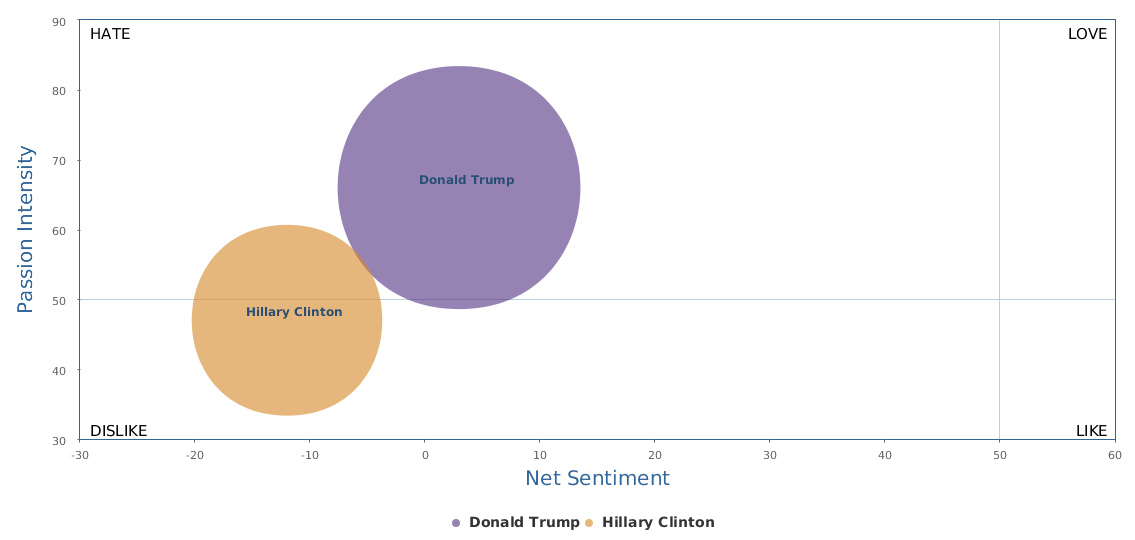
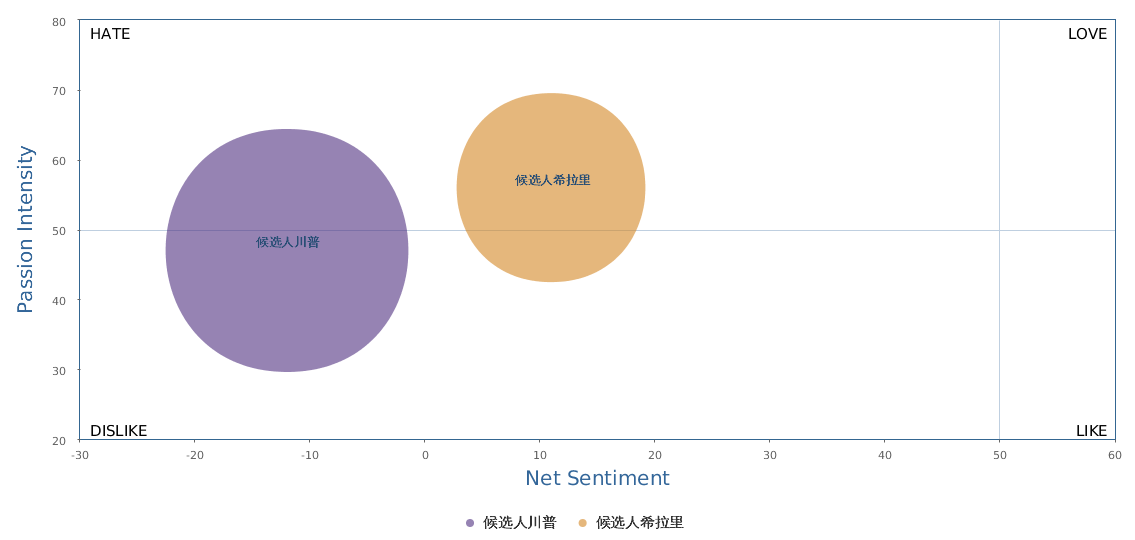
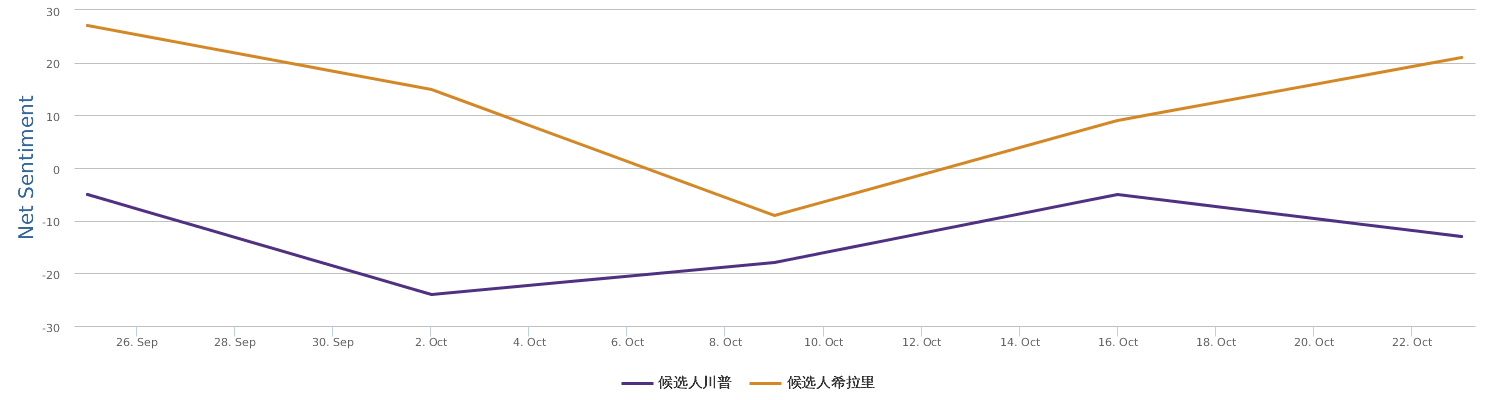
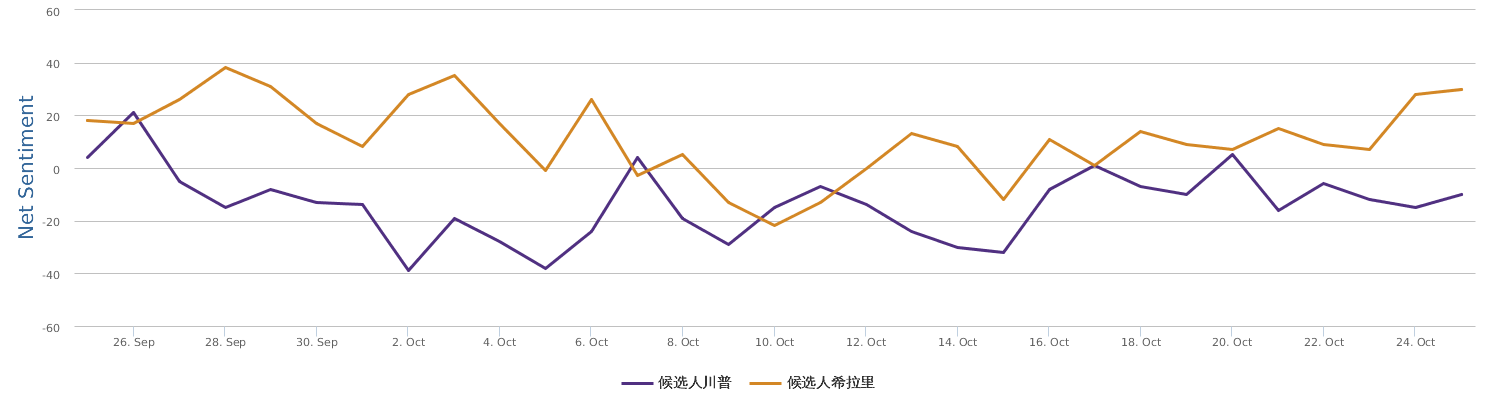
FBI director 说这次重启调查,需要很长时间才能厘清。现在只是有了新线索需要重启,不能说明希拉里有罪无罪。没有结论前,先弄得满城风雨,客观上就是给选情带来变数。虽然在 prove 有罪前,都应该假定无罪,但是只要有风声,人就不可能不受影响。所以说这个时间点是最关键的。如果这次重启调查另有黑箱,就更惊心动魄了。如果不是有背后的黑箱和势力,这个时间点的电邮门爆炸纯属与新线索的发现巧合,那就是希拉里的运气不佳,命无天子之福。一辈子强性格,卧薪尝胆,忍辱负重,功亏一篑,无功而返,保不准还有牢狱之灾。可以预测,大选失败就是她急剧衰老的开始。
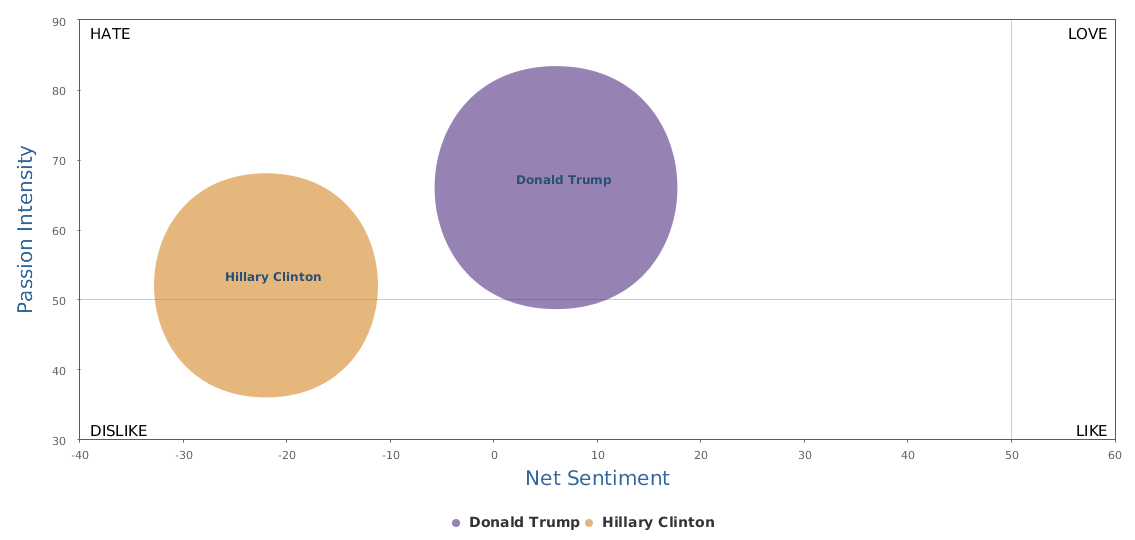
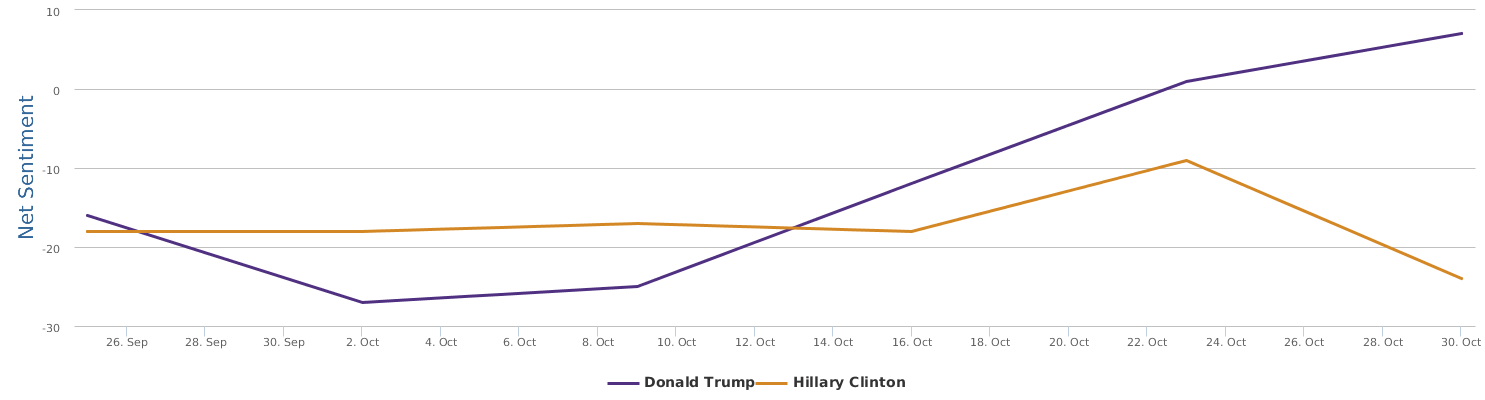
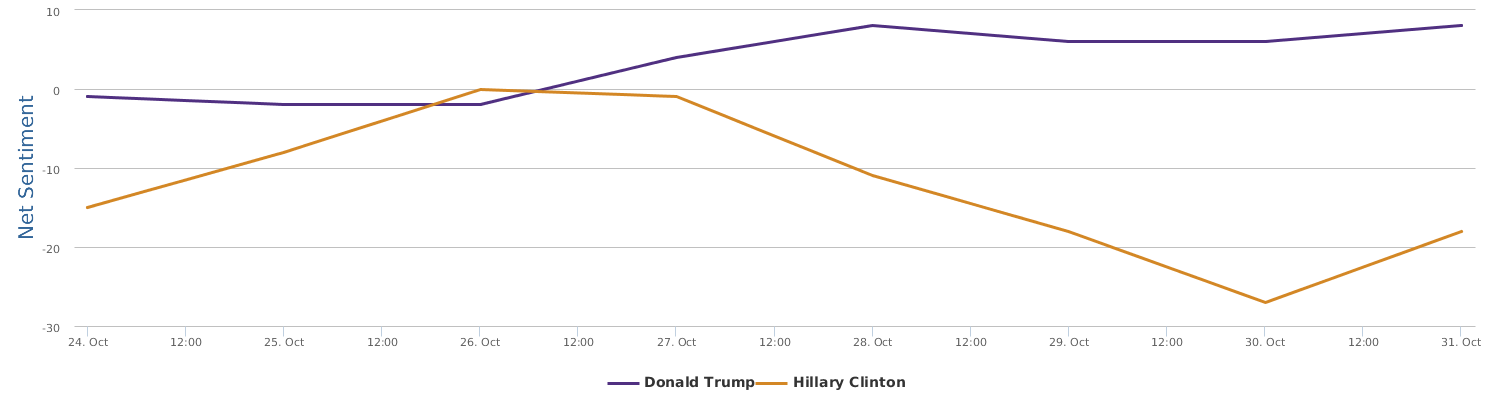
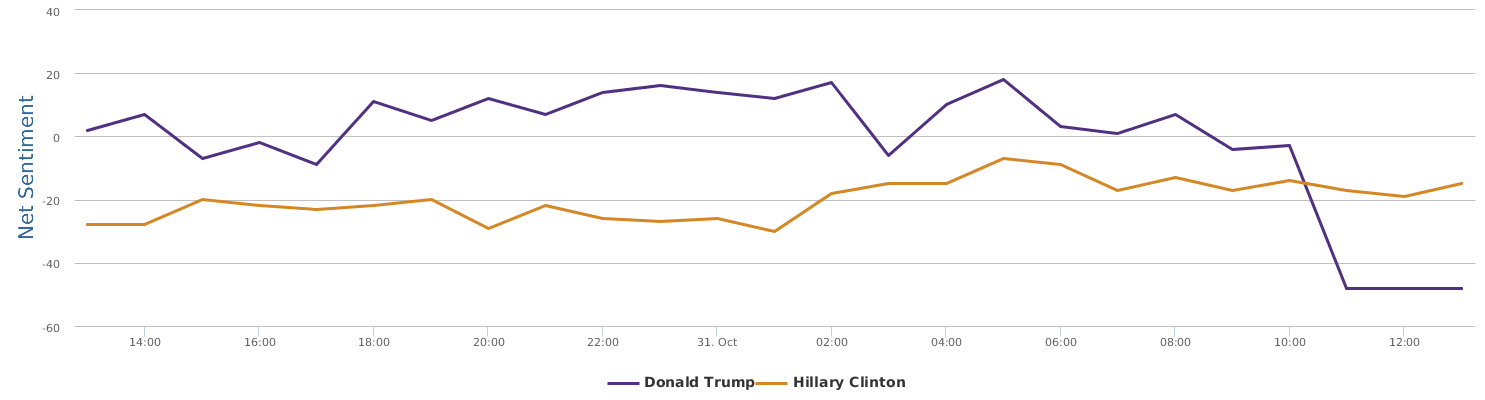
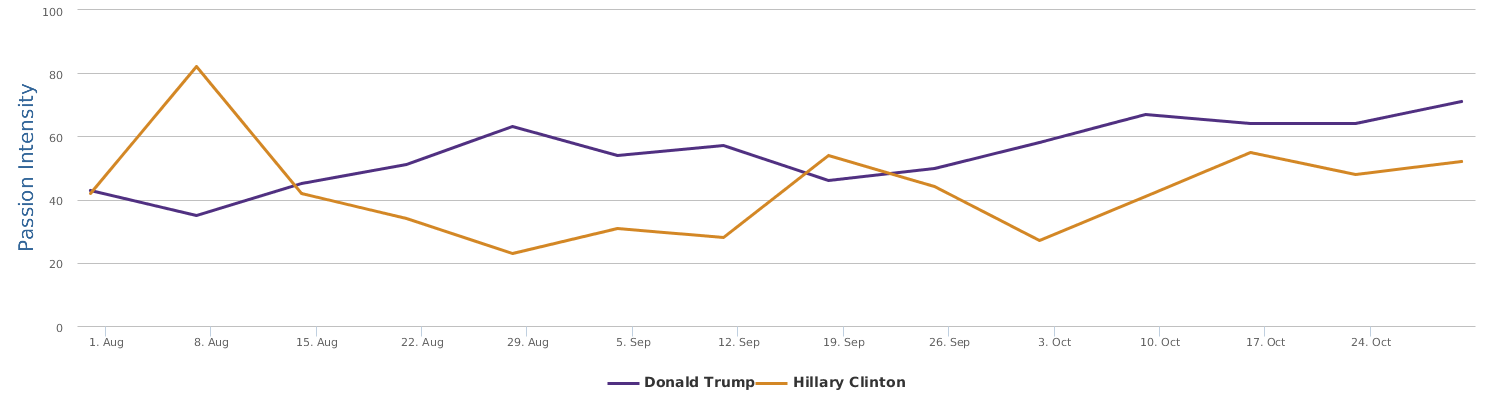
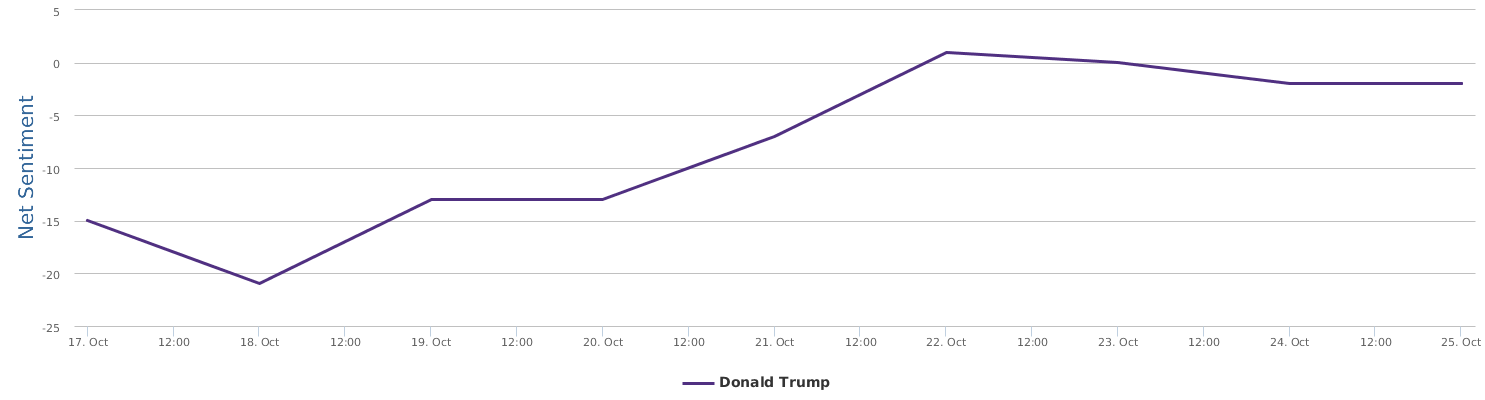
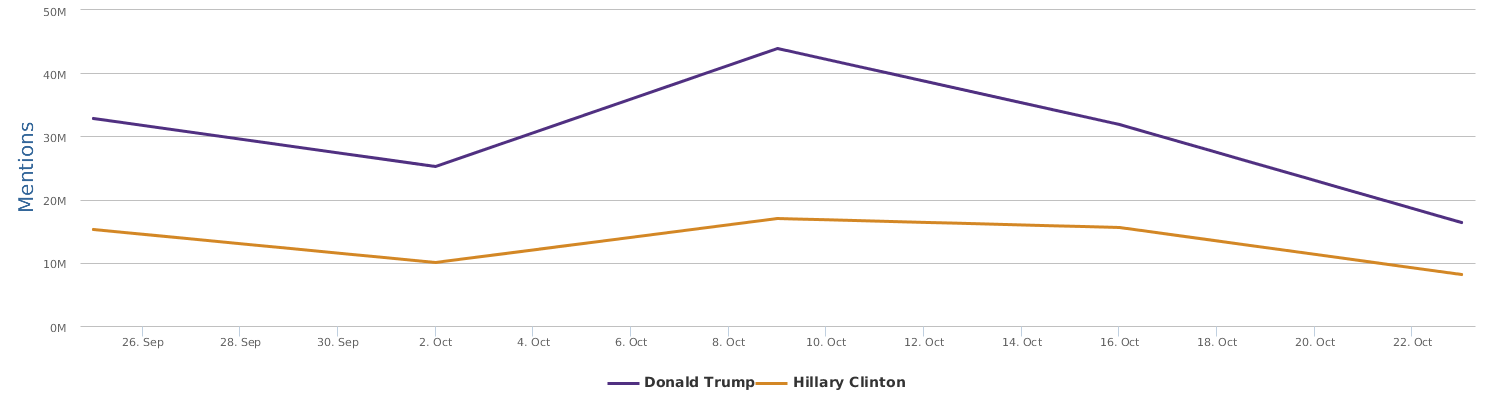
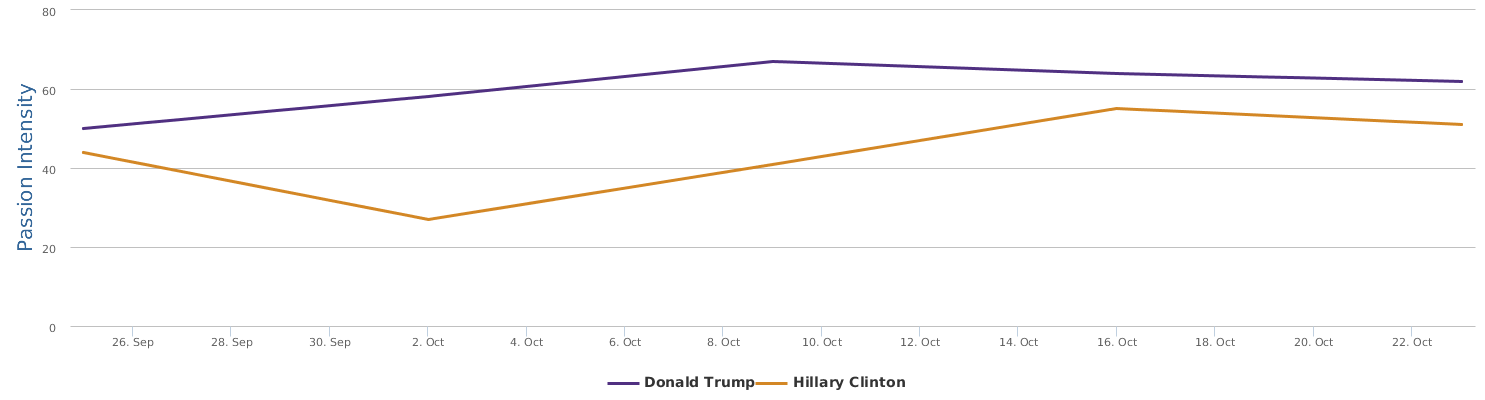
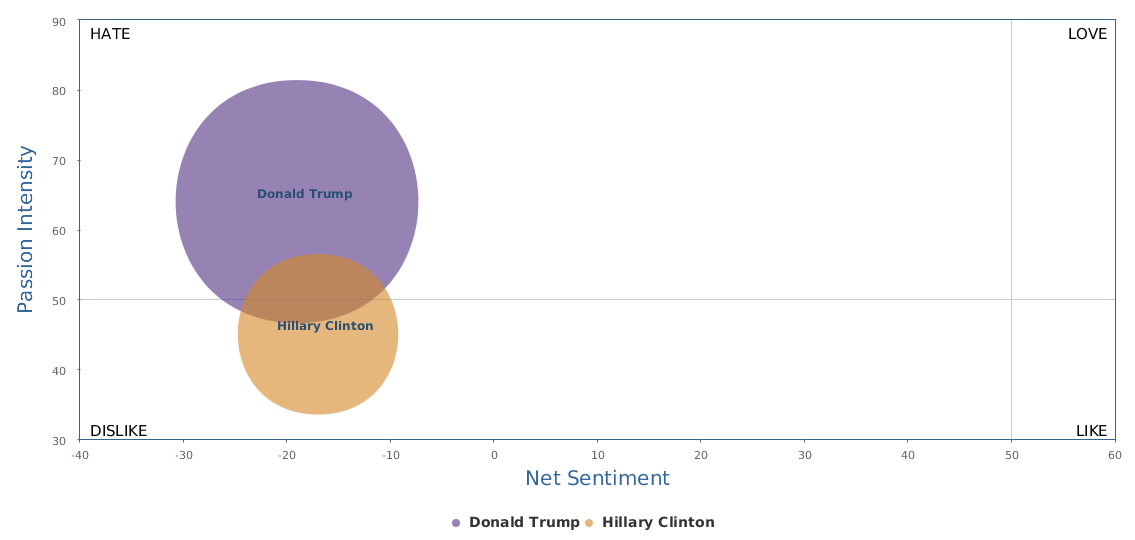
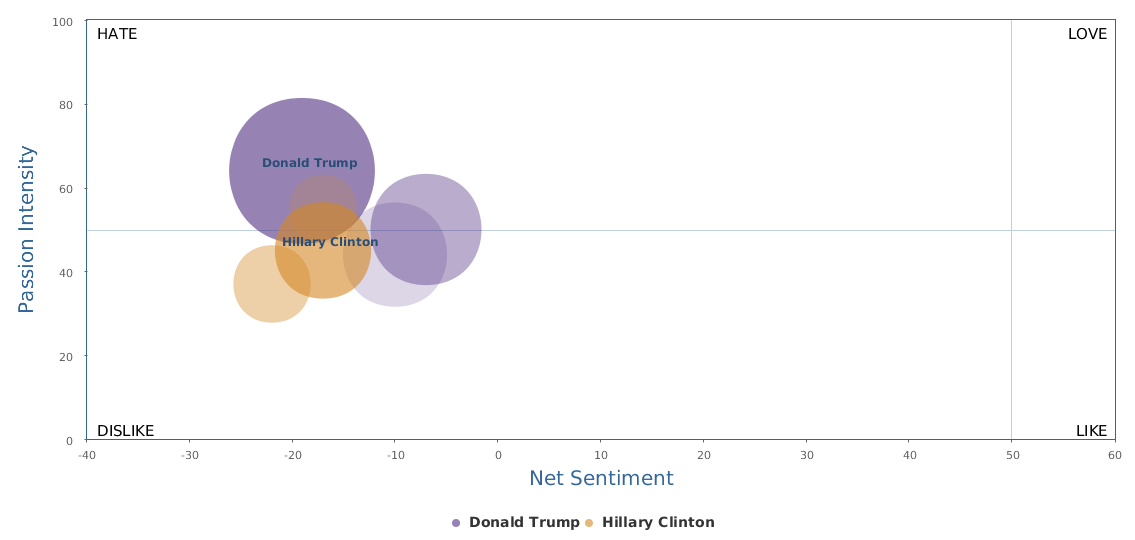
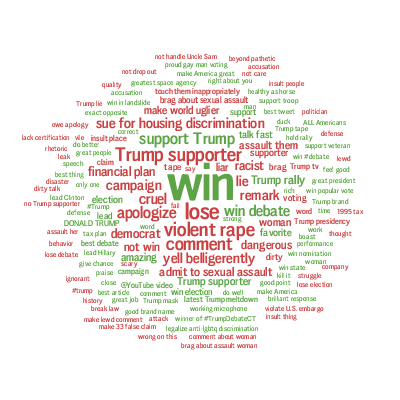
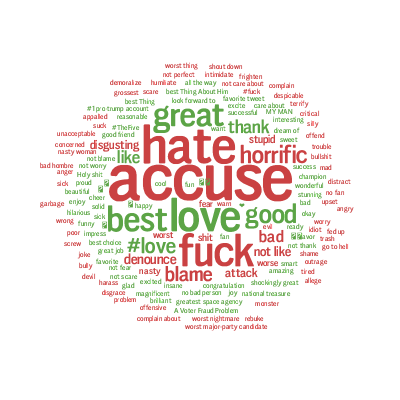
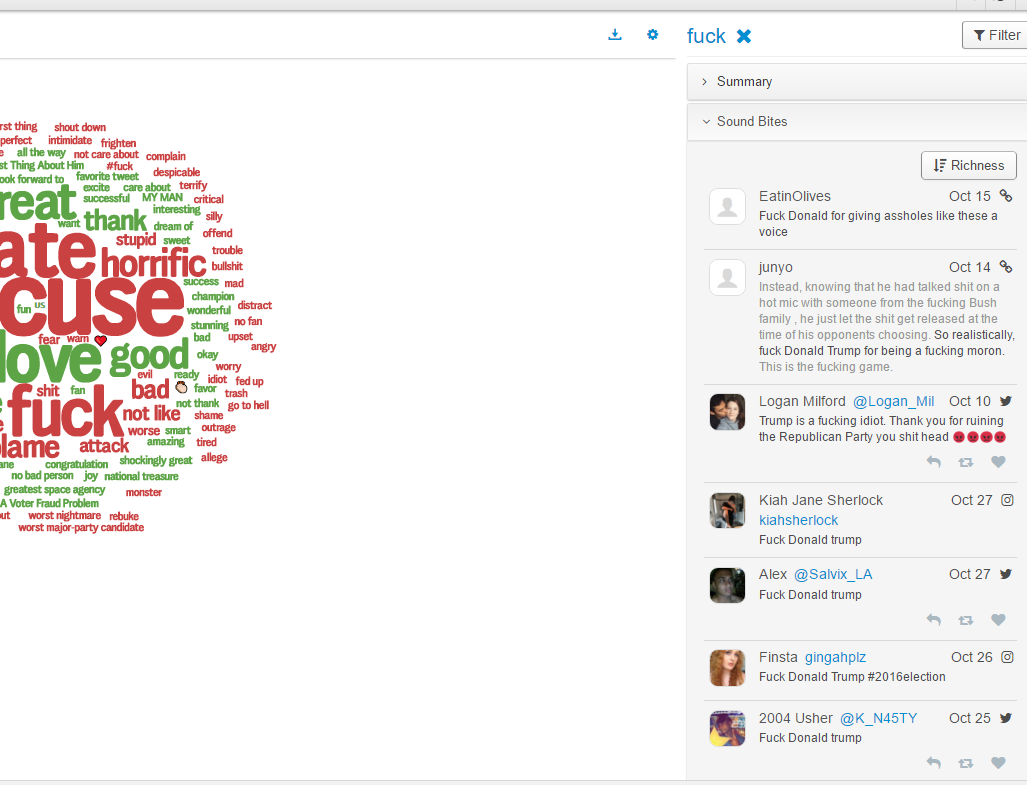
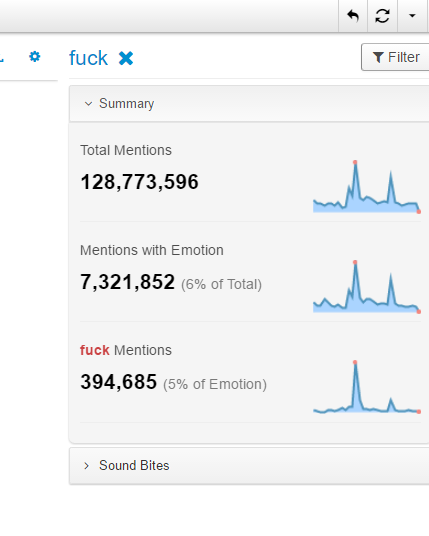
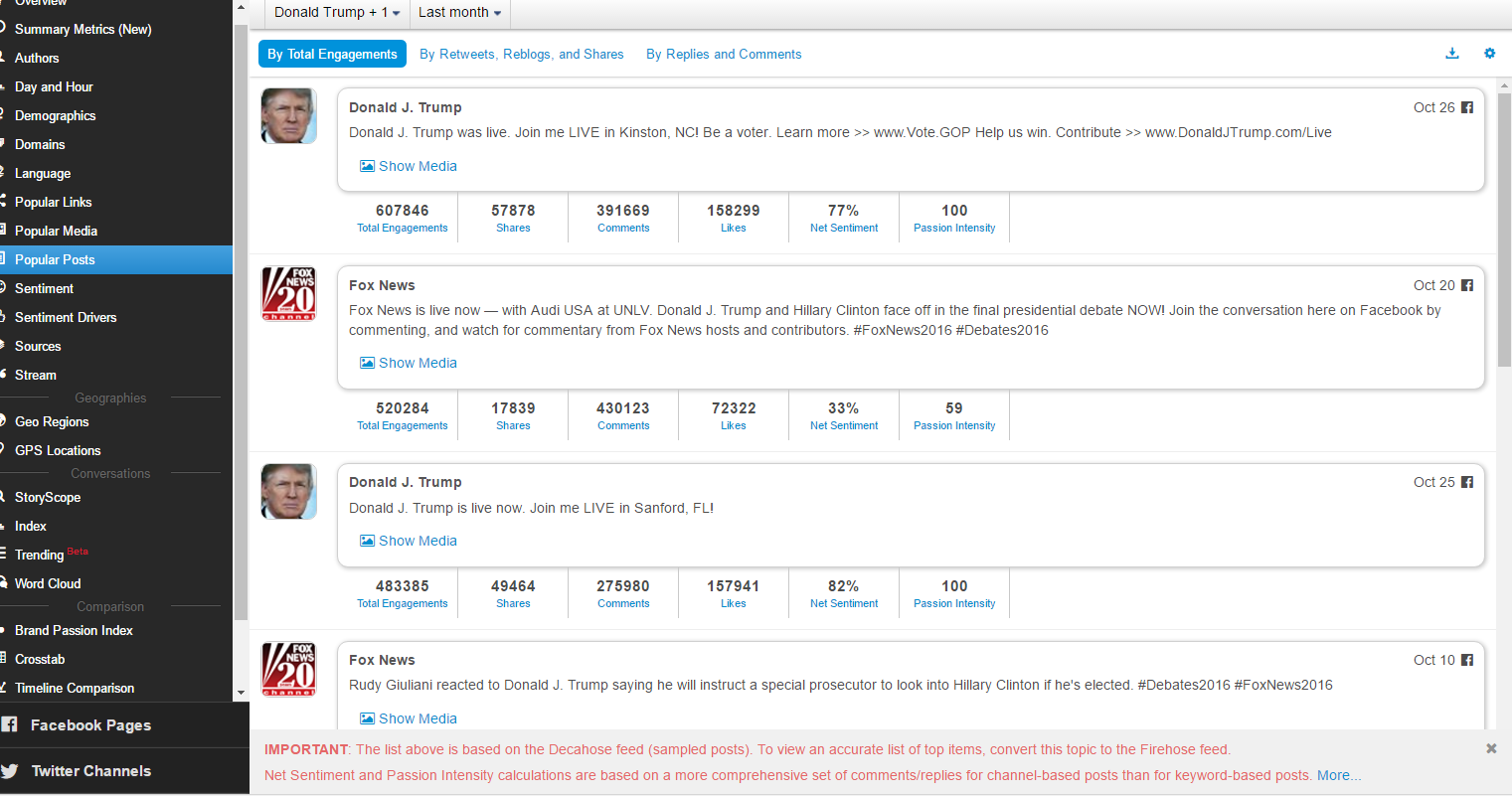
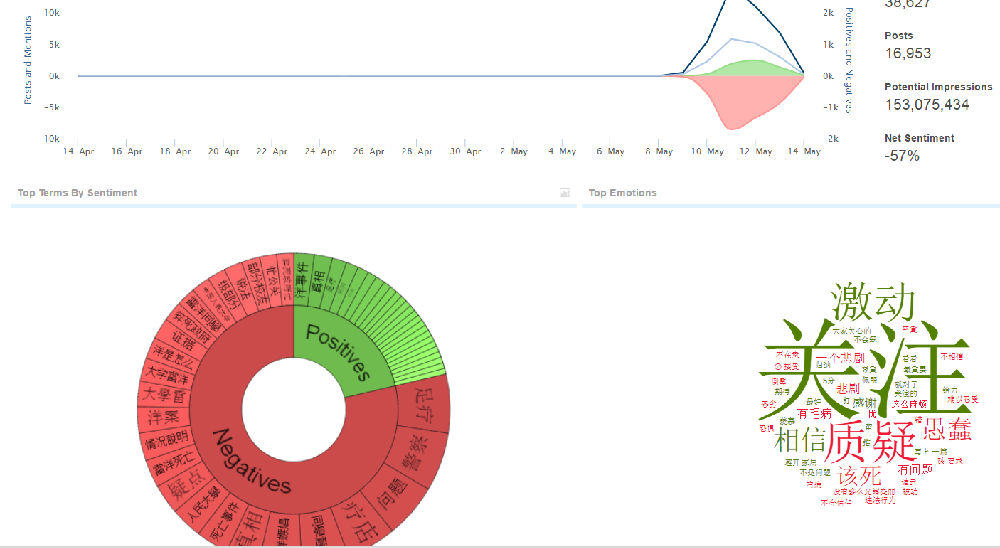
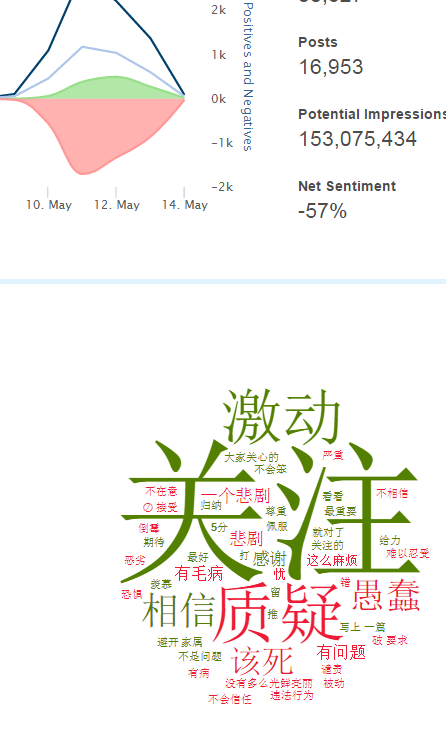
不过最近克林顿的选情是原地踏步,并没有明显进展。比较克林顿的三个圈可知,最淡的圈是过去30天的前10天,明显落后于川普,后两个圈是最近20天,基本原地,只是圈子变大了,说明竞选的投入和力度加大了,但效益并不明显。而从川普方面的三个圈圈看趋势,这老头儿实际的总体趋势是下跌,过去三十天,中间的十天舆情有改观,但最近的十天又倒回去了,虽然热议度有增长。(MD,这个分析没法细做,越做越惊心动魄,很难保持平和的心态,可咱是 data scientist 啊。朋友说,“就是要挖点惊心动魄的”,真心唯恐天下不乱啊。)看看川普的30天社煤的褒贬云图(Word Cloud for pros and cons)和情绪云图(Word Cloud for emotions)吧:
"But the entrepreneur admitted that there were limitations to the data in that sentiment around social media posts is difficult for the system to analyze. Just because somebody engages with a Trump tweet, it doesn't mean that they support him. Also there are currently more people on social media than there were in the three previous presidential elections."
haha,同行是冤家,他的AI能比我自然语言deep parsing支持的 I 吗?从文中看,他着重 engagement,这玩意儿的本质就是话题性、热议度吧。早就说了,川普是话题大王,热议度绝对领先。(就跟冰冰一样,话题女王最后在舆情上还是败给了舆情青睐的圆圆,不是?)不是码农相轻,他这个很大程度上是博眼球,大家都说川普要输,我偏说他必赢。两周后即便错了,这个名已经传出去了。川普团队也会不遗余力帮助宣传转发这个。
I showed the First Lady's news pictures to my daughter. She was so intrigued, "Dad, Mom told me that you used to teach First Lady many years ago, is that true?" "It is true, but that was only a short time, one or two semesters, and it was not her major course. As a part-time lecturer, I was teaching Advanced English to graduate students in the music conservatory and she happened to be one in my class. She was already famous then as a new star for folk songs." Tanya got excited, "Well, you never know, maybe her English training in graduate school helps her in state visits today. My Dad is cool." She continued, "Dad, Mom also told me that you were interpreter for foreign minister when she dated you, is that true?" "Well, that was largely an accident, only happened once when I substituted some professor to act as interpreter for the former foreign minister and former Chinese congress vice-chairman Mr. Huang Hua. Your Mom agreed to date me partially because of her seeing a picture of me interporeting for the VIP Mr. Huang. So I guess I benefited from that 'accident'." Tanya was amused and felt very proud, "I have the coolest Dad in the world. He was so successful even when he was young, teaching future first lady and interpreting for the then foreign minister. Wow."
The personal story aside, Chinese social media are never short of coverage and fans of Chinese First Lady Mrs Peng Liyuan in the last few years. For too long China watched the western media covering first ladies in the US and other countries without being able to brag about its own. Since Mrs. Peng went on the spotlight and accompanied Chinese President Xi Jinping on world trips, the Chinese netters have been overjoyed to follow her all the way with compliments and amazement in her gracefulness. Mrs. Peng has been a star in the Chinese music industry for decades and knows how to present herself in the public. A more recent story came from APEC last year when the Russian president Putin was seen to stand up, gracefully placing a blanket around the shoulders of Chinese First Lady, too gentleman an act that triggered waves of online comments.
Using our own text mining tool, we collected one year Chinese social media data to see what the public image looks like for the First Lady. Overwhelming praises and admiration, on her grace, intelligence and personality, with almost no negative comments. The only eye-catching criticism that was uncovered involves early days of Peng Liyuan "wearing fat army trousers (穿肥大的军裤)", which seems not to be something that agrees with first lady's image in people's mind. (It turned out that this was a story about the First Lady's dating the president long ago when she wanted to test the present if he was only attracted to her appearance by wearing not as nice on purpose.
The story got spread all over the net.) But look at the Photo News today, First Lady is now leading the fashion trend of China.
Chinese TV star Bi Fujian caught on tape privately insulting Mao, which triggered a huge political debate in social media between the leftist and the rightist. China is presently stuck between post-Mao era entering modern society with limited speech freedom (at least on private occastions) and the totalitarian government inheriting Mao's legacy, hence the regulatory pressure to the star himself suspending his job for 4 days. Bi's speech would have made him sentenced to death or life in prison in Mao's time.
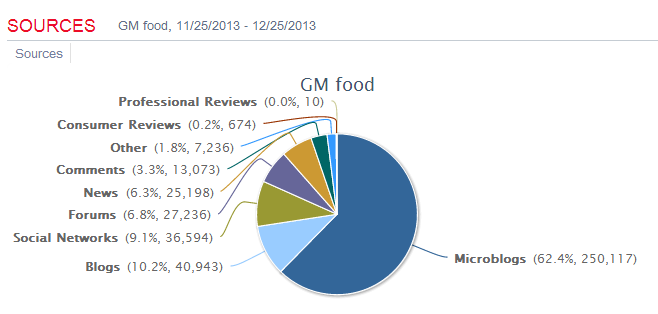
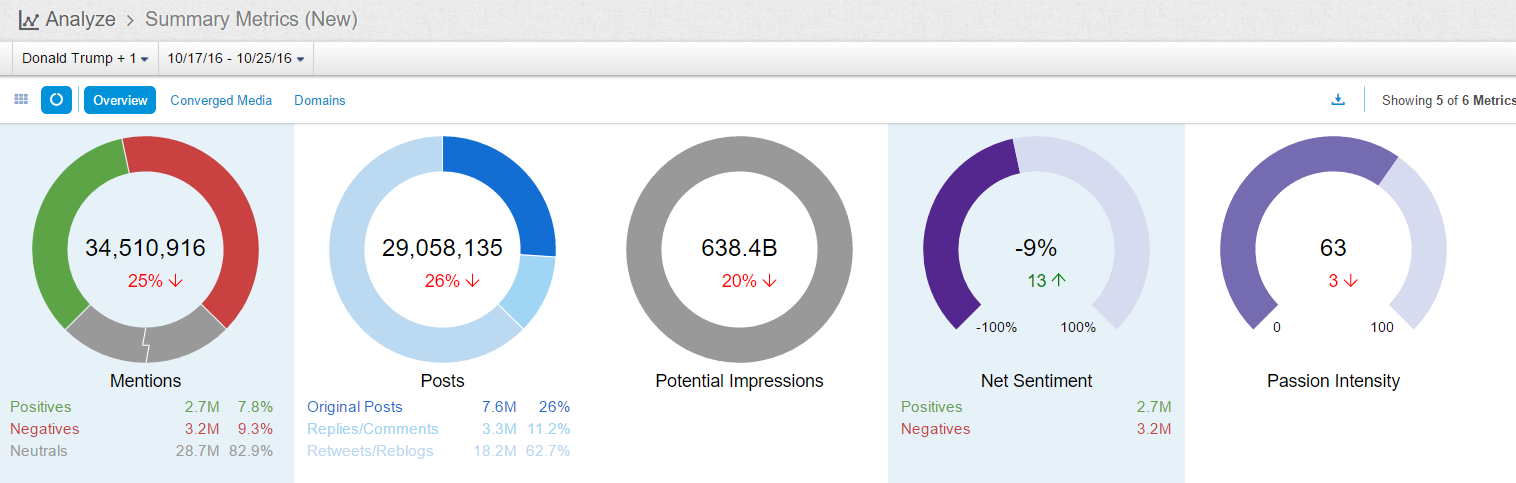
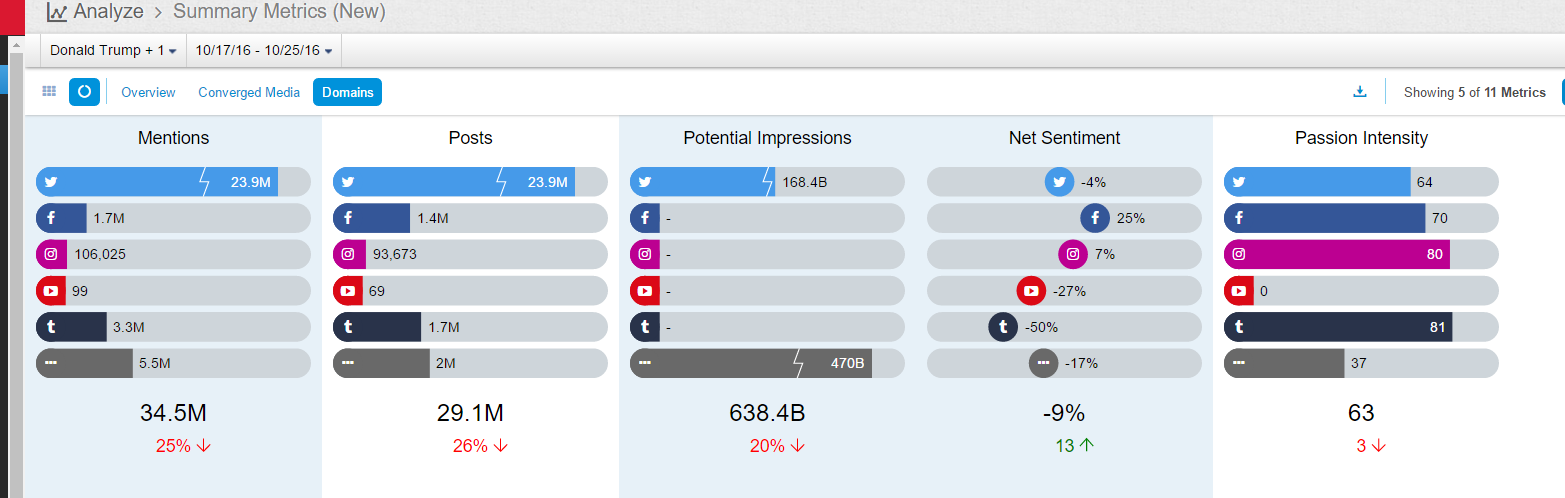
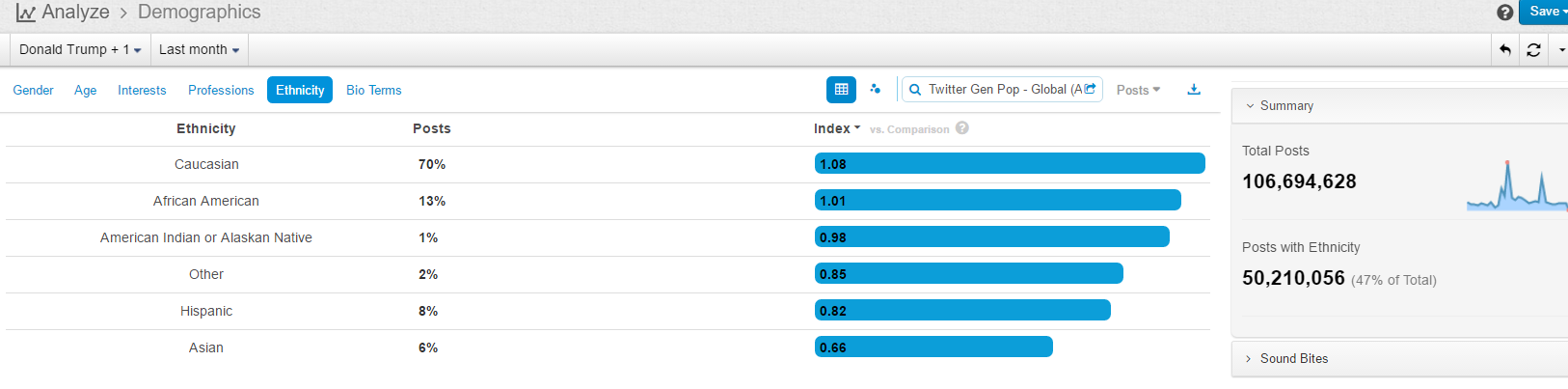
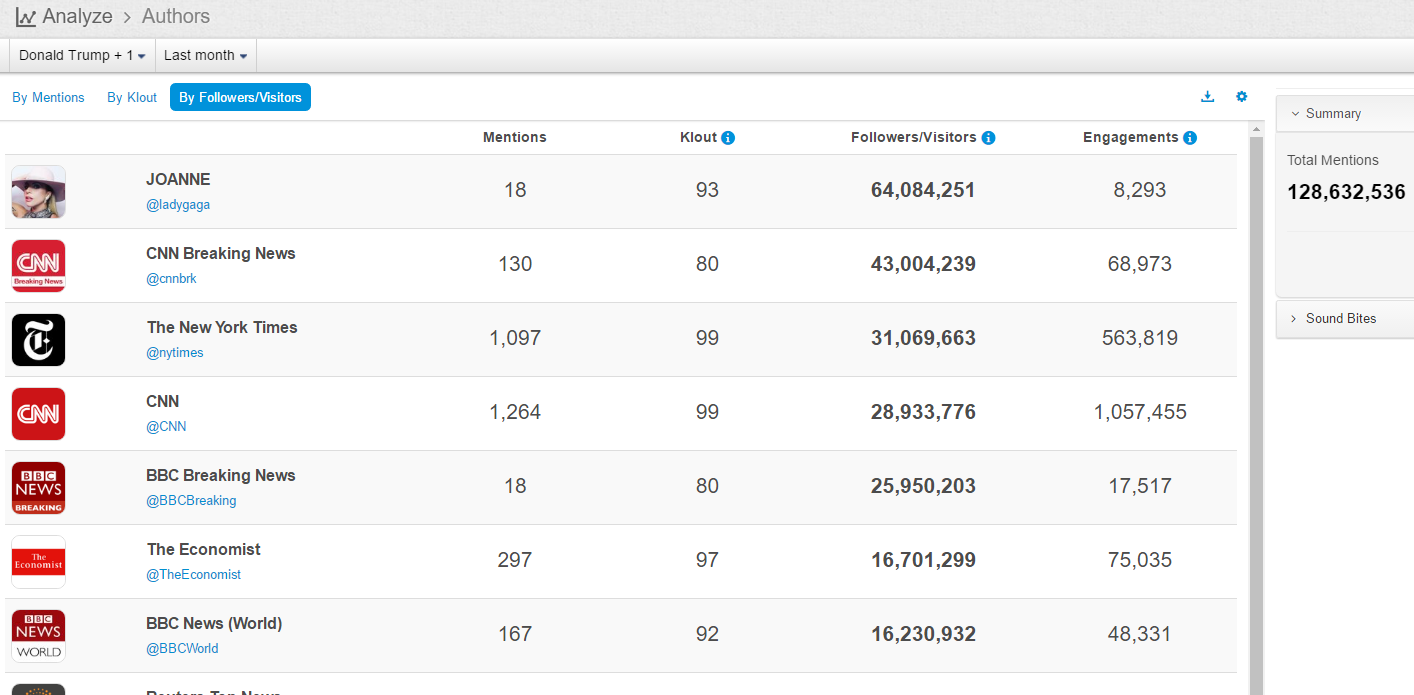
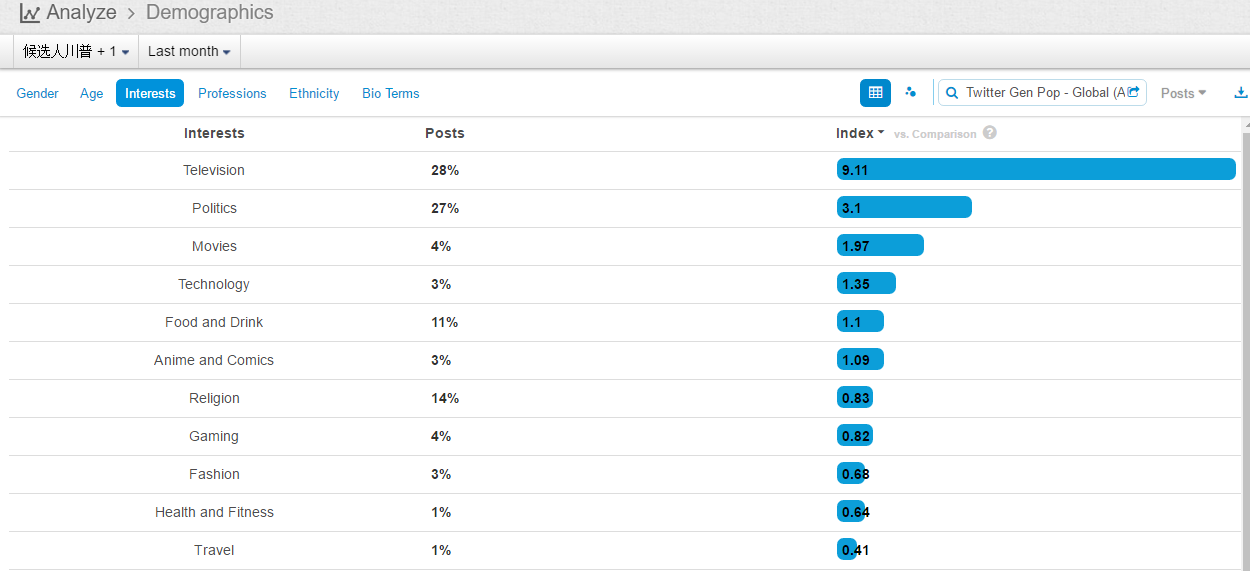
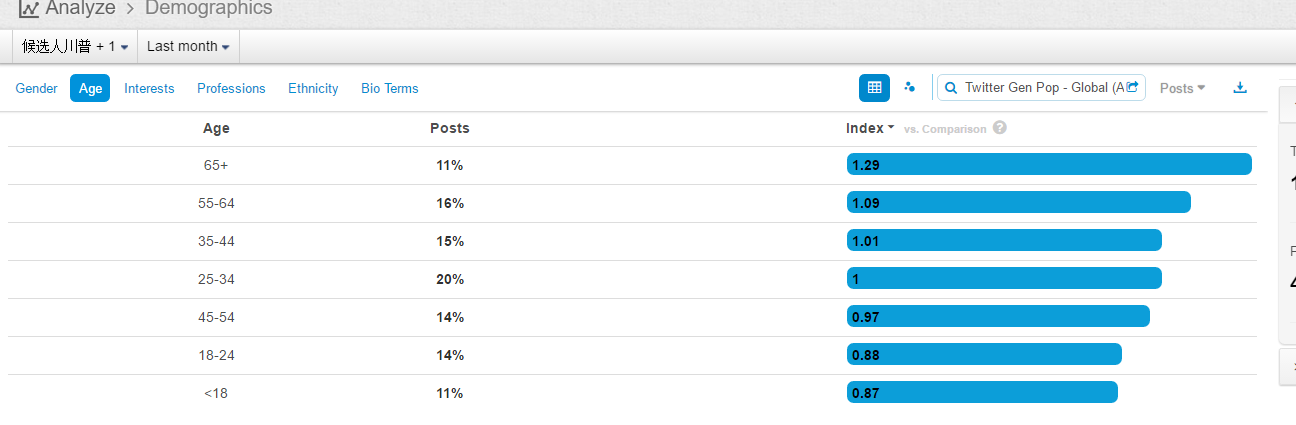
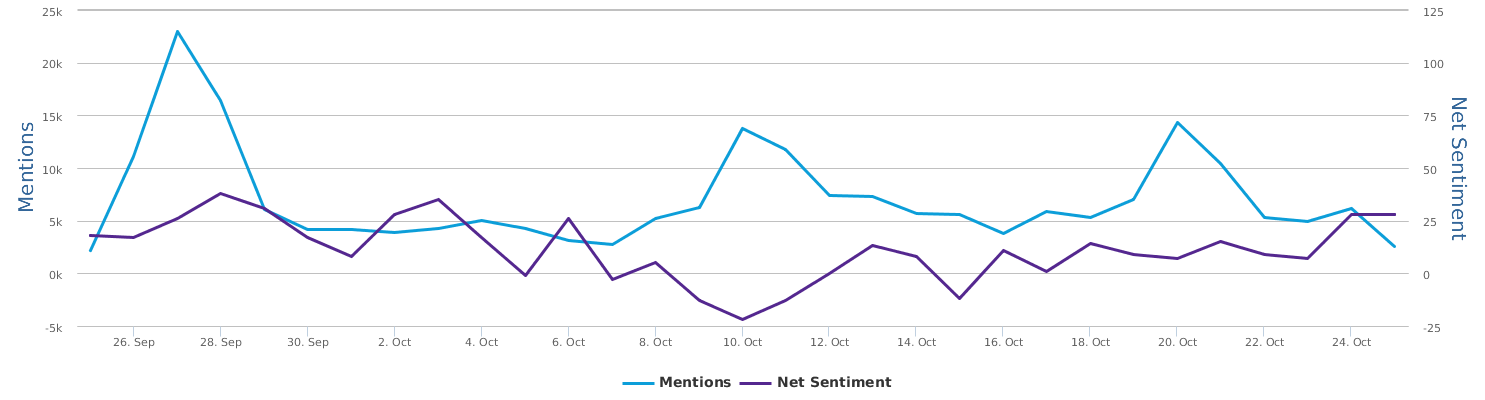
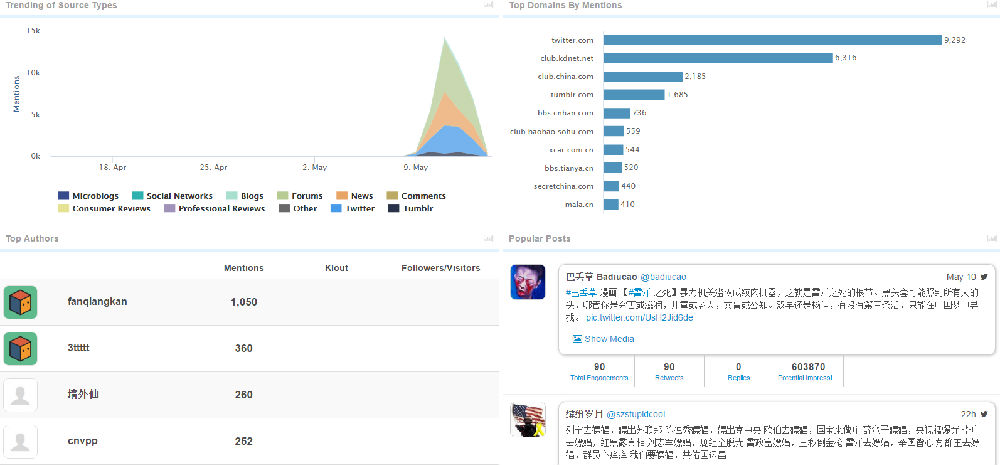
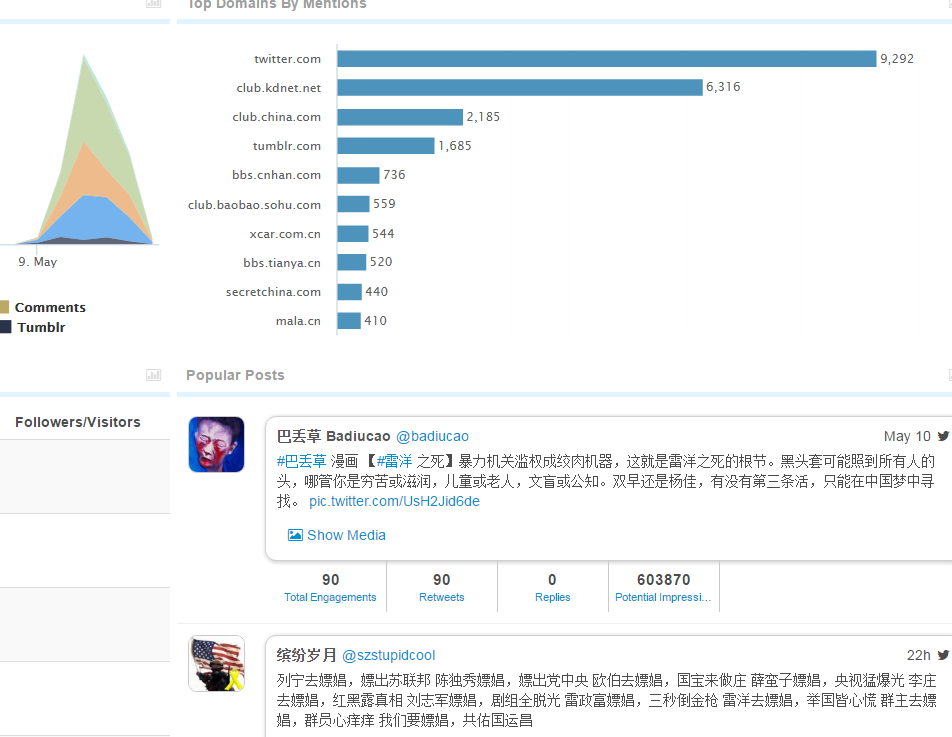
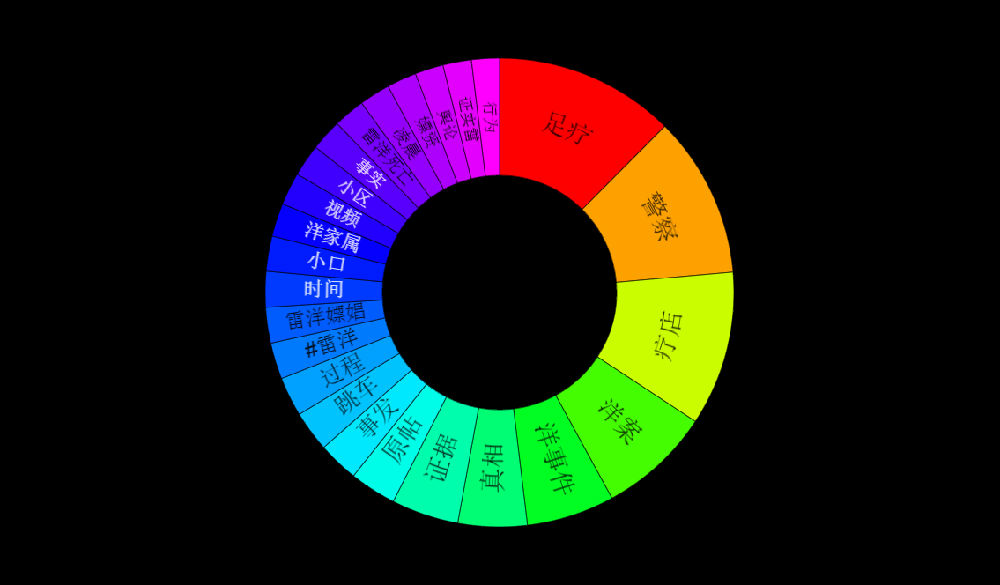
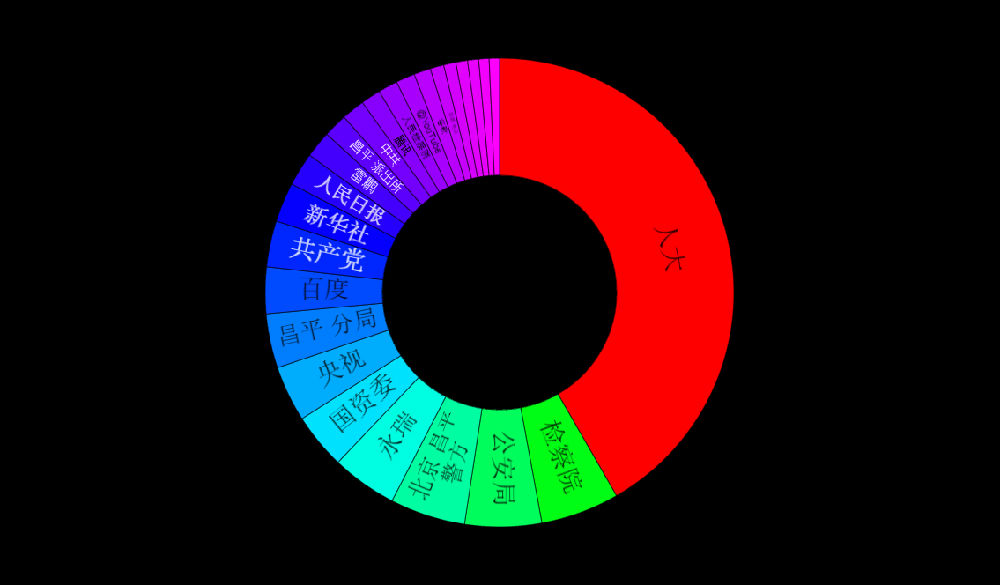
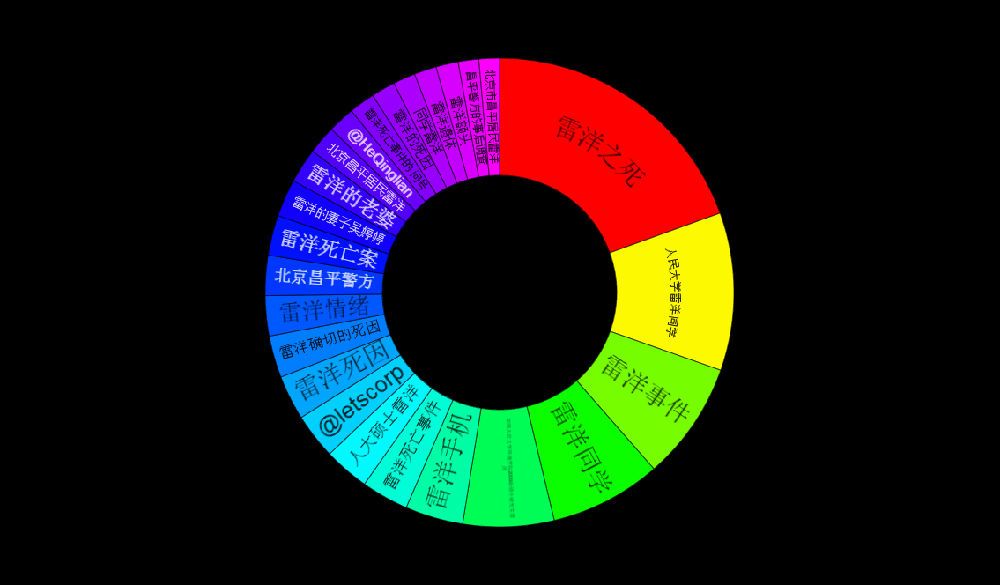
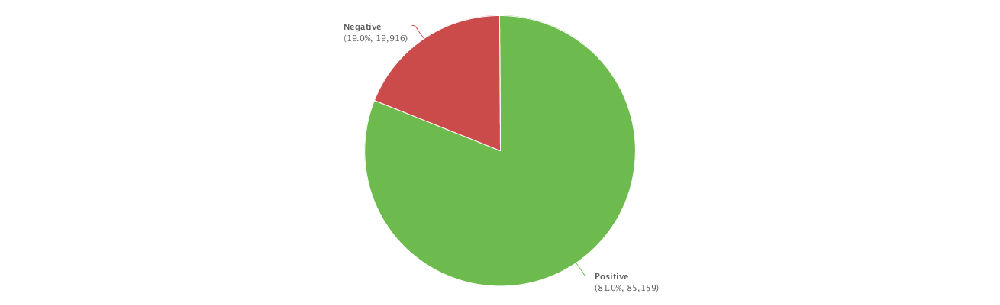
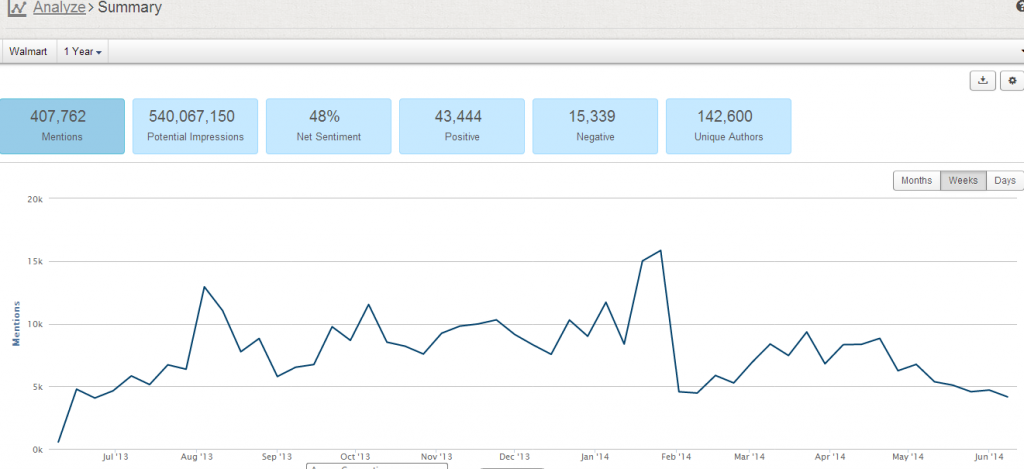
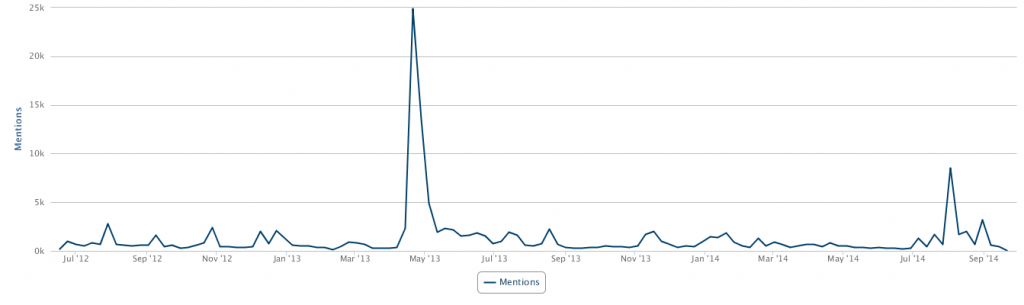
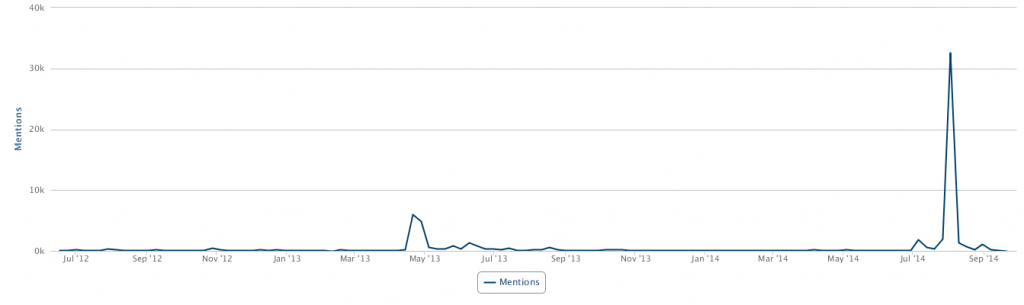
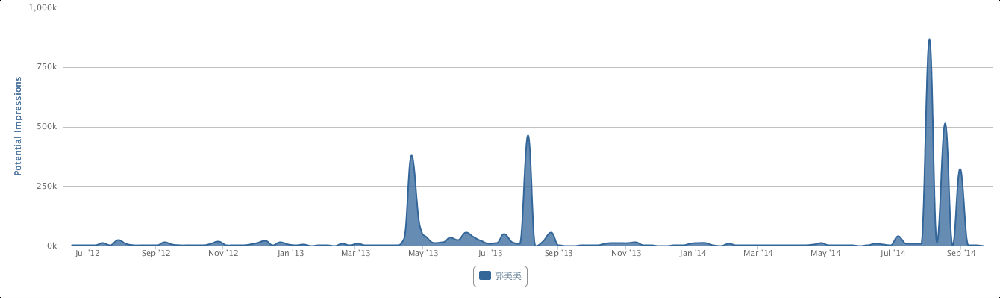
1. The existing data are not very large (400k mentions a year), but the results make sense with decent data quality
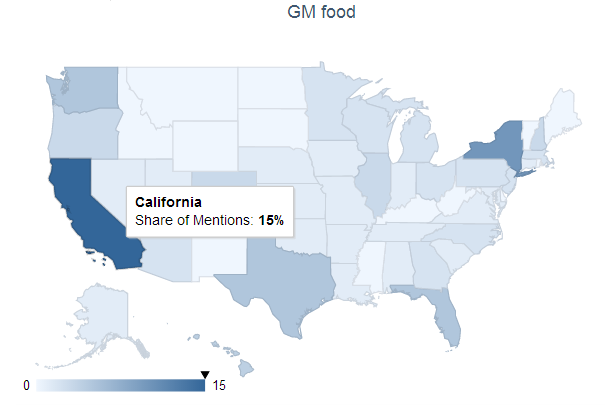
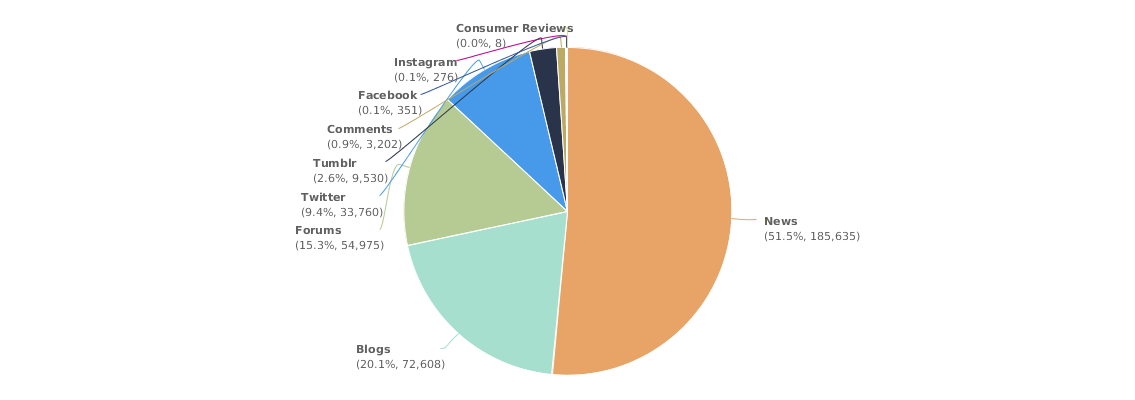
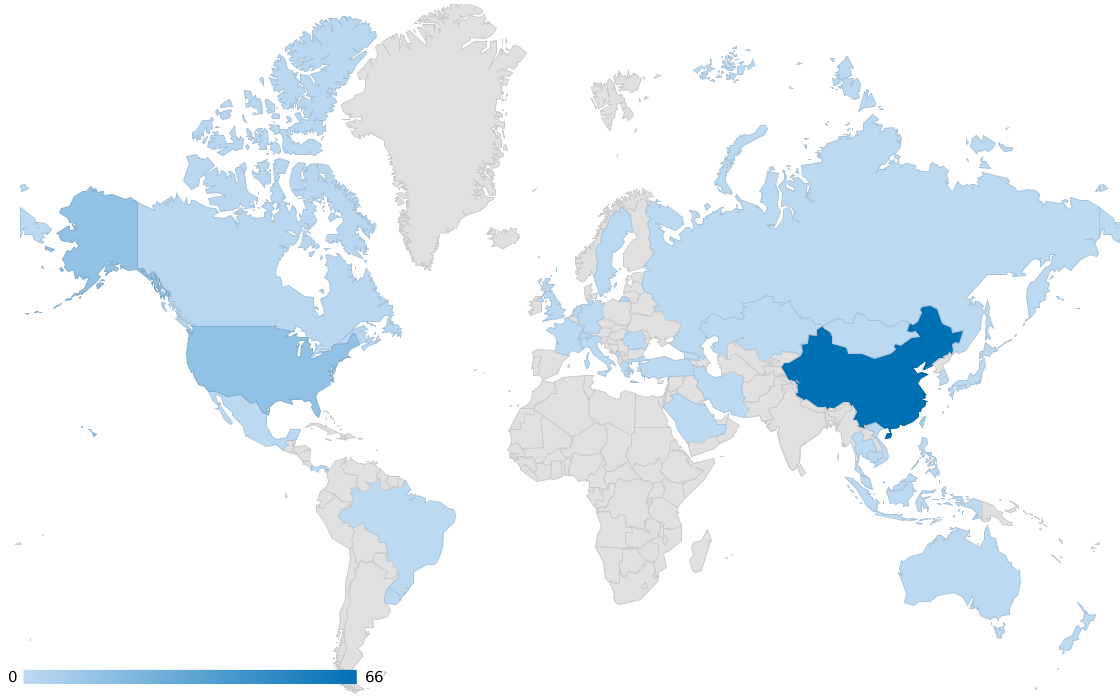
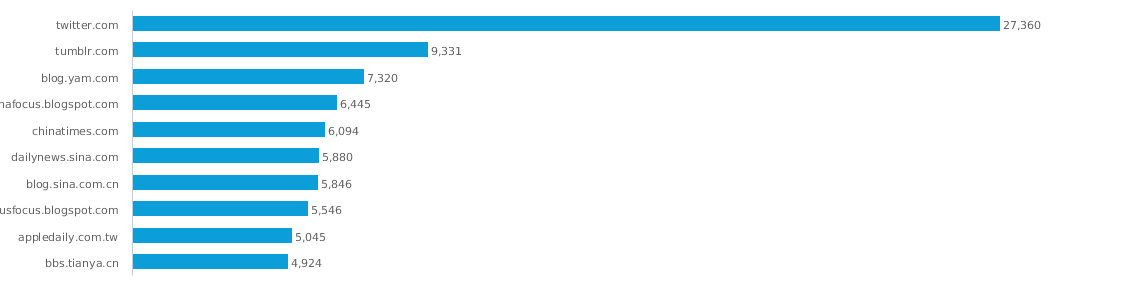
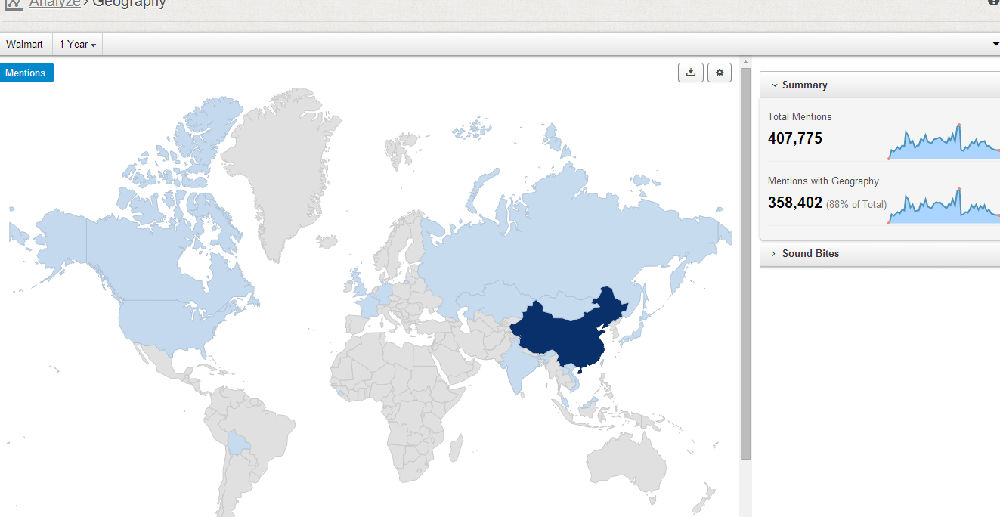
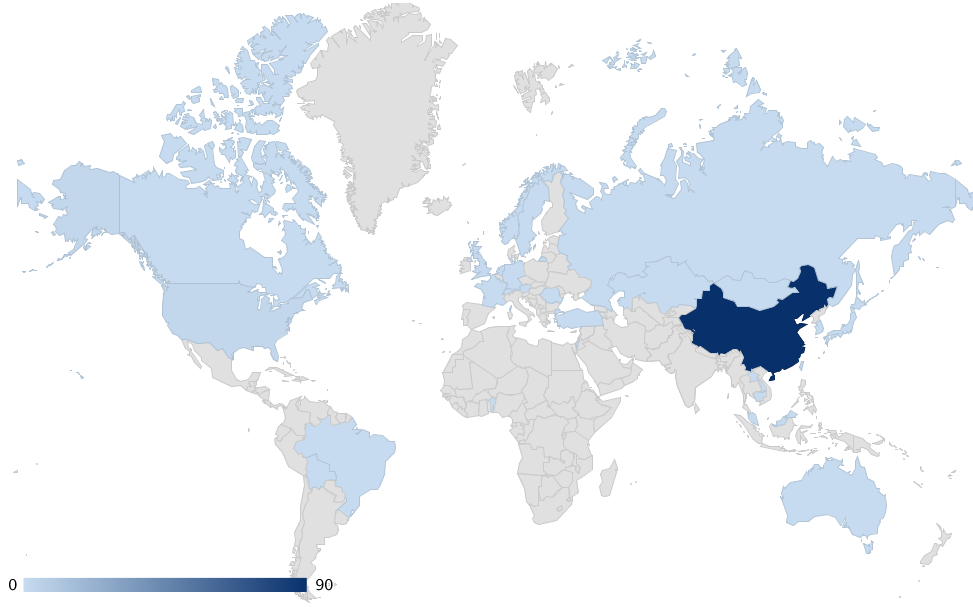
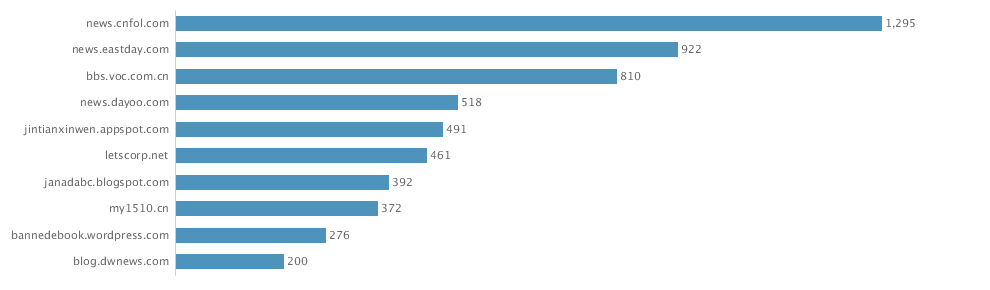
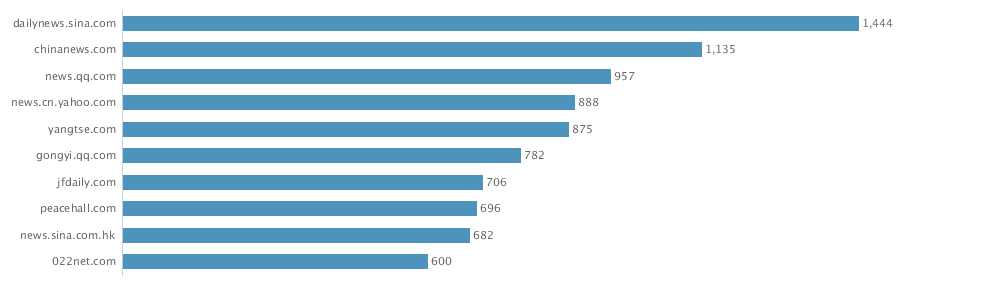
2. From geos stats, we know most data on Walmart come from China (dark color) instead of overseas sources
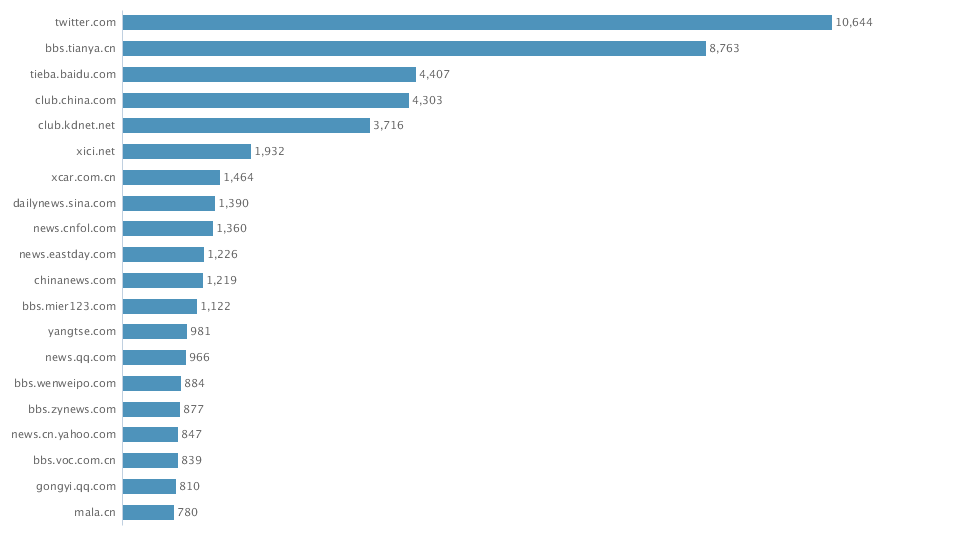
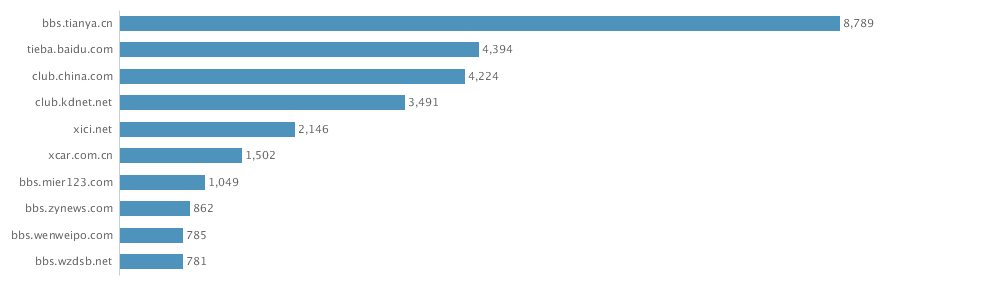
3. From domains stats, the data actually include data from Sina Weibo (weibo.com) and Tencent Weibo (t.qq.com) although the data flow from these two important Microblog sources is not stable at this point. Also the domains stats show that the major domains are all from China. I know that Walmart is a very influential brand in China and has many stores in cities of China.
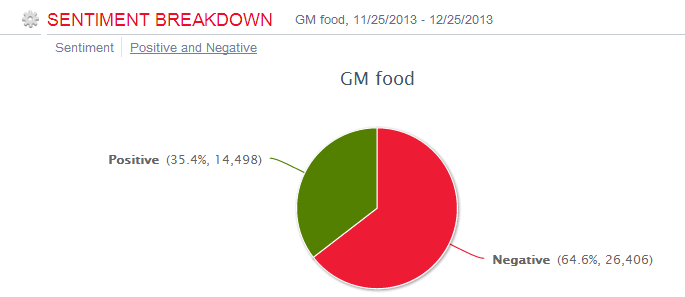
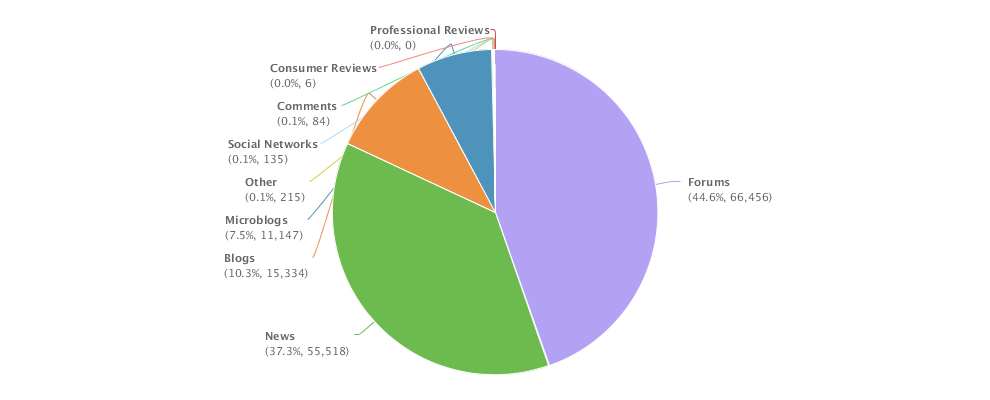
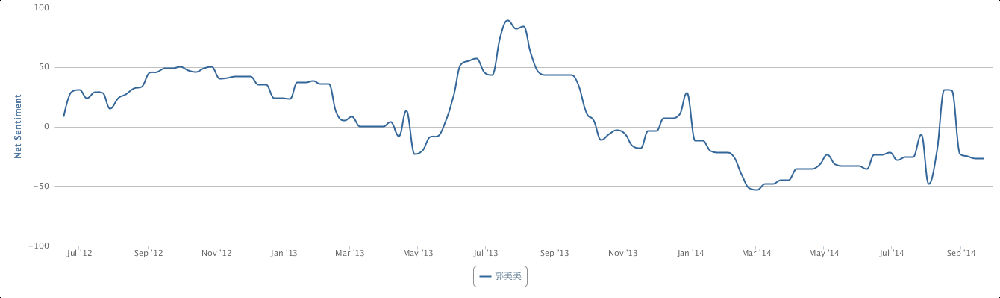
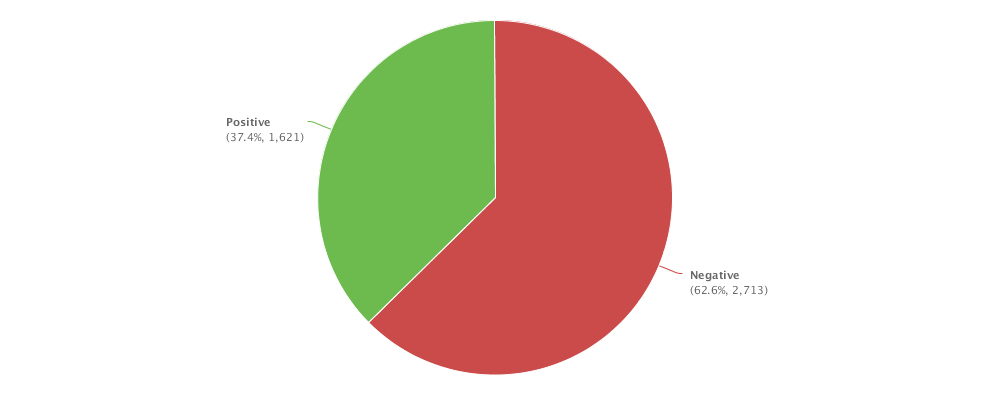
4. The net sentiment 48% is fairly high, which is reflected in the emotions stats (data quality very good): big green fonts emotional terms include 放心 (piece of mind),喜欢 (like),乐 (happy),支持/推 (support),很好 (very good), 不错(not bad),成功 (success) etc. The negative emotional words (in small red font) are not many, including 差劲 (bad),抱怨 (complain),不喜欢 (dislike),垃圾 (garbage),很一般 (very so-so: meaning not as good as expected).
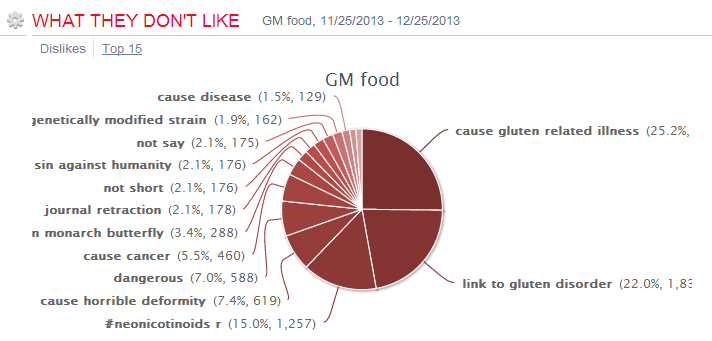
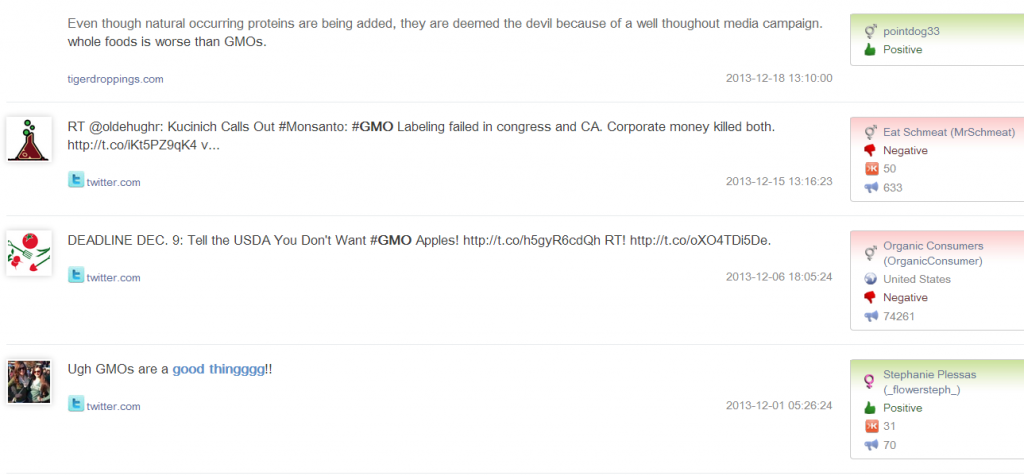
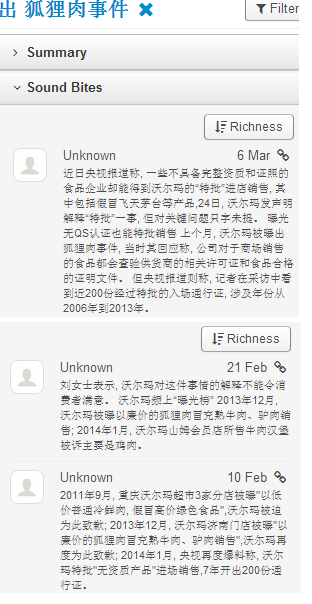
5. In the proscons word cloud, the likes include money-saving (省钱/便宜)and first-class service(服务一流); more interesting insights come from the dislikes, including (1) fake beef (using fox meat 狐狸肉事件); (2) recall (召回some product?); (3) cheating(欺诈); (4) scandal(丑闻) etc.
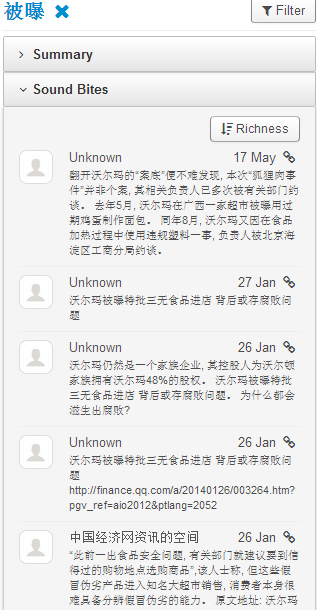
6. In order to drill down to see what negative incidents led to the above dislikes, the Walmart_con_sample shows some related sound bites which look like negative news on some incidents: 1st sound bite reports CCTV news on Walmart’s fake alcohol and fake meat (using fox meat) incidents; 2nd sound bite reports using fox meat to fake beef and donkey meat and using chicken to fake beef in the sold burgers at its Sam’s Club; the third sound bite reports three incidents of Walmart at different times and its apologies, including using cheap frozen meat to fake organic green food; using cheap fox meat to fake beef; and its lack of quality control in importing low quality products for sale, having issued 200 permits within 7 years for disqualified products to be on shelf.
7. Note that the above sound bites are selectively collected to show that our system can indeed capture detailed negative incidents of the brand in the media. When I drill down, there are quite some duplicates in our sound bites (one bad news gets re-posted everywhere); another thing is that the negative comments are not mainly from social media users, but from news (state-run news which get posted in social media too).
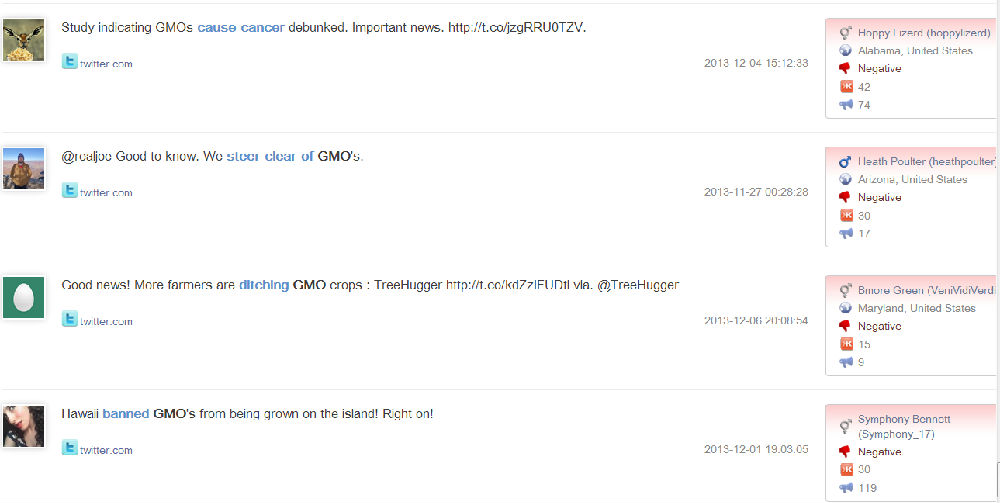
8. Unlike the overwhelming positive terms in emotions word cloud and the summary, the behavior word cloud shows more or bigger negative behavior terms than the positive terms. This is understandable because of the heavily reported incidents as shown above in the sample sound bites. Eye-catching negative behavior terms include “revealed”(被曝), “take to court”/”being sued”(告上法庭); “closed”(关闭); “have to take off shelf” (下架)etc.
9. From the above negative behavior terms, I drilled down to see more details in the sample sound bites below, which is similar to the sample discussed in 6. These two sound bites both come from negative news of Walmart, which originated from traditional news and got spread all over Internet.
有问,这一波热潮会不会是类似2000年的又一个巨大的泡沫?我的观察是,也是,也不是。的确,在大数据的市场还不成熟,发展和盈利模式还很不清晰的时候,大家一窝蜂拥上来创业、投资和冒险,其过热的行为模式确实让人联想到世纪之交的互联网 dot com 的泡沫。然而,这次热潮不是泡沫那么简单,里面蕴含了实实在在的内容和价值潜力,我们下面会具体谈到。当然这些潜在价值与市场的消化能力是否匹配,仍是一个巨大的问题。可以预见三五年之后的情景,涅磐的凤凰和死在沙滩上的前浪共同谱写了大数据交响乐的第一乐章。
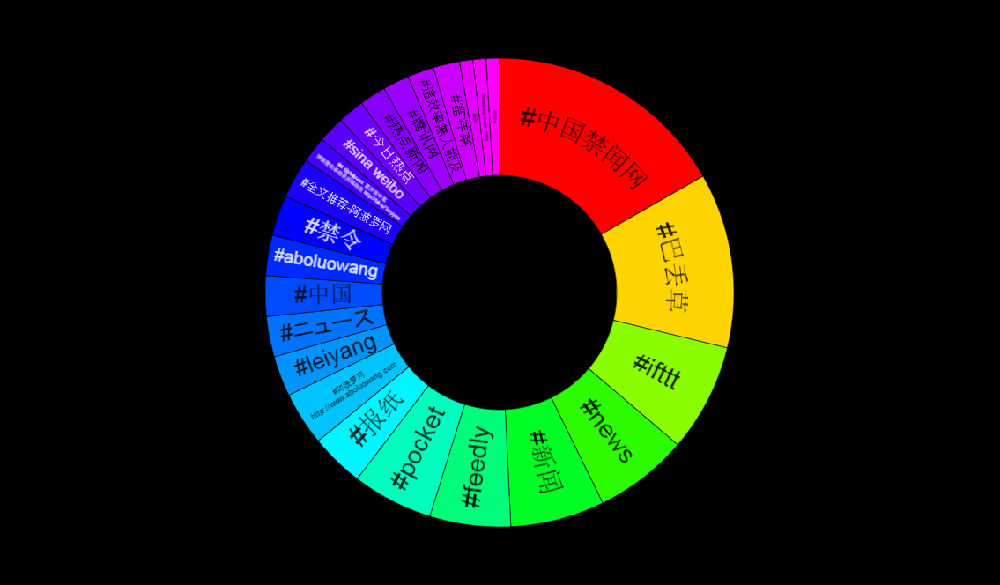
所谓大数据,更多的是社会媒体火热以后的专指,是已经与施事背景相关联的数据,而不是搜索引擎从开放互联网搜罗来的混杂集合。没有社会媒体及其用户社会网络作为背景,纯粹从量上看,“大数据”早就存在了,它催生了搜索产业。对于搜索引擎,big data 早已不是新的概念,面对互联网的汪洋大海,搜索巨头利用关键词索引(keyword indexing)为亿万用户提供搜索服务已经很多年了。我们每一个网民都是受益者,很难想象一个没有搜索的互联网世界。但那不是如今的 buzz word,如今的大数据与社会媒体密不可分。当然,数据挖掘领域把用户信息和消费习惯的数据结合起来,已经有很多成果和应用。自然语言的大数据可以看作是那个应用的继续,从术语上说就是,text mining (from social media big data)是 data mining 的自然延伸。对于语言技术,NLP 系统需要对语言做结构分析,理解其语义,这样的智能型工作比给关键词建立索引要复杂千万倍,也因此 big data 一直是自然语言技术的一个瓶颈。
在处理海量数据的问题解决以后,查准率和查全率变得相对不重要了。换句话说,即便不是最优秀的系统,只有平平的查准率(譬如70%,抓100个,只有70个抓对了),平平的查全率(譬如30%,三个只能抓到一个),只要可以用于大数据,一样可以做出优秀的实用系统来。其根本原因在于两个因素:一是大数据时代的信息冗余度;二是人类信息消化的有限度。查全率的不足可以用增加所处理的数据量来弥补,这一点比较好理解。既然有价值的信息,有统计意义的信息,不可能是“孤本”,它一定是被许多人以许多不同的说法重复着,那么查全率不高的系统总会抓住它也就没有疑问了。从信息消费者的角度,一个信息被抓住一千次,与被抓住900次,是没有本质区别的,信息还是那个信息,只要准确就成。疑问在一个查准率不理想的系统怎么可以取信于用户呢?如果是70%的系统,100条抓到的信息就有30条是错的,这岂不是鱼龙混杂,让人无法辨别,这样的系统还有什么价值?沿着这个思路,别说70%,就是高达90%的系统也还是错误随处可见,不堪应用。这样的视点忽略了实际的挖掘系统中的信息筛选(sampling)与整合(fusion)的环节,因此夸大了系统的个案错误对最终结果的负面影响。实际上,典型的情景是,面对海量信息源,信息搜索者的几乎任何请求,都会有数不清的潜在答案。由于信息消费者是人,不是神,即便有一个完美无误的理想系统能够把所有结果,不分巨细都提供给他,他也无福消受(所谓 information overload)。因此,一个实用系统必须要做筛选整合,把统计上最有意义的结果呈现出来。这个筛选整合的过程是挖掘的一部分,可以保证最终结果的质量远远高于系统的个案质量。总之,size matters,多了就不一样了。大数据改变了技术应用的条件和生态,大数据 更能将就不完美的引擎。
3 大数据不是决策的唯一依据,只是依据之一。正确的决策必须综合各种信息来源。大事不提,看看笔者购买洗衣机是怎样使用大数据、朋友口碑、实地考察以及种种其他考量的吧。以为有了大数据,就万事大吉,是不切实际的。值得注意的是,即便被认为是真实反映的同一组数据结果也完全可能有不同的解读(interpretations),人们就是在这种解读的争辩中逼近真相。一个好的大数据系统,必须创造条件,便于用户 drill down 去验证或否定一种解读,便于用户通过不同的条件限制及其比较来探究真相。
分享【3】On Big Data NLP热度 1 李维2013-7-27 20:43Admittedly, it is not easy to develop an NLP ( Natural Language Processing ) system with both high precision and high recall (i.e. high F-score) due to the ambiguity and complexity of natural language phenomena. Social media is even more challenging, full of misspellings, irregularities, and ...个人分类: 立委科普|766 次阅读|2 个评论
【9】【立委科普:所谓大数据(BIG DATA)】热度 3 李维2013-3-21 04:58Big data is not just data that are big. In the sense of data load, big data has been there for quite a while in Internet, on which the entire search industry was based and developed. The current buzz word big data is different, it is innately associated with users' background and social ...个人分类: 立委科普|1175 次阅读|3 个评论
【10】广而告之:科学网“双百”博主立委四月一日在北京演讲大数据挖掘热度 11 李维2013-3-20 19:57UPDATE:立委愚人节北京讲演时间地点已经确认,感谢中文信息学会孙教授的邀请和安排,也感谢董振东前辈教授的建议和推举: The loacation is : Room 334, 3rd floor, building 5 Institute of Software, Chinese Academy of Sciences, No. Zhongguancun South 4th Street 10:00~12:00 It' ...个人分类: 立委科普|1283 次阅读|13 个评论
分享【11】Coarse-grained vs. fine-grained sentiment extraction李维2013-3-12 06:51As for sentiment extraction itself, there are different layers: 1. sentiment classification: thumbs-up and down (or plus neutral) 2. sentiment association: to associate a sentiment with a topic or brand 3. fine-grained sentiment extraction: for example, who made the sentiment comment? about w ...个人分类: 立委科普|671 次阅读|没有评论
Five challenges to keyword-based sentiment classification: (1) domain portability; (2) micro-blogs: sentence/twit classification is a lot tougher than document classification; (3) when big data become small: big data load when sliced and diced based ...个人分类: 立委科普|1372 次阅读|1 个评论
【17】【科研笔记:big data NLP, how big is big?】热度 1 李维2012-10-31 19:03Big data 与 云计算一样,成为当今 IT 的时髦词 (buzzword / fashion word ). 随着社会媒体的深入人心以及移动互联网的普及,人手一机,普罗百姓都在随时随地发送消息,发自民间的信息正在微博、微信和各种论坛上遍地开花,big data 呈爆炸性增长。对于信息受体(人、企业、政府等),信息过载(information overlo ...个人分类: 立委科普|967 次阅读|1 个评论
Automatic survey complements and/or replaces manual survey. That is the increasingly apparent direction and trend as social media are getting more popular everyday. 自动民调(or 机器民调: Automatic Survey / Machine Survey)指的是利用电脑从语言数据中自动抽取挖掘有关特定话题的民间舆论,其技术 ...个人分类: 立委科普|1530 次阅读|3 个评论
分享【23】比起英语,汉语感情更外露还是更炽烈?李维2012-4-28 04:29Chinese is a more sentiment-intensive language than English?? FW: Counts of sentiment words in Chinese and English Interesting finding: that Chinese more than doubles the negative words and more than triples the positive words in comparison with the English vocabulary. This is based on the 5 ...个人分类: 立委科普|1158 次阅读|没有评论
【26】《科普随笔:机器八卦》李维2011-10-14 17:09机器八卦:Text Mining and Intelligence Discovery (13219) Posted by: liwei999 Date: June 10, 2006 10:07PM 犀角提议,干脆用机器挖掘吧。我不想吓唬大家,但是,理论上说,除非你不冒泡,言多必失,机器八卦,比人工挖掘,可能揭示出你的更多特征。好在该技术还不成熟。 Text mining 是我这 ...个人分类: 立委科普|863 次阅读|没有评论
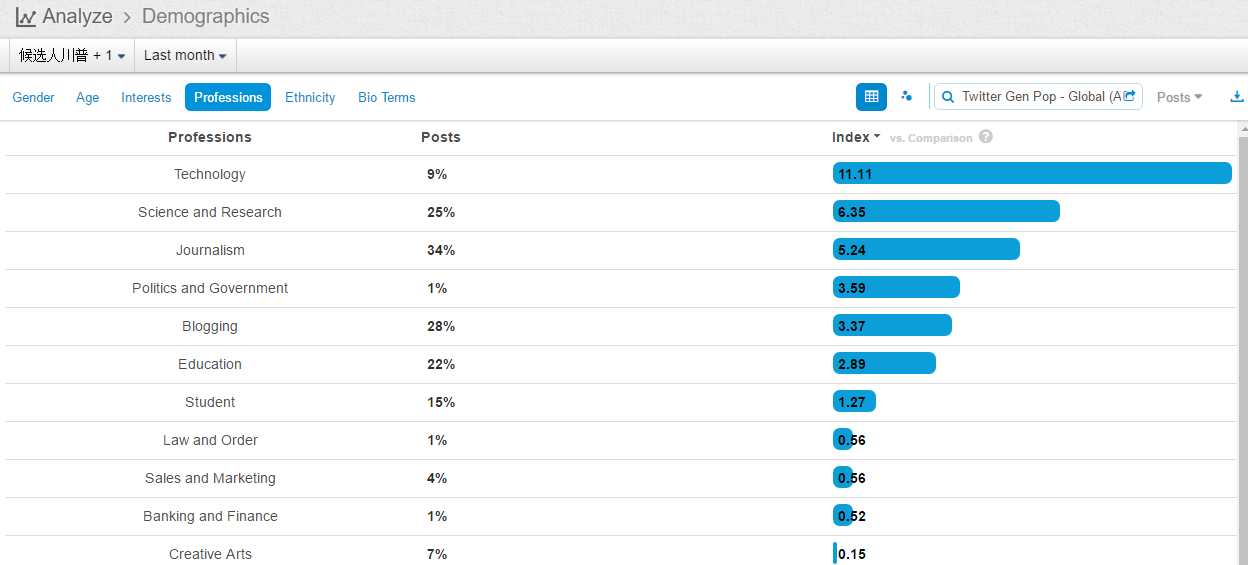
【27】言多必露,文本挖掘可以揭示背景信息热度 1 李维2011-7-11 01:03言多必露,挖掘有商用价值的背景信息 文本挖掘(text mining)中,Demographic Profile Extraction 的任务是要给网虫自动分类,揭示其背景信息(年龄,性别,身份,族裔,人生阶段,家庭背景等)。 一些简单的规则,查准率高(high precision),查全率并不高(moderate recall),譬如: I am X -- X (student, t ...个人分类: 立委科普|939 次阅读
分享【43】只认数据不认人:IRT 的鼓噪左右美国民情了么?热度 3 李维2013-12-30 06:27套用北韩最近流行的歌颂红太阳金正恩的红歌,数据,数据,《除了它我们谁也不认!》 当然,还有上帝: In God We Trust. In everyone else we need data. 大数据时代更是如此,只认数据不认人。道理很简单,在信息爆炸的时代,任何个人的精力、能力和阅历都是有限的,所看到听到的都是冰山一角。小崔如此,其他大V也 ...个人分类: 社媒挖掘|918 次阅读|10 个评论
分享【48】Social media mining: Teens and Issues李维2013-9-9 21:36As is well known, the teenager years are a special and important period of growth for children, or young adults, to be more precise. It is growing pain, mixed with joy. It is often a rebellious phase when both parents and teens find it difficult to communicate with each other. Thi ...个人分类: 社媒挖掘|542 次阅读|没有评论
分享【49】【微博自动民调:薄熙来、薛蛮子和李天一】热度 2 李维2013-8-30 09:33Automatic Survey from the last month of Sina Weibo (Chinese twitter, the most influential social media Microblog site) on three major characters: the former Chinese politician Bo Xilai in his on-going trial, the very famous social media figure Charles Xue who is said to have millions of fans and w ...个人分类: 社媒挖掘|898 次阅读|2 个评论
分享【54】【自动民调:美国名牌大学人气排名】热度 1 李维2013-8-12 16:46For the first time, the automatic survey of social media 1-year archive on some US brand name universities shows the rankings as follows, which are quite different from official ranking (Harvard and Caltech accidentally not included): 1. UCSD; 2.Chicago; 3. UPenn; 4. Carnegie Mellon ...个人分类: 社媒挖掘|794 次阅读|1 个评论
分享【57】舆情挖掘用于股市房市预测靠谱么?热度 1 李维2013-4-18 21:24Can social media sentiment mining be used for predicting stock/property market? I tried our Chinese system for that and it proved to be right. Is that pure luck or there is some value in using public opinions and sentiments to assist prediction of markets? 作为技术展示,曾经用中文社交媒体的舆 ...个人分类: 社媒挖掘|605 次阅读|1 个评论
Maytag Maxima 4.3 cu. ft. High-Efficiency Front Load Washer with Steam in Granite, ENERGY STAR Model # MHW7000XG 989.10/EA−EachWAS989.10/EA−EachWAS1,399.0 0 LG Electronics 4.0 cu.ft. High-Efficiency Front Load Washer in Graphite Steel, ENE ...个人分类: 社媒挖掘|943 次阅读|2 个评论
分享【63】《大数据时代的购物策略:洗衣机寻购记(2)》热度 3 李维2013-2-25 22:41洗衣机的选择:top loading 抑或 front loading? 作者: 立委 日期: 02/24/2013 23:35:39 本来我们是要放弃 front loading (镜先生考证,国内叫滚筒式)洗衣机,去选更容易清洁的 top loading (国内称作 波轮式 )的。可是如今大数据了,领导还是要看看二者的优劣,听听用户都怎么选择的。 于是挖掘 ...个人分类: 社媒挖掘|1067 次阅读|4 个评论
分享【64】《大数据时代的购物策略:洗衣机寻购记(1)》热度 8 李维2013-2-25 21:07ABSTRACT Brand Passion Index (BPI) is used to help us make an informed decision in our on-going purchase of a new washer. Using our own product, we generated two BPIs, one to compare the major washer brands in the US market and the other to compare front loading vs. top loading. With ...个人分类: 社媒挖掘|1996 次阅读|10 个评论
【Brand Passion Index 3: international fast food brands in China market face challenges】 Chinese Social Media Mining: Brand Passion Index for international fast food brands McDonald's, Pizza Hut, KFC and Yoshinoya in China. Fairly negative. The golden time when McDonald's ...个人分类: 社媒挖掘|1858 次阅读|9 个评论
Chinese mobile phone market is found to be still in the stage of multiple vendors competing with each other with no single one clearly ahead of others. Even Apple iPhone is on a par, in terms of net sentiments and consumer passion, with HTC, Samsung, Nokia and Chinese brand Xiaomi d ...个人分类: 社媒挖掘|810 次阅读|1 个评论
RE: What do these tell us more than we've known already? very good question: however, if it is known info, it confirms its validity 日期: 01/01/2013 11:11:49 it builds the users' (and developers') confidence in the automatic summerization of the computer processing of t ...个人分类: 社媒挖掘|644 次阅读|没有评论
Let us have a look at the past year 2012, which is more associated with the hardest year in people's mind than a good/best year.个人分类: 社媒挖掘|838 次阅读|没有评论
Most every hot topic coming to my mind these days, I will check our social media system to see how social media reflects it. Word clouds are intriguing vehicles to present the common social image. Most word clouds generated by other systems are based on statistics of keywords mentioned ...个人分类: 社媒挖掘|804 次阅读|1 个评论
一个偶然的系统测试,暴露出百度与“哪里有小姐”身影相随。这个发现在朋友间立即引起轩然大波,有称妙的(way to go, u r onto sth),有调侃的(曰:百度本来就源自“众里寻她千百度”嘛),有怀疑的( the results are not faked? )。阴谋论者伊妹儿我,指责此云有侮辱百度之嫌。 我跟老友说:我没有结论。有 ...个人分类: 社媒挖掘|1518 次阅读|没有评论
今天测试知名品牌百度的TagCloud,有惊人发现 日期: 12/12/2012 18:51:14 在简体字的world里面,与百度最紧密关联的词语是: 哪里有小姐 在繁体字的 world,最关联的词是 美元 不知怎么就想起了 Google 被赶出中国前对谷歌的指责:说 Google 太黄了。 黄得过百度么? A follow-up post a ...个人分类: 社媒挖掘|888 次阅读|3 个评论
Obama won the debate, see our evidence 民调自动化,技术带领你自动检测舆情: 社会媒体twitter的自动检测表明,奥巴马显然赢了昨晚的第二次辩论。人 气曲线表明他几乎在所有议题上领先罗梅尼。 对奥巴马真正具有挑战性的议题有二:一是他在第一任总统期间的经 济表现(6:55pm);二是批判他对中国不够强硬 ...个人分类: 社媒挖掘|1209 次阅读|1 个评论
分享【99】社会媒体舆情自动分析:马英九 vs 陈水扁李维2012-9-29 16:51Different social images and social media sentiments for Ma Yingjiu, Taiwan President, and Chen Shuibian, Taiwan former president. 不同的社会媒体评价,截然不同的民间形象,台湾现总统马英九 vs 台湾前总统陈水扁,社会媒体自动分析的初步结果凸显二者的不同形象和风格。 (1) 高频情绪性词的词频分析的对 ...个人分类: 社媒挖掘|830 次阅读|没有评论
分享【101】舆情自动分析表明,谷歌的社会评价度高出百度一倍李维2012-9-8 20:32拖了这么久,中文系统的初步试验终于开始 日期: 09/06/2012 21:04:35 本来核心系统的开发最难,最耗时间 ,结果在真实生活中,工程架构、存贮和搞定content这些纯技术性操作性环节往往也会成为时间瓶颈,怪也不怪。 这次试验只有海外twitter和百度贴吧天涯论坛等来源的半年数据,但做出的分析也蛮有意思。 I did a ...个人分类: 社媒挖掘|987 次阅读|没有评论
国人爱说反话:夸奖的背后藏着冷笑,社会媒体尤其如此 作者: 立委 (*) 日期: 09/07/2012 15:42:32 大陆政客属于敏感词,这里不表。以台湾政客为例, 譬如说陈水扁是“中国最清廉的总统”,就明显是反话。 It is interesting to find that many positive comments about A Bian are sarcastic. In thi ...个人分类: 社媒挖掘|892 次阅读|1 个评论
》》这样的访谈,应该能做到基本不看稿子的。
没有稿子啊,就是一张表格和一张白纸,表格填写了基本信息:题目之类。坏菜的是,我老低头给人一种似乎是在看提纲的样子。其实我根本啥也没看,拿笔和纸做样子而已。纸上就写了两个自我警告的大字:SLOW,CLEAR,但还是没用。说话的时候,啥也看不见,就是在急速找词,赶集似地往外说。因为赶,Broken English 就出来了。还有不少低级文法错误。









































































 I showed the First Lady's news pictures to my daughter. She was so intrigued, "Dad, Mom told me that you used to teach First Lady many years ago, is that true?" "It is true, but that was only a short time, one or two semesters, and it was not her major course. As a part-time lecturer, I was teaching Advanced English to graduate students in the music conservatory and she happened to be one in my class. She was already famous then as a new star for folk songs." Tanya got excited, "Well, you never know, maybe her English training in graduate school helps her in state visits today. My Dad is cool." She continued, "Dad, Mom also told me that you were interpreter for foreign minister when she dated you, is that true?" "Well, that was largely an accident, only happened once when I substituted some professor to act as interpreter for the former foreign minister and former Chinese congress vice-chairman Mr. Huang Hua. Your Mom agreed to date me partially because of her seeing a picture of me interporeting for the VIP Mr. Huang. So I guess I benefited from that 'accident'." Tanya was amused and felt very proud, "I have the coolest Dad in the world. He was so successful even when he was young, teaching future first lady and interpreting for the then foreign minister. Wow."
I showed the First Lady's news pictures to my daughter. She was so intrigued, "Dad, Mom told me that you used to teach First Lady many years ago, is that true?" "It is true, but that was only a short time, one or two semesters, and it was not her major course. As a part-time lecturer, I was teaching Advanced English to graduate students in the music conservatory and she happened to be one in my class. She was already famous then as a new star for folk songs." Tanya got excited, "Well, you never know, maybe her English training in graduate school helps her in state visits today. My Dad is cool." She continued, "Dad, Mom also told me that you were interpreter for foreign minister when she dated you, is that true?" "Well, that was largely an accident, only happened once when I substituted some professor to act as interpreter for the former foreign minister and former Chinese congress vice-chairman Mr. Huang Hua. Your Mom agreed to date me partially because of her seeing a picture of me interporeting for the VIP Mr. Huang. So I guess I benefited from that 'accident'." Tanya was amused and felt very proud, "I have the coolest Dad in the world. He was so successful even when he was young, teaching future first lady and interpreting for the then foreign minister. Wow."





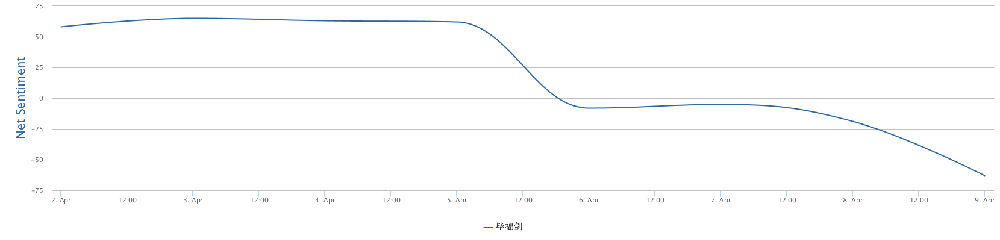
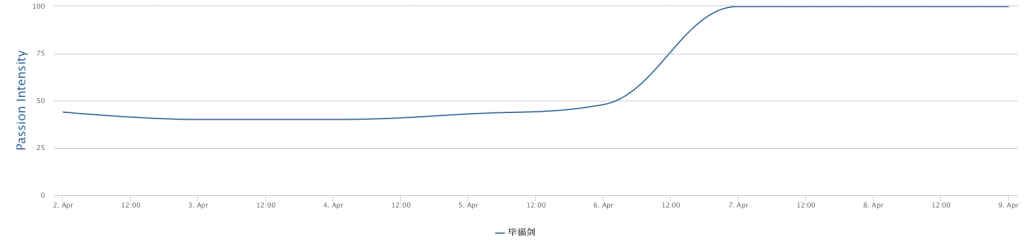


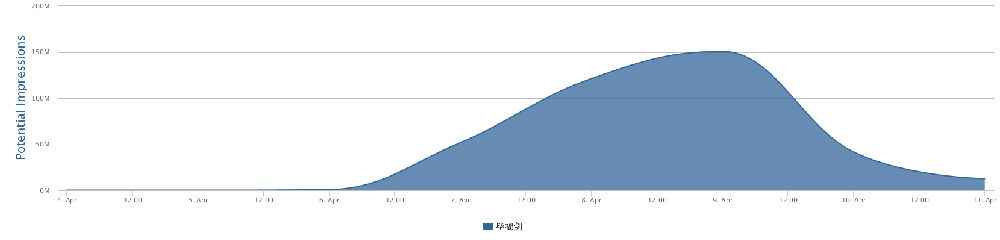
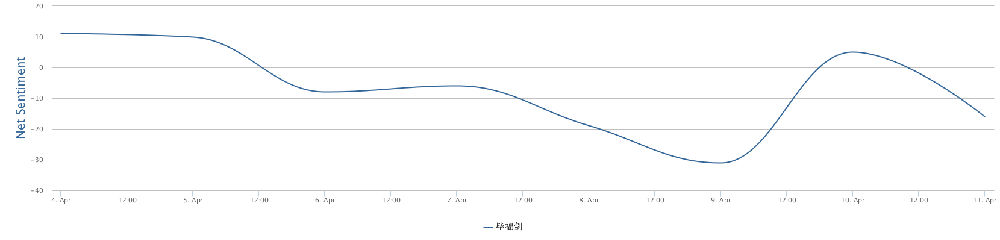










 您知道发一个好评多少钱吗?大公司有公关部的。
您知道发一个好评多少钱吗?大公司有公关部的。 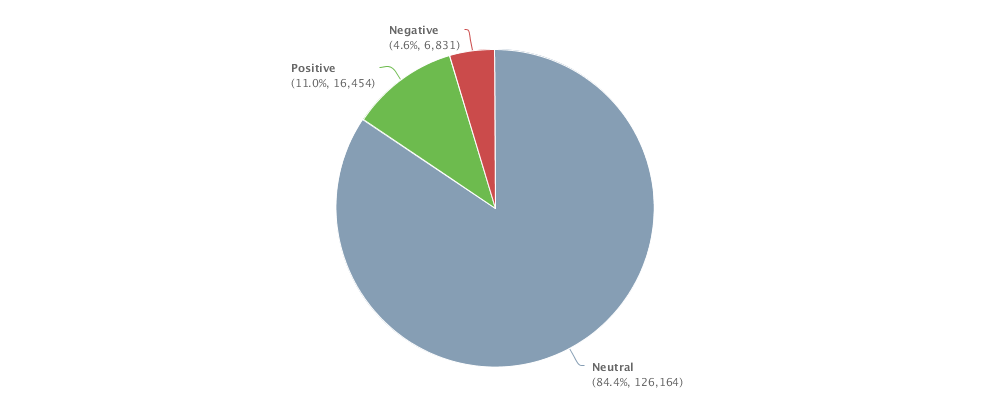
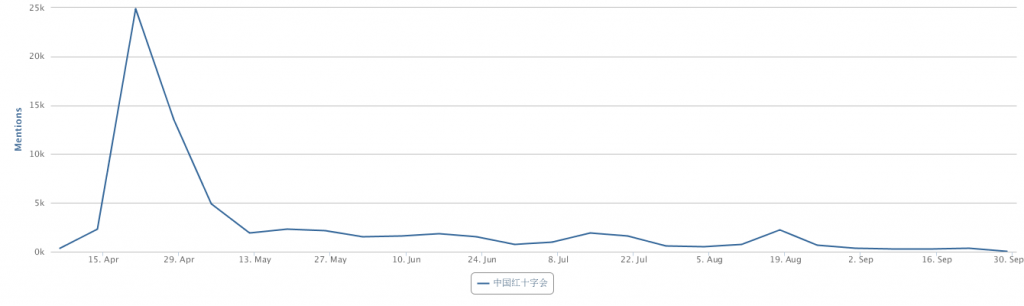
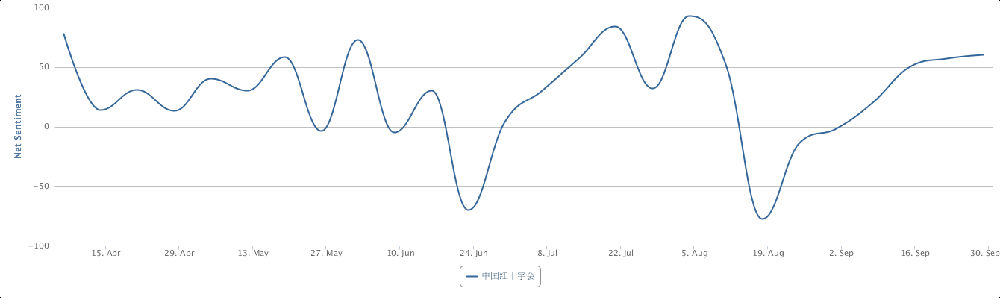



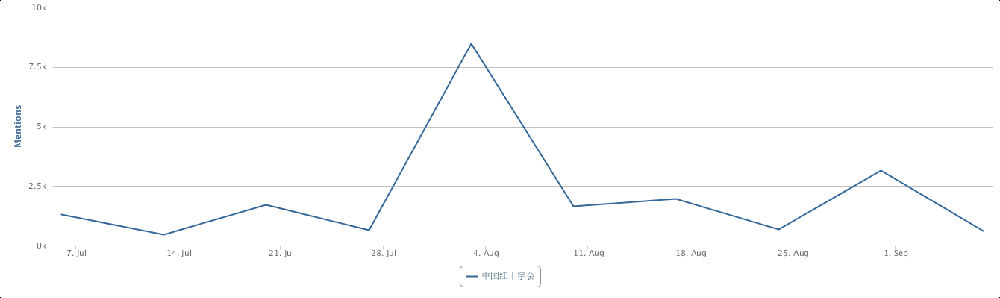
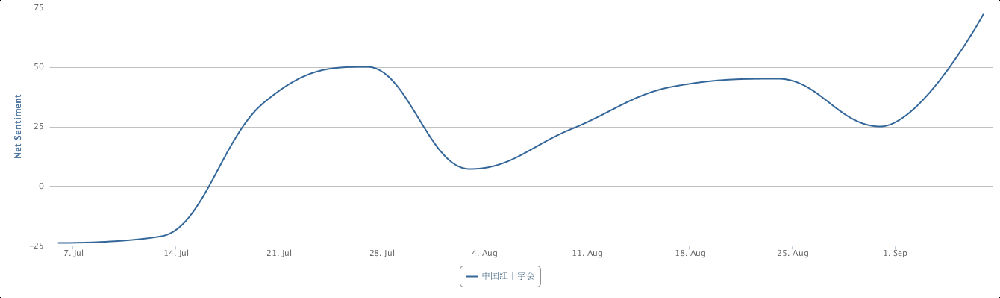

































































 两相对比,立委这个interview让我看到了你坐backoffice的巨大潜力
两相对比,立委这个interview让我看到了你坐backoffice的巨大潜力 - 立委
- 立委  台上一秒钟,台下几年功,一点不错!立委多年的奋斗终于开花结果了!
台上一秒钟,台下几年功,一点不错!立委多年的奋斗终于开花结果了!