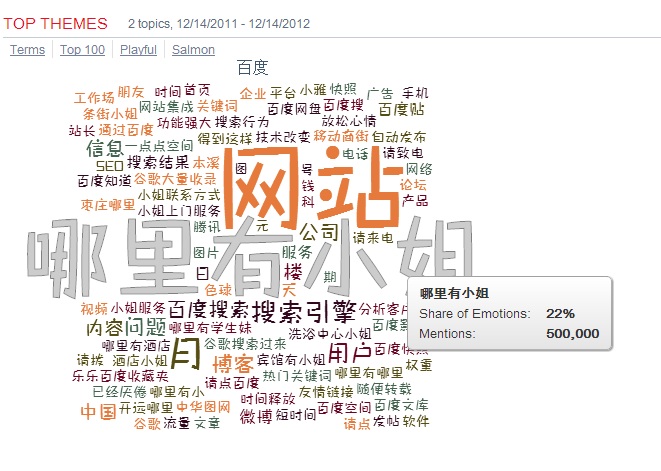
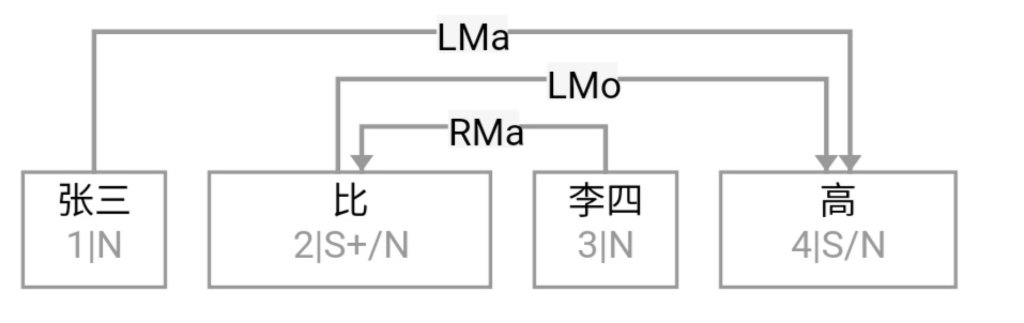
关于转基因及其社会媒体大数据挖掘的种种问题
屏蔽 |||

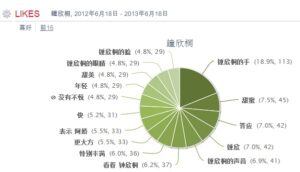
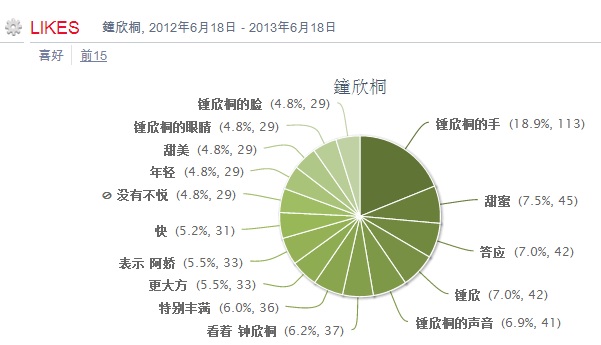
没想到转基因话题这么热,随手做了一个自动调查发在博客上( 【西方怎么看转基因:英文社交媒体大数据调查告诉你】),一天多就达到 7000 点击,40 多评论。先把我对问题的回应整理如下。
【西方怎么看转基因:英文社交媒体大数据调查告诉你】),一天多就达到 7000 点击,40 多评论。先把我对问题的回应整理如下。
1. 关于数据问题
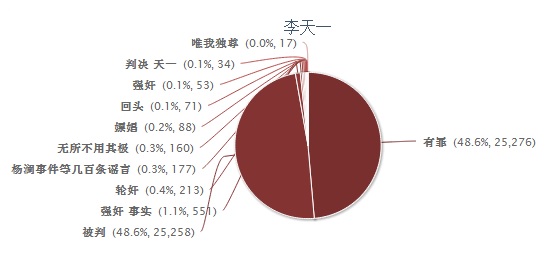
你这个数据是有问题的,想想看,美国加州、华盛顿州的公民投票结果都是不同意转基因标识,大多数民意连转基因标识都不要了,对转基因食品安全性的担心能有多少呢?这个样本比你那个说明问题吧?
博主回复(2013-12-24 10:04):这个数据是没有问题的,因为我们对于最近一个月的社交媒体是不做品牌针对性筛选的,是普适的。对于一个月之上的数据,可以根据 GM Food 这样的主题词去筛选也可以一网打尽,但是有数据成本的问题。至于数据挖掘有没有偏差?文本挖掘技术当然不可能是完美的,但是统计上没有问题,因为第三方多次测试精确度都是接近90%。
2. 关于结论的对错
转基因的安全性靠调查研究难以给出正确评价。
博主回复(2013-12-24 12:47):两码事。
安全性是科学问题,假以时间应该由科学解答,或者有些已经回答并得到权威部门认证。
舆情调查反映的是普罗百姓对事物的方方面面(包括安全性)的看法而已。
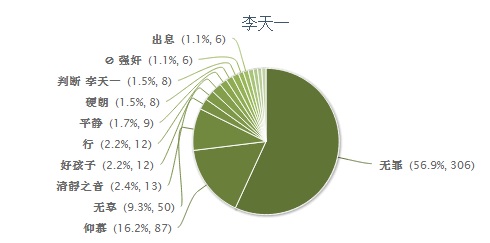
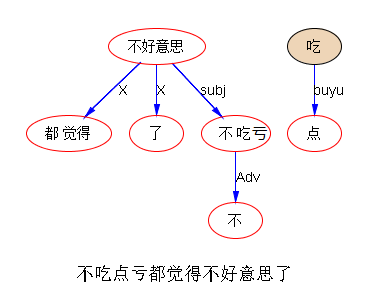
还有一点, 博文中说的Gluten引起的各种那个过敏症。 我一直都不理解美国曹氏中标识的gluten-free的食品为何就那么重要? 因为gluten就是我们中国人飞铲喜欢吃的面筋, 各位都喜欢吃油面筋塞肉, 北方人吃面要“筋”, 都是gluten含量很高的食品, 跟转基因毫无关系。
而且超市中真正gluten-free的食品货架上很少的,现在美国飞机航班上不提供花生, 只有那个非常难吃的 pretzel 据说是因为有些人对花生过敏, 所以航班不供应花生了。
博主回复(2013-12-24 17:55):听我的专家朋友说,Gluten 确实与转基因无关,是有公认的科学结论的。
那为什么舆情中,这一项作为转基因的主要问题呢?
没办法,这就是舆情,我不能改变它,只能反映它。
也许这正说明,科普还没做到家,还没能让老百姓了解和信服。任重道远。
3. 关于阴谋论
菜老师有奇文 http://blog.sciencenet.cn/blog-789923-752383.html,说:“李维先生说,该英文社交媒体大数据调查反映了民间的真实态度,这个观点看来要打个问号了。” 这个“该”字从何谈起,我们对社交媒体是一网打尽(因为企业用户要求如此),其组成和来源都在文中有交待。他下面的推测充满了细节,实在太异想天开了。蔡老师怎么不询问一下就这样胡乱猜测呢,描述了一个天大阴谋似的。
“搞这个调查的英文社交媒体的完全可能是反转基因团体控制的,其调查的人群经过了特异的选择,或者说该英文社交媒体的读者主要以反对转基因人士为主。这样的数据即使是“大数据”,又有什么意义呢?”(下划线是立委加的)
蔡老师哎,你这样善于胡乱猜测还怎么做学问呢。这是我自己主持开发的软件,用的是未经任何人控制的原始数据(英文叫做 firehose,就是直接从社交网站流出来的),没有人工干预,靠的是自然语言挖掘技术自动生成的。这样说,应该够清楚了吧。我的本行就是舆情自动调查,这只是针对热点问题,从系统输出结果而已,供大家做舆情分析时候一个参考。
说明一下,所用的软件本来是为企业用户做客户情报调查用的。社交媒体一网打尽是指在我们的 index (库存)里面,我们包括所有够得着的社交媒体,英文社交媒体从比重上看,twitter 为主,Facebook 其次,其他论坛上百万个来源只占少数,这是当今社交媒体的自然现状。
我自己是系统架构师和主要实现人,所以不时用系统挖掘热点话题,一来可以看看系统还有什么可以改良的地方,而来也算是对社区做一些大数据语言挖掘的科普展示。阴谋论简直匪夷所思。
蔡老师(2013-12-24 16:24):我的推测是否正确,不是关键。关键是你的舆情分析软件结果与公民的投票结果相反,必须做出解释,否则这样的舆情分析只会造成更大的认识混乱;如果领导据此决策了,更加有误导嫌疑。
(2013-12-24 16:15):我不怀疑你的数学分析能力,你的数学模型包括软件应该是不错的。但是,出色的数学分析能力并不能保证你的结果是正确的。牛老师比我说得更全面,还有其他网友对此也有分析。
我再将我当年的生物统计学老师说过的话告诉你,让我们共勉吧:数学模型应当建立在具有生物学意义的基础上,离开了这个基础,哪怕数据再充分、模型再漂亮,也是没有意义的。
博主回复(2013-12-24 18:07):您的思维很怪异:说什么领导据此决策错误,我就更加有误导嫌疑。
这是什么话。领导面对这么多志愿免费提供的不同侧面的信息源,依然决策错误,那就是狗屁领导,没有领导能力、决策能力,领导应该下台,这个决策错误与信息提供者有一毛钱的干系?
又:说什么数学模型要建立在生物学意义上对于我们文本挖掘媒体调查领域完全是瞎掰。我一个语言学家懂什么生物学,我做语言文本调查要什么生物学的基础?我的对象是自然语言(社交媒体),不是生物啥的。我的模型建立在语言学(语言分析,parsing)基础上,这才是我们这个领域的基础。你隔行传授的经验没有一丝的适应性和可行性。
博主回复(2013-12-24 16:44):喂,喂,我为什么要为我的自动调查与公民投票的差异做出解释?
我只是提供一个信息源而已。这个信息源是大数据高技术的结果。投票那是另外一个信息源。二者吻合还是不吻合,可能有一千个因素,我有什么责任和义务解释?
我也从来没关心过那次投票。
博主回复(2013-12-24 16:38):
您如果质疑“调查反映了民间的真实态度”,完全没有问题,因为同样的数据可能有不同解读和 interpretation
如果质疑质量或操作过程中的误差,也还不算离谱。
可您凭空从头脑想出来并 描述了我的数据被操纵的过程和细节,就让人跌破眼镜了。
4. 关于噪音处理
至于博主和蔡晓宁先生说的大数据处理的技术我不会, 还得在学习了。 不过google或百度上的绝大多数数据是垃圾数据。 如果要使用大数据处理来统计, 我建议博主把CA或Medlines或 Bological abstrct里的数据做个大数据处理,看看你能得出一个什么结论。 这些可就是科学的结论了。
至于垃圾过滤,这是任何大数据系统都必须要做的工作,我们也有这个过滤,经过几年的不断改进,测试证明英文大数据的垃圾已经不再是大问题了。
不过中文媒体的垃圾过滤还有很多工作要做,有国内微博水军和僵尸的问题。不过对于热点话题,可以只选取带 V 的样本,也就杜绝了水军和僵尸。但对于冷门话题就不好办了。
另外一个工作是避免过量重复(de-dup),英文也已经做得很好。
对于大数据处理, 我完全是外行, 现在说几句外行的话, 不对就当垃圾处理
1. 任何数据的输入的前提是数据的可靠性, 不分青红皂白的把所有数据输入, 输入的数据就没有科学性, 可靠性, 由此而来的结论当然就没有任何意义了
2. 现在网络上有所谓的大V, 用定贴机为某一个题目专门不断发帖顶贴, 所以不分青红皂白的输入这种数据, 实际上是被其他人所误导。
3. 所以要用大数据, 必须界定你的大数据来源。 否则同一事物, 被不同人选择来源, 完全就有不同的结论。
以上是外行的话。
博主回复(2013-12-24 18:35):当然你的担心是有理由的。做大数据的人当然要过滤垃圾(包括无处不渗入的色情),而且要 detect 僵尸、水军和数据的过分重复(机器人发贴)等。
大数据挖掘有没有价值很多时候是可以验证的。因此上述问题的严重程度,可以从过往的验证中得到一个大概的置信区间。细节就不谈了。
总之是,由于大数据的存在以及大数据处理能力的不断完善,舆情挖掘提供了一个难以取代的情报源,在决策中有参考价值。这是可以基本肯定的。
5. 有比较才有鉴别
其实这些问题只要放在比较的框架中就不是严重问题。虽然具体语言中褒贬比例和分布可能不同,但是如果一个对象的褒贬指数放在其他对象的褒贬指数的 reference frame 里面来阐释,其解读就比较真实。比如,在过往的许多调查中,我们知道褒贬度降到零下20以后就很不妙,说明媒体形象差,老百姓很多怨气。有了这样一个历史积累,新的品牌或话题如果达到类似的指标,解读就不大会离谱了。
特别是,我们做一个行业的多品牌调查和比较的时候更是如此。品牌A与品牌B的在舆情中的相对位置非常说明问题。系统的误差,质量的不完美,语言数据的不完整,以及语言现象的分布不匀,所有这些统统不再成为问题,除非这些差异是针对特定品牌的(这种现象基本不出现)。
这一点毛委员早就说过:有比较才有鉴别。
有比较才有鉴别,这是铁律。任何指标单看,其意义就很悬。包括我说转基因不受美国人民喜欢(零下29度),也是因为有过往的褒贬指标平均值作为 reference frame 才说的。
6. 大数据是忽悠么?
是的,有很多忽悠。但是立委论大数据不是忽悠。
》》这篇博文充分说明,“大数据”并不是神仙,完全可能得出错误的结论,“大数据”只是一种工具,要看使用者如何使用它了。
博主回复(2013-12-25 00:30):说大数据是神仙的,多半是忽悠。
今天忽悠大数据,明天其他东西流行了,就忽悠其他东西。
但是大数据给决策人(政府、企业或者犹豫如何选择的消费者)提供了一个前所未有的方便工具,去纵览有统计意义的舆情。这在以前只能通过小规模误差很大的人工问卷调查来做。如今自动化了,而且样本量高出好几个量级。拜科学技术所赐。
7. 关于系统可靠性
任何一门新的方法的建立,都需要首先用对照验证其有效性。这种抓取网络关键词,有没有与大样本的问卷调查等传统方法进行对比,验证过有效性?看到fear,就下结论说是人民害怕,也许是有人说不用fear呢?至于英文网络的数据,为什么下结论时认为只是美国人的意见,把欧洲人等排除掉了?
博主回复(2013-12-25 07:09):你提到“抓取关键词”,怀疑系统不能处理否定式(“也许是有人说不用 fear 了”),那是你不了解我的背景,虽然我在100多篇科普性博客已经多方面描述过系统的能力。简言之,我们的舆情挖掘不是通常的关键词技术,而是建立在高级得多的深度语法分析(deep parsing)之上的信息抽取和挖掘。不仅可以对付否定式,否定之否定等更复杂的语言现象也能处理。
博主回复(2013-12-25 00:59):至于意见中是不是只有美国?
这个还真可能不准确。我说的不严谨。英文社交媒体从分布上看,美国网民比重很大,但这个世界是地球村了,当可能包括西方其他国家的舆情夹在里面了。
其实很好解决,系统有地理过滤器,我可以只挖掘美国来源的社交媒体。但这样数据量就需要超过一个月的积累才好挖掘,有成本的。今后高兴了,再做吧。博主回复(2013-12-25 00:53):有没有与问卷调查以及用其他方式验证过这个系统的有效性?
有过。很多次。而且还在不断定期进行中。为什么要这样做?因为质量是系统的生命线,否则怎么取信于客户。
大数据挖掘热点话题(冷门话题数据量少,就不好说了)作为舆情的反映,基本可信,至少不比传统手工问卷差。作为决策参考没有问题。
你不必相信我的 claim。我也不必提供验证细节。你也不是我的客户。我免费提供信息,权当 raise awareness 和科普。
我的论点,您可能只看到了其中一部分。我再多说一点,人们的用词习惯在这个比较里面没有被考虑到。比如,说一个人很丑可能多数人用单词A,而说她美可能会有十种表达方式。假定认为美的有十个人,用词个不一样,说她丑的只有三个人,但看起来是显然的高频词。这不是误导吗?这种现象往往在理性精细思维和随意发泄情绪两种情况下对比很明显。
博主回复(2013-12-24 17:45):要想做这种矫正,你先得研究清楚这种现象在真实语料中确实存在,严重程度,分布如何。听上去,这一步你还停留在假说层面上。这时候说系统误导是欠公允的。
另外,一个概念有多少词来表示只会影响 Word Cloud 图示中的 fonts 的大小(其实即便在那里,我们对比较严格的同义词还是做了合并处理的,因此问题没有想像的严重),但并不影响最重要的 net sentiment (褒贬度)的指标,因为后者是根据褒贬两大类来计算,而不问具体的用词。
很多事情都是这样的:赞成的人不怎么发声,而反对的人则会闹出很大的动静。从国人对待转基因的态度到泰国黄红两派的斗争死结,这种现象在社会中普遍存在。这可能有社会心理学的解释。
因此,所谓相对客观的大数据,也许本身就已经预设了立场。博主回复(2013-12-25 11:08):这种情况是可能的。所以我说,同样的数据结果可以有不同的解读。
你可以打折来看褒贬指数。譬如,指数为零表面上似乎是褒贬民意旗鼓相当,你可以打个折扣,理解成其实是褒多于贬,只不过很多满意的人不言声而已。
这个折扣怎么打,可以根据经验法则,多一些实验也许慢慢可以显现出来。
8. 我只做民意,不介入转基因的争论
老师可以写得更简洁些,并且有学术数据支撑,而不仅仅是民意支撑么?
从学术原理上来讲风险,用数据说话,现在大家抄来抄去,感觉不专业.
博主回复(2013-12-25 00:39):我只做民意。别的你们做,或谁爱做谁做。
我不反对转基因,也不大关心转基因因为没感觉有什么危险。我的不少懂行朋友也持拥抱态度,我没有理由不相信这些专家。但是民意也需要一定程度的尊重和引导,不能强迫人们吃转基因,或任何东西。在民意有很多顾虑的时候,给民众选择的权利是合理的(除非标识成本太高:其实高成本只要转嫁给要求标识的消费群体就合理了)。
题外话:我的转基因立场
我其实没有什么立场,也没有相关的生物知识背景,转基因从来不是我关注的对象(因为是热点话题才选它当小白鼠做舆情挖掘的试验,而不是对其感兴趣)。通过朋友的争论和综述, 觉得两边的极端派掐架很难看,都有误导和蛊惑。(By the way,我觉得挺转人士当年犯了致命错误,他们不该把 GM 翻译成转基因,要是翻译成生物高科技最新改良食品伍的,就会减少很多阻力和疑虑。名不正则言不顺,言不顺则事不成。现在好多百姓听到转基因就跟听到癌症似的,你说说这个术语翻译是不是害死人。后来金大米起的名字就很好,无奈受转基因的牵累,还是遭到很多人的排斥。)
我本人不介意吃转基因食品,因为从来没有感受到有危险。我去肯德基最喜欢买的就是他们的烤玉米。从来不问出处。但事已至此,转基因就不单是科学的问题了。要上老百姓餐桌的话,老百姓的感受不能不顾及。作为一种过渡,我觉得在中国有必要给转基因食品做标识(或给非转食品做标识,one way or the other),给人民选择的权利。这个不必要循美国不标识的例,原因是国情不同,老百姓为食品安全困扰太久,井绳之忧是自然的反应。转基因的最终胜出,应该靠自己的实力,譬如价格的低廉,日益显示出来的安全性等。标识以后,科学人士和我等无所谓(畏)人士会自然成为其消费者。最后会争取到其他中间用户。至于反转死硬分子,就让他们一辈子多花冤枉钱去消费“纯天然”食品也蛮好的。
最后来点 fun,转发老友的一个评论。
2。看不出钓鱼岛的归属依据
3。比较不出社会主义或资本主义的优越性
4。 对国际贸易的趋势做不出专家评论
5。完全忽视不上网不用手机的(或上网用手机但不进入他搜索网络)人群的话语权,比重
6。对测量(不是影响)湾区华人选票的帮助不大
7。依然无法用大数据得出吃一顿简单中餐得到的卡路里
暂时想到现在,希望立委有突破,我们LBC可以近水楼台先得月。
【相关篇什】
小数据和个案分析:个人在美国对转基因的感觉 2013-12-26
既然大家感兴趣,圣诞没事在家,就继续做一点转基因的大数据挖掘 2013-12-26
关于转基因及其社会媒体大数据挖掘的种种问题 2013-12-25
【美国网民怎么看转基因:英文社交媒体大数据调查告诉你】 2013-12-24
17 陈安 刘旭霞 孙根年 强涛 蔡小宁 杨宁 常顺利 武夷山 周雄伟 薛宇 郑小康 孙平 陈儒军 周洲 卢长明 bridgeneer biofans
发表评论评论 (19 个评论)

- 删除 |
 赞[10]苏晓慧
赞[10]苏晓慧 - 哈哈,这个技术很好,我现在也很着迷,可惜数学不好不会玩。回归正题,我的疑问是,怎么就没有学生物的尤其是分子生物学的出来发博客说说呢,除了植物所的蒋高明,但是一家之言不可尽信。那些生物大博主们都避开了这个话题啊


- 删除 |赞[9]mirrorliwei
- 【转BT基因的BT蛋白是否引起过敏是FDA/EPA必须检测的项目】就表明了有这个担心。
这里不需要讲什么“转基因的蛋白会引起面筋过敏的实例和原理”,只要相信墨菲的定律(http://zh.wikipedia.org/zh-cn/摩菲定理):“凡是可能出错的事均会出错。”(Anything that can go wrong will go wrong.)。可引申为“若缺陷有很多个可能性,则它必然会朝着最坏、最可怕的方向发展”。
- 删除 |赞[8]王大元
- [3]mirrorliwei 2013-12-25 09:06
镜女士(李薇): 请你讲讲转基因的蛋白会引起面筋过敏的实例和原理?转BT基因的BT蛋白是否引起过敏是FDA/EPA必须检测的项目, 所有批准了的转BT基因的玉米, 其BT蛋白都没有致敏性, 你去查EPA/FDA的批准报告, 每一个批准报告在250页以上, 其中有关过敏性的试验数据大概在1-2页。
如果美国有个别人的试验报告说转BT基因的BT蛋白恶意造成面筋过敏, 那么这种试验结果先要被FDA/EPA采用, 一个在自己国家的权威部门都不采信的试验结果, 我们中国人没有必要为这种垃圾结果张灯结彩作为根据

- 删除 |赞[7]cuixiangmi
- 大数据挖掘还是比较有意思的,但分析应该要更科学。比如来源同样是News,大报和小报,应该乘不同因子。
- 删除 |赞[6]王大元
- 博主先生: 在你上一篇博文中我做的第一个评述,得到你的同意。 后来我发现那是你自己用大数据工具统计的资料, 由于我不懂大数据统计, 所以我又提出了几点疑问。我现在正在学习大数据的基本知识, 以便对大数据作为工具来调查舆情或者其它领域的应用前景。 现在还是作为外行向你求教几个问题?
1. 你能举几个例子来说明在那几个重大问题上, 大数据的统计结果被政府采纳了的, 或者做出了正确的预见的重大例子
2. 你能用大数据工具预言明天的那个股票会涨和跌吗?
3, 你能用你的大数据统计预测朝鲜1年后是什么样吗?
4. 你能用大数据统计预测中国明年的房地产涨还是跌, 涨幅或跌幅是多少?你的这个预测与其他不用大数据人做的预测有多大区别?
4. 你的转基因大数据的统计的结果能肯定现在的舆情结果将来肯定是对的或错的吗?
5. 如果我不用你的大数据统计,而是用科学杂志的数据来统计可以预测比你大数据的结果更准确的结果, 那么大数据的统计结果有什么意义 ?
我最基本的观点就是不管你的数据有多大, 但最关键的是你输入的数据是否正确和准确。 尽管你说了有删选数据的软件把关, 但我感到你的转基因那篇的大数据输入的数据的可靠性是有疑问的,你的软件似乎没有管好这个关, 例如与转基因无关的面筋竟然作为最主要的指标。 我建议你把转基因致癌那一部分, 单独拿出来用大数据统计一下, 其中输入持这种观点(致癌)的人的各种身份群体的比例:例如没有文化的老大娘, 小学, 中学程度的群体, 非专业人士群体的比例,科学家的比例, 统计一下, 看看中学学历以下和非科学家的群体比例的意见占多少, 我估计你可能会有完全不同的结论。 在这样的前提下输入你的数据, 看的人心里就踏实了: 哦!原来猪转基因致癌的是这么一部分人。

- 删除 |赞[5]huluhuluhulu
- 看了“浅谈立委大数据利用的局限性”,真欢乐啊。我还以为大数据能得到一顿西餐的卡路里呢。哈哈
- 删除 |赞[4]蔡小宁
- 感谢李老师将我的观点列入博文!在这里我做点解释。
我的博文是在刚刚看到李老师那篇大数据舆情调查博文出来的时候,当时的感觉是为什么结果与加州、华盛顿州的公民投票不符?于是推测了一种可能性,并不是说一定是那样的。后来,随着我们讨论的深入,对李老师的认识也在加深,现在可以确信,“阴谋论”的可能性可以排除,在此特别声明。另一点就是,我不怀疑李老师的数学能力,做软件的水平肯定很高。我想要说的是,一个好的工具需要人们正确地使用,一个好的工具仍然可以继续改进。软件实际使用得出的结果要尽可能与事实相符,如果出现不符合的情况就要考虑是否参数设计出现了错误或不够完善;或者有其适用范围,超过这个范围,结论可能就是相反的了。可以适当做点解释,以减少误会。
- 删除 |赞[3]mirrorliwei
- 【我一直都不理解美国曹氏中标识的gluten-free的食品为何就那么重要? 因为gluten就是我们中国人飞铲喜欢吃的面筋, 各位都喜欢吃油面筋塞肉, 北方人吃面要“筋”, 都是gluten含量很高的食品, 跟转基因毫无关系。】的说法镜某以为不妥。因为很多所谓专业人员都不知道“gluten”是什么!所以他们直接用了洋文表述此概念。这个说法的依据是来自饭桌上的谈话。镜某的饭桌上,以为是所谓的专业人士(本科教育名牌生化),一个是正在复习考试这门功课。“gluten”就是中国人喜欢吃的面筋不假。而面筋又是什么????就言语不详了
面筋就是面粉里面的蛋白质!!一种巨大的分子。转基因的风险就是可能会引起蛋白质的结构变化,带来新的过敏因子。
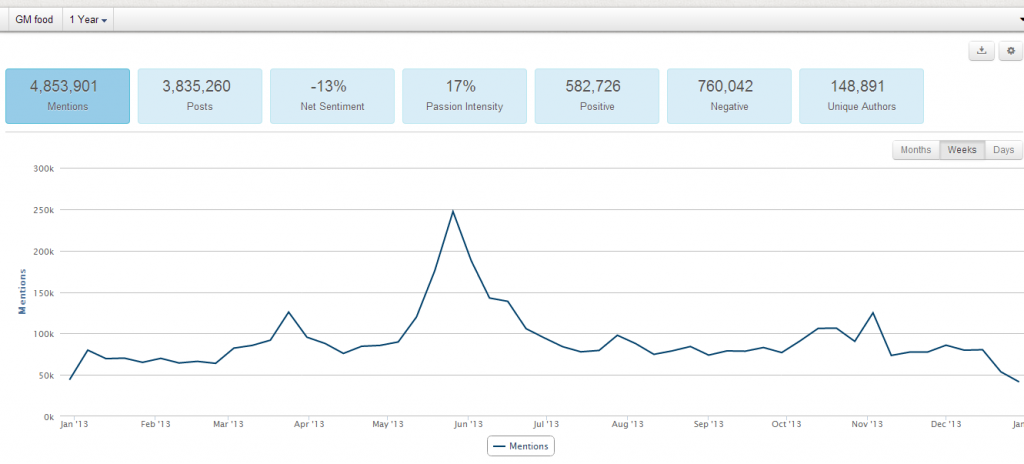

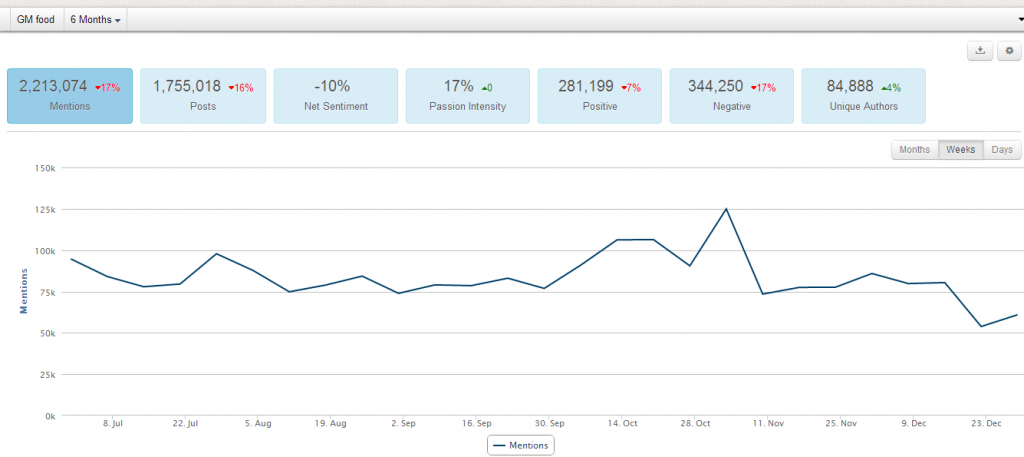






 大数据崇拜要不得
大数据崇拜要不得