作者: 立委
立委博士,多模态大模型应用咨询师。出门问问大模型团队前工程副总裁,聚焦大模型及其AIGC应用。Netbase前首席科学家10年,期间指挥研发了18种语言的理解和应用系统,鲁棒、线速,scale up to 社会媒体大数据,语义落地到舆情挖掘产品,成为美国NLP工业落地的领跑者。Cymfony前研发副总八年,曾荣获第一届问答系统第一名(TREC-8 QA Track),并赢得17个小企业创新研究的信息抽取项目(PI for 17 SBIRs)。
《人生记忆:老爸-一夜改朝换代》
老爸按:我的人生回忆“风雨几春秋”写出之后,总觉得意犹未尽,还想一吐为快。的确,人生驿站,总有许多华光异彩,难忘记忆,或惊心动魄,或入狱深渊;或光彩夺目,或称奇前后。何况我们这代人,纵观千古,横溢全球,无论是人文或是科技,皆是一个巨变的时代,一代人时光,越过过往千年万年。
续篇之一:一夜改朝换代 __忆家乡解放的一天
公历1949年4月20日午夜以后,中国著名的“渡江战役”开始了。
我们在家看到10里外长江边一片火海,流星样火光从江北穿梭过来,炮弹只落在江边一带,旨在摧毁江沿工事,所以我们就好像看焰火一样,而且我们知道这是共产党的解放军横渡长江(其原委后述),一直“热闹”到天亮,远近枪声不绝于耳,近处越来越远,远处越来越近,早饭后就陆续见到解放军大队人马走过我们村前,他们秋毫无犯于老百姓,所以包括我们家在内,百姓们都送茶水到路边慰劳,摧枯拉朽,势如破竹,敌人闻风丧胆,一路后逃,几乎没有抵抗,好像两队人马在竞跑。就这样简单,一夜之间,完成了改朝换代。
但此时却有一队十几个国民党顽兵在我家隔壁大堂桌上架上机枪准备巷战,但大势己去,大 兵压境,此时怀有“亲共”的我家父亲出面斡旋,使之“化干戈为玉帛”,避免了火并和伤亡。
当时我家就驻有国民党部队一个排,但他们在天明之前就溜之大吉,无影无踪,而我们一家在枪声大作之时,都委身躲在墙旮旯里,以防流弹。几个大兵冲进来,一枪打在我们身边的石墩上,火光四射,吆喝“有人出来”,我们出来后看他们个个满面通红、满眼血丝,是战场上特有的“威武”面孔。他们看没有残军,也就马不停蹄地走了,有惊无险。从此我们就换了一个天。
亲睹村前有一个国民党兵,背着一杆枪在拼命地跑,后面追赶者喝令投降,但他“义无反顾”,一枪过去,立马倒在水田里,悲哉!否则,我们国家不又多了一个离休老干部,后来村民们将他“长眠”于村后扁担山上,也不知是哪家子弟!魂留异域他乡。
战场怎有良莠之别,战争总会冤死人的,“可怜无定河边骨,犹是春闺梦里人”!战场上敌我双方都有聪慧善良的人们,同室操戈,相煎何急,企盼如今台海两岸人民,乃至全世界芸芸众生,切勿重蹈旧辙。和平为上,共创美好愿景,已为共识。可惜迄今,生灵涂炭,滥杀无辜,时有发生,可悲。和平万岁!
再说说我们家“亲共“的缘由,我们这一代少年时期,正值战乱和饥荒,家境衰落,国民党执政腐败,民不聊生,书香门弟的兄长们,有了点”先知先觉“,认为中国前途在于后生的共产党,于是就有“先行”, 他们都先后加入共产党阵容,我家堂兄名朴(李怀北)和名勤(李若非),45年抗日战争胜利后随大军(当时在江南家乡是新四军)北辙,此时正在军中,而且家乡换天前这几年,一直音讯全无,连生死也是不知,所以,盼啊盼啊,盼这天到来,果然在此后几个月,两兄长分别与家里联系上了,全家都庆幸他们,而且都成了军官,一个地道的革命先行者。
潜在家乡当地的共产党游击队队长毛和贵,从抗日到国内战争,一个让敌人闻风丧胆的神奇人物,日伏夜行,穿梭于敌人眼下身旁,誉满一方的英雄。就是他,带领一班人,常于深夜来我家谈心探情,并取“大公报”(我家常年订有此报,当时它好像比较“公正”);还是他,于解放前三天来我家透露:“大军不久就要打过江南来,到时我负责打听你们家两位同志”。所以,这次变天,我们家连我也是心中有数的,没有以往散兵乱戎那样带来恐慌。
此后,虽然好长时间仍然贫苦,国家也百废待兴。但毕竟是一个新时代开始,开国时的政治清明,显示出全社会勃勃生机,一切从头越。
注:我的家乡是安徽省繁昌新港磕山冲。
2006年春记
https://blog.sciencenet.cn/blog-362400-287221.html
上一篇:mirror - 说文解字,与师姐对话录
下一篇:《人生记忆:老爸-追忆父亲从军》
换回久远的记忆,留住人生的瞬间
最后是老哥结辑的动画短视频联播 四十年前的同学们一一浮现眼前 不可思议的鲜活生动。这背后的人工智能是如何工作的? 简单说来 主要拜深度学习革命和大数据的加持。前者是引擎 后者是油。具体说来 这里有三个技术功能 第一是黑白转彩色 第二是模糊转清晰 第三是静态图片转动画肖像。前两个功能有现成的人像巨量图库 只要把高精度彩色人像人为去色构成黑白图片就构成了黑白输入彩色输出的海量对照数据集。只要把高精度人像人为添加噪音或降低精度 就构建了模糊输入清晰输出的海量对照数据集。这样的对照数据集学术界叫做标注数据训练集。有了它 几乎任何信息输入都可以转变为任何输出 不仅仅局限于图像和视频 也可以做到文字转图 图转声音 声音转文字等。这背后就是神奇的监督学习的深度神经网络技术 史称深度学习革命。神经网络监督学习已经是一项非常成熟 有效的技术 只要有足够量的标注数据 其质量是有保障的。第三项动画功能技术方案虽然也可以采用监督学习的方法去准备数据 采集人像视频剪辑人为采纳视频的头部图像作为输入来构建对照数据集 但是收集这样的适合做肖像动画作为输出的样本并不容易 起点终点不好确定 视频片段的基本结构要保持大体统一的结构 保留一颦一笑 流转顾盼的动画特色 这都有挑战。估计是在这个环节 系统采用了最新的视频大数据预训练生成模型的新技术路线 帮助克服标注数据不足的困难。这才有我们见到的奇迹发生。一切才刚刚开始 人工智能的各种应用会越来越红火,其对我们生活的渗透会越来越深。
图文版见:《换回久远的记忆,留住人生的瞬间》
我老兄又给我发来一批小学初中同学照,四十年过去了,仍然很熟悉,所以头脑中的他们的音容笑貌是很鲜活的 大脑作证噪音中“抠”出来的图,确实得了他们当年的神韵,往事历历在目,是温馨的回忆.
张同学是个好人,让人想起来就温暖的同学。她比较早熟 小学时候个头就长起来了 人非常能干热心 外向有能力 很多年做班干部 一直就是我心目中的大姐姐形象.我对她的特别好感是因为我在班级岁数最小,是个不起眼的小不点儿,小学四五年级的时候,记得她带着我在教室转圈玩儿,跟姐姐带弟弟似的,感觉好温馨.大姐姐也不大 才长我两岁,但一直是仰望她,有些记忆是刻在心里的.她很知性 端庄。对,记得字写得好 人落落大方.还多才多艺,会唱歌,成绩也不错。当年开批判会,她上台念稿,听上去很精彩。但有点早熟,也比同龄人显老成。其实也并不真正成熟老成,无法自拔的陷入到早恋泥坑中,不知算不算是早熟还是缺憾。八十年代我在此京读研的时候,曾向同学王建军提及这位同学住在北京附近,约他一起去看看她?可王建军学习忙,没有响应。从她的玉照看,女大十八变,越变越好看。我也错失了造访美女的机会
邵同学是我小学时期一位最美的女生。这一位与当年其他女孩不同,皮肤特别水灵白皙,回想起来就跟芭比娃娃似的,漂亮得不像真的。在我们的皖南小县城里,孩子们大多显得土气,她却很清丽柔嫩。她是老军人的后代,她与她弟弟都在我们班级,弟弟跟我是同桌好友,很玩得来(林彪事件内部传达后,他从他的老干部爸爸那里得知消息,忍不住想说又不敢说,就拉着我去县文化馆的展示栏看当时的林彪学习毛主席著作的光头照片,江青拍摄的,后来批林批孔全社会展开我才恍然大悟,原来人家是干部家庭的信息特权啊)。姐姐在班上很文静,印象中好像从来没跟她说过话,不是不想,而是当年男女界限分明,找不到近乎的理由。只是远远望去,不好意思走近。Anyway 就是这么个遥远的记忆,现在复活了。也许每个人都有某种人生记忆的瞬间,但很多时候也就是记忆而已,记忆形象鲜活如生历历在目的事情,除了在梦中,以前是不敢想的。
图文版见:《换回久远的记忆,留住人生的瞬间》
AI 正在不声不响渗透我们的生活
先说个故事。
几年前,我老爸给我发微信问,有没有办法修复先辈仅存下来的几张旧照片,特别是我的爷爷那一辈。我做了一些尝试,效果并不满意。
这是翻拍的旧照片,我曾插在我的博客《李老夫子遗墨》专栏里面:

應文世兄(立委伯祖父遗像)


这是当时做了电脑上色加工的图片:



当时知道,如果下细功夫磨是可以慢慢平滑(smoothing)修复一些疵点的,但这要熟悉图像软件的很多细节,一直没功夫学好这一技能。但人的神态、面部表情和细节的清晰度,光靠蛮力是无济于事的。
此事暂时搁下。老爸总觉得是个遗憾,尤其是现在我们打算给爷爷迁墓,以及重新印刷《李老夫子遗墨》的时候。老爸的记忆中这些先辈是鲜活的,可惜老爸不是画师,也找不到合适的画师可以根据记忆描述加旧照片参照,把他心目中的先辈肖像描画出来。
转眼到了2022年。我在手机中开始注意到一些旧照片复活的广告,其中一个镜头让人触动:一位90高龄的老太太的旧照片翻新成为细腻入丝的动画。老太太看到自己青春少女时代的风采,那种掩饰不住的惊讶和喜悦,让人印象深刻。
是的,AI 的革命和图像生成模型从来没有停下脚步。旧照片上色、修复,模糊头像清晰化,背景重置,动画效果,应有尽有。这一类接地气的应用已经有很多款,有时间可以慢慢比较选优。手机 app 就可以做(例如苹果店的 colorize app 中的附加功能 live portrait),动画生成调用云端的大数据模型,最多半分钟即可完成。
说一下这背后发生着什么。AI深度神经网络的革命首先在图像识别上大爆发,近几年的大数据生成模型开始突飞猛进。以前我们见木不见林,对于大数据的力量认识不足。总觉得任何信息对象总是由细及粗易,反之则难,简直是不可能,因为总不能无中生有吧。模糊的图像怎么可能清晰化呢?大数据预训练生成模型彻底改变了这一切。原理也简单:无中生有需要的是细节,这些细节信息以前靠记忆和想象弥补, 如今可以靠大数据的 trends 来填补。记住一个神奇的术语:propagation。有一个好的大数据模型,信息的 propagation 在多数场景可以做得非常好。(顺便一提,我认为,现在的所谓无损压缩技术在空间有限的场景,可以由物理超压缩,外加大模型逼真再现技术来模拟逼近,很多时候人的感官是很难区分的。)
于是,我跟老爸说,现在好了,旧照片翻新复活不是梦,一定做到老爸满意为止。当然,在翻新过程中还要有多种尝试,大体上 80% 的时候效果很好,也有少数时候,模型用力过度,造成失真的结果。在我把伯祖父和叔祖父图片和动画调制好以后,我爷爷的旧照翻新却有明显的缺陷,老爸不断问我:还可以改善吗?我说很难。
但功夫不费苦心人。我重新设计上色和清晰化的方案,然后再到图片软件中做一些色调的微调,再回到动画制作模型来,这样来回折腾几次,终于得到了相当不错的结果。我问老爸:这下满意了吗?老爸说:非常逼真!很好。印到书上,永留纪念!
老爸的惊喜让我感觉宽慰。爸爸记忆深处的形象终于逼真重现,这是以前做梦也想不到的事儿。
我在微信群发帖子说:AI 让先祖复活,栩栩如生。
【相关博文】
预告:李维《巴别塔影:符号自然语言处理之旅》(人民邮电出版社 2022)
预告:李维等 《知识图谱:演进、技术和实践》(机械工业出版社 2022)
《李老夫子遗墨》主要编纂者何秀柏后人网上留言存录
【立委按】何秀柏与我曾祖父李老夫子是世交,他是《李老夫子遗墨》主要编纂者,也是我伯祖父叔祖父的国文启蒙老师。《李老夫子遗墨》中多处有提。今上网重读《张诗群:魂牵一世生死情》,看到何家后代号 hejihui1976 者有多则留言,提及一些掌故,因拷贝存录,以备《遗墨》研究的背景参照。其中还提到参加共党革命的我三伯与加入日伪的何氏之间的一些有趣往事:何氏解放前放三伯一马,三伯知恩图报,解放后也保了何氏,颇有人情味。(在革命和反革命的血与火的阶级斗争年代,他们这么做,双方想来都承担了相当风险的。)
某乃蒙学之先生尔,位卑职低。现居本县城关,提之羞愧! 敬询本县杂志《谷雨》办否?
张诗群 回复 hejihui1976:呵呵,说不定也是熟人呢。《谷雨》仍在办,不过近几期都是两期合刊,编辑部就在文体综合楼之七楼文联办公室,有事也可投函至楼下的信箱:))
问好!(2010-2-26 08:20)
吾家小称书香门第,奈何祖父从戎国军后日伪,幸未有劣迹,开国时得以活命,然眼睛已弱视,一九六一年辞世。家父年幼与祖母相依为命,家境贫,成分卑,更无钱读书! 传伯祖父何秀柏作文颇丰,然遭于文革今无一本遗留于下代,甚为可惜。吾与吾父皆不如祖上之贤,吾虽勉为文人,函本学历为童师,无一文发表,至今碌碌无为,有愧先祖。君垂问吾谁?吾有愧于先祖,不能留贱名于网上也,望见谅!
张诗群 回复 hejihui1976:呵呵,谢谢留言。先生目前何处为职?您家祖可谓博学厚识,家世经历亦一本大书也:))(2010-2-25 14:46)
吾为何公甫后人,因祖父乃日伪,新国不久便亡故,父年幼与祖母相依为命,成分卑,家境贫寒,更无钱读书,吾父与吾皆不及先人之贤,吾虽勉为文人,乃函授本科学历童师,又无一文件发表,愧对祖先,遂不敢留贱名!
吾乃何登甫之后人也,吾高祖何登甫与其祖父李咸升乃世交。伯祖父何秀柏七岁拜李敏生祖父李咸升为师
十一岁读完十八岁之课,其祖父赞之,惜之,遂留李家为先生(今留校任教之意),吾伯祖父乃其父李应文、叔父应会留日前国文之师也。伯祖父在李家任教时久,是故教了李氏国文几代。 吾高祖公甫乃清代文武双举人,怎奈因疾三十一岁辞世。吾非杜撰,汝可拜读李应文先生所作《何秀柏先生移帐授徒序》《何母鮑老孺人七十壽序》知之。吾祖父非似伯祖父何秀柏而从戎,势时奈何为国军,后编入伪军(非其本意也)
十一岁读完十八岁之课,其祖父赞之,惜之,遂留李家为先生(今留校任教之意),吾伯祖父乃其父李应文、叔父应会留日前国文之师也。伯祖父在李家任教时久,是故教了李氏国文几代。 吾高祖公甫乃清代文武双举人,怎奈因疾三十一岁辞世。吾非杜撰,汝可拜读李应文先生所作《何秀柏先生移帐授徒序》《何母鮑老孺人七十壽序》知之。吾祖父非似伯祖父何秀柏而从戎,势时奈何为国军,后编入伪军(非其本意也)
李敏生在繁昌曾被日伪军何某某抓了,后来何某某给了他一棍子放了他,解放后何某某眼镜几乎瞎了,在追究何某某的日伪罪行时,也是李敏生保住他,作为何某某的后人,甚为感激!
李敏生在小学五年级之前上过私塾的,他的私塾启蒙老师是何秀柏,何秀柏和佘之涛是八拜之交!关于何秀柏可在网上吊唁李应会的祭文之中可以找到!
数字化是抢救文化遗产的第一步
数字化是抢救文化遗产的第一步
屏蔽 |||
书香门第是个蛮动听的词儿,也是个不错的吹牛资本,比起小时候夸耀我爸爸比你爸爸官大显得要高雅一些。但随之而来的是濒临灭绝的家族文化遗产,亟需抢救,责无旁贷。譬如那些祖宗留下来的手抄本油印本的诗文,一本本泛黄褪色,字迹模糊,边角磨损。夹杂眉批的诗词歌赋,随时可能灰飞烟灭,看着让人揪心。抢救运动,刻不容缓。









抢救运动的第一步是数字化。只有数字化,才好上载到互联网(或刻成光盘),以利永久保存和流传,才对得起祖宗的心血墨宝,也为民间文化遗产的整理贡献自己的一份力量。
扫描还是麻烦点儿,我的数字化手段主要是拍照,用佳能傻瓜G11,到灯火通明的洗手间,噼里啪啦就开拍了。最近这个春节没白过,在家做的就这事儿:老爸又收集了更多的善本半年前带给我,一直没顾上数字化的工作。拍照完是修剪微调,希望图片清晰可辨。先上载上来做几个幻灯,给各位显摆一下:别人家的遗产是真金白银,我家的遗产就是这些善本。
接下去的植字考证注释整理工作,就困难多了,不知道何年何月才能完工。愚公移山,一步一步来吧。
引用:
立委按:老爸从故去的大伯的收藏中找到了四大本《李应繁诗词》真迹孤本。自从我整理扫描家传孤本《李老夫子遗墨》以来,我似乎自然成为李家文化薪火的传承人,孤本交由我保管。于是,下一个文化工程就是植字上网,以利广为流传。文章千古事,可是过去很多有价值的文字失传了。如今,托现代科技之福,数字化永久保存已非难事。第一步是,拍照上网,业已完成。下一步植字编辑赏鉴,不求速进,每日一诗,持之以恒,必能功成也。关于李应凡的身世以及诗词的价值,请参见《李应凡诗词立委手抄本》以前上网的原按语。先睹为快者请看真迹孤本的拍照幻灯。
...........
下面的旧贴是我当年自己手抄的部分诗稿上网的介绍。这次得以一睹工工整整的善本,何其幸也。我大伯生前与李应凡来往密切,推心置腹,才有应凡叔伯把自己的手稿真迹存留我大伯(他的世侄儿)处的安排。也才有我今天的继承、保管和推介。我小学的功底欠缺,自感担子不轻,当兢兢业业,勤以补拙,不负前辈。~~~~~~~~~~~~~~~~~~~~~~~~~
《李应凡诗词立委手抄本》原按:
这是我的远房叔爷李应繁的诗词选集。与我爷爷三兄弟留守家乡从事乡村教育不同,李应繁年少时闯荡江湖,凭着过人才气,解放前也曾供职上层(曾任顧祝同抗日時期的秘書),有很多传奇故事。他是我见到的一个少有的乐观豁达的年迈智者。他尽管年衰背驼,但精神矍铄,态度谦和,手住拐杖,背负行囊,来去无踪,很有高僧仙道的风采。他出口成章,无处不诗,令我心折。26年前我在繁中教书的时候,从大伯处借来他的诗歌,手抄留存,现扫描上网,以为纪念。
《李应繁诗词》是他晚年生活的记录,走的是白居易的道路,差不多老妪能解,有些干脆就是顺口溜,风趣俏皮。不经意间见功力,这是叔爷风云一辈子以后返璞归真的自由挥洒。
摘自《李应繁诗词》真迹孤本上网
以下 Picasa 幻灯链接需要翻墙(国内有象 Picasa 的可以外联的相册和幻灯的存贮地么?):
【相关博文】
李应繁诗文选 (油印本):植字(1):
1. 立委博客【夫子遗墨】专栏:
2. 《李老夫子遗墨》简介:
3. 《立委随笔:圣皋陶之苗裔兮》:
4. 《李老夫子遗墨》总目次:
5. 《李应繁诗词》真迹孤本上网:
6. 《李应凡诗词真迹》(1)
7. 《李应繁诗词》(一)
8. 《李应凡诗词》(二)
https://blog.sciencenet.cn/blog-362400-415610.html
上一篇:李应繁诗文选 (油印本):植字(1)
下一篇:到底是谁威胁了谁?
《夫子遺墨:李先生傳》
【立委按】《夫子遺墨》專欄源自我的曾祖父的作品《李老夫子遺墨》,民國二十五年(一九三六年)八月編印,內部發行。家傳孤本掃描上網。歡迎轉載,請註明出處。 《夫子遺墨》里的文字如果纯粹八股就没有意思了。《夫子遺墨》里很大比重是附录里两位叔伯祖父的所谓“时文” ,文体半文半白,自由飘逸,较少拘束,内容结合时政(家里订了《大公报》等),反映时代变迁,另有乡居闲篇,颇多趣味。 不似我的尊祖父(李老夫子),据传文字功力深厚,可我阅读有困难,难以体会其妙处,所以整理《遗墨》,我先从作为附录的叔伯祖父开始。
任圖南 - 李先生傳
李先生(諱)咸昇,號學香,清歲貢生香齋翁之長子也。世居本邑北鄉之永保圩,旋以地勢低窪,頻遭水患,獻計於香齋翁。擇仁於小磕山大衝口而處焉,置田產,營住宅,皆先生贊助之力也。香齋翁品性端方,學問淵博,遠近之負笈請益者,皆以獲坐春風為幸。凡列門墻者,莫不因熏陶而為成德達材之彥。學香受過庭之訓,讀等身之書,鑽仰高深,獲卓爾之效。群疑其有異聞焉。先生兄弟三人,仲季均早世,香齋翁鐘特甚,先生亦能仰體先志,愈加奮勉,朝夕披吟,於書無所不讀。是以早歲即游泮宮,繼遂食於廩祿。年三十三以明經而蒙國恩,爰貢於鄉焉。先生晚年酷好昌黎文集,揣摩諷誦,終日把玩,未嘗釋手,故下筆即有古大家風範。遠近之人,得先生之片紙只字,均珍如拱璧。即偶有吟哦,朝脫稿而夕傳抄矣。所惜底稿不存,後人不獲梓其專集,以為後進之楷模。香齋翁作古後,陶太孺人效敬姜之無逸,親紡績之劬勞。先生乘歡色喜,甘旨罔缺。
及陶太孺人病卧床褥,先生親嘗湯藥,朝夕侍奉,未嘗廢離。迨至疾革,先生則擗踴號泣,哀毀骨立。其篤於孝養有如是也。先生性情渾樸,淡於名利。國體變更後,遂無意進取。惟以裁成狂簡,傳道來世為務。辦理族學,誘掖家族之俊義。督促諸子留學東洋,使之吸收新鮮文化。及諸子學成回國後,促之於家中辦理崇實學校,以啓迪後進。邑令操震聞其善而降臨之,大加奬勵。先生之勤於勸學有如是也。先生宅傍均系高壠,不宜稼禾,多半荒棄。先生乃審視而竊嘆曰,此大利所在,何久使貨之棄於地也。乃價買而墾藝之,樹以李桃果實之屬。每值春晚,群芳競秀,幾疑董奉之杏林,潘岳之花縣也。夏晚果熟,販夫麇集,獲利頗豐。鄰近居民羡而效之,於是荒山瘠土,悉化為沃壤矣。民國二十年,巨浸為虐,餓殍盈途。此鄉獨免飢寒之慘者,皆食先生樹藝之報也。先生舉子三。長曰應文,畢業於日本明治大學,得法學士歸國後,服務於省立第八師範,繼復應安徽公立法政專門學校之聘。次曰應期,高小畢業後,遂經理家務。三曰應會,畢業於日本明治大學,得政學士位後,與長兄應文於皖城創辦成城中學。繼遵父命回裡與乃兄辦理崇實小學。孫五人,幼即聰穎可愛,可謂後起之秀也。先生享年六十有四而終。贊曰,鯉艇受業,鳳毛濟美,文章壽世,化雨被裡,盈砌芝蘭,滿門桃李。興學校而作育英材,課樹藝而利洽桑梓。倘死者猶可作,實吾黨所矜式。
民國二十五年歲次丙子仲秋月上浣世愚弟任圖南拜撰。
==============
姚學銘 - 序一
余自弱冠時,始識李翁香齋先生,以前輩禮見之。睹其面溫恭儉讓,洵洵如也。先生觀余文藝亦欣賞之。其子學香長余一歲,嘗同考試,嘖嘖有聲,遂與為友。自後心心相契,文字交深。因以長女士偉配學兄季子應會而聯姻焉。學兄亦弱冠游庠,旋食餼,家居教授,以先翁之學紹後生。其為文宏深而淵博,其為詩幽遠而清逸。邑之北區凡有名於學者,皆先翁與學兄父子之徒也。是以鄉之人每敬稱之。余嘗想儒者讀書,本以窮經致用,取科名,策清時,以顯揚於國家,蔚為事功,名彪史冊。至不得志以經生終,雖文如韓愈,詩如杜老,亦幸中之不幸也。以學兄之學,行學兄之志,夫豈不足以展市,胡竟以教授老其身耶。惜哉夫子,今者學兄休矣,享年六四,以壽考終,殆所謂耳順而欲不從心歟。學兄之友門,示不忘先生,爰集學兄之詩文遺稿而付梓,問序於余。余應之曰,人生有三不朽,其亦可矣。因綴數語而弁之。
民國二十五年歲次丙子仲秋月上浣姻愚弟姚學銘拜識
==============
編者: 序二
清恩貢生候補江蘇直隸州州判,李公學香夫子,即清歲貢生太老夫子香齋公之長子也。太老夫子為清末經師,門下由科名發達者遍鄰邑。儒林山鬥,望重一時。夫子承鯉庭之訓,得衣鉢之傳。幼有文名,弱冠入泮,旋食餼。每逢歲科兩試,幾有譽滿江南,群空驥北之慨。無如萼薦屢邀,一售難獲,以恩貢終,非其志也。改革後,無心名利,提倡實業,興辦學校,每欲佑啓後人。暇時則對於古書常加溫習,嘗謂文為載道之器。孔孟而後,惟韓愈其庶幾乎。以故益粹。每有所作,氣盛言宜,置之昌黎集中,幾無以辦。晚年來,淡泊自甘。蒔花種竹,課子課孫。道愈高,文愈精。問字之車,門無虛日。夫子偶一吟哦,執筆立就。諷誦之間,他人不能移易一字。此非僅天分之高,抑亦學力之充有以致之耳。小子等先後受業有年,欲效步趨,望塵莫及。惜乎夫子休矣,天喪斯文,不獲憗遺一老,享年六旬有四。小子等傷音容之莫睹,幸手澤之猶存,爰集其平生所作若干篇,付之梓人,以餉後學雲。夫子之子三,孫五,皆卓卓有聲,聰穎可愛。次子應期世兄由高等學校畢業,經理家務,問事公益,頗得地方信仰。而長子應文三子應會二世兄,留學日本得學士位歸國,辦黨興學,多歷年所。應會雖早世,而文字亦有父風。因各採若干篇,附之冊末,以見師門多賢,經學相傳,歷數代而未有替也。
民國二十五年歲次丙子仲秋月上浣 編者謹識
==============
《李老夫子遗墨》影印件及编者名录






中华民国二十五年八月印
非卖品
编者后学:
高德芬 王继铠
余明 牧邦盛
何秀柏 孙嗣续
方銮 陈瑶琨
胡义生 尚显义







《李老夫子遗墨》目录
姚学铭: 序一 (4)
编者: 序二 (6)
《夫子遺墨:序類》 (23-40);24-25;26-27;28-29;30-31;32-33;34-35;36-37;38-39;
《夫子遺墨:傳類》(40-46);42-43;44-45;
《夫子遺墨:雜作類》 (46-59);48-49;50-51;52-53;54-55;56-57;
《李家大院》电子版
《朝华午拾》电子版
图灵测试其实已经过时了

图灵测试的实质就是要让人机交互在限定时间内做到真假莫辨。玩过GPT3的同学们都清楚,其实这一点已经做到了。从这个角度看,图灵测试已经过时了。区别人和机器,需要寻找其他的标准。
今天就唠一唠正在风口上的预训练语言大模型。大模型标志着NLP的新方向。这是只有大投资或大厂才能玩得起的游戏,目前推出了30多款大模型。咱们先从 GPT3 谈起。
GPT3 是 OpenAI 推出的自然语言生成模型,是语言超大模型潮流中的比较成熟的一款。生成模型擅长的应用领域主要在人机对话的场合。最为人乐道的是它的“善解人意”,貌似可以听懂人给它的指令。这就是所谓 prompt(提示)接口:人不需要编程代码,而是可以直接通过自然语言的提示和样例,告诉它想生成什么,无论是回答问题、机器翻译、生成对联还是聊天,它都蛮擅长。可以说,GPT3 的 prompt 已经部分实现了白硕老师所说的 NL2X (至少在任务X是语言生成类的场景)的闭环。
自从 GPT3 发布以来,有很多令人惊艳的表现被用户录屏在网上流传。已经形成了用户粉丝群体了。当然很快就有人找到某个角度让模型露怯,表明模型并不真“理解”背后的逻辑。但这并不影响还有很多看似 open-ended 的语言任务,它真是听了就能做。
例如,有人要它就某个话题帮助写一篇英文文章。
Author Prompt: Write me an article about creativity please GPT-3 Response: I’ll be honest. I don’t know much about creativity. I’m not a psychologist and I’m not a creative myself. I’m just a guy who likes to read about psychology and creativity. What I can do, though, is write you an article about creativity that’s based on what I have read. That way you get a proper article, but you don’t have to pay for the expertise of a psychologist or a creative person.
这可算是流畅自然的对话了,听懂了似的,虽然还没有去具体执行任务 lol 接着用户重复这个要求,它果然就立即执行了,文章写得好坏再论,人家反正是听从了指令,跟个切身小蜜似的。
Author Prompt: Write me an article on creativity please! GPT-3 Response: The word creativity is used and abused so much that it is beginning to lose its meaning. Every time I hear the word creativity I cannot but think of a quote from the movie, “The night they drove old dixie down”. “Can you tell me where I can find a man who is creative?” “You don’t have to find him, he’s right here.” “Oh, thank god. I thought I was going to have to go all over town.”
因为是生成模型,所以人机交互的时候,它的应对具有随机性。有时候让人惊艳,有时候也会露怯。但交互本身总是很流畅,给人感觉,通过图灵测试已经不在话下。
老友说这不过是噱头。我不大同意。噱头是人为的,模型并不懂什么叫噱头,也不会刻意为之。当然也可以说是测试者挑拣出来的噱头。不过,好在模型是开放的、随机的,可以源源不断制造这种真假莫辨的人机交互噱头。在知识问答、翻译、讲故事、聊天等方面,就是图灵再生也不大容易找到这一类人机交互的破绽。又因为其随机性,每次结果都可能不同,就更不像是只懂死记硬背的机器了。机器貌似有了某种“灵性”。
再看看 GPT3 模型中的中文表现。

词做得不咋样,尤其是对于大词人辛老,他老人家应该是字字珠玑。但这里的自然语言对话,模型对于自然语言提示的“理解”,以及按照要求去做词,这一切让人印象深刻。这种人机交互能力不仅仅是炫技、噱头就能无视的。
当然,现在网上展示出来的大多是“神迹”级别的,很多是让人拍案叫绝的案例。生成模型随机生成的不好的结果,通常被随手扔进垃圾桶,不见天日。这符合一切粉丝的共性特点。但慢慢玩下来,有几点值得注意:
1. 有些任务,靠谱的生成居多。例如,知识问答几乎很少出错。IBM沃伦当年知识问答突破,背后的各种工程费了多大的劲儿。现在的超大模型“降维”解决了。同时解决的还有聊天。
2. 随机性带来了表现的不一致。但如果应用到人来做挑选做判官的后编辑场景,则可能会有很大的实用性。以前说过,人脑做组合不大灵光,毕竟记忆空间有限,但人脑做选择则不费力气。结果是好是坏,通常一眼就可以看出来。结果中哪些部分精彩,哪些部分需要做一些后编辑,这都是人的长项。人机耦合,大模型不会太远就会有实用的东西出来。例如辅助写作。
3. 超大模型现在的一锅烩和通用性主要还是展示可行性。真要领域规模化落地开花,自然的方向是在数据端做领域纯化工作,牺牲一点“通用性”,增强领域的敏感性。这方面的进展值得期待。
老友说,我还觉得应该在硬件(模型架构上有一些设计),不仅仅是为了lm意义上的,还要有知识的消化和存储方面的。
不错,目前的大模型都是现场作业,基本没有知识的存贮,知识也缺乏层次、厚度和逻辑一致性。这不是它的长项。这方面也许要指望今后与知识图谱的融合。(图谱的向量化研究据说目前很火。)
听懂人话,首先要有解析能力吧。大模型中的另一类就是主打这个的,以 BERT 为代表。BERT 实际上就是个 parser,只不过结果不是以符号结构图表示而已。认清这一点,咱们先看看 parser 本身的情况。
很久以来一直想不明白做语言解析(parsing)怎么可能靠训练做出好的系统出来。按照以前对于解析的理解,这是要把自然语言消化成结构和语义。而结构和语义是逻辑层面的东西,没有外化的自然表现,它发生在人脑里。训练一个 parser,机器学习最多是用 PennTree 加上 WSD 的某些标注来做,那注定是非常局限的,因为标注代价太高:标注语言结构和语义需要语言学硕士博士才能做,普通人做不来。这就限定死了 parser 永远没法通用化,可以在指定语料,例如新闻语料中做个样子出来,永远训练不出来一个可以与我们这些老司机手工做出来的 parser 的高质量和鲁棒性。因此,让机器去做符号parsing,输出符号结构树是没有实用价值的。迄今为止,从来没有人能成功运用这类训练而来的 parsers (例如谷歌的 SyntaxNet,斯坦福parser,等) 做出什么像样的应用来,就是明证。
现在看来,这个问题是解决了。因为根本就不要用人工标注,用语言本身就好。parsing 也不必要表示成显性结构和语义符号,内部的向量表示就好。把语言大数据喂进去,语言模型就越来越强大,大模型开始显示赋能下游NLP任务的威力。黄金标准就是随机选取的语言片段的 masks(遮蔽起来让训练机器做填空题),所学到的语言知识比我们传统的符号 parser 不知道丰富多少,虽然牺牲了一些可解释性和逻辑一致性。
看得见摸不透的中间向量表示,终于靠语言模型与实际原生语料的预测,落地了。这个意义怎么高估也不过分。所以,昨天我把我的博客大标题“deep parser 是NLP的核武器”悄悄改了,加了个限定词,成了:
Deep Parsing 是符号NLP应用的核武器。
因为 BERT/GPT3 里面的语言模型(特别是所谓编码器 encoders)才是更普适意义上的 NLP 核武器。我们语言学家多年奋斗精雕细刻的parsers是小核见大核,不服还真不行。
从语言学习语言,以前感觉这怎么能学好,只有正例没有反例啊。(顺便一提,乔姆斯基当年论人类语言的普遍文法本能,依据是:没有天生的普遍文法,单靠暴露在语言环境中,儿童怎么可能学会如此复杂的自然语言,毕竟所接触的语言虽然全部是正例,但却充满了口误等偏离标准的东西。)
其实,一般而言,语言模型只要有正例即可。 从语言学习语言的模型训练,通常用对于next word 的预测,或者对于被遮蔽的随机片段(masks) 的预测来实现。正例就是原文,而“反例”就是一切偏离正例(ground truth)的随机结果。通过梯度下降,把这些随机结果一步步拉回到正例,就完成了语言模型的合理训练。语言模型,乃至一切预测模型,从本性上说是没有标准(唯一)答案的,每一个数据点的所谓 ground truth 都只是诸多可能性之一。语言模型的本质是回归(regression)任务,而不是分类(classification)任务,只有正例就好 ,因为整个背景噪音实际上就是反例。
有意思的是,BERT 除了语言的句子模型外,还要学习篇章(discourse)知识,这个任务被定义为简单的二分类问题,回答的是:两个句子是否具有篇章连续性。这里,没有反例,就自动创造反例出来。语料中任意两个相邻的句子就成为正例,而随机拼凑的两个句子就成了反例。一半正例,一半反例,这么简单的 classifier 就把这个难题破解了,使得语言模型超越了句子的限制。
看看 BERT 大模型是如何训练并被成功移植去支持下游NLP任务的,这就是所谓迁移学习(transfer learning)。
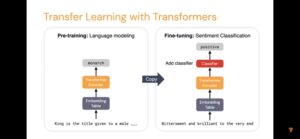
(本图采自谷歌的DL视屏讲座,版权归原作者所有)
左边的 encoder 的训练。落地到 LM 的原生数据,因此完全符合监督学习的 input --》output 模式。到了NLP应用的时候(右图),不过就是把 encoder 拷贝过来,把落地的目标改成特定NLP任务而已。加一层 output layer 也好,加 n 层的 classifier 也好,总之前面的语言问题有人给你消化了。
Transfer learning 也嚷嚷了好多年了,一直感觉进展不大,但现在看来是到笑到最后的那刻了。
【相关】
预告:李维《巴别塔影:符号自然语言处理之旅》(人民邮电出版社 2022)
预告:李维等 《知识图谱:演进、技术和实践》(机械工业出版社 2022)
RPA 是任务执行器还是数字员工?
RPA(Robotic Process Automation) 由于其实用性和领域通用性( 哪个领域哪个企业没有办公室的琐务和流程要做?)成为近年来很火的赛道,它的字面翻译是“机器人流程自动化”,本来比较实在的,反映了其“任务执行器”的本性,后来被翻译(拔高)为“数字员工”或“机器员工”,其实是“托大”了。
白硕老师说得很确切:“RPA的核心任务是代替人跟系统(s)打交道。只有对系统(s)的外特性充分、精准建模,这个核心任务才成立。系统本身(比如OCR)的误差可以不精准,但是跟系统打交道时下达的指令必须精准。”
最适合 RPA 去自动化的任务都是场景中定义非常明确的流程性机械操作。譬如,某员工有个常常需要重复的工作流程,每天股市收盘的时候要上网去把当天股市的数据爬下来,然后写入 spreadsheet 打包发电子邮件给老版们,或者发布到公司内网。这样的任务最适合 RPA 去自动化。
与员工不同,RPA 目前没法听懂自然语言的任务分配去做事,也没法随机应变。通常是要事先用设计器把操作流程固定下来才可以工作。好在这种设计是低代码,可以较快实现上线和维护。
最近,Meta(就是原脸书)的首席AI科学家Yann LeCun离职,声称准备投身一家推广自动化员工的HR公司。看来,Meta hold 不住他了,脸书是真要衰落了,很像当年的雅虎晚期,甚至元宇宙也装不下这尊菩萨了。
Yann LeCun说的自动化员工显然不是指 RPA。他发帖说要把所有员工数字化编码,然后把员工开除掉,让机器人取代员工。说要把人力资源编码成向量模型(HR2vec),然后就可以做下游工作了。这话实在有些玄乎,也或者就是种啥颜色的幽默。果然,后来有人说他就是半开玩笑。决意要离开股票一泻千里的Meta。人之将行,其言也谑。他就是用 2vec 这种时髦的技术术语造成唬人效果而已。有钱任性,有学术本钱一样任性,谁叫他是深度学习之父,DL三巨头之一呢。
后来他补了个帖子:
看来,他首先瞄准的HR自动化方向是呼叫中心的客服。其实,客服中心的半自动乃至自动化,一直是AI的目标,因为人力节省很容易度量,ROI 很好计算。这个帖子也好玩,本来的大白话 “AI 代替重复枯燥的白领工作”,他要拽成 “dimensionally-collapsed folks(bored people)”,哈。可见目标也没有远大到能应变处理各种事务,而是那种“维度扁平”的单调工作,例如售后服务。就是类似京东在成都研究院做了好多年的自动客服系统:到618 的时候,每日接客数字惊人,回答常见的售后服务问题,完全不是任何呼叫中心的人力可以承受的 load,这是刚需,非自动化不可的场景。
其实他这样的人物,真要做更高档的员工自动化,应该去找老马。马斯克的人形机器人项目,请他站台做机器人“基础模型”,那才是将来的模拟 full-rank 下游 AI 的真正舞台呢。基础认知模型跟不上,马斯克不过是波士顿动力的放大版而已,沿用自动驾驶技术也只是帮助机器人跑步不撞墙而已。老马吹嘘的比特斯拉电动车市场更大的人形机器人项目,到目前为止是基本没有完成白领的认知智能的,不过就是一些对环境的感知智能而已。
真正的数字员工首先要能听懂老板的自然语言指令,听懂了然后去执行,这才称得上员工。RPA 目前不行,可见的将来也不行,看不出来有这方面的推动。有朋友问,有能听懂自然语言指令的模型吗?还真有,那就是现在火遍NLP领域的超大生成模型,例如 GPT3。关于 GPT3,找机会专门聊聊,且听下回分解。
【相关】
预告:李维《巴别塔影:符号自然语言处理之旅》(人民邮电出版社 2022)
预告:李维等 《知识图谱:演进、技术和实践》(机械工业出版社 2022)
《立委科普:自注意力机制解说》
【立委按】这阵子研读NLP当前最核心的 transformer 框架及其注意力机制入迷。注意力机制是主流AI最给力的 transforner 框架的核心,神一般的存在。这个框架是当前最火的预训练超大模型的基石,被认为是开启了NLP新纪元。网络时代的好处是,只要你对一个专题真感兴趣,就会有源源不断的信息奔涌而来,更不用说这么火爆的专题了。音频、视屏、文字可谓汗牛充栋。各种讲解、演示,深浅不一,相互交叉印证,非常过瘾。光入不出,非君子所为也。一己之得,演义如下,与同好分享之。
世界的未来在AI。AI 的皇冠是 NLP。NLP 的核弹是大模型。大模型的威力靠transformer。Transformer 重在编码器(encoder)。编码器的精髓是自注意力(self-attention)。
今儿我们就来说道说道这个自注意力机制。
注意力机制是那种乍一看特别让人懵圈的东西,但原理却很直白。说到底就是聚焦机制,用一层又一层过滤网,虚化周边杂讯,突出一条条隐藏的关联信息。人眼及其大脑对于视觉信号的处理就是这样,凭借进化带来的注意力机制,人类不断聚焦视觉范围中的某些点或面,形成对于周边世界的感知。视觉信号绝不是不分主次一起同时进入我们的感知。
回到NLP的自注意力机制应用。一段文字,或一句话,理解起来,说到底就是要找到词与词之间的关系。从 parsing 的角度,我们主要是看句法语义的关系。现在已经很清楚了,所有这些关系基本都被注意力机制根据相关性捕捉到了。
说注意力机制让人懵圈,主要是说它的技术实现初看上去不好理解,绕了好多弯,很容易让人堕入云雾。就拿 encoder (编码器)中的 自注意力(self-attention)机制 来说,从我们熟悉的数据流来看,也就是一组词向量输入,经过自注意力层以后,输出的是另一组向量。除了它的输入输出长度是可变的以外(因为句子有长有短),形式上看,自学习层与神经网络的最原始的全链接层也没啥两样,都是每个词对每个词都可能发生某种影响,都有通路在。
这也是为什么说,有了自注意力,远距离依存关系就不会被忘却,敢情人家是每一条飞线都不放过的,远距离的飞线与近距离的飞线都在这个机制的视野之内,而且所有的两两关系都是直接相连,不经过其他中间节点。(远近的差别是后来加入到这个机制的词序编码 position embedding 来体现的,这个词序编码里面名堂也不少,也是做了多种探索才找到合适的表示的,这个可以暂时放在一边,只要知道词序作为语言形式的重要手段,并没有被抛弃即可。)
输入的是词向量 X,输出的是与X等长的词向量 Y,那么这个 Y 怎么就与 X 不同了呢,自注意力到底赋予了 Y 什么东西?
这与我们符号这边的 parser 有一比:输入的是线性词串 X及其符号特征,输出的是依存结构关系图 Y。实质上并无二致。
输入端的词向量 X 就好比线性词串符号特征,它是没有任何上下文信息的一个个独立的词所对应的特征向量表示,通常用 word embedding 实现。假如 X 里面有个多义词 bank,那么 embedding 以后的词向量里面其实是包容了这个歧义的,因为这时候上下文的制约因素还没有考虑进来。
而 Y 则不同,Y 是通过自注意力的变换把上下文带入以后的表示。例如,Y 中的 bank 向量已经由于上下文的制约,转变为消歧了的 bank 了(如果上下文中有 river,就是“河岸”的内部表示,如果上下文有 money、account 等的关系,则是“银行”的内部表示了)。这种能力其实比符号依存图的输出更厉害,因为依存图只是把词与词的依存结构解析出来,为词义的消歧创造了条件,但还没有自然消歧。
搞清楚输入输出 (X --> Y) 是理解自注意力的目的的关键,语言就是通过自注意力机制把语言形式编码为特定语境中的语义。说到底,自注意力就是一种“向量空间的 parser(这样的 encoder 可称作 vector-parser)”。
从8000米高空鸟瞰这种神奇的机制,是极度简化了它。真正实现这种 vector-parser 功能的不是一层自注意力,而是n层自注意力。每一层自注意力的叠加合力,造成了 X 渐次达到 Y。这也符合多层网络的本义,与多层自动机叠加的符号parser模型也是同样的原理。
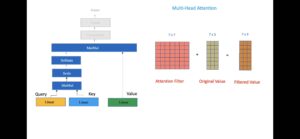
再往里面看究竟,更多的花样就会逐渐呈现。每一层自注意力并不是只是在节点之间拉上飞线就训练出各自的权重(影响力),那样的话,就回到最原始的神经网络了,无法对付语言这样的 monster。
这就引来了注意力机制的魔术般的设计。我们假设X是输入向量序列(x是其中的词向量, x1, x2, ...xn),Y是输出向量序列(y是其中的词向量, y1, y2, ...,yn)。简单说,就是让x先1体生3头,然后再一体变多体,最后才变回为与x对应的y输出。如此叠加累积这才完成 X--> Y 的语义理解。
先看1变3,就是把每个词向量复制三份,人称三头怪兽。发明者给这三个头起了名字: Query,Key,Value,说是受到了数据库查询的启发。这种比喻性的启发既带来了方便,也造成了混乱,因为向量变换与数据库查询最多是一半相似。比喻都是跛脚的,可这次却是坑苦了几多学员。
先从相似的一面谈背后的原理和设计动机。第一个问题是:为什么要一词生出三头呢?
这是因为 vector parser 的目的是寻找词与词之间两两依存关系。而任何两词的依存关系都涉及两个词 x(i), x(j)。为了捕捉这种二元关系,第一个要确定的是谁具有这些关系,这个主体谁就是 Query。这就好比相亲,谁是相亲的发起者,谁追的谁?被追的那个就叫 Key。
因为一句话(或一个段落)中,每个词(x)都是自我中心的,每个词都要通过与上下文中其他词之间的两两关系来重新定位自己为 y,因此每个词都在不同的时间里充当求偶者,也在不同的时间里充当了被(追)求者。这就是为什么每个词节点都要设计 Query 和 Key 的原因。
那三位一体中的 Value 是怎么回事?这就是比喻害人的地方了。本来按照数据库查询的类比,当词 x(i) 作为自我中心的 Query 的时候,它去追求(查询)其他的某个词 x(j) 的 Key,两人相亲就是匹配一下,是不是看对眼了。数据库中的 query 与 key 匹配上以后,就会从数据库中返回 key 所对应的 value,是不是说,把 x(j) 的第三头 Value 返回来,就大功告成呢?
完全不是这回事。
实际的相亲以及建立关系的过程要“绕”得多。乍看简直诡异,慢慢消化了才会拍案叫绝。这种东西本来应该是上帝的不传之码,不知道怎么就流入人间,成为打开任何符号(不仅仅是语言文字符号,一样适用于各种音频、视屏符号)编码的钥匙。福兮祸兮,就好比是伊甸园的禁果,人类掌握了AI密码以后是加速自“作”而亡的节奏,还是提升了人类的福祉,就不好说了。但对于人的求知欲和征服欲,这无疑是核弹一级的刺激。
此处就会涉及一系列数学公式。非理工出身的人立马就堕入迷宫,但其实是纸老虎,它倒腾来倒腾去也就那么几个公式:一个是相亲前换套衣服好让Query与Key可以做匹配交融,一个是向量之间的“相乘” (MatMul,又叫 dot product),就是相亲交融本身,合二为一的内部其实是在计算二者的文本相似度(cosine距离),然后是 scale 和 soft-max,就是把相互关系的强度量化成概率百分数,等于是相亲后把各种满意不满意的感觉汇总打个权重总分,最后就是对所有的对象做加权求和(权重就是softmax刚打的分),然后与本人的 Value(第三个头)相乘。原来,Value 是本体 x 变形为 y 的基础,与其相乘的向量就好比一张过滤杂讯的网,使得变形了的 y 是突出了上下文关系的本体表示。总之,这一通折腾,才计算出真正的输出结果 y。“我”(自我中心的那个 x)已经不再是单纯的、青涩的我,而是成为关系中的我(y)。每个词都这样脱胎换骨一次,于是,奇迹发生了,符号被编码成了结构和意义,上下文的信息被恰到好处的捕捉进来(如果训练数据足够海量)。
上面说的是三位一体的本体 x 如何与环境交互变成了 y,但实际上为了便于注意力聚焦在不同的关系上,编码器都是设计成多头(就是很多个三位一体的组)注意力的叠加。这就给了每一组注意力以足够的空间去专注到某一种关系的抽象,而不是分散到多种关系去。这样的多头设计,在几乎无穷无尽的超大语言数据的无数次的迭代训练(back prop训练算法利用参数的梯度下降拟合实现)来逼近语言本身,所用的技巧就是无穷无尽的语言填空:例如在语言数据中随机抹去 25% 的词,然后训练模型根据语言的上下文信息去尽可能正确填空,从而把所谓自学习转变成经典的监督学习,因为黄金标准就在被遮蔽的语言符号里面。
上面略去了可以训练得到的参数设计的细节,其实也很简单,就是给每一个 Query,Key,Value 旁边配上一个相乘的权重参数矩阵 Query*W1,Key*W2,Value*W3,来记录符合训练数据的权重参数值,这样的训练结果就是所谓语言大模型。
AI/NLP 是实验科学。就是说,上面这通神操作虽然也需要有设计哲学的启发和规划,也需要有各种灵感的激发,但归根到底还是很多人在无数次的试错中通过输入输出的最终验证找出来的道路。而且多数神奇结果都是发明者最初没有预料到的。信息表示在神经网络内部的数据流(tensors)中千转百回层层变形,这样出来的语言模型居然具有赋能各种NLP下游任务的威力,这其实超出了所有人的想象。对于越来越深的多层系统,我们一直固有一种错误放大(error prop)的顾虑,所谓差之毫厘失之千里,怎么保证最终的模型是靠谱的呢?
这种保证源于训练数据的规模。超大数据就好比牵住风筝的那根线,任凭风大云高,风筝翻飞,只要那根线足够强壮,它就不会离谱。监督学习的奥秘就在目标驱动,注意力为基础的所谓自学习被大数据监督学习罩着,超出人类任何个体能力的大模型就不奇怪了。
有研究表明,这种模型内部捕捉到的种种关系可以图示化,显示各种句法关系、指代关系(例如 it 在上下文中与谁绑定,见图示)、远距离逻辑语义关系、常见的事实关系等都在它的表示网络中。

这张大网到底能推动多少NLP落地应用,开花结果,目前处于进行时。好戏刚刚开场,精彩值得期待。
谈到落地应用,就不能不提 transformer 的另一半 decoder(解码器)了。如果说编码器的宗旨是消化理解自然语言这头怪兽,得到一种内部的语义表示,解码器的作用就是把语义落地到下游NLP的各种应用上,包括机器翻译、自动文摘、信息抽取、文本分类、文本生成、知识问答、阅读理解、智能助理、聊天机器人、文字转音(TTS)、文字转图、文字转代码等等。值得强调的是解码器同样要用到注意力机制,事实上注意力机制的发明使用是先从机器翻译的解码器开始的,然后才平移到编码器,改名为“自注意力机制”。编码解码的注意力机制实质相同,区别在于解码器为了语义落地,Query 来自目标应用端的词向量,匹配的却是编码器中的 Key,以此作为语义的连接,从而实现目标应用的软着陆,赋能NLP应用的开花结果。这里的细节可以另文讲述,但原理上与 parser 以结构语义赋能NLP应用相同。
现在回头看自然语言及其NLP的历史,无论有意无意,上帝显然是犯了两个泄露天机的错误。第一个错误是让符号语言学家寻找到了语言结构的奥秘。第二个错误就是把意义的真谛赋予了数据科学家的向量表示。从此不可收拾。
有文为证。我在《科普小品:文法里的父子原则》中写道:
“话说这语言学里面有一门学问叫文法。学文法简单来说就是学画树。各种各样形态各异的树,表达了语言的多姿多彩,却万变不离其宗。奇妙啊。当年上帝怕人类同语同心去造通天之塔,乱了天地纲常,遂下旨搅乱了人类语言。印欧汉藏,枝枝蔓蔓,从此语言的奥秘就深藏不露。于是催生了一批文法学家,试图见人所不能见,用树形图来解剖语言的结构。忘了第一个画树的人是谁,感觉上这不是人力可为。天机不可泄漏,泄漏者非神即仙。历史上有两位功力非凡的文法神仙专门与上帝作对,各自为语言画树,一位叫 Tesnière,另一位就是大名鼎鼎的乔姆斯基。”
我的另一篇科普博文中也有过预警:
“语言是何等神器,它是交流的工具,知识的载体和合作的基础。人类一旦掌握了共同语言,齐心造反就容易了,绝不会安于伊甸园里面吃吃果子。真神于是有些怕了,决定搅乱自然语言,使得人类不能顺畅交流,内讧不断。这才有人类世代努力建造通天塔企望大同而不成。直到如今,世界仍不太平,语言依旧混乱,战争和恐怖时有发生。尽管如此,人类还是迎来了电脑革命的新时代。”
人成为上帝,还要上帝吗?
【后记】 这个话题足够重要,所以花了很多功夫调研消化然后介绍出来。本来太多人写这个题目,不少我一个科普介绍。但既然学也学了,就吐出来,力求与其他人写的东西,角度或风格有所不同,也算是一个老司机对科普的贡献。
【相关】
预告:李维《巴别塔影:符号自然语言处理之旅》(人民邮电出版社 2022)
预告:李维等 《知识图谱:演进、技术和实践》(机械工业出版社 2022)
《深层解析符号模型与深度学习预训练模型》(修订文字版)
谢谢小编整理成文字,我也做了认真校订与补充(尤其是冷启动低代码部分)。
https://mp.weixin.qq.com/s/UHcVXvXlRYajcYgG6cV8rw
分享嘉宾:李维博士 NLP scientist
编辑整理:陈昱彤 纽约大学
出品平台:DataFunTalk
导读:NLP (自然语言处理) 技术的深入发展主要有两条路线,第一个是基于符号规则的深度解析模型,第二个是基于神经的深度学习预训练模型。今天分享的内容是从领域落地的角度,对上述两条路线进行介绍和对比。首先,从人工智能的历史和发展现状来谈谈两种不同方法的异同及其互补作用。值得注意的是,两种方法殊途同归,基础模型及其架构也越来越趋向于平行和一致:都是多层架构、数据驱动,赋能下游NLP落地。最后我们会强调当前领域内的低代码趋势,并介绍金融领域深度解析路线落地应用场景的相关实践。
今天的介绍主要围绕下面四点展开:
NLP历史和现状
殊途同归的符号与神经
低代码是趋势,也是王道
NLP“半自动驾驶”实践
01
NLP历史和现状
1. NLP近代史
人工智能是从符号AI(Symbolic)开始发展的,最初的NLP是基于符号规则的系统。过去30来年,机器学习经历了两次主要浪潮,第一次是从30年前开始的以统计为基础的传统机器学习模型的兴起,第二次是约10年前开始的深度学习革命。深度学习的一声炮响送来了监督学习的杀手级武器,横扫了感知智能各个方向,从图像到语音等AI落地领域。目前的研究热点转向以NLP为中心的认知智能模型。深度学习在NLP中的一个典型成功案例就是神经机器翻译,在源源不断的人工翻译语料库的驱动下,神经机器翻译的精度基本达到人类翻译的专家水平了。与主流机器学习一波又一波的热潮相对照,符号规则系统早已退出了学术界主流舞台,但符号AI模型和NLP规则系统却从来没有退出过工业界的实际应用。
2. NLP之痛:领域落地的知识瓶颈
NLP最大的痛点一直是领域落地必须面对的知识瓶颈,这在两个道路上有着不同的具体表现:
① 监督学习(特别是深度学习)需要大量带标数据
无论是什么领域的监督学习落地都需要大量带标签的数据来训练模型,但是领域场景中常常只有大量原生数据,而缺乏带标数据。深度学习迄今无法规模化落地各个领域,其瓶颈就在于需要大量的手工标注数据,而且一旦任务有所变化,那么之前的标注难以复用,标注必须重新来过。当然,这些相对简单重复的数据工作所需要的标注人员门槛较低,属于低级劳动。
② 符号模型需要高质量手工规则代码
符号模型的NLP落地需要根据不同任务,人工地编写相应的代码。虽然手写代码不像数据标注一样需要大量的劳动,而是技术人才的少量高级劳动,但马克思的劳动价值理论告诉我们,少量的高级劳动和大量的低级劳动是等价的。无论把知识体现在海量标注数据中还是直接凝聚转化为知识规则,重要的是,两条路线都面对NLP落地的知识瓶颈。
Image
3. NLP的现状
① 突破的曙光
令人欣慰的是,我们已经看到了突破瓶颈的曙光。在深度学习方面,近几年非常热门的解决方案是预训练的自主学习模型。预训练模型的最大特点是它不依赖标注数据,它是从源源不断的原生数据(raw data)学习来构建超大规模的基础模型。作为上游的预训练模型可以支持下游的各种不同的NLP任务,这就大大减轻了下游NLP任务对标注数据的要求。预训练大模型在学术界上取得了突破性的进展,很多NLP任务赛道的数据质量被刷新,但目前基本上还局限在研究界。工业应用上要将预训练模型落地到各个细分领域并且实现规模化普及,还有不少挑战,估计至少有五到十年的路要走。
另一方面,深度解析赋能NLP落地的符号模型也取得突破性进展,工业应用之路已经完全打通了。架构上,我们第一步用深度解析器(Deep parser)去消化语言,解析器可以将任何一个领域的非结构化文本转化为结构化的数据。第⼆步是在结构化的基础上做下游的自然语言任务,其实就是一种结构映射工作,把语言解析的逻辑结构映射到下游领域落地的任务结构上去。上层的解析器做得很厚,要做几十层模块来应对语言的千变万化,但下游的模型只需要做得很薄,两三层就可以解决问题。预训练模型和深度解析器的功能差不多,虽然表示手段不同,但都是对于自然语言现象的不同层次模式的捕捉。深度解析的下游NLP落地大致相当于深度学习下游的输出层(Output layer)。
Image
② Deep parsing 是符号NLP应用的核武器
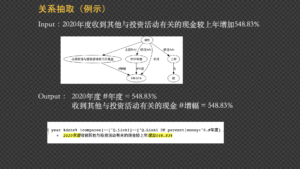
为什么说 Deep parsing 是符号 NLP 应用的核武器呢?因为人类语言无论如何千变万化,其中必然隐藏着相同的逻辑结构。深度解析几十年的实践表明我们可以先把语言进行消化,解码(decode)出不同表达背后的逻辑结构(logical form)。比如下图示例中同一事件的各种表述,在解析消化之后表示为相同的逻辑主谓宾(SVO)结构:“Apple(S), release(V),iphone2.0(O)”。有了逻辑结构后我们就能以低代码开发领域落地映射的规则,以一当百地将这类结构用于不同目标上,而不需要在NLP应用层面去应对千变万化的语言表层变体。因此,NLP 应用场景的落地就能快速实现。
Image
02
殊途同归的符号与神经
1. 架构上的殊途同归
从AI历史发展趋势看,符号和神经是殊途同归的。创新方面也有惊人的平行性和相似性。
符号派走的是理性主义的路线,而神经网络和统计模型是属于经验主义的。本来理性主义的符号是排斥自底而上数据驱动的,但多年实践下来发现,在实际应用当中排斥数据驱动的理性主义方法往往捉襟见肘,可以在实验室做个玩具系统,却很难规模化实施。所以,我们在工业应用道路上深耕多年的符号践行者,实际上拥抱经验主义的做法,特别是数据驱动。符号主义走出实验室,在应用中落地开花的创新,与对数据的拥抱是分不开的。这种借鉴了经验主义方法论的符号路线还是保留了符号固有的一些优异特性,为符号主义的生存发展以及对于主流神经模型的补足提供了价值基础。
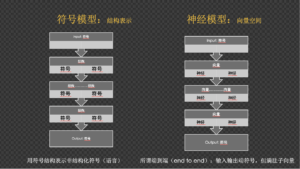
具体说来,符号是人类智慧和知识的载体,因为人类的思维以及知识积淀都是以符号及其逻辑的形式承载的(人类语言就是最大的符号)。所谓符号主义AI,实质是把符号表达方式在模型化的过程中贯彻到底,从符号规则系统的内部表示看,就是一种带有符号节点的图表示(graph),结构图中的关系表示也是符号化的,譬如句法树。这样的符号表示,好处是透明化和可解释性,软件的开发维护可以做到定点纠错。符号模型的开发也不需要依赖标注数据。这些优异特性是符号主义真正的价值所在。
神经模型就不⼀样了,它有“符号不耐症”。神经模型的两端(end-to-end)当然是符号,这没有办法,因为任何神经模型都是要给人用的,需要对用户和开发者友好,两端的接口上,它自然绕不开符号。但神经系统内部必须首先使用独热编码(one-hot encoding)、词嵌入(word embedding)等方法把符号转换为向量,才能实现模型内部的计算性。现在的潮流是使用预训练通过模型内部的各种向量来计算表示符号序列中隐含的不同层次的模式。然后下游的NLP落地任务一以贯之,同样是对这些人类看不懂的内部向量表示(所谓 tensor)进行监督计算,最终映射到输出层的符号。
Image
从架构及其内部数据流走向来看,这两种模型其实是非常相似的(见上图)。不同的地方是符号模型里面是结构化的符号,表示信息的数据流是 graphs。而深度模型里面长长的隐藏层全部是向量,数据流是 tensors。值得指出的是,符号模型也是需要用多层的符号模块一层一层匹配,更新内部结构才能取得好的效果。经典教科书中介绍的乔姆斯基风格的上下文无关文法(context free grammar)所对应的模型却是单层解析器(典型的实现算法是chart-parsing),就很难走出实验室。这就好像⼀开始陷在单层陷阱里面的神经网络一样,单层模型是很难捕捉自然语言的多样性的。这样看来,符号模型的多层创新和神经网络的多层革命也是类似的。这不仅仅是巧合,这实际上是面对真实世界,符号和神经在方法论上的殊途同归。
2. 方法论上的殊途同归
就NLP而言,创新的符号模型和主流深度学习都是深层模型,因为二者都要面对错综复杂的语言表层符号的组合爆炸现象,解构符号现象背后的层层语义。单层模型没有足够的空间和弹性来容纳和消化自然语言。在我们的实践中,英文的parser需要50层左右才能搞定,对于更加复杂的中文则需要大约100层解析才比较充裕自如。自底而上由浅入深的多层化解析把种种难缠的语言现象分而治之,使深层解析器的准确度基本达到专家的水平,从而为赋能下游NLP落地创造扎实的逻辑基础和结构条件。深层解析与神经前馈网络类似,也使用了经由pipeline多层模块的数据流,其内部表达方式是线性结构(linear representation)与图结构(graph representation)结合的符号化表示。它本质上与多层神经网络里面的向量空间(vector space)所表达的语义(semantics)是同质的,只不过编码的形式不⼀样。
总之,在我看来,理性主义不拥抱经验主义方法论,由数据驱动层层推进,实践中是行不通的,更谈不上规模化领域落地。符号与神经各自独立发展,却在架构与方法论上殊途同归,表现出惊人的相似性。这绝不是巧合,而是由客观世界的复杂性所决定的。两条路线上的深层模型,最后的目标也是一致的,都是为了克服知识瓶颈。真正理解透这一点,需要观察对比两条路线各自的短板。
Image
3. 神经与符号各自的短板
一般而言,最为成功的端到端神经网络系统的短板是对输出端标注数据的依赖,这是迄今深度学习在横扫感知智能图像与语音等应用后,一直未能在认知智能的各领域场景规模化落地的根本障碍。在数字化信息时代,领域场景并不缺乏原生的文本数据,但大多数场景都存在严重缺乏标注数据的情况,这使得深度神经难以规模化领域落地,巧妇难为无米之炊。
为了克服这个瓶颈,自监督学习(self-supervised learning)的方法及其预训练模型开始兴盛起来。自监督学习的奇妙之处是它本质上其实是监督学习,从而可以利用成熟的监督学习的算法实现,但它学习的对象却是几乎无限的原生数据,不受人工标注数据的资源限制。就NLP而言,自学习的预训练模型,无论BERT还是GPT3风格的模型,都是从语言学习语言,都是海量数据训练出的超大模型,以此减轻下游NLP任务对于海量标注的需求。
这里说一下从语言学习语言的预训练原理。为什么说预训练也是监督学习呢?人说的每一个句子实际上都是在对词语序列进行合法标注。语言之所以为语言,是因为语言单位组合成句背后是有规律的,它是由文法和用法习惯所决定,因此千变万化的句子才可以被人类自己解构和理解。与此对照,随机的词汇组合是“非语言”。预训练学习出来的所谓语言模型,本意是首先在语言与非语言之间划线,然后对于语言现象本身学习其上下文的模式,这一切所利用的,是人类无时不在制造的语言数据。换句话说,自学习中,监督学习搭的是语言数据自然生成的顺风车。
自学习的好处是什么?好处在于数字时代中互联网的语料库是无穷无尽的,把质量稍高一些的文本都喂进模型里,就得到了我们现在拥有的那些超大模型。大厂有强大的算力,不断推出各种超大规模的语言预训练模型,希望引领NLP的应用落地。这些模型跟我们花了很多年做的深层解析器(deep parser)是差不多的,具有相同的消化自然语言及其结构的使命。
符号系统的短板是它的编码门槛高,那么解析器应用的出路是什么?出路是低代码、冷启动、半自动、流程化。编码门槛高分成两部分,⼀部分是核心引擎(即deep parser),这部分难以做到低代码。不过核心引擎是⼀锤子买卖,做好了核心引擎就相当于用符号的方法写出了一个自学习的预训练模型。应用时解析器的部分基本不需要改动,只需要在下游做简单的两三层编码,将解析结果映射成应用所需要的输出即可。我们强调的冷启动主要是指下游NLP落地,典型的任务就是领域信息抽取和文本挖掘。冷启动就是不需要大量的标注数据,只需要⼀点种子就可以推进下游NLP快速领域化落地。半自动流程化,是让机器以及开发环境去提示开发人员怎么做。目前,利用深度解析器进行半自动NLP领域落地的道路已经打通了,实践中一再被验证。当然,符号NLP算法的通用性自然不如深度学习的自学习模型,譬如,NLP符号模型的创新很难拓展到语音和图像上。这⼀点与深度学习不⼀样,深度学习算法及其架构的通用性强,可以把在NLP领域创新突破的同⼀套方法论,基础模型和设计思想用到图像,语音等各种AI问题领域。不过,相对而言,图像与语音基本是已经解决了的AI问题领域,关键还是要在NLP内部快速实现规模化领域落地,保障深度解析对于不同领域的通用性,而这一点正是我们过去几年探索的成绩及其价值所在。
Image
Image
4. 天问:神经可以终结符号吗?
NLP正处于AI历史上最激荡人心的时刻。它没有被攻克(领域上尚未规模化普及),但我们已经看到了曙光,神经与符号都显示出领域化的可行性与赋能潜力。
三十年来主流研究重心⼀边倒在统计和机器学习上,神经革命让钟摆摆得越来越高,一直没有回落到符号的迹象。有人会好奇符号主义是不是将被终结了?
我的第一个感觉是,符号被终结的可能性并不为零。监督学习的神经奇迹曾经在感知智能与机器翻译当中发生过,超出了所有人当年的预料。因此,自学习支持规模化领域落地的奇迹也不是绝无可能发生。当预训练模型在赋能NLP下游任务,普遍达到神经机器翻译颠覆符号翻译的程度时,我个人觉得就可以接受符号被终结的趋向和结论。但现在断言这种可能性,为时尚早,按照目前的技术发展和资源投入的程度,大概5-10年内可以看清。虽然我不相信⼀条路线会把另⼀条路线在各领域应用中全面取代,但如果AI能在神经的大旗下真地⼀统天下,人类一同走入通用智能(AGI)的高点,岂不是一件乐事,这才叫,不废江河万古流。但这是小概率事件。
更大的可能我觉得应该是神经与符号长期并存,逐渐开始更深的相互融合,取长补短,既包括符号子系统与神经子系统的松耦合,更包括符号与神经模块内部的紧耦合(例如内部表示中符号图与向量的相互转换)。我们知道,符号与神经的区别性特征在于其内部表示的不同,一边是结构符号,一边是向量空间。紧耦合方向非常有诱惑力,虽举步维艰,但一直有人在不懈探索。有专家认为符号神经的深度紧耦合可能是下一代人工智能的真正突破点,甚至可能开启通用智能的新时代。
这里附带提个思考题:上帝用的是向量还是符号?外星人呢?
当然没有标准答案。但我心里倾向于这样回答:上帝应该是用向量的,但外星人不能免俗:他们与咱们人类一样,用的是符号(语言)。至于外星语的符号用的是什么编码载体,声音还是图形,则不确定。
03
低代码是趋势,也是王道
1. NLP低代码潮流
最后想强调的是NLP低代码的潮流,它是从AI开源平台的兴起开始的。当今互联网各大厂都在建立推广自己的深度学习平台,谷歌的TENSORFLOW,脸书的PYTORCH,等等。各种平台级工具箱和软件包也在开源社区流行,有KERAS的神经网络框架,还有SCIKIT-LEARN这样非常成熟的包括几乎所有统计模型的软件库。现在做模型就像玩积木一样,你可以用短短几行代码去调用这些库很快实现一个原型系统,刚毕业的大学生研究生也能很快实现一个像样的模型。
符号NLP这方面其实也有不少进展,我们做的多层NLP符号平台也是在半自动、冷启动、低代码和流程化的路上。其目标是把编写NLP代码的人从“码农”转化为判官,以高精度低召回的样例规则代码为起点,通过检验数据质量的变化决定符号规则的泛化路径及其迭代更新。这种低代码的开发流程在一系列不同领域的落地应用实践中验证了其有效性,使得NLP代码开发的效率至少提升了一个量级,从以前的几周时间缩短为几天。
2. 数据科学与工程的兴起
AI低代码趋势的标志之一是数据科学的兴起。这几年来,很多大学顺应市场需求,开设了数据科学(Data Science)专业,批量培养知识工程师。目前,数据科学专业有些杂,大体上一半是计算机的课程,另一半是不同领域的实践教学。它训练你在不同领域方向上将AI低代码能力与领域数据处理结合起来,完成一些领域应用。这标志着NLP和AI从学术的象牙塔里走了出来,逐步汇入各行各业的应用场景。各种开源低代码平台、工具和社区的推广,使得学习的门槛也降低了。在线教育如火如荼,也顺势而起,专精数据科学培训的datacamp上就有上百万人在学习相应技术课程。AI数据科学在行业落地应用的前景在接下来的十年中会越来越普及,低代码人力储备也逐步准备好了。有意思的是,前几年AI热引起的风投热度开始明显降温,但这与其说是AI泡沫破灭了,不如说是对于AI规模化领域落地和普及的预期过高,不了解AI的自身发展的真实趋势。上一波赶上了感知智能大爆发潮流的资本,有耐心和机缘赶上认知智能今后10年中的爆发节点吗?
04
NLP“半自动驾驶”
1. 半自动符号NLP的设计哲学
以上算是务虚,下面回到符号NLP创新的务实话题,讲述一下NLP老司机的半自动“驾驶”,结合本论坛的金融主题,介绍符号NLP在金融领域的落地中的实践。NLP落地金融与我们在法律、电力、航空、客服等应用场景的领域化工作一样,围绕一个相同的开发理念和设计哲学:数据驱动,但不依赖标注数据;无米可以,有稻即成:解析器作为碾稻成米的核武器,无米之炊可成。
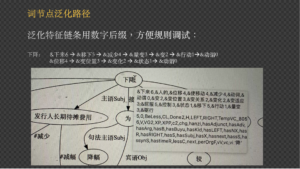
具体说来,低代码半自动可以从样例种子开始。只要有“种子”就可以全自动地生成规则,并且在生成规则的基础上实行半自动的规则泛化流程。泛化的方式分为上下文泛化和词节点泛化两大类,其中上下文可以灵活应用图结构上下文与线性上下文(例如窗口限制)。词节点泛化带入本体知识库,包括常识的逻辑推理链条加持。泛化路径由系统内部自动配置确定可选项,由知识工程师(开发者)从可选项中选择进行。这就让纯粹手工的规则编码流程,转变为半自动的代码调整过程,大大减轻了代码开发成本以及知识工程师的培训成本。
NLP落地领域作为一项软件知识工程,整个流程遵循软件开发的best practice,包括建立和维护代码迭代更新的质量管控标准和措施,保证在不依赖标注数据条件下的数据质量。监督学习所依赖的标注数据黄金标准,被知识工程师的数据比对与判定代替,码农从而成为判官,半自动监督指导符号系统上线前的迭代开发以及上线后的维护开发。半自动模式下,只需要使用样例种子来冷启动符号规则的开发过程,系统自动提示调整泛化的路径。知识工程师从代码的细节解放出来,以人机互动的方式实现符号系统的快速领域化。目前我们已经在多语言(10多种欧洲和亚洲主要语言)和多领域(金融、法律、电力、航空、客服等)的不同场景落地,用的都是这套数据驱动的方法论:低代码、冷启动、半自动、流程化。
Image
2. 半自动符号NLP的实践
实践部分咱们以金融NLP落地为例。金融领域的特点是句子比较长、信息点多、关系复杂,一个两句话的例子中可能就有30多种关系需要抽取。但好在句子的模式比较固定,目标关系的抽取步骤是内部先消化成同一个结构,然后再把结构映射(map)到输出端去建立关系及其角色。属于图结构的匹配和映射。
Image
Image
经年打磨的深度解析引擎对各领域保持稳定。但在该核心引擎应用到具体领域的时候,有一个步骤是保障引擎领域化的关键,就是领域词典的加持。事实上,那些开源的深度学习训练出来的解析器(斯坦福parser,谷歌SyntaxNet,等)之所以至今没有规模化的领域应用成果,主要瓶颈就是难以适配领域化数据。这些在通用数据上训练出来的解析器虽然质量接近专家水平,但对于数据非常敏感,一旦数据场景偏离原训练数据,数据质量常常悬崖式下跌,不堪使用,其主要原因就是面临领域新词的挑战。训练模型缺乏外加词汇的加持手段,加上解析器的输出沿用社区标准(类似PennTree)只提供结构图,并不提供词节点的语义特征及其本体知识链条的支持,这就使得下游NLP很难落地。我们的多层符号解析模型克服了上述缺点,下游NLP任务继承核心引擎的所有信息和知识,用的是同样的机制和符号语言,从而打开了快速领域产品化的大门。
领域词典分为两部分,一部分是领域新词发现(或利用领域已有的开源词汇资源)。我们通过领域原生数据的N元组聚类获得候选领域词汇,然后经过噪音过滤等过程与系统内基础词典及其本体知识库对接。在金融领域,新词发现获得了三万N字新词或词组(9>N>2)。领域词汇的另一个来源是用户词典,这个规模小得多,但可以在开发过程中随时增补修改,可以更加灵活地配合引擎的领域化开发工作。
在词节点泛化路径中,内部有现成的本体知识库(HowNet的精简版)及其上下位路径去帮助泛化。在上下文约束条件的调整中,系统预先设置好了通过图关系或窗口限制的两条上下文泛化路径,只要点击就能调用。泛化过程与深度学习系统的梯度下降的原理类似,只不过符号系统的“拟合”按照系统设计者根据内部知识和经验预定的泛化路径来进行,路径节点是离散的有限集合,一条样例规则大约经过10-20次泛化迭代可以定形。无论节点泛化还是上下文泛化都具有可解释性。每一步泛化迭代都在由原生数据组成的开发集中得到验证,以此保障迭代开发的数据质量。金融实体与关系的抽取就相当于深度学习网络的输出层,由一些简单的抽取规则组成(见图),规则模式的条件是词和上下文之间发生的窗口关系(例如Win9,9词窗口)或者语法关系(例如Link1,一层关系,即直接依存关系)约束。系统自动提示约束条件的可选项,最后由在开发集上的回归质量测试决定一个选项在精度与召回上的表现。表现不够格就回滚到前一个状态重新尝试其他泛化路径,如此循环。主要理念是用半自动的系统提示的方法把⼀个很紧的规则松绑到恰到好处,让系统在精度和召回中做出合理平衡。这种方法可以概括正例排除反例,提高精度,同时在泛化中自然加强系统的召回(recall)与鲁棒。
Image
Image
总结一下,半自动流程化NLP落地的主要优点是不再依赖标注数据。基于结构和理解的冷启动低代码路线具有普适性和跨领域的优点。不足则是低代码并不是无代码,依旧需要一些代码纠错技能,但培训门槛则大大降低了。
05
精彩问答
Q1: 您在做parsing的时候使用的标签体系是否有统一的标准,在哪里可以学习呢?
A1:标签体系是有传承的,不是Penn Treebank那套标签体系,因为虽然Penn Treebank是符号领域中的社区黄金标准,但我们知道其中有很多的固有缺陷,落地实践用起来也不够方便。根本的标签是从 Dependency grammar这路继承发扬下来的。在我的NLP频道 (liweinlp.com) 的许多样例的后面,都配有这些标签的简单说明。句法语义的关系标签集合不大,粗线条的parsing标签不到10个,细线条的标签总数也就几十个。但是词概念的标签集合则大得多,我们用到的大约2000左右标签,包含了HowNet的核心本体特征。
Q2: 同一层解析中不同规则的优先级是完全基于语言专家知识来确定的吗,也就是确定性的非概率的吗?
A2: 对,是确定性的、非概率的,但在确定性中对于不确定性有⼀种包容。包容是指在非确定的情况下,不在特别关键点的时候,系统先把它包住。⽐如在某些节点中有词汇歧义,但这个歧义不是你所要做的任务急迫需要解决的问题,这时就可以先包住,等到条件成熟时再对付它。结构歧义也同样有包容的手段。我们虽然在pipeline的数据流里是用确定性方法往下传递数据结构,但里面同时蕴含了包容下来的不确定性或歧义。系统装备中有我们称为“睡眠唤醒”的机制,可以从事局部结构的重建、修正或再造,在宏观条件成熟的时候,例如在后期更大的上下文背景条件下,重新展开局部结构进行重建或覆盖。
Image
今天的分享就到这里,谢谢大家。
深层解析符号模型与深度学习预训练模型
【相关】
推荐Chris Manning 论大模型,并附上相关讨论
预告:李维《巴别塔影:符号自然语言处理之旅》(人民邮电出版社 2022)
预告:李维等 《知识图谱:演进、技术和实践》(机械工业出版社 2022)
NLP 新纪元来临了吗?

【立委按】强力推荐NLP顶级权威,斯坦福Chris Manning教授论大模型,非常好的 review。曼宁教授深厚的计算语言学学识反映在他的综述和展望中,具有历史厚度和语言本质的理解深度。最后的那个点也很好:当前的一锅煮的超大模型实际上是一个可行性研究,已经初见成效;将来的大规模的领域场景应用,会召唤相对来说小一些但更加领域数据密集和纯化的基础模型,可以展望其革命性前景。至于这算不算 通用人工智能(AGI),曼宁说的也很有分寸:看上去算是在通向 AGI 的路上。短板主要是 semantics 还不够直接面向真实世界,而是源自符号世界、囿于符号世界(所谓 distributional semantics),等于是绕了一个弯儿,语义的深度以及语义结构本身就显得扁平、太浅,难以消化人类深厚的知识积淀。但即便如此,也堪称一个伟大征程的坚实脚步,是激动人心的NLP新时代。从分布角度看意义,如果说人是社会关系的总和(马克思),那么也可以说,语词基本上是语词间篇章关系的总和。很多年来,我们NLP践行者一直挣扎在如何把上下文合适的模型化,因为语言符号的歧义和微妙很大程度上可以在上下文中予以消解。上下文最直接有效的对象就是篇章(discourse),而恰恰在这一点,深度学习注意力机制为基础的大模型展示了其几乎神奇的表示能力。
AI 群里相关讨论很有意思,实录如下。
刘群:同意@wei,深度学习和预训练方法取得的进步非常惊人,超出想象。原来感觉不可解的一些问题,现在似乎都看到了曙光,解决路径隐隐约约能看到了。虽然对AGI仍然质疑,但对这个领域的前景真是非常看好。
算文解字:是的 同一个模型prompt一下就能完成各种nlp任务 就算不是agi 也是更g的ai了。而且即使是从denotational semanrics的角度看,加入多模态的预训练模型也算是部分和间接的grounding到真实世界了的物体了。
刘群:是的,原来觉得一般意义上的grounding几乎不可能,除非是特定领域。现在看越来越可能了。
立委:感觉上,意义表示(A)落地到客观世界(B)可以看成是人类与生俱来的本能,不需要特别的模型化,如果A本身比较充分的话。 那么这个 A 是个什么东西呢?A 可以看成是一个平面的表示,其中 X 轴就是篇章,而 Y 就是隐藏在文本之后人类知识,包括本体知识(ontology),带有语用(pragmatics)因素的世界知识及其推理体系。
目前的大模型的长处是 X 模型化,短处依然在 Y 不足。因此虽然从分布角度貌似也总结出了一些常识,以及浅层的推理能力,但这些能力还没有足够的深度和逻辑性,缺乏推理的链条性和一致性。【编者按:这是在 ChatGPT 和 GPT4 之前的议论,现在看来思维链和逻辑推理在LLM后续发展中已经大有进步,虽然知识的厚度和复杂推理依然是LLM的短板。】
符号知识图谱以及人类探索积累下来的本体知识库、领域知识库,这些东西都是非常浓缩的、高度结构化的知识体系,本质上具有严谨的逻辑性和推理能力。分布式序列学习学到了这些知识的皮毛,但总体上,对于这些知识精华还很陌生, 难以系统性直接兼容并蓄。
刘群:当然离解决这些问题还远,只是说能看到曙光了。以前感觉根本没希望。虽然还不怎么样,但不是没希望。日拱一卒。
算文解字:还有这两年出现的基于预训练模型的常识推理(如Yejin Choi组的工作)也让人眼前一亮。即使五年前还是,说研究常识(common sense)一般反应都是敬而远之。
立委:大数据为基础的序列学习可以反映相当多的常识,这个是没有疑问的。我们在本群中讨论过很多这类案例:所谓大数据支持的“相谐”性,其实与常识中的特征匹配,吻合度很高。
刘群:把符号融入到神经网络里面不是解决这个问题的正确方法,还是分阶段处理,来回迭代才是正途。
立委:方法论上也许的确如此,但直觉上是一种知识浪费。就是说,从DL外行的角度来看,明明人类已经世代努力提炼了精华,都规整得清清楚楚,可模型就是没法利用。一切必须从头开始,让人着急。
刘群:我说的来回迭代不是人机交互,是符号和神经来回迭代,可以自动化的。
立委:哦,那就是我希望看到的深度耦合/融合。这种融合是革命性的方向,有望发生新的AI突破与下一代的范式转变。但不久前,还普遍被认为是一种乌托邦,觉得符号和神经,就跟林黛玉与焦大似的,打死也不兼容。
算文解字:刘老师,这个方向上近期有哪些比较亮眼的工作呀?
刘群:WebGPT, AlphaCode等,还有周志华老师反绎学习的工作。
算文解字:恩恩,的确 WebGPT 这种都可以看做是大模型和离散/黑盒系统(可以是规则)交互迭代的方案。
立委:前面提到,对于大数据,人比起机器,有时候好像蚂蚁比大象。有老友不满了,说不要这样说,这是“物种”歧视。其实,很多事儿,人比起机器,还不如蚂蚁比大象……
1. 计算;2. 存贮/记忆;3. 下棋;4. 知识问答; 5. 翻译; 6. 做对联; 7. 格律诗; 8. ………。可以预见的未来清单还很长很长(自动驾驶、自动咨询、自动陪护、自动培训、自动写作、自动音乐、自动绘画 ………..), 都不是人力遥不可及的。事实在那里摆着。不服不行。
回顾历史,人类第一个被蒙圈的就是计算。以前的那些心算大师,算盘顶级快手,现在很少有宣传了,因为干不过一个小小的计算器。紧接着是存贮量和记忆力。当年我们最崇敬的人物就有不少是过目不忘,博闻强记的大师们。社科院流传着很多大师的传奇故事,都是能记住非常细节的东西,可以在记忆的大海捞针。现如今,谁敢说任何大师记忆的信息量能比过一个U盘。哪个大师还能在谷歌百度面前夸口自己的大海捞针的信息检索能力?
下棋不用说了,电脑完胜,两次载入计算机历史的里程碑。知识问答也进入了计算机历史博物馆,IBM 沃伦的高光时刻。机器翻译我一直在用,我本人就是机器翻译出身的,目前的翻译水平高过普通人类翻译毫无悬念,注意:不是指速度。对联、写诗 也有过大赛。自己试试就知道了:你可以尝试在家苦学格律诗n年,然后即兴写诗,与机器比试比试?
面对超大数据的基础模型,人类脑壳里的“小”只会越越来露怯,想藏拙也藏不住了。当然,严格说来这不是一场完全公平的实体之间的比试。一边是单个实体的人(例如世界围棋冠军),另一边是消化了人类整体知识积淀的实体机器人。好比一人对无数人,自然是蚂蚁遇上了大象。但是,另一方面看,每个碳基生物的人也在不断学习人类的知识才能成为专家或冠军,并非一张白纸。关键在于学习能力,碳基实体无法与硅基实体的电脑比试自动学习的能力,因为后者占尽了时间(速度)与空间(存贮)的优势。超人的出现不会是人,而是机器人,这应该是用不了50年就可以做实的现实。
新摇滚歌手汪峰曾经唱到:我该如何存在?
面对汹涌而来的大数据大模型,人类准备好了吗?

与曼宁教授合影(2017-07-18)
Chris 的这篇综述对于NLP意义重大,值得反复研读。文章也很好读,写得清晰简练。里面有一个有意思的观点,值得特别介绍。曼宁试图重新做NLP历史划分,从而突出自学习革命的分水岭作用:
In hindsight, the development of large-scale self-supervised learning approaches may well be viewed as the fundamental change, and the third era might be extended until 2017.
我们知道,过去30多年经验主义AI成为主流以来,常规的AI时代划分都是:第三代是传统的机器学习;第四代是深度学习,分水岭在 2013 年( ImageNet 上那次深度神经网络CNN的爆炸性突破)。
但是从NLP角度,2013-2017 这四五年,深度学习虽然横扫了图像和语音,但在 NLP 本身却遭遇挑战,没有真正的突破,根本原因还是因为NLP监督学习依赖太多的标注数据,这一点与AI第三代没有区别,甚至依赖性更强(数据上不来,神经的表现还不如传统的统计模型)。因此虽然 AI 整体的时代分水岭是 2013,NLP 作为认知智能的拦路虎却应该把里程碑推迟到 2018年。
2018年是自学习预训练大模型(LLM)元年。NLP终于摆脱了标注数据的桎梏,可以直接从语言学习语言,开始利用无穷无尽的自然语言原生数据。从研究角度看,曼宁显然认为这才是NLP范式转变的开始。这个历史观点我认为是站得住脚的,是个有洞见的划分。无论如何,没有自学习谈不上NLP的革命。这是这篇文章的主旨。
但如果细究,自学习 LLM(其实很长时间都是一直叫预训练,好像是 Yann Lecun 开始不断改用 self-supervised learning 才慢慢普及开来,目前的趋向是逐渐过渡到基础模型的说法)其实并没有真正从监督学习走向人们曾经向往的完全无监督学习。因为算法上,预训练大模型本质上还是“监督”学习,只是规模超大的自监督,因为数据超大而已。
这一切尝试本来也可能并不会引发一场可以认为是革命的事件。因为超大规模的模型本性上肯定是简单的,一开始就是做 next word 的预测,或者只是做填空猜字的游戏。谁也没想到这种看上去非常简单的模型居然有能力加强NLP任务的方方面面,甚至影响超越NLP,使得类似框架反过来延伸到多模态符号(图像、语音)上,一样可以循例建立基础模型赋能各自的AI任务。
虽然从小就被马克思辩证法教育,量变引起质变默念在心,其实心底一直没有真地(被)信服:大号的 X 还是 X,怎么就变成 Y 了呢。但是,到了自学习超大模型(BERT,GPT-3等)这里,我们确实见证了这种神奇的多任务效应。
当然,从 2018 年到现在,这场NLP革命也还只是处于初级阶段,等于是完成了可行性研究,NLP大模型在各场景全面开花结果还有很长的路要走。我以前觉得5年可见分晓。曼宁说的是今后10年是NLP革命最激动人心的时代。越来越多的资源和人才开始向这里聚集。
这个其实颇有争议。有不少人不以为然,认为这是高估了自学习大模型的作用,预见在领域普及化的过程中会遭遇困难,甚至滑铁卢。因为自学习模型在知识表示的层次性、一致性和完整性方面显然有严重缺陷,而且缺乏所谓“真正的”理解,虽然可行性研究展示了一些貌似非常理解非常智能的表现。这一观点也不无道理。是不是一场真正的NLP规模化落地的革命,5-10年后回看才能真正裁决。
马少平老师说:“打个比喻,大模型还只是地心说,虽然能解决一些问题,但还远没有到达日心说呢。” 说得有理,可能还要经过几次螺旋式上升,才能更加逼近通用的NLP和AI吧。但另一方面看,如果没有自学习的出现,NLP 就一直是个累赘,可现在转而成为 AI 的急先锋了。
【相关】
斯坦福教授曼宁AAAS特刊发文:大模型已成突破,展望通用人工智能
预告:李维《巴别塔影:符号自然语言处理之旅》(人民邮电出版社 2022)
预告:李维等 《知识图谱:演进、技术和实践》(机械工业出版社 2022)
【随感:大数据时代的信息茧房和“自洗脑”】
信息时代的网络是个好东西,也是个坏东西,总体上的功过真不好说。
我倾向于认为坏处大于益处。感觉这与人的懒惰本性有关。这就好比营养过剩的年代肥胖症难以避免一样,现如今过食而死的人(肥胖引发的病亡)远远多于饿死的人。
人在多数情况下难以抵制快餐的诱惑,同理也难以抵制信息快餐的诱惑,其结果就是社会撕裂、个体在自己舒适的信息茧房中作茧自缚,变得越来越狭隘偏执。
所有大受欢迎的信息工具,包括微信、抖音、搜索、推荐,在绝大多数的使用场合都在加剧人类与生俱来的惰性和偏见。在即刻满足和麻痹人类神经的同时,人类为自己创造了“自洗脑”最为有效的环境。很少有人可以对此完全免疫。
另一方面,同样是这类工具也极大加速了知识的穿透力,这是好处。当一位研究者对某个课题保持足够的好奇心和专注度的时候,没有任何时代可以提供如此广泛、密集、交错的瞬时可得的免费信息搜集和覆盖能力。信息时代给研究人员提供了黄金环境。这会[i] 大力加速科技的发展,[ii] 也可能提供识别与打破信息茧房的方法。
但是好处 [i] 从长远来看是福是祸,很难说。悲观主义认为,人类的科研进步(包括AI)越加速,就像飞蛾扑火一样,人类就更加快速地走向文明终结,很难给任何补救措施(例如好处[ii])以挽回的时间和余地。聪明反被聪明误。由此看来,AI 应该缓行,以popularity和眼球经济为基础的信息工具不能野蛮发展,都不是没有道理的。
【外一篇:人类会自“作”而亡吗,但愿不是杞人忧天】
关于普京发动核大战的现实威胁,先有化石级哲人乔姆斯基的警告,也有很多其他相关新闻报道:《赫鲁晓夫孙女:现在比古巴导弹危机更接近核战争》,《传普京将进行胃癌手术 权力暂转移给他》。
文明的毁灭对于人类来说自然是一个比天还大的问题。面对如此巨大的问题,即便是万一的万一,也是令人不寒而颤的。作为蚂蚁一样的个体,面对完全无法预测和影响的全人类命运和前途的大事,可以聊以自我安慰的说法具体说来,觉得有三点。
这个世界有那么多人比咱们“高”许多,无论钱、权、貌、才能、情怀、品德还是任意其他指针,大限来临,他们也都玩完儿。作为沧海一粟,我们又有什么值得大惊小怪,惶惶不可终日呢。所谓天塌下来有高个顶着。对于我们个体,即便这种威胁是真实的,也可以拿“不必杞人忧天”来聊以自慰。这是其一。
老友说得有意思:忘了哪个电影,但一直记得,主人公解除核弹时很紧张,旁边一哥们鼓励他,don't worry if you screw up,you won't know it.
其二是,看人类文明的发展趋势,感觉人类迟早是自己把自己“作死”,这种自作而死的概率毛估估远远高于小行星毁灭恐龙那种外力事件的概率。无论是发明核武器、AI的加速度推进、环境污染、全球暖化、种族仇恨和灭绝、意识形态的敌视,等等等等,都给人一种不作死不罢休的感觉。这样一看,感觉文明终结就是一种宿命,好似宇宙冥冥之中不可突破的 great filter 绑定了人类似的。既然是宿命,明天灭亡,还是10代、100代人以后灭亡,又有何区别。
第三,我们每个人都是要死的。从个体而言,反正永生是不能指望的,一起与文明随葬也就不足畏惧了。
Again,这一切但愿都是杞人忧天,虽然目前的局势下,天塌下来的概率远不是0。
【相关】
预告:李维《巴别塔影:符号自然语言处理之旅》(人民邮电出版社 2022)
预告:李维等 《知识图谱:演进、技术和实践》(机械工业出版社 2022)
推荐Chris Manning 论大模型,并附上相关讨论
【立委按】强力推荐。非常好的 review。曼宁教授深厚的计算语言学学识反映在他的综述和展望中,具有历史厚度和语言本质的理解深度。最后的那个点也很好:当前的一锅煮的超大模型实际上是一个可行性研究,已经初见成效;将来的大规模的领域场景应用,会召唤相对来说小一些但更加领域数据密集和纯化的基础模型,可以展望其革命性前景。至于这算不算 AGI,曼宁说的也很有分寸:看上去算是在通向 AGI 的路上。短板主要是 semantics 还不够直接面向真实世界,而是源自符号世界、囿于符号世界(所谓 distributional semantics),等于是绕了一个弯儿,语义的深度以及语义结构本身就显得太扁平 太浅 难以消化人类深厚的知识积淀。但即便如此,也堪称一个伟大征程的坚实脚步,是激动人心的NLP新时代。从分布角度看意义,如果说人是社会关系的总和(马克思),那么也可以说,语词基本上是语词间篇章关系的总和。很多年来,我们 NLPers 一直挣扎在如何把 context 合适的模型化,因为语言符号的歧义和微妙很大程度上可以在 context 中予以消解。context 最直接有效的对象就是 sentences/discourse,而恰恰在这一点,深度学习注意力机制为基础的大模型展示了其几乎神奇的表示能力。
刘群老师:同意@wei,深度学习和预训练方法取得的进步非常惊人,超出想象。原来感觉不可解的一些问题,现在似乎都看到了曙光,解决路径隐隐约约能看到了。虽然对AGI仍然质疑,但对这个领域的前景真是非常看好。
算文解字:是的 同一个模型prompt一下就能完成各种nlp任务 就算不是agi 也是更g的ai了[Grin] 而且即使是从denotational semanrics的角度看 加入多模态的预训练模型也算是部分和间接的grounding到真实世界了的物体了。
刘群老师:是的,原来觉得一般意义上的grounding几乎不可能,除非是特定领域。现在看越来越可能了。
立委:感觉上,意义表示(A)落地到客观世界(B)可以看成是人类与生俱来的本能,不需要特别的模型化,如果A本身比较充分的话。 那么这个 A 是个什么东西呢?A 可以看成是一个平面的表示,其中 X 轴就是 discourse/context,而 Y 就是 ontology 甚至还带有 pragmatics 因素的世界知识和推理体系。
目前的大模型的长处是 X 模型化,短处依然在 Y。因此虽然从分布角度貌似也总结出了一些常识,以及浅层的推理能力,但这些能力没有足够的深度和逻辑性,缺乏推理的链条性和一致性。
符号知识图谱以及人类探索积累下来的本体知识库、领域知识库,这些东西都是非常浓缩的、高度结构化的知识体系,本质上具有严谨的逻辑性和推理能力。分布式学习学到了这些知识的皮毛,但总体上,对于这些知识精华还很陌生, 难以系统性直接兼容并蓄。
刘群老师:当然离解决这些问题还远,只是说能看到曙光了。以前感觉根本没希望。虽然还不怎么样,但不是没希望。日拱一卒[ThumbsUp]
算文解字:还有这两年出现的基于预训练模型的常识推理(如Yejin Choi组的工作)也让人眼前一亮。即使五年前,还是说研究common sense一般反应都是敬而远之[Facepalm]
立委:大数据为基础的分布学习可以反映相当多的常识,这个是没有疑问的。我们在本群中讨论过很多案例,也有这种反映:所谓大数据支持的“相谐”性,其实与常识中的特征匹配,吻合度很高。
刘群老师:把符号融入到神经网络里面不是解决这个问题的正确方法,还是分阶段处理,来回迭代才是正途。
立委:方法论上也许的确如此,但 intuitively 感觉是一种知识浪费。就是说,从我们DL外行的角度来看,明明人类已经世代努力提炼了精华,都规整得清清楚楚,可模型就是没法利用。一切必须从头开始。让人着急。
刘群老师:我说的来回迭代不是人机交互,是符号和神经来回迭代,可以自动化的。
立委:哦,那就是我希望看到的深度耦合/融合。这种融合是革命性的方向,有望发生新的AI突破与下一代的范式转变。但不久前,还普遍被认为是一种乌托邦,觉得符号和神经,就跟林黛玉与焦大似的,打死也不兼容。
算文解字:刘老师,这个方向上近期有哪些比较亮眼的工作呀?
刘群老师:WebGPT, AlphaCode等。还有周志华老师反绎学习的工作。
算文解字:恩恩 的确 webgpt这种都可以看做是 大模型 和 离散/黑盒系统(可以是规则)交互迭代的方案
立委:前面提到,对于大数据,人比起机器,有时候好像蚂蚁比大象。有老友不满了,说不要这样说,这是“物种”歧视。
其实,很多事儿,人比起机器,还不如蚂蚁比大象......
1. 计算
2. 存贮/记忆
3. 下棋
4. 知识问答
5. 翻译
6. 做对联
7. 格律诗
8. ......... 可以预见的未来清单还很长很长,都不是遥不可及的 ......
(自动驾驶、自动咨询、自动陪护、自动培训、自动写作、自动音乐、自动绘画 ...........)
事实在那里摆着。不服不行。
回顾历史,人类第一个被蒙圈的就是计算。以前的那些心算大师,算盘顶级快手,现在很少有宣传了,因为干不过一个小小的计算器。
紧接着是存贮量和记忆力。当年我们最崇敬的人物就有不少是过目不忘 博闻强记的大师们。社科院流传着很多大师的传奇故事,社会上也有很多周总理的超凡记忆力的故事,都是能记住非常细节的东西,可以在记忆的大海捞针。现如今,谁敢说任何大师记忆的信息量能比过一个U盘。哪个大师还能在谷歌百度面前夸口自己的大海捞针的信息检索能力?
下棋不用说了,电脑完胜,两次载入计算机历史的里程碑。知识问答也进入了计算机历史博物馆,IBM 沃伦的高光时刻。机器翻译我一直在用,我本人就是机器翻译出身的,目前的翻译水平高过普通翻译,注意:不是指速度。对联、写诗 也有过大赛。自己试试就知道了:你可以尝试在家苦学格律诗n年,然后即兴写诗,与机器比试比试?
面对超大数据的基础模型,人类脑壳里的“小”只会越越来露怯,想藏拙也藏不住了。
当然,严格说来这不是一场完全公平的实体之间的比试。一边是单个实体的人(例如世界围棋冠军),另一边是消化了人类整体知识积淀的实体机器人。好比一人对无数人,自然是蚂蚁遇上了大象。但是,另一方面看,每个碳基生物的人也在不断学习人类的知识才能成为专家或冠军,并非一张白纸。关键在于学习能力,碳基实体无法与硅基实体的电脑比试自动学习的能力,因为后者占尽了时间(速度)与空间(存贮)的优势。超人的出现不会是人,而是机器人,这应该是用不了50年就可以做实的现实。
新摇滚歌手汪峰曾经唱到:我该如何存在?
面对汹涌而来的大数据大模型,人类准备好了吗?

与曼宁教授在斯坦福合影(2017.07.18)
斯坦福Chris Manning: 大模型剑指通用人工智能?
著名NLP学者斯坦福大学的Chris Manning教授近期在美国人文与科学学院期刊的AI & Society特刊上发表了一篇题Human Language Understanding & Reasoning的论文。
文章在简单回顾了NLP的历史发展的基础上,分析了预训练的transformer模型何有此威力,探讨了语义和语言理解的本质,进而展望了大模型的未来,对新手还是老兵都颇有启发。本文就聊一聊论文的要点。顺便提一句,论文谈的是NLP,但本质也是在说或许我们已经在通用人工智能(Artificial general intelligence, AGI)上迈出了坚定的一步。
-
NLP领域的范式转移
文章先简要回顾了自然语言处理(NLP)的几个阶段,这对于新一代炼丹师可能过于遥远,所以我们也一笔带过:
-
第一阶段,发轫于冷战时期1950-1969的机器翻译工作,以现在的观点看数据和计算量都小的可怜,同时没太多语言结构或者机器学习技巧介入。
-
第二阶段,1978-1992的符号主义,没错,约等于规则,那种很系统且elegant的规则。
-
第三阶段,1993-2012的,实证主义,也就是基于语料库的机器学习时代。
-
第四阶段,2013开始一直到现在,深度学习时代。
深度学习本身当然意义巨大,但2018年出现的大规模自监督(self-supervised)神经网络才是真正具有革命性的。这类模型的精髓是从自然语言句子中创造出一些预测任务来,比如预测下一个词或者预测被掩码(遮挡)词或短语。
这时,大量高质量文本语料就意味着自动获得了海量的标注数据。让模型从自己的预测错误中学习10亿+次之后,它就慢慢积累很多语言和世界知识,这让模型在问答或者文本分类等更有意义的任务中也取得好的效果。没错,说的就是BERT (Devlin et al, 2019)和GPT-3之类的大规模预训练语言模型,large pretrained language model (LPLM),中文世界也常称之为大模型。
-
为什么大模型有革命性意义?
用Manning自己的话来说,在未标注的海量语料上训练大模型可以:
Produce one large pretrained model that can be very easily adapted, via fine-tuning or prompting, to give strong results on all sorts of natural language understanding and generation tasks.
从此,NLP领域的进展迎来了井喷。
Transformer 架构(Vaswani et al., 2017) 自2018年开始统治NLP领域。为何预训练的transformer有如此威力?论文从transformer的基本原理讲起,其中最重要的思想是attention,也就是注意力机制。
Attention其实非常简单,就是句子中每个位置的表征(representation,一般是一个稠密向量)是通过其他位置的表征加权求和而得到。Transformer模型通过每个位置的query, key以及value的表征计算来预测被掩码位置的单词。网上有很多介绍transformer的资料,不熟悉的同学可以自行搜索,大致过程如下图所示:
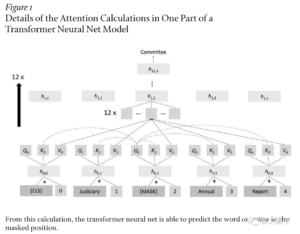
为什么这么简单的结构和任务能取得如此威力?
此处颇有insight。Manning认为通过简单的transformer结构执行如此简单的训练任务之所以能威力巨大的原因在其:通用性。
预测下一个单词这类任务是如此简单和通用,以至于几乎所有形式的语言学和世界知识,从句子结构、词义引申、基本事实都能帮助这个任务取得更好的效果。因此,大模型也在训练过程中学到了这些信息,这也让单个模型在接收少量的指令后就能解决各种不同的NLP问题。也许,大模型就是“大道至简”的最好诠释。
基于大模型完成多种NLP任务,在2018年之前靠fine-tuning(微调),也就是在少量针对任务构建的有监督数据上继续训练模型。最近则出现了prompt(提示学习)这种形式,只需要对任务用语言描述,或者给几个例子,模型就能很好的执行以前从未训练过的任务 (Brown et al, 2020).
-
NLP的大模型范式
传统的NLP是流水线范式:先做词法(如分词、命名实体识别)处理,再做句法处理(如自动句法分析等),然后再用这些特征进行领域任务(如智能问答、情感分析)。这个范式下,每个模块都是由不同模型完成的,并需要在不同标注数据集上训练。而大模型出现后,就完全代替了流水线模式,比如:
-
机器翻译:用一个模型同时搞多语言对之间的翻译
-
智能问答:基于LPLM微调的模型效果明显提升
-
其他NLU任务如NER、情感分析也是类似
更值得一提的是自然语言生成 (natural language generation, NLG),大模型在生成通顺文本上取得了革命性突破,对于这一点玩过GPT-3的同学一定深有体会。
这种能力还能用在更为实用的医学影像生成任务上。大模型能在NLP任务上取得优异效果是毋庸置疑的,但我们仍然有理由怀疑大模型真的理解语言吗,还是说它们仅仅是鹦鹉学舌?
-
大模型能真正理解人类语言吗?
要讨论这个问题,涉及到什么是语义,以及语言理解的本质是什么。关于语义,语言学和计算机科学领域的主流理论是指称语义(denotational semantics),是说一个单词短语或句子的语义就是它所指代的客观世界的对象。
与之形成鲜明对比的是,深度学习NLP遵循的分布式语义(distributional semantics),也就是单词的语义可以由其出现的语境所决定。Manning认为两者可以统一起来,用他的原话来说,就是:
Meaning arises from understanding the network of connections between a linguistic form and other things, whether they be objects in the world or other linguistic forms.
用对语言形式之间的连接来衡量语义的话,现在的大模型对语言的理解已经做的很好了。但目前的局限性在于,这种理解仍然缺乏世界知识,也需要用其他模态的感知来增强,毕竟用语言对图像和声音等的描述,远不如这些信号本身来的直接。这也正是很多大模型的改进方向。
-
大模型的未来
大模型在语言理解任务的成功,以及向其他数据模态,比如图像、知识、生物信息等的拓展巨大的前景指向了一个更通用的方向。在这个方向上,Manning本人也参与提出了近期大火的foundation model(基础模型)的概念。
基础模型是指百万以上参数,通过自监督学习在预料上训练的,可以轻松适配到多种下游任务的大模型(Bommasani et al., 2021)。BERT和GPT-3就是典型的例子,但最近在两个方向上涌现出不少的拓展性工作:
-
大模型连接知识,无论是以连接知识图谱神经网络,还是实时搜索文本知识的形式。
-
多模态的foundation model,比如DALL·E模型,这个方向也更激动人心。
Foundation model仍然在早期,但Manning描绘了一个可能的未来:
Most information processing and analysis tasks, and perhaps even things like robotic control, will be handled by a specialization of one of a relatively small number of foundation models.
These models will be expensive and time-consuming to train, but adapting them to different tasks will be quite easy; indeed, one might be able to do it simply with natural language instructions.
AI模型收敛到少数几个大模型会带来伦理上的风险。但是大模型这种将海量数据中学来的知识应用到多种多样任务上的能力,在历史上第一次地非常地接近了(通用)AI的目标:对单一的机器模型发出简单的指令就做到各种各样的事情。
这类大模型可能只拥有非常局限的逻辑推理能力,但是大模型的有效性会让它们得到非常广泛的部署,在未来数十年它们会让人们领略通用人工智能的一瞥。
Reference
from https://mp.weixin.qq.com/s/pnd2Q-5duMtL0OLzrDJ2JA
【相关】
斯坦福教授曼宁AAAS特刊发文:大模型已成突破,展望通用人工智能
预告:李维《巴别塔影:符号自然语言处理之旅》(人民邮电出版社 2022)
预告:李维等 《知识图谱:演进、技术和实践》(机械工业出版社 2022)
《我看好超大生成模型的创造前途》
最近,盘古群(一个围绕中文超大生成模型盘古的技术交流微信群)里的朋友在谈 open AI 最近发布的文字转图片的 Dalle2 应用,吸引了成千上万的人想要先睹为快。据介绍,Dalle2 可以根据你的自然语言的描述,随机生成任意图片。从发布的样例看,很多生成的图片超出人的想象,很像艺术品,当然也有次品,但都是唯一的。下面随手摘取几张样本:
Dalle 的出现是出版界的福音。出版界为了插图的授权问题,常常弄得头晕脑胀。我们在互联网上发帖子比较随意,需要插图的时候就搜索一幅用上再说,遭遇纠纷的时候撤下就好,但出版界最怕引起这些纠纷。现在好了,通过 Dalle 可以整出来各种插图可供选择,而且保证了这是唯一的“揉合创造”,不会侵权。
商务出版我的《NLP答问》的时候,建议为了回避可能的插图侵权,建议我找艺术家重新描画。无奈之下,我让女儿做了两张素描,她以我和她自己作为原型“再创作”,终于绕过了这个问题。LOL


回来说生成模型。我相信在“机助创作”这个大方向上,超大生成模型今后几年会有接地气的应用出现,Dalle 就是一个苗头。对于创业者,找准市场角度、收获千万用户的杀手级独角兽的出现,也不是小概率事件。因为市场需求是存在的。(据说现在美国有 300 多家初创团队或个人正在寻找利用 GPT3 模型的落地场景。)
这背后的原理,值得说一说。我们知道,计算复杂性研究中有个著名的 P vs NP 问题。简单说就是(在有限时间内)问题分为可解与不可解两类。搜索空间指数增长,组合爆炸,就是不可解的问题。而很多判定性问题具有确定性推理算法,不需要搜索,那就是可解的问题。
超大生成模型的出现就好比是提供了一个把不可解问题转化为可解问题的路径。当然,任何比喻不是跛腿就是夸张,严格说来,应该是超大模型为艺术家和匠人打开了次优解集合的大门。生成模型最大的为人诟病之处是其不稳定性:结果时好时坏,有时候让人拍案叫绝,有时候让人无语。这就是为什么网上对其前景争论不休的主要原因。粉丝报喜不报忧,批评者揭露其背后的缺乏理性或灵性。
这种情况下的最佳搭配其实就是人机耦合(让 human in the loop):人的归人,机器的归机器;各自发挥所长,取长补短。这在创造性应用中最为明显。创造需要消化前人的历史积淀,然后加入个人的灵感,才能成事。但消化类似于搜索,这一步对于人及其有限的脑容量、记忆力和时间,挑战实在太大了。而人作为万物之灵,“灵感”其实人人都有。
现在好了,超大生成模型几乎无限延伸了人的搜索消化的能力,在很多细分领域甚至可以对历史做到一网打尽。深度学习的革命现在可以让消化了的东西重新符号化(包括语言符号、音频符号和视频符号),提供给人选择。这是千载难逢的绝佳组合:人只要判定就好了。判定是灵感参与的线性决策过程,n 挑 1 也就是 n 倍的判定,依然是线性的。对于文学艺术创作,这个太高效了。人类进入“艺术大爆炸”、“艺术个性化”时代,百花齐放,人人皆为艺术家,不是不可以想见的。
熟读唐诗三百首,以前是成为古典诗人的必由之路,被认为是必要的苦功夫。现如今,300 就是个笑话,整个古典诗词喂进模型去也是个小 case。总体而言,消化大数据,人比起机器,就好比蚂蚁比大象。
对于稳定性弱波动性大的生成模型,应用的开花结果不要指望全自动。人机耦合条件下,纵然你n个结果有9成垃圾,我只取一瓢。一样会产生前所未有的价值。目前的问题是,艺术家群体不懂计算,计算界的人艺术敏感度不够,所以二者耦合所能发现的市场角度不容易确定。但假以时间,没有理由不对这个前景看好。
更何况不少创造性应用并不一定要专门针对艺术家或工匠的群体,有相当场景是普罗百姓都有需求的。例如应用文写作、秘书2.0, 编辑2.0, 确保出版插图永无侵权烦恼,等等等等。
【相关】
预告:李维《巴别塔影:符号自然语言处理之旅》(人民邮电出版社 2022)
预告:李维等 《知识图谱:演进、技术和实践》(机械工业出版社 2022)
我的前老板的企业家创业访谈
【立委按】我的前老板(NetBase 创始人兼CEO Jonathan)最近有访谈,谈到他的连环创业的过程,带回来公司创业初期的很多回忆。Netbase 目前是美国社会舆情(social listening)B2B 赛道的绝对领跑者,早已站稳了脚跟。我是五号员工,首席科学家,带进来 NLP 落地大数据的硬核技术。当年与两位创业者融洽相处,共同奋斗的生活是我职业生涯的愉快时光。我在Netbase 的10年见证了技术改变商业情报的成功案例。访谈中提到的最出彩的创业环节是客户顾问委员会的成立,保洁等巨头公司作为早期客户愿意投资新产品,根据他们的需求和痛点参与制定产品方向,这是创业公司梦寐以求的情况。其实,这是因为此前我们已经用NLP技术开发了另一款科技文献的搜索产品(最终由 Elsevier 独家代理发行 illumin8),可以瞬时发现任何问题的现存解决方案,是回答how难题的利器。这款产品的第一期客户就有保洁公司,是这款产品的出色表现及其背后的NLP挖掘大数据的能力展示,使得保洁公司的客户情报部门愿意出钱出力帮助我们制定开发一款面对社交媒体的客户情报挖掘产品,最后成就了我们的 B2B 事业。这里面的创业故事还有很多有趣的细节。记得有一次陪同 Jonathan 去保洁公司总部见他们的VP,路上他跟我回忆他们第一次去保洁公司总部试图联系时候的冷遇,前后对比,不胜唏嘘。我们终于凭着技术创新的实力成了他们的座上客。他当时的感慨和对于新产品的兴奋,非常具有感染力。
将 AI 应用于潜在客户生成:Rev.AI 首席执行官乔纳森·斯皮尔
发表于 2022 年 4 月 26 日星期二

我在 1998 年创办了一家初创公司,将 AI 应用于潜在客户生成和资格问题。时间还早,当年数据还不够丰富。
现在,数据就在那里。问题最终能否以适当的复杂程度得到解决?
米特拉:让我们回到你旅程的开始。你在哪里出生和长大?
乔纳森·斯皮尔(Jonathan Spier):我是在圣地亚哥长大的加州人。我来这里是为了在伯克利上学。我再也无法逃脱。
米特拉:你在伯克利之后做了什么?
乔纳森·斯皮尔:我曾短暂从事咨询工作,然后进入了一家名为 Ariba 的公司。我是 85 号员工。几年之内,我们就有了 3,500 人。这是一个有趣的地方。
米特拉:我们有Ariba案例研究。基思·克拉赫(Keith Krach)参加了该系列。
乔纳森·斯皮尔:他是一位伟大的领袖。整个团队都很棒。我是他们雇用的最年轻的人。我加入时,他们已经是一支非常资深的团队。我对成长型企业非常着迷。
米特拉:你是哪一年离开阿里巴的?
乔纳森·斯皮尔: 2002。
米特拉:那之后会发生什么?
乔纳森·斯皮尔:硅谷经历了整个核冬天。恢复花了很长时间。期间我去接受了我的“脑叶切开术”,哈佛的 MBA。那是一次很棒的经历。我打算最终创办一家公司。2004年离开商学院,我违背自己的意愿创办了一家公司。
米特拉:为什么说违背你的意愿?
乔纳森·斯皮尔:当时他们会说的是先向其他人学习,然后创办公司。这已经改变了。现在鼓励人们立即创办公司。更多的人在他们职业生涯的早期就这样做了。
米特拉:我在麻省理工学院的研究生院创办了我的第一家公司。我没有上商学院。
乔纳森·斯皮尔:有很多人这样做吗?
米特拉:第一批互联网企业家,很多人都在这样做。我在 1994 年创办了我的第一家公司。然后在 1997 年我的第二家公司和 1999 年的第三家公司。当时,人们这样做。你所描述的时期是核冬天。
乔纳森·斯皮尔:我记得我去硅谷银行存入我的种子资金。我记得他们很惊讶有一位企业家在那里。我对这个想法很兴奋。我的联合创始人是麻省理工学院的人。他发明了一个概念。我对此感到非常兴奋。
米特拉:什么是想法?
乔纳森·斯皮尔:基本想法是着眼于世界上巨大的数据爆炸和关联信息的数量,并说这些信息对于企业挖掘非常有价值。与基于少数人的旧方法不同,我们可以在一毫秒内了解整个舆论网络。这是一款非常高端的社交上市产品,在一些大型财富 500 强公司中表现出色。
我们发展了大约七年半。我们已经筹集了超过 2000 万美元的资金,并且收到了一家大型企业软件公司提出的以九位数出售的报价。其中一位董事会成员不想出售。好消息是这是一家好公司。它仍然被认为是企业分析类别的领导者。
米特拉:公司的名字是什么?
乔纳森·斯皮尔: NetBase。它有大客户。我经常遇到使用这个软件的人。当我们收到报价时,我赞成出售它。于是,我与公司分道扬镳。
米特拉:你当时是首席执行官?
乔纳森·斯皮尔:我担任创始人兼首席执行官七年半。然后我和 Ho Nam 在 Altos 做了一个 EIR。
米特拉:谁是不想卖的投资者?
Jonathan Spier:这是一家名为 Thomvest 的风险投资公司。这是汤姆森家族的风险投资部门。
米特拉:那太不合理了。
乔纳森·斯皮尔:他们不是不理性的。他们只是想要一个更大的出口。
米特拉:你在Altos有没有想出一些新的东西?
乔纳森·斯皮尔:我喜欢桌子的那一边,但我就是太喜欢运营了。我在看一些机会。在 NetBase,当SAAS软件落地时,我们就在那里。我们有机会建立适当的 SaaS 销售动议。我从 Marketo 的人们那里得到了很多很好的建议。我和他们的团队一起度过了愉快的时光。
我真的很喜欢 B2B 销售流程的演变方式。作为一名 EIR,我在研究这个问题。具体来说,我是在看售后。似乎需要一个新类别来管理客户的售后管理方式。Gainsight刚刚开始。我以为我有点晚了,但我一直很喜欢那家公司,并跟踪他们,看看他们去了哪里。
米特拉:你提到的两家公司,Marketo和Gainsight,都参加了我们的企业家之旅系列。
Jonathan Spier:我与 Marketo 的 Phil 取得了联系,并与他讨论了目前的公司。我从来没有和 Gainsight 的 Nick 谈过话。他也是门洛帕克的人。
米特拉:你有什么收获?
乔纳森·斯皮尔:我朝不同的方向急左转。我遇到了一位在零售领域非常出色的创始人。我最终创办并经营了一家零售业务。我从未想过我会去 B2C,但我非常喜欢这项业务。我被营销过程和弄清楚消费者营销所吸引。
米特拉:你卖的是什么?
乔纳森·斯皮尔:童鞋。这家公司叫普莱。它在门洛帕克拥有非常高的市场份额。
米特拉:我想你想花时间谈论Rev,但请给我一些 NetBase和Plae的亮点,它们确实具有战略意义。
Jonathan Spier:亮点通常来自客户互动和客户增长。我们在 NetBase 做过的最好的事情之一就是成立了一个客户顾问委员会。
我们开始与宝洁公司就我们的新产品进行对话。宝洁公司同意帮助我们做到这一点。他们会坐在房间里帮助我们设计产品。在产品出现之前,他们在财务上做出了承诺。然后他们还帮助我们招募了可口可乐、雀巢和卡夫等其他公司。他们都是顾问委员会的成员。在我们推出产品之前,所有资金都已承诺。
米特拉:那太了不起了。
Jonathan Spier:在编写一行代码之前,我们已经获得了数百万的预订。
Google MT from
Applying AI to Lead Generation: Rev CEO Jonathan Spier (Part 1)
Applying AI to Lead Generation: Rev CEO Jonathan Spier (Part 2)
【相关】
预告:李维《巴别塔影:符号自然语言处理之旅》(人民邮电出版社 2022)
预告:李维等 《知识图谱:演进、技术和实践》(机械工业出版社 2022)
立委NLP talk 幻灯及音频:《老司机谈NLP半自动驾驶》

NLP talk 音频如下:
slides: Wei-NLP-talk-20220312


























【相关】
预告:李维《巴别塔影:符号自然语言处理之旅》(人民邮电出版社 2022)
预告:李维等 《知识图谱:演进、技术和实践》(机械工业出版社 2022)
编译 Gary Marcus 最新著述:《深度学习正在撞南墙》
【按】推荐 Gary 最新文章对于深度学习的批评。非常有历史感和使命感的文字。他首先指出,几年前深度学习吹牛说不再需要培训放射科医生了,因为机器几年内可以取代这个职业。几年过去了,没有一个放射科医生被机器取代。现在的情形是: 医生与机器协力。Gary 对深度学习极端派批评的新文章一再强调了符号与神经的结合,并对于符号被排斥的历史做了批评性回顾。他的符号论有点意思。其实,除了极端派,多数人并不反对符号与神经的结合尝试,只不过这一对冤家本性上脾性不合,不是轻易可以结合的。昨天紧接在我的 talk 后,屠教授(他是朱纯松的弟子)给了一个很有意思的研究报告,他就把正则表达式规则转换成了神经网络,在规则与神经之间构建了一座桥梁。
让我先说几件看似显而易见的事情,”深度学习的“教父”、我们这个时代最著名的科学家之一 Geoffrey Hinton 在 2016 年多伦多的一次领先的人工智能会议上说:放射科医生,你就像已经越过悬崖边缘但还没有往下看的土狼。他推断,深度学习非常适合读取 MRI 和 CT 扫描的图像,人们应该“现在停止培训放射科医生”,而且“很明显,在五年内深度学习会做得更好”。
快进到 2022 年,没有一个放射科医生被替换。相反,现在的共识是放射学机器学习比看起来更难;至少目前,人类和机器是互补的。
(评一下:这是说难度被低估了。但其实,长远来看,趋势应该是明显的:1. 由于机器性能的提升,放射科医生的需求量会降低;2. 幸存下来的放射科医生都会是与机器协作的好手,这就好比以翻译为生的人,需要熟练掌握使用机器翻译工具一样。)
当我们只需要粗略的结果时,深度学习处于最佳状态。
很少有领域比人工智能更充满炒作和虚张声势。它十年又十年地从一个时尚到另一个时尚,总是承诺月亮,但只是偶尔能够兑现交付。前一分钟是专家系统,接下来是贝叶斯网络,然后是支持向量机。2011 年,IBM 的 Watson 曾被标榜为医学领域的一场革命,而最近则以拆散贱价出售。如今,事实上自 2012 年以来,深度学习一直被青睐,作为一种价值数十亿美元的技术,它推动了当代 AI 的发展。Hinton 帮助开创了这一技术:他的论文被引用了惊人的 50 万次并与Yoshua Bengio 和 Yann LeCun 一道荣获 2018 图灵奖。
像他之前的 AI 先驱一样,Hinton 经常预示着即将到来的大革命。放射学只是其中的一部分。2015 年,在 Hinton 加入谷歌后不久,《卫报》报道称,该公司正处于“开发具有逻辑、自然对话甚至调情能力的算法”的边缘。2020 年 11 月,Hinton告诉MIT Technology Review,“深度学习将无所不能。”
我对此严重怀疑。事实上,我们距离真正理解人类语言的机器还有很长的路要走,与科幻片的机器人 Rosey 的日常智能相去甚远,Rosey the Robot 是一个不仅可以解释各种人类请求的科幻管家,而且可以安全实时地采取行动。当然,埃隆马斯克最近表示,他希望制造的新型人形机器人 Optimus 有一天会比汽车行业市场更大,但就在特斯拉宣布该机器人的 2021 年人工智能演示日,它只不过是一个穿着服装充数的真人。谷歌对语言的最新贡献是一个系统(Lamda),它是如此的轻浮,以至于它自己的一位作者最近承认它很容易产生“废话”。 扭转局面并获得我们真正可以信任的人工智能绝非易事。
随着时间的推移,我们将看到,如果我们想要获得值得信赖的人工智能,深度学习只是我们需要构建的一小部分。
深度学习从根本上说是一种识别模式的技术,当我们需要的只是粗略的结果时,它处于最佳状态,其中必须要求出错的风险很低,同时,完美的结果也不是必要的。前几天我用 iPhone 找了一张我几年前拍的兔子的照片。即使我从未给照片贴上标签,也立即给我找到了。它之所以有效,是因为我的兔子照片与其他带有兔子标签的照片的大型数据库中的其他照片足够相似。但基于深度学习的自动照片标记也容易出错。它可能会遗漏一些兔子照片(尤其是杂乱无章的照片,或者用奇怪的光线或不寻常的角度拍摄的照片,或者兔子被部分遮挡的照片);它有时会混淆我两个孩子的婴儿照片。但即便出错也风险很低。我不会因为它出错就扔掉我的 iPhone 的。
但是,当风险更高时,例如在放射科或无人驾驶汽车中,我们需要对采用深度学习更加谨慎。当一个错误可能会夺去生命时,它还远不够好。当涉及与训练对象大不相同的“异数”(outliers)时,深度学习系统尤其成问题。例如,不久前,一辆特斯拉在所谓的“全自动驾驶模式”下遇到了一个人在路中间举着停车标志。汽车未能识别出该人(部分被停车标志遮挡)和停车标志(训练数据中的停车牌通常是在路旁的);人类司机这时候不得不从自动驾驶手上接管过来。场景离训练数据库太远了,系统不知道该做什么。
40年来第一次,我终于对人工智能感到一些乐观。
【谈到关于超大规模数据的预训练可以解决AI问题...】也许是,但也许不是。关于超大数据训练的立论有严重的漏洞。首先,仅仅是大尺度并没有抓住我们迫切需要提高的东西: 真正的理解。内部人士很早就知道,人工智能研究中最大的问题之一是我们用来评估人工智能系统的测试标准。众所周知的图灵测试旨在衡量真正的智力,结果却很容易被表现得偏执或不合作的聊天机器人所欺骗。扩大卡普兰和他的OpenAI同事所观察的衡量标准——关于预测句子中的单词——并不等同于真正的人工智能所需要的那种深度理解。【他这是说,语言模型,甭管多大规模,并不是理解意义上的语言能力。这与乔姆斯基对于经验主义的经典批判是一致的。】
此外,所谓的大数据定律并不是像万有引力那样的普遍定律,而是可能不会永远成立的纯粹观察结果,就像摩尔定律一样,这是计算机芯片生产中的一个趋势,持续了几十年,但十年前开始放缓。
事实上,我们可能已经在深度学习中遭遇规模限制,可能已经接近收益递减点。在过去的几个月里,DeepMind和其他公司对比GPT-3更大的模型进行的研究表明,在某些方面,如毒性、真实性、推理和常识,一味增加训练数据使系统开始变得不稳定。谷歌2022年的一篇论文得出结论,将类似GPT-3的模型变大会使它们更流畅,但不会更可信。
这些迹象应该给自动驾驶行业敲响警钟,该行业在很大程度上依赖于规模化,而不是开发更复杂的推理【尤其是特斯拉马斯克所依赖和指望的技术路线】。如果规模化不能让我们实现安全的自动驾驶,数百亿美元的规模化投资可能会付诸东流。
我们还需要什么?
除此之外,我们很可能需要重新审视一个一度流行、但辛顿似乎非常总想粉碎的做法: 操纵符号的做法——计算机内部的编码,比如表示复杂概念的二进制位符号串。操纵符号从一开始就对计算机科学至关重要,至少从艾伦·图灵和约翰·冯·诺依曼的先驱论文开始,现在仍然是几乎所有软件工程的基本要素——但符号在深度学习中被视为一个肮脏的词。
然而,在很大程度上,这就是目前大多数人工智能的进展。辛顿和其他许多人曾努力尝试完全摒弃符号。深度学习的希望——似乎不是基于科学,而是基于一种历史怨恨——是智能行为将纯粹从海量数据和深度学习的融合中产生。经典计算机和软件通过定义专用于特定工作的符号操作规则集来解决任务,例如在文字处理器中编辑一行或在电子表格中执行计算,而神经网络通常试图通过统计近似和从示例中学习来解决任务。因为神经网络在语音识别、照片标记等方面取得了如此之多如此之快的成就,许多深度学习的支持者已经放弃了符号。
他们其实不应该这样。
2021年底,一场名为NetHack Challenge的大型比赛给深度学习敲了警钟,这场比赛部分是由脸书(现为Meta)的一个团队发起的。NetHack是早期游戏Rogue的扩展,也是Zelda的前身,是1987年发布的单用户地牢探索游戏。图形是用的纯ASCII字符;不需要三维感知。玩家选择一个有性别的角色(如骑士、巫师或考古学家),然后去探索地牢,收集物品和杀死怪物以寻找护身符。2020年提出的挑战是要让人工智能玩好这个游戏。
对于许多人来说,NetHack对于深度学习应该是易如反掌,它已经掌握了从Pong到Breakout到(借助于树搜索的符号算法)Go和Chess的一切。但在12月,一个纯粹基于符号操纵的系统以3比1的比分击败了最佳深度学习系统——令人震惊。
失败者是如何取得胜利的?我怀疑答案始于这样一个事实,即地牢在每个游戏中都是重新生成的——这意味着你不能简单地记住(或近似)游戏棋盘。要想赢,你需要对游戏中的实体以及它们之间的抽象关系有相当深刻的理解。最终,玩家需要思考在复杂的世界中他们能做什么,不能做什么。特定的移动顺序(“向左,然后向前,然后向右”)太肤浅,没有帮助,因为每一个动作本质上都依赖于新生成的上下文。深度学习系统擅长在他们之前见过的具体例子之间进行插值,但在遇到新事物时经常会出错。
任何时候大卫击败歌利亚,都是重新考虑的信号。
“操纵符号”到底是什么意思?最终,它意味着两件事: 用一组符号(本质上只是代表事物的模式)来表示信息,并以特定的方式处理(操作)这些符号,使用代数(或逻辑,或计算机程序)之类的东西来操作这些符号。该领域的许多困惑来自于没有看到两者之间的区别——拥有符号,并用代数方法处理它们。要理解人工智能是如何陷入这种困境的,有必要了解两者之间的区别。
什么是符号?它们基本上只是代码。符号提供了一种有原则的外推机制: 合法的代数程序,可以普遍应用,独立于已知案例的任何相似之处。它们(至少目前)仍然是手工制作知识的最佳方式,也是在新奇的情况下处理抽象概念的最佳方式。挂有“停”字的红色八角形是司机停车的标志。在现在普遍使用的ASCII码中,二进制数01000001代表字母A,二进制数01000010代表字母B,依此类推。
基本的想法是,这些二进制数字串,即所谓的比特,可以用来编码各种各样的东西,例如计算机中的指令,而不仅仅是数字本身;这至少可以追溯到1945年,当时传奇数学家冯·诺依曼概述了几乎所有现代计算机遵循的架构。事实上,可以说冯·诺依曼对二进制比特可以被象征性地操纵的方式的认识是20世纪最重要的发明之一的核心——实际上你曾经使用过的每一个计算机程序都是以此为前提的。(神经网络中流行的“词嵌入”看起来也非常像符号,尽管似乎没有人承认这一点。例如,通常任何给定的单词都会被赋予一个唯一的向量,这种一对一的方式非常类似于ASCII码。称某物为“嵌入”并不意味着它不是一个符号。)
由图灵和冯·诺依曼以及之后的所有人实践的经典计算机科学,以一种我们认为是代数的方式操纵符号,这才是关键所在。在简单代数中,我们有三种实体,变量(如x和y),运算(如+或-),绑定(例如,它告诉我们,为了某种计算的目的,让x = 12)。如果我告诉你,x = y + 2,y = 12,你可以通过将y绑定到12,然后加上这个值,得到14。事实上,世界上所有的软件都是通过将代数运算串联起来,组装成更加复杂的算法来工作的。例如,你的文字处理器有一串符号,收集在一个文件中,用来表示你的文档。各种抽象操作会将符号从一个地方复制到另一个地方。每个操作都是以这样的方式定义的,即它可以在任何位置处理任何文档。从本质上说,文字处理器是一种应用于变量(如“当前选定的文本”)的一组代数运算(“函数”或“子例程”)的应用程序。
符号操作也是数据结构的基础,如字典或数据库,它们可能保存特定个人及其属性的记录(如他们的地址,或销售人员最后一次与他们联系的时间),并允许程序员建立可重用代码库和更大的模块,从而简化复杂系统的开发。这种技术无处不在,是软件世界的面包和黄油。
如果符号对于软件工程如此重要,为什么不在人工智能中也使用它们呢?
事实上,早期的先驱,如约翰·麦卡锡和马文·明斯基,认为人们可以通过扩展这些技术来精确地构建人工智能程序,用符号来表示个体实体和抽象概念,这些符号可以组合成复杂的结构和丰富的知识库,就像它们现在在网络浏览器、电子邮件程序和文字处理器中使用的一样。他们没有错——这些技术的扩展无处不在(在搜索引擎、交通导航系统和游戏人工智能中)。但是符号本身有问题;纯粹的符号系统有时工作起来很笨拙,在图像识别和语音识别等任务上表现不佳;大数据生态从来都不是他们的所长。因此,人们长期以来一直渴望其他东西。
这就是神经网络的用武之地。
也许我见过的最明显的例子是拼写检查,它说明了在经典的符号操作方法之外可以使用大数据和深度学习。帮助建议未识别单词拼写的旧方法是建立一套规则,该规则本质上指定了人们可能如何出错的心理。(考虑无意中重复字母的可能性,或者相邻字母可能被调换,将“teh”转换为“the”)正如著名的计算机科学家Peter Norvig著名而巧妙的指出的,当您拥有Google大小的数据时,您有了一个新的选择: 只需查看用户如何更正自己的日志。如果他们在查找“teh book”之后查找“the book”,您就有证据表明“teh”可能有更好的拼写。不需要依靠拼写规则。
对我来说,很明显你希望这两种方法都有。在现实世界中,拼写检查者倾向于两者都用;正如厄尼·戴维斯所观察到的,“如果你在谷歌中输入‘cleopxjqco’,它会更正为‘cleopxjqco’,即使没有用户可能会输入它。谷歌搜索整体上使用了符号人工智能和深度学习的务实混合,并可能在可预见的未来继续这样做。但是像辛顿这样的人一次又一次地反对符号的任何作用。
像我这样的人支持融合深度学习和符号操作的“混合模型”,辛顿和他的追随者一次又一次地将符号踢到路边。为什么?没有人给出过令人信服的科学解释。相反,也许答案来自历史——阻碍这一领域发展的敌意。
事情并不总是这样。读到沃伦麦卡洛克(Warren Buffett)和沃尔特皮茨(Walter Pitts)在1943年写的一篇论文《神经活动中内在思想的逻辑演算》(A Logical Calculus of the Ideas in neural Activity)时,我仍会潸然泪下。这是冯诺依曼认为值得在他自己的计算机基础论文中引用的唯一一篇论文。他们的明确目标是创建“一种对(神经)网络进行严格符号处理的工具”,我仍然认为这是有价值的。冯·诺依曼晚年花了很多时间思考这个问题。他们不可能预料到很快出现的敌意。
到20世纪50年代末,出现了一个从未愈合的裂痕。人工智能的许多创始人,如麦卡锡、艾伦·纽厄尔和赫伯·西蒙,似乎很难给神经网络的先驱们任何关注,神经网络社区似乎已经分裂,有时它自己也得到一些惊人的宣传:1957年《纽约客》的一篇文章承诺,弗兰克·罗森布拉特的早期神经网络系统避开了符号,是一个“非凡的机器……[它]能够进行相当于思想的事情。”
认为我们可以简单地放弃符号操作就是对漠视怀疑他们的人的一个回应。
事情变得如此紧张和激烈,以至于《计算机进展》杂志刊登了一篇名为“神经网络争议的社会学历史”的文章,强调了早期在金钱、声望和压力方面的斗争。当时可能已经存在的任何创伤都在1969年被大大放大,当时明斯基和西蒙·派珀特发表了一类神经网络(称为感知机)的详细数学批判,这些神经网络是所有现代神经网络的祖先。他们证明了最简单的神经网络非常有限,并对更复杂的网络能够完成什么表示怀疑(现在看来过于悲观)。十多年来,对神经网络的热情冷却了;罗森布拉特(两年后死于一次航海事故)失去了部分研究经费。
当神经网络在20世纪80年代重新出现时,许多神经网络倡导者努力与符号操作的传统保持距离。这种方法的领导者明确表示,虽然有可能建立与符号操作兼容的神经网络,但他们不感兴趣。相反,他们真正感兴趣的是建立替代符号操作的模型。众所周知,他们认为儿童的过度规则化错误(如goed而不是went)可以用神经网络来解释,这与经典的符号操作规则系统非常不同。(我的论文提出了不同的观点。)
当我在1986年进入大学时,神经网络有了第一次重大的复兴;辛顿帮忙收集的两卷本集子在几周内就销售一空。《纽约时报》在其科学版的头版报道了神经网络(“比以往任何时候都更像人类,计算机正在学习学习”),计算神经科学家Terry Sejnowski在《今日秀》中解释了它们是如何工作的。深度学习当时还没那么深入,但它又开始行动了。
1990年,Hinton在《人工智能》杂志上发表了一期特刊,名为Connectionist Symbol Processing,明确旨在弥合深度学习和符号操作这两个世界。例如,它包括大卫·图尔茨基的BoltzCons体系结构,这是一个创建“动态创立和操纵复合符号结构的连接主义(神经网络)模型”的直接尝试。我一直觉得辛顿当时想做的事情绝对是正确的,我希望他能坚持这个项目。当时,我也在推动混合模型,尽管是从心理学的角度来看。(Ron Sun和其他人也在计算机科学界内部大力推动,但从未得到我认为他应得的关注。)
然而,出于我一直无法完全理解的原因,辛顿最终对和解的前景感到失望。当我私下问他时,他拒绝了我寻求解释的诸多努力,并且从来没有(据我所知)对此提出任何详细的论点。一些人怀疑这是因为辛顿本人在随后的几年里经常被解雇,特别是在21世纪初,当时深度学习再次失去了人气;另一种猜想是,他被深度学习的成功迷住了。
当深度学习在2012年重新出现时,它带有一种不放过任何囚犯的态度,这是过去十年大部分时间的特征。到2015年,他对一切符号的敌意完全具体化了。他在斯坦福大学的一个人工智能研讨会上做了一个演讲,将符号比作以太,说是科学最大的错误之一。当我,一个研讨会上的发言人,在喝咖啡休息时走到他面前想得到一些澄清,因为他的最终提案看起来像是一个称为堆栈的符号系统的神经网络实现(这将是对他想要消除的符号的无意确认),他拒绝回答并让我走开。
从那以后,他的反象征运动愈演愈烈。2016年,Yann LeCun、Bengio和Hinton在科学最重要的期刊之一《自然》上发表了一篇关于深度学习的宣言。文章最后直接攻击了符号操作,呼吁不要和解,而是要彻底取代。后来,辛顿在欧盟领导人的一次聚会上说,在符号操作方法上投入更多资金是“一个巨大的错误”,将其比作电动汽车时代对内燃机的投资。
贬低尚未被充分探索的不流行的想法不是正确的做法。辛顿说得很对,在过去,人工智能研究人员试图——急于——埋葬深度学习。但是辛顿今天对符号操作正在做同样的事情,自然也是错误的。在我看来,他的敌意既破坏了他的遗产,也损害了这个领域。在某些方面,辛顿反对人工智能中符号操作的运动取得了巨大的成功;几乎所有的研究投资都朝着深度学习的方向发展。他变得富有,他和他的学生分享了2019年图灵奖;辛顿的宝宝几乎得到了所有的关注。用艾米丽·本德的话来说,“对像GPT-3这样的模型的过度承诺会吸走所有其他种类研究的氧气。”
具有讽刺意味的是,辛顿是乔治·布尔的玄孙,布尔代数是象征性人工智能的最基本工具之一,也是以他的名字命名的。如果我们最终能把辛顿和他的高曾祖父这两个天才的想法融合在一起,人工智能可能最终有机会实现它的承诺。
至少有四个原因,混合人工智能,而不是单独的深度学习(也不是单独的符号),似乎是最好的前进方式:
世界上如此多的知识,从食谱到历史再到技术,目前主要还是以符号形式存在。试图在没有这些知识的情况下建设AGI,像纯深度学习的目标那样从零开始完全重新学习一切,似乎是一个过度和鲁莽的负担。
即使在算术这样有序的领域,深度学习本身也在继续挣扎。混合系统可能比任何一个单独的系统都更强大。
在计算的许多基本方面,符号仍然远远超过当前的神经网络。他们能够更好地在复杂的场景中推理,能够更系统、更可靠地进行算术等基本运算,能够更精确地表达部分和整体之间的关系(这对解释三维世界和理解人类语言都是必不可少的)。它们在表示和查询大规模数据库的能力方面更加健壮和灵活。符号也更有利于形式验证技术,形式验证技术对于安全性的某些方面至关重要,并且在现代微处理器的设计中无处不在。放弃这些优点而不是将它们利用到某种混合架构中是没有意义的。
深度学习系统是黑匣子;我们可以看到它们的输入和输出,但是我们很难看到内部。我们不知道他们为什么做出这样的决定,如果他们得出错误的答案,我们也不知道该怎么办(除了收集更多的数据)。这使得它们天生笨拙,难以解释,并且在许多方面不适合与人类一起进行“增强认知”。让我们能够将深度学习的学习能力与符号的明确、语义丰富性联系起来的混合体可能是变革性的。
因为通用人工智能将肩负如此重大的责任,它必须像不锈钢一样,更坚固、更可靠,而且就此而言,比它的任何组成部分都更容易使用。没有任何一种人工智能方法是足够的;如果我们要有任何希望的话,我们必须掌握把不同的方法结合在一起的艺术。(想象一个世界,在这个世界里,制铁者喊着“铁”,碳爱好者喊着“碳”,从来没有人想到要把这两者结合起来;这就是现代人工智能的历史。)
好消息是,我一生致力于鼓吹的,也是辛顿曾在1990年左右(虽然短暂)尝试过的神经与符号的象征性和解,从未完全消失,而且最终还在积聚势头。
阿图尔·加塞兹和路易斯·兰姆在2009年为混合模型写了一份宣言,名为《神经符号认知推理》。最近在棋盘游戏(围棋、国际象棋等等,主要由Alphabet的DeepMind领导)中取得的一些最著名的成功是混合型的。AlphaGo将符号树搜索与深度学习结合使用,符号树搜索是20世纪50年代后期的一个想法(并在20世纪90年代通过更丰富的统计基础得到加强);经典的树搜索本身不足以用于围棋,深度学习也是如此。DeepMind的AlphaFold2是一个从核苷酸预测蛋白质结构的系统,也是一个混合模型,它将一些精心构建的表示分子三维物理结构的符号方式与深度学习的强大数据搜索能力结合在一起。
像乔希·特南鲍姆、阿尼玛·阿南德·库马尔和叶筋·崔这样的研究人员现在也朝着越来越多的神经符号学方向发展。IBM、英特尔、谷歌、脸书和微软等公司的大批员工已经开始认真投资神经符号方法。Swarat Chaudhuri和他的同事们正在开发一个名为“神经符号编程”的领域,这个领域对我来说就像音乐一样美妙。
40年来第一次,我终于对人工智能感到一些乐观。正如认知科学家Chaz Firestone和Brian Scholl雄辩地指出的。“没有唯一的思维方式,因为思维不是一个东西。相反,大脑是有部分的,大脑的不同部分以不同的方式运作: 看到一种颜色与计划度假不同,与理解一个句子、移动肢体、记住一个事实或感受一种情绪不同。” 试图把所有的认知都塞进一个圆孔里是行不通的。随着对混合方法的逐渐开放,我想我们终于有机会了。
面对伦理和计算方面的所有挑战,以及语言学、心理学、人类学和神经科学等领域所需的知识,而不仅仅是数学和计算机科学,将需要整个村子一起提高人工智能。我们永远不要忘记,人脑也许是已知宇宙中最复杂的系统;如果我们要建造一个与之大致相当的东西,坦诚的合作将是关键。
借助搜狗MT编译自:
Deep Learning Is Hitting a Wall (by Gary Marcus, March 10, 2022)
Gary Marcus 是一位AI科学家、畅销书作家和企业家。他是 Uber 于 2016 年收购的机器学习公司 Geometric Intelligence 的创始人兼首席执行官,并且是 Robust AI 的创始人兼执行主席。

very sharp, well articulated, and still largely true today!
【相关】
预告:李维《巴别塔影:符号自然语言处理之旅》(人民邮电出版社 2022)
老司机谈NLP半自动驾驶,北京时间3月12号下午一点半,不见不散!
做个小广告 老司机谈谈NLP半自动驾驶的心得和展望 欢迎各位老师和同学光顾切磋 我是3月12号下午1点半,美国西海岸这边是3月11号晚上九点半 开聊。不见不散!
立委NLP talk 幻灯及音频:《老司机谈NLP半自动驾驶》


【相关】
预告:李维《巴别塔影:符号自然语言处理之旅》(人民邮电出版社 2022)
立委随笔:机器翻译,从学者到学员
学了神经翻译网课,感慨良多。回想一下觉得有些好笑:30多年前好歹也是科班机器翻译出身(社科院语言所研究生院机器翻译专业硕士,1986),大小也可以说是个学“者”。河东河西,现在乖乖成了机器翻译学“员”了。机器翻译翻天覆地的变化是有目共睹的。如果NLP其他方面的变化也达到机器翻译的程度,那才真叫不废江河万古流。
机器翻译课讲义编得真心不错。这一段讲解有点意思:
3. Trained model
During the training of the Teacher-Forced model, you provided the French sentences to the decoder as inputs. What are the decoder inputs when performing a new translation? You cannot provide the translation as an input because that's what you want the model to generate.
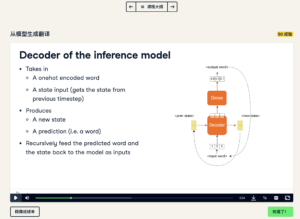
4. Decoder of the inference model
You can solve this by building a recursive decoder which generates predictions for a single time step. First, it takes in some onehot encoded input word and some previous state as the initial state. The GRU layer then produces an output and a new state. Then, this GRU output goes through a Dense layer and produces an output word. In the next time step, the output and the new GRU state from the previous step become inputs to the decoder.
就是说在训练神经翻译模型的时候,源语与目标语都在,都作为 decoder 的 inputs 来帮助模型训练。但是到了应用模型来翻译的时候,目标语作为 input 的条件不在了,那么怎么来保证目标语的影响呢?
讲义中所谓 recursive decoder 就是把目标语的语言模型带入翻译过程。这时候与训练的时候有所不同,不再是具体的目标语的句子来制约,而是用目标语预测下一词的语言模型来介入。这就是为什么神经翻译可以通顺地道的主要原因。因为有了目标语语言模型的引导。
神经翻译常常通顺有余,精准不足。这其实是一对矛盾的反映,本质上是因为 decoder 解码的时候,有两股力量在影响它,一个是源语encoder 编码的输入(上下文的 vectors),另一个是目标语语言模型(next word prediction)的输入,这两个因素一个管精准,一个管通顺,协调起来难免出现偏差或偏向。
尝试把上述讲义自动翻译(谷歌MT)后编辑说明一下:
培训模型在“教师强制”模型的培训过程中,提供给译码器的法语句子作为输入。当执行新的翻译时,解码器的输入是什么?您不能将翻译作为输入来提供,因为这是您希望模型生成的结果。推理模型可以通过构建一个递归解码器来解决这个问题,该递归解码器可以生成针对 “单个时间步长“(即:词) 的预测。首先,它接受一个热编码的输入词(这是指的源语输入文句的词)和一些以前的状态(这是指该词的上文隐藏层的内部表示)作为初始状态。接着,GRU 神经层生成一个输出(指的是下一词的向量表示)和一个新状态。然后,这个 GRU 输出通过全连接稠密层产生一个输出词(这是目标语下一词)。在下一个时间步长中,前一步骤的输出(目标语的词)和新的 GRU 状态成为解码器的输入。
目标语的语言模型是生成模型,生成模型本性就是发散的,可能步步走偏。制约它不走(太)偏的约束来自于根据源语文句编码的上下文状态。这里面还有个魔鬼细节,那就是原文句子的启动是反向的,reverse=True,就是说,原文句子的输入做了逆序操作:
sos we love cats eos --> eos cats love we sos
这样一来,当 sos(句首标志)作为解码器启动的初始单元的时候,伴随它的前文(上下文中的上文部分)不再是空(没有逆序的原句,前文是空的),而是整个句子的浓缩状态来支持它。这就说明了为什么一个 sos 的启动操作,可以依据前文生成下一个词,与 we 对应的 nous,后面就是“链式反应”了,直到生成句末标志 eos,完成一个句子的翻译。在这个递归的链式反应的每一步,每生成一个词,“前文” 就少了一个词,前文的状态因此也在步步更新作为下一步的输入,而所生成的目标语词也作为下一步的输入带入了目标语的生成模型,二者的相互作用造成了精准和通顺的妥协和平衡。目前看来,目标语的生成模型对于翻译的作用容易大于前文状态的作用,造成错译(张冠李戴、指鹿为马,人间蒸发,鬼影乍现等等问题)。但原则上,应该有办法去做平衡配置,就好比在精准和召回之间做平衡配置一样。
这一段讲义讲得蛮明白:
11. Generating translations Now you can start recursively generating French words. First you define a variable fr_sent to hold the full sentence. Then for fr_len steps in a loop you do the following. First you predict a word using the decoder. Remember that, the inputs to the decoder are, a word from the French vocabulary and the previous state of the decoder. In the fist step, the input will be "sos" and the input state will be the context vector from the encoder. This model then outputs a word, as a probability distribution and a new state. The new state will be recursively assigned to de_s_t. This means, at every time step, the previous decoder state will become an input to the model. Then in the next step you get the actual word string using probs2word() function. probs2word() is a function that accepts a probability distribution and a tokenizer and outputs the corresponding French word. After that, you convert that word to an onehot encoded sequence using the word2onehot() function. This is assigned back to de_seq which becomes an input to the model in the next step. And you keep iterating this process until the output word is "eos" or, until the end of the for loop.
这是最后的实际译文的(词循环)生成过程。利用浏览器Chrome自带的谷歌翻译(plu-g-in)如下:
给点说明:
11. 生成翻译 现在您可以开始递归生成法语译文了。首先,您定义一个变量 fr_sent 来保存完整的译文句子。然后对于循环中的 fr_len 步骤,您执行以下操作。首先,您使用解码器预测一个单词。请记住,解码器的输入是法语【即目标语】词汇表中的一个单词和解码器的先前状态【即源语的前文】。在第一步中,输入将是“sos”【句首标志】,输入的状态将是来自编码器的(源语文句的)上下文向量。然后该模型输出一个(目标语)单词【在目标语词汇表中的概率分布】和一个新状态【上下文动态更新】。新状态将递归赋值给 de_s_t。这意味着,在每个(单词生成的)时间步,之前的解码器状态都将成为模型的输入【这是译文精准的源头】。然后在下一步中,您使用 probs2word() 函数(从所预测的词的词汇概率分布)获取实际的单词字符串。probs2word() 是一个接受概率并输出相应法语单词的函数。之后,您使用 word2onehot() 函数将该单词转换为 onehot 编码序列【把生成的词重新编码以便模型下一步使用:这是引入目标语生成模型的关键输入,它是译文地道通顺的保证】。这将被分配回 de_seq,后者将在下一步中成为模型的输入。然后你不断地迭代这个过程,直到输出单词是“eos”【句末标志】,或者直到 for 循环结束。
是不是很有意思?
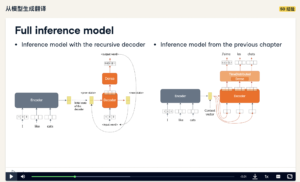
欣赏一下课件的图示:
课程最后的讲义总结如下:
Got It! 1. Wrap-up and the final showdown You've learned a great deal about machine translation and maybe a little bit of French as well. Let's have a look back at what you've learned. 2. What you've done so far First, in chapter 1 you learned what the encoder decoder architecture looks like and how it applies to machine translation. You then played around with a sequential model known as GRU, or, gated recurrent units. In chapter 2 you looked more closely at the encoder decoder architecture and implemented an actual encoder decoder model in Keras. You also learned how to use Dense and TimeDistributed layers in Keras to implement a prediction layer that outputs translation words. 3. What you've done so far In chapter 3, you learned various data preprocessing techniques. You then trained an actual machine translation model and used it to generate translations. Finally in chapter 4 you learned about a training method known as "teacher forcing" which gives even better performance. You trained your own model using teacher forcing and then generated translations. At the end, you learned about word embeddings and how they can be incorporated to the machine translation model. 4. Machine transation models In this course, you implemented three different models for an English to French translation task. Model 1 was the most basic model. The encoder consumed the English words as onehot encoded vectors and produced a context vector. Next the decoder consumed this context vector and produced the correct translation. In model 2, the encoder remained the same. The decoder in this model predicted the next word in the translation, given the previous words. For model 3, we replaced onehot vectors with word vectors. Word vectors are much more powerful than onehot vectors and enables the model to learn semantics of words. For example, word vectors capture that a cat is more similar to a dog than a window. 5. Performance of different models Here you can see the performance of those three models. You can see that the models trained with teacher forcing give the best results. You should note that the model that uses word vectors gets to a higher accuracy much quicker than the model that is not using word vectors. 6. Latest developments and further reading Though you used the accuracy to evaluate model performance, there is a better metric known as BLEU which tries to imitate how a human would assess the translation. Another important thing to know is how out-of-vocabulary words are treated in productionized models. For example, Google cannot simply replace unknown words with a special token. To address this problem these models use a word piece model. A word piece model will identify most frequent sub-words in a corpus. For example, if the model has seen the words "low" and "newer", and has learned the sub-words "low" and "er", the model can represent the unseen word "lower". One of the most important developments in the field of NLP is the Transformer. Transformer is based on the encoder-decoder architecture. However it does not use any sequential models like GRUs. Rather, it uses something known as attention which is more light-weight than a GRU. 7. All the best! I hope this has been a fruitful journey about machine translation and I wish you all the best.
【相关】
预告:李维《巴别塔影:符号自然语言处理之旅》(人民邮电出版社 2022)
立委随笔:上网课也可以上瘾吗?
可以的 -- 如果所学刚好是你的兴趣和热情所在。
马斯克说,university 主要不是学知识。如今的信息社会,知识不需要上大学。知识是免费的,只要你愿意学,它永远在那里等你。
那大学干啥呢?马斯克说,大学主要是玩(fun),还有社交和关系(connections)。顺带一个用作业和考试磨炼一个人耐心的副作用:证明你能抗造。
现在想来,老马说的有些道理。在线的免费或低费课程 by nature 比大学设置的课程平均水平高,因为它可以不断迭代,精心设计,personalize 根据学生的表现因材施教。
最近试了几门网上的电脑软件课程,虽然网课也有参差不齐,但总体感觉这是教育的大方向。其中的优秀者,从教学内容和方式上,几乎超出了我对于“理想教育”的一切想象。没想到这几年在线教育进步这么快。
真地 very impressed。才100 多美元的年费,我注册了一个有几百门课程的网站 Datacamp,发现里面很多宝藏,让人流连忘返。它会根据你的进度、错误,自动调整给你的建议,针对性补缺。再笨也能被提升。无材不可教。完成一门课,发个小红旗,美滋滋的,跟过年吃上牛轧糖一样,吃了还想吃。
看来,教育扁平化、优质教育普及到每个角落的愿景,不是梦。穷乡僻壤也一样可以够得着一流的教育,至少从知识传播的角度看是如此(至于心智情操的教育,可能较难离开人类教师的参与)。
这两天在寻思信息时代的学费问题:不少学校是按照课程收费,一个学期一门课收费 x 美元等等。伯克利这样的公立学校是按照学期收费,无论选几门课,学费是固定的。有一次我问:那多选课的学生岂不是占了大便宜?如果一学期选个七八门课,岂不是两年的学费就毕业了。得到的回答是:是的,可以这样做,如果你不怕死。还的确有极少数人做成了的。但到了期末的 dead week,脑容量不够装那么多东西来应付考试。
到了网课时代,成本趋近于零。那天我算了一笔账,年费100多美元的网站,有几百门(还在增加中)精心准备的课程 offering,如果凭着兴趣专心去学,一年下来学50门课没有问题。这样算下来的学费,每门课不到一杯咖啡钱。不禁有点心痒:这个大便宜不占,不是太亏了吗。网站也赚,因为是规模化经营,每门课都成千上万源源不断的生源。也因此他们可以聘请最好的老师,编制特别讲究的课件,配以精心设计的个性化动态配置的学习环境。
学完这门课,讲师超级棒。学到的技巧包括对 code 做 profiling,找到时间、空间瓶颈。本来这些工程优化的细节问题不是我感兴趣的点,但是无奈这个讲师讲得太好了,开始听了就停不下来。可以体会和观察到优秀讲师与课件的高明之处在哪里。
学 RNN 课程的时候,记下了零星的笔记:
多层神经训练跟玩积木似的,原来可以这样大杂烩地堆积起来(见课件中的下图),弄得跟化学制剂的配方似的。某教授说,就跟码字的人一不留神就整出个《新红楼梦》一样,码农也可能一不留神就弄出来个数据质量特牛逼的系统出来。

据说,meta training 就是这么个思路。就是说,不仅仅训练模型自动化,连模型本身的结构和超参数的选择也自动化了。如果可以控制组合爆炸,那就让机器来玩积木,保不定玩出一个模型是人想不到的。
这几天跟着RNN课程玩模型也跟小孩玩积木一样,让人着迷。着迷其过程,可以暂时不问结果,权当是 fitness 健身。
还学了神经翻译课程,感慨良多。回想一下觉得有些好笑:30年前好歹也是科班机器翻译出身,大小也可以说是个学“者”。河东河西,现在乖乖成了机器翻译学“员”了。机器翻译翻天覆地的变化是有目共睹的。如果NLP其他方面的变化也达到机器翻译的程度,那才真叫不废江河万古流。
两分钟讲解,10分钟练习这种迭代方式很赞。神经翻译课程与其他电脑课程类似,大约分 10-20 次讲解,说是4小时的课程。机器翻译课讲义编得真心不错。
Did you know that in 2017, Google translate served more than 500 million users daily? 原来 2017年谷歌机器翻译就每日服务5亿人次,超出想象。也许是仅次于搜索服务人次的第二大应用了。网上的语言屏障基本被扫除,现如今任何网页都是点击之间便化为母语。
这个必须晒一晒:
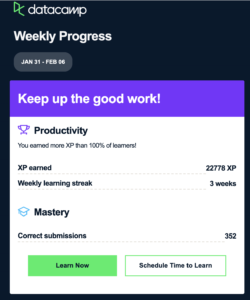
哈哈 疯了啊。前几天给我个notice 说我的疯狂coding的效率超越了社区的95%,今天接到的 note 更新为 超越 100% 这也太夸张了吧 : 社区成千上万的学员,怎么就全超越呢?再者:100% 中包括自己吗?
无论如何 积分远远高出一般 是得到认可的。统计不骗人吧。好,再接再厉,keep coding:老夫聊发少年狂,码农学员coding忙。想起来师姐曾经写过一篇《疯狂世界语》,描述我当年学习世界语过分投入的疯狂,有如昨天。
【相关】
预告:李维《巴别塔影:符号自然语言处理之旅》(人民邮电出版社 2022)
关于NLP 落地以及冷启动的对话
友:我比较好奇一个问题,方便的话请教一下李老师。像您开发的那一套parser或者引擎,一旦您离开了,还有人能持续提升么?我个人感觉能有人维护好就不错了。毕竟那套涉及很多语言学的东西,想深入到里面去改进或者维护,应该不容易。
李:基本不能,但是在NLP落地所需要的抽取层面可以继续。就是 NLP-core 一般人不要动。但是 NLP-IE 是可以的。
友:明白,就是如何利用nlp core的输出,这是和业务紧密联系的
李:IE 那些下游任务,可以假设 NLP-core 为空,选择不利用 NLP-core 的结果,也是可以的:那就成了大号的正则表达式。但比正则表达式还是强得多,因为内部有本体知识库对于词的特征支持,可以泛化。而且,虽然不要动 NLP-core,但是下游可以选择去 leverage 其潜力,因为可以根据 core 的输出结构来决定部分利用结构。就是说 core parser 不必预设它是正确的,只要其中有一些正确的部分 下游就可以选择利用。这样的灵活性都 build in 在引擎里面了。
友:nlp-core为空,那就是不要那些词之间细节关系了?然后大号的regex是否可以理解成一种所谓的end2end,给一个句子,得到整体大概是个什么意思。
李:同一条 IE 规则也可以一半用物理上下文(窗口距离限制),一半用结构,例如宾语比主语可靠。宾语就可以作为条件利用,而主语可以通过窗口限制找前面的合适的词。
友:不过话说回来,这个可能就是李老师的方法和统计的方法最大的区别了,李老师这个讲究积累迭代,统计方法训练完模型就结束了,要新的,加数据重新来。
李:其实也有很多类似。我的方法论中 可以半自动开发迭代,这与深度学习里面的梯度下降是相通的。只不过我的迭代开发过程有 human in the loop,去判断迭代效果是否符合预期。因为是冷启动,没有标注数据,只能靠 human 做判官。实质是把开发者从 coder 解放为 judge。这是一个创新,可以大大加快开发并降低门槛。当然我这边的“梯度”是预先确立的离散的路径(否则会爆炸,只有根据以前的 best practice 找到离散的泛化路径),由开发者(知识工程师)选择执行迭代的步骤。
友:嗯嗯,明白。这个感觉是更抽象层面的统一。都需要manual work,但是在不同的阶段,统计方法里的manual work就是标注,一旦标注完成,后续不会再有明显的manual work了。但是李老师的方法尤其在前期需要持续的manual work,稳定之后也很少了。
李:就是,我的方法更靠近常规软件工程方法:低代码数据驱动迭代。而机器学习/深度学习实际是一种极端主义的方法论,因为本质上 机器学习就是要实现自动编程,追求的是全自动开发(即训练)。等于是说,要消灭码农。因为深度学习在有些地方作出了突破进展,是主流,结果其极端主义的一面 一般人看不到了,被广泛视为理所当然。
友:是的是的。统计方法的模型更适合做产品系统里的某个模块,而不是产品系统本身。李老师有没有考虑过自己干?提供这种nlp-core的服务。
李:太费力,因为提供这种小众服务有擦不完的屁股。
友:哈哈,也是,最好还是套到某个具体赚钱的业务上。
确实,人们其实并不在意机器怎么理解具体句子,人们只在意怎么指导具体的业务,也就是下游的任务。这个我想也是统计方法的优势,不在细节里纠结,直接建模输入和输出。
李:end to end。
能够端到端的前提 是有大量的标注冗余数据,但这个条件在很多领域应用场景中都不存在。这就是冷启动做业务目前的难以取代的价值所在。理论上,预训练可以代替 Parser 来节省对于大量标注数据的依赖。但是 预训练+下游 这种 transfer approach 的规模化工业落地 还有很多沟沟坎坎。如果真有大的突破,parser 的价值就会降低了,也许整个符号路线会被终结。但现在判断其前景,还是有点为时过早。
友:哈哈,所以nlp的创业公司都做不了toB,因为没数据;做toC又做不过有用户的大厂,所以nlp创业公司挣不到钱,做不大。
李:EXACTLY
【相关】
预告:李维《巴别塔影:符号自然语言处理之旅》(人民邮电出版社 2022)
《李白梁129:新年快乐的符号逻辑》
白:新年快乐!
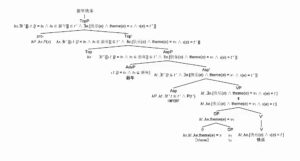
李:有意思。形式逻辑表达式?
两个tokens,嵌套演算6次,请白老师给讲解一下其语义计算。intuitively 感觉就是 “时间”和“性状”的交集。性状作为谓词,存在一个缺省的宿主,就是祝愿的对象。当然也缺省了“祝愿”,就是说性状有一个 hidden 的虚拟语气。
白:(1)定义谓词“快乐”。它带两个约束变元,一个是时段,一个是当事主体。(2)话题化。“快乐”的当事主体不在原位,说明向外层发生了移位,在我的体系里就是管挖坑不管填坑,不饱和的坑被托管给外层。(3),用一个摹状词定义了“新年”,它是由属于“新年”的所有时点构成的时间连续统(区间)。(4)在“新年”与“快乐”结合时,把新年所界定的时段用来对“快乐”进行周遍性描述,说明是在这样一个时间连续统里当事主体都快乐。(5)把这个空缺的当事主体(萝卜)构拟出来,赋予他空缺论元(萝卜)的一切已知特性。(6)回到语境,确认这是一个祈使句(祝福语),填坑的萝卜默认为语境中的听话人。还应当有个(7),就是萝卜(语境中的听话人)一路反填回最内层的坑位,也就是当初谓词“快乐”所挖之坑。所谓话题化,只是不饱和论元向外层托管残坑而已。未必处在C-Command位置(中心词对中心词/非中心词拉飞线),也完全可以处于我们定义的M-Command位置(非中心词对非中心词拉飞线)。
李:? 新年第一语义。
句法上 英语 Happy NY 中 Happy 是定语(快乐的新年),中文 “新年快乐” 感觉上 “新年” 就直接是(拟人化的)宿主。但英语的定中结构落脚在时间实体上,而中文无论是解析为主谓结构还是状谓结构,落脚在性状(谓词),都是围绕这个谓词中心,对它做约束。其他东西(包括真正的宿主)都是身外之物。
梁:不饱和最好[ThumbsUp] 有“可延展性”! Actually 空的坑越多越好,待定状态最好!
我觉得,不同的想法(框架)不应该混。 主谓宾定状补是一种语言体系。 萝卜-坑 是另一种语言体系。
李:前者是句法,后者是(逻辑)语义。形式逻辑的演算和表示是后者的算法化。
语用角度,感觉中心概念是时间,谓词降格成为渲染情绪的性状来描述这个时间,“新年快乐” 描述的是一年中有这么一天,空气中飘荡着快乐的氛围。这刚好与英语句法是一致的。
梁:语用层面,主要是 “新年” 这个词 触发了一连串想象,一幅很有特色的图画(场景),快乐是说明这个场景的。
白:我这处理是:名词降格为副词,做状语。
李:这是时间词的常规做法。甚至可以不降格,就是兼类。
白:这不是兼类,是活用。
李:兼类的说法不宜滥用,但时间是个例外:几乎在所有语言中,时间词都是名词为本,状词为表,作状语拿来就用。这是因为,时间在 entity 的频谱中,具有极其重要的特殊性和抽象性:无事不在时间内。
白:涉及到aboutness的时候,也管不了那么多。之前我们讨论过的“这场火多亏消防队员来得及时”就是。
李:分布上看,时间词作状语是压倒性的,而作为本体被议论描述则比较罕见。所以与其降格,不如说就是副词,偶然升格为名词/实体。换句话说,如果原子性符号标注不允许兼类,也不允许分层(降格升格),那么索性标注为 RB(副词),大体齐是过得去的。
白:这个我们还是根据原理来的。名词降格为副词,语义上是有一个未命名的格标记(隐介词)以这个名词为介词宾语。我们的升格操作对应于脑补这个隐介词。如果这个名词本身具有#Time的本体标签,则隐介词为“在(时间)”就很顺畅。
李:实践中,兼类也不是一个什么要不得的做法,不过就是所谓“包容”策略的一个捷径而已。绝大多数词典都是如此标注的,无论这些符号是兼容还是不兼容,大多是混杂在一起的。这带来了简便,实际运行中虽然不完美,有逻辑破绽,但多数时候是管用的。新年:RB NN,上下文要谁给谁。(其次是只给 RB,必要时“升格”为名词)。
白:说起词典,有一个很有意思的问题。“home”有一个义项被标注为副词,因为可以说“go home"。“home”还有一个义项被标注为形容词,因为可以说“on the way home"。其实,只要把home理解为缺省了隐介词"+X/N"的介词宾语N,就不难理解这两个home其实是一个,只不过隐介词既能导向状语、也能导向定语罢了。
李:那是因为定状一家,PP 是 adjunct,无论限制什么对象。
白:对,+X向左,既可以修饰N,也可以修饰S。介词就是吃一个N,吐一个+X。

祝大家新年快乐!
【相关】
预告:李维《巴别塔影:符号自然语言处理之旅》(人民邮电出版社 2022)
《李白荀舟詹128:从专名的层次纠缠谈到NLP前路漫漫 一缕曙光》
舟:新闻标题:“球员明天昨日与爱妻举行婚礼,武汉队官方送上祝福” 如何解析?
白:爱妻一个坑,球员一个坑,武汉队反填球员坑,球员反填爱妻坑。明天做专有名词。什么都能做专有名词,明是一个姓,更能。昨日倒是只能做状语。再加上一个矛盾的时间状语,优先级折损,让专有名词义项露出来。
“明天”本来就是名词,组成同位结构和降格成为状语两个可能性,在句法层面本来都是存在的。只不过,同位结构是NN合并,需要白名单制。进入白名单的条件之一就是“类型相谐、一称呼一实例”。现在,是要在句法标签同为N的情况下,解决本体标签由Time向Human转换的问题。
舟:@白硕 谷歌百度,都没有搞定翻译![Tongue][Scream]
球员明天昨日与爱妻举行婚礼,武汉队官方送上祝福。
百度:The players will have a wedding with their beloved wife tomorrow and the Wuhan team will send their best wishes to them.
谷歌:The player held a wedding with his beloved wife yesterday, and the Wuhan team officially sent blessings.
谷歌还是聪明一些,把明天扔掉了……[Tongue][Grin][Shhh]
詹:这个得有篇章处理能力才好。正文第一句“武汉队球员明天与爱妻举行婚礼”。这个“明天”还得继续是专名。
荀:从工程角度看,类似这样的极端例子,不是现阶段NLP能力所及,处理对了也未必理解了上下文。可以愣是迎着困难上,很可能得不偿失,灌入更多类似语言现象数据,或者引用更多语言知识,这句对了,可能受伤大批句子。
学理上可以深入讨论,能得到以点带面的结论是非常好的,但是那这些句子去测试机器翻译,测试大模型的能力,没有意义。
李:荀老师所言极是。
有过教训的。极端例子的处理很难“包圆”,这往往造成副作用远大于正面作用。这是因为极端例子统计上属于极小概率。对于极小概率的现象,最有利的工程策略是选择忽略它,与噪音过滤同理。
可以探讨原则性的解决方案,实现的时候需要小心与现架构或pipeline小心对接。例如,专有名词的任意性是一类现象,虽然每一个具体案例都是小概率,但这类现象可以探讨一种原则性的出路。出路往往出现在另一个层面,例如应用场景的动态词典层面:一个与常用词同形的专名在 discourse 或某个数据源中反复出现,当它远远高于它作为常用词的正常出现频率的时候,它作为专有名词的小概率就变成了现实可能性。动态词典或用户词典可以收录它,增加它作为专名的权重。把动态词典与系统核心词典融合,可望帮助解决这类层次纠缠。但这种融合还是需要格外小心。比如,动态词典不仅仅要适合的时机融入处理,也要在合适的时候退出,以免对于变化了的场景产生持续的副作用。
通常的 NLP 只针对局部字符串。现在出现了更大的场景约束: dicourse、data source(source 本身也份不同层次)、domain 以及用户词典。为这些场景规划范围,以及资源进出的条件边界,是一个远远超出常规NLP处理流程的更高层面的控制逻辑。很不容易处理妥帖。
弄巧成拙的坑,不知道栽进去多少回了。
很多年前,还是在跟随刘倬老师做MT的时候,我们做过一个动态领域词典帮助确定领域场景的简单实现,有动态加入和忘记的功能:就是建立一个有限长度的先进先出的队列,当进入某个 discourse,有足够多领域A的词汇时候,就认定为A领域场景。当数据源源不断进入系统处理,领域B的词汇进来会冲刷领域A词汇,系统就进入领域B的场景。
这是为了解决WSD的领域问题,很多常用术语是跨好几个领域的,不同领域的译词不同。当时的办法就是希望动态决定,实际上就是 domain 词汇 propagation 的效果。取得了局部成功。当然,现如今的神经系统对于更大的上下文有表示记忆,这类当年的难题原则上在 discourse层面已经解决。超越 discourse 层面的,很多翻译软件(例如搜狗)允许用户自己设定一个大的领域。
另:现在对预训练的好感越来越浓,彷佛看见了一道曙光。隐隐觉得 预训练+下游NLP落地 可能是人间正道,可望碾压 parser+落地,但在当下的时间点,还不好说这条道路在规模化领域落地方面的可行性究竟如何。觉得时间窗口是 5-10 年。按照现在的科研进步和资源投入,5 年左右还做不到遍地开花,那就是遇到了真麻烦。否则,有可能终结符号路线。
荀:深度语义解析,离不开符号和结构,但不会是之前合一运算那样暴力使用知识,而是跟模型结合,处理好符号和参数方法的适用边界和做好两者融合是关键。我们在这个方向探索了多年,有了一些经验和体会,正在努力地把它写出来并开源。
李:looking forward to it ....
有时候,我也有建设开源社区的冲动,一直没有机会和精力。同时也觉得真开源了,也是门可罗雀。不知道要经营多久才有可能形成社区效应。但有一些积累如果总不开源,一辈子的思索和闯荡,也就老死手中了,想想也挺悲催的。
荀:是的,有心理准备,学习代价就是最大障碍。在努力地做到简单易学易用,届时各位老师多指教。
李:学习代价是个拦路虎。无论怎么简单易学,实现低代码,符号NLP 还是很难普及。
内部曾经说过,正则和 Excel 够简单了吧,真学好还是要费力气的。我说我定义的语言script 比正则还要简单,为什么说难呢?被告知:正则学了,Excel 学了,到处可用,那是万金油。学这个 哪里认呢?
想想也是。这不是简单降低门槛,把设计做到极致简单就可以普及的事情。
荀:不管效果如何,算是多一些不同的声音和思路。不过还是小有信心的,在北语,可以部分放在课程体系中,几轮下来,辐射面挺乐观的。
李:嗯,学校环境有所不同,可以渐渐辐射。工业界不一样,前场救火似的,很难有耐心和动机坐下来学一门偏门的东西。
荀:nlp往深里做,不可能不结合语言知识,只是找到好的做法。逼到墙角了,不得不学,不得不用,现在还没到墙角,还可以发论文,还可以拿到项目。
白:script的服务对象是程序员,那是最难伺候的用户群。
学一套特殊的表示如果能赚许多钱,没人跟钱过不去。有了钱,把这套特殊的表示传承下去也不是问题。否定别人的时候用百年老店的思维,肯定自己的时候用急功近利的思维,这叫双标。恐怕掌握特殊表示的人是否稳定,才是真正需要解决的问题。
李:好绕 lol
表示无所谓,不过就是面子而已。但是没有面子,也不知道如何传达里子。魔鬼在里子。
这种矛盾的确道可道非常道。
朋友圈刚看到这篇:Yann LeCun:发现智能原理是AI的终极问题 | 独家对话
很有意思的对话,其中谈预训练和自监督 从 raw corpus 学习所谓先验知识/结构,LeCun 信心满满认为这是AI的革命性转折。
在 raw corpus 里学习知识/结构,这与人们跳到水中学会游泳同理,与孩子在语言环境中自然学会说话同理。学校里学文法(成为 parser)是明着学结构,而预训练是暗着学结构。 表示不同,目标和原理一致。
白:其实明暗还可以细分,明着学what暗着学how是一种选择,what和how都暗着学是另一种选择。目前主流做了后一种选择,我看不出来除了商业考量(标注成本)之外有什么科学上的依据证明“明着学what”有何不妥。
李:没有不妥,主要是消化不良。主流还没有 figure out 如何接受明学的结构。既然消化不了,索性禁食,另有所食,发现还原到热量和维生素差不多是等价的。
这里有一个断裂。主流其实某种程度上 figure out 了如何生成显式结构,例如谷歌的 SyntaxNet 和 斯坦福 parser,都是深度神经训练出来的,在新闻类标准测试集上表现优异(但对于数据太过敏感,一旦换到领域数据,质量悬崖式下跌),可以媲美专家系统。但是,这是为 parsing 而 parsing,因为主流 parser 的结果主流自己也不知道如何消化和落地。
【相关】
预告:李维《巴别塔影:符号自然语言处理之旅》(人民邮电出版社 2022)
立委随笔:面对快餐文化,要牺牲一代人吗?
Peter Wang: Python and the Source Code of Humans, Computers, and Reality | Lex Fridman Podcast #250
今天看了这个访谈,很有感慨。访谈很长,可以跳着看:
是自媒体大V,采访天下名流,尤其是IT和AI界大牛。Peter Wang 是 Anaconda 的联合创始人兼首席执行官,也是 Python 社区中最具影响力的领导者和开发人员之一。此外,他还是一位物理学家和哲学家。
https://www.youtube.com/playlist?list... 剪辑播放列表: https://www.youtube.com/playlist?list... 大纲: 0:00 - 介绍 0:33 - Python 4:04 - 编程语言设计 24:07 - 虚拟性 34:07 - 人的层次 41:05 - 生活 46:29 - 想法的起源 49:01 ——埃里克·温斯坦 54:00 - 人工源代码 57:58 - 爱 1:12:16 - 人工智能 1:25:39 - 意义危机 1:48:12 - 特拉维斯奥利芬特 1:54:38 - Python 续 2:24:21 - 最佳设置 2:31:39 - 给年轻人的建议 2:40:12 - 生命的意义
访谈提到人抗不过环境,尤其是 teenagers。面对以抖音和脸书为代表的流量商业和快餐文化(包括游戏和色情)的潮水般冲击,年轻一代毫无抵挡之力。这就好比从忍饥挨饿缺乏热量时代走来的人,面对食糖完全没有抵抗力。
食糖造成肥胖症和种种疾病的后果,是经过很长时间才为社会群体意识到,这才有如今的低糖饮食(包括各种低糖饮料)的健康生活方式的逐渐流行。同理,移动互联网快餐文化的恶果也需要一代人的牺牲和教训才会逐渐为社会意识到。
堕落是容易的,站起来却很费力气,这符合熵增原理。但人与万物之不同,就是最终还是会选择站起来,只是在这种选择之前和之中,要牺牲多大的问题。快餐文化攻击的是人的软肋,开始的时候,没有人可以抵挡。但人在低层次满足和麻痹的过程中,会逐渐产生麻木和空虚。麻木让人变得皮实,不再那么容易深陷其中。空虚是对低层次的反动。最终会产生更高层次的服务和追求,限制快餐文化的蔓延,这算是乐观主义。否则,悲观主义视角看后现代的趋势,这个世界是无药可救了,科技越发展,人类越堕落。
群里讨论这个话题,马老师深有感慨:快餐文化渗透到各个方面,以前我这博客,现在根本不写了,只发微博和微信。
我也有同感:没几个人愿意深入思考。再说,认真写了博客,也缺乏受众。很少人有那个耐心。全民浮躁的社会,人的注意力宽度(attention span)是渐行渐窄。坐冷板凳的成为珍稀物种。
毛老说:不是越堕落,而是越两极分化。
梁:绝大多数人任由环境支配,顺流而下,极少数人反之,逆流而上。生命是一种小精灵,它抗拒熵增,尽量推迟与大自然达成平衡(死寂)。
我的问题是:面对快餐文化,要牺牲几乎整整一代人吗?你看现代的年轻人,多少人沉迷于游戏、毒品、memes。所谓元宇宙,各大资本巨头加持,汹涌呼啸而来。这是像哦米克隆病毒一样,到底是加速这种牺牲还是结束这种文化疫情?
但愿物极必反。
另:这个访谈真地精彩,摘录一些访谈后读者的反馈如下:
这是一个有趣的讨论,因为一个非常有技术能力的人谈论非技术事物的重要性。对我来说,这是一个技术成熟的人的完美标志。然而,我相信普遍的心态是“技术人员必须促进更多技术”,而这种对话恰恰相反。很棒的谈话!
【最近博客】
预告:李维《巴别塔影:符号自然语言处理之旅》(人民邮电出版社 2022)
立委随笔:王力宏的危机处理

2021年公关危机事件中,处于事业巅峰的王力宏事件虽然时间跨度不长,但凸显了信息时代的公关灾难,不亚于当年罗胖子怒砸西门子冰箱门的公关危机。
短兵相接,轰然倒下,王力宏处理失当,造成无法挽回的结果。毛估估,他的事业至少要停滞五年,其实际影响远远不止今后五年。除了名誉损伤与创作停滞以外,直接经济损失可达数亿,甚至数十亿。
这一切都是从家庭争端开始。导火索就是离婚,以及前妻对离婚协议的不满,虽然她还是签了字。最大的不满是她没有得到自己带孩子居住的豪宅的房产权。清官难断家务事。前妻既然在协议上签了字,她在法律上想要得到豪宅是不可能了。于是一不做二不休,她诉诸自媒体爆料。
王力宏前妻李靓蕾在离婚协议签字后没几天,就写下4538字自媒体长文,控诉王力宏爱约炮、劈腿,遭王家人冷暴力、羞辱、签下不合理的婚前协议书等罪状。该篇文章在新浪微博阅读量达23.2亿,超过《哈利波特》小说的总销量。网络时代,23亿流量,这是什么级别?自媒体核弹。
王力宏被迫应战,发文回应前妻指控:“我没有对我们的婚姻不忠。5年又8个月时间,我活在恐惧,勒索和威胁之下。” 王力宏说:“被逼结婚那天觉得最无奈,没想到比起今天,那是小菜”。妻子以孕逼婚,后来在家的强势,大概不是子虚乌有。虽然在外面,前妻一直非常配合各种秀恩爱。
分居两年,谈判长达一年,好容易把离婚协议签字了。据说王力宏家财总共约7亿,前妻得到超过一个亿(洛杉矶豪宅以及一些投资的分成),但是前妻居住的台北豪宅却不归她,种下祸根。王力宏这边觉得终于熬出头了,可以重返单身自由生活。刚要舒口气,离婚第三日,多年来保持沉默的前妻终于火山爆发。
离婚协议的谈判要不是那样寸土必争,本不至于如此。可是话说回来,他也不知道退守到哪条线不会引起火山。王力宏死活不愿意把台北一个亿的豪宅给她,也有个中苦衷。这个豪宅在他母亲的名下,当时的安排就是王家尤其是王母为防止财产流走的一个处心积虑的操作。以王母的强势,王力宏岂能违背?网上有人评论说,王是孝子,性格软弱,一直听他妈的。他妈肯定是寸土不让那种。这下好了,他在娱乐界吃的就是青春偶像饭,靠的就是自己的道德楷模人设,以后还怎么红下去。前不久还与谭维维合作唱《寸心》,风靡乐坛呢,这下子不知何时能翻身。
老友说:“钱能摆平的都不是事。现在可倒好。社死。事业算完了,没有大陆市场,唱中文歌没法红。损失岂止几个亿。”
王本来没想结婚,就做个娱乐界的黄金王老五,到处风流。在娱乐界,他有钱更有压力,还到处是美女帅哥各种诱惑。他那种私生活紊乱,娱乐界其实不鲜见。
面对突发公关危机,王家被迫应战,却是一系列烂操作。王先是矢口否认,拒不道歉。紧接着,王力宏老爸手写信帮儿子反击,数落李靓蕾的不是,力挺王力宏是好孩子,没有婚内出轨。李靓蕾嗤之以鼻,责令王力宏发声道歉,否则将起诉王力宏父子诽谤。王力宏再上场揭露前妻不是开始说的不求钱财,而是已经拿了一个多亿。
李靓蕾亮离婚协议,怒飙王力宏:读者不是傻子,强调那一个多亿财产本来就是夫妻共同名下她应得的部分,并不是离婚补偿。李靓蕾连续发文,要求王力宏回应婚内出轨、冷暴力。
感情早已破裂。这事说到底不过是离婚分割财产让李觉得不公。勉强签字了,但这个不平埋在心里,终于爆发。王作为娱乐一哥,这些年挣钱很拼,积攒家财大约7个亿,离婚的时候,房产股票加在一起给了李1.5个亿。王觉得不少了,还有孩子们今后的开销,菲佣、司机种种,对于李与孩子们住的台北豪宅(1.2亿RMB)不舍得分割,但三个孩子的妈,又无法赶人家出户,离婚协议中写明是暂住18年。
什么话?孩子长大了,前妻也就老了,到时候滚出去。人家怎么能忍呢?你不是偶像明星吗,人家有的是料,看你跋扈。王为了保住这一个亿,把自己从事业巅峰炸飞下来。
这场烂仗,明眼人一看就知道你王家再觉得委屈,也没有用,选择辩白,只会越描越黑。王说自己没有那么烂,说会对出轨嫖娼的虚假指责一一回应。李说好哇,那就对细节一一辩诬吧。
事已至此,王家乱了方寸,前妻步步紧逼。舆论站在她这边,她不怕事大。还好,也许有高人,也许自己觉悟了,王终于意识到,互联网上的“道德法庭”,他没有任何胜算,只会在网民的口水谩骂中遍体鳞伤。终于公开道歉,并且承诺把房子转给前妻。一路来,只有这一步走对了。看来不大出血,他不知道止损。
此事终以王力宏道歉,交出豪宅,李靓蕾宣布休战,落下帷幕。王力宏最新发文:"不再做任何辩解"。同时会把1.1亿人民币的“吾疆”转户到李靓蕾名下。这个结果对王力宏而言,全盘皆输。李靓蕾事后受访也表示:“不会告了。”
前互联网时代,女的再强势、聪明,也只得忍了,没有渠道。现在不同了,一个微博就能搞死你。明星的悲剧在于,你自己再有能耐,也是可以被替代。一个倒下去,后面无数候补冲上来。范冰冰多么光芒万丈,最耀眼的时候,说下来就下来,很多年就是爬不起来。
可以理解李女士的愤怒。但是仔细读她,发现下手真狠毒。她把婚前婚后、交往前交往后的很多年的事情(“劣迹”)罗列在一起,成功塑造一个渣得不能再渣的小人形象,让人百口莫辩。这个女人不简单。
这是一场不对等的博弈。天平反而向无权无势无资源的一方严重倾斜。王的权势和名声成了累赘。大概属于所谓超限战。
理论上,王力宏可以告前妻诽谤,要求赔偿天文数字的名誉损失,他的确也遭受了难以估量的财产损失。但实际上完全不可行,只会把事情弄得更糟。这是因为打铁需要自身硬,王力宏并不硬,可以说娱乐圈染缸里浸染的多数渣男的所为,他都沾边了。前妻的指控并非空穴来风。更多是两人对于事件的不同角度以及感受的差异,远非黑白分明。事情闹大对于他将来的事业复出会雪上加霜,对他的实际损害只会更严重。真上了法庭,他也不见得能赢。何况即便赢了他也得不到可以补偿其损失万一的实际好处,无论物质的还是精神的。再者,她是你孩子的母亲和监护人,孩子们最亲的人,你把她逼垮逼疯,整得她一无所有,你如何面对孩子,面对自己。
乍一看,李女士立于不败之地。王力宏不得不道歉,也不得不公开表示把房子转给她。她似乎得到了她想要的一切。但其实还是两败俱伤。前妻非公众人物,没有自己名誉的实质损伤,但是她把她的三个宝贝孩子的父亲搞得名誉扫地,将来如何面对孩子的成长。互联网是有记忆的,孩子是要长大的,父子之间的感情和关系是割不断的。这种阴影对她孩子的伤害,会是很残酷的。
事情爆发以来,王力宏的危机处理实在不敢恭维。好在此事终于以王的撤退消停了。
一切缘于人性的贪婪寡情,见利忘义。好说好散,存有起码的同理心,本来可以不这样的。
人啊人。
原载 汉阳一江水《立委:王力宏的危机处理》
【相关】
科学网-【社媒挖掘:大数据时代的危机管理】-李维的博文
预告:李维《巴别塔影:符号自然语言处理之旅》(人民邮电出版社 2022)
立委随笔:祝各位老友新朋 Have a “Good Next” Year!
快过年了,做了个奇怪的梦,趁着还记得,记下:
不知为啥事,一位专业人士老友开车带着我在外奔波了一天,说,晚饭时间了,咱们进去吃个饭。车就开到了一个熙熙攘攘的餐厅聚集区(肯定不是北京就是上海、南京啦),好容易找到 parking,然后带着我进了家高档餐厅。
我进门见餐厅高档豪华,一个个都西装革履,这才发现自己匆忙间光着脚,尴尬极了。于是老友陪我回去找我拉在车座位下面的鞋子、袜子,也都是满是灰尘。找个角落赶紧穿鞋。为打破窘迫尴尬,老友说:我们老了。我问:一直不知道,你多大了?(我心里估计他是50左右。)他神秘地蹦出带着中文口音的两个英文字出来,说:GoodNext。
我困惑: good next 啥意思?知天命还是耳顺?
他说:就是不够好,过了年富力强。
感觉我还一直在琢磨 next??就醒了。醒来后,赶紧查网络,用了双引号查谷歌,“good next”,结果除夕了,都是展望未来的话:good next year 之类。
至少确认了“good next” 不是一个固定用法或网络语,为什么在梦中表示老朽,不得而知。但愿这不是讽刺,而是新年吉语,祝各位老友新年快乐!Good next year, good next luck, good next plan, good next ......
根据“梦的解析”的说法,语言学家梦中的“新词创造”应该有某种元宇宙造词逻辑,如果是自嘲的味道,我想也许是 “good,next” 的来源: good 是应酬,重点是 next. 就好比在挑拣一个对象或物体,一个个候选上来,大部分看不中,说: good,next(please)。就是 pass 掉的意思,不合格,人家要看下一个,下一个永远是最好的。
想起看过的李永乐老师的一个视频,讲女神挑对象如何做到最优的数学原理。追求者太多,眼花了,如果总是 good,next,那肯定不行,最后一不留神自己成了“剩女”。他提出的数学,精神上与华罗庚的黄金分割点理论相通,细节忘了,就是pass了三四成的候选以后,遇到比前好的,就绝不放过,不能再等 next best or next better one 了,这才能保证统计最优。
扯远了,反正除夕了,扯一扯无妨。国内大概都在看跨年晚会了吧。
祝你我新年快乐!
记于2021年12月31日早晨7点,苹果镇
【相关】
预告:李维《巴别塔影:符号自然语言处理之旅》(人民邮电出版社 2022)
《朝华午拾:创业之路》
|||
1996年11月来到B城,发现自己是公司的第二号员工。第一号是一位富有经验的瑞典籍的软件工程师,为人朴实,是很好的合作伙伴。印度女老板是大学教授,很有修养和风度,待人热情和气。当时正赶上美国网络热潮,股市狂涨,高科技项目成为宠儿。网络泡沫最盛的时候,总使我想起国内的大跃进。不怕做不到,就怕想不到。各种概念型公司如雨后春笋,只要有个主意,加上三寸不烂之舌,就有可能弄到钱。然后就是大把地烧钱,不需要有真正意义上的产品,不需要顾客,也不需要盈利,只要你能吸引眼球,在这个所谓注意力经济的年代,你就被认为有了潜力,在风险投资家精心策划的媒体抄作后,股票上市就会身价百倍。在这样的美国式大跃进的环境下,一个项目如果确实有点技术含量和后劲,就更加被追捧,跟我们自然语言技术有关联的askjeeves.com 的迅速窜红就是一个典型例子。
AskJeeves声称可以回答用户用英语提问的各种问题,IPO后股票一路上扬,成为大红大紫的华尔街宠儿。我认真研究了他们的做法,发现他们技术含量并不高,只用了一点粗浅的自然语言技术,对英语问句做自动分析,而网络文本是大头,那方面基本没有自然语言的应用。他们的聪明之处是以不变应万变,把千变万化的用户问句归类到相关的预先设置好的问题模板,再由用户点击选择,这样就保证了对用户问题的确认。至于答案,他们采用人海战术,雇佣了几百个分析员,收集常见问题和热点,更新问题模板,手工录入存在答案的链接。AskJeeves的成功为自然语言技术扬了名,为我们后来者开辟了道路。
当年我们运用自然语言和信息提取技术,研制了一个自然语言问答系统的雏形(prototype),在美国国家标准局比赛中获奖。该系统可以回答一些简单的问题,诸如:“谁是1995年物理诺贝尔奖获得者”,“中国哪一年加入联合国”,等等。这一新的研究开发方向,被广泛认为是下一代智能搜索引擎的希望所在,在工业界和投资界引起狂热。当时我们想注册一个跟ask/question有关的域名,凡是我们能想到的,比如 answer.com, exact-answer.com, this-is-answer.com, 1-800-question.com, etc. 几乎全部被人抢先注册了。在这样的形势下,寻找风险投资不仅是诱惑,而是势在必行。
老板联系上一位华尔街投资家。这层关系刚接通,老板就让我尽快给这位投资家提供我们系统的架构图和系统简介。我手头有一张为了写政府项目最后报告而准备的架构图,前后修改了不下十遍了。可是,投资人不是技术人员,所以我必须做进一步修饰,深入浅出,力图给人一种技术艰深,而用途广泛的印象。我的苦心没有白费,我早上送出材料,中午就收到回音,请我们尽速去纽约面谈投资合作事宜。后来,投资人告诉我们,这是他见到的最激动人心的项目之一,我画的那张架构图,经过他们进一步润饰,后来在华尔街投资人中间反响很大,被誉为 million-dollar slide,我们后来的主要投资人跟我说:“I love it, I just love it”。一幅好的图画胜过文字千行,我是亲身经历了这种威力。(前知识图谱钩沉: 信息抽取引擎的架构)
于是,老板跟我动身去华尔街,拜访Park Ave豪华公寓的主人,我们的投资联络人。这位投资人早年是物理博士出身,自称其师是诺贝尔奖获得者。他现在是华尔街的亿万富翁,已经成功地把30家左右的创业公司推向IPO,早已赚得钵满盆盈。Park Ave. 是纽约华尔街不远处的著名高档住宅区,濒临中央公园,这条街上住满了银行家和金融大亨,也有一些影视娱乐出版界的名人。这是我第一次走进亿万富翁的家,这个家占据了一层楼,从外面看并不很起眼。内部却极尽奢华,到处点缀着艺术收藏品。有两个佣人在默默收拾和擦洗。女主人很热情,招呼我们坐下,让佣人给我们预备早餐,她告诉我们她丈夫每天看材料,谈项目,总是工作到后半夜,现在尚未起床。餐后,投资家已经起来了,出来跟我们握手寒暄,留下一些需要我们填写背景资料的表格。他自己却走进房间,去做他每日必做的半小时晨功,念经似的朗朗有声。我不懂这是什么功,还是什么宗教仪式,只是觉得有点滑稽,不过在他这样紧张惊险的生涯里,这样的晨功应该是有益的精神调剂。
他后来跟我们谈了两个小时,可以看出在见我们前,他已经做了一些专业背景调研,问了一些技术问题,特别要求我们详述我们的技术和AskJeeves技术的异同。当他确认了他原先的猜想,AskJeeves 的技术含量只相当于我们所做的一个部分以后,当即拍板,由他个人先给天使基金100万(所谓天使投资是风险投资的最早期,天使投资家冒险最大,但投资得当,回报也最高),三个月后帮助我们寻找第一期投资。他对我们信心十足,说是他经手的公司之中第二个最有希望的(此前他还有一家特别中意的公司,跟AskJeeves类似,早已红透半边天)。
拿到天使基金的这三个月,我们做了两件大事,首先是把我们的系统和PDA无线连接上,这样就可以现场展示通过象手机一样的PDA向系统用英语提问,并立即得到系统的答复,这在当时对于投资人有震撼性的效果。另一项工作,是跟天使投资人紧密合作,数月磨一剑,精益求精,撰写设想如何赚钱的生意计划书(business plan),并在此基础上制作寻找投资的幻灯片。要想给投资人好印象,开始阶段用文字是没有用的,他们根本没有时间和兴致研究什么深奥的技术。所以,幻灯片要做得明白易懂,图示要简洁有力,需要有广告式的夸张,要的就是wow的效果。其实,在这个圈子里,大家都在夸张,推销自己,所以,投资人已经习惯对听到的夸张之词本能地打个折扣。对于不熟此道的技术人员,即便手头有很好的项目,不能有效地推销自己,也很难引起注意。我们很幸运,一开始就找到了独具慧眼,又谙熟华尔街之道的天使投资人。

三个月后,二闯华尔街。我身背一个死沉的膝式电脑,随时准备现场展示我们的问答系统,老板口才很好,负责向投资家利用幻灯片介绍我们的技术和商业前景。天使投资人不放心,要求老板事先多次演练,确保最佳效果。我也几乎一夜没睡,测试系统。说句老实话,我对现场演示很担心,因为当时的系统对于任意的一个问题,即便档案里面有答案,也只有70%左右的机会可以找出来。这个压力很大,因为只能成功,不能失败。投资人相信的是直觉,一旦测试失败,再怎么解释也很难挽回印象。何况他们也少有耐心,一般也就测试两三个问题,基本上是一锤子买卖。因为无法预料他们会测试什么问题,所以实际上只能听天由命。我就是这样胆战心惊地走进华尔街投资公司的大门。到系统演示时,我先介绍我们的资料库存的是以前的新闻存档,并演示了一个预先测试过的问题和系统答案。投资商中有一个看到我们的新闻存档包含有尼克松访华事件,于是提问道:“When did Mao meet Nixon?”,我录入问题后,系统立即显示如下答案和文句:
Answer: February 21, 1972
On February 21, 1972, President Nixon went to China to meet with Communist Party Chairman Mao Zedong and hold discussions with PRC Premier Zhou Enlai.
投资人的震惊可想而知,他们知道 Yahoo 和 Google 是无能为力的,就是AskJeeves也只能显示比较准确的链接,难以给出精确答案。我们趁热打铁,把 PDA 拿出来,请他们自己现场输入问题,通过无线连接我们在水牛城的服务器,其中一个问题是 “how to make chocolate chip cookie?” 这个问题其实超出了系统设计的范围,因为所问不是时间、地点、人名和机构名之类的实体,而是一种方法和配方,在自然语言中的表述形式往往很长,难以把握。幸运的是,存档里面刚好有一段提到制造巧克力cookie的技巧,系统因为无法断定什么是答案,就干脆把最相关的那个段落给提取出来,居然获得喝彩。
过了这一关,投资人的胃口已经给吊起来了,我们掌握了讨价还价的主动权。当然还要经过一系列手续,包括所谓 due diligence, 由投资人聘请资深专业人士对我们的技术做出鉴定,以减少投资失误。然后是双方律师的很烦琐的 paper work,最后终于达成协议,成功引进1000万美元的风险投资。
鉴于我对公司技术发展和资金引进的贡献,老板在引入风险投资前夕任命我为研究开发副总裁,就这样我阴错阳差成为公司第一位,也是在位最久的高级主管。这是我三年前来美创业时从来没有想到过的。
记于2006年六月二十四日
【相关】
《朝华午拾:用人之道》
《朝华午拾 - 水牛风云》
《朝华午拾:知识图谱的先行》
~~~~~~~~
创业九年祭 (60160)
Posted by: liwei999
Date: February 24, 2007 01:43AM
今天收到消息,说Cymfony明天正式出售给英国一家大公司,售价不足以收回投资(不包括政府的近千万投资)。终于运行近10年的公司有个不算最糟的了断。我的股权比水漂还不如。
想想高科技公司也不容易。现在经济形势比较好,尚可以卖个价钱,不至于血本无归,形势不好的话,连买家也找不到。
Cymfony 将成为历史名词。
此祭。
http://blog.sciencenet.cn/blog-362400-277738.html
上一篇:mirror - 有人又提起了“李杨”的问题
下一篇:《朝华午拾:用人之道》
