有问,这一波热潮会不会是类似2000年的又一个巨大的泡沫?我的观察是,也是,也不是。的确,在大数据的市场还不成熟,发展和盈利模式还很不清晰的时候,大家一窝蜂拥上来创业、投资和冒险,其过热的行为模式确实让人联想到世纪之交的互联网 dot com 的泡沫。然而,这次热潮不是泡沫那么简单,里面蕴含了实实在在的内容和价值潜力,我们下面会具体谈到。当然这些潜在价值与市场的消化能力是否匹配,仍是一个巨大的问题。可以预见三五年之后的情景,涅磐的凤凰和死在沙滩上的前浪共同谱写了大数据交响乐的第一乐章。
所谓大数据,更多的是社会媒体火热以后的专指,是已经与施事背景相关联的数据,而不是搜索引擎从开放互联网搜罗来的混杂集合。没有社会媒体及其用户社会网络作为背景,纯粹从量上看,“大数据”早就存在了,它催生了搜索产业。对于搜索引擎,big data 早已不是新的概念,面对互联网的汪洋大海,搜索巨头利用关键词索引(keyword indexing)为亿万用户提供搜索服务已经很多年了。我们每一个网民都是受益者,很难想象一个没有搜索的互联网世界。但那不是如今的 buzz word,如今的大数据与社会媒体密不可分。当然,数据挖掘领域把用户信息和消费习惯的数据结合起来,已经有很多成果和应用。自然语言的大数据可以看作是那个应用的继续,从术语上说就是,文本挖掘(text mining,from social media big data)是数据挖掘(data mining) 的自然延伸。对于语言技术,NLP 系统需要对语言做结构分析,理解其语义,这样的智能型工作比给关键词建立索引要复杂百倍,也因此 big data scale up 一直是自然语言技术的一个瓶颈。
大数据时代只认数据不认人。Of course, In God We Trust. But in everything else we need data. 道理很简单,在信息爆炸的时代,任何个人的精力、能力和阅历都是有限的,所看到听到的都是冰山一角。大V也是如此,大家都在盲人摸象。唯有大数据挖掘才有资格为纵览全貌提供导引。
在处理海量数据的问题解决以后,查准率和查全率变得相对不重要了。换句话说,即便不是最优秀的系统,只有平平的查准率(譬如70%,抓100个,只有70个抓对了),平平的查全率(譬如30%,三个只能抓到一个),只要可以用于大数据,一样可以做出优秀的实用系统来。其根本原因在于两个因素:一是大数据时代的信息冗余度;二是人类信息消化的有限度。查全率的不足可以用增加所处理的数据量来弥补,这一点比较好理解。既然有价值的信息,有统计意义的信息,不可能是“孤本”,它一定是被许多人以许多不同的说法重复着,那么查全率不高的系统总会抓住它也就没有疑问了。从信息消费者的角度,一个信息被抓住一千次,与被抓住900次,是没有本质区别的,信息还是那个信息,只要准确就成。疑问在一个查准率不理想的系统怎么可以取信于用户呢?如果是70%的系统,100条抓到的信息就有30条是错的,这岂不是鱼龙混杂,让人无法辨别,这样的系统还有什么价值?沿着这个思路,别说70%,就是高达90%的系统也还是错误随处可见,不堪应用。这样的视点忽略了实际的挖掘系统中的信息筛选(sampling)与整合(fusion)的环节,因此夸大了系统的个案错误对最终结果的负面影响。实际上,典型的情景是,面对海量信息源,信息搜索者的几乎任何请求,都会有数不清的潜在答案。由于信息消费者是人,不是神,即便有一个完美无误的理想系统能够把所有结果,不分巨细都提供给他,他也无福消受(所谓 information overload)。因此,一个实用系统必须要做筛选整合,把统计上最有意义的结果呈现出来。这个筛选整合的过程是挖掘的一部分,可以保证最终结果的质量远远高于系统的个案质量。总之,size matters,多了就不一样了。大数据改变了技术应用的条件和生态,大数据更能将就不完美的引擎。
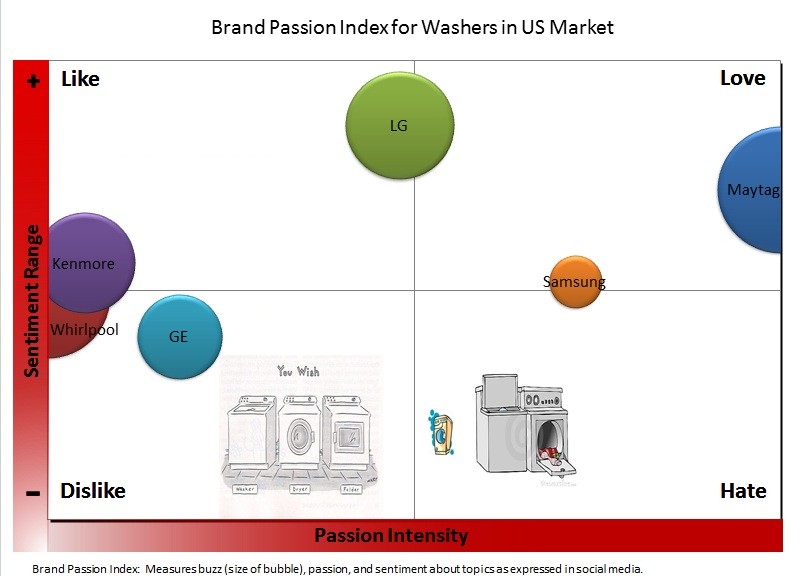
大数据不是决策的唯一依据,只是依据之一。正确的决策必须综合各种信息来源。大事不提,看看笔者购买洗衣机是怎样使用大数据、朋友口碑、实地考察以及种种其他考量的吧。以为有了大数据,就万事大吉,是不切实际的。值得注意的是,即便被认为是真实反映的同一组数据结果也完全可能有不同的解读(interpretations),人们就是在这种解读的争辩中逼近真相。一个好的大数据系统,必须创造条件,便于用户 drill down 去验证或否定一种解读,便于用户通过不同的条件限制及其比较来探究真相。
所列“成见”有两类:一类是“偏”见,如【成见一】至【成见五】。这类偏见主要源于不完全归纳,他们也许看到过或者尝试过规则系统某一个类型,浅尝辄止,然后遽下结论(jump to conclusions)。盗亦有道,情有可原,虽然还是应该对其一一纠“正”。成见的另一类是谬见,可以事实证明其荒谬。令人惊诧的是,谬见也可以如此流行。【成见五】以降均属不攻自破的谬见。譬如【成见八】说规则系统只能分析规范性语言。事实胜于雄辩,我们开发的以规则体系为主的舆情挖掘系统处理的就是非规范的社交媒体。这个系统的大规模运行和使用也驳斥了【成见六】。
米拉宝鉴:确实应该展开讨论,不着急,慢慢来。所罗列的“偏见”有两类:一类是谬见,可以证明其荒谬,譬如说规则系统不能处理社会媒体,只能分析规范性语言。另一类就是“偏”见,盗亦有道,情有可原,虽然还是应该对其纠“正”。这类偏见主要源于不完全归纳,他们也许看到过或者尝试过规则系统某一个类型。 浅尝辄止,然后 jump to conclusion
回复 : 改弦易辙没有问题。从一个 school 转学到一个新 school 很自然,我要是年轻20岁,也一定加入 converting 的潮流。本文揭示的是偏见为什么如此流行,被很多高智商学者视为理所当然,乃至于不得不怀疑宗教疑似的世界观在作祟。至于翘翘板现象,又称按下葫芦起了瓢的问题,以后单论,其实是有有效对策的。当然,也必须承认统计路线的性质决定了它们比较善于在多种因素中玩平衡。
由于自然语言的歧义性和复杂性以及社交媒体的随意性和不规范,要想编制一套查准率(precision)和查全率(recall)两项指标综合水平(所谓 F-score)都很高的NLP(Natural Language Processing)系统非常不容易。但是,研发实践发现,自然语言系统能否实用,很多时候并不是决定于上述两个指标。还有一个更重要的指标决定着一个系统在现实世界的成败,这个指标就是系统对于大数据的处理能力,可以不可以真正地 scale-up 到大数据上。由于电脑业的飞速发展,云计算技术的成熟,大数据处理在现实中的瓶颈往往是经济上的羁绊,而不是技术意义上的难关。其结果是革命性的。
在处理海量数据的问题解决以后,查准率和查全率变得相对不重要了。换句话说,即便不是最优秀的系统,只有平平的查准率(譬如70%,抓100个,只有70个抓对了),平平的查全率(譬如30%,三个只能抓到一个),只要可以用于大数据,一样可以做出优秀的实用系统来。其根本原因在于两个因素:一是大数据时代的信息冗余度;二是人类信息消化的有限度。查全率的不足可以用增加所处理的数据量来弥补,这一点比较好理解。既然有价值的信息,有统计意义的信息,不可能是“孤本”,它一定是被许多人以许多不同的说法重复着,那么查全率不高的系统总会抓住它也就没有疑问了。从信息消费者的角度,一个信息被抓住一千次,与被抓住900次,是没有本质区别的,信息还是那个信息,只要准确就成。疑问在一个查准率不理想的系统怎么可以取信于用户呢?如果是70%的系统,100条抓到的信息就有30条是错的,这岂不是鱼龙混杂,让人无法辨别,这样的系统还有什么价值?沿着这个思路,别说70%,就是高达90%的系统也还是错误随处可见,不堪应用。这样的视点忽略了实际的挖掘系统中的信息筛选(sampling)与整合(fusion)的环节,因此夸大了系统的个案错误对最终结果的负面影响。实际上,典型的情景是,面对海量信息源,信息搜索者的几乎任何请求,都会有数不清的潜在答案。由于信息消费者是人,不是神,即便有一个完美无误的理想系统能够把所有结果,不分巨细都提供给他,他也无福消受(所谓 information overload)。因此,一个实用系统必须要做筛选整合,把统计上最有意义的结果呈现出来。这个筛选整合的过程是挖掘的一部分,可以保证最终结果的质量远远高于系统的个案质量。总之,size matters,多了就不一样了。大数据改变了技术应用的条件和生态,大数据 更能将就不完美的引擎。
NLP 这个领域,统计学家完胜,是有其历史必然性的,不服不行。虽然统计学界有很多对传统规则系统根深蒂固的偏见和经不起推敲但非常流行的蛮横结论(以后慢慢论,血泪账一笔一笔诉 :),但是机器学习的巨大成果和效益是有目共睹无所不在的:机器翻译,语音识别/合成,搜索排序,垃圾过滤,文档分类,自动文摘,知识习得,you name it
不容易复制的成功就跟中国餐一样,同样的材料和recipe,不同的大厨可以做出完全不同的味道来。这就注定了中华料理虽然遍及全球,可以征服食不厌精的美食家和赢得海内外无数中餐粉丝,但中餐馆还是滥竽充数者居多,因此绝对形成不了麦当劳这样的巨无霸来。而统计NLP和机器学习就是麦当劳这样的巨无霸:味道比较单调,甚至垃圾,但绝对是饿的时候能顶事儿, fulfilling,最主要的是 no drama,不会大起大落。不管在世界哪个角落,都是一条流水线上的产品,其味道和质量如出一辙。
就说过去10多年吧,我一直坚持做多层次的 deep parsing,来支持NLP的各种应用。当时看到统计学家们追求单纯,追求浅层的海量数据处理,心里想,难怪有些任务,你们虽然出结果快,而且也鲁棒,可质量总是卡在一个口上就过不去。从“人工智能”的概念高度看,浅层学习(shallow learning)与深层分析(deep parsing)根本就不在一个档次上,你再“科学”也没用。可这个感觉和道理要是跟统计学家说,当时是没人理睬的,是有理说不清的,因为他们从本质上就鄙视或忽视语言学家 ,根本就没有那个平等对话的氛围(chemistry)。最后人家到底自己悟出来了,因此近来天上掉下个多层 deep learning,视为神迹,仿佛一夜间主导了整个机器学习领域,趋之者若鹜。啧啧称奇的人很多,洋洋自得的也多,argue 说,一层一层往深了学习是革命性的突破,质量自然是大幅度提升。我心里想,这个大道理我十几年前就洞若观火,殊途不还是同归了嘛。想起在深度学习风靡世界之前,曾有心有灵犀的老友这样评论过:
To me, Dr. Li is essentially the only one who actualy builds true industrial NLP systems with deep parsing. While the whole world is praised with heavy statistics on shallow linguistics, Dr. Li proved with excellent system performances such a simple truth: deep parsing is useful and doable in large scale real world applications.
[Abstract] Five challenges to keyword-based sentiment classification: (1) domain portability; (2) micro-blogs: sentence/twit classification is a lot tougher than document classification; (3) when big data become small: big data load when sliced and diced based on the users' needs quickly becomes mall, and a precision-challenged classifier is bound to have trouble; (4) association of sentiments with object: e.g. comparative expressions like "Google is a lot better than Yahoo"; (5) too coarse-grained: no actionable insights, this is fatal.
做自动舆情挖掘(sentiment mining)已经好几年了,做之前思考这个课题又有好多年(当年我给这个方向的项目起了个名字,叫 Value Tagging,代码 VTag,大约2002年吧,做了一些可行性研究,把研发的 proposal 提交给老板,当时因为管理层的意见不一和工程及产品经理的合作不佳,使得我的研发组对这个关键项目没能上马,保守地说,由此而来的技术损失伤害了公司的起飞),该是做一个简单的科普式小结的时候了。本片科普随笔谈机器分类系统在舆情抽取中的应用,算是这个系列中的一篇。
舆情抽取的主流是利用机器学习基于关键词的分类(sentiment classification),通常的做法非常粗线条,就是把要处理的语言单位(通常是文章 document,或帖子 post)分类为正面(positive)和负面(negative),叫做 thumbs up and down classification。后来加入了中性(neutral),还有在中性之外加入一类 mixed (正反兼有)。这种做法非常流行快捷,在某个特定领域(譬如影评论坛),分类质量可以很高。我们以前的一位实习生做过这样的暑假项目,用的是简单的贝叶斯算法,在影评数据上精度也达到90%以上。这是因为在一个狭窄的领域里面,评论用语相当固定有限,正面负面的评价用词及其分布密度不同,界限清晰,识别自然不难。而且现在很多领域都不愁 labeled data,越来越多的用户评价系统在网络上运转,如 Amazon,Yelp,积累了大量的已经分类好的数据,给机器分类的广泛应用提供了条件。
第二个挑战就是,语言单位的缩小使得分类所需要的词汇证据减少,分类难为无米之炊,精度自然大受影响。从文件到帖子到段落再到短句,语言单位每一步变小,舆情分类就日益艰难。这就是为什么多数分类支持的舆情系统在微博(tweets)主导的社会媒体应用时文本抽取质量低下的根本原因(一般精度不过50%-60%)。当然,文本抽取精度不好并不表明不可用,它可以用大数据来弥补(由于大数据信息天生的大冗余度,利用sampling、整合等方法,一个大数据源的整体精度可以远远高于具体文本抽取的精度),使得最终挖掘出来的舆情概貌还是靠谱的。然而,大数据即便在大数据时代也不是总是存在的,因为一个真实世界的应用系统需要提供各种数据切割(slicing n dicing)的功能,这就使得很多应用场景大数据变成了小数据,这是下面要谈的第三个问题。
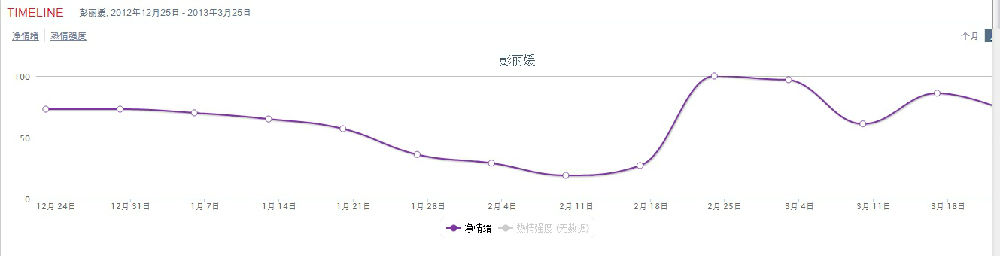
第三是大数据切割的挑战。本来我们利用机器来应对大数据时代的信息挑战,起因就是信息时代的数据量之大。如果数据量小,蛮可以利用传统方式雇佣分析员,用人的分析来提供所要的情报,很多年以来的客户调查就是如此。可是现在大数据了,别说社会媒体整体的爆炸性增长,就是一个大品牌的粉丝网页(fan pages)或一个企业的官方网页,每时每刻所产生的数据也相当惊人,总之无法依靠人工去捕捉、监测情报的变化,以便随时调整与客户的互动策略。这是机器挖掘(无论分类还是更细致的舆情分析)不可不行的时代召唤和现实基础。但是,观察具体应用和情报需求的现场就会发现,用户不会满足于一个静态的、概览似的情报结果,他们所需要的是这样一个工具,它可以随时对原始数据和抽取情报进行各种各样的动态切割(slice/dice 原是烹饪术语,用在情报现场,就是,"to break a body of information down into smaller parts or to examine it from different viewpoints so that you can understand it better", 摘自 http://whatis.techtarget.com/definition/slice-and-dice)。舆情切割有种种不同依据的需求,譬如根据舆情的类别,根据男女的性别,根据数据源,根据时间或地理位置,根据数据的点击率等。有的时候还有多次切割的需求,譬如要看看美国加州(地理)的妇女(性别)对于某个品牌在去年夏季(时间)的舆论反映。最典型的切割应用是以时间为维度的《动态晴雨表》,可以反映一个研究对象的情报走势(trends)。譬如把一年的总数据,根据每月、每周、每日,甚至每小时予以切割,然后观察其分布走势,这对于监测和追踪新话题的舆情消长,对于新产品的发布,新广告的效用评估(譬如美式足球赛上的巨额品牌广告的客户效应)等,都有着至关重要的情报作用。总之,大数据很可能在具体应用时要被切割成小数据,一个分类精度不高(precision-challenged)的系统就会捉襟见肘,被大数据遮盖的缺陷凸显,被自然过滤净化的结果在小数据时会变得不再可信。
第四个挑战是找舆情对象的问题。在几乎所有的舆情分析应用中,舆情与舆情的对象必须联系起来,而这一基本要求常常成为舆情分类系统的软肋。当然,在特定数据源和场景中,可能不存在这个问题,比如对 Amazon/Yelp 这类客户评价数据 (review data) 的舆情分析,可以预设舆情的对象是已知的(往往在标题上,或者其他 meta data 的固定位子),每一个review都是针对这个对象(虽然不尽然,review中也可能提到其他的品牌或产品,但是总体上是没问题的,这是由 review data 的特性决定的)。然而在很多社会媒体的自发舆情表述中(譬如微博/脸书/论坛等),在舆情分类之后就有一个找对象的问题。这个问题在比较类语言表达中(比如,"谷歌比雅虎强老鼻子啦" 这样语句,正面评价“强”到底是指雅虎还是谷歌,这看似简单的问题,就难倒了一大帮机器学家,道理很简单,机器分类系统依靠的是keywords,一般没有语言结构的支持,更谈不上理解)。与青春躁动期的小屁孩也差不多,满腔情绪却找不到合适的表达或发泄对象,这几乎成了所有褒贬分类系统的克星。在随兴自发的社会媒体中,这类语言现象并不鲜见,一边夸张三一边骂李四更是网络粉丝们常见的表达(譬如方韩粉丝的网络大战)。
从技术上讲,在大数据的尺度下,不管什么原因缺失部分数据(server down,数据库 bug,数据提供人改主意突然把发出的帖子又很快删除,非民主社会的政府censorship,还有由于成本原因有意排除一些原始数据而只取一定比例的样本,还有垃圾过滤系统太aggressive的误删,或者我们系统本身查全率 (recall) 不理想,比如明明有褒贬却没有识别出来,等等等等:缺失是常态,而求全则是不现实也是不必要的),都不是大问题,as long as 这种缺失对于要挖掘的话题或品牌没有歧视性/针对性。大数据追求的是舆情动态和salient情报,而这些原则上都不会因为数据的部分缺失而改变,因为动态和 salience 的根基就是信息的高冗余度,而不是真正意义上的大海捞针。不亲手做系统,你难以想象互联网的大海里面,冗余的信息有多少。重要的是,冗余本身也是情报的题中应有之义。所谓舆情就是人民(客户)的呼声,而人民的呼声只有通过个体信息的大量冗余才能听得见。这与同一个情愿诉求为什么要征集成千上万的签名道理一样,至于最终是10万签名还是9万五千人签名了,完全不影响舆情的内容及其整体效应。
安娜是个很可爱的俄罗斯上进女青年,从小弹钢琴跳芭蕾,小学没毕业即随父母移民美国。她身材高佻,曲线优美,性情温和,举止得体,善解人意,给人一种古典但不古板,现代却不俗艳,阳光而浪漫的印象。大家知道,虽然俄罗斯大嫂大多偏胖粗线条,但俄罗斯姑娘却多有迷人的风采,老帮菜耳熟能详念念不忘的就有钢铁怎样炼成里面的资产阶级小姐冬妮亚,芭蕾舞天后乌兰诺娃,风华绝代的花样滑冰艺术家 Ekaterina Gordeeva。安娜也是这样一位俄罗斯女郎,每天就在身边,给满屋大多是 boys 的办公室带来了温馨柔和的气息。自然地,大家都喜欢她。
然而,安娜辞职了,很快就要离开,大家都舍不得。我心里也不是滋味,想到午餐时不再有她的说说笑笑,餐后也不能邀她打乒乓球了,失落落的。我问她一定要离开么,你不是说很喜欢这个环境么?You know this office is already too crowded with boys, and we are trying to change this situation, trying to find some girls with affirmative action, and you are leaving?
她回说,我喜欢这个环境,是因为在这里我接触的都是你这样的世界上最聪明的人,因为你们太聪明了,结果我的发展道路堵死了,只好痛下决心离开了,我还是去 consulting company 做我擅长的分析工作去吧。两年来,我亲眼目睹我的20小时的人工怎样被你的20秒的全自动搜索所替代,而且结果往往比人工更好更全更有一致性。
两年前我加入公司的时候,公司基本上是一个 professional service 类型的公司,虽然也开发了一个内部使用的系统,但系统的输出只是缩小了人工范围,必须有长时间的后编辑,手动增删修补,分析归纳,才能提供给客户。编辑人员我们称为信息分析员,要求语言能力强,阅读理解一目十行,并具有分析综合的技能。安娜就是信息分析员中的佼佼者。经她过手的分析报告,客户特别满意。
可是公司需要成本核算。核算的结果是,肉工可以,要适度,否则入不敷出,是亏本买卖。当时平均每个搜索分析的订单需要肉工22小时方能完工,这22小时叫做 pain time (既是分析员的pain, 更是公司的pain)。要想赚钱,理想的 pain time 支出需要控制在两个小时之内,在当时有点天方夜谭。老板找我谈的时候,就把它定为主要目标,但并没有设置时间限度,因为没有人知道其可行性以及达成这样的目标需要多少资源。我自己也不明白,只是感觉到了这个重担。我以前做过的工作,都是先研究,后做原形引擎,然后寻找应用领域,最后开发产品。而这家公司与多数技术创新公司截然相反,它是先有客户,后有粗糙的引擎,最后才引进人才和技术,把希望寄托在技术的快速转移身上。这条路子让我觉得新鲜和刺激,觉得可以试一下,我的技术转移技能能不能如鱼得水,发挥出来。先有客户和应用领域的好处是显而易见的,就向搞共产主义有了遵义会议的明灯一样,省却了在黑暗中的漫长摸索。道路是光明的,就看路怎样走才能赚钱了。
人心不足蛇吞象,老板告诉我,Wei,你知道,你的技术给我们的业务带来了革命性变化。我们的立足已经不成问题,只要我们愿意,维持一个机器加人工的服务,发展成年入几千万的企业指日可待。但是,只要有人工,就不能 scale up, 赚钱就有限,盘子就做不大。我知道你是有雄心的人(我心里说,子非鱼),肯定不满足小打小闹。不管多大风险,我们还是决定放弃这条道路,而走全自动的路子,让系统可以服务所有的分析客户,而不是只供我们内部人工(安娜这样的)或者需要专门训练的 power users 使用。我们的目标是让世界上每个分析员都离不开我们,就如大家离不开Google一样。为此,我们必须做到 pain time 为零,这是着险棋,但是前景不可限量。
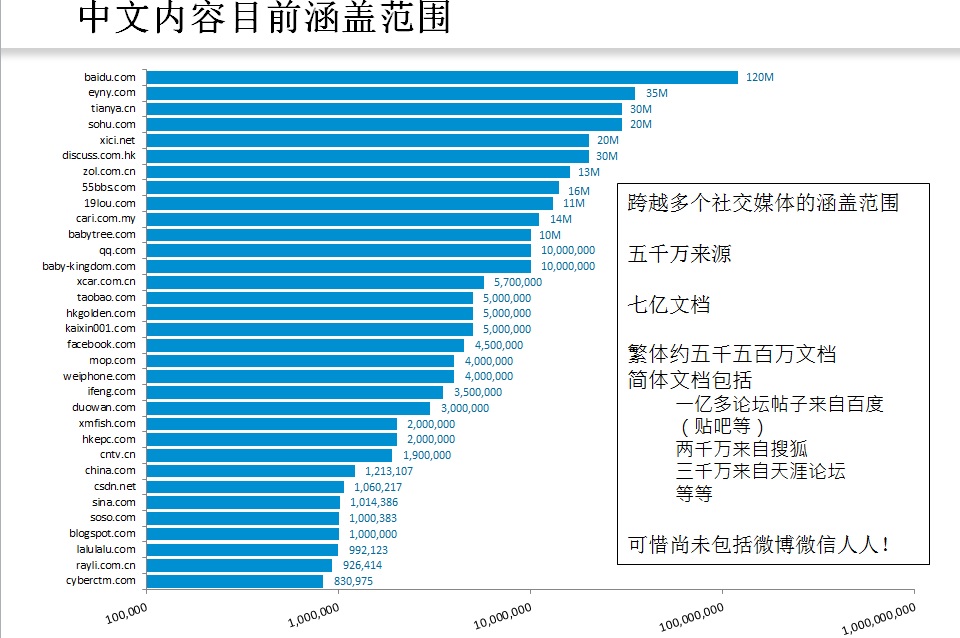
Big data 与 云计算一样,成为当今 IT 的时髦词 (buzzword / fashion word). 随着社会媒体的深入人心以及移动互联网的普及,人手一机,普罗百姓都在随时随地发送消息,发自民间的信息正在微博、微信和各种论坛上遍地开花,big data 呈爆炸性增长。对于信息受体(人、企业、政府等),信息过载(information overload)问题日益严重,利用 NLP 等高新技术来帮助处理抽取信息,势在必行。
对于搜索引擎,big data 早已不是新的概念,面对互联网的汪洋大海,搜索巨头利用关键词索引(keyword indexing)为亿万用户提供大海捞针的搜索服务已经很多年了。我们每一个网民都是big data搜索的受益者,很难想象一个没有搜索的互联网世界。可是对于语言技术,NLP 系统需要对语言做结构分析,理解其语义,这样的智能型工作比给关键词建立索引要复杂千万倍,也因此 big data 一直是自然语言技术的一个瓶颈。不说整个互联网,光社会媒体这块,也够咱喝一壶了。
目前的状况如何呢?
我们的语言系统每天阅读分析五千万个帖子。如果帖子的平均词量是30,就是 15 亿词的处理量。This is live feed,现炒现卖,立等可取。 至于社会媒体的历史档案,系统通常追溯到一年之前,定期施行深度分析并更新数据库里的分析结果。我们的工程师们气定神闲,运筹帷幄之中,遥控着数百台不知身处哪块祥云的虚拟服务器大军,令其在“云端”不分昼夜并行处理海量数据,有如巨鲸在洋,在数据源与数据库之间吞吐自如,气派不凡。
when we talk about NLP scaling up to big data, it is this BIG
This is the progress we have made over the last two years. I feel extremely lucky to work with the engineering talents and product managers who made this possible. It is hardly imaginable that this can be done at this speed in other places than the Valley where magic happens everyday.
Where are we?
deep parsing 50 MILLION posts a day!!!
For one year NLP-indexing of social media data we use to support our products, we have
11 billion tweets (about 6-7% of the entire sample from twitter)
1 billion Facebook posts
1 billion forum posts from 5 million domains
430 million blog posts from 160 million domains
30 million reviews from 300 domains
55 million news reports from 55,000 domains
225 million comments from 100 million domains
And that is by no means the limit for our NLP distributed computing: the real bottleneck comes from the cost considerations rather than the technical barriers of the architecture. Money matters. Archimedes said, "Give me a place to stand on, and I will move the Earth." With the NLP magic in hands, we can say, give me a large cloud, we can conquer the entire info world!
I never responded to this. Actually please notice that I have a space between 性 and 交. Furthermore, please notice the difference between the last one (where I have < [ 一 次 ] 性 > and the first two. What behind is, I have the assumption (a truth I think) that ALL (well, except for 葡萄, 玻璃 and the like) multi-character 'words' are ambiguous (so-called hidden ambiguity) and hence have to be handled with dictionary at 'application' time (在‘用’字上狠下功夫). This is consistent with your 词汇主义 and your rule-of-thumb "keeping ambiguity untouched". I actually pushed that one step further by keeping ambiguity only one level (that is, you only need to look ONE level deeper). This is consistent with your 自底而上 but more concrete/specific -- whenever I see potential ambiguity at my level, I keep them there (as in < 性 交 > and then 断链.
I mean I agree with you fully. And by today if I have a bit more added info in dictionary, I think I can do 'shallow parsing' better.
很 < 不 [ 明 白 ] > < [ 北 大 ] [ 法 ( 学 院 ) ] > < [ 怎 么 ] 会 > < 变 成 > < [ 法 轮 ] [ 大 法 ] > 的 < 大 法 >
At that time I have entity but no event.
回复 : “消费品公司预测未来的客户需要的开发”,正是我们所做的主打之一,在那里,了解why客户喜欢或不喜欢某种产品至关重要。科技文献检索方面的应用我们也做过,主要是帮助解决 how 的问题。至于文章的错误或者信息的过时,说到底是人的判断,机器最多可以帮助排一下序,比如把最新的文献信息排在前面。一个问题出来了,解决问题的答案分门别类给你列出来就完成使命了。根据这些信息做判断或决策,那是万物之灵自己的事儿。
说起教英语,我当年的学生中名人可不少,皆因中国音乐学院是中国民族音乐的最高学府,能够攻读研究生的都不是等闲人物,甚至名冠中外的作曲家金湘(当时是作曲系主任,曾创作歌剧《原野》,华夏文摘当年为他出过专集,说他集古今中外之大成)也是我的编外学生。其他学生如今有的官至音乐学院副院长,有的是中国琵琶皇后,还有的被誉为某少数民族偶像级“夜莺”。最知名的当然是彭丽媛。平时聊起来,她对媒体恭维她是歌唱皇后或巨星什么的很不以为然,她 preferred 的称号是歌唱艺术家。其实彭丽媛一个学期也就能上5-6节课意思意思。就这样,常常她在上课,门外就有记者等着采访她。因为长期缺课,她实际上跟不上进度,但她到堂了,总不能晾在一边。所以,当我循环提问时,就找比较容易的给她,比如让她重复我的句子。让人惊异的是,无论句子多长,我说得多快,她都可以八九不离十的复述出来。有些句子显然她并不理解,看来她的音乐训练培养了她敏感的听觉。这样一学期下来,到期末我开始犯愁,怎样给这个特殊人物评分呢?跟学院教导处一商量,说特殊情况,特殊处理,你看着办吧。我体会的言下之意是,总不能不让她及格吧。音乐学院的公共外语虽然是研究生必修课程,毕竟不是他/她们 career 的重要内容。后来,我网开一面,期末给她单独出题,允许查词典,让她带回家做,第二天交来。她大概是熬了夜认真做的,可以看出是个很有天分的人,也确实花了功夫。里面存在一些低级错误,可以判断她是诚实的(其实她那样的地位请人代劳是很容易的)。看在她对这份试卷的认真态度上,我最终给了65分。
我1986年硕士研究生毕业留语言研究所,受到导师器重,春风得意。除了组里的日常研究开发外,每个周末都泡在所里,干些自己感兴趣的项目,都与世界语(Esperanto)的研究和应用有关。第一个项目是把自己的硕士毕业设计从封闭系统转为开放系统。这是我用 BASIC 编写的一款从世界语自动翻译成汉语和英语的系统 E-Ch/A。麻雀虽小,五脏俱全,是当年少有的一个一对多系统,也算填写了“空白”。这项工作的直接结果有三。一是在演示后,受到德国控制论专家 Frank 教授激赏,除了决定在他的控制论杂志发表该系统的论文外,教授还写了长信,要资助我到他的实验室去继续开发这个系统(“我非常希望,北京的立委硕士能到德国工作数月以便使他的国际语到民族语的翻译程序能适应我们的需要”)。这本是一个千载难逢的出国机会,又不用考TOFEL, GRE和到处发信申请。当年出国热已经持续升温,而我和太太却浑然不觉,自得其乐。并没有把这次机会认真当回事,加上我的老板和导师刘教授巧妙劝阻,说要继续开发可以,让Frank教授出钱,承包到语言所来。知道自己走不成(觉得中途离开,跟导师面子抹不开),我就做顺水人情,把我的同事兼师兄乔毅介绍给 Frank 教授,成就了他的出国。研发世界语系统的第二个结果是,我发表在El Popola Chinio(中国报道)上的世界语语言学特点的粗浅论文引起了一个著名的西班牙教授 Juan Regulo 的注意。这位老先生是世界语界老前辈,在他的大学和城市威望极高,以他名字命名街道、广场等。正值他退休,学校决定给他出四大卷印制精美的专辑,表彰他的贡献。其中一卷是关于世界语学(Esperantologio)的论文专集,于是老先生邀请我在《中国报道》的论文基础上,扩展加工,单成一章。我文思泉涌,洋洋洒洒写了17页,有老先生来来回回多次校改修正,发表了我平生第一次的Book Chapter ” Lingvistikaj trajtoj de la lingvo internacia Esperanto”(发表时老先生已经过世,他的去世在国际世界语界引起很多纪念,老先生千古!)。 我的世界语活动的第三个结果,是使我一夜之间成了万元户。在那个年头,市场经济刚刚萌芽,开始出现了第一批市场经济催生的万元户,但与多数知识分子无关。我们这些助理研究员,每月工资100元左右,即便加上工余的兼课外快(我由导师和师母引荐,在中国音乐学院兼职教授研究生英语,每课时不到10块钱,还要备课和自理交通),做梦也不敢指望哪天成为万元户。
话说当年荷兰有一家软件公司 BSO,从政府申请到一笔科研资金,公司本身补足另一半,做一个以世界语为媒介语的分布式多语机器翻译项目 DLT。五年下来,成绩斐然,开发了一个很像样的原型系统(但是分布式翻译的设想有点超越时代,最终没有找到后续资金去做商业开发)。为了对多语言机器翻译做可行性研究,BSO 要求按照一个统一的依存关系句法的理论框架,对十几种主要语言编写形式句法,用来支持媒介语和自然语言的相互转换。他们看到我在世界语机器翻译上有研究,于是请我承包汉语的依存句法的编写项目。也算他们找对了人,我周末日以继夜,努力工作五六个月,编写了一部比较完整的汉语形式句法-现代汉语依存关系句法(A Dependency Syntax of Contemporary Chinese),给他们交活,极受欣赏。他们先给了我1000荷兰盾的支票作为报酬,于是拿到中国银行托收。大概是荷兰太遥远,需要通过多次银行间的中转,结果三个月了,钱还收不到,我就写信抱怨。过了一周,突然接到中国银行通知,让我去取一笔电汇。我跟太太去王府井中国银行,惊奇地发现在我的名下有1000美元汇款。拿到这笔折合人民币约万元的“巨款”,当时没有顾上高兴,一路走一路嘀咕,难道钱真可以从天上掉下来。太太甚至坚持这肯定是搞错了,说要回去把不义之财退还。第二天接到荷兰公司的信,才明白是他们电汇的,作为对我的工作的额外奖赏,同时对支票不能及时兑现致歉(后来还是兑现了)。汉语是主要语言,我承包的项目对于他们的多语研究和寻找后续资金意义重大。后来乘我1989年去德国开机器翻译高峰会议,他们还特地邀请我和我的导师去他们实验室访问一周,进一步探讨汉语用于多语机器翻译的一些问题。
1989年夏天,我和导师去德国慕尼黑应参加第二次国际机器翻译最高级会议。此前,我跟荷兰BSO(Buro voor Systeemontwikkeling BV)公司的机器翻译研究组一直有联络,应约为他们的以世界语作为媒介语的多语机器翻译系统 DLT,编写了一部现代汉语依从关系的形式句法。他们听说我们要来欧洲,就邀请我和我的导师,还有中国机器翻译界知名人物董老师,会后顺道访问他们的实验室一周,做学术交流,共同讨论汉语句法里的一些疑难问题。这次活动,他们称作 Chinese Week.
游览阿姆斯特丹后,我们按计划去Utrecht的BSO公司访问一周。DLT 项目研究组十几个人,一半是语言学家,一半是工程师,看得出来,这是个气氛融洽的团队。德国世界语者 Klaus Schubert 博士是系统枢纽“依存关系句法”(dependency grammar)的设计人,在项目第二阶段继 Witkam 成为项目组长。71届大会后招进来的美国世界语者 Dan Maxwell 博士,负责东方语言的句法项目的承包、质询和验收,是我的直接领导(十年河东,十年河西,后来我成为他的 boss,这是后话,见《朝华午拾:水牛风云》)。Dan一看就是老实人,照顾我们客人殷勤有加。我看到他早上骑自行车来上班,笑着跟他说:“我在北京上班跟你一样”。
研究组的骨干还有国际世界语协会的财务总监,知名英国籍世界语者Victor Sadler 博士,我在71届国际世界语大会上跟他认识。作为高级研究员,他刚刚完成一项研究,利用 parsed (自动语法分析)过的双语对照的语料库(BKB, or Bilingual Knowledge Base)的统计信息,匹配大小各异的翻译单位(translation unit)进行自动翻译,这一项原创性研究比后来流行的同类研究早了5-10年。显然,大家都看好这一新的进展,作为重点向我们推介。整个访问的中心主题,仍然是解答他们关于汉语句法方面一些疑难问题。他们当时正在接洽欧洲和日本的可能的投资人,预备下一步大规模的商业开发,汉语作为不同语系的重要语言,其可行性研究对于寻找投资意义重大。
期间,Victor以世界语朋友身份,请我到他家吃晚饭。他住在离公司不远的一栋公寓里,太太来开门,先跟丈夫轻吻,然后招呼我进来。太太也是世界语者,忘了哪国人了,总之是个典型的世界语之家,家庭用语是世界语。Victor告诉我,太太实际上会一些英语,但是用英语对她不公平啊。太太很和善,跟我说,他们俩非常平等,她做饭,Victor洗碗。我说,这跟我家的分工一样,我最爱洗碗这种简单劳动。她笑着说,“Victor, vi havas helpanton hodiau (你今天有帮手了)”。饭后Victor洗碗,并没有让我插手,我站在旁边陪他聊天,一边看他倒进大把的洗涤液,满是泡沫把餐具拿出来,用干布擦
干。我告诉他们,这跟我的做法不同,我们总是怀疑化学制品有毒或副作用,最后必须用清水涮净才好。太太不解地问:“洗涤液如果有毒,厂家怎么能生产呢?” 这倒把我问住了。Victor夫妇和蔼可亲,我感觉在老朋友家一样,饭后一边吃甜点和水果,一边闲聊,尽兴而归。
说得多了,实际的意思是大家没有必要在美国这么干耗自己的青春年华,仰天大笑出门去,从此投军从戎,回到中国多快好省建设社会主义也不错,兴许还能和一把大的,比自己在北美30岁就可以看到自己60岁是什么样子好得多,无非就是住House跟Condo的区别,开大奔与开Focus的区别,别人儿子女儿上哈佛耶鲁,自己的孩子因为学区不好只能上个洋野鸡,其实说白了有什么区别,都是一嘴听着巨恶的ABC英文,中国人不是中国人,洋人不是洋人的怪物,而且大部分都有心理阴影,对自己的root and identity怀疑。特别是男孩子, 在学校受很多欺负,精神上就是一侏儒,搞不好成为新的VT小赵。
IT 中除了软件硬件工程师外,还有一些专门的方向工作前景也不错。一种是 DBA (data base administer 数据库管理员),还有 graphic design,包括网页设计、产品UI设计等,都是需要一定编程能力、operations support 或更多的设计技能,都是有职业市场的行当。DBA要保证DB的运行,要随时处理出现的问题,要做performance tuning。现在稍大的DB就是TB级的,而且很多都是要7x24不间断运行,这里面名堂多了。网页设计产品界面设计,也有很多才华、经验和技能成分。以前我们引擎开发出来以后需要做应用,就高价请过一个有名的UI设计家,对用户体验有深刻的理解,他的蓝图做得那个漂亮,工程师实现的时候基本就是照葫芦画瓢。所以,DBA和图形设计在IT行业中也是收入比较高的。高级DBA和设计者都是稀缺人才。
MBA 其实没必要有多年工作经验。有更好,但是也有从学校到学校去修这个的。不过,MBA 在专业学位中,是属于万金油性质。将来的职业发展,主要是做项目经理、产品经理、marketing 宣传、sales 销售、物流管理、分析员等,也有做到高级管理CEO/COO/CMO等的(老中能做到的很少)。能把这条路走通,需要很强的沟通能力、严谨的办事风格,这些素质不是短短一年的 MBA 培训可以学到的。因此,职业顺利发达与否,一多半决定于本人的素质, MBA 最多就是一个敲门砖。后去更多决定于个人素质和实际职场上的磨练。有些人适合,有很多人不适合。(我就不行。)另外要注意的是,MBA programs 特别讲究牌子,名牌学校的很难进,但出来前景好。也有很多杂牌的 programs,混一个牌子而已,后去如何,看造化了。
美国的孩子一进入最后一年高四就要着手大学申请了,全部申请圣诞节前搞定,来年春天逐步发榜。一般是选择8-10所大学分别申请,包括自己梦寐以求的名校(dream school),理想也现实的学校,以及几所保底的学校。申请过程很繁琐,很多 paper work,因此各种助学机构遍地开花。尤其是在亚裔社区,大家为尽量考取名校都不惜血本。
1) Please list the public and private colleges/universities that you will be applying to.
2) For each of the schools listed, please indicate the average GPA and test scores for admissions.
3) Which college is your first choice and why?
4) Describe your educational goals and possible career(s) you envision for yourself.
5) Why do you want to go to college?
6) What are three adjectives that best describe you? Please explain.
7) Which high school courses have you enjoyed most and why?
8) Is your high school record an accurate measure of your ability and potential? If not, why not?
9) How do you spend your time outside of school?
10) Describe your volunteer/community service and approximately how many hours you have completed.
11) What accomplishments are you most proud of?
12) What are you passionate about?
13) Please explain if there are any unusual or personal circumstances that have affected your educational experiences in a positive or negative way?
14) What points or qualities would you like to be included in your letter of recommendation? Responses can include traits from academics, personal life, activities, athletics, community, religious, work experience, special talents, etc.
删除回复 |赞[2]刘苏峡 2013-9-4 08:44Thanks for share. Is religious very important? Besides athelets, communities, special talents, what on earth do the activities mean?
李维 回复 刘苏峡 : leadership experience is important.
prizes or winners on all events, especially at national or international levels, are shining.
删除回复 |赞[1]虞左俊 2013-9-3 16:16Each school is different. In my son's case, he was told to identify and contact the teachers who knew him well. So, during the junior year each student should have a list of the teachers for writing him/her recommendation letters
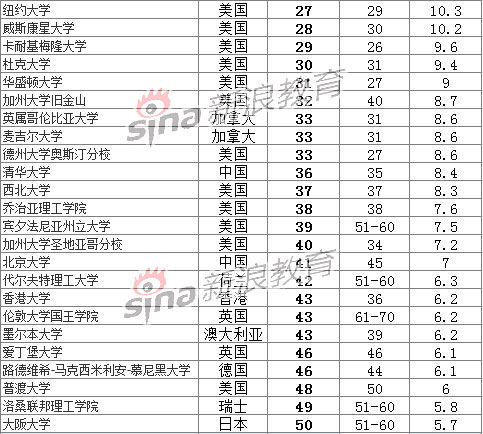
【立委按】英国泰晤士报的世界名校排名据说更加客观公正,调查的范围之广和问卷之多,无出其右。可它与美国的排名相差真不小。要说英国也是老牌权威了,不时想表现自己的不俗,可多少人信他呢?不过美国排名也明显 favor 私校了。二者应该折中一下。美国公校大哥大加大伯克利(UCB)排名老六(去年是老八),加大洛杉矶(UCLA)也高居第10(去年是12),居然超过老牌长春藤哥大(Columbia)和宾大(UPenn)呢。真长社会主义志气,灭资本主义威风啊。可是其实在美国的百姓眼中,这种排法是倒置了,不是说一流公校不好,但论师资比例和生源等条件,无法与一流私校比。泰晤士看重的是科研,其次才是教学,说是2比1的权重差,所以这个排名似乎更适合研究生做参考。另外,美国人青睐的与长春藤比肩的一流文理学院(liberal arts schools),由于其规模较小,研究能力不足,虽然其本科被广泛认为是超一流的个性化教育,也几乎无一入围。而在美国,进入一流文理学院的难度和光荣,绝不亚于进入长春藤牛校。
The promise of an elite public university education for California’s top high school students continues to fade as record numbers of qualified in-state applicants are being rejected from every UC campus they applied to.
Admission rates at UC Berkeley, UCLA, UC San Diego and UC Santa Barbara have plummeted to less than half of what they were in the mid-1990s, a new analysis by this newspaper shows. This year, 11,183 freshman applicants who qualified for UC admission had no offers from their chosen campuses and were referred to UC Merced, the Central Valley campus that opened in 2005.
Some strove mightily and successfully in high school but found their aspirations opened few doors.
Student tour guide and Cal senior Sam Kirschner, right, leads a tour group past South Hall for students that have been accepted to the University of California in Berkeley, Calif. on Tuesday, April 29, 2014. Kirschner, originally from Louisville, CO, but now a California resident, is part of the trend to accept greater numbers of out-of-state students at the university. (Kristopher Skinner/Bay Area News Group) (Kristopher Skinner)
Aman Shergill — an A student who juggled an after-school job with a boatload of Advanced Placement classes and extracurricular activities — applied to seven UC campuses and got into one: UC Santa Cruz.
“It was within two weeks that I got all my rejections. It was pretty bad,” the Folsom teen said. “I just thought that with what I had done and all my hard work, I was hoping for a little more.”
Every year, more college-bound Californians feel the sting of rejection as spaces for the state’s college-bound students lag further behind the soaring demand for Cal and other popular UC campuses.
The ease of applying to many campuses online, the relatively low sticker price for in-state students compared to private colleges and population growth have radically changed the outlook for applicants. Growing numbers of out-of-state and international students, who pay nearly three times the tuition and fees, also fuel the competition for a spot in the class.
By Thursday, students must make the difficult decision about where to go in August. UC Berkeley gave thousands of fall applicants another option to consider: Wait until the spring term for a spot, when graduating students free up more space.
The options are more limited than parents and educators from past generations might assume, one expert said.
“Students need to be exposed to the truth,” said Lisa Garcia, director of outreach projects for USC’s Pullias Center for Higher Education. “I tell all my students, even the valedictorians, ‘You can’t just apply to Berkeley and (UCLA) and San Diego and Santa Barbara.’”
Excellent grades, solid SAT scores and a long list of activities these days might not be enough to get you noticed by Cal, which turned away some 20,000 more applicants this year than Stanford, the nation’s most selective campus.
Berkeley’s admitted class, as described in a campus announcement, included national robotics and debate winners, “a ballerina who has danced internationally,” Junior Olympics athletes, a Disney Channel series actor and “musicians, dancers and other artists who have performed at prestigious venues around the world.”
But three justices in the majority, Chief Justice John Roberts, Anthony Kennedy and Samuel Alito. concluded that the lower court did not have the authority to set aside the law.
"This case is not about how the debate about racial preferences should be resolved. It is about who may resolve it," Kennedy wrote.
"Michigan voters used the initiative system to bypass public officials who were deemed not responsive to the concerns of a majority of the voters with respect to a policy of granting race-based preferences that raises difficult and delicate issues," he added.
如果不想进UC,可以考虑州立大学里的学校。Cal Poly SLO, San Jose State, 等在湾区的高科技界口碑不错。湾区也有一些“Wild bird",主要赚外国人钱的,也能签证出来。但我不会推荐给ABC。回复穿鞋的蜻蜓2014-5-13 10:16伯克利加大一直有“中国城”的绰号,达特茅斯别说在中国鲜为人知,在美国知道的人也不多:)这两种学校互相借鉴一下可能更有好处,伯克利可以再贵族俗气一点,达特茅斯可以再大众高端(科研)一点。回复看得开2014-5-13 10:59
那么谁是伯克利的这个如意算盘的失意者哪?毫无疑问是加州的学生和他们的家长。如果你感觉到伯克利比以前难考了,You are right!总人数没有增加,非本州学生增加了800,当然是本州学生就减少了800。就这么简单。因为亚裔占伯克利学生的40%,所有肯定首当其冲的受到影响。而最有可能被挤掉的是那些在录取的边缘上又是低收入的学生。









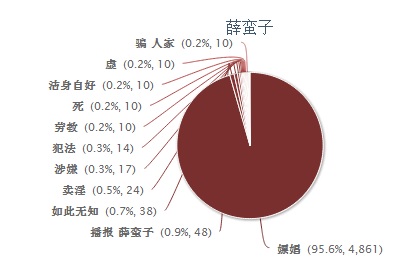
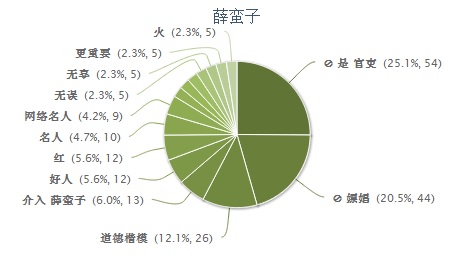
 【科普随笔:NLP主流最大的偏见,规则系统的手工性】
【科普随笔:NLP主流最大的偏见,规则系统的手工性】



 ,也许是我的电脑有问题
,也许是我的电脑有问题













 and the first two. What behind is, I have the assumption (a truth I think) that ALL (well, except for 葡萄, 玻璃 and the like) multi-character 'words' are ambiguous (so-called hidden ambiguity) and hence have to be handled with dictionary at 'application' time (
and the first two. What behind is, I have the assumption (a truth I think) that ALL (well, except for 葡萄, 玻璃 and the like) multi-character 'words' are ambiguous (so-called hidden ambiguity) and hence have to be handled with dictionary at 'application' time (











 很大部分的大学学生在大学一二年转专业。
很大部分的大学学生在大学一二年转专业。
