【立委按】很久很久以前,我发表过一篇世界语语言学特点的论文,后应邀扩展为一个 chapter,这段经历我在博客有记录。记得只看到样本,密密麻麻都是老先生对我论文的校对,但未等到付印我就出国了。后来流浪世界,一直没有顾上追踪这篇论文的下落,直到博士毕业来美国加入创业公司。我在公司做了主管以后,想到在世界语圈子的 Paul,他当时是加拿大世界语协会主席,也是我的兄弟学校的语言学博士候选人。Paul 苦读多年终于要毕业了,我就把他招来做了我的手下。有一天我提到这篇论文的事儿,他主动说我可以到图书馆查询,看到底发表了没有。后来他果然找到了,复印给我当年我呕心沥血写就的长篇论文。这篇论文的底稿早就不存了,只剩下这篇复印件,我一直想把这篇论文重新数字化,但还没找到合适的世界语文字识别软件,可是要是一字字地敲进去又没有这个耐心。在这喧嚣的世界里,我们越来越浮躁,很难静下心来。现在加入了这个群组,左右都是同仁和老师,感觉给了我动力。近20页密密麻麻,我就一点一点植字,也算是重温旧梦吧。
Li,Ŭej (Wei) 1991. Lingvistikaj trajtoj de la lingvo internacia Esperanto.
In Serta gratulatoria in honorem Juan Rgulo, Vol. IV. pp. 707-723. La Laguna: Universidad de La Laguna
1. Aglutineco de Esperanto
1.0. Kiel sciate al ĉiuj, Esperanto estas grandparte tipa aglutina lingvo, kies morfemoj (finaĵoj, afiksoj kaj radikoj) havas siajn apartajn signifojn kaj povas aglutini unu sur alia por vortofarado. Ni intencas portempe esplori sube ĉefe pri la aglutineco pri la finaĵoj, kvankam estas same studindaj la trajtoj por la aglutineco pri afiksoj (lige kun derivaĵfarado) kaj pri radikoj (lige kun kunmetaĵofarado).
[Klarigo] La termino finaĵo en tiu ĉi arktikolo specifikas je gramatika finaĵo.
1.1. Aglutineco pri Finaĵoj
Principe vortofinaĵoj estas nur uzataj por montri gramatikajn informojn: vortospecon, kazon, nombron, tenson, voĉon, modon kaj aliajn.
1.1.1. Kiom da sendependaj finaĵmorfemoj estas en Esperanto?
La absoluta nombro multe limigitas, nur 17: -o, -a, -e, -n, -j, -i, -u, -as, -is, -os, -us, -ant-, -int-, -ont-, -at-, -it-, -ot-. Tamen, estas admirinde, ke ili sufiĉe kompletas kaj proksimume esprimriĉas kiel en fleksiegaj lingvoj, dank' al sia aglutineco.
1.1.2. Baze de la 17 fundamentaj finaĵoj, po kiom da vortoj oni povas produkti el unu vortokorpo laŭregule?
La teoria respondo estas 112: 42 verboj, 28 substantivoj, 28 adjektivoj kaj 14 adverboj (Vd. APENDICON I).
1.1.3. Kiuj estas la reguloj, laŭ kiuj la finaĵoj sinaglutinas?
1.1.3.1. Ĉiu vorto havas nur unu vortospecon, nociaj vortoj ĉiam per siaj finaĵoj sinaspektas je siaj specoj ĉu kiel substantivo, aŭ adjectivo aŭ verbo aŭ adverbo; funkciaj vortoj, kiel prepozicio, originala adverbo, kaj aliaj, tamen, gajnas siajn specojn artefarite, kaj ili estas nombreblaj. Tial, ne estas permesite, ke interaglutiniĝu la finaĵoj indikantaj specojn, -o, -a, -e, -i/-u/-as/-is/-os/-us, t. e. ne ekzistas la formoj kielsube:
** -as-o / ** -e-i
[KLARIGO] ** estas indiko por negramtikaĵo (ne-vorto aŭ ne-frazo) dum ?? por gramtikeproblemaĵo.
1.1.3.1.1. Tio estas granda avantaĝo por la internacia lingvo, ke en Esperanto ne povas esti gramatikaj samformoj, kio sendube estas eksterordinare favora kondiĉo por rekoni (far ĉu homoj ĉu maŝinoj) la funkcion en frazo de la minimuma sintaksa unuo vorto. La alta reguleco tipe enkorpiĝas ĉi tie, ĉu ne?
1.1.3.1.2. Sekve kaj aliflanke, Esperanto sin karakterizas per laŭplaĉa transformado de vortospecoj, se nur la transformaĵo ne kontraŭas al logiko (kp. 1.1.5.1). Ĉu tio ne estas okulfrapa sinmanifesto de alta fleksebleco de Esperanto? Ekzemble:
La flor-OJ flor-AS.
Li kan-AS italan popolan kant-ON.
Mi estas ĝoj-A. Mi ĝoj-AS.
la propon-ITA propon-O
La sama laŭplaĉeco je specotransformo sintrovas ankaŭ en la antikva ĉina lingvo. Tamen, treege bedaŭrinde, la transformo sin montras per neniaj videblaj morfologiaj formoj, kaj tio povrekoniĝas nur laŭ kunteksta sintaksa aŭ/kaj logika analizo. Komparu:
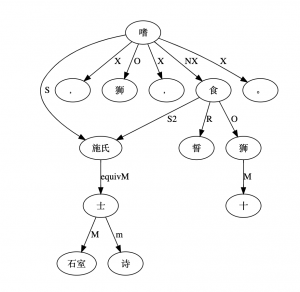
1) 三人行,必有我师。(ĉine) Tri hom-OJ iras, (inter kiuj) nepre estus mia instruisto.
(vorto-al-vorte: tri hom? ir?, nepr? est? mi? instruist?).
其狼人立而嗥。(ĉine) La lupo hom-E staras kaj hurlas (t.e. kvazaŭ homo starus).
(vorto-al-vorte: tiu? lup? hom? star? kaj hurl?).
2) 其物净且清。(ĉine) la aĵo pur-AS kaj klaras.
(vorto-al-vorte: tiu? aĵ? pur? kaj klar?)
净其身,食其肉,乃去。(ĉine) Pur-IG-IS la korpon, manĝis la viandon, kaj eliris.
(vorto-alvorte: pur? tiu? korp?, manĝ? tiu? viand?, kaj elir?)
1.1.3.2. Ĉiuj specofinaĵoj bone sinaglutinas sur la 7 "interfinaĵoj" (kiuj neniam aperas je la fino de vortoj), t.e. la 6 participaj formoj indikantaj aspektojn (kontinuan, perfektan kaj malperfektan) kaj voĉojn (aktivan kaj pasivan), kaj 1 nulformo, kiu fakte indikas ĝeneralan aspekton (aŭ nulaspekton) kaj aktivan voĉon. Tamen, la participaj por si mem ne povas interaglutini unu sur la alia.
1.1.3.3. Aglutinaj Reguloj por Verbo
1.1.3.3.1. Verbo finas nepre je unu el la subaj finaĵoj: -i/-u/-as/-is/-os/-us, kiuj tial certe aperas je vortofinoj kaj inter kiuj ne plu estas la eblo por aglutinado, t.e. la formoj kun -i, -u aŭ -us kiel finaĵo ne plu sinvarias je tenso-signifo, kaj -as/-is/-os nur povas enhavi la signifon de ĝenerala modo (aŭ nulmodo).
1.1.3.3.2. Esperantaj verboj ne sinvarias pro nombro aŭ kazo, verbofinaĵoj do ne aglutineblas al la finaĵoj -j kaj -n. Tial en Esperanto ne ekzistas la kontrasto inter la subaj 2 formoj:
Mi skrib-as. / ** Ni skrib-j-as. (aŭ: ** Ni skrib-as-j.)
1.1.3.3.3. La 6 verboformoj indikantaj tensojn (prezencan, preteritan kaj futuran) kaj modojn (infinitivan, kondicionalan kaj volitivan) kaj la 7 interfinaĵoj por aspektoj kaj voĉoj interaglutinas kun la rezulto de 6*7=42 verboformoj.
[PROBLEMO] Ĉu infinitivo vere estas ia modo aŭ ia sendependa vortospeco?
1.1.3.4. Aglutinaj Reguloj por Substantivo kaj Adjektivo
1.1.3.4.1. Substantivoj kaj adjektivoj fleksias je nombro (singularo per nulformo kaj pluralo per -j) kaj kazo (nominativo per nulformo kaj akuzativo per -n). La 2 nombroj kaj 2 kazoj aglutinantaj sur la 7 interfinaĵoj fariĝas fine 2*2*7=28 formoj.
1.1.3.4.2. Jen la ordo inter ili: (korpo)-interfinaĵo + speco + nombro + kazo, interkie korpo = prefikso(j) + radiko(j) + sufikso(j). Ekzemple: stud-ant-o-j-n. Nur radiko kaj speco nepre kunaperas, la aliaj morfemoj povas tute ne aperi. La supra interordo establiĝas tre nature, kun fonetika kialo (kvankam morfologie la finaĵ-ordo estas pure arbitra, ĉar la ordo mem ne variigas iliajn grametikajn signifojn, kio tiurilate diferencas de la stato pri afiksoaglutinado! Kp. 1.2. Ordite kiel supre, la vokalo o aŭ a, la duonvokalo j kaj la nazala konsonanto n prononciĝus kaj aŭskultiĝus plej facile, eĉ en la okazo, ke la korpo hazardus kun vokalo je fino:
sci-aj-n / ** sci-j-an
1.1.3.5. Aglutinaj Reguloj por Adverbo
Ili multe similas al tiuj por substantivo kaj adjektivo, nur adverbo ne inkluzivas en si la gramatikan kategorion de nombro (por kazo, menciindas, ke la adverba akuzativo signife ne malgrande foras de la substantiva). La formoj do rezultiĝas entute je 2*7=14.
1.1.3.6. La aglutinaj reguloj pri finaĵoj bone fundamencas al la establado de la algoritmoj por fortranĉi finaĵojn kaj por ilin adicii, kiu estas la unua necesa etapo por maŝine kompreni kaj traduki Esperanton. Dank' al la alta reguleco, inkluzive de iugrada rekursiveco, interna en la aglutinareguloj, estas ne malfacile elesplori tiajn algoritmojn kontentigajn (Vd. APENDICON 2).
1.1.4. Ĉu la 17 fundamentaj finaĵoj ĉiuj semantike senmiksas?
1.1.4.1. Bedaŭrinde, ne. Tio klare evidentas en la algoritmo de APENDICO 2.
1.1.4.2. Jen la senmiksaj finaĵoj: -o/-a/-e/-i/-n. Estas klarigende, ke la tiel nomata semantike senmiksa finaĵo tute ne necese signifas, ke ĝi devu signife specifiki nure. La Esperanta senmiksa finaĵo -n signife inkluzivas fakte de tri apartaj funkcioj sintaksaj aŭ logikaj (neniam kunekzistaj, kompreneble): objekto, direkto (kutime lige kun adverbo aŭ postprepozicia substantivo) kaj adjekto (ofte kun la substantivoj de tempo, distanco aŭ similaj). Plurekzemple, en iuj lingvoj estas tri nombroj, singularo (1), duumo (2) kaj pluralo (pli ol 2), tamen la Esperanta pluralofinaĵo -j plivaste signifas, inkluzive de kaj 2 kaj pli ol 2.
1.1.4.3. En Esperanto ne estas elementaj finaĵoj por respekte indiki verbon, predikaton kaj la signifojn de tenso, voĉo, modo kaj aspekto. La signifoj de aspekto kaj voĉo miksiĝas en la koncepto de participo. Kaj tenso, modo ankaŭ sinmiksas kun verbo aŭ/kaj predikato. Tiuj netravideblaj miksaĵoj, tamen, ne kaŭzas malfacilon por homa rekonado; anstataŭe, ili aspektas sufiĉe nature kaj favore, ĉefe ĉar la signifoj miksitaj kune estas tiuj, kiuj proksime interrilatas.
[PLUVORTOJ] Participo ne estas sendependa vortospeco, kiu povas aparteni al ajna el la 4 ĉefaj specoj kaj kies vera senco nur efikas je tio, ke ĝi, kiel la sufikso aŭ kvazaŭ interfinaĵo -ad-, donus al vorto la logike verban signifon.
1.1.4.4. Estas sufiĉe interese ke ankaŭ estas iugrada "travidebleco" eĉ en Esperantaj netravideblendaj miksaj finaĵoj. El la formoj -as/-is/-os/-ant-/-int-/-ont-/-at-/-it-/-ot-, verŝajnas al ni, ke -a- signifus "presencon" aŭ "kontinuon", -i- "preteriton" aŭ "perfekton", -o- "futuron" aŭ "malperfekton", -s "predikaton" (escepte nur de la volitiva predikato -u), kaj -n- "aktivon", ktp. Kvankam morfologie tiuj kvazaŭfinaĵoj ne povas sinsendependi kiel elementaj finaĵoj, tamen, tia "travidebleco" objetive multe helpas nin por memorado, kaj plue, oni ĉiam sentas la belecon je la paraleleco en la miksformoj konsistantaj el ili.
[PLUVORTOJ] Kiel sintaksaj kategorioj, tenso kaj aspekto ja evidente diferencas unu de la alia, sed je praktika uzado ege malklariĝas la interlimo:
Verk-ONT-oj estas tiuj, kiuj verk-OS aŭ verk-ONT-AS.
Stud-ANT-oj estas tiuj, kiuj stud-AS (ne nepre stud-ANT-AS!).
Hav-ANT-e multon da mono, mi ĝojas.
= Ĉar mi hav-AS (neniel necese hav-ANT-AS) multon da mon, mi ĝojas.
Li jam vid-IS/vid-INT-AS la filmon.
Fakte, la 2 konceptoj ambaŭ rilatas al TEMPO en la objektiva mondo. Tio eble ĝuste estas la kialo, pro kio Zamenhof, kiel lingva majstro, maldogmiste elektis la samvokalojn por la 2 objektive similaj konceptoj.
1.1.4.5. Tamen, guste ĉar en Esperanto ne estas elementaj finaĵoj por voĉoj, kies informoj sin montras nur en la 6 participoj, do formas la situacio, ke 1 pasivformo kontrastas al 2 aktivformoj kielsube:
-as / -antas --> -atas; -as / estas -anta(j) --> estas -ata(j)
-is / -antis --> -atis; -is / estis -anta(j) --> estis -ata(j)
-os / -antos --> -atos; -os / estos -anta(j) --> estos -ata(j)
La esenco de ĝi estas, ke en Esperanto estas efektive 4 aspektoj: ĝeneralo (per nulformo), kontinuo, perfekto kaj malperfekto, kaj ekzistas 2 voĉoj: aktivo (per nulformo) kaj pasivo. La 6 paralelaj participoj konsistas el nur 3 aspektoj kaj 2 voĉoj, dum la nulforma ĝenerala aspekto ne havas sian respondan pasivformon, rezultante, ke ĝi senrimede kunĝuas la kontinuan pasivaĵon! Ni ne povas ne konfesi, ke kvankam -at- estas teorie formala kontrastaĵo al -ant-, tamen oni efektive emas rigardi -at- kiel la pasivan formon por ĝenerala aspektom, kiu pli often uziĝas ol la kontinua. Tial, iuj proponas, ke oni uzu la aglutinan formon -ant-at- aŭ -at-ant- kiel la kunaĵon de kontinuo kaj pasivo, aŭ plue, tute sendependigu la 2 katekoriojn, sekve estus: -int-at- anstataŭ -it-, -ont-at- anstataŭ -ot-, ktp. Tiaj travideblaj formoj eble ja efikas por maŝinoj, sed por ni homoj ili estas troaj kaj nenecesaj ŝarĝoj.
1.1.4.6. [Sumeto] Ideala pure aglutina lingvo estas tia, ke ĉiu morfemo, almenaŭ ĉiu finaĵo, devas havi elementan aŭ simplan signifon, tiel, kompleksa signifo estas esprimata en la formo de morfemaglutinaĵo. Tio ja estas la fundamenta diferenco inter aglutina lingvo kaj alia fleksitipa lingvo, kaj nur pro tio la vortoj fariĝus travideblaj, tute analizeblaj. Kompreneble, finaĵoj estas tiuj morfemoj, kiujn oni plej facile aglutinigas tutpure. Tamen, eĉ tiurilate, Esperanto ne sinmontras je 100% senmiksa aglutineco, kio povas, laŭ mi, klarigata fonetike: signife simpligi ĉiujn finaĵojn en elementojn certe kaŭzas la plimultigon de silaboj por vorto, kaj la aglutinaĵo sekve tro kompleksas por homa akcepteblo. Plue, en Esperanto estas nur 5 vokaloj a/i/e/o/u, kiuj ĉiuj estas sufiĉe ŝarĝitaj jam! Esperanto estis, estas kaj estos HOMA PRAKTIKUZA kaj sufiĉe NATURA lingvo (kvankam origine artefarita) anstataŭ maŝinlingvo. (Vd. Sekcion 4.)
1.1.5. Ĉu la 112 formoj ĉiuj estas uzataj?
1.1.5.1. Gramatike, jes. Praktike, estas nur unu limigo: la ligaĵo de korpo kaj finaĵo devas esti logike komprenebla, t.e. semantike ligebla. Ŝajnas al mi, ke tiuj konkretaj aĵo-radikoj kiel "tabl-" ne povas fariĝi en participformojn:
?? tabl-ant-i / tabl-ot-a / tabl-ant-a / tabl-int-o
Tiun limigon laŭas nature la uzantoj, kiuj verŝajne ne eblas esprimi iun informon eĉ ne kompreneblan al si mem!
1.1.5.2. Kvankam pragmatike la uzofteco por la 112 formoj multe varias unu de alia, tamen oni neniel povas diri, ke kiuj formoj estas neuzeblaj. La efikeco kaj la komprenebleco de la ĉiuj 112 formoj estas same certaj. La problemo, kiuj el ili estas prefere elektitaj por esprimado, decidiĝas de variaj faktoroj: la lingva kutimo kaj origino de la parolanto, la stilo, la situacio, kiaj aŭskultantoj ĉeestas kaj kia efiko estas intencita, la poveco de la uzanto, ktp.
Tamen, Esperanta Ŝpara Principo bezonas, ke oni plej ofte eble uzu malmultajn simplajn formojn. Ekzemple:
"Mi NUN stud-AS (aŭ: Mi ESTAS stud-ANTA)" anstataŭ "Mi stud-ANT-AS".
"Ili JAM ir_IS (aŭ: Ili ESTAS ir-INTAJ)" anstataŭ "Ili ir-INT-AS".
"veredir-E" anstataŭ "veredir-ANT-E" (kp. angle: truly speak-ING).
Do, oni prefere uzas "la parol-O far_E de Zamenhof" anstataŭ "la parol-ADO far-ITA de Zamenhof", aŭ plue plisimpligus la vortogrupan prepozicion FARE DE en la novan prepozicion FAR: la parolo FAR Zamenhof (kp. "la parolo de Zamenhof", formon pli abstraktan).
Ĉar en la homa pensado mem iugrade ekzistas necesinda nebuleco, kaj samtempe, ofte helpas ankaŭ la kunteksto kaj funkciaj vortoj inkluzive de la nura fleksia efektive funkcieca vorto EST- (helpe de ĝi, oni bone sinesprimas per analizaj formoj ĝenerale pli klaraj ol la sintezaj kompleksaj formoj, kiel jam montrite en la supraj ekzemploj. Vd. ankaŭ 3.2.1), Ŝpara Principo de Esperanto ne malfacile laŭiĝas.
1.1.5.3. [SUMETO] Nur 17 fundamentaj finaĵoj povas interaglutiniĝi fine en 112 efikaj finaĵoformojn! Ĝi estas miraklo por vortofarado dank' al aglutineco. Kaj, plue, tiel multaj formoj neniel fariĝas ŝarĝo sur homoj ĉu por esprimo aŭ por kompreno. ĉu tio ne estas la plej bona pruvo por la Esperanta aglutina reguleco? La esenco de aglutineco estas faket ne plu ol elekta permutado (el la anglo de rezulto) kaj kvazaŭrekursiveco (el la angulo de procezo, Vd. APENDICON 2), aŭ pli abstrakte, ia matematikeco, kiu plej multe eble enkondukiĝis en nian lingvon. Ĝuste pro tio, Esperanta vortofarado estas tipa ekzemplo de la alta unuiĝo de reguleco kaj fleksebleco, kiuj estas en Esperanto interdependaj flankoj de la sama fenomeno.
1.2. Aglutineco pri Afisoj
Afiksoj ĉefe poras esprimi vortonuancojn. La aglutino ofte limigatas de natura logiko aŭ semantika kunligebleco, kiu estas grandparte komuna al la tuta homaro, tial ne ekzistas, kaj ankaŭ necesas, perfortaj reguloj por la afiksordo, la uzantoj en komunikado nature interkompreniĝas tiurilate. Funkcias ĉi tie la Esperanta Interproksima Principo, kiu bezonas la interrilatajn 2 elementojn kiel eble plej proksimaj por facila kaj klara komprenado. Komparu la nuancon inter PLIMALBONIGI kaj MALPLIBONIGI:
bon-a --> mal-bona --> malbon-ig-i --> pli-malbonigi
bon-a --> bon-ig-i --> pli-bonigi --> mal-plibonigi (aŭ: bon-a --> malpli-bon-a --> malplibon-ig-i)
1.2.1. Estas diferenco je abstrakteco de afiksoj. La plej abstraktaj kaj ankaŭ plej ofte uzataj afiksoj kiel -et-/ -eg-/-aĉ-/mal-/ne- ĉie uzeblas kun kiu ajn radiko, kies logika speco (principe, ĉiu radiko kutime havas unu logikan specon, ĝuste kiel ĉiu vorto havas unu gramatikaspecon) estas ne antaŭkondiĉita, dum aliaj kiel -ul-/-ing-/el-/kun- multe konkretas.
1.2.2. La povecon je prefiksa aglutino estas pli-malpli limigita, kompare kun tiu je la sufiksa, kaj fonetike ne kiele permesitas la kunprononco de la silaboj inter prefisoj aŭ inter prefiso kaj radiko (kielekzemple MALAPERI kaj MALANTAŬPORDO: mal-a-pe-ri / ** ma-la-pe-ri; mal-an-taŭ-por-do / ** ma-lan-taŭ-por-do).
1.2.3. Multe pli flekseblas la aglutinado pri sufiksoj:
rid-i
rid-et-i
ridet-em-a
ridetem-et-a
ridetemet-ul-o
ridetemetul-in-o
ridetemetulin-et-o
ridetemetulinet-aĉ-o
ridetemetulinetaĉ-et-o ...
(= la ete aĉa eta knabino, kiu ete emas rideti)
Ni trovu, ke la samafikso povas aperi plurfojoin en unu vorto nur laŭ la sence celita, tio estas tute malsama de finaĵo. Teorie, la nombro de sufiksoj dum aglutinado semlimas, kvankam oni prefere uzas analizan formon anstataŭ tro kompleksan plursufiksan aglutinaĵon, limigite de la povo de homaj organoj.
[PLUVORTOJ] Estas en Esperanto 2 malaglutinecaj sufiksoj -ĉj-/-nj-, kiuj ŝanĝas la antaŭajn silabojn: patro / patrino --> pa-ĉj-o / pa-nj-o.
1.3. Aglutineco pri Radikoj
Radikaglutineco uziĝas por manifesti malsimplan koncepton, kaj la aglutina regulo tre simplas kaj naturas: aksa elemento ĉiam sekvu. La laŭplaĉeco por kunmetaĵfarado kaj la aglutina regulo tre similas al la vortofarado en la ĉina lingvo (kaj ankaŭ la germana). Ekzemplojn:
(Esperante : ĉine)
(1) akvo-fonto: 水/源
(2) varm-energio: 热/能
(3) arbo-branĉo: 树/枝
(4) surd-mut-ulo: 聋/哑/人
(5) blank-hara: 白/发
(6) nur-pieda: 光/脚
(7) bon-kora: 好/心
(8) fonto-lingvo: 源/语
(9) celo-lingvo: 目标/语
(10) naci-lingvo: 民族/语
(11) internaci-lingvo: 国际/语
2. Fleksebleco De Esperanto
2.1 En Esperanto malklariĝas la limoj ...
2.1.1 Inter transitivo kaj netransitivo
Mi IRAS.
/ IRU vian propran voj-ON.
La tuta homaro PAROLOS nur unu lingv-ON.
/ Mi PAROLAS Esperant-E (en Esperanto / per Esperanto).
2.1.2 Inter objektoj rekta kaj nerekta :
informi ION al IU / informi IUN pri IO
2.1.3 Inter objekto kaj adjekto
Mi invitas vin vojaĝi kun mi PEKINON.
2.1.4 Inter radiko kaj afikso (eĉ finaĵo), sekve inter derivaĵo kaj kunmetaĵo, kiel ekzemple:
Kion vi UM-as nun? (angle: What the devil are you doing?)
sekret-ET-o / ET-a sekreto
ANTAŬ-vidi / Sinjorinoj ANTAŬ-u
kred-IND-a / ne-IND-a / IND-igi / sen-IND-ulo
AĈ-ulo / FI-ulo
Mi neniam ŝatas lin, nek IS nek OS.
2.1.5. Inter sufikso kaj finaĵo
am-AT-o / am-AT-IN-o
kaj parol-e kaj skrib-e / kaj je parol-AD-o kaj je skrib-AD-o
(kp. angle: both in speak-ING and in writ-ING)
instru-ANTO / instru-ISTO / instru-EMULO // ?? instru-ANO
(Ĉiu el tiuj vortoj estas tiu, kiu rilatas kun la ago instruado.)
2.1.6 Inter nocia vorto-radiko kaj funkcia vorto, t.e. funkciaj vortoj ankaŭ povas sekvati de finaĵoj eĉ afiksoj ĝuste kiel radikoj, se necese:
JES, mi JES-as vian opinion.
Li TRO ĝojas. --> Li ĝojas TRO-e.
tie --> tie-aj homoj
nur --> la nur-a studento / nur-ul-o / nur-ul-in-o
per --> per-anto
tre --> tre-ege
2.1.7 Inter vortogrupo kaj grupovorto (kunmetaĵo), speciale prepozitivo kaj ĝiaj respondaj adverbo, adjektivo, verbo kaj eĉ substantivo:
laŭ mia opini-o / miaopini-e
sur la tabl-o / surtabl-e
sur la tabl-on / surtabl-en
la lingvo por homoj / porhom-a lingvo (porhomalingvo)
(sed ĉu "porhomlingva" = "porhom-lingva" aŭ "por-homlingva"?)
la reĝimo el la popolo, sub la popolo, inter la popolo, kaj por la popolo
La reĝimo elpopol-U, subpopol-U, interpopol-U kaj porpopol-U.
Ĉio estu la popolo. / Ĉio porpopolu!
transformi specon laŭ via plaĉo / la laŭplaĉo en speca transformado
zorgi PRI (io) / PRI-zorgi (ion / PRI io)
maŝina tradukado / maŝintraduko
ponta lingvo kaj intera lingvo / pontolingvo kaj interlingvo
2.1.8 Inter predikato kaj predikata komplemento (predikativo):
Mi ESTAS studant-A. / Mi ESTAS ĝoj-A.
2.1.9. Fine inter la konceptoj de aglutinado, kunmetado kaj derivado (Rf. Sekcion 1); inter la konceptoj de substantivo nombrebla kaj nenombrebla (ekz. konklud-o / konklud-oj), difinita kan nedifinita (sinmotrante je iugrada laŭplaĉo en la uzado de la artikolo LA), ktp.
2.2. En Esperanto kreiĝis la ĉiopova prepozicio JE. Kiam oni esprimas sian penson, oni ofte sentas, ke ekzistas iagrada nubula determina rilato inter konceptoj, sed ne povas diri klare kaj ne bezonas klare montri ilian semantikan rilaton. Por adapti la lingvon al tia nebuleco de homa pensado, Zamenhof, same kiel li elpensis la sufikson -UM-, genie kreis la prepozicion JE (kiu eble estas la dua plej grava analizaĵo en Esperanto. La unua estas la vorto EST-, Vd. 3.2.) Oni povas esprimi tian nebulan rilaton ankaŭ per fleksiaj formoj (sintezaĵoj), kiel akuzativo aŭ adverbo.
2.3. En Esperanto estas mirinda unueco en la uzado de kazo kaj vortospeco, kio estas ĝia treege elstara lingvistika trajto. La vortospeco kaj kazo estas ambaŭ dinamikaj sintaksaj karakteroj, kiuj sinmontras nur dum la konstruado de frazo. Tial, ili same povas esprimi abstraktajn semantikaj rilatojn, kvankam diferencajn, kaj efektive kompletigas unu la alian. (Diferencante de la analizforma prepozitivo, kiu en Esperanto estas uzata ĝenerale por esprimi kompare koncretan kaj determinan semantikan rilaton, escepte de la prepozicio JE. Porplue, vd. 3.2.2.) Ni komparu jenajn frazojn:
Mi skribas plum-E. / (ruse)
Kiel supre jam menciite (vd. 1.1), bazaj finaĵformoj en Esperanto, kvankam nemultaj, estas sufiĉe kompletaj kaj esprimriĉaj. Ni nun citu kazon kiel pluan ekzemplon. Esperanto havas nur du kazojn, t.e. nominativon, aŭ alivorte neakuzativon (per nulformo), kaj akuzativon (kun la finaĵo "-N"). Kun la kazoj kaj vortospecoj, kaj analiza formo prepozitivo (se necese), Esperanto estas tiel esprimriĉa kiel aliaj fleksiegaj lingvoj. La rusa estas unu el la lingvoj kurante plej fleksiriĉaj, kun 6 kazoj. Estas ne malinspirante kaj ne malinterese kompari la rusan lingvon kun Esperanto tiurilate. Proksimumedire, la unua kazo de la rusa respondas al nominativo de Esperanto, la dua kazo al adjektivo (kun la finaĵo "-A"), la kvara al akuzativo (kun la finaĵo "-[OJ]N"), kaj la kvina al adverbo (kun la finaĵo "-E"). Nur la tria kazo ne havas sian respondan fleksian formon en la internacia lingvo kaj estas ansataŭata ĝenerale de la prepozicio "AL". La sesa kazo per si mem ne esprimas difinitan semantikan rilaton kaj funkcias nur kune kun la prepozicioj kiel "O", "HA", "B". Estas interese, ke en Esperanto prepozicioj povas esti sekvataj kaj de nominativo kaj de akuzativo, montrante nedirekton kaj directon respektive. Kompare kun la simila uzo en la rusa lingvo, Esperanto estas multe pli simpla kaj perfekta. (Vd. APENDICON 3.)
2.4. En Esperanto estas sufiĉe libera vortordo
2.4.1
(1) Mi amas vin;
(2) Mi vin amas;
(3) Vin mi amas;
(4) Vin amas mi;
(5) Amas mi vin;
(6) Amas vin mi.
(ĉiuj permutaĵoj de tri elementojn)
2.4.2
(1) la homoj studantaj matematikon
(2) la homoj matematikon studantaj
(3) la studantaj matematikon homoj
(Sed: ?? Mi ŝatas la studant-AN matematik-ON hom-ON.)
(4) ?? la matematikon studantaj homoj
(plibone: la matematikon-studantaj (matematik-studantaj) homoj
2.4.3
(1) la propono proponita de mi
(2) la propono de me proponita
(3) la de mi proponita propono
(4) la proponita de me propono
(5) la proponita propono de mi
(6) ?? la de mi propono proponita
Ĉi tie ni vidas, ke la malibereco sinmontras nur je la ordo inter artikolo aŭ prepozicio kaj ĝia ĉiam sekvanta rilata subsvantivo, tial, en la ĵuscititaj frazoj estas fakte 3 ordo-varieblaj elementoj: la (...) propono; de mi; proponita, kies permutado nombriĝas je 6.
2.4.4 Esperanto eĉ permesas tian uzadon:
Nun de loko flugu ĝi al loko. (Kp. Nun ĝi flugu de loko al loko.)
Ne al glavo sangonsoifanta, Ĝi la hom-AN tiras famili-ON. (Ĝi tiras la homan familion ne al glavo sangonsoianta.)
Certe, en la supraj du ekzemploj, multe helpas la poetika licenco, kiu povas, tamen, tiel libere kaj efike funkcii je vortordo nur kondiĉe, ke ĝi estu en iu treege milda lingvo kiel Esperanto kaj samtempe ke ĝi tute ne kontraŭu al la fundamenta gramatiko de la lingvo.
2.5. La konjugacia sistemo de Esperanto (kvankam kun, tamen, la difekto supremenciita en 1.1.4.5.) kaj la tabelo de korelativaj vortoj de Esperanto estas mirindaj kreaĵoj. Per la nura help-verbo EST- (kiu estas la plej grava analizaĵo en Esperanto! Vd. 3.2.), oni povas bone esprimi analizforme diversajn kompleksajn tensojn kaj voĉojn. (Sen la help-verbo, dank' al la aglutineco de gramatikaj finaĵoj, oni ankaŭ egale pove ilin esprimas sintezforme.) La tabelo de korelativaj vortoj estas eksterordinare riĉa kaj konciza por esprimi semantikajn rilatojn. Ĝi estas tiel perfekta, logika kaj bela, ke ĉiuj esperantistoj spertas ĝian belecon, same kiel kemiistoj la belecon de la Mendeleeva tabelo de kemiaj elementoj.
2.6. En Esperanto almenaŭ ĉiuj prepozicioj estas samtempe prefiksoj. Do sekvas nature la granda fleksebleco je esprimado (vd. 2.1.7.).
3. ANALIZAJ KAJ SINTEZAJ FORMOJ
3.1. Alia elstara lingvistika trajto de Esperanto estas, ke ĝi havas la esencojn de kaj analiza lingvo kaj de sinteza lingvo, sufiĉe riĉante je kaj funkciaj vortoj kaj fleksiaĵoj. Oni povas sin esprimi semantike aŭ per analiza formo (helpe de funkciaj fortoj) aŭ per sinteza formo (helpe de fleksioj). La du formoj, kompreneble, ne tute identiĝas. Ili sin montras diversastile. Pro tio, Esperanto estas elastega kaj esprimriĉa. Kiel celolingvo, ĝi povas plej bone imiti la lingvajn karakterizaĵojn de originala verko, ĉu la mildan slavan stilon kun libera vortordo, ĉu la stilon de fleksimankaj lingvoj, kiel la ĉina kaj angla. Sube estas kelkaj ekzemploj de ĉiea kaj ĉiutavola kunekzistado de analizaj kan sintezaj formoj en Esperanto:
Analizaj Formoj / Sintezaj Formoj
1. Tenso:
Mi ESTAS srib-ANTA. / Mi skrib-AS. Mi skrib-ANTAS.
2. Voĉo:
Ĝi ESTAS limig-ITA. / Ĝi limig-ITAS. Ĝi lim-IĜAS. Ĝi SIN-limig-AS
3. Senco:
Tio estas MALGRANDA (ETA) sekreto. / Tio estas sekret-ETO.
4. Preposicioj kaj la kazo akuzativo aŭ vortospecoj -E aŭ -A:
Li parolas EN (PER) Esperanto. / Li parolas Esperant-E (EsperantON).
la libroj DE mi / mi-AJ libroj
Ŝi parolis POR (JE) 30 minutoj. / Ŝi parolis 30 minut-OJN.
LAŬ mia opinio / miaopini-E
ridi JE iu / ridi iu-N
EN (JE) fakto / fakt-E
inkluzive DE 2 poemoj / inkluzive 2 poemoj-N (adverbo sekvata de akuzativo!)
vidi mult-E DA homoj (mult-ON DA homoj) / vidi mult-AJN hom-OJN
5. Prepozicio kaj vorto:
finiĝi tie, KIE VI TROVAS BONA / finiĝi laŭ via BONTROVO; finiĝi LAŬBONTROVE
(Por aliaj ekzemploj vd. APENDICON 3 kaj 2.1.7.)
3.2. Plej Gravaj Analizaj Formoj: Vorto EST- kaj Prepozicio
3.2.1. Nura Helpa aŭ Liga Vorto EST-
3.2.1.1. Verŝajnas, ke ne estas nocia senco en la vorto EST-, kiu, el la punkto de sinteza lingvo, tute ne necesas:
Ili ESTOS skrib-ITAJ ĉe la jarfino. --> Ili skribi-ITOS ĉe la jarfino.
Ni ESTAS ĝoj-AJ ESTI ricev-INTAJ iliajn leterojn. --> Ni ĝoj-AS ricev-INTI iliajn leterojn.
Vi ESTAS vere bonkor-AJ (vi en pluralo). --> Vi vere bonkor-AS (nombro nur certita en kunteksto).
Li ESTAS profesor-O (laboradis kiel profesoro) en tiu universitato. --> Li profesor-IS (profesor-ADIS) en tiu universitato.
Tamen, ankoraŭ estas problemoj:
Ĝi ESTAS tablo. / ?? Ĝi tabl-AS.
Ĝi ESTAS biciklo. / ** Ĝi bickl-AS.
Kp. Li bicikl-AS. = Li ESTAS bicikl-ANTA. = Li bicikl-ANTAS.
ESTAS 3 homoj en la ĉambro. / ?? 3 homas en la ĉambro.
3.2.1.2. Kun la vorto EST-, kvankam nur unu, Esperanto treege riĉiĝas je esprimado per analiza rimedo! Alie, la lingvo havus tute alian aspekton, kiu tro konpaktus kaj malmildus, kaj kiu plejeble malakceptitus de homoj el la analizalingva tipo.
3.2.2. Prepozicio
3.2.2.1. Estas kutime akceptite en la lingvistika rondo, ke prepozitivo (aŭ prepozicia sintagmo = prepozicio + substantiva komplemento) estas esence ankaŭ ia kazo, kun la nura malsamo, ke prepozicio ĝenerale pli knokretas ol kazo. Fakte, prepozicioj mem enhavas variajn gradojn de konkreteco inter si, kiel ekzemple, komparu:
instituto JE lingvistiko --> instituto DE lingvistiko --> instituto PRI lingvistiko (plikonkretiĝas unu ol alia)
Estas kelkaj sufiĉe abstraktaj prepozicioj, kiuj efektive funkcias ĝuste kiel kazoj en iuj aliaj lingvoj, kiel JE/DE/AL/PRI/PER (vd. APENDICON 3). (Notu, ke la semantikoj de kazoj ankaŭ varias je abstrakteco.)
3.2.2.2. Kiel jam iom menciite en 2.3., adverbo (kun finaĵo -E) estas ankaŭ iu semantike abstrakta kazo. Sed, adverbo en Esperanto anaŭ povas indiki tiel konkretajn rilatojn kiel ajna prepozicio! Nur kondiĉas, ke la vortocorpo deriviĝas de radiko kaj prepozicioprefikso. Kp:
LAŬ (la) regulo(j) --> LAŬ-regul-E (kp. la pli abstraktan vorton: regul-E)
Estas multaj tiaj ekzemploj (vd. 2.1.7.). Fakte, oni povas libere intertransformi prepozitivon kaj ĝian respondan adverbon (kun la ofteapera artikolo LA ellasita).
3.2.2.3. Ĉar almenaŭ ĉiuj prepozicioj samtempe ankaŭ povas funkcii kiel prefiksoj (la ĉefa parto en la Esperanta prefiksaro!), la tiel nomata "grava ANALIZA formo" prepozicio vere estas egale unu el la plej gravaj SINTEZAJ formoj!
3.3. [SUMEO] En Esperanto ĉie kaj ĉiutavole videblas la kunekzitado de analiza kaj sinteza formoj, per kiu Esperanto sin diferencas de naciaj lingvoj. Kvankam ne ekzistas pura sinteza lingvo sen ajna analiza formo, nek pura analiza lingvo sen ajna sinteza formo, tamen ĉia nacia lingvo havas nur unu formon kiel la ĉefan: aŭ la analizan aŭ la sintezan, kaj almenaŭ ĉiu estas tia, ke la du formoj ne ekzistas samokaze.
4. TRAVIDEVLECO DE ESPERANTO
4.0. Estas naturo de Esperanto, ke sufiĉe travideblas Esperantaj formoj (ĉu analizaj aŭ sintezaj, tamen, la analizaj formoj ŝajne ĝuas pli da travidebleco ol la sintezaj), kio estas certe unu el la plej elstaraj avantaĝoj kaj la ĉefa kialo por la facileco en la lernado de Esperanto, ĉar ono povas uzi malmultajn formojn (elementojn) por esprimi senlimajn informojn, aŭ analizi la akceptitajn formojn en elementojn por komprenado.
4.1. Ĉu Esperanto estas perfekte travidebla?
Ne. Kaj neniam povos. Kaj ankaŭ neniam necesos - almenaŭ por homa lingvo.
La antaŭkondiĉo por tutetravidebleco estas, ke ĉiu koncepto povus esti analizata en nombreblajn semantikajn atomojn aŭ semantikemojn (ĉu tio ja eblas? Referencu la progreson en la rondo de artefarita intelekto), kaj plue, ke la semantikemoj, kiam ili interkunligas, devus esti kompleksece homtolereblaj - tio certe ne povas ĉiam kontentiĝi, speciale por scienca fakotermino, kiu estas kutime tiel enhavo-riĉa kaj signifo-ekzakta, ke ĝia difino bone fariĝus iu plena disertacio. Tial, tia koncepto nur povas fiksiĝi en homan cerbon per iu fonetika formo, kies surfaca respondaĵo estas ne alia ol maltravidebla vorto! Aliflanke, plejmulte da scienca terminaro ĝuas internaciecon, do ŝajnas ne saĝe ĝin Esperantecigi eĉ eble, ekz., nombroscienco / matematiko, sed ĉu matematiko estas simple nombroscienco? (Vd. 4.4.)
4.2. Ĝuste kiel la kunekzistado de analizaj formoj kaj sintezaj, en Esperanto multokaze (sed alitavole, kompreneble), ankaŭ troviĝas la kunekzistado de la travideblaj kaj ne travideblaj formoj.
Pekino: Beijing
;ingvoscienco : lingvistiko
preskaŭ ne: apenaŭ
elektre kalkula maŝino: komputilo (aŭ: komputomaŝino): komputoro (aŭ: komputero).
Oni eĉ toleras tiajn tiel-nomatajn "ne-Esperantajn" vortojn kile "komputoro" kaj "komputero" en Esperanton!
4.3. Iuj plefote uzataj ĉiutagaj vortoj jam sinstabliĝas kiel travideblaj formoj, kio manifestas la fortan emon de Esperanto por Esperantecigi aliajn!
patrino: ?? matro
malbona: ?? bada
maldekstra: ?? lefta
Tamen, bonstila Esperanto neniam ekstremigasiun ajn rimedon, eĉ plej efikan kaj facilan:
?? malkun: sen
?? malmorgaŭ: hieraŭ (aŭ ?? malhieraŭ: morgaŭ)
4.4. Dilemo de Esperanto
4.4.1. Esperanto kiel internacia lingvo, celas la facilan komunikadon por la tuta homaro. Tamen, en la lingvopraktikado aperas la kontraŭo inter travidebleco (la lingva naturo de Esperanto) kaj internacieco (laa celo de Esperanto), kiu plej evidente sinmontras je la konstruado de terminoj. Rezulte, la vortaro de Esperanto estas multe pli vasta ol on atendis.
4.4.2. Esperanto kiel efika ilo por komunikado devas esiti, kaj efektive ja estas, sufiĉe kompakta, do venas la kontraŭo inter travidebleco kaj kompakteco. Fakte ju pli travideblas, des pli malkompaktas.
4.4.3. Kaj fine ankaŭ estas la kontraŭo inter travidebleco (sekve lernofacileco kun malmulte da elspezo de memoro kaj energio) kaj inkluziveco. Esperanto kiel scienca kaj portuthomara lngvo inkluzivus morfologie kaj sintakse ĉiujn efikajn lingvajn rimedojn, kio bezonas la kunekzistadon de variaj formoj, inkluzive de la maltravideblaj.
5. SUMO
5.1. La supre diritaj montras, ke ĝueste male al tio, kion oni subjektive dedukts, Esperanto estas treege fleksebla lingvo kun variaj esprimmanieroj, kiuj povas sin reciproke kompletiĝi kaj intertransformi, kaj la granda fleksebleco de la lingvo ĝuste konformas al la nebuleco de la homa pensado. Ĝi donas al homoj grandan liberecon je esprimado kaj la plej bonajn kondiĉojn por plene montri ilian lingvan kompetentecon. Aliflanke, ĝi ankaŭ enhavas tiel grandan tolerecon, ke eĉ komencantoj aŭ lingvo-nesaĝuloj povas facile kaj simple sinesprimi kompreneblige. Ĉi tio estas kampo konvena por ĉiuj, ĉu genioj ĉu malsaĝuloj. Tamen tia fleksebleco ne influas la rigoran neŝanĝeblecon de la fundamenta gramatiko de Esperanto. Ĉi tie la libereco kaj rigoreco ekzistas harmonie. En Esperanto, ĉiuj estas kreantoj kaj ĉiuj povas ĝui la plezuron de tia kreado. Oni ne plu estas sklavoj de lingvaj kutimoj. La granda harmonio de la fleksebleco kaj reguleco de Esperanto estas vere mirakla kreaĵo lingvistika.
5.2. Ecaro de Esperanto - Ŝlosilovortoj:
porhomeco / natureco / scienceco / reguleco / inkluziveco / toler(ebl)eco (elasteco) / aglutineco / matematikeco (kvazaŭrekursiveco) / logikeco / travidebleco (analizebleco) / fleksebleco
5.2.1. Proksimume ni havus: Fleeksebleco <-- aglutineco (sekve travidebleco) kaj inkluziveco de variaj formoj (ĉu analiza ĉu sinteza; ĉu travidebla ĉu netravidebla); Reguleco kan scienceco <-- matematikeco kaj logikeco.
5.2.2. El la punkto de toler(ebl)eco kaj la praktika informokomunikado, almenaŭ ĉiuj supraj ekzemploj kun ?? je la antaŭo estas tolereblaj, minimume kompreneblaj. Kompare kun naciaj lingvoj, tia tolereco estas multe pli elstara.
5.3. [KONKLUDO] La eksterordinara sukceso de Esperanto grandega miraklo en la historio de homaj lingvoj. Ĝi estas la venko de homa racio, la venko de lingvistiko! Estas nepovtroe laŭdite kaj fiere hurainde, ke en la inta lingva kampo, kie "ekutimo estas Dio", fositas sulko por INTERNACIA LINGVO kiel contrasto al nacia lingvaro!
APENDICO 1
Ni citu kiel ekzemplon la radikon STUD- en formo de verboj kaj adjec=ktivoj, kan komparu ĝin kun la angla vorty STUDY.
Gramatikformoj por Radiko STUD- [angle: STUDY]
1. 42 verboj:
stud-I [to study]
stud-U [(let...) study]
stud-US [would (should) study / stud-IED / would have stud-IED / ...]
stud-AS [study 9stud-IES)]
stud-IS [stud-IED]
stud_OS [will (shall) study]
stud-ANT-I [to be study-ING]
stud-ANT-U [?? (let...) be study-ING]
stud-ANT-US [would be study-ING / ...]
stud-ANT-AS [is (am, are) study-ING]
stud-ANT-IS [was (were) study-ING]
stud-ANT-OS [will (shall) be study-ING]
stud-INT-I [to have stud-IED]
stud-INT-U [?? (let...) have stud-IED]
stud-INT-US [had (would have) stud_IED]
stud_INT-AS [have (has) stud-IED]
stud-INT-IS [had stud-IED]
stud-INT-OS [will (shall) have stud-IED]
stud-ONT-I [?? to be to study]
stud-ONT-U [?? (let...P be to study]
stud-ONT-US [?? should (would) (be to) study]
stud-ONT-AS [am (is, are) to study]
stud-ONT-IS [was (were) to study]
stud-ONT-OS [will (shall) be to study]
stud-AT-I [to be (being) stud-IED]
stud-AT-U [?? (let...) be (being) stud-IED]
stud-AT-US [would (should) be stud-IED]
stud-AT-AS [am (is, are) (being) stud-IED]
stud-AT-IS [was (were) (being) stud-IED]
stud-AT-OS [will (shall) be (being) stud-IED]
stud-IT-I [to have been stud-IED]
stud-IT-U [?? (let...) have been stud-IED]
stud-IT-US [?? would (should) have been stud-IED / ...]
stud-IT-AS [have (has) been stud-IED]
stud-IT-IS [had been stud-IED]
stud-IT-OS [will (shall) have been stud-IED]
stud-OT-I [to be stud-IED]
stud-OT-U [?? (let...) be stud-IED]
stud-OT-US [would (should be stud-IED]
stud-OT-AS [is (am, are) to be stud-IED]
stud-OT-IS [was (were) to be stud-IED]
stud-OT-OS [will (shall) (be to) be stud-IED]
(2) 28 adjektivoj
stud-A/stud-A-J/stud-A-N/stud-A-J-N [study]
stud-ANT-A/stud-ANT-A-J/stud-ANT-A-N/stud-ANT-A-J-N [study-ING]
stud-INT-A/stud-INT-A-J/stud-INT-A-N/stud-INT-A-J-N [having stud-IED]
stud-ONT-A/stud-ONT-A-J/stud-ONT-A-N/stud-ONT-A-J-N [to study]
stud-AT-A/stud-AT-A-J/stud-AT-A-N/stud-AT-A-J-N [(being) stud-IED]
stud-IT-A/stud-IT-A-J/stud-IT-A-N/stud-IT-A-J-N [(having been) stud-IED]
stud-OT-A/stud-OT-A-J/stud-OT-A-N/stud-OT-A-J-N [to be stud-IED]
APENDICO 2
Algoritmo por Fortranĉi Finaĵojn de Esperanto
(1) Se la finaĵ estas -O, do konkludu "Substantivon / Nominativon / Singularon", iru al (2); alie, iru al (11).
(2) Konsultu la korpo-vortaron post fortranĉo de la finaĵo. Se sukcesas en konsulto al la vortaro, konkludu "Nulmodon/Aktivon", finiĝu la prilaborado; alie, iru al (3).
(3) Se la finaĵo estas -ANT, do konkludu "Participon / Aktivon / Kontinuon", iru al (9); alie, iru al (4).
(4) Se la finaĵo estas -INT, do konkludu "Participon / Aktivon / Perfekton", iru al (9); alie, iru al (5).
(5) Se la finaĵo estas -ONT, do konkludu "Participon / Aktivon / Malperfekton", iru al (9); alie, iru al (6).
(6) Se la finaĵo estas -AT, do konkludu "Participon / Pasivon / Kontinuon", iru al (9); alie, iru al (7).
(7) Se la finaĵo estas -IT, do konkludu "Participon / Pasivon / Perfekton", iru al (9); alie, iru al (8).
(8) Se la finaĵo estas -OT, do konkludu "Participon / Pasivon / Malperfekton", iru al (9); alie, iru al (10).
(9) Konsultu la korpo-vortaron post fortranĉo de la finaĵo. Se suksecas en konsulto al la vortaro, finiĝu la prilaborado; alie iru al (10)
(10) konkludu "Novavorton", finiĝu la prilaborado.
(11) Se la finaĵo estas -A, do konkludu "Adjektivon / Nominativon / Singularon", iru al (2); alie, iru al (12).
(12) Se la finaĵo estas -E, do konkludu "Adverbon / Nominativon", iru al (2); alie, iru al (13).
(13) Se la finaĵo estas -OJ, do konkludu "Substantivon / Nominativon / Pluralon", iru al (2); alie, iru al (14).
(14) Se la finaĵo estas -AJ, do konkludu "Adjektivon / Nominativon / Pluralon", iru al (2); alie, iru al (15).
(15) Se la finaĵo estas -ON, do konkludu "Substantivon / Akuzativon / Singularon", iru al (2); alie, iru al (16).
(16) Se la finaĵo estas -AN, do konkludu "Adjektivon / Akuzativon / Singularon", iru al (2); alie, iru al (17).
(17) Se la finaĵo estas -EN, do konkludu "Adverbon / Akuzativon", iru al (2); alie, iru al (18).
(18) Se la finaĵo estas -OJN, do konkludu "Substantivon / Akuzativon / Pluralon", iru al (2); alie, iru al (19).
(19) Se la finaĵo estas -AJN, do konkludu "Adjektivon / Akuzativon / Pluralon", iru al (2); alie, iru al (20).
(20) Se la finaĵo estas -AS, do konkludu "Verbon / Predikaton / Prezencon", iru al (2); alie, iru al (21).
(21) Se la finaĵo estas -IS, do konkludu "Verbon / Predikaton / Preteriton", iru al (2); alie, iru al (22).
(22) Se la finaĵo estas -OS, do konkludu "Verbon / Predikaton / Futuron", iru al (2); alie, iru al (23).
(23) Se la finaĵo estas -US, do konkludu "Verbon / Predikaton / Kondicionalon", iru al (2); alie, iru al (24).
(24) Se la finaĵo estas -U, do konkludu "Verbon / Predikaton / Volitivon", iru al (2); alie, iru al (25).
(25) Se la finaĵo estas -I, do konkludu "Verbon / Infinitivon", iru al (2); alie, iru al (26).
(26) La vorto ne havas finaĵon. Konsultu la vortaron pri funkciaj vortoj. Se sukcesas, konkludu "Funkcivorton"; alie, konkludu "Novavorton / Substantivon / Propranomon". Finiĝu la prilaborado.
[KLARIGO] La supra algoritmo jam proviĝas tre efika ĉe maŝino.
APENDICO 3
La Kontrasta Tabelo por Kaza Sistemo


















【相关】
灵感有如神授,巧夺岂止天工
世界语论文钩沉:世界语的语言学特点(3/3)
世界语论文钩沉:世界语的语言学特点(2/3)
世界语论文钩沉:世界语的语言学特点(1/3)
《学外语的紧箍咒,兼谈世界语的前途》
《立委:一小时学会世界语语法》
《朝华午拾:我的世界语国》
《朝华午拾 – 世界语之恋》
《朝华午拾:朋友遍天下》
《朝华午拾 – 欧洲之行》
《朝华午拾:与白衣天使擦肩而过》
硕士论文: 世界语到汉语和英语的自动翻译试验
立委硕士论文全文(世界语版)
《朝华午拾:shijie-师弟轶事(3)——疯狂世界语 》
灵感有如神授,巧夺岂止天工
立委世界语文章 (1987): 《中国报道:通天塔必将建成》
立委世界语论文(1986): 《国际语到汉语和英语的自动翻译》
立委(1988)《世界科技:世界语到汉语和英语的自动翻译试验》
DLT项目背景介绍
《李白詹120:乔老爷老矣》
【关于机器翻译】
【语义计算:李白对话录系列】
【置顶:立委NLP博文一览】
《朝华午拾》总目录