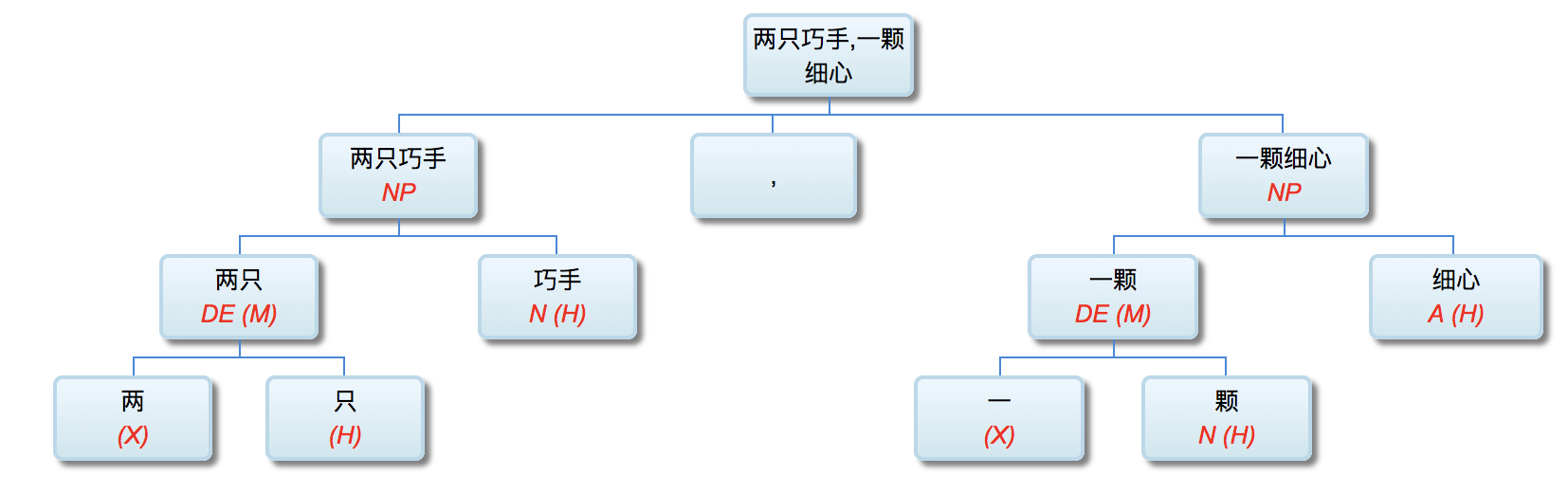
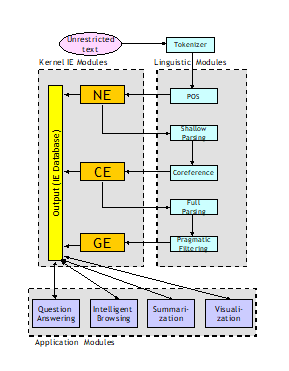
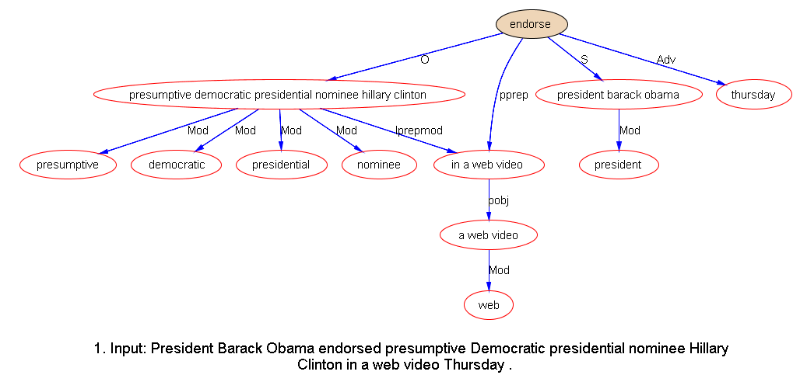
Me:
NLP:人工智能的诗与远方
好像是白老师的最新指示。刚在微博看到。金句连珠,隆重推荐。行文如流水,简洁 干净 深刻。
“无论使用什么样的句法分析技术,有一点必须明确,就是句法本身是不自足的。细粒度描述的句法不具备鲁棒性和可行性,而粗粒度描述的句法往往必然带有伪歧义。”
“粗粒度描述的句法往往必然带有伪歧义”没疑问,为什么“细粒度描述的句法不具备鲁棒性和可行性”?是的,细粒度描述的句法不具备完备性,但鲁棒性与细不细的关系何在呢,可行性就更可以商榷了。
细颗粒的极致就是“词专家”,没有看到不鲁棒或不可行的问题,就是琐碎,劳动量大,概括性弱。
“句法本身是不自足的”,是反乔姆斯基的论点,反得好。但与鲁棒和可行不是一类概念。白老师自己给的简要定义是:鲁棒性(对灵活语序和修辞性失配的适应性)。
鲁棒与规则层级体系(hierarchy)关系大,与规则本身的颗粒度关系小。语序说到底是(显性)形式条件,语义适配(语义相谐)也是(隐性)形式条件, 所有的形式条件都有弹性(优选语义),可松可紧,这就是层级安排因而鲁棒的根本原因:紧的条件精确但不鲁棒,松的条件鲁棒但不精确,配合得好,就可以又鲁棒又精确,或者至少维持在一个兼顾鲁棒和精准的准入门槛之上。
白老师的《NLP:人工智能的诗与远方》值得咀嚼。标题好文科、浪漫。但这是一篇严肃的高阶科普。一如既往,白老师的文字,举重若轻,高屋建瓴。
wang:
在我看来,李老师最后这一段描述,和白老师对句法所描述的,是一致的,并不矛盾。只是选的视角不一样罢了。完全同意李老师的弹性适应,这一点我也是这样做到
白:
1、琐碎到不合算就是不可行;2、一头扎进细粒度,一定会失去对灵活语序和修辞性失配的宏观把握;3、分层就是在粒度方面保持弹性的good approach之一。顺便说一句,这个是节选版本,原稿比这干货多得多。
李:
原稿在哪?
wang:
期待白老师,合适时机放出
李:
1. 琐碎到不合算其实很少存在:
如果是狭窄domain(譬如天气预报),琐碎是可行的,也就谈不上合算不合算。
白:
狭窄 domain甚至不需要deep parsing
李:
如果是 open domain,几乎没有琐碎单打一的。总是在一个大的框架下(better,层级体系的设计中),利用琐碎(细颗粒度)做增量修补。
白:
这就是分层了
李:
换句话说,琐碎不可行,最多是一个吃饱了不饿的真理。这也就回答了第2个问题:一头扎进去,单打一,做系统没人这么做。
白:
不是人人如伟哥般真理在握的。从外面搬来开源系统就想比划的不知道有多少,伟哥这是高处不胜寒。
李:
“3、分层就是在粒度方面保持弹性的good approach之一”, I cannot agree more
期待看原稿:这篇稿子太过简洁,很多地方真地是点到即止。
好,再精读一遍,摘录一些当面请教白老师,摘录可classify 为:1. 可圈可点;2. 可商榷;3. 没看懂
“鉴于自然语言丰富地表现了人类的认知、情感和意志,潜在地使用了大量常识和大数据,自身在算法和模型上也多采用各种启发式线索,目前一般均把自然语言处理作为人工智能的一个分支”
“算法和模型上也多采用各种启发式线索”:heuristics?
白:
是
李:
这个总结直感上很精到:无论什么模型,规则也好,统计也好,联结也好,其实都是反映 heuristics,英语没问题,汉语读者大概搞不清“启发式线索”的不在少数,这个术语以前论过,从来就没有好的译法。
白:
启发式这个翻译,在中国大陆的大学里正式的人工智能课程里应该是比较通行了的。
李:
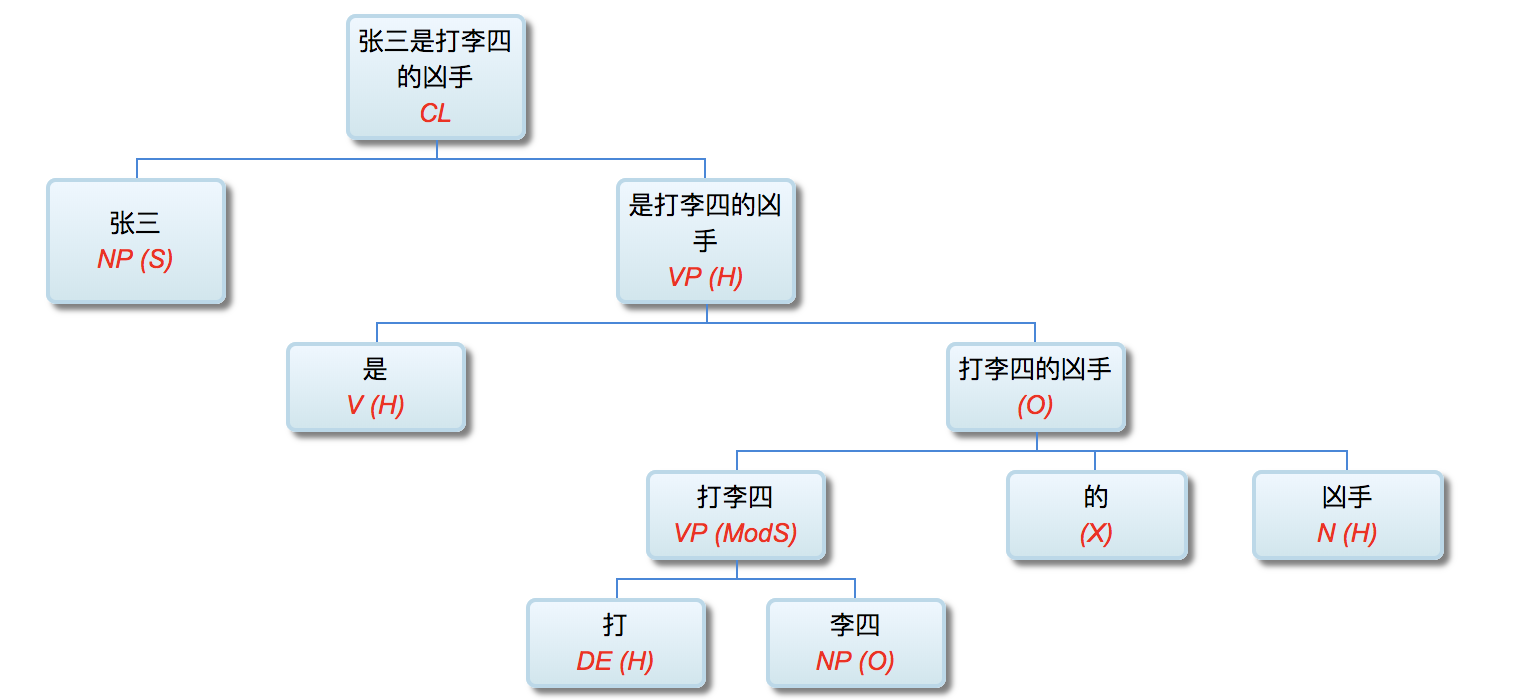
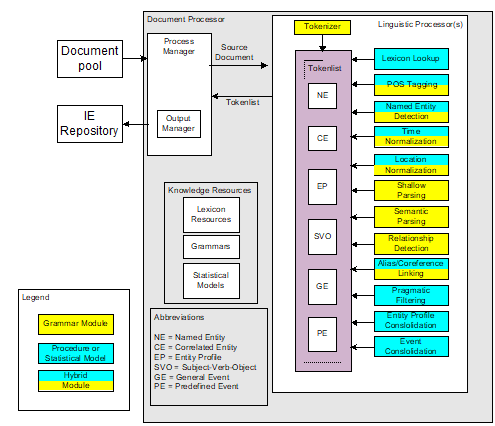
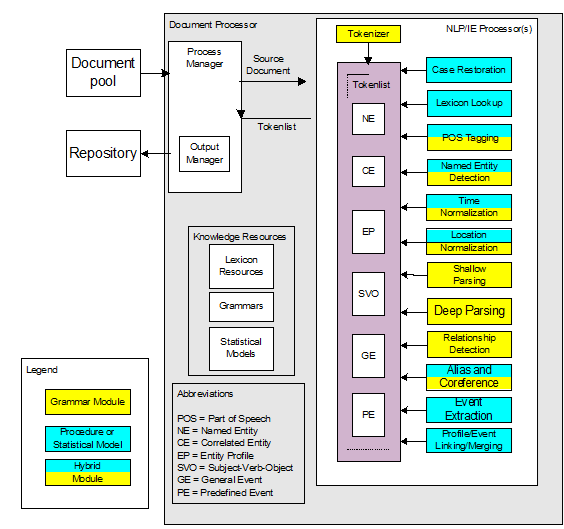
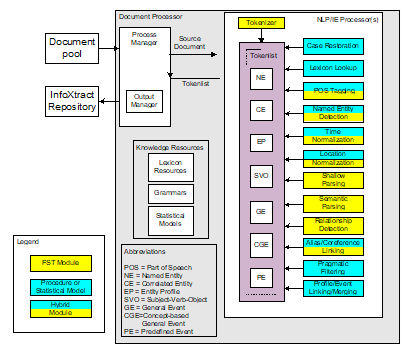
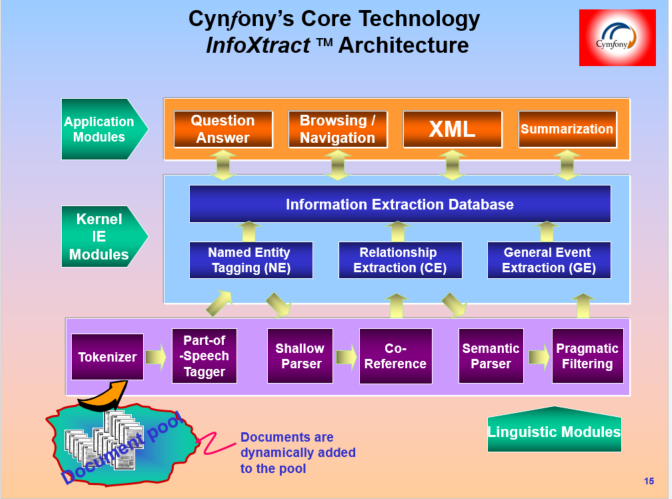
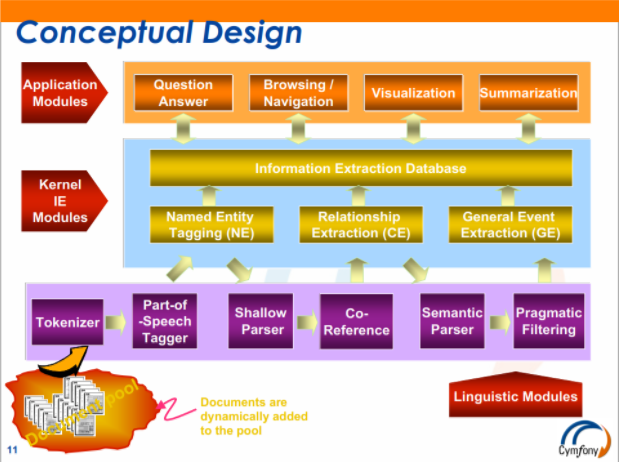
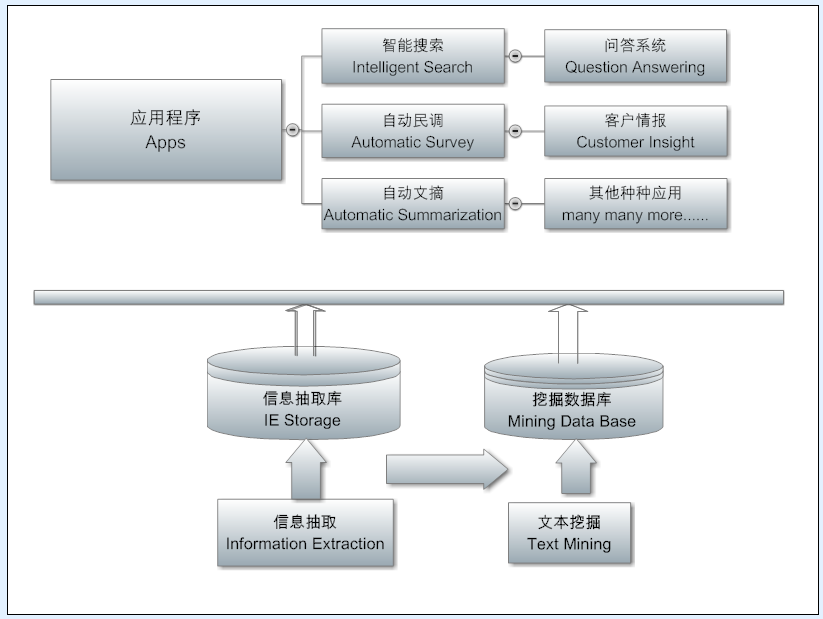
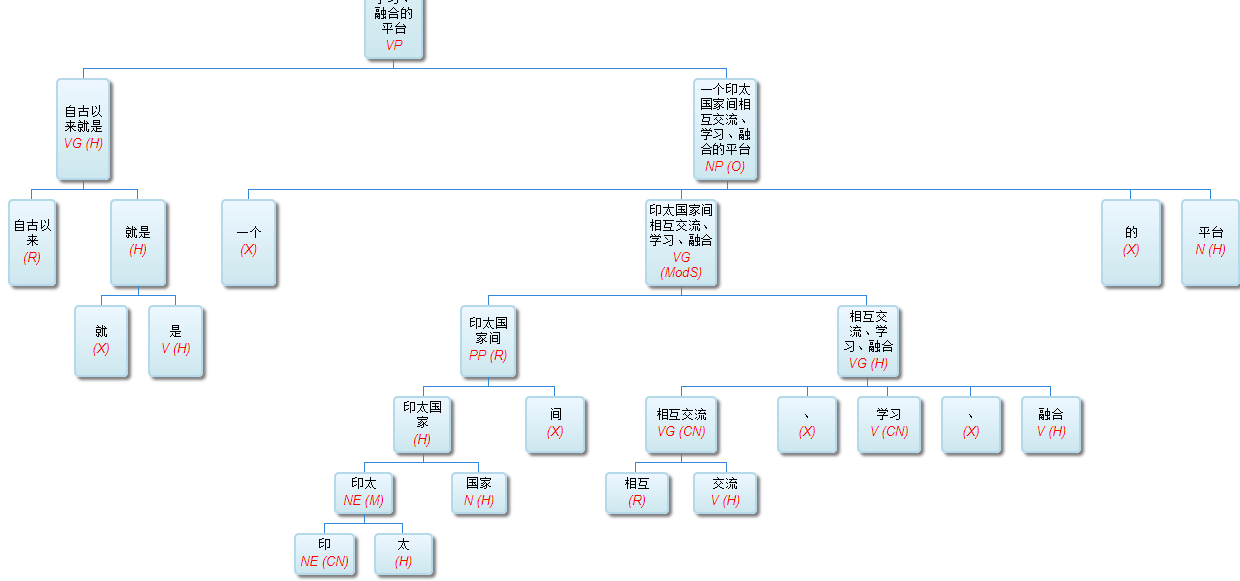
第一张图,机器翻译和人机接口作为NLP的现实代表,很合适。但什么叫“纯人机对话”?
白:
就是没有任何grounding的人机对话。
李:
哦,以前是玩具 bot,现在是聊天机器人,将来可以落地(grounding)到老人陪护或心理疏导。
落地艰难:非良定义?
什么样叫非良定义?点解?
不能完备定义,只能例举,或就事论事?
白:
说不清标准,说得清答案。ill-defined
知道输入对应什么输出,但不知道依据什么得到输出。
李:
我其实想问:这里想说明什么?是说NLP落地很难,主要是因为目标不明确吗?
白:
非良定义和落地艰难是并列关系不是因果关系。
李:
这句赞 赞:对于各种自然语言来说,大体上占到2型的很少但很不规则的一部分,但部分现象呈现上下文相关性,会在局部对2型有所突破。这就是笔者所说的“毛毛虫”现象。
其实2以降“很少”到几乎可以忽略(或绕道而行)。“突破”一般不必是着力点。
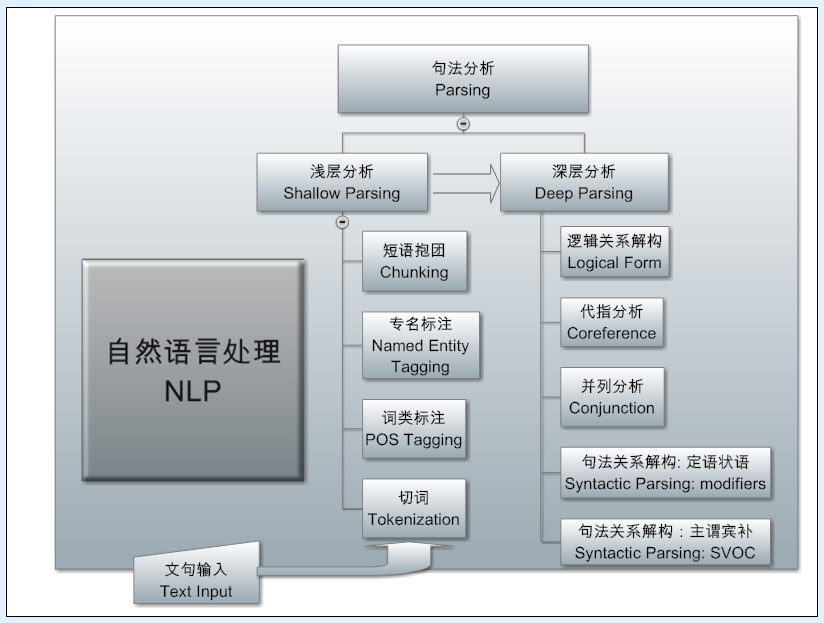
0型语言是翻译为“递归语言”吗?文法上,0 型是短语结构文法。这个其实也很 confusing,因为层级体系是蕴含关系的:3 也属于2,1和0,但窄义或另义的 PSG或短语结构图,是相对于 DG 而言,PS 是 constituency 的同义词,讲的是“兔子吃窝边草”的路数,而不是 DG 的兔子不必吃窝边草的逻辑跳跃的路数。
白:
PSG的原始定义就是0型。窝边草是对的,但窝边草怎么来的有玄机。把一堆窝边草重写为另一堆草,这就是0型。
李:
从语言类型学角度,一般而言,PSG 适用语序相对固定的语言,英语、汉语等;DG 适用自由语序的语言(如 俄语)。0 型 从复杂度角度,不是没有章法么?爱怎么整都行。因此,最有章法的正则自然也属于0型,有限制的一定落在没有限制之内。
白:
只是对重写有不同的限制,依据都是窝边草
李:
但学习这个层级体系的不少人,可能本能地把层与层隔绝在互不包含的院墙里(也许只是文科生容易这样陷入?)
白:
这篇文章不是讲给没学过类型分层体系的人的。计算机专业学过形式语言与自动机或编译原理的都应该不陌生。
李:
不懂:“实际上,鉴于欧氏空间具有良好和丰富的数学工具可用,语言/文本的向量化努力是跨越统计和联结两大阵营的”。
不过,这不是行文的问题,应该是受体的知识缺陷,可能讲解了还是不懂。
白:
欧氏空间这段,详解被删了。统计的典型是LSI,联结的典型是词嵌入。
李:
word embedding 最近体验了一点,是有点神奇。
可圈可点:这段时期之所以NLP既远离“人工智能”的招牌,也远离“计算语言学”招牌,是因为人工智能招牌在当时并无正面贡献,而语言学家在经验主义范式下不得施展甚至每每成为负担。
这是对历史的精确描述。AI 曾经像个丑小鸭(或瘟神),人人避之不及。计算语言学名不副实或有名无实,久矣。
白:
原来这杆旗下的人还要继续混日子啊
李:
后面一段是革命乐观主义和浪漫主义,蛮鼓舞人心的:
深度学习技术以摧枯拉朽之势横扫语音、图像识别和浅层自然语言处理各类任务,知识图谱技术为语义知识处理走向各行各业做好技术栈和工具箱的铺垫,人工智能招牌强势的王者归来已经在所难免,自然语言处理技术也自然地成为了这王者头上的王冠。这是因为,语音和图像识别大局已定。自然语言处理已经成为一种应用赋能技术,随着实体知识库的构建、知识抽取和自动写作在特定领域的实用化和对话机器人从对接语料到对接知识图谱的换代,正通过新一代人工智能创新创业团队,全面渗透到人工智能应用的各个角落。
其中强调两个支柱:(i)深度学习的算法;(ii)知识图谱的表示。
其实有点格格不入:前者是经验主义的极致,后者是理性主义的表现;前者显得高大上,后者显得平庸但实在。
白:
所以波粒二象性啊
李:
by the way, “对话机器人从对接语料到对接知识图谱的换代”这是在下目前的重点课题或挑战。
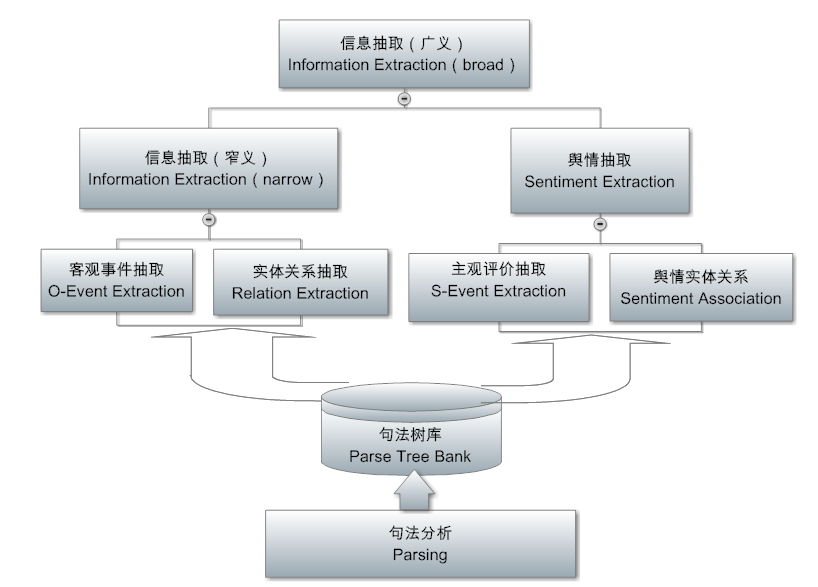
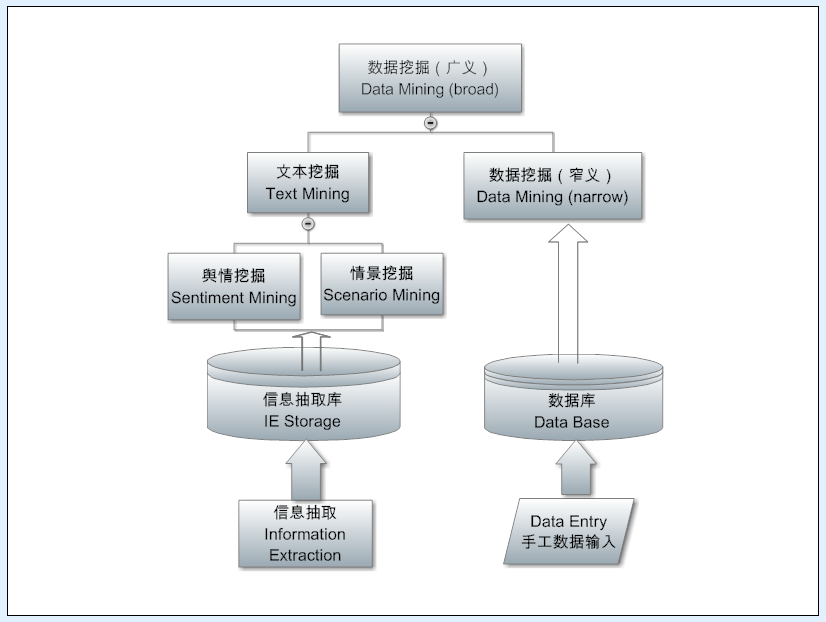
知识图谱的概念被谷歌炒热以后,其实稍微拔高一点看,没有多少“新意”。不过就是“结构化”的具象而已,结构的图示(visualization)化、大众化而已。图谱早就植根在乔姆斯基符号体系以及其他种种语义流派的传统里,通过MUC的信息抽取的语用落地,导致谷歌利用搜索把它活生生展示给亿万受众,激发了大家的想象。
白:
而且只是一小部分。被删掉的部分讲了哪些地方是“一小部分”不能涵盖的。
李:
对的,被炒热的知识图谱就是结构化中的一小部分。也是最简单的一部分。知识图谱是很平民化的东西,讲到底就是一个烧钱烧资源的知识工程。典型代表就是一个多少亿的三元组,还不如 tree bank,从数据结构看。更不如各种规则 formalism,最简单的产生式规则也有 if then。
白:
挑战性的东西不少,看不到就没办法了。不能光看表达力,还要看技术栈、工具箱。后者丰富前者贫乏,仍可以做大事情;前者丰富后者贫乏,只能做玩具。
李:
是 是:“后者丰富前者贫乏,仍可以做大事情;前者丰富后者贫乏,只能做玩具。”
自然语言处理从浅层到深层面临范式转换,还处在对接情感计算与常识计算的战略性要地的关键位置。谁能拔得头筹,谁就能在当下的人工智能“军备竞赛”中处于有利地位。
深层解析需要常识计算我们在本群讨论中见过无数例证了。需要情感计算也见过一些。
基于统计的范式繁荣了近二十年,终于在2010年前后被同为“经验主义”学派的基于联结的范式所全面取代。这是深度学习算法显现的巨大威力,也是数据和算力积累到临界点的一次综合性的爆发。
据说,有一代人有失落感,他们当年横扫千军如卷席,各种算法花样翻新,从朴素贝叶斯,HMM,CRF,MaxEnt,。。。各种参数设计身怀绝技,突然九九归一,以前的绝技似乎不再闪光。这种失落不亚于语言学家面对统计学家长驱直入而带来的边缘化的失落感。历史循环还是报应?真是 30 年河东,20 年河西。
白:
没那么不堪吧,有啥用啥,干嘛一定站队。
李:
目前,基于联结的范式风头正盛,但“深度”自然语言处理的需求压力之下,“理性主义”学派以某种方式再度回归,实现“波粒二象性”的有机结合,也是可期待的。
这个有机结合,NLP老司机呼吁较多,新一代的联结主义者似乎无暇他顾。当然,无暇不仅仅是“攻城掠地忙”(毛委员打土豪那阵,农民革命就曾“分田分地忙”),也因为这种“有机”结合,真心不容易。
看今后10年吧。
词法分析领域绝非基于词典的分词这么简单,这个领域还有大量有待攻克的难关,有些难题已经与句法分析搅在一起,非统筹考虑是无法单独推进的
这个观察到位,但真认识到的人不多。特别是汉语,在进入句子结构之前,基本分词之后,还有一个广阔的地带。其中不乏难题。有些是致命的。领域化在这个方面也有很大的挑战。譬如,看电商的标题,那种 sub language 简直就不是汉语。
白:
这一节删掉甚多。提到了词性标注、命名实体识别、形态还原、构词法。形态还原中特别提到了离合词。
李:
的确删太多了。
还有一个可以探讨的事儿:觉得 DG 和 CFG不好相提并论。DG 本身不是算法,只是表达法。
白:
都不是算法
李:
CFG 比较直接地蕴含了算法,譬如 chart parsing,DG 不蕴含任何方法,也许隐隐蕴含了自由语序的匹配方式。从表达法(representations)角度,DG与PSG并列,是两套表达体系。声称 DG parsing 的人,其实用的 formalism 与做 PSG parsing 的人无异,逃不过乔姆斯基的佛掌。anyway,只是感觉大家在讨论中这方面有时候似乎容易概念混淆。从表达法来看,也没有单单的 CFG,CFG 属于 PSG,所以表达法只有 PSG 与 DG 之别。
Nick:
白老师这篇要认真学习
李:
@Nick 咱有样学样啊。。。
最后要说明,即使语言的结构表示模型是基于理性主义(符号或规则)路线的,但语言解析过程本身仍可以采用基于统计的或基于联结的方法。比如PCFG就是基于规则的结构表示与基于统计的过程控制的有机结合。
PCFG 是有机结合的先行,但不算成功,文章似乎不少,但没见多少实效。今后几年看白老师的了。
词典化(免规则)、单子性(免复杂层次)、局域化(免跨成分关联)和鲁棒性(对灵活语序和修辞性失配的适应性),是自然语言句法分析技术未来的发展趋势。
“局域化(免跨成分关联)”不大明白,其他几方面可说是有相当共识,所见略同。
“知识图谱的技术栈里算力充足工具齐全”:这个需要检阅一番。
白:
PCFG不见实效的关键原因,一是CFG先天不足,二是标注成本过高。如果不能变为非监督或弱监督,必死。
李:
对,P 要到位就要超大数据,否则怎么个概率法?可是结构标注根本就不是人做的的活儿(PennTree 这么多年成长也很有限,增长部分大概是语言学研究生的苦力)。
quote 此外,人类的语义解析过程充满了所谓“脑补”。可见,借助知识图谱,智能化地完成这类需要“脑补”的语义理解过程,是语义分析技术走向实用和深化的必然要求。
这段话群里的人 可能会理解,但对于大众,无异天书,必须要有相当的 illustrations,脑补的是常识,专业知识?是常识中的默认选项,etc. etc.
白:
这里也删去几百字。
李:
知识图谱的好处是为结构化张目。很久以来,没人尿结构化这壶,一草包词 多厉害啊,鲁棒到极致。用于搜索,不仅鲁棒,还特擅长长尾,tf-idf,越长尾 关键词越灵 要什么结构劳什子。连词序都可以舍弃,何况结构?
到了 ngram,词序带入考量了,算是对语言结构的一个看上去拙劣粗鄙 但实践中颇有效的模拟近似,因此也不用着急蹚结构这个浑水了,来个 bigram or trigram model,还有个 viterbi 的高效算法。
现在好了,趁着图谱热,结构化的旗帜高高飘扬。终于可以理直气壮、名正言顺地大谈结构化乃是自然语言理解的正道,乃是人类智能的基石。为这一点,要感谢谷歌。就好比我们应该感谢苹果,通过 Siri 把自然语言接口送到千家万户,教育培养了用户。
下面这些都是字字真理:
自然语言处理能力以平台化方式提供服务,是广大自然语言处理技术提供者求之不得的事情,但目前还受到一些因素的限制。现实中,更多的自然语言处理技术是融合于一个更大的行业应用场景中,作为其中一项核心技术来发挥自己的作用的。
NLP平台化迄今没有大规模成功案例。趋势上是必由之路,但今后何时真地可以平台化广泛赋能,真地是一个未知数,我们从业人员都在努力 。。。。
除了法律、医疗、教育等先行行业之外,金融证券行业对自然语言处理技术业有很迫切的落地需求,但往往必须结合专业领域知识和私有数据才能构建有价值的场景。
就是。
熬了一夜,精读了白老师最高指示。
两个等待:一是等着看原文(非删节版);二是等着看白老师的系统。
宋:
读白硕的文章,的确高屋建瓴,分析得透彻。我觉得还应该补充一点(也许是简本删掉了的),就是语言学研究的必要性。具体来说,就是语素、词、词组、小句、句子(小句复合体)的定义,以及相关属性(如词性)及关系的定义。对于英语等西方语言,似乎一切都很清楚,不言自明,无需当回事儿去研究,但是论及到汉语一切就都糊涂了。不能适用于汉语的语言学概念的归纳,都是偏置的。基本对象及其属性、关系的概念不清楚,相应的模型和计算就不可能完全适用。
白老师的全本中会讲离合词,这个概念就是其他多数语言中没有的。但是,如何从人类语言的高度看待离合词,期待看白老师的全本。
白:
@宋柔 我感觉语言学并没闲着,只是节奏慢了点,在NLP这边是没人理睬,而不是挑出很多毛病。挑拣的才是买主。挑拣才能让语言学加速。
宋:
语言学方面的问题是没有照着机械化的可操作的要求去做研究。
白:
@宋柔 光算法层面的机械化,语言学家或可手工模仿;扯进大数据,连手工模仿都不可能了。
宋:
基本概念的定义,比如词的定义,应当适用于大数据中的所有样本,语言学应当做这件事。
白:
只要承认运用中可拆解,词的定义不难。@宋柔
宋:
不仅是运用中拆解的问题,还有一个粘着性的问题。
白:
粘着性倒是真的可以大数据说话
宋:
你说的有道理。语言学的基本概念的定义。真的不能是静态的,需要在大数据的环境中定义。基本原则是这样。定义的结果,哪个是词哪个不是,要看参照哪一堆文本。
白:
“以国防部长的身份”当中的“以”,可以是介词,也可以是名词的拆解物(“以色列”的简称)。这个拆解物当名词用。
宋:
即使数据集定了,也还有模糊性、两可性。那又是另一个问题,即符号的歧义问题。
白:
承认可拆解的另一面就是承认微结构。宋老师说的粘着性,可以从词根与词缀结合的微结构角度来考虑。
宋:
微结构的节点应当有波粒二象性,既是词,又不是词。
白:
拆解出来当词用,封在里面就是词素。
宋:
微结构可能会有相当大的跨度:这个澡啊,从来没洗得这样舒服过。语言学理论必须把这些现象包容进去。
白:
必须的
宋:
这样的澡我从小到大,再到老,还没洗过。
李:
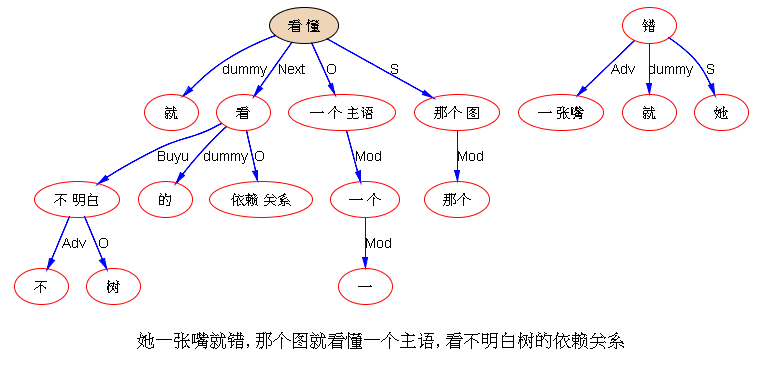
离合词是可以解决到很完美的不再是问题的问题,关键就在词典与句法的接口上。大规模验证过的。
【相关】
白硕:知识图谱,就是场景的骨架和灵魂
【语义计算:李白对话录系列】
《朝华午拾》总目录
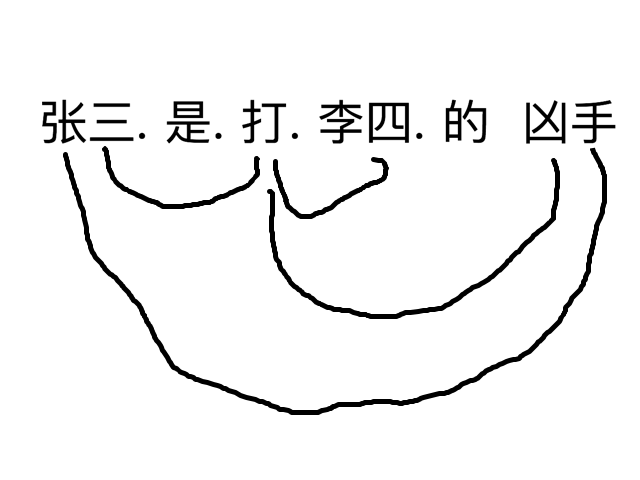 【SV: 张三,打】
【SV: 张三,打】