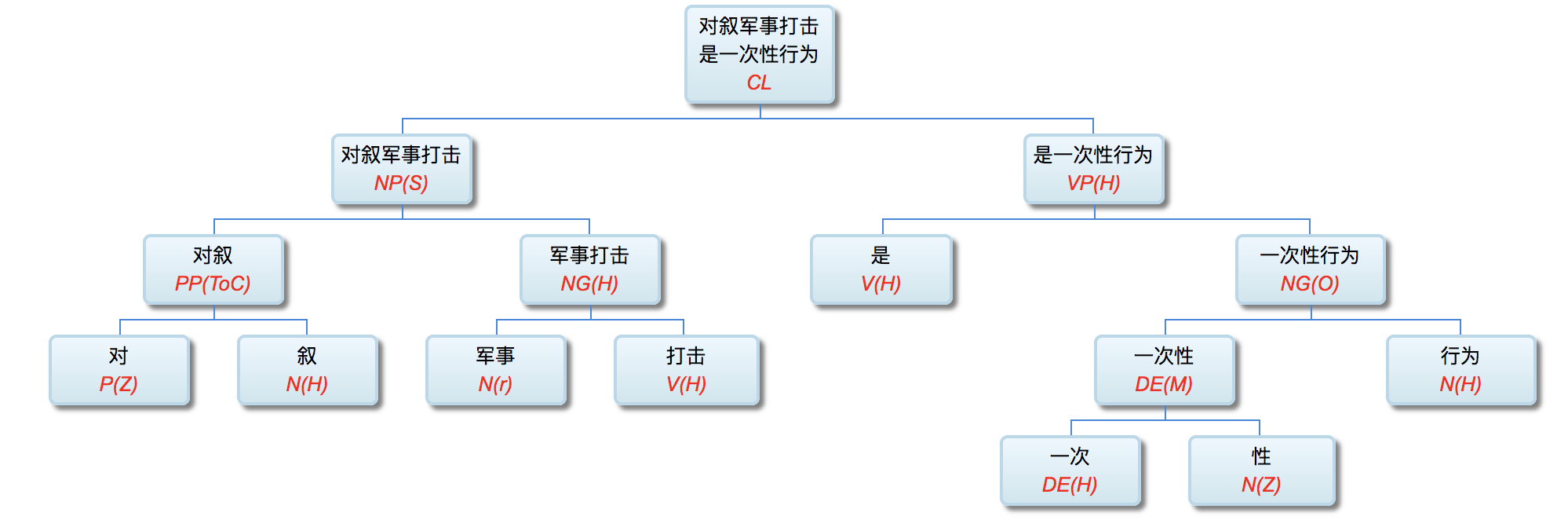
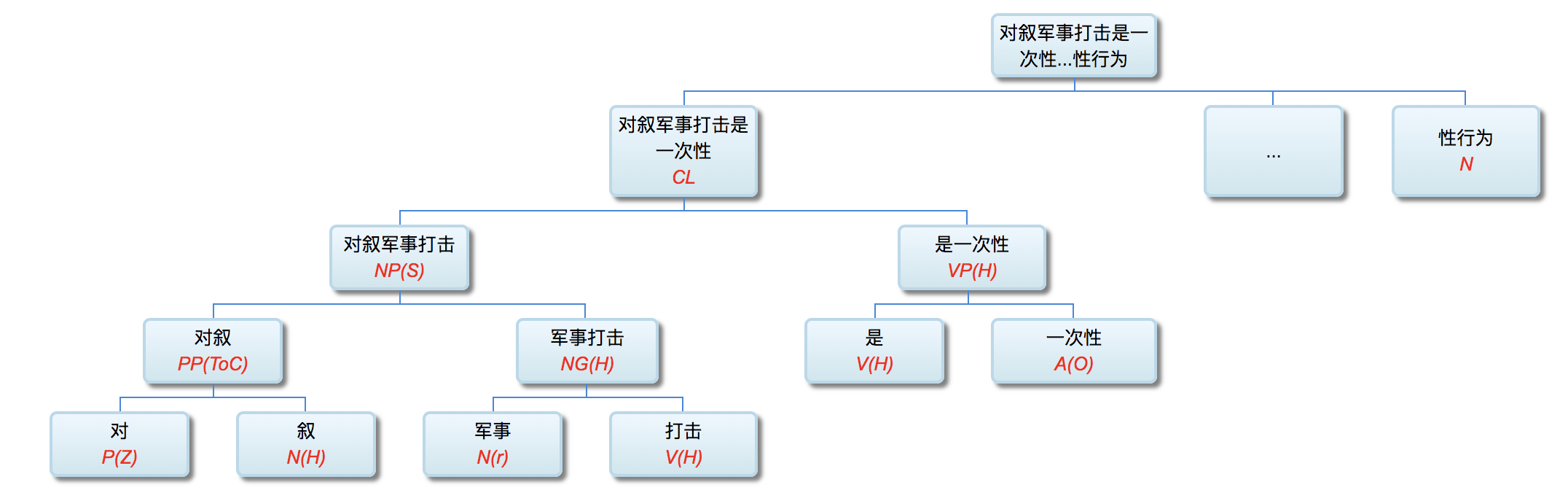
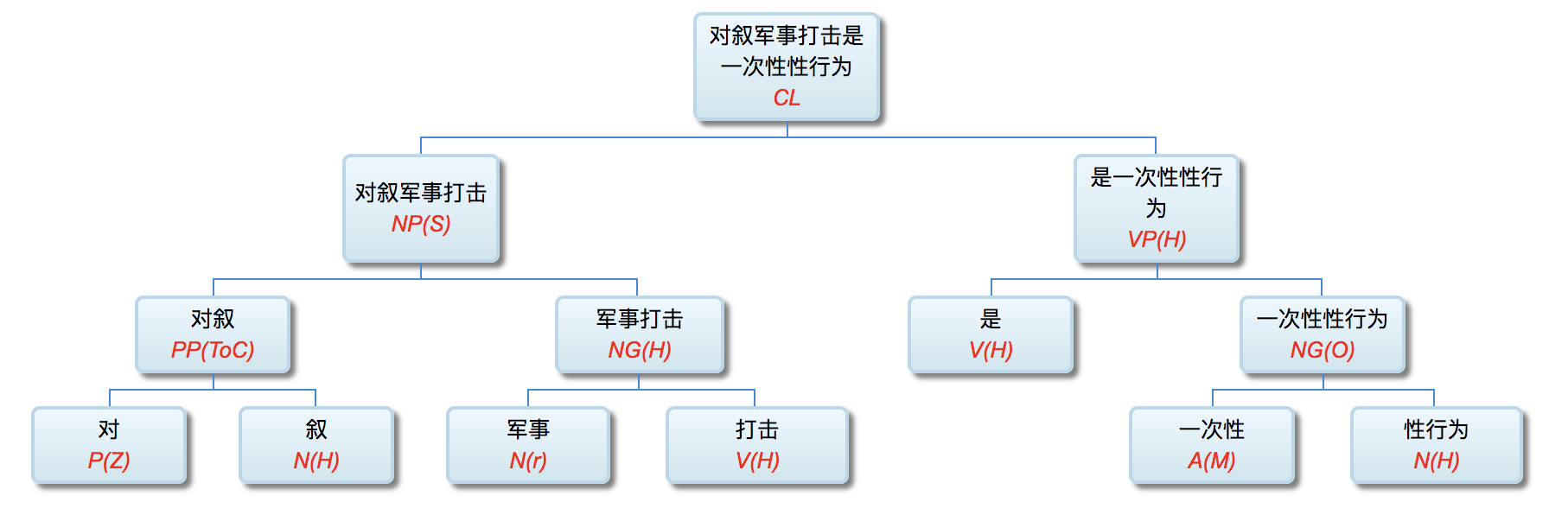
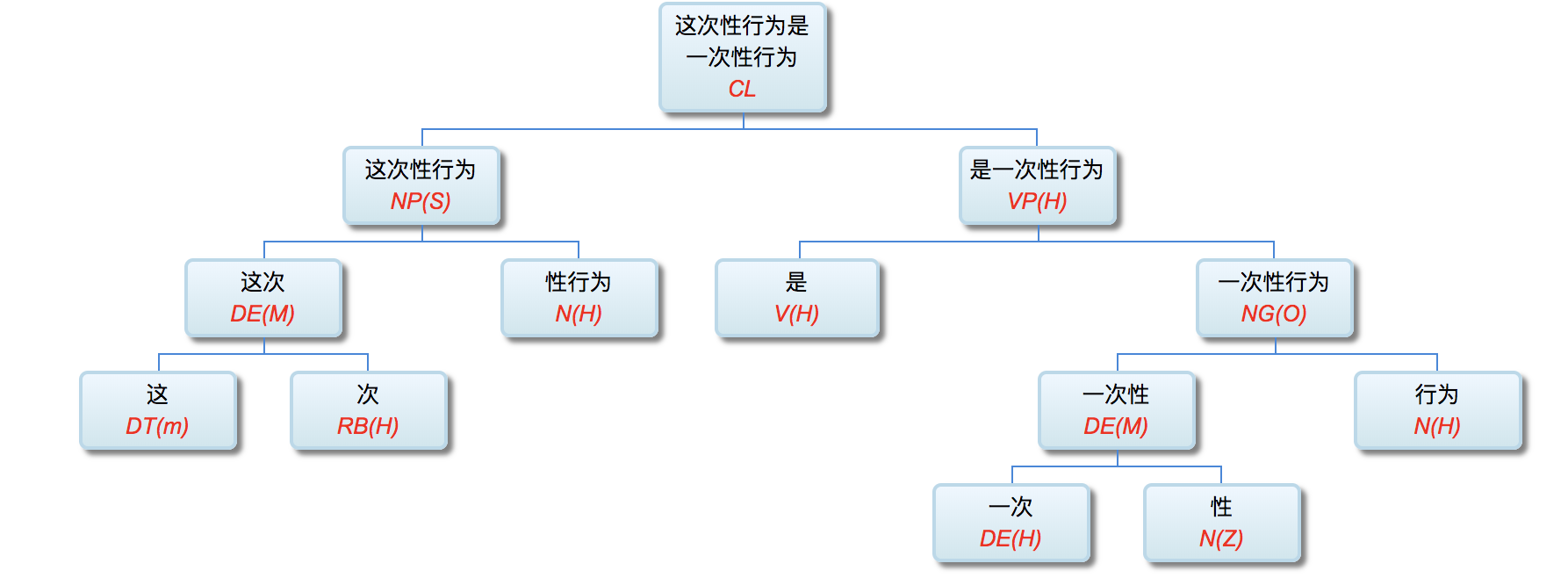
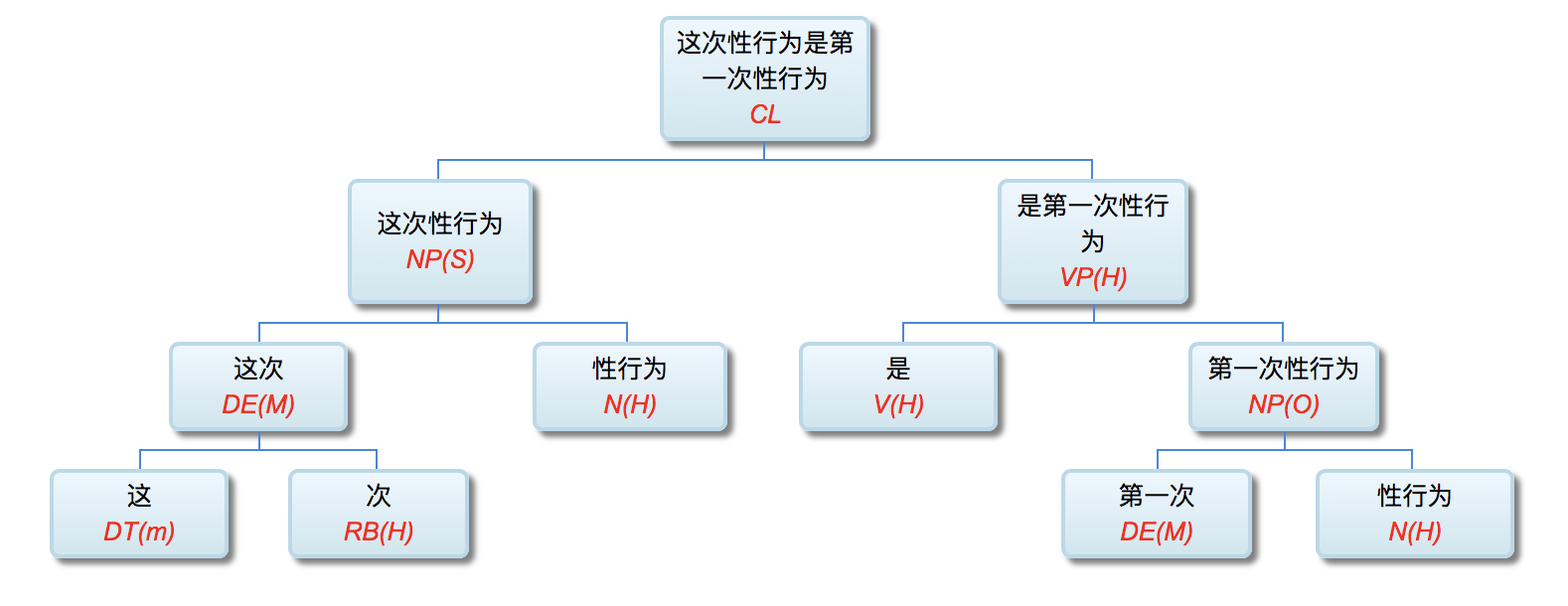
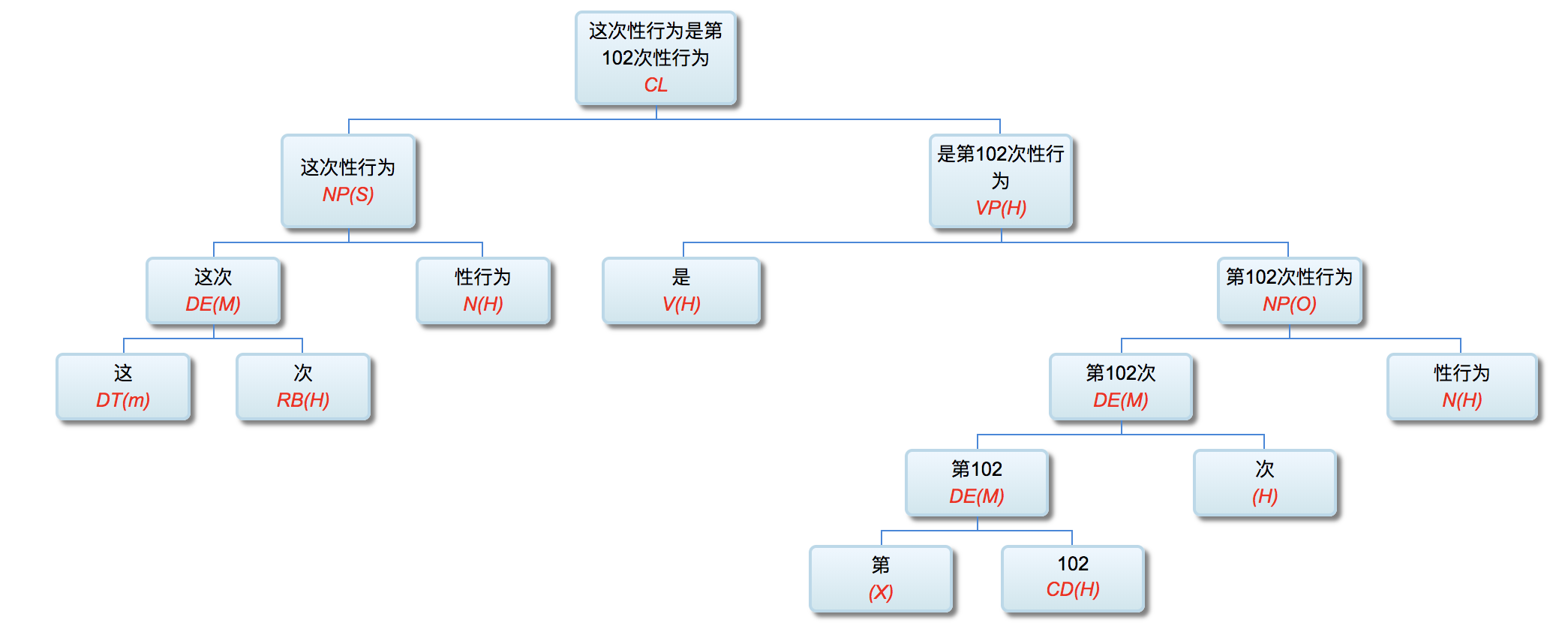
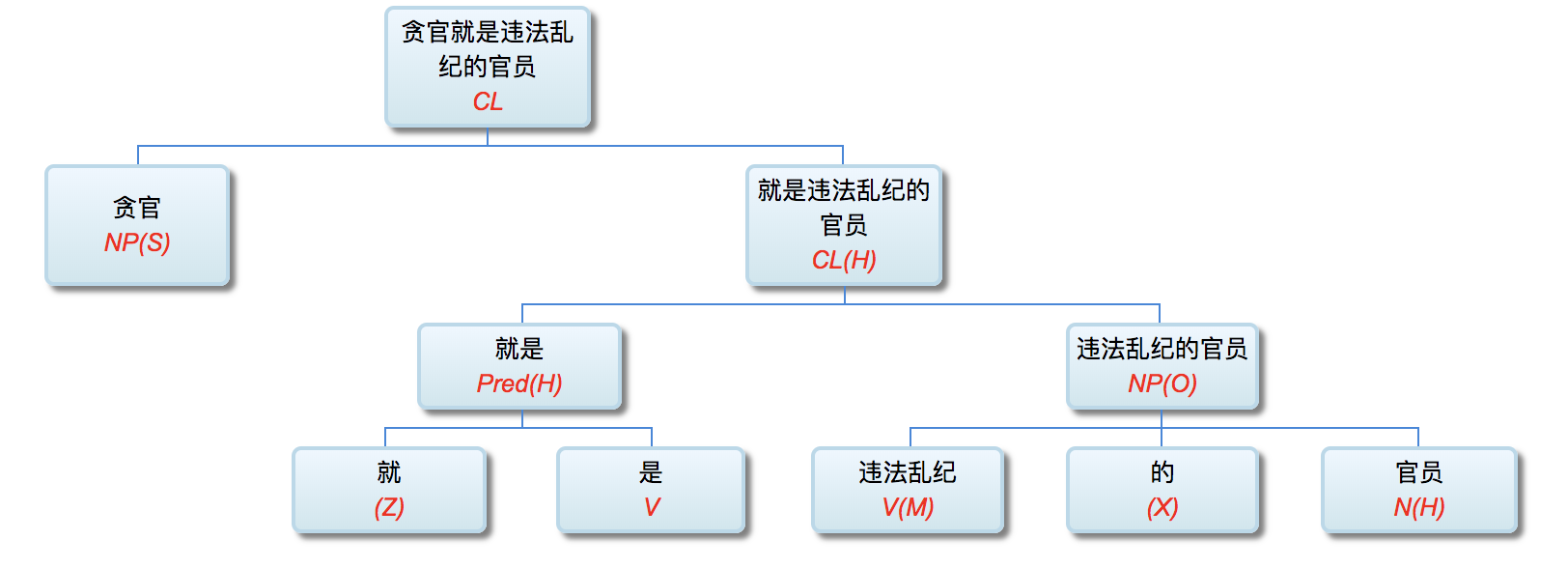
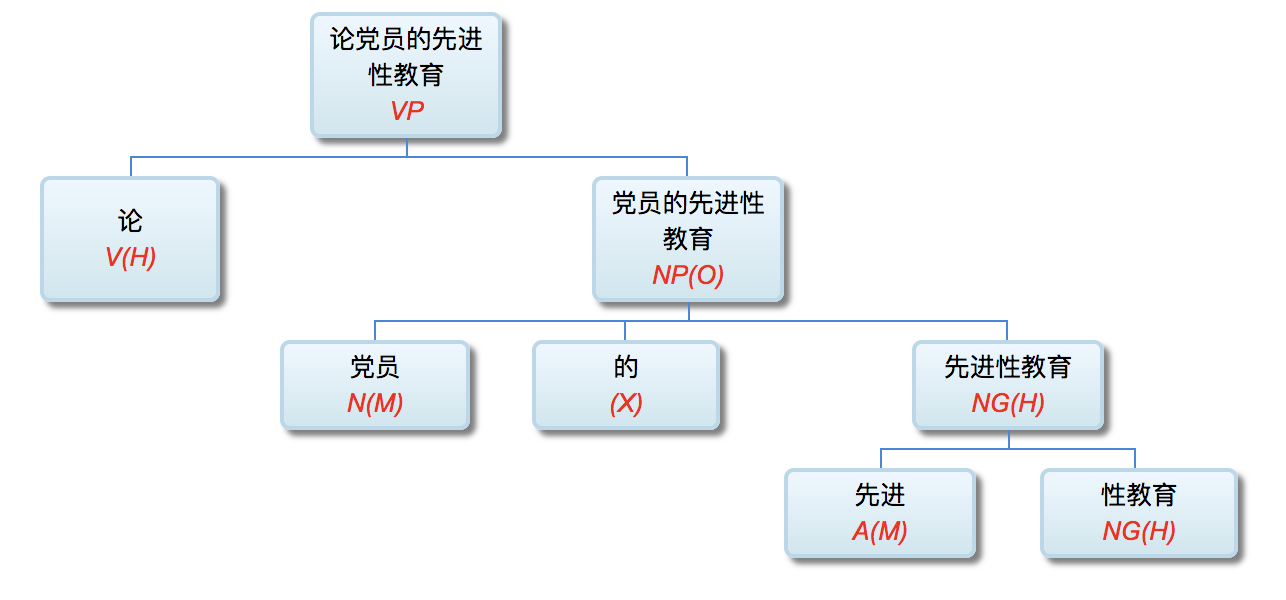
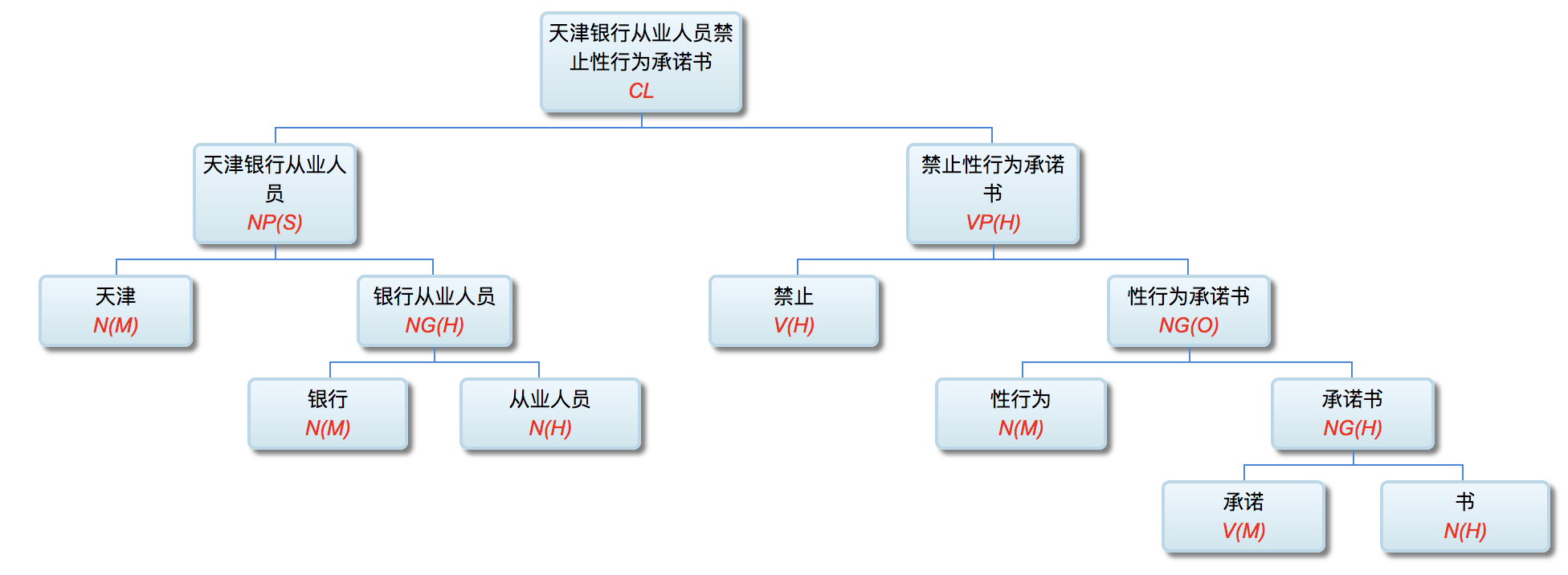
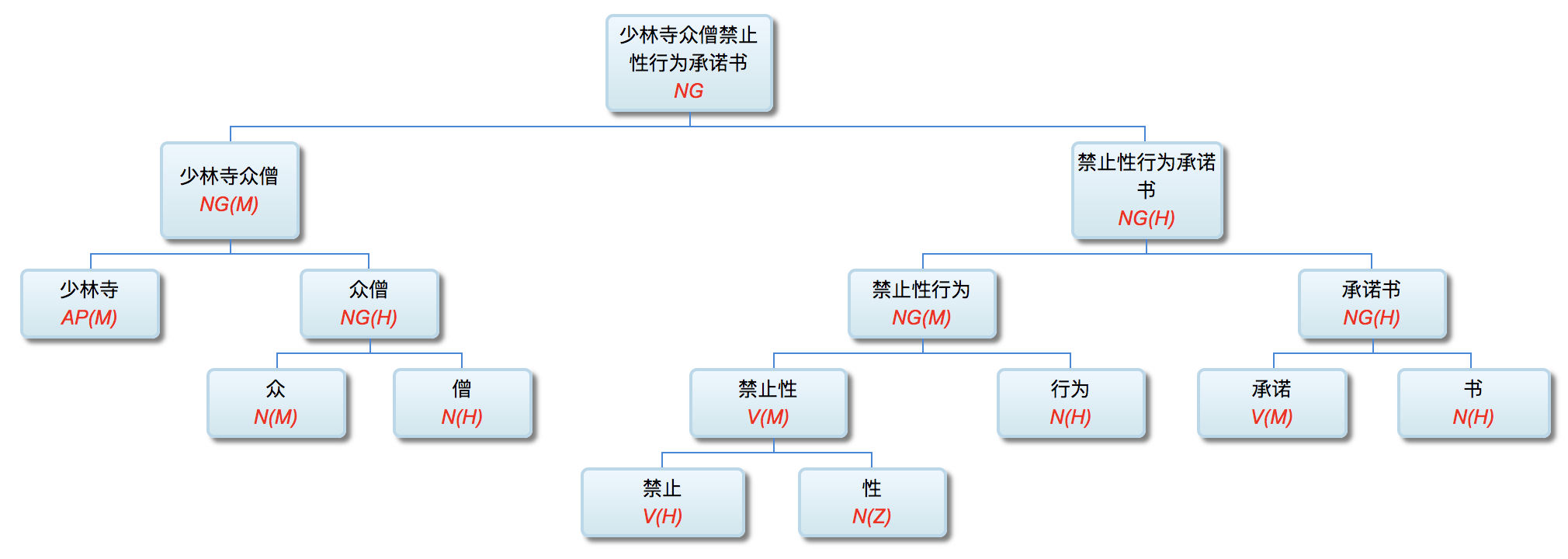
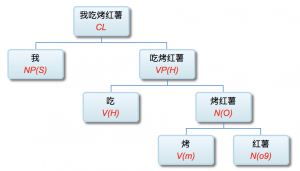
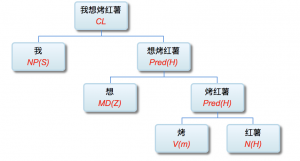
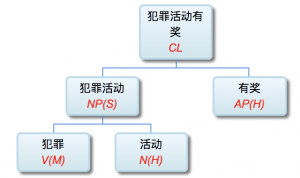
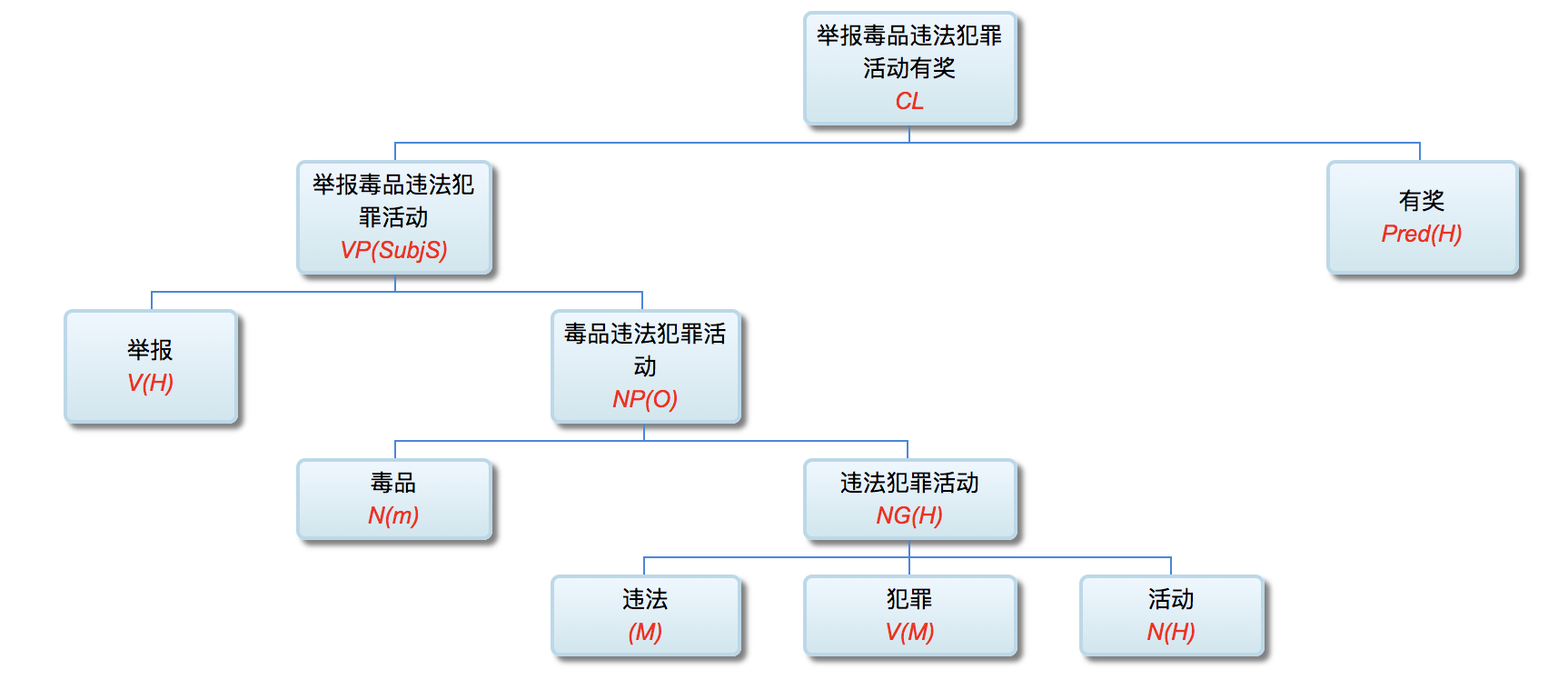
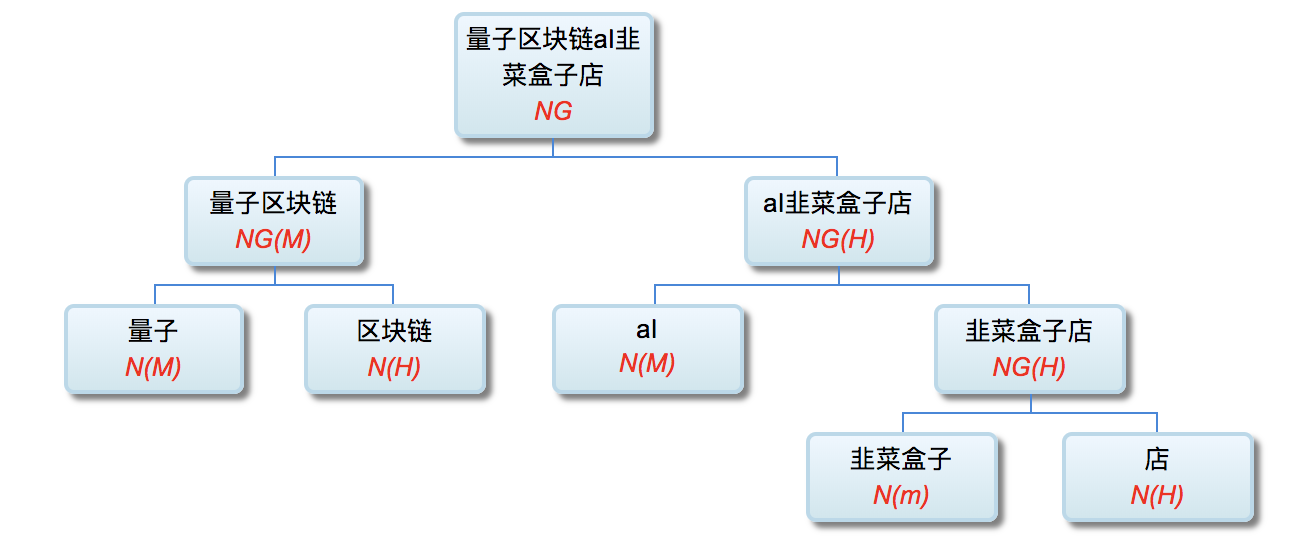
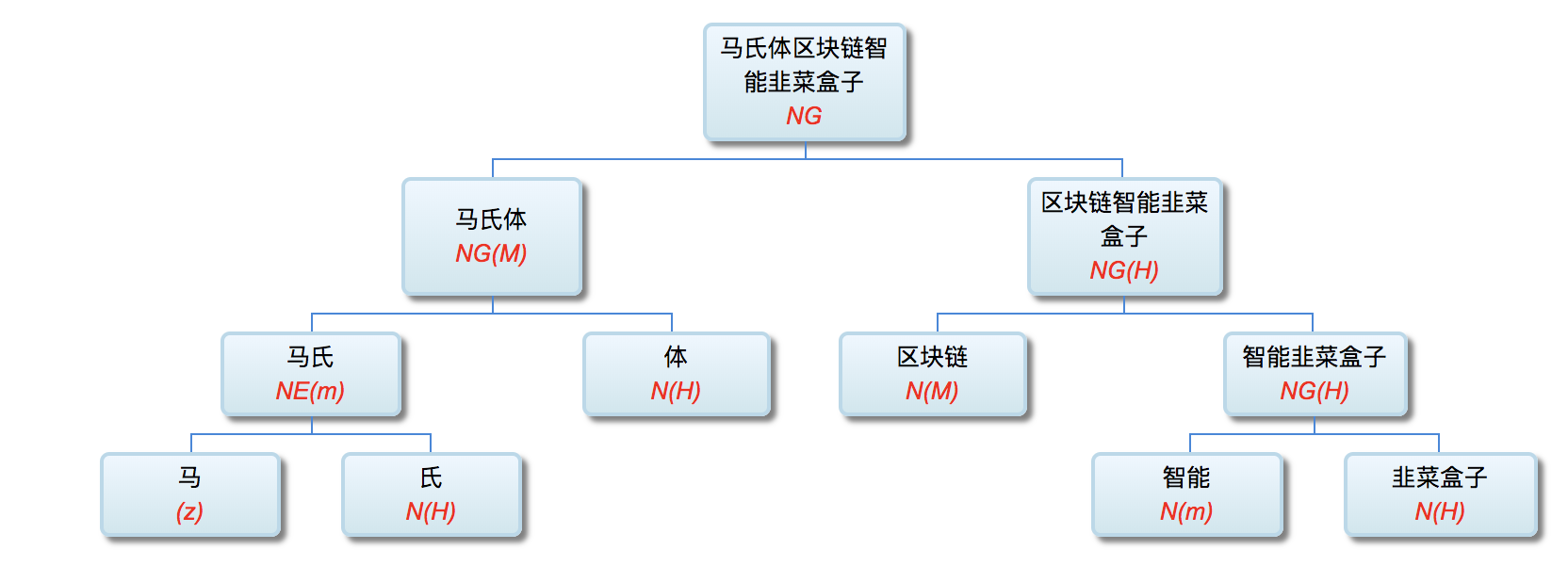
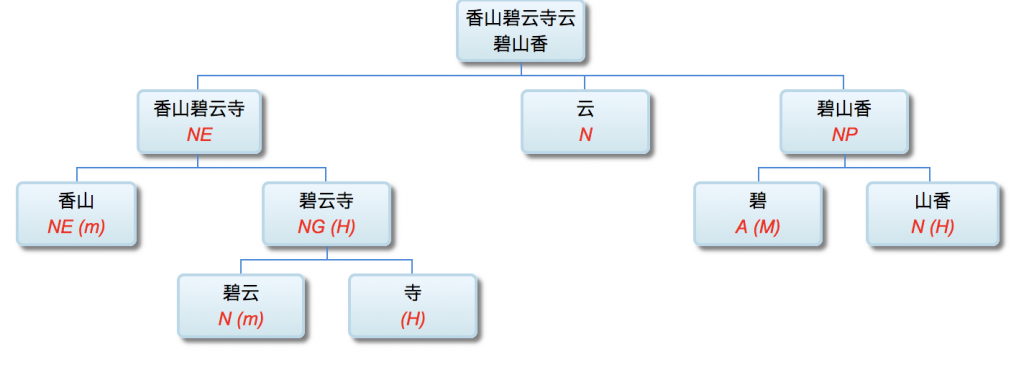
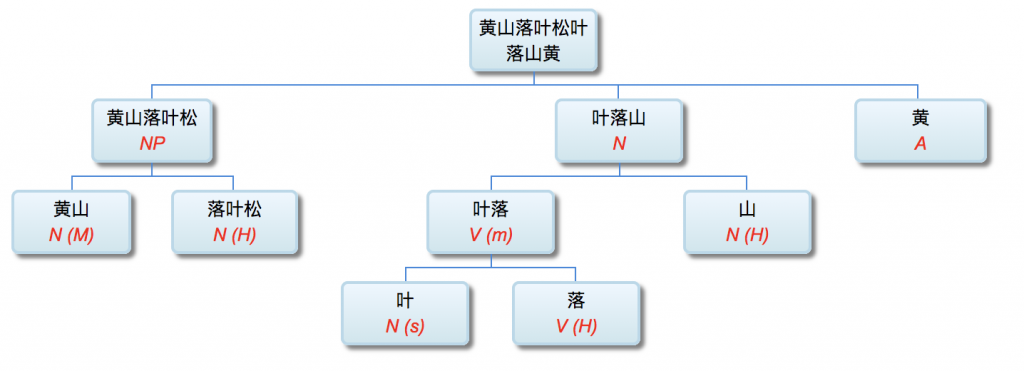
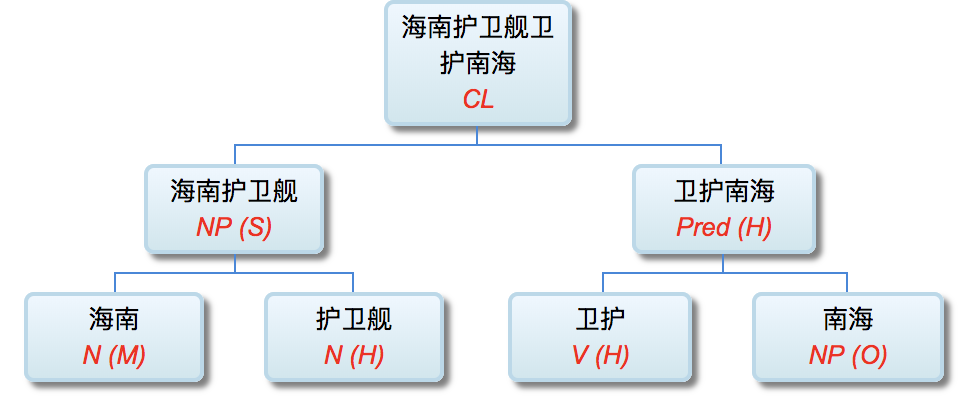
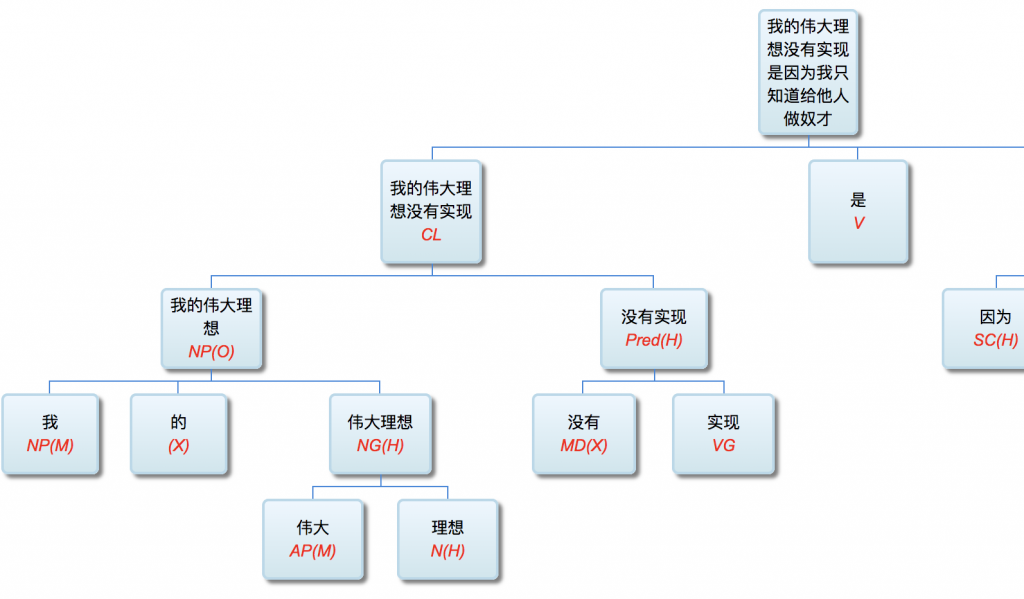
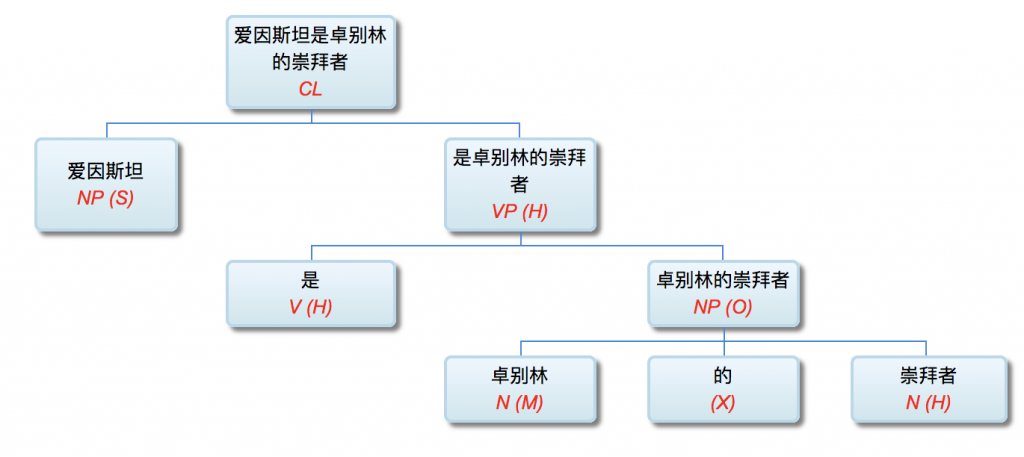
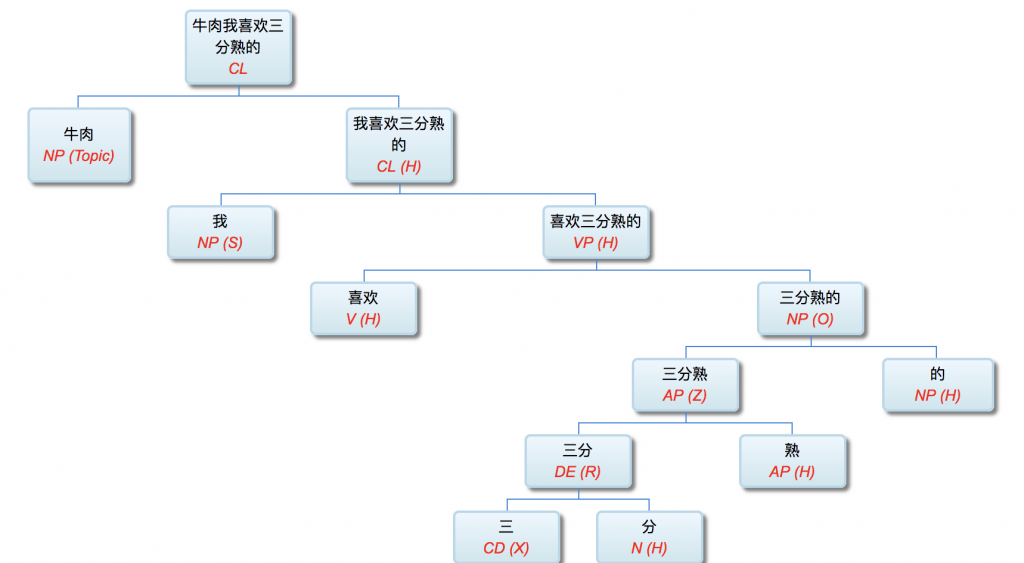
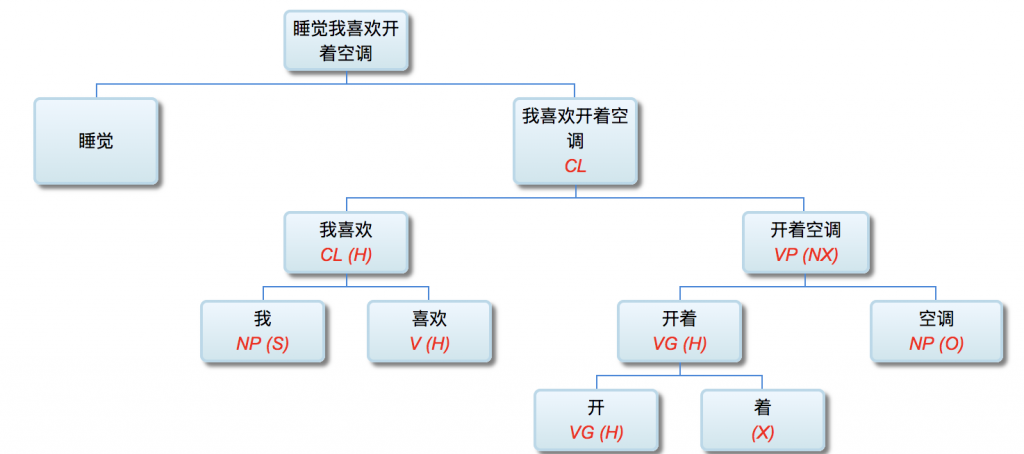
李:
上周,周志华教授作为神秘AI大咖嘉宾,请到京东的AI峰会做了个主题演讲。有意思的是他讲到的三点。他的讲演主题是“满足这三大条件,可以考虑不用深度神经网络”: 1. 有逐层的处理;2 有特征的内部变化; 3. 有足够的模型复杂度。
这就有意思了。我们符号派所说的深度解析(deep parsing)和主流当红的深度学习(deep learning),在这三点上,是英雄所见还是殊途同归?不知道这种“巧合”是不是有些牵强,或者是非主流丑小鸭潜意识对主流白天鹅的“攀附”?总之,fellows大满贯的周教授的这个总结不仅字字珠玑,深入本质,而且非常受用。他是说深度神经的突破,根本原因是由于上面三条。所以,反过来论证说,既然如此,如果有了这三条,其他模型未尝不能突破,或者其他模型可以匹敌或弥补深度神经。
陈:
有了dl,谁还费力想其它的
李:
周教授就是“费力”想其他的人。他指出了深度神经的缺陷:1 调参的困扰;2. 可重复性差;3. 模型复杂度不能随数据自动适应;4. 理论分析难;5. 黑箱;6. 依赖海量标注。由于这些问题的存在,并不是每一个AI任务都合适用深度神经。对于同一个任务,也不是每一个AI团队都可以重复AI大咖的成绩。
毛:
谁说每个AI任务都合适用深度神经了?DL只是补上缺失的一环。
李:
没人明说,无数人这么 assume
毛:
应该说,无数人这么 misunderstand。
李:
哈,我称之为“迷思”:misconception
毛:
反正是mis-something
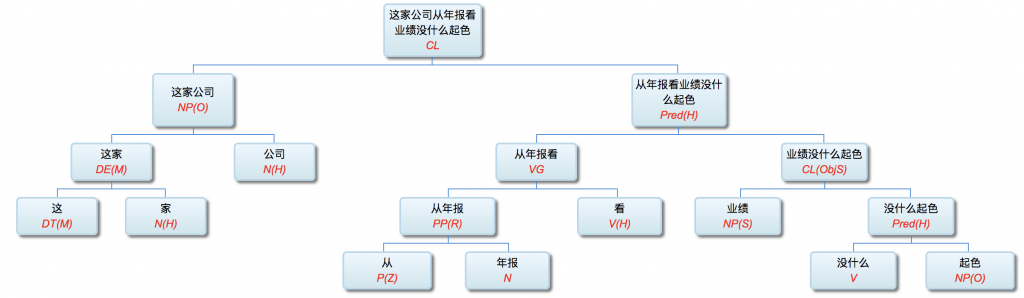
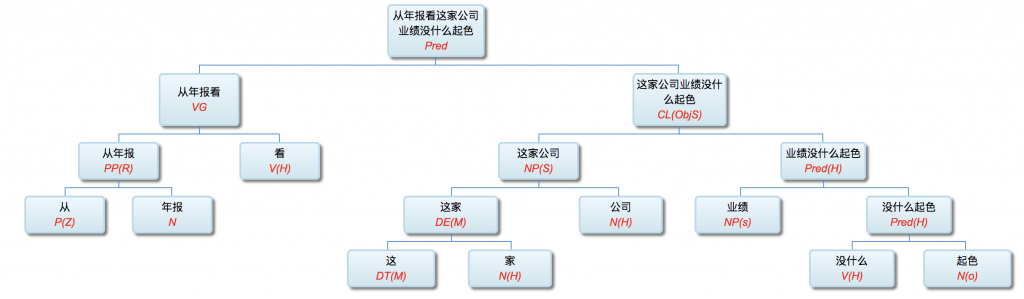
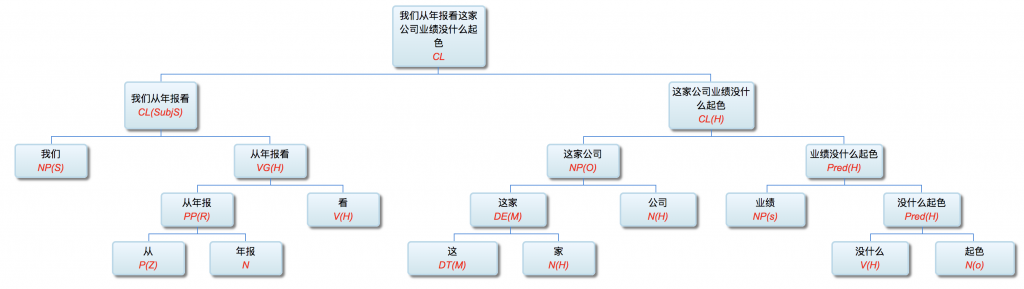
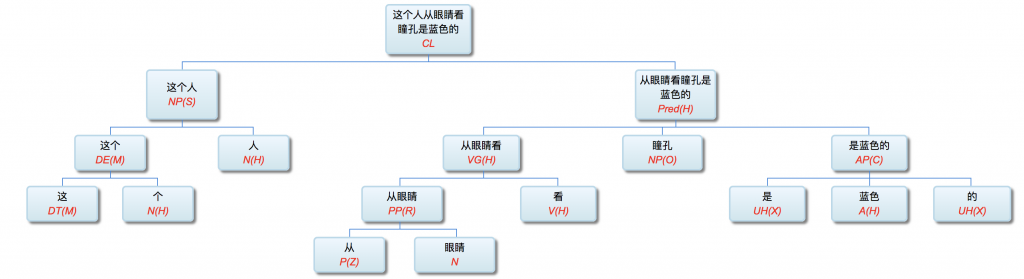
李:
从我的导师辈就开始的无数探索和实践,最后得出了自然语言的解析和理解必须多层进行的结论。虽然这与教科书,与乔姆斯基相悖。
陈:
小孩好像从不这么理解
李:
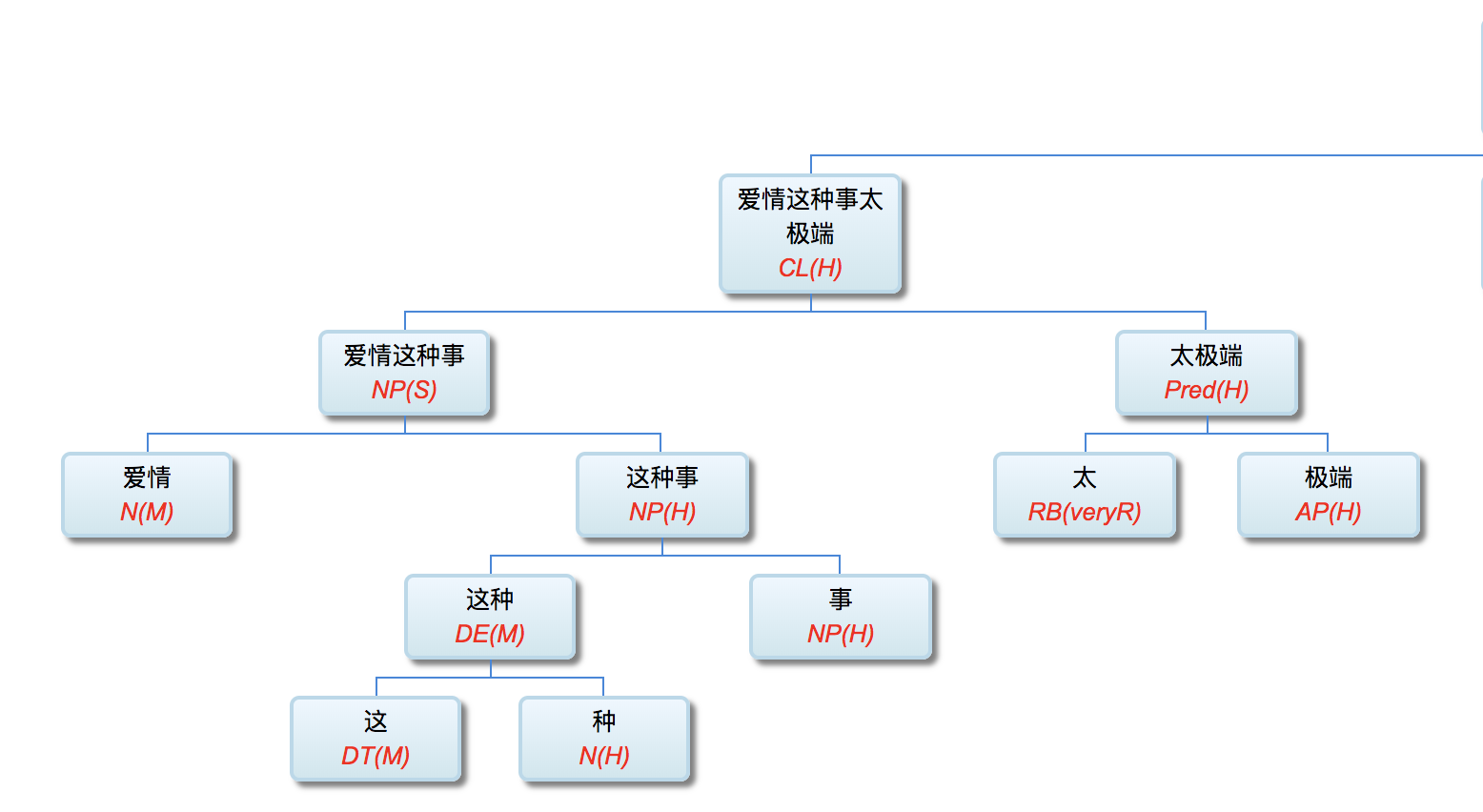
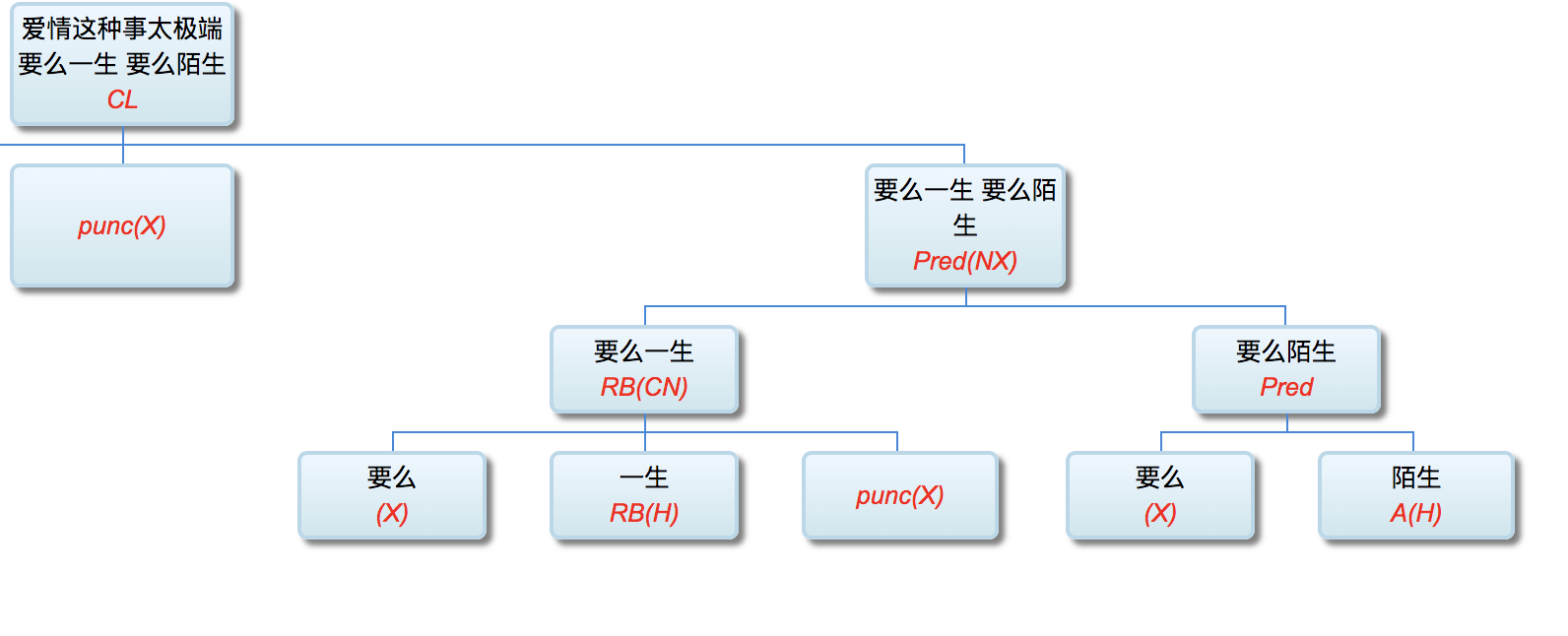
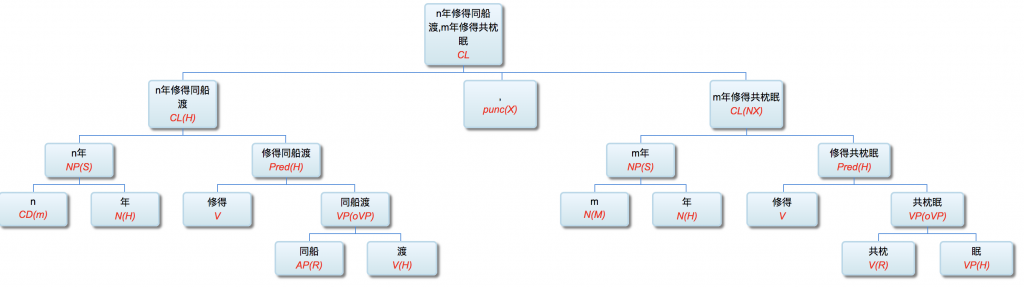
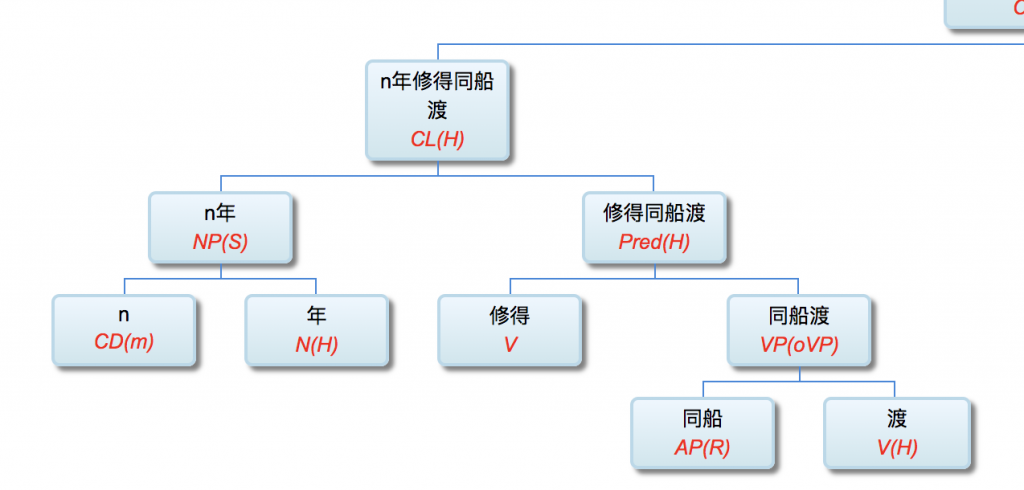
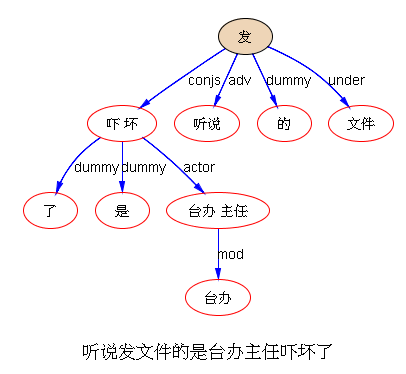
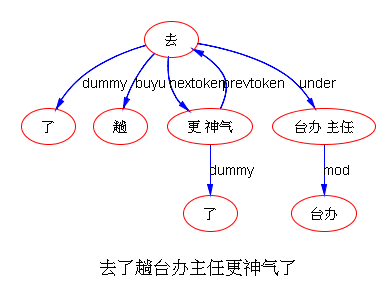
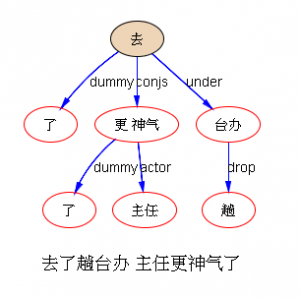
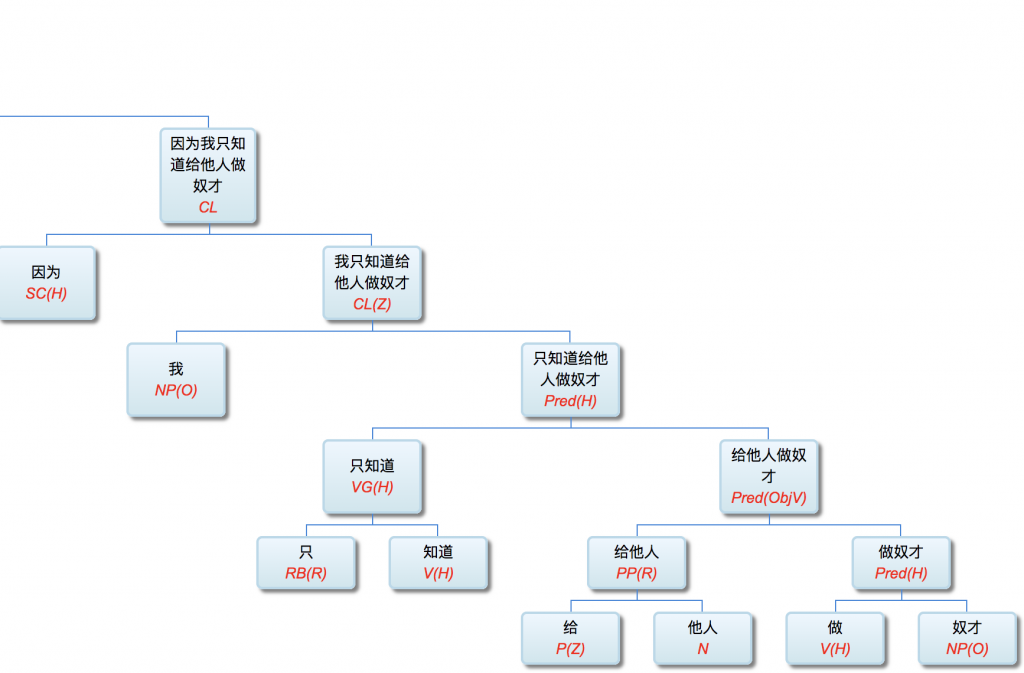
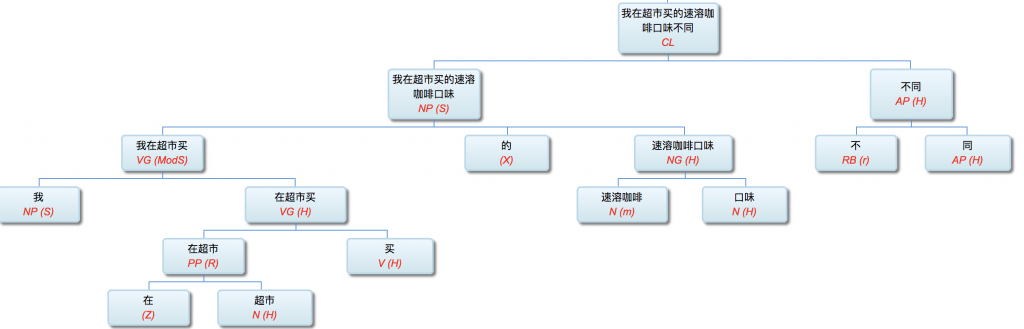
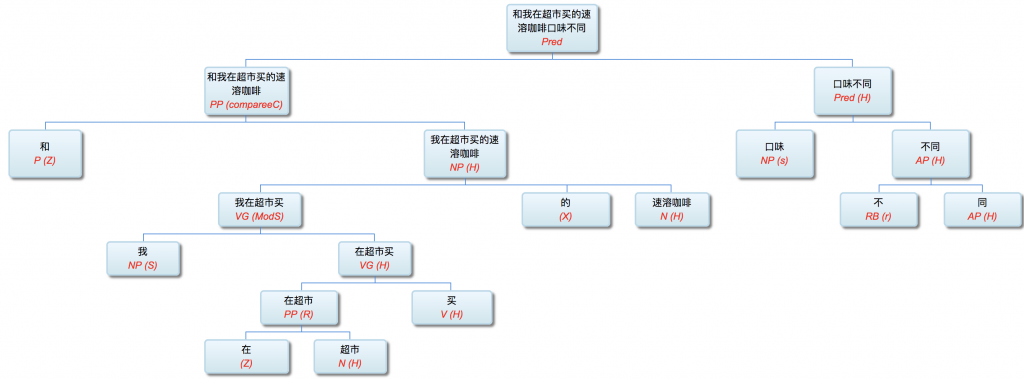
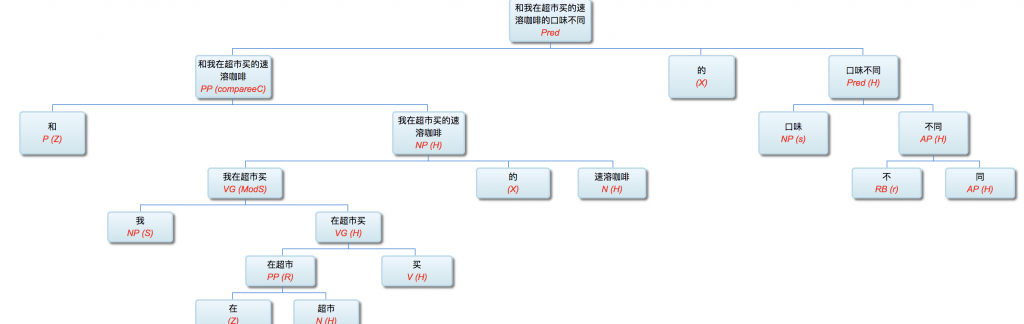
以前论过的:鉴于自然语言的结构复杂性,文句的深度解析和理解很难在单层的系统一蹴而就,自浅而深的多层管式系统于是成为一个很有吸引力的策略。多年的实践表明,多层系统有利于模块化开发和维护,为深度解析的工程化和实用化开辟了道路。但多层系统面临一个巨大的挑战,这个挑战来自于语言中的并不鲜见的相互依赖的歧义现象。
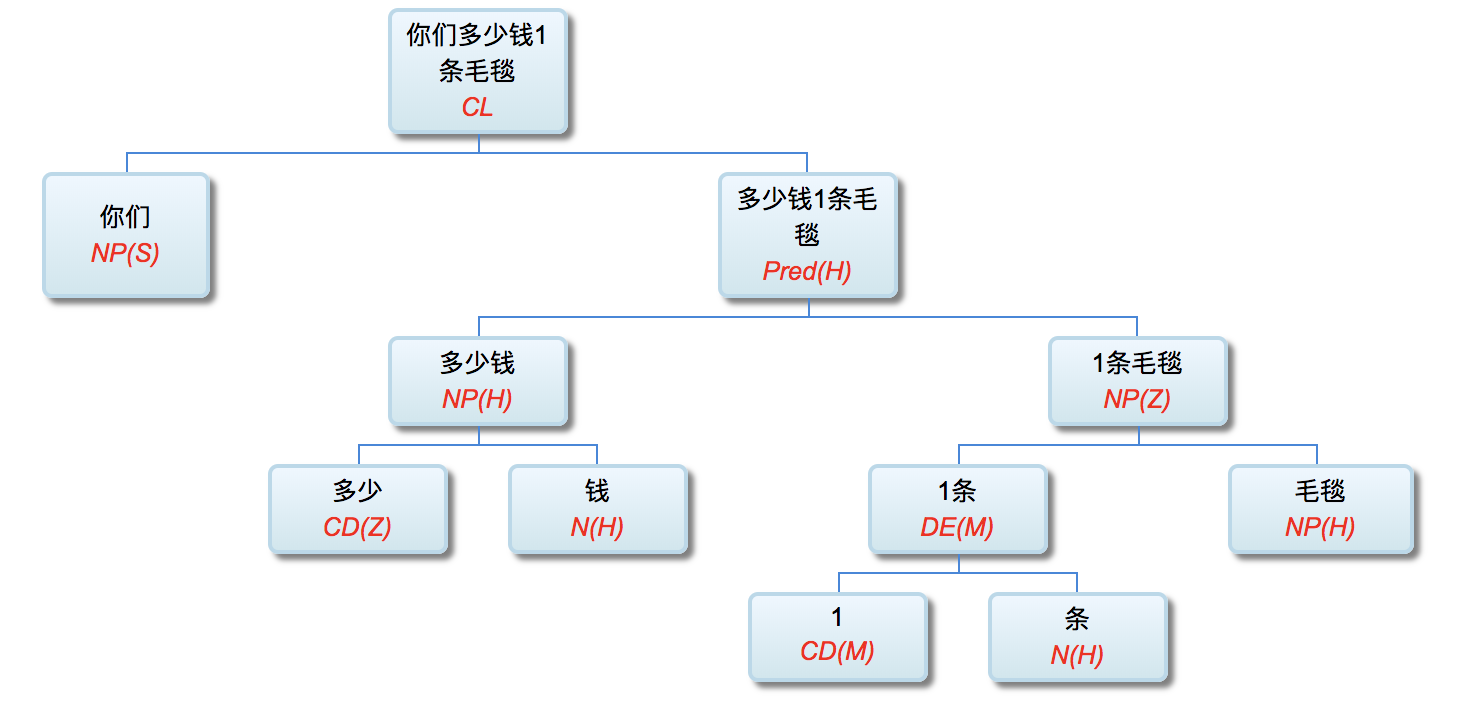
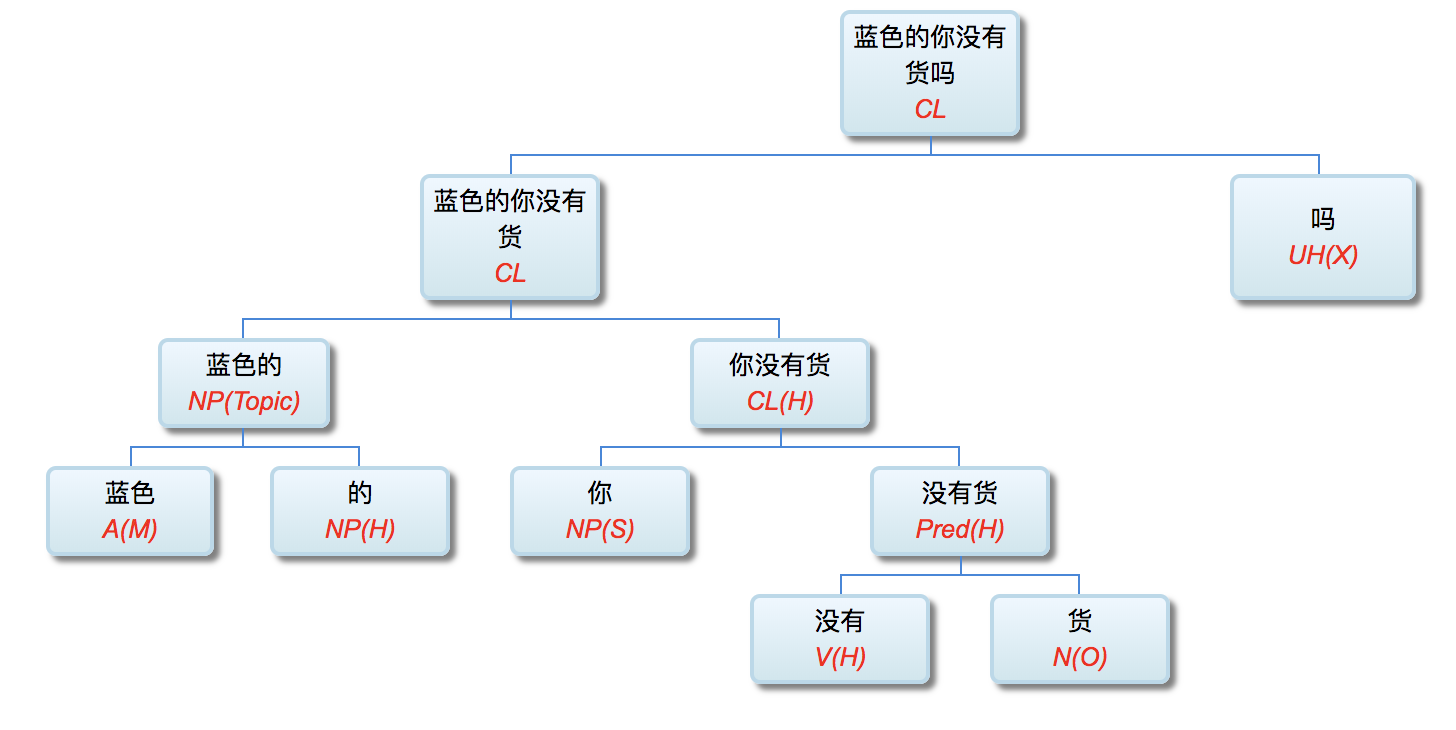
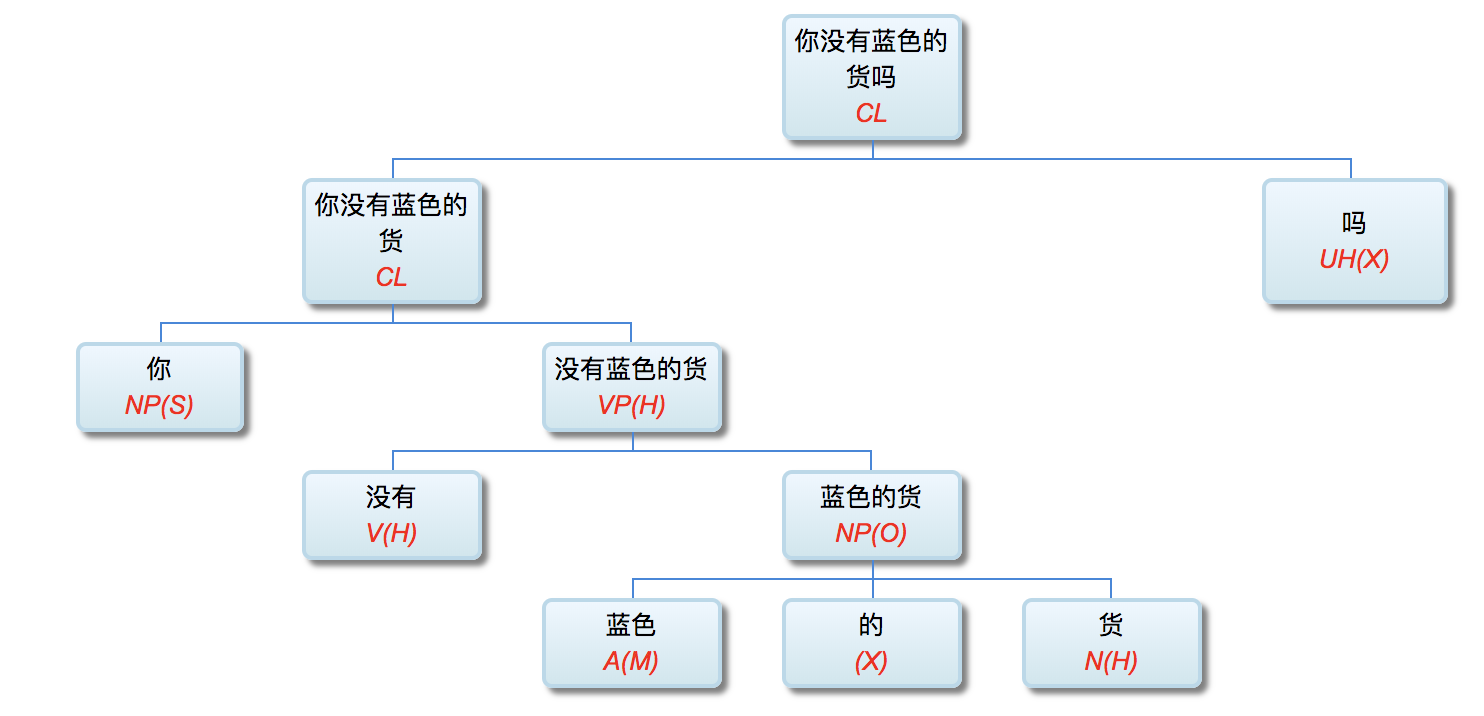
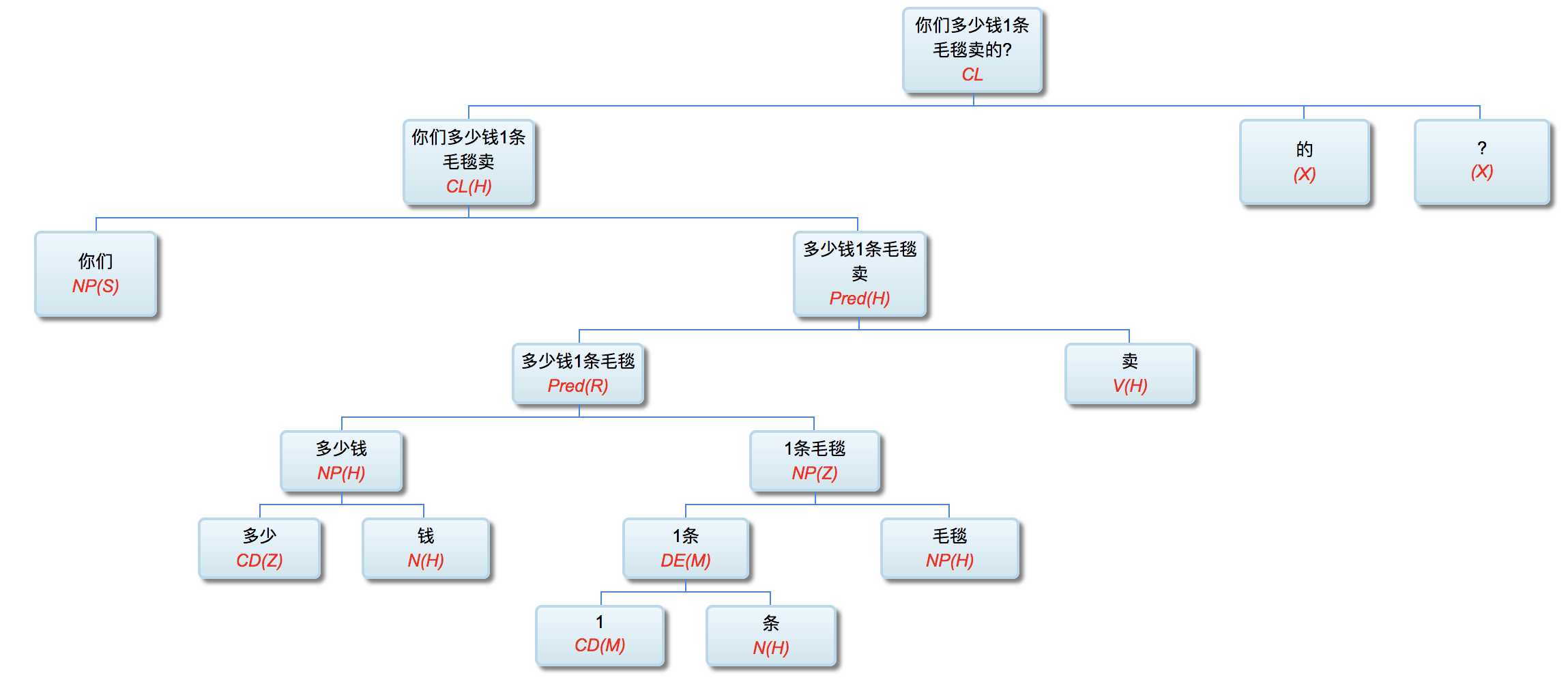
多层了以后,很多不可解的问题,变得可解了。论解析的深度和应对复杂现象和结构能力,多层系统与单层系统完全不可同日而语。30多年前,我的导师做的解析系统是四、五层。但是多层的思路已经萌芽,而且方法论得到确认。最近20多年,我自己的摸索和尝试,发现大约是 50-100 层这个区间比较从容和自如。这不是因为语言中表现出来的递归结构需要这么多层,如果只是为了对付真实语言的递归,五六层也足够了。多层的必要性为的是要有足够的厚度及其动态的中间表达,去容纳从词法分析、实体识别、(嵌套)短语分析、单句分析、复句分析乃至跨句分析(篇章分析)以及从形式分析、语义分析到语用分析的全谱。
当然,这么多层能够顺利推展,前提是要找到解决多层系统面临的挑战的有效方法,即:对相互依赖现象的化解之策。如何在多层系统中确保“负负得正”而不是“错误放大”(error propagation)(【立委科普:管式系统是错误放大还是负负得正?】 )?如何应对 nondeterministic 结果的多层组合爆炸?如果采用 deterministic 的结果,多层的相互依赖陷阱如何规避?我们论过的“休眠唤醒”的创新就是其中一个对策(【立委科普:结构歧义的休眠唤醒演义】)。
毛:
乔老爷没说不能多层啊。递归与多层不就是一回事?
李:
他的递归是在一层里面 parse 的,CFG chart parsing 是教科书里面的文法学派的经典算法。
毛:
这只是形式和实质的区别。我觉得只是深度优先与宽度优先的区别。
李:
他鼓吹 CFG 的递归特性,正是因为他不懂得或不屑认真对待多层叠加的道路。
后者理论上的确不够漂亮。多少有些“凑”的意思,太多工程的味道,模块化的味道,补丁摞补丁的味道,这不符合乔老爷的口味,但实践中比他的递归论要强得多。CFG 能做到的,叠加和拓展了的 FSAs 全部可以做到,但是 叠加的 FSAs 所能达到的深度和能力,CFG 却望尘莫及。递归算个啥事儿嘛,不过是在多层里n次循环调用而已。多层所解决的问题比递归结构的挑战要广得多,包括困扰parsing界很久的“伪歧义”问题(【李白雷梅59:自动句法分析中的伪歧义泥潭】)。
毛:
我倒也是更赞同你说的 FSA,但是认为本质上没有什么不同,不同的只是方法。
李:
这是第一个英雄所见,或殊途同归。深度神经现在几百层了,deep parsing 也 50-100 层了。不是不能超过 100 层,而是确实没有这个必要。迄今还没有发现语言现象复杂到需要超过百层的符号逻辑。
毛:
这两个多层,性质是不一样的。
李:
所以我说这种比对可能“牵强”。但哲学上有诸多相通之处,的确二者都是很 deep 的,有厚度。
那边叫隐藏层,反正我是搞不懂。这边倒是小葱拌豆腐,一清二白的,不说老妪能解吧,但这些个符号逻辑的层次,至少可以对语言学家,领域专家,还有AI哲学家像毛老和群主,还有AI工程大咖利人,可以对你们这些“老人”讲清楚的。这就是我说的,所谓符号逻辑,就是人类自己跟自己玩一个游戏,其中的每一个步骤都是透明的,可解释的。符号派的旗号可以是“模拟”人脑的思维逻辑,其实这个旗号也就是个旗号而已。模拟不摸拟,这一点已经不重要了,关键是效果。何况鬼知道人的语言认知是不是这么乏味、死板、机械,拼拼凑凑,还不如玩家家呢(如果人类思维真的是符号派所模型的那个样子,其实感觉人类蛮可怜的)。
毛:
大多数人的思维可能还没有这么复杂。
李:
但这种游戏般的模拟,在实践中的好处是显然的,它利于开发(自己能跟自己玩的那些游戏规则有助于步骤的梳理,以便各个击破),容易维护和debug(比较容易知道是哪一层的错误,或哪几层有修复的机会及其各自的利弊).
马:
越是层次的思维越是更容易模拟,符号派模拟的是高层次的。
毛:
对,就是缺了低层次这一环,才需要由DL来补上。
郭:
@毛德操,周志华 这次演讲,还特别强调了 深度之于广度的核心差异,那就是他的第二条:每层都是在不同特征维度上。
他从两个角度阐明这点。一,至少在1989年,大家就已经知道,在无限逼近任意连续可微函数这件事上,只要宽度足够,单隐含层就好。多层貌似并非必要,或者说多层并没有提高“表达力”。但是,单层系统,从来没能达到同规模多层系统的学习和泛化能力。
二,多层,就可以有结构。譬如resnet,可以在不同层面选取综合不同维度的特征,可以有多信息流。这条,貌似隐含地说了,人的干预还是重要的。
李:
是的,周教授强调的第二点是特征逐层更新。深度学习之前的系统是在同一个静态特征集上work的,包括最像符号逻辑的决策树模型。而深度之所以 deep,之所以有效和powerful,是与特征的变化更新分不开的,这个道理不难理解。深度的系统不可能在静态的特征上发力,或者说,特征静态也就没有深度的必要了。深度系统是一个接力赛的过程,是一浪推一浪的。这一点在我们的实践中是预设的,当成不言而喻的公理。
我们的深度解析,起点就是词典特征和形态特征,随着从浅层到深层的逐层推进,每一步处理都是在更新特征:根据各种角度的上下文条件,不断增加新特征,消除过时的旧特征,或细化已有的特征。后面一层层就这样在越来越优化的特征上,逐步取得对于语言的结构解析和理解。
毛:
深度优先与广度优先,没有绝对的好坏或强弱,要看具体的应用。在NLP中也许是广度优先好一些。乔姆斯基讲的是专门针对 CFG 的,你那个实际上已经越出了这个范畴。
李:
特征是动态的,反映了搜素空间不断缩小,是真理不断逼近的认知过程。很难想象一个系统在一个静态特征的平面可以达到对于复杂语言现象的深度解析。
马:
在某些特殊情况下,已经证明层数少,需要指数级的增加神经元才可以达到层数深的效果。而神经元的增加又加大了计算复杂性,对数据量的要求更大。
毛:
如果上下文相关,那么分层恐怕确实更灵活一些。
李:
这就是我说的乔老爷把“power”这个日常用词术语化以后,实际上给人带来了巨大的误导:他的更 “powerful” 的 递归 CFG 比二等公民的 less powerful 的 FSA 所多出来的 “power” 不过就是在单层系统里面可以处理一些递归结构而已。而把一批 FSAs 一叠加,其 power 立马超越 CFG。
总之,特征不断更新是深度解析的题中应有之义。而这一点又恰好与深度神经不谋而合,殊途同归了。
周教授眼毒啊。
教授的第三点,关于深度系统需要足够的模型复杂度,我不大有把握可以做一个合适的比对。直觉上,由于分而治之由浅入深的多层系统对于组合爆炸的天然应对能力,如果我们假想我们有一种超自然的能力能够把一个 50 层的解析系统,完全碾压到一个平面,那将是一个多大的 network,遮天蔽日,大到难以想象!
马:
符号表示的复杂性可以说是无穷大吧?模型的复杂度指表达能力?太复杂又容易过拟合
李:
周说的是,因为不知道多复杂合适,所以得先弄得很复杂,然后再降低复杂度。他把这个说成是深度神经的一个缺陷。
郭:
周志华特别强调,他的“复杂度”,不是指“表达力”(“单层多层同样的表达力,但多层可以复杂的多”)。
他没给定义,但举了resnet作为例子,并且明确提了“特征信息流的数目”,还说了:多层,但特征信息流动单一的,也没有复杂度。
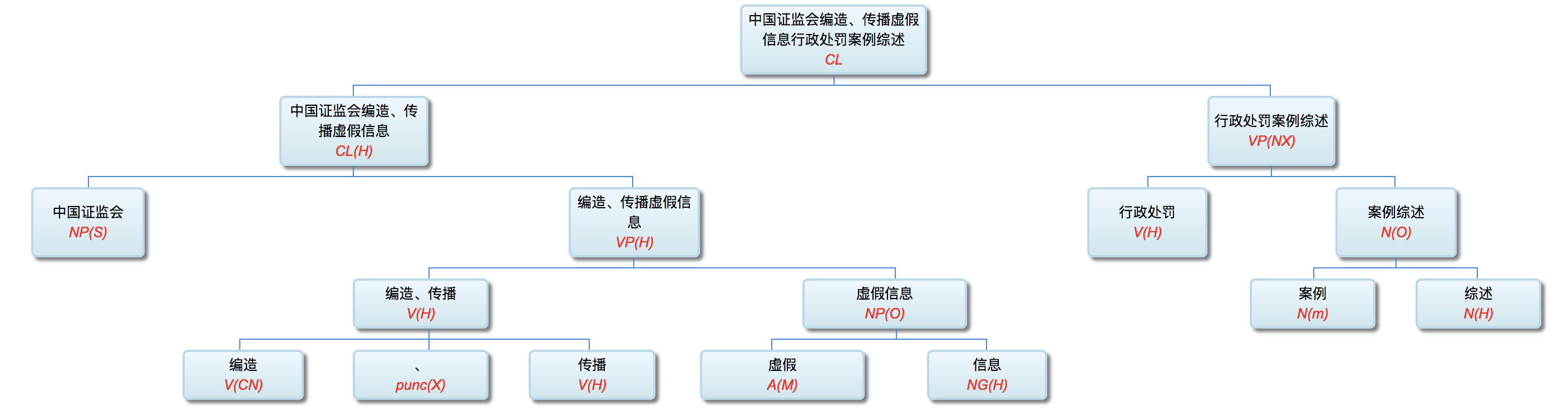
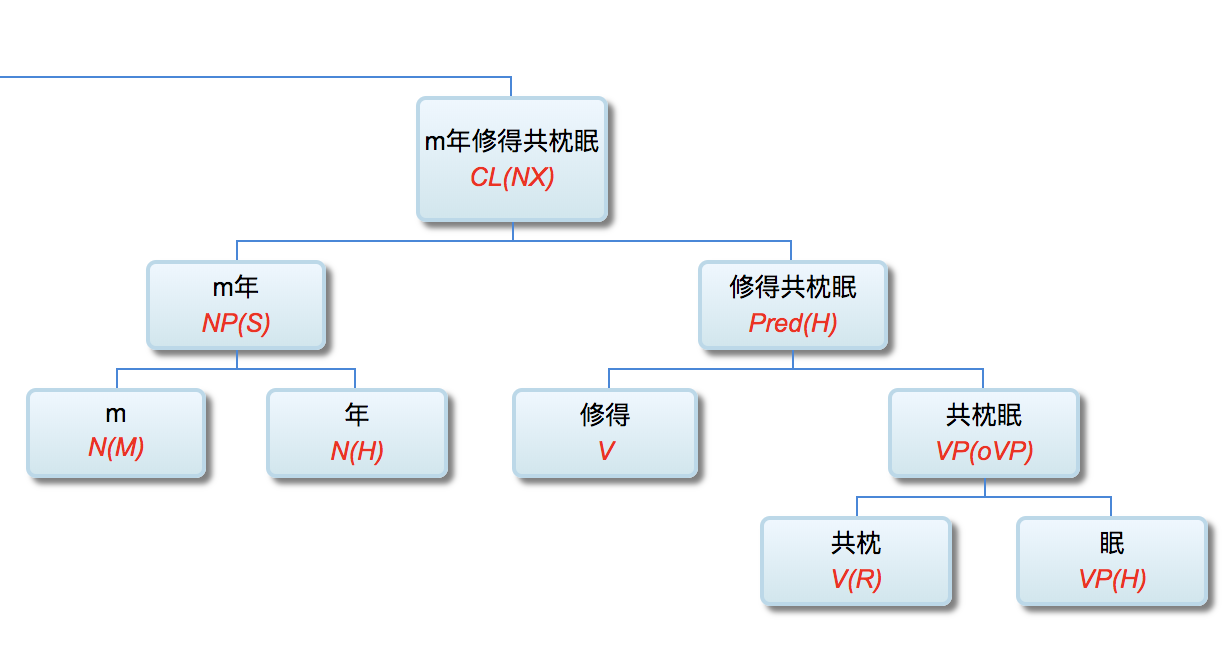
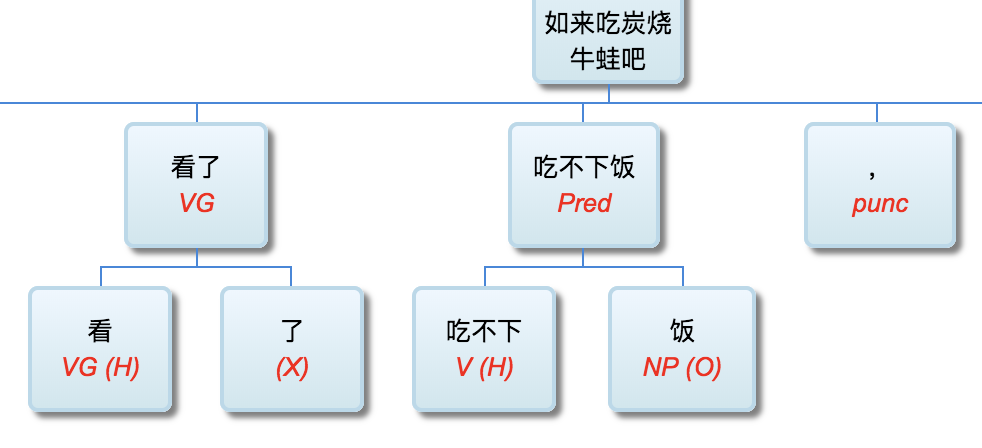
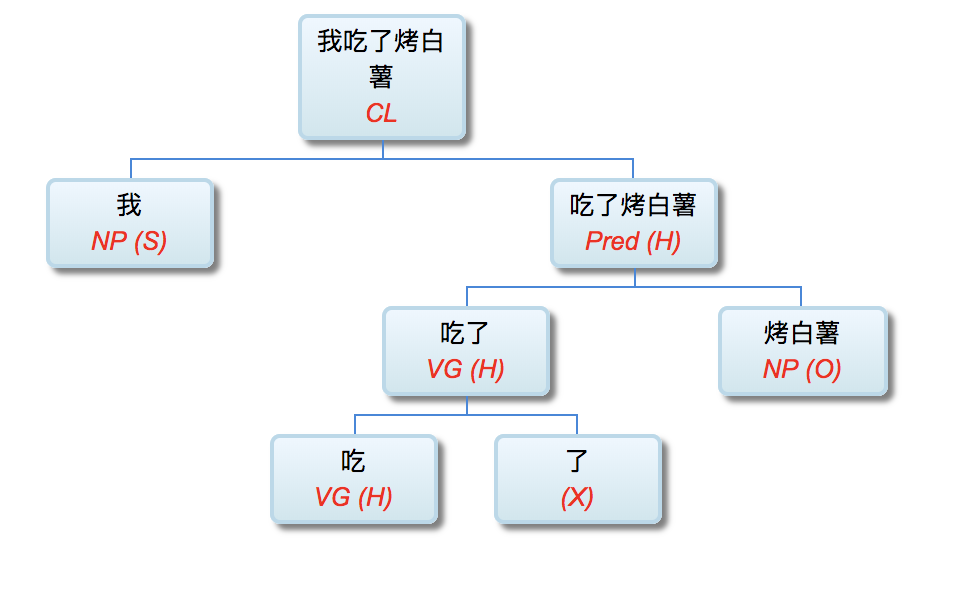
回顾周说的这三条,李维的 deep parser 条条符合!
有逐层的处理 -- 李维的,少说也有50层吧!
有特征的内部变化 -- 李维的,每层都在不同的维度/颗粒度/角度,用不同的特征/属性,产生新的特征/属性
有足够的模型复杂度 -- 李维的,也有明显的“复杂度”(周志华强调,“复杂度”,不是指“表达力”。过度的“表达力”,往往是负面的)。李维的,不仅有传统的 linguistics motivated 概念/特征/属性,也广泛采用“大数据”(基于统计的)。最近也开始利用“AI”(基于分布式表示的)。
还有一点,周志华多次强调(我认为是作为“三条件”必然推论的),“深度学习,关键是深度,但不一定要 '端到端' ”。他更强调(至少是我的理解),为了端到端,一味追求可微可导,是本末倒置。深度学习,中间有 不可微不可导 的特征/存储,应该是允许甚至是必要的。
对这一点,李维的“休眠唤醒”,大概也可算是 remotely related.
白:
拉倒。带前后条件的FSA早已不是纯种的FSA,只是拿FSA说事儿而已,真实的能力早已超过FSA几条街。
毛:
这就对了。其实,自然语言哪里是 CFG 可以套得上的。
李:
我其实不想拿 FSA 或 FSA++ 说事儿,听上去就那么低端小气不上档次。可总得有个名儿吧,白老师帮助起个名字?教给实习生的时候,我说你熟悉 regex 吧,这就好比是个大号的 regex,可实习生一上手 说不对呀 这比 regex 大太多了。这套 formalism 光 specs,已经厚厚一摞了,的确太超过。要害是剔除了没有线性算法的递归能力。
毛:
记得白老师提过毛毛虫的说法,我还说了句“毛毛虫的长度大于CFG的直径”。(【白硕– 穿越乔家大院寻找“毛毛虫”】)
白:
有cat,有subcat,还拿这些东西的逻辑组合构成前后条件,还有优先级。有相谐性,有远距离雷达,有实例化程度不等带来的优先级设定。哪个FSA有这么全套的装备?
陈:
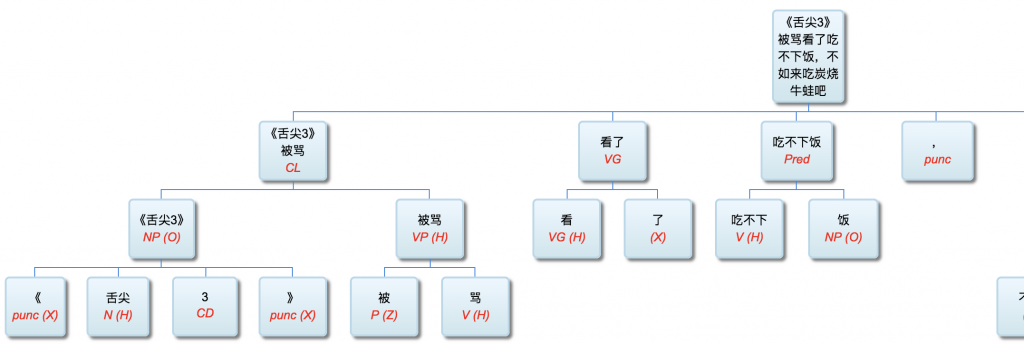
基于规则,遇到长句子一般必死
李:
非规则的 找个不死的瞧瞧。再看看规则的怎么个死法。反正是死。看谁死得优雅。你出一组长句子,找一个学习的 parser,然后咱们可以比较一下死的形态。
白:
先说任务是啥,再说死活。
李:
我是说利人的腔调,极具代表性,那种典型的“成见/偏见”(【W. Li & T. Tang: 主流的傲慢与偏见:规则系统与机器学习】)。
马:
人家DL端到端,不做parser。现在有人做从语音直接到文本的翻译,不过效果还不行,主要可能是数据问题
李:
苹果梨子如何比较死活。
毛:
乔老爷的CFG不应该算入AI,那只是形式语言的解析。
陈:
确实都死。。。但一个死了也没法解释,不要解释。另一个就得思考哪个规则出问题了
毛:
人也好不到哪里,只不过人不死,只是懵了。
李:
? 懵了就是人造死,artificial death
马:
规则的好处是,你说什么不行?我马上可以加一个规则。这就是我前面说的复杂性无穷。? 即表达能力无穷
白:
假设任务是从文本抽取一堆关系,放进知识图谱。
假设任务是根据用户反馈,把错的对话改对,同时对的对话不错。
陈:
抽取这个很重要,很多理解的问题其实是抽取问题。比如,阅读问答题
毛:
我还是相信多层符号会赢。
李:
从文本抽取关系 谁更行,需要假设同等资源的投入才好比。我以前一直坚信多层符号,现在有些犹疑了,主要是标注人工太便宜了。到了标注车间,简直就是回到了卓别林的《摩登时代》,生产线上的标注“白领”面对源源不断的数据,马不停蹄地标啊标啊,那真不是人干的活儿啊,重复、单调、乏味,没看见智能,只看见人工,甭管数据有多冗余和灰色。这就是当今主流“人工智能”的依托,让人唏嘘。当然,另一方面看,这是当今AI在取代了很多人工岗位后,难得地给社会创造就业机会呢,将功补过,多多益善,管他什么工作,凡是创造就业机会的,一律应予鼓励。
毛:
@wei 这不正好是训练条件反射吗
陈:
反正智能的事都让机器去做了,人就只好做些低级如标注的活了
白:
问题是啥叫符号?基于字节?字符?基于词已经是符号了吧。是不是要退到茹毛饮血,连词也不分,才算非符号。否则都是站在符号肩膀上
毛:
我认为可以这样来类比: 一个社会经验丰富、老江湖的文盲,跟一个教授,谁能理解更多的语句。我想,除那些江湖切口和黑话,还有些需要“锣鼓听声,说话听音”的暗示以外,一定是教授能理解更多的语句。而且,即使是江湖切口黑话,也能慢慢加到教授的知识库中。
李:
都是站在符号肩膀上。然而,符号系统的实质不是符号,而是显性的 可解释的符号逻辑。就是那套自己跟自己玩 系统内部能够自圆其说 有过程 有因果链条的针对符号及其动态特征做处理的算法。相对于建立在符号和特征基础上的不可解释的学习系统,很多时候这些系统被归结为一个分类问题,就是用原子化的类别符号作为语言落地的端对端目标。如果一个落地场景需要10个分类,只要定义清晰界限相对分明,你就找一批大学生甚至 crowd source 给一批在家的家庭妇女标注好了,一个类标它百万千万,然后深度训练。要是需要100个分类,也可以这么办,虽然标注的组织工作和质量控制要艰难得多,好在大唐最不缺的就是人工。可是,如果落地场景需要一千个、一万个不同侧面的分类,标注和学习的路线就难以为继了。
白:
结果是一个集合,已经比较复杂了。结果是关系集合,又更加复杂。让人类标注,好不到哪儿去。标注一个关系集合,等价于标注一个结构。
【相关】