也许是吧。可小崔有新闻人的资格和耐力干劲,虽然缺乏科学理解能力。而某些据说有科学学养的人,又专门爱忽悠,欺负国内老百姓没在美国生活过,不通英文。小崔至少指出了后者的一些明显的忽悠,什么美国人放心吃转基因n多年,什么转基因安全无争议,扯嘛。
让科学人士痛心疾首的转基因在中国的挫折(在世界范围,甚至在美国,也处于挫折中),主要不是小崔,更不是所谓反转控造成的。恰恰相反,科学主义者忽悠大众是起因之一。很大程度上,本来没有所谓反转控(很长时间,无论中美,听都没听说过转基因或GMO,没有概念,反个鬼) ,一定意义上是科学主义的挺转(控)催生了反转控。另一个全球性的原因,是环境保护主义运动在全世界的发展和深入人心。与科学技术背道而驰的返璞归真的自然主义理念随着科技现代化的加速也加速了。在美国,吃有机食品已经成为“富裕高尚”人士引领的时尚。
转基因在民间真地很臭了,不到亲友圈转转是难以体会民间的厌恶和恐慌的。连陈(章良)大人也发现转基因太臭了。多少年来,我们有杂交水稻,杂交水果,大众是拥抱、欢迎和enjoy的。甚至化肥、杀虫剂(666等),我们使用了很多年,大家也接受了,尽管很无奈。如今转基因的名声连化肥、杀虫剂甚至地沟油都不如了。
转基因本来没有那么臭,其实也没必要那么恐慌,美国上亿的人民莫名其妙被做了20年的小白鼠,也没发现什么灾难性事故,这个基本事实其实应该有说服力的,可是挺转科学主义为什么非要忽悠那些明显的谎言呢。
大概还需要几年,恐慌才会减退,双方才会趋于冷静。
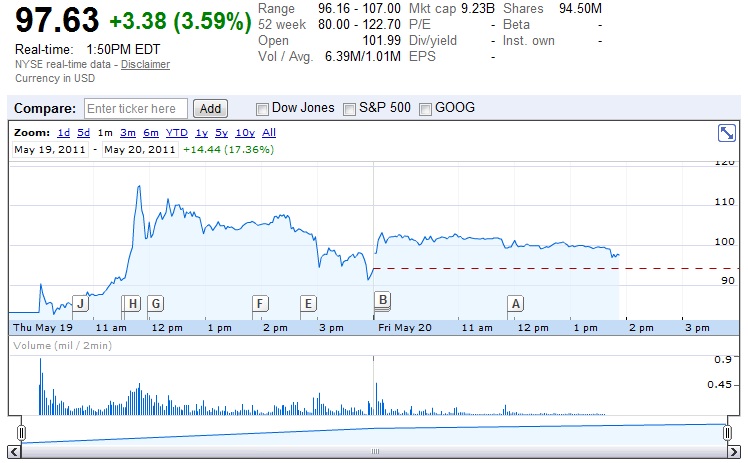
把关于“美国人放心吃转基因20年”的讨论提上来:
[1]蔡小宁 2014-3-2 21:23“美国人放心吃转基因n多年”?是崔永元编出来的靶子,我可没有这么说过,因为谁不知道美国也有反对转基因的人?从逻辑上考虑,我也不会这么说的。
博主回复(2014-3-2 21:30):没说你或者某个特定人造的谣。但据我了解,也不是小崔凭空编出的靶子。有兴趣的人可以研究一下真正的起源及其蔓延过程。但我看到的事实是,在小崔美国行戳穿这个谎言之前,这个谎言已经相当流行了。至少,这个谎言被一部分科学人士有意无意地用来忽悠老百姓。
[6727]bioxncai 2014-3-2 21:39文章标题:看小崔的转基因美国行的录像风传互联网
“美国人放心吃转基因n多年”这个说法不排除有极少数人说过,世界这么大,我无法排除。但是可以肯定,支持转基因阵营的主流说法,绝不是这样的,通常的说法是:美国人吃转基因n多年(了)。崔永元这么一弄就会让人误解成主流说法是这个了,崔永元玩这一手不是一次了。
博主回复(2014-3-2 22:19):小崔由于其大V的影响力放大了这个问题是肯定的。但他不是凭空制造的,因为在我还没听说或意识到小崔涉及到转基因争论之前,就注意到这个提法及其蔓延,并且为此困惑过,还在内部与朋友就这个貌似谣言争论过。无论小崔是不是打自立的靶子,现在转基因在民间越来越臭是难以否认的事实了,小崔的这个录像为这个臭化的过程又点了一把火。甭管民间对美国有多少怨气,国人的崇美是骨子里的。小崔深入美国各个阶层的实地录像尽管带有明显的倾向性(挺转的声音不及反转的声音的一个零头),还是有震撼性效果。媒体人的一发炮弹,够科学人士忙好几年了。
恐慌是不必要的,但揭示的有些问题仍然值得深思:
1. 科学忽悠也是忽悠,包括把话说死(安全性无可置疑,没有争议,凡争议都是骗子或不具有科学精神等),忽悠可以一时,但不得永久,最后适得其反;
2. 作为消费者,我为什么要吃转基因?那些转基因品尝活动跟宗教仪式一样,没有一丝科学精神。实在的理由必须给出:或者转基因食品更加美味、更加便宜(让利给消费者),否则转基因只能是科学主义者高高在上,用来彰显其科学素养的道具而已;
3. 转基因不标识的理由很脆弱,必须接受这个事实。中国不用说了,转基因标识势在必行。连美国,趋势也是要标识:不信咱们看今后的结果好了。美国民间的反转或怀疑转基因的意识也在发酵,迟早会有越来越多的州实行(强制)标识,感觉就跟同性婚姻合法化的趋势类似。另外,美国越来越多的食品志愿标识有机食品或 non-GMO,以前不注意,如今去超市购物开始关注这种标识了。这显然是为讨好消费者对 GMO 的厌恶情绪。如果这种趋势延续下去,强制标识也就不必要了,因为其他食品都与它划清界限了。志愿标识的进程和强制标识的公投立法过程,看哪个走得快了,总之结果是标识。说什么因为品质(和安全)没有区别所以不标识不过是利益方的托词罢了。傻瓜都知道,标识以后,转基因食品就卖不好了,除非让利给消费者。而让利是一个合理的出路,新技术无论多好,不能价廉物美,也是白搭。
4. 这场争论以反转走了上风,实际上是便宜了有机食品供应商,小崔有意无意成为他们的吹鼓手;
5. 必须承认反转挺转都不仅仅是科学争论,转基因背后的集团利益是显而易见的。反转后面的利益方已经说了,是有机食品制造商,据说还有研制测试转基因仪器的。挺转后面的利益方是那些生物技术种子公司,他们插手科学研究是否具有足够的透明性公平性成为一个大众疑点。科学家也是利益方,毕竟那是他们的事业和饭碗。进出口组织(小崔录像中的美国大豆出口协会的官员等)和商人也是,农场主和农民也是(农民得利是值得欣喜和庆幸的,希望他们多得一些,录像中那位农家女提到以前手工除草的辛劳很让我这辈“曾插队过的知识青年”触动,没有经历过的人难以体会汗滴禾下土的滋味)。离开利益方,一位强调转基因的科学性不免遭到大众的怀疑。
6. 反转挺转超越科学争论的另一点是意识形态和世界观:是自然主义还是科学主义?是人定胜天还是返璞归真?这不仅仅是科学和迷信,或者科学和愚昧的问题。这种世界观之争会永远持续下去,挺转反转只是其表现之一。打压、嘲笑对方是无效的,只能引发更多的反弹。启发民智和说服(科普)的办法也难以奏效。很多时候是相互 agree to disagree,淡化理念的冲突,学会和平共处。正如镜兄说的:
[2]mirrorliwei 2014-3-2 21:28如果能够“容忍”、需要“容忍”人们祈祷、进香的行为的话,就必然要“容忍”他们反对、不理解转基因。因为两者的根源是一样的。
[101]mirrorliwei 2014-3-4 08:10
好家伙,跟帖过了一百了么。
从认识论上说,对不知的“未知”,有几种态度:保守的、小心的做法,认为“不存在”的思考。追求漂亮女孩的事情没有人反对。但是追求理由就是人家的脸皮漂亮,不能说是因为会生健康的孩子。
转基因的工作就是就是追漂亮女孩。追也就罢了。但是追的人们都声称能让这个漂亮女孩给生个优秀的后代,为此要别人掏钱。当有人出来质疑“漂亮女孩是否一定能给生个优秀的后代”的时候,就有些人不高兴了。。。。
其他有关评论:
[95]kongshl 2014-3-3 21:50说转基因食品的安全性没有争议也是对的,因为科学界的主流观点认为是安全的,而且到现在为止,没有令人信服的确切的证据表明转基因食品有不安全性。当然了,任何事物出来都会有人反对,但反对的人要有确切的证据拿出来,那才是真正的争议,不然,任何事物都可以说是有争议的。确定的事物不能因为有人反对就说有争议。有人还说爱因斯坦的相对论错了呢,能说相对论的正确性在科学界有争议吗。大家都知道五次和五次以上的代数方程没有一般的根式解,但就有人说他证明了有根式解,这难道能说数学界对这个结论是有争议的?
博主回复(2014-3-4 00:23):可以理解您的说法后面的理由。但是,在争论中使用这种说法(伎俩,且不说狡辩)注定适得其反。因为常识告诉我们,说有容易说无难。
显然科学界也是有争论的。严谨的挺转派或科学家(如蔡老师)说的是,科学界主流没有或较少争论。
实际上,科学界主流也不是不可以质疑(不过能够质疑主流,需要蛮高的门槛,否则就是民科笑话了;相对来说,主流和权威仍然在我们外行和老百姓相信系统中具有或应该具有很重的砝码)。生物我不懂,但是在我的这个行业中(CL/NLP),以我30年的切身体会,学界主流存在一般人难以想象的很深的偏见。为此我去年专门撰文《NLP主流的傲慢与偏见》,后来“正式发表”在《中国计算机通讯》期刊上,公开让同行评议(或批判)。
另一方面,美国主流媒体包括 CNN 也开始陆续报道 GMO 引发的争论和安全隐患。说明事情并非像某些挺转科学人士宣扬的那么简单和黑白分明。刚看到报道,美国主流权威机构农业部(USDA)也不是对GMO安全那么信心满满了:
删除 回复
[94]kongshl 2014-3-3 21:32说美国人放心在吃了n年是说得通的,因为到目前为止没有发现因为吃转基因食品而发生问题,可以说是令人放心的。而且大部人美国对这个并不关心,他们相信FDA的观点,FDA说安全的,他们就相信是安全的。不象我们这里,权威部门说什么都不相信,只相信小道消息。
博主回复(2014-3-4 00:13):不是“在”,是“地”。您的中文语文包括词汇都需要加强。
“放心”是常用词,如果小学语文没学好,查一下词典那么难么?
就是因为你们这样的强词夺理去挺转,才使得一门好好的研究搞得如此声名狼藉。
【相关】
 谁应该为转基因的困境负主要责任? 2014-03-04
谁应该为转基因的困境负主要责任? 2014-03-04
 上周出差到硅谷,朋友周日载我到旧金山去看一年一度的多元文化狂欢节。以下是实况报道。
上周出差到硅谷,朋友周日载我到旧金山去看一年一度的多元文化狂欢节。以下是实况报道。 上面这张就是临街的一群人随着摇滚乐猫王Elvis的歌曲,狂歌劲舞。据说30%的人都有酒精作用,表现很癫狂。有些男男女女裸体游行。
上面这张就是临街的一群人随着摇滚乐猫王Elvis的歌曲,狂歌劲舞。据说30%的人都有酒精作用,表现很癫狂。有些男男女女裸体游行。 上面这张的右侧中年妇女,身材中上,赘肉不多,特别爱show, 摆出各种姿势让人拍照(可惜没有抓拍到她的正面照)。她显然在来前把阴毛给剃光了,不知道是否认为这样更美。
上面这张的右侧中年妇女,身材中上,赘肉不多,特别爱show, 摆出各种姿势让人拍照(可惜没有抓拍到她的正面照)。她显然在来前把阴毛给剃光了,不知道是否认为这样更美。 跟天体海滩类似,多数裸体男女都是中老年,他/她们最大方,大大小小器官各异,但不好看。
跟天体海滩类似,多数裸体男女都是中老年,他/她们最大方,大大小小器官各异,但不好看。

















 。
。


























又是一次动荡,事情终于闹大了。
呵呵,开后门进来的事情,此事不可公开说啊:-)
“德赛不过是一种生活方式“,就是说不要将德赛二先生推向神坛,而是在日常小事(网络上=发文留言etc)上体现科学和民主的精神。没有什么热恋过头的感觉啊,this year head,想要热恋的感觉都找不到了,哪里还会有过头的感觉:-(
顺便说一句,任何博主进来也没有被要求签字画押,保持高度一致的。
无论如何,用技术手段屏蔽是不必的。
希望站方调整一下姿态。
寻正一直说立委是“人文学者”,在留言中提醒寻正好几回,今天的帖子里还是这么说,唉。
如果不禁言、不删贴,大家可以各说各话,就没什么大不了的,真理越辩越明。
到现在为止,还没有看到对liwei的批评,liwei多虑了。
另外从事科技或科学工作的人,不一定就不是反科学,至少liwei如此热衷的转载mirror的言论,就已经朝反科学的方向前进了。
最后,这里“小将”固然不少,“老兵”也是有很多的,不管是谁,都要努力学习科学精神,这里不是凭资历或名气来装神弄鬼的地方。
红叶:科学精神固然重要,但那是虚的啊!听听“老兵”的“know how”和”心得”不是一件愉快的事情吗?
科学精神一点都不虚。
要反科学,总得有个貌似不反科学的借口。把科学家打成人文学者,就是一个不错的借口。
人家怕的就是真理越辩越明,所以才要封杀。如果心里有着科学的底气,又何须成天高举科学的大旗?
得了吧,Liwei是不吭声,后来又要把问题往什么“宽妥”上扯;Mirror是不正面讨论问题,跟贴除了嘲笑,就是玩文字游戏。这就是你说的“真理越辩越明”?笑话。
虽然我不认同Qbit的观点,但至少他有讨论问题的诚意,这一点上,上述两位加起来都不如Qbit。
【我入公园走的是后门,没有宣誓效忠,也没有签字画押要保持与中央的高度一致。】
網主也 不容易,既要繼承甚至超過新語絲的科學主義帝國風格,又要顯示比新語絲更寬容,真是難以完成的任務啊!
【以组织和长老的名义耍流氓,开互联网先河】
立委老師這句話站不住腳。
【立委是个标准的科学工作者或科学家 (立委作为Principal Scientist承担国家17个科研项目的PI,立委技术移民美国走的就是 Outstanding Researcher 的优先通道),】
可見國家的科研項目是“偽科學項目”,美國更是一個偽科學當道的國度,比不得賽園科學主義純度高!
科学编辑部的负责人、代表“主流科学”发言的,都不曾“有讨论问题的诚意”,而是一开始就扣“伪科学”、“骗子”的帽子,倒要非科学编辑部的、不敢代表“主流科学”的,对这样的“科学”代言人,“有讨论问题的诚意”?^_^
当然,职业科学人也难免滥竽充数,缺乏科学精神,只要不骂人,广大小将的批判和帮助,立委还是心存感激的。
===================
立委老兄心胸过人,不错!当初我来德赛,原因就是喜欢德赛和xys分家后,偏安一隅,低调地坚守自己的阵地。原本觉得来德赛可能会低调好一段时间,想不到造化弄人,冉匪加盟,新老右派来归,国内的整风运动又把德赛推到风口浪尖上,德赛又颇有几个能做事的人,想低调都不行。还请立委兄继续支持!