“大数据与认识论”研讨会的书面发言
屏蔽 |||
【立委按】刘钢老师来函,邀请我从我的大数据博文系列选辑一篇书面发言,参加社科院哲学所题为“大数据与认识论”的研讨会。盛情难却,更不用说社科院是我老家了。那就把散在科学网博客【社媒挖掘】专栏的博文中的立委论大数据拼接汇总一下吧。无论国内国外,学界业界,“大数据”都是滚烫的热词。上次愚人节应中文信息学会邀请在软件所做了一个题为【大数据时代中文社会媒体的舆情挖掘】的演讲,科学网编辑还特地录了像,高挂在【科学网公开课】里,与那些世界级的大师的讲座并列,与有荣焉,不胜惶恐(倒不是要自我矮化,说自己的大数据工作不在世界水平之列,但科学大讲堂里面的人物大多是科学殿堂让人高山仰止的大科学家,而在下不过是一介匠人)。无独有偶,去年流行大数据,硅谷科学家和工程师举行一系列关于大数据的讨论会,被邀请作为 panelist 参加了两个大数据研讨会,现场问答热烈,气氛很活跃。旅美华人科学家协会也征集出版了一期大数据专刊,也发表了几篇论文。硅谷的【丁丁电视】也早邀请立委在其创新频道做一个大数据的科技访谈,一直抽不开身准备,推迟到三月左右。一来二去,俨然是大数据专家了。其实,立委所长不过是大数据之一部,即自然语言的文本挖掘这块儿。而对于大数据的非文本形式(譬如语音、图片、录像、数字记录等),对于大数据的云处理手段及其工程架构等,所知十分有限。因此,本文仅仅就自然语言文本挖掘,特别是对近年火热的社会媒体的挖掘,谈一点一己之见,抛砖引玉,供各位参考。
(1) 大数据热的背景
我们现在正处在一个历史契机,近几年发生了一连串值得注意的相关事件。其热门关键词是社会媒体(social media) 、云计算(cloud computing),移动互联网(mobile web)和大数据(big data)情报挖掘。针对社会媒体内容利用云计算作为支撑的高新技术产业成为潮流。
社会媒体尤其是微博持续升温,无论是用户还是其产生的内容,都以爆炸性速度增长,一场悄悄的社会媒体革命正在发生,它从根本上改变着社会大众以及企业对信息的接受和传播方式。传统的由媒体巨头主导经由电视、广播和报纸的自上而下的新闻和宣传的传播方式,正在逐渐让步于基于网络与网民的社交媒体的蛛网方式。最新的新闻(无论是天灾人祸、名人掐架还是品牌褒贬)常常发端于处在现场的网民或当事人的微博,然后瞬间辐射到整个互联网,传统传媒往往紧随其后。在这样的形势下,企业软件巨头纷纷把目光聚焦在对于社会媒体舆论和民意的跟踪上,视其为品牌和客户情报的重要来源。
2011年初,美国做市场情报的巨头之一 Salesforce以三亿多美元 (326million)的价钱并购了社会媒体客户情报检测系统Radian6,说明社会媒体中客户对产品的评价情报对于企业的重要性不容忽视。Oracle对从事云计算和社会媒体追踪的公司RightNow的并购更是高达15亿(1.5 billion). HP在逐渐放弃低利润的PC和平板等硬件产业的同时,开始加强企业软件的投资力度,以120亿天价购并了从事文本情报的英国公司Autonomy(12billion)。最后,接近2011年末的时候,全球企业软件的另一家巨头SAP以34亿收购了云计算公司SuccessFactors(3.4 billion),并决定与专事社会媒体深度分析的公司 Netbase 建立战略伙伴关系,分销并整合其社会媒体情报作为企业情报解决方案的重要一环。加上IBM自己的 Coremetrics Social 和 Adobe的 SocialAnalytics,可以看到所有企业软件巨头不约而同看好社会媒体的情报价值。
在这个领域的投资和竞争日趋激烈。越来越多的华尔街主流投资公司开始加大对社交媒体 (social media) 分析系统公司的投资力度。如 Jive Software,连续得到 Sequoia Capital 两轮投资 (2007 和2010)。Sequoia Capital 是“重中之重”的 投资大鳄,曾是如下名牌企业的最早投资商,战略眼光犀利: Apple, Google, Cisco, Oracle.
对于中文社交媒体大规模处理的应用型软件,目前才刚起步。然而中文网络信息的增长速度却是扶摇直上,最值得重视的是爆炸性增长的腾讯微信对个人网络及其社交方式的革命性影响,以及新浪微博在社会公共生活中的巨大影响。社交媒体所产生的巨量内容有如深埋的富矿,亟待开采。
有问,这一波热潮会不会是类似2000年的又一个巨大的泡沫?我的观察是,也是,也不是。的确,在大数据的市场还不成熟,发展和盈利模式还很不清晰的时候,大家一窝蜂拥上来创业、投资和冒险,其过热的行为模式确实让人联想到世纪之交的互联网 dot com 的泡沫。然而,这次热潮不是泡沫那么简单,里面蕴含了实实在在的内容和价值潜力,我们下面会具体谈到。当然这些潜在价值与市场的消化能力是否匹配,仍是一个巨大的问题。可以预见三五年之后的情景,涅磐的凤凰和死在沙滩上的前浪共同谱写了大数据交响乐的第一乐章。
回顾一下互联网技术公司的里程碑吧:
很多人这样预测。 Google 首席科学家前不久也列此为未来十年的高新技术第一块牌子。所不清晰的是谁家会胜出。看样子是有志之士摩拳擦掌弄潮儿的时机了。
(2)什么是大数据
顾名思义就是强调数据的量,但其实这个概念并不是那样简单。如果单纯论量,大数据不是今天才有的,而且数据的量也是一个积累渐变(当然可能是加速度增长)的过程。
所谓大数据,更多的是社会媒体火热以后的专指,是已经与施事背景相关联的数据,而不是搜索引擎从开放互联网搜罗来的混杂集合。没有社会媒体及其用户社会网络作为背景,纯粹从量上看,“大数据”早就存在了,它催生了搜索产业。对于搜索引擎,big data 早已不是新的概念,面对互联网的汪洋大海,搜索巨头利用关键词索引(keyword indexing)为亿万用户提供搜索服务已经很多年了。我们每一个网民都是受益者,很难想象一个没有搜索的互联网世界。但那不是如今的 buzz word,如今的大数据与社会媒体密不可分。当然,数据挖掘领域把用户信息和消费习惯的数据结合起来,已经有很多成果和应用。自然语言的大数据可以看作是那个应用的继续,从术语上说就是,text mining (from social media big data)是 data mining 的自然延伸。对于语言技术,NLP 系统需要对语言做结构分析,理解其语义,这样的智能型工作比给关键词建立索引要复杂千万倍,也因此 big data 一直是自然语言技术的一个瓶颈。
大数据也包括声音、 图片和录像等媒体。本文只谈文本大数据。
随着社会媒体的深入人心以及移动互联网的普及,人手一机,普罗百姓都在随时随地发送消息,发自民间的信息正在微博、微信和各种论坛上遍地开花。对于信息受体(人、企业、政府等),信息过载(information overload)问题日益严重,利用 NLP 等高新技术来帮助处理抽取信息,势在必行。
除了与社会媒体以及施事背景密切相关以外,大数据此时的当红也得力于技术手段的成熟。大数据的存贮架构以及云计算的海量处理能力,为大数据时代的到来提供了技术支撑平台。在此基础上,大数据的深度挖掘才有可能跳出实验室,在具体应用和服务中发挥作用。
大数据时代只认数据不认人。In God We Trust. In everything else we need data. 道理很简单,在信息爆炸的时代,任何个人的精力、能力和阅历都是有限的,所看到听到的都是冰山一角。大V也如此,大家都在盲人摸象。唯有大数据挖掘才有资格为纵览全貌提供导引。
当然,这不是说,大数据挖掘就是完美的解决方案。但是,正如一人一票的民主选举也不是人类社会完美的体制,而只是最少犯错误的机制一样,大数据挖掘比任何其他个人或利益集团的分析,较少受到主观偏见的干扰。这是由大数据本性决定的。
大数据是忽悠么?吆喝多了,烂了,就跟转基因似的,本来是正经的研究,也要被人怀疑是忽悠,甚至骗局。要说忽悠,大数据有没有忽悠?当然有,应该说很多。所有的泡沫都是吹起来的,但特别大的泡沫其所以能被吹起来并且持续,就不仅仅是吹功可为。正如我演讲中说过的,大数据不仅仅是忽悠,一场革命也许在酝酿着。
(3)大数据挖掘技术及其挑战
面对呈指数增长的海量信息,人类越来越面对信息获取的困境。唯一的出路是依靠电脑挖掘。对付文本大数据的核心技术是自然语言处理(NLP),没有鲁棒高效的 NLP,电脑挖掘得不到什么有指导价值的情报。就说社会媒体对产品和服务的评价吧,每时每刻,无数用户的抱怨和推荐不断出现在网上,这些客户对产品的评价情报对于企业加强产品功能和研发新产品,具有很高的应用价值。可是怎么获取这些淹没在语言海洋中的情报呢?出路就是:1 自动分析; 2. 自动抽取;3 挖掘整合。这就是我们正在做而且已经取得显著效果的工作。
社会媒体的特点是什么?概括来说,就是:1. 不断翻新的海量信息源;2. 满是不规范的字词和表达法。这就要求研发的系统,首先必须具有大数据处理能力( scalability),实验室的玩具系统无论其数据分析多么精准深入也是不行的;同等重要的还有分析系统的鲁棒性(robustness)。在这两者的基础上,如果再能做到有深度(depth),则更佳。深度分析的优势在于能够支持应用层面的以不变应万变。因为应用层面的变数大,不同的客户、不同的产品对于信息的关注点不同,所以抽取信息应该越灵活越好,最好能做到象目前运用搜索引擎或数据库查询那样方便。但数据的语言表达是千变万化的,要做到信息的灵活抽取,而不是根据事先预定的信息模板来抽取,那就需要相当的语言分析深度来支持一个逻辑化的语义表达。要一个系统既有 scalability,robustness,还要有 depth,不是一件容易的事儿。
在处理海量数据的问题解决以后,查准率和查全率变得相对不重要了。换句话说,即便不是最优秀的系统,只有平平的查准率(譬如70%,抓100个,只有70个抓对了),平平的查全率(譬如30%,三个只能抓到一个),只要可以用于大数据,一样可以做出优秀的实用系统来。其根本原因在于两个因素:一是大数据时代的信息冗余度;二是人类信息消化的有限度。查全率的不足可以用增加所处理的数据量来弥补,这一点比较好理解。既然有价值的信息,有统计意义的信息,不可能是“孤本”,它一定是被许多人以许多不同的说法重复着,那么查全率不高的系统总会抓住它也就没有疑问了。从信息消费者的角度,一个信息被抓住一千次,与被抓住900次,是没有本质区别的,信息还是那个信息,只要准确就成。疑问在一个查准率不理想的系统怎么可以取信于用户呢?如果是70%的系统,100条抓到的信息就有30条是错的,这岂不是鱼龙混杂,让人无法辨别,这样的系统还有什么价值?沿着这个思路,别说70%,就是高达90%的系统也还是错误随处可见,不堪应用。这样的视点忽略了实际的挖掘系统中的信息筛选(sampling)与整合(fusion)的环节,因此夸大了系统的个案错误对最终结果的负面影响。实际上,典型的情景是,面对海量信息源,信息搜索者的几乎任何请求,都会有数不清的潜在答案。由于信息消费者是人,不是神,即便有一个完美无误的理想系统能够把所有结果,不分巨细都提供给他,他也无福消受(所谓 information overload)。因此,一个实用系统必须要做筛选整合,把统计上最有意义的结果呈现出来。这个筛选整合的过程是挖掘的一部分,可以保证最终结果的质量远远高于系统的个案质量。总之,size matters,多了就不一样了。大数据改变了技术应用的条件和生态,大数据 更能将就不完美的引擎。
(4)客户评价和民意舆论的抽取挖掘
人民是由个体组成的,网民是由网虫组成的。网民的声音来自一个个网虫的帖子。网民声音的载体就是社会媒体大数据。在大数据的尺度下,个体声音的过细分类没有太大意义,因为只要数据足够大,其最终舆情结果(结论)是不变的。举例来说,10万个正面呼声,100万个负面呼声,其综合舆情结果并不会因为这10万中有 1万crazy,1万love,8万like,负面中有10万fuck,10万hate,80万dislike 等等而有大的改变。无论如何计算,结论依然是天怒人怨。
大数据系统情报挖掘的真正价值何在呢?就是揭示冗余度支持的有统计意义的情报及其关联。在大数据的尺度下,个体情报的引擎查全率的不足不是问题,因为在大数据整体挖掘的背景下,样本空间的问题消失了。个体的不足或遗漏,不过是等价于样本空间缩小了那么一点点儿,对于统计情报的完备、性质和价值不具有负面影响。考虑到很多年来,统计情报都是手工 survey 而来,其样本空间由于预算以及时效的制约,大多是几千个数据点(data points)而已,统计人员一直在预算、时效和 error margin 之间挣扎。如今的大数据挖掘,随便一个调查都有百万甚至千万的数据点支持,与手工调查完全不可同日而语,样本空间的些微变化因此不能对情报价值造成伤害。总之,与其追求引擎的查全率,不如把精力放在查准率上,然后着力于应对数据量的挑战(scale up)。
采样大就可以弥补个体颗粒度的粗疏,这在机器学习领域被一再证明,也是很多统计学家不屑于语言学家精雕细刻雕虫小技的缘由之一。这么说,语言学可以退出舞台了?
并非如此。主要原因有二。
第一是大数据并非总存在。冷门品牌或者新出的品牌的数据量就往往不够,另外很多分析要求对数据进行切割,比如从时间维度的切割可以反映舆情的消长(trends),是制定决策时非常重要的情报,可是大数据一切隔往往就成了小数据,没有语言学上比较细致的分析来弥补,舆情分析就不靠谱,没有足够的置信度。
第二是褒贬分析只提供舆情的一个概览,它本身并不是 actionable insights. 知道很多人喜欢或者不喜欢一个品牌,so what?企业还是不知道怎么办,最多是在广告宣传投资量的决策上有些参考价值,对于改进品牌产品,适应用户需求,褒贬舆情太过抽象,不能提供有价值的情报。这就要求舆情分析冲破两分、三分、五分的分类法,去发掘这些情绪的背后的动因(reasons/motivation),回答为什么网民喜欢(不喜欢)一个品牌的问题。譬如挖掘发现,原来喜欢麦当劳的主要原因是它发放优惠券,而不喜欢它的原因主要是嫌它热量太大,不利减肥。这样的舆情才是企业在了解自己品牌基本形象以后,最渴望得到的 actionable 情报,因为他们可以据此调整产品方向(如增加绿色品种和花样,水果、色拉等),改变广告策略(如强调其绿色的部分)。
大数据给决策人(政府、企业或者犹豫如何选择的消费者)提供了一个前所未有的方便工具,去纵览有统计意义的舆情。这在以前只能通过小规模误差很大的人工问卷调查来做。如今自动化了,而且样本量高出好几个量级,拜科学技术所赐。
(5)自动民调: 社媒大数据挖掘的重要应用
自动民调(Automatic Survey)指的是利用电脑从语言数据中自动抽取挖掘有关特定话题的民间舆论,其技术领域即所谓舆情挖掘(sentiment mining),通常需要自然语言(NLP)和机器学习(Machine Learning)等技术作为支持。自动民调是对传统的问卷调查一个补充或替代。在社会媒体日益普及的今天,民间情绪和舆论通过微博、博客或论坛等社会媒体管道铺天盖地而来,为了检测、采集和吸收这些舆论,自动民调势在必行,因为手工挖掘面对大数据(big data)已经完全不堪负荷。
民意调查(poll)可以为政府、企业以及民众的决策提供量化情报,应用范围极其广泛。总统大选是一个突出的例子,对于总统候选人本人及其竞选团队,对于选民,民调的结果可以帮助他们调整策略或作出选择。产品发布是企业的例子,譬如 iPhone 5 发布以后,民调的反馈可以帮助苹果及时发现问题。对于有意愿的消费者,民调的结果也有助于他们在购买、等待还是转向别家的决策时,不至于陷入盲目。
相对于传统的以问卷(questionnaire)调查为基础的民调,自动民调有以下几个突出特点。
及时性。传统民调需要经过一系列过程,设计问卷、派发问卷(通过电话采访、街头采访、有奖刺激等手段)、回收问卷,直到整合归纳,所有程序都须手工进行,因此难以做到及时响应。一个认真的客户产品调查常常需要几天甚至几周时间方可完成。自动民调可以做到立等可取。对于任意话题,使用自动民调系统就像利用搜索引擎一样方便,因为背后的处理机在不分昼夜地自动分析和索引有关的语言资料(通常来自社会媒体)。
高性价。传统民调的手工性质使得只有舍得不菲的花费,才可以做一项有足够规模的民调(样本小误差就大,难以达到民调的目的)。自动民调是由系统自动完成,同一个系统可以服务不同客户不同话题的各种民调,因此可以做到非常廉价,花费只需传统民调的零头。样本数可以高出手工调查回收数量的n个量级,是传统民调无法企及的。至于话费,通常的商业模式有两种,客户可以订阅(license)这样的系统的使用权,然后可以随时随地对任意多话题做任意多民调。零散客户也可以要求记件使用,每个话题民调一次缴纳多少钱。
客观性。传统民调需要设计问卷,这就可能有意无意引入主观因素,因此不能完全排除模糊歧义乃至误导的可能。自动民调是自底而上的自动数据分析,用的是归纳整合的方法,因此更加具有客观性。为了达成调查,调查者有时不得不施行物质刺激,这也产生了部分客户纯粹为了奖励而应付调查、返回低质问卷的弊端。自动民调的对象是民意的自然流露(水军和恶意操纵另论),基数大,也有利于降噪,这就保障了情报的客观性。
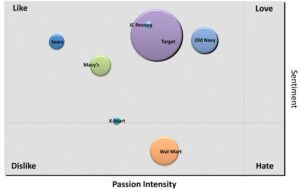
对比性。这一点特别重要,因为几乎任何话题的民调,都需要竞争对手或行业的背景。正面反面的舆论,问题的严重性等等,只有通过对比才能适当体现。譬如民调奥巴马的总统竞选效益,离不开对比其对手罗梅尼。客户调查 AT&T 手机网络的服务,离不开比较其竞争者 Verizon,等。很多品牌实际上需要与一系列同类品牌做对比,才好确定其在市场的地位(如上图所示)。这种对比民调,虽然在理论上也可以手工进行,但是由于手工民调耗时耗力耗钱,很多时候调查者不得不减少或者牺牲对于竞争对手的调查,利用有限的资源只做对本企业的品牌调查。可自动调查就不同了,多话题的调查和对比是这类产品设计的题中应有之义,可以轻易完成。
自动民调也有挑战,主要挑战在于人为噪音:面对混乱的社会媒体现实,五毛、水军以及恶意舆论的泛滥,一个有效的舆情系统必须不断与垃圾作战。好在这方面,搜索引擎领域已经积攒了丰富的经验可以借鉴。另一个挑战是需要对网络世界做两类媒体的分类(所谓push/pull的媒体分野)。民意调查切忌混入“长官意志”,客户情报一定要与商家宣传分开:同是好话,商家是王婆卖瓜,客户才是上帝下旨。这种媒体分类可以结合来源(sources)、语气(宣传类材料常常是新闻官方语气,而客户评价则多用口语和网络语)来决定,是有迹可寻的。
总之,在互联网的时代,随着社会媒体的深入民间,民间情绪和舆论的表达越来越多地诉诸于社会媒体。因此,民调自动化势必成为未来民调的方向和主流。其支持技术也基本成熟,大规模多语言的应用指日可待。

民调自动化,技术带领你自动检测舆情: 社会媒体twitter的自动检测表明,奥巴马显然赢了昨晚的第二次辩论。人气曲线表明他几乎在所有议题上领先罗梅尼。
对奥巴马真正具有挑战性的议题有二:一是他在第一任总统期间的经济表现(6:55pm);二是批判他对中国不够强硬 (7:30pm)。人气曲线反映了由我们自然语言技术支持的实时舆情挖掘。


(6)实时监测: 大数据时代的危机管理
大数据挖掘第二个重要应用就是为公关危机提供实时检测和预警的工具。


话说这危机管理(risk management)在进入社交媒体大数据时代,确实成为一个大问题。老话说,好话不出门,坏话传千里。在微博微信的时代,岂止千里,有时候一件事被疯狂推转,能传遍全世界。如果没有危机管理的意识以及迅速发现和应对的技术手段和公关技巧,损失的就是企业的信誉,外加金钱。这一点大名鼎鼎的跨国公司西门子最清楚,由于公关处理失当,发现和应对的不及时不诚恳不懂心理学,惹恼了一位叫做罗永浩的胖大哥。老罗是大 V,嗓子亮,因此一个简单的产品质量问题(好像是西门子冰箱的门不太容易关严实)演变成一场社交媒体的戏剧性的消费者维权事件。老罗愤而砸西门子冰箱的行为艺术和形象,成为家喻户晓的消费者维权的特征符号。西门子为此损失了多少银子,百万还是千万,只有他们自己可以算清楚,打落牙齿自己吞,这是傲慢的西门子的血的教训。

企业大数据运用的主要 use scenarios,其中 risk management 最容易打动客户,他们也最愿意花大钱帮助实时监控。一个可能的公关灾难从火种到无法收拾,里面可以调控的时间不长,他们希望电脑大数据监控能在第一时间发出预警,然后他们可以及时应对。
曾经测试中文系统一个月的微博数据(新浪微博和腾讯微博),想看看系统对于类似危机的监测效果如何,结果发现了一个当时闹得沸沸扬扬的必胜客虾球广告事件,涉嫌侮辱视力残障人士。下面的 挖掘抓取令人印象深刻,显然这次事件严重影响了企业的社会形象,是一个不折不扣的公关危机。


好在必胜客管理层应对迅速,及时道歉,逐渐平息了事态。
(7)大数据及其挖掘的局限性
先说它的不宜和禁忌。
1 这种挖掘不宜做预测,更适合做回顾。当然,历史是未来的镜子,回顾过去也未尝不能透出一点趋向的预测。
2 这种挖掘一般不提供问题的答案,特别是科学问题,答案在专家或上帝手中,不在网民的口水中。
3 大数据不是决策的唯一依据,只是依据之一。正确的决策必须综合各种信息来源。大事不提,看看笔者购买洗衣机是怎样使用大数据、朋友口碑、实地考察以及种种其他考量的吧。以为有了大数据,就万事大吉,是不切实际的。值得注意的是,即便被认为是真实反映的同一组数据结果也完全可能有不同的解读(interpretations),人们就是在这种解读的争辩中逼近真相。一个好的大数据系统,必须创造条件,便于用户 drill down 去验证或否定一种解读,便于用户通过不同的条件限制及其比较来探究真相。
社媒是个大染缸,顽主比烂,僵尸横行,水军泛滥,大数据挖掘又有什么意义?无论是怎样大的染缸,它实际上成为最具规模、最便捷、有时甚至是唯一的普罗网民的舆情宣泄口。水军僵尸总会有对付的办法。社媒的混沌和杂乱不是不作为的理由。从情报角度,它可能不是富矿,但肯定是金矿,就看你有没有本事挖掘它。
有网友怕大数据挖掘误导读者。的确,大数据的操作和挖掘可能有 bug。但大数据提供的舆情全貌鸟瞰是其他手段代替不了的,而我们每个个体在日常接触中只能看到舆情信息海洋的一滴水。事实上,无视大数据更容易被自己的局限所误导。害怕大数据,就好比蒙上眼睛,世界就不见了一样可笑。
应该指出的是,挖掘本身虽然可能有 bug ,数据本身也有不少噪音,但它们对所有搜索的话题是一视同仁的,是独立于话题的。这些数据及其挖掘的不完善只要放在比较的框架中就不是严重问题。虽然具体语言中褒贬比例和分布可能不同,但是如果一个对象的褒贬指数放在其他对象的褒贬指数的背景(reference frame) 下来阐释,其解读就比较真实。比如,在过往的许多调查中,我们知道褒贬度降到零下20以后就很不妙,说明媒体形象差,老百姓很多怨气。有了这样一个历史积累,新的品牌或话题如果达到类似的指标,解读就不大会离谱了。
特别是,我们做一个行业的多品牌调查和比较的时候更是如此。品牌A与品牌B的在舆情中的相对位置非常说明问题。系统的误差,质量的不完美,语言数据的不完整,以及语言现象的分布不匀,所有这些统统不再成为问题,除非这些差异是针对特定品牌的(这种现象基本不出现)。
这一点毛委员早就说过:有比较才有鉴别。
(8)大数据创业的喜和乐
高新技术的好处在于做前人没做过的创新。创新的真义在于在技术手段面对应用现场的无数应用可能的组合方案中,在与用户的交互与市场的培育下,你找到了那一个很小子集中的一员。这个子集里的产品定义因应时代的召唤,生逢其时,不早也不晚,而且有技术门槛(entry barrier)。
如果你做到了这一点,你会发现,你的客户不乏热情先行者(early adopters),他们不吝啬溢美之辞,为了 现实需求中疑难的解决。也有客户大喜过望,把他们不理解的语言技术,视为未来世界奇迹的提前来临。他们的欣喜会感染开发者。当这种感染不再是个案,而是每日在发生的时候,你不可能无动于衷,也不可能不加入客户成为创新的吹鼓手。
http://blog.sciencenet.cn/blog-362400-758135.html
上一篇:毛巾冻冰会断,为什么地上长的草冻冰不会断?
下一篇:留学资讯:美国牛排榜