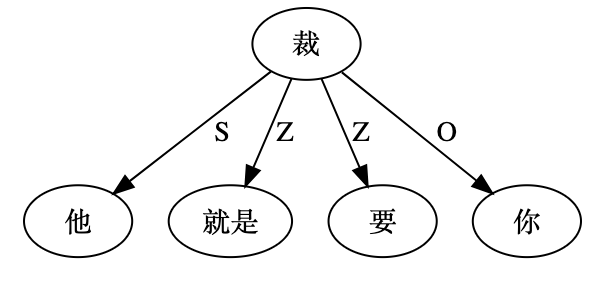
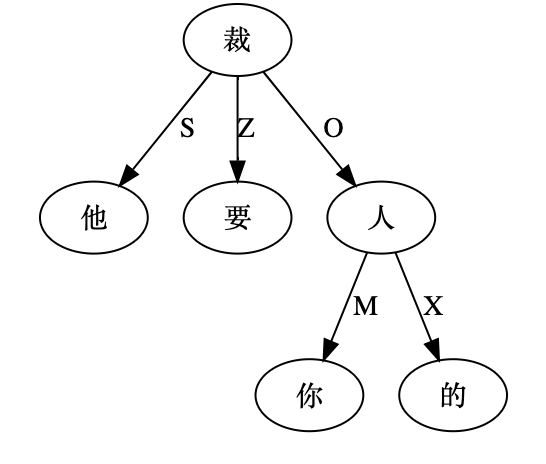
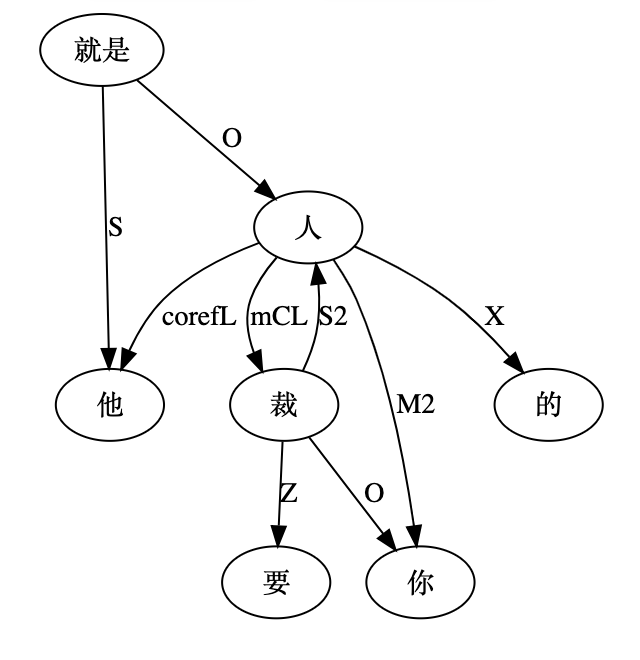
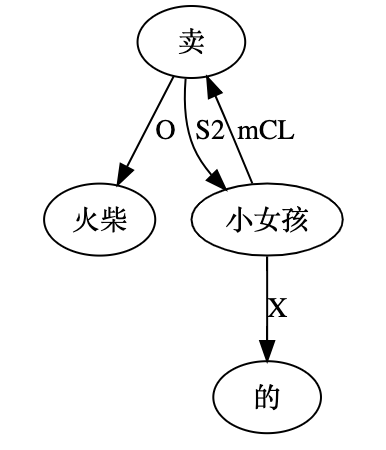
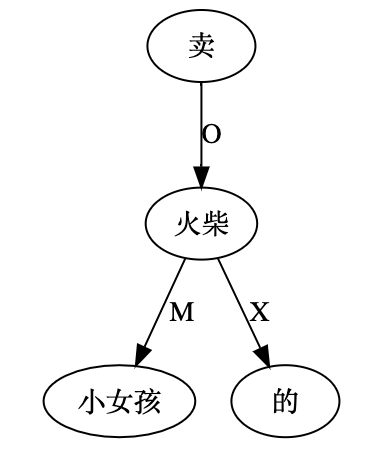
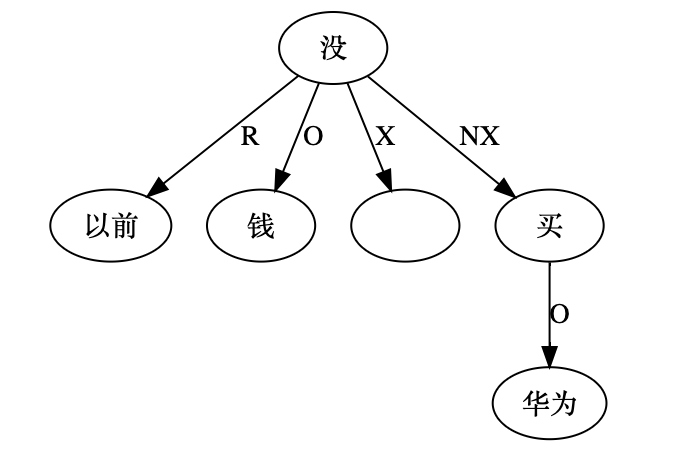
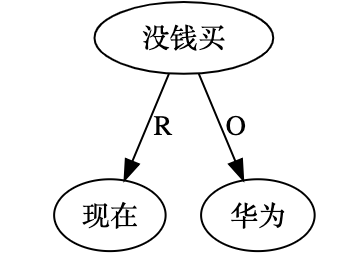
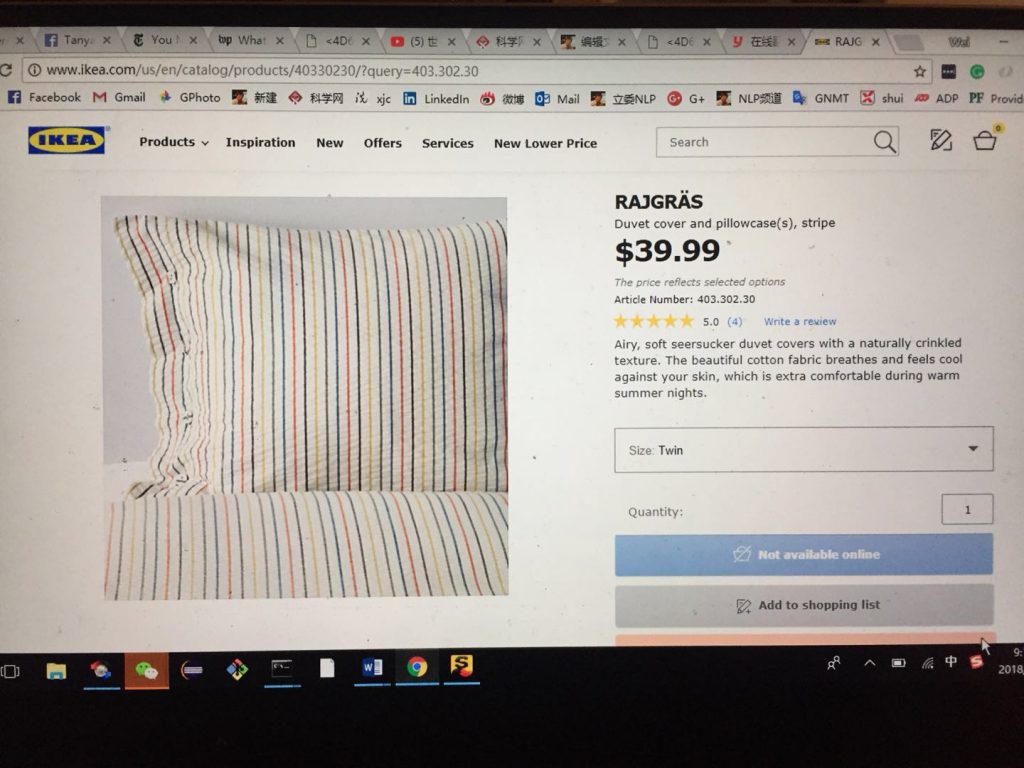
尼:
罗素说科学够不着的哲学,哲学够不着的宗教。科学和宗教有交集,如生死,意识,自由意志等。我有篇未完长文 "当我们谈论生死时我们在谈论什么" , 准备作为我《人工智能简史》最后一章。再长的话,得问洪爷了。
@洪 邓总问哲学和宗教啥关系。我昨晚没回复。你接茬说。
邓:
原始问题是宗教、哲学和科学的关系是啥?
白:
科学尽头是哲学,哲学尽头是八卦。
邓:
宗教呢?
白:
宗教尽头是科学啊
洪:
好比有个大鱼缸,
鱼游随便哲学想。
科学只限缸内忙,
缸外有宗教对象。

尼:
@洪 缸能自动变大或变小吗?
邓:
@白 @洪 你俩意见貌似相反
洪:
缸是人所能感知的;如果人类感知进步了人,例如开了天眼啥的,边界就能扩大
邓:
我等白老师和洪爷打起来
邓:
罗素原话怎么说的?
白老师和洪爷彼此惺惺相惜,不打……
白:
缸外有缸
邓:
请白老师明示。解说解说。
马:
探索哲学的小孩
尼:
这小屁孩把想哲学的鱼都给捞走了
邓:
你们都是禅宗的
洪:
身心灵各有其缸,
有界有墙可以撞。
科学自觉不骑墙,
宗教墙外寄希望。
李:
除了红包与痛苦为真 一切皆假。宗教貌似也远不能普度众生,最多是抚慰一小片。至于科学 则是鸦片。让所谓科学家在虚假的高高在上中,求得半片玩积木的兴奋和满足。
邓:
立委登场,讨论正式开始,
彭:
已有的宗教如果不能普渡众生,就只能创新教,当教主了。@wei
李:
当教主肯定更惨。做个追随者至少还可以把负担转嫁 教主的重负转谁呢?
白:
不同领域,宗教尽头到来的时点不同。有的早有的晚。
洪:
假设鱼缸水不浑,
科学/哲学可显灵。
鱼缸壁若玻璃弄,
宗教可以很理性。
李:
面对终极问题 一切那么苍白。高人不高 哲人不哲 敬畏之心难存。
邓:
白老师本质上是认为科学发展会终结宗教?
张:
还有一种可能就是科学发展证实了宗教
邓:
洪爷的说法是两者之间有无法逾越的边界?
李:
都不能解决人类的痛苦问题。
白:
说的就是人类的痛苦问题,科学一定会有办法。
邓:
刺激神经中枢吗?
白:
不是人类整体的痛苦,是一个个具体个体的痛苦。
张:
具体个体的身体痛苦通过科学一个个在解决了。但是精神层面的痛苦无法解决的。就像科学对我们身体的自愈能力一无所知一样。
白:
精神痛苦需要举例,然后看搞定它的途径和时间表
洪:

鱼跃出水有可能,
科学宗教一时懵。
落回或许先知成,
天慧法佛眼开睁。

白:
@张 现阶段科学不等于科学。
邓:
@白 终极的科学是不是等价为绝对真理?
白:
不是。搞科学一般都怕谈“真理”。
张:
精神痛苦的例子太多了,幼年丧母、青年丧父、中年丧妻、老年丧子、失恋,被甩。。。
邓:
如果科学认为不存在真理,宗教又把自己定义为真理,那么是不是可以理解为完全两件事?
张:
估计在地球上找到绝对真理的时候我们要移民外太空了。科学的真理好像是相对的,而宗教的真理是绝对的。
白:
失恋跟记忆关系很密切。如果可以干预和改变记忆,对待失恋的态度也会有所不同。
邓:
原来@尼 大师提到“自我”的容器问题,就是那个换头术悖论,跟白老师这个观点探讨的方向一致吧。
鸣:
精神痛苦,多与欲望相关
白:
执着都是有物质基础的。现在不敢动这个物质基础,主要是怕误伤。如果定点改变,确保不误伤,改了又何妨。离开要解决的问题,真理的绝对还是相对就是个伪问题。有了要解决的问题,大家就直接比疗效好了,不必涉及那些伪问题。
张:
失恋不要被忘记。那也是一种情感需要被回忆的。有了痛苦才有反差,否则人生又有什么意思。
白:
想保留反差就谁也别找,不想反差太大就定点微剂量清除记忆,在这点上宗教活儿太糙,论精准还得寄希望于科学。
邓:
@白 “基督教是现代科学的接生婆”跟您的说法一致吗?
白:
也不尽然吧……
邓:
宗教的尽头是科学
张:
或者科学的尽头是宗教
邓:
现在是张老师力战白老师
张:
来搅浑水。
白老师是严谨的科学家,我们是来搅搅乱。
邓:
必须有人捣乱才能激发白老师讲话的欲望。
白:
娱乐而已。
邓:
@尼 大师该你了。向白老师开炮。咱们那天关于这个主题聚聚。顺便听白老师弹琴。
@白 《those were the days》这歌用曼陀铃应该不错。
尼:
好多讨论的词汇没法定义。例如,"人文"在文艺复兴时的意思是为了和“神”唱反调,科学也算人文,但几经周转,人文语义迁移了。在中国,就成文科生的意思了。
邓:
请大师先定义词汇
尼:
哲学也一样。一种方便的定义是哲学就是哲学系教的那些玩意。那恐怕现在的哲学和100年前哲学不一样了。再过10年,逻辑就不算哲学了。我得开会去,晚上喝两口再聊。
阮:
对于一个生命有穷的个体来说,科学能解决的问题少之又少,当科学不能解决时,就赖宗教获得个体幸福了。因此,科学的终端是宗教。
白:
@阮 宗教就是昨天的科学
李:
一个显而易见的事实是 科学技术的进步带来了物质繁荣 但人类的精神问题没有减少 貌似日趋严重,至少是停滞的感觉 与科技的一日千里 无法比拟。
白:
人类不好伺候啊。
穷也矫情,富也矫情。
阮:
科学伺候的是客观世界,宗教伺候的是人类精神世界,目的不同。
张:
白老师,宗教比科学早啊
白:
对啊,宗教的明天是科学。一个意思。
李:
宗教要真伺候得好 为什么还有那么多迷途羔羊?
譬如 执着心,佛教 甚至fl功 都有很多放下执着心的教义,道理是深刻的,几乎无懈可击,可是怎么那么违背人性 难以接受?
张:
其实科学和宗教确实很难放在一起,科学也许永远找不到最终的答案。
阮:
这世上有这么多无知的人,为什么不说科学伺候得不好?
白:
@阮 不一定啊。你以为高保真音响只是伺候耳朵的?不是的,是伺候听觉欣赏的。
马:
@阮 看你怎么定义终端。科学和技术要分开。享受属于技术。
阮:
@白 科学求真,让人类获得享受是副产品。
李:
好吧 就说死亡不可抗拒 这个我等可以接受 (虽然也是经历很多才接受的)。那么 在我们死亡之前的这些日子里,我们每个人都想减免痛苦,可痛苦依然挥之不去。
马:
所谓死亡只是换了一个躯体而已。
白:
说不定吃一种药就不怕。又减少痛苦又不上瘾。到时候再痛苦就矫情了。
dl:
人之所以痛苦,在于欲望,而其中相当部分欲望,与个体独立性反相关,社会科技越发达,社会越富有,反而大家都落不着好了,这就是现代社会的一个毛病。典型的是权力的欲望。
白:
藏族人对死的态度很豁达
李:
痛苦二字也许太抽象 但我们多少人没感受过一个 “累” 字。人生真累。活着真累。
dl:
越是发达的社会,越是号称平等自由的社会,人们从权力方面获得的满足感越少。越是专制,反而每层都能找到权力的感觉。
阮:
人类麻烦事太多,除了生死,还有一堆其他的。科学帮助解决问题,不能解决的就用宗教。
白:
能量极小化,就是懒;物质极大化,就是贪。
李:
其实这种累的感觉,不是简单的欲望不得满足。
白:
都想出人头地才累。
dl:
归根结底,出人头地也是权力欲望。没有雄心壮志,就比较容易快乐。
熊:
虚其心,实其腹,弱其志,强其骨,美国政府在做的。
白:
权力欲望也一定有物质基础的。吃药可医。早晚的事。
李:
在古代 流行的是简单的快乐。进入文明社会 简单的快乐的能力 现代人丧失了。
我们的远亲 猿猴就没有人类这么多这么深这么厚的痛苦。
dl:
以前皇帝的物质条件未必比现在普通人好啊,但是快乐太多了。现代社会另外一块问题,就是虚伪性,其中最大的就是婚姻制度,也是导致痛苦的主要原因。本来古代制度性解决的问题,现在需要每个聪明人耗尽自己的才智,其实也解决不了问题。@wei 主要是一夫一妻制度的推广造成的。
李:
那就废除这个制度好了。可群婚也不会幸福。
dl:
太多成功学,个人奋斗案例,给大家打鸡血,也是导致大家辛苦的原因。美国鼓吹的那一套人人奋斗也是大家痛苦的原因。以前不成功还可以把原因推到制度上,现在只能埋怨自己了,能不痛苦吗。
邓:
看高手过招真心快乐。@白 将来我们都喝老爸茶、弹琴、斗嘴。
李:
过度紧张 过度竞争 恶性竞争 肯定是罪魁之一。
dl:
人之所以快乐,无外乎比别人优越那么一点点。也许现在宗教存在的意义,就是我失败了,能让我找到一点点借口。否则就是赤裸裸的自我解剖,太痛苦,没几个人受得了。
李:
找不到工作 社会上混得不好 肯定不快乐。
但有一个不错工作的人 也往往快乐不起来
白:
这点借口,科学也会给的。将来都ai了,找不到工作是常态。
dl:
很重要的一点,和身边的人比较起来,是不是优越。最谦虚的人,内心也是希望得到别人的恭维的。最不在乎的人,他在乎的东西,超乎我们的想象,除非这个人完全破罐破摔。
白:
把自己贬低到常人难以接受的水平,来恭维别人的人,一定极其阴暗,破坏力不可低估。自尊心是守恒的。这里按下去,就意味着一定会在其他地方冒出来。
李:
回想起来 人生中比较真切的快乐的确有 就是助人为乐 远比自己得到好处快乐得多。这个助人为乐 首先是亲友。看到自己爱的人 亲友 由于自己而改善了境遇 那种满足幸福感相当不赖。如果觉得自己可以帮助全世界,快乐就源源而来。
dl:
@wei 这也算一个麻醉剂。中国人这个达则兼济天下的思想,本来就是高高在上的。
明白嘛,高高在上。帮助他人,也是体现自己优越感的好地方,当然客观上是有好处的。仔细分析,从内心来讲,并不比我要出人头地高尚多少。
白:
精英已经失去了代表人类平均感受的资格。
dl:
@白 现代社会的痛苦,就是精英阶层弱化的痛苦。
白:
去精英化
李:
暴发户回家乡办学 就是这种幸福的展示。
dl:
@wei 你说的这种东西,并非精英阶层追求的东西,而是把精英阶层平民化的过程。这里有一种不可调和的东西存在。
李:
雷锋的快乐就是,做好事不留名,记在日记里自我欣赏的感觉超级棒。
高:
雷锋不识字,何故多记事
dl:
@wei 雷锋这种现象,主要还是愚民策略的一个证明
李:
一介武夫 无权无钱 不富不贵 但没人否认,雷锋是幸福的 每一天活得那么充实满足。
dl:
反正在这个群里,我得到的快乐,肯定没有我的粉丝群里得到的多,这是肯定的。原因是肯定的,这个群里大家都很自我。没有人太屌谁,这就是以后社会发展的一个趋势。
白:
反过来说,精英扎堆儿的地方,不适合精英自我表扬。
桂:
李白是计算语言学界活雷锋。
dl:
所以每个人权力获得感会大幅下降,这是必然的。预测以后的世界,每个人的存在感问题会更大。这会是一个主要问题。
白:
唱戏当皇上也是爽的。
以后ai发达了,nlp发达了,慕容复何至于那么孤单,可以乱真的奴才臣子还不是要多少有多少?权力欲真那么难满足吗
dl:
@白 反正我不会和机器人谈恋爱。
这个每个人细细体察内心就可以知道
李:
不要说那么绝对。没人会拒绝快乐,快乐来自人和机器 不重要。
白:
来自药物和现实乃至虚拟现实,也不重要,关键是不要有副作用
dl:
精英阶层的人士,快乐在于控制和影响力,不在于太物质的东西。而世界趋势在背道而驰。庸俗化正在席卷全球。
@白 吃药也许可以。五石散。魏晋南北朝,其实也是一个世家没落的时代,和现在有点像。
白:
所以科学宗教哲学,说到底都是solution,是骡子是马,最后都要在problem面前遛遛。
dl:
@白 同意。问题是这里面存在不可调和性。发展趋势和人快乐的基础之间有不可调和性。这是现代社会的一个重要问题。庸俗化引起的权力满足感丢失,可能是问题的核心。
顾:
科学和宗教类同,只不过科学适用面宽些,预测能力强些。
白:
人太多了,逆选择一下也是必要的。这么辛辛苦苦伺候都快乐不起来的人,还是哪儿凉快哪儿呆着去吧。
dl:
目前解决方案,就是创立一个公司,然后去当土皇帝。这才是正道。所以要创业。这才是创业的终极目标啊。公司目前是满足权力感最好的形式。
白:
权力自由但财务不自由的创业,好不到哪儿去。
dl:
@白 这就是你说的唱戏当皇帝也快乐啊。
白:
自己印钱啊,虚拟货币。
想象力太受现实束缚了。
dl:
@白 我只是调侃一下而已
白:
我调侃两下行不
dl:
当然可以。以后都去参加拜公司教就好了。这就是宗教。solution直面最核心的问题,精英阶层存活的意义就在于此。
白:
ai让你唱戏当皇上比真皇上还爽,连个不爽的理由都找不出来。
dl:
@白 现在很多人沉醉于虚拟网络,可能也和这个有关系。找到了存在感。但是如果获得太容易,就没优越感了。存在感其实在某些意义上等同于优越感。
白:
那容易啊,工作量证明,挖矿挖到了的当皇上。
dl:
@白 其实发明一种机制,让人去做梦,这样人的一生其实不需要活动。可以拍一个电影,以后少数精英人士操纵社会,大多数人生下来,就被装在器皿里培养做梦,大家觉得如何?都很快乐。其实社会本质未尝不是这样?
邓:
今天讨论这么热闹@尼 得发个红包。