



by Hanyang Yijiangshui
Let me share a few anecdotes about my father to provide a glimpse into his professional life.
During one Lunar New Year, Hanyang and I went back to our hometown to celebrate with our father.
After the New Year's Eve dinner, we all sat together watching TV and chatting. Around eleven, a call came in for my father. It was from the hospital where he served. They had an emergency and wanted him to consult. Without hesitation, my father got ready and asked Hanyang to drive him to the hospital.
He worked throughout the night and only called Hanyang to pick him up the next morning. On the way home, Hanyang inquired about the emergency. My father, visibly exhausted, simply said, "Doctors often face such situations. Emergencies don’t care about holidays. It's been this way since I was young." He then closed his eyes to rest.
Days later, my father recounted the event with pride. That night, an emergency case was admitted with a suspected acute appendicitis. Two on-duty surgeons began the surgery, but upon opening the patient, they were puzzled to find no inflammation. As they debated the next steps, one suggested consulting my father.
Upon arrival, my father swiftly diagnosed a stomach perforation with gastric contents spilling into the abdominal cavity. He then skillfully performed the surgery, saving the patient from potential complications. This type of condition, where the symptoms are hidden, often goes undiagnosed, requiring both experience and theoretical knowledge to identify.
He later said that had they not properly diagnosed the issue, the patient would've faced further surgeries, and if the acidic gastric content had remained in the abdomen for too long, it could've been life-threatening.
During the Cultural Revolution, my father had a close friend, Uncle Gui, from a neighboring county. His 16-year-old son had a neck condition, which was misdiagnosed as a recurrent malignant tumor. The family was advised amputation, a heartbreaking prognosis. Desperate, they turned to my father. After a careful examination, my father determined it was another type of benign tumor. He successfully performed surgery, saving both the boy's arm and his life. The boy went on to have a successful international career, and they still visit my father in gratitude.
In the 1970s, a 35-year-old female patient came in with a vertebral issue. She was emaciated, weighing only 40 kilograms, and suffered from paraplegia. With a challenging surgery involving careful removal of the necrotic material and grafting, my father successfully treated her. The husband, a blacksmith, gifted my father with handmade stainless steel kitchen tools, which are still in use today.
Among his notable achievements in orthopedics, my father performed hundreds of surgeries for lumbar disc herniation. Many patients, immobilized by pain, found instant relief post-surgery and went on to live healthy lives.
My father practiced medicine for over sixty years, performing surgeries on more than ten thousand patients. Were there any medical accidents? None at all! However, he did have a few surgical failures in his career. One particular case deeply pained him, reminding him that intentions don't always match outcomes, leading to self-reproach. My father's surgical mentor, the former head of surgery at Wannan Medical College's Second Affiliated Hospital, Mr. Min Mei, once consoled him with a story from his time at Beijing Fuwai Hospital, a renowned cardiology institution. Many patients entered the hospital walking but were carried out after unsuccessful surgeries. Leading Chinese medical authorities had once advised Min Mei that while some patients might die without surgery, there's still a glimmer of hope with surgery. Science comes with its costs, and doctors often work on the front lines of life and death, carrying the weight of their successes and failures.
A particularly heartbreaking case for my father involved surgery on a middle school teacher who came to him by reputation. The 64-year-old teacher was diagnosed with gallstones based on his medical history and an ultrasound. My father had successfully performed over a thousand such surgeries. On October 16, 1984, my father removed the teacher's gallbladder, discovering 23 cholesterol gallstones inside. The surgery seemed to proceed "smoothly," lasting 75 minutes. However, the patient's unique anatomy presented a congenital variation that wasn't detected until complications arose post-surgery. Three days post-operation, jaundice appeared and worsened. Subsequent surgeries on November 9, 1984, and February 10, 1985, failed to save the teacher, who succumbed to multi-organ failure five days after the last operation. My father was deeply affected and often cited this tragic case as a cautionary tale. He penned a medical paper based on these experiences to remind himself and others to be diligent and continuously learn.
A 29-year-old male patient, after colliding with a stationary cart while riding his bicycle, experienced intense pain, difficulty breathing, and palpitations. He was admitted to my father's hospital an hour later. Preliminary examinations showed no internal organ injuries or fluid accumulation in the abdominal cavity. However, after 16 hours of observation, the patient complained of pain in the right flank and testicle. A diagnosis of posterior peritoneal duodenal injury was made, leading to an exploratory laparotomy 28 hours post-injury. During the procedure, some bile-like fluid was found in the abdominal cavity. No injuries were detected in the gallbladder, extrahepatic bile duct, or liver. Swelling and green discoloration were observed in the posterior peritoneum. Upon further examination, a 1.5 cm rupture was found in the descending part of the duodenum, causing leakage of intestinal fluid and tissue necrosis. After thorough cleaning and repair, intestinal motility was restored within 48 hours. The patient fully recovered after three weeks, with no complications or aftereffects. Such posterior peritoneal duodenal injuries are rare and severe, often presenting subtle early symptoms that can lead to misdiagnosis. The surgery itself is intricate and demanding. Surgical precision and adaptability are crucial as a slight oversight can be life-threatening. Fortunately, my father's skillful hands saved this patient, who now leads a normal life.
The patient, a male, suffered from melanin spots and gastrointestinal polyposis syndrome. Over fourteen years, he underwent three surgeries, all of which were performed by my father. Particularly challenging was the patient's extremely rare intestinal and biliary obstruction, a condition possibly unparalleled worldwide! Complications were the primary reason for his medical consultations, typically manifesting during his youth. Being a congenital condition with no complete cure, its prognosis can be favorable with proper management, even though it necessitates multiple surgeries. It doesn't necessarily shorten the lifespan. With my father's meticulous treatment, the patient was given a new lease on life. Throughout his career, my father encountered many such critically ill patients. Practically self-taught and working in a basic grassroots hospital, he took saving lives as his mission, creating miracles one after another.
In 1968, in a remote mountainous village called Hewan in southern Anhui, a 13-year-old boy fell off a bull's back. My father, upon examining him, found a ruptured right liver and significant internal bleeding, requiring a thoracotomy to be treated. Even in big cities, liver surgeries were major procedures at the time, and my father had never performed one before. Especially in such a remote village, ensuring an adequate blood supply for the operation was a challenge. With the boy's life hanging by a thread and time running out, my father, in a moment of quick thinking and audacity, decided to draw accumulated blood from the abdominal cavity and re-transfuse it. This innovative approach of re-transfusing abdominal blood mixed with bile was a first in China. (From a theoretical standpoint, the idea of re-transfusing liver blood, especially contaminated with bile, was barely mentioned in medical literature then. Only a decade later was it reported and subsequently confirmed in various studies.) Relying on his previous experience with blood transfusion (without bile) and given the urgent situation, my father performed this transfusion technique throughout the night, extracting, filtering, and re-transfusing a total of 1700 ml of blood, buying precious time. Operating under a kerosene lamp in a rural health center, with rudimentary anesthesia, my father proceeded to carry out both a thoracotomy and laparotomy. The surgery was a triumphant first attempt, successfully repairing the liver. In a tiny village with no electricity, limited assistance, basic equipment, scarce medicine and blood supplies, and without the guidance of a senior surgeon, my father's successful completion of his first-ever liver surgery was nothing short of miraculous. The postoperative recovery was also "smooth," and the patient's life was saved. Given the conditions and technical expertise of that era, it was a remarkable achievement.
The procedure represented the pinnacle of surgical expertise in county hospitals of China at that time, truly cutting-edge. Accomplishing such a surgery in a small village operating room, lacking electricity and running water, is unprecedented in China.
In October 1965, following the “6.26” directive, my father led a medical team of seven, including one internist, five nurses/midwives, and himself, a surgeon, to the Yandun Commune in southern Anhui. Although he held the position of deputy leader, the actual leader was Dr. Tian, an internist in his fifties with poor health, who often stayed home for recuperation and rarely spent time in the countryside. This effectively put my father, who was not yet thirty, in charge of the entire operation for three straight months.
During the last 100 days of 1965, without electricity, an anesthetist, assistants, or adequate equipment and medicine, my father, on his own, set up a makeshift “operating room.” With cloth overhead as a ceiling, the ground wetted to keep dust down, and lit by a kerosene lamp and flashlight, this “room” was where he performed 612 surgeries of various sizes without a single mishap. All patients recovered, a testament to the miracles he performed in the rural setting. Of these, 121 were major open surgeries ranging across general surgery, gynecology, orthopedics, and otorhinolaryngology. Surgeries included stomach, gall bladder, intestine, and uterus removals, bile-intestine internal drainage, vaginal total hysterectomies, bladder-vaginal fistula repairs, and many others. In an era when even basic medicines like penicillin were rare, to perform such a diverse range of surgeries in 100 days was a feat – a testament to my father's exceptional surgical skills and innovation.
At the same time, the medical team organized training for health workers from all six production brigades in the commune, established a health-conscious village, and dug two wells, forever changing the village's history of consuming muddy water.
My father, always on duty, never took a single day off during these intense three-plus months. Although he was only an hour's drive from home, where both the elderly and children awaited, he didn't return even once in over 100 days. This unparalleled dedication to work, without any financial incentive, would be unimaginable today.
On one particular afternoon during this medical outreach, with the assistance of the only anesthetist from the county hospital who had temporarily come over, my father single-handedly performed three vaginal total hysterectomies with pelvic floor repair and reconstruction. This was in the aftermath of China’s infamous famine, which left many with malnutrition-related conditions. On the same day, he continued to operate until 3 am, performing over ten other surgeries and working continuously for nearly 18 hours. Such a work rate is unmatched even today.
For these achievements, the medical team was recognized and rewarded by the county and district (city) governments. My father was specially invited to give a presentation at the commendation meeting, where he displayed all the surgical instruments he used. His methods were promoted throughout the Wuhu region, a grand acknowledgment and reward for his efforts.
During this period, several unforgettable cases stood out:
The adage goes: necessity is the mother of invention. In this case, dire circumstances crafted the hero. Theoretical support and recognition for some of these groundbreaking procedures would only emerge in the literature later on.

Dad, second from right on the front row
On July 28, 1976, the historic Tangshan earthquake occurred, and my father had a deep connection to it. On August 2, he was summoned to join a three-person medical team from Wuhu district (city) to aid in the earthquake-stricken areas. Upon their arrival in Nanjing, they received a call from Beijing, advising that the injured were being sent south and that medical teams from various locations should prepare to treat them locally, eliminating the need to go directly to the disaster site. Consequently, my father was stationed at a treatment center in E'Qiao, Fanchang. Leading a 25-person medical team, with another 25 locals supporting logistics, they received 100 injured individuals. As the team leader overseeing all operations, my father had three deputy leaders and two instructors with him — an impressively robust leadership team. All the selected members were the "elites", directly under city and county leadership. The national government covered all expenses for the injured, prioritizing this as a top-tier political task.
My father, along with a few doctors, went to the Nanjing railway station to inspect and receive the injured from a medical-special train. When the train reached E'Qiao, a team awaited to carry the patients into the "wards". Most of the injured had non-life-threatening injuries, mainly bone and muscle injuries. Fortunately, my father was well-versed in orthopedics. Switching from administrative duties to focus on clinical medical care, over the subsequent months, they worked tirelessly to ensure the recovery of every individual and even sent doctors to accompany the injured back to their hometowns. In this catastrophic event that shocked the world and claimed 240,000 lives, my father contributed his bit, accomplishing this historical mission.
That year, China faced multiple calamities. After the deaths of prominent national leaders Zhou and Zhu, during this national disaster caused by the earthquake, on September 9th, Mao — China's paramount leader, also passed away. This cast a shadow over the entire nation, with the populace uncertain and apprehensive about China's future.
During this tumultuous period, my father, away from home, bore the significant responsibility of managing 100 injured individuals and 50 staff members. With the local region also experiencing aftershocks and given the concerns of staff about their own safety and their families, coupled with the successive deaths of national "parental" figures, it's easy to imagine the pervasive sense of despair and hopelessness. However, my father, leveraging his skills and leading by example, accomplished the task brilliantly, once again submitting a perfect report card.

Dad, 5th from left in the middle row
During the violent confrontations of the Cultural Revolution, different factions armed themselves, leading to disrupted transportation and hospital shutdowns. However, bullets don't discriminate, and gunshot wounds were rampant, affecting vital organs like the liver, lungs, blood vessels, kidneys, and the gastrointestinal tract. This often necessitated on-the-spot surgeries. It was under these dire circumstances that my father was forced to self-learn and master the techniques for repairing organs, particularly in cases of brain injuries.
Despite the challenging environment and conditions, my father managed to save many lives. While he undoubtedly had his share of successes, even in the instances where he couldn't save a life, there was minimal blame attributed to him (given the circumstances). These experiences significantly honed his technical skills and expertise.
The confrontations resulted in hospitals operating at limited capacities, granting my father ample free time. He used this period to systematically read medical textbooks and study English, thereby solidifying his foundational knowledge in medical theories. This self-learning phase marked a significant leap in his theoretical understanding, which, when applied practically, further solidified his expertise. The synergy of theory guiding practice, and practice leading to real insights, elevated my father's knowledge and application to new heights.
Ironically, the violent confrontations of the Cultural Revolution ended up cultivating surgical talent. This can be seen as a peculiar silver lining — a dark kind of humor in the midst of chaos.
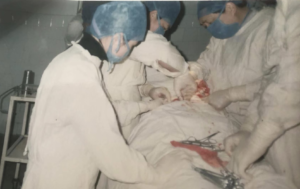
Throughout my father's medical career, which spanned over 60 years, he performed countless surgeries. In his practice, he often introduced minor improvements, innovations, and breakthroughs that yielded highly effective results.
a. Except for special requirements, my father abandoned the convention of pre-inserting gastric tubes in the thousands of gastrectomy procedures he performed (a procedure recommended in textbooks). He had no failures with this approach. This demanded meticulous suturing, impeccable hemostasis, intraoperative emptying of gastric residues, and rigorous post-operative observation, which greatly enhanced patient comfort.
b. In cases of diffuse peritonitis, after removing the lesions and infectious materials, he discarded intraperitoneal drainage, thus reducing post-operative adhesions. The key was thorough intraoperative washing and cleaning. He believed that drain fluid in the peritoneal cavity would quickly get clogged by fibrin, which only added to the patient's discomfort. Certainly, in cases like pancreatitis or abdominal abscesses where ongoing leakage is expected, negative pressure drainage with double tubes is necessary.
c. In circumcision, standard procedures often led to misalignments, hematomas, edemas, and difficulties in removing stitches, causing distress to both doctors and patients. My father modified the procedure, using local venous anesthesia, precise cutting under tourniquet control, impeccable hemostasis, and meticulous suturing with human hair or absorbable sutures, resulting in a pain-free procedure with excellent alignment, quick healing, and no stitch removal.
d. Fistulectomy for anal fistulas traditionally involved threading or open excision, causing significant post-operative pain and a lengthy recovery. My father adopted long-acting local anesthesia (with a diluted methylene blue injection) for a one-stage excision and suturing, usually resulting in a single-phase healing and a shorter treatment duration.
e. Controlling wound infections, especially traumatic ones, hinges on the thorough cleaning during the initial treatment, rather than relying on drainage or antibiotics. Extensive washing with water to remove foreign bodies and dead tissue, meticulous disinfection, tension-free sutures, and, if post-operative inflammation occurs, supplemental alcohol compresses – with or without antibiotics – ensured infections were largely eliminated in wounds treated within 6 hours.
f. In inguinal hernia repairs, the focus was on the transverse abdominal fascia. My father used a modified Madden technique instead of the traditional Bassini method, greatly alleviating the post-operative pain from tensioned sutures. This also promoted healing and significantly reduced the recurrence rate.
My father was brilliant. Not only was he adept in surgery, but he also had a knack for writing articles effortlessly. Although he only received a vocational education, his surgical skills, prolific writing, and fluency in English allowed him to smoothly acquire mid-level, associate, and full professional titles without any disputes.
However, many of his colleagues (excluding the leadership) weren't as fortunate. Some lacked the necessary skills, others didn't have enough research articles. Even though many had higher educational qualifications than my father, they struggled to achieve the highest professional titles.
My father had strong reservations about this system. He believed that several of his friends, who were competent in clinical surgeries, were hindered due to their inability to write articles. Without publications, they couldn't ascend the professional ladder.
He argued that clinical work is practical, especially in surgery. It requires dexterity and intuition. Improvement comes from experience and observation, not from writing research papers. Clinical work is not about research. Considering the massive patient load and back-to-back surgeries and shifts, it's already taxing. Being in a non-academic hospital, who has the time to sit, apply for research topics, conduct studies, and write articles?
Clinical doctors need extensive training and a wealth of experience. Combining research tasks with clinical duties and judging doctors based on their research publications rather than their clinical expertise is unfair. It's absurd for a profession that's fundamentally about clinical skills to prioritize publications over actual patient care proficiency.
Being kind-hearted and always eager to help, on one occasion, he told two friends, both highly skilled surgeons who were held back in their professional advancements due to a lack of publications: "I'll write several articles for you both. You can revise them, provide feedback, and then publish them under your names."
True to his word, my father promptly wrote several medical articles and handed them over to his two friends.
Despite being 88 years old, my father has an insatiable curiosity about new technology. He's deeply interested in emerging knowledge and science and is adept at adapting to novel concepts. He's a progressive thinker, always reflecting on novel ideas and not just sticking to traditional views. He's always driven to achieve excellence and delves into unknown territories. From computers, mobile phones, and the internet to intelligent AI applications, he has been at the forefront, keen to experience the latest technological advancements and to understand their innovation. He often says that to avoid being left behind in this world, one must be open to new things. This way, life doesn't stagnate, and we can continually enhance our lives and improve our quality of living. Staying updated and keeping pace with the times has always been his life's norm.
When OpenAI's ChatGPT was introduced, he was immediately intrigued. Almost daily, he would inquire about it with his son, my younger brother Li Wei, who works in natural language processing, eager to understand ChatGPT's applications, its current status, and future direction. Recently, Wei managed to set up ChatGPT for him to work via VPN, having made father one of the most senior users of ChatGPT in China.
Of course, as LLM applications are being rapidly deployed, we'll see a seamless integration with smart home functionalities in the future. People will increasingly rely on artificial intelligence, which often determines the quality of life. While domestic AI research might be a step behind Western countries, its practical application is not lacking, and the adoption rate in China exceeds that of the West. This allows the public to experience the convenience of the latest tech products, providing my father ample opportunities to try out various AI products and software at home. He thoroughly enjoys it, making him a genuine AI application enthusiast.
My father is witnessing the AI boom of the 2020s and certainly won't miss out on this magnificent era. He currently uses an Apple 15 Pro, the latest model with three-nanometer technology. Paired with the newest VPN software on his iPad and ChatGPT, he has the latest tech tools at his disposal. It's rare to find an elderly individual with such a tech setup in the entire country. At 88, my 'fully-equipped' father remains ahead of the curve, always staying at the forefront of technological advancements.
Dad's passion and pursuit of technology are not only to satisfy his own curiosity but also to maintain competitiveness and adaptability in an ever-changing era. In this age where technology evolves rapidly, Dad shows us through his actions what it truly means to 'learn as long as you live'. His positive attitude and curiosity about new things are worth learning and passing on by each of us.
Closing Words: In the quiet depths of night, the familiar silhouette, a symbol of tireless dedication, invariably emerges before my eyes, invoking clear and heartfelt memories. It brings back scenes of my father's hard work and life from yesteryears. Though many of those moments have faded into the annals of time, spanning over half a century, they remain ever-present in my mind, etching deep imprints in my heart, evoking emotions, instilling strength, and radiating warmth.
Dad, you stand as my beacon, my source of pride. I love you.
这是我的老家,我长大的地方。山水还是那个山水,但建筑不再是那个建筑。不认识了,但的确很美。城建超出想象。
中国的经济起飞,不仅仅有一线(如上海北京)二线(如南京、武汉)三线(如 芜湖)城市的巨变,四线县城也是换了人间。这个成就还是值得称道的。江南是个好地方,感觉真要生活在三线四线,应该很容易适应。生活的便利、烟火味儿,啥也不缺。并不是只有大城市才宜居。且不说生活成本的差异。
"Though turtles live long, they meet their end. Though dragons ride the mist, they eventually turn to dust. Aged but still full of fire, ambitious till the very end. The natural order isn't the only clock; contentment brings longevity. How fortunate indeed, to express these sentiments through song." — "Though Turtles Live Long" by Cao Cao of the Eastern Han Dynasty
My father was born on November 3rd, 1936, or September 20th according to the lunar calendar. He's a Rat in the Chinese Zodiac. Following our local tradition, which counts one extra year, he is currently 88 years old.
Father's name is Li, Mingjie, his courtesy name Hao, and his art name is Cuisheng. Born into a struggling intellectual family, his youth was filled with hardship and adversity. Lack of finances kept him from attending university, a lifelong regret.
In March 1956, my dad graduated from the Wuhu Health School and has been involved in medical work for 67 years. After a stint in schistosomiasis prevention and two years in public health administration, he shifted his focus to surgical clinical work in 1961. He has been practicing for over six decades now. He served in Nanling County Hospital for 25 years, Wuhu Changhang Hospital for 22 years, and China Railway Wuhu Hospital for 16 years. Approaching his nineties, he still hasn't fully retired. His vision remains clear, his hearing sharp, and his hands steady. He conducts research, reads literature, remains engrossed in his profession, and stays updated with the latest surgical developments. His thoughts are coherent, and he still performs surgeries. Moreover, as the medical industry transitioned to digital documentation, he adapted seamlessly, never falling behind. His age hasn't dampened his spirit; he continues to contribute to society with undiminished vigor. Truly, he is a tireless father.
My father has dedicated his life to medicine and saving lives. Over the course of more than half a century, he has understood the emotional states of patients, and monitored their health conditions, and with his exceptional intellect, energy, and skilled hands, he has tailored treatments to individual needs. He has brought health to countless patients, saved numerous lives from the brink of death, and restored joy to many families clouded with sorrow.
My father worked diligently at the grassroots level. Despite only having a diploma from a technical health school, he had no formal professor or mentor to guide him. He was self-taught. His medical skills came from personal insights and countless hours spent studying medical books. His natural talent, intelligence, diligence, and unwavering passion paved the way for his medical aspirations. Even in remote and impoverished regions, and in an era when intellectuals were often marginalized, he carved out his own success. As my father often says, 'My surgical career has been one of the longest, with numerous surgeries across a wide spectrum of specialties.' He also notes that many of the surgeries he performed at the grassroots level were highly challenging. Some of these procedures are still considered cutting-edge in the world of surgery. For instance, liver and lung surgeries, removal of cervical spine tuberculosis lesions, and repairs of injuries to the duodenum behind the peritoneum – such surgeries were rarely conducted even in the provincial hospitals during the 1960s. Yet, my father took the initiative to perform these complex operations in a modest county hospital and achieved success. He often proudly asserts: 'In surgery, sometimes, you have to pull a tooth from a tiger's mouth. It's not about blind risk-taking! It's about taking calculated risks, having advanced skills, and providing high-level treatment. Being brave yet cautious, breaking the norm, and always prioritizing scientific and pragmatic approaches are essential.
My father has practiced across a broad spectrum of medical specialties, from abdominal surgery, thoracic surgery, orthopedics, obstetrics and gynecology, neurosurgery, urology, otolaryngology, ophthalmology, radiology to anesthesiology. He has successfully performed many high-difficulty level-4 surgeries in each specialty, which is truly an astounding achievement. These surgeries range from operations for acute pancreatitis in abdominal surgery, carotid artery aneurysm resections in head and neck surgery, spinal tumors in neurosurgery, lung malignancies and esophageal cancer in thoracic surgery, clearing lesions of various osteomyelitis and tuberculosis of the cervical, thoracic, lumbar, and sacral vertebrae, and other fractures in orthopedics. Additionally, he has conducted lymph node stripping in urology, hysterectomy and ovariectomy in gynecology, nasolacrimal duct anastomosis in otolaryngology, cataract surgeries, and artificial pupil operations in ophthalmology. He's also proficient in different forms of anesthesia, including epidural blocks, brachial plexus blocks, spinal anesthesia, intubation general anesthesia, and intravenous composite anesthesia. The breadth of medical categories my father has mastered is unparalleled and unmatched, both domestically and internationally.
The unique circumstances of that era provided my father with a rare opportunity to showcase his talents and capabilities. Facing a continuous influx of impoverished rural patients, the stakes were high. To not treat was to let die. Treating them was always better than leaving them to their fates. He had significant autonomy. With an endless drive to work hard, he performed surgeries almost daily for decades. With exceptional professional skills, noble medical ethics, passion for medicine, dedication to his patients, persistence, diligence, and unwavering perseverance, he emerged as an outstanding major surgery doctor. My father seized fleeting opportunities, often breaking barriers and shining in his field. His achievements made him stand out, eventually reaching the pinnacle of clinical practice in grassroots hospitals.
For decades, when not performing surgeries, he would immerse himself in medical books, often sacrificing sleep and meals. Rarely did we see him rest; he was a true workaholic. We've always felt that my father is the modern-day Hua Tuo, crafted by his era. Considering the breadth of his medical practice, the number of patients he's aided, and the length of his service, he stands almost unparalleled in history—perhaps with the exception of Hua Tuo—and likely unmatched in the future.
Surgical practitioners need intuition. The stability and flexibility of one's fingers and wrists are incredibly crucial. My father seemed to be naturally made for surgery. He had an insatiable thirst for knowledge, a bold yet meticulous approach, an innate intelligence, and an innovative spirit. His expertise in surgery enabled him to comprehend concepts instantly and perform operations with exceptional precision. Especially during his younger years, he honed exceptional skills. Additionally, his team spirit was exemplary. Every subordinate doctor trained under him developed rigor, dedication, and a relentless pursuit of excellence, shaping a generation of medical leaders and experts.
As soon as he stepped onto the operating table, it was as if my father became a different person—calm, confident, and masterfully executing each surgical procedure. His surgical precision and speed earned him accolades from peers, patients, and their families. Over the years, his reputation spread far and wide, attracting a steady stream of patients seeking his expertise. Even the relatives of the chief surgeons from top-tier hospitals would seek my father for surgeries, trusting only in his magic hands. The renowned Director of the Surgery Department from the original Yijishan Hospital, Dr. Chen, entrusted my father with the surgery of his wife, Madam Xie, who was the head of the Nursing Department in Changhang Hospital. Despite her being in her eighties and diagnosed with breast cancer, my father's successful surgery ensured her well-being well into her nineties. She considered my father her lifetime "personal physician". Similarly, Wang Ping, the Head of the ENT department at Nanling County Hospital, trusted my father to operate on his daughter, Dong Wei, who had breast cancer. Years later, the Chief of the Obstetrics and Gynecology Department of the same hospital entrusted the care of her daughter in the same manner to my father.
The director of the surgery department at Changhang Hospital, Mr. Shen, had an elderly father-in-law in Shanghai, a distinguished professor, who was diagnosed with stomach cancer and pyloric obstruction. After being unable to eat or drink for several days and his body deteriorating, his family had almost given up hope. Yet, my father undertook the "risky" direct radical surgery, having saved his life. The patient lived for another five years before succumbing to other illnesses. Conventionally, patients of this age and condition would first undergo a bypass surgery to relieve the obstruction, and only later would they have the surgery to remove the lesion. In reality, few would get the chance for this second operation.
Back in 1970, my elder uncle, Pan Yaoyi, had hepatic and biliary stones along with obstructive jaundice. Refused by a renowned hospital in Hefei, he turned to my father in desperation. At the Nanling County Hospital, my father personally performed the surgery to remove the stones, excise the gallbladder, and establish an internal biliary-duodenal drainage, ensuring his full recovery. In 1986, another uncle of ours, Pan Yaotong, was diagnosed with rectal cancer and similarly turned away by the provincial hospital. Once again, my father stepped in, performing the radical surgery that lasted over seven hours.
Back in the 1980s, numerous patients would report their symptoms over the phone, and my father could make a diagnosis then and there. For instance, his colleague Cheng Daben had a perforated stomach. The young doctors at Yijishan Hospital misdiagnosed it as renal colic and treated it by administering laxatives to clean the intestines. The urinary system imaging examination the next day proved them all wrong! This not only delayed the crucial time for life-saving treatment but also exacerbated the perforation and leakage, pushing the patient into critical condition! The patient, in excruciating abdominal pain, desperately called my father and urged a return to our hospital, where an emergency surgery to cut into the stomach cured him. The husband of the head nurse Gao at the undergraduate department, Tao, experienced a similar ordeal. Nowadays, it's more common for patients to seek medical advice remotely through mobile "WeChat" at any time and place, resolving many medical issues this way. What's particularly remarkable is that all the surgeries for our immediate family members were personally performed by my father. This demanded immense confidence, determination, and mental fortitude.
We once knew a young rural doctor who, feeling constrained in his medical career, chose to pursue an English teaching degree instead. When discussing my father's medical skills, he expressed deep admiration: "Do you know? Your father is one of the most incredible doctors in the world. He can perform complex surgeries that many top-tier hospitals have yet to introduce or popularize." He shared several cases with us, and even though we might not have understood all the medical intricacies, one thing was clear: my father consistently pushed boundaries, always striving for surgical excellence.
Later, when we asked my father about any complicated surgeries he wished to perform but couldn't, he mentioned microsurgery, limb reattachment, and other surgeries requiring advanced equipment that were beyond the reach of the county hospital at the time. He also expressed admiration for the fields of stem cell regenerative medicine, gene-editing techniques, genetic engineering to reverse aging cells, and precision medicine, recognizing them as the frontiers of medical research, while humbly admitting that as a grassroots clinician, he could only admire them from afar.
After the Cultural Revolution, with the resumption of professional promotions, my father climbed the ranks seamlessly, from Medical Practitioner, Physician, Attending Physician, Associate Chief Physician to Chief Physician. His progress was smooth, never missing a step. In all three secondary hospitals, each with over a hundred staff where he served throughout his life, he was the sole Chief Surgeon. In fact, in the entirety of these institutions, there were only one or two with such a distinguished title. Compared to his peers who graduated from technical health schools like him, almost none had the chance to rise to such a senior position. Even graduates from medical colleges in his generation, the majority in secondary hospitals couldn't attain such a high-ranking title. The criteria for grassroots hospitals were even more stringent. One needed to excel in clinical practice, publish academic papers, and be proficient in English. Typically, only one chief position each was reserved for internal medicine and surgery specialties. They preferred having a vacancy rather than compromising on quality. This emphasizes how my father was truly a rare gem among his contemporaries, standing head and shoulders above the rest.
The era shapes individuals. My father never attended elementary school, high school, undergraduate, or postgraduate courses. His formal education consisted of only middle school and a medical diploma from a technical health school. Yet, he relied primarily on countless hours of medical practice, learning through hands-on experiences. With sheer skill and determination, he ascended the ranks to become a Chief Surgeon in general surgery, ultimately earning a reputation as a renowned all-around physician.
While doctors are respected, many lead modest lives. A bit of hardship in life didn't bother my father, but the challenge he faced was how to save up money to buy medical books. Those thick professional volumes like "Surgery" and "Orthopedics" were expensive, yet indispensable for his work. Who could have imagined that many of these medical books were acquired by my father secretly selling his own blood? Each time he would donate 300cc of fresh blood and receive 30 yuan – an amount that would typically take him half a year to save. My father would brush it off, saying: "humans have a hematopoietic system, so losing a little blood doesn't matter. There are often stories of doctors donating their own blood in emergencies to save patients, and I've experienced this myself several times during my medical career". But acquiring professional books by selling one's blood, such instances are probably rare across all of history and around the world and perhaps only characteristic of that particular era in China. Perhaps only in that specific era could a reputed doctor resort to such means to own medical books.
On June 3, 2007, my father faced the greatest ordeal of his life. Suddenly, he began vomiting blood and developed an inexplicable fever reaching 40°C. The once indomitable spirit, who often claimed to be "forever young and vital", was suddenly brought to his knees. He lost over 2000ml of blood, putting him in grave danger. He was rushed to the hospital and was diagnosed with 'low-differentiated gastric adenocarcinoma.' On June 21, he underwent major surgery in Wuhan, having his entire stomach and gallbladder (due to pre-existing gallstones) removed. He narrowly escaped the clutches of death. Having worked tirelessly throughout his life, he always took pride in his robust health and positive attitude. Who would've thought? A man so rarely ill could be brought down so severely. This incident was the most significant challenge he had ever faced and marked a turning point in his health journey.
My father has always been the backbone of our family, typically appearing youthful and vigorous, especially for his age, without a hint of any vices and never having stayed in a hospital before. Despite the hardships, life was always vibrant for him. Thankfully, his sudden illness led to an early diagnosis and timely treatment. Being under the best medical care and surrounded by family during his recovery gave everyone peace of mind. After the surgery, he aged noticeably, and it took him over six months to regain his strength. Now, he speaks with such vigor and frequently performs surgeries, which is a huge relief for our entire family.
Now semi-retired, my father, at the age of 88, is astonishingly spry for his age. Despite his modest living, he keeps an orderly life and continues to be eager to learn new things. Although he no longer drives, his curiosity about the latest tech developments remains. Just this February, he was asking me about the etymology and background of OpenAI and ChatGPT. He's more tech-savvy with smartphones and computers than many youngsters I know, ordering food from Meituan, hailing cars from DiDi, and shopping on Taobao. He also frequently consults English professional materials, absorbing new knowledge, proving the adage true: you're never too old to learn. He even outpaces English-major graduate Wei in English technical vocabulary, truly an exemplary lifelong learner.
Before his major illness, he was a whirlwind of energy, performing surgeries, driving, browsing the internet, writing memoirs, and enjoying chess games. In the decade since his surgery, even with a decline in his physical condition, he hasn't given up his lifelong passion for clinical medicine. He may have set aside other specialties, such as orthopedics, gynecology, and urology, but he remains steadfast in his dedication to general surgery, continuously contributing to the field and aiding patients. Medicine is an eternal bond he could never sever.
Gentle in nature and kind to all, my father has always been upright and warm-hearted. His patience and attentiveness when diagnosing patients, regardless of their socio-economic status, genuinely exemplify the benevolent spirit and humanistic essence of a doctor.
With progressive thoughts and a modern mindset, he always treated his children as equals, never reprimanding them, let alone resorting to physical punishment. He has always gently guided us, both through his words and his actions. Our individual successes are his greatest solace, and the growth and antics of his grandchildren bring him immense joy and satisfaction.
This book is a compilation of some of the medical papers my father published after the Cultural Revolution. Although it's not exhaustive, it preserves many invaluable experiences and theoretical summations from his medical career, standing as an enduring testament to his dedication. These papers encapsulate how a doctor from a grassroots hospital refined himself through challenges, continuously pushing his boundaries. They embody a physician's fundamental principles, conscience, responsibility, commitment, and mission, spotlighting the gallantry of medical professionals in their efforts to save lives and epitomizing the profound essence of "healing the world."
Recently, as we were compiling some of these medical papers, my father reflected on his journey spanning over 60 years, filled with both pride and nostalgia. While his papers primarily encapsulate his clinical experiences and might not be heavily research-oriented, their practical utility is undeniable. They are meticulously crafted, adhering to strict academic standards, and represent the crystallization and theoretical evolution of his medical practice, holding a certain legacy value. The excellence he has demonstrated throughout his life, his unwavering dedication to medicine, his relentless pursuit of knowledge, and his humble, upright, and benevolent character serve as a priceless heritage for our generation.
Given the vast timeline, locating all his papers was challenging, and unfortunately, many have been lost over the years. We've done our best to gather as many of his past medical writings as possible, compiling them into this volume as a birthday gift for our 88-year-old father, who has been practicing medicine for 67 years non-stop. We wish him a happy birthday, good health, and a peaceful twilight year!

《小雅人生系列》
我是小雅,立委先生打造的数字主播品牌,关注科技与生活的点点滴滴。
我今天在想竖屏、横屏的事情,寻思下来觉得有点意思。这个问题或矛盾的起源,感觉是来自于听说器官和视力器官的“错位”。怎么讲?
电话为的是听说,必须竖着来,因为嘴巴到耳朵之间有距离。为了够得着口、耳两个端点,传统电话设计成圆弧形,智能电话做成了长条形,竖着拿,倾斜45度角,基本上可以把耳朵与嘴巴连起来。
这样一来,竖屏就成了智能电话的最常见的默认形态。说默认是因为,理论上你总可以把竖屏横过来变成(宽银幕)横屏。实际上我们看视屏有时候也确实这么做,但毕竟不仅多了一个动作,手握横屏也不自然,加上在竖屏中的横屏视频还需要软件配合,才能支持需要90度旋转的横屏,而软件并不总是聪明友好。由于这些原因,短视频霸王抖音就坚持用竖屏作为默认。
久而久之,用户也习惯了看竖屏,用手指上下滑动翻屏,成为信息接受的最简易懒惰和放松的方式。全民刷短视频的习惯就此形成,虽然这个习惯显然不符合人类眼睛的设计。人成为信息时代最懒惰、最被动、也最容易满足于自己信息茧房的动物。
双眼是水平设计的,为的是看到更大广度。从视野雷达角度看,这个世界的水平方向的信息,显然比上下方向的信息更加丰富密集。目前大约能看到180度左右的水平视野,有些动物双眼长在两侧,比人类强,大约可以看到270度的视野,这样对于感知危险和逃生更有益。
动物没有在后脑勺进化出第三只眼或第四只眼,是进化历史上的一个遗憾和谜团,道理上360度无死角的水平视野才是最有利于生存的。人类技术弥补了这个不足,自动驾驶车辆上的 cameras 至少8个以上,就做到了360度无死角。
祸从天降的事情相对小概率,所以感知地上的危险和机会(譬如食物或捕猎对象)更加重要。这就是双眼水平设计的上帝理念。到了人人手机的时代,竖屏居然风行,双眼的水平优势被晾在一边。可见--也许,人的懒惰本性超越了人类的功能性。
当然,现代的世界与丛林不一样,危险也不是无处不在,虽然拿着手机跌进坑里去的事故也时有报道。
我是小雅,每次几分钟,与您分享不一样的科技生活视角。

提示词:a detailed artistic photograph as portrait of a beautiful Chinese young girl next door, beautiful lighting

















小稚是小雅的数字分身

465KB
小娴是小雅的 twin sister

234 KB
其他小雅的派生分身形象

1.3MB

1.1MB

1.2MB

5.7MB

5.6MB

1.1MB

1.4MB

1.3MB

1.2MB

1.1 MB

1.2MB

484KB

495KB

老哥问: 能否用 ChatGTP4 给这几张照片取个名字?汉江边,琴台公园旁






It all starts with this piece of AIGC original about 2 years ago (2021):

Then:

小雅高清 8.3 MB

2.5MB

2 MB

1.9 MB

2.4MB

1.8MB

2.3MB

2MB

1.8MB

1.8MB

309KB

220KB

317 KB

1.8MB

596KB

179KB




285 KB

262 KB

《 Collected Works in Commemoration of Mingle Li’s 67 Years of Medical Practic (Chinese Version) 》
《Li Family: Legends and Legacy》
Editor’s Afterword
My father has devoted his entire life to the practice of medicine, marrying unparalleled skill with a heart full of compassion. Over the span of his remarkable 67-year career, he has not only saved innumerable lives but also alleviated the suffering of countless patients. His impact reverberates through the community, earning him both love and the highest form of respect.
This book serves as a tribute to his enriching and inspirational life. While it may not encapsulate every facet of his luminary career, it gathers a treasure trove of invaluable medical experiences and insightful professional theories for the next generation of healthcare practitioners. This tome stands as an enduring monument to his legacy.
Yet, what elevates his story even further is his relentless passion and dedication to medical excellence. At nearly ninety years of age, my father remains as diligent and curious as ever, ceaselessly serving and learning. He sets an unparalleled example of a life well-lived, full of purpose and meaning, for all of us to follow.
As he transitions into semi-retirement, let us extend our warmest wishes for his continued good health and everlasting happiness.
[Annex 1] Publication of papers
[Annex 2] Relevant materials and surgical records
Education Campus
【立委按】老爸的医学生涯电子版另开辟【教育园地】专栏,整理刊载老爸医学生涯中所做的医学讲座、代表性手术记录以及对后生传帮带方面的资料。相信这些资料对于同行和后学自有其参考价值。在老爸一路向上的医学生涯中,职称上最高的一级当然是主任医师的评定。材料中,五例四类手术例案是九四年申报主任医师的必备附件之一。当然,申报成功还要加上省级至全国核心期刊发表论文五篇以上、专业英文笔试合格、医学教学能力(例如下面的医学讲座)及临床领导经验等综合考核评价。
[Editor’s Comment] Dad's electronic version of his medical career has a separate column entitled [Education Garden], which collates and publishes medical lectures given by Dad in his medical career, records of representative surgeries and information on mentoring epigenetic patients. I believe these materials have their own reference value for peers and postgraduates. In dad all the way up in the medical career, title on the highest level, of course, is the chief physician evaluation. Among the materials, five cases with four types of operations were one of the necessary accessories for reporting to the chief physician in 1994. Of course, the success of the application also requires the comprehensive assessment and evaluation of more than five papers published in provincial to national core journals, qualified professional English written examination, medical teaching ability (such as the following medical lectures) and clinical leadership experience.
1. Yellow resistance related clinical problems
1 Jaundice–syndrome. Pre-liver (hemolytic), hepatocellular, and post-liver (obstructive). mixed type
2 Yellow resistance-intrahepatic capillary duct–small bile duct–hepatobiliary duct–common hepatic duct–common bile duct … obstruction.
3 Internal medicine jaundice—surgical jaundice: internal and external hepatic obstruction. (15%-20% difficult to identify)
4 Diagnostic procedures and methods of yellow resistance: clinical, laboratory tests, X-ray, B-US, CT, MRI, PTC, ERCP, radionuclide (isotope iodine 131, De99) imaging, selective angiography ... liver biopsy, laparotomy ...
5 Three elements of diagnosis—yellow stalk or not–location and degree of obstruction–cause of obstruction.
6 the characteristics of surgical jaundice: (1) Biliary colic (Charcot triad, Ranold pentalogy); Painless progressive jaundice is often suggestive of cancer. (2) Physical examination: The right upper abdomen or the whole abdomen shows peritoneal irritation sign and swollen gallbladder. (3) Laboratory tests: bilirubin +85.5umol/L and direct/total bilirubin > 35% or "biliary enzyme separation", AKP↑ and urine bilirubin+and urobilinogen-. (4) Common causes: cholelithiasis, biliary parasites, bile duct stenosis, cancer, inflammation and pancreatic cancer, inflammation, hilar metastatic cancer, Mirizzi snidrome (5) Internal medicine jaundice that needs to be excluded—for example, viral hepatitis, drug-induced liver damage, idiopathic jaundice of pregnancy, sclerosing cholangitis ...
7 Surgical jaundice treatment: strive for early surgery.
8 For preoperative jaundice reduction (especially malignant terrigenous jaundice—liver and kidney, coagulation function, gastric mucosa damage, and immunologic hypofunction, with blood bilirubin of 170umol/L). Methods: (1) External drainage technique —— PTCD, U-tube, cholecystostomy, choledochostomy. (2) Internal drainage technique—biliary and intestinal drainage.
9 Surgeries
9.1 Stone removal+external and internal drainage (T-tube drainage, pelvic biliary-intestinal drainage, Roux-Y, diseased hepatectomy ...)
9.2 Pancreas cancer resection: Whipple and Child surgery
1、阻黄的有关临床问题 (讲稿提要)
1 黄疸 —— 症候群。肝前 (溶血性)、肝细胞性、肝后性 (梗阻性)。混合型
2 阻黄 —— 肝内毛细胆管 – 小胆管 – 肝胆管 – 肝总管 – 胆总管 … 梗阻。
3 内科黄疸 —— 外科黄疽: 肝内、外梗阻。(15%-20%难以鉴别)
4 阻黄的诊断程序和方法: 临床、化验、X线、B-US、CT、MRI、PTC、ERCP、核素 (同位素碘131、得99) 显象、选择性动脉造影 … 肝活检、剖腹探查…
5 诊断三要素 —— 梗黄与否 – 梗阻部位、程度 – 梗阻原因。
6 外科黄疸的特点:
(1) 胆绞痛 (Charcot三联征、Ranold五联征); 无痛性进行性黄疸常提示癌症。
(2) 查体: 右上腹或全腹呈腹膜刺激征、肿大的胆囊。
(3) 化验: 胆红素+85.5umol/L 且直接/总胆红素 >35%或“胆酶分离”、 AKP↑、尿胆红素 +、尿胆原 -。
(4) 常见原因: 胆石症、胆道寄生虫、胆管狭窄、癌、炎症及胰癌、炎、肝门转移癌、Mirizzi Snydrome
(5) 需除外内科黄疸 —— 如: 病毒性肝炎、药物性肝损害、妊娠特发性黄疸、硬化性胆管炎 ……
7 外科黄疸的治疗: 力争早期手术。
8 关于术前减黄问题 (尤其恶性梗黄 —— 肝肾、凝血机能、胃粘膜损害及免疫功能低下等,血胆红素在170umol/L)。方法: (1) 外引流技术 —— PTCD、U管、胆囊造口、胆总管造口术。(2) 内引流技术 —— 胆肠内引流。
9 手术
9.1 取石术+外、内引流术 (T管引流、盆式胆肠内引流、Roux-Y、
病肝切除…)
9.2 胰癌切除: Whipple、Child手术2. Complications of most gastric resection
1 Recent complications
1.1 intraoperative injuries: common bile duct, pancreas, and middle colon artery.
1.2 Postoperative gastric bleeding
1.2.1 Recent—incomplete hemostasis, and open ulceration.
1.2.2 7–10 days after surgery (secondary hemorrhage)–most cases can be self-stopped.
1.3 Leak of duodenal stump (Billroth-II type): (1) poor suture, (2) obstruction of jejunal afferent loop, (3) local poor blood supply.
1.4 3-4% anastomotic emptying disorders
1.4.1 Full anastomosis.
1.4.2 Output loop.
1.5 Input loop syndrome (Formula B-II)
1.5.1 Chronic simple partial obstruction (technical factor) —— Braun anastomosis, Roux-Y anastomosis (30-40Cm).
1.5.2 Causes of acute strangulation complete obstruction (excluding pancreatitis): (1) Input/output junction (high pressure—necrotic perforation), (2) Input loop is too long—internal hernia. Treatment: emergency operation.
1.6 Surgical exploration of output loop obstruction (barium meal examination). Causes: retrocolonic—mesangial foramen narrowing, anterior to the colon—internal hernia.
1.7 Postoperative acute pancreatitis 1% (abdominal amylase—diagnosis). Causes: trauma, sphincter of Oddi spasm, afferent loop obstruction, decreased postoperative protease inhibitor secretion. Treatment: Surgical drainage.
2 Long-term complications
2.1 causes and mechanisms of "dumping" syndrome: ① high pressure in the small intestine—intestinal distension—intestinal hormones such as 5-hydroxytryptamine—accelerated peristalsis and vasodilation—decreased blood volume, k ↑– gravity pulling the residual stomach—stimulating visceral nerves—epigastric and cardiovascular symptoms. Treatment: Surgery to avoid small residual stomach, large anastomosis, diet, posture adjustment, drugs: antihistamine or anti-acetylcholine, anti-spasm and sedatives or anti-5- hydroxytryptamine and other drugs, surgery: aims to reduce the speed of food directly into the jejunum (narrow the anastomosis, change B-11 to B-I type, gastroduodenal jejunal interposition.
2.2 Hypoglycemia syndrome: mechanistic food-rapid-small intestine-blood glucose-insulin-blood glucose treatment: slight food intake.
2.3 Mechanism of basic reflux gastritis: it is caused by the difference in PH of the gastrointestinal tract. The procedure was chan to Roux-Y or plus Braun for that purpose of reducing reflux of intestinal fluid to the stomach.
2.4 Loss of function of pylorus in food mass ileus—coarse fiber, ropy—simple obstruction of small intestine.
2.5 Anemia
2.5.1 Iron deficiency-caused by low acid in the stomach, iron supplement.
2.5.2 Giant cell sex—lack of internal factors, V-B12, folic acid, liver preparations.
2.6 Malnutrition is generally normal.
2.7 Surgical failure of an anastomotic ulcer (Zollinger-Elison syndrome).
1999-5-8 wuhu changhang hospital
2、胃大部分切除的并发症 (讲稿摘要)
1 近期并发症
1.1 术中损伤: 胆总管、胰腺、结肠中动脉。
1.2 术后胃出血
1.2.1 近期 —— 止血不彻底、溃疡旷置。
1.2.2 术后7~10天 (继发性出血) —— 多可自止。
1.3 十二指肠残端漏 (Billroth-Ⅱ式): (1) 缝合不佳,(2) 空肠输入袢梗阻,(3) 局部血供不良。
1.4 吻合口排空障碍 3-4%
1.4.1 全吻合口。
1.4.2 输出袢。
1.5 输入袢综合征 (B-Ⅱ式)
1.5.1 慢性单纯性部分梗阻 (技术因素) —— Braun式吻合、Roux-Y 式吻合(30-40Cm)。
1.5.2 急性绞窄性完全性梗阻 (剔除胰腺炎) 原因: (1) 输入、出交叉 (压力过高—— 坏死穿孔),(2) 输入袢过长 —— 内疝,治疗: 急症手术。
1.6 输出袢梗阻 (钡餐检查) 手术探查。原因: 结肠后 —— 系膜孔缩窄、结肠前 —— 内疝。
1.7 术后急性胰腺炎1% (腹液淀粉酶 —— 诊断)。原因: 创伤、Oddi 括约肌痉挛、输入袢梗阻、术后抑蛋白酶分泌减少。治疗: 手术引流。
2 远期并发症
2.1 “倾倒”综合征 原因和机理: ① 小肠内高压 —— 肠管膨胀 —— 5-羟色胺等肠道激素 —— 蠕动增快和血管扩张 —— 血容量降低,K↑ —— &重力牵拉残胃 —— 刺激内脏神经 —— 上腹和心血管症状。治疗: 手术避免残胃过小、吻合口过大,饮食、体位调节,药物: 抗组织胺或抗乙酰胆碱、抗痉挛和镇静剂或抗5-羟色胺等药物,手术: 旨在减少食物直接进入空肠的速度 (缩小吻合口、改B-11为B-I式、胃十二指肠空肠间置。
2.2 低血糖综合征:机理食物 —— 快速 —— 小肠 —— 血糖↓ —— 胰岛素↓ —— 血糖↓ 治疗: 稍进食物。
2.3 碱性返流性胃炎 机理: 胃肠PH差异致使。改手术为Roux-Y或加 Braun,目在减少肠液向胃返流。
2.4 食物团肠梗阻 幽门失功能 —— 粗纤维、粘稠 —— 小肠单纯梗阻。
2.5 贫血
2.5.1 缺铁性 —— 胃内低酸致使,补铁。
2.5.2 巨细胞性 —— 内因子缺乏,V-B12、叶酸、肝制剂。
2.6 营养不良 一般还正常。
2.7吻合口溃疡 手术失败 (胃切除不足,Zollinger-Elison syndrome)。
1999-5-8芜湖长航医院
3. Large intestinal cancer
1 Colon and rectum anatomy: The colon is 150Cm in length and can be divided into cecum, ascending colon, transverse colon, descending colon and sigmoid colon. The rectum was about 12.5Cm long, connected with the anal canal (3–4 cm) under the sigmoid colon, and the retroperitoneal fold was 7.5Cm away from the anal margin.
2 Anatomical and physiological characteristics of colon and rectum: (1) The blood supply is that the terminal artery is poorer than the small intestine; (2) The intestinal wall is thin; (3) There are many enteric bacteria's, with high infection; (4) Absorbing water makes the feces form.
3 Once the colorectal cancer is definitely diagnosed, surgical treatment should be performed as soon as possible. Of course, comprehensive treatment should also be considered. Colorectal cancer has liver metastasis, but if the primary cancer and mesangial lymph node metastasis can still be completely removed, and the metastatic lesions touched in the liver are single, and it is not difficult to locally resect the site, the primary cancer can also be resected and the intrahepatic metastatic lesions can be resected at the same time, which can result in a long-term remission for some patients and a survival period of 5 years or more for a few patients. Cancer at the junction of straight and B accounts for 60% of all colorectal cancers.
4 Operating technical principles of radical resection of colorectal cancer: in order to prevent hematogenous dissemination and local planting of cancer cells during the operation as much as possible, the operation on cancer should be light and squeezing should be avoided; Before free cancer, the pathways of cancer cell intestinal implantation and hematogenous metastasis were blocked first.
5 Intestinal preparation before surgery: Preoperative preparation of the colon (intestine) is an important measure to reduce intraoperative pollution, prevent postoperative infection of the abdominal cavity and incision, and ensure good healing of the anastomosis. The purpose of intestinal preparation is to empty the feces in the colon without flatulence, and the number of intestinal bacteria will be reduced. Bowel preparation method: The colon is cleaned during the operation by regulating diet, taking laxative and cleaning the bowel.
6 Colonic surgery includes right hemicolectomy, transverse colectomy, left hemicolectomy and sigmoidectomy; Rectal resection includes anterior rectal resection (Dixon's technique), pullout resection (Bacon's technique), abdominoperineal resection (Miles's technique), and retrosacral approach (Klarsks's technique).
7 Surgical procedures:
8 Postoperative complications:
9 Post-operative treatment:
April 8, 2005 Li Mingjie Yu Changhang Hospital
3、大肠癌
1 结、直肠解剖:
结肠长度150Cm,可分盲肠、升结肠、横结肠、降结肠、和乙状结肠; 直肠长约12.5Cm, 上接乙状结肠下连肛管 (肛管 3-4Cm),其腹膜反折部距肛缘7.5Cm。
2 结、直肠解剖、生理特点: (1) 血供为终末动脉较小肠差,(2) 肠壁薄,(3) 肠内细菌多,感染性高,(4) 吸收水份使粪成形。
3 结、直肠癌一旦明确诊断后应尽早地施行手术治疗,当然,还应考虑综合性治疗。
结、直肠癌虽已有肝转移,但如原发癌及系膜淋巴结转移癌尚可完全切除,而肝内触及的转移灶为单个, 且其所在部位做局部切除困难不大时,也可以切除原发癌的同时,将肝内转移灶切除,部分病人可因此而获得较长时间的缓解,少数病人尚可有5年或更长的生存期。
直、乙交界处癌占全部大肠癌的60%。
4 结、直肠癌根治术的操作技术原则: 为了尽可能防止术中癌细胞的血行播散和局部种植,对癌肿的操作要轻,避免挤压; 游离癌肿前,先阻断癌细胞肠腔内种植和血行转移的途径。
5 手术前的肠道准备:
结肠的术前准备 (肠道) 是减轻术中污染,预防术后腹腔和切口感染,以及保证吻合口良好愈合的重要措施。肠道准备的目的是使结肠内粪便排空,无胀气,肠道细菌数量随之减少。
肠道准备方法:
主要是通过调节饮食,服用泻剂及清洁肠道,达到手术时结肠“清洁”的目的。
(1) 术前三天进全流质,同时口服番泻叶30克冲服,三次/日,每天补液1500-2000ml。或术前1天服硫酸镁 25 克,二次/日。
(2) 术前三天口服灭滴灵 0.5,四次/日,加氟哌酸 0.2,四次/日。
(3) 术前一天晚上清洁灌肠 (肥皂水),次日晨再行清水灌肠。
6 结肠手术分右半结肠切除、横结肠切除、左半结肠切除、乙状结肠切除; 直肠切除分为直肠前切除 (Dixon术式)、拉出切除 (Bacon术式)、腹会阴联合切除 (Miles术式)、经骶后入路 (Klarsks术式) 等…….
7 手术步聚:
(1) 在距癌肿缘远近侧各10cm处,将肠管包括边缘血管在内,以布带扎紧以阻断肠
(2) 在系膜根部显露准备切断的动静脉,分别结扎,切断,自此开始逐步切断系膜至拟切断的肠管部。(切断前可指压试行,以视保留肠管血运)
(3) 游离包括癌肿在内的肠段,予以切除。
(4) 肠吻合完毕后,用无菌蒸馏水冲洗手术区,以期能破坏脱落的癌细胞。
8 术后并发症:
(1) 若病程长,有不全梗阻症状,肠道准备工作可能达不到应有的要求,术中一旦腹腔受到污染后,会引起腹腔感染。
(2) 由于肠壁水肿,又有不同程度肠管扩张,结、直肠切除后,吻合易发生吻合口瘘或因吻合口张力大引起吻合口狭窄。
(3) 结、直肠切除,腹腔搔扰性大,易引起腹腔肠管的粘连。
(4) 术中易出血或引起其他脏器的误伤如输尿管、十二指肠、胰腺、下腔静脉等。
(5) 腹部切口大,易发生切口感染。
9 术后处理:
(1) 术后48小时内注意血压、脉搏、呼吸。
(2) 注意腹腔内出血和伤口出血。
(3) 术后保留导尿48小时后拔除。
(4) 每天注意液体、营养和电解质的补充。
(5) 大量应用广谱抗菌素。
April 8, 2005 李名杰于长航医院
4. Umbilical disease
1 Umbilical embryology - body pedicle: umbilical artery-lateral umbilical ligament (2); Umbilical vein-umbilical intermediate ligament (1); Vitelline canal; Urachal.
2 IgY duct deformity
2.1 Complete patent of vitelline duct — vitelline duct fistula (navel-gut fistula).
2.2 Partial patent yolk sac
2.2.1 Umbilical region — umbilical sinus
2.2.2 Middle part — yolk sac cyst
2.2.3 Bowel — Meckel diverticulum
2.3 Umbilical mucosal residue — umbilical cord (umbilical polyp)
2.4 Residues of vitelline tubule and its vascular fibrotic zona — umbilical enterozona
3 Urachal malformation
3.1 Urachal fistula-patent
3.2 Partial Closure
3.2.1 Umbilical region — urachal sinus
3.2.2 Middle part - urachal cyst
3.2.3 Bladder region-bladder diverticulum
4 Vascular malformations — persistent vitelline canal, urachal and umbilical blood vessels
5 Diseases of navel itself — umbilical hernia, omphalocele, infection, endometriosis, epithelial neoplasm, etc
4、脐部疾病 (讲稿提要)
1 脐部胚胎学 —— 体蒂: 脐动脉-脐外侧韧带(2); 脐静脉-脐中间韧带(1); 卵黄管; 脐尿管。
2卵黄管畸形
2.1 卵黄管完全未闭 —— 卵黄管瘘 (脐肠瘘)。
2.2 卵黄管部分未闭
2.2.1 脐部 —— 脐窦
2.2.2 中间部 —— 卵黄管囊肿
2.2.3 肠部 —— 麦克耳憩室 (Meckel diverticulum)
2.3 脐部粘膜残余 —— 脐茸 (脐息肉)
2.4 卵黄管及其血管纤维化索带残留 —— 脐肠索带
3脐尿管畸形
3.1 脐尿管瘘 —— 未闭
3.2 部分未闭
3.2.1 脐部 —— 脐尿管窦
3.2.2 中间部 —— 脐尿管囊肿
3.2.3 膀胱部 —— 膀胱憩室
4 血管畸形 —— 永存的卵黄管、脐尿管及脐部的血管
5 脐本身疾患 —— 脐疝、脐膨出、感染、子宫内膜异位症、上皮赘生物等
5. Congenital biliary malformations
1 Congenital biliary atresia (divided into six types)
bilioenteral drainage (50 cases +44 cases only, omitted)
2 Congenital choledochal cyst
2.1 Etiology:
2.1.1 Abnormal development of autonomic nerves in the terminal wall of common bile duct (similar to the etiology of Hirschsprung's disease)
2.1.2 Development disorder of common bile duct itself — weak duct wall (similar to the cause of congenital primary hydronephrosis)
2.1.3 Viral infection - obstruction/weak wall - dilatation-cyst
2.2 Pathology:
2.2.1 Extrahepatic (majority): cystic dilatation of common bile duct, diverticulum
2.2.2 Intra-hepatic (Caroli's cyst)
2.2.3 Mixed type (rare)
2.3 Symptom: three major symptoms (usually appear when the patient is three years old, but usually sees doctors later); abdominal pain 60%, lump 90%, jaundice 70%, fever 30%, pale feces, gallbladder pigment urine, intussusception perforation peritonitis and abnormal liver function.
2.4 Diagnosis: (i) three major Intermittent symptoms, (ii) ultrasonic diagnosis, (iii) abdominal X-ray or barium meal examination cholangiography. (iv) cyst puncture.
2.5 Treatment:
2.5.1 Cystectomy — Roux-Y cholangioenterostomy (difficult and with high mortality).
2.5.2 Cyst – duodenal anastomosis (easy and effective): low position, large incision (6Cm), and mucosa aligned suture.
2.5.3 Cyst - jejunal Roux-Y anastomosis.
2.5.4 External drainage of cysts (emergency transition).
2.5.5 Treatment of intrahepatic cyst: hepatectomy
3 Congenital gallbladder malformation
3.1 Abnormal number
3.1.1 Absence of gallbladder – 0.07% – predisposing to bile duct stones.
3.1.2 Double gall bladders – 0.025% of the double gall bladders are more prone to lithiasis and inflammation.
3.2 Location abnormality
3.2.1 intrahepatic gallbladder – 10% more children, with gradual emigration later on.
3.2.2 Left subtalar gallbladder
3.2.3 Right retrohepatic gallbladder
3.3 Morphological abnormalities
3.3.1 Biliary gall bladder – mediastinal membrane in the gall bladder.
3.3.2 bilobar gallbladder – bottom separation.
3.3.3 Leg sac diverticulum
3.3.4 gourd-shaped gallbladder
4 Abnormal adhesion — free gallbladder.
5 Abnormal tissue structure — ectopic tissue: pancreas and gastric mucosa.
This article was originally published in Proceedings of Wuhu Annual Surgical Conference,1996;28-30 Changhang Hospital, Li Mingjie
from 外科截瘫14例手术分析






































































